Blog
The European Commission's 'European Data Strategy' states that the creation of a single market for shared data is key. In this strategy, the Commission has set as one of its main objectives the promotion of a data economy in line with European values of self-determination in data sharing (sovereignty), confidentiality, transparency, security and fair competition.
Common data spaces at European level are a fundamental resource in the data strategy because they act as enablers for driving the data economy. Indeed, pooling European data in key sectors, fostering data circulation and creating collective and interoperable data spaces are actions that contribute to the benefit of society.
Although data sharing environments have existed for a long time, the creation of data spaces that guarantee EU values and principles is an issue. Developing enabling legislative initiatives is not only a technological challenge, but also one of coordination among stakeholders, governance, adoption of standards and interoperability.
To address a challenge of this magnitude, the Commission plans to invest close to €8 billion by 2027 in the deployment of Europe's digital transformation. Part of the project includes the promotion of infrastructures, tools, architectures and data sharing mechanisms. For this strategy to succeed, a data space paradigm that is embedded in the industry needs to be developed, based on the fulfilment of European values. This data space paradigm will act as a de facto technology standard and will advance social awareness of the possibilities of data, which will enable the economic return on the investments required to create it.
In order to make the data space paradigm a reality, from the convergence of current initiatives, the European Commission has committed to the development of the Simpl project.
What exactly is Simpl?
Simpl is a €150 million project funded by the European Commission's Digital Europe programme with a three-year implementation period. Its objective is to provide society with middleware for building data ecosystems and cloud infrastructure services that support the European values of data sovereignty, privacy and fair markets.
The Simpl project consists of the delivery of 3 products:
- Simpl-Open: Middleware itself. This is a software solution to create ecosystems of data services (data and application sharing) and cloud infrastructure services (IaaS, PaaS, SaaS, etc). This software must include agents enabling connection to the data space, operational services and brokerage services (catalogue, vocabulary, activity log, etc.). The result should be delivered under an open source licence and an attempt will be made to build an open source community to ensure its evolution.
- Simpl-Labs: Infrastructure for creating test bed environments so that interested users can test the latest version of the software in self-service mode. This environment is primarily intended for data space developers who want to do the appropriate technical testing prior to a deployment.
- Simpl-Live: Deployments of Simpl-open in production environments that will correspond to sectorial spaces contemplated in the Digital Europe programme. In particular, the deployment of data spaces managed by the European Commission itself (Health, Procurement, Language) is envisaged.
The project is practically oriented and aims to deliver results as soon as possible. It is therefore intended that, in addition to supplying the software, the contractor will provide a laboratory service for user testing. The company developing Simpl will also have to adapt the software for the deployment of common European data spaces foreseen in the Digital Europe programme.
The Gaia-X partnership is considered to be the closest in its objectives to the Simpl project, so the outcome of the project should strive for the reuse of the components made available by Gaia-X.
For its part, the Data Space Support Center, which involves the main European initiatives for the creation of technological frameworks and standards for the construction of data spaces, will have to define the middleware requirements by means of specifications, architectural models and the selection of standards.
Simpl's preparatory work was completed in May 2022, setting out the scope and technical requirements of the project which have been the subject of detail in the currently open contractual process. The tender was launched on 24 February 2023. All information is available on TED eTendering, including how to ask questions about the tendering process. The deadline for applications is 24 April 2023 at 17:00 (Brussels time).
Simpl expects to have a minimum viable platform published in early 2024. In parallel, and as soon as possible, the open test environment (Simpl-Labs) will be made available for interested parties to experiment. This will be followed by the progressive integration of different use cases, helping to tailor Simpl to specific needs, with priority being given to cases otherwise funded under the Europe DIGITAL work programme.
In conclusion, Simpl is the European Commission's commitment to the deployment and interoperability of the different sectoral data space initiatives, ensuring alignment with the specifications and requirements emanating from the Data Space Support Center and, therefore, with the convergence process of the different European initiatives for the construction of data spaces (Gaia-X, IDSA, Fiware, BDVA).
Noticia
Gaia-X represents an innovative paradigm for linking data more closely to the technological infrastructure underneath, so as to ensure the transparency, origin and functioning of these resources. This model allows us to deploy a sovereign and transparent data economy, which respects European fundamental rights, and which in Spain will take shape around the sectoral data spaces (C12.I1 and C14.I2 of the Recovery, Transformation and Resilience Plan). These data spaces will be aligned with the European regulatory framework, as well as with governance and instruments designed to ensure interoperability, and on which to articulate the sought-after single data market.
In this sense, Gaia-X interoperability nodes, or Gaia-X Digital Clearing House (GXDCH), aim to offer automatic validation services of interoperability rules to developers and participants of data spaces. The creation of such nodes was announced at the Gaia-X Summit 2022 in Paris last November. The Gaia-X architecture, promoted by the Gaia-X European Association for Data & Cloud AISBL, has established itself as a promising technological alternative for the creation of open and transparent ecosystems of data sets and services.
These ecosystems, federated by nature, will serve to develop the data economy at scale. But in order to do so, a set of minimum rules must be complied with to ensure interoperability between participants. Compliance with these rules is precisely the function of the GXDCH, serving as an "anchor" to deploy certified market services. Therefore, the creation of such a node in Spain is a crucial element for the deployment of federated data spaces at national level, which will stimulate development and innovation around data in an environment of respect for data sovereignty, privacy, transparency and fair competition.
The GXDCH is defined as a node where operational services of an ecosystem compliant with the Gaia-X interoperability rules are provided. Operational services" should be understood as services that are necessary for the operation of a data space, but are not in themselves data sharing services, data exploitation applications or cloud infrastructures. Gaia-X defines six operational services, of which at least two must be part of the mandatory nodes hosting the GXDCHs:
Mandatory services
- Gaia-X Registry: Defined as an immutable, non-repudiable, distributed database with code execution capabilities. Typically it would be a blockchain infrastructure supporting a decentralised identity service ('Self Sovereign Identity') in which, among others, the list of Trust Anchors or other data necessary for the operation of identity management in Gaia-X is stored.
