Evento
Marzo se acerca y con ello una nueva edición del Open Data Day. Se trata de una celebración anual a nivel mundial que se organiza desde hace 12 años, impulsada por la fundación Open Knowledge a través de la Open Knowledge Network. Su objetivo es promover el uso de los datos abiertos en todos los países y culturas.
El tema central de este año es “Datos abiertos para abordar la policrisis”. El término policrisis hace referencia a una situación en la que existen diferentes riesgos en el mismo periodo temporal. Con esta temática se quiere poner el foco en los datos abiertos como herramienta para abordar, a través de su reutilización, desafíos globales como la pobreza y las múltiples desigualdades, la violencia y los conflictos, y los riegos climáticos y las catástrofes naturales.
Si hace varios años las actividades se limitaban a un único día, desde 2023 tenemos una semana para poder disfrutar de diversas conferencias, seminarios, talleres, etc. centradas en esta temática. En concreto, en 2025, las actividades relacionadas con el Open Data Day tendrán lugar del 1 al 7 de marzo.
A través de su página web puedes ver las diversas actividades que se realizarán a lo largo de la semana en todo el planeta. En este artículo repasamos algunas de las que puedes seguir desde España, bien porque se realizan en el territorio nacional o porque se pueden seguir online.
Open Data Day 2025: mujeres liderando datos abiertos para la igualdad
Iniciativa Barcelona Open Data organiza una sesión la tarde del 6 de marzo centrada en cómo los datos abiertos pueden ayudar a abordar los retos relacionados con la igualdad. La cita reunirá a mujeres expertas en tecnologías de datos y open data, para compartir conocimiento, experiencias y buenas prácticas tanto en la publicación como en la reutilización de datos abiertos en este campo.
El evento comenzará a las 17:30 con la bienvenida e introducción. A continuación, tendrán lugar dos mesas redondas y una entrevista:
- Mesa redonda 1. Instituciones publicadoras. Estrategia de datos con perspectiva de género para abordar la agenda feminista.
- Diálogo. Data lab. Construyendo la práctica feminista Tech Data.
- Mesa redonda 2. Reutilizadores/as. Proyectos basados en el uso de datos abiertos para abordar la agenda feminista.
La jornada terminará a las 19:40 con un cóctel y la oportunidad para los asistentes de conversar sobre los temas tratados y ampliar la red de contactos a través del networking.
¿Cómo lo puedes seguir? Se trata de un evento presencial, que se celebrará en Ca l’Alier, en la calle de Pere IV, 362 (Barcelona).
Las publicaciones científico-académicas de acceso abierto como herramientas para enfrentar la policrisis del siglo XXI: el rol clave de los editores
Organizada por un particular, el profesor Damián Molgaray, esta conferencia analiza el rol clave de los/as editores/as en las publicaciones científico-académicas de acceso abierto. La idea es que los participantes reflexionen sobre cómo el conocimiento abierto se posiciona como una herramienta fundamental para enfrentar los desafíos de la policrisis del siglo XXI, con el foco puesto en América Latina.
La cita será el 4 de marzo a las 11:00 de Argentina (15:00 en España peninsular).
¿Cómo lo puedes seguir? Se trata de un evento online a través de Google Meet.
WhoFundsThem
La organización mySociety mostrará los resultados de su último proyecto. Durante los últimos meses, un equipo de voluntarios ha recopilado datos de los intereses financieros de los 650 diputados de la Cámara de los Comunes del Reino Unido, a través de fuentes como el Registro de Intereses oficial, el Registro Mercantil, las participaciones de los diputados a los debates, etc. Eso datos, comprobados y verificados con los propios diputados mediante un sistema de “derecho de réplica”, se han transformado a un formato de fácil acceso, para que cualquier persona pueda entenderlos fácilmente, y se publicarán en el sitio web de seguimiento parlamentario TheyWorkForYou.
En este evento se presentará el proyecto y se analizarán las conclusiones. Se celebra en martes 4 a las 14:00 hora de Londres (15:00 en España peninsular).
¿Cómo lo puedes seguir? La sesión se puede seguir online, pero es necesario registrarse. El evento será en inglés.
Science on the 7th: A conversation on Open Data & Air Quality
El viernes 7 a las 9:00 EST – (15:00 en España peninsular) se podrá seguir online una conferencia sobre datos abiertos y calidad del aire. La sesión reunirá a diversos expertos para debatir los temas de actualidad en materia de calidad del aire y salud mundial, y se examinará la contaminación atmosférica procedente de fuentes clave, como las partículas, el ozono y la contaminación relacionada con el tráfico.
Esta iniciativa está organizada por Health Effects Institute, una corporación sin ánimo de lucro que proporciona datos científicos sobre los efectos de la contaminación atmosférica en la salud.
¿Cómo lo puedes seguir? La conferencia, que será en inglés, se puede ver a través de YouTube. No es necesario inscribirse.
Abierto el plazo para recibir nuevas propuestas de eventos
Los eventos anteriores son solo algunos ejemplos de las actividades que forman parte de esta celebración mundial, pero, como se mencionó anteriormente, puedes ver todas las acciones en la página web de la iniciativa.
Además, todavía está abierto el plazo para inscribir nuevos eventos. Si tienes una propuesta, puedes registrarla a través de este enlace.
Desde datos.gob.es te invitamos a unirte a esta semana de celebración, que sirve para reivindicar el poder de los datos abiertos para generar cambios positivos en nuestra sociedad. ¡No te lo pierdas!
Documentación
Los portales de datos abiertos son una fuente invaluable de información pública. Sin embargo, extraer insights significativos de estos datos puede resultar desafiante para usuarios sin conocimientos técnicos avanzados.
En este ejercicio práctico, exploraremos el desarrollo de una aplicación web que democratiza el acceso a estos datos mediante el uso de inteligencia artificial, permitiendo realizar consultas en lenguaje natural.
La aplicación, desarrollada utilizando el portal datos.gob.es como fuente de datos, integra tecnologías modernas como Streamlit para la interfaz de usuario y el modelo de lenguaje Gemini de Google para el procesamiento de lenguaje natural. La naturaleza modular permite que se pueda utilizar cualquier modelo de Inteligencia Artificial con mínimos cambios. El proyecto completo está disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en cuatro apartados principales e interconectados que trabajan para procesar las consultas de la persona usuaria:
- Generación del Contexto
- Analiza las características del dataset elegido.
- Genera una descripción detallada incluyendo dimensiones, tipos de datos y estadísticas.
- Crea una plantilla estructurada con guías específicas para la generación de código.
- Combinación de Contexto y Consulta
- Une el contexto generado con la pregunta de la persona usuaria creando el prompt que recibirá el modelo de inteligencia artificial.
- Generación de Respuesta
- Envía el prompt al modelo y obtiene el código Python que permite resolver la cuestión generada.
- Ejecución del Código
- Ejecuta de manera segura el código generado con un sistema de reintentos y correcciones automáticas.
- Captura y expone los resultados en el frontal de la aplicación.

