Publication date
13/02/2026
Update date
09/03/2026

Description
Since its origins, the open data movement has focused mainly on promoting the openness of data and promoting its reuse. The objective that has articulated most of the initiatives, both public and private, has been to overcome the obstacles to publishing increasingly complete data catalogues and to ensure that public sector information is available so that citizens, companies, researchers and the public sector itself could create economic and social value.
However, as we have taken steps towards an economy that is increasingly dependent on data and, more recently, on artificial intelligence – and in the near future on the possibilities that autonomous agents bring us through agentic artificial intelligence – priorities have been changing and the focus has been shifting towards issues such as improving the quality of published data.
It is no longer enough for the datasets to be published in an open data portal complying with good practices, or even for the data to meet quality standards at the time of publication. It is also necessary that this publication of the datasets meets service levels that transform the mere provision into an operational commitment that mitigates the uncertainties that often hinder reuse.
When a developer integrates a real-time transportation data API into their mobility app, or when a data scientist works on an AI model with historical climate data, they are taking a risk if they are uncertain about the conditions under which the data will be available. If at any given time the published data becomes unavailable because the format changes without warning, because the response time skyrockets, or for any other reason, the automated processes fail and the data supply chain breaks, causing cascading failures in all dependent systems.
In this context, the adoption of service level agreements (SLAs) could be the next step for open data portals to evolve from the usual "best effort" model to become critical, reliable and robust digital infrastructures.
What are an SLA and a Data Contract in the context of open data?
In the context of site reliability engineering (SRE), an SLA is a contract negotiated between a service provider and its customers in order to set the level of quality of the service provided. It is, therefore, a tool that helps both parties to reach a consensus on aspects such as response time, time availability or available documentation.
In an open data portal, where there is often no direct financial consideration, an SLA could help answer questions such as:
- How long will the portal and its APIs be available?
- What response times can we expect?
- How often will the datasets be updated?
- How are changes to metadata, links, and formatting handled?
- How will incidents, changes and notifications to the community be managed?
In addition, in this transition towards greater operational maturity, the concept, still immature, of the data contract (data contract) emerges. If the SLA is an agreement that defines service level expectations, the data contract is an implementation that formalizes this commitment. A data contract would not only specify the schema and format, but would act as a safeguard: if a system update attempts to introduce a change that breaks the promised structure or degrades the quality of the data, the data contract allows you to detect and block such an anomaly before it affects end users.
INSPIRE as a starting point: availability, performance and capacity
The European Union's Infrastructure for Spatial Information (INSPIRE) has established one of the world's most rigorous frameworks for quality of service for geospatial data. Directive 2007/2/EC, known as INSPIRE, currently in its version 5.0, includes some technical obligations that could serve as a reference for any modern data portal. In particular , Regulation (EC) No 976/2009 sets out criteria that could well serve as a standard for any strategy for publishing high-value data:
- Availability: Infrastructure must be available 99% of the time during normal operating hours.
- Performance: For a visualization service, the initial response should arrive in less than 3 seconds.
- Capacity: For a location service, the minimum number of simultaneous requests served with guaranteed throughput must be 30 per second.
To help comply with these service standards, the European Commission offers tools such as the INSPIRE Reference Validator. This tool helps not only to verify syntactic interoperability (that the XML or GML is well formed), but also to ensure that network services comply with the technical specifications that allow those SLAs to be measured.
At this point, the demanding SLAs of the European spatial data infrastructure make us wonder if we should not aim for the same for critical health, energy or mobility data or for any other high-value dataset.
What an SLA could cover on an open data platform
When we talk about open datasets in the broad sense, the availability of the portal is a necessary condition, but not sufficient. Many issues that affect the reuser community are not complete portal crashes, but more subtle errors such as broken links, datasets that are not updated as often as indicated, inconsistent formats between versions, incomplete metadata, or silent changes in API behavior or dataset column names.
Therefore, it would be advisable to complement the SLAs of the portal infrastructure with "data health" SLAs that can be based on already established reference frameworks such as:
- Quality models such as ISO/IEC 25012, which allows the quality of the data to be broken down into measurable dimensions such as accuracy (that the data represents reality), completeness (that necessary values are not missing) and consistency (that there are no contradictions between tables or formats) and convert them into measurable requirements.
- FAIR Principles, which stands for Findable, Accessible, Interoperable, and Reusable. These principles emphasize that digital assets should not only be available, but should be traceable using persistent identifiers, accessible under clear protocols, interoperable through the use of standard vocabularies, and reusable thanks to clear licenses and documented provenance. The FAIR principles can be put into practice by systematically measuring the quality of the metadata that makes location, access and interoperability possible. For example, data.europa.eu's Metadata Quality Assurance (MQA) service helps you automatically evaluate catalog metadata, calculate metrics, and provide recommendations for improvement.
To make these concepts operational, we can focus on four examples where establishing specific service commitments would provide a differential value:
- Catalog compliance and currency: The SLA could ensure that the metadata is always aligned with the data it describes. A compliance commitment would ensure that the portal undergoes periodic validations (following specifications such as DCAT-AP-ES or HealthDCAT-AP) to prevent the documentation from becoming obsolete with respect to the actual resource.
- Schema stability and versioning: One of the biggest enemies of automated reuse is "silent switching." If a column changes its name or a data type changes, the data ingestion flows will fail immediately. A service level commitment might include a versioning policy. This would mean that any changes that break compatibility would be announced at least notice, and preferably keep the previous version in parallel for a reasonable amount of time.
- Freshness and refresh frequency: It's not uncommon to find datasets labeled as daily but last actually modified months ago. A good practice could be the definition of publication latency indicators. A possible SLA would establish the value of the average time between updates and would have alert systems that would automatically notify if a piece of data has not been refreshed according to the frequency declared in its metadata.
- Success rate: In the world of data APIs, it's not enough to just receive an HTTP 200 (OK) code to determine if the answer is valid. If the response is, for example, a JSON with no content, the service is not useful. The service level would have to measure the rate of successful responses with valid content, ensuring that the endpoint not only responds, but delivers the expected information.
A first step, SLA, SLO, and SLI: measure before committing
Since establishing these types of commitments is really complex, a possible strategy to take action gradually is to adopt a pragmatic approach based on industry best practices. For example, in reliability engineering, a hierarchy of three concepts is proposed that helps avoid unrealistic compromises:
- Service Level Indicator (SLI): it is the measurable and quantitative indicator. It represents the technical reality at a given moment. Examples of SLI in open data could be the "percentage of successful API requests", "p95 latency" (the response time of 95% of requests) or the "percentage of download links that do not return error".
- Service Level Objective (SLO): this is the internal objective set for this indicator. For example: "we want 99.5% of downloads to work correctly" or "p95 latency must be less than 800ms". It is the goal that guides the work of the technical team.
- Service Level Agreement (SLA): is the public and formal commitment to those objectives. This is the promise that the data portal makes to its community of reusers and that includes, ideally, the communication channels and the protocols for action in the event of non-compliance.
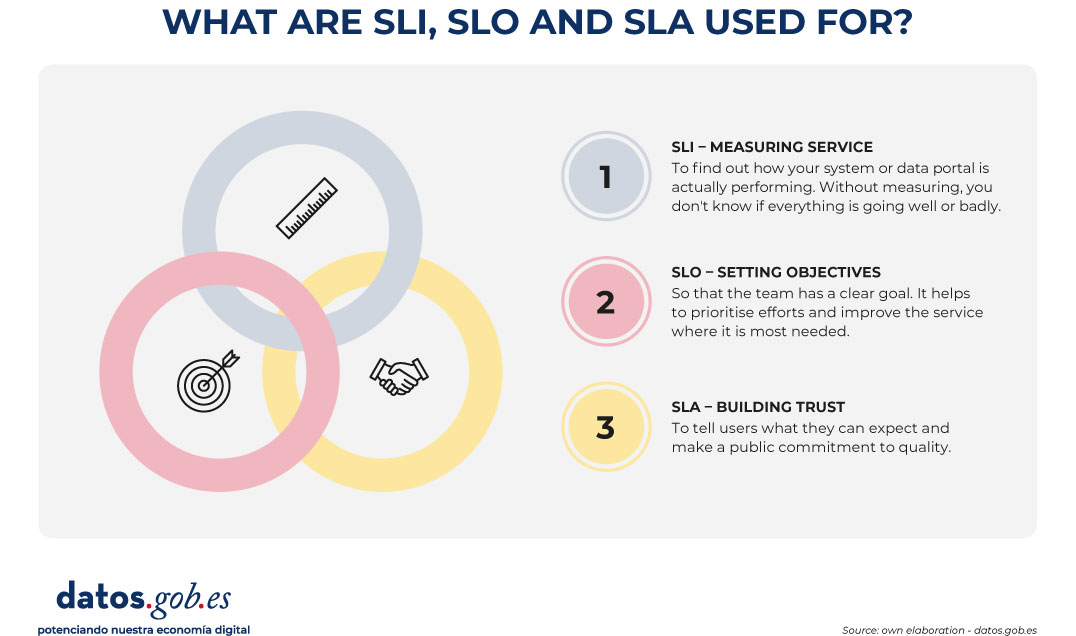
Figure 1. Visual to explain the difference between SLI, SLO and SLA. Source: own elaboration - datos.gob.es.
This distinction is especially valuable in the open data ecosystem due to the hybrid nature of a service in which not only an infrastructure is operated, but the data lifecycle is managed.
In many cases, the first step might be not so much to publish an ambitious SLA right away, but to start by defining your SLIs and looking at your SLOs. Once measurement was automated and service levels stabilized and predictable, it would be time to turn them into a public commitment (SLA).
Ultimately, implementing service tiers in open data could have a multiplier effect. Not only would it reduce technical friction for developers and improve the reuse rate, but it would make it easier to integrate public data into AI systems and autonomous agents. New uses such as the evaluation of generative Artificial Intelligence systems, the generation and validation of synthetic datasets or even the improvement of the quality of open data itself would benefit greatly.
Establishing a data SLA would, above all, be a powerful message: it would mean that the public sector not only publishes data as an administrative act, but operates it as a digital service that is highly available, reliable, predictable and, ultimately, prepared for the challenges of the data economy.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.



Comments