- Gaia-X Compliance Service or Gaia-X Compliance Service: Belongs to the so-called Gaia-X Federation Services and its function is to verify compliance with the minimum interoperability rules defined by the Gaia-X Association (e.g. the Trust Framework).
Optional services
- Self-Descriptions (SDs) or Wizard Edition Service: SDs are verifiable credentials according to the standard defined by the W3C by means of which both the participants of a Gaia-X ecosystem and the products made available by the providers describe themselves. The aforementioned compliance service consists of validating that the SDs comply with the interoperability standards. The Wizard is a convenience service for the creation of Self-Descriptions according to pre-defined schemas.
- Catalogue: Storage service of the service offer available in the ecosystem for consultation.
- e-Wallet: For the management of verifiable credentials (SDs) by participants in a system based on distributed identities.
- Notary Service: Service for issuing verifiable credentials signed by accreditation authorities (Trust Anchors).
What is the Gaia-X Compliance Service (i.e. Compliance Service)?
The Gaia-X Compliance Service belongs to the so-called Gaia-X Federation Services and its function is to verify compliance with the minimum interoperability rules defined by the Gaia-X Association. Gaia-X calls these minimum interoperability rules (Trust Framework). It should be noted that the establishment of the Trust Framework is one of the differentiating contributions of the Gaia-X technology framework compared to other solutions on the market. But the objective is not just to establish interoperability standards, but to create a service that is operable and, as far as possible, automated, that validates compliance with the Trust Framework. This service is the Gaia-X Compliance Service.
The key element of these rules are the so-called "Self-Descriptions" (SDs). SDs are verifiable credentials according to the standard defined by the W3C by which both the participants of a data space and the products made available by the providers describe themselves. The Gaia-X Compliance service validates compliance with the Trust Framework by checking the SDs from the following points of view:
- Format and syntax of the SDs
- Validation of the SDs schemas (vocabulary and ontology)
- Validation of the cryptography of the signatures of the issuers of the SDs
- Attribute consistency
- Attribute value veracity.
Once the Self-Descriptions have been validated, the compliance service operator issues a verifiable credential that attests to compliance with interoperability standards, providing confidence to ecosystem participants. Gaia-X AISBL provides the necessary code to implement the Compliance Service and authorises the provision of the service to trusted entities, but does not directly operate the service and therefore requires the existence of partners to carry out this task.

Blog
There is such a close relationship between data management, data quality management and data governance that the terms are often used interchangeably or confused. However, there are important nuances.
The overall objective of data management is to ensure that data meets the business requirements that will support the organisation's processes, such as collecting, storing, protecting, analysing and documenting data, in order to implement the objectives of the data governance strategy. It is such a broad set of tasks that there are several categories of standards to certify each of the different processes: ISO/IEC 27000 for information security and privacy, ISO/IEC 20000 for IT service management, ISO/IEC 19944 for interoperability, architecture or service level agreements in the cloud, or ISO/IEC 8000-100 for data exchange and master data management.
Data quality management refers to the techniques and processes used to ensure that data is fit for its intended use. This requires a Data Quality Plan that must be in line with the organisation's culture and business strategy and includes aspects such as data validation, verification and cleansing, among others. In this regard, there is also a set of technical standards for achieving data quality] including data quality management for transaction data, product data and enterprise master data (ISO 8000) and data quality measurement tasks (ISO 25024:2015).
Data governance, according to Deloitte's definition, consists of an organisation's set of rules, policies and processes to ensure that the organisation's data is correct, reliable, secure and useful. In other words, it is the strategic, high-level planning and control to create business value from data. In this case, open data governance has its own specificities due to the number of stakeholders involved and the collaborative nature of open data itself.
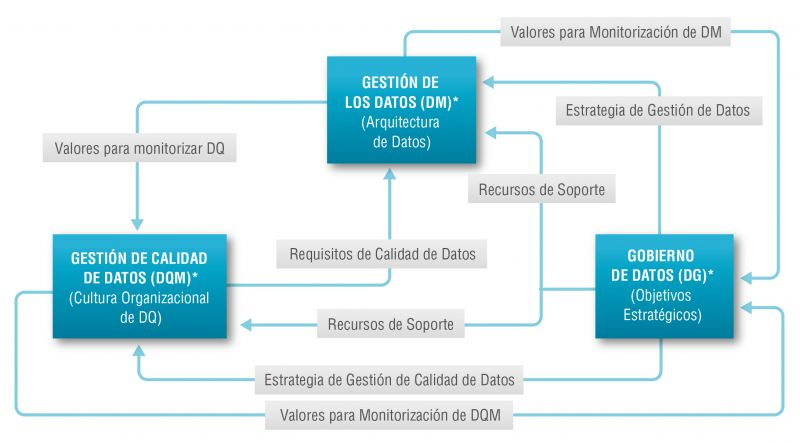
The Alarcos Model
In this context, the Alarcos Model for Data Improvement (MAMD), currently in its version 3, aims to collect the necessary processes to achieve the quality of the three dimensions mentioned above: data management, data quality management and data governance. This model has been developed by a group of experts coordinated by the Alarcos research group of the University of Castilla-La Mancha in collaboration with the specialised companies DQTeam and AQCLab.
The MAMD Model is aligned with existing best practices and standards such as Data Management Community (DAMA), Data management maturity (DMM) or the ISO 8000 family of standards, each of which addresses different aspects related to data quality and master data management from different perspectives. In addition, the Alarcos model is based on the family of standards to define the maturity model so it is possible to achieve AENOR certification for ISO 8000-MAMD data governance, management and quality.
