Blog
The European Union aims to boost the Data Economy by promoting the free flow of data between member states and between strategic sectors, for the benefit of businesses, researchers, public administrations and citizens. Undoubtedly, data is a critical factor in the industrial and technological revolution we are experiencing, and therefore one of the EU's digital priorities is to capitalise on its latent value, relying on a single market where data can be shared under conditions of security and, above all, sovereignty, as this is the only way to guarantee indisputable European values and rights.
Thus, the European Data Strategy seeks to enhance the exchange of data on a large scale, under distributed and federated environments, while ensuring cybersecurity and transparency. To achieve scale, and to unlock the full potential of data in the digital economy, a key element is building trust. This, as a basic element that conditions the liquidity of the ecosystem, must be developed coherently across different areas and among different actors (data providers, users, intermediaries, service platforms, developers, etc.). Therefore, their articulation affects different perspectives, including business and functional, legal and regulatory, operational, and even technological. Therefore, success in these highly complex projects depends on developing strategies that seek to minimise barriers to entry for participants, and maximise the efficiency and sustainability of the services offered. This in turn translates into the development of data infrastructures and governance models that are easily scalable, and that provide the basis for effective data exchange to generate value for all stakeholders.
A methodology to boost data spaces
Spain has taken on the task of putting this European strategy into practice, and has been working for years to create an environment conducive to facilitating the deployment and establishment of a Sovereign Data Economy, supported, among other instruments, by the Recovery, Transformation and Resilience Plan. In this sense, and from its coordinating and enabling role, the Data Office has made efforts to design a general conceptual methodology , agnostic to a specific sector. It shapes the creation of data ecosystems around practical projects that bring value to the members of the ecosystem.
Therefore, the methodology consists of several elements, one of them being experimentation. This is because, by their flexible nature, data can be processed, modelled and thus interpreted from different perspectives. For this reason, experimentation is key to properly calibrate those processes and treatments needed to reach the market with pilots or business cases already close to the industries, so that they are closer to generating a positive impact. In this sense, it is necessary to demonstrate tangible value and underpin its sustainability, which implies, as a minimum, having:
- Frameworks for effective data governance
- Actions to improve the availability and quality of data, also seeking to increase their interoperability by design
- Tools and platforms for data exchange and exploitation.
Furthermore, given that each sector has its own specificity in terms of data types and semantics, business models, and participants' needs, the creation of communities of experts, representing the voice of the market, is another key element in generating useful projects. Based on this active listening, which leads to an understanding of the dynamics of data in each sector, it is possible to characterise the market and governance conditions necessary for the deployment of data spaces in strategic sectors such as tourism, mobility, agri-food, commerce, health and industry.
In this process of community building, data co-operatives play a fundamental role, as well as the more general figure of the data broker, which serves to raise awareness of the existing opportunity and favour the effective creation and consolidation of these new business models.
All these elements are different pieces of a puzzle with which to explore new business development opportunities, as well as to design tangible projects to demonstrate the differential value that data sharing will bring to the reality of industries. Thus, from an operational perspective, the last element of the methodology is the development of concrete use cases. These will also allow the iterative deployment of a catalogue of reusable experience and data resources in each sector to facilitate the construction of new projects. This catalogue thus becomes the centrepiece of a common sectoral and federated platform, whose distributed architecture also facilitates cross-sectoral interconnection.
On the shoulders of giants
It should be noted that Spain is not starting from scratch, as it already has a powerful ecosystem of innovation and experimentation in data, offering advanced services. We therefore believe it would be interesting to make progress in the harmonisation or complementarity of their objectives, as well as in the dissemination of their capacities in order to gain capillarity. Furthermore, the proposed methodology reinforces the alignment with European projects in the same field, which will serve to connect learning and progress from the national level to those made at EU level, as well as to put into practice the design tasks of the "cyanotypes" promulgated by the European Commission through the Data Spaces Support Centre.
Finally,the promotion of experimental or pilot projects also enables the development of standards for innovative data technologies, which is closely related to the Gaia-X project. Thus, the Gaia-X Hub Spain has an interoperability node, which serves to certify compliance with the rules prescribed by each sector, and thus to generate the aforementioned digital trust based on their specific needs.
At the Data Office, we believe that the interconnection and future scalability of data projects are at the heart of the effort to implement the European Data Strategy, and are crucial to achieve a dynamic and rich Data Economy, but at the same time a guarantor of European values and where traceability and transparency help to collectivise the value of data, catalysing a stronger and more cohesive economy.
Noticia
Under the Spanish Presidency of the Council of the European Union, the Government of Spain has led the Gaia-X Summit 2023, held in Alicante on November 9 and 10. The event aimed to review the latest advances of Gaia-X in promoting data sovereignty in Europe. As presented on datos.gob.es, Gaia-X is a European private sector initiative for the creation of a federated, open, interoperable, and reversible data infrastructure, fostering digital sovereignty and data availability.
The summit has also served as a space for the exchange of ideas among the leading voices in the European data spaces community, culminating in the presentation of a statement to boost strategic autonomy in cloud computing, data, and artificial intelligence—considered crucial for EU competitiveness. The document, promoted by the State Secretariat for Digitization and Artificial Intelligence, constitutes a joint call for a "more coherent and coordinated" response in the development of programs and projects, both at the European and member state levels, related to data and sector technologies.
