Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas, de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es mostrar cómo generar un mapa personalizado de Google Maps mediante la herramienta "My Maps" partiendo de datos abiertos. Este tipo de mapas son altamente populares en páginas, blogs y aplicaciones del sector turístico, no obstante, la información útil proporcionada al usuario suele ser escasa.
En este ejercicio, utilizaremos el potencial de los datos abiertos para ampliar la información a mostrar en nuestro mapa y hacerlo de una forma automática. También mostraremos como realizar un enriquecimiento de los datos abiertos para añadir información de contexto que mejore significativamente la experiencia de usuario.
Desde un punto de vista funcional, el objetivo del ejercicio es la creación de un mapa personalizado para planificar rutas turísticas por los espacios naturales de la Comunidad Autónoma de Castilla y León. Para ello se han utilizado conjuntos de datos abiertos publicados por la Junta de Castilla y León, que hemos preprocesado y adaptado a nuestras necesidades de cara a generar el mapa personalizado.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos contienen distinta información turística de interés geolocalizada. Dentro del catálogo de datos abiertos de la Junta de Castilla y León, encontramos el “diccionario de entidades” (sección información adicional), documento de vital importancia, ya que nos define la terminología utilizada en los distintos conjuntos de datos.
Estos conjuntos de datos también se encuentran disponibles en el repositorio de Github
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o también llamado "Google Colaboratory", es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google My Maps.
"Google My Maps" es una herramienta online que permite crear mapas interactivos que pueden ser incrustados en sitios web o exportarse como archivos. Esta herramienta es gratuita, sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de los datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que podrás ejecutar desde Google Colab.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso a dar es generar las tablas de datos preprocesados que usaremos para alimentar el mapa. Para ello, transformaremos los sistemas de coordenadas, modificaremos y filtraremos la información según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en el Notebook, son los siguientes:
- Instalación y carga de librerías
- Carga de los conjuntos de datos
- Análisis exploratorio de datos (EDA)
- Preprocesamiento de los conjuntos de datos
- Transformación de coordenadas
- Filtrado de la información
- Representación gráfica de los conjuntos de datos
- Almacenamiento de las nuevas tablas de datos transformadas
Durante el preprocesado de las tablas de datos, hay que hacer un cambio de sistema de coordenadas ya que en los conjuntos de datos de origen el sistema en el que se encuentran es ESTR89 (sistema estándar que se usa en la Unión Europea), mientras que las necesitaremos en el sistema WGS84 (sistema usado por Google My Maps entre otras aplicaciones geográficas). La forma de realizar este cambio de coordenadas se encuentra explicado en el Notebook. Si quieres saber más sobre tipos y sistemas de coordenadas, puedes recurrir a la “Guía de datos espaciales”
Una vez terminado el preprocesamiento, obtendremos las tablas de datos "recreativas_parques_naturales.csv", "alojamientos_rurales_2estrellas.csv", "refugios_parques_naturales.csv", "observatorios_parques_naturales.csv", "miradores_parques_naturales.csv", "casas_del_parque.csv", "arboles_parques_naturales.csv" las cuales incluyen campos de información genéricos y comunes como: nombre, observaciones, geoposición, … junto a campos de información específicos, los cuales se definen en detalle en el apartado 6.2 Personalización de la información a mostrar en el mapa.
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Enriquecimiento de los datos
Con la finalidad de aportar mayor información relacionada, se realiza un proceso de enriquecimiento de datos sobre el conjunto de datos “registro de alojamientos hoteleros” explicado a continuación. Con este paso vamos a lograr añadir de forma automática información complementaria que no está inicialmente incluida. Con ello, conseguiremos mejorar la experiencia del usuario durante su uso del mapa al proporcionar información de contexto relacionada con cada punto de interés.
Para ello vamos a utilizar una herramienta útil para este tipo de tarea, OpenRefine. Esta herramienta de código abierto permite realizar múltiples acciones de preprocesamiento de datos, aunque en esta ocasión la usaremos para llevar a cabo un enriquecimiento de nuestros datos mediante la incorporación de contexto enlazando automáticamente información que reside en el popular repositorio de conocimiento Wikidata.
Una vez instalada la herramienta en nuestro ordenador, al ejecutarse se abrirá una aplicación web en el navegador.
A continuación, se detallan los pasos a seguir.
Paso 1
Carga del CSV en el sistema (Figura 1). En esta caso, el conjunto de datos “Registro de alojamientos hoteleros”.
Figura 1. Carga de archivo CSV en OpenRefine
Paso 2
Creación del proyecto a partir del CSV cargado (Figura 2). OpenRefine se gestiona mediante proyectos (cada CSV subido será un proyecto), que se guardan en el ordenador dónde se esté ejecutando OpenRefine para un posible uso posterior. En este paso debemos dar un nombre al proyecto y algunos otros datos, como el separador de columnas, aunque lo más habitual es que estos últimos ajustes se rellenen automáticamente.
Figura 2. Creación de un proyecto en OpenRefine
Paso 3
Enlazado (o reconciliación, usando la nomenclatura de OpenRefine) con fuentes externas. OpenRefine nos permite enlazar recursos que tengamos en nuestro CSV con fuentes externas como Wikidata. Para ello se deben realizar las siguientes acciones:
- Identificación de las columnas a enlazar. Habitualmente este paso suele estar basado en la experiencia del analista y su conocimiento de los datos que se representan en Wikidata. Como consejo, de forma genérica se podrán reconciliar o enlazar aquellas columnas que contengan información de carácter más global o general como nombres de países, calles, distritos, etc., y no se podrán enlazar aquellas columnas como coordenadas geográficas, valores numéricos o taxonomías cerradas (tipos de calles, por ejemplo). En este ejemplo, disponemos de la columna “municipios” que contiene el nombre de los municipios españoles.
- Comienzo de la reconciliación. (Figura 3) Comenzamos la reconciliación y seleccionamos la fuente por defecto que estará disponible: Wikidata(en). Después de hacer clic en Start Reconciling, automáticamente comenzará a buscar la clase del vocabulario de Wikidata que más se adecue basado en los valores de nuestra columna.
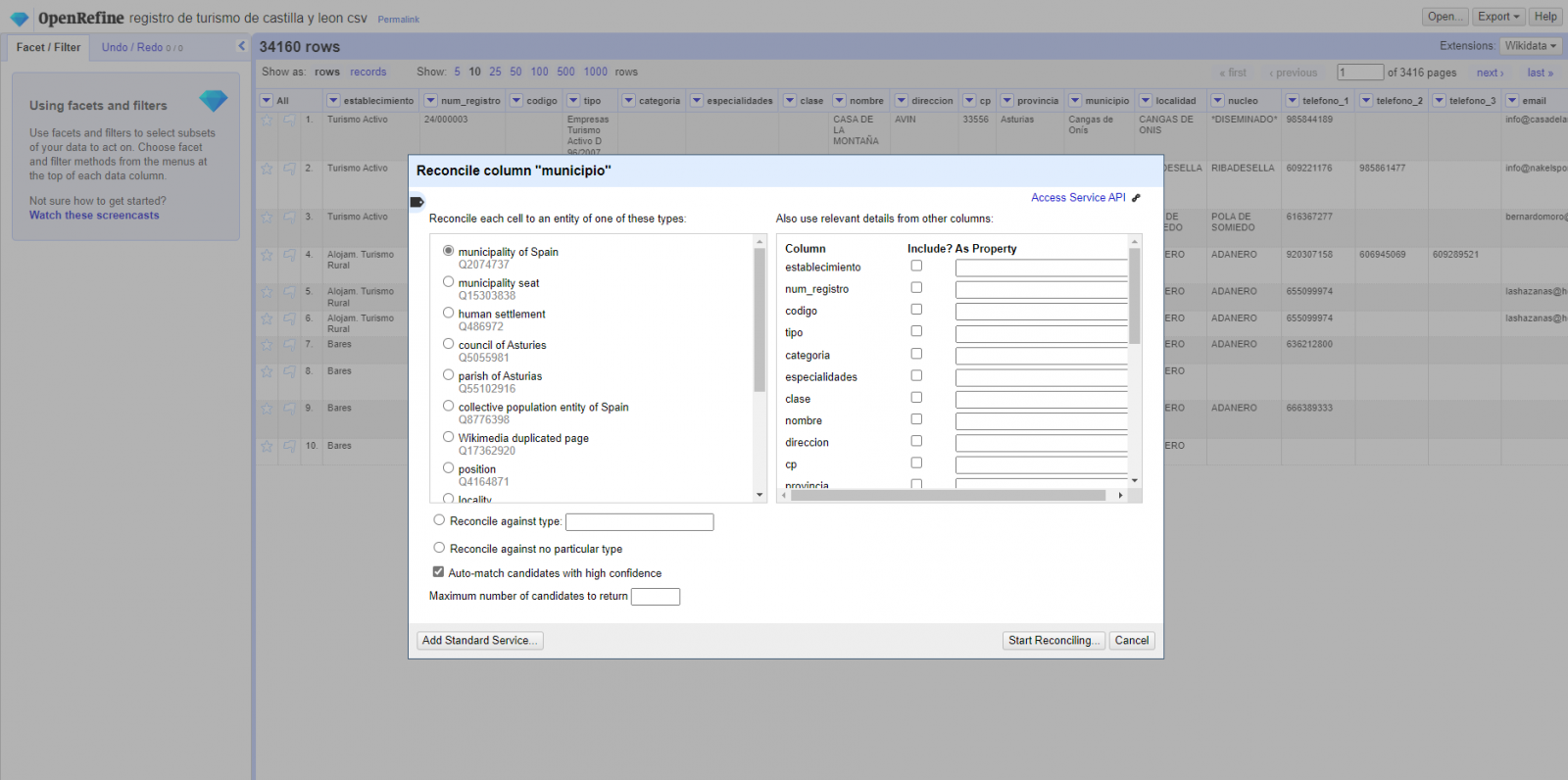
Figura 3. Selección de la clase que mejor representa los valores de la columna "municipio"
- Obtención de los valores de la reconciliación. OpenRefine nos ofrece la posibilidad de mejorar el proceso de reconciliación agregando algunas características que permitan orientar el enriquecimiento de la información con mayor precisión.
Paso 4
Generar una nueva columna con los valores reconciliados o enlazados. (Figura 4) Para ello debemos pulsar en la columna “municipio” e ir a “Edit Column → Add column based in this column”, dónde se mostrará un texto en la que tendremos que indicar el nombre de la nueva columna (en este ejemplo podría ser “wikidata”). En la caja de expresión deberemos indicar: “http://www.wikidata.org/entity/”+cell.recon.match.id y los valores aparecen como se previsualiza en la Figura. “http://www.wikidata.org/entity/” se trata de una cadena de texto fija para representar las entidades de Wikidata, mientras el valor reconciliado de cada uno de los valores lo obtenemos a través de la instrucción cell.recon.match.id, es decir, cell.recon.match.id(“Adanero”) = Q1404668
Mediante la operación anterior, se generará una nueva columna con dichos valores. Con el fin de comprobar que se ha realizado correctamente, haciendo clic en una de las celdas de la nueva columna, está debería conducir a una página web de Wikidata con información del valor reconciliado.
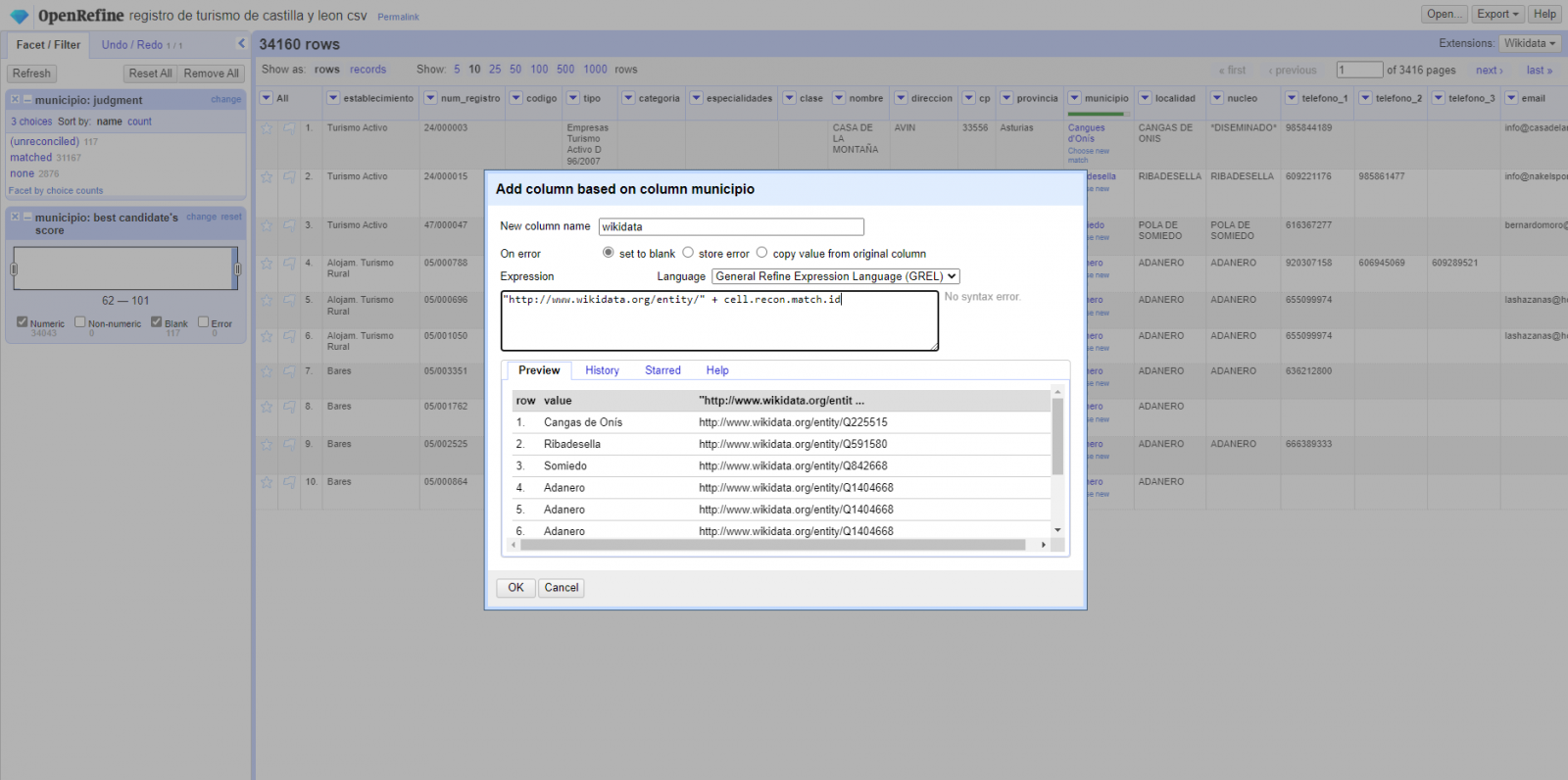
Figura 4. Generación de nueva columna con valores reconciliados
Paso 5
El proceso lo repetimos modificando en el paso 4 el “Edit Column → Add column based in this column” por “Add columns from reconciled values” (Figura 5). De esta forma, podremos elegir la propiedad de la columna reconciliada.
En este ejercicio hemos elegido la propiedad “image” con identificador P18 y la propiedad “population” con identificador P1082. No obstante, podríamos añadir todas las propiedades que consideremos útiles, como el número de habitantes, el listado de monumentos de interés, etc. Cabe destacar que al igual que enriquecemos los datos con Wikidata, podemos hacerlo con otros servicios de reconciliación.
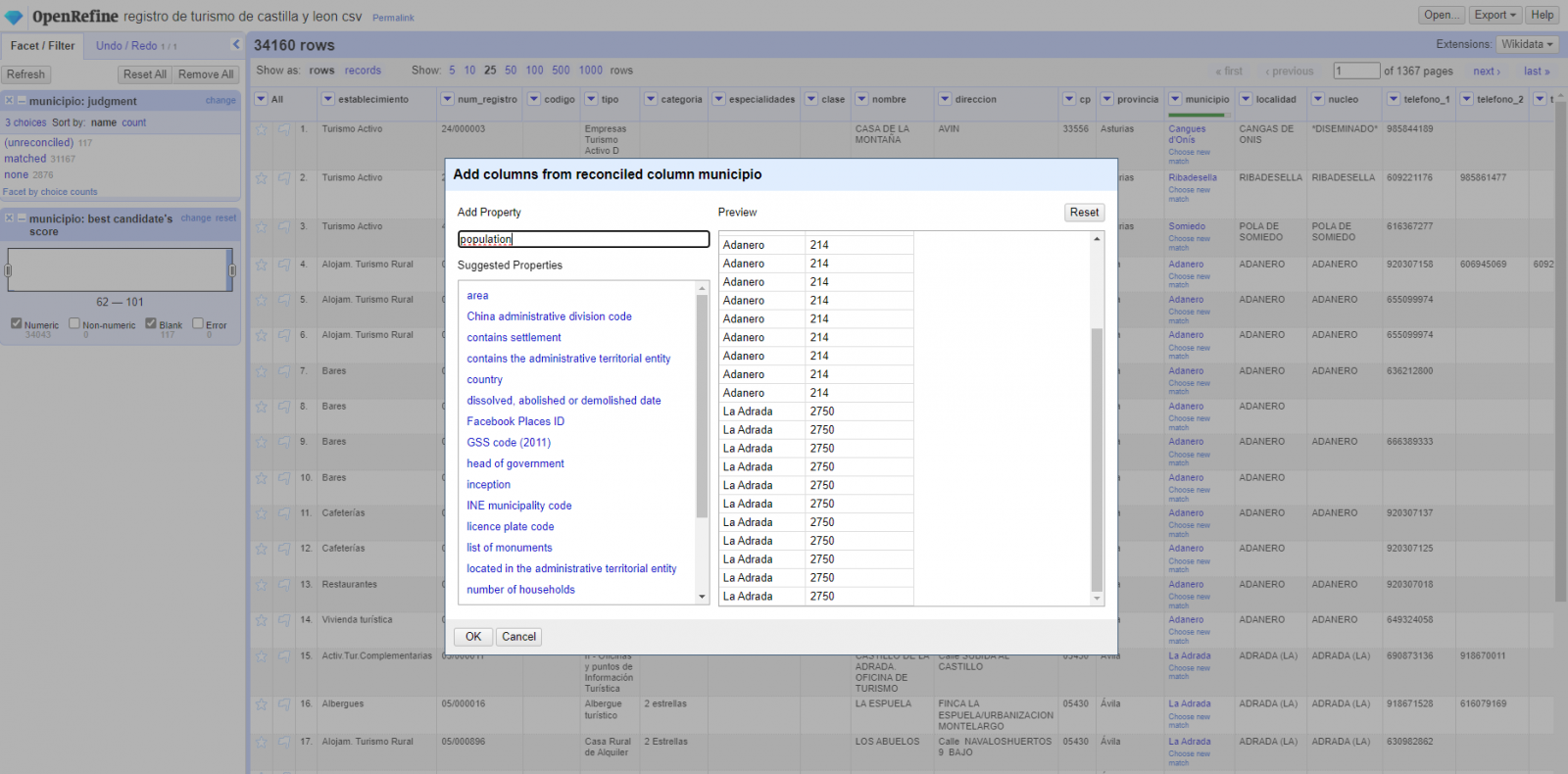
Figura 5. Elección propiedad para reconciliación
En el caso de la propiedad “image”, debido a la visualización, queremos que el valor de las celdas tenga forma de link, por lo que hemos realizado varios ajustes. Estos ajustes han sido la generación de varias columnas según los valores reconciliados, adecuación de las columnas mediante comandos en lenguaje GREL (lenguaje propio de OpenRefine) y unión de los diferentes valores de ambas columnas. Puedes consultar estos ajustes y más técnicas para mejorar tu manejo de OpenRefine y adaptarlo a tus necesidades en el siguiente User Manual.
6. Visualización del mapa
6.1 Generación del mapa con "Google My Maps"
Para generar el mapa personalizado mediante la herramienta My Maps, hemos seguidos los siguientes pasos:
- Iniciamos sesión con una cuenta Google y vamos a "Google My Maps", teniendo acceso de forma gratuita sin tener que descargar ningún tipo de software.
- Importamos las tablas de datos preprocesados, uno por cada nueva capa que añadimos al mapa. Google My Maps permite importar archivos CSV, XLSX, KML y GPX (Figura 6), los cuales deberán tener asociada información geográfica. Para realizar este paso, primero se debe crear una capa nueva desde el menú de opciones lateral.
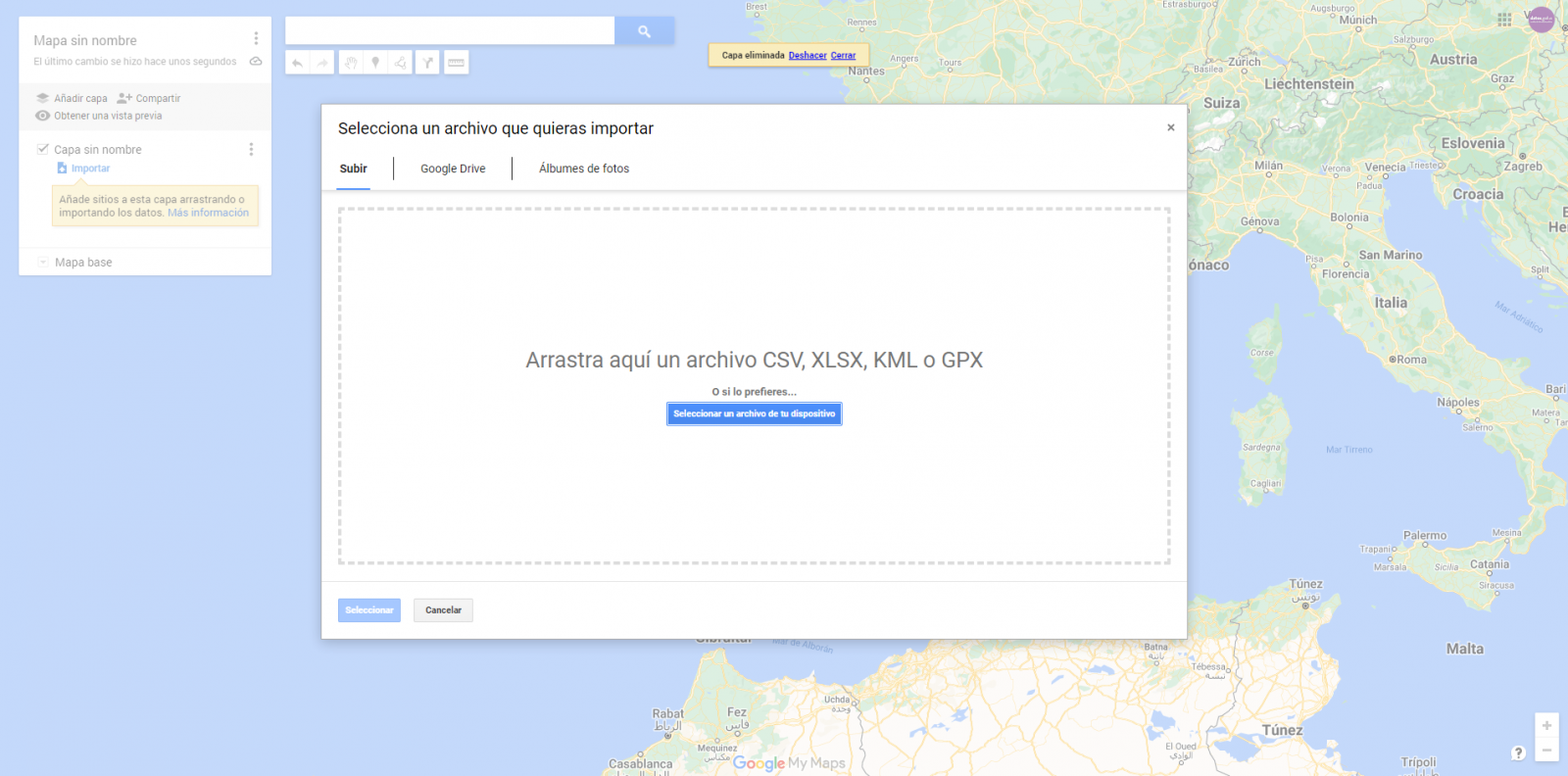
Figura 6. Importación de archivos en "Google My Maps"
- En este caso práctico, importaremos tablas de datos preprocesados que contienen una variable con la latitud y otra con la longitud. Esta información geográfica se reconocerá automáticamente. My Maps también reconoce direcciones, códigos postales, países, ...
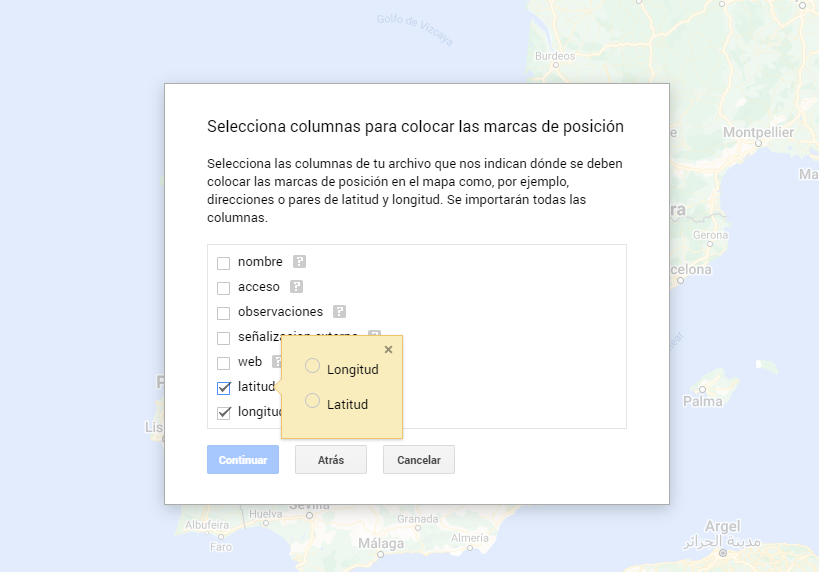
Figura 7. Selección columnas con valores de posición
- Mediante la opción de editar estilo que aparece en el menú lateral izquierdo, en cada una de las capas, podemos personalizar los pines, editando el color y su forma.

Figura 8. Edicción de pines de posición
- Por último, podemos elegir el mapa base que queremos visualizar en la parte inferior de la barra lateral de opciones.
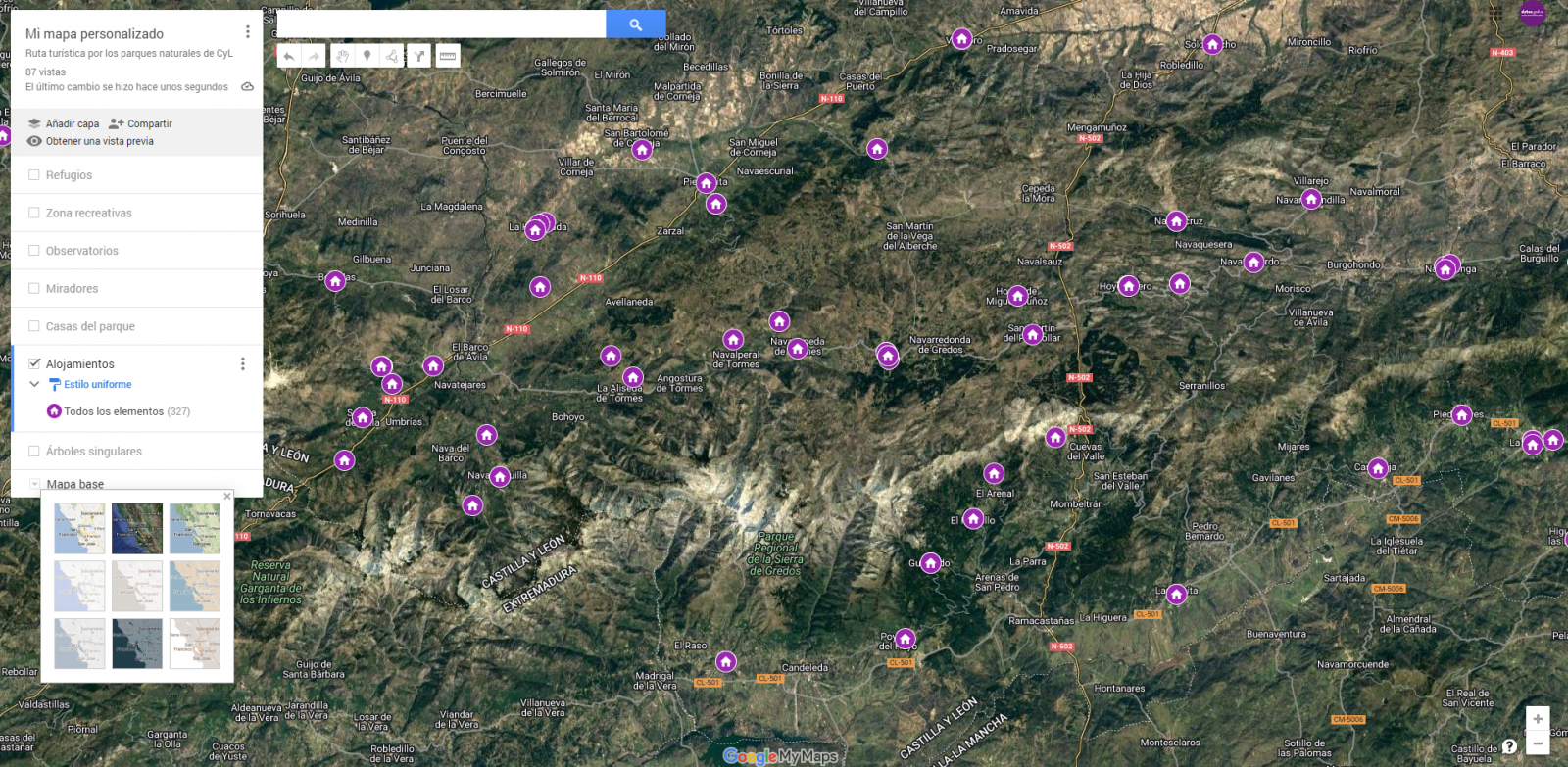
Figura 9. Selección de mapa base
Si quieres conocer más sobre los pasos para la generación de mapas con “Google My Maps”, consulta el siguiente tutorial paso a paso.
6.2 Personalización de la información a mostrar en el mapa
Durante el preprocesamiento de las tablas de datos, hemos realizado un filtrado de la información según el enfoque del ejercicio, que es la generación de un mapa para realizar rutas tusísticas por los espacios naturales de Castilla y León. A continuación, se describe la personalización de la información que hemos llevado a cabo para cada uno de los conjuntos de datos.
- En el conjunto de datos perteneciente a los árboles singulares de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a las casas del parque de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso, la web y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los miradores de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los observatorios de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los refugios de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud). Dado que los refugios pueden encontrarse en estados muy diferentes y que algunos registros no ofrecen información en el campo “observaciones”, hemos decidido filtrar para que nos muestre solamente aquellos que tengan información en dicho campo.
- En el conjunto de datos perteneciente a las áreas recreativas de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud). Hemos decidido filtrar para que nos muestre solamente aquellos que tengan información en los campos de “observaciones” y “acceso”.
- En el conjunto de datos perteneciente a los alojamientos, la información a mostrar para cada registro es el nombre, tipo de establecimiento, categoría, municipio, web, teléfono y la posición (latitud/longitud). Hemos filtrado el “tipo” de establecimiento para que nos muestre solamente los que están categorizados como alojamientos de turismo rural y hemos filtrado para que nos muestre los que son de 2 estrellas.
A continuación, tenemos la visualización del mapa personalizado que hemos creado. Seleccionando el icono para agrandar el mapa que aparece en la esquina superior derecha, podrás acceder su visualización en pantalla completa.
6.3 Funcionalidades sobre el mapa (capas, pines, rutas y vista inmersiva 3D)
En este punto, una vez creado el mapa personalizado, explicaremos diversas funcionalidades que nos ofrece "Google My Maps" durante la visualización de los datos.
-
Capas
Mediante el menú desplegable de la izquierda, podemos activar y desactivar las capas a mostrar según nuestras necesidades.
Figura 10. Capas en "My Maps"
-
Pines
Pinchando en cada uno de los pines del mapa podemos acceder a la información asociada a esa posición geográfica.
Figura 11. Pines en "My Maps"
-
Rutas
Podemos crear una copia del mapa sobre la que añadir nuestros recorridos personalizados.
En las opciones del menú lateral izquierdo, seleccionamos “copiar mapa”. Una vez copiado el mapa, mediante el símbolo de añadir indicaciones, situado debajo de la barra buscador, generaremos una nueva capa. A esta capa podremos indicarle dos o más puntos, junto al medio de transporte y nos creará el trazado junto a las indicaciones de trayecto.

Figura 12. Rutas en "My Maps"
-
Mapa inmersivo en 3D
Mediante el símbolo de opciones que aparece en el menú lateral, podemos acceder a Google Earth, desde donde podemos realizar una exploración del mapa inmersiva en 3D, destacando el poder observar la altitud de los distintos puntos de interés. También puedes acceder mediante el siguiente enlace.
Figura 13. Vista inmersiva en 3D
7. Conclusiones del ejercicio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos. Cabe destacar la vital importancia que los datos geográficos tienen en el sector del turismo, lo cual hemos podido comprobar en este ejercicio.
Como resultado, hemos desarrollado un mapa interactivo con información aportada por los datos abiertos enriquecidos (Linked Data), la cual hemos personalizado según nuestros intereses.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
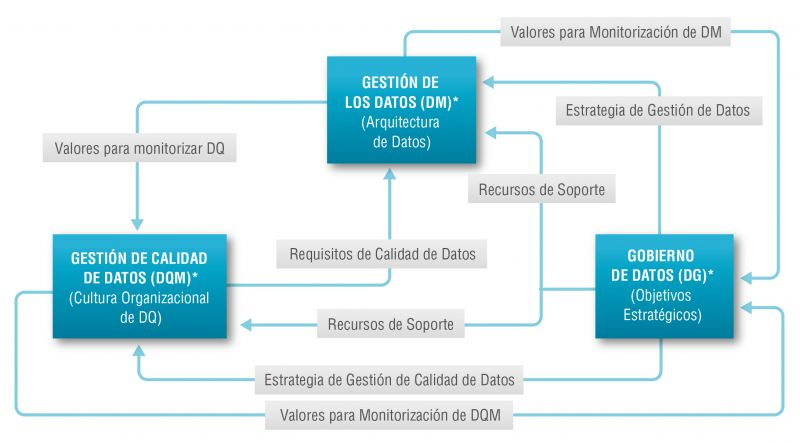
Existe una tan estrecha relación entre la gestión del dato, la gestión de calidad del dato y el gobierno del dato que en muchas ocasiones los términos se utilizan de forma indistinta o directamente se confunden. Sin embargo, existen importantes matices.
El objetivo general de la gestión de datos es asegurar que los datos satisfacen los requisitos de negocio que darán soporte a los procesos de la organización, tales como recopilar, almacenar, proteger, analizar y documentar los datos, con el objetivo de implementar los objetivos de la estrategia de gobierno del dato. Se trata de un conjunto de tareas tan amplio que existen diversas categorías de normas para certificar cada uno de los diferentes procesos: ISO/IEC 27000 para la seguridad y privacidad de la información, ISO/IEC 20000 para la gestión de servicios de TI, ISO/IEC 19944 para interoperabilidad, arquitectura o acuerdos de nivel de servicio en la nube, o ISO/IEC 8000-100 para el intercambio de datos y la gestión de datos maestros.
La gestión de calidad de datos, por su parte, se refiere a las técnicas y procesos utilizados para asegurar que los datos son adecuados para el uso que se pretende hacer de ellos. Para ello se requiere un Plan de calidad de los datos que debe ser acorde con la cultura de la organización y con la estrategia de negocio e incluye aspectos como la validación, verificación y limpieza de datos, entro otros. En este sentido también existe un conjunto de normas técnicas para conseguir que los datos tengan calidad] entre las que se incluyen la propia gestión de la calidad de los datos de transacción, los datos de producto y los datos maestros empresariales (ISO 8000) y las tareas de medición de la calidad de los datos (ISO 25024:2015).
Por su parte, el gobierno del dato, de acuerdo con la definición de Deloitte, está formado por conjunto de normas, políticas y procesos de una organización que permiten asegurar que los datos de la organización sean correctos, fiables, seguros y útiles. Es decir, es la parte estratégica y de planificación y control a alto nivel para conseguir crear valor para el negocio a partir de los datos. En este caso, el gobierno de los datos abiertos tiene sus propias especificidades debido al número de partes interesadas que intervienen y la propia naturaleza colaborativa de los datos abiertos.
El modelo Alarcos
En este contexto el Modelo Alarcos de Mejora de Datos (MAMD), actualmente en su versión 3, tiene como objetivo recoger los procesos necesarios para alcanzar la calidad de las tres citadas dimensiones: la gestión de los datos, la gestión de la calidad de los datos y el gobierno de los datos. Este modelo ha sido desarrollado por un grupo de expertos coordinado por el grupo de investigación Alarcos de la Universidad de Castilla-La Mancha.
El Modelo MAMD está alineado con las mejores prácticas y estándares existentes tales como Data Management Community (DAMA), Data management maturity (DMM) o la propia familia de normas ISO 8000, cada una de las cuáles aborda diferentes aspectos relacionados con la calidad de los datos y la gestión de los datos maestros desde diferentes perspectivas. Además, el modelo Alarcos está basado en la familia de estándares para definir el modelo de madurez por lo que es posible conseguir la certificación de AENOR para el gobierno, gestión y calidad de datos ISO 8000-MAMD.
El modelo MAMD consiste de 21 procesos, 9 procesos corresponden a la gestión de los datos (DM), la gestión de la calidad de datos (DQM) incluye 4 procesos más y el gobierno del dato (DG), que añade otros 8 procesos.
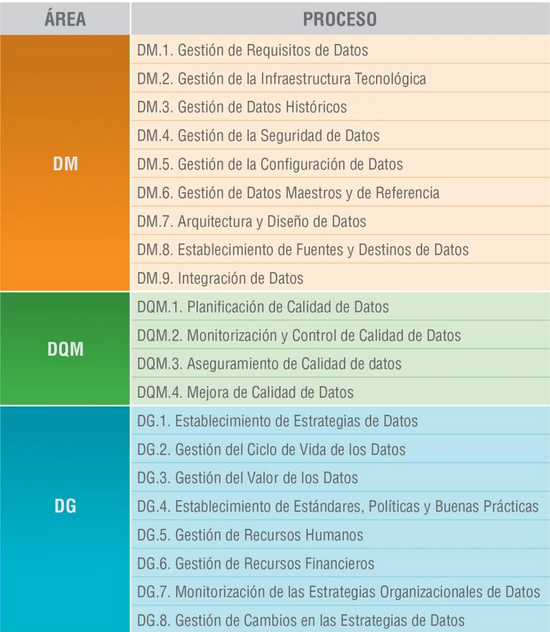
La incorporación progresiva de los 21 procesos permite la definición de 5 niveles de madurez que contribuyen a que la organización mejore su gestión, calidad y gobierno de datos. Comenzando con el nivel 1 (Realizado) en el que el organismo puede demostrar que utiliza buenas prácticas en el uso de los datos y tiene el soporte tecnológico necesario, pero no presta atención al gobierno ni a la calidad de los datos, hasta el nivel 5 (Innovado) en el que el organismo es capaz de alcanzar sus objetivos y está continuamente mejorando.
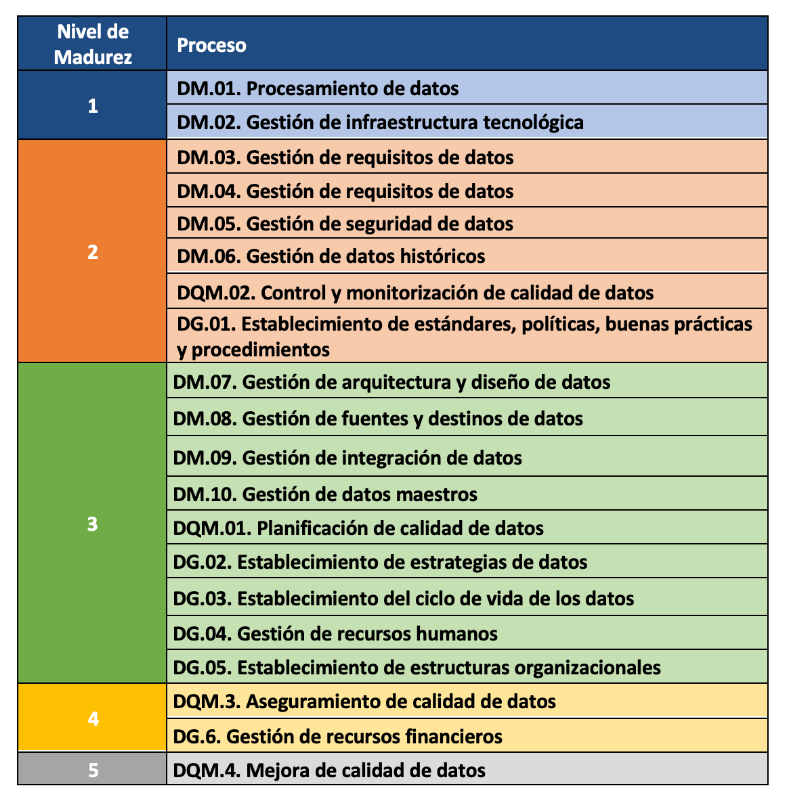
El modelo puede certificarse con una auditoría equivalente a la de otras normas de AENOR por lo que existe la posibilidad de incluirlo en el ciclo de mejora continua y control interno de cumplimiento normativo de las organizaciones que ya cuentan con otros certificados.
Experiencias prácticas
La Biblioteca de la Universidad de Castilla-La Mancha (UCLM), que da soporte a más de 30.000 alumnos y 3.000 profesionales entre profesores y personal de administración y servicios, es una de las primeras organizaciones que pudo superar la auditoría de certificación y por tanto obtener el nivel 2 de madurez en ISO/IEC 33000 – ISO 8000 (MAMD).
Los puntos más fuertes que se identificaron en este proceso de certificación fueron el compromiso del equipo directivo y el nivel de coordinación con otras universidades. Como en toda auditoría, se propusieron mejoras como la necesidad de documentar las revisiones periódicas de seguridad de datos que contribuyeron a alimentar el ciclo de mejora.
El hecho de que las organizaciones de todo tipo otorguen un valor cada vez mayor a sus activos de datos hace que los modelos y normas técnicas de certificación tengan un papel fundamental en garantizar la calidad, la seguridad, la privacidad, la gestión o el adecuado gobierno de estos activos de datos. Además de los estándares ya existentes se sigue haciendo un importante esfuerzo para desarrollar nuevas normas que cubran aspectos que hasta ahora no se habían considerado centrales debido a la menor importancia de los datos en las cadenas de valor de las organizaciones. Sin embargo, aún es necesario continuar con la formalización de modelos que como el Modelo Alarcos de Mejora de Datos permitan abordar de forma holística, y no sólo desde sus diferentes dimensiones, la evaluación y el proceso de mejora de la organización en el tratamiento de sus activos de datos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones utilizando el lenguaje visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio del laboratorio de datos de Github perteneciente a datos.gob.es.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es mostrar cómo realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos utilizado un dataset proporcionado por el Ministerio de Justicia que contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico, que cruzaremos con los datos que publica la Jefatura Central de Tráfico que contienen el detalle sobre el parque de vehículos matriculados en España.
A partir de este cruce de datos analizaremos y podremos observar las ratios de resultados toxicológicos positivos en relación con el parque de vehículos matriculados.
Cabe destacar que el Ministerio de Justicia pone a disposición de los ciudadanos diversos cuadros de mando donde visualizar los datos sobre los resultados toxicológicos realizados en accidentes de tráfico. La diferencia radica en que este ejercicio práctico hace hincapié en la parte didáctica, mostraremos cómo procesar los datos y cómo diseñar y construir las visualizaciones.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se ha utilizado un conjunto de datos proporcionado por el Ministerio de Justicia, el cual contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico. Este conjunto de datos se encuentra en el siguiente repositorio de Github:
También se han utilizado los conjuntos de datos del parque de vehículos matriculados en España. Estos conjuntos de datos son publicados por parte de la Jefatura Central de Tráfico, organismo dependiente del Ministerio del Interior. Se encuentran disponibles en la siguiente página del catálogo de datos de datos.gob.es:
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Tratamiento o preparación de los datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab. Link al notebook de Google Colab
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es la generación de las tablas de datos preprocesados que usaremos para generar las visualizaciones. Para ello ajustaremos las variables, realizaremos el cruce de datos entre ambos conjuntos y filtraremos o agruparemos según sea conveniente.
