Blog
Vivimos en la era de los datos, palanca de transformación digital y un activo estratégico para la innovación y el desarrollo de nuevas tecnologías y servicios. Los datos, más allá de las habilidades que aportan al generador y/o dueño de los mismos, tienen además la peculiaridad de ser un activo no-rival. Esto quiere decir que pueden ser reutilizados sin que ello suponga un detrimento para el dueño de los derechos originales, lo que los convierte en un recurso con un alto grado de escalabilidad en su compartición y explotación.
Esta posibilidad de compartición no-rival, además de abrir potenciales nuevas líneas de negocio a los dueños originales, conlleva también un ingente valor latente para el desarrollo de nuevos modelos de negocio. Y aunque la compartición no es algo novedoso, ésta se encuentra todavía muy limitada a contextos nicho de especialización sectorial, mediados bien por la confianza entre partes (generalmente forjada de antemano), o tediosas y disciplinadas condiciones contractuales. Es por ello que surge el innovador concepto de espacio de datos, que en su acepción más simplificada no es más que la modelización de las condiciones generales con que desplegar una compartición voluntaria, soberana y segura de datos. Una vez modelizadas, la prescripción de consideraciones y metodologías (tanto tecnológicas, como organizativas y operativas) permite hacer tangible esa compartición en base a interacciones punto a punto, que conjuntamente dan forma a ecosistemas federados de conjuntos y servicios de datos.
Por ello, y dada la naturaleza distribuida de los espacios de datos (no son un sistema informático monolítico, ni una plataforma centralizada), una manera óptima de aproximarse de su construcción es a través de la creación y despliegue de casos de uso.
La Oficina del Dato ha creado esta infografía de un ‘Modelo de desarrollo de casos de uso dentro de los espacios de datos’, con el objetivo de definir sintéticamente las fases de ese viaje iterativo, que progresivamente va dando forma a un espacio de datos. Este modelo sirve además de marco general para otros entregables técnicos y metodológicos venideros, como por ejemplo la ‘Guía de Evaluación de Viabilidad de Casos de Uso’, o la ‘Guía de Diseño de Casos de Uso’, elementos con que facilitar la puesta en marcha de experiencias prácticas (y escalables por diseño) de compartición de datos, condición sine qua non para articular el ansiado mercado único de datos europeo.
El reto de construir un espacio de datos
Para hacer más accesible el proceso de desarrollar un espacio de datos, podríamos asimilar la definición y construcción de un caso de uso como un proyecto de construcción, en el que desde un problema de negocio inicial (necesidades o retos, deseos, o problemas a resolver) se llega a una meta en la que se aporta valor al negocio, dando solución a esas necesidades iniciales. Esta infografía ofrece una síntesis de ese viaje.
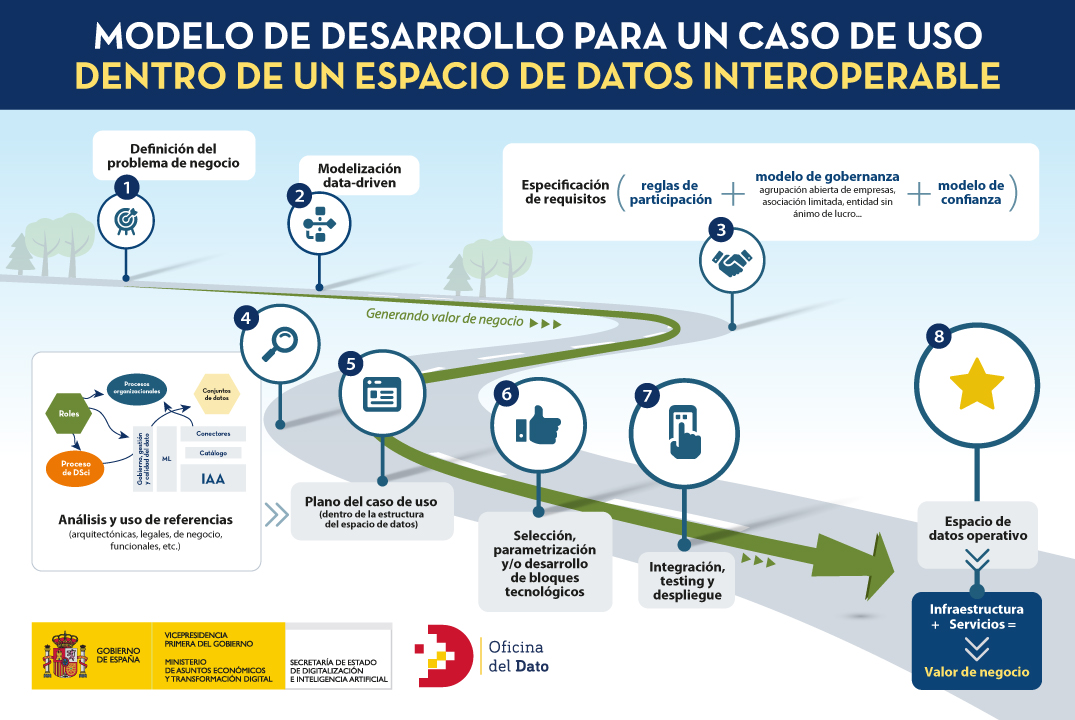
Estas son las fases del modelo:
- FASE 1: Definición del problema de negocio. En esta fase un grupo de potenciales participantes detecta una oportunidad alrededor de la compartición de sus datos (hasta ahora en silos) y su correspondiente explotación. Esta oportunidad puede ser nuevos productos o servicios (innovación), mejoras de eficiencia, o la resolución de un problema de negocio. Es decir, existe un objetivo de negocio que el grupo es capaz de resolver de forma conjunta, compartiendo datos.
- FASE 2: Modelización data-driven. En esta fase se identificarán aquellos elementos que sirvan para estructurar y organizar los datos para la toma de decisiones estratégicas en base a su explotación. Implica definir un modelo que posiblemente emplee herramientas multidisciplinarias para conseguir resultados de negocio. Es la parte que tradicionalmente se asocia a tareas de la ciencia de datos.
- FASE 3: Consenso en la especificación de requisitos. Aquí, los actores que auspician el caso de uso deben establecer el modelo de relación a tener durante este proyecto colaborativo alrededor de los datos. Dicha fórmula debe: (i) definir y establecer las reglas de participación, (ii) definir un conjunto común de políticas y modelo de gobierno, y (iii) definir un modelo de confianza que actúe como raíz de dicha relación.
- FASES 4 y 5: Plano del caso de uso. Como en un proyecto de construcción, el plano es el medio de expresión de las ideas de quienes han definido y acordado el caso de uso, y debe recoger de forma explícita las soluciones planteadas para cada una de las partes del desarrollo del mismo. Ese plano es único para cada caso de uso, y la fase 5 corresponde a su construcción. Sin embargo, no se crea desde la nada, sino que existen múltiples referencias que permiten utilizar materiales y técnicas previamente identificadas. Por ejemplo, modelos, metodologías, artefactos, plantillas, componentes tecnológicos o soluciones como servicio. Así, al igual que un arquitecto proyectando un edificio puede reutilizar estándares reconocidos, en el mundo de los espacios de datos también existen modelos sobre los que pintar los componentes y procesos de un caso de uso. El análisis y síntesis de esas referencias es la fase 4.
- FASE 6: Selección, parametrización y/o desarrollo tecnológico. La tecnología habilita el despliegue de la transformación y explotación del dato, favoreciendo todo el ciclo de vida, desde su recopilación hasta su puesta en valor. En esta fase se implementa la infraestructura que da soporte al caso de uso, entendida ésta como la colección de herramientas, plataformas, aplicaciones y/o piezas de software necesarias para la operación del aplicativo.
- FASE 7: Integración, test y despliegue. Como todo proceso de construcción tecnológico, el caso de uso pasará por las fases de integración, prueba y despliegue. Los trabajos de trabajos de integración y las pruebas funcionales, de usabilidad, de carácter exploratorio, de aceptación, etc. nos ayudarán a alcanzar la configuración deseada para el despliegue operativo del caso de uso. En el caso de desear la incorporación de un caso de uso a un espacio de datos preexistente, la integración buscaría encaje dentro de su estructura, lo que supone modelizar los requisitos de dicho caso de uso dentro de los procesos y bloques constructivos del espacio de datos.