To achieve this, the statement advocates for interoperability supported by a robust cloud services infrastructure and the development of high-quality data-based artificial intelligence with a robust governance framework in compliance with European regulatory frameworks. Specifically, it highlights the possibilities offered by Deep Neural Networks, where success relies on three main factors: algorithms, computing capacity, and access to large amounts of data. In this regard, the document emphasizes the need to invest in the latter factor, promoting a neural network paradigm based on high-quality, well-parameterized data in shared infrastructures, not only saving valuable time for researchers but also mitigating environmental degradation by reducing computing needs beyond the brute force paradigm.
For this reason, another aspect addressed in the document is the stimulation of access to data sources from different complementary domains. This would enable a "flexible, dynamic, and highly scalable" data economy to optimize processes, innovate, and/or create new business models.
The call is optimistic about existing European initiatives and programs, starting with the Gaia-X project itself. Other projects highlighted include IPCEI-CIS or the Simpl European project. It also emphasizes the need for "broader and more effective coordination to drive industrial projects, advance the standardization of cloud and reliable data tags, ensuring high levels of cybersecurity, data protection, algorithmic transparency, and portability."
The statement underscores the importance of achieving a single data market that includes data exchange processes under a common governance framework. It values the innovative set of digital and data legislation, such as the Data Act, with the goal of promoting data availability across the Union. The statement is open to new members seeking to advance the promotion of a flexible, dynamic, and highly scalable data economy.
You can read the full document here: The Trinity of Trusted Cloud Data and AI as a Gateway to EU's Competitiveness
Evento
Alicante will host the Gaia-X Summit 2023 on November 9 and 10, which will review the latest progress made by this initiative in promoting data sovereignty in Europe. Interoperability, transparency and regulatory compliance acquire a practical dimension through the exchange and exploitation of data articulated under a reliable cloud environment.
It will also address the relationships established with industry leaders, experts, companies, governments, academic institutions and various organisations, facilitating the exchange of ideas and experiences between the various stakeholders involved in the European digital transformation. The event will feature keynotes, interactive workshops and panel discussions, exploring the limitless possibilities of cooperative digital ecosystems, and a near future where data has become a high value-added asset.
This event is organised by the european association Gaia-X, in collaboration with the Spanish Gaia-X Hub. It also counts with the participation of the Data Office the project is being developed under the auspices of the Spanish Presidency of the Council of the European Union. The project is being developed under the auspices of the Spanish Presidency of the Council of the European Union.
The Gaia-X initiative aims to ensure that data is stored and processed in a secure and sovereign manner, respecting European regulations, and to foster collaboration between different and heterogeneous actors, such as companies, governments and organisations. Thus, Gaia-X promotes innovation promotes innovation and data-driven economic development in Europe. The open and collaborative relationship with the European Union is therefore essential for the achievement of its objectives.
Digital sovereignty: a Europe fit for the data age
As for Gaia-X, one of the major objectives of the European Union is to to promote digital sovereignty throughout the European Union. To this end, it promotes the development of key industries and technologies for its competitiveness and security, strengthens its trade relations and supply chains, and mitigates external dependencies, focusing on the reindustrialisation of its territory and on ensuring its strategic digital autonomy.
The concept of digital sovereignty encompasses different dimensions: technological, regulatory and socio-economic. The technology dimension refers to the hardware, software, cloud and network infrastructure used to access, process and store data. Meanwhile, the regulatory dimension refers to the rules that provide legal certainty to citizens, businesses and institutions operating in a digital environment. Finally, the socio-economic dimension focuses on entrepreneurship and individual rights in the new global digital environment. To make progress in all these dimensions, the EU relies on projects such as Gaia-X.
The initiative seeks to create federated, open, secure and transparent open, secure and transparent ecosystems, where data sets and services comply with a minimum set of common rules, thus allowing them to be reusable under environments of trust and transparency. In turn, this enables the creation of reliable, high-quality data ecosystems, with which European organisations will be able to drive their digitisation process, enhancing value chains across different industrial sectors. These value chains, digitally deployed on federated and trusted cloud environments ("Trusted Cloud"), are traceable and transparent, and thus serve to drive regulatory compliance and digital sovereignty efforts.
In short, this approach is based on building on and reinforcing values reflected in a developing regulatory framework that seeks to embed concepts such as trust and governance in data environments. This seeks to make the EU a leader in a society and economy where digitalisation is a vector for re-industrialisation and prosperity, but always within the framework of our defining values.
The full programme of the Summit is available on the official website of the European association: https://gaia-x.eu/summit-2023/agenda/.
