Blog
In the fast-paced world of Generative Artificial Intelligence (AI), there are several concepts that have become fundamental to understanding and harnessing the potential of this technology. Today we focus on four: Small Language Models(SLM), Large Language Models(LLM), Retrieval Augmented Generation(RAG) and Fine-tuning. In this article, we will explore each of these terms, their interrelationships and how they are shaping the future of generative AI.
Let us start at the beginning. Definitions
Before diving into the details, it is important to understand briefly what each of these terms stands for:
The first two concepts (SLM and LLM) that we address are what are known as language models. A language model is an artificial intelligence system that understands and generates text in human language, as do chatbots or virtual assistants. The following two concepts (Fine Tuning and RAG) could be defined as optimisation techniques for these previous language models. Ultimately, these techniques, with their respective approaches as discussed below, improve the answers and the content returned to the questioner. Let's go into the details:
- SLM (Small Language Models): More compact and specialised language models, designed for specific tasks or domains.
- LLM (Large Language Models): Large-scale language models, trained on vast amounts of data and capable of performing a wide range of linguistic tasks.
- RAG (Retrieval-Augmented Generation): A technique that combines the retrieval of relevant information with text generation to produce more accurate and contextualised responses.
- Fine-tuning: The process of tuning a pre-trained model for a specific task or domain, improving its performance in specific applications.
Now, let's dig deeper into each concept and explore how they interrelate in the Generative AI ecosystem.
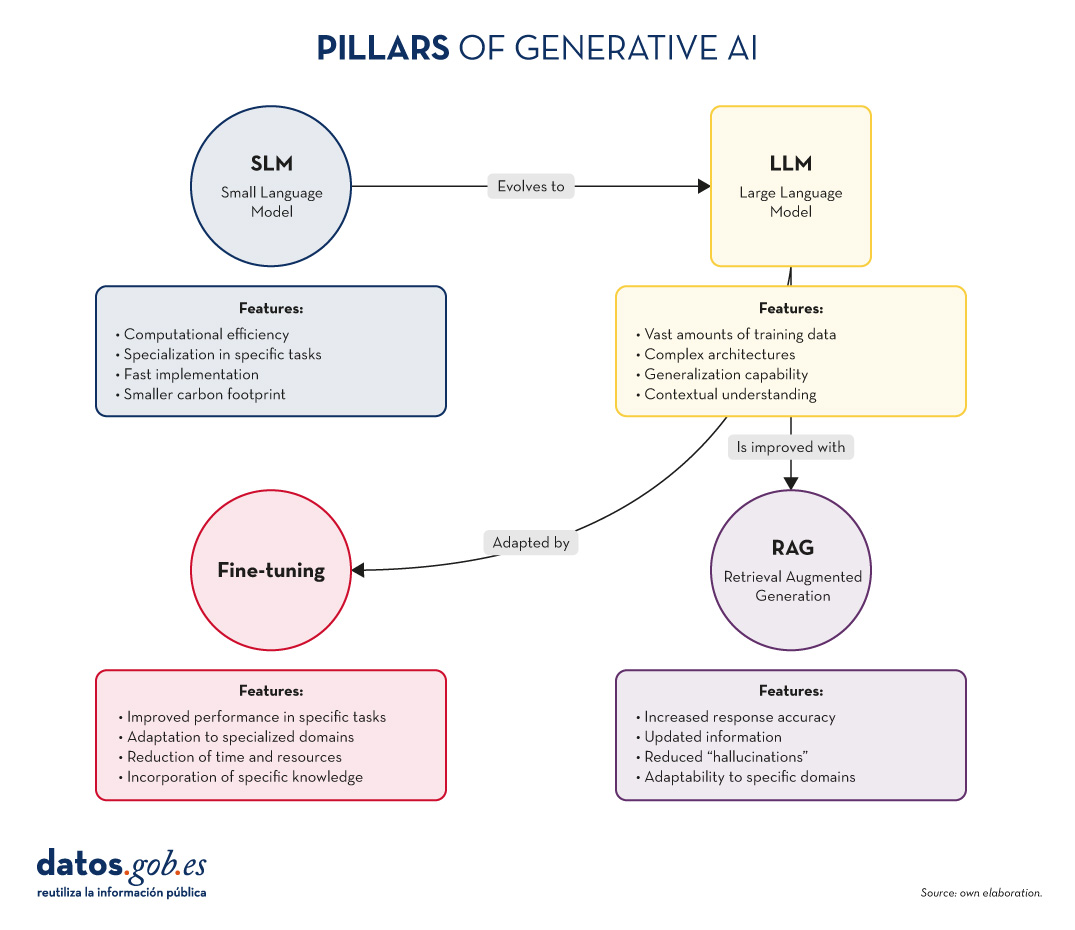
Figure 1. Pillars of Generative AI. Own elaboration.
SLM: The power of specialisation
Increased efficiency for specific tasks
Small Language Models (SLMs) are AI models designed to be lighter and more efficient than their larger counterparts. Although they have fewer parameters, they are optimised for specific tasks or domains.
Key characteristics of SLMs:
- Computational efficiency: They require fewer resources for training and implementation.
- Specialisation: They focus on specific tasks or domains, achieving high performance in specific areas.
- Rapid implementation: Ideal for resource-constrained devices or applications requiring real-time responses.
- Lower carbon footprint: Being smaller, their training and use consumes less energy.
SLM applications:
- Virtual assistants for specific tasks (e.g. booking appointments).
- Personalised recommendation systems.
- Sentiment analysis in social networks.
- Machine translation for specific language pairs.
LLM: The power of generalisation
The revolution of Large Language Models
LLMs have transformed the Generative AI landscape, offering amazing capabilities in a wide range of language tasks.
Key characteristics of LLMs:
- Vast amounts of training data: They train with huge corpuses of text, covering a variety of subjects and styles.
- Complex architectures: They use advanced architectures, such as Transformers, with billions of parameters.
- Generalisability: They can tackle a wide variety of tasks without the need for task-specific training.
- Contextual understanding: They are able to understand and generate text considering complex contexts.
LLM applications:
- Generation of creative text (stories, poetry, scripts).
- Answers to complex questions and reasoning.
- Analysis and summary of long documents.
- Advanced multilingual translation.
RAG: Boosting accuracy and relevance
The synergy between recovery and generation
As we explored in our previous article, RAG combines the power of information retrieval models with the generative capacity of LLMs. Its key aspects are:
Key features of RAG:
- Increased accuracy of responses.
- Capacity to provide up-to-date information.
- Reduction of "hallucinations" or misinformation.
- Adaptability to specific domains without the need to completely retrain the model.
RAG applications:
- Advanced customer service systems.
- Academic research assistants.
- Fact-checking tools for journalism.
- AI-assisted medical diagnostic systems.
Fine-tuning: Adaptation and specialisation
Refining models for specific tasks
Fine-tuning is the process of adjusting a pre-trained model (usually an LLM) to improve its performance in a specific task or domain. Its main elements are as follows:
Key features of fine-tuning:
- Significant improvement in performance on specific tasks.
- Adaptation to specialised or niche domains.
- Reduced time and resources required compared to training from scratch.
- Possibility of incorporating specific knowledge of the organisation or industry.
Fine-tuning applications:
- Industry-specific language models (legal, medical, financial).
- Personalised virtual assistants for companies.
- Content generation systems tailored to particular styles or brands.
- Specialised data analysis tools.
Here are a few examples
Many of you familiar with the latest news in generative AI will be familiar with these examples below.