Figura 1. Flujo de procesamiento de solicitudes
Proceso de desarrollo
El primer paso es establecer una forma de acceder a los datos públicos. El portal datos.gob.es ofrece vía API los datasets. Se han desarrollado funciones para navegar por el catálogo y descargar estos archivos de forma eficiente.
Figura 2. API de datos.gob
El segundo paso aborda la cuestión: ¿cómo convertir preguntas en lenguaje natural en análisis de datos útiles? Aquí es donde entra Gemini, el modelo de lenguaje de Google. Sin embargo, no basta con simplemente conectar el modelo; es necesario enseñarle a entender el contexto específico de cada dataset.
Se ha desarrollado un sistema en tres capas:
- Una función que analiza el dataset y genera una "ficha técnica" detallada.
- Otra que combina esta ficha con la pregunta del usuario.
- Y una tercera que traduce todo esto en código Python ejecutable.
Se puede ver en la imagen inferior como se desarrolla este proceso y, posteriormente, se muestran los resultados del código generado ya ejecutado.

Figura 3. Visualización del procesamiento de respuesta de la aplicación
Por último, con Streamlit, se ha construido una interfaz web que muestra el proceso y sus resultados al usuario. La interfaz es tan simple como elegir un dataset y hacer una pregunta, pero también lo suficientemente potente como para mostrar visualizaciones complejas y permitir la exploración de datos.
El resultado final es una aplicación que permite a cualquier persona, independientemente de sus conocimientos técnicos, realizar análisis de datos y aprender sobre el código ejecutado por el modelo. Por ejemplo, un funcionario municipal puede preguntar "¿Cuál es la edad media de la flota de vehículos?" y obtener una visualización clara de la distribución de edades.

Figura 4. Caso de uso completo. Visualizar la distribución de los años de matriculación de la flota automovilística del ayuntamiento de Almendralejo en 2018
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Integración de IA en Aplicaciones Web:
- Cómo comunicarse efectivamente con modelos de lenguaje como Gemini.
- Técnicas para estructurar prompts que generen código preciso.
- Estrategias para manejar y ejecutar código generado por IA de forma segura.
- Desarrollo Web con Streamlit:
- Creación de interfaces interactivas en Python.
- Manejo de estado y sesiones en aplicaciones web.
- Implementación de componentes visuales para datos.
- Trabajo con Datos Abiertos:
- Conexión y consumo de APIs de datos públicos.
- Procesamiento de archivos Excel y DataFrames.
- Técnicas de visualización de datos.
- Buenas Prácticas de Desarrollo:
- Estructuración modular de código Python.
- Manejo de errores y reintentos.
- Implementación de sistemas de feedback visual.
- Despliegue de aplicaciones web usando ngrok.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos públicos y los usuarios finales. A través del caso práctico desarrollado, hemos podido observar cómo la combinación de modelos de lenguaje avanzados con interfaces intuitivas permite democratizar el acceso al análisis de datos, transformando consultas en lenguaje natural en análisis significativos y visualizaciones informativas.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de modelos de lenguaje más avanzados que permitan análisis más sofisticados.
- Implementación de sistemas de aprendizaje que mejoren las respuestas basándose en el feedback del usuario.
- Integración con más fuentes de datos abiertos y formatos diversos.
- Desarrollo de capacidades de análisis predictivo y prescriptivo.
En resumen, este ejercicio no solo demuestra la viabilidad de democratizar el análisis de datos mediante la inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el acceso y análisis de datos públicos sea verdaderamente universal. La combinación de tecnologías modernas como Streamlit, modelos de lenguaje y técnicas de visualización abre un abanico de posibilidades para que organizaciones y ciudadanos aprovechen al máximo el valor de los datos abiertos.
Noticia
Impulsar la cultura del dato es un objetivo clave a nivel nacional que también comparten las administraciones autonómicas. Uno de los caminos para llevar a cabo este propósito es premiar aquellas soluciones que han sido desarrolladas con conjuntos de datos abiertos, una iniciativa que potencia su reutilización e impacto en la sociedad.
En esta misión, la Junta de Castilla y León y el Gobierno Vasco llevan años organizando concursos de datos abiertos, temática de la que hablamos en nuestro primer episodio del pódcast de datos.gob.es que puedes escuchar aquí.
En este post, repasamos cuáles han sido los proyectos premiados en las últimas ediciones de los concursos de datos abiertos de Euskadi y Castilla y León.
Premiados en el VIII Concurso de Datos Abiertos de Castilla y León
En la octava edición de esta competición anual, que suele abrir su plazo a finales de verano, se presentaron 35 candidaturas, de las cuales se han escogido 8 ganadores divididos en diferentes categorías.
Categoría Ideas: los participantes tenían que describir una idea para crear estudios, servicios, sitios web o aplicaciones para dispositivos móviles. Se repartían un primer premio de 1.500€ y un segundo premio de 500€.
- Primer premio: Guardianes Verdes de Castilla y León presentado por Sergio José Ruiz Sainz. Se trata de una propuesta para desarrollar una aplicación móvil que oriente a los visitantes de los parques naturales de Castilla y León. Los usuarios pueden acceder a información (como mapas interactivos con puntos de interés) a la vez que pueden contribuir con datos útiles de su visita, que enriquecen la aplicación.
- Segundo premio: ParkNature: sistema inteligente de gestión de aparcamientos en espacios naturales presentado por Víctor Manuel Gutiérrez Martín. Consiste en una idea para la crear una aplicación que optimice la experiencia de los visitantes de los espacios naturales de Castilla y León, mediante la integración en tiempo real de datos sobre aparcamientos y la conexión con eventos culturales y turísticos cercanos.
Categoría Productos y Servicios: premiaba estudios, servicios, sitios web o aplicaciones para dispositivos móviles, los cuales deben estar accesibles para toda la ciudadanía vía web mediante una URL. En esta categoría se repartieron un primer, segundo y tercer premio de 2.500€, 1.500€ y 500€, respectivamente, además de un premio específico de 1.500€ para estudiantes.
- Primer premio: AquaCyL de Pablo Varela Vázquez. Es una aplicación que ofrece información sobre las zonas de baño en la comunidad autónoma.
- Segundo premio: ConquistaCyL presentado por Markel Juaristi Mendarozketa y Maite del Corte Sanz. Es un juego interactivo pensado para hacer turismo en Castilla y León y aprender a través de un proceso gamificado.
- Tercer premio: Todo el deporte de Castilla y León presentado por Laura Folgado Galache. Es una app que presenta toda la información de interés asociada a un deporte según la provincia.
- Premio estudiantes: Otto Wunderlich en Segovia por Jorge Martín Arévalo. Es un repositorio fotográfico ordenado según tipo de monumentos y localización de las fotografías de Otto Wunderlich.
Categoría Recurso Didáctico: consistía en la creación de recursos didácticos abiertos nuevos e innovadores, que sirvieran de apoyo a la enseñanza en el aula. Estos recursos debían ser publicados con licencias Creative Commons. En esta categoría se otorgaba un único primer premio de 1.500€.
- Primer premio: StartUp CyL: Creación de empresas a través de la Inteligencia Artificial y Datos Abiertos presentado por José María Pérez Ramos. Es un chatbot que utiliza la API de ChatGPT para asistir en la creación de una empresa utilizando datos abiertos.