Documentación
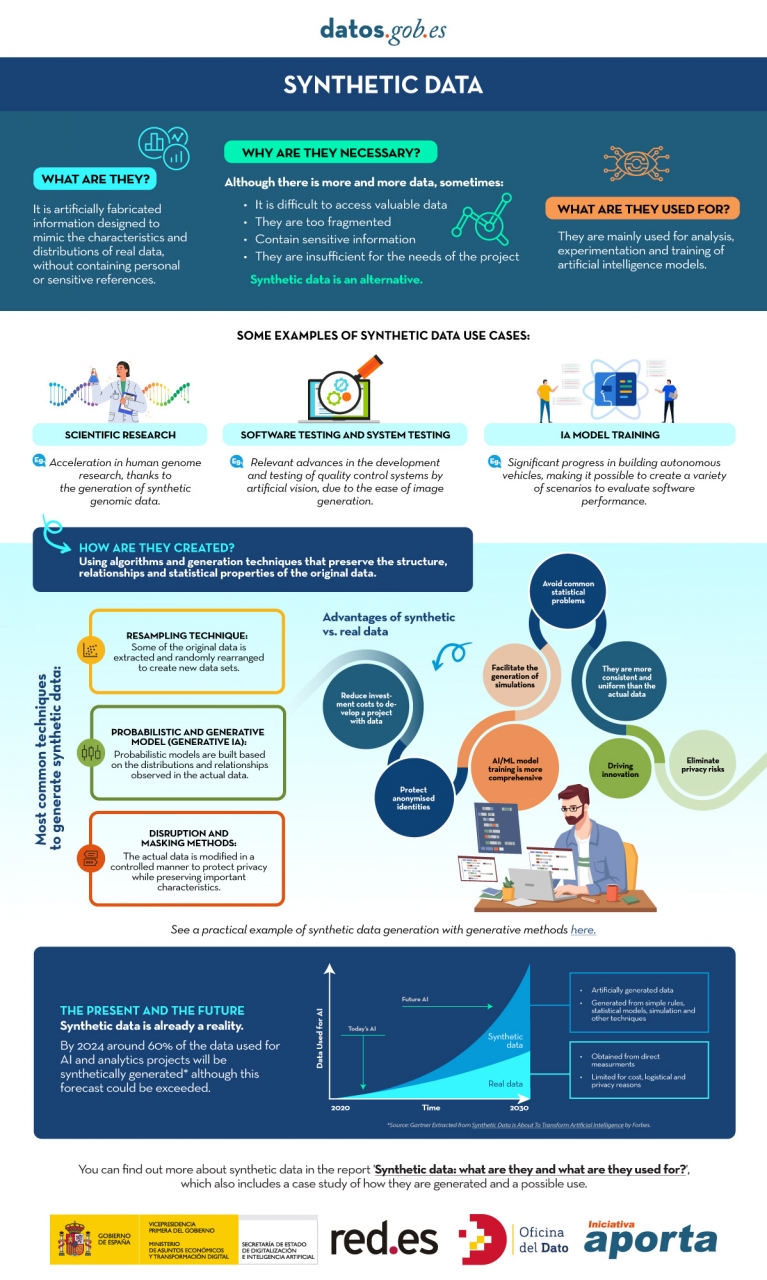
In the era of data, we face the challenge of a scarcity of valuable data for building new digital products and services. Although we live in a time when data is everywhere, we often struggle to access quality data that allows us to understand processes or systems from a data-driven perspective. The lack of availability, fragmentation, security, and privacy are just some of the reasons that hinder access to real data.
However, synthetic data has emerged as a promising solution to this problem. Synthetic data is artificially created information that mimics the characteristics and distributions of real data, without containing personal or sensitive information. This data is generated using algorithms and techniques that preserve the structure and statistical properties of the original data.
Synthetic data is useful in various situations where the availability of real data is limited or privacy needs to be protected. It has applications in scientific research, software and system testing, and training artificial intelligence models. It enables researchers to explore new approaches without accessing sensitive data, developers to test applications without exposing real data, and AI experts to train models without the need to collect all the real-world data, which is sometimes simply impossible to capture within reasonable time and cost.
There are different methods for generating synthetic data, such as resampling, probabilistic and generative modeling, and perturbation and masking methods. Each method has its advantages and challenges, but overall, synthetic data offers a secure and reliable alternative for analysis, experimentation, and AI model training.
It is important to highlight that the use of synthetic data provides a viable solution to overcome limitations in accessing real data and address privacy and security concerns. Synthetic data allows for testing, algorithm training, and application development without exposing confidential information. However, ensuring the quality and fidelity of synthetic data is crucial through rigorous evaluations and comparisons with real data.
In this report, we provide an introductory overview of the discipline of synthetic data, illustrating some valuable use cases for different types of synthetic data that can be generated. Autonomous vehicles, DNA sequencing, and quality controls in production chains are just a few of the cases detailed in this report. Furthermore, we highlight the use of the open-source software SDV (Synthetic Data Vault), developed in the academic environment of MIT, which utilizes machine learning algorithms to create tabular synthetic data that imitates the properties and distributions of real data. We present a practical example in a Google Colab environment to generate synthetic data about fictional customers hosted in a fictional hotel. We follow a workflow that involves preparing real data and metadata, training the synthesizer, and generating synthetic data based on the learned patterns. Additionally, we apply anonymization techniques to protect sensitive data and evaluate the quality of the generated synthetic data.
In summary, synthetic data is a powerful tool in the data era, as it allows us to overcome the scarcity and lack of availability of valuable data. With its ability to mimic real data without compromising privacy, synthetic data has the potential to transform the way we develop AI projects and conduct analysis. As we progress in this new era, synthetic data is likely to play an increasingly important role in generating new digital products and services.
If you want to know more about the content of this report, you can watch the interview with its author.
Below, you can download the full report, the executive summary and a presentation-summary.
Blog
We live in a constantly evolving environment in which data is growing exponentially and is also a fundamental component of the digital economy. In this context, it is necessary to unlock its potential to maximize its value by creating opportunities for its reuse. However, it is important to bear in mind that this increase in speed, scale and variety of data means that ensuring its quality is more complicated.
In this scenario, the need arises to establish common processes applicable to the data assets of all organizations throughout their lifecycle. All types of institutions must have well-governed, well-managed data with adequate levels of quality, and a common evaluation methodology is needed that can help to continuously improve these processes and allow the maturity of an organization to be evaluated in a standardized way.
