Data publicación
21/04/2022
Comparte este contido

Descrición
¿Te has preguntado alguna vez cómo Alexa es capaz de reconocer nuestra voz y entender lo que le estamos diciendo (algunas veces mejor que otras)? ¿Te has parado a pensar cómo Google es capaz de buscar imágenes similares a la que le estamos proporcionando? Probablemente sepas que estas técnicas pertenecen al ámbito de la inteligencia artificial. Pero no te engañes, construir estos modelos sofisticados solo está al alcance de unos pocos. En este post te contamos por qué y qué podemos hacer el común de los mortales para entrenar modelos de inteligencia artificial.
Introducción
En los últimos años hemos sido testigos de avances increíbles y sorprendentes en el ámbito del entrenamiento de modelos de Deep Learning. En anteriores ocasiones hemos citado los ejemplos más relevantes cómo GPT-3 o Megatron-Turing NLG. Estos modelos, optimizados para el procesamiento de lenguaje natural (en inglés, NLP), son capaces de escribir artículos completos (prácticamente indistinguibles de los escritos por un humano) o realizar resúmenes coherentes de obras clásicas, de cientos de páginas, sintetizando el contenido en tan solo unos párrafos. Impresionante ¿verdad?
Sin embargo, estos logros no son ni mucho menos baratos. Es decir, la complejidad de estos modelos es tal que, se necesitan miles de gigabytes de información pre-procesada - lo que denominamos datasets anotados- que han sido previamente analizados (etiquetados) por un humano experto en la materia. Por ejemplo, el último entrenamiento del modelo Megatron-Turing NLG, creado en colaboración por Microsoft y NVIDIA, utilizó 270.000 millones de tokens (pequeños trozos de texto que pueden ser palabras o sub-palabras que constituyen la base para el entrenamiento de estos modelos de lenguaje natural). Además de la información necesaria para poder entrenar estos modelos, está el hecho de las necesidades especiales de computación que requieren estos entrenamientos. Para ejecutar tareas de entrenamiento de estos modelos, se necesitan las máquinas (los ordenadores) más avanzados del mundo y los tiempos de entrenamiento se cuentan por semanas. Aunque no existen datos oficiales, algunas fuentes citan que el coste de entrenamiento de los últimos modelos como GPT-3 o Megatron-Turing se cuentan por decenas de millones de dólares. Así, cabría preguntarnos, cómo podemos utilizar y entrenar modelos si no tenemos acceso a los clusters de cálculo más potentes del mundo.
La respuesta: Transfer Learning
Cuando trabajamos en un proyecto de machine learning o deep learning y no disponemos de acceso a grandes conjuntos de datos preparados para entrenamiento, podemos partir de modelos pre-entrenados para crear un nuevo modelo ajustado o afinado a nuestro caso de uso concreto. Es decir, cargamos un modelo previamente entrenado con un conjunto muy grande de datos de entrenamiento y re-entrenamos sus últimas capas para ajustarlo a nuestro conjunto concreto de datos. Esto es lo que se conoce como Transfer Learning.
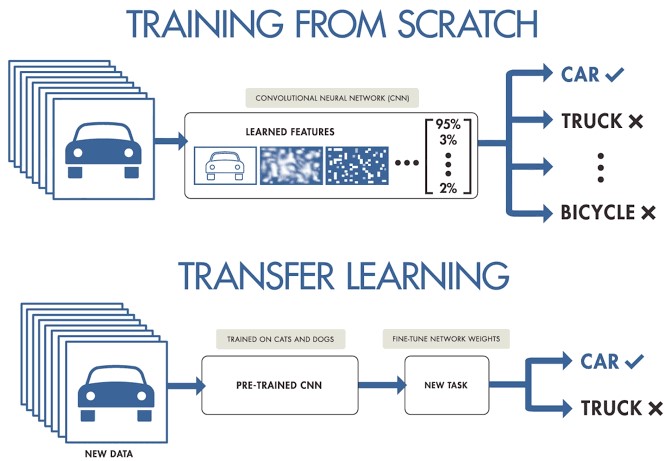
Fuente original: Transfer Learning en Deep Learning: Más allá de nuestros modelos. Post de Josu Alonso en Medium.
Simplificando mucho, se podría decir que el Machine Learning tradicional aplica en tareas de aprendizaje aisladas, donde no es necesario retener el conocimiento adquirido, mientras que en un proyecto de Transfer Learning el aprendizaje es fruto de tareas previas, logrando una buena precisión precisión en menos tiempo y con menos datos. Esto conlleva muchas oportunidades, aunque también algunos retos, como por ejemplo que el nuevo dominio herede sesgos del dominio anterior.
Veamos un ejemplo concreto. Supongamos que tenemos un nuevo desafío de Deep Learning y queremos hacer un clasificador automático de razas de perros. En este caso, podemos aplicar la técnica de transfer learning a partir de un modelo general de clasificación de imágenes, para posteriormente ajustarlo a un conjunto concreto de fotografías de razas de perro. La mayoría de los modelos pre-entrenados parten de un subconjunto de la base de datos de ImageNet, de la que ya hemos hablado en varias ocasiones. La red neuronal (de ImageNet), que es el tipo de algoritmo base que se utiliza en estos modelos de clasificación de imágenes, ha sido entrenada con 1.2 millones de imágenes de más de 1000 categorías de objetos diferentes como teclados, tazas de café, lápices y muchos animales. Al utilizar una red pre-entrenada para aplicar Transfer Learning, conseguimos resultados mucho más rápidos y sencillos que si tuviéramos que entrenar una red desde cero.
Por ejemplo, en este fragmento de código, se muestra el proceso de partir de un modelo pre-entrenado con ImageNet y re-entrenar o añadir nuevas capas para conseguir ajustes finos sobre el modelo original.
# creamos la base del modelo pre-entrenado partiendo de ImageNET
base_model <- application_inception_v3(weights = 'imagenet', include_top = FALSE)
# Añadimos capas adicionales a nuestra red neuronal
predictions <- base_model$output %>%
layer_global_average_pooling_2d() %>%
layer_dense(units = 1024, activation = 'relu') %>%
layer_dense(units = 200, activation = 'softmax')
# creamos un nuevo modelo para entrenar
model <- keras_model(inputs = base_model$input, outputs = predictions)
# Nos aseguramos de entrenar solo nuestras nuevas capas para no destruir el entrenamiento previo.
freeze_weights(base_model)
# compilamos el modelo
model %>% compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy')
# entrenamos el modelo
model %>% fit_generator(...)
Conclusiones
Entrenar un modelo de deep learning para propósito general no está al alcance de todo el mundo. Las barreras son varias, desde la dificultad de acceso a los datos de entrenamiento de calidad y en suficiente volumen, cómo la capacidad de computación necesaria para procesar billones de imágenes o textos. Para casos de uso más acotados, donde solamente requerimos un refinamiento de los modelos generalistas, aplicar la técnica de Transfer Learning, nos posibilita conseguir resultados fantásticos en términos de precisión y tiempo de entrenamiento, con un coste asumible por la mayoría de científicos de datos. Las aplicaciones de Transfer Learning son muy numerosas y los sitios web especializados están llenos de ejemplos de aplicación. Alineado con esta tendencia, recientemente se ha popularizado mucho la técnica de Style Transfer Learning, que consiste en reconstruir imágenes basándose en el estilo de una imágen previa. Seguiremos hablando sobre este tema en próximos posts.

Ejemplo de Style Transfer Learning en Kaggle
No es el objetivo de este post explicar con detalle cada una de las secciones de este fragmento de código.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Comentarios