- FASE 8: Espacio de datos operativo. El punto de llegada de este viaje es el caso de uso en funcionamiento, que empleará servicios digitales desplegados por encima de la estructura del espacio de datos, y cuya arquitectura da soporte a diferentes recursos y funcionalidades federada por diseño. Esto implica que se habría articulado eficientemente el ciclo de vida de creación de valor en base a los datos compartidos, y se obtiene rédito de negocio según el planteamiento original. Sin embargo, esto no impide que el espacio de datos pueda seguir evolucionando a posteriori, ya que su vocación es crecer bien con la entrada de nuevos retos, o actores a casos de uso ya existentes. De hecho, la escalabilidad del modelo es una de sus bondades singulares.
En esencia, los datos compartidos por medio de un ecosistema federado e interoperable son la entrada que alimenta una capa de servicios que generará valor y resolverá las necesidades y retos originales planteados, en un viaje que va desde la definición de un problema de negocio hasta su resolución.
Noticia
El pasado 13 de marzo se celebró una jornada del Grupo de Trabajo de Movilidad del Hub Gaia-X España, donde se abordaron los principales retos del sector en lo referente a proyectos sobre la compartición y explotación de datos. La sesión, que se desarrolló en la Escuela Técnica Superior de Ingenieros de Caminos, Canales y Puertos de la Universidad Politécnica de Madrid, permitió a los asistentes conocer de primera mano los principales retos del sector, así como algunos de los proyectos de datos punteros de la industria de la movilidad. El evento fue también un punto de encuentro en el que se compartieron ideas y reflexiones entre los actores clave del sector.
La jornada comenzó con la presentación del Ministerio de Transportes, Movilidad y Agenda Urbana, intervención que destacó la gran importancia del Punto de Acceso Nacional de Transporte Multimodal, un proyecto de ámbito europeo, que permite concentrar toda la información de la oferta de transporte de viajeros del país en un único punto nacional, con el objetivo de proporcionar los cimientos para impulsar el desarrollo de los servicios de movilidad del futuro.
A continuación, la Oficina del Dato de la Secretaría de Estado de Inteligencia Artificial (SEDIA) aportó la visión del modelo de desarrollo de Espacios de Datos y los principios de diseño de dichos espacios alineados con los valores europeos. Se destacó la importancia de las redes de negocio en base a ecosistemas de datos, el carácter intersectorial de la industria de la Movilidad y el importante papel de los datos abiertos en los espacios de datos del sector.
Seguidamente, se presentaron casos de uso por parte de Vicomtech, Amadeus, i2CAT y el Ayuntamiento de Alcobendas, que permitieron conocer de primera mano algunos ejemplos de uso de tecnología para proyectos de compartición de datos (tanto de espacios de datos como de data lakes, o lagos de datos).
Finalmente, se presentó un estudio inicial de la Fundación i2CAT, FACTUAL Consulting y EIT Urban Mobility sobre los componentes básicos de los futuros espacios de datos de movilidad en España. El estudio, que puede descargarse aquí en español, aborda el potencial de los espacios de datos de movilidad para el mercado español. Aunque se centra en España, recoge un enfoque sobre la investigación tanto nacional como internacional , enmarcado en el contexto europeo para establer estándares, el desarrollo de los componentes técnicos que habilitan los espacios de datos, los primeros proyectos faro y el abordaje de desafíos comunes para cumplir hitos en materia de movilidad sostenible en Europa.
Las presentaciones utilizadas en la sesión están disponibles en este enlace.
Blog
La ‘Estrategia europea de datos’ de la Comisión Europea establece que es clave la creación de un mercado único de datos compartidos. En dicha estrategia, la Comisión se ha marcado como uno de sus principales objetivos el impulso de una economía del dato acorde a los valores europeos de autodeterminación en la compartición de datos (soberanía), confidencialidad, transparencia, seguridad y competencia justa.
Los espacios de datos comunes a nivel europeo son un recurso fundamental en la estrategia de datos porque actúan como habilitadores del impulso de la economía del dato. De hecho, poner en común los datos europeos de sectores clave, fomentar la circulación de los datos y crear espacios de datos colectivos e interoperables son acciones que contribuyen al beneficio de la sociedad.
Aunque los entornos de compartición de datos existen desde hace tiempo, se plantea la creación de espacios de datos que garanticen los valores y principios de la UE. Desarrollar iniciativas legislativas que los habiliten no solo es un reto tecnológico, sino también de coordinación entre los participantes, de gobernanza, de adopción de estándares y de interoperabilidad.
Para abordar un desafío de tal magnitud, la Comisión tiene previsto invertir cerca de 8.000 millones de euros hasta 2027 en el despliegue de la transformación digital europea. Como parte del proyecto se incluye el fomento de infraestructuras, herramientas, arquitecturas y mecanismos para compartir datos. Para que triunfe esta estrategia es necesario que, desde el cumplimiento de los valores europeos, se plantee un paradigma de espacio de datos que tenga calado en la industria. Este paradigma de espacio de datos actuará como un estándar tecnológico de facto y permitirá que avance la concienciación social sobre las posibilidades del dato, algo que posibilitará el retorno económico de las inversiones requeridas para crearlo.
Con el fin de hacer realidad el paradigma de espacios de datos, desde la convergencia de las actuales iniciativas, la Comisión Europea ha apostado por el desarrollo del proyecto Simpl.
¿En qué consiste exactamente Simpl?
Simpl es un proyecto financiado por el programa Digital Europe de la Comisión Europea, dotado con 150 millones de euros y con un plazo de ejecución de tres años. Su objetivo es poner a disposición de la sociedad un software (middleware) para la construcción de ecosistemas de datos y servicios de infraestructuras en la nube que soporten los valores europeos de soberanía el dato, privacidad y mercado justo.
El proyecto Simpl consiste en la entrega de 3 productos:
- Simpl-Open: Middleware propiamente dicho. Se trata de una solución de software para crear ecosistemas de servicios de datos (compartición de datos y aplicaciones) y servicios de infraestructura en la nube (IaaS, PaaS, SaaS, etc). Este software debe incluir agentes que habiliten la conexión al espacio de datos, servicios operacionales y servicios de intermediación (catálogo, vocabulario, registro de actividad, etc). El resultado deberá entregarse bajo licencia de fuentes abiertas y se intentará construir una comunidad open source que garantice su evolución.
- Simpl-Labs: Infraestructura para crear entornos de trabajo de pruebas (test bed) para que los usuarios interesados pueden probar la última versión del software en la modalidad de autoservicio. Este entorno está pensado principalmente para promotores de espacios de datos que quieran hacer las oportunas pruebas técnicas antes de un despliegue.
- Simpl-Live: Despliegues de Simpl-open en entornos de producción que se corresponderán a espacios sectoriales contemplados en el programa Digital Europe. En concreto, se plantea el despliegue de espacios de datos gestionados por la propia Comisión Europea (Salud, Procurement, Lenguaje).
El proyecto tiene una orientación práctica y busca obtener resultados a la mayor brevedad. Por lo que se pretende que, además de suministrar el software, el contratista preste un servicio de laboratorio para que los usuarios puedan realizar pruebas. La empresa que desarrolle Simpl también deberá adaptar el software para el despliegue de espacios de datos comunes europeos previstos en el programa Digital Europe.
La asociación Gaia-X está considerada como la más próxima en sus objetivos al proyecto Simpl, así que el resultado del proyecto deberá esforzarse en la reutilización de los componentes que Gaia-X ponga a su disposición.
Por su parte, el centro Data Space Support Center, en el que participan las principales iniciativas europeas de creación de marcos tecnológicos y estándares para la construcción de espacios de datos, deberá definir los requisitos del middleware mediante especificaciones, modelos arquitectónicos y selección de estándares.
Los trabajos preparatorios de Simpl finalizaron en mayo de 2022, fijando el alcance y los requerimientos técnicos del proyecto que han sido objeto de detalle en el proceso contractual actualmente abierto. La licitación se puso en marcha el pasado 24 de febrero de 2023. Toda la información está disponible en TED eTendering, incluida la manera de formular preguntas sobre el proceso de licitación. El plazo para la presentación de solicitudes finaliza el 24 de abril de 2023 a las 17: 00 (hora de Bruselas).