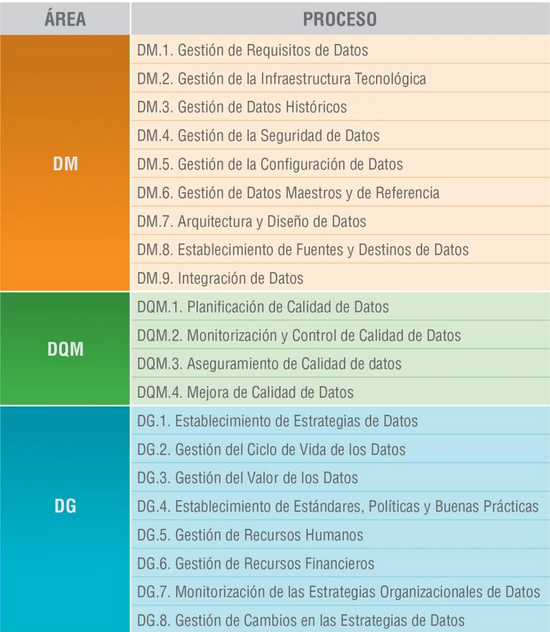
The MAMD model consists of 21 processes, 9 processes correspond to data management (DM), data quality management (DQM) includes 4 more processes and data governance (DG), which adds another 8 processes.
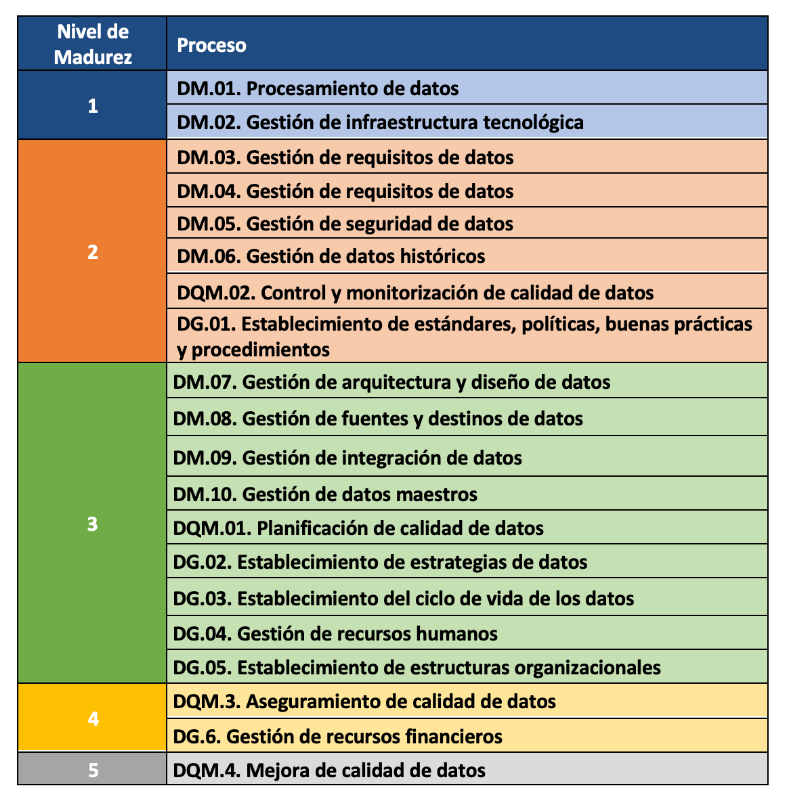
The progressive incorporation of the 21 processes allows the definition of 5 maturity levels that contribute to the organisation improving its data management, data quality and data governance. Starting with level 1 (Performed) where the organisation can demonstrate that it uses good practices in the use of data and has the necessary technological support, but does not pay attention to data governance and data quality, up to level 5 (Innovative) where the organisation is able to achieve its objectives and is continuously improving.
The model can be certified with an audit equivalent to that of other AENOR standards, so there is the possibility of including it in the cycle of continuous improvement and internal control of regulatory compliance of organisations that already have other certificates.
Practical exercises
The Library of the University of Castilla-La Mancha (UCLM), which supports more than 30,000 students and 3,000 professionals including teachers and administrative and service staff, is one of the first organisations to pass the certification audit and therefore obtain level 2 maturity in ISO/IEC 33000 - ISO 8000 (MAMD).
The strengths identified in this certification process were the commitment of the management team and the level of coordination with other universities. As with any audit, improvements were proposed such as the need to document periodic data security reviews which helped to feed into the improvement cycle.
The fact that organisations of all types place an increasing value on their data assets means that technical certification models and standards have a key role to play in ensuring the quality, security, privacy, management or proper governance of these data assets. In addition to existing standards, a major effort continues to be made to develop new standards covering aspects that have not been considered central until now due to the reduced importance of data in the value chains of organisations. However, it is still necessary to continue with the formalisation of models that, like the Alarcos Data Improvement Model, allow the evaluation and improvement process of the organisation in the treatment of its data assets to be addressed holistically, and not only from its different dimensions.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
The Spanish Hub of Gaia-X (Gaia-X Hub Spain), a non-profit association whose aim is to accelerate Europe's capacity in data sharing and digital sovereignty, seeks to create a community around data for different sectors of the economy, thus promoting an environment conducive to the creation of sectoral data spaces. Framed within the Spain Digital 2026 strategy and with the Recovery, Transformation and Resilience Plan as a roadmap for Spain's digital transformation, the objective of the hub is to promote the development of innovative solutions based on data and artificial intelligence, while contributing to boosting the competitiveness of our country's companies.
The hub is organized into different working groups, with a specific one dedicated to analyzing the challenges and opportunities of data sharing and exploitation spaces in the tourism sector. Tourism is one of the key productive sectors in the Spanish economy, reaching a volume of 12.2% of the national GDP.