Los pasos que se siguen en este preprocesamiento de los datos son los siguientes:
- Importación de librerías
- Carga de archivos de datos a utilizar
- Detención y tratamiento de datos ausentes (NAs)
- Modificación y ajuste de las variables
- Generación de tablas con datos preprocesados para las visualizaciones
- Almacenamiento de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Generación de las visualizaciones
Una vez hemos realizado el preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente, para ello hemos realizado los pasos anteriores para la preparación de los datos.
El punto de partida es el planteamiento de una serie de preguntas que la visualización nos ayudará a resolver. Proponemos las siguientes:
-
¿Cómo está distribuido el parque de vehículos en España por comunidades autónomas?
-
¿Qué tipo de vehículo está implicado en mayor y en menor medida en accidentes de tráfico con resultados toxicológicos positivos?
-
¿Dónde se producen más hallazgos toxicológicos en víctimas mortales de accidentes de tráfico?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Parque de vehículos matriculados por CCAA y por típo de vehículo
Esta representación visual se ha realizado teniendo en cuenta el número de vehículos matriculados en las distintas comunidades autónomas, desglosando el total por tipo de vehículo. Los datos, correspondientes a la media de los registros mes a mes de los años 2020 y 2021, están almacenados en la tabla “parque_vehiculos.csv” generada en el preprocesamiento de los datos de partida.
Mediante un mapa coroplético podemos visualizar qué CCAAs son las que poseen un mayor parque de vehículos. El mapa se complementa con un gráfico de anillo que aporta información de los porcentajes sobre el total por cada CCAA.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los mapas coropléticos o de coropletas muestran los valores de una variable sobre un mapa pintando las áreas de cada región afectada de un color determinado. Son utilizados cuando se quieren encontrar patrones geográficos en los datos que están categorizados por zonas o regiones.
Los gráficos de anillo, englobados en los gráficos de sectores, utilizan una representación circular que muestra cómo se distribuyen proporcionalmente los datos.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de vehículo.
Ver la visualización en pantalla completa
5.2. Ratio resultados toxicológicos positivos para los distintos tipos de vehículos
Esta representación visual se ha realizado teniendo en cuanta las ratios de los resultados toxicológicos positivos por número de vehículos a nivel nacional. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_vehiculos.csv”
Mediante un gráfico de barras apiladas, podemos evaluar los ratios de los resultados toxicológicos positivos por número de vehículos para las distintas sustancias y los distintos tipos de vehículos.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los gráficos de barras se utilizan cuando se quiere comparar el valor total de la suma de los segmentos que forman cada una de las barras. Al mismo tiempo, ofrecen información sobre cómo son de grandes estos segmentos.
Cuando las barras apiladas suman un 100%, es decir, que cada barra segmenteada ocupa la altura de la representación, el gráfico se puede considerar un gráfico que permite representar partes de un total.
La tabla aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
5.3. Ratio resultados toxicológicos positivos para las CCAAs
Esta representación visual se ha realizado teniendo en cuenta las ratios de los resultados toxicológicos positivos por el parque de vehículos de cada CCAA. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_ccaa.csv”.
Hay que remarcar que no tiene por qué coincidir la CCAA de matriculación del vehículo con la CCAA donde se ha registrado el accidente, no obstante, ya que este es un ejercicio didáctico y se presupone que en la mayoría de los casos coinciden, se ha decido partir de la base de que ambos coinciden.
Mediante un mapa coroplético podemos visualizar que CCAAs son las que poseen las mayores ratios. A la información aportada en la primera visualización sobre este tipo de gráficos, hay que añadir lo siguiente.
Según se define en la “Guía de visualización de datos para Entidades Locales” uno de los requisitos de los mapas coropléticos o de coropletas es utilizar una medida o dato numérico, un dato categórico para el territorio y un dato geográfico de polígono.
La tabla y el gráfico de barras aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña despegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
6. Conclusiones del estudio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
El parque de vehículos de las Comunidades Autónomas de Andalucía, Cataluña y Madrid corresponde a cerca del 50% del total del país.
-
Las ratios de resultados toxicológicos positivos más altas se presentan en las motocicletas, siendo del orden de tres veces superior a la siguiente ratio, los turismos, para la mayoría de las sustancias.
-
Las ratios de resultados toxicológicos positivos más bajas se presentan en los camiones.
-
Los vehículos de dos ruedas (motocicletas y ciclomotores) presentan ratios en \"cannabis\" superiores a los obtenidos en \"cocaina\", mientras que los vehículos de cuatro ruedas (turismos, furgonetas y camiones) presentan ratios en \"cocaina\" superiores a los obtenidos en \"cannabis\".
-
La comunidad autónoma donde mayor es la ratio para el total de sustancias es La Rioja.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por tipo de vehículo y tipo de sustancia. Te animamos a lo que lo hagas para sacar conclusiones más específicas sobre la información concreta en la que estés más interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Evento
El próximo 21 de noviembre tendrá lugar el primer Encuentro Nacional de Datos Abiertos en Barcelona. Se trata de una iniciativa impulsada y coorganizada por la Diputación de Barcelona, el Gobierno de Aragón y la Diputación de Castellón, con el fin de identificar y elaborar propuestas concretas que impulsen la reutilización de los datos abiertos.
Este primer encuentro estará centrado en el papel de los datos abiertos a la hora de desarrollar políticas de cohesión territorial que contribuyan a superar el reto demográfico.
Agenda
La jornada comenzará a la 9:00 de la mañana y se extenderá hasta las 18:00 de la tarde.
Tras la inauguración, que correrá a cargo de Marc Verdaguer, diputado del Área de Innovación, gobiernos locales y cohesión territorial de la Diputación de Barcelona, tendrá lugar una ponencia principal, donde Carles Ramió, vicerrector de Planificación y Evaluación Institucional en la Universidad Pompeu Fabra, expondrán el contexto de la materia.
A continuación, la jornada se estructurará en cuatro sesiones donde se debatirá sobre los siguientes temas:
- 10:30 horas. Estado de la cuestión: luces y algunas sombras de abrir y reutilizar datos
- 12:30 horas. ¿Qué necesita y espera la sociedad de los portales de datos abiertos de las AAPP?
- 15:00 horas. Apuesta local para luchar contra el despoblamiento a través de los datos abiertos
- 16:30 horas. ¿Qué pueden hacer las AAPP usando sus datos para luchar conjuntamente contra la despoblación?
En la jornada participarán expertos ligados a diversas iniciativas de datos abiertos, organizaciones públicas y asociaciones empresariales. En concreto, la Iniciativa Aporta participará en la primera sesión, donde se hablará de los retos y oportunidades del uso de los datos abiertos.
La importancia de abordar el reto demográfico
Durante la jornada se abordará cómo el envejecimiento de la población, el aislamiento geográfico que dificulta el acceso a centros sanitarios, administrativos y educativos o la pérdida de la actividad económica afectan a los municipios de menor población, tanto rurales como urbanos. Una situación con gran repercusión en la sostenibilidad y abastecimiento de todo el país, así como en preservación de la cultura y la diversidad.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información en forma de conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre los embalses nacionales. A partir de estos datos realizaremos el análisis de su estado y de su evolución temporal en los últimos años.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio para la Transición Ecológica y el Reto Demográfico, que dentro del boletín hidrológico recoge series temporales de datos sobre él volumen de agua embalsada de los últimos años para todos los embalses nacionales con una capacidad superior a 5hm3. Datos históricos del volumen de agua embalsada disponibles en:
También se ha seleccionado un conjunto de datos geoespaciales. Durante su búsqueda, se han encontrado dos posibles archivos con datos de entrada, el que contiene las áreas geográficas correspondientes a los embalses de España y el que contiene las presas que incluye su geoposicionamiento como un punto geográfico. Aunque evidentemente no son lo mismo, embalses y presas guardan relación y para simplificar este ejercicio práctico optamos por utilizar el archivo que contiene la relación de presas de España. Inventario de presas disponible en: https://www.mapama.gob.es/ide/metadatos/index.html?srv=metadata.show&uuid=4f218701-1004-4b15-93b1-298551ae9446 , concretamente:
Este conjunto de datos contiene geolocalizadas (Latitud, Longitud) las presas de toda España con independencia de su titularidad. Se entiende por presa, aquellas estructuras artificiales que, limitando en todo o en parte el contorno de un recinto enclavado en el terreno, esté destinada al almacenamiento de agua dentro del mismo.
Para generar los puntos geográficos de interés se realiza un procesamiento mediante la herramienta QGIS, cuyos pasos son los siguientes: descargar el archivo ZIP, cargarlo en QGIS y guardarlo como CSV incluyendo la geometría de cada elemento como dos campos que especifican su posición como un punto geográfico (Latitud y Longitud).
También se he realizado un filtrado para quedarnos con los datos correspondientes a las presas de los embalses que tengan una capacidad mayor a 5hm3
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación Python desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Enriquecimiento de los datos
Con la finalidad de aportar mayor información relacionada a cada una de las presas en el dataset con datos geoespaciales, se realiza un proceso de enriquecimiento de datos explicado a continuación.
Para ello vamos a utilizar una herramienta útil para este tipo de tarea, OpenRefine. Esta herramienta de código abierto permite realizar múltiples acciones de preprocesamiento de datos, aunque en esta ocasión la usaremos para llevar a cabo un enriquecimiento de nuestros datos mediante la incorporación de contexto enlazando automáticamente información que reside en el popular repositorio de conocimiento Wikidata.
Una vez instalada la herramienta en nuestro ordenador, al ejecutarse se abrirá una aplicación web en el navegador, en caso de que eso no ocurriese, se accedería a dicha aplicación tecleando en la barra de búsqueda del navegador \"localhost:3333\".
Pasos a seguir:
- Paso 1: Carga del CSV en el sistema (Figura 1).

Figura 1 - Carga de un archivo CSV en OpenRefine
- Paso 2: Creación del proyecto a partir del CSV cargado (Figura 2). OpenRefine se gestiona mediante proyectos (cada CSV subido será un proyecto), que se guardan en el ordenador dónde se esté ejecutando OpenRefine para un posible uso posterior. En este paso debemos dar un nombre al proyecto y algunos otros datos, como el separador de columnas, aunque lo más habitual es que estos últimos ajustes se rellenen automáticamente.

Figura 2 - Creación de un proyecto en OpenRefine
- Paso 3: Enlazado (o reconciliación, usando la nomenclatura de OpenRefine) con fuentes externas. OpenRefine nos permite enlazar recursos que tengamos en nuestro CSV con fuentes externas como Wikidata. Para ello se deben realizar las siguientes acciones (pasos 3.1 a 3.3):
- Paso 3.1: Identificación de las columnas a enlazar. Habitualmente este paso suele estar basado en la experiencia del analista y su conocimiento de los datos que se representan en Wikidata. Como consejo, habitualmente se podrán reconciliar o enlazar aquellas columnas que contengan información de carácter más global o general como nombres de países, calles, distritos, etc., y no se podrán enlazar aquellas columnas como coordenadas geográficas, valores numéricos o taxonomías cerradas (tipos de calles, por ejemplo). En este ejemplo, hemos encontrado la columna NOMBRE que contiene el nombre de cada embalse que puede servir como identificador único de cada ítem y puede ser un buen candidato para enlazar.
- Paso 3.2: Comienzo de la reconciliación. Comenzamos la reconciliación como se indica en la figura 3 y seleccionamos la única fuente que estará disponible: Wikidata(en). Después de hacer clic en Start Reconciling, automáticamente comenzará a buscar la clase del vocabulario de Wikidata que más se adecue basado en los valores de nuestra columna.

Figura 3 – Inicio del proceso de reconciliación de la columna NOMBRE en OpenRefine
- Paso 3.3: Selección de la clase de Wikidata. En este paso obtendremos los valores de la reconciliación. En este caso como valor más probable, seleccionamos el valor de la propiedad “reservoir” cuya descripción se puede ver en https://www.wikidata.org/wiki/Q131681, que corresponde a la descripción de un “lago artificial para acumular agua”. Únicamente habrá que pulsar otra vez en Start Reconciling.
OpenRefine nos ofrece la posibilidad de mejorar el proceso de reconciliación agregando algunas características que permitan orientar el enriquecimiento de la información con mayor precisión. Para ello ajustamos la propiedad P4568 cuya descripción se corresponde con el identificador de un embalse en España, en el SNCZI-Inventario de Presas y Embalses, como se observa en la figura 4.

Figura 4 - Selección de la clase de Wikidata que mejor representa los valores de la columna NOMBRE
- Paso 4: Generar una nueva columna con los valores reconciliados o enlazados. Para ello debemos pulsar en la columna NOMBRE e ir a “Edit Column → Add column based in this column”, dónde se mostrará un texto en la que tendremos que indicar el nombre de la nueva columna (en este ejemplo podría ser WIKIDATA_EMBALSE). En la caja de expresión deberemos indicar: “http://www.wikidata.org/entity/”+cell.recon.match.id y los valores aparecen como se previsualiza en la Figura 6. “http://www.wikidata.org/entity/” se trata de una cadena de texto fija para representar las entidades de Wikidata, mientras el valor reconciliado de cada uno de los valores lo obtenemos a través de la instrucción cell.recon.match.id, es decir, cell.recon.match.id(“ALMODOVAR”) = Q5369429.
Mediante la operación anterior, se generará una nueva columna con dichos valores. Con el fin de comprobar que se ha realizado correctamente, haciendo clic en una de las celdas de la nueva columna, está debería conducir a una página web de Wikidata con información del valor reconciliado.
El proceso lo repetimos para añadir otro tipo de información enriquecida como la referencia en Google u OpenStreetMap.

Figura 5 - Generación de las entidades de Wikidata gracias a la reconciliación a partir de una nueva columna
- Paso 5: Descargar el CSV enriquecido. Utilizamos la función Export → Custom tabular exporter situada en la parte superior derecha de la pantalla y seleccionamos las características como se indica en la Figura 6.

Figura 6 - Opciones de descarga del fichero CSV a través de OpenRefine
5. Preprocesamiento de datos
Durante el preprocesamiento es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creadas posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Modificación y ajuste de las variables
- Detención y tratamiento de datos ausentes (NAs)
- Generación de nuevas variables
- Creación de tabla para visualización \"Evolución histórica de la reserva hídrica entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Reserva hídrica (hm3) entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Reserva hídrica (%) entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Evolución mensual de la reserva hídrica (hm3) para distintas series temporales\"
- Guardado de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
6. Visualización de datos
Una vez hemos realizado un preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos las siguientes:
- ¿Cuál es la localización de los embalses dentro del territorio nacional?
-
¿Qué embalses son los de mayor y menor aporte de volumen de agua embalsada (reserva hídrica en hm3) al conjunto del país?
-
¿Qué embalses poseen el mayor y menor porcentaje de llenado (reserva hídrica en %)?
-
¿Cuál es la tendencia en la evolución de la reserva hídrica en los últimos años?
¡Vamos a buscar las respuestas viendo los datos!
6.1. Localización geográfica y principal información de cada embalse
Esta representación visual se ha realizado teniendo en cuenta las coordenadas geográficas de los embalses y distinta información asociada a cada uno de ellos. Para ello se ha generado durante el preprocesamiento de datos la tabla “geo.csv”
Mediante un mapa de puntos geográficos se visualiza la localización de los embalses en el territorio nacional.
Una vez obtenido el mapa, pinchando en cada uno de los embalses podemos acceder a información complementaria sobre dicho embalse en la tabla inferior. También, mediante las pestañas despegables, aparece la opción de filtrar el mapa por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.2. Reserva hídrica (hm3) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) por embalse entre los años los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “volumen.csv”
Mediante un gráfico de jerarquía rectangular se visualiza de forma intuitiva la importancia de cada embalse en cuanto a volumen embalsado dentro del conjunto nacional para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.3. Reserva hídrica (%) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (%) por embalse entre los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “porcentaje.csv”
Mediante un gráfico de barras se visualiza de forma intuitiva el porcentaje de llenado de cada embalse para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.4. Evolución histórica de la reserva hídrica entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta los datos históricos de la reserva hídrica (hm3 y %) para todas las mediciones semanales registradas entre los años 2012(inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas.csv”
Mediante gráficos de líneas y sus líneas de tendencia se visualiza la evolución temporal de la reserva hídrica (hm3 y %).
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos modificar la serie temporal, filtrar por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.5. Evolución mensual de la reserva hídrica (hm3) para distintas series temporales
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) de los distintos embalses desglosada por meses para distintas series temporales (cada uno de los años desde el 2012 hasta el 2022). Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas_mensual.csv”
Mediante un gráfico de líneas se visualízala la reserva hídrica mes a mes para cada una de las series temporales.
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos filtrar por demarcación hidrográfica y por embalse. También tenemos la opción de elegir la serie o series temporales (cada uno de los años desde el 2012 hasta el 2022) que queremos visualizar mediante el icono que aparece en la parte superior derecha del gráfico.
Ver la visualización en pantalla completa
7. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
Se observa una tendencia significativa en la disminución del volumen de agua embalsada por el conjunto de embalses nacionales entre los años 2012 y 2022.
-
El año 2017 es el que presenta valores más bajos de porcentaje de llenado total de los embalses, llegando a ser este inferior al 45% en ciertos momentos del año.
-
El año 2013 es el que presenta valores más altos de porcentaje de llenado total de los embalses, llegando a ser este superior al 80% en ciertos momentos del año.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por demarcación hidrográfica y por embalse. Te animamos a lo que lo hagas para sacar conclusiones más específicas de las demarcaciones hidrográficas y embalses que estés interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
Este informe que publica el European Data Portal (EDP) tiene como objetivo avanzar en el debate sobre la sostenibilidad a medio y largo plazo de las infraestructuras de los portales de datos abiertos.
Ofrece recomendaciones a los publicadores de datos abiertos y a los intemediarios de datos sobre cómo hacer que los datos abiertos estén disponibles y como promover su reutilización. Está basado en el trabajo realizado anteriomente por el equipo de data.europa.eu, en la investigación sobre la gestión de datos abiertos, y en la interacción entre los humanos y los datos.
Teniendo en cuenta las conclusiones, se proponen 10 recomendaciones para el aumento en la reutilización de los datos.
El informe se encuentra disponible en este enlace: " Principles and recommendations to make data.europa.eu data more reusable: A strategy mapping report "
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información que finalmente se resume en unas conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre el alumnado de la universidad española a lo largo de los últimos años. A partir de estos datos observaremos las características que presenta el alumnado de la universidad española y cuáles son los estudios más demandados.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio de Universidades, que recoge series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presenta el alumnado de la universidad española. Estos datos se encuentran disponibles en el catálogo de datos.gob.es y en el propio catálogo de datos del Ministerio de Universidades. Concretamente los datasets que usaremos son:
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de doctorado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de máster por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de grado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculaciones por cada una de las titulaciones impartidas por las universidades españolas que se encuentra publicado en la sección de Estadísticas de la página oficial del Ministerio de Universidades. El contenido de esta dataset abarca desde el curso 2015-2016 al 2020-2021, aunque para este último curso los datos con provisionales.
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación R desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Datawrapper.
Datawrapper es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en línea o exportarse como PNG, PDF o SVG. Esta herramienta es muy sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Preprocesamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Creación de tablas de trabajo
- Ajuste del nombre de algunas variables
- Agrupación de varias variables en una única con diferentes factores
- Transformación de variables
- Detección y tratamiento de datos ausentes (NAs)
- Creación de nuevas variables calculadas
- Resumen de las tablas transformadas
- Preparación de datos para su representación visual
- Almacenamiento de archivos con las tablas de datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
5. Visualización de datos
Una vez realizado el preprocesamiento de los datos, vamos con la visualización. Para la realización de esta visualización interactiva usamos la herramienta Datawrapper en su versión gratuita. Se trata de una herramienta muy sencilla con especial aplicación en el periodismo de datos que te animamos a utilizar. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que la tabla de datos que le proporcionemos este estructurada adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos la siguientes:
- ¿Cómo se está distribuyendo el número de hombres y mujeres entre los alumnos matriculados de grado, máster y doctorado a lo largo de los últimos cursos?
Si nos centramos en el último curso 2020-2021:
- ¿Cuáles son las ramas de enseñanza más demandadas en las universidades españolas? ¿Y las titulaciones?
- ¿Cuáles son las universidades con mayor número de matriculaciones y dónde se ubican?
- ¿En qué rangos de edad se encuentra el alumnado universitario de grado?
- ¿Cuál es la nacionalidad de los estudiantes de grado de las universidades españolas?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Distribución de las matriculaciones en las universidades españolas desde el curso 2015-2016 hasta 2020-2021, desagregado por sexo y nivel académico
Esta representación visual la hemos realizado teniendo en cuenta las matriculaciones de grado, master y Doctorado. Una vez que hemos subido la tabla de datos a Datawrapper (conjunto de datos \"Matriculaciones_NivelAcademico\"), hemos seleccionado el tipo de gráfico a realizar, en este caso un diagrama de barras apiladas (stacked bars) para poder reflejar por cada curso y sexo, las personas matriculadas en cada nivel académico. De esta forma podemos ver, además, el global de estudiantes matriculados por curso. A continuación, hemos seleccionado el tipo de variable a representar (Matriculaciones) y las variables de desagregación (Sexo y Curso). Una vez obtenido el gráfico, podemos modificar de forma muy sencilla la apariencia, modificando los colores, la descripción y la información que muestra cada eje, entre otras características.
Para responder a las siguientes preguntas, nos centraremos en el alumnado de grado y en el curso 2020-2021, no obstante, las siguientes representaciones visuales pueden ser replicadas para el alumnado de máster y doctorado, y para los diferentes cursos.
5.2. Mapa de las universidades españolas georreferenciadas, donde se muestra el número de matriculados que presentan cada una de ellas
Para la realización del mapa hemos utilizado un listado de las universidades españolas georreferenciadas publicado por el Portal de Datos Abiertos de Esri España. Una vez descargados los datos de las distintas áreas geográficas en formato GeoJSON, los transformamos en Excel, para poder realizar una unión entre el datasets de las universidades georreferenciadas y el dataset que presenta el número de matriculados por cada universidad que previamente hemos preprocesado. Para ello hemos utilizado la función BUSCARV() de Excel que nos permitirá localizar determinados elementos en un rango de celdas de una tabla.
Antes de subir el conjunto de datos a Datawrapper, debemos seleccionar la capa que muestra el mapa de España dividido en provincias que nos proporciona la propia herramienta. Concretamente, hemos seleccionado la opción \"Spain>>Provinces(2018)\". Seguidamente procedemos a incorporar el conjunto de datos \"Universidades\", antes generado, (este conjunto de datos se adjunta en la carpeta de conjuntos de datos de GitHub para esta visualización paso a paso), indicando que columnas contienen los valores de las variables Latitud y Longitud.
A partir de este punto, Datawrapper ha generado un mapa en el que se muestran las ubicaciones de cada una de las universidades. Ahora podemos modificar el mapa según nuestras preferencias y ajustes. En este caso, haremos que el tamaño de los puntos y el color dependa del número de matriculaciones que presente cada universidad. Además, para que estos datos se muestren, en la pestaña “Annotate”, en la sección “Tooltips”, debemos indicarle las variables o el texto que deseemos que aparezca.
5.3. Ranking de matriculaciones por titulación
Para esta representación gráfica utilizamos el objeto visual de Datawrapper tabla (Table) y el conjunto de datos \"Titulaciones_totales\" para mostrar el número de matriculaciones que presenta cada una de las titulaciones impartidas durante el curso 2020-2021. Dado que el número de titulaciones es muy extenso, la herramienta nos ofrece la posibilidad de incluir un buscador que permite filtrar los resultados.
5.4. Distribución de matriculaciones por rama de enseñanza
Para esta representación visual, hemos utilizado el conjunto de datos \"Matriculaciones_Rama_Grado\" y seleccionado gráficos de sectores (Pie Chart), donde hemos representado el número de matriculaciones según sexo en cada una de las ramas de enseñanza en las cuales se dividen las titulaciones impartidas por las universidades (Ciencias Sociales y Jurídicas, Ciencias de la Salud, Artes y Humanidades, Ingeniería y Arquitectura y Ciencias). Al igual que en el resto de gráficos, podemos modificar el color del gráfico, en este caso en función de la rama de enseñanza.
5.5. Matriculaciones de Grado por edad y nacionalidad
Para la realización de estas dos representaciones de datos visuales utilizamos diagramas de barras (Bar Chart), donde mostramos la distribución de matriculaciones en el primero, desagregada por sexo y nacionalidad, utilizaremos el conjunto de datos \"Matriculaciones_Grado_nacionalidad\" y en el segundo, desagregada por sexo y edad, utilizando el conjunto de datos \"Matriculaciones_Grado_edad\". Al igual que los visuales anteriores, la herramienta facilita de forma sencilla la modificación de las características que presentan los gráficos.
6. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implamentar se puede observar lo siguiente:
- El número de matriculaciones aumenta a lo largo de los cursos académicos independientemente del nivel académico (grado, máster o doctorado).
- El número de mujeres matriculadas es mayor que el de hombres en grado y máster, sin embargo es menor en el caso de las matriculaciones de doctorado, excepto en el curso 2019-2020.
- La mayor concentración de universidades la encontramos en la Comunidad de Madrid, seguido de la comunidad autónoma de Cataluña.
- La universidad que concentra mayor número de matriculaciones durante el curso 2020-2021 es la UNED (Universidad Nacional de Educación a Distancia) con 146.208 matriculaciones, seguida de la Universidad Complutense de Madrid con 57.308 matriculaciones y la Universidad de Sevilla con 52.156.
- La titulación más demandada el curso 2020-2021 es el Grado en Derecho con 82.552 alumnos a nivel nacional, seguido del Grado de Psicología con 75.738 alumnos y sin apenas diferencia, el Grado en Administración y Dirección de Empresas con 74.284 alumnos.
- La rama de enseñanza con mayor concentración de alumnos es Ciencias Sociales y Jurídicas, mientras que la menos demandada es la rama de Ciencias.
- Las nacionalidades que más representación tienen en la universidad española son de la región de la unión europea, seguido de los países de América Latina y Caribe, a expensas de la española.
- El rango de edad entre los 18 y 21 años es el más representado en el alumnado de las universidades españolas.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
Las visualizaciones son una representación gráfica que nos permite comunicar de una manera sencilla la información ligada a los datos. Mediante elementos visuales, como gráficos, mapas o nubes de palabras, las visualizaciones, también nos ayudan a comprender tendencias, patrones o valores atípicos que pueden presentar los datos.
Las visualizaciones se pueden generar a partir de datos de diferente naturaleza, como pueden ser las palabras que conforman una noticia, un libro o una canción. Para realizar visualizaciones a partir de este tipo de datos, es necesario que las maquinas, mediante programas de software, sean capaces de entender, interpretar y reconocer las palabras que configuran el lenguaje humano (escrito o hablado) en múltiples idiomas. El campo de estudio enfocado en el tratamiento de estos datos se denomina Procesamiento del Lenguaje Natural (PLN). Es un campo interdisciplinar que combina el poder de la inteligencia artificial, la lingüística computacional y la informática. Los sistemas basados en PLN han permitido grandes innovaciones como el buscador de Google, el asistente de voz de Amazon, los traductores automáticos, el análisis de sentimientos de diferentes redes sociales o incluso detección de spam en una cuenta de correo electrónico.
En este ejercicio práctico, vamos a implementar una visualización gráfica de un resumen de palabras clave representativas de varios textos extraídas mediante la aplicación de técnicas de PLN. En concreto, vamos a crear una nube de palabras que resuma cuál son los términos que más se repiten en varios posts del portal.
Esta visualización se engloba dentro de la serie de ejercicios prácticos, en los cuales se utilizan datos abiertos disponibles en el portal datos.gob.es. En estos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar transformaciones y análisis que resulten pertinentes para la creación de la visualización, extrayendo la máxima información. En cada uno de los ejercicios prácticos se usan sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en GitHub.
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización que incluya imágenes, generadas a partir de conjuntos de palabras representativas de diversos textos, conocidas popularmente como “nubes de palabras”. Para este ejercicio práctico hemos escogido 6 post publicados en la sección de blog del portal de datos.gob.es. A partir de estos textos y utilizando técnicas de PLN generaremos una nube de palabras para cada texto que nos permitirá detectar de manera sencilla y visual la frecuencia e importancia de cada palabra, facilitando la identificación de las palabras clave y la temática principal de cada uno de los posts.

A partir de un texto construimos una nube de palabras aplicando técnicas de Procesamiento de Lenguaje Natural (PLN)
3. Recursos
3.1. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo), como la visualización propiamente dicha, se utiliza Python (versión 3.7) y Jupyter Notebook (versión 6.1), herramientas que encontraras integradas en, junto con muchas otras, en Anaconda, una de las plataformas más populares para instalar, actualizar y administrar software para trabajar en ciencia de datos. Para abordar las tareas relacionadas con el Procesamiento del Lenguaje Natural, utilizamos dos librerías, Scikit-Learn (sklearn) y wordcloud. Todas estas herramientas son Open Source y están disponibles de manera gratuita.
Scikit-Learn es una amplia librería muy popular, diseñada principalmente para llevar a cabo tareas de aprendizaje automático sobre datos en forma de texto. Entre otros, cuenta con algoritmos para realizar tareas de clasificación, regresión, clustering y reducción de dimensionalidades. Además, está diseñada para el aprendizaje profundo sobre datos textuales, siendo útil para el manejo de conjuntos de características textuales en forma de matrices, la realización de tareas como el cálculo de similitudes, la clasificación de texto y la agrupación de clústeres. En Python, para realizar este tipo de tareas, también es posible trabajar con otras librerías igualmente populares como NLTK o spacy, entre otras.
wordcloud es una librería especializada en la creación de nubes de palabras utilizando un algoritmo simple y que puede ser modificado fácilmente.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en Python que se incluye a continuación, al que puedes acceder haciendo click en el botón “Código” de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren formas alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de GitHub de datos.gob.es. La forma de proporcionar el código es a través de un Jupyter Notebook, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
3.2. Conjuntos de datos
Para este análisis se han seleccionado 6 posts publicados recientemente en el portal de datos abiertos datos.gob.es, en su sección de blog. Estos posts están relacionado con diferentes temáticas relativas a los datos abiertos:
- Lo último en el procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cientos de palabras.
- La importancia de la anonimización y la privacidad de datos.
- El valor de los datos en tiempo real a través de un ejemplo práctico.
- Nuevas iniciativas para abrir y aprovechar datos para investigación en salud.
- Kaggle y otras plataformas alternativas para aprender ciencia de datos.
- La infraestructura de Datos Espaciales de España (IDEE), un referente de la información geoespacial.
4. Tratamiento de datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos o preprocesamiento de los datos, prestando atención a la obtención de los mismos, asegurando que no contienen errores y se encuentran en un formato adecuado para su procesamiento. Un tratamiento previo de los datos es esencial para construir cualquier representación visual efectiva y consistente.
En PLN, el preprocesamiento de los datos consiste fundamentalmente en una serie de transformaciones que se realizan sobre los datos de entrada, en nuestro caso varios posts en formato TXT, con el objetivo de obtener datos uniformes y sin elementos que puedan afectar a la calidad de los resultados, con el fin de facilitar su posterior procesamiento para realizar tareas como, generar una nube de palabras, realizar minería de opiniones/sentimientos o generar resúmenes automatizados a partir de textos de entrada. De forma general, el flujograma que se sigue para realizar un preprocesamiento de texto incluye las siguientes etapas:
- Limpieza: eliminación de los caracteres y símbolos especiales que contribuyen a distorsionar los resultados, por ejemplo, los signos de puntuación.
- Tokenizar: la tokenización es el proceso de separar un texto en unidades más pequeñas, tokens. Los tokens pueden ser oraciones, palabras o incluso caracteres.
- Derivación y Lematización: este proceso consiste en transformar las palabras a su forma básica, es decir a su forma canónica o lema, eliminando plurales, tiempos verbales o géneros. Esta acción en ocasiones no es necesaria ya que no siempre se requiere para el procesamiento posterior saber la similitud semántica entre las diferentes palabras del texto.
- Eliminación de stop words: las stop words o palabras vacías son aquellas palabras de uso común pero que no contribuyen de una manera significativa en el texto. Estas palabras deben eliminarse antes del procesamiento del texto ya que no aportan ninguna información única que pueda ser usada para la clasificación o agrupación del texto, por ejemplo, los artículos determinantes como ‘los’, ‘las’, ‘una’ ‘unos’, etc.
- Vectorización: en este paso transformamos cada uno de los tokens obtenidos en el paso anterior a un vector de números reales que se genera en base a la frecuencia de la aparición de cada palabra en el texto. La vectorización permite que las maquinas sean capaces de procesar texto y aplicar, entre otras, técnicas de aprendizaje automático.
4.1. Instalación y carga de librerías
Antes de empezar con el preprocesamiento de datos, debemos importar las librerías con las cuales vamos a trabajar. Python dispone de una gran cantidad de librerías que permiten implementar funcionalidades para muchas tareas, como visualización de datos, Machine Learning, Deep Learning o Procesamiento del Lenguaje Natural, entre muchas otras. Las librerías que utilizaremos para este análisis y visualización son:
- os, que permite acceder a funcionalidades dependientes del sistema operativo, como manipular la estructura de directorios.
- re, proporciona funciones para procesar expresiones regulares.
- pandas, es una librería muy popular y esencial para procesar tablas de datos.
- string, proporciona una serie de funciones muy útiles para el manejo de cadenas de caracteres.
- matplotlib.pyplot, contiene una colección de funciones que nos permitirán generar las representaciones gráficas de las nubes de palabras.
- sklearn.feature_extraction.text (librería Scikit-Learn), convierte una colección de documentos de texto en una matriz de vectores. De esta librería usaremos algunos comandos que comentaremos más adelante.
- wordcloud, librería con la cual podremos generar la nube de palabras.
# Importaremos las librerías necesarias para realizar este análisis y la visualización. import os import re import pandas as pd import string import matplotlib.pyplot as plt from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from wordcloud import WordCloud4.2. Carga de datos
Una vez cargadas las librerías, preparamos los datos con los cuales vamos a trabajar. Antes de comenzar a cargar los datos, en el directorio de trabajo debemos tener: (a) una carpeta denominada “post” que contendrá todos los archivos en formato TXT con los cuales vamos a trabajar y que están disponibles en el repositorio de este proyecto del GitHub de datos.gob.es; (b) un archivo denominado “stop_words_spanish.txt” que contiene el listado de las stop words en español, que también está disponible en dicho repositorio y (c) una carpeta llamada “imagenes” donde guardaremos las imágenes de las nubes de palabras en formato PNG, que crearemos a continuación.
# Generamos la carpeta \"imagenes\".nueva_carpeta = \"imagenes/\" try: os.mkdir(nueva_carpeta)except OSError: print (\"Ya existe una carpeta llamada %s\" % nueva_carpeta)else: print (\"Se ha creado la carpeta: %s\" % nueva_carpeta)Seguidamente, procederemos a cargar los datos. Los datos de entrada, como ya hemos comentado anteriormente, se encuentran en ficheros TXT y cada fichero contiene un post. Como queremos realizar el análisis y la visualización de varios posts al mismo tiempo, cargaremos en nuestro entorno de desarrollo todos los textos que nos interesen, para posteriormente insertarlos en una única tabla o dataframe.
# Generamos una lista donde incluiremos todos los archivos que debe leer, indicándole la carpeta donde se encuentran.filePath = []for file in os.listdir(\"./post/\"): filePath.append(os.path.join(\"./post/\", file))# Generamos un dataframe en el cual incluiremos una fila por cada post.post_df = pd.DataFrame()for file in filePath: with open (file, \"rb\") as readFile: post_df = pd.DataFrame([readFile.read().decode(\"utf8\")], append(post_df)# Nombramos la columna que contiene los textos en el dataframe.post_df.columns = [\"texto\"]4.3. Preprocesamiento de datos
Para el objetivo que nos hemos planteado, generar nubes de palabras para cada post, vamos a realizar las siguientes tareas de preprocesamiento.
a) Limpieza de datos
Una vez generada la tabla que contiene los textos con los cuales vamos a trabajar, debemos eliminar el ruido ajeno al texto que nos interesa: caracteres especiales, signos de puntuación y retornos de carro.
En primer lugar, ponemos en minúscula todos los caracteres para evitar cualquier error en los procesos que distinguen entre mayúsculas y minúsculas, mediante el uso del comando lower().
Seguidamente eliminamos los signos de puntuación, como puntos, comas, exclamaciones, interrogaciones, entre muchos otros. Para la eliminación de estos recurriremos a la cadena preinicializada string.punctuacion de la librería string, que devuelve un conjunto de símbolos considerados signos de puntuación. Además, debemos eliminar las tabulaciones, saltos de carro y espacios extra, que no aportan información en este análisis, mediante el uso de expresiones regulares.
Es fundamental aplicar todos estos pasos en una única función para que se procesen de forma secuencial, debido a que todos los procesos están altamente relacionados.
# Eliminamos los signos de puntuación, los saltos de carro/tabulaciones y espacios en blanco extra.# Para ello generamos una función en la cual indicamos todos los cambios que queremos aplicar al texto.def limpiar_texto(texto): texto = texto.lower() texto = re.sub(\"\\[.*?¿\\]\\%\", \" \", texto) texto = re.sub(\"[%s]\" % re.escape(string.punctuation), \" \", texto) texto re.sub(\"\\w*\\d\\w*\", \" \", texto) return texto# Aplicamos los cambios al texto.limpiar_texto = lambda x: limpiar_texto(x)post_clean = pd.DataFrame(post_clean.texto.apply/limpiar_texto)b) Tokenizar
Una vez que hemos eliminado el ruido en los textos con los cuales vamos a trabajar, “tokenizaremos” en palabras cada uno de los textos. Para ello utilizaremos la funció split(), usando como separador entre palabras, el espacio. Esto permitirá separar las palabras de manera independiente (tokens) para análisis futuros.
# Tokenizar los textos. Se crea una nueva columna en la tabla con los tokens con el texto \"tokenizado\".def tokenizar(text): text = texto.split(sep = \" \") return(text)post_df[\"texto_tokenizado\"] = post_df[\"texto\"].apply(lambda x: tokenizar(x))c) Eliminación de \"stop words\"
Después de eliminar los signos de puntuación y otros elementos que pueden distorsionar la visualización objetivo, eliminaremos las “stop words” o palabras vacías. Para la realización de este paso usamos una lista de stop words del castellano dado que cada idioma posee su propia lista. Esta lista consta de un total de 608 palabras, en las que se incluyen artículos, preposiciones, verbos copulativos, adverbios, entre otros y está actualizada recientemente. Esta lista puede descargarse desde la cuenta de GitHub de datos.gob.es en formato TXT y debe estar ubicada en el directorio de trabajo.
# Leemos el archivo que contiene las palabras vacías en castellano.with open \"stop_words_spanish.txt\", encoding = \"UTF8\") as f: lines = f.read().splitlines()En esta lista de palabras, incluiremos nuevas palabras que no aportan información relevante a nuestros textos o aparecen recurrentemente debido al contexto de los mismos. En este caso, existe una serie de palabras, que nos conviene eliminar ya que están presentes en todos los posts de manera repetitiva dado que todos tratan sobre el tema de datos abiertos y existe una alta probabilidad de que éstas sean las palabras más significativas. Algunas de estas palabras son, “datos”, “dato”, “abiertos”, “caso”, entre otras. Esto permitirá obtener una representación gráfica más representativa del contenido de cada post.
Por otro lado, una inspección visual de los resultados obtenidos permite detectar palabras o caracteres derivados de errores incluidos en los textos, que evidentemente no tienen significado y que no han sido eliminados en los pasos anteriores. Estos, deben ser retirados del análisis para que no distorsionen los resultados posteriores. Se trata de palabras como, “nen”, “nun” o “nla”.
# Actualizamos nuestra lista de stop words.stop_words.extend((\"caso\", \"forma\",\"unido\", \"abiertos\", \"post\", \"espera\", \"datos\", \"dato\", \"servicio\", \"nun\", \"día\", \"nen\", \"data\", \"conjuntos\", \"importantes\", \"unido\", \"unión\", \"nla\", \"r\", \"n\"))# Eliminamos las stop words de nuestra tabla.post_clean = post_clean [~(post_clean[\"texto_tokenizado\"].isin(stop_words))]d) Vectorización
Las maquinas no son capaces de comprender palabras y oraciones, por lo que estas deben convertirse en alguna estructura numérica. El método consiste en generar vectores a partir de cada token. En este post utilizamos una técnica sencilla conocida como bolsa de palabras (BoW). Consiste en asignar un peso a cada token proporcional a la frecuencia de aparición de dicho token en el texto. Para ello, trabajamos sobre una matriz en la que cada fila representa un texto y cada columna un token. Para realizar la vectorización recurriremos a los comandos CountVectorizer() y TfidTransformer() de la lirería Scikit-Learn.
La función CountVectorizer() permite transformar un texto en un vector de frecuencias o recuentos de palabras. En este caso obtendremos 6 vectores con tantas dimensiones como tokens hay en cada texto, uno por cada post, que integraremos en una única matriz, donde las columnas serán los tokens o palabras y las filas serán los posts.
# Calculamos la matriz de frecuencia de palabras del texto.vectorizador = CountVectorizer()post_vec = vectorizador.fit_transform(post_clean.texto_tokenizado)Una vez generada la matriz de frecuencia de palabras, es necesario convertirla en una forma vectorial normalizada con el objetivo de reducir el impacto de los tokens que ocurren con mucha frecuencia en el texto. Para ello utilizaremos la función TfidfTransformer().
# Convertimos una matriz de frecuencia de palabras en una forma vectorial regularizada.transformer = TfidfTransformer()post_trans = transformer.fit_transform(post_vec).toarray()Si quieres saber más sobre la importancia de aplicar está técnica, encontrarás numerosos artículos en Internet que hablan sobre ello y lo relevante que es, entre otras cuestiones, para la optimización de SEO.
5. Creación de la nube de palabras
Una vez que hemos realizado un preprocesamiento del texto, como indicábamos al inicio del post, es posible realizar tareas propias de PLN. En este ejercicio crearemos una nube de palabras o “WordCloud” para cada uno de los textos analizados.
Una nube de palabras, es una representación visual de las palabras con mayor número de ocurrencias en el texto. Permite detectar de manera sencilla la frecuencia e importancia de cada una de las palabras, facilitando la identificación de las palabras clave y descubriendo con un solo golpe de vista la temática principal tratada en el texto.
Para ello vamos a utilizar la librería “wordcloud” que incorpora las funciones necesarias para construir cada representación. En primer lugar, debemos indicar las características que presentará cada nube de palabras, como es el color de fondo (función background_color), el mapa de colores que tomaran las palabras (función colormap), el tamaño máximo de letra (función max_font_size) o fijar una semilla para que la nube de palabras generada siempre sea igual (función random_state) en futuras ejecuciones. Podemos aplicar estas y muchas otras funciones para personalizar cada nube de palabras.
# Indicamos las características que presentará cada nube de palabras.wc = WordCloud(stopwords = stop_words, background_color = \"black\", colormap = \"hsv\", max_font_size = 150, random_state = 123)Una vez que hemos indicado las características que queremos que presente cada nube de palabras, procedemos a crearla y guardarla como imagen en formato PNG. Para generar la nube de palabras, usaremos un bucle en el cual le indicaremos diferentes funciones de la librería matplotlib (representada por el prefijo plt) necesarias para generar gráficamente la nube de palabras según la especificación definida en el paso anterior. Debemos indicarle que debe realizar una nube de palabras por cada fila de la tabla, es decir por cada texto, con la función plt.subplot(). Con el comando plt.imshow() indicamos que el resultado es una imagen en 2D. Si queremos que no se muestren los ejes debemos indicárselo con la función plt.axis(). Por último, con la función plt.savefig() guardaremos la visualización generada.
# Generamos las nubes de palabras para cada uno de los posts.for index, i in enumerate(post.columns): wc.generate(post.texto_tokenizado[i]) plt.subplot(3, 2, index+1 plt.imshow(wc, interpolation = \"bilinear\") plt.axis(\"off\") plt.savefig(\"imagenes/.png\")# Mostramos las nubes de palabras resultantes.plt.show()La visualización obtenida es:

Visualización de las nubes de palabras obtenidas a partir de los textos de diferentes posts de la sección de blog de datos.gob.es
5. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Las nubes de palabras son una herramienta que permite agilizar el análisis de datos textuales, puesto que a través de ellas podemos identificar e interpretar de manera rápida y sencilla las palabras con mayor relevancia en el texto analizado, lo que nos da una idea de la temática.
Si quieres aprender más sobre el Procesamiento del Lenguaje Natural, puedes consultar la guía \"Tecnologías emergentes y datos abiertos: Procesamiento del lenguaje natural\" y los posts \"Procesamiento del lenguaje natural\" y \"Lo último en procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cuentos de palabras\".
Esperemos que esta visualización paso a paso te haya enseñado algunas cosas sobre los entresijos del Procesamiento del Lenguaje Natural y la creación de nubes de palabras. Volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
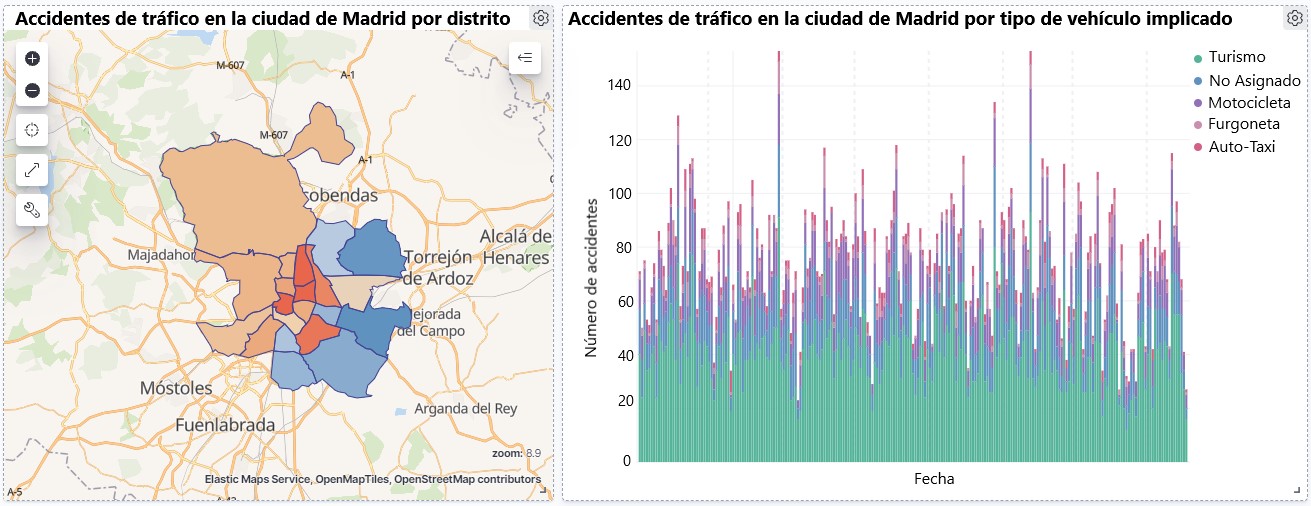
Visualización sobre la accidentalidad de tráfico ocurrida en la ciudad de Madrid, por distrito y tipo de vehículo
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos disponibles en este portal. Para este ejercicio práctico hemos escogido un conjunto de datos que abarca una amplio periodo temporal y que contiene información relevante sobre el registro de accidentes de tráfico que ocurren en la ciudad de Madrid. A partir de estos datos observaremos cuál es el tipo de accidentes más comunes en Madrid y la incidencia que en ellos tiene algunas variables como la edad, el tipo de vehículo o la lesividad que produce el accidente.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se ha seleccionado un conjuntos de datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid publicados por el Ayuntamiento de Madrid y que se encuentra disponible en datos.gob.es. Este conjunto de datos contiene una serie temporal que abarca el periodo 2010 hasta 2021 con diferentes desagregaciones que facilitan el análisis de las características que presentan los accidentes de tráfico ocurridos, entre otras, las condiciones ambientales en las que se produjo cada siniestro o el tipo de accidente. La información de la estructura de cada archivo de datos está disponible en documentos que abarcan el periodo 2010-2018 y 2019 en adelante. Cabe destacar que existen inconsistencias en los datos antes y después del año 2019, ya que la estructura de datos varía. Esta es una situación bastante habitual a la que deben enfrentarse los analistas de datos a la hora de abordar las tareas de preprocesamiento de los datos con los que se trabajará posteriormente, derivada de la carencia de una estructura homogénea de los datos a lo largo del tiempo. Por ejemplo, alteración del número de variables, modificación del tipo de variables o cambios a diferentes unidades de medida. Esta es una razón de peso que justifica la necesidad de acompañar cada conjunto de datos abiertos de un completo documento que explique su estructura.
3.2. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
R es un lenguaje de programación open source orientado a objetos e interpretado, creado inicialmente para la computación estadística y la creación de representaciones gráficas. En la actualidad, es una herramienta muy poderosa para todo tipo de procesamiento y manipulación de datos que está permanentemente actualizada. Además dispone de un entorno de programación, RStudio, también open source.
Para la creación de la visualización interactiva se ha utilizado la herramienta Kibana.
Kibana es una herramienta open source que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstash y Kibana) que permite la creación de visualización y la exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres saber más sobre estas herramientas u otras que puedan ayudarte en el procesado de datos y la creación de visualizaciones interactivas, puedes consultar el informe \"Herramientas de procesado y visualización de datos\".
4. Tratamiento de datos
Para la realización de los análisis y visualizaciones posteriores, es necesario preparar los datos de una forma adecuada, para que los resultados obtenidos sean consistentes y efectivos. Debemos realizar un análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer y comprender los datos con los cuales queremos trabajar. El objetivo principal de este pre-procesamiento de los datos es detectar posibles anomalías o errores que pudieran afectar a la calidad de los resultados posteriores e identificar patrones de información contenidos en los datos.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo click en el botón de \"Código\" de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren forma alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de texto plano, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
Para el desarrollo de este análisis necesitamos instalar una serie de paquetes de R adicionales a la distribución base, incorporando al entorno de trabajo las funciones y objetos definidos por ellas. Hay muchos paquetes disponibles en R pero las más adecuadas para trabajar con este conjunto de datos son: tidyverse, lubridate y data.table. tidyverse es una colección de paquetes de R (contiene a su vez otros paquetes como dplyr, ggplot2, readr, etc) diseñados específicamente para trabajar en Data Science, que facilitar la carga y tratamiento de datos, y las representaciones gráficas, entre otras funcionalidades esenciales para el análisis de datos, pero que requiere un conocimiento progresivo para obtener el máximo partido de los paquetes que integra. Por otro lado, el paquete lubridate lo usaremos para el manejo de variables tipo fecha y por último el paquete data.table permite realizar una gestión más eficiente de conjuntos de datos grandes. Estos paquetes será preciso descargarlos e instalarlos en el entorno de desarrollo.
#Lista de librerías que queremos instalar y cargar en nuestro entorno de desarrollo librerias <- c(\"tidyverse\", \"lubridate\", \"data.table\")#Descargamos e instalamos las librerías en nuestros entorno de desarrollo package.check <- lapplay (librerias, FUN = function(x) { if (!require (x, character.only = TRUE)) { install.packages(x, dependencies = TRUE) library (x, character.only = TRUE } }4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros CSV. Como queremos realizar un análisis de varios años debemos descargar y cargar en nuestro entorno de desarrollo todos los conjuntos de datos que nos interesen.
Para ello, generamos el directorio de trabajo \"datasets\", donde descargaremos todos los conjuntos de datos. Usamos dos listas, una con todas las URLs donde se encuentran localizados los datasets y otra con los nombres que asignamos a cada fichero guardado en nuestra maquina, con ello facilitamos posteriores referencias a estos ficheros.
#Generamos una carpeta en nuestro directorio de trabajo para guardar los datasets descargadosif (dir.exists(\".datasets\") == FALSE)#Nos colocamos dentro de la carpetasetwd(\".datasets\")#Listado de los datasets que nos interese descargardatasets <- c(\"https://datos.madrid.es/egob/catalogo/300228-10-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-11-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-12-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-13-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-14-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-15-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-16-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-17-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-18-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-19-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-21-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-22-accidentes-trafico-detalle.csv\")#Descargamos los datasets de interésdt <- list()for (i in 1: length (datasets)){ files <- c(\"Accidentalidad2010\", \"Accidentalidad2011\", \"Accidentalidad2012\", \"Accidentalidad2013\", \"Accidentalidad2014\", \"Accidentalidad2015\", \"Accidentalidad2016\", \"Accidentalidad2017\", \"Accidentalidad2018\", \"Accidentalidad2019\", \"Accidentalidad2020\", \"Accidentalidad2021\") download.file(datasets[i], files[i]) filelist <- list.files(\".\") print(i) dt[i] <- lapply (filelist[i], read_delim, sep = \";\", escape_double = FALSE, locale = locale(encoding = \"WINDOWS-1252\", trim_ws = \"TRUE\") }b. Creación de la tabla de trabajo
Una vez que tenemos todos los conjuntos de datos cargados en nuestro entorno de desarrollo, creamos una única tabla de trabajo que integra todos los años de la serie temporal.
Accidentalidad <- rbindlist(dt, use.names = TRUE, fill = TRUE)Una vez generada la tabla de trabajo, debemos solucionar uno de los problemas más comunes en todo preprocesamiento de datos: la inconsistencia en el nombre de las variables en los diferentes ficheros que componen la serie temporal. Esta anomalía produce variables con nombres diferentes, pero sabemos que representan la misma información. En este caso porque está explicado en el diccionario de datos descrito en la documentación de los archivos, si no fuese así, es necesario recurrir a la observación y exploración descriptiva de los archivos. En este caso, la variable \"RANGO EDAD\" que presenta datos desde 2010 hasta 2018 y la variable \"RANGO DE EDAD\" que presenta los mismos datos pero desde el año 2019 hasta 2021 son diferentes. Para solucionar esta problemática debemos unificar las variables que presentan esta anomalía en una única variable.
#Con la función unite() unimos ambas variables. Debemos indicarle el nombre de la tabla, el nombre que queremos asignarle a la variable y la posición de las variables que queremos unificar. Accidentalidad <- unite(Accidentalidad, LESIVIDAD, c(25, 44), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, NUMERO_VICTIMAS, c(20, 27), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, RANGO_EDAD, c(26, 35, 42), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, TIPO_VEHICULO, c(20, 27), remove = TRUE, na.rm = TRUE)Una vez que tenemos la tabla con la serie temporal completa, generamos una nueva tabla contiendo únicamente las variables que nos interesan para realizar la visualización interactiva que queremos desarrollar.
Accidentalidad <- Accidentalidad %>% select (c(\"FECHA\", \"DISTRITO\", \"LUGAR ACCIDENTE\", \"TIPO_VEHICULO\", \"TIPO_PERSONA\", \"TIPO ACCIDENTE\", \"SEXO\", \"LESIVIDAD\", \"RANGO_EDAD\", \"NUMERO_VICTIMAS\") c. Transformación de variables
A continuación, examinamos el tipo de variables y valores para transformar los tipos que sea necesario para poder realizar futuras agregaciones, gráficos o diferentes análisis estadísticos.
#Re-ajustar la variable tipo fechaAccidentalidad$FECHA <- dmy (Accidentalidad$FECHA #Re-ajustar el resto de variables a tipo factor Accidentalidad$'TIPO ACCIDENTE' <- as.factor(Accidentalidad$'TIPO.ACCIDENTE')Accidentalidad$'Tipo Vehiculo' <- as.factor(Accidentalidad$'Tipo Vehiculo')Accidentalidad$'TIPO PERSONA' <- as.factor(Accidentalidad$'TIPO PERSONA')Accidentalidad$'Tramo Edad' <- as.factor(Accidentalidad$'Tramo Edad')Accidentalidad$SEXO <- as.factor(Accidentalidad$SEXO)Accidentalidad$LESIVIDAD <- as.factor(Accidentalidad$LESIVIDAD)Accidentalidad$DISTRITO <- as.factor (Accidentalidad$DISTRITO)d. Generación de nuevas variables
Vamos a dividir la variable \"FECHA\" en una jerarquía de variables de tipo fecha, \"Año\", \"Mes\" y \"Día\". Esta acción es muy común en la analítica de datos, ya que en muchas ocasiones interesa analizar otros rangos de tiempo, por ejemplo, años, meses, semanas y cualquier otra unidad de tiempo, o necesitamos generar agregaciones a partir del día de la semana.
#Generación de la variable AñoAccidentalidad$Año <- year(Accidentalidad$FECHA)Accidentalidad$Año <- as.factor(Accidentalidad$Año) #Generación de la variable MesAccidentalidad$Mes <- month(Accidentalidad$FECHA)Accidentalidad$Mes <- as.factor(Accidentalidad$Mes)levels (Accidentalidad$Mes) <- c(\"Enero\", \"Febrero\", \"Marzo\", \"Abril\", \"Mayo\", \"Junio\", \"Julio\", \"Agosto\", \"Septiembre\", \"Octubre\", \"Noviembre\", \"Diciembre\") #Generación de la variable DiaAccidentalidad$Dia <- month(Accidentalidad$FECHA)Accidentalidad$Dia <- as.factor(Accidentalidad$Dia)levels(Accidentalidad$Dia)<- c(\"Domingo\", \"Lunes\", \"Martes\", \"Miercoles\", \"Jueves\", \"Viernes\", \"Sabado\")e. Detección y tratamiento de datos perdidos
La detección y tratamiento de datos perdidos (NAs) es esencial para poder procesar de manera adecuada las variables que contiene la tabla, ya que la ausencia de datos puede ocasionar problemas a la hora de realizar agregaciones, gráficos o análisis estadísticos.
A continuación analizaremos la ausencia de datos (detección de NAs) en la tabla:
#Suma de todos los NAs que presenta el datasetsum(is.na(Accidentalidad))#Porcentaje de NAs en cada una de las variablescolMeans(is.na(Accidentalidad))Una vez detectados los NAs que presenta el dataset, debemos tratarlos de alguna forma. En este caso, como todas las variables de interés, son categóricas, vamos a completar los valores ausentes por un valor de \"No asignado\", para no perder tamaño muestral e información relevante.
#Sustituimos los NAs de la tabla por el valor \"No asignado\"Accidentalidad [is.na(Accidentalidad)] <- \"No asignado\"f. Asignaciones de niveles en las variables
Una vez que tenemos en la tabla las variables de interés, podemos realizar un examen más exhaustivo de los datos y categorías que presenta cada una de las variable. Si analizamos cada una de manera independiente, podemos observar que algunas de ellas presentan categorías repetidas, simplemente por uso de tildes, caracteres especiales o mayúsculas. Para que las futuras visualizaciones o análisis estadísticos se construyan de manera eficiente y sin errores, vamos a reasignar los niveles a las variables que lo requieran.
Por razones de espacio, en este post solo mostraremos un ejemplo con la variable \"LESIVIDAD\". Esta variable estaba tipificada hasta 2018 con una serie de categorías (IL, HL, HG, MT), mientras que a partir de 2019 se usaron otras categorías (valores del 0 al 14). Afortunadamente esta tarea resulta fácilmente abordable dado que está documentada en la información sobre la estructura que acompaña cada dataset, cuestión, como hemos comentado con anterioridad que no siempre ocurre, lo que dificulta enormemente este tipo de transformaciones de datos.
#Comprobamos las categorías que presenta la variable \"LESIVIDAD\"levels(Accidentalidad$LESIVIDAD)#Asignamos las nuevas categoríaslevels(Accidentalidad$LESIVIDAD)<- c(\"Sin asistencia sanitaria\", \"Herido leve\", \"Herido leve\", \"Herido grave\", \"Fallecido\", \"Herido leve\", \"Herido leve\", \"Herido leve\", \"Ileso\", \"Herido grave\", \"Herido leve\", \"Ileso\", \"Fallecido\", \"No asignado\")#Comprobamos de nuevo las catergorías que presenta la variablelevels(Accidentalidad$LESIVIDAD)4.3. Resumen del dataset
Veamos que variables y estructura presenta el nuevo conjunto de datos tras las transformaciones realizadas:
str(Accidentalidad)summary(Accidentalidad)La salida de estos comandos la omitiremos para simplificar lectura. Las principales características que presenta el conjunto de datos son:
- Está compuesto por 14 variables: 1 variable tipo fecha y 13 variables de tipo categórico.
- El rango temporal abarca desde 01-01-2010 hasta el 31-06-2021 (la fecha final puede variar, ya que el dataset del año 2021 se esta actualizando periódicamente).
- Por cuestiones de espacio en este post, no todas las variables disponibles se han tenido en cuenta para el análisis y la visualización.
4.4. Guardar el dataset generado
Una vez que tenemos el conjunto de datos con la estructura y variables que nos interesan para realizar la visualización de los datos, lo guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos como la que abordamos a continuación. Es importante guardarlo con una codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier software.
write.csv(Accidentalidad, file = Accidentalidad.csv\", fileEncoding=\"UTF-8\")5. Creación de la visualización sobre los accidentes de tráfico que ocurren en la ciudad de Madrid usando Kibana
Para la realización de esta visualización interactiva se ha usado la herramienta Kibana en su versión gratuita sobre nuestro entorno local. Antes de poder realizar la visualización es necesario tener instalado el software y para ello hemos seguido los pasos del tutorial de descarga e instalación proporcionado por la compañía Elastic.
Una vez instalado el software de Kibana, procedemos a desarrollar la visualización interactiva. A continuación se incluyen dos vídeo tutoriales, en los cuales se muestra el proceso de realización de la visualización interactiva y la interacción con la misma.
En este primer vídeo tutorial, se muestra el proceso de desarrollo de la visualización realizando los pasos que se indican a continuación:
- Carga de datos en Elasticsearch, generación de un índice en Kibana que nos permita interactuar con los datos prácticamente en tiempo real e interacción con las variables que presenta el conjunto de datos.
- Generación de las siguientes representaciones gráficas:
- Gráfico de líneas para representar la serie temporal sobre los accidentes de tráfico ocurridos en la ciudad de Madrid.
- Gráfico de barras horizontales mostrando el tipo de accidente más común.
- Mapa temático, mostraremos el número de accidentes que ocurren en cada una de los distritos de la ciudad de Madrid. Para la creación de este visual es necesario la descarga del \"conjunto de datos que contiene los distritos georreferenciados en formato GeoJSON\".
- Construcción del dashboard integrando los visuales generados en el paso anterior.
En este segundo vídeo tutorial mostraremos la interacción con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid desde 2010 hasta junio de 2021, se pueden obtener, entre otras, las siguientes conclusiones:
- El número de accidentes que ocurren en la ciudad de Madrid es estable a lo largo de los años, a excepción del año 2019 donde se observa un fuerte incremento y durante el segundo trimestre de 2020 donde se observa una significativa disminución, que coincide con el período del primer estado de alarma a causa de la pandemia del COVID-19.
- Todos los años se observa una disminución del número de accidentes durante el mes de agosto.
- Los hombres suelen tener un número significativamente mayor de accidentes que las mujeres.
- El tipo de accidente más común es la colisión doble, seguido del atropello a un animal y la colisión múltiple.
- Alrededor del 50% de los accidentes no ocasionan daños a las personas implicadas.
- Los distritos con mayor concentración de accidentes son: el distrito de Salamanca, el distrito de Chamartín y el distrito Centro.
La visualización de datos es una de los mecanismos más potentes para explotar y analizar de manera autónoma el significado implícito de los datos, independientemente del grado del conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Si quieres aprender cómo realizar una predicción sobre la siniestralidad futura de accidentes de tráfico utilizando técnicas de Inteligencia Artificial a partir de estos datos, consulta el post sobre \"Tecnologías emergentes y datos abiertos: Analítica Predictiva\".
Esperamos que os haya gustado este post y volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
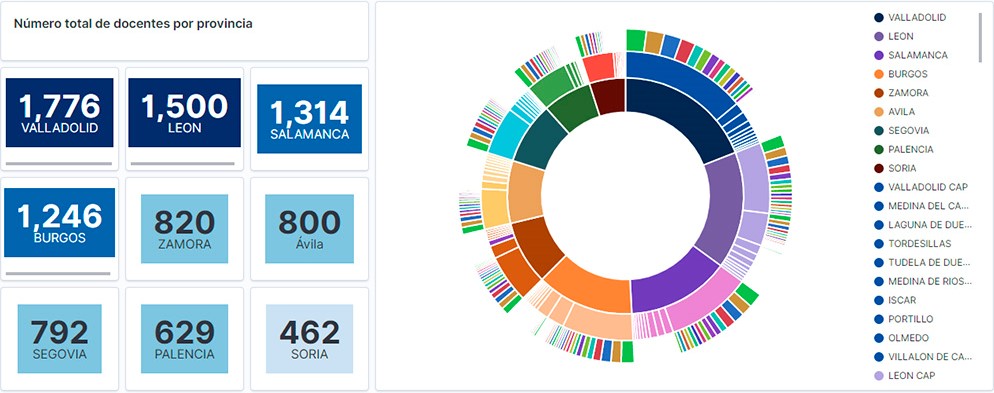
Visualización del personal docente de Castilla y León clasificados por Provincia, Localidad y Especialidad docente
2. Objetivos
El objetivo principal de este post es aprender a tratar un conjunto de datos desde su descarga hasta la creación de uno o varios gráficos interactivos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre los docentes y alumnos matriculados en los centros públicos de Castilla y León durante el año académico 2019-2020. A partir de estos datos se realizan análisis de varios indicadores que relacionan docentes, especialidades y alumnado matriculado en los centros de cada provincia o localidad de la comunidad autónoma.
3. Recursos
3.1. Conjuntos de datos
Para este estudio se han seleccionado conjuntos de datos de la temática Educación publicados por la Junta de Castilla y León, disponibles en el portal de datos abiertos datos.gob.es. Concretamente:
- Dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros, durante el curso académico 2019-2020. Este dataset se encuentra desagregado por especialidad del docente, centro educativo, localidad y provincia.
- Dataset de las matriculaciones de alumnos en centros educativos durante el curso académico 2019-2020. Este conjunto de datos se obtiene a través de una consulta que admite diferentes parámetros de configuración. Las instrucciones para realizarla se encuentran disponibles en el mismo punto de descarga del dataset. El conjunto de datos se encuentra desagregado por centro educativo, localidad y provincia.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado el lenguaje de programación Python (versión 3.7) y JupyterLab (versión 2.2), herramientas que encontrarás integradas en Anaconda, una de las plataformas más populares para instalar, actualizar o administrar software para trabajar con Data Science. Todas estas herramientas son abiertas y están disponibles de forma gratuita.
JupyterLab es una interfaz de usuario basada en web que proporciona un entorno de desarrollo interactivo donde el usuario puede trabajar con los denominados cuadernos Jupyter sobre los que podrás integrar y compartir fácilmente texto, código fuente y datos.
Para la creación de la visualización interactiva se ha usado la herramienta de Kibana (versión 7.10).
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Logstash, Beats y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres conocer más sobre estas herramientas u otras que pueden ayudarte en el tratamiento y la visualización de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son consistentes y confiables.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas! Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de Github. La forma de proporcionar el código es a través de un documento realizado sobre JupyterLab que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla.
4.1. Instalación y carga de librerías
Lo primero que debemos hacer es importar las librerías para el pre-procesamiento de los datos. Hay muchas librerías disponibles en Python pero una de las más populares y adecuada para trabajar con estos conjuntos de datos es Pandas. La librería Pandas es una librería muy popular para manipular y analizar conjuntos de datos.
import pandas as pd 4.2. Carga de datasets
En primer lugar descargamos los conjuntos de datos del catálogo de datos abiertos datos.gob.es y los cargamos en nuestro entorno de desarrollo como tablas para explorarlos y realizar algunas tareas básicas de limpieza y procesado de datos. Para la carga de los datos recurriremos a la función read_csv(), donde le indicaremos la url de descarga del dataset, el delimitador (\";\" en este caso) y, para que interprete correctamente los caracteres especiales como las letras con tildes o \"ñ\" presentes en las cadenas de texto del conjunto de datos, le añadimos el parámetro \"encoding\" que ajustamos al valor \"latin-1\".
#Cargamos el dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros url = \"https://datosabiertos.jcyl.es/web/jcyl/risp/es/educacion/plantillas-centros-educativos/1284922684978.csv\"docentes = pd.read_csv(url, delimiter=\";\", header=0, encoding=\"latin-1\")docentes.head(3)#Cargamos el dataset de los alumnos matriculados en los centros educativos públicos de Castilla y León alumnos = pd.read_csv(\"matriculaciones.csv\", delimiter=\",\", names=[\"Municipio\", \"Matriculaciones\"], encoding=\"latin-1\") alumnos.head(3)La columna \"Municipio\" de la tabla \"alumnos\" está compuesta por el código del municipio y el nombre del mismo. Debemos dividir esta columna en dos, para que su tratamiento sea más eficiente.
columnas_Municipios = alumnos[\"Municipio\"].str.split(\" \", n=1, expand = TRUE)alumnos[\"Codigo_Municipio\"] = columnas_Municipios[0]alumnos[\"Nombre_Munipicio\"] = columnas_Munipicio[1]alumnos.head(3)4.3. Creación de una nueva tabla
Una vez que tenemos ambas tablas con las variables de interés, creamos una nueva tabla resultado de su unión. La variables de unión serán: \"Localidad\" en la tabla de \"docentes\" y \"Nombre_Municipio\" en la de \"alumnos\".
docentes_alumnos = pd.merge(docentes, alumnos, left_on = \"Localidad\", right_on = \"Nombre_Municipio\")docentes_alumnos.head(3)4.4. Exploración del conjunto de datos
Una vez que disponemos de la tabla que nos interesa, debemos dedicar un tiempo a explorar los datos e interpretar cada variable. En estos casos es de enorme utilidad disponer del diccionario de datos que siempre debe acompañar a cada dataset descargado para conocer todos sus detalles, pero en esta ocasión no disponemos de esta esencial herramienta. Observando la tabla, además de interpretar las variables que lo integran (tipos de datos, unidades, rangos de valores), podemos detectar posibles errores como variables mal tipificadas o la presencia de valores perdidos (NAs) que pueden restar capacidad de análisis.
docentes_alumnos.info()En la salida de esta sección de código, podemos observar las principales características que presenta la tabla:
- Contiene un total de 4.512 registros
- Está compuesto de 13 variables, 5 variables numéricas (de tipo entero) y 8 variables de tipo categórico (tipo \"object\")
- No hay ausencia de valores.
Una vez que conocemos la estructura y contenido de la tabla, debemos rectificar errores, como es el caso de la transformación de algunas de las variables que no están tipificadas de manera adecuada, por ejemplo, la variable que alberga el código del centro (\"Código.centro\").
docentes_alumnos.Codigo_centro = data.Codigo_centro.astype(\"object\")docentes_alumnos.Codigo_cuerpo = data.Codigo_cuerpo.astype(\"object\")docentes_alumnos.Codigo_especialidad = data.Codigo_especialidad.astype(\"object\")Una vez que tenemos la tabla libre de errores, obtenemos una descripción de las variables numéricas, \"Plantilla\" y \"Matriculaciones\", que nos ayudará a conocer detalles importantes. En la salida del código que presentamos a continuación observamos la media, la desviación estándar, el número máximo y mínimo, entre otros descriptores estadísticos.
docentes_alumnos.describe()4.5. Guardar el dataset
Una vez que tenemos la tabla libre de errores y con las variables que nos interesa graficar, lo guardaremos en una carpeta de nuestra elección para usarla posteriormente en otras herramientas de análisis o visualización. Lo guardaremos en formato CSV codificada como UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta que usemos posteriormente.
df = pd.DataFrame(docentes_alumnos)filname = \"docentes_alumnos.csv\"df.to_csv(filename, index = FALSE, encoding = \"utf-8\")5. Creación de la visualización sobre los docentes de los centro educativos públicos de Castilla y León usando la herramienta Kibana
Para la realización de esta visualización hemos usado la herramienta Kibana en nuestro entorno local. Para realizarla es necesario tener instalado y en funcionamiento Elasticsearch y Kibana. La compañía Elastic nos pone a disposición toda la información sobre la descarga e instalación en este tutorial.
A continuación se adjuntan dos vídeo tutoriales, donde se muestra el proceso de realización de la visualización y la interacción con el dashboad generado.
En este primer vídeo, podrás ver la creación del cuadro de mando (dashboard) mediante la generación de diferentes representaciones gráficas, siguiendo los siguientes pasos:
- Cargamos la tabla de datos previamente procesados en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
- Gráfico de sectores donde mostrar la plantilla docente por provincia, localidad y especialidad.
- Métricas del número de docentes por provincia.
- Gráfico de barras, donde mostraremos el número de matriculaciones por provincia.
- Filtro por provincia, localidad y especialidad docente.
- Construcción del dashboard.
En este segundo vídeo, podrás observa la interacción con el cuadro de mando (dashboard) generado anteriormente.
6. Conclusiones
Observando la visualización de los datos sobre el número de docentes de los centros educativos públicos de Castilla y León, en el curso académico 2019-2020, se pueden obtener, entre otras, las siguientes conclusiones:
- La provincia de Valladolid es la que posee el mayor número de docentes e igualmente, el mayor número de alumnos matriculados. Mientras que Soria es la provincia con menor número de docentes y menor número de alumnos matriculados.
- Como era de esperar, las localidades que presentan mayor número de docentes son las capitales de provincia.
- En todas las provincias, la especialidad con mayor número de alumnos es Inglés, seguida de Lengua Castellana y Literatura y Matemáticas.
- Llama la atención, que la provincia de Zamora, aunque posee un número bajo de alumnos matriculados, está en quinta posición en el número de docentes.
Esta sencilla visualización nos ha ayudado a sintetizar una gran cantidad de información y a obtener una serie de conclusiones a golpe de vista, y si fuera necesario tomar decisiones en función de los resultados obtenidos. Esperamos que os haya resultado útil este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!