Categoría Periodismo de Datos: premiaba piezas periodísticas publicadas o actualizadas (de forma relevante), tanto en soporte escrito como audiovisual, y ofrecía un premio de 1.500€.
- Primer premio: Codorniz, perdiz y paloma torcaz son las especies más cazadas en Burgos, presentado por Sara Sendino Cantera, que analiza datos sobre la caza en Burgos.
Premiados de la 5ª edición del Concurso de Datos Abiertos de Open Data Euskadi
Como ya venía sucediendo en ediciones anteriores, el portal de datos abiertos de Euskadi abrió dos modalidades de premios: un concurso de ideas y otro de aplicaciones, cada uno de los cuales estaba dividido en varias categorías. En esta ocasión, se presentaron 41 candidaturas en el concurso de ideas y 30 para el de aplicaciones
Concurso de ideas: en esta modalidad se han repartido dos premios por categoría, el primero de 3.000€ y el segundo de 1.500€.
Categoría Sanitaria y Social
- Primer premio: Desarrollo de un Modelo de Predicción de Volumen de Pacientes que acudirán al Servicio de urgencias de Osakidetza de Miren Bacete Martínez. Propone el desarrollo de un modelo predictivo usando series temporales capaz de anticipar tanto el volumen de personas que acudirán a urgencias, como el nivel de gravedad de los casos.
- Segundo premio: Euskoeduca de Sandra García Arias. Es una propuesta de solución digital diseñada para brindar orientación académica y profesional personalizada a estudiantes, padres y tutores.
Categoría Medio ambiente y Sostenibilidad
- Primer premio: Baratzapp de Leire Zubizarreta Barrenetxea. La idea consiste en el desarrollo de un software que facilita y asiste en la planificación de un huerto mediante algoritmos que buscan potenciar el conocimiento relacionado con la huerta de autoconsumo, a la vez que integra, entre otras, la información climatológica, medioambiental y parcelaria de una manera personalizada para el usuario.
- Segundo premio: Euskal Advice de Javier Carpintero Ordoñez. El objetivo de esta propuesta es definir un recomendador turístico basado en inteligencia artificial.
Categoría General
- Primer premio: Lanbila de Hodei Gonçalves Barkaiztegi. Es una propuesta de app que utiliza IA generativa y datos abiertos para emparejar curriculum vitae con ofertas de empleo de forma semántica. Proporciona recomendaciones personalizadas, alertas proactivas de empleo y formación, y permite decisiones informadas a través de indicadores laborales y territoriales.
- Segundo premio: Desarrollo de un LLM para la consulta interactiva de Datos Abiertos del Gobierno Vasco de Ibai Alberdi Martín. La propuesta consiste en el desarrollo de un Modelo de Lenguaje a Gran Escala (LLM) similar a ChatGPT, entrenado específicamente con datos abiertos, enfocado en proporcionar una interfaz conversacional y gráfica que permita a los usuarios obtener respuestas precisas y visualizaciones dinámicas.
Concurso de aplicaciones: esta modalidad ha seleccionado un proyecto en la categoría de servicios web, premiado con 8.000€, y dos más en la Categoría General que han recibido un primer premio de 8.000€ y 5.000€ como segundo premio.
Categoría Servicios web
- Primer premio: Bizidata: Plataforma de visualización del uso de bicicletas en Vitoria-Gasteiz de Igor Díaz de Guereñu de los Ríos. Es una plataforma que visualiza, analiza y permite descargar datos del uso de bicicletas en Vitoria-Gasteiz, y explorar cómo factores externos, como la climatología y el tráfico, influyen en el uso de la bicicleta.
Categoría General
- Primer premio: Garbiñe AI de Beatriz Arenal Redondo. Es un asistente inteligente que combina la inteligencia artificial (IA) con datos abiertos de Open Data Euskadi para promover la economía circular y mejorar los ratios de reciclaje en Euskadi.
- Segundo premio: Vitoria-Gasteiz Businessmap de Zaira Gil Ozaeta. Es una herramienta de visualización interactiva basada en datos abiertos, diseñada para mejorar las decisiones estratégicas en el ámbito del emprendimiento y la actividad económica en Vitoria-Gasteiz.
Todas estas soluciones premiadas reutilizan conjuntos de datos abiertos del portal autonómico de Castilla y León o Euskadi, según el caso. Te animamos a que eches un vistazo a las propuestas que pueden inspirarte de cara a participar en la próxima edición de estos concursos. ¡Síguenos en redes sociales para no perderte las convocatorias de este año!
Evento
ASEDIE, Asociación Multisectorial de la Información, celebrará el próximo 12 de diciembre su habitual Conferencia Internacional sobre Reutilización de la Información del Sector Público. Esta será su 16ª edición y el lema central es “ASEDIE, 25 años impulsando la economía del dato”. El objetivo del encuentro es abordar los avances realizados durante este tiempo, ofrecer una foto de la situación actual y debatir sobre barreras y posibles soluciones para la reutilización de información del sector público.

¿Cuándo y dónde se celebra?
El evento se celebrará en formato presencial el próximo 12 de diciembre de 2024 en el Instituto Nacional de Estadística (INE), ubicado en la Avenida de Manoteras 52, en Madrid. El aforo es limitado, la recepción de asistentes comenzará a las 9:00 y el acto finalizará a las 13:40. Para asistir al evento debes registrarte en este enlace.
¿Cuál es el programa?
El foco de esta edición estará puesto en la reutilización de la información del sector público y en conmemorar los 25 años que lleva la Asociación ASEDIE impulsando la economía del dato en España.
La sesión se abrirá a las 9:30 con la inauguración del evento a cargo del
Presidente de ASEDIE, Ignacio Jiménez y de la Presidenta del INE, Elena Manzanera, para dar la bienvenida a los asistentes.
El evento contará con tres mesas redondas:
- La primera mesa tendrá lugar de 9:45 a 10:30 y versará sobre ‘Inteligencia Artificial y protección de datos conviviendo con la reutilización’. Contará con la participación de Miguel Valle del Olmo, Consejero de Transformación Digital de la Representación Permanente de España en la Unión Europea y Leonardo Cervera Navas, Secretario General de European Data Protection Supervisor; y será moderada por Valentín Arce, Vicepresidente de ASEDIE.
Una vez finalizado este bloque temático, se hará entrega del Premio ASEDIE 2024 que tiene como finalidad reconocer a aquellas personas, empresas o instituciones que se distingan por el mejor trabajo o la mayor contribución a la innovación y desarrollo del sector Infomediario en el año en curso.
Después de una pausa de café, a partir de las 11:30, dará comienzo la segunda mesa redonda:
- Esta segunda mesa bajo el título “Liderando los datos abiertos” reunirá a figuras líderes del sector público para destacar su rol coordinador. En ella participarán Carmen Cabanilla, Directora General de Gobernanza Pública de la Secretaría de Estado de Función Pública; Ruth del Campo, Directora General del Dato y Francisco Javier García Vieira, Director de RedIRIS y Servicios Públicos Digitales de Red.es. Todo ello, moderado por Manuel Suarez, Vocal de la Junta Directiva de ASEDIE.
- A partir de las 12:30, dará comienzo la tercera mesa redonda sobre “La realidad de los datos abiertos: calidad, gobernanza y acceso” que será moderada por la Catedrática de la Universidad Rey Juan Carlos, Carmen de Pablo. En esta mesa participarán Fernando Serrano, Vocal Asesor de la Dirección General del Catastro; Joseba Asiain, Director General de Presidencia, Gobierno Abierto y Relaciones con el Parlamento del Gobierno de Navarra y Ángela Perez, Directora General de Transparencia y calidad del Ayuntamiento de Madrid.
Finalmente, el evento acabará con una breve intervención de clausura de Ignacio Jiménez, presidente de ASEDIE.
Puedes consultar el programa completo aquí.
¿Cómo puedo inscribirme?
La asistencia es presencial con aforo limitado y las inscripciones pueden realizarse en la web de ASEDIE.
Documentación
Los portales de datos abiertos juegan un papel fundamental en el acceso y reutilización de la información pública. Un aspecto clave en estos entornos es el etiquetado de los conjuntos de datos, que facilita su organización y recuperación.
Los word embeddings representan una tecnología transformadora en el campo del procesamiento del lenguaje natural, permitiendo representar palabras como vectores en un espacio multidimensional donde las relaciones semánticas se preservan matemáticamente. En este ejercicio se explora su aplicación práctica en un sistema de recomendación de etiquetas, utilizando como caso de estudio el portal de datos abiertos datos.gob.es.
El ejercicio se desarrolla en un notebook que integra la configuración del entorno, la adquisición de datos y el procesamiento del sistema de recomendación, todo ello implementado en Python. El proyecto completo se encuentra disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Entendiendo los word embeddings
Los word embeddings son representaciones numéricas de palabras que revolucionan el procesamiento del lenguaje natural al transformar el texto en un formato matemáticamente procesable. Esta técnica codifica cada palabra como un vector numérico en un espacio multidimensional, donde la posición relativa entre vectores refleja relaciones semánticas y sintácticas entre palabras. La verdadera potencia de los embeddings radica en tres aspectos fundamentales:
- Captura de contexto: a diferencia de técnicas tradicionales como one-hot encoding, los embeddings aprenden del contexto en el que aparecen las palabras, permitiendo capturar matices de significado.
- Algebra semántica: los vectores resultantes permiten operaciones matemáticas que preservan relaciones semánticas. Por ejemplo, vector('Madrid') - vector('España') + vector('Francia') ≈ vector('París'), demostrando la captura de relaciones capital-país.
- Similitud cuantificable: la similitud entre palabras se puede medir mediante métricas, permitiendo identificar no solo sinónimos exactos sino también términos relacionados en diferentes grados y generalizar estas relaciones a nuevas combinaciones de palabras.
En este ejercicio se han utilizado embeddings pre-entrenados GloVe (Global Vectors for Word Representation), un modelo desarrollado por Stanford que destaca por su capacidad de capturar relaciones semánticas globales en el texto. En nuestro caso, empleamos vectores de 50 dimensiones, un equilibrio entre complejidad computacional y riqueza semántica. Para evaluar exhaustivamente su capacidad de representar el lenguaje castellano, se han realizado múltiples pruebas:
- Se ha analizado la similitud entre palabras mediante la similitud coseno, una métrica que evalúa el ángulo entre los vectores de dos palabras. Esta medida resulta en valores entre -1 y 1, donde valores cercanos a 1 indican alta similitud semántica, mientras que valores cercanos a 0 indican poca o ninguna relación. Se evaluaron términos como "amor", "trabajo" y "familia" para verificar que el modelo identificara correctamente palabras semánticamente relacionadas.
- Se ha probado la capacidad del modelo para resolver analogías lingüísticas, por ejemplo, "hombre es a mujer lo que rey es a reina", confirmando su habilidad para capturar relaciones semánticas complejas.
- Se han realizado operaciones vectoriales (como "rey - hombre + mujer") para comprobar si los resultados mantenían coherencia semántica.
- Finalmente, se han aplicado técnicas de reducción de dimensionalidad sobre una muestra representativa de 40 palabras en español, permitiendo visualizar las relaciones semánticas en un espacio bidimensional. Los resultados revelaron patrones de agrupación natural entre términos semánticamente relacionados, como se observa en la figura:
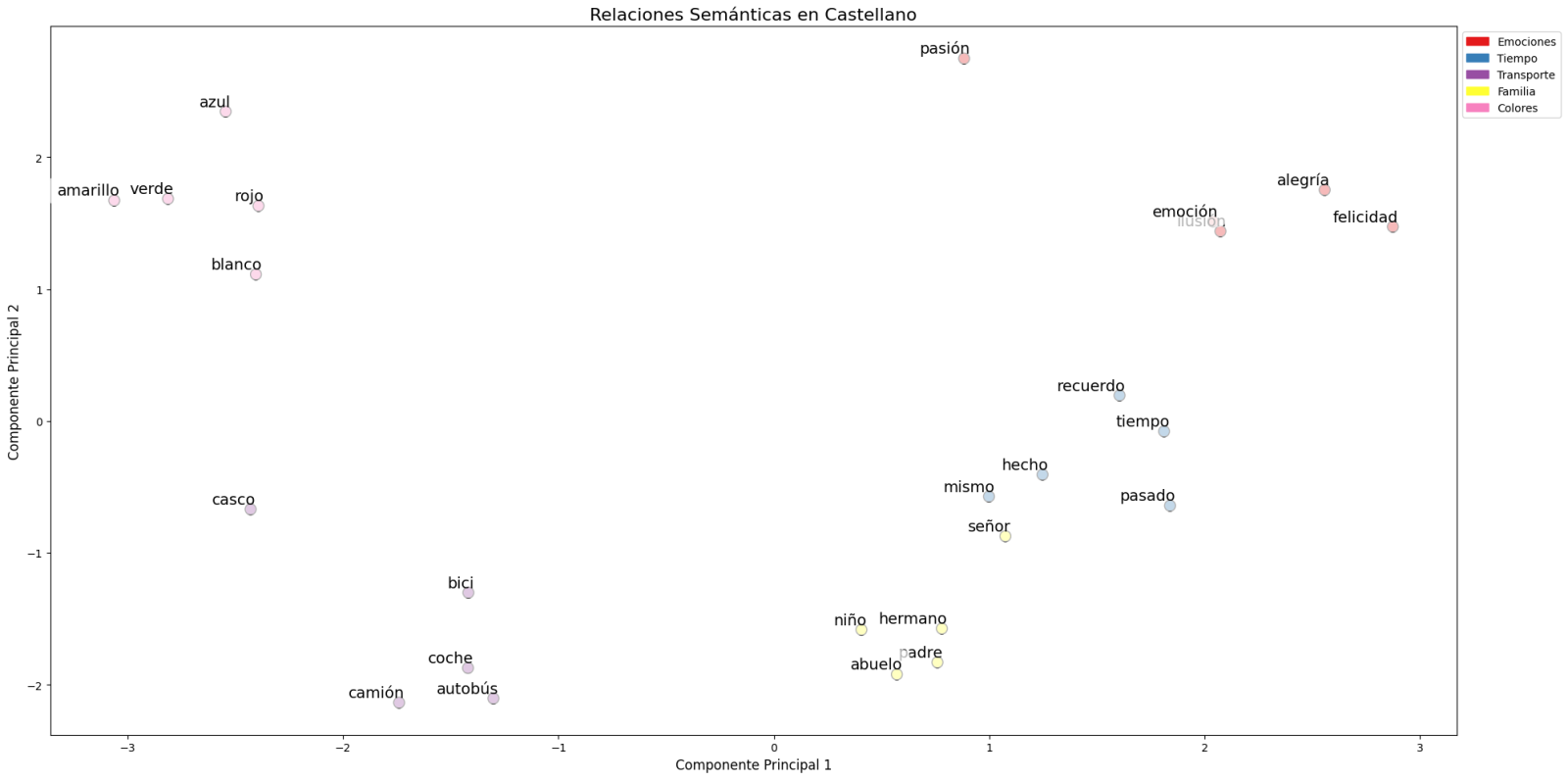
Figura 1. Análisis de Componentes principales sobre 50 dimensiones (embeddings) con un porcentaje de variabilidad explicada por los dos componentes de 0.46
- Los términos relacionados con familia (padre, hermano, abuelo) se concentran en la parte inferior.
- Los medios de transporte (coche, autobús, camión) forman un grupo distintivo.
- Los colores (azul, verde, rojo) aparecen próximos entre sí.
Para sistematizar este proceso de evaluación, se ha desarrollado una función unificada que encapsula todas las pruebas descritas anteriormente. Esta arquitectura modular permite evaluar de manera automática y reproducible diferentes modelos de embeddings pre-entrenados, facilitando así la comparación objetiva de su rendimiento en el procesamiento del lenguaje castellano. La estandarización de estas pruebas no solo optimiza el proceso de evaluación, sino que también establece un marco consistente para futuras comparaciones y validaciones de nuevos modelos por parte del público.
La buena capacidad para capturar relaciones semánticas en el lenguaje castellano es la que aprovechamos en nuestro sistema de recomendación de etiquetas.
Sistema de recomendación basado en embeddings
Aprovechando las propiedades de los embeddings, desarrollamos un sistema de recomendación de etiquetas que sigue un proceso de tres fases:
- Generación de embeddings: para cada conjunto de datos del portal, generamos una representación vectorial combinando el título y la descripción. Esto nos permite comparar datasets por su similitud semántica.
- Identificación de datasets similares: utilizando la similitud coseno entre los vectores, identificamos los conjuntos de datos más similares semánticamente.
- Extracción y estandarización de etiquetas: a partir de los conjuntos similares, extraemos sus etiquetas asociadas y las mapeamos con términos del tesauro Eurovoc. Este tesauro, desarrollado por la Unión Europea, es un vocabulario controlado multilingüe que proporciona una terminología estandarizada para la catalogación de documentos y datos en el ámbito de las políticas europeas. Aprovechando nuevamente la potencia de los embeddings, identificamos los términos de Eurovoc semánticamente más cercanos a nuestras etiquetas, garantizando así una estandarización coherente y una mejor interoperabilidad entre sistemas de información europeos.
Los resultados muestran que el sistema es capaz de generar recomendaciones de etiquetas coherentes y estandarizadas. Para ilustrar el funcionamiento del sistema, tomemos el caso del conjunto de datos “Agenda de Actividades Ciudad de Tarragona”:
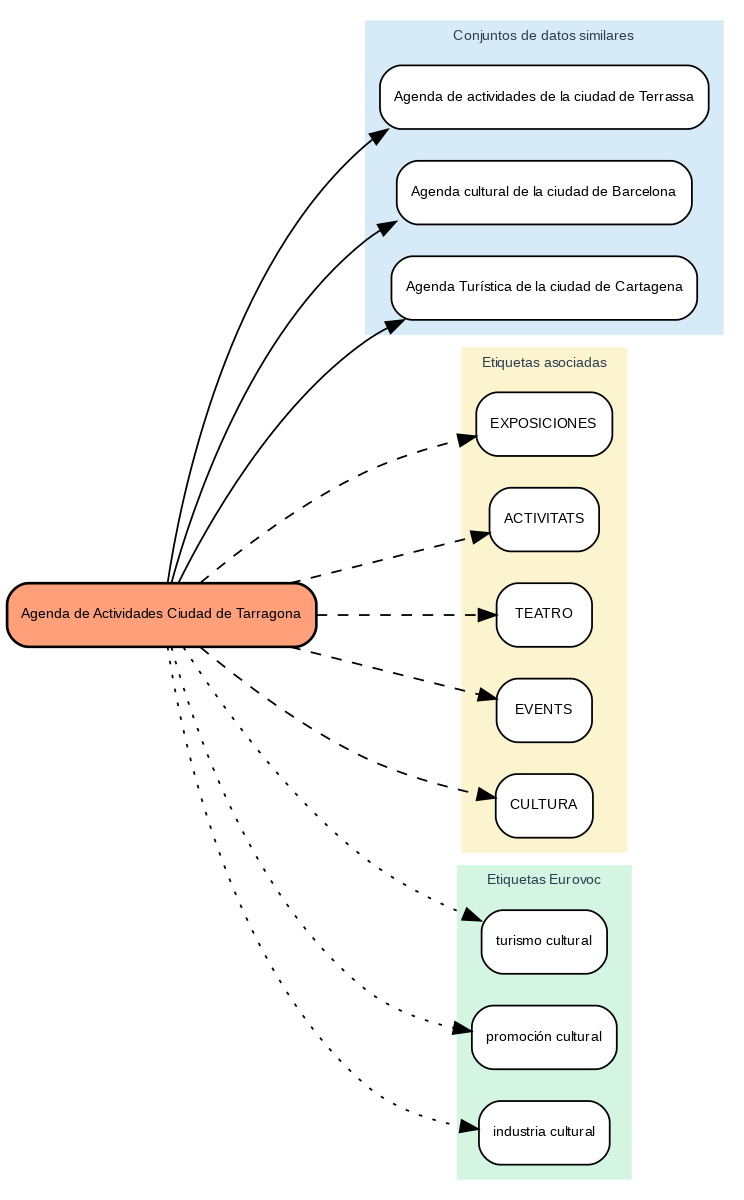
Figura 2. Agenda de Actividades Ciudad de Tarragona
El sistema:
- Encuentra conjuntos de datos similares como "Agenda de actividades de Terrassa" y "Agenda cultural de Barcelona".
- Identifica etiquetas comunes de estos conjuntos de datos, como "EXPOSICIONES", "TEATRO" y "CULTURA".
- Sugiere términos Eurovoc relacionados: "turismo cultural", "promoción cultural" e "industria cultural".
Ventajas del enfoque
Este enfoque ofrece ventajas significativas:
- Recomendaciones Contextuales: el sistema sugiere etiquetas basándose en el significado real del contenido, no solo en coincidencias textuales.
- Estandarización Automática: la integración con Eurovoc garantiza un vocabulario controlado y coherente.
- Mejora Continua: el sistema aprende y mejora sus recomendaciones a medida que se añaden nuevos datasets.
- Interoperabilidad: el uso de Eurovoc facilita la integración con otros sistemas europeos.
Conclusiones
Este ejercicio demuestra el gran potencial de los embeddings como herramienta para la asociación de textos en función de su naturaleza semántica. A través del caso práctico analizado, se ha podido observar cómo, mediante la identificación de títulos y descripciones similares entre datasets, es posible generar recomendaciones precisas de etiquetas o keywords. Estas etiquetas, a su vez, pueden vincularse con palabras clave de un tesauro estandarizado como Eurovoc, aplicando el mismo principio.
A pesar de los retos que pueden surgir, la implementación de este tipo de sistemas en entornos de producción presenta una valiosa oportunidad para mejorar la organización y recuperación de información. La precisión en la asignación de etiquetas puede verse influenciada por diversos factores interrelacionados del proceso:
- La especificidad de los títulos y descripciones de los datasets es fundamental, ya que de ella depende una correcta identificación de contenidos similares y, por tanto, una adecuada recomendación de etiquetas.
- La calidad y representatividad de las etiquetas existentes en los datasets similares determina directamente la relevancia de las recomendaciones generadas.
- La cobertura temática del tesauro Eurovoc, que, si bien es extensa, puede no abarcar términos específicos necesarios para describir ciertos datasets de manera precisa.
- La capacidad de los vectores para capturar fielmente las relaciones semánticas entre los contenidos, lo cual impacta directamente en la precisión de las etiquetas asignadas.
Para aquellos que deseen profundizar en el tema, existen otras aproximaciones interesantes al uso de embeddings que complementan lo visto en este ejercicio, tales como:
- Utilización de modelos de embeddings más complejos y computacionalmente costosos (como BERT, GPT, etc.).
- Entrenamiento de modelos en un corpus propio adaptado al dominio.
- Aplicación de técnicas más profundas de limpieza de datos.
En resumen, este ejercicio no solo demuestra la eficacia de los embeddings para la recomendación de etiquetas, sino que abre la puerta a que el lector explore todas las posibilidades que esta poderosa herramienta ofrece.
Evento
Los datos espaciales y geoespaciales son esenciales en la toma de decisiones, la planificación territorial y la gestión de recursos. La capacidad de visualizar y analizar datos en un contexto espacial ofrece herramientas valiosas para enfrentar desafíos complejos en diversas áreas, desde la defensa hasta la sostenibilidad. Participar en eventos que abordan estas temáticas no solo amplía nuestros conocimientos, sino que también fomenta la colaboración y la innovación en el sector.
En este post, presentamos dos eventos próximos que versan sobre datos geoespaciales y sus usos más innovadores. ¡No te los pierdas!
II Jornada de Inteligencia Geoespacial: Territorio y Defensa
El Instituto Geográfico de Aragón (IGEAR) en colaboración con la Academia General Militar, el Centro Universitario de la Defensa y Telespazio Ibérica, ha organizado la segunda edición de la Jornada de Inteligencia Geoespacial: Territorio y Defensa, un evento que reunirá a profesionales del sector para explorar cómo los datos geoespaciales pueden optimizar las estrategias en el ámbito de la seguridad y la gestión del territorio.
Durante el próximo 21 de noviembre, la sala de la corona del Edificio Pignatelli en Zaragoza reunirá ponentes y asistentes para debatir sobre el impacto de la inteligencia geoespacial en España. El evento acogerá a un máximo de 100 asistentes que podrán acudir por invitación.
La inteligencia geoespacial, o GEOINT por su abreviatura en inglés (Geospatial Intelligence), se enfoca en comprender las dinámicas que ocurren dentro de un determinado espacio geográfico. Para lograr esto, GEOINT se apoya en el análisis detallado de imágenes, bases de datos y otra información relevante, partiendo de la idea de que, aunque las circunstancias que rodean cada situación puedan variar, existe una característica común: toda acción tiene lugar en coordenadas geográficas específicas.
La GEOINT es un campo muy amplio que se puede aplicar tanto al ámbito militar, para ejecutar movimientos analizando el terreno, como en el científico, para estudiar entornos, o incluso en el ámbito empresarial, para ayudar a adaptar información censal, histórica, meteorológica, agrícola y geológica hacia usos comerciales.
En la II Jornada de Inteligencia Geoespacial se presentarán casos prácticos y avances tecnológicos y se promoverán debates sobre el futuro de la inteligencia geoespacial en contextos de defensa. Para más detalles, puedes visitar el sitio web del evento.
- ¿Cuándo? El próximo 21 de noviembre de 2024 a las 8:00h.
- ¿Dónde? Sala de la Corona del Edificio Pignatelli. Paseo María Agustín, 36. Zaragoza.
- ¿Cómo acceder? A través de este enlace
XV Edición de las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) y III geoEuskadi
Este año, el Consejo Directivo de la Infraestructura de Información Geográfica de España (CODIIGE) organiza de manera conjunta las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) y el III Congreso geoEuskadi Kongresua. Ambos eventos pretenden potenciar y promover las actividades vinculadas a la información geográfica en diversos sectores, abarcando tanto la publicación y accesibilidad normalizada de datos geográficos como su producción, procesamiento y explotación.
Por un lado, en las JIIDE colaboran la Direção-Geral do Território de Portugal, el Instituto Geográfico Nacional de España, a través del Centro Nacional de Información Geográfica, y el Govern d’Andorra.
Por su parte, el geoEuskadi Kongresua es organizado por la Dirección de Planificación Territorial y Agenda Urbana del Gobierno Vasco. Este año, todas estas entidades se unirán para llevar a cabo un único evento bajo el lema “El valor del dato geoespacial”.
Las jornadas se centrarán en las nuevas tendencias tecnológicas relacionadas con la accesibilidad y reutilización de datos, así como en las técnicas actuales de observación y representación de la Tierra.
Los datos geoespaciales digitales son un motor clave para el crecimiento económico, la competitividad, la innovación, la creación de empleo y el progreso social. Por ello, III geoEuskadi y la XV edición JIIDE 2024 enfatizarán la importancia de tecnologías, como el big data y la inteligencia artificial, para generar ideas que mejoren la toma de decisiones empresariales y la creación de sistemas que realicen tareas que tradicionalmente requieren intervención humana.
Además, se pondrá en valor la colaboración para la coproducción y armonización de datos entre diferentes administraciones y organizaciones, algo que sigue siendo esencial para generar datos geoespaciales de valor, que puedan convertirse en verdaderas referencias. Este es un momento de renovación, impulsado por la revisión de la Directiva INSPIRE, la actualización de las normativas sobre datos espaciales medioambientales y las nuevas regulaciones sobre datos abiertos y gobernanza de datos que propician una modernización en la publicación y reutilización de estos datos.
Durante el evento, también se presentarán ejemplos de reutilización de conjuntos de datos de alto valor, tanto a través de las OGC API como mediante servicios de descarga y formatos interoperables.
La combinación de estos eventos representará un espacio privilegiado para reflexionar sobre la información geográfica y será un escaparate de los proyectos más innovadores en la península ibérica. Además, se llevarán a cabo talleres técnicos para compartir conocimientos específicos y mesas redondas que promoverán el debate. Para conocer más sobre este evento, visita el portal de JIIDE.
- ¿Cuándo? Del 13 al 15 de noviembre.
- ¿Dónde? Palacio de Congresos Europa (Vitoria-Gasteiz).
- ¿Cómo me inscribo? A través de este enlace.
No pierdas la oportunidad de participar en estos eventos que promueven el avance en el uso de datos espaciales y geoespaciales. Te animamos a unirte a estas jornadas para aprender, colaborar y contribuir al desarrollo de este sector en constante evolución.
Blog
Muchas personas utilizan aplicaciones para desplazarse en su día a día. Apps como Google Maps, Moovit o CityMapper facilitan la ruta más rápida y eficaz para llegar a un destino. Sin embargo, lo que muchos usuarios desconocen es que tras estas plataformas se encuentra una valiosa fuente de información: los datos abiertos. Gracias a la reutilización de conjuntos de datos públicos, como los relacionados con la calidad del aire, el tráfico o el transporte público, estas aplicaciones pueden ofrecer un mejor servicio.
En este post, exploraremos cómo la reutilización de datos abiertos por parte de estas plataformas potencia un ecosistema urbano más inteligente y sostenible.
Google Maps: agrega información de calidad del aire y datos de transporte en GTFS.
Más de mil millones de personas utilizan Google Maps mensualmente alrededor del mundo. El gigante tecnológico ofrece un mapa mundial actualizado y gratuito que obtiene sus datos de diferentes fuentes, algunas de ellas, abiertas.
Una de las funciones que brinda la app es la información sobre la calidad del aire en la ubicación en la que se encuentra el usuario. El Índice de Calidad del Aire (ICA) es un parámetro que viene determinado por cada país o región. La referencia europea se puede consultar en este mapa que muestra calidad del aire por zonas geolocalizadas en tiempo real.
Para mostrar la calidad de aire de la ubicación del usuario, Google Maps aplica un modelo basado en un enfoque multicapa conocido como “enfoque de fusión”. Este método combina datos de varias fuentes de entrada y pondera las capas con un procedimiento sofisticado. Las capas de entrada son:
- Estaciones de monitorización de referencia de los gobiernos
- Redes de sensores comerciales
- Modelos de dispersión mundiales y regionales
- Modelos de polvo y humo de incendios
- Información obtenida por satélite
- Datos del tráfico
- Información auxiliar como la superficie
- Meteorología
En el caso de España, esta información se obtiene de fuentes de datos abiertos como el Ministerio de Transición Ecológica y Reto Demográfico, el Instituto Geográfico Nacional (que le permite obtener la cartografía con nombres oficiales de carreteras, poblaciones, etc.) la Conselleria de Medio Ambiente, Territorio y Vivienda de la Xunta de Galicia o la Comunidad de Madrid. Puedes consultar aquí las fuentes de datos abiertos que se utilizan en otros países del mundo.
Otra funcionalidad que ofrece Google Maps para planificar las mejores rutas para llegar a un destino es la información sobre el transporte público. Estos datos son proporcionados de manera voluntaria por las empresas públicas que ofrecen el servicio de transporte en cada ciudad. Para que estos datos abiertos estén a disposición del usuario, primero se vuelcan en Google Transit y deben cumplir el estándar abierto de transporte público GTFS (General Transit Feed Specification). Además, Google Maps también integra datos de transporte en GTFS del Punto de Acceso Nacional.
Moovit: reutiliza datos abiertos para ofrecer información en tiempo real
Moovit es otra de las aplicaciones de movilidad urbana, que utiliza datos abiertos y colaborativos para facilitar a los usuarios la planificación de sus desplazamientos en transporte público.
Desde su lanzamiento en 2012, la app de descarga gratuita ofrece información en tiempo real de las distintas opciones de transporte, sugiere las mejores rutas para llegar al destino indicado, guía al usuario durante su recorrido (cuánto tiene que esperar, cuántas paradas faltan, cuándo tiene que bajar, etc.) y realiza actualizaciones constantes ante cualquier alteración en el servicio.
Como otras apps de movilidad, también está disponible en modalidad offline y permite guardar las rutas y líneas frecuentes en “Favoritos”. Además, se trata de una solución inclusiva ya que integra VoiceOver (iOs) o TalkBack (Android) para personas invidentes.
La plataforma no solo aprovecha datos abiertos proporcionados por gobiernos y autoridades locales, sino que también recopila información de sus usuarios, lo que le permite ofrecer un servicio dinámico y constantemente actualizado.
CityMapper: nace como reutilizador de datos abiertos de movilidad
El equipo de desarrollo de CityMapper reconoce que la aplicación nació con un ADN abierto que todavía se mantiene. Reutilizan conjuntos de datos abiertos de, por ejemplo, OpenStreetMap a nivel global o RENFE y Cercanías Bilbao a nivel nacional. A medida que la aplicación está disponible en más ciudades, mayor es la lista de fuentes de referencia de datos abiertos de las que obtiene información.
La plataforma ofrece información en tiempo real sobre rutas de transporte público, incluyendo autobuses, trenes, metro o bicicletas compartidas. También añade opciones para desplazarse a pie, en bici o en sistemas de transporte compartido. Está diseñada para proporcionar la ruta más eficiente y rápida para llegar a un destino, integrando datos de diferentes medios de transporte en una sola interfaz.
Tal y como publicamos en el informe monográfico “Innovación municipal a través de datos abiertos” CityMapper utiliza principalmente open data de las autoridades de transporte locales normalmente utilizando el estándar GTFS (General Transit Feed Specification). No obstante, cuando estos datos no son suficientes o no son suficientemente precisos, CityMapper los combina con conjuntos de datos generados por los propios usuarios de la aplicación que colaboran voluntariamente. También utiliza datos mejorados y gestionados por el trabajo de los propios empleados locales de la empresa. Todos estos datos se combinan con algoritmos de inteligencia artificial desarrollados para optimizar las rutas y ofrecer recomendaciones ajustadas a las necesidades de los usuarios.
En conclusión, el uso de datos abiertos en el transporte impulsa una transformación significativa en el sector de la movilidad en ciudades. Gracias al aporte que ofrecen a las aplicaciones, los usuarios pueden acceder a datos actualizados y precisos, planificar sus viajes de manera eficiente y tomar decisiones informadas. Los gobiernos, por su parte, han asumido el rol de facilitadores al hacer posible la difusión de datos mediante plataformas abiertas, optimizando recursos y fomentando la colaboración entre distintos sectores. Además, los datos abiertos han creado nuevas oportunidades para los desarrolladores y el sector privado, quienes han contribuido con soluciones tecnológicas, como pueden ser Google Maps, Moovit o CityMapper. En definitiva, el potencial de los datos abiertos para transformar el futuro de la movilidad urbana es algo innegable.
Aplicación
Es una web que recopila información pública sobre el estado de los diferentes embalses que hay en España. El usuario puede filtrar la información por cuencas hidrográficas y unidades administrativas como provincias o comunidades autónomas.
Los datos se actualizan diariamente y se muestran con porcentajes y gráficas. Además, también ofrece información sobre pluviómetros y la comparación entre el porcentaje de agua embasada actual y la que había hace un año y hace 10 años.
Embales.net comparte de manera clara y entendible datos abiertos que obtiene de AEMET y el Ministerio de Transición Ecológica y Reto Demográfico.
Blog
En la era digital actual, la compartición de datos y los datos abiertos (open data) han emergido como pilares fundamentales para la innovación, la transparencia y el desarrollo económico. Diversas compañías y organizaciones alrededor del mundo están adoptando estos enfoques para fomentar el acceso abierto a la información y potenciar la toma de decisiones basada en datos. A continuación, exploramos algunos ejemplos internacionales y nacionales de cómo estas prácticas están siendo implementadas.
Casos de éxito globales
Uno de los referentes globales en la compartición de datos es LinkedIn con su programa Data for Impact. Este programa facilita a gobiernos y organizaciones el acceso a datos económicos agregados y anonimizados, basados en el Economic Graph de LinkedIn, el cual representa la actividad profesional global. Es importante aclarar que los datos solo pueden utilizarse con fines de investigación y desarrollo. El acceso debe solicitarse vía email, adjuntando una propuesta para su evaluación, y se priorizan propuestas de gobiernos y organizaciones multilaterales. Estos datos han sido utilizados por entidades como el Banco Mundial y el Banco Central Europeo para informar de políticas y decisiones económicas clave. El enfoque de LinkedIn en la privacidad y la calidad de los datos asegura que estas colaboraciones beneficien tanto a las organizaciones como a los ciudadanos, promoviendo un crecimiento económico inclusivo, verde y alineado con las tecnologías digitales.
Por otro lado, el Registry of Open Data on AWS (RODA) es un repositorio gestionado Amazon Web Services (AWS) que alberga conjuntos de datos públicos. Los datasets no son proporcionados directamente por AWS, sino que son mantenidos por organizaciones gubernamentales, investigadores, empresas y particulares. Podemos encontrar, en el momento de escribir este post, más de 550 conjuntos de datos publicados por diferentes organizaciones, incluyendo algunas como el Allen Institute for Artificial Intelligence (AI2) o la propia NASA. Esta plataforma facilita que los usuarios aprovechen los servicios de computación en la nube de AWS para su análisis.
En el ámbito del periodismo de datos, FiveThirtyEight, propiedad de ABC News, ha adoptado un enfoque de transparencia radical al compartir públicamente los datos y códigos detrás de sus artículos y visualizaciones. Estos se encuentran accesibles a través de GitHub en formatos fácilmente reutilizables como CSV. Esta práctica no solo permite la verificación independiente de su trabajo, sino que también impulsa la creación de nuevas historias y análisis por parte de otros investigadores y periodistas. FiveThirtyEight se ha convertido en un modelo a seguir en lo relativo a cómo los datos abiertos pueden mejorar la calidad y la credibilidad del periodismo.
Casos de éxito en España
España no se queda atrás en cuanto a iniciativas de compartición de datos y open data por parte de compañías privadas. Varias empresas españolas están liderando iniciativas que promueven la accesibilidad y transparencia de los datos en diferentes sectores. Veamos algunos ejemplos.
Idealista, uno de los portales inmobiliarios más importantes del país, ha publicado un conjunto de datos abiertos que incluye información detallada sobre más de 180,000 viviendas en Madrid, Barcelona y Valencia. Este conjunto de datos proporciona las coordenadas geográficas y los precios de venta de cada propiedad, junto con sus características internas y la información oficial del catastro español. Este conjunto de datos está disponible para su acceso a través de GitHub como un paquete en R y se ha convertido en una gran herramienta para el análisis del mercado inmobiliario, permitiendo a investigadores y profesionales del sector desarrollar modelos de valoración automática y realizar estudios detallados sobre la segmentación del mercado. Cabe destacar que Idealista también reutiliza datos públicos de organismos como el catastro o el INE para ofrecer servicios de datos que dan soporte a las decisiones en el mercado inmobiliario, como contratación de hipotecas, estudios de mercado, valoración de carteras, etc.Por su parte BBVA, a través de su Fundación, ofrece acceso a un extenso fondo estadístico con bases de datos que incluyen cuadros, tablas y gráficos dinámicos. Estas bases de datos, de descarga libre, cubren temas como la productividad, la competitividad, el capital humano o la desigualdad en España, entre otros. Además, proporcionan series históricas sobre la economía española, inversiones, actividades culturales y gasto público. Estas herramientas están diseñadas para complementar publicaciones impresas y ofrecer una visión profunda sobre la evolución económica y social del país.
Además, Esri España habilita su Portal de Datos Abiertos, que pone a disposición de los usuarios una amplia variedad de contenidos que pueden ser consultados, analizados y descargados. Este portal incluye datos gestionados por Esri España, junto con una recopilación de otros portales de datos abiertos desarrollados con tecnología Esri. Esto amplía significativamente las posibilidades para investigadores, desarrolladores y profesionales que buscan aprovechar los datos geoespaciales en sus proyectos. Podemos encontrar conjuntos de datos en las categorías de salud, ciencia y tecnología o economía, entre otros.
En el ámbito de las empresas públicas, España también cuenta con ejemplos destacados de compromiso con los datos abiertos. Renfe, la principal operadora ferroviaria, y Red Eléctrica Española (REE), la entidad responsable de la operación del sistema eléctrico, han desarrollado programas de open data que facilitan el acceso a información relevante para la ciudadanía y para el desarrollo de aplicaciones y servicios que mejoren la eficiencia y la sostenibilidad. Destaca, en el caso de REE, la posibilidad de consumo de los datos disponibles a través de APIs REST, que facilitan la integración de aplicaciones sobre conjuntos de datos que reciben continuas actualizaciones sobre el estado de los mercados eléctricos.
Conclusión
La compartición de datos y el open data representan una evolución crucial en la forma en que las organizaciones gestionan y aprovechan la información. Desde gigantes tecnológicos internacionales como LinkedIn y AWS hasta innovadores nacionales como Idealista y BBVA, están proporcionando acceso abierto a los datos con el fin de impulsar un cambio significativo en cómo se toman decisiones, el desarrollo de políticas y la creación de nuevas oportunidades económicas. En España, tanto las empresas privadas como las públicas están mostrando un fuerte compromiso con estas prácticas, posicionando al país como un líder en la adopción de modelos de datos abiertos y de compartición de datos que beneficien a toda la sociedad.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Empresa reutilizadora
Coopdevs es una cooperativa abierta que tiene como objetivo mejorar la sociedad a través de la tecnología, sus valores se enmarcan dentro del cooperativismo abierto, es decir, se centran en aportar valor tanto a clientes o proyectos en los que participan como a un ecosistema de procomunes digitales mucho más amplio.