Tourism, given its ecosystem of public and private participants of different sizes and levels of technological maturity, constitutes an optimal environment to contrast the benefits of these federated data ecosystems. Thanks to them, the extraction of value from non-traditional data sources is facilitated, with high scalability, and ensuring robust conditions of security, privacy, and thus data sovereignty.
Thus, with the aim of producing the first X-ray of this dataspace in Spain, the Data Office, in collaboration with the Spanish Hub of Gaia-X, has developed the report 'X-ray of the Tourism Dataspace in Spain', a document that seeks to summarize and highlight the current status of the design of this dataspace, the different opportunities for the sector, and the main challenges that must be overcome to achieve its deployment, offering a roadmap for its construction and deployment.
Why is a tourism data space necessary?
If something became clear after the outbreak of the COVID-19 pandemic, it is that tourism is an interdependent activity with other industries, so when it was paused, sectors such as mobility, logistics, health, agriculture, automotive, or food, among others, were also affected.
Situations like the one mentioned above highlight the possibilities offered by data sharing between sectors, as they can help improve decision-making. However, achieving this in the tourism sector is not an easy task since deploying a data space for this sector requires coordinated efforts among the different parts of society involved.
Thus, the objective and challenge is to create intelligent "spaces" capable of providing a context of security and trust that promotes the exchange and combination of data. In this way, and based on the added value generated by data, it would be possible to solve some of the existing problems in the sector and create new strategies focused on better understanding the tourist and, therefore, improving their travel experience.
The creation of these data sharing and exploitation spaces will bring significant benefits to the sector, as it will facilitate the creation of more personalized offers, products, and services that provide an enhanced and tailored experience to meet the needs of customers, thus improving the capacity to attract tourists. In addition, it will promote a better understanding of the sector and informed decision-making by both public and private organizations, which can more easily detect new business opportunities.
Challenges of security and data governance to take advantage of digital tourism market opportunities
One of the main obstacles to developing a sectoral data space is the lack of trust in data sharing, the absence of shared data models, or the insufficient interoperability standards for efficient data exchange between different existing platforms and actors in the value chain.
Moving to more specific challenges, the tourism sector also faces the need to combine B2B data spaces (sharing between private companies and organizations) with C2B and G2B spaces (sharing between users and companies, and between the public sector and companies, respectively). If we add to this the ideal need to land the tourism sector's datasets at the national, regional, and local levels, the challenge becomes even greater.
To design a sector data space, it is also important to take into account the differences in data quality among the aforementioned actors. Due to the lack of specific standards, there are differences in the level of granularity and quality of data, semantics, as well as disparity in formats and licenses, resulting in a disconnected data landscape.
Furthermore, it is essential to understand the demands of the different actors in the industry, which can only be achieved by listening and taking notes on the needs present at the different levels of the industry. Therefore, it is important to remember that tourism is a social activity whose focus should not be solely on the destination. The success of a tourism data space will also rely on the ability to better understand the customer and, consequently, offer services tailored to their demands to improve their experience and incentivize them to continue traveling.
Thus, as stated in the report prepared by the Data Office, in collaboration with the Spanish hub of Gaia-X, it is interesting to redirect the focus and shift it from the destination to the tourist, in line with the discovery and generation of use cases by SEGITTUR. While it is true that focusing on the destination has helped develop digital platforms that have driven competitiveness, efficiency, and tourism strategy, a strategy that pays the same attention to the tourist would allow for expanding and improving the available data catalogs.
Measuring the factors that condition tourists' experience during their visit to our country allows for optimizing their satisfaction throughout the entire travel circuit, while also contributing to creating increasingly personalized marketing campaigns, based on the analysis of the interests of different market segments.
Current status of the construction of the Spanish Tourism data space and next steps
The lack of maturity of the market in the creation of data spaces as a solution makes an experimental approach necessary, both for the consolidation of the technological components and for the validation of the different facets (soft infrastructure) present in the data spaces.
Currently, the Tourism Working Group of the Spanish Gaia-X Hub is working on the definition of the key elements of the tourism data space, based on use cases aligned with the sector's challenges. The objective is to answer some key questions, using existing knowledge in the field of data spaces:
- What are the key characteristics of the tourism environment and what business problems can be addressed?
- What data-oriented models can be worked on in different use cases?
- What requirements exist and what governance model is necessary? What types of participants should be considered?
- What business, legal, operational, functional, and technological components are necessary?
- What reference technology architecture can be used?
- What development, integration, testing, and technology deployment processes can be employed?
Noticia
Updated: 21/03/2024
On January 2023, the European Commission published a list of high-value datasets that public sector bodies must make available to the public within a maximum of 16 months. The main objective of establishing the list of high-value datasets was to ensure that public data with the highest socio-economic potential are made available for re-use with minimal legal and technical restriction, and at no cost. Among these public sector datasets, some, such as meteorological or air quality data, are particularly interesting for developers and creators of services such as apps or websites, which bring added value and important benefits for society, the environment or the economy.
The publication of the Regulation has been accompanied by frequently asked questions to help public bodies understand the benefit of HVDS (High Value Datasets) for society and the economy, as well as to explain some aspects of the obligatory nature of HVDS (High Value Datasets) and the support for publication.
In line with this proposal, Executive Vice-President for a Digitally Ready Europe, Margrethe Vestager, stated the following in the press release issued by the European Commission:
"Making high-value datasets available to the public will benefit both the economy and society, for example by helping to combat climate change, reducing urban air pollution and improving transport infrastructure. This is a practical step towards the success of the Digital Decade and building a more prosperous digital future".
In parallel, Internal Market Commissioner Thierry Breton also added the following words on the announcement of the list of high-value data: "Data is a cornerstone of our industrial competitiveness in the EU. With the new list of high-value datasets we are unlocking a wealth of public data for the benefit of all”. Start-ups and SMEs will be able to use this to develop new innovative products and solutions to improve the lives of citizens in the EU and around the world.
Six categories to bring together new high-value datasets
The regulation is thus created under the umbrella of the European Open Data Directive, which defines six categories to differentiate the new high-value datasets requested:
- Geospatial
- Earth observation and environmental
- Meteorological
- Statistical
- Business
- Mobility
However, as stated in the European Commission's press release, this thematic range could be extended at a later stage depending on technological and market developments. Thus, the datasets will be available in machine-readable format, via an application programming interface (API) and, if relevant, also with a bulk download option.
In addition, the reuse of datasets such as mobility or building geolocation data can expand the business opportunities available for sectors such as logistics or transport. In parallel, weather observation, radar, air quality or soil pollution data can also support research and digital innovation, as well as policy making in the fight against climate change.
Ultimately, greater availability of data, especially high-value data, has the potential to boost entrepreneurship as these datasets can be an important resource for SMEs to develop new digital products and services, which in turn can also attract new investors.
Find out more in this infographic:


Access the accessible version on two pages.
Blog
The promotion of the so-called data economy is one of the main priorities on which the European Union, in general, and Spain, in particular, are currently working. Having a single digital market for data exchange is one of the keys to achieving this momentum among the Member States, and data spaces come into play for this purpose.
Data Spaces Business Alliance (DSBA)
A data space is an ecosystem capable of realising the voluntary sharing of data among its participants, while respecting their sovereignty over it, i.e. being able to set the conditions for its access and use. The DSBA, founded in 2021, is composed of the main actors in the definition of standards, models and technological frameworks for the construction and operation of data spaces. Specifically, the alliance is composed of the Big Data Value Association (BDVA), the FIWARE Foundation and the Gaia-X European Association for Data and Cloud AISBL and the International Data Spaces Association (IDSA). The purpose of the alliance is to agree on a common technological framework that avoids technological fragmentation of the activity, as well as harmonisation in messaging and dissemination activities.
Technical Convergence Discussion Document
On the technological side, the DSBA published in September 2022 a first approximation of the desired technological convergence.
The document technically analyses the anchor points for creating trusted data spaces, federated catalogues and shared markets, and the ability to define data use policies (based on the use of a common language). This ability to share while respecting the sovereignty of the data owner is what makes these spaces novel and truly disruptive, offering for the first time technical elements with which to control the risks associated with information sharing.
The document explains, step by step and from a purely technical perspective, the actions to be addressed by each of the identified roles, with the purpose of guiding potential scenarios that could occur in reality.
To achieve technical convergence, the partnership agreed on the development of a minimum viable framework (MVF) based on three pillars:
- Interoperability in data exchange through the use of the standard NGSI-LD data exchange protocol/API and the extended Smart Data Models for the adoption of the information model defined by the IDS architecture.
- Sovereignty and trust in data exchange through the adoption of a decentralised model (Self-Sovereign Identity) as proposed by Gaia-X (with its Trust Framework) that would use the DLT (Distributed Ledger Technologies) promoted by the European Commission (EBSI). The result will be a trust environment compatible with the EU's eIDAS 2.0 regulation.
- Value creation (brokering) services consisting of a decentralised data catalogue and trading services based on TM Forum standards.
The alliance believes that this MVF would be a good starting point from which to work towards the desired technological convergence, counting and reusing parts of the current solutions provided by the different suppliers.
Example of a public data marketplace
The paper gives the example of a data service provider offering its service in a public data marketplace, so that consumers can easily access this offer. In addition, providers can also delegate access to their users to modify attributes of the service they contract.
This is an example that can be seen in detail in the document, which is interesting because different authentication systems, security and access policies and, in short, different systems that must interoperate with each other come into play.

Additionally, an example of integration between the Data Marketplace and a data catalogue is presented using the approach followed by the European Horizon 2020 project 'Digital Open Marketplace Ecosystem' (DOME). In this way, offers are created in the shared catalogue and can be subsequently consulted following the defined access policies.
The future of the DSBA
The DSBA considers that the aforementioned MVF is only the first step towards the convergence of the different existing architectures and technologies in the construction of data spaces. The next steps of the alliance will take into account the roles assigned to each of the participants. More specifically:
-
IDSA: Develops data space architectures and standards. In particular, a model for connectors to ensure sovereign data sharing in a scalable way.
-
Gaia-X: Develops and deploys an architecture, a governance model according to business specifications for sectoral data spaces, as well as a toolkit (Gaia-X Federation Services toolkit) to instantiate interoperability, composability and transparency of infrastructure and cloud data services.
- FIWARE: With a technology stack that comes from the world of Digital Twins, the community develops software components that allow to implement the construction of data spaces.
The DSBA has also set itself the following priority objectives:
- The compatibility of the IDS architecture with an identity management mechanism based on decentralised identifiers.
- The integration of a federated catalogue such as the one proposed with the metadata broker proposed in the IDS architecture.
- The definition of a common vocabulary.
- Advancing jointly with the work of the Data Space Support Center (a programme funded by the European Commission, where these associations play a leading role), as well as with the standardisation efforts based on the EC's Smart Middleware Platform (SIMPL) project.
Content prepared by Juan Mañes, expert in Data Governance.
The contents and views expressed in this publication are the sole responsibility of the author.
Noticia
Just a few days before the end of 2022, we’d like to take this opportunity to take stock of the year that is drawing to a close, a period during which the open data community has not stopped growing in Spain and in which we have joined our joint forces and desires with the Data Office. The latter unit is responsible for boosting the management, sharing and use of data throughout all the production sectors of the Spanish Economy and Society, focusing its efforts in particular on promoting spaces for sharing and making use of sectoral data.
It is precisely thanks to the incorporation of the Data Office under the Aporta Initiative that we have been able to double the dissemination effect and promote the role that open data plays in the development of the data economy.
Concurrently, during 2022 we have continued working to bring open data closer to the public, the professional community and public administrations. Thus, and with the aim of promoting the reuse of open data for social purposes, we have once again organised a new edition of the Aporta Challenge.
Focusing on the health and well-being of citizens, the fourth edition of this competition featured three winners of the very highest level and the common denominator of their digital solutions is to improve the physical and mental health of people, thanks to services developed with open data.
New examples of use cases and step-by-step visualisations
In turn, throughout this year we have continued to characterise new examples of use cases that help to increase the catalogue of open data reuse companies and applications. With the new admissions, datos.gob.es already has a catalogue of 84 reuse companies and a total of 418 applications developed from open data. Of the latter, more than 40 were identified in 2022.
Furthermore, since last year we inaugurated the step-by -step visualisations section, we have continued to explore their potential so that users can be inspired and easily replicate the examples.
Reports, guides and audio-visual material to promote the use of open data
For the purpose of continuing to provide advice to the communities of open data publishers and reusers, another of the mainstays in 2022 has been a focus on offering innovative reports on the latest trends in artificial intelligence and other emerging technologies, as well as the development of guides , infographics and videos which foster an up-close knowledge of new use cases and trends related with open data.
Some of the most frequently read articles at the datos.gob.es portal have been '4 examples of projects by private companies that are committed to open data sharing', 'How is digital transformation evolving in Spain?' either 'The main challenges to promote sectoral data spaces', inter alia. As far as the interviews are concerned, we would highlight those held with the winners of the 4th “Aporta” Challenge, with Hélène Verbrugghe, Public Policy Manager for Spain and Portugal of Meta or with Alberto González Yanes, Head of the Economic Statistics Service of the Canary Islands Institute of Statistics (ISTAC), inter alia.
Finally, we would like to thank the open data community for its support for another year. During 2022, we have managed to ensure that the National Data Catalogue exceeds 64,000 published data sets. In addition, datos.gob.es has received more than 1,300,000 visits, 25% more than in 2021, and the profiles of datos.gob.es on LinkedIn and Twitter have grown by 45% and 12%, respectively.
Here at datos.gob.es and the Data Office we are taking on this new year full of enthusiasm and a desire to work so that open data keep making progress in Spain through publishers and reusers.
Here's to a highly successful 2023!

If you’d like to see the infographic in full size you can click here.
{kind=link}
** In order to access the links included in the image itself, please download the pdf version available below.
Documentación
The FEMP's Network of Local Entities for Transparency and Citizen Participation has just presented a guide focused on data visualisation. The document, which takes as a reference the Guide to data visualisation developed by the City Council of L'Hospitalet, has been prepared based on the search for good practices promoted by public and private organisations.
The guide includes recommendations and basic criteria to represent data graphically, facilitating its comprehension. In principle, it is aimed at all the entities that are members of the FEMP's Network of Local Entities for Transparency and Citizen Participation. However, it is also useful for anyone wishing to acquire a general knowledge of data visualisation.
Specifically, the guide has been developed with three objectives in mind:
- To provide principles and good practices in the field of data visualisation.
- To provide a model for the visualisation and communication of local authority data by standardising the use of different visual resources.
- Promote the principles of quality, simplicity, inclusiveness and ethics in data communication.
What does the guide include?
After a brief introduction, the guide begins with a series of basic concepts and general principles to be followed in data visualisation, such as the principle of simplification, the use of space or accessibility and exclusive design. Through graphic examples, the reader learns what to do and what not to do if we want our visualisation to be easily understood.
The guide then focuses on the different stages of designing a data visualisation through a sequential methodological process, as shown in the following diagram:
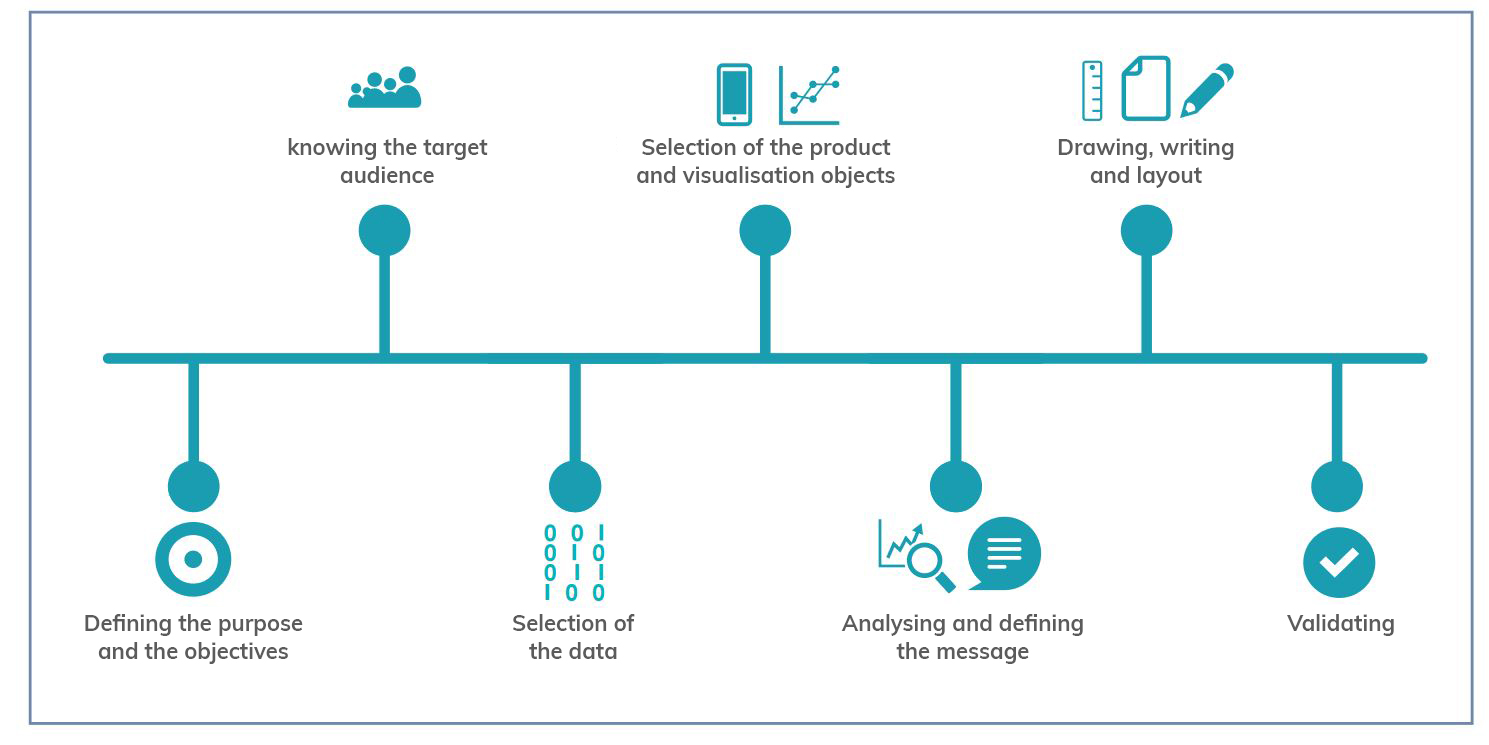
As the image shows, before developing the visualisation, it is essential to take the time to establish the objectives we want to achieve and the audience we are targeting, in order to tailor the message and select the most appropriate visualisation based on what we want to represent.
When representing data, users have at their disposal a wide variety of visualisation objects with different functions and performance. Not all objects are suitable for all cases and it will be necessary to determine the most appropriate one for each specific situation. In this sense, the guide offers several recommendations and guidelines so that the reader is able to choose the right element based on his or her objectives and audience, as well as the data he or she wants to display.
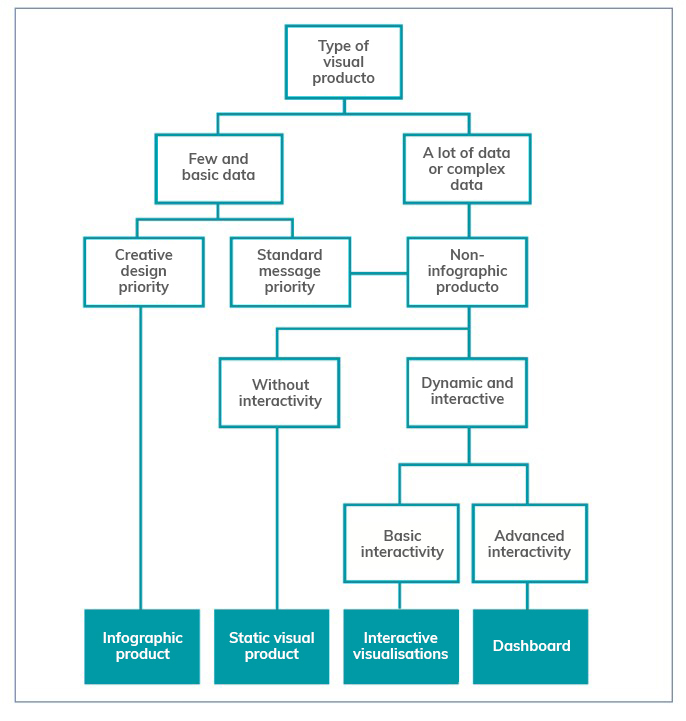
The following chapters focus on the various elements available (infographics, dashboards, indicators, tables, maps, etc.) showing the different subcategories that exist and the good practices to follow in their elaboration, showing numerous examples that facilitate their understanding. Recommendations on the use of the text are also provided.
The guide ends with a selection of resources for further knowledge and data visualisation tools to be considered by anyone who wants to start developing their own visualisations.
You can download the complete guide below, in the "Documentation" section.
Documentación
Data anonymization defines the methodology and set of best practices and techniques that reduce the risk of identifying individuals, the irreversibility of the anonymization process, and the auditing of the exploitation of anonymized data by monitoring who, when, and for what purpose they are used.
This process is essential, both when we talk about open data and general data, to protect people's privacy, guarantee regulatory compliance, and fundamental rights.
The report "Introduction to Data Anonymization: Techniques and Practical Cases," prepared by Jose Barranquero, defines the key concepts of an anonymization process, including terms, methodological principles, types of risks, and existing techniques.
The objective of the report is to provide a sufficient and concise introduction, mainly aimed at data publishers who need to ensure the privacy of their data. It is not intended to be a comprehensive guide but rather a first approach to understand the risks and available techniques, as well as the inherent complexity of any data anonymization process.
What techniques are included in the report?
After an introduction where the most relevant terms and basic anonymization principles are defined, the report focuses on discussing three general approaches to data anonymization, each of which is further integrated by various techniques:
- Randomization: data treatment, eliminating correlation with the individual, through the addition of noise, permutation, or Differential Privacy.
- Generalization: alteration of scales or orders of magnitude through aggregation-based techniques such as K-Anonymity, L-Diversity, or T-Closeness.
- Pseudonymization: replacement of values with encrypted versions or tokens, usually through HASH algorithms, which prevent direct identification of the individual unless combined with additional data, which must be adequately safeguarded.
The document describes each of these techniques, as well as the risks they entail, providing recommendations to avoid them. However, the final decision on which technique or set of techniques is most suitable depends on each particular case.
The report concludes with a set of simple practical examples that demonstrate the application of K-Anonymity and pseudonymization techniques through encryption with key erasure. To simplify the execution of the case, users are provided with the code and data used in the exercise, available on GitHub. To follow the exercise, it is recommended to have minimal knowledge of the Python language.
You can now download the complete report, as well as the executive summary and a summary presentation.
Noticia
On 20 October, Madrid hosted a new edition of the Data Management Summit Spain, an international summit that this year also took place in Italy (7 July) and Latam (20 September). The event brought together CiOs, CTOs, CDOs, Business Intelligence Officers and Data Scientists in charge of implementing emerging technologies in order to solve new technological challenges aligned with new business opportunities.
This event was preceded by a prologue held the previous evening, in collaboration with DAMA Spain and the Data Office. This was a session aimed exclusively at representatives of different levels of public administration and focused on open data and information sharing between administrations. During the day, participants discussed the transformative role of data and how its intensive use and enhancement are essential to achieve the digital transformation of public administrations.
As was mentioned in the session, data plays an essential role in the development of disruptive technologies such as Artificial Intelligence, and is a differential factor when it comes to launching an industrial and technological revolution that allows for the consolidation of a fairer, more inclusive digital economy in line with the SDGs and the 2030 Agenda. A true data economy with the vocation to nurture the development of two key and strategic processes for the reconstruction of our country: the digital transformation and the ecological transition.
Data spaces and open data, key to achieving data-driven government
The institutional opening was given by Carlos Alonso, Director of the Data Office Division. His speech focused on highlighting how the achievement of a data-oriented administration, an inseparable part of its digital transformation process, depends on the development of public sector data spaces, which enable data sharing with sovereignty and its large-scale exploitation. Data is a public good, to be preserved and processed in order to implement quality public services and policies. The aim is to achieve a data-driven, citizen-centred, open, transparent, inclusive, participatory and egalitarian administration, ensuring ethical, secure and responsible use of data.
In this process of designing public and private sector data spaces, open data is fundamental, as Carlos Alonso highlighted during his speech: "Data spaces are major consumers and generators of open data, and their availability must be ensured. That is, it is necessary to establish certain service level agreements to ensure access".
Sharing experiences between administrations
After this institutional opening, the conference addressed the opportunity provided by the creation of spaces for sharing and exploiting data in public administrations, and allowed for the dissemination of different data-related projects by representatives of the different administrative levels, including autonomous communities and local entities.
Andreu Francisco, Director General of the Localret consortium, formed by the local administrations of Catalonia for the development of telecommunications services and networks and the application of ICT, presented a digital metamodel, which aims to structure the technological architecture and services required in a digital city. It is a comprehensive solution that can be implemented in different territories and personalised according to the singularities of each city, making it easier for the inhabitants of the 877 Catalan municipalities to develop professionally and personally.
César Priol, Director General of Digitalisation and Citizen Services, of Bizkaiko Foru Aldundia (Basque Country) shared his experience in the creation of the Data Office, highlighting the importance of self-organising on an organisational, regulatory and legal level in order to have the capacity to transform not only the organisation, but also the territory with data.
Magda Lorente, Head of the Local Information Systems Assistance Section, and Sara Aguilar, Head of the Service of the Official Gazette of the Province of Barcelona and other Official Publications of the Barcelona Provincial Council, spoke of good practices in data management. Magda Lorente highlighted the importance of the Diputacions becoming data-oriented in order to assume their relevant role in the promotion of municipal data governance. According to a study carried out by the Diputació de Barcelona, which will be published at the end of November, 85% of municipalities could be left out of artificial intelligence and intelligent administration because their technical capacities do not allow them to materialise the necessary data orientation.
Sara Aguilar, for her part, presented an example of how the administrations are consolidating the way in decision-making based on quality data: the CIDO, a search engine for official information and documentation. This tool was created in 2000 with the aim of bringing government information closer to citizens in a user-friendly way. It provides access, for example, to more than 2,600 selection processes with open calls for applications and 1,600 open subsidies, thanks to the open data offered by the different municipalities of Catalonia. CIDO is based on a tag reader model and the use of artificial intelligence algorithms, which classify the information collected from the municipalities. They have more than 2 million ads, structured and documented open data that they serve through an API that can be integrated into any platform.
Roundtables and group dynamics to promote debate
During the course of the day, attendees were able to participate in different dynamics for the exchange of experiences. The first dynamic focused on open data and the second on interoperability.
In addition, two round tables were held, which allowed the subject to be approached from different points of view:
- The first round table, moderated by Carlos Alonso, focused on the challenges and barriers to data exchange in the public sector. Current methodologies, specifications and practices related to the processing of information, in order to achieve a fluid and continuous exchange of data between administrations, industrial sectors and citizens, were projected on a larger scale. The round table was attended by: Carlos Alonso, Jose Antonio Eusamio (General Secretariat for Digital Government), César Priol (Vizcaya Provincial Council), Miguel Angel Martinez Vidal (INE) and Magda Lorente.
- The second round table focused on how to accelerate the adoption of Open Linked Data in the public administration domain, moderated in this case by Oscar Alonso (IBM Consulting & DAMA Spain). Participants included Sara Aguilar (Barcelona Provincial Council), Oscar Alonso (DAMA Spain & IBM), Sonia Castro (datos.gob.es), Juan José Alonso (Orange) and Olga Quiros (ASEDIE). The conversation revolved around EU initiatives, such as the Data Governance Act, which are acting as a turning point in data policies. The act seeks to establish robust mechanisms to facilitate the re-use of certain categories of protected public sector data, increase trust in data brokering services and promote data altruism across the EU. This highlights how the EU is working to strengthen various data sharing mechanisms to promote the availability of data that can be used to drive advanced applications and solutions in artificial intelligence, personalised medicine, green mobility, smart manufacturing and many other areas. The importance of data ethics was also highlighted during the debate.
Materials available on the day
If you missed the session, the video is available on Youtube. The recording of the summit on the 20th has also been made public, a session that had a more business-oriented approach, with expert presentations and group dynamics focused on data governance, data quality, master data and data architecture, among other topics. Photos from the event are also available.
In addition, interviews with some of the speakers have been published on the summit's website, allowing a deeper insight into the projects they are carrying out.