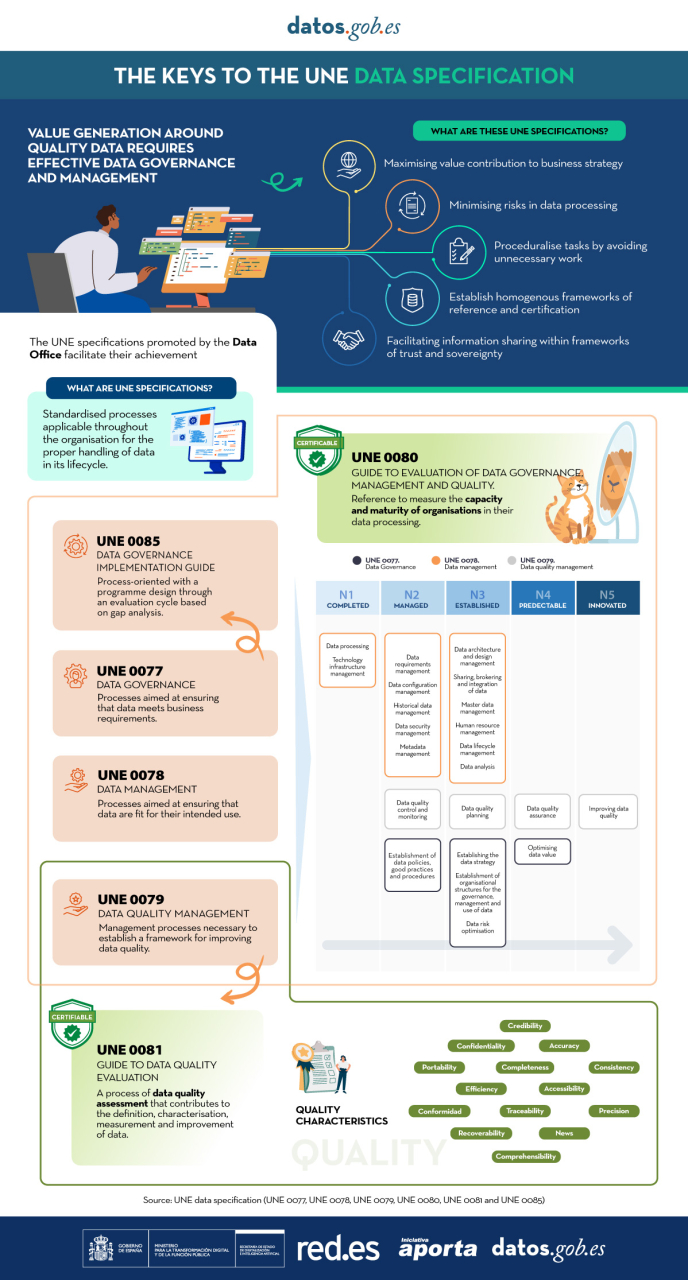
The Data Office has sponsored, promoted and participated in the generation of the UNE specifications, normative resources that allow the implementation of common processes in data management and that also provide a reference framework to establish an organizational data culture.
On the one hand, we find the specifications UNE 0077:2023 Data Governance, UNE 0078:2023 Data Management and UNE 0079:2023 Data Quality Management, which are designed to be applied jointly, enabling a solid reference framework that encourages the adoption of sustainable and effective practices around data.
In addition, a common assessment methodology is needed to enable continuous improvement of data governance, management and data quality management processes, as well as the measurement of the maturity of organizations in a standardized way. The UNE 0080 specification has been developed for the development of a homogeneous framework for the evaluation of an organization's treatment of data.
With the aim of offering a process based on international standards that helps organizations to use a quality model and to define appropriate quality characteristics and metrics, the UNE 0081 Data Quality Assessment specification has been generated, which complements the UNE 0079 Data Quality Management.
The following infographic summarizes the key points of the UNE Specifications on data and the main advantages of their application (click on the image to access the infographic).
Blog
Today, data quality plays a key role in today's world, where information is a valuable asset. Ensuring that data is accurate, complete and reliable has become essential to the success of organisations, and guarantees the success of informed decision making.
Data quality has a direct impact not only on the exchange and use within each organisation, but also on the sharing of data between different entities, being a key variable in the success of the new paradigm of data spaces. When data is of high quality, it creates an environment conducive to the exchange of accurate and consistent information, enabling organisations to collaborate more effectively, fostering innovation and the joint development of solutions.
Good data quality facilitates the reuse of information in different contexts, generating value beyond the system that creates it. High-quality data are more reliable and accessible, and can be used by multiple systems and applications, which increases their value and usefulness. By significantly reducing the need for constant corrections and adjustments, time and resources are saved, allowing for greater efficiency in the implementation of projects and the creation of new products and services.
Data quality also plays a key role in the advancement of artificial intelligence and machine learning. AI models rely on large volumes of data to produce accurate and reliable results. If the data used is contaminated or of poor quality, the results of AI algorithms will be unreliable or even erroneous. Ensuring data quality is therefore essential to maximise the performance of AI applications, reduce or eliminate biases and realise their full potential.
With the aim of offering a process based on international standards that can help organisations to use a quality model and to define appropriate quality characteristics and metrics, the Data Office has sponsored, promoted and participated in the generation of the specification UNE 0081 Data Quality Assessment that complements the already existing specification UNE 0079 Data Quality Management, focused more on the definition of data quality management processes than on data quality as such.
UNE Specification - Guide to Data Quality Assessment
The UNE 0081 specification, a family of international standards ISO/IEC 25000, makes it possible to know and evaluate the quality of the data of any organisation, making it possible to establish a future plan for its improvement, and even to formally certify its quality. The target audience for this specification, applicable to any type of organisation regardless of size or dedication, will be data quality officers, as well as consultants and auditors who need to carry out an assessment of data sets as part of their functions.
The specification first sets out the data quality model, detailing the quality characteristics that data can have, as well as some applicable metrics, and once this framework is defined, goes on to define the process to be followed to assess the quality of a dataset. Finally, the specification ends by detailing how to interpret the results obtained from the evaluation by showing some concrete examples of application.
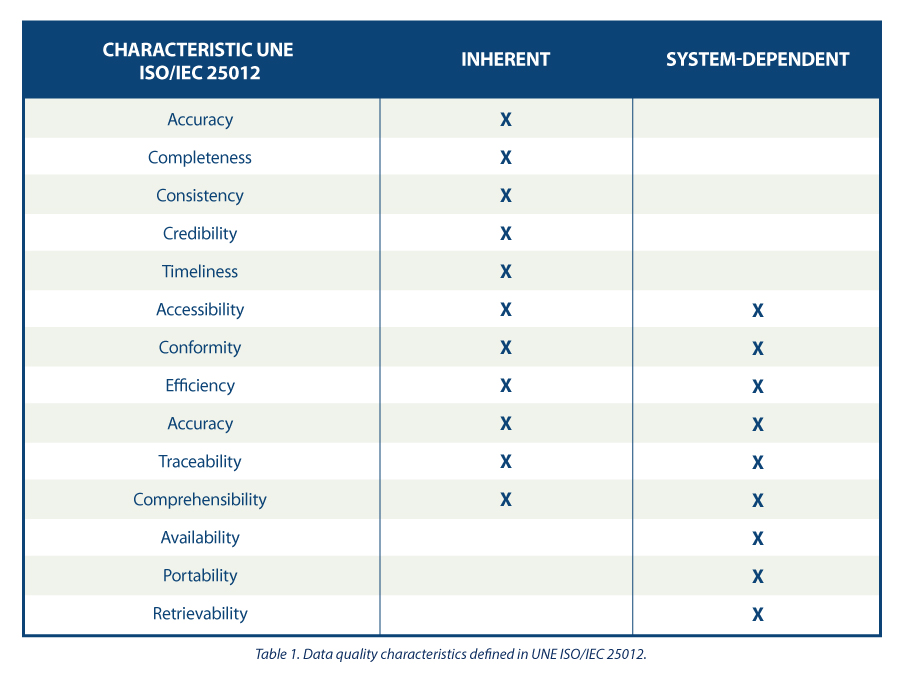
Data quality model
The guide proposes a series of quality characteristics following those present in the ISO/IEC 25012 standard , classifying them between those inherent to the data, those dependent on the system where the data is hosted, or those dependent on both circumstances. The choice of these characteristics is justified as they encompass those present in other frameworks such as DAMA, FAIR, EHDS, IA Act and GDPR.
Based on the defined characteristics, the guide uses ISO/IEC 25024 to propose a set of metrics to measure the properties of the characteristics, understanding these properties as "sub-characteristics" of the characteristics.
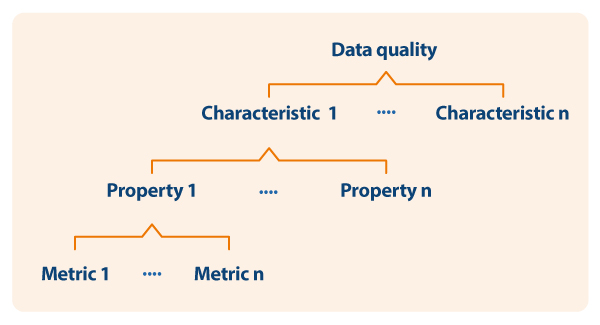
Thus, as an example, following the dependency scheme, for the specific characteristic of "consistency of data format" its properties and metrics are shown, one of them being detailed


Process for assessing the quality of a data set
For the actual assessment of data quality, the guide proposes to follow the ISO/IEC 25040 standard, which establishes an assessment model that takes into account both the requirements and constraints defined by the organisation, as well as the necessary resources, both material and human. With these requirements, an evaluation plan is established through specific metrics and decision criteria based on business requirements, which allows the correct measurement of properties and characteristics and interpretation of the results.
Below is an outline of the steps in the process and its main activities:
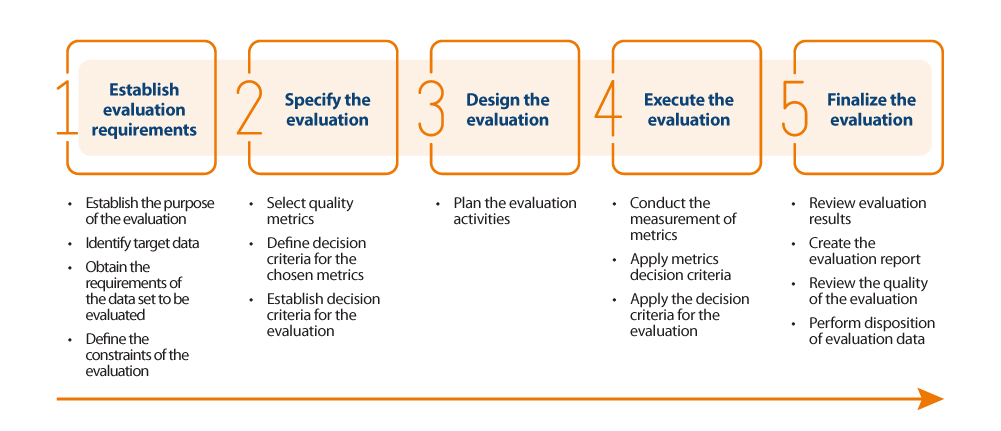
Results of the quality assesment
The outcome of the assessment will depend directly on the requirements set by the organisation and the criteria for compliance. The properties of the characteristics are usually evaluated from 0 to 100 based on the values obtained in the metrics defined for each of them, and the characteristics in turn are evaluated by aggregating the previous ones also from 0 to 100 or by converting them to a discrete value from 1 to 5 (1 poor quality, 5 excellent quality) depending on the calculation and weighting rules that have been established. In the same way that the measurement of the properties is used to obtain the measurement of their characteristics, the same happens with these characteristics, which by means of their weighted sum based on the rules that have been defined (being able to establish more weight to some characteristics than to others), a final result of the quality of the data can be obtained. For example, if we want to calculate the quality of data based on a weighted sum of their intrinsic characteristics, where, because of the type of business, we are interested in giving more weight to accuracy, then we could define a formula such as the following:
Data quality = 0.4*Accuracy + 0.15*Completeness + 0.15*Consistency + 0.15*Credibility + 0.15*Currentness
Assume that each of the quality characteristics has been similarly calculated on the basis of the weighted sum of their properties, resulting in the following values: Accuracy=50%, Completeness=45%, Consistency=35%, Credibility=100% and Currency=50%. This would result in data quality:
Data quality = 0.4*50% + 0.15*45% + 0.15*35% + 0.15*100% + 0.15*50% = 54.5%
Assuming that the organisation has established requirements as shown in the following table:

It could be concluded that the organisation as a whole has a data score of "3= Good Quality".
In summary, the assessment and improvement of the quality of the dataset may be as thorough and rigorous as necessary, and should be carried out in an iterative and constant manner so that the data is continuously increasing in quality, so that a minimum data quality is ensured or can even be certified. This minimum data quality can refer to improving data sets internal to an organisation, i.e. those that the organisation manages and exploits for the operation of its business processes; or it can be used to support the sharing of data sets through the new paradigm of data spaces generating new market opportunities. In the latter case, when an organisation wants to integrate its data into a data space for future brokering, it is desirable to carry out a quality assessment, labelling the dataset appropriately with reference to its quality (perhaps by metadata). Data of proven quality has a different utility and value than data that lacks it, positioning the former in a preferential position in the competitive market.
The content of this guide, as well as the rest of the UNE specifications mentioned, can be viewed freely and free of charge from the AENOR portal through the link below by accessing the purchase section and marking “read” in the dropdown where “pdf” is pre-selected. Access to this family of UNE data specifications is sponsored by the Secretary of State for Digitalization and Artificial Intelligence, Directorate General for Data. Although viewing requires prior registration, a 100% discount on the total price is applied at the time of finalizing the purchase. After finalizing the purchase, the selected standard or standards can be accessed from the customer area in the my products section.
https://tienda.aenor.com/norma-une-especificacion-une-0080-2023-n0071383
https://tienda.aenor.com/norma-une-especificacion-une-0079-2023-n0071118
https://tienda.aenor.com/norma-une-especificacion-une-0078-2023-n0071117
https://tienda.aenor.com/norma-une-especificacion-une-0077-2023-n0071116
Noticia
On September 11th, a webinar was held to review Gaia-X, from its foundations, embodied by its architecture and trust model called Trust Framework, to the Federation Services that aim to facilitate and speed up access to the infrastructure, to the catalogue of services that some users (providers) will be able to make available to others (consumers).
The webinar, led by the manager of the Spanish Gaia-X Hub, was led by two experts from the Data Office, who guided the audience through their presentations towards a better understanding of the Gaia-X initiative. At the end of the session, there was a dynamic question and answer session to go into more detail. A recording of this seminar can be accessed from the Hub's official website,[Forging the Future of Federated Data Spaces in Europe | Gaia-X (gaiax.es)]
Gaia-X as a key building block for forging European Data Spaces
Gaia-X emerges as an innovative paradigm to facilitate the integration of IT resources. Based on Web 3.0 technology models, the identification and traceability of different data resources is enabled, from data sets, algorithms, different semantic or other conceptual models, to even underlying technology infrastructure (cloud resources). This serves to make the origin and functioning of these entities visible, thus facilitating transparency and compliance with European regulations and values.
More specifically, Gaia-X provides different services in charge of automatically verifying compliance with minimum interoperability rules, which then allows defining more abstract rules with a business focus, or even as a basis for defining and instantiating the Trusted Cloud and sovereign data spaces. These services will be operationalised through different Gaia-X interoperability nodes, or Gaia-X Digital Clearing Houses.
Using Gaia-X as a tool, we will be able to publish, discover and exploit a catalogue of services that will cover different services according to the user's requirements. For instance, in the case of cloud infrastructure, these offerings may include features such as residence in European territory or compliance with EU regulations (such as eIDAS or GDPR, or data intermediation rules outlined in the Data Governance Regulation). It will also enable the creation of combinable services by aggregating components from different providers (which is complex now). Moreover, specific datasets will be available for training Artificial Intelligence models, and the owner of these datasets will maintain control thanks to enabled traceability, up to the execution of algorithms and apps on the consumer's own data, always ensuring privacy preservation.
As we can see, this novel traceability capability, based on cutting-edge technologies, serves as a driver for compliance, and is therefore a fundamental building block in the deployment of interoperable data spaces at European level and the digital single market.
Blog
A data space is a development framework that enables the creation of a complete ecosystem by providing an organisational, regulatory, technical and governance structure with the objective of facilitating the reliable and secure exchange of different data assets for the common benefit of all actors involved and ensuring compliance with all applicable laws and regulations. Data spaces are also a key element of the European Union's new data strategy and an essential building block in realising the goal of the European single data market.
