Fecha publicación
13/02/2026
Fecha actualización
09/03/2026
Comparte este contenido

Descripción
Desde sus orígenes el movimiento de datos abiertos se ha centrado fundamentalmente en el impulso de la apertura de los datos y en el fomento de su reutilización. El objetivo que ha articulado la mayoría de las iniciativas, tanto públicas como privadas, ha sido el de vencer los obstáculos para publicar catálogos de datos cada vez más completos y asegurar que la información del sector público estuviera disponible para que la ciudadanía, las empresas, los investigadores y el propio sector público pudieran crear valor económico y social.
Sin embargo, a medida que hemos ido dando pasos hacia una economía cada vez más dependiente de los datos y, más recientemente, de la inteligencia artificial -y en un futuro próximo de las posibilidades que nos traen los agentes autónomos a través de la inteligencia artificial agéntica-, las prioridades han ido cambiando y el foco ha ido girando hacia cuestiones como la mejora de la calidad de los datos publicados.
Ya no es suficiente con que los conjuntos de datos estén publicados en un portal de datos abiertos cumpliendo buenas prácticas, ni tan siquiera con que el dato cumpla unos estándares de calidad en el momento de su publicación. También es necesario que esta publicación de los conjuntos de datos cumpla con unos niveles de servicio que transformen la mera puesta a disposición en un compromiso operativo que mitigue las incertidumbres que, a menudo, obstaculizan la reutilización.
Cuando un desarrollador integra una API de datos de transporte en tiempo real en su app de movilidad, o cuando un científico de datos trabaja en un modelo de IA con datos climáticos históricos está asumiendo un riesgo si no tiene certeza sobre las condiciones en las que los datos estarán disponibles. Si en un momento dado los datos publicados dejan de estar disponibles porque cambia el formato sin previo aviso, porque el tiempo de respuesta se dispara o por cualquier otra razón, los procesos automatizados fallan y la cadena de suministro de datos se rompe, provocando fallos en cascada en todos los sistemas dependientes.
En este contexto, la adopción de acuerdos de nivel de servicio (ANS) también conocidos por su terminología en inglés, service level agreements (SLA), podrían ser el siguiente paso para que portales de datos abiertos evolucionen desde el habitual modelo “best effort” hasta convertirse en infraestructuras digitales críticas, fiables y robustas.
¿Qué son un ANS o SLA y un contrato de datos en el contexto de los datos abiertos?
En el contexto de la ingeniería de fiabilidad (site reliability engineering o SRE), un ANS es un contrato negociado entre un proveedor de servicios y sus clientes con objeto de fijar el nivel de calidad del servicio prestado. Es, por tanto, una herramienta que ayuda a ambas partes a llegar a un consenso en aspectos tales como el tiempo de respuesta, la disponibilidad horaria o la documentación disponible.
En un portal de datos abiertos, donde a menudo no existe una contraprestación económica directa, un ANS podría ayudar a responder preguntas como:
- ¿Cuánto tiempo estará disponible el portal y sus API?
- ¿Qué tiempos de respuesta podemos esperar?
- ¿Con qué frecuencia se actualizarán los conjuntos de datos?
- ¿Cómo se gestionan los cambios en metadatos, enlaces y formatos?
- ¿Cómo se gestionarán incidencias, cambios y avisos a la comunidad?
Adicionalmente, en esta transición hacia una mayor madurez operativa surge el concepto, aún inmaduro, del contrato de datos (data contract). Si el ANS es un acuerdo que define las expectativas de nivel de servicio, el contrato de datos es una implementación que formaliza este compromiso. Un contrato de datos no solo especificaría el esquema y el formato, sino que actuaría como una salvaguarda: si una actualización del sistema intenta introducir un cambio que rompa la estructura prometida o que degrade la calidad del dato, el contrato de datos permite detectar y bloquear dicha anomalía antes de que afecte a los usuarios finales.
INSPIRE como punto de partida: disponibilidad, rendimiento y capacidad
La infraestructura de la Unión Europea para la información espacial (INSPIRE) ha establecido uno de los marcos más rigurosos del mundo en cuanto a calidad de servicio para datos geoespaciales. La Directiva 2007/2/CE, conocida como INSPIRE, actualmente en su versión 5.0, incluye algunas obligaciones técnicas que podrían servir como referencia para cualquier portal de datos modernos. En particular el Reglamento (CE) nº 976/2009 establece criterios que bien podrían servir como patrón para cualquier estrategia de publicación de datos de alto valor:
- Disponibilidad: la infraestructura debe estar disponible el 99% del tiempo durante el horario de funcionamiento normal.
- Rendimiento: para un servicio de visualización la respuesta inicial debe llegar en menos de 3 segundos.
- Capacidad: para un servicio de localización el mínimo número de peticiones simultáneas servidas con rendimiento garantizado debe ser de 30 por segundo.
Para ayudar al cumplimiento de estos estándares de servicio, la Comisión Europea ofrece herramientas como el INSPIRE Reference Validator. Esta herramienta ayuda no solo a verificar la interoperabilidad sintáctica (que el XML o GML esté bien formado), sino también a asegurar que los servicios de red cumplen con las especificaciones técnicas que permiten medir esos ANS.
En este punto, los exigentes ANS de la infraestructura de datos espaciales europea nos hacen preguntarnos si no deberíamos aspirar a lo mismo para datos críticos de salud, energía o movilidad o para cualquier otro conjunto de datos de alto valor.
Qué podría cubrir un ANS en una plataforma de datos abiertos
Cuando hablamos de conjuntos de datos abiertos en sentido amplio, la disponibilidad del portal es una condición necesaria, pero no suficiente. Muchas incidencias que afectan a la comunidad de reutilizadores no son caídas completas del portal, sino errores más sutiles como enlaces rotos, conjuntos de datos que no se actualizan con la periodicidad indicada, formatos inconsistentes entre versiones, metadatos incompletos o cambios silenciosos en el comportamiento de las API o en los nombres de las columnas de los conjuntos de datos.
Por ello, convendría complementar los ANS propios de la infraestructura del portal con ANS de “salud del dato” que pueden basarse en marcos de referencia ya consolidados como:
- Modelos de calidad como ISO/IEC 25012, que permite desglosar la calidad del dato en dimensiones medibles como la exactitud (que el dato represente la realidad), la completitud (que no falten valores necesarios) y la consistencia (que no haya contradicciones entre tablas o formatos) y convertirlas en requisitos medibles.
- Principios FAIR, siglas de Findable (Localizable), Accessible (Accesible), Interoperable (Interoperable), y Reusable (Reutilizable). Estos principios enfatizan que los activos digitales no solo deben estar disponibles, sino que deben ser localizables mediante identificadores persistentes, accesibles bajo protocolos claros, interoperables mediante el uso de vocabularios estándar y reutilizables gracias a licencias claras y procedencia documentada. Los principios FAIR se pueden poner en práctica midiendo de forma sistemática la calidad de los metadatos que hacen posible la localización, el acceso y la interoperabilidad. Por ejemplo, el servicio Metadata Quality Assurance (MQA) de data.europa.eu ayuda a hacer una evaluación automática de los metadatos de los catálogos, a calcular métricas y a ofrecer recomendaciones de mejora.
Para convertir en operativos estos conceptos, podemos centrarnos en cuatro ejemplos donde establecer compromisos de servicio específicos aportaría un valor diferencial:
- Conformidad y vigencia del catálogo: el ANS podría garantizar que los metadatos estén siempre alineados con los datos que describen. Un compromiso de conformidad aseguraría que el portal se somete a validaciones periódicas (siguiendo especificaciones como DCAT-AP-ES o HealthDCAT-AP) para evitar que la documentación se volviese obsoleta respecto al recurso real.
- Estabilidad del esquema y versionado: uno de los mayores enemigos de la reutilización automatizada es el "cambio silencioso". Si una columna cambia de nombre o un tipo de dato varía, los flujos de ingesta de datos fallarán inmediatamente. Un compromiso de nivel de servicio podría incluir una política de versionado. Esto implicaría que cualquier cambio que rompiese la compatibilidad se anunciase con una antelación mínima y, preferiblemente, mantuviese la versión anterior en paralelo durante un tiempo prudencial.
- Frescura y frecuencia de actualización: no resulta infrecuente encontrar conjuntos de datos etiquetados como de actualización diaria pero cuya última modificación real fue hace meses. Una buena práctica podría ser la definición de indicadores de latencia de publicación. Un posible ANS establecería el valor del tiempo medio entre actualizaciones y contaría con sistemas de alerta que notificasen automáticamente si un dato no se ha refrescado según la frecuencia declarada en su metadato.
- Tasa de éxito: en el mundo de las API de datos, no es suficiente con recibir un código HTTP 200 (OK) para determinar si la respuesta es válida. Si la respuesta es, por ejemplo, un JSON sin contenido, el servicio no es útil. El nivel de servicio tendría que medir la tasa de respuestas exitosas y con contenido válido, asegurando que el endpoint no solo responde, sino que entrega la información esperada.
Un primer paso, SLA, SLO y SLI: medir antes de comprometer
Dado que establecer este tipo de compromisos es realmente complejo, una posible estrategia para pasar a la acción de forma gradual es adoptar un enfoque pragmático basado en las mejores prácticas de la industria. Por ejemplo, en la ingeniería de fiabilidad, se propone una jerarquía de tres conceptos que ayuda a evitar compromisos poco realistas:
- Indicador de Nivel de Servicio (SLI): es el indicador medible y cuantitativo. Representa la realidad técnica en un momento dado. Ejemplos de SLI en datos abiertos podrían ser el "porcentaje de peticiones exitosas a la API", la "latencia p95" (el tiempo de respuesta del 95% de las solicitudes) o el "porcentaje de enlaces de descarga que no devuelven error".
- Objetivo de Nivel de Servicio (SLO): es el objetivo interno que se marca sobre ese indicador. Por ejemplo: "queremos que el 99,5% de las descargas funcionen correctamente" o "la latencia p95 debe ser inferior a 800 ms". Es la meta que guía el trabajo del equipo técnico.
- Acuerdo de Nivel de Servicio (ANS o SLA): es el compromiso público y formal sobre esos objetivos. Es la promesa que el portal de datos hace a su comunidad de reutilizadores y que incluye, idealmente, los canales de comunicación y los protocolos de actuación en caso de incumplimiento.
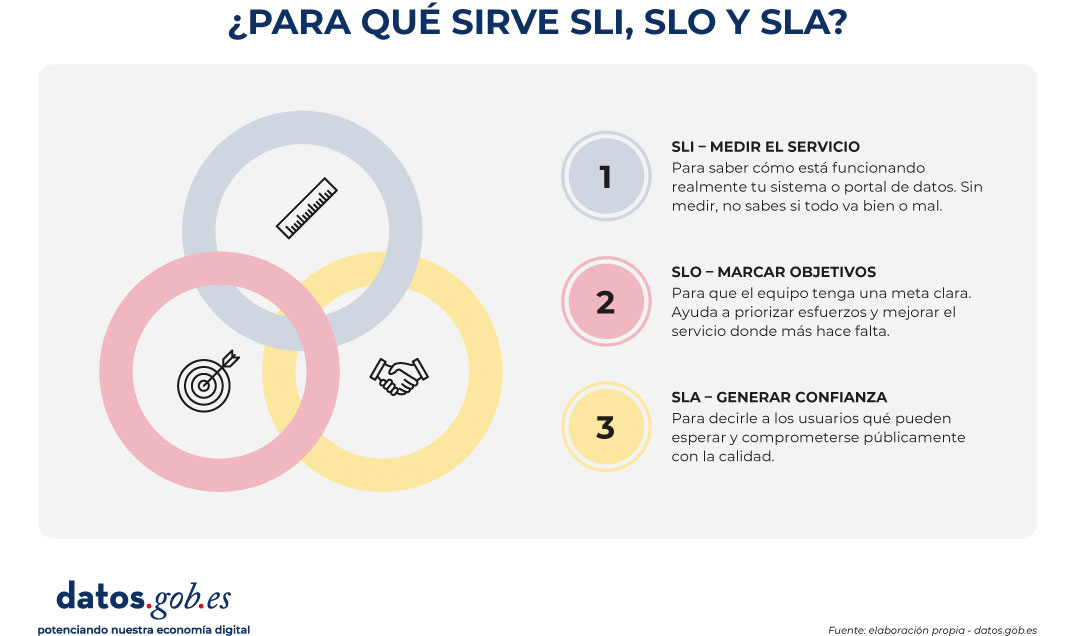
Figura 1. Visual elaborado para explicar la diferencia entre SLI, SLO y SLA. Fuente: elaboración propia - datos.gob.es.
Esta distinción es especialmente valiosa en el ecosistema de los datos abiertos debido a la naturaleza híbrida de un servicio en el que no solo se opera una infraestructura, sino que se gestiona el ciclo de vida de los datos.
En muchos casos, el primer paso podría ser no tanto publicar un ANS ambicioso de inmediato, sino empezar por definir sus SLI y observar sus SLO. Una vez que la medición estuviese automatizada y los niveles de servicio se estabilizasen y fuesen predecibles, sería el momento de convertirlos en un compromiso público (SLA).
En última instancia, la implementación de niveles de servicio en los datos abiertos podría tener un efecto multiplicador. No solo reduciría la fricción técnica para los desarrolladores y mejoraría la tasa de reutilización, sino que facilitaría la integración de los datos públicos en sistemas de IA y agentes autónomos. Los nuevos usos como la evaluación de sistemas de Inteligencia Artificial generativa, la generación y validación de conjuntos de datos sintéticos o incluso la propia mejora de la calidad de los datos abiertos se verían muy beneficiados.
Establecer un SLA de datos sería, por encima de todo, un potente mensaje: significaría que el sector público no solo publica los datos como un acto administrativo, sino que los opera como un servicio digital de alta disponibilidad, fiable, predecible y, en definitiva, preparado para los retos de la economía del dato.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.



Comentarios