Entrevista
Vivimos rodeados de decisiones que, aunque no siempre lo parezca, tienen una dimensión geográfica: dónde se construyen viviendas, cómo se organizan las ciudades, qué zonas son más vulnerables a incendios o inundaciones, o incluso dónde se instalan servicios públicos esenciales. Detrás de muchas de estas decisiones hay datos. Datos que, cuando se representan sobre el territorio, nos permiten ver patrones, anticipar problemas y planificar mejor el futuro.
En este pódcast hablamos precisamente de eso, de los datos geográficos abiertos, con dos invitados que nos darán una visión tanto académica como de gestión pública.
- Paco Pellicer, Profesor Titular en el área de Geografía Física de la Universidad de Zaragoza.
- Fernando López, Director del Instituto Geográfico de Aragón (IGEAR).
Resumen / Transcripción de la entrevista
1. ¿Por qué la geografía es fundamental para entender el mundo actual?
Fernando López: Básicamente la geografía lo que ayuda es a entender mejor las relaciones del hombre con el medio. Con lo cual, la geografía para nosotros, los profesionales de la geografía, entendemos que es el instrumento fundamental para solucionar problemas complejos.
Paco Pellicer: Nuestras relaciones con el territorio y con las personas se realizan muchas veces a través de instrumentos geográficos que hasta hace poco eran un poco extraños y ahora todos los llevamos en el bolsillo.
2. Cuando hablamos de datos geográficos abiertos, ¿de qué estamos hablando exactamente?
Fernando López: Por normativa europea, nacional y autonómica, los datos están en formato abierto para que todo el mundo pueda acceder. Los datos tienen que ser accesibles, interoperables y de acceso gratuito, a ser posible. No hay que olvidar que no hace más de quince años el Instituto Geográfico Nacional (IGN) ofrecía datos geográficos con coste económico. Hoy en día, son datos abiertos porque son accesibles y son gratuitos. Como lo hacemos en prácticamente la mayoría de las instituciones de las comunidades autónomas que gestionamos información geográfica. Nosotros decimos, como broma, que salvo el alma (estamos trabajando en ello), todo lo demás se puede georreferenciar. Por tanto, todos son datos geográficos y tenemos la obligación de darlos de forma abierta, accesible y de forma absolutamente sencilla para el ciudadano, para la administración y para los investigadores.
Paco Pellicer: Como dice Fernando, esto es una auténtica revolución que se ha producido en las dos últimas décadas, porque no podemos ir mucho más lejos. Yo recuerdo cuando me iniciaba en la investigación que conseguí información de fotografías aéreas de 1956 que había que pedirlo al servicio geográfico del Ejército, con unos permisos especiales dedicados a la investigación y pagándolas...
Hoy tenemos multitud de información fantástica validada por organismos oficiales y que son datos contrastados, verificados, científicamente correctos. El poder acceder a ellos, en directo, de forma gratuita, disponer de toda esta información adaptada a tus necesidades es una auténtica revolución. Y esto nos hace que, junto con los dispositivos móviles y demás, la geografía se nos haya metido en el bolsillo y que sea imprescindible para muchas actividades de la vida, desde desplazarnos o saber dónde hay un determinado recurso o riesgo.
3. ¿Qué herramientas o plataformas facilitan el acceso y uso de datos geográficos abiertos?
Fernando López: Desde la parte administrativa, en cumplimiento de la normativa europea tenemos obligación de la directiva INSPIRE para mantener infraestructuras de datos espaciales. Deben estar disponibles para la ciudadanía en diferentes formatos, bien sean servicios de mapas o sean servicios de capas o sean servicios de conjuntos de datos.
Pero, algunas comunidades hemos ido más allá y esa información la hemos relacionado entre ellas siguiendo la teoría de grafos y hemos ido a lo que hemos llamado en Aragón “infraestructura de conocimiento espacial” donde la información está relacionada.
Y, por lo tanto, a estas infraestructuras ya no solo se les puede pedir datos, sino que se le puede hacer preguntas, porque en realidad el objetivo final de la información geográfica, como la entendemos la mayor parte de los geógrafos y desde luego en el Instituto la entendemos así, es que nosotros tenemos que ayudar a tomar mejores decisiones. Es decir, no estamos simplemente para ser una biblioteca en el sentido amplio de la información geográfica, sino que tenemos que realizar geo análisis territoriales, desarrollar aplicaciones, proponer soluciones para que los responsables de la toma de decisiones se equivoquen lo menos posible.
Por lo tanto, todas estas infraestructuras son las herramientas que hoy día están ayudando a que efectivamente haya aplicaciones que mejoren la toma de decisiones territoriales, que es fundamental.
Paco Pellicer: Sí, hay muchas plataformas en las que se puede acceder a estos datos. A escala nacional, el IGN; a escala regional aquí en Aragón, pues tenemos el ICEAragón, que es fundamental para buena parte de nuestros trabajos. Pero también tenemos el Sistema de Información Territorial de la Confederación Hidrográfica del Ebro, por citar algunas fuentes, que hay muchas más... También en el propio Ayuntamiento tienen una plataforma que ofrece mucha información.
Y, así como, Fernando hablaba desde la Administración, a mí me gustaría de forma complementaria hablar desde la sociedad civil. Y es que este fenómeno lo que nos lo que produce es una importantísima democratización y facilita la participación en la gestión de cualquier evento de frente a cualquier desafío de nuestra vida moderna.
Nos permite que la población civil interactúe de manera corresponsable con la Administración. La sociedad civil alcanza un punto de madurez muy importante porque estamos trabajando, la Administración y la sociedad civil, con los mismos datos. Esto aumenta la corresponsabilidad de la sociedad civil. Muchas veces cuando hay un problema le echamos a las administraciones y nos quedamos tan anchos. Eso es completamente falso. La sociedad civil tenemos un papel muy relevante y en la medida en la que estamos trabajando en un plano de igualdad, en cuanto que estamos manejando los mismos datos validados por las administraciones que nos dan seguridad a la sociedad civil.
En definitiva, la sociedad civil puede ofrecer su particular manera de ver ese fenómeno, el que estemos tratando, por ejemplo, inundaciones. La Administración tiene los mismos datos que tenemos la sociedad civil y nosotros podemos ver si soy regante si me afecta a una propiedad o lo que sea. Y yo tengo esa información y puedo proponer también a la Administración otras soluciones o podemos de forma colegiada o asociativa, pues participar y dar nuestras ideas también a la Administración. Esto es enormemente democrático, enormemente interesante en la geografía. En este caso, a través de todos estos instrumentos, nos está haciendo una sociedad mucho más avanzada.
4. Para aterrizarlo en lo práctico: ¿cómo se utiliza la geoinformación en la ordenación del territorio?
Fernando López: En la administración tenemos múltiples casos como la gestión de medio ambiente, de la agricultura, de las redes energéticas, etc. Con mejor o menor acierto, porque como yo comparto con Paco totalmente este efecto democratizador de la difusión de la información geográfica.
La sociedad civil no siempre está de acuerdo con las decisiones de la Administración. Pero al compartir información se puede debatir y se puede interpelar a la Administración a que tome mejores decisiones. Nosotros interactuamos absolutamente con todos los departamentos, incluso con aquellos que parece que no tienen nada que ver con la información geográfica. Por ejemplo, con la gente del ámbito de la salud pública, nuestros MIR se forman con el Atlas de Salud Pública, lo utilizan como elemento de formación, porque ahí hemos incluido toda la información de determinantes de mortalidad, de morbilidad por zonas sanitarias, por áreas sanitarias.
Por poner anécdotas un poco menos clásicas, por ejemplo, la semana que viene empieza el plazo de solicitud de plazas escolares en Aragón y la única herramienta válida para la medición de distancias para la puntuación para obtener plazas escolares en los centros, pues es la herramienta del Instituto Geográfico de Aragón.
O, por ejemplo, el próximo 12 de agosto tenemos un eclipse solar total donde mejor se va a ver, sobre todo en el sur de Zaragoza y en la provincia de Teruel. El propio Estado español estima que pueden acudir unos cuatro millones de personas al territorio aragonés. Esperemos que no porque es inviable absorber en dos o tres días a cuatro millones de personas en esta comunidad autónoma. Pero hay que colocarlos en algún sitio con seguridad. ¿Qué es lo que se ha hecho en los grupos de trabajo en los que estamos interministeriales interdepartamentales? Coger al Instituto Geográfico y decirle: “por favor, dime cuáles son las áreas adecuadas combinando pendientes, combinando sombras, combinando seguridad, combinando salidas, combinando abastecimiento de agua, posibles servicios sanitarios y dame al menos una docena de lugares donde se puedan acumular diez o doce mil personas durante dos o tres días prestándole servicios".
Al final, como decía al principio de la entrevista, la información geográfica propone soluciones o aporta informaciones para problemas tremendamente complejos como este que acabo de poner encima de la mesa. La geografía está directamente implicada en el intento de que las cosas salgan bien.
Paco Pellicer: Un ejemplo que puede ilustrar también lo que acaba de explicarnos Fernando es que tenemos una exposición ahora que se llama Zaragoza Mapa en la que Zaragoza se ha dividido hemos dividido la ciudad por manzanas y hemos introducido una serie de datos: edad de la construcción de la casa, los habitantes que la ocupan y el nivel de renta, procedencia geográfica, etc. Esto nos da garantías de anonimato y nos ofrece mucha información.
Si aplicamos una serie de filtros y vamos agrupando información, podemos ver el mapa de vulnerabilidad de la ciudad, es decir, dónde viven las personas más vulnerables, que necesidades tienen, etcétera.
Y, por otra parte, como estamos con el fenómeno del cambio climático, la isla de calor, etcétera, tenemos una red de sensores en los que se está tomando datos precisos, con una periodicidad muy estrecha de las temperaturas que se dan en los distintos puntos. Si cruzamos las temperaturas en los momentos extremos con el mapa de vulnerabilidad estamos viendo cuáles son las partes de la ciudad que más sufren ese fenómeno, que a lo mejor no solamente son los pobres sino también los ricos.
Al final nos hace un mapa en el que nos marca por dónde podemos intervenir, por ejemplo, para hacer un parque nuevo. Si vemos una zona densamente poblada, vulnerable y queremos mejorar ese espacio y tenemos terrenos que nos ha dejado pues un cambio de uso en la ciudad, ahí podemos desarrollar un parque equipado en el que te podemos tener desde servicios escolares, servicios sanitarios, deportivos, infraestructura verde en el sentido medioambiental, pero también infraestructura social, porque estamos introduciendo también la población que ahí vive.
5. ¿Qué tendencias marcarán el futuro de los datos geográficos abiertos? ¿Cómo afectarán tecnologías emergentes como los gemelos digitales o la inteligencia artificial?
Fernando López: Pues la verdad es que a mí es un tema que me preocupa enormemente porque lo vivo a diario. Institucionalmente, tenemos que estar al día de lo que suponen todas las innovaciones respecto a la información geográfica y va a una velocidad que las administraciones son imposibles de soportar.
Como decía Paco, se ha conseguido que la geografía esté en el bolsillo de la gente a través de su smartphone pero vivimos un momento contradictorio porque la geografía en la enseñanza media y en la enseñanza primaria prácticamente ha desaparecido.
Pero el futuro es realmente desbordante. La inteligencia artificial la estamos utilizando ya. Hay que utilizarla con extremada precaución, porque la inteligencia artificial, al fin y al cabo, es un algoritmo, que tiene sus sesgos y sus tendencias en función de quien lo entrena y de cómo se entrena.
Entonces estamos ante retos en que la Administración va a tener que crear sus propios algoritmos de inteligencia artificial que solo se abastezcan de información oficial contrastada, como decía Paco. O sea que no puedan beber de otras fuentes que no sean fuentes oficiales y que además las reglas de juego del algoritmo sean las reglas jurídico-administrativas de la Administración. Este es un gran reto que nosotros, desde el IGEAR nos hemos planteado.
Y otro gran reto es el de los gemelos digitales. Yo tengo mis discrepancias con algunos gemelos digitales que no dejan de ser copias de seguridad en la nube y poco más. Un verdadero gemelo digital geográfico debe simular, tanto hacia adelante como hacia atrás, proyectos sobre el territorio que realmente nos den simulaciones reales de lo que puede ocurrir, de lo que puede impactar, de lo que puede suceder con la experiencia, de lo que ha ocurrido en el pasado.
Además, hay que introducir la tecnología BIM, la sexta dimensión. Es decir, tenemos una serie de retos que, solo para estar informado, no digo formado, solo para estar informado de todo lo que hay y de todas las posibilidades de lo que se puede hacer ya es complejo.
Pero también es muy ilusionante, siempre y cuando no perdamos de vista que todos los resultados de estas tecnologías tienen que tener delante y detrás a un experto que sepa interpretar los resultados. Como caigamos en el error de que la máquina, la inteligencia, el gemelo, ya es darle al botón y hacerlo, lo haremos muy mal, fracasaremos estrepitosamente. Tiene que haber antes, durante y después un técnico que supervise el proceso y que al final haga la interpretación de las herramientas.
Nos van a ayudar a que crezcamos en velocidad. Ahora, nosotros lanzamos geoprocesos que antes duraban entre tres semanas y cuatro semanas y ahora mismo tenemos un servidor que nos lo hace en tres horas, lo que hacía antes, casi en cuatro semanas. Es una grandísima herramienta, pero al final del proceso quién lo interpreta y valida que eso es correcto y permite dar la solución razonable es el técnico, es el experto, el geógrafo u otras profesiones que están en equipos multidisciplinares.
Por tanto, ilusionante, pero también a la vez preocupante y tiene costes altamente elevados que no sé cuánta gente va a poder soportar para estar en vanguardia.
Paco Pellicer: Coincido plenamente con Fernando. Uno de los de los desafíos es precisamente la calidad de los datos. Todos nos damos cuenta de los fakes que estamos padeciendo continuamente, hasta el punto de que se produce una incertidumbre en el que no sabes si algo es real. Hace falta que sean personas con una formación muy avanzada y que den garantías de ese trabajo, que trabajen en la Administración, donde se produce una independencia también de otros poderes del mundo en el que nos están distorsionando.
Es importante que haya una Administración que con seguridad y con una calidad técnica muy grande, esté validando todos esos datos para ofrecerlos y saber que cuando tú vas al Ebro vas a tener información fidedigna. Eso es importantísimo.
La IA es un caballo magnífico, me parece adorable. Pero un caballo sin jinete nos lleva a la ruina. Por eso hace falta hacerse algunas preguntas que son eternas: ¿A dónde vamos? ¿Para qué? ¿Quiénes somos? Nos podemos dejar llevar por la capacidad, la rapidez, etc. Todo eso es envidiable. Pero si no se hacen las preguntas adecuadas, las respuestas pueden ser perfectamente erróneas. Por mucho que haya multitud de datos. Yo en esto sí que reclamo formación y carácter científico de los datos.
Si no sabemos lo que queremos, si no sabemos a dónde vamos, pues nos lleva a ninguna parte. Entonces, el hacer preguntas inteligentes es muy importante. De ahí la investigación, muchas veces básica, además de la investigación aplicada, de la que soy muy partidario. Pero esta información básica inicial de los conceptos, de rigor en las metodologías y demás, es fundamental.
Formación, formación, formación… y geografía.