SLM: The power of specialisation
Ejemplo: BERT for sentiment analysis
BERT (Bidirectional Encoder Representations from Transformers) is an example of SLM when used for specific tasks. Although BERT itself is a large language model, smaller, specialised versions of BERT have been developed for sentiment analysis in social networks.
For example, DistilBERT, a scaled-down version of BERT, has been used to create sentiment analysis models on X (Twitter). These models can quickly classify tweets as positive, negative or neutral, being much more efficient in terms of computational resources than larger models.
LLM: The power of generalisation
Ejemplo: OpenAI GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is one of the best known and most widely used LLMs. With 175 billion parameters, GPT-3 is capable of performing a wide variety of natural language processing tasks without the need for task-specific training.
A well-known practical application of GPT-3 is ChatGPT, OpenAI's conversational chatbot. ChatGPT can hold conversations on a wide variety of topics, answer questions, help with writing and programming tasks, and even generate creative content, all using the same basic model.
Already at the end of 2020 we introduced the first post on GPT-3 as a great language model. For the more nostalgic ones, you can check the original post here.
RAG: Boosting accuracy and relevance
Ejemplo: Anthropic's virtual assistant, Claude
Claude, the virtual assistant developed by Anthropic, is an example of an application using RAGtechniques. Although the exact details of its implementation are not public, Claude is known for his ability to provide accurate and up-to-date answers, even on recent events.
In fact, most generative AI-based conversational assistants incorporate RAG techniques to improve the accuracy and context of their responses. Thus, ChatGPT, the aforementioned Claude, MS Bing and the like use RAG.
Fine-tuning: Adaptation and specialisation
Ejemplo: GPT-3 fine-tuned for GitHub Copilot
GitHub Copilot, the GitHub and OpenAI programming assistant, is an excellent example of fine-tuning applied to an LLM. Copilot is based on a GPT model (possibly a variant of GPT-3) that has been specificallyfine-tunedfor scheduling tasks.
The base model was further trained with a large amount of source code from public GitHub repositories, allowing it to generate relevant and syntactically correct code suggestions in a variety of programming languages. This is a clear example of how fine-tuning can adapt a general purpose model to a highly specialised task.
Another example: in the datos.gob.es blog, we also wrote a post about applications that used GPT-3 as a base LLM to build specific customised products.
Interrelationships and synergies
These four concepts do not operate in isolation, but intertwine and complement each other in the Generative AI ecosystem:
- SLM vs LLM: While LLMs offer versatility and generalisability, SLMs provide efficiency and specialisation. The choice between one or the other will depend on the specific needs of the project and the resources available.
- RAG and LLM: RAG empowers LLMs by providing them with access to up-to-date and relevant information. This improves the accuracy and usefulness of the answers generated.
- Fine-tuning and LLM: Fine-tuning allows generic LLMs to be adapted to specific tasks or domains, combining the power of large models with the specialisation needed for certain applications.
- RAG and Fine-tuning: These techniques can be combined to create highly specialised and accurate systems. For example, a LLM with fine-tuning for a specific domain can be used as a generative component in a RAGsystem.
- SLM and Fine-tuning: Fine-tuning can also be applied to SLM to further improve its performance on specific tasks, creating highly efficient and specialised models.
Conclusions and the future of AI
The combination of these four pillars is opening up new possibilities in the field of Generative AI:
- Hybrid systems: Combination of SLM and LLM for different aspects of the same application, optimising performance and efficiency.
- AdvancedRAG : Implementation of more sophisticated RAG systems using multiple information sources and more advanced retrieval techniques.
- Continuousfine-tuning : Development of techniques for the continuous adjustment of models in real time, adapting to new data and needs.
- Personalisation to scale: Creation of highly customised models for individuals or small groups, combining fine-tuning and RAG.
- Ethical and responsible Generative AI: Implementation of these techniques with a focus on transparency, verifiability and reduction of bias.
SLM, LLM, RAG and Fine-tuning represent the fundamental pillars on which the future of Generative AI is being built. Each of these concepts brings unique strengths:
- SLMs offer efficiency and specialisation.
- LLMs provide versatility and generalisability.
- RAG improves the accuracy and relevance of responses.
- Fine-tuning allows the adaptation and customisation of models.
The real magic happens when these elements combine in innovative ways, creating Generative AI systems that are more powerful, accurate and adaptive than ever before. As these technologies continue to evolve, we can expect to see increasingly sophisticated and useful applications in a wide range of fields, from healthcare to creative content creation.
The challenge for developers and researchers will be to find the optimal balance between these elements, considering factors such as computational efficiency, accuracy, adaptability and ethics. The future of Generative AI promises to be fascinating, and these four concepts will undoubtedly be at the heart of its development and application in the years to come.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
The era of digitalisation in which we find ourselves has filled our daily lives with data products or data-driven products. In this post we discover what they are and show you one of the key data technologies to design and build this kind of products: GraphQL.
Introduction
Let's start at the beginning, what is a data product? A data product is a digital container (a piece of software) that includes data, metadata and certain functional logics (what and how I handle the data). The aim of such products is to facilitate users' interaction with a set of data. Some examples are:
- Sales scorecard: Online businesses have tools to track their sales performance, with graphs showing trends and rankings, to assist in decision making.
- Apps for recommendations: Streaming TV services have functionalities that show content recommendations based on the user's historical tastes.
- Mobility apps. The mobile apps of new mobility services (such as Cabify, Uber, Bolt, etc.) combine user and driver data and metadata with predictive algorithms, such as dynamic fare calculation or optimal driver assignment, in order to offer a unique user experience.
- Health apps: These applications make massive use of data captured by technological gadgets (such as the device itself, smart watches, etc.) that can be integrated with other external data such as clinical records and diagnostic tests.
- Environmental monitoring: There are apps that capture and combine data from weather forecasting services, air quality systems, real-time traffic information, etc. to issue personalised recommendations to users (e.g. the best time to schedule a training session, enjoy the outdoors or travel by car).
As we can see, data products accompany us on a daily basis, without many users even realising it. But how do you capture this vast amount of heterogeneous information from different technological systems and combine it to provide interfaces and interaction paths to the end user? This is where GraphQL positions itself as a key technology to accelerate the creation of data products, while greatly improving their flexibility and adaptability to new functionalities desired by users.
What is GraphQL?
GraphQL saw the light of day on Facebook in 2012 and was released as Open Source in 2015. It can be defined as a language and an interpreter of that language, so that a developer of data products can invent a way to describe his product based on a model (a data structure) that makes use of the data available through APIs.
Before the advent of GraphQL, we had (and still have) the technology REST, which uses the HTTPs protocol to ask questions and get answers based on the data. In 2021, we introduced a post where we presented the technology and made a small demonstrative example of how it works. In it, we explain REST API as the standard technology that supports access to data by computer programs. We also highlight how REST is a technology fundamentally designed to integrate services (such as an authentication or login service).
In a simple way, we can use the following analogy. It is as if REST is the mechanism that gives us access to a complete dictionary. That is, if we need to look up any word, we have a method of accessing the dictionary, which is alphabetical search. It is a general mechanism for finding any available word in the dictionary. However, GraphQL allows us, beforehand, to create a dictionary model for our use case (known as a "data model"). So, for example, if our final application is a recipe book, what we do is select a subset of words from the dictionary that are related to recipes.
To use GraphQL, data must always be available via an API. GraphQL provides a complete and understandable description of the API data, giving clients (human or application) the possibility to request exactly what they need. As quoted in this post, GraphQL is like an API to which we add a SQL-style "Where" statement.
Below, we take a closer look at GraphQL's strengths when the focus is on the development of data products.
Benefits of using GraphQL in data products:
- With GraphQL, the amount of data and queries on the APIs is considerably optimised . APIs for accessing certain data are not intended for a specific product (or use case) but as a general access specification (see dictionary example above). This means that, on many occasions, in order to access a subset of the data available in an API, we have to perform several chained queries, discarding most of the information along the way. GraphQL optimises this process, as it defines a predefined (but adaptable in the future) consumption model over a technical API. Reducing the amount of data requested has a positive impact on the rationalisation of computing resources, such as bandwidth or caches, and improves the speed of response of systems.
- This has an immediate effect on the standardisation of data access. The model defined thanks to GraphQL creates a data consumption standard for a family of use cases. Again, in the context of a social network, if what we want is to identify connections between people, we are not interested in a general mechanism of access to all the people in the network, but a mechanism that allows us to indicate those people with whom I have some kind of connection. This kind of data access filter can be pre-configured thanks to GraphQL.
- Improved safety and performance: By precisely defining queries and limiting access to sensitive data, GraphQL can contribute to a more secure and better performing application.
Thanks to these advantages, the use of this language represents a significant evolution in the way of interacting with data in web and mobile applications, offering clear advantages over more traditional approaches such as REST.
Generative Artificial Intelligence. A new superhero in town.
If the use of GraphQL language to access data in a much more efficient and standard way is a significant evolution for data products, what will happen if we can interact with our product in natural language? This is now possible thanks to the explosive evolution in the last 24 months of LLMs (Large Language Models) and generative AI.
The following image shows the conceptual scheme of a data product, intLegrated with LLMS: a digital container that includes data, metadata and logical functions that are expressed as functionalities for the user, together with the latest technologies to expose information in a flexible way, such as GraphQL and conversational interfaces built on top of Large Language Models (LLMs).

How can data products benefit from the combination of GraphQL and the use of LLMs?
- Improved user experience. By integrating LLMs, people can ask questions to data products using natural language, . This represents a significant change in how we interact with data, making the process more accessible and less technical. In a practical way, we will replace the clicks with phrases when ordering a taxi.
- Security improvements along the interaction chain in the use of a data product. For this interaction to be possible, a mechanism is needed that effectively connects the backend (where the data resides) with the frontend (where the questions are asked). GraphQL is presented as the ideal solution due to its flexibility and ability to adapt to the changing needs of users,offering a direct and secure link between data and questions asked in natural language. That is, GraphQl can pre-select the data to be displayed in a query, thus preventing the general query from making some private or unnecessary data visible for a particular application.
- Empowering queries with Artificial Intelligence: The artificial intelligence not only plays a role in natural language interaction with the user. One can think of scenarios where the very model that is defined with GraphQL is assisted by artificial intelligence itself. This would enrich interactions with data products, allowing a deeper understanding and richer exploration of the information available. For example, we can ask a generative AI (such as ChatGPT) to take this catalogue data that is exposed as an API and create a GraphQL model and endpoint for us.
In short, the combination of GraphQL and LLMs represents a real evolution in the way we access data. GraphQL's integration with LLMs points to a future where access to data can be both accurate and intuitive, marking a move towards more integrated information systems that are accessible to all and highly reconfigurable for different use cases. This approach opens the door to a more human and natural interaction with information technologies, aligning artificial intelligence with our everyday experiences of communicating using data products in our day-to-day lives.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Standardisation is essential to improve efficiency and interoperability in governance and data management. The adoption of standards provides a common framework for organising, exchanging and interpreting data, facilitating collaboration and ensuring data consistency and quality. The ISO standards, developed at international level, and the UNE norms, developed specifically for the Spanish market, are widely recognised in this field. Both catalogues of good practices, while sharing similar objectives, differ in their geographical scope and development approach, allowing organisations to select the most appropriate standards for their specific needs and context.
With the publication, a few months ago, of the UNE 0077, 0078, 0079, 0080, and 0081 specifications on data governance, management, quality, maturity, and quality assessment, users may have questions about how these relate to the ISO standards they already have in place in their organisation. This post aims to help alleviate these doubts. To this end, an overview of the main ICT-related standards is presented, with a focus on two of them: ISO 20000 on service management and ISO 27000 on information security and privacy, and the relationship between these and the UNE specifications is established.
Most common ISO standards related to data
ISO standards have the great advantage of being open, dynamic and agnostic to the underlying technologies. They are also responsible for bringing together the best practices agreed and decided upon by different groups of professionals and researchers in each of the fields of action. If we focus on ICT-related standards, there is already a framework of standards on governance, management and quality of information systems where, among others, the following stand out:
At the government level:
- ISO 38500 for corporate governance of information technology.
At management level:
- ISO 8000 for data management systems and master data.
- ISO 20000 for service management.
- ISO 25000 for the quality of the generated product (both software and data).
- ISO 27000 and ISO 27701 for information security and privacy management.
- ISO 33000 for process evaluation.
In addition to these standards, there are others that are also commonly used in companies, such as:
- ISO 9000-based quality management system
- Environmental management system proposed in ISO 14000
These standards have been used for ICT governance and management for many years and have the great advantage that, as they are based on the same principles, they can be used perfectly well together. For example, it is very useful to mutually reinforce the security of information systems based on the ISO/IEC 27000 family of standards with the management of services based on the ISO/IEC 20000 family of standards.
The relationship between ISO standards and UNE data specifications
The UNE 0077, 0078, 0079, 0080 and 0081 specifications complement the existing ISO standards on data governance, management and quality by providing specific and detailed guidelines that focus on the particular aspects of the Spanish environment and the needs of the national market.
When the UNE 0077, 0078, 0079, 0080, 0080, and 0081 specifications were developed, they were based on the main ISO standards, in order to be easily integrated into the management systems already available in the organisations (mentioned above), as can be seen in the following figure:

Figure 1. Relation of the UNE specifications with the different ISO standards for ICT.
Example of application of standard UNE 0078
The following is an example of how the UNE and ISO standards that many organisations have already had in place for years can be more clearly integrated, taking UNE 0078 as a reference. Although all UNE data specifications are intertwined with most ISO standards on IT governance, management and quality, the UNE 0078 data management specification is more closely related to information security management systems (ISO 27000) and IT service management (ISO 20000). On Table 1 you can see the relationship for each process with each ISO standard.
| Process UNE 0078: Data Management | Related to ISO 20000 | Related to ISO 27000 |
|---|---|---|
| (ProcDat) Data processing | ||
| (InfrTec) Technology infrastructure management | X | X |
| (ReqDat) Data Requirements Management | X | X |
| (ConfDat) Data Configuration Management | ||
| (DatHist) Historical data management | X | |
| (SegDat) Data security management | X | X |
| (Metdat) Metadata management | X | |
| (ArqDat) Data architecture and design management | X | |
| (CIIDat) Sharing, brokering and integration of data | X | |
| (MDM) Master Data Management | | |
| (HR) Human resources management | ||
| (CVidDat) Data lifecycle management | X | |
| (AnaDat) Data analysis |
| Process UNE 0078: Data Management | Related to ISO 20000 | Related to ISO 27000 |
|---|---|---|
| (ProcDat) Data processing | ||
| (InfrTec) Technology infrastructure management | X | X |
| (ReqDat) Data Requirements Management | X | X |
| (ConfDat) Data Configuration Management | ||
| (DatHist) Historical data management | X | |
| (SegDat) Data security management | X | X |
|
(Metdat) Metadata management |
X | |
|
(ArqDat) Data architecture and design management |
X |
|
|
(CIIDat) Sharing, brokering and integration of data |
X |
|
|
(MDM) Master Data Management |
|
|
|
(HR) Human resources management |
|
|
|
(CVidDat) Data lifecycle management |
X |
|
|
(AnaDat) Data analysis |
|
Figure 2. Relationship of UNE 0078 processes with ISO 27000 and ISO 20000.
Relationship of the UNE 0078 standard with ISO 20000
Regarding the interrelation between ISO 20000-1 and the UNE 0078 specification, here you can find a use case in which an organisation wants to make relevant data available for consumption throughout the organisation through different services. The integrated implementation of UNE 0078 and ISO 20000-1 enables organisations:
- Ensure that business-critical data is properly managed and protected.
- Improve the efficiency and effectiveness of IT services, ensuring that the technology infrastructure supports the needs of the business and end users.
- Align data management and IT service management with the organisation''s strategic objectives, improving decision making and market competitiveness.
The relationship between the two is manifested in how the technology infrastructure managed according to UNE 0078 supports the delivery and management of IT services according to ISO 20000-1.
This requires at least the following:
- Firstly, in the case of making data available as a service, a well-managed and secure IT infrastructureis necessary. This is essential, on the one hand, for the effective implementation of IT service management processes, such as incident and problem management, and on the other hand, to ensure business continuity and availability of IT services.
- Secondly, once the infrastructure is in place, and it is known that the data will be made available for consumption at some point in time, the principles of sharing and brokering of that data need to be managed. For this purpose, the UNE 0078 specification includes the process of data sharing, intermediation and integration. Its main objective is to enable its acquisition and/or delivery for consumption or sharing, noting if necessary the deployment of intermediation mechanisms, as well as its integration. This UNE 0078 process would be related to several of the processes in ISO 20000-1, such as the Business Relationship Managementprocess, service level management, demand management and the management of the capacity of the data being made available.
Relationship of the UNE 0078 standard with ISO 27000
Likewise, the technological infrastructure created and managed for a specific objective must ensure minimum data security and privacy standards, therefore, the implementation of good practices included in ISO 27000 and ISO 27701 will be necessary to manage the infrastructure from the perspective of information security and privacy, thus showing a clear example of interrelation between the three management systems: services, information security and privacy, and data.
Not only is it essential that the data is made available to organisations and citizens in an optimal way, but it is also necessary to pay special attention to the security of the data throughout its entire lifecycle during commissioning. This is where the ISO 27000 standard brings its full value. The ISO 27000 standard, and in particular ISO 27001 fulfils the following objectives:
- It specifies the requirements for an information security management system (ISMS).
- It focuses on the protection of information against unauthorised access, data integrity and confidentiality.
- It helps organisations to identify, assess and manage information security risks.
In this line, its interrelation with the UNE 0078 Data Management specification is marked through the Data Security Management process. Through the application of the different security mechanisms, it is verified that the information handled in the systems is not subject to unauthorised access, maintaining its integrity and confidentiality throughout the data''s life cycle. Similarly, a triad can be built in this relationship with the data security management process of the UNE 0078 specification and with the UNE 20000-1 process of SGSTI Operation - Information Security Management.
The following figure presents how the UNE 0078 specification complements the current ISO 20000 and ISO 27000 as applied to the example discussed above.
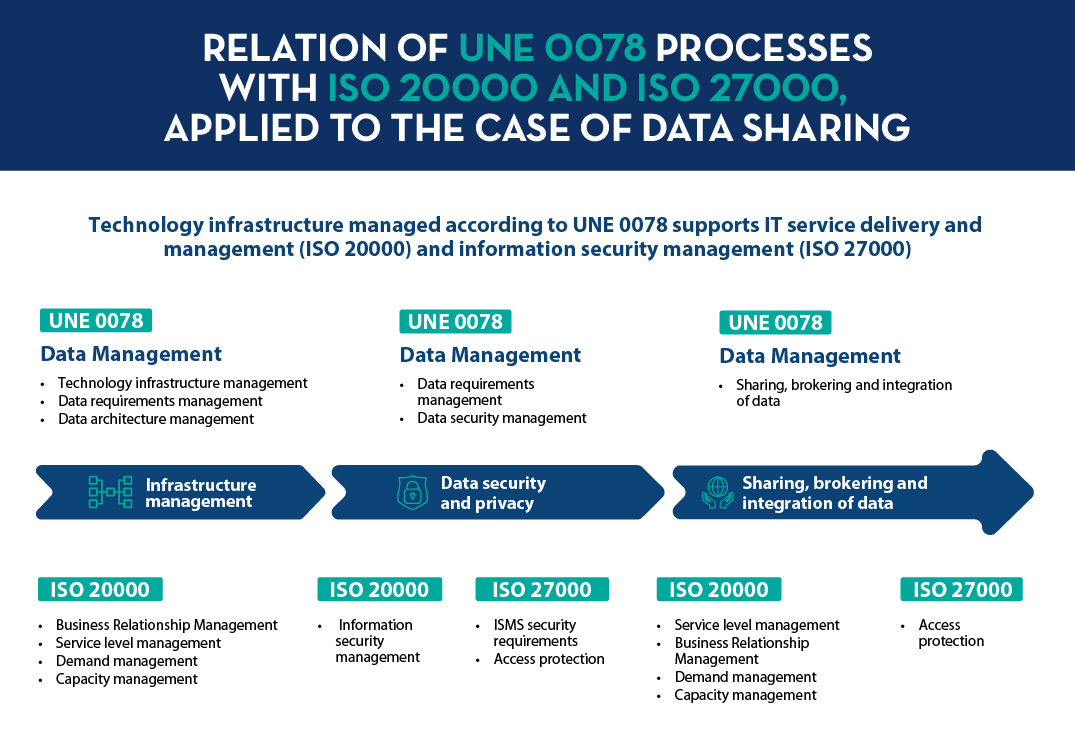
Figure 3. Relation of UNE 0078 processes with ISO 20000 and ISO 27000 applied to the case of data sharing.
Through the above cases, it can be seen that the great advantage of the UNE 0078 specification is that it integrates seamlessly with existing security management and service management systems in organisations. The same applies to the rest of the UNE standards 0077, 0079, 0080, and 0081. Therefore, if an organisation that already has ISO 20000 or ISO 27000 in place wants to implement data governance, management and quality initiatives, alignment between the different management systems with the UNE specifications is recommended, as they are mutually reinforcing from a security, service and data point of view.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Teaching computers to understand how humans speak and write is a long-standing challenge in the field of artificial intelligence, known as natural language processing (NLP). However, in the last two years or so, we have seen the fall of this old stronghold with the advent of large language models (LLMs) and conversational interfaces. In this post, we will try to explain one of the key techniques that makes it possible for these systems to respond relatively accurately to the questions we ask them.
Introduction
In 2020, Patrick Lewis, a young PhD in the field of language modelling who worked at the former Facebook AI Research (now Meta AI Research) publishes a paper with Ethan Perez of New York University entitled: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks in which they explained a technique to make current language models more precise and concrete. The article is complex for the general public, however, in their blog, several of the authors of the article explain in a more accessible way how the RAG technique works. In this post we will try to explain it as simply as possible.
Large Language Models are artificial intelligence models that are trained using Deep Learning algorithms on huge sets of human-generated information. In this way, once trained, they have learned the way we humans use the spoken and written word, so they are able to give us general and very humanly patterned answers to the questions we ask them. However, if we are looking for precise answers in a given context, LLMs alone will not provide specific answers or there is a high probability that they will hallucinate and completely make up the answer. For LLMs to hallucinate means that they generate inaccurate, meaningless or disconnected text. This effect poses potential risks and challenges for organisations using these models outside the domestic or everyday environment of personal LLM use. The prevalence of hallucination in LLMs, estimated at 15% to 20% for ChatGPT, may have profound implications for the reputation of companies and the reliability of AI systems.
What is a RAG?
Precisely, RAG techniques have been developed to improve the quality of responses in specific contexts, for example, in a particular discipline or based on private knowledge repositories such as company databases.
RAG is an extra technique within artificial intelligence frameworks, which aims to retrieve facts from an external knowledge base to ensure that language models return accurate and up-to-date information. A typical RAG system (see image) includes an LLM, a vector database (to conveniently store external data) and a series of commands or queries. In other words, in a simplified form, when we ask a natural language question to an assistant such as ChatGPT, what happens between the question and the answer is something like this:
- The user makes the query, also technically known as a prompt.
- The RAG enriches the prompt or question with data and facts obtained from an external database containing information relevant to the user's question. This stage is called retrieval
- The RAG is responsible for sending the user's prompt enriched or augmented to the LLM which is responsible for generate a natural language response taking advantage of the full power of the human language it has learned with its generic training data, but also with the specific data provided in the retrieval stage.

Understanding RAG with examples
Let us take a concrete example. Imagine you are trying to answer a question about dinosaurs. A generalist LLM can invent a perfectly plausible answer, so that a non-expert cannot distinguish it from a scientifically based answer. In contrast, using RAG, the LLM would search a database of dinosaur information and retrieve the most relevant facts to generate a complete answer.
The same was true if we searched for a particular piece of information in a private database. For example, think of a human resources manager in a company. It wants to retrieve summarised and aggregated information about one or more employees whose records are in different company databases. Consider that we may be trying to obtain information from salary scales, satisfaction surveys, employment records, etc. An LLM is very useful to generate a response with a human pattern. However, it is impossible for it to provide consistent and accurate data as it has never been trained with such information due to its private nature. In this case, RAG assists the LLM in providing specific data and context to return the appropriate response.
Similarly, an LLM complemented by RAG on medical records could be a great assistant in the clinical setting. Financial analysts would also benefit from an assistant linked to up-to-date stock market data. Virtually any use case benefits from RAG techniques to enrich LLM capabilities with context-specific data.
Additional resources to better understand RAG
As you can imagine, as soon as we look for a moment at the more technical side of understanding LLMs or RAGs, things get very complicated. In this post we have tried to explain in simple words and everyday examples how the RAG technique works to get more accurate and contextualised answers to the questions we ask to a conversational assistant such as ChatGPT, Bard or any other. However, for those of you who have the desire and strength to delve deeper into the subject, here are a number of web resources available to try to understand a little more about how LLMs combine with RAG and other techniques such as prompt engineering to deliver the best possible generative AI apps.
Introductory videos:
LLMs and RAG content articles for beginners
- DEV - LLM for dummies
- Digital Native - LLMs for Dummies
- Hopsworks.ai - Retrieval Augmented Augmented Generation (RAG) for LLMs
- Datalytyx - RAG For Dummies
Do you want to go to the next level? Some tools to try out:
- LangChain. LangChain is a development framework that facilitates the construction of applications using LLMs, such as GPT-3 and GPT-4. LangChain is for software developers and allows you to integrate and manage multiple LLMs, creating applications such as chatbots and virtual agents. Its main advantage is to simplify the interaction and orchestration of LLMs for a wide range of applications, from text analysis to virtual assistance.
- Hugging Face. Hugging Face is a platform with more than 350,000 models, 75,000 datasets and 150,000 demo applications, all open source and publicly available online where people can easily collaborate and build artificial intelligence models.
- OpenAI. OpenAI is the best known platform for LLM models and conversational interfaces. The creators of ChatGTP provide the developer community with a set of libraries to use the OpenAI API to create their own applications using the GPT-3.5 and GPT-4 models. As an example, we suggest you visit the Python library documentation to understand how, with very few lines of code, we can be using an LLM in our own application. Although OpenAI conversational interfaces, such as ChatGPT, use their own RAG system, we can also combine GPT models with our own RAG, for example, as proposed in this article.
Content elaborated by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Digital transformation affects all sectors, from agriculture to tourism and education. Among its objectives is the optimization of processes, the improvement of the customer experience and even the promotion of new business models.
The legal sector is no exception, which is why in recent years we have seen a boom in solutions and tools aimed at helping lawyers to perform their work more efficiently. This is what is known as LegalTech.
What is LegalTech?
The LegalTech concept refers to the use of new technological processes and tools to offer more efficient legal services. It is therefore an extensive concept, applying both to tools that facilitate the execution of tasks (e.g. financial management) and to services that take advantage of disruptive technologies such as artificial intelligence or blockchain.
The term LawTech is sometimes used as a synonym for LegalTech. Although some legal scholars say that they are distinct terms and should not be confused, there is no consensus and in some places, such as the UK, LawTech is widely used as a substitute for LegalTech.
Examples of LegalTech or LawTech tools
Through the application of different technologies, these tools can perform different functions, such as:
- Locating information in large volumes of judgments. There are tools capable of extracting the content of court rulings, using Natural Language Processing (NLP) techniques. The aim of these tools is to facilitate the filtering and location of information of interest, as well as to make it available to the user in a visual way. This helps lawyers to carry out a better investigation and, consequently, to reduce the preparation time of cases and to define more solid procedural strategies. An example of a tool in this area is Ross Intelligence.
- Perform predictive analytics. In the market we also find tools aimed at analyzing sentences and making predictions that anticipate the behaviors and outcomes of, using artificial intelligence. These tools try to answer questions such as how long a judicial process will take, what is the most probable sentence or if there is a possibility of appeal. Tools of this type are LexMachina, Blue J, IBM's Watson or Jurimetria.
- Solving legal queries. Using AI-based conversational assistants (chatbots), answers can be given to various questions, such as how to overcome parking fines, how to appeal bank fees or how to file a complaint. These types of tools free lawyers from simple tasks, allowing them to devote their time to more valuable activities. An example of legal chatbots is DoNotPay.
- Assist in drafting contracts and lawsuits. LegalTech tools can also help automate and simplify certain tasks, generating time and cost savings. This is the case of Contract Express, which automates the drafting of standard legal documents.
- Resolving legal disputes. There are some disputes that can be resolved simply using open source technology tools such as Kleros, an online dispute resolution protocol o. Kleros uses blockchain to resolve disputes as fairly as possible.
The role of open data in Legal Tech
For all these tools to work properly, optimizing the work of jurists, it is necessary to have valuable data. In this sense, open data is a great opportunity.
According to the Legal Data Vision initiative, which uses UK data and was launched in March 2022, by LawtechUK and the Open Data Institute 67% of innovation companies claim to need access to data to develop transformative legal solutions and only 20% of lawyers claim that their organization captures data effectively. This initiative aims to promote responsible access to and use of legal data to drive innovation in the industry and deliver results that benefit society.
According to Gartner, legal areas are set to increase spending on technology solutions by 200% by 2025. In countries such as France, a large number of start-ups focused on this area are already emerging, many of which reuse open data. In Spain we are also experiencing an expansion of the sector, which will enable improvements to be implemented in the processes and services of legal companies. In 2021 there were more than 400 companies operating in this field and, globally, according to figures from Stadista, the sector generated more than €27 billion.
However, for this field to make further progress, it is necessary to promote access to judgments in machine-readable formats that allow mass processing.
In short, this is a booming market, thanks to the emergence of disruptive technologies. Legal firms need access to up-to-date, quality information that will enable them to perform their work more efficiently. One of the methods to achieve this is to take advantage of the potential of open data.

(Click here to access the accessible version)
Content prepared by the datos.gob.es team.
Blog
Few abilities are as characteristic of human beings as language. According to the Aristotelian school, humans are rational animals who pursue knowledge for the mere fact of knowing. Without going into deep philosophical considerations that far exceed the purpose of this space for dissemination, we can say that this search for knowledge and the accumulation of knowledge would not be possible without the intervention of human language. Hence, in this 21st century - the century of the explosion of Artificial Intelligence (AI) - a large part of the efforts are focused on supporting, complementing and increasing human capabilities related to language.
Introduction
In this space, we have repeatedly discussed the discipline of natural language processing (NLP). We have approached it from different points of view, all of them from a practical, technical and data-related approach - texts - which are the real fuel of the technologies that support this discipline. We have produced monographs on the subject, introducing the basics of the technology and including practical examples. We have also commented on current events and analysed the latest technological trends, as well as the latest major achievements in natural language processing. In almost all publications on the subject, we have mentioned tools, libraries and technological products that, in one way or another, help and support the different processes and applications of natural language. From the creation of reasoned summaries of works and long texts, to the artificial generation of publications or code for programmers, all applications use libraries, packages or frameworks for the development of artificial intelligence applications applied in the field of natural language processing.
On previous occasions we have described the GPT-3 algorithm of the OpenAI company or the Megatron-Turing NLG of Microsoft, as some of the current exponents in terms of analysis power and precision in the generation of quality results. However, on most occasions, we have to talk about algorithms or libraries that, given their complexity, are reserved for a small technical community of developers, academics and professionals within the NLP discipline. That is, if we want to undertake a new project related to natural language processing, we must start from low-level libraries, and then add layers of functionality to our project or application until it is ready for use. Normally, NLP libraries focus on a small part of the path of a software project (mainly the coding task), being the developers or software teams the ones who must contemplate and add the rest of the functional and technical layers (testing, packaging, publishing and putting into production, operations, etc.) to convert the results of that NLP library into a complete technological product or application.
The challenge of launching an application
Let's take an example. Let's suppose that we want to build an application that, based on a starting text, for example, our electricity bill, gives us a simple summary of the content of our bill. We all know that electricity bills or employee pay slips are not exactly simple documents for the general public to understand. The difficulty usually lies in the use of highly technical terminology and, why not say it, in the low interest of some organisations in simplifying the life of citizens by making it easier to understand basic information such as what we pay for electricity or our salaries as employees. Back to the topic at hand. If we want to build a software application for this purpose, we will have to use an algorithm that understands our bill. For this, NLP algorithms have to, first of all, perform an analysis of the text and detect the keywords and their relationships (what in technical terminology is called detecting entities and recognising them in context). That is, the algorithm will have to detect the key entities, such as energy consumption, its units in kWh, the relevant time periods (this month's consumption, last month's consumption, daily consumption, past consumption history, etc.). Once these relevant entities have been detected (and the others discarded), as well as their relationships, there is still a lot to do. In terms of a software project in the field of NLP, Named-Entity-Recognition (NER) is only a small part of an application ready to be used by a person or a system. This is where we introduce you to the SpaCy software library.
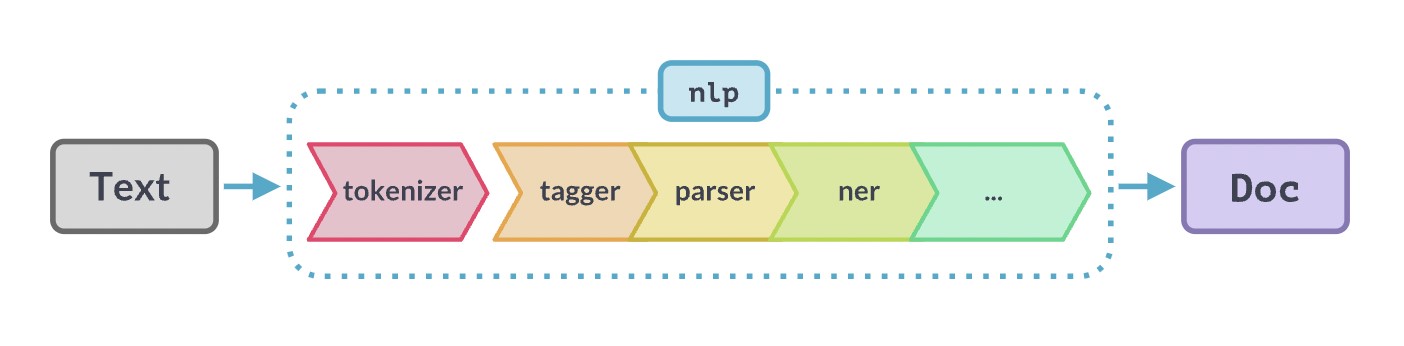
Example of NLP flow or pipeline from the moment we start from the original text we want to analyse until we obtain the final result, either a rich text or a web page with help or explanations to the user. Original source: https://SpaCy.io/
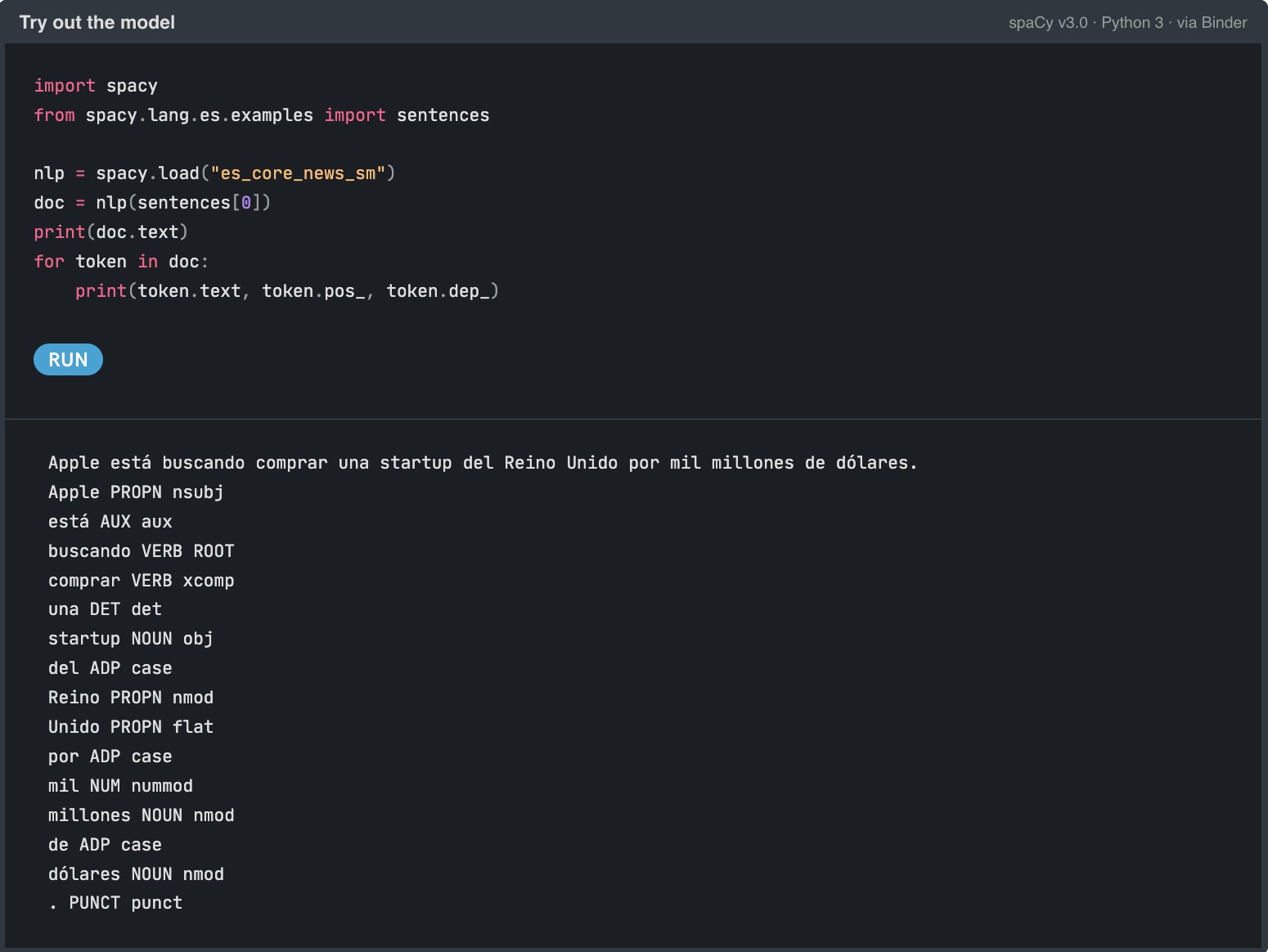
Example of the use of Spacy's es_core_news_sm pipeline to identify entities in a Spanish sentence.
What is Spacy?
SpaCy aims to facilitate the production release (making an application ready for use by the end consumer) of software applications in the natural language domain. SpaCy is an open source software library designed to facilitate advanced natural language processing tasks. SpaCy is written in Python and Cython (C language extensions for Python that allow very efficient low-level programming). It is an open-source library under the MIT license and the entire project is accessible through its Github account.
The advantages of Spacy
But what makes SpaCy different? SpaCy was created with the aim of facilitating the creation of real products. That is to say, the library is not just a library for the most technical and lowest levels within the layers that make up a software application, from the most internal algorithms to the most visual interfaces. The library contemplates the practical aspects of a real software product, in which it is necessary to take into account important aspects such as:
- The large data loads that are required to be processed (imagine what is involved, for example, loading the entire product reviews of a large e-commerce site).
- The speed of execution, since when we have a real application, we need the experience to be as smooth as possible and we can't put up with long waiting times between algorithm executions.
- The packaging of NLP functionality (such as NER) ready to deploy on one or more production servers. SpaCy, not only provides low-level code tools, but supports the processes from the time we create (compile and build a part of a software application) until we integrate this algorithmic part with other parts of the application such as databases or end-user interfaces.
- The optimisation of NLP models so that they can easily run on standard (CPU-based) servers without the need for graphics processors (GPUs).
- Integrated graphical visualisation tools to facilitate debugging or development of new functionality.
- Also important to mention, its fantastic documentation, from its most introductory website to its community on Github. This greatly facilitates rapid adoption among the development community.
- The large number of pre-trained models and flows (73 flows) in 22 different languages. In addition to support for more than 66 languages. In particular, in the case of Spanish language, it is difficult to find models optimised for Spanish in other libraries and tools.

Example of a graphical entity viewer. Original source: https://SpaCy.io/
As a conclusion to this post. If you are a beginner and just starting out in the world of NLP, SpaCy makes it easy to get started and comes with extensive documentation, including a 101 guide for beginners, a free interactive online course and a variety of video tutorials. If you are an experienced developer or part of an established software development team and want to build a final production application, SpaCy is designed specifically for production use and allows you to create and train powerful NLP data streams (texts) and package them for easy deployment. Finally, if you are looking for alternatives to your existing NLP solution (looking for new NLP models, need more flexibility and agility in your production deployments or looking for performance improvements), SpaCy allows you to customise, test different architectures and easily combine existing and popular frameworks such as PyTorch or TensorFlow.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Our language, both written and spoken, constitutes a peculiar type of data. Language is the human means of communication par excellence and its main features are ambiguity and complexity. Due to language is unstructured data, its processing has traditionally been a challenge to the machines, making it difficult to use in the analysis processes of the information. With the explosion of social networks and the advancement of supercomputing and data analytics in fields as diverse as medicine or call-centers, it is not surprising that a large part of artificial intelligence subfields are dedicated to developing strategies and algorithms to process and generate natural language.
Introduction
In the domain of data analysis applied to natural language processing, there are two major goals: Understanding and Generating.
- Understand: there are a set of techniques, tools and algorithms whose main objective is to process and understand the natural language to finally transform this information into structured data that can be exploited / used by a machine. There are different levels of complexity, depending on whether the message that is transmitted in natural language have a written or spoken format. In addition, the language of the message greatly increases the processing complexity, since the recognition algorithms must be trained in that specific language or another similar one.
- Generate: we find algorithms that try to generate messages in natural language. That is, algorithms that consume classical or structured data to generate a communication in natural language, whether written or spoken.
Figure 1. Natural language processing and its two associated approaches show a diagram to better understand these tasks that are part of natural language processing.

To better understand these techniques, let's give some examples:
Natural Language Understanding
In the first group, we can find those applications using by a human to request a certain information or describe a problem and a machine is responsible for receiving and processing that message with the aim of resolving or addressing the request. For example, when we call the information services of almost any company, our call is answered by a machine that, through a guided or assisted dialogue, tries to direct us to the most appropriate service or department. In this concrete example, the difficulty is twofold: the system has to convert our spoken message into a written message and store it, and then treat it with a routine or natural language processing algorithm that interprets the request and makes the correct decision based on a pre-established decision tree.
Another example of application of this techniques is those situations whit lot of written information from routine reports. For example, a medical or a police report. This type of reports usually contain structured data, filling different boxes into a specific software applications - for example, date, subject, name of the declarant or patient, etc. - However, they also usually contain one or several free-format fields where the events are described.
Currently, that free-format text (written digitally) is stored, but is not processed to interpret its content. In Health field, for example, the Apache CTAKES tool could be used to change this situation. It is a software development framework that allows the interpretation and extraction of clinical terms included in medical reports for later use in the form of diagnostic assistant or the creation of medical dictionaries (you can find more information in this interesting video that explains how CTAKES works).
Natural Language Generation
On the other hand, the applications and examples that demonstrate the potential of natural language generation, whether text-form or speech-form, are multiple and very varied. One of the best known examples is the generation of weather summaries. Most of the summaries and meteorological reports found on the Web have been generated with a natural language generation engine based on the quantitative prediction data offered by official agencies. In a very simplified way, a natural language generation algorithm would generate the expression “Time is getting worse” as a linguistic description of the next quantitative variable (∆P=Pt0-Pt1), which is a calculation that shows that atmospheric pressure is going down. Changes in atmospheric pressure are a well-known indicator of the evolution of short-term weather. The obvious question now is how the algorithm determines what to write. The answer is simple. Most of these techniques use templates to generate natural language. Templates that use phrases that are combined depending on the outputs determined by the algorithm. That said, this might seem simple, however, the system can reach a high degree of complexity if fuzzy logic is introduced to determine (in the example) to what degree the time is getting worse.
Other typical examples where natural language generation is commonly found are the summaries of sporting events or the periodic reports of some markets such as stock market or real estate. For example, making use of a simple tool to generate natural language from the following set of structured data (in JSON format):

We will obtain the following summary in natural language, in addition to some details regarding the readability and metrics of the returned text:

Another example is machine translation, one of the applications with most impact in natural language processing. It covers both comprehension and generation with an added complexity: understanding and processing is based on the origin-language and the message-generation is written on the target language.
All these examples show that the benefits of using tools for processing natural language are multiple. These tools facilitate an escalation that allows some companies to generate 10,000 or 100,000 weekly narratives that give value to their clients. Without these generation and automation tools it would be impossible to reach these levels. These tools allow the democratization of certain services for non-expert users in the management of quantitative variables. This is the case of narratives that summarize our electricity consumption without having to be an expert aware of variables such as kWh.
From the point of view of natural language processing, these technologies have radically changed the way to understand after-sales service to the customer. Combined with technologies such as chatbots or conversational robots, they improve the customer experience, taking care of clients quickly and without schedules needs. Executed by machines, these natural language processing technologies can also consult customer data efficiently while being guided through (assisted) dialogue in their natural language.
Given all these possibilities for the future, it is not surprising that an increasing number of companies and organizations are developing natural language processing, a field that can bring great benefits to our society. Noteworthy is the initiative of the State Secretariat for Digital Progress, which has designed a specific plan for the promotion of language technologies (www.PlanTL.es), meaning natural language processing, machine translation and conversational systems.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Entrevista
qMe-Aporta, third prize winner at Desafío Aporta 2017, is a prototype for the intuitive construction of queries, in guided natural language, based on datos.gob.es knowledge. It is a system that guides the user in the construction of the question, showing multiple alternatives to start and continue the question. It not only uses the system terms (metadata), but also the data and its synonyms. These questions can be asked in several languages.
We have spoken with Mariano Rico Almodóvar, researcher at the Polytechnic University of Madrid (UPM) and responsible for this initiative, to tell us how he is carrying out this project.
Currently, at what of qMe-Aporta development are you?
We are waiting for funding. It is a pity that a system so useful, from our point of view, for the reuse of data from public administrations is stopped, but it is. We made the effort, at zero cost, to analyze the application of Dylan-Q system (the core of qMe-Aporta) to the datasets related to Desafío Aporta (datos.gob.es) but we have not yet been able to create the system.
I'm applying Dylan-Q to a European project called SlideWiki, and that's where we hope to achieve the visibility needed for private funding. We also trust that the UPM Technologies Catalog (Dylan-Q technology is part of it), will give us enough visibility to attract customers or investors.
What information sources, public or private, is your project based on?
Dylan-Q technology is applied to RDF datasets, the standard semantic data format. In the case of Desafío Aporta, we focus on RDF datasets from datos.gob.es, where there is all kinds of data: trade, demography, education, etcetera. Most of the 2018 datasets that were available on the date of the contest were not RDF datasets. But it should be noted that we have tools to convert RDF datasets (files and databases) in any format.
Semantic technologies allow us to integrate information much more easily than with traditional techniques. If we add to this the lexicalization of the ontologies and a bit of magic (we have a positive patent report of the Dylan-Q technology), we achieve systems that allow guided consultations in natural language related to any RDF data set.
Do you think that initiatives such as the Desafio Aporta 2017 can help companies and entrepreneurs launch their open data reuse projects? What other initiatives of this kind do you think should be put into practice?
The visibility that these awards give us is very important, but other elements are necessary to be able to materialize these projects. It is common for companies to be interested in projects they know through awards like this one, but they usually demand the development at zero cost of a prototype (what in the jargon is called "proof of concept"). In addition, although the results of the prototype are good, the full implementation of the project is not guaranteed. It is also common for potential investors to demand exclusive dedication without pay for a period of up to two years. There is a tendency to think of innovation as a lottery in which it is known that one in ten start-ups will be successful and will considerably multiply their investment, but, in general, long-term investment criteria are not followed and the objective is just to make the investment profitable within a typical period of two years. In these conditions it is very difficult to undertake.
In countries such as Germany or the United States, the idea of a non-repayable investment is more widespread among companies. They understand that you have to take risks to win, and are willing to assume the cost of risk. There is no fear of "failure", which is seen as something natural in innovation processes. On the contrary, it is very widespread in the companies of our country that the risk should be assumed by the Administration or, as our case, the researchers. A century after the sentence of Unamuno " Let them do the inventing", The situation seems not to have changed. And I do not believe that it is a matter of higher or lesser economy, or of major or minor economic crisis, traditional excuses to condition the investment in R & D, but of a higher culture of innovation investment. In fact, we have known for a long time that investment in R + D + I is what makes countries more or less prosperous, and not vice versa.
But do not lose heart. We continue attending all meetings that organizations request. We dream of a company that is willing to risk a small amount, say 30 thousand euros, for us to make a prototype adapted to their business and a sample of their data, for 6 months. If that prototype convinces them, we would make a new project using all data and the entire business model. Who wants to be the first?
But in spite of all that has been said, I must insist that initiatives as Aporta or those promoted by the Technological Innovation Support Center (CAIT) of the UPM are excellent for bringing together technologists and companies. There should be meetings of this type more frequently.
As a user of open data, what challenges have you found when reusing public information? How have you solved those challenges?
The main challenge has been, and still is, to find the dataset that best suits our needs. Sometimes it is a single dataset, but most of the time we want several datasets initially unrelated. I think it is illustrated with the phrase "in a sea of data, we fish with a rod". We need more powerful tools to be able to fish more efficiently.
The search for information is a difficult problem when the volume of data increases, not so much by the number of data of a given type, but by the number of data categories and the relationships between them. Semantic technologies allow us to relate categories of data and give them meaning, so we can address this problem with more chances of success.
What actions do you consider that Spain should prioritize in terms of data provision?
I think you have to clearly divide the tasks. On the one hand, local administrations must collect the data. On the other hand, the General Administration must provide the necessary tools so that the local administrations incorporate in a simple and efficient way the collected data. The initiative datos.gob.es works in this line, but you can still go further. For example, it is necessary to integrate the data collected by local administrations, that is, link data categories. It could be facilitated through the use of semantic technologies. Once the information is integrated, the Administration could offer new services to users, such as the one provided by QMe-Aporta, and many others that we still cannot imagine.
Finally, what are your future plans? Are you immersed or have any other open data reuse project in mind?
In our research group we have several projects that use open data, in what has been called "citizen science", such as Farolapp (http://farolapp.linkeddata.es), or Stars4All (http://stars4all.eu), but perhaps our main contribution is the Spanish DBpedia (es.dbpedia.org). We have a project with the Spanish multinational TAIGER to increase the quality of Spanish DBpedia data, and we have developed several techniques with very good results. In June (2018) we organized the first international congress of knowledge graphs applied to tourism and travel, where we have confirmed the importance of this sector, which represents 14% of Spanish GDP and 10% worldwide. We think that the information stored in the Spanish DBpedia can be very useful for this economic sector. You have to know that 40% of the DBpedia data in Spanish is only found in our DBpedia.
Most of the techniques we have applied to DBpedia can be applied to other data sets, so that open data can benefit from these techniques.
Fortunately, we continue to research and develop projects where we apply our knowledge on semantic technologies, natural language processing and machine learning. I would like to take this opportunity to thank those responsible for the research group, Asunción Gómez Pérez and Oscar Corcho, for the trust they have placed in us, and the time they have allowed us to spend in this contest.