As part of this strategy, the EU is currently exploring the creation of several data space pilots in a number of strategic sectors and domains: health, industry, agriculture, finance, mobility, Green Pact, energy, public administration and skills. These data spaces offer great potential to help organisations improve decision-making, increase innovation, develop new products, services and business models, reduce costs and avoid duplication of efforts. However, creating a successful data space is not a trivial activity and requires first carefully analysing the use cases and then facing major business, legal, operational, functional, technological and governance challenges.
This is why, as a support measure, the Data Spaces Support Centre (DSSC) has also been created to provide guidance, tools and resources to organisations interested in creating or participating in new data spaces. One of the first resources developed by the DSSC was the Data Spaces Starter Kit, the final version of which has recently been published and which provides a basic initial guide to understanding the basic elements of a data space and how to deal with the different challenges that arise when building them. We review below some of the main guidelines and recommendations offered by this starter kit.
The value of data spaces and their business models
Data spaces can be a real alternative to current unidirectional platforms, generating business models based on network effects that respond to both the supply and demand of data. Among the different business model patterns existing in data spaces, we can find:
- Cost sharing: all participants save time and money by sharing data for a common purpose, such as the smart network of connected SCSN providers.
- Joint innovation: innovation is only possible if data is shared as none of the participants have the complete data individually, e.g., the Eona-X platform for mobility, transport and tourism.
- Combined forces: different actors join forces to prevent a single actor from dominating a certain space, as in the EuPro Gigant manufacturing data network.
- Shared market: actors with common interests share data with each other in order to benefit each other, such as the Catena-X automotive network.
- Greater common good: when the public and private sectors share data for a social purpose, as for example in the mobility data space developed in Spain through the Mobility Working Group of the Gaia-X Hub.
The legal aspects
The legal side of data spaces can be a major challenge as they necessarily move between multiple legal frameworks and regulations, both national and European. To address this challenge, the Data Spaces Support Centre proposes the elaboration of a reference framework composed of three main instruments:
- The cross-cutting legal frameworks that will apply to all data spaces, such as contract law, data protection, intellectual property, competition or cybersecurity laws.
- The organisational aspects to consider when establishing models and mechanisms for data governance in each specific case.
- The contractual dimension to be taken into account when exchanging data and the agreements and terms of use to be established to make this possible.
Operational activities
The design of operational activities should address the arrangements that enable the organisational functioning of the data space, such as guidelines for onboarding new participants, decision-making and conflict resolution.
In addition, consideration should also be given to business operations, such as process streamlining and automation, marketing tasks and awareness-raising activities, which are also important components of operational activities.
Functionality of data spaces
Data spaces shall share a number of basic components (or building blocks) that will provide the minimum functionality expected of them, including at least the following elements:
- Interoperability: data models and formats, data exchange interfaces and origin and traceability.
- Trust: identity management, access and usage control and secure data exchanges.
- Data value: metadata and location protocols, data usage accounting, publishing and commercial services.
- Governance: cooperation and service level agreements and continuity models.
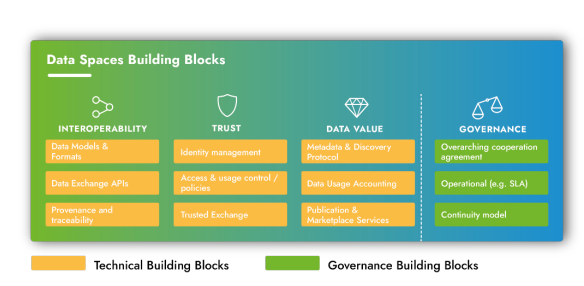
While these components can be expected to be common to all data spaces and provide similar functionality, each individual data space can make its own design choices in implementing and realising them.
Technological aspects
Data spaces are designed to be technology agnostic, i.e., defined solely in terms of functionality and with freedom in the choice of specific technologies for implementation. In this scenario it will be important to establish clear references in terms of:
- A formal basis of de facto standards to be followed.
- Specifications to serve as a reference for the different implementations.
- Open source implementations of the basic components carried out by other actors.
Governance of data spaces
Designing, implementing and maintaining a data space requires multiple organisations to collaborate together across different functions. This requires these entities to build a common vision of the key aspects of such collaboration through a governance framework.
This will require a joint design exercise through which stakeholders formalise a set of agreements defining key strategic and operational aspects, such as legal issues, description of the network of participants, code of conduct, terms and conditions of use, data space incorporation and membership agreements, and governance model.
In the near future the DSSC support centre will identify the core components of each of the dimensions described above and provide additional guidance for each of them through the development of a common blueprint for data spaces. So, if you are considering participating in any of the data spaces initiatives that are being launched, but are not quite sure where to start, then this basic starter kit will certainly be a valuable resource in understanding the basic concepts - along with the glossary that explains all the related terminology. Also, don't forget to subscribe to the support centre's newsletter to keep up to date with all the latest news, documentation and support services on offer.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
We live in the era of data, a lever of digital transformation and a strategic asset for innovation and the development of new technologies and services. Data, beyond the skills it brings to the generator and/or owner of the same, also has the peculiarity of being a non-rival asset. This means that it can be reused without detriment to the owner of the original rights, which makes it a resource with a high degree of scalability in its sharing and exploitation.
This possibility of non-rival sharing, in addition to opening potential new lines of business for the original owners, also carries a huge latent value for the development of new business models. And although sharing is not new, it is still very limited to niche contexts of sector specialisation, mediated either by trust between parties (usually forged in advance), or tedious and disciplined contractual conditions. This is why the innovative concept of data space has emerged, which in its most simplified sense is nothing more than the modelling of the general conditions under which to deploy a voluntary, sovereign and secure sharing of data. Once modelled, the prescription of considerations and methodologies (technological, organisational and operational) allows to make such sharing tangible based on peer-to-peer interactions, which together shape federated ecosystems of data sets and services.
