Blog
Los datos son una pieza clave en la economía digital europea. Así lo reconoce la Estrategia de Datos cuyo objetivo es crear un mercado único que permita su libre circulación para fomentar así la transformación digital y la innovación tecnológica. No obstante, alcanzar este objetivo conlleva superar diferentes obstáculos. Uno de los más destacados es la desconfianza que la ciudadanía puede sentir respecto al proceso.
Como respuesta ante esta necesidad, surge la Ley de Gobernanza del Dato o Data Governance Act (DGA), un instrumento horizontal que busca regular la reutilización de datos sobre los que concurren derechos de terceros, e impulsar su intercambio bajo los principios y valores de la Unión Europea. Entre los objetivos de la DGA se encuentra reforzar la confianza de ciudadanos y empresas en que sus datos se reutilicen bajo su control, conforme a unos mínimos estándares jurídicos.
Entre otras cuestiones, la DGA profundiza en el concepto de los intermediarios de datos, para quienes establece un marco de notificación y supervisión.
¿Qué son los intermediarios de datos?
El concepto de intermediario de datos es relativamente nuevo en la economía de datos, así que existen múltiples definiciones. Si nos centramos en el contexto de la DGA, los proveedores de servicios de intermediación de datos (Data Intermediation Services Providers o DISPs) son aquellos “cuyo objeto sea establecer relaciones comerciales para el intercambio de datos entre un número indeterminado de interesados y titulares de datos, por una parte, y usuarios de datos, por otra”.
La Data Governance Act también diferencia entre los Proveedores de servicios de intermediación de datos de las Organizaciones de gestión de datos con fines altruistas reconocidas en la Unión (Data Altruism Organisations Recognised in the Union o RDAOs). Este último concepto describe una relación de intercambio de datos, pero sin buscar un rédito por ello, de forma altruista.

¿Qué tipos de servicios de intermediación de datos existen según la DGA?
Los servicios de intermediarios de datos son una pieza más en la compartición de datos, ya que facilitan a los titulares compartir sus datos para que puedan ser reutilizados. También pueden proporcionar infraestructura técnica y experiencia para respaldar la interoperabilidad entre conjuntos de datos, o actuar como mediadores que negocian acuerdos de intercambio entre partes interesadas en compartir, acceder o agrupar datos.
En el Capítulo III de la Data Governance Act se explican tres tipos de servicios de intermediación de datos:
- Servicios de intermediación entre titulares de datos y sus posibles usuarios, incluyendo la facilitación de los medios técnicos o de otro tipo para habilitar dichos servicios. Podrán comprender el intercambio bilateral o multilateral de datos, así como la creación de plataformas, bases de datos o infraestructuras que posibiliten su intercambio o uso común.
- Servicios de intermediación entre personas físicas que deseen poner a disposición sus datos, ya sean o no personales, con posibles usuarios, incluyendo también los medios técnicos. Estos servicios deben posibilitar el ejercicio de los derechos de los interesados previstos en el Reglamento general de protección de datos (Reglamento 2016/679).
- Cooperativas de datos. Son estructuras organizativas constituidas por sujetos de datos, empresas unipersonales o pymes. Estas entidades ayudan a los miembros de la cooperativa a ejercer sus derechos sobre sus datos.
En resumen, el primer tipo de servicio puede facilitar el intercambio de datos industriales, el segundo se centra principalmente en el intercambio de datos personales y el tercero abarca el intercambio colectivo de datos y los esquemas de gobernanza relacionados.
Categorías de intermediarios de datos en detalle:
Para profundizar en estos conceptos, la Comisión Europea ha publicado el informe ‘Mapping the landscape of data intermediaries’, donde se profundiza en los tipos de intermediación de datos existentes. Los hallazgos del informe resaltan la fragmentación y heterogeneidad del campo.
Los tipos de intermediarios de datos van desde los individualistas y orientados a los negocios hasta modelos más colectivos e inclusivos que respaldan una mayor participación en la gobernanza de datos por parte de comunidades y sujetos de datos individuales. Teniendo en cuenta las categorías que se incluyen en la DGA, se describen seis tipos de intermediarios de datos:
| Tipos de servicios de intermediación de datos según al DGA |
Equivalencia en el informe “Mapping the landscape of data intermediaries” |
|---|---|