Simpl espera disponer de una plataforma viable mínima publicada a principios de 2024. Paralelamente, y lo antes posible, el entorno abierto de pruebas (Simpl-Labs) se pondrá a disposición de las partes interesadas en experimentar. A continuación, se procederá a integrar progresivamente diferentes casos de uso, ayudándolos a ajustar Simpl a las necesidades específicas, considerando prioritarios los casos financiados de otro modo en el marco del programa de trabajo Europa DIGITAL.
Como conclusión, cabe remarcar que Simpl es la apuesta de la Comisión Europea para el despliegue e interoperabilidad de las diferentes iniciativas de espacios de datos sectoriales, garantizándose su concordancia con las especificaciones y requisitos emanados del Data Space Support Center y, por tanto, con el proceso de convergencia de las diferentes iniciativas europeas de construcción de espacios de datos (Gaia-X, IDSA, Fiware, BDVA).
Noticia
Gaia-X representa un innovador paradigma con el que vincular más estrechamente los datos con la infraestructura tecnológica que hay por debajo, de forma que se garantice la transparencia, el origen y el funcionamiento de estos recursos. Este modelo nos permite desplegar una Economía del Dato soberana y transparente, que respete los derechos fundamentales europeos, y que en España tomará forma en torno a los espacios de datos sectoriales (C12.I1 y C14.I2 del Plan de Recuperación, Transformación y Resiliencia). Estos se alinearán con el marco regulatorio europeo, así como con una gobernanza e instrumentos pensados para asegurar la interoperabilidad, y sobre la que articular el buscado mercado único de datos.
En este sentido, los nodos de interoperabilidad de Gaia-X, o Gaia-X Digital Clearing House (GXDCH), tienen por objeto ofrecer servicios de validación automática de las reglas de interoperabilidad a promotores y participantes de espacios de datos. La creación de este tipo de nodos fue anunciada en la Gaia-X Summit 2022, el pasado mes de noviembre en París. La arquitectura Gaia-X, promovida por la asociación Gaia-X European Association for Data & Cloud AISBL, se ha consolidado como una prometedora alternativa tecnológica para la creación de ecosistemas abiertos y transparentes de conjuntos y servicios de datos.
Estos ecosistemas, por naturaleza federados, servirán para el desarrollo a escala de la citada Economía del Dato. Pero para ello, deben cumplirse una serie de reglas mínimas que aseguren la interoperabilidad entre participantes. La conformidad con dichas reglas es precisamente la función de la GXDCH, sirviendo como "ancla" para desplegar servicios de mercado certificados. Por tanto, la creación en España de un nodo de estas características supone un elemento crucial para el despliegue de los espacios federados de datos a nivel nacional, lo que estimulará el desarrollo y la innovación en torno al dato bajo un entorno de respeto a la soberanía del dato, la privacidad, transparencia y la justa competencia.
La GXDCH se define como un nodo en el que se prestan servicios operacionales de un ecosistema que cumpla con las reglas de interoperabilidad de Gaia-X. Como “servicios operacionales” se deben entender aquellos servicios que son necesarios para el funcionamiento de un espacio de datos, pero que no son en sí mismos servicios de compartición de datos, ni de aplicaciones de explotación de datos, ni de infraestructuras en la nube. Gaia-X define seis servicios operacionales, de los cuales al menos dos deben formar parte de los nodos obligatorios que alberguen las GXDCHs:
Servicios obligatorios
- Gaia-X Registry: Definida como una base de datos inmutable, no repudiable y distribuida con capacidad de ejecutar código. Típicamente sería una infraestructura blockchain que soporta un servicio de identidad descentralizada (‘Self Sovereign Identity’) en la que se almacenan, entre otras, la lista de autoridades emisoras de credenciales (Trust Anchors) u otros datos necesarios para el funcionamiento de la gestión de identidad en Gaia-X.
- Servicio de conformidad de Gaia-X o Gaia-X Compliance Service pertenece a los denominados Gaia-X Federation Services y su función es verificar el cumplimiento de las reglas mínimas de interoperabilidad definidas por la asociación Gaia-X (por ejemplo, el Trust Framework)
Servicios opcionales
- Servicio de edición de Self-Descriptions (SDs) o Wizard: Las SDs son credenciales verificables según el estándar definido por el W3C mediante las cuales se describen a sí mismos tanto los participantes de un ecosistema Gaia-X como los productos puestos a disposición por los proveedores. El servicio de conformidad antes mencionado consiste en validar que las SDs cumplen con las normas de interoperabilidad. El Wizard es un servicio de conveniencia para la creación de Self-Descriptions según esquemas predefinidos.
- Catálogo: Servicio de almacenamiento de la oferta de servicios disponible en el ecosistema para su consulta.
- e-Wallet: Para la gestión de credenciales verificables (SDs) por parte de los participantes en un sistema basado en identidades distribuidas.
- Servicio de Notaría: Servicio de emisión de credenciales verificables firmadas por autoridades de acreditación (Trust Anchors).
En qué consiste el servicio de conformidad de Gaia-X (p.e. Compliance Service)
El servicio de conformidad de Gaia-X pertenece a los denominados Gaia-X Federation Services, y su función es verificar el cumplimiento de las reglas mínimas de interoperabilidad definidas por la asociación Gaia-X. Gaia-X denomina a estas reglas mínimas de interoperabilidad (Trust Framework). Se debe tener en cuenta que el establecimiento del Trust Framework es una de las contribuciones diferenciadoras del marco tecnológico de Gaia-X frente a otras soluciones de mercado. Pero el objetivo no se limita a establecer normas de interoperabilidad, sino que pretende crear un servicio que sea operable y, en la medida de lo posible, automatizado, que valide el cumplimiento del Trust Framework. Este servicio es el Gaia-X Compliance Service.
El elemento clave de estas reglas son las denominadas “Self-Descriptions” (SDs). Las SDs son credenciales verificables según la norma definida por el W3C mediante las cuales se describen a sí mismos tanto los participantes de un espacio de datos como los productos puestos a disposición por los proveedores. El servicio Gaia-X Compliance valida el cumplimiento del Trust Framework mediante un chequeo de las SDs desde los siguientes puntos de vista:
- Formato y sintaxis de las SDs
- Validación de los esquemas de las SDs (vocabulario y ontología)
- Validación de la criptografía de las firmas de los emisores de las SDs
- Consistencia de los atributos
- Veracidad del valor de los atributos.
Una vez validadas las Self-Descriptions, el operador del servicio de conformidad emite una credencial verificable que da fe del cumplimiento de las normas de interoperabilidad, aportando confianza a los participantes del ecosistema. La Gaia-X AISBL proporciona el código necesario para implementar el Compliance Service y autoriza la prestación del servicio a entidades de confianza, pero no opera directamente el servicio por lo que requiere la existencia de socios que se encarguen de esta labor.

Blog
Existe una tan estrecha relación entre la gestión del dato, la gestión de calidad del dato y el gobierno del dato que en muchas ocasiones los términos se utilizan de forma indistinta o directamente se confunden. Sin embargo, existen importantes matices.
El objetivo general de la gestión de datos es asegurar que los datos satisfacen los requisitos de negocio que darán soporte a los procesos de la organización, tales como recopilar, almacenar, proteger, analizar y documentar los datos, con el objetivo de implementar los objetivos de la estrategia de gobierno del dato. Se trata de un conjunto de tareas tan amplio que existen diversas categorías de normas para certificar cada uno de los diferentes procesos: ISO/IEC 27000 para la seguridad y privacidad de la información, ISO/IEC 20000 para la gestión de servicios de TI, ISO/IEC 19944 para interoperabilidad, arquitectura o acuerdos de nivel de servicio en la nube, o ISO/IEC 8000-100 para el intercambio de datos y la gestión de datos maestros.
La gestión de calidad de datos, por su parte, se refiere a las técnicas y procesos utilizados para asegurar que los datos son adecuados para el uso que se pretende hacer de ellos. Para ello se requiere un Plan de calidad de los datos que debe ser acorde con la cultura de la organización y con la estrategia de negocio e incluye aspectos como la validación, verificación y limpieza de datos, entro otros. En este sentido también existe un conjunto de normas técnicas para conseguir que los datos tengan calidad] entre las que se incluyen la propia gestión de la calidad de los datos de transacción, los datos de producto y los datos maestros empresariales (ISO 8000) y las tareas de medición de la calidad de los datos (ISO 25024:2015).
Por su parte, el gobierno del dato, de acuerdo con la definición de Deloitte, está formado por conjunto de normas, políticas y procesos de una organización que permiten asegurar que los datos de la organización sean correctos, fiables, seguros y útiles. Es decir, es la parte estratégica y de planificación y control a alto nivel para conseguir crear valor para el negocio a partir de los datos. En este caso, el gobierno de los datos abiertos tiene sus propias especificidades debido al número de partes interesadas que intervienen y la propia naturaleza colaborativa de los datos abiertos.
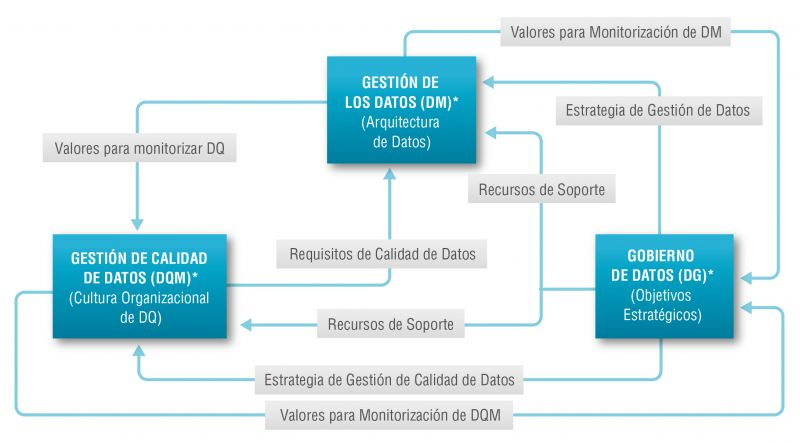
El modelo Alarcos
En este contexto el Modelo Alarcos de Mejora de Datos (MAMD), actualmente en su versión 3, tiene como objetivo recoger los procesos necesarios para alcanzar la calidad de las tres citadas dimensiones: la gestión de los datos, la gestión de la calidad de los datos y el gobierno de los datos. Este modelo ha sido desarrollado por un grupo de expertos coordinado por el grupo de investigación Alarcos de la Universidad de Castilla-La Mancha.
El Modelo MAMD está alineado con las mejores prácticas y estándares existentes tales como Data Management Community (DAMA), Data management maturity (DMM) o la propia familia de normas ISO 8000, cada una de las cuáles aborda diferentes aspectos relacionados con la calidad de los datos y la gestión de los datos maestros desde diferentes perspectivas. Además, el modelo Alarcos está basado en la familia de estándares para definir el modelo de madurez por lo que es posible conseguir la certificación de AENOR para el gobierno, gestión y calidad de datos ISO 8000-MAMD.
El modelo MAMD consiste de 21 procesos, 9 procesos corresponden a la gestión de los datos (DM), la gestión de la calidad de datos (DQM) incluye 4 procesos más y el gobierno del dato (DG), que añade otros 8 procesos.
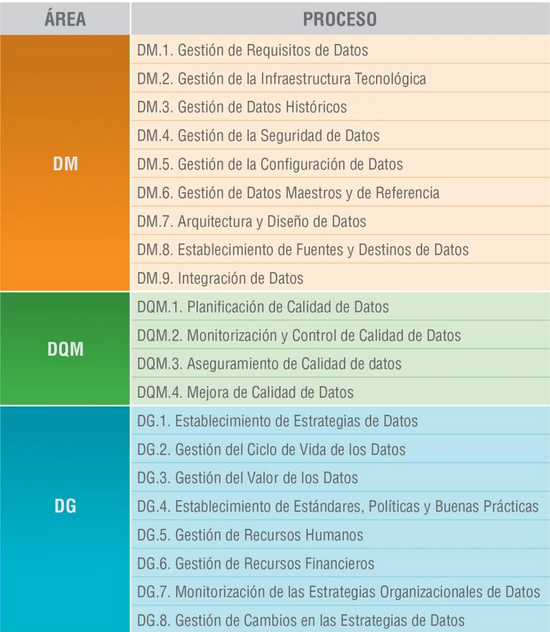
La incorporación progresiva de los 21 procesos permite la definición de 5 niveles de madurez que contribuyen a que la organización mejore su gestión, calidad y gobierno de datos. Comenzando con el nivel 1 (Realizado) en el que el organismo puede demostrar que utiliza buenas prácticas en el uso de los datos y tiene el soporte tecnológico necesario, pero no presta atención al gobierno ni a la calidad de los datos, hasta el nivel 5 (Innovado) en el que el organismo es capaz de alcanzar sus objetivos y está continuamente mejorando.
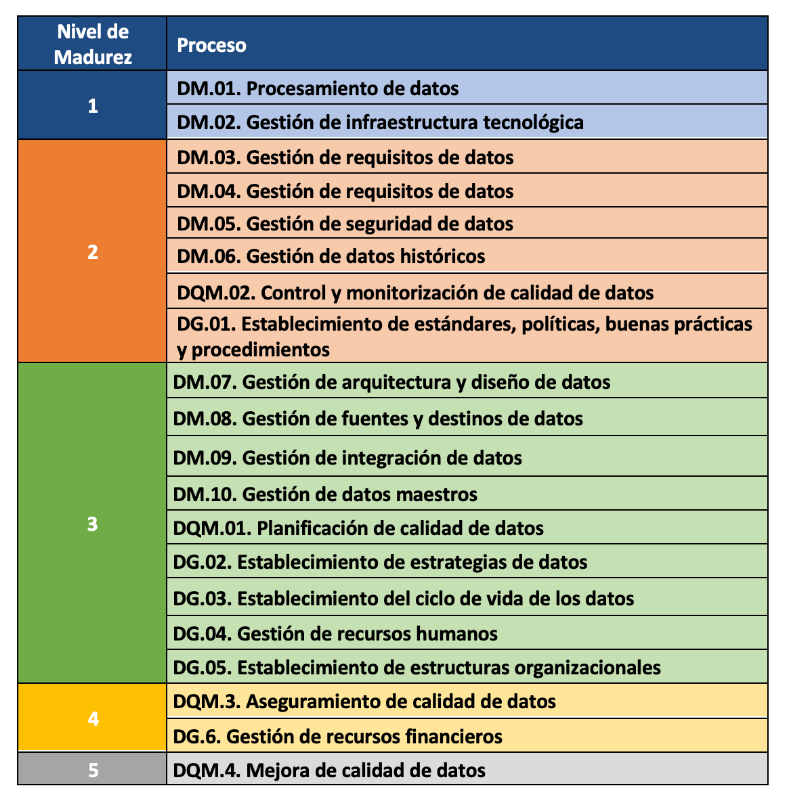
El modelo puede certificarse con una auditoría equivalente a la de otras normas de AENOR por lo que existe la posibilidad de incluirlo en el ciclo de mejora continua y control interno de cumplimiento normativo de las organizaciones que ya cuentan con otros certificados.
Experiencias prácticas
La Biblioteca de la Universidad de Castilla-La Mancha (UCLM), que da soporte a más de 30.000 alumnos y 3.000 profesionales entre profesores y personal de administración y servicios, es una de las primeras organizaciones que pudo superar la auditoría de certificación y por tanto obtener el nivel 2 de madurez en ISO/IEC 33000 – ISO 8000 (MAMD).
Los puntos más fuertes que se identificaron en este proceso de certificación fueron el compromiso del equipo directivo y el nivel de coordinación con otras universidades. Como en toda auditoría, se propusieron mejoras como la necesidad de documentar las revisiones periódicas de seguridad de datos que contribuyeron a alimentar el ciclo de mejora.
El hecho de que las organizaciones de todo tipo otorguen un valor cada vez mayor a sus activos de datos hace que los modelos y normas técnicas de certificación tengan un papel fundamental en garantizar la calidad, la seguridad, la privacidad, la gestión o el adecuado gobierno de estos activos de datos. Además de los estándares ya existentes se sigue haciendo un importante esfuerzo para desarrollar nuevas normas que cubran aspectos que hasta ahora no se habían considerado centrales debido a la menor importancia de los datos en las cadenas de valor de las organizaciones. Sin embargo, aún es necesario continuar con la formalización de modelos que como el Modelo Alarcos de Mejora de Datos permitan abordar de forma holística, y no sólo desde sus diferentes dimensiones, la evaluación y el proceso de mejora de la organización en el tratamiento de sus activos de datos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El Hub español de Gaia-X (Gaia-X Hub Spain), asociación sin ánimo de lucro cuyo objetivo es acelerar la capacidad europea en materia de compartición de datos y soberanía digital, busca que los diferentes sectores de la economía construyan una comunidad en torno al dato para, así, poder promover un entorno propicio para la creación de espacios de datos sectoriales. Enmarcado en la estrategia España Digital 2026 y con el Plan de Recuperación, Transformación y Resiliencia como hoja de ruta para la transformación digital de España, el objetivo del hub es potenciar el desarrollo de soluciones innovadoras basadas en datos e inteligencia artificial, a la par que contribuye a impulsar la competitividad de las empresas de nuestro país.
El hub se organiza a lo largo de diferentes grupos de trabajo, existiendo uno específico dedicado a analizar los restos y oportunidades de los espacios de datos de compartición y explotación de datos en el sector turístico. El turismo es uno de los sectores productivos clave en la economía española, llegando a alcanzar un volumen del 12,2% del PIB nacional.
El turismo, dado su ecosistema de participantes públicos y privados, de diferentes dimensiones y grado de madurez tecnológico, constituye un entorno óptimo donde contrastar las bondades de estos ecosistemas federados de datos. Gracias a ellos se facilita la extracción de valor de fuentes de datos no tradicionales, con una elevada escalabilidad, y garantizando en todo caso unas condiciones robustas de seguridad, privacidad y, por en ende, de soberanía del dato.
Así, y con la finalidad de producir la primera radiografía de dicho espacio de datos en España, desde la Oficina del dato, en colaboración con el Hub español de Gaia-X se ha elaborado el informe ‘Radiografía del Espacio de Datos de Turismo en España’, un documento que busca resumir y resaltar en qué momento se encuentra actualmente el diseño de dicho espacio de datos, las diferentes oportunidades para el sector y cuáles son los principales retos que deben superarse para conseguir el despliegue del mismo, ofreciendo una hoja de ruta para su construcción y despliegue.
¿Por qué es necesario un espacio de datos de turismo?
Si algo quedó claro tras el estallido de la pandemia por COVID-19 es que el turismo es una actividad interdependiente de otras industrias por lo que, al pausarse esta, sectores como la movilidad, la logística, la salud, la agricultura, la automoción o la alimentación, entre otros, se vieron también afectados.
Situaciones como la anterior, evidencian las posibilidades que ofrece la compartición de datos entre sectores, ya que éstos pueden ayudar a mejorar la toma de decisiones. Sin embargo, conseguirlo en el ámbito turístico no es una tarea sencilla dado que desplegar un espacio de datos para este sector requiere del esfuerzo coordinado entre las distintas partes de la sociedad implicadas.
Por ello, el objetivo y el reto es crear "espacios" inteligentes capaces de aportar un contexto de seguridad y confianza que favorezca el intercambio y la combinación de datos. De este modo y a partir de la generación del valor añadido que aportan los datos, sería posible resolver algunos de los problemas existentes actualmente en el sector para crear nuevas estrategias enfocadas a conocer mejor al turista y, por ende, a mejorar su experiencia a la hora de viajar.
La generación de estos espacios de compartición y explotación de datos supondrá grandes ventajas para el sector, ya que se facilitará la creación de ofertas, productos y servicios más personalizados que proporcionen una experiencia mejorada y adaptada a las necesidades de los clientes, mejorando así la capacidad de atraer turistas. Además de impulsar un mayor conocimiento del sector y una toma de decisiones informada tanto por parte de organizaciones públicas como privadas, que pueden detectar más fácilmente nuevas oportunidades de negocio.
Retos de seguridad y gobernanza de datos para aprovechar las oportunidades del mercado turístico digital
Uno de los principales escollos a la hora de desarrollar un espacio de datos sectorial es la falta de confianza en el intercambio de datos, la ausencia de modelos de datos compartidos o la insuficiencia de normas de interoperabilidad para un intercambio de datos eficiente entre las diferentes plataformas existentes y los actores de la cadena de valor.
Yendo a los retos más específicos, el sector turístico se encuentra, además, con la necesidad de combinar los espacios de datos B2B (compartición entre empresas y organizaciones privadas) con los C2B y G2B (compartición de usuarios a empresas y sector público a empresas). Si a esto le sumamos que lo ideal es aterrizar los conjuntos de datos del sector turístico a nivel nacional, regional y local, el reto se torna aún mayor.
De forma paralela, para diseñar un espacio de datos del sector, también debe tenerse en cuenta que existen diferencias respecto a la calidad de los datos de los actores anteriormente mencionados. Al no existir una serie de estándares concretos, encontramos diferencias en el nivel de granularidad y calidad de los datos, la semántica, así como disparidad entre formatos y licencias, lo que deja un escenario de datos inconexo.
A su vez, es fundamental conocer de primera mano cuáles son las demandas que tienen los distintos actores de la industria, algo que solo se consigue escuchando y tomando notas sobre las necesidades presentes en los distintos niveles de la industria. Por ello, conviene recordar que el turismo es una actividad social cuyo foco no debe posicionarse solamente en el destino, ya que el éxito de un espacio de datos turístico residirá también en la capacidad para conocer mejor al cliente y, por ende, poder ofrecerle servicios adecuados a sus demandas que mejoren su experiencia e incentiven sus ganas de continuar viajando.
De este modo, y tal y como recoge el informe elaborado por la Oficina del Dato, en colaboración con el hub español de Gaia-X, resulta interesante reorientar el foco y desplazarlo del destino hacia el turista, en línea con el descubrimiento y generación de casos de uso de SEGITTUR. Y es que, aunque es cierto que la focalización en el destino ha servido para desarrollar plataformas digitales que han impulsado la competitividad, la eficiencia y la estrategia turística, plantear una estrategia que preste la misma atención al turista permitiría ampliar y mejorar los catálogos de datos disponibles.
Medir los factores que condicionan la experiencia de los turistas durante la visita a nuestro país permite optimizar su satisfacción en todo el circuito del viaje, a la par que contribuir a crear campañas de marketing cada vez más personalizadas, tomando como el análisis de los intereses de los diferentes segmentos de mercado.
Situación actual de la construcción del espacio de datos del Turismo español y próximos pasos
La falta de madurez del mercado en la creación de espacios de datos como solución, hace necesario un enfoque de experimentación, tanto para la consolidación de los componentes tecnológicos, como para la validación de las diferentes facetas (infraestructura soft) presentes en los espacios de datos.
Actualmente, el Grupo de Trabajo de Turismo del Hub español de Gaia-X trabaja en la definición de los elementos clave del espacio de datos de turismo, a partir de casos de uso alineados con los retos del sector. El objetivo es dar respuesta a algunas preguntas clave, utilizando el conocimiento existente en materia de espacios de datos:
- ¿Cuáles son las características clave del entorno turístico y qué problemas de negocio pueden abordarse?
- ¿Qué modelos orientados a datos se pueden trabajar en los diferentes casos de uso?
- ¿Qué requisitos existen y qué modelo de gobernanza es necesario? ¿Qué tipologías de participantes deben considerarse?
- ¿Qué componentes de negocio, legales, operativos, funcionales, tecnológicos son necesarios?
- ¿Qué arquitectura tecnológica de referencia puede utilizarse?
- ¿Qué procesos de desarrollo, integración, test y despliegue de la tecnología pueden emplearse?
Noticia
Actualizado: 21/03/2024
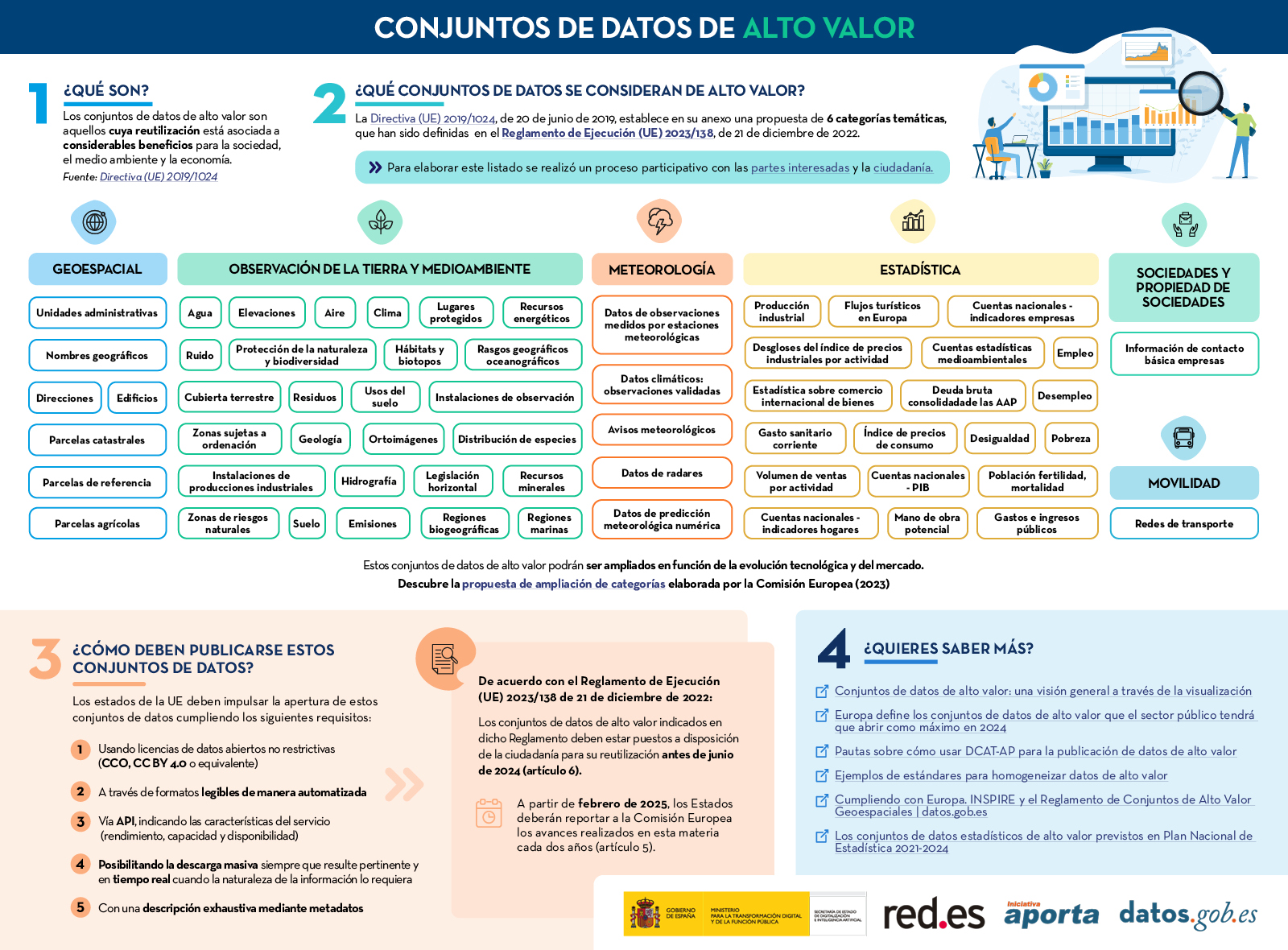
En enero de 2023, la Comisión Europea publicó un listado de conjuntos de datos de alto valor que los organismos del sector público deberían poner a disposición de la ciudadanía en un plazo máximo de 16 meses. El principal objetivo de establecer la lista de conjuntos de datos de alto valor es garantizar que los datos públicos de mayor potencial socioeconómico se pongan a disposición para su reutilización con una restricción jurídica y técnica mínima, y sin coste alguno. Dentro de estos conjuntos de datos del sector público, algunos como los meteorológicos o los relativos a la calidad del aire, resultan especialmente interesantes para desarrolladores y creadores de servicios como aplicaciones o páginas webs, que reportan valor añadido e importantes beneficios para la sociedad, el medioambiente o la economía.
La publicación del Reglamento se acompañó de unas preguntas frecuentes para ayudar a los organismos públicos a entender el beneficio de los HVDS (High Value Datasets) en la sociedad y la economía, así como para explicar algunos aspectos sobre la obligatoriedad y las ayudas para la publicación.
En línea con esta propuesta, la Vicepresidenta Ejecutiva para una Europa adaptada a la era digital, Margrethe Vestager, declaró lo siguiente en la nota de prensa lanzada por la Comisión Europea:
“Poner a disposición del público conjuntos de datos de gran valor beneficiará tanto a la economía como a la sociedad, por ejemplo, ayudando a combatir el cambio climático, reduciendo la contaminación atmosférica urbana y mejorando las infraestructuras de transporte. Se trata de un paso práctico hacia el éxito de la Década Digital y la construcción de un futuro digital más próspero”.
De forma paralela, Thierry Breton, Comisario de Mercado Interior, quiso añadir también las siguientes palabras a colación del anuncio del listado de los datos de alto valor: “Los datos son una piedra angular de nuestra competitividad industrial en la UE. Con la nueva lista de conjuntos de datos de alto valor estamos desbloqueando una gran cantidad de datos públicos en beneficio de todos. Las nuevas empresas y las pymes podrán utilizar estos para desarrollar nuevos productos y soluciones innovadoras que mejoren la vida de los ciudadanos de la UE y de todo el mundo”.
Seis categorías para aglutinar los nuevos conjuntos de datos de alto valor
De este modo, el reglamento se crea al amparo de la Directiva Europea de Datos Abiertos, que define seis categorías para diferenciar los nuevos conjuntos de datos de alto valor solicitados:
- Geoespaciales
- De observación de la Tierra y medioambiente
- Meteorológicos
- Estadísticos
- De empresas
- De movilidad
No obstante, tal y como recoge la nota de prensa de la Comisión Europea, esta gama temática podría ampliarse posteriormente en función de la evolución de la tecnología y el mercado. Así, los conjuntos de datos estarán disponibles en formato legible por máquina, a través de una interfaz de programación de aplicaciones (API) y, si fuera relevante, también con opción de descarga masiva.
Además, la reutilización de conjuntos de datos como los de movilidad o geolocalización de edificios puede ampliar las oportunidades de negocio disponibles para sectores como la logística o el transporte. De forma paralela, los datos de observación meteorológica, de radar, de calidad del aire o de contaminación del suelo también pueden apoyar la investigación y la innovación digital, así como la elaboración de políticas en la lucha contra el cambio climático.
En definitiva, una mayor disponibilidad de datos y, en especial de alto valor, tiene la capacidad de impulsar el espíritu empresarial ya que estos conjuntos de datos pueden ser un recurso importante para que las pymes desarrollen nuevos productos y servicios digitales, lo que a su vez también puede atraer nuevos inversores.
Descubre más en esta infografía:
Blog
El impulso de la llamada economía del dato es una de las grandes prioridades en las que se encuentra trabajando actualmente la Unión Europea, en general, y España, en particular. Disponer de un mercado único digital de intercambio de datos es una de las claves para lograr este impulso entre los Estados miembro, y para ello, entran en juego los espacios de datos.
Data Spaces Business Alliance (DSBA)
Un espacio de datos es un ecosistema capaz de materializar la compartición voluntaria de datos entre sus participantes, respetando su soberanía sobre los mismos, esto es, siendo capaces de fijar las condiciones de su acceso y uso. La DSBA, fundada en 2021, está compuesta por los principales actores en la definición de estándares, modelos y marcos tecnológicos para la construcción y operación de espacios de datos. En concreto, la alianza está compuesta por la Big Data Value Association (BDVA), la Fundación FIWARE y las asociaciones Gaia-X European Association for Data and Cloud AISBL y la International Data Spaces Association (IDSA). El propósito de la alianza es acordar un marco tecnológico común que evite la fragmentación tecnológica de la actividad, así como la armonización en el mensaje y las actividades de difusión.
Technical Convergence Discussion Document
Respecto a la parte tecnológica, la DSBA publicó en septiembre de 2022 una primera aproximación a la deseada convergencia tecnológica.
El documento analiza técnicamente los puntos de anclaje para crear espacios de datos confiables, catálogos federados y mercados compartidos y la capacidad de definir políticas de uso de los datos (en base al uso de un lenguaje común). Esta capacidad para compartir respetando la soberanía del dueño de los datos es lo que hace de estos espacios algo novedoso y verdaderamente disruptor, pues por primera vez ofrece elementos técnicos con que controlar los riesgos asociados a la compartición de información.
Para conseguir la convergencia técnica, la asociación acordó el desarrollo de un marco mínimo viable (MVF, minimal viable framework) basado en tres pilares:
- Interoperabilidad en el intercambio de datos mediante la utilización del protocolo/API estándar de intercambio de datos NGSI-LD y los modelos de datos "Smart Data Models" ampliados para la adopción del modelo de información definido por la arquitectura IDS.
- Soberanía y confianza en el intercambio de datos mediante la adopción de un modelo descentralizado (Self-Sovereign Identity) como el propuesto por Gaia-X (con su Trust Framework) que emplearía la DLT (Distributed Ledger Technologies) impulsada por la Comisión Europea (EBSI). El resultado será un entorno de confianza compatible con la normativa eIDAS 2.0 de la UE.
- Servicios de creación de valor (intermediación) consistentes en un catálogo de datos descentralizado y servicios de comercialización basados en estándares del TM Forum.
La alianza considera que este MVF sería un buen punto de partida sobre el que trabajar para alcanzar la deseada convergencia tecnológica, contando y reutilizando piezas de las actuales soluciones aportadas por los distintos suministradores.
Ejemplo de mercado público de datos
El documento plantea el ejemplo de un proveedor de servicios de datos que ofrece su servicio en un mercado público de datos (Data Marketplace), de modo que los consumidores puedan acceder fácilmente a esta oferta. Además, los proveedores pueden también delegar el acceso a sus usuarios para modificar atributos del servicio que contratan.
Es un ejemplo que puede verse en detalle en el documento, éste resulta interesante porque entran en juego diferentes sistemas de autenticación, políticas de seguridad y acceso y, en definitiva, diferentes sistemas que deben interoperar entre sí.
Adicionalmente, se expone un ejemplo de integración entre el Data Marketplace y un catálogo de datos mediante el enfoque seguido por el proyecto europeo Horizonte 2020 'Digital Open Marketplace Ecosystem' (DOME). De esta manera, se crean las ofertas en el catálogo compartido y pueden ser consultadas posteriormente siguiendo las políticas de acceso definidas.

El documento explica, paso por paso y desde una perspectiva puramente técnica, las acciones a abordar por cada uno de los roles identificados, con el propósito de orientar potenciales escenarios que pudieran producirse en la realidad.
El futuro de la DSBA
La DSBA considera que el mencionado MVF es sólo el primer paso para la convergencia de las diferentes arquitecturas y tecnologías existentes en la construcción de espacios de datos. Los siguientes pasos de la alianza tendrán en cuenta los roles asignados a cada uno de los participantes. Más concretamente:
- IDSA: Desarrolla arquitecturas y estándares de espacios de datos. En particular, un modelo para conectores que garantiza la compartición soberana de datos de forma escalable.
- Gaia-X: Desarrolla y despliega una arquitectura, un modelo de gobernanza acorde a especificaciones de negocio para espacios de datos sectoriales, así como un set de herramientas (Gaia-X Federation Services toolkit) con que instanciar la interoperabilidad, componibilidad y transparencia de los servicios de infraestructura y datos en nube.
- FIWARE: Con un stack tecnológico que viene del mundo de los Gemelos Digitales, la comunidad desarrolla componentes software que permiten llevar a la práctica la construcción de espacios de datos.
Así mismo, la DSBA se marca como objetivos prioritarios:
- La compatibilidad de la arquitectura de IDS con un mecanismo de gestión de identidad basado en identificadores descentralizados.
- La integración de un catálogo federado como el propuesto con el bróker de metadatos propuesto en la arquitectura IDS.
- La definición de un vocabulario común.
- Avanzar conjuntamente con la labor del Data Space Support Center (un programa financiado por la Comisión Europea, y donde estas asociaciones desarrollan un papel protagonista), así como con los esfuerzos de normalización en base al proyecto ‘Smart Middleware Platform’ (SIMPL) de la CE.
Contenido elaborado por Juan Mañes, experto en Data Governance.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
A tan solo unos días de que finalice 2022, queremos aprovechar para hacer un pequeño balance del año que termina, un periodo en el que la comunidad de datos abiertos no ha dejado de crecer en España y en el que hemos sumado fuerzas e ilusión con la adhesión de la Oficina del Dato, unidad encargada de dinamizar la gestión, compartición y el uso de los datos a lo largo de todos los sectores productivos de la Economía y Sociedad española, focalizando sus esfuerzos en particular en el impulso de los espacios de compartición y explotación de datos sectoriales.
Gracias precisamente a la incorporación de la Oficina del Dato, desde la Iniciativa Aporta hemos podido duplicar el efecto divulgativo, y promover el papel que desempeñan los datos abiertos en el desarrollo de la economía del dato.
De forma paralela, durante este 2022, hemos continuado trabajando para acercar los datos abiertos a la ciudadanía, la comunidad profesional y las administraciones públicas. Así y con el objetivo de fomentar la reutilización de los datos abiertos con fines sociales, hemos vuelto a organizar una nueva edición del Desafío Aporta.
Con el foco puesto en la salud y el bienestar de los ciudadanos, la cuarta edición de esta competición contó con tres ganadores del más alto nivel y cuyas soluciones digitales tienen como denominador común, mejorar la salud física y mental de las personas, gracias a servicios desarrollados con datos abiertos.
Nuevos ejemplos de casos de uso y visualizaciones paso a paso
A su vez, a lo largo de este año, hemos continuado caracterizando nuevos ejemplos de casos de uso que contribuyen a aumentar el catálogo de empresas reutilizadoras de datos abiertos y aplicaciones. Con las nuevas incorporaciones, datos.gob.es ya cuenta con un catálogo de 84 empresas reutilizadoras y un total de 418 aplicaciones desarrolladas a partir de datos abiertos. De estas, más de 40 han sido identificadas en 2022.
Además, desde que el pasado año inauguramos la sección de visualizaciones paso a paso, seguimos explorando el potencial de las mismas para que los usuarios puedan inspirarse y replicar los ejemplos de manera sencilla.
Informes, guías y material audiovisual para promover el uso de los datos abiertos
Con el propósito de seguir brindando asesoramiento a las comunidades de publicadores y reutilizadores de datos abiertos, otro de los ejes de este 2022 se ha focalizado en ofrecer informes innovadores sobre las últimas tendencias en inteligencia artificial y otras tecnologías emergentes, así como el desarrollo de guías, infografías y vídeos que ayudan a conocer de cerca nuevos casos de uso y tendencias relacionadas con los datos abiertos.
Algunos de los artículos más leídos en el portal datos.gob.es han sido ‘4 ejemplos de proyectos de empresas privadas que apuestan por la compartición de datos en abiertos’, ‘¿Cómo evoluciona la transformación digital en España?’ o ‘Los principales retos para impulsar espacios de datos sectoriales’, entre otros. Respecto a las entrevistas, destacamos las realizadas a los ganadores del IV Desafío Aporta, a Hélène Verbrugghe, Public Policy Manager para España y Portugal de Meta o a Alberto González Yanes, Jefe de Servicio de Estadísticas Económicas del Instituto Canario de Estadística (ISTAC), entre algunos ejemplos.
Por último, queremos agradecer un año más a la comunidad open data su apoyo. Durante 2022, hemos conseguido que el Catálogo Nacional de Datos supere los 64.000 conjuntos de datos publicados. Además, datos.gob.es ha recibido más de 1.300.000 visitas, un 25% más que en 2021, y los perfiles de datos.gob.es en LinkedIn y en Twitter han crecido un 45% y un 12% respectivamente.
Desde datos.gob.es y la Oficina del Dato afrontamos este nuevo año cargados de ilusión y ganas de trabajar para que los datos abiertos sigan avanzando en España de la mano de publicadores y reutilizadores.
¡Por un 2023 cargado de éxitos!
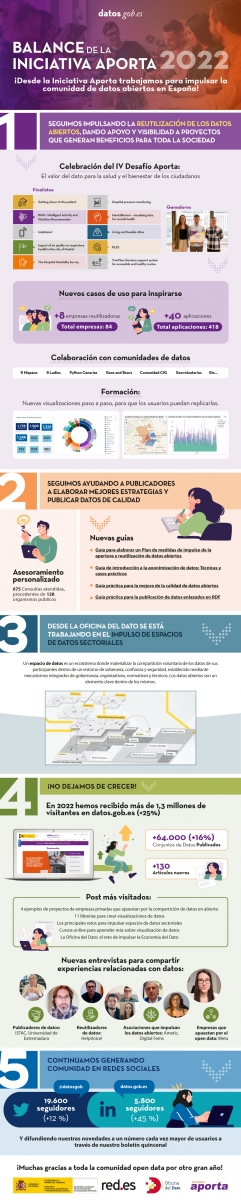
Si deseas ver la infografía a tamaño completo puedes hacer click aquí.
{kind=link}
** Para poder acceder a los enlaces incluidos dentro de la propia imagen descargar la versión pdf disponible a continuación.
Documentación
La RED de Entidades Locales por la Transparencia y Participación Ciudadana de la FEMP acaba de presentar una guía centrada en la visualización de datos. El documento, que toma como referencia la Guía de visualización de datos elaboradora por el Ayuntamiento de L’Hospitalet, ha sido elaborado a partir de la búsqueda de buenas prácticas impulsada por organismos públicos y privados.
La guía incluye recomendaciones y criterios básicos para representar datos gráficamente, facilitando su comprensión. En principio, está dirigida al conjunto de las entidades adheridas a la Red de Entidades locales por la transparencia y la participación ciudadana de la FEMP. No obstante, también es de utilidad para todo aquel que desee adquirir un conocimiento general sobre la visualización de datos.
En concreto, la guía ha sido elaborada con tres objetivos en mente:
- Facilitar principios y buenas prácticas en el ámbito de la visualización de datos.
- Disponer de un modelo de visualización y comunicación de los datos de las entidades locales gracias a la estandarización del uso de diferentes recursos visuales.
- Promover los principios de calidad, sencillez, inclusión y ética en la comunicación de datos.
¿Qué incluye la guía?
Tras una breve introducción, la guía comienza con una serie de conceptos básicos y principios generales a seguir en la visualización de datos, como el principio de simplificación, de aprovechamiento del espacio o de accesibilidad y diseño exclusivo. A través de ejemplos gráficos, el lector aprende lo que se debe y no se debe hacer si queremos que nuestra visualización se entienda fácilmente.
A continuación, la guía se centra en las diferentes etapas del diseño de una visualización de datos a través de un proceso metodológico secuencial, como el que muestra la siguiente imagen:
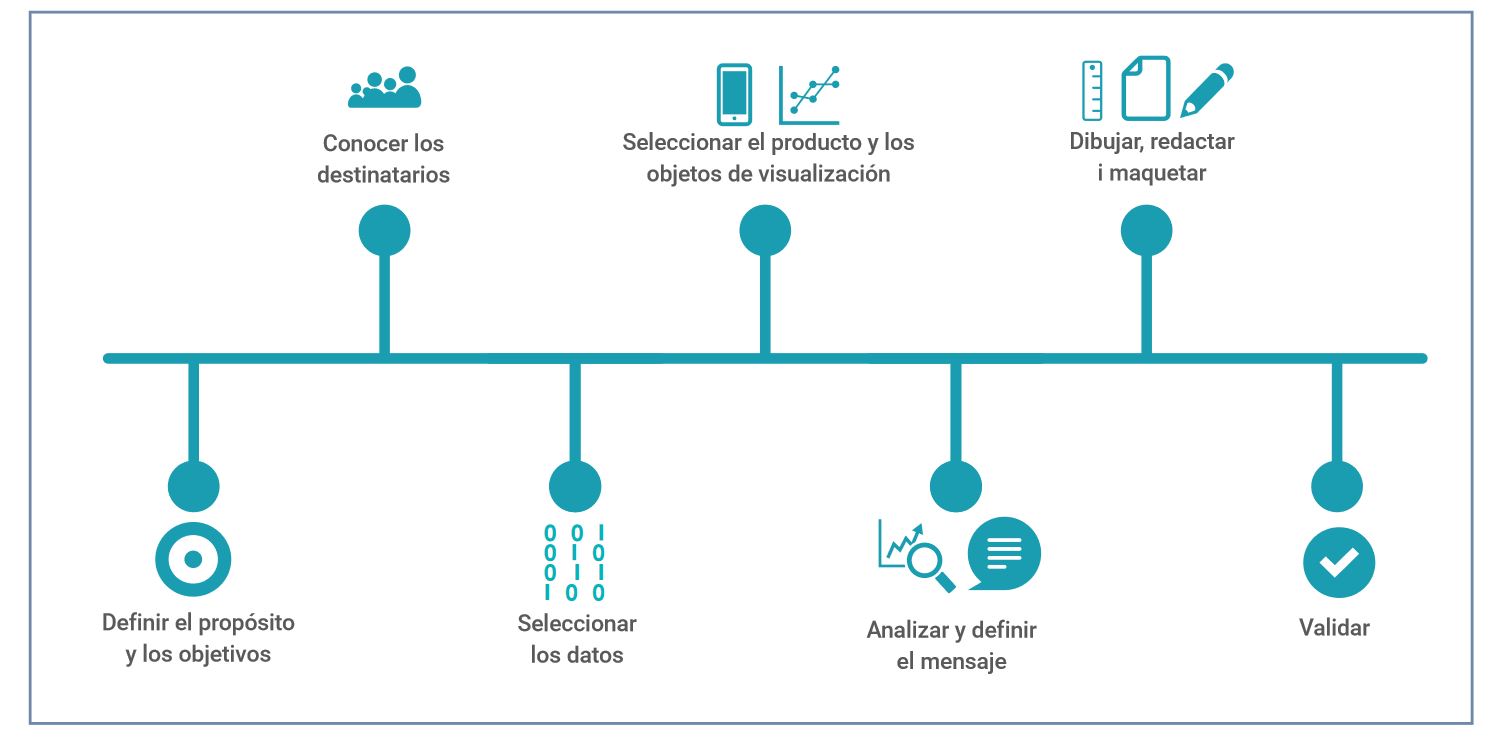
Como muestra la imagen, antes de elabora la visualización es fundamental dedicar tiempo a establecer los objetivos que queremos alcanzar y el público al que nos dirigimos, para poder adaptar el mensaje y seleccionar la visualización más adecuada en base a aquello que queramos representar.
A la hora de representar datos, los usuarios tienen a su disposición una amplia variedad de objetos de visualización con distintas funciones y rendimiento. No todos los objetos son apropiados para todos los casos y habrá que determinar el más adecuado en cada situación concreta. En este sentido, la guía ofrece diversas recomendaciones y pautas para que el lector sea capaz de elegir el elemento adecuado en base a sus objetivos y audiencia, así como a los datos que quiere mostrar.
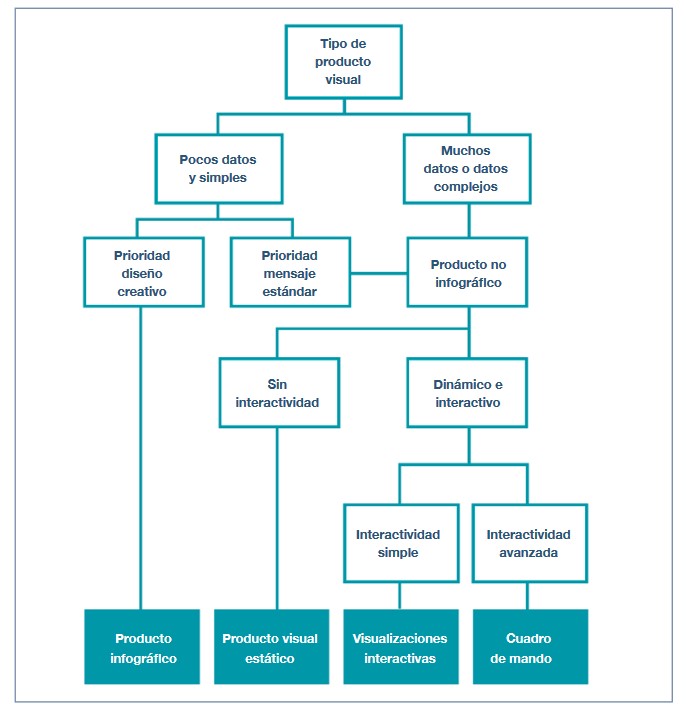
Los siguientes capítulos se centran en los diversos elementos disponibles (infografías, cuadros de mandos, indicadores, tablas, mapas, etc.) mostrando las distintas subcategorías que existen y las buenas prácticas a seguir en su elaboración, mostrando numerosos ejemplos que facilitan su comprensión. También se ofrecen recomendaciones sobre el uso del texto.
La guía finaliza con una selección de recursos, que permiten ampliar el conocimiento, y de herramientas de visualización de datos a considerar por todo aquel que quiera empezar a elaborar sus propias visualizaciones.
Puedes descargar la guía completa a continuación, en el aparatado de “Documentación”.