Therefore, and given the distributed nature of data spaces (they are not a monolithic computer system, nor a centralised platform), an optimal way to approach their construction is through the creation and deployment of use cases.
The Data Office has created this infographic of a 'Model of use case development within data spaces', with the objective of synthetically defining the phases of this iterative journey, which progressively shapes a data space. This model also serves as a general framework for other technical and methodological deliverables to come, such as the 'Use Case Feasibility Assessment Guide', or the 'Use Case Design Guide', elements with which to facilitate the implementation of practical (and scalable by design) data sharing experiences, a sine qua non condition to articulate the longed-for European single data market.
The challenge of building a data space
To make the process of developing a data space more accessible, we could assimilate the definition and construction of a use case as a construction project, in which from an initial business problem (needs or challenges, desires, or problems to be solved) a goal is reached in which value is added to the business, providing a solution to those initial needs. This infographic offers a synthesis of that journey.

These are the phases of the model:
PHASE 1: Definition of the business problem. In this phase a group of potential participants detects an opportunity around the sharing of their data (hitherto siloed) and its corresponding exploitation. This opportunity can be new products or services (innovation), efficiency improvements, or the resolution of a business problem. In other words, there is a business objective that the group can solve jointly, by sharing data.
PHASE 2: Data-driven modelling. In this phase, those elements that serve to structure and organise the data for strategic decision-making based on its exploitation will be identified. It involves defining a model that possibly uses multidisciplinary tools to achieve business results. This is the part traditionally associated with data science tasks.
PHASE 3: Consensus on requirements specification. Here, the actors sponsoring the use case must establish the relationship model to have during this collaborative project around the data. Such a formula must: (i) define and establish the rules of engagement, (ii) define a common set of policies and governance model, and (iii) define a trust model that acts as the root of the relationship.
PHASES 4 and 5: Use case mapping. As in a construction project, the blueprint is the means of expressing the ideas of those who have defined and agreed the use case, and should explicitly capture the solutions proposed for each part of the use case development. This plan is unique for each use case, and phase 5 corresponds to its construction. However, it is not created from scratch, but there are multiple references that allow the use of previously identified materials and techniques. For example, models, methodologies, artefacts, templates, technological components or solutions as a service. Thus, just as an architect designing a building can reuse recognised standards, in the world of data spaces there are also models on which to paint the components and processes of a use case. The analysis and synthesis of these references is phase 4.
PHASE 6: Technology selection, parameterisation and/or development. The technology enables the deployment of the transformation and exploitation of the data, favouring the entire life cycle, from its collection to its valorisation. In this phase, the infrastructure that supports the use case is implemented, understood as the collection of tools, platforms, applications and/or pieces of software necessary for the operation of the application.
PHASE 7: Integration, testing and deployment. Like any technological construction process, the use case will go through the phases of integration, testing and deployment. The integration work and the functional, usability, exploratory and acceptance tests, etc. will help us to achieve the desired configuration for the operational deployment of the use case. In the case of wanting to incorporate a use case into a pre-existing data space, the integration would seek to fit within its structure, which means modelling the requirements of the use case within the processes and building blocks of the data space.
PHASE 8: Operational data space. The end point of this journey is the operational use case, which will employ digital services deployed on top of the data space structure, and whose architecture supports different resources and functionalities federated by design. This implies that the value creation lifecycle would have been efficiently articulated based on the shared data, and business returns are achieved according to the original approach. However, this does not prevent the data space from continuing to evolve a posteriori, as its vocation is to grow either with the entry of new challenges, or actors to existing use cases. In fact, the scalability of the model is one of its unique strengths.
In essence, the data shared through a federated and interoperable ecosystem is the input that feeds a layer of services that will generate value and solve the original needs and challenges posed, in a journey that goes from the definition of a business problem to its resolution.
Noticia
Last March 13th, a session of the Mobility Working Group of the Gaia-X Spain Hub was held, addressing the main challenges of the sector regarding projects related to data sharing and exploitation. The session, which took place at the Technical School of Civil Engineers of the Polytechnic University of Madrid, allowed attendees to learn firsthand about the main challenges of the sector, as well as some of the cutting-edge data projects in the mobility industry. The event was also a meeting point where ideas and reflections were shared among key actors in the sector.
The session began with a presentation from the Ministry of Transport, Mobility, and Urban Agenda, which highlighted the great importance of the National Access Point for Multimodal Transport, a European project that allows all information on passenger transport services in the country to be centralized in a single national point, with the aim of providing the foundation for driving the development of future mobility services.
Next, the Data Office of the State Secretariat for Artificial Intelligence (SEDIA) provided their vision of the Data Spaces development model and the design principles of such spaces aligned with European values. The importance of business networks based on data ecosystems, the intersectoral nature of the Mobility industry, and the significant role of open data in the sector's data spaces were highlighted.
Next, use cases were presented by Vicomtech, Amadeus, i2CAT, and the Alcobendas City Council, which allowed attendees to learn firsthand about some examples of technology use for data sharing projects (both data spaces and data lakes).
Finally, an initial study by the i2CAT Foundation, FACTUAL Consulting, and EIT Urban Mobility on the basic components of future mobility data spaces in Spain was presented. The study, which can be downloaded here in Spanish, addresses the potential of mobility data spaces for the Spanish market. Although it focuses on Spain, it takes a national and international research approach, framed in the European context to establish standards, develop the technical components that enable data spaces, the first flagship projects, and address common challenges to achieve milestones in sustainable mobility in Europe.
The presentations used in the session are available at this link.