| Servicios de intermediación entre titulares de datos y posibles usuarios de datos (I) |
|
| Servicios de intermediación entre sujetos de datos o individuos y usuarios de datos (II) |
|
| Cooperativas de datos (III) |
|
Fuente: Traducción del box 4 del informe Mapping the landscape of data intermediaries publicado por la Comisión Europea
A continuación, se describe cada uno de ellos:
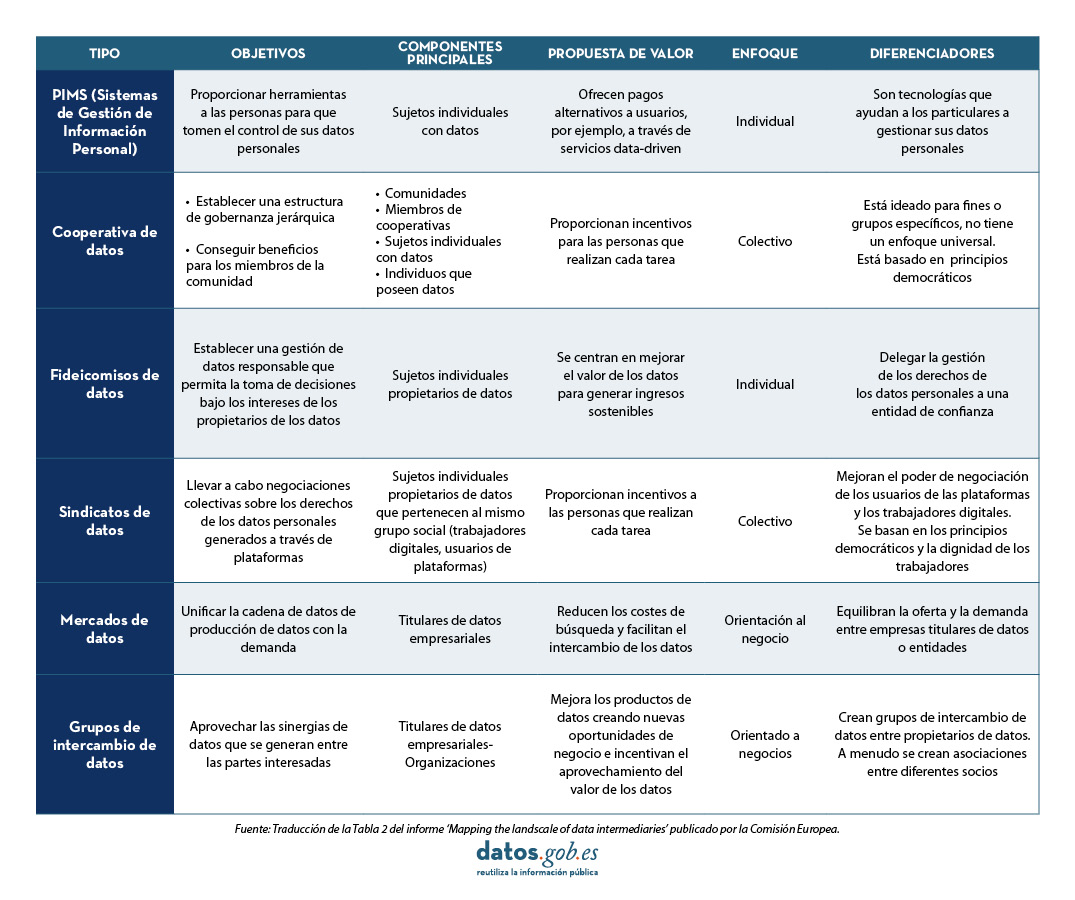
- Sistemas de Gestión de Información Personal (PIMS): proporciona herramientas a individuos para que controlen y dirijan el tratamiento de sus datos.
- Cooperativas de datos: fomentan la gobernanza democrática a través de acuerdos entre los miembros. Los individuos gestionan sus datos en favor de toda la comunidad.
- Fideicomisos de datos: establecen mecanismos jurídicos específicos para garantizar la gestión responsable e independiente de los datos entre dos entidades, un intermediario que administra los datos y sus derechos, y un beneficiario y propietario de los datos.
- Sindicatos de datos: son uniones sectoriales o territoriales entre distintos propietarios de datos que gestionan y protegen los derechos sobre los datos personales generados a través de plataformas tanto por usuarios como por trabajadores.
- Mercados de datos: impulsan plataformas que permiten poner en contacto la oferta y la demanda de datos o productos/servicios basados en ellos.
- Grupos de intercambio de datos: son alianzas entre partes interesadas en la compartición de datos para mejorar sus activos (productos de datos, procesos y servicios) aprovechando la complementariedad de los datos puestos en común.
Los tipos de intermediarios de datos difieren según varios parámetros, pero son complementarios y pueden superponerse en ciertos aspectos. Para cada tipo de intermediario de datos presentado, el informe proporciona información sobre cómo funciona, sus características principales, ejemplos seleccionados y consideraciones sobre el modelo de negocio.
Requisitos para los intermediarios de datos en la Unión Europea
La DGA establece reglas de juego para garantizar que los proveedores de servicios de intercambio de datos realizan sus servicios bajo los principios y valores de la Unión Europea (UE). Los proveedores estarán sometidos al ordenamiento jurídico del Estado miembro donde tenga su sede principal. Si se trata de un proveedor no establecido en la UE, debe designar un representante legal en uno de los Estados miembros en los que se ofrezca sus servicios.
Todo proveedor de servicios de intermediación de datos que opere en la UE deberá notificarlo a la autoridad competente. Dicha autoridad será designada por cada Estado y velará porque el proveedor realice su actividad bajo el cumplimiento de las leyes. La notificación incluirá información sobre el nombre del proveedor, naturaleza jurídica (incluyendo información sobre la estructura y las filiales), dirección, sitio web con información sobre sus actividades, persona de contacto y estimación de la fecha de inicio de la actividad. Además, deberá incluir una descripción del servicio de intermediación de datos que lleva a cabo, indicando a la categoría detallada en la DGA a la que pertenecen, es decir, servicios de intermediación entre titulares de datos y usuarios, servicios de intermediación entre sujetos de datos o individuos y usuarios de datos o cooperativas de datos.
Además, en su artículo 12, la DGA estable una serie de condiciones para la prestación de servicios de intermediación de datos. Por ejemplo, los proveedores no podrán utilizar los datos en relación con los que presten sus servicios, sino que se limitarán a su puesta a disposición. Así mismo, deberán respetar los formatos originales y solo podrán hacer transformaciones para mejorar su interoperabilidad. También deberán disponer procedimientos para impedir prácticas fraudulentas o abusivas de los usuarios. Con todo ello se busca garantizar que los servicios sean neutrales, transparentes y no discriminatorios.
Escenarios futuros para los intermediarios de datos
De acuerdo con el informe “Mapping the landscape of data intermediaries”, en el horizonte, el escenario previsto para los intermediarios de datos conlleva superar diversos desafíos:
- Identificar modelos de negocio adecuados que garanticen la sostenibilidad económica.
- Ampliar la demanda de los servicios de intermediación de datos.
- Comprender el requisito de neutralidad establecido por la DGA y cómo podría implementarse.
- Alinear los intermediarios de datos con otros instrumentos de la política de datos de la UE.
- Considerar las necesidades de los desarrolladores y emprendedores.
- Suplir la demanda de los intermediarios de datos.