Blog
La gobernanza de datos es un elemento central de cualquier estrategia digital. Gobiernos, empresas, organizaciones sociales e instituciones internacionales coinciden en que, sin reglas claras sobre cómo se recopilan, gestionan, comparten y utilizan los datos, es imposible aprovechar todo su valor.
Este artículo busca aclarar este concepto, aportando información sobre sus principios básicos. Para ello, nos hemos basado en dos informes: Data Governance Toolkit: Navigating Data in the digital era de la Broadband Commission, cofundada por la UNESCO y la Unión Internacional de Telecomunicaciones (ITU en sus siglas en inglés), y What is Data Governance: 30 Questions and Answers, elaborado por The Govlab. El segundo informe profundiza en las definiciones y conceptos incluidos en el primero. Ambos documentos coinciden en que la gobernanza de datos no es solo un conjunto de normas, sino un marco integral que orientan todo el ciclo de vida de los datos.
A continuación, se recoge un resumen de lo que dicen ambos informes.
¿Qué es la gobernanza de datos?
La gobernanza de datos puede definirse como el conjunto de procesos, personas, políticas, prácticas y tecnologías que guían cómo se generan, gestionan y reutilizan los datos a lo largo de todo su ciclo de vida. Su objetivo es aumentar la confianza, el valor y la equidad, al tiempo que se minimizan los riesgos y los perjuicios, de conformidad con un conjunto de principios fundamentales.
Las 4P del Data Governance Toolkit
La Broadband Commission subraya cuatro elementos esenciales de la gobernanza de datos:
Por qué: definir la visión y el propósito de los datos y de su gobernanza.
- Cómo: establecer los principios que guiarán las decisiones y prácticas.
- Quién: identificar los roles, responsabilidades y procesos institucionales.
- Qué: concretar las políticas, mecanismos y tecnologías que se aplicarán en cada fase del ciclo de vida del dato.
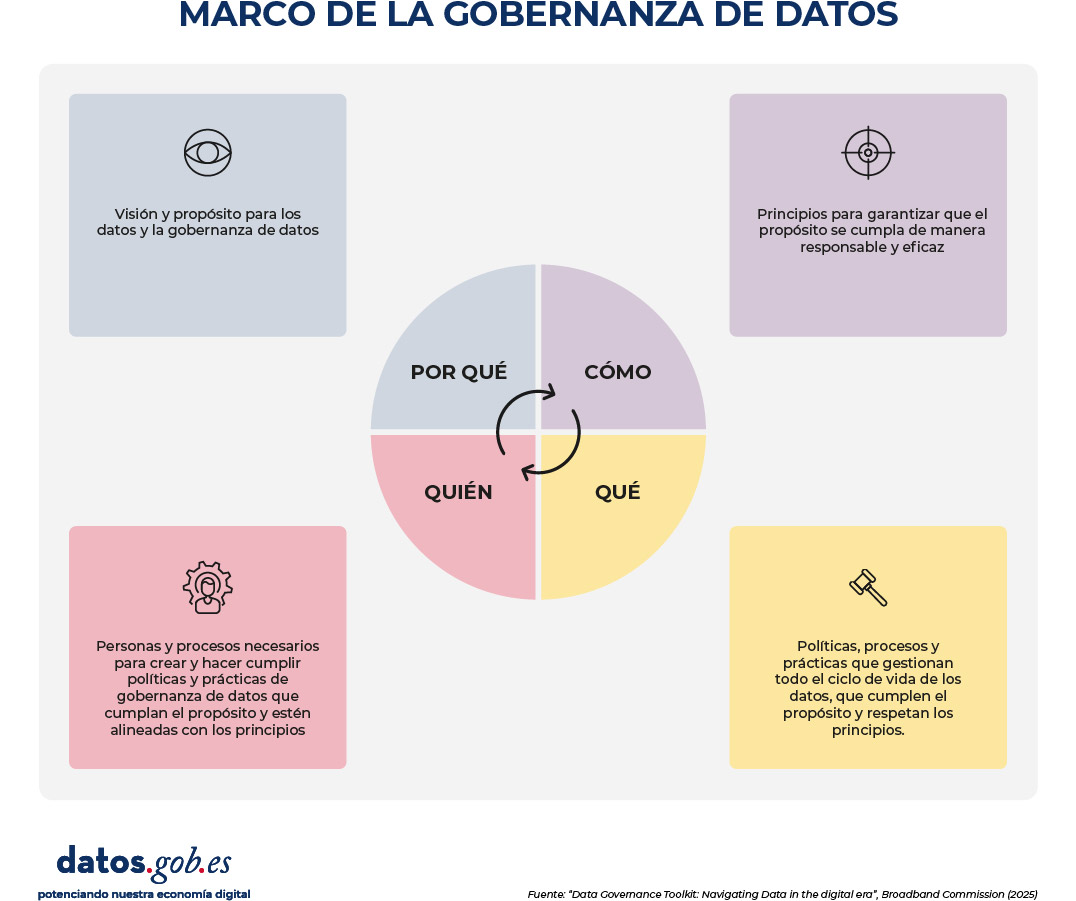
Figura 1. Marco de la gobernanza de datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Esta estructura -conocida como los 4P del Toolkit por sus nombres en inglés (Purpose, Principles, People, and Practices)- permite que la gobernanza no sea un ejercicio abstracto, sino una práctica operativa y medible. Funciona como bloques (building blocks) que pueden aprovecharse y adaptarse para orientar el desarrollo de nuevas estrategias de gobernanza de datos.
A continuación, se detallan cada uno de ellos:
1. ¿Por qué? (Purpose)
- El propósito y la visión son esenciales para orientar la gobernanza de los datos, dar coherencia a las iniciativas y garantizar una gestión responsable a lo largo de todo el ciclo de vida del dato.
- Un buen propósito de gobernanza debe reflejar valores y prioridades sociales, ser accionable y equilibrar oportunidades (como innovación o reutilización de datos) con riesgos (como sesgos, exclusión o daños).
- Los propósitos más habituales incluyen maximizar el valor de los datos, fomentar la innovación y el desarrollo sostenible, promover la equidad, apoyar objetivos de política pública y reforzar la participación y la agencia de las personas.
Un propósito bien formulado actúa como marco de referencia para asegurar alineación, coherencia y rendición de cuentas. Además, ayuda a evitar usos indebidos, duplicidades o esfuerzos desconectados. Para que sea eficaz, este propósito debe:
- Reflejar los valores fundamentales de la organización y las prioridades sociales (por ejemplo, la equidad, la innovación y los derechos humanos).
- Ser aplicables y estar en consonancia con los objetivos de la empresa.
- Abordar tanto las oportunidades (por ejemplo, la reutilización de datos o la implementación de la inteligencia artificial) como los riesgos (por ejemplo, los perjuicios, la exclusión o los sesgos).
- Servir de referencia para las decisiones de gobernanza, los indicadores de éxito y la mejora continua.
En la práctica, las organizaciones suelen orientar su gobernanza hacia metas como maximizar el valor económico y social del dato, fomentar la innovación y el desarrollo sostenible, promover la equidad, apoyar objetivos de política pública (como resultados en salud o protección ambiental) o fortalecer la participación y la autodeterminación digital. Estas finalidades no son excluyentes. Al combinarse permiten construir ecosistemas de datos más responsables, útiles y legítimos.
2. ¿Cómo? (Principles)
Es necesario desarrollar principios de gobernanza de datos mediante un proceso estructurado que parta de definir objetivos y alcance. Estos principios deben:
- Incorporar marcos de derechos humanos y principios básicos como transparencia, responsabilidad, proporcionalidad, equidad, participación, legalidad, seguridad, privacidad, calidad, etc.
- Anclarse en estándares internacionales ligados a la interoperabilidad, la ética de la IA o la protección de datos.
- Tener en cuenta el contexto cultural y los valores sociales locales mediante la participación de actores diversos y pruebas basadas en escenarios concretos.
- Revisarse y actualizarse de forma continua para mantener su relevancia ante cambios legales y tecnológicos.
3. ¿Quién? (People)
La creación de marcos eficaces de gobernanza de datos requiere involucrar a múltiples actores mediante procesos colaborativos que garanticen inclusión, transparencia y coherencia con estándares legales y éticos. Este bloque conlleva identificar a las principales partes interesadas, sus roles y responsabilidades, y establecer mecanismos eficaces de coordinación y rendición de cuentas. Para ello, se recomienda:
- Desarrollar talleres, consultas y mecanismos de retroalimentación para que gobiernos, empresas, sociedad civil y expertos técnicos contribuyan a definir principios y responsabilidades.
- Implementar herramientas como el mapeo de actores, la revisión de políticas y la comparación con marcos globales, incluidos derechos humanos, estándares de procedencia de datos o guías de IA ética.
- Realizar pruebas basadas en escenarios concretos para identificar brechas y fortalecer la resiliencia de los marcos de gobernanza.
- Desarrollar capacidades en gobernanza de datos combinando formación continua, estructuras claras y herramientas de gestión.
- Diseñar estructuras de responsabilidad y mecanismos de supervisión transparentes para garantizar el cumplimiento.
- Implementar acuerdos contractuales, políticas institucionales, enfoques de gobernanza por diseño y medidas de seguridad, como cifrado o controles de acceso.
Es importante tener en cuenta modelos como RACI. Así mismo, las evaluaciones de madurez y las auditorías ayudan a revisar y mejorar las prácticas.
4. ¿Qué? (Practices)
Antes de abordar este apartado, es necesario comprender en qué consiste el ciclo de vida del dato. El ciclo de vida del dato describe las distintas etapas por las que atraviesa la información, desde que se concibe su necesidad hasta que se utiliza para generar conocimiento o apoyar decisiones. Aunque existen múltiples marcos y cada uno puede emplear terminologías ligeramente distintas, la mayoría coincide en seis fases fundamentales: planificación, recogida, procesamiento, compartición, análisis y uso.
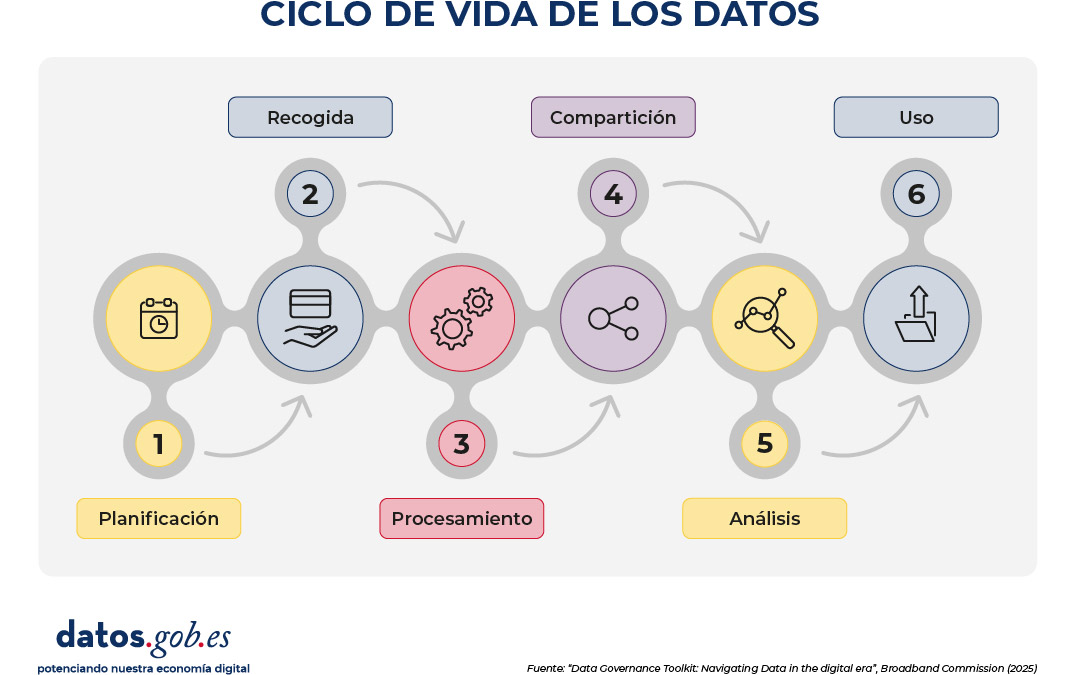
Figura 2. Ciclo de vida de los datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Estas fases consisten en:
1. Planificación. En esta fase se definen las necesidades de datos, los usos previstos y los requisitos de gobernanza que se aplicarán posteriormente. Es el momento de aclarar el propósito, alcance, viabilidad, identificar riesgos, establecer criterios de calidad y determinar quién será responsable de cada decisión. Una planificación deficiente -por ejemplo, un propósito ambiguo- puede comprometer todo el ciclo posterior.
2. Recogida. Consiste en obtener los datos mediante encuestas, sensores, transacciones, registros administrativos u otros mecanismos. Aquí se decide qué datos son realmente necesarios, cómo se obtienen de forma equitativa y ética, y cómo se garantiza que su captura respete principios como la privacidad o la minimización. Una fase de recogida desordenada o excesiva puede generar riesgos y costes innecesarios.
3. Procesamiento. Incluye todas las tareas de limpieza, validación, organización, almacenamiento y preservación de los datos. También abarca la eliminación cuando ya no son necesarios. La fase de procesamiento es crítica para asegurar la calidad, la trazabilidad y el manejo adecuado de la información. Un procesamiento deficiente puede introducir sesgos, errores o pérdidas de integridad que afectarán al análisis posterior.
4. Compartición. En esta etapa los datos se ponen a disposición de terceros para su reutilización, ya sea a través de plataformas, API, acuerdos de intercambio o espacios colaborativos. La gobernanza determina quién puede acceder, bajo qué condiciones, con qué salvaguardas y con qué mecanismos de control. Una compartición bien diseñada multiplica el valor del dato; una mal gestionada puede generar riesgos de seguridad o uso indebido.
5. Análisis. Aquí los datos se interpretan para generar conocimiento, mediante estadísticas, visualizaciones, modelos o técnicas avanzadas como la inteligencia artificial. La gobernanza influye en cómo se documentan los métodos, cómo se gestionan los sesgos y cómo se garantiza la reproducibilidad. Un análisis sin controles puede conducir a conclusiones erróneas o discriminatorias.
6. Uso. Finalmente, los resultados del análisis se aplican para informar decisiones, diseñar políticas, mejorar servicios o crear productos. Esta fase debe estar alineada con el propósito definido al inicio y con los principios éticos y legales establecidos. Un uso inadecuado puede generar impactos negativos, incluso si las fases anteriores se realizaron correctamente.
En cada una de estas etapas se toman decisiones clave: quién accede a los datos, cómo se garantiza su calidad, qué salvaguardas se aplican, cómo se documentan los procesos o qué mecanismos de supervisión existen. Estas decisiones no son independientes: se acumulan y condicionan lo que es posible en las fases posteriores.
Aplicar los principios y decisiones de gobernanza de datos a lo largo de todo el ciclo de vida del dato requiere integrarlos en procesos, herramientas y marcos de cumplimiento alineados con requisitos normativos. Además, es necesario adaptarse a las necesidades de cada sector, apoyándose en estándares globales o jurisdiccionales. Algunos aspectos a consideran son:
- Definir roles y requisitos legales desde la planificación.
- Usar marcos como DAMA‑DMBOK o acuerdos de intercambio, apoyándose en metadatos, trazabilidad y estándares de interoperabilidad para garantizar la transparencia y el uso responsable.
- Apoyarse en acuerdos legales, cooperación regulatoria y tecnologías de mejora de la privacidad para garantizar flujos correctos de datos.
- Garantizar un uso seguro y responsable de la inteligencia artificial mediante datos fiables, bien documentados y gestionados con transparencia y supervisión.
- Medir el éxito de la iniciativa evaluando el cumplimiento, la calidad, la seguridad y la madurez.
La guía de la Broadband Commission incluye un mecanismo de autoevaluación con diversas listas de validación (checklist). El objetivo es que gobiernos, instituciones públicas y organizaciones puedan conocer el estado actual de sus sistemas de gobernanza de datos e identificar oportunidades de mejora. Estas listas abarcan tanto las actividades del resto de bloques como los procesos recomendados en cada fase del ciclo de vida de los datos.
Otros marcos a considerar
La Broadband Commission no es la única organización que ha elaborado un marco de referencia. La siguiente tabla recoge otras iniciativas que también pueden ser de interés.
| Toolkit | Autor | Audiencia |
|---|---|---|
| Data Governance Toolkit | Gobierno del estado de Nueva Gales del Sur (Australia) | Sector público |
| Data Innovation Toolkit | Laboratorio de Innovación Digital de la Comisión Europea | Sector público |
| OECD Data Governance | Organización para la Cooperación y el Desarrollo Económicos (OECD, en inglés) | Sector público |
| Data to Policy Navigator | Iniciativa Data4Policy de la GIZ y la Oficina Digital del Programa de las Naciones Unidas para Desarrollo (PNUD, en inglés) | Sector público |
| Data policy Framework | Unión Africana (AU, en inglés) | Sector público |
| Data Management Framework | Asociación de Naciones de Asia Sudoriental (ASEAN, en inglés) | Sector público |
| Navigating Data Governance | Unión Internacional de Telecomunicaciones (ITU, en inglés) | Reguladores |
| The Data Playbook | Federación Internacional de Sociedades de la Cruz Roja y de la Media Luna Roja (IFRC, en inglés) y Solferimo Academy | Sector humanitario |
| Data Responsability Journey | The GovLab | Sector público y privado |
| Data Governance and Management Toolkit | Miembros del Comité de Dirección de Datos de los Gobiernos Indígenas Autónomos (SGIG DSC Members, en inglés) | Gobiernos indígenas |
Figura 2. Mapeo de conjuntos de herramientas para la gobernanza de datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Todos los marcos coinciden en un aspecto: la clave de la gobernanza de datos está en combinar un propósito claro, principios sólidos, mecanismos de participación y legitimidad y procesos aplicables a todo el ciclo de vida del dato.
En España contamos con la familia de normas UNE de gobierno, gestión y calidad del dato 0077, 0078, 0079 0080 y 0085, concebidas para aplicarse de manera conjunta y ofrecer un marco de referencia sólido que impulse la adopción de prácticas sostenibles y efectivas en torno al dato.
En un momento en que los datos impulsan desde la IA hasta los servicios públicos digitales, avanzar hacia una gobernanza responsable es una oportunidad para reforzar la confianza, potenciar la innovación y garantizar que los beneficios del dato se distribuyan de forma equitativa. Por ello es importante que todas las organizaciones apliquen un marco claro que garantice una gobernanza sólida de los datos.
Entrevista
En los últimos años, la inteligencia artificial (IA) ha pasado de ser una promesa futurista a convertirse en una herramienta cotidiana: hoy convivimos con modelos de lenguaje, sistemas generativos y algoritmos capaces de aprender cada vez más tareas. Pero mientras su popularidad crece, también lo hace una pregunta esencial: ¿cómo garantizamos que estas tecnologías sean realmente fiables y dignas de confianza? Hoy vamos a explorar ese desafío con dos invitados expertos en la materia:
- David Escudero, director del Centro de Inteligencia Artificial de la Universidad de Valladolid.
- José Luis Marín, consultor senior en estrategia, innovación y digitalización.
Resumen / Transcripción de la entrevista
1. ¿Por qué es necesario conocer cómo funcionan las inteligencias artificiales y evaluar ese comportamiento?
Jose Luis Marín: Es necesario por una razón muy sencilla: cuando un sistema influye en decisiones importantes, no es suficiente con que parezca que funciona bien en una demo llamativa, sino que tenemos que saber cuándo acierta, cuándo puede fallar y por qué. Ahora mismo ya estamos en una fase en la que la IA se comienza a aplicar en cuestiones tan delicadas como los diagnósticos médicos, la concesión de ayudas públicas o la propia atención al ciudadano en muchísimos escenarios. Por ejemplo, si nos preguntamos si nos fiaríamos de un sistema que opera como una caja negra y que decide si nos conceden una ayuda, si nos seleccionan para una entrevista o si aprobamos un examen sin poder explicarnos cómo se ha tomado esa decisión, seguramente la respuesta sería que no nos fiaríamos; y no porque la tecnología sea mejor o peor, sino sencillamente porque necesitamos entender qué hay detrás de estas decisiones que nos afectan.
David Escudero: Efectivamente, no es tanto entender cómo funcionan los algoritmos internamente, cómo funciona la lógica o la matemática que hay detrás de todos estos sistemas, pero sí entender o hacer ver a los usuarios que este tipo de sistemas tienen unos grados de fiabilidad que tienen sus límites, igual que las personas. Las personas también se pueden equivocar, pueden fallar en un momento determinado, pero hay que dar garantías para que los usuarios los usen con cierto nivel de seguridad. Ofrecer métricas del rendimiento de estos algoritmos y hacer ver que son fiables hasta cierto grado es fundamental.
2. Un concepto que surge cuando hablamos de estas cuestiones es el de inteligencia artificial explicable ¿Cómo definiríais esta idea y por qué es tan relevante ahora?
David Escudero: IA explicable es un tecnicismo que surge por la necesidad de que el sistema, no solamente ofrezca decisiones, no solamente diga si determinado expediente tiene que ser clasificado de determinada forma o de otra, sino que dé las razones que le llevan al sistema a tomar esa decisión. Es abrir esa caja negra. Hablamos de caja negra porque el usuario no ve cómo funciona el algoritmo. Tampoco lo necesita, pero sí al menos darle unas claves de por qué el algoritmo ha tomado cierta decisión u otra, que es extremadamente importante. Imagínate un algoritmo que clasifica expedientes para derivar a una administración u otra. Si el usuario final se siente perjudicado, necesita tener una razón por la cual eso ha sido así, y la va a pedir; la puede pedir y la puede exigir. Y si desde un punto de vista tecnológico no somos capaces de darle esa solución, la inteligencia artificial tiene un problema. En ese sentido, existen técnicas que avanzan en aportar no solamente soluciones, sino en decir cuáles son las razones que llevan a un algoritmo para tomar determinadas decisiones.
Jose Luis Marín: Yo no puedo explicarlo mucho mejor de lo que lo ha explicado David. Realmente lo que buscamos con la inteligencia artificial explicable es entender el porqué de esas respuestas o de esas decisiones que toman los algoritmos de inteligencia artificial. Simplificándolo mucho, creo que en realidad no hablamos de otra cosa que no sea aplicar los mismos estándares que cuando esas decisiones las toman las personas, a las que además hacemos responsables de las decisiones. Necesitamos poder explicar por qué se ha tomado una decisión o qué reglas se han seguido, para poder confiar en esas decisiones.
3. ¿Cómo se está abordando esta necesidad de explicabilidad y evaluación rigurosa? ¿Qué metodologías o marcos están ganando más peso? ¿Y cuál es el papel de los datos abiertos en ellos?
Jose Luis Marín: Esta pregunta tiene muchas dimensiones. Diría que aquí están convergiendo varias capas. Por un lado, técnicas concretas de explicabilidad como LIME (Interpretable Model-agnostic Explanations) o SHAP (SHapley Additive exPlanations) u otras muchas. Yo suelo seguir, por ejemplo, el catálogo de herramientas y métricas de IA confiable del Observatorio de Políticas Públicas de Inteligencia Artificial de la OCDE, porque ahí se registran bastante bien los avances en el dominio. Pero, por otro lado, tenemos marcos más amplios de evaluación, que no miran solo cuestiones puramente técnicas, sino también cuestiones como los sesgos, la robustez, la estabilidad en el tiempo y el cumplimiento normativo. Ahí hay distintos frameworks como el de gestión del riesgo del NIST (National Institute of Standards and Technology), la evaluación de impacto de los algoritmos del Gobierno de Canadá o nuestro propio Reglamento de IA. Estamos en una fase en la que están surgiendo un montón de iniciativas públicas y privadas que nos irán ayudando a tener cada vez mejores herramientas.
David Escudero: Para la investigación es un campo bastante abierto todavía. Existen metodologías, efectivamente, pero los nuevos modelos basados en redes neuronales han abierto un desafío enorme. La inteligencia artificial que se venía desarrollando en los años anteriores al boom de la IA generativa, en buena medida, se basaba en sistemas expertos que acumulaban un montón de reglas de conocimiento sobre el dominio. En ese tipo de tecnología, la explicabilidad venía dada porque, como lo que se hacía era desencadenar una serie de reglas para tomar decisiones, siguiendo hacia atrás el orden en el que se habían aplicado las reglas, tenías una explicación; pero ahora con los sistemas neuronales, sobre todo con los modelos grandes, donde estamos hablando de miles y miles de millones de parámetros, ese tipo de aproximaciones han quedado imposibles, inabordables, y se aplican otro tipo de metodologías que están basadas principalmente en saber, cuándo entrenas un modelo de machine learning, cuáles son las propiedades o los atributos en el entrenamiento que te llevan a tomar unas u otras decisiones. Digamos, cuáles son los pesos de cada una de las propiedades que están utilizando.
Por ejemplo, si estás utilizando un sistema de machine learning para decidir si mandas publicidad sobre un determinado automóvil a un montón de potenciales clientes, el sistema de machine learning se entrena en base a una experiencia. Al final, te queda un modelo neuronal donde es muy difícil entrar, pero lo puedes hacer analizando el peso de cada una de las variables de entrada que has utilizado para tomar esa decisión. Por ejemplo, la renta de la persona será uno de los atributos más importantes, pero ahí pueden aparecer otras cuestiones que te llevan a consideraciones muy importantes, como pueden ser los sesgos. Imagínate que te sale que una de las variables más importantes es el género de la persona. Ahí entras en una serie de consideraciones que son delicadas. En otros tipos de algoritmos, por ejemplo, que se basen en imágenes, un algoritmo de IA explicable te puede decir qué parte de la imagen ha sido más relevante. Por ejemplo, si estás utilizando un algoritmo para, a partir de la imagen de la cara de una persona - estoy hablando de un hipotético, de un futurible, que además sería un caso extremo-, decidir si esa persona es confiable o no. Entonces podrías mirar en qué rasgos de esa persona se está fijando más la inteligencia artificial, por ejemplo, en los ojos o en la expresión. Ese tipo de consideraciones es lo que haría la IA explicable actualmente: saber cuáles son las variables o cuáles son los datos de entrada del algoritmo que toman mayor valor a la hora de tomar decisiones.
Esto me lleva a hablar de otra parte de tu pregunta sobre la importancia de los datos. La calidad de los datos de entrenamiento es absolutamente importante. Estos datos, estos algoritmos explicables, te pueden llevar incluso a derivar conclusiones que te indiquen que necesitas datos de más o menos calidad, porque te pueda estar dando algún resultado sorprendente, que puede indicar que algún dato de entrenamiento o entrada está derivando salidas y no debería. Entonces tienes que revisar tus propios datos de entrada. Tener datos de referencia de calidad como los que puedes encontrar en datos.gob.es. es absolutamente imprescindible para poder contrastar las informaciones que te va dando este tipo de sistemas.
José Luis Marín: Creo que los datos abiertos son clave en dos dimensiones. Primero porque permiten contrastar y replicar las evaluaciones con mayor independencia. Por ejemplo, cuando existen conjuntos de datos de validación que son públicos no solo evalúa quién construye el sistema, sino que también terceros podamos evaluar (las universidades, las administraciones o la propia sociedad civil). Esa apertura de los datos de evaluación es muy importante para que la IA sea verificable y mucho menos opaca. Pero además creo que los datos abiertos para el entrenamiento y la evaluación también aportan diversidad y contexto. En cualquier contexto minoritario en el que pensemos, seguramente los grandes sistemas no le han prestado la misma atención a estos aspectos, sobre todo los sistemas comerciales. Seguro que no han sido probados al mismo nivel en los contextos mayoritarios que en los minoritarios y de ahí que aparezcan muchos sesgos o malos funcionamientos. Entonces, los conjuntos de datos abiertos pueden contribuir en gran medida a cubrir esos gaps y corregir esos problemas.
Creo que los datos abiertos en la inteligencia artificial explicable encajan muy bien, porque en el fondo comparten un objetivo muy parecido, relacionado con la transparencia.
4. Otro reto que nos encontramos es la rápida evolución en el ecosistema de la inteligencia artificial. Hemos empezado hablando de la popularidad de los chatbots y LLM, pero nos encontramos con que seguimos avanzando, ahora hacia la IA agéntica, sistemas capaces de actuar de forma más autónoma. ¿En qué consisten estos sistemas y qué desafíos específicos plantean desde el punto de vista ético?
David Escudero: La IA agéntica parece que es el gran tema del 2026. No es un término tan nuevo, pero si el año pasado hablábamos de agentes IA, ahora estamos hablando de IA agéntica como una nueva tecnología que coordina diferentes agentes para resolver tareas más complejas. Por simplificar, si un agente te sirve para realizar una actividad concreta, por ejemplo, para reservar un billete de avión, la IA agéntica lo que haría es: planificar el viaje, contrastar diferentes ofertas, reservar el avión, planificar el viaje de ida, la estancia, de nuevo la vuelta y, finalmente, evaluar toda la actividad. El sistema basado en IA agéntica lo que hace es ir coordinando diferentes agentes. Además, con un matiz. Cuando hablamos de la palabra agéntica -que no tenemos una traducción en español muy directa-, pensamos en un sistema que toma la iniciativa. Al final ya no eres tú solamente el que, como usuario, le pides cosas a la inteligencia artificial, sino que la IA ya es capaz de saber cómo puede resolver cosas. Te pedirá información cuando la necesite e intentará adaptarse para darte una solución final a ti como usuario, pero de forma más o menos autónoma, tomando decisiones en procesos intermedios.
Aquí la precisión y la explicabilidad son fundamentales porque se abre de nuevo un desafío muy importante. Si en un momento dado uno de estos agentes que utiliza la IA agéntica falla, se puede crear el efecto de suma de errores y al final acaba como el teléfono escacharrado. De un sistema a otro, de un agente a otro, se va pasando información y si esa información no es tan precisa como debería ser, al final la solución puede ser catastrófica. Entonces se introducen nuevos elementos que hacen, desde un punto de vista tecnológico, más apasionante si cabe el problema. Pero también hay que entender que es absolutamente necesario, porque al final tenemos que avanzar de sistemas que den una solución muy concreta para un caso muy particular a sistemas que combinen la salida de diferentes sistemas para ser un poco más ambiciosos en la respuesta que se da a posibles usuarios.
Jose Luis Marín: Efectivamente. En el momento en el que pasamos de un tipo de sistemas a los que, en principio, les otorgamos la “capacidad de pensar” en las acciones que habría que hacer y nos las cuentan, a otros sistemas que es como si tuviesen manos para interactuar con el mundo digital - y empezamos a ver sistemas que incluso interactúan con el mundo físico y pueden ejecutar esas acciones, que no se quedan en decírtelas o recomendártelas-, se abren oportunidades muy interesantes. Pero también se multiplica la complejidad de la evaluación. El problema ya no es solo si la respuesta es correcta o incorrecta, sino que empieza a ser quién controla qué hace el sistema, qué margen de decisión tiene, quién lo supervisa y, sobre todo, quién responde si algo sale mal, porque no hablamos solo de recomendaciones, hablamos de acciones que a veces pueden no ser tan fácil deshacerlas. Esto hace que aparezcan riesgos nuevos o al menos más intensos: si se pierde esa trazabilidad en la ejecución de las acciones que no estaban previstas o que no tenían que haber ocurrido en un momento determinado; o puede haber usos indebidos de información, o muchos otros riesgos. Creo que la IA agéntica exige todavía más gobernanza y un diseño mucho más cuidadoso y alineado con los derechos de las personas.
5. Hablemos de aplicaciones reales, ¿Dónde veis más potencial y necesidad de evaluación y explicabilidad en el sector público?
Jose Luis Marín: Diría que la necesidad de evaluación y explicabilidad es mayor donde la IA pueda influir en las decisiones que afecten a las personas. Cuanto mayor sea el impacto en derechos o en oportunidades o, mismamente, en la confianza en las instituciones, mayor tiene que ser esa exigencia. Si pensamos, por ejemplo, en ámbitos como la sanidad, los servicios sociales, el empleo, la educación… En todos ellos lógicamente es ineludible esa necesidad de evaluación en el sector público.
En todos los casos, la IA puede ser muy útil para apoyar decisiones para conseguir eficiencias en múltiples escenarios. Pero necesitamos saber muy bien cómo se comporta y qué criterios se está utilizando. Esto no afecta solo a los sistemas más complejos. Creo que hay que fijarse en los sistemas que en principio nos puedan parecer más o menos sensibles a primera vista, como los asistentes virtuales que ya empezamos a ver en bastantes administraciones o los sistemas de traducción automática… Ahí no hay una decisión final que tome la IA, pero una mala recomendación o una respuesta errónea, también puede tener consecuencias para las personas. O sea, creo que no depende tanto de la complejidad tecnológica como del contexto de uso. En el sector público incluso un sistema aparentemente sencillo puede tener mucho impacto.
David Escudero: Os lanzo el trapo de hacer otro podcast sobre el concepto también muy de moda que es Human in the loop o Human on the loop. En el sector público tenemos un cuerpo de funcionarios públicos que conocen muy bien su trabajo y que pueden ayudar. Human in the loop sería el papel que puede tener el funcionario a la hora de generar datos que puedan ser útiles para entrenar sistemas, revisar que los datos con los que se pueden entrenar sistemas sean fiables, etc.; y Human on the loop sería la supervisión de las decisiones que pueda tomar una inteligencia artificial. Quien puede revisar, quien puede saber si esa decisión tomada por un sistema automático es buena o mala, es un funcionario público.
En ese sentido, y relacionado también con la IA agéntica, nosotros tenemos un proyecto con la Fundación Española de Ciencia y Tecnología para asesorar a la Diputación de Valladolid en tareas de inteligencia artificial en la administración. Y vemos que muchas de las tareas que nos piden los propios funcionarios no tienen tanto que ver con la IA, sino con la interoperabilidad de los propios servicios que ya ofrecen y que son automáticos. A lo mejor en una administración tienen un servicio desarrollado por un sistema automático, junto a otro servicio que les ofrece un formulario con resultados, pero después les toca teclear a mano los datos que comunican ambos servicios. Ahí estaríamos también hablando de posibilidades para la IA agéntica de intercomunicar. El desafío es implicar en todo ese proceso el papel del funcionario como velador de que las funciones públicas se hacen con rigor.
Jose Luis Marín: El concepto de Human in the loop es clave en muchos de los proyectos en los que trabajamos. Al final es la combinación no solo de tecnología, sino de las personas que conocen realmente los procesos y pueden supervisarlos y complementar esas acciones que puede realizar la IA agéntica. En cualquier sistema simplemente de atención ya es necesaria esa supervisión en muchos casos, porque una mala recomendación puede tener también muchas consecuencias, no solo en la acción de un sistema complejo.
6. Para cerrar, me gustaría que cada uno compartiera una idea clave sobre lo que necesitamos para avanzar hacia una IA más confiable, evaluable y explicable.
David Escudero: Apuntaría, aprovechando que estamos en el podcast de datos.gob.es, la importancia de la gobernanza del dato: asegurarse de que las instituciones, tanto públicas como privadas se preocupen mucho por la calidad del dato, por tener unos datos bien compartidos que sean representativos, que estén bien documentados y, por supuesto, que sean accesibles. Los datos de las instituciones públicas son fundamentales para que los ciudadanos tengan esas garantías y para que empresas e instituciones puedan preparar algoritmos que puedan utilizar esa información para mejorar servicios o dar garantías a los ciudadanos. La gobernanza del dato es fundamental.
Jose Luis Marín: Si yo tuviese que resumir todo en una sola idea, diría que todavía estamos muy lejos de que la evaluación sea una práctica habitual. En los sistemas de IA tendremos que convertirla en algo obligatorio dentro de los procesos de desarrollo y despliegue. Evaluar no es probar una vez y darlo por resuelto, hay que comprobar de forma continua cómo y dónde pueden fallar, qué riesgos introducen y si siguen siendo adecuados cuándo ha cambiado el contexto en el que se pensó un determinado sistema. Yo creo que aún estamos lejos de esto.
Efectivamente, los datos abiertos son clave para contribuir a este proceso. Una IA va a ser más confiable cuanto más podamos observarla y mejorarla con criterios compartidos, no solo con los de la organización que los diseñan. Por eso los datos abiertos aportan transparencia, pueden ayudarnos a facilitar la verificación y a construir una base más sólida para que realmente los servicios vayan alineados con el interés general.
David Escudero Mancebo: En ese sentido también agradecer espacios como este que sin duda sirven para potenciar esa cultura del dato, de la calidad y de la evaluación tan necesaria en nuestra sociedad. Creo que se ha avanzado muchísimo, pero que, sin duda, todavía queda y abrir espacios para la divulgación es muy importante.
Clips de la entrevista
1. ¿Qué es la inteligencia artificial explicable?
2. ¿Qué rol pueden desempeñar los datos abiertos en la IA explicable?
Blog
Hay una idea que se repite en casi cualquier iniciativa de datos: “si conectamos fuentes distintas, sacaremos más valor”. Y suele ser verdad. El matiz es que el valor aparece cuando podemos combinar datos sin fricción, sin malentendidos y sin sorpresas. El Decálogo del reutilizador de datos del sector público lo resume muy bien: la interoperabilidad es especialmente crítica justo cuando intentamos mezclar datos de diversas fuentes, que es donde los datos abiertos suelen aportar más.
En la práctica, la interoperabilidad no es solo “que haya una API” o “que el fichero sea descargable”. Es un concepto más amplio, con varias capas: si solo cuidamos una, las demás acaban rompiendo la reutilización. Conectamos… pero no entendemos qué significa cada campo. Entendemos… pero no hay estabilidad ni versionado. Hay estabilidad… pero no existe un proceso común para resolver incidencias. Y, aun teniendo todo lo anterior, pueden faltar reglas claras de uso. Por eso, también es un error pensar que la interoperabilidad es un problema puramente informático que se arregla “comprando el software adecuado”: la tecnología es solo la punta del iceberg. Si queremos que los datos fluyan de verdad entre administración pública, empresa y centros de investigación, necesitamos una visión holística.
Y aquí viene la buena noticia: se puede abordar de forma incremental, paso a paso. Para hacerlo bien, lo primero es aclarar qué tipo de interoperabilidad estamos buscando en cada caso, porque no todas las barreras son técnicas ni se resuelven del mismo modo.
En este post vamos a desglosar los distintos tipos de interoperabilidad que existen, para identificar qué aporta cada uno y qué falla cuando lo dejamos fuera.
Los distintos tipos de interoperabilidad
Siguiendo el Marco Europeo de Interoperabilidad (EIF), conviene pensar la interoperabilidad como un edificio con cuatro principales capas: técnica, semántica, organizativa y jurídica. Si una falla, el conjunto se resiente.
A continuación, unificamos las cuatro capas con un enfoque centrado en datos, incluyendo ejemplos aplicados a distintos sectores.
1. Interoperabilidad técnica: que los sistemas puedan intercambiar datos
Es la capa “visible”: infraestructuras, protocolos y mecanismos para enviar/recibir datos de forma fiable.
Pero, ¿qué implica en la práctica?
-
Formatos legibles por máquina: como CSV, JSON, XML, RDF, evitando los documentos solo para lectura humana (como PDF).
-
API y endpoints estables: con documentación, autenticación cuando aplique y versionado.
-
Requisitos no funcionales: disponibilidad, rendimiento, seguridad y trazabilidad técnica.
¿Cuáles son los errores o fallos típicos que generan problemas?
En el caso específico de la interoperabilidad técnica, estos vienen principalmente originados por cambios “silenciosos”, como, por ejemplo, que se alteren columnas y/o estructura y se rompan integraciones, o que haya URL no persistentes, API sin versionado o sin documentación.
Ejemplo: vamos a aterrizarlo a un caso concreto para el dominio de la movilidad
Imaginemos que un ayuntamiento publica en tiempo real la ocupación de aparcamientos. Si la API cambia el nombre de un campo o el endpoint sin avisar, las apps de navegación dejan de mostrar plazas disponibles, aunque “el dato exista”. El problema es técnico: falta estabilidad, versionado y contrato de interfaz.
2. Interoperabilidad semántica: que, además, se entiendan entre sí
Si la interoperabilidad técnica es “las tuberías”, la semántica es el idioma. Podemos tener sistemas perfectamente conectados y, aun así, obtener resultados desastrosos si cada parte interpreta los datos de forma distinta.
Pero, ¿qué implica en la práctica?
-
Glosarios de términos claros: definición de cada campo, unidad, formato, rango, reglas de negocio, granularidad y ejemplos.
-
Vocabularios controlados, taxonomías y ontologías para clasificar y codificar valores sin ambigüedad.
-
Identificadores unívocos y referencias normalizadas a través de datos de referencia con códigos oficiales, catálogos comunes, etc.
¿Cuáles son los errores o fallos típicos que generan problemas?
Normalmente aparecen cuando hay ambigüedad (por ejemplo, si solo pone fecha, no sabemos si es la fecha de registro, publicación o efecto), unidades distintas (por ejemplo, no se conoce la unidad de medida del dato: kWh vs MWh, euros vs miles de euros), códigos incompatibles (H/M vs 1/2 vs masculino/femenino) o incluso cambios de significado en series históricas sin explicarlo.
Ejemplo: vamos a aterrizarlo a un caso concreto en el sector energía
Una administración publica datos de consumo eléctrico por edificios. Un reutilizador cruza esos datos con otro dataset regional, pero uno está en kWh y el otro en MWh, o uno mide consumo “final” y el otro “bruto”. El cruce “cuadra” técnicamente, pero las conclusiones salen mal porque falta semántica: definiciones y unidades compartidas.
3. Interoperabilidad organizativa: que los procesos sostengan la coherencia
Aquí hablamos menos de sistemas y más de personas, responsabilidades y procesos. Los datos no se mantienen solos: se publican, se actualizan, se corrigen y se explican porque hay una organización detrás que lo hace posible.
Pero, ¿qué implica en la práctica?
-
Roles y responsabilidades claras: quién define, quién valida, quién publica, quién mantiene y quién responde ante incidencias.
-
Gestión de cambios: qué es un cambio mayor/menor, cómo se versiona, cómo se comunica y si se conserva el histórico.
-
Gestión de incidencias: canal único, tiempos de respuesta, priorización, trazabilidad y cierre.
-
Compromisos operativos (tipo acuerdos de nivel de servicio o SLA en sus siglas en inglés): frecuencia de actualización, ventanas de mantenimiento, criterios de calidad y revisiones periódicas.
Aquí pueden ayudarnos, por ejemplo, las especificaciones UNE sobre gobierno y gestión del dato donde se dan las claves para establecer modelos organizativos, roles, procesos de gestión y mejora continua. Por lo tanto, encajan precisamente en esta capa: ayudan a que publicar y compartir datos no dependa del “esfuerzo heroico” de un equipo, sino de un modo de trabajo estable en el que el equipo vaya madurando.
¿Cuáles son los errores o fallos típicos que generan problemas?
Los clásicos: “cada unidad publica a su manera”, no hay responsable claro, no existe un circuito para corregir errores, se actualiza sin avisar, no se conserva histórico o el feedback del reutilizador se pierde en un buzón genérico sin seguimiento.
Ejemplo: vamos a aterrizarlo a un caso concreto en medio ambiente
Una confederación publica datos de calidad del agua y varias unidades aportan mediciones. Si no hay un proceso común de validación, un calendario coordinado y un canal de incidencias, el dataset empieza a tener valores inconsistentes, lagunas y correcciones tardías. El problema no es la API ni el formato: es organizativo, porque el mantenimiento no está gobernado.
4. Interoperabilidad jurídica: que el intercambio sea viable y conforme
Esta es la capa que convierte el intercambio en algo seguro y escalable. Puedes tener datos perfectos a nivel técnico, semántico y organizativo… y aun así, no poder reutilizarlos si no hay claridad jurídica.
Pero, ¿qué implica en la práctica?
-
Licencia y condiciones de uso claras: atribución, redistribución, uso comercial, obligaciones, etc.
-
Compatibilidad entre licencias cuando se mezclan fuentes: evitando combinaciones inviables.
-
Cumplimiento de protección de datos: como el Reglamento General de Protección de Datos (RGPD), propiedad intelectual, secretos empresariales o límites sectoriales.
-
Reglas explícitas sobre qué se puede hacer y qué no: indicando también con qué requisitos.
¿Cuáles son los errores o fallos típicos que generan problemas?
La “jungla” clásica: licencias ausentes o ambiguas, condiciones contradictorias entre datasets, dudas sobre si hay datos personales o riesgo de reidentificación, o restricciones que se descubren cuando el proyecto ya está avanzado.
Ejemplo: vamos a aterrizarlo a un caso concreto en cultura y patrimonio
Un archivo público publica imágenes y metadatos de una colección. Técnicamente todo está bien, y los metadatos son ricos, pero la licencia es confusa o incompatible con otros datos que se quieren cruzar (por ejemplo, un repositorio privado con restricciones). Resultado: una empresa o una universidad decide no reutilizar por inseguridad jurídica. El bloqueo no es técnico: es jurídico.
En resumen, la interoperabilidad funciona como un “pack” de cuatro capas: conectar (técnica), entender lo mismo (semántica), mantenerlo de forma sostenida (organizativa) y poder reutilizar sin riesgo (jurídica).
Para verlo de un vistazo y con ejemplos reales, la siguiente infografía resume cómo se materializa cada capa en distintos sectores (estándares, modelos, prácticas y marcos normativos) y qué piezas suelen usarse como referencia en cada caso.
 Figura 1. Infografía: "Interoperabilidad: la clave para trabajar con datos de diversas fuentes". Versión accesible disponible aquí. Fuente: elaboración propia - datos.gob.es.
Figura 1. Infografía: "Interoperabilidad: la clave para trabajar con datos de diversas fuentes". Versión accesible disponible aquí. Fuente: elaboración propia - datos.gob.es.
La infografía anterior deja una idea clara: la interoperabilidad no depende de una sola decisión, sino de combinar estándares, acuerdos y reglas que cambian según el sector. A partir de aquí, tiene sentido bajar un nivel y ver qué referencias y herramientas se usan en España y en Europa para que esas cuatro capas (técnica, semántica, organizativa y jurídica) no se queden en teoría.
Una referencia práctica en España: NTI-RISP (y por qué tiene sentido citarla)
En el contexto español, la NTI-RISP es una guía muy útil porque pone negro sobre blanco qué hay que cuidar cuando publicamos información para que otros la puedan reutilizar: identificación, descripción (metadatos), formatos y términos de uso, entre otros aspectos.
Metadatos como pegamento: DCAT-AP y DCAT-AP-ES
En datos abiertos, donde más se nota la interoperabilidad “en el día a día” es en los catálogos: si los conjuntos de datos no se describen de forma coherente, cuesta encontrarlos, entenderlos y federarlos.
-
DCAT-AP aporta un modelo común de metadatos para catálogos de datos en Europa, apoyándose en vocabularios ampliamente reutilizados.
-
En España, DCAT-AP-ES se impulsa precisamente para reforzar esa interoperabilidad de catálogos con un perfil común que facilite intercambio y federación entre portales.
Cómo abordar la interoperabilidad sin morir de ambición
En lugar de “arreglarla de golpe”, suele funcionar mejor tratar la interoperabilidad como mejora continua porque se rompe con cambios en tecnología, organización o normativa. Un enfoque sencillo y realista:
-
Empieza por el “para qué”: ¿Quieres integrar en un servicio, cruzar para análisis, construir indicadores comparables, enriquecer entidades…? El objetivo determina el nivel de rigor necesario.
-
Asegura el mínimo técnico estable: acceso y formatos legibles por máquina, identificadores persistentes, documentación mínima, y algún versionado (aunque sea básico). Esto evita datasets “útiles hoy” que se rompen mañana.
-
Aplica semántica donde duele (principio de Pareto: 80/20 - establece que el 80% de los resultados provienen del 20% de las causas o acciones-): define muy bien los campos críticos (los que se cruzan/filtran), unidades, tablas de códigos y el significado exacto de fechas/estados. No hace falta “modelarlo todo” para reducir la mayoría de los errores.
-
Pon acuerdos operativos mínimos: quién mantiene, cuándo se actualiza, cómo se reportan incidencias, cómo se anuncian cambios y si se conserva el histórico. Aquí es donde un enfoque de gobierno del dato (y guías como NTI-RISP) marca la diferencia entre “dataset publicado” y “dataset sostenible”.
-
Pilota con un cruce real: un piloto pequeño detecta rápido si el problema era técnico, semántico, organizativo o jurídico, y te da una lista concreta de fricciones a eliminar.
Como conclusión, la interoperabilidad no es simplemente “tener una API”: es el resultado de alinear cuatro capas —técnica, semántica, organizativa y jurídica— para poder combinar datos sin fricción, sin malentendidos y con seguridad. Cada capa resuelve un problema distinto: la técnica evita roturas de integración, la semántica evita interpretaciones erróneas, la organizativa hace sostenible la publicación y el mantenimiento en el tiempo, y la jurídica elimina la inseguridad sobre qué se puede hacer con los datos.
En ese contexto, los marcos y estándares sectoriales actúan como atajos prácticos para acelerar acuerdos y reducir ambigüedad, y por eso es útil ver ejemplos por sectores. Además, los metadatos y los catálogos interoperables son un auténtico multiplicador: cuando un conjunto de datos está bien descrito, se encuentra antes, se entiende mejor y se puede federar con menos coste. Por último, lo más efectivo suele ser un enfoque incremental y medible: empezar por el “para qué”, asegurar estabilidad técnica, reforzar la semántica crítica (80/20), formalizar acuerdos operativos mínimos y validar con un cruce real, en lugar de intentar “solucionar la interoperabilidad” como un único proyecto cerrado.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
“Voy a subirte un fichero CSV. Quiero que lo analices y me resumas las conclusiones más relevantes que puedas extraer de los datos”. Hace unos años, el análisis de datos era territorio de quien sabía escribir código y utilizar entornos técnicos complejos, y una petición así habría requerido programación o habilidades avanzadas de Excel. Hoy, poder analizar en poco tiempo ficheros de datos con herramientas de IA nos aporta una gran autonomía profesional. Formular preguntas, contrastar ideas preliminares y explorar de primera mano la información cambia nuestra relación con el conocimiento, sobre todo, porque dejamos de depender de intermediarios para obtener respuestas. Ganar la capacidad de analizar datos con IA de manera independiente acelera los procesos, pero también puede provocarnos un exceso de confianza en las conclusiones.
A partir del ejemplo de un fichero de datos en bruto, vamos a revisar posibilidades, precauciones y pautas básicas para explorar la información sin asumir conclusiones demasiado rápido.
El fichero:
Para mostrar un ejemplo de análisis de datos con IA utilizaremos un fichero del Instituto Nacional de Estadística (INE) que recoge información sobre flujos turísticos en Europa, en concreto sobre ocupación en alojamientos de turismo rural. El fichero de datos contiene información desde enero de 2001 hasta diciembre de 2025. Contiene desagregaciones por sexo, edad y comunidad o ciudad autónoma, lo que permite realizar análisis comparativos a lo largo del tiempo. En el momento de escribir este artículo, la última actualización de este conjunto de datos fue el 28 de enero de 2026.

Figura 1. Información del dataset. Fuente: Instituto Nacional de Estadística (INE).
1. Exploración inicial
Para esta primera exploración vamos a utilizar una versión gratuita de Claude, el chat multitarea basado en IA desarrollado por Anthropic. Es uno de los modelos de lenguaje más avanzados en benchmarks de razonamiento y análisis, lo que lo hace especialmente adecuado para este ejercicio, y es la opción más utilizada actualmente por la comunidad para realizar tareas que requieren código.
Pensemos que nos enfrentamos al fichero de datos por primera vez. Sabemos a grandes rasgos qué contiene, pero desconocemos la estructura de la información. Nuestro primer prompt, por tanto, debería centrarse en describirla:
PROMPT: Quiero trabajar con un fichero de datos sobre ocupación en alojamientos de turismo rural. Explícame qué estructura tiene el fichero: qué variables contiene, qué mide cada una y qué posibles relaciones existen entre ellas. Señala también posibles valores ausentes o elementos que requieran aclaración.

Figura 2. Exploración inicial del fichero de datos con Claude. Fuente: Claude.
Una vez que Claude nos ha dado la idea general y la explicación de las variables, es buena práctica abrir el fichero y hacer una comprobación rápida. El objetivo es evaluar que, como mínimo, el número de filas, el número de columnas, los nombres de las variables, el período temporal y el tipo de datos coinciden con lo que nos ha dicho el modelo.
Si detectamos algún error en este punto, el LLM puede no estar leyendo correctamente los datos. Si después de intentarlo en otra conversación el error persiste, es señal de que hay algo en el fichero que dificulta su lectura automática. En este caso, lo más recomendable es no proseguir con el análisis, ya que las conclusiones serán muy aparentes, pero estarán basadas en datos mal interpretados.
2. Gestión de anomalías
En segundo lugar, si hemos descubierto anomalías, lo habitual es documentarlas y decidir cómo manejarlas antes de seguir con el análisis. Podemos pedir al modelo que nos sugiera qué hacer, pero las decisiones finales serán nuestras. Por ejemplo:
- Valores faltantes: si hay celdas vacías, tenemos que decidir si rellenarlas con un valor “promedio” de la columna o simplemente eliminar esas filas.
- Duplicados: tenemos que eliminar filas repetidas o que no aportan información nueva.
- Errores de formato o inconsistencias: debemos corregirlos para que las variables sean coherentes y comparables. Por ejemplo, fechas representadas en distintos formatos.
- Outliers: si aparece un número que no tiene sentido o es exageradamente distinto del resto, tenemos que decidir si corregirlo, ignorarlo o tratarlo tal y como está.

Figura 3. Ejemplo de análisis de valores faltantes con Claude. Fuente: Claude.
En el caso de nuestro fichero, por ejemplo, hemos detectado que en Ceuta y Melilla los valores ausentes en la variable Total son estructurales, no hay turismo rural registrado en esas ciudades, por lo que podríamos excluirlas del análisis.
Antes de tomar la decisión, una buena práctica en este punto es pedir al LLM los pros y contras de la modificación en los datos. Su respuesta puede darnos alguna pista de cuál es la mejor opción, o indicarnos algún inconveniente que no habíamos tenido en cuenta.

Figura 4. Análisis de Claude sobre la posibilidad de eliminar o no valores. Fuente: Claude.
Si decidimos seguir adelante y excluir las ciudades de Ceuta y Melilla del análisis, Claude puede ayudarnos a efectuar esta modificación directamente sobre el fichero. El prompt sería el siguiente:
PROMPT: Elimina del fichero todas las filas correspondientes a Ceuta y Melilla, de manera que el resto de los datos se mantenga intacto. Explica también los pasos que estás siguiendo para que pueda revisarlos.
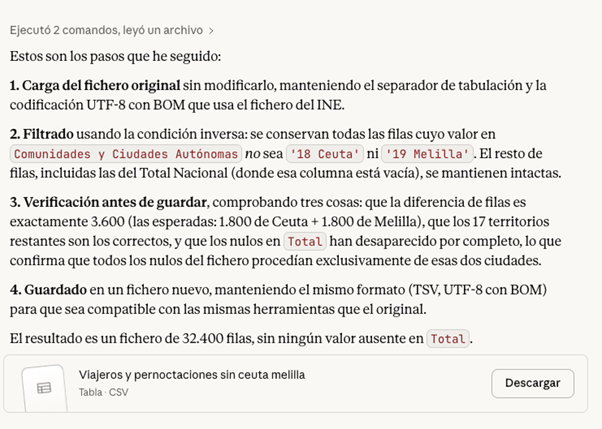
Figura 5. Paso a paso en la modificación de datos en Claude. Fuente: Claude.
En este punto, Claude nos ofrece descargar de nuevo el fichero modificado, así que una buena práctica de comprobación sería validar de forma manual que la operación se hizo bien. Por ejemplo, revisar el número de filas en un fichero y otro o cotejar algunas filas al azar con el primer fichero para asegurarnos de que los datos no se han corrompido.
3. Primeras preguntas y visualizaciones
Si el resultado hasta aquí es satisfactorio, ya podemos empezar a explorar los datos para hacernos preguntas iniciales y buscar patrones interesantes. Lo ideal al empezar la exploración es hacer preguntas grandes, claras y fáciles de responder con los datos, porque nos dan una primera visión.
PROMPT: Trabaja con el fichero sin Ceuta y Melilla a partir de ahora. ¿Cuáles han sido las cinco comunidades con más turismo rural en el período total?

Figura 6. Respuesta de Claude a las cinco comunidades con más turismo rural en el período. Fuente: Claude.
Por último, podemos pedirle a Claude que nos ayude a visualizar los datos. En lugar de hacer el esfuerzo de indicarle un tipo de gráfico concreto, le damos libertad para elegir el formato que mejor muestre la información.
PROMPT: ¿Puedes visualizar esta información en un gráfico? Elige el formato más adecuado para representar los datos.
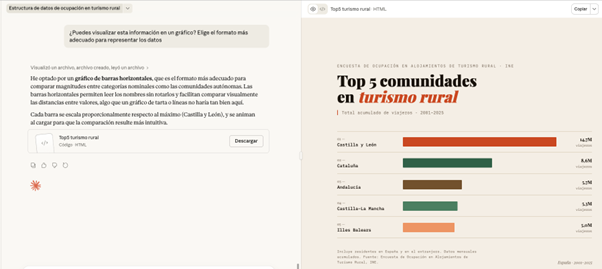
Figura 7. Gráfico elaborado por Cloude para representar la información. Fuente: Claude.
Aquí, la pantalla se desdobla: a la izquierda, podemos continuar con la conversación o descargar el fichero, mientras que a la derecha podemos visualizar el gráfico directamente. Claude ha generado una gráfica de barras horizontales muy visual y lista para usar. Los colores diferencian las comunidades y se indica correctamente el período y el tipo de datos.
¿Qué ocurre si le pedimos cambiar la paleta de color del gráfico por una inadecuada? En este caso, por ejemplo, vamos a pedirle una serie de tonos pastel que apenas se diferencian.
PROMPT: ¿Puedes cambiar la paleta de colores del gráfico por esta otra? #E8D1C5, #EDDCD2, #FFF1E6, #F0EFEB, #EEDDD3
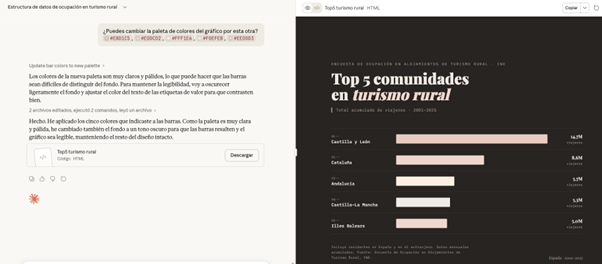
Figura 8. Ajustes realizados en el gráfico por Claude para representar la información. Fuente: Claude.
Ante el reto, Claude ajusta por sí mismo el gráfico de manera inteligente, oscurece el fondo y cambia el texto de las etiquetas para mantener legibilidad y contraste.
Todo el ejercicio anterior se ha realizado con Claude Sonnet 4.6, que no es el modelo de mayor calidad de Anthropic. Sus versiones superiores, como Claude Opus 4.6, tienen mayor capacidad de razonamiento, comprensión profunda y resultados más finos. Además, existen muchas otras herramientas para trabajar con datos y visualizaciones basadas en IA, como Julius o Quadratic. Aunque en ellas las posibilidades son casi infinitas, cuando trabajamos con datos sigue siendo fundamental mantener una metodología y un criterio propios.
Contextualizar en la vida real los datos que estamos analizando y conectarlos con otros conocimientos no es una tarea que se pueda delegar; necesitamos tener una mínima idea previa de qué queremos conseguir con el análisis para poder transmitirla al sistema. Esto nos permitirá hacer mejores preguntas, interpretar adecuadamente los resultados y por tanto hacer un prompting más eficaz.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La adopción del nuevo perfil DCAT-AP-ES alinea a España con el perfil de aplicación en Europa (DCAT-AP), facilitando la federación automática entre catálogos de datos definidos en RDF (Resource Description Framework).
En este entorno de grafos RDF donde la flexibilidad es la norma, la ausencia de esquemas rígidos tradicionales puede derivar en una degradación silenciosa de la calidad de los datos, si no se sigue de forma rigurosa el estándar. Para mitigar este riesgo, existe el lenguaje de restricciones de formas SHACL (Shapes Constraint Language), recomendación del W3C. Estas pautas permiten definir «formas» que funcionan como verdaderos guardianes de la calidad y el cumplimiento de la interoperabilidad.
Las etapas del proceso de validación SHACL son las siguientes:
- Se dispone de un grafo de datos RDF
- Se selecciona un subgrado del grafo anterior
- Se comprueban las restricciones SHACL que aplican al subgrafo anterior
- Se obtiene un informe de validación con los elementos conformes, con errores o con recomendaciones.
En la siguiente figura se muestran estas etapas:

Figura 1: Etapas principales del proceso de validación SHACL
Objetivos y audiencia destino
Esta guía técnica tiene como objetivo ayudar a que los publicadores y reutilizadores incorporen la validación SHACL como una práctica continua de mejora de calidad, mediante un enfoque didáctico y accesible, inspirado en recursos claros y herramientas de validación abiertas del ecosistema de datos.
Además, se profundiza de forma especial en su relación con DCAT-AP-ES, detallando un caso práctico y exhaustivo del flujo de trabajo completo de validación y gobernanza de un catálogo conforme a dicho perfil.
Estructura y contenidos
El documento sigue un enfoque progresivo, partiendo de fundamentos teóricos hasta llegar a la implementación técnica e integración automática, estructurándose en los siguientes bloques clave:
- Fundamentos de la validación semántica: RDF y el desafío del mundo abierto que supone así como SHACL como mecanismo de realizar validaciones, definiendo conceptos clave como Shape o Validation Report.
- DCAT-AP-ES y la adopción de SHACL para su validación: se explican las formas SHACL definidas en DCAT-AP-ES y el caso de aplicación de las mismas en el proceso de federación del Catálogo Nacional.
- Caso práctico: Validación de grafos RDF: un tutorial paso a paso sobre cómo validar un catálogo con las formas SHACL de DCAT-AP-ES, resolución de problemas comunes y herramientas disponibles.
- Conclusiones: reflexiones sobre las ventajas de integrar validación SHACL para mejorar la gobernanza de catálogos de datos.
La validación mediante SHACL representa un cambio de paradigma en la gestión de la calidad de metadatos en los catálogos de datos. Esta guía recorre el proceso completo desde los fundamentos teóricos hasta la aplicación práctica, demostrando que la adopción de SHACL no es simplemente un requisito técnico, sino una oportunidad para fortalecer y mejorar la gobernanza de datos.
Blog
Vivimos en una era en la que la ciencia depende cada vez más de datos. Desde la planificación urbana hasta la transición climática, el gobierno del dato se ha convertido en un pilar estructural de la toma de decisiones basada en evidencia. Sin embargo, existe un ámbito donde los principios tradicionales de gestión, validación y control del dato se ven sometidos a tensiones extremas: el universo.
Los datos espaciales —producidos por satélites científicos, telescopios, sondas interplanetarias y misiones de exploración— no describen realidades accesibles ni repetibles. Observan fenómenos que ocurrieron hace millones de años, a distancias imposibles de recorrer y bajo condiciones que nunca podrán replicarse en laboratorio. No existe una medición “in situ” que confirme directamente estos fenómenos.
En este contexto, el gobierno del dato deja de ser una cuestión organizativa y pasa a ser un elemento estructural de la confianza científica. La calidad, la trazabilidad y la reproducibilidad no pueden apoyarse en referencias físicas directas, sino en la transparencia metodológica, la documentación exhaustiva y la solidez de los marcos instrumentales y teóricos.
Gobernar datos del universo implica, por tanto, enfrentarse a retos únicos: gestionar incertidumbre estructural, documentar escalas extremas y garantizar la confianza en información que nunca podremos tocar.
A continuación, exploramos los principales desafíos que plantea el gobierno del dato cuando el objeto de estudio está más allá de la Tierra.
I. Retos específicos del dato del universo
1. Más allá de la Tierra: nuevas fuentes, nuevas reglas
Cuando hablamos de datos espaciales, nos referimos a mucho más que a imágenes de satélite de la superficie terrestre. Nos adentramos en un ecosistema complejo que incluye telescopios espaciales y terrestres, sondas interplanetarias, misiones de exploración planetaria y observatorios diseñados para detectar radiación, partículas o fenómenos físicos extremos.
Estos sistemas generan datos con retos claramente diferentes respecto a otros dominios científicos:
|
Desafío |
Impacto en el gobierno del dato |
|---|---|
| Acceso físico inexistente | No hay validación directa; la confianza reside en la integridad del canal. |
| Dependencia instrumental | El dato es "hijo" directo del diseño del sensor; si el sensor falla o se descalibra, la realidad se distorsiona. |
| Singularidad | Muchos eventos astronómicos son únicos. No hay una "segunda oportunidad" para capturarlos. |
| Coste extremo | El valor de cada byte es altísimo debido a la inversión necesaria para poner el sensor en órbita. |
Figura 1. Desafíos en el gobiernos de datos del universo. Fuente: elaboración propia - datos.gob.es.
A diferencia de los datos de observación de la Tierra —que en muchos casos pueden contrastarse mediante campañas de campo o sensores redundantes— los datos del universo dependen fundamentalmente de la arquitectura de la misión, la calibración del instrumento y los modelos físicos utilizados para interpretar la señal capturada.
En numerosos casos, lo que se registra no es el fenómeno en sí, sino una señal indirecta: variaciones espectrales, emisiones electromagnéticas, alteraciones gravitacionales o partículas detectadas tras recorrer millones de kilómetros. El dato es, en esencia, una traducción instrumental de un fenómeno inaccesible.
Por todo ello, en el espacio el dato no puede entenderse sin el contexto técnico que lo genera.
2. Incertidumbre estructural y escalas extremas
La incertidumbre se refiere al grado de margen de error o indeterminación asociado a una medición, interpretación o resultado científico debido a los límites de los instrumentos, las condiciones de observación y los modelos utilizados para analizar los datos. Si en otros ámbitos la incertidumbre es un factor que se intenta reducir mediante mediciones directas, repetibles y contrastables, en la observación del universo la incertidumbre forma parte del propio proceso de conocimiento. No se trata simplemente de “no saber lo suficiente”, sino de enfrentarse a límites físicos y metodológicos que no pueden eliminarse por completo.
Por tanto, en la observación del universo la incertidumbre es estructural. No se trata de una anomalía puntual, sino de una condición inherente al objeto de estudio.
Existen varias dimensiones críticas:
- Escalas espaciales y temporales extremas: las distancias cósmicas impiden cualquier validación directa. Las escalas temporales implican que, con frecuencia, el dato captura un “instante” del pasado remoto y no una realidad presente verificable.
- Señales débiles y ruido inevitable: los instrumentos capturan emisiones sumamente sutiles. La señal útil convive con interferencias, limitaciones tecnológicas y ruido de fondo. La interpretación depende de tratamientos estadísticos avanzados y de modelos físicos complejos.
- Fenómenos de observación limitada: algunos fenómenos astrofísicos —como determinadas supernovas, estallidos de rayos gamma o configuraciones gravitacionales singulares— no pueden recrearse experimentalmente y solo pueden observarse cuando ocurren. En estos casos, el registro disponible puede ser único o profundamente limitado, lo que incrementa la responsabilidad en su documentación y preservación.
No todos los fenómenos son irrepetibles, pero en muchos casos las oportunidades de observación son escasas o dependen de condiciones excepcionales.
II. Construir confianza cuando no podemos tocar el objeto observado
Ante estos retos, el gobierno del dato adquiere un papel estructural. No se limita a garantizar almacenamiento o disponibilidad, sino que define las reglas mediante las cuales los procesos científicos quedan documentados, trazables y auditables.
En este contexto, gobernar no significa producir conocimiento, sino garantizar que su producción sea transparente, verificable y reutilizable.
1. Calidad sin validación física directa
Cuando no puede verificarse directamente el fenómeno observado, la calidad del dato se apoya en:
- Protocolos rigurosos de calibración: los instrumentos deben someterse a procesos sistemáticos de calibración antes, durante y después de su operación. Esto implica ajustar sus mediciones frente a referencias conocidas, caracterizar sus márgenes de error, documentar desviaciones y registrar cualquier modificación en su configuración. La calibración no es un evento puntual, sino un proceso continuo que garantiza que la señal registrada refleje, con la mayor precisión posible, el fenómeno observado dentro de los límites físicos del sistema.
- Validación cruzada entre instrumentos independientes: cuando distintos instrumentos —ya sea en la misma misión o en misiones diferentes— observan un fenómeno similar, la comparación de resultados permite reforzar la fiabilidad del dato. La convergencia entre observaciones obtenidas con tecnologías distintas reduce la probabilidad de sesgos instrumentales o errores sistemáticos. Esta coherencia inter-instrumental actúa como un mecanismo de verificación indirecta.
- Repetición observacional cuando es posible: aunque no todos los fenómenos pueden repetirse, muchas observaciones sí pueden realizarse en diferentes momentos o bajo distintas condiciones. La repetición permite evaluar la estabilidad de la señal, identificar anomalías y estimar variabilidad natural frente a error de medición. La consistencia en el tiempo fortalece la robustez del resultado.
- Revisión por pares y consenso científico progresivo: los datos y sus interpretaciones son sometidos a evaluación por parte de la comunidad científica. Este proceso implica escrutinio metodológico, análisis crítico de supuestos y verificación de coherencia con el conocimiento existente. El consenso no surge de forma inmediata, sino a través de acumulación de evidencia y debate científico. La calidad, en este sentido, es también una construcción colectiva.
La calidad no es solo una propiedad técnica; es el resultado de un proceso documentado y auditable.
2. Trazabilidad científica completa
En el contexto espacial, el dato es inseparable del proceso técnico y científico que lo genera. No puede entenderse como un resultado aislado, sino como la culminación de una cadena de decisiones instrumentales, metodológicas y analíticas.
Por ello, la trazabilidad debe cubrir de forma explícita y documentada:
- Diseño y configuración del instrumento: es necesario conservar información sobre las características técnicas del instrumento que capturó la señal, por ejemplo, su arquitectura, capacidades de detección, límites de resolución y configuraciones operativas. Estas condiciones determinan qué tipo de señal puede registrarse y con qué precisión.
- Parámetros de calibración: deben registrarse los ajustes aplicados para asegurar que el instrumento opere dentro de los márgenes previstos, así como las modificaciones realizadas a lo largo del tiempo. Los parámetros de calibración influyen directamente en la interpretación de la señal obtenida.
- Versiones del software de procesamiento: el tratamiento del dato bruto depende de herramientas informáticas específicas. Conservar las versiones utilizadas permite comprender cómo se generaron los resultados y evitar ambigüedades si el software evoluciona.
- Algoritmos aplicados en la reducción de ruido: dado que las señales suelen estar acompañadas de interferencias o ruido de fondo, es esencial documentar los métodos empleados para filtrar, limpiar o transformar la información antes de su análisis. Estos algoritmos influyen en el resultado final.
- Supuestos científicos utilizados en la interpretación: la lectura del dato no es neutra: se apoya en marcos teóricos y modelos físicos aceptados en el momento del análisis. Registrar estos supuestos permite contextualizar las conclusiones y comprender posibles revisiones futuras.
- Transformaciones sucesivas del dato bruto al dato publicado: desde la señal original hasta el producto científico final, el dato atraviesa distintas fases de procesamiento, agregación y análisis. Cada transformación debe poder reconstruirse para entender cómo se llegó al resultado comunicado.
Sin trazabilidad exhaustiva, la reproducibilidad se debilita y la interpretabilidad futura se compromete. Cuando no es posible reconstruir el proceso completo que dio lugar a un resultado, su evaluación independiente se vuelve limitada y su reutilización científica pierde solidez.
3. Reproducibilidad a largo plazo
Las misiones espaciales pueden extenderse durante décadas, y sus datos pueden seguir siendo relevantes mucho después de que la misión haya finalizado. Además, la interpretación científica evoluciona con el tiempo: nuevos modelos, nuevas herramientas y nuevas preguntas pueden requerir volver a analizar información generada años atrás.
Por ello, los datos deben mantenerse interpretables incluso cuando los equipos originales ya no existen, los sistemas tecnológicos han cambiado o el contexto científico ha evolucionado.
Esto exige:
- Metadatos ricos y estructurados: la información contextual que acompaña al dato —sobre su origen, condiciones de adquisición, procesamiento y limitaciones— debe estar organizada de forma clara y normalizada. Sin metadatos suficientes, el dato pierde significado y se vuelve difícil de reinterpretar en el futuro.
- Identificadores persistentes: cada conjunto de datos debe poder localizarse y citarse de manera estable en el tiempo. Los identificadores persistentes permiten mantener la referencia incluso si cambian los sistemas de almacenamiento o las infraestructuras tecnológicas.
- Políticas de preservación digital robustas: la conservación a largo plazo requiere estrategias que contemplen la obsolescencia de formatos, la migración tecnológica y la integridad de los archivos. No basta con almacenar; es necesario asegurar que los datos sigan siendo accesibles y legibles con el paso del tiempo.
- Documentación accesible de los pipelines de procesamiento: el proceso que transforma el dato bruto en producto científico debe estar descrito de forma comprensible. Esto permite que investigadores futuros puedan reconstruir el análisis, verificar los resultados o aplicar nuevos métodos sobre los mismos datos originales.
La reproducibilidad, en este contexto, no significa repetir físicamente el fenómeno observado, sino poder reconstruir el proceso analítico que condujo a un resultado determinado. La gobernanza no solo gestiona el presente; garantiza la reutilización futura del conocimiento y preserva la capacidad de reinterpretar la información a la luz de nuevos avances científicos.
El siguiente visual resumen los tres desafíos:
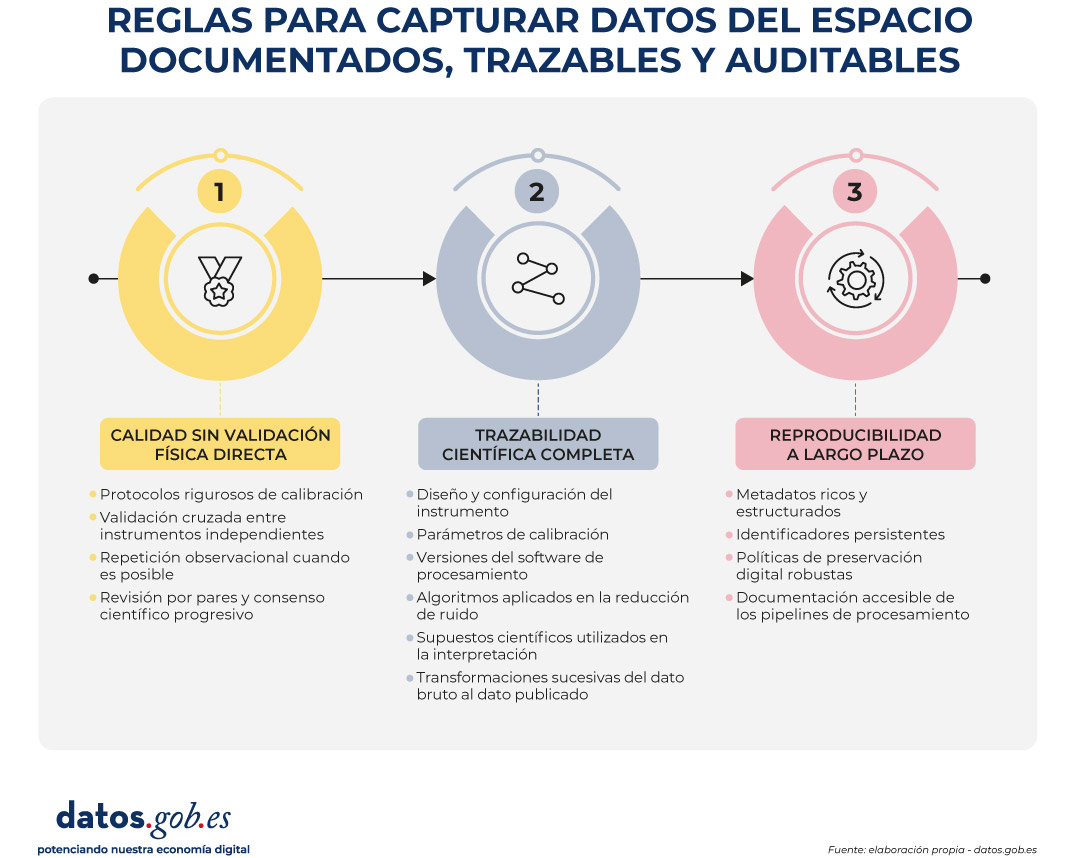
Figura 2. Reglas para capturar datos espaciales documentados, trazables y auditables. Fuente: elaboración propia - datos.gob.es.
Conclusión: gobernar lo que no podemos tocar
Los datos del universo nos obligan a repensar cómo entendemos y gestionamos la información. Estamos trabajando con realidades que no podemos visitar, tocar ni comprobar directamente. Observamos fenómenos que ocurren a distancias inmensas y en tiempos que superan la escala humana, a través de instrumentos altamente especializados que traducen señales complejas en datos interpretables.
En este contexto, la incertidumbre no es un error ni una debilidad, sino una característica natural del estudio del cosmos. La interpretación de los datos depende de modelos científicos que evolucionan con el tiempo, y la calidad no se basa en una verificación directa, sino en procesos rigurosos, bien documentados y revisados por la comunidad científica. La confianza, por tanto, no surge de la experiencia directa, sino de la transparencia, la trazabilidad y la claridad con la que se explican los métodos utilizados.
Gobernar datos espaciales no significa únicamente almacenarlos o ponerlos a disposición del público. Significa conservar toda la información que permite entender cómo se obtuvieron, cómo se procesaron y bajo qué supuestos fueron interpretados. Solo así pueden ser evaluados, reinterpretados y reutilizados en el futuro.
Más allá de la Tierra, el gobierno del dato no es un detalle técnico ni una tarea administrativa. Es el fundamento que sostiene la credibilidad del conocimiento humano sobre el universo y la base que permite que nuevas generaciones continúen explorando lo que aún no podemos alcanzar físicamente.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
Desde sus orígenes el movimiento de datos abiertos se ha centrado fundamentalmente en el impulso de la apertura de los datos y en el fomento de su reutilización. El objetivo que ha articulado la mayoría de las iniciativas, tanto públicas como privadas, ha sido el de vencer los obstáculos para publicar catálogos de datos cada vez más completos y asegurar que la información del sector público estuviera disponible para que la ciudadanía, las empresas, los investigadores y el propio sector público pudieran crear valor económico y social.
Sin embargo, a medida que hemos ido dando pasos hacia una economía cada vez más dependiente de los datos y, más recientemente, de la inteligencia artificial -y en un futuro próximo de las posibilidades que nos traen los agentes autónomos a través de la inteligencia artificial agéntica-, las prioridades han ido cambiando y el foco ha ido girando hacia cuestiones como la mejora de la calidad de los datos publicados.
Ya no es suficiente con que los conjuntos de datos estén publicados en un portal de datos abiertos cumpliendo buenas prácticas, ni tan siquiera con que el dato cumpla unos estándares de calidad en el momento de su publicación. También es necesario que esta publicación de los conjuntos de datos cumpla con unos niveles de servicio que transformen la mera puesta a disposición en un compromiso operativo que mitigue las incertidumbres que, a menudo, obstaculizan la reutilización.
Cuando un desarrollador integra una API de datos de transporte en tiempo real en su app de movilidad, o cuando un científico de datos trabaja en un modelo de IA con datos climáticos históricos está asumiendo un riesgo si no tiene certeza sobre las condiciones en las que los datos estarán disponibles. Si en un momento dado los datos publicados dejan de estar disponibles porque cambia el formato sin previo aviso, porque el tiempo de respuesta se dispara o por cualquier otra razón, los procesos automatizados fallan y la cadena de suministro de datos se rompe, provocando fallos en cascada en todos los sistemas dependientes.
En este contexto, la adopción de acuerdos de nivel de servicio (ANS) también conocidos por su terminología en inglés, service level agreements (SLA), podrían ser el siguiente paso para que portales de datos abiertos evolucionen desde el habitual modelo “best effort” hasta convertirse en infraestructuras digitales críticas, fiables y robustas.
¿Qué son un ANS o SLA y un contrato de datos en el contexto de los datos abiertos?
En el contexto de la ingeniería de fiabilidad (site reliability engineering o SRE), un ANS es un contrato negociado entre un proveedor de servicios y sus clientes con objeto de fijar el nivel de calidad del servicio prestado. Es, por tanto, una herramienta que ayuda a ambas partes a llegar a un consenso en aspectos tales como el tiempo de respuesta, la disponibilidad horaria o la documentación disponible.
En un portal de datos abiertos, donde a menudo no existe una contraprestación económica directa, un ANS podría ayudar a responder preguntas como:
- ¿Cuánto tiempo estará disponible el portal y sus API?
- ¿Qué tiempos de respuesta podemos esperar?
- ¿Con qué frecuencia se actualizarán los conjuntos de datos?
- ¿Cómo se gestionan los cambios en metadatos, enlaces y formatos?
- ¿Cómo se gestionarán incidencias, cambios y avisos a la comunidad?
Adicionalmente, en esta transición hacia una mayor madurez operativa surge el concepto, aún inmaduro, del contrato de datos (data contract). Si el ANS es un acuerdo que define las expectativas de nivel de servicio, el contrato de datos es una implementación que formaliza este compromiso. Un contrato de datos no solo especificaría el esquema y el formato, sino que actuaría como una salvaguarda: si una actualización del sistema intenta introducir un cambio que rompa la estructura prometida o que degrade la calidad del dato, el contrato de datos permite detectar y bloquear dicha anomalía antes de que afecte a los usuarios finales.
INSPIRE como punto de partida: disponibilidad, rendimiento y capacidad
La infraestructura de la Unión Europea para la información espacial (INSPIRE) ha establecido uno de los marcos más rigurosos del mundo en cuanto a calidad de servicio para datos geoespaciales. La Directiva 2007/2/CE, conocida como INSPIRE, actualmente en su versión 5.0, incluye algunas obligaciones técnicas que podrían servir como referencia para cualquier portal de datos modernos. En particular el Reglamento (CE) nº 976/2009 establece criterios que bien podrían servir como patrón para cualquier estrategia de publicación de datos de alto valor:
- Disponibilidad: la infraestructura debe estar disponible el 99% del tiempo durante el horario de funcionamiento normal.
- Rendimiento: para un servicio de visualización la respuesta inicial debe llegar en menos de 3 segundos.
- Capacidad: para un servicio de localización el mínimo número de peticiones simultáneas servidas con rendimiento garantizado debe ser de 30 por segundo.
Para ayudar al cumplimiento de estos estándares de servicio, la Comisión Europea ofrece herramientas como el INSPIRE Reference Validator. Esta herramienta ayuda no solo a verificar la interoperabilidad sintáctica (que el XML o GML esté bien formado), sino también a asegurar que los servicios de red cumplen con las especificaciones técnicas que permiten medir esos ANS.
En este punto, los exigentes ANS de la infraestructura de datos espaciales europea nos hacen preguntarnos si no deberíamos aspirar a lo mismo para datos críticos de salud, energía o movilidad o para cualquier otro conjunto de datos de alto valor.
Qué podría cubrir un ANS en una plataforma de datos abiertos
Cuando hablamos de conjuntos de datos abiertos en sentido amplio, la disponibilidad del portal es una condición necesaria, pero no suficiente. Muchas incidencias que afectan a la comunidad de reutilizadores no son caídas completas del portal, sino errores más sutiles como enlaces rotos, conjuntos de datos que no se actualizan con la periodicidad indicada, formatos inconsistentes entre versiones, metadatos incompletos o cambios silenciosos en el comportamiento de las API o en los nombres de las columnas de los conjuntos de datos.
Por ello, convendría complementar los ANS propios de la infraestructura del portal con ANS de “salud del dato” que pueden basarse en marcos de referencia ya consolidados como:
- Modelos de calidad como ISO/IEC 25012, que permite desglosar la calidad del dato en dimensiones medibles como la exactitud (que el dato represente la realidad), la completitud (que no falten valores necesarios) y la consistencia (que no haya contradicciones entre tablas o formatos) y convertirlas en requisitos medibles.
- Principios FAIR, siglas de Findable (Localizable), Accessible (Accesible), Interoperable (Interoperable), y Reusable (Reutilizable). Estos principios enfatizan que los activos digitales no solo deben estar disponibles, sino que deben ser localizables mediante identificadores persistentes, accesibles bajo protocolos claros, interoperables mediante el uso de vocabularios estándar y reutilizables gracias a licencias claras y procedencia documentada. Los principios FAIR se pueden poner en práctica midiendo de forma sistemática la calidad de los metadatos que hacen posible la localización, el acceso y la interoperabilidad. Por ejemplo, el servicio Metadata Quality Assurance (MQA) de data.europa.eu ayuda a hacer una evaluación automática de los metadatos de los catálogos, a calcular métricas y a ofrecer recomendaciones de mejora.
Para convertir en operativos estos conceptos, podemos centrarnos en cuatro ejemplos donde establecer compromisos de servicio específicos aportaría un valor diferencial:
- Conformidad y vigencia del catálogo: el ANS podría garantizar que los metadatos estén siempre alineados con los datos que describen. Un compromiso de conformidad aseguraría que el portal se somete a validaciones periódicas (siguiendo especificaciones como DCAT-AP-ES o HealthDCAT-AP) para evitar que la documentación se volviese obsoleta respecto al recurso real.
- Estabilidad del esquema y versionado: uno de los mayores enemigos de la reutilización automatizada es el "cambio silencioso". Si una columna cambia de nombre o un tipo de dato varía, los flujos de ingesta de datos fallarán inmediatamente. Un compromiso de nivel de servicio podría incluir una política de versionado. Esto implicaría que cualquier cambio que rompiese la compatibilidad se anunciase con una antelación mínima y, preferiblemente, mantuviese la versión anterior en paralelo durante un tiempo prudencial.
- Frescura y frecuencia de actualización: no resulta infrecuente encontrar conjuntos de datos etiquetados como de actualización diaria pero cuya última modificación real fue hace meses. Una buena práctica podría ser la definición de indicadores de latencia de publicación. Un posible ANS establecería el valor del tiempo medio entre actualizaciones y contaría con sistemas de alerta que notificasen automáticamente si un dato no se ha refrescado según la frecuencia declarada en su metadato.
- Tasa de éxito: en el mundo de las API de datos, no es suficiente con recibir un código HTTP 200 (OK) para determinar si la respuesta es válida. Si la respuesta es, por ejemplo, un JSON sin contenido, el servicio no es útil. El nivel de servicio tendría que medir la tasa de respuestas exitosas y con contenido válido, asegurando que el endpoint no solo responde, sino que entrega la información esperada.
Un primer paso, SLA, SLO y SLI: medir antes de comprometer
Dado que establecer este tipo de compromisos es realmente complejo, una posible estrategia para pasar a la acción de forma gradual es adoptar un enfoque pragmático basado en las mejores prácticas de la industria. Por ejemplo, en la ingeniería de fiabilidad, se propone una jerarquía de tres conceptos que ayuda a evitar compromisos poco realistas:
- Indicador de Nivel de Servicio (SLI): es el indicador medible y cuantitativo. Representa la realidad técnica en un momento dado. Ejemplos de SLI en datos abiertos podrían ser el "porcentaje de peticiones exitosas a la API", la "latencia p95" (el tiempo de respuesta del 95% de las solicitudes) o el "porcentaje de enlaces de descarga que no devuelven error".
- Objetivo de Nivel de Servicio (SLO): es el objetivo interno que se marca sobre ese indicador. Por ejemplo: "queremos que el 99,5% de las descargas funcionen correctamente" o "la latencia p95 debe ser inferior a 800 ms". Es la meta que guía el trabajo del equipo técnico.
- Acuerdo de Nivel de Servicio (ANS o SLA): es el compromiso público y formal sobre esos objetivos. Es la promesa que el portal de datos hace a su comunidad de reutilizadores y que incluye, idealmente, los canales de comunicación y los protocolos de actuación en caso de incumplimiento.
Figura 1. Visual elaborado para explicar la diferencia entre SLI, SLO y SLA. Fuente: elaboración propia - datos.gob.es.
Esta distinción es especialmente valiosa en el ecosistema de los datos abiertos debido a la naturaleza híbrida de un servicio en el que no solo se opera una infraestructura, sino que se gestiona el ciclo de vida de los datos.
En muchos casos, el primer paso podría ser no tanto publicar un ANS ambicioso de inmediato, sino empezar por definir sus SLI y observar sus SLO. Una vez que la medición estuviese automatizada y los niveles de servicio se estabilizasen y fuesen predecibles, sería el momento de convertirlos en un compromiso público (SLA).
En última instancia, la implementación de niveles de servicio en los datos abiertos podría tener un efecto multiplicador. No solo reduciría la fricción técnica para los desarrolladores y mejoraría la tasa de reutilización, sino que facilitaría la integración de los datos públicos en sistemas de IA y agentes autónomos. Los nuevos usos como la evaluación de sistemas de Inteligencia Artificial generativa, la generación y validación de conjuntos de datos sintéticos o incluso la propia mejora de la calidad de los datos abiertos se verían muy beneficiados.
Establecer un SLA de datos sería, por encima de todo, un potente mensaje: significaría que el sector público no solo publica los datos como un acto administrativo, sino que los opera como un servicio digital de alta disponibilidad, fiable, predecible y, en definitiva, preparado para los retos de la economía del dato.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Durante más de una década, las plataformas de datos abiertos han medido su impacto a través de indicadores relativamente estables: número de descargas, visitas a la web, reutilizaciones documentadas, aplicaciones o servicios creados en base a ellos, etc. Estos indicadores funcionaban bien en un ecosistema donde los usuarios - empresas, periodistas, desarrolladores, ciudadanos anónimos, etc. - accedían directamente a las fuentes originales para consultar, descargar y procesar los datos.
Sin embargo, el panorama ha cambiado radicalmente. La irrupción de los modelos de inteligencia artificial generativa ha transformado la forma en que las personas acceden a la información. Estos sistemas generan respuestas sin necesidad de que el usuario visite la fuente original, lo que está provocando una caída global del tráfico web en medios, blogs y portales de conocimiento.
En este nuevo contexto, medir el impacto de una plataforma de datos abiertos exige repensar los indicadores tradicionales para incorporar a las métricas ya utilizadas otras nuevas que capturen también la visibilidad e influencia de los datos en un ecosistema donde la interacción humana está cambiando.
Un cambio estructural: del clic a la consulta indirecta
El ecosistema web está experimentando una transformación profunda impulsada por el auge de los modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés). Cada vez más personas formulan sus preguntas directamente a sistemas como ChatGPT, Copilot, Gemini o Perplexity, obteniendo respuestas inmediatas y contextualizadas sin necesidad de recurrir a un buscador tradicional.
Al mismo tiempo, quienes continúan utilizando motores de búsqueda como Google o Bing también experimentan cambios relevantes derivados de la integración de la inteligencia artificial en estas plataformas. Google, por ejemplo, ha incorporado funciones como AI Overviews, que ofrece resúmenes generados automáticamente en la parte superior de los resultados, o el Modo IA, una interfaz conversacional que permite profundizar en una consulta sin navegar por enlaces. Esto genera un fenómeno conocido como Zero-Click: el usuario realiza una búsqueda en un motor como Google y obtiene la respuesta directamente en la propia página de resultados. En consecuencia, no tiene necesidad de hacer clic en ningún enlace externo, lo cual limita las visitas a las fuentes originales de las que está extraída la información.
Todo ello implica una consecuencia clave: el tráfico web deja de ser un indicador fiable de impacto. Una página web puede estar siendo extremadamente influyente en la generación de conocimiento sin que ello se traduzca en visitas.

Figura 1. Métricas para medir el impacto de los datos abiertos en la era de la IA. Fuente: elaboración propia.
Nuevas métricas para medir el impacto
Ante esta situación, las plataformas de datos abiertos necesitan nuevas métricas que capturen su presencia en este nuevo ecosistema. A continuación, se recogen algunas de ellas.
-
Share of Model (SOM): presencia en los modelos de IA
Inspirado en métricas del marketing digital, el Share of Model mide con qué frecuencia los modelos de IA mencionan, citan o utilizan datos procedentes de una fuente concreta. De esta forma, el SOM ayuda a ver qué conjuntos de datos concretos (empleo, clima, transporte, presupuestos, etc.) son utilizados por los modelos para responder preguntas reales de los usuarios, revelando qué datos tienen mayor impacto.
Esta métrica resulta especialmente valiosa porque actúa como un indicador de confianza algorítmica: cuando un modelo menciona una página web, está reconociendo su fiabilidad como fuente. Además, contribuye a aumentar la visibilidad indirecta, ya que el nombre de la web aparece en la respuesta incluso cuando el usuario no llega a hacer clic.
-
Análisis de sentimiento: tono de las menciones en IA
El análisis de sentimiento permite ir un paso más allá del Share of Model, ya que no solo identifica si un modelo de IA menciona una marca o dominio, sino cómo lo hace. Habitualmente, esta métrica clasifica el tono de la mención en tres categorías principales: positivo, neutro y negativo.
Aplicado al ámbito de los datos abiertos, este análisis ayuda a comprender la percepción algorítmica de una plataforma o conjunto de datos. Por ejemplo, permite detectar si un modelo utiliza una fuente como ejemplo de buenas prácticas, si la menciona de forma neutral como parte de una respuesta informativa o si la asocia a problemas, errores o datos desactualizados.
Esta información puede resultar útil para identificar oportunidades de mejora, reforzar la reputación digital o detectar posibles sesgos en los modelos de IA que afecten a la visibilidad de una plataforma de datos abiertos.
-
Categorización de prompts: en qué temas destaca una marca
Analizar las preguntas que hacen los usuarios permite identificar en qué tipos de consultas aparece con mayor frecuencia una marca. Esta métrica ayuda a entender en qué áreas temáticas -como economía, salud, transporte, educación o clima- los modelos consideran más relevante una fuente.
Para las plataformas de datos abiertos, esta información revela qué conjuntos de datos están siendo utilizados para responder preguntas reales de los usuarios y en qué dominios existe mayor visibilidad o potencial de crecimiento. También permite detectar oportunidades: si una iniciativa de datos abiertos quiere posicionarse en nuevas áreas, puede evaluar qué tipo de contenido falta o qué conjuntos de datos podrían reforzarse para aumentar su presencia en esas categorías.
-
Tráfico procedente de IA: clics desde resúmenes generados
Muchos modelos ya incluyen enlaces a las fuentes originales. Aunque muchos usuarios no hacen clic en dichos enlaces, algunos sí lo hacen. Por ello, las plataformas pueden empezar a medir:
- Visitas procedentes de plataformas de IA (cuando estas incluyen enlaces).
- Clics desde resúmenes enriquecidos en buscadores que integran IA.
Esto supone un cambio en la distribución del tráfico que llega a las webs desde los distintos canales. Mientras el tráfico orgánico —el que proviene de los motores de búsqueda tradicionales— está disminuyendo, empieza a crecer el tráfico referido desde los modelos de lenguaje.
Este tráfico será menor en cantidad que el tradicional, pero más cualificado, ya que quien hace clic desde una IA suele tener una intención clara de profundizar.
Es importante que se tengan en cuenta estos aspectos a la hora de fijar objetivos de crecimiento en una plataforma de datos abiertos.
-
Reutilización algorítmica: uso de datos en modelos y aplicaciones
Los datos abiertos alimentan modelos de IA, sistemas predictivos y aplicaciones automatizadas. Conocer qué fuentes se han utilizado para su entrenamiento sería también una forma de conocer su impacto. Sin embargo, pocas soluciones proporcionan de manera directa esta información. La Unión Europea está trabajando para promover la transparencia en este campo, con medidas como la plantilla para documentar los datos de entrenamiento de modelos de propósito general, pero su implantación -y la existencia de excepciones a su cumplimiento- hacen que el conocimiento sea aún limitado.
Medir el incremento de accesos a los datos mediante API podría dar una idea de su uso en aplicaciones para alimentar sistemas inteligentes. Sin embargo, el mayor potencial en este campo pasa por colaboración con empresas, universidades y desarrolladores inmersos en estos proyectos, para que ofrezcan una visión más realista del impacto.
Conclusión: medir lo que importa, no solo lo que es fácil de medir
La caída del tráfico web no significa una caída del impacto. Significa un cambio en la forma en que la información circula. Las plataformas de datos abiertos deben evolucionar hacia métricas que reflejen la visibilidad algorítmica, la reutilización automatizada y la integración en modelos de IA.
Esto no significa que las métricas tradicionales deban desaparecer. Conocer los accesos a la web, los conjuntos de datos más visitados o los más descargados sigue siendo una información de gran valor para conocer el impacto de los datos proporcionados a través de plataformas abiertas. Y también es fundamental monitorizar el uso de los datos a la hora de generar o enriquecer productos y servicios, incluidos los sistemas de inteligencia artificial. En la era de la IA, el éxito ya no se mide solo por cuántos usuarios visitan una plataforma, sino también por cuántos sistemas inteligentes dependen de su información y la visibilidad que ello otorga.
Por eso, integrar estas nuevas métricas junto a los indicadores tradicionales a través de una estrategia de analítica web y SEO * permite obtener una visión más completa del impacto real de los datos abiertos. Así podremos saber cómo circula nuestra información, cómo se reutiliza y qué papel juega en el ecosistema digital que hoy da forma a la sociedad.
*El SEO (Search Engine Optimization) es el conjunto de técnicas y estrategias destinadas a mejorar la visibilidad de un sitio web en los motores de búsqueda.
Blog
El acceso a datos a través de API se ha convertido en una de las piezas clave del ecosistema digital actual. Administraciones públicas, organismos internacionales y empresas privadas publican información para que terceros puedan reutilizarla en aplicaciones, análisis o proyectos de inteligencia artificial. En esta situación, hablar de datos abiertos es, casi inevitablemente, hablar también de API.
Sin embargo, el acceso a una API rara vez es completamente libre e ilimitado. Existen restricciones, controles y mecanismos de protección que buscan equilibrar dos objetivos que, a primera vista, pueden parecer opuestos: facilitar el acceso a los datos y garantizar la estabilidad, seguridad y sostenibilidad del servicio. Estas limitaciones generan dudas frecuentes: ¿son realmente necesarias?, ¿van contra el espíritu de los datos abiertos?, ¿hasta qué punto pueden aplicarse sin cerrar el acceso?
Este artículo aborda cómo se gestionan estas limitaciones, por qué son necesarias y cómo encajan —lejos de lo que a veces se piensa— dentro de una estrategia coherente de datos abiertos.
Por qué es necesario limitar el acceso a una API
Una API no es simplemente un “grifo” de datos. Detrás suele haber infraestructura tecnológica, servidores, procesos de actualización, costes operativos y equipos responsables de que el servicio funcione correctamente.
Cuando un servicio de datos se expone sin ningún tipo de control, aparecen problemas bien conocidos:
- Saturación del sistema, provocada por un número excesivo de consultas simultáneas.
- Uso abusivo, intencionado o no, que degrade el servicio para otros usuarios.
- Costes descontrolados, especialmente cuando la infraestructura está desplegada en la nube.
- Riesgos de seguridad, como ataques automatizados o scraping masivo.
En muchos casos, la ausencia de límites no conduce a más apertura, sino a un deterioro progresivo del propio servicio.
Por este motivo, limitar el acceso no suele ser una decisión ideológica, sino una necesidad práctica para asegurar que el servicio sea estable, predecible y justo para todos los usuarios.
La API Key: control básico, pero efectivo
El mecanismo más habitual para gestionar el acceso es la API Key. Mientras que en algunos casos como la API del catálogo nacional de datos abiertos de datos.gob.es no se requiere ningún tipo de clave para poder acceder a la información publicada, otros catálogos solicitan una clave única que identifica a cada usuario o aplicación y que se incluye en cada llamada a la API.
Aunque desde fuera pueda parecer una simple formalidad, la API Key cumple varias funciones importantes. Permite identificar quién consume los datos, medir el uso real del servicio, aplicar límites razonables y actuar ante comportamientos problemáticos sin afectar al resto de usuarios.
En el contexto español existen ejemplos claros de plataformas de datos abiertos que funcionan así. La Agencia Estatal de Meteorología (AEMET), por ejemplo, ofrece acceso abierto a datos meteorológicos de alto valor, pero exige solicitar una API Key gratuita para consultas automatizadas. El acceso es libre y gratuito, pero no anónimo ni descontrolado.
Hasta aquí, el enfoque es relativamente conocido: identificación del consumidor y límites básicos de uso. Sin embargo, en muchas situaciones nos esto ya no es suficiente.
Cuando la API se convierte en un activo estratégico
Las plataformas líderes de gestión de API, como MuleSoft o Kong entre otros, fueron pioneras en implantar mecanismos avanzados de control y protección del acceso a las API. Su foco inicial estaba ligado a entornos empresariales complejos, donde múltiples aplicaciones, organizaciones y países consumen servicios de datos de forma intensiva y continuada.
Con el tiempo, muchas de estas prácticas han ido extendiéndose también a plataformas de datos abiertos. A medida que ciertos servicios de datos abiertos ganan relevancia y se convierten en dependencias clave para aplicaciones, investigaciones o modelos de negocio, los retos asociados a su disponibilidad y estabilidad se vuelven similares. La caída o degradación de servicios de datos abiertos de gran escala —como los relacionados con observación de la Tierra, clima o ciencia— puede tener un impacto significativo en múltiples sistemas que dependen de ellos.
En este sentido, la gestión avanzada del acceso deja de ser una cuestión exclusivamente técnica y pasa a formar parte de la propia sostenibilidad de un servicio que se vuelve estratégico. No se trata tanto de quién publica los datos, sino del papel que esos datos juegan dentro de un ecosistema más amplio de reutilización. Por ello, muchas plataformas de open data están adoptando, de forma progresiva, mecanismos ya probados en otros ámbitos, adaptándolos a sus principios de apertura y acceso público. A continuación, se detallan algunos de ellos.
Limitar el caudal: regular el ritmo, no el derecho de acceso
Una de las primeras capas adicionales es la limitación del caudal de uso, lo que habitualmente se conoce como rate limiting. En lugar de permitir un número ilimitado de llamadas, se define cuántas peticiones pueden realizarse en un intervalo de tiempo determinado.
La clave aquí no es impedir el acceso, sino regular el ritmo. Un usuario puede seguir utilizando los datos, pero se evita que una única aplicación monopolice los recursos. Este enfoque es habitual en las API de datos meteorológicos, movilidad o estadísticas públicas, donde muchos usuarios acceden simultáneamente.
Las plataformas más avanzadas van un paso más allá y aplican límites dinámicos, que se ajustan según la carga del sistema, el momento del día o el comportamiento histórico del consumidor. El resultado es un control más justo y flexible.
Contexto, origen y comportamiento: más allá del volumen
Otra evolución importante es dejar de mirar solo cuántas llamadas se hacen y empezar a analizar desde dónde y cómo se realizan. Aquí entran medidas como la restricción por direcciones IP, el control geográfico (geofencing) o la diferenciación entre entornos de prueba y producción.
En algunos casos, estas limitaciones responden a marcos regulatorios o licencias de uso. En otros, simplemente permiten proteger partes más sensibles del servicio sin cerrar el acceso general. Por ejemplo, una API puede ser accesible globalmente en modo consulta, pero limitar determinadas operaciones a situaciones muy concretas.
Las plataformas también analizan patrones de comportamiento. Si una aplicación empieza a realizar consultas repetitivas, incoherentes o muy distintas a su uso habitual, el sistema puede reaccionar automáticamente: reducir temporalmente el caudal, lanzar alertas o exigir un nivel adicional de validación. No se bloquea “porque sí”, sino porque el comportamiento deja de encajar con un uso razonable del servicio.
Medir impacto, no solo llamadas
Una tendencia especialmente relevante es dejar de medir únicamente el número de peticiones y empezar a considerar el impacto real de cada una. No todas las consultas consumen los mismos recursos: algunas transfieren grandes volúmenes de datos o ejecutan operaciones más costosas.
Un ejemplo claro en datos abiertos sería una API de movilidad urbana. Consultar el estado de una parada o el tráfico en un punto concreto implica pocos datos y un impacto limitado. En cambio, descargar de una sola vez todo el histórico de posiciones de vehículos de una ciudad durante varios años supone una carga mucho mayor para el sistema, aunque se realice en una única llamada.
Por este motivo, muchas plataformas introducen cuotas basadas en volumen de datos transferidos, tipo de operación o peso de la consulta. Esto evita situaciones en las que un uso aparentemente moderado genera una carga desproporcionada sobre el sistema.
¿Cómo encaja todo esto con el open data?
Llegados a este punto, surge inevitablemente la pregunta: ¿siguen siendo abiertos los datos cuando existen todas estas capas de control?
La respuesta depende menos de la tecnología y más de las reglas del juego. Los datos abiertos no se definen por la ausencia total de control técnico, sino por principios como el acceso no discriminatorio, la ausencia de barreras económicas, la claridad en las licencias y la posibilidad real de reutilización.
Solicitar una API Key, limitar el caudal o aplicar controles contextuales no contradice estos principios si se hace de forma transparente y equitativa. De hecho, en muchos casos es la única manera de garantizar que el servicio siga existiendo y funcionando correctamente a medio y largo plazo.
La clave está en el equilibrio: reglas claras, acceso gratuito, límites razonables y mecanismos pensados para proteger el servicio, no para excluir. Cuando este equilibrio se consigue, el control deja de percibirse como una barrera y pasa a ser parte natural de un ecosistema de datos abiertos, útiles y sostenibles.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.