Documentación
La anonimización de datos define la metodología y el conjunto de buenas prácticas y técnicas que reducen el riesgo de identificación de personas, la irreversibilidad del proceso de anonimización y la auditoría de la explotación de los datos anonimizados, monitorizando quién, cuándo y para qué se usan.
Este proceso es fundamental, tanto cuando hablamos de datos abiertos como de datos en general, para proteger la privacidad de las personas, garantizando el cumplimiento normativo y de los derechos fundamentales.
El informe “Introducción a la anonimización de datos: Técnicas y casos prácticos”, elaborado por Jose Barranquero, define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
El objetivo del informe es ofrecer una introducción suficiente y concisa, principalmente orientada a publicadores de datos que necesitan garantizar la privacidad de estos. No se trata de una guía exhaustiva, sino una primera toma de contacto para entender los riesgos y técnicas disponibles, así como la complejidad inherente a cualquier proceso de anonimización de datos.
¿Qué técnicas se incluyen en el informe?
Tras una introducción donde se definen los términos más relevantes y los principios básicos de anonimización, el informe se centra en comentar tres enfoques generales para la anonimización de datos, cada uno de los cuales está integrado a su vez por diversas técnicas:
- Aleatorización: tratamiento de datos, eliminando la correlación con el individuo, mediante la adición de ruido, la permutación, o la Privacidad Diferencial.
- Generalización: alteración de escalas u órdenes de magnitud a través de técnicas basadas en agregación como Anonimato-K, Diversidad-L, o Proximidad-T.
- Seudonimización: reemplazo de valores por versiones cifradas o tokens, habitualmente a través de algoritmos de HASH, que impiden la identificación directa del individuo, a menos que se combine con otros datos adicionales, que deben estar custodiados de forma adecuada.
El documento describe cada una de estas técnicas, así como los riesgos que suponen, aportando recomendaciones para evitarlos. Si bien, la decisión final sobre qué técnica o conjunto de técnicas es más adecuada depende de cada caso particular.
El informe finaliza con un conjunto de ejemplos prácticos sencillos que muestran la aplicación de las técnicas Anonimato-K y seudonimización mediante cifrado con borrado de clave. Para simplificar la ejecución del caso, se pone a disposición de los usuarios el código y los datos utilizados en el ejercicio, disponibles en Github. Para seguir el ejercicio, es recomendable tener unos conocimientos mínimos del lenguaje pyhton.
A continuación, puedes descargar el informe completo, así como el resumen ejecutivo y una presentación-resumen.
Noticia
El pasado 20 de octubre, Madrid acogió una nueva edición del Data Management Summit Spain, una cumbre internacional que este año también tuvo lugar en Italia (7 de julio) y Latam (20 de septiembre). La cita reunió a CiOs, CTOs, CDOs, Directores de Sistemas, Responsables de Inteligencia de Negocio y Científicos de Datos encargados de implementar tecnologías emergentes con el fin de resolver nuevos retos tecnológicos y alinearse con nuevas oportunidades de negocio.
Este evento fue precedido de un prólogo celebrado la tarde anterior, en colaboración con DAMA España y la Oficina del Dato. Se trataba de una sesión dirigida exclusivamente a representantes de los distintos niveles de la administración pública y centrado en los datos abiertos y el intercambio de información entre administraciones. Durante la jornada se debatió el papel transformador del dato y cómo su uso intensivo y puesta en valor son fundamentales para lograr la transformación digital de las administraciones públicas.
Tal y como se refirió en la sesión, el dato tiene un papel esencial en el desarrollo de tecnologías disruptivas como la Inteligencia Artificial, y supone un factor diferencial a la hora de poner en marcha una revolución industrial y tecnológica que permita consolidar una economía digital más justa, inclusiva y en línea con los ODS y la Agenda 2030. Una auténtica economía del dato con la vocación de nutrir con todas las garantías el desarrollo de dos procesos clave y estratégicos para la reconstrucción de nuestro país: la transformación digital y la transición ecológica.
Los espacios de datos y los datos abiertos, claves para conseguir una administración orientada al dato
La apertura institucional corrió a cargo de Carlos Alonso, director de la División Oficina del Dato. Su intervención se centró en resaltar cómo la consecución de una administración orientada al dato, parte inseparable de su proceso de transformación digital, pasa por el desarrollo de los espacios de datos del sector público, los cuales habilitan la compartición de datos con soberanía y su explotación a gran escala. El dato es un bien público, a conservar y tratar en aras de una aplicación de servicios y políticas públicas de calidad. El objetivo es conseguir una administración orientada al dato, centrada en la ciudadanía, abierta, transparente, inclusiva participativa e igualitaria, asegurando un uso ético, seguro y responsable de los datos.
En este proceso de concepción de los espacios de datos del sector público y privado son fundamentales los datos abiertos, como resaltó Carlos Alonso durante su intervención: “Los espacios de datos son grandes consumidores y generadores de datos abiertos, debiéndose asegurar su disponibilidad. Esto es, se precisa fijar unos determinados acuerdos de nivel de servicio que aseguren el acceso”.
Compartición de experiencias entre administraciones
Tras esta apertura institucional, la jornada ha abordado la oportunidad que suponen la creación de espacios de compartición y explotación de datos en las administraciones públicas, y ha permitido difundir diferentes proyectos en torno al dato por parte de representantes de los diferentes niveles administrativos, incluyendo también Comunidades Autónomas y entidades locales.
Andreu Francisco, Director General del Consorcio local Localret, formado por las administraciones locales de Cataluña para el desarrollo de los servicios y redes de telecomunicaciones y la aplicación de las TIC, presentó un metamodelo digital, cuyo fin es estructurar la arquitectura tecnológica y de servicios necesarios en una ciudad digital. Se trata de una solución integral, que puede ser implementada en distintos territorios y personalizada en función de las singularidades de cada ciudad, facilitando que los habitantes de los 877 municipios catalanes puedan desarrollarse a nivel profesional y personal.
César Priol, Director General de Digitalización y Atención Ciudadana, de Bizkaiko Foru Aldundia (País Vasco) compartió su experiencia en la creación de la Oficina de Datos, resaltando la importancia de organizarse tanto a nivel organizativo como normativo y legal para tener la capacidad de transformar con los datos no solo la organización, sino también el territorio.
Magda Lorente, Jefa de la Sección de Asistencia en Sistemas de Información Local, y Sara Aguilar, Jefa del Servicio del Boletín Oficial de la Provincia de Barcelona y otras Publicaciones Oficiales de la Diputación de Barcelona, hablaron de buenas prácticas en la gestión de datos. Magda Lorente resaltó la importancia de que las diputaciones se orienten al dato para así poder asumir su papel relevante en el impulso del gobierno del dato municipal. Según un estudio realizado por la Diputación de Barcelona, que verá la luz a finales de noviembre, el 85% de los municipios podrían quedarse al margen de la inteligencia artificial y de la administración inteligente debido a que sus capacidades técnicas no permiten materializar la orientación al dato que se precisa.
Sara Aguilar, por su parte, presentó un ejemplo de cómo las administraciones están consolidando el camino en la toma de decisiones en base al dato de calidad: el CIDO, un buscador de información y documentación oficial. Esta herramienta nació en el año 2000 con el fin de acercar la información de las administraciones a la ciudadanía de forma amigable. Desde él se puede acceder, por ejemplo, a más de 2.600 procesos selectivos con convocatoria abierta y a 1.600 subvenciones abiertas, gracias a los datos abiertos ofrecidos por los distintos municipios de Cataluña. CIDO se basan en un modelo de lector de etiquetas y en el uso de algoritmos de inteligencia artificial, que clasifican la información recogida de los municipios. Disponen de más de 2 millones de anuncios, datos abiertos estructurados y documentados que sirven a través de una API que se puede integrar en cualquier plataforma.
Mesas redondas y dinámicas de grupo para promover el debate
Durante el desarrollo de la jornada los asistentes pudieron participar en diferentes dinámicas de intercambio de experiencias. La primera dinámica estuvo centrada en los datos abiertos y la segunda en la interoperabilidad.
Además, se celebraron dos mesas redondas que han permitido abordar la materia desde diferentes prismas de opinión:
- La primera mesa redonda, moderada por Carlos Alonso, se centró en los retos y barreras para el intercambio de datos en el sector públicos. En ella se proyectaron a mayor escala las actuales metodologías, especificaciones y prácticas relacionadas con el tratamiento de la información, para conseguir un intercambio de datos fluido y continuo entre administraciones, sectores industriales y ciudadanos. La mesa conto con la participación de: Carlos Alonso, Jose Antonio Eusamio (Secretaría General de Administración Digital), César Priol (Diputación de Vizcaya), Miguel Angel Martinez Vidal (INE) y Magda Lorente.
- La segunda mesa redonda se centró en cómo acelerar la adopción de Open Linked Data en el dominio de la administración pública, moderada en este caso por Oscar Alonso (IBM Consulting & DAMA España). En ella participaron Sara Aguilar (Diputación de Barcelona), Oscar Alonso (DAMA España e IBM), Sonia Castro (datos.gob.es), Juan José Alonso (Orange) y Olga Quiros (ASEDIE) La conversación giró en torno a las iniciativas de la UE, como la Ley de gobernanza de datos, que están actuando como punto de inflexión en las políticas de datos. Dicha ley busca establecer mecanismos sólidos para facilitar la reutilización de ciertas categorías de datos protegidos del sector público, aumentar la confianza en los servicios de intermediación de datos y promover el altruismo de datos en toda la UE. Con ello se pone de manifiesto como desde UE está trabajando para reforzar diversos mecanismos de intercambio de datos con el objetivo de fomentar su disponibilidad y que puedan utilizarse para impulsar aplicaciones y soluciones avanzadas en inteligencia artificial, medicina personalizada, movilidad ecológica, fabricación inteligente y muchos otros ámbitos. Durante el debate también se resaltó la importancia que tiene la ética del dato.
Materiales disponibles sobre la jornada
Si te perdiste la sesión, el video de la misma está disponible en Youtube. También se ha hecho pública la grabación de la cumbre del día 20, una jornada que contó con un enfoque más empresarial, con ponencias de expertos y dinámicas de grupo centradas en la gobernanza de datos, su calidad, los datos maestros y la arquitectura de datos, entre otros temas. También está disponibles las fotos del evento.
Además, en la página web de la cumbre se han ido publicando entrevistas a algunos de los ponentes, que permiten profundizar un poco más en los proyectos que llevan a cabo.
Evento
Asedie, la Asociación Multisectorial de la Información, organiza, un año más, su Conferencia internacional sobre reutilización de la información del sector público. La edición de este año, que ya es la catorce, tendrá como lema “La Estrategia de Datos en Europa y en España”.
El evento busca servir de plataforma para compartir conocimientos y experiencias entre todos los implicados en la comunidad de la información y de los datos, así como promover la colaboración público-privada en beneficio del interés general.
¿Cuándo y dónde se celebra?
Se trata de un evento presencial. La cita tendrá lugar el 17 de noviembre 2022 en el Colegio de Registradores (Calle Alcalá 540), en Madrid. La recepción de asistentes comienza a las 9:00h y el acto finalizará a las 13.40h.
¿Cuál es el programa?
El foco de esta edición estará puesto en la Economía del Dato y el desarrollo práctico de la Ley de Reutilización de la Información del Sector Público. También se abordarán temas interrelacionados con los datos, como es la transparencia, la inteligencia artificial, la digitalización, la información geoespacial o la protección de datos personales, entre otros. Para tratar estos temas, se contará con grandes expertos en la materia.
La sesión se abrirá a las 9:30 con la bienvenida de la Decana del CORPME, Dª María Emilia Adán García, seguida de la inauguración del Presidente de Asedie, D. Ignacio Jiménez.
El evento contará con dos mesas redondas:
- La primera estará centrada en “La Economía del dato: derechos, obligaciones, oportunidades y barreras”. En ella participará Carlos Alonso, Director de la División Oficina del Dato, junto con representantes del Ministerio de Hacienda y Función Pública, la Comunidad Autónoma de Madrid y el Colegio de Registradores.
- La segunda mesa redonda, moderada por Emilio López, Director del CNIG, lleva por título “El potencial de la información geoespacial como conjunto de datos de alto valor”, y contará con la presencia de representantes de la Comisión Europea, el Instituto Nacional de Estadística, la Dirección General del Catastro y la Comunidad Autónoma de La Rioja.
Durante la jornada, también habrá ponencias ligadas a la Comisión Europea, como la de D. Szymon Lewandowski, quien hablará de políticas de datos e innovación, y la de Martin Ulbrich sobre inteligencia artificial. También participará D. Leandro Cervera-Navas, Director del European Data Protection Supervisor (EDPS).
Además, como viene siendo habitual, dentro del marco de la Conferencia se entregará el Premio Asedie, que ya va por su novena edición. Este galardón tiene como finalidad reconocer a aquellas personas, empresas o instituciones que destacan por su contribución a la innovación y desarrollo del sector infomediario en el año en curso.
Puedes consultar el programa completo aquí.
¿Cómo puedo inscribirme?
Dado que el aforo es limitado, es necesario inscribirse a través de la web de Asedie antes del martes 15 de noviembre.
Noticia
El pasado 25 de octubre se celebró el taller de trabajo “Casos de uso del espacio de datos del Turismo español”, con el objetivo de arrancar el diseño y despliegue del primer dataspace del turismo interoperable a nivel europeo, construido bajo el sello de Gaia-X.
Esta actividad, organizada por la Oficina del Dato en colaboración con la Secretaría de Estado de Turismo, a través de SEGITTUR, se encuadra dentro del modelo de colaboración público privado para la constitución de los espacios de datos sectoriales impulsada por la Secretaria de Estado de Digitalización e Inteligencia Artificial del Ministerio de Asuntos Económicos y Transformación Digital. La cita supone la continuación al proceso de dinamización de los espacios de datos nacionales que se inició con la jornada abierta “Impulso gubernamental a una reindustrialización data-driven - Espacio de datos del Turismo español”, y se enmarca dentro de las acciones llevadas a cabo por el Gobierno de España para crear el entorno legal, político, tecnológico y de financiación propicio al despliegue de la economía del dato, tal y como se detalla en la estrategia España Digital 2026. Esta actuación está alineada con la escena europea.
¿Por qué un espacio de datos de turismo?
Los datos son un elemento vital del desarrollo y sostenibilidad del sector turístico. Permitiendo su adecuada puesta en valor se refuerza la ya significativa contribución del sector a la economía nacional. El lugar donde materializar este valor latente son los espacios de datos.
De acuerdo con su acepción europea, los espacios de datos son ecosistemas donde diversos actores comparten datos de manera voluntaria y segura. De esta forma se materializa la compartición de datos entre los partícipes respetando los principios de auto determinación en la compartición de datos (soberanía), privacidad, transparencia, seguridad y competencia justa.
El turismo, dado su ecosistema de participantes públicos y privados, de diferentes dimensiones y grado de madurez tecnológico, constituye un entorno óptimo donde contrastar las bondades de estos ecosistemas federados de datos. Gracias a ellos se facilita la extracción de valor de fuentes de datos no tradicionales, con una elevada escalabilidad, y garantizando en todo caso unas condiciones robustas de seguridad, privacidad y en ende de soberanía del dato.
La alta disponibilidad de datos sobre turismo supone grandes ventajas para el sector, ya que facilita la creación de ofertas, productos y servicios más personalizados que proporcionen una experiencia mejorada y adaptada a las necesidades de los clientes, mejorando así la capacidad de atraer turistas. Además de impulsar un mayor conocimiento del sector y una toma de decisiones informada tanto por parte de organizaciones públicas como privadas, que pueden detectar más fácilmente nuevas oportunidades de negocio.
Un taller eminentemente práctico
Durante el desarrollo del taller, los más de cien participantes, tanto del sector turístico como tecnológico, abordaron la caracterización en detalle de diferentes casos de uso de compartición de datos susceptibles de satisfacer necesidades de negocio concretas del sector turístico. Los participantes se organizaron a lo largo de diferentes mesas de trabajo considerando la madurez de los casos de uso planteados, buscando fomentar la variedad de perfiles y la agrupación de intereses. Las diferentes dinámicas de trabajo que se llevaron a cabo, se realizaron de acuerdo con la metodología de descubrimiento y diseño de casos de uso elaborada por la Oficina del dato, permitiendo validar su contenido y su escalabilidad al resto de espacios de datos sectoriales por constituir.
Durante las conclusiones finales de la jornada, la Oficina del Dato hizo énfasis en el papel central de los espacios de datos como lugar donde crear nuevas oportunidades de negocio dentro del sector turístico. También se resaltó que las sinergias derivadas de la compartición de datos van más allá de la suma de los datos individuales, y las inversiones, debidamente apoyadas por la colaboración pública-privada, deben verse más allá del corto plazo necesitando ser respaldadas por la Dirección. El problema a resolver es un problema de negocio y la solución no es exclusivamente tecnológica, deben buscarse soluciones simples con facilidad de adopción y uso, de despliegue robusto, ágil y sencillo que no generen barreras de entrada a pequeños participantes. Aprovechando el momento tecnológico, económico, político y social, es posible desarrollar un sector turístico orientado al dato, sostenible, generador de valor social e inclusivo.
En este enlace puedes ver la presentación del taller, donde se recogen, entre otros, aspectos metodológicos para la creación de espacios de datos, como las características a cumplir o los elementos a considerar. A continuación también puedes acceder a varias infografías:
- Los espacios de datos de turismo y el modelo Gaia-X
- Ficha del caso de uso para la compartición de datos
- Identificación y propuesta de casos de uso en turismo
- Elementos que intervienen en el proceso de compartición de datos
Blog
Muchas organizaciones y administraciones han encontrado en los datos abiertos un pilar transformacional sobre el que ejercer la estrategia hacia la cultura del dato. Tener acceso a datos de forma estructurada es la base de nuevos modelos de negocio, así como de nuevas iniciativas dirigidas al ciudadano en los diferentes ámbitos de actuación.
Sin embargo, obtener todo el potencial de los datos abiertos, requiere de una plataforma capaz de poner a disposición de terceros estos datos asegurando su calidad, entendimiento, privacidad y seguridad.
En este contexto, el libro “Designing Data Spaces”, incluye un capítulo, firmado por Fabian Kirstein and Vincent Bohlen, donde se propone el uso de la arquitectura IDS-RAM propuesta por la International Data Spaces (IDS) para el desarrollo de ecosistemas de datos abiertos. En él se aborda una prueba de concepto sobre la viabilidad de la arquitectura de IDS para disponer espacios de datos públicos con el objetivo de lograr una base sólida que permita construir y mantener ecosistemas de datos abiertos interoperables, capaces de hacer frente a los retos existentes.
A continuación, se resumen las opiniones recogidas en el capítulo.
Ecosistemas de datos abiertos
Los espacios de datos son ecosistemas donde diversos actores comparten datos de manera voluntaria y segura, siguiendo mecanismos comunes de gobernanza, organizativos, normativos y técnicos.
Con el objetivo de impulsar la economía digital global, mediante un sistema seguro y soberano de intercambio de datos en el que todos los participantes puedan obtener el máximo valor de sus datos, en 2016 surge IDSA (International Data Spaces Association), una coalición de más de 130 empresas internaciones con representación en más de 20 países en todo el mundo.
Entre otras iniciativas, promueve un modelo de referencia arquitectónico denominado IDS-RAM, que pretende facilitar el intercambio de datos para optimizar su valor, pero sin perder su control. Ofrece varios enfoques cuya aplicabilidad puede entenderse tanto en el contexto de datos privados como de datos abiertos, ya que se basa en repositorios de metadatos para compartir información. Es decir, los datos permanecen bajo el control de sus propietarios y son los metadatos estandarizados los que se gestionan de forma centralizada para su compartición.
La creación de los espacios de datos conlleva una serie de riesgos a los que hacer frente, tanto desde el punto de vista del consumidor como del proveedor. Los proveedores de datos ponen el foco en el cumplimiento legal, mediante aspectos como la propiedad de los datos. Aunque existen normas comunes para aspectos como la descripción de metadatos - La World Wide Web Consortium no es ajena al problema y por ello propuso hace ya varios años su Data Catalog Vocabulary (DCAT), un estándar para describir catálogos de datos - lo cierto es que la interoperabilidad, en ocasiones, está lejos de su mayor potencial. Esto se debe a que a veces existen metadatos incompletos, la calidad es escasa, los datos están obsoletos, existen dificultades para acceder a datos e interoperar, etc.
La aplicabilidad de IDS-RAM en entornos de datos abiertos
IDS ofrece un enfoque basado en garantizar la soberanía de los datos a los proveedores, facilitando el intercambio de datos y dando respuesta a las preocupaciones tanto de consumidores como de proveedores.
Los conceptos y tecnologías subyacentes a los datos abiertos y al IDS-RAM son muy similares. Ambas iniciativas se basan en repositorios de metadatos para compartir información sobre la disponibilidad y accesibilidad de los datos. Estos repositorios almacenan metadatos, sin necesidad de transferir los datos reales. Por lo tanto, ambos conceptos siguen los principios de descentralización y transferencia de metadatos desde y hacia los puntos centrales de acceso a la información. Los datos reales permanecen bajo el control de la infraestructura del editor de datos hasta que un usuario los solicita. Además, el modelo de información de IDS se basa en los principios de Linked Data y DCAT. Esto hace que sea un sistema fácilmente compatible con los portales de datos abiertos, impulsando la interoperabilidad entre espacios de datos y portales de datos abiertos.
La arquitectura que propone IDS se basa principalmente en dos artefactos, un conector a las fuentes de datos (Open Data Connector) y un almacén de metadatos (Open Data Broker), tal como muestra la siguiente imagen extraída del libro “Designing Data Spaces”:
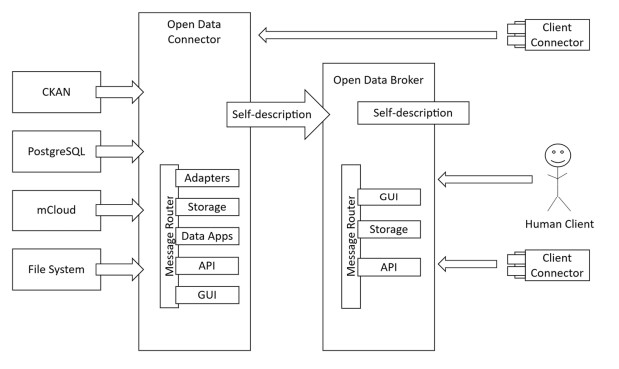
- Open Data Connector: adopta el rol de proveedor de datos abiertos. Cada entidad publicadora, aplica una instancia del conector para anunciar la disponibilidad y conceder accesos a los datos. Al tratarse de datos abiertos, y por tanto públicos, no es necesario aplicar políticas de uso o restricciones tan estrictas como cuando hablamos de otros conectores de datos privados basados en esta arquitectura, lo que permite una configuración y manejo a priori más sencillo.
- Open Data Broker: el repositorio centralizado de metadatos cumple una función similar a la de un portal de datos abiertos. A partir de estos metadatos, la interfaz de portal ofrece funcionalidades para localizar y descargar los datos desde los conectores.
Esta gestión permite agrupar por diferentes ámbitos de aplicación, es decir, se pueden crear repositorios de metadatos centralizadosde sectores como salud o turismo, así como a nivel municipal, regional, nacional o internacional.
En un ecosistema de datos como el que se propone por IDS, el conector informa sobre los datos disponibles o actualizados, y en el repositorio de metadatos estos se actualizan en consecuencia. Para ello se utilizan mecanismos de comunicación basados en el modelo de información de IDS (IDS information model) y el protocolo IDS (IDS Communication Protocol o IDSCP) que anuncian posibles modificaciones en la disponibilidad de los datos. De esta manera, se garantiza la disponibilidad de los datos actualizados.
En los portales de datos abiertos que recogen un gran número de fuentes de datos, la accesibilidad y la usabilidad general dependen de los metadatos suministrados por los proveedores de datos originales. Las normas como DCAT proporcionan una base común, pero IDS ofrece especificaciones más estrictas en el proceso de comunicación.
Aunque es una propuesta interesante, en el contexto de datos abiertos, este enfoque aún no ha sido implantada en ningún espacio. No obstante, ya se han realizado pruebas de concepto, como puede verse en el Public Data Space, un escaparate disponible desde diciembre de 2020 que reproduce cómo funciona la solución. En él, los conectores exponen la oferta de datos abiertos de diferentes portales de datos de Alemania y se registran en un almacén de metadatos.
La siguiente imagen muestra el flujo de trabajo de un modelo basado en IDS-RAM versus un enfoque más tradicional:
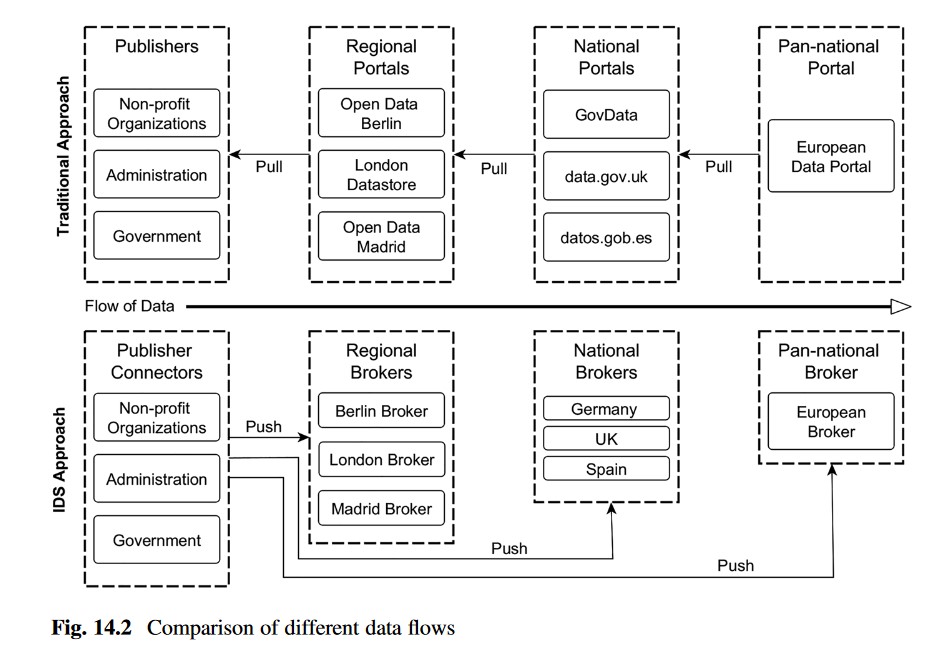
Conclusiones
Los portales de datos abiertos suministran acceso a datos abiertos procedentes de diversos proveedores. La usabilidad general de estos portales, está supeditada en cierto modo al descubrimiento de los datos, que a su vez depende de la calidad de sus metadatos.
Para contrarrestar los problemas de datos no disponibles o enlaces muertos que en ocasiones se producen en entornos de datos abiertos, los portales recogen periódicamente los catálogos de datos del publicador y realizan comprobaciones de disponibilidad. En el ecosistema de datos abiertos basado en IDS-RAM, el conector informa al bróker sobre los conjuntos de datos disponibles o actualizados. El enfoque "pull" de la responsabilidad en los entornos habituales de datos abiertos se invierte en un enfoque "push" en el ecosistema de IDS. Este enfoque focaliza en la responsabilidad del publicador de mantener la oferta de datos y además presenta nuevas posibilidades para controlar su difusión. Utilizando IDS-RAM, el publicador elige a qué broker de metadatos se inscribe, lo que le otorga una mayor soberanía sobre sus datos.
Para los consumidores de datos, este enfoque puede suponer mejoras en cuanto a la posibilidad de encontrar los datos en el momento oportuno y reduce la fragmentación. Además, si los datos abiertos pueden adquirirse, manejarse y procesarse con las mismas herramientas y aplicaciones que ya se aplican en la industria, las posibilidades de integración y reutilización se multiplican.
Contenido elaborado por Juan Mañes, experto en Data Governance.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Para que un espacio de datos funcione correctamente, es necesario contar con actores suficientes para cubrir un conjunto de roles y una serie de componentes tecnológicos. Estos elementos permiten fijar un marco común de gobernanza para compartir los datos de manera segura, garantizando la soberanía de los participantes sobre sus propios datos. Este concepto, la soberanía de los datos, se puede definir como la capacidad del dueño de los datos para establecer las políticas de uso y acceso de los datos que va a intercambiar, y es el elemento nuclear de un espacios de datos.
En este sentido, el informe “Principios de diseño para los espacios de datos” (abril 2021), financiado por la Unión Europea, ofrece los fundamentos que deben seguir los espacios de datos para actuar de acuerdo con los valores de la UE: descentralización, apertura, transparencia, soberanía e interoperabilidad. El informe fue elaborado por expertos de 25 compañías diferentes, por lo que da una visión consensuada con la industria.
A continuación se resumen algunas de las principales aportaciones del documento, tomando como referencia el artículo “Elementos de un espacio de datos” publicado en la revista Boletic, de la Asociación profesional de Cuerpos Superiores de Sistemas y Tecnologías de la Información. En dicho artículo, los elementos de un espacio de datos se dividen en dos categorías:
- Roles y ámbitos de actuación
- Componentes fundamentales
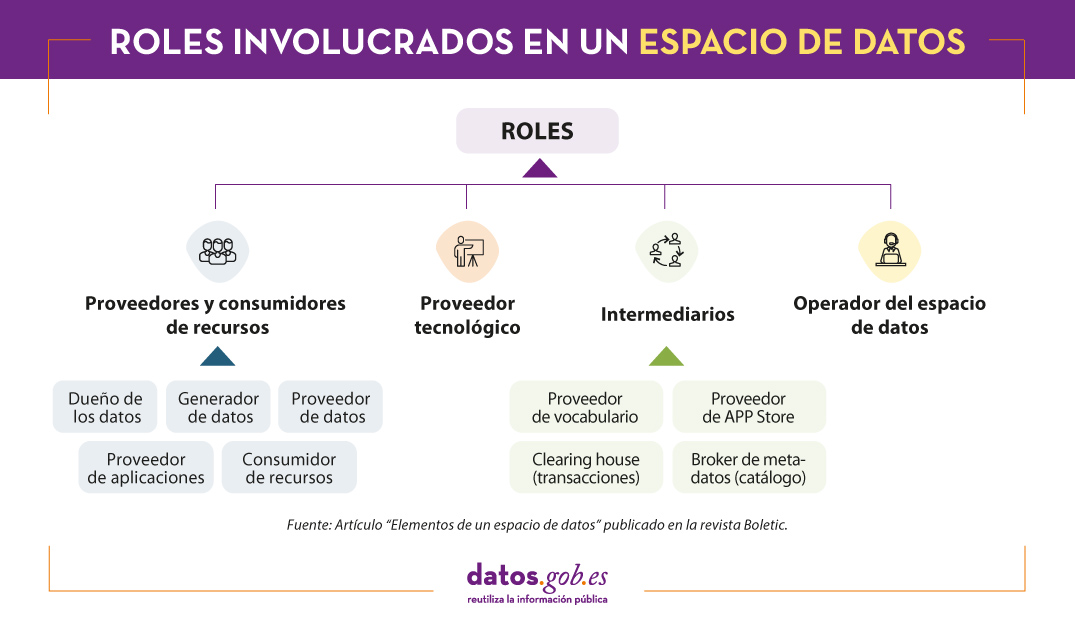
Roles
En un espacio de datos podemos encontrar diversos participantes, cada uno de ellos enfocados en un ámbito de actuación. Es lo que se conoce como roles:
-
Proveedores y consumidores de datos
Son los participantes que proporcionan e interactúan con los datos. Dentro de esta categoría encontramos varios roles:
- Productor de los datos: Genera los datos.
- Dueño de los datos: Es el titular de los derechos de acceso y utilización de los datos.
- Proveedor de datos: Capta los datos y los ofrece a través del catálogo del espacio de datos.
- Consumidor de datos: Accede a los datos del catálogo.
- Proveedor de aplicaciones: Proporciona aplicaciones que permiten trabajar con los datos ofreciendo valor añadido (por ejemplo, modelos de machine learning, visualizaciones, procesos de limpieza, etc.).
-
Intermediarios
En este caso hablamos de terceros que ofrecen los servicios necesarios para la publicación, búsqueda de recursos y registro de transacciones. Algunos ejemplos de servicios que ofrecen los intermediarios son:
- Vocabularios y ontologías, que permiten organizar, categorizar o etiquetar sistemáticamente la información, mejorando la interoperabilidad.
- Tiendas de aplicaciones, donde figuran las herramientas ofrecidas por los proveedores de aplicaciones, garantizándose que han pasado un proceso de control de calidad.
- Servicios de bróker de metadatos para la publicación de un catálogo de ofertas de recursos (datos y aplicaciones) con la máxima información posible.
- Servicios de orquestación, que permiten automatizar diversas actividades.
- Registros de transacciones (clearing house), que permiten mantener el control de las operaciones realizadas.
-
Proveedores tecnológicos
Proporcionan componentes para que el espacio de datos opere correctamente, convirtiéndose en un entorno seguro y de confianza. Ejemplos de estos componentes son el conector -un elemento fundamental que veremos a continuación-, los sistemas de gestión de usuarios o los sistemas de supervisión.
No entrarían en esta categoría los servicios de intermediación ni las aplicaciones.
-
Operadores del espacio de datos
Centrados en la gestión del espacio, realizan tareas como la tramitación de peticiones o incidencias, control de cambios, mantenimiento software, etc. Entre otras cuestiones, certifican a los participantes, ejercen la gobernanza del espacio de datos y definen el roadmap de funcionalidades.
Todos estos roles no son exclusivos, y un mismo usuario puede adoptar varios de ellos.
Componentes de un espacio de datos
Existen diferentes aproximaciones sobre los componentes que debe tener un espacio de datos. Se puede acudir a Gaia-X y/o tomar como referencia el modelo de arquitectura IDS-RAM (Reference Architecture model), caracterizado por presentar una arquitectura abierta, confiable y federada para un intercambio de datos intersectorial.
En todo caso, para que la actividad se desarrolle de una manera segura y controlada, son necesarios, al menos, los siguientes bloques:
-
Componentes para el acceso al espacio de datos: conector
Uno de los principales elementos de los espacios de datos es el conector, mediante el cual los participantes acceden al espacio de datos y a los propios datos. Es el encargado de tratar los datos según las políticas de uso definidas por el dueño de los derechos de acceso y utilización, garantizando su soberanía. Para evitar su manipulación maliciosa, los conectores pueden ir firmados mediante un certificado suministrado por la gobernanza del espacio de datos, de forma que se garantice su integridad y el cumplimiento de los derechos de uso establecidos por el dueño de los datos.
-
Componentes para la intermediación
Permiten los servicios de intermediación antes mencionados, el bróker de metadatos, la tienda de aplicaciones, etc. De todos ellos, el más fundamental es el catálogo de recursos. Además de un listado con la oferta disponible, también es la herramienta que permite localizar al proveedor del recurso, las características del mismo y sus condiciones de uso.
-
Componentes para la gestión de identidad y el intercambio seguro de datos
Estos componentes permiten garantizar la identidad de los participantes y la seguridad de las transacciones. Por ello se suele exigir a los participantes la presentación de credenciales (por ejemplo, vía certificados X.509)
-
Componentes para la gestión del espacio de datos
Se trata de herramientas que permiten que el espacio de datos opere con normalidad, facilitando las operaciones diarias, la gestión de los participantes (alta, baja, revocación, suspensión), la supervisión de la actividad, etc.
¿Cómo interactúan todos estos elementos?
Todos estos roles y componentes interactúan entre sí. Primero, el proveedor de datos registra su oferta de datos en el catálogo, incluyendo metadatos relevantes, como las políticas de uso. El consumidor de datos busca en el catálogo los conjuntos de datos y aplicaciones de su interés. Una vez localizados, contacta con el proveedor, comunicándole cuáles son los recursos que quiere adquirir. En este proceso, puede producirse una negociación adicional de las condiciones. Una vez alcanzado el acuerdo, el consumidor puede descargar los datos.
La operación debe ser registrada tanto por el proveedor como por el consumidor.
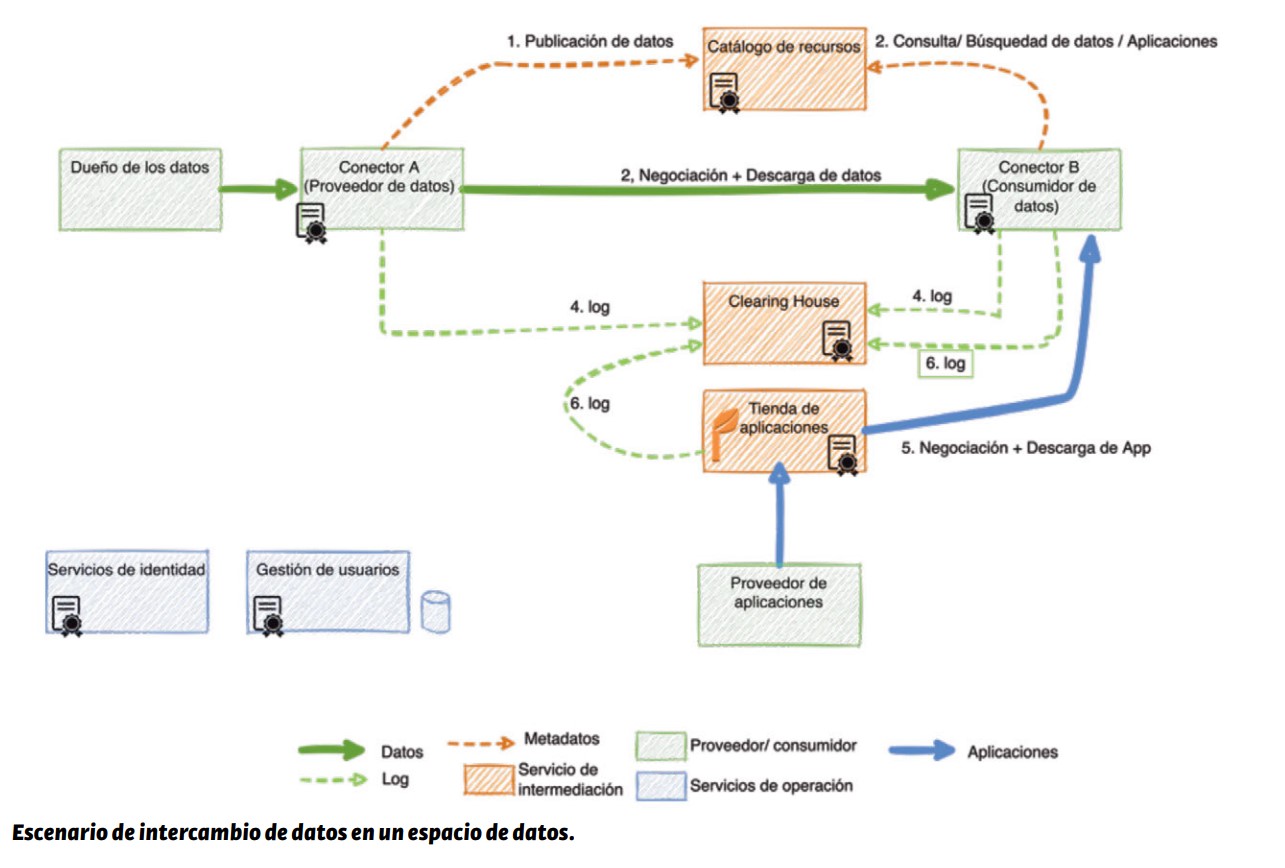
Todos estos elementos (roles, componentes y procesos) permiten que el intercambio de datos se realice de manera segura y controlada, en un entorno gestionado de confianza. Con todo ello se busca que las empresas y organismos europeos puedan intercambiar informacion generando un mercado europeo de datos que de lugar a nuevos productos y servicios de valor, impulsando la economía europea.
Contenido elaborado por el equipo de datos.gob.es.
Evento
El próximo 20 de octubre, Madrid acogerá una nueva edición del Data Management Summit Spain. Esta cita forma parte del Data Management Summit (DMS) 2022, que ya contó con dos jornadas previas en Italia (7 de julio) y Latam (20 de septiembre).
El evento está dirigido a una audiencia técnica: CiOs, CTOs, CDOs, Directores de Sistemas, Responsables de Inteligencia de Negocio y Científicos de Datos encargados de implementar tecnologías emergentes con el fin de resolver nuevos retos tecnológicos y alinearse con nuevas oportunidades de negocio.
Fecha y hora
La jornada tendrá lugar en la Universidad Nebrija, el día 20 de octubre de 2022, en horario de de 9:30 a 19:30.
El día anterior tendrá lugar, en el mismo espacio, un prólogo del DMS solo para representantes de administraciones públicas, con horario de 14:00 a 19:30.
Agenda
La agenda está integrada por ponencias, mesas redondas y dinámicas de grupo entre profesionales, las cuales permitirán potenciar el networking.
El prólogo del día 19 estará focalizada en los datos abiertos y el intercambio de información entre administraciones. Carlos Alonso, Director de la División Oficina del Dato, será uno de los ponentes. Entre las distintas actividades, encontramos dos dinámicas de grupos que girarán en torno a los datos abiertos y la interoperabilidad, así como dos mesas redondas, en la primera de las cuales participará la coordinadora en red.es de la plataforma datos.gob.es:
- Mesa redonda 1: "Open Data y la interoperabilidad de datos en las AAPP".
- Mesa redonda 2: "Desafíos y barreras para el intercambio de datos en el sector público".
Por su parte, el día 20 contará con un enfoque más empresarial. Este segundo día también contará con ponencias de expertos y dinámicas de grupo centradas en la gobernanza de datos, su calidad, los datos maestros y la arquitectura de datos, entre otros temas. Las mesas redondas serán tres:
- Mesa redonda 1: "Arquitectura de datos, ¿malla de datos o tejido de datos?", donde se hablará del patrón de arquitectura Data Mesh (malla de datos), con un enfoque descentralizado, en contraposición a Data Fabric (tejido de datos), que promueve una única arquitectura de datos unificada.
- Mesa redonda 2: "Cómo cambia el Gobierno del Dato con el nuevo paradigma de la banca abierta", donde se abordará la evolución hacia una economía basada en la interoperabilidad total y las API, donde la trazabilidad de los procesos sea completa.
- Mesa redonda 3: "¿Cómo converger los diferentes modelos de calidad de datos?", enfocada en cómo medir la calidad de los datos, cómo administrar los procesos de calidad automáticamente y cómo evitar la corrupción de Data Lake.
Puedes ver más sobre cómo será la jornada en este vídeo.
¿Cómo puedo asistir?
El aforo de cada sesión está limitado a 60 plazas presenciales y a 100 online.
La inscripción para la jornada del día 20 se realiza a través de este enlace (actualmente el aforo está completo, pero puedes apuntarte a la lista de espera). Sí está disponible el registro para el día 19, pero recuerda que dicha sesión es exclusiva para Administraciones Públicas.
Más información en la página web de la cumbre.
Documentación
A la hora de publicar datos abiertos, es fundamental garantizar su calidad. Si los datos están bien documentados y cuentan con la calidad necesaria, será más fácil su reutilización, ya que serán menores los trabajos adicionales de depuración y procesamiento. Además, la baja calidad de los datos puede suponer un coste para los publicadores, que pueden llegar a gastar más dinero en solucionar los errores que en evitar con antelación los potenciales problemas.
Para ayudar en esta tarea, en el marco de la Iniciativa Aporta se ha elaborado la “Guía práctica para la mejora de la calidad de datos abiertos”, que proporciona un compendio de directrices para actuar sobre cada una de las características que definen la calidad, impulsando su mejora. El documento toma como referente la guía para la calidad de datos de data.europe.eu, publicada en 2021 por la Oficina de Publicaciones de la Unión Europea.
¿A quién está dirigida la guía?
La guía está dirigida a publicadores de datos abiertos, a quienes proporciona una serie de pautas claras para mejorar la calidad de sus datos.
No obstante, esta recopilación también puede orientar a los reutilizadores de datos sobre cómo afrontar las debilidades de calidad que pueden presentar los conjuntos de datos con los que trabajan.
¿Qué incluye la guía?
El documento comienza definiendo las características, según la norma ISO/IEC 25012, que deben cumplir los datos para considerarse de calidad, las cuales se recogen en la siguiente imagen.

A continuación, el grueso de la guía está enfocado en la descripción de recomendaciones y buenas prácticas para evitar los problemas más habituales que suelen surgir a la hora de publicar datos abiertos, estructuradas de la siguiente manera:
- Una primera parte donde se detallan una serie pautas generales para garantizar la calidad de los datos abiertos, como, por ejemplo, utilizar una codificación de caracteres estandarizada, evitar la duplicidad de registros o incorporar variables con información geográfica. Para cada pauta se proporciona una descripción detallada del problema, las características de calidad afectadas y las recomendaciones para su resolución, junto a ejemplos prácticos que facilitan su comprensión.
- Una segunda parte con pautas concretas para asegurar la calidad de los datos abiertos según el formato de datos utilizado. Se han incluido pautas específicas para los formatos CSV, XML, JSON, RDF y APIs.
- Por último, la guía también incluye recomendaciones para la estandarización y enriquecimiento de datos, así como para su documentación, y un listado de herramientas útiles para trabajar la calidad de los datos.
Puedes descargar la guía aquí o al final de la página.
Materiales adicionales
La guía va acompañada de una serie de infografías que recopilan las pautas antes indicadas:


Noticia
La Data Spaces Business Alliance (DSBA) nació en septiembre de 2021, fruto de la colaboración de cuatro grandes organizaciones con mucho que aportar a la economía del dato: la Big Data Value Association (BDVA), FIWARE, Gaia-X y la International Data Spaces Association (IDSA). Su objetivo: impulsar la adopción de espacios de datos en toda Europa aprovechando sinergias.
¿Cómo funciona la DSBA?
La DSBA reúne a diversos agentes para hacer realidad un futuro impulsado por los datos, donde las organizaciones públicas y privadas puedan compartirlos y así liberar todo su valor, garantizando la soberanía, interoperabilidad, seguridad y fiabilidad. Para alcanzar este objetivo, la DSBA ofrece apoyo a las organizaciones, así como herramientas, recursos y conocimientos especializados. Por ejemplo, se trabaja en el desarrollo de un framework común de bloques tecnológicos agnósticos reutilizables en diferentes dominios, con que asegurar la interoperabilidad de los diferentes espacios de datos.
Las cuatro organizaciones fundadoras, BDVA, FIWARE, Gaia-X e IDSA, cuentan con una serie de redes internacionales de "Hubs" nacionales o regionales, con más de 90 iniciativas distribuidas en 34 países. Estas iniciativas, pese a ser muy heterogéneas en foco, forma jurídica, nivel de madurez, etc., cuentan con puntos en común y con un gran potencial para colaborar, complementarse y crear impacto. Además, al operar a nivel local, regional y/o nacional, estas iniciativas proporcionan información periódica a las asociaciones europeas sobre las diferentes políticas, culturas y ecosistemas empresariales regionales dentro la UE.
Además, la postulación de la DSBA ha resultado ganadora a la convocatoria de la Comisión Europea para la creación de un Centro de Soporte, que promoverá y coordinará acciones relativas a los espacios de datos sectoriales. Este centro pondrá a disposición tecnologías, procesos, estándares y herramientas con que apoyar el despliegue de los espacios de datos comunes, permitiendo así la reutilización de datos entre sectores.
Los hubs de la DSBA
Cuando se habla de los hubs de la DSBA se hace referencia a la red global que combina las iniciativas ya existentes de BDVA, FIWARE, Gaia-X e IDSA, como recoge la siguiente figura.
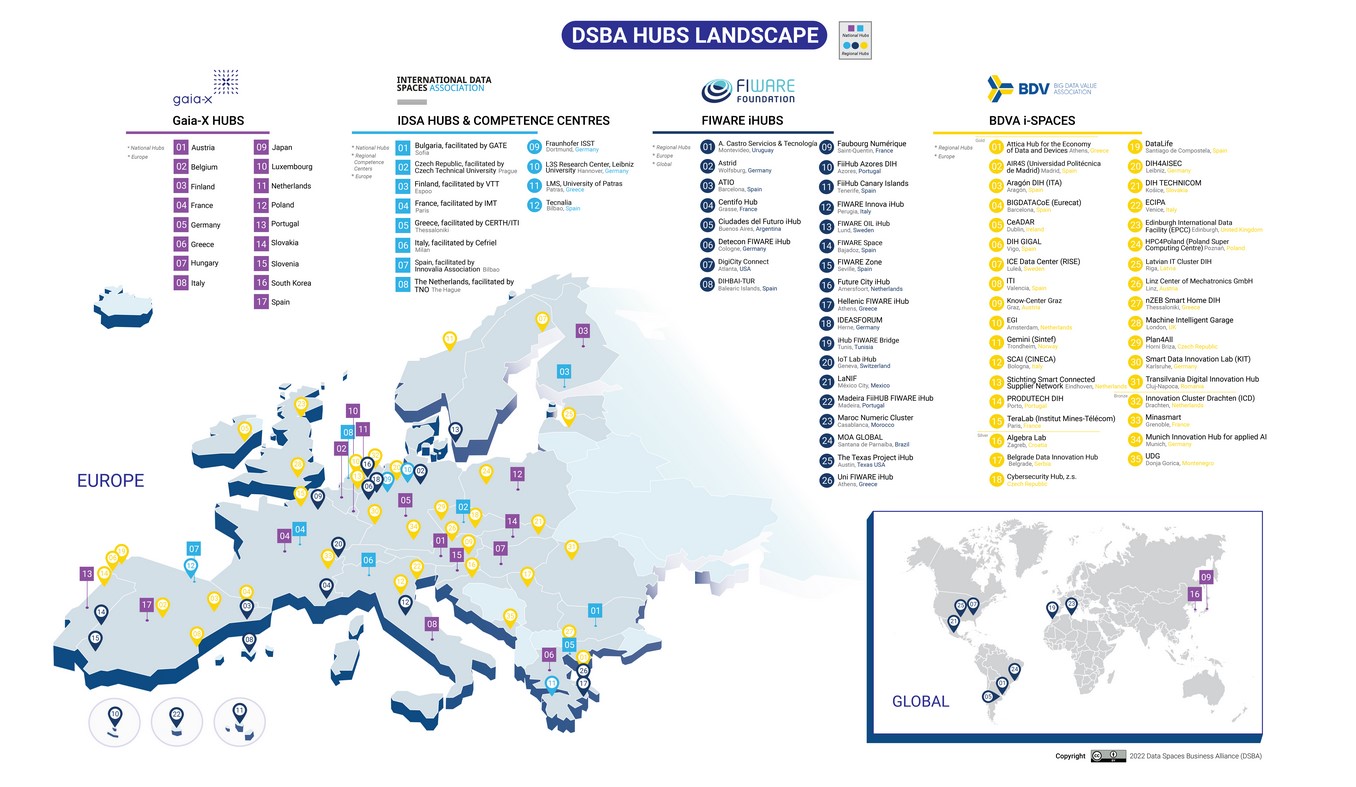
Las principales características de cada uno de estos grupos son:
BDVA i-Spaces
Los i-Spaces de BDVA son incubadoras de datos y centros de innovación intersectoriales e interorganizativos, cuyo fin es acelerar la innovación basada en datos y la inteligencia artificial en los sectores público y privado. Ofrecen entornos seguros de experimentación, que reúnen todos los aspectos técnicos y no técnicos necesarios para que las organizaciones, especialmente las PYMEs, puedan probar, pilotar y explotar rápidamente sus servicios, productos y aplicaciones.
Los i-Spaces ofrecen acceso a fuentes de datos, herramientas para gestionarlos y tecnologías de inteligencia artificial, entre otros. Alojan datos cerrados y abiertos de fuentes empresariales y públicas, como recursos lingüísticos, datos geoespaciales, datos sanitarios, estadísticas económicas, datos de transporte, datos meteorológicos, etc. Los i-spaces cuentan con su propia infraestructura Big Data con potencia de procesamiento ad hoc, almacenamiento en línea y aceleradores de última generación, todas dentro de las fronteras europeas.
Para convertirse en un i-Space las organizaciones deben pasar por un proceso de evaluación, utilizando para ello un sistema de 5 categorías, que se clasifican de acuerdo a los niveles de oro, plata y bronce. Estos hubs deben renovar sus etiquetas cada dos años, y estas certificaciones les permiten unirse a una federación pan-europea para fomentar la innovación de datos transfronterizos, a través del proyecto EUHubs4Data.
FIWARE iHubs
FIWARE es una comunidad de software abierto promovida por la industria TIC, que -con el apoyo de la Comisión Europea- proporciona herramientas y conforma un ecosistema de innovación para que emprendedores creen nuevas aplicaciones y servicios Smart. Los iHubs de FIWARE son centros de innovación enfocados a la creación de comunidades y entornos de colaboración que impulsen el avance de las empresas digitales en esta área. Estos centros proporcionan a empresas privadas, administraciones públicas, instituciones académicas y desarrolladores, acceso a conocimiento y una red mundial de proveedores e integradores de esta tecnología, que además ha sido avalada por organismos de normalización internacionales.
Existen 5 tipos de iHubs:
- iHub School: Entorno enfocado en el aprendizaje de FIWARE, desde una perspectiva empresarial y técnica, aprovechando casos de uso prácticos.
- iHub Lab: Laboratorio donde ejecutar pruebas y pilotos, así como obtener certificaciones FIWARE.
- iHub Business Mentor: Espacio para aprender a construir un modelo de negocio viable a medida.
- iHub Community Creator: Punto físico de encuentro para la comunidad local donde reunir a todas las partes interesadas, que actúa como puerta de entrada al ecosistema local y global de FIWARE.
Gaia-X Hubs
Los Gaia-X Hubs son los puntos de contacto nacionales sobre la iniciativa Gaia-X. Hay que destacar que no son parte como tal de la Gaia-X AISBL (la asociación europea sin ánimo de lucro), sino que actúan como grupos de reflexión independientes, que cooperan con la asociación en el despliegue de proyectos, tareas de comunicación, y generación de requerimientos de negocios para la definición de la arquitectura de la iniciativa (ya que los hubs tienen cercanía con los proyectos industriales de cada país).
A través de ellos se desarrollan espacios de datos específicos en base a las necesidades nacionales, así como la identificación de oportunidades de financiación para implementar los servicios y tecnología de Gaia-X. También se busca que interactúen con otras regiones para construir espacios de datos transnacionales, facilitando el intercambio de información y que los casos de uso nacionales escalen internacionalmente. Para ello, la AISBL proporciona acceso a una plataforma de colaboración, así como apoyo a los respectivos hubs en la distribución y comunicación de los casos de uso.
IDSA Hubs
Los IDSA Hubs permiten intercambiar conocimiento en torno a la arquitectura de referencia (conocida como el IDS-RAM) a nivel país. Reuniendo a las organizaciones de investigación, de promoción de la innovación, sin ánimo de lucro, y a las empresas que utilizan los conceptos y normas de IDS en la región, buscan impulsar su adopción, y -por ende- fomentar una economía del dato soberana con mayor capilaridad.
Estos centros son impulsados en cada país por una universidad, una organización de investigación, o una entidad sin ánimo de lucro, que trabajan junto a IDSA para crear conciencia sobre la soberanía en torno a los datos, transferir conocimientos, reclutar nuevos miembros y difundir casos de uso en base al IDS-RAM. Para ello, desarrollan actividades que van desde sesiones formativas hasta reuniones con responsables de las diferentes administraciones públicas. También fomentan y coordinan proyectos de investigación y desarrollo con organizaciones y empresas internacionales, así como con gobiernos y otras entidades de carácter público.
Conclusión
Como decíamos al principio, existe un gran potencial de sinergias entre estos grupos, que deben explorarse, debatirse y articularse en acciones y proyectos concretos. Nos encontramos ante una prometedora oportunidad de aunar esfuerzos y seguir avanzando en el desarrollo y expansión de los espacios de datos, para generar un impacto notable en la Economía del Dato.
Para estimular el debate inicial, desde la Data Spaces Business Alliance han elaborado el documento “Data Spaces Business Alliance Hubs: potential for synergies and impact”, donde se profundiza en la coyuntura desarrollada anteriormente.
Noticia
El pasado 18 de marzo se celebró la Asamblea Constituyente de la Asociación Gaia-X España, cuya sede se ubica en Talavera de la Reina. La cita reunió a más de 150 entidades de todo tipo, incluyendo empresas, organismos públicos, universidades e instituciones de innovación, con el objetivo de aunar esfuerzos para la creación de una infraestructura de datos abierta, federada e interoperable, siguiendo los valores de soberanía digital y disponibilidad de datos. El fin último es impulsar la transformación de sectores estratégicos dentro del marco de la Economía del dato.
Para avanzar en este ámbito, se han creado una serie de grupos de trabajo. Estos grupos buscan aprovechar las ventajas de Gaia-X para desarrollar espacios de datos sectoriales donde diversos actores compartan datos de manera voluntaria y segura.
Los grupos de trabajo del hub nacional de Gaia-X
Entre los diversos grupos de trabajo que se han puesto en marcha, encontramos tanto grupos sectoriales, como grupos horizontales enfocados en tecnologías habilitadoras, ética y legislación. Con ello se busca desarrollar la visión del espacio de datos en cada sector de actividad, así como obtener unos principios comunes y regidores a todos ellos.
Los grupos de trabajo del hub nacional de Gaia-X facilitan la conexión entre las empresas, las administraciones y el resto de entidades que ofrecen y demandan servicios y tecnologías de datos, con el fin de obtener un adecuado desarrollo e interoperabilidad de los espacios de datos sectoriales. También actúan como punto de encuentro donde difundir experiencias, casos de éxito y lecciones aprendidas.
Estos grupos también participan en diversos eventos. Uno de ellos fue Global Mobility Call, organizado por IFEMA MADRID y Smobhub el pasado 16 de junio para hablar de movilidad sostenible. En él participaron miembros del grupo de trabajo de movilidad del Hub nacional Gaia-X. Durante la sesión salieron a relucir diversos retos relacionados con la creación de espacios de datos, que, si bien estaban focalizados en el ámbito de la movilidad, pueden ser aplicables a otros sectores.
4 desafíos a considerar
1. Pasar de la teoría a la práctica
La creación de un espacio de datos debe hacerse desde un claro enfoque bottom-up partiendo de casos de uso concretos, y aprovechando al máximo los bloques constructivos tecnológicos ya disponibles.
Para ello, el primer paso es identificar las necesidades y oportunidades que se pueden abordar con el intercambio y explotación de los datos dentro de cada sector. Los casos de uso deben resolver una necesidad concreta de negocio. Debe acordarse un modelo económico y fijar las responsabilidades que adquirirán los agentes involucrados, así como un programa de incentivos. Más allá de los componentes técnicos, se necesitan certezas sobre las consideraciones operativas, legales y comerciales que han de regir los intercambios de datos.
Al desarrollar los casos de uso, es fundamental establecer los catálogos de datos objeto de intercambio y explotación, así como la semántica de dichos datos. También es importante que la solución creada busque la interoperabilidad con soluciones análogas, así como establecer mecanismos de mejora continua de la calidad del dato intercambiado.
Los casos de uso deben evidenciar el valor derivado de la compartición del dato. Para ello se puede aprovechar los espacios de experimentación disponibles dentro de los hubs de Data Spaces Business Alliance (DSBA), así como utilizar metodologías agile que permitan visualizar resultados de forma temprana.
2. Estandarización
La reciente propuesta de la Ley de Datos de la Unión Europea prevé el desarrollo de estándares de interoperabilidad para la reutilización de datos entre sectores, en un intento por eliminar las barreras para el intercambio de datos. En ausencia de estándares aplicables, la Comisión dictará Ordenes de ejecución al respecto.
En este sentido, es necesario cambiar la forma en la que se generan los estándares para ganar agilidad. Los integrantes de los grupos de trabajo pueden detectar necesidades concretas de estandarización e incluso proponer soluciones que lleguen a ser estándares de facto.
En otro orden de cosas, es necesario apostar por la convergencia de las diferentes perspectivas y aproximaciones a la creación de espacios de datos actualmente existentes. Su desarrollo no debe concebirse de manera aislada, o desde la visión exclusiva de una sola asociación, sino de la forma más holística posible.
3. Acciones de concienciación y gestión del cambio
Para poder compartir datos externamente, debe existir una mentalidad de compartir internamente. Este cambio de mentalidad implica una compleja gestión del cambio donde el apoyo de la dirección es fundamental. Es necesario instaurar una cultura del dato en las organizaciones que permita maximizar su valor.
4. Acciones de comunicación y dinamización para difundir el modelo
También es fundamental el desarrollo de workshops y congresos donde abordar problemáticas comunes, buenas prácticas y buscar sinergias de actuación. Para generar concienciación, es necesario evangelizar acerca de la rentabilidad que genera la compartición de datos para los agentes del sector. Esta rentabilidad no deriva solamente de su venta, sino también de la generación de nuevos productos o del enriquecimiento de los ya existentes, lo cual aporta valor al negocio.
Estas cuatro consideraciones generales deben ser matizadas teniendo en cuenta las necesidades concretas de cada sector para impulsar el desarrollo de espacios de datos sectoriales efectivos. Estos espacios facilitaran la creación de soluciones innovadoras basadas en datos y tecnologías disruptivas, como la inteligencia artificial, contribuyendo a impulsar la competitividad de las empresas y el avance de la sociedad en general.