Para consolidar los intermediarios de datos habrá que seguir realizando más investigaciones que ayuden a definir más profundamente el concepto de intermediarios de datos. Este proceso conllevará evaluar las necesidades de desarrolladores y empresarios sobre asuntos económicos, legales y técnicos que desempeñan un papel en el establecimiento de intermediarios de datos, los incentivos tanto para el lado de la oferta como de la demanda de intermediarios de datos, y las posibles conexiones de estos con otros instrumentos de políticas de datos de la UE.
Aplicación
Esta aplicación móvil desarrollada por el Ayuntamiento de Ourense permite consultar información actualizada sobre la ciudad: noticias, avisos o próximos eventos sobre diferentes temáticas como:
-
Artes y festejos: Eventos culturales organizados por el ayuntamiento.
-
Turismo: Información sobre instalaciones termales, atracciones turísticas, patrimonio, rutas y gastronomía.
-
Avisos: Notificaciones en tiempo real sobre posibles cortes de tráfico, apertura de monumentos u otras cuestiones puntuales.
-
Información: Datos de interés general como números de teléfono de emergencias o atención al ciudadano del ayuntamiento.
La app mOUbil, desarrollada mediante conjuntos de datos abiertos locales, unifica toda la información de interés para los vecinos y vecinas de Ourense, así como los turistas que quieran conocer la ciudad. Además, cualquier persona puede realizar sugerencias de mejora sobre la aplicación a través de este formulario: Consultas y Sugerencias (ourense.gal)
Su descarga está disponible tanto para Android mOUbil - Ourense no peto! - Aplicaciones en Google Play como iOS: moubil - Ourense no peto! en App Store (apple.com)
Blog
Vivimos un momento histórico en el que los datos son un activo clave, del que dependen cada día multitud de pequeñas y grandes decisiones de empresas, organismos públicos, entidades sociales y ciudadanos. Por ello, es importante conocer de donde proviene cada dato, para garantizar que las cuestiones que afectan a nuestra vida están basadas en información veraz.
¿Qué es la citación de datos?
Cuando hablamos de “citar” nos referimos al proceso de indicar qué fuentes externas se han utilizado para crear contenidos. Una cuestión ampliamente recomendable que afecta a todos los datos, incluidos los datos públicos como está recogido en nuestro ordenamiento jurídico. En el caso de los datos ofrecidos por las adminstraciones, el Real Decreto 1495/2011 incluye la necesidad del reutilizador de citar la fuente de origen de la información.
Para ayudar a los usuarios en esta tarea, la Oficina de Publicaciones de la Unión Europea editó Data Citation: A guide to best practice, donde se habla de la importancia de la citación de datos y se recogen recomendaciones de buenas prácticas, así como los retos a superar para citar conjuntos de datos de manera correcta.
¿Por qué es importante la citación de datos?
La guía menciona las razones más relevantes por las que es recomendable llevar a cabo esta práctica:
- El crédito. Crear conjuntos de datos conlleva trabajo. Citar al autor o autores les permite recibir feedback y saber que su trabajo es útil, lo que les anima a seguir trabajando en nuevos conjuntos de datos.
- La transparencia. Cuando los datos se citan, el lector puede acudir a ellos para revisarlos, comprender mejor su alcance y evaluar su idoneidad.
- La integridad. Los usuarios no deben de caer en el plagio. No deben atribuirse el mérito de la creación de conjuntos de datos que no son suyos..
- La reproducibilidad. La citación de los datos permite que una tercera persona pueda intentar reproducir los mismos resultados, utilizando la misma información.
- La reutilización. La citación de datos facilita que cada vez más conjuntos de datos se den a conocer y, por tanto, aumente su uso.
- Minería de textos. Los datos no solo son consumidos por humanos, también pueden serlo por máquinas. Una correcta citación ayudará a las máquinas a comprender mejor el contexto de los conjuntos de datos, amplificando los beneficios de su reutilización.
Buenas prácticas generales
De entre todas las buenas prácticas generales incluidas en la guía, a continuación destacamos algunas de las más relevantes:
- Sé preciso. Es necesario que los datos citados estén definidos con exactitud. La citación de datos debe indicar qué datos concretos se han utilizado de cada conjunto de datos. También es importante señalar si han sido procesados y si provienen directamente del creador o de algún agregador (como un observatorio que ha tomado datos de diversas fuentes).
- Utiliza "identificadores persistentes" (persistent identifiers o PID). Al igual que cada libro que encontramos en una biblioteca tiene su identificador, los conjuntos de datos también pueden (y deben) tenerlo. Los identificadores persistentes son esquemas formales que proporcionan una nomenclatura común, que identifican de manera única los conjuntos de datos, evitando ambigüedades. A la hora de citar conjuntos de datos, es necesario localizarlos y escribirlos como un hipervínculo accionable, sobre el que se puede hacer clic para acceder al conjunto de datos citado y a sus metadatos. Existen diferentes familias de PID, pero la guía destaca dos de las más comunes: el sistema Handle y el identificador de objeto digital (DOI).
- Indica el momento en el que se ha accedido a los datos. Esta cuestión es de gran importancia cuando trabajamos con datos dinámicos (que se actualizan y cambian periódicamente) o continuos (sobre los que se añaden datos adicionales sin modificar los antiguos). En estos casos, es importante citar la fecha de acceso. Además, si es necesario, el usuario puede añadir “snapshots” o instantáneas del conjunto de datos, es decir, copias tomadas en momentos concretos.
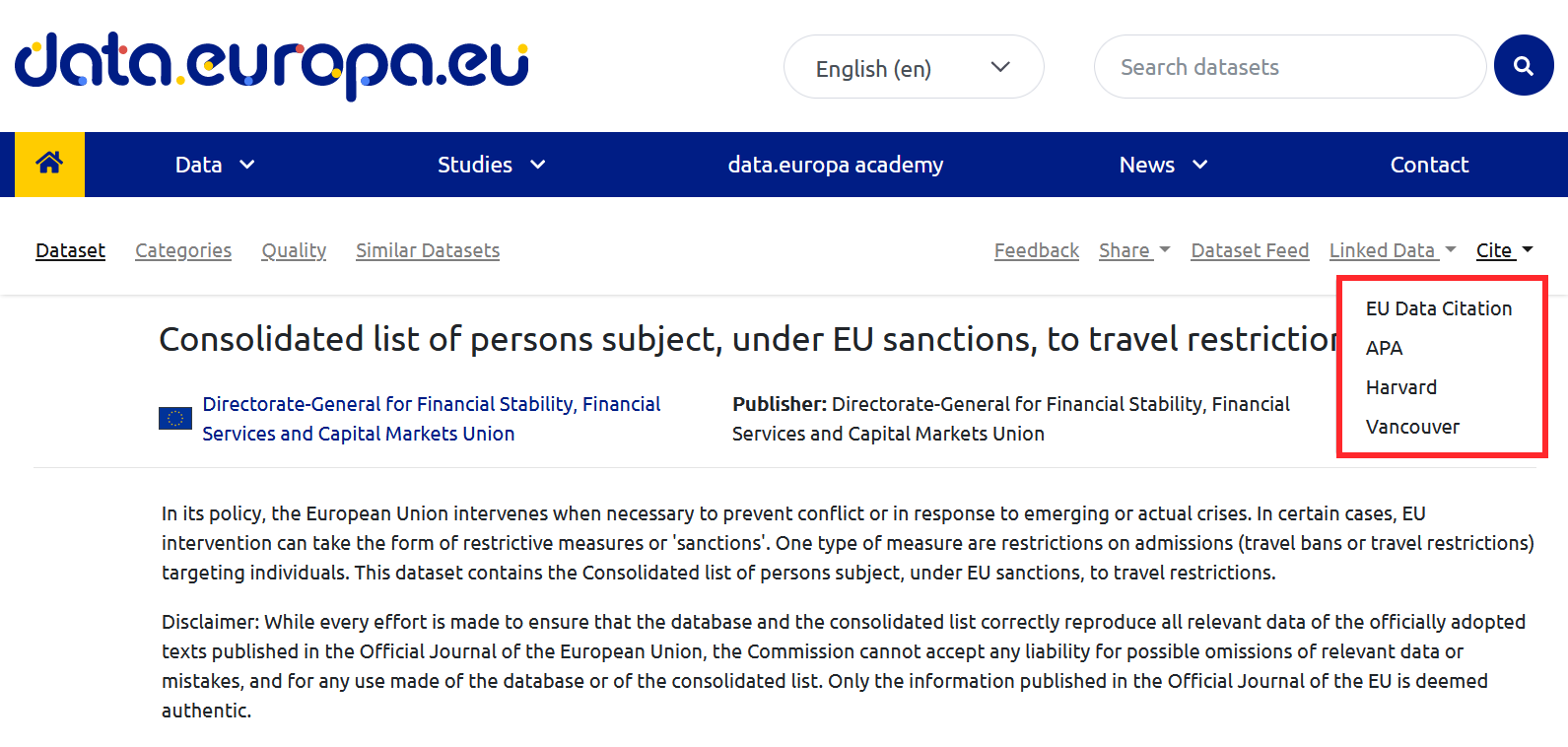
- Consulta los metadatos del conjunto de datos utilizado y las funcionalidades del portal en que se ubica. En los metadatos se encuentra gran cantidad de la información necesaria para la cita.
Además, los portales de datos pueden incluir herramientas que ayuden a la citación. Es el caso del Portal de datos abiertos de la Unión Europea en cuyo menú superior se puede encontrar el botón de citación.
- Apóyate en herramientas de software. La mayoría de los programas informáticos utilizados para crear documentos permiten crear y formatear citas automáticamente, asegurando su formato. Además, existen herramientas específicas de gestión de citas como BibTeX o Mendeley, que permiten crear bases de datos de citas teniendo en cuenta sus peculiaridades, una función de gran utilidad cuando es necesario citar numerosos conjuntos de datos en múltiples documentos.
Cómo citar correctamente
La segunda parte del informe contiene el material técnico de referencia para crear citas que cumplan las recomendaciones indicadas. Abarca los elementos que debe incluir una cita y cómo ordenarlos para distintos fines.
Entre los elementos que debe incluir una cita se encuentran:
- Autor, puede referir tanto al individuo que ha creado el conjunto de datos (autor personal) como a la organización responsable (autor corporativo).
- Título del dataset.
- Versión/edición.
- Publicador, que es la entidad que hace disponible el conjunto de datos y puede coincidir o no con el autor (en caso de que coincidan no es necesario repetirlo).
- Fecha de publicación, donde se indica el año en que se creó. Es importante incluir entre paréntesis el momento de la última actualización.
- Fecha de citación, que expresa la fecha en la que el creador de la cita accedió a los datos, incluyendo la hora si es necesario. Para los formatos de fechas y horas, la guía recomienda acudir a la especificación DCAT, ya que ofrece una precisión mayor en términos de interoperabilidad.
- Identificador persistente.
Respeto al orden de toda esa información, existen diferentes directrices en relación con la estructura general de las citas. La guía muestra las diferentes formas más adecuadas de citar según el tipo de documento en el que aparece la cita (documentos periodísticos, online, etc.), incluyendo ejemplos y recomendación. Entre otros, destaca el ejemplo del Libro de estilo interinstitucional (ISG), que edita la Oficina de Publicaciones de la UE. Este libro de estilo no contiene orientaciones específicas sobre cómo citar datos, pero sí una estructura general para citas que puede aplicarse a los conjuntos de datos, recogida en la siguiente imagen.

La guía finaliza con una serie de anexos con listas de control, diagramas y ejemplos.
Si quieres saber más sobre este documento, te recomendamos ver este seminario online donde se resumen los puntos más importantes.
En definitiva, citar correctamente los conjuntos de datos mejora la calidad y la transparencia del proceso de reutilización de los datos, estimulándolo al mismo tiempo. Por tanto, fomentar la citación correcta de los datos es una práctica no solo recomendable, sino cada vez más necesaria.
Aplicación
ContratosMenores.es es una web que brinda información sobre los contratos menores realizados en España desde enero de 2022. A través de esta aplicación se pueden localizar los contratos según su clasificación en el Vocabulario Común de la Contratación Pública (CPV), siguiendo el árbol jerárquico de los Órganos de Contratación públicos, con una búsqueda de texto libre, o a partir de diferentes rankings, por ejemplo, de contratos más caros, adjudicatarias más frecuentes y otros.
En la ficha de cada organismo y de cada adjudicataria se detallan sus relaciones destacadas con otras entidades, las categorías más frecuentes de sus contratos, empresas similares, duración de los contratos, importe, y muchos datos más.
En el caso de las empresas adjudicatarias se dibuja un mapa con la ubicación de los contratos que han recibido.
La web es totalmente gratuita, no requiere registro, y se actualiza diariamente, comenzando con más de un millón de contratos menores registrados.
Blog
El enfoque de la regulación de la Unión Europea ha dado un giro importante desde que en 2003 se impulsara la primera normativa sobre reutilización de la información del sector público. En concreto, como consecuencia de la Estrategia Europea de Datos aprobada en 2020 se está ampliando el enfoque regulatorio al menos desde dos puntos de vista:
-
por una parte, se están impulsando modelos de gobernanza que tengan en cuenta la necesidad de integrar, desde el diseño y por defecto, el respeto a otros derechos e intereses jurídicamente relevantes, como es el caso de la protección de los datos personales, la propiedad intelectual o el secreto comercial, tal y como ha sucedido singularmente a través del Reglamento de Gobernanza de los Datos;
-
por otra parte, ampliando el ámbito subjetivo de las normas para ir más allá del sector público, de manera que también se empiezan a contemplar obligaciones dirigidas específicamente a entidades privadas, tal y como demuestra la aprobación en noviembre de 2023 del Reglamento sobre normas armonizadas para un acceso justo a los datos y su utilización (conocido como Ley de Datos).
En este nuevo planteamiento adquieren un singular protagonismo los espacios de datos, tanto por lo que se refiere a la importancia de los sectores sobre los que versan (salud, movilidad, medio ambiente, energía…) como, sobre todo, por el destacado papel que están llamados a jugar a la hora de facilitar la puesta a disposición de grandes cantidades de datos, en concreto a la hora de superar los obstáculos técnicos y jurídicos que dificultan su puesta en común. A este respecto, en España ya disponemos de una previsión legal al respecto, que se ha concretado con la creación de una sección específica en la Plataforma de Contratación del Sector Público.
En la propia Estrategia se contempla la creación de “un espacio común europeo de datos relativos a las administraciones públicas, a fin de mejorar la transparencia y la rendición de cuentas respecto del gasto público y la calidad del gasto, luchar contra la corrupción tanto a nivel nacional como de la UE, y abordar las necesidades en relación con el cumplimiento de las normas, además de apoyar la aplicación efectiva de la legislación de la UE y favorecer aplicaciones innovadoras”. Si bien, al mismo tiempo se reconoce, que “los datos concernientes a la contratación pública se difunden a través de varios sistemas en los Estados miembros, están disponibles en diferentes formatos y no son fáciles de utilizar” concluyendo la necesidad, en muchos casos, de “mejorar la calidad de los datos”.
¿Por qué un espacio de datos en el ámbito de la contratación pública?
Dentro de la actividad que llevan a cabo las entidades públicas destaca la contratación pública, cuya relevancia en la economía del conjunto de la UE llega hasta casi el 14% del PIB, por lo que se trata de un polo estratégico para dinamizar una economía más innovadora, competitiva y eficiente. Sin embargo, tal y como se reconoce expresamente en la Comunicación de la Comisión titulada Contratación pública: Un espacio de datos para mejorar el gasto público, impulsar la elaboración de políticas basadas en datos y mejorar el acceso de las pymes a las licitaciones, publicada en marzo de 2023, aunque existe una gran cantidad de datos sobre contratación pública, sin embargo “de momento su utilidad para los contribuyentes, los responsables públicos y los compradores públicos es escasa”.
La regulación sobre contratación pública aprobada en 2014 incorporó una decidida apuesta por el uso de medios electrónicos en la divulgación de la información relativa a la convocatoria y la adjudicación de los procedimientos, si bien dicha normativa adolece de algunas limitaciones importantes:
-
se refiere únicamente a los contratos que superen unos umbrales mínimos fijados a nivel europeo, lo que limita la medida al 20% de la contratación pública en la UE, de manera que son los propios Estados quienes han de promover medidas de transparencia propias para el resto de los supuestos;
-
no afecta a la fase de ejecución contractual, de manera que no se aplica a cuestiones tan relevantes como el precio finalmente pagado, los plazos de ejecución realmente consumidos o, entre otras cuestiones, los posibles incumplimientos por parte del contratista y, en su caso, las medidas adoptadas por las entidades públicas al respecto;
-
aunque se refiere al uso de medios electrónicos a la hora de cumplir con la obligación de transparencia, sin embargo, no contempla la necesidad de que se articule en base a formatos abiertos que permitan la reutilización automatizada de la información.
Ciertamente, desde la aprobación de la regulación de 2014 se han producido importantes avances a la hora de facilitar la normalización del proceso de recogida de datos, sobre todo al imponerse la utilización de formularios electrónicos para los umbrales antes indicados desde el 25 de octubre de 2023. Sin embargo, resultaba imprescindible un planteamiento más ambicioso que permitiera “aprovechar plenamente el poder que ofrecen los datos sobre contratación pública”. Para ello, en esta nueva iniciativa se contemplan no sólo medidas dirigidas a incrementar decididamente la cantidad de datos disponibles y su calidad sino, además, la creación de una plataforma a escala de la UE para hacer frente a la dispersión actual, así como la combinación con un conjunto de herramientas basadas en tecnologías avanzadas, singularmente la inteligencia artificial.
Las ventajas de este planteamiento son evidentes desde diversos puntos de vista:
-
por una parte, podría proporcionase una información más precisa a las entidades públicas a la hora de planificar y adoptar sus decisiones;
-
pero también, por otro lado, se facilitarían las funciones de control y supervisión por parte de las autoridades competentes y, en general, de la sociedad;
-
y, sobre todo, se impulsaría de manera decisiva el acceso efectivo de las empresas y, en particular, de las pymes a la información sobre procedimientos actuales o futuros a los que poder concurrir.
¿Cuáles son los principales retos que se han de afrontar desde el punto de vista jurídico?
La Comunicación sobre el espacio de datos europeo de la contratación pública supone una importante iniciativa de gran interés por cuanto esboza el camino a seguir, planteando las ventajas que podría suponer su puesta en marcha, enfatizando las posibilidades que ofrece un planteamiento tan ambicioso y, asimismo, identificando las principales condiciones que lo harían viable. Todo ello desde el análisis de relevantes casos de uso, la identificación de los actores claves en este proceso y el establecimiento de un calendario preciso con un horizonte temporal hasta 2025.
El impulso de un espacio europeo de datos específico en el ámbito de la contratación pública es, sin duda, una iniciativa que potencialmente podría tener un enorme impacto tanto en la propia actividad contractual de las entidades públicas como, asimismo, por lo que se refiere a las empresas y, en general, a la sociedad. Pero para que esto sea posible también habría que plantearse importantes desafíos desde la perspectiva jurídica:
En primer lugar, actualmente no se contempla ampliar la obligación de publicación a los contratos que se encuentran por debajo de los umbrales establecidos a nivel europeo, lo que supone que la mayor parte de las licitaciones quedarían fuera del ámbito del espacio. Esta limitación plantea una consecuencia adicional, ya que supone dejar en manos de los Estados miembros el establecimiento adicional de obligaciones de publicidad activa a partir de las cuales proceder a la recogida y, en su caso, integración de los datos, lo que podría suponer una dificultad importante a la hora de asegurar la integración de múltiples y heterogéneas fuentes de datos, en particular desde la perspectiva de la interoperabilidad. A este respecto, la Comisión pretende crear un conjunto armonizado de datos que, en el caso de que fueran de obligado acatamiento por parte de todas las entidades públicas a nivel europeo, permitiría no sólo que los datos se recopilen por medios electrónicos, sino que, además, puedan traducirse a un lenguaje común que facilite su tratamiento automatizado.
En segundo lugar, aunque la Comunicación inste a los Estados para que se esfuercen “por recopilar datos tanto en la fase previa a la adjudicación como en la fase posterior a esta”, sin embargo, configura como voluntarios los anuncios de finalización de los contratos. Si fueran obligatorios se podría “alcanzar una comprensión mucho más detallada de la totalidad del ciclo de la contratación pública”, además de impulsar la adopción de medidas correctoras ante situaciones jurídicamente discutibles tanto por lo que se refiere a la posición jurídica de las empresas que no resultaron adjudicatarias como, asimismo, de las autoridades encargadas de llevar a cabo funciones de fiscalización.
Otro de los principales retos para el óptimo funcionamiento del espacio europeo de datos consiste en la fiabilidad de los datos publicados, ya que con frecuencia se pueden deslizar errores a la hora de cumplimentar los formularios o, incluso, dicha tarea puede percibirse como una actividad rutinaria que se realiza en ocasiones sin prestar la debida atención a su ejecución, tal y como viene demostrando la práctica administrativa con relación a los CPV. Aunque es preciso reconocer que en la actualidad existen herramientas avanzadas que podrían ayudar a corregir este tipo de disfunciones, lo cierto es que resulta imprescindible ir más allá de una mera digitalización de los procesos de gestión y apostar decididamente por modelos de tramitación automatizados que estén basados en los datos y no en los documentos, como todavía hoy resulta habitual en muchos ámbitos del sector público. Desde estas premisas se podría avanzar decididamente desde las exigencias de interoperabilidad antes referidas e implementar las herramientas analíticas basadas en tecnologías emergentes a que se refiere la Comunicación.
La necesaria adaptación de la regulación europea sobre contratación pública
Dada la relevancia de los objetivos planteados y la enorme dificultad que conllevan los retos anteriormente indicados, parece justificado que una iniciativa tan ambiciosa y con un potencial impacto tan destacado se articule a partir de una sólida base normativa. Resulta imprescindible ir más allá de las recomendaciones, estableciendo claras y precisas obligaciones jurídicas para los Estados miembros y, en general, para las entidades públicas, a la hora de gestionar y difundir la información sobre su actividad contractual, tal y como se ha planteado por ejemplo en el espacio de datos sanitarios.
En definitiva, casi diez años después de la aprobación del paquete de directivas sobre contratación pública, quizás haya llegado el momento de proceder a su actualización con un planteamiento más ambicioso que, desde las exigencias y posibilidades de la innovación tecnológica, permita poner realmente en valor la ingente cantidad de datos que se generan en este ámbito. Más aún, ¿por qué no configurar los datos de la contratación pública como datos de alto valor al amparo de la regulación sobre datos abiertos y reutilización de la información del sector público?
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Desde el pasado 24 de septiembre el Reglamento (UE) 2022/868 del Parlamento Europeo y del Consejo, de 30 de mayo de 2022, relativo a la gobernanza europea de datos (Reglamento de Gobernanza de Datos) resulta de aplicación en toda la Unión Europea. Al tratarse de un Reglamento, sus previsiones son directamente eficaces sin necesidad de una normativa estatal de transposición, como sucede por el contrario en el caso de las directivas. Sin embargo, por lo que se refiere a la aplicación de su regulación a las Administraciones Públicas, el legislador español ha considerado oportuno realizar algunas modificaciones en la Ley 37/2007, de 16 de noviembre, sobre reutilización de la información del Sector Público. En concreto:
- Se ha incorporado un régimen sancionador específico en el ámbito de la Administración General del Estado para los supuestos de incumplimiento de sus previsiones por parte de los reutilizadores, tal y como se explicará en detalle más adelante;
- Se han establecido criterios específicos sobre el cálculo de las tasas que pueden cobrar las Administraciones Públicas y entidades del sector público que no tengan carácter industrial o mercantil;
- Y, finalmente, se ha fijado algunas singularidades con relación al procedimiento administrativo para solicitar la reutilización, en particular se establece un plazo máximo de dos meses para notificar la correspondiente resolución –que se podrá ampliar hasta un máximo de treinta días debido a la extensión o complejidad de la solicitud–, transcurrido el cual se entenderá desestimada la petición.
¿Cuál es el ámbito de aplicación de esta nueva regulación?
Al igual que sucede con la Directiva (UE) 2019/1024 del Parlamento Europeo y del Consejo, de 20 de junio de 2019, relativa a los datos abiertos y la reutilización de la información del sector público, este Reglamento se aplica a los datos que se generen con ocasión de la “misión de servicio público” con el fin de facilitar su reutilización. Sin embargo, aquella no contemplaba la reutilización de aquellos datos protegidos por la concurrencia de ciertos bienes jurídicos, como es el caso de la confidencialidad, los secretos comerciales, la propiedad intelectual o, singularmente, la protección de los datos de carácter personal.
Puedes ver un resumen del reglamento en esta infografía.
Precisamente, uno de los principales objetivos del Reglamento consiste en facilitar la reutilización de este tipo de datos en manos de las Administraciones y otras entidades del sector público con fines de investigación, innovación y estadísticos, contemplando unas garantías reforzadas para ello. Se trata, por tanto, de establecer las condiciones jurídicas que permitan el acceso a los datos y su uso posterior sin que, por ello, se vean afectados otros derechos y bienes jurídicos de terceros. En consecuencia, el Reglamento no establece nuevas obligaciones para que los organismos públicos permitan el acceso a la información y su posterior reutilización, competencia que sigue reservada para los Estados miembros. Simplemente se incorporan una serie de mecanismos novedosos que tienen por finalidad hacer compatibles, en la medida de lo posible, el acceso a la información con el respeto a las exigencias de confidencialidad antes aludidas. De hecho, se advierte expresamente que, en caso de conflicto con el Reglamento (UE) 2016/679 relativo a la protección de las personas físicas en lo que respecta al tratamiento de datos personales y a la libre circulación de estos datos (RGPD), en todo caso habrá de prevalecer este último.
Al margen de la regulación referida al sector público, –a la que nos referiremos más adelante–, el Reglamento incorpora previsiones específicas para cierto tipo de servicios que, si bien podrían prestar también las entidades públicas en algún caso, normalmente serán asumidos por sujetos privados. En concreto, se regulan los servicios de intermediación y la cesión altruista de datos, estableciendo un régimen jurídico específico para ambos supuestos. El Ministerio de Asuntos Económicos y Transformación Digital será el encargado en España de supervisar este proceso
Por lo que se refiere, en concreto, a la incidencia del Reglamento en el sector público, sus previsiones no resultan aplicables a las empresas públicas –esto es, aquellas en las que exista una influencia dominante de un organismo del sector público–, a las actividades de radiodifusión ni, entre otros supuestos, a los centros culturales y de enseñanza. Tampoco a los datos que, aun siendo generados en ejecución de una misión de servicio público, se encuentren protegidos por motivos de seguridad pública, defensa o seguridad nacional.
¿En qué condiciones se puede reutilizar la información?
Con carácter general, las condiciones en que se autorice la reutilización han de preservar la naturaleza protegida de la información. Por esta razón, como regla general, el acceso tendrá lugar a datos anonimizados o, en su caso, agregados, modificados o sometidos a un tratamiento previo que permita cumplir con dicha exigencia. A este respecto, se autoriza a los organismos públicos para que cobren tasas que, entre otros criterios, habrán de calculase en función de los costes necesarios para la anonimización de los datos personales o la adaptación de los sometidos a confidencialidad.
Asimismo, se contempla expresamente que el acceso y la reutilización tengan lugar en un entorno seguro controlado por la propia entidad pública, ya sea un entorno físico o virtual. De esta manera, se puede realizar una supervisión directa que podría consistir, no sólo en verificar la actividad del reutilizador, sino incluso, en prohibir los resultados de aquellos tratamientos que pongan en peligro los derechos e intereses de terceros cuya integridad debe garantizarse. Precisamente, el coste por el mantenimiento de estos espacios se incluye entre los criterios que se pueden tener en cuenta a la hora de calcular la correspondiente tasa que puede cobrar el organismo público.
Cuando se trate de datos de carácter personal, el Reglamento no añade una nueva base jurídica que legitime su reutilización distinta de las que ya establece la normativa general en dicha materia. Por ello, se insta a los organismos públicos a que, en este tipo de supuestos, presten asistencia a los reutilizadores para ayudarles a obtener el permiso de los interesados. Ahora bien, se trata de una medida de apoyo que en ningún caso puede suponer cargas desproporcionadas para los organismos. A este respecto, la posibilidad de reutilizar datos seudonimizados debe encontrar amparo en algunos de los supuestos que contempla el RGPD. Asimismo, como garantía adicional, la finalidad para la que se pretendan reutilizar los datos habrá de ser compatible con la que inicialmente justificara el tratamiento de los datos por parte de la entidad pública en el ejercicio de su actividad principal, debiendo adoptarse las garantías adecuadas.
Un ejemplo práctico de gran interés es el relativo a la reutilización de datos de salud con fines de investigación biomédica que ha establecido el legislador español al amparo de lo previsto en este último precepto. En concreto, la disposición adicional 17ª de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos de Carácter Personal y Garantía de los Derechos Digitales, admite la reutilización de datos seudonimizados en este ámbito cuando se establezcan ciertas garantías específicas, que podrían reforzarse con el uso de los referidos entornos seguros en el caso de que se empleen tecnologías especialmente incisivas, como podría ser la inteligencia artificial. Todo ello sin perjuicio de cumplir, asimismo, con otras obligaciones que deban tenerse en cuenta en función de las condiciones del tratamiento de los datos, singularmente la realización de evaluaciones de impacto.
¿Qué instrumentos se prevén para garantizar la efectividad de su aplicación?
Desde una perspectiva organizativa, los Estados han de garantizar que la información se encuentre fácilmente accesible a través de un punto único. En el caso de España, este punto se encuentra habilitado a través de la plataforma datos.gob.es, si bien pueden existir también otros puntos de acceso para sectores concretos y diferentes niveles territoriales, en cuyo caso deberán estar vinculados. Los reutilizadores podrán dirigirse a dicho punto para formular consultas y solicitudes, que se remitirán a la entidad o al órgano competente para su tramitación y respuesta.
Asimismo, se han de designar y notificar a la Comisión Europea una o varias entidades especializadas que cuenten con los medios técnicos y personales adecuados, que podrían ser algunas de las ya existentes, que desarrollan la función de prestar asistencia a los organismos públicos a la hora de conceder o denegar la reutilización. No obstante, si lo previera la regulación europea o de los Estados, dichos organismos podrían asumir funciones decisorias y no únicamente de mera asistencia. En todo caso, se prevé que sean las Administraciones y, en su caso, las entidades del sector público institucional ‑‑según la terminología del artículo 2 de la Ley 27/2007‑‑ quienes realicen esta designación y la comuniquen al Ministerio de Asuntos Económicos y Transformación Digital, que por su parte se encargará de la correspondiente notificación a nivel europeo.
Finalmente, como se indicaba al principio, se han tipificado como infracciones específicas para el ámbito de la Administración General del Estado algunas conductas de los reutilizadores que se sancionan con multas que van desde los 10.001 a los 100.000 euros. En concreto, se trata de conductas que, de forma deliberada o por negligencia, supongan el incumplimiento de las principales garantías que contempla la normativa europea: en concreto, el incumplimiento de las condiciones de acceso a los datos o a los espacios seguros, la reidentificación o la falta de comunicación de problemas de seguridad.
En definitiva, como señalaba la Estrategia Europea de Datos, si la Unión Europea quiere desempeñar un papel de liderazgo en la economía de los datos resulta imprescindible, entre otras medidas, mejorar las estructuras de gobernanza e incrementar los repositorios de datos de calidad que, con frecuencia, se encuentran afectados por relevantes obstáculos jurídicos. Con el Reglamento de Gobernanza de Datos se ha dado un paso importante a nivel regulatorio, pero ahora resta por comprobar si los organismos públicos son capaces de asumir una posición proactiva para facilitar la puesta en marcha de sus medidas que, en última instancia, implica importantes desafíos en la transformación digital de su gestión documental.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada uno de estos ejercicios prácticos, se utilizan desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El principal objetivo de este ejercicio es mostrar cómo realizar, de una forma didáctica, un análisis predictivo de series temporales partiendo de datos abiertos sobre el consumo de electricidad en la ciudad de Barcelona. Para ello realizaremos un análisis exploratorio de los datos, definiremos y validaremos el modelo predictivo, para por último generar las predicciones junto a sus gráficas y visualizaciones correspondientes.
Los análisis predictivos de series temporales son técnicas estadísticas y de aprendizaje automático que se utilizan para prever valores futuros en conjuntos de datos que se recopilan a lo largo del tiempo. Estas predicciones se basan en patrones y tendencias históricas identificadas en la serie temporal, siendo su objetivo principal anticipar cambios y eventos en función de datos pasados.
El conjunto de datos abiertos inicial consta de registros desde el año 2019 hasta el año 2022 ambos inclusive, por otra parte, las predicciones las realizaremos para el año 2023, del cual no tenemos datos reales.
Una vez realizado el análisis, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la predicción futura de consumo eléctrico?
- ¿Cómo de preciso ha sido el modelo con la predicción de datos ya conocidos?
- ¿Qué días tendrán un consumo máximo y mínimo según las predicciones futuras?
- ¿Qué meses tendrán un consumo medio máximo y mínimo según las predicciones futuras?
Estas y otras muchas preguntas pueden ser resueltas mediante las visualizaciones obtenidas en el análisis que mostrarán la información de una forma ordenada y sencilla de interpretar.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre el consumo eléctrico en la ciudad de Barcelona en los últimos años. La información que aportan es el consumo en (MWh) desglosados por día, sector económico, código postal y tramo horario.
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Barcelona en el catálogo de datos.gob.es, mediante ficheros que recogen los registros de forma anual. Cabe destacar que el publicador actualiza estos conjuntos de datos con nuevos registros con frecuencia, por lo que hemos utilizado solamente los datos proporcionados desde el 2019 hasta el 2022 ambos inclusive.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización del análisis se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de las visualizaciones interactivas se ha usado la herramienta Looker Studio.
"Looker Studio", antiguamente conocido como Google Data Studio, es una herramienta online que permite realizar visualizaciones interactivas que pueden insertarse en sitios web o exportarse como archivos.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Análisis predictivo de series temporales
El análisis predictivo de series temporales es una técnica que utiliza datos históricos para predecir valores futuros de una variable que cambia con el tiempo. Las series temporales son datos que se recopilan en intervalos regulares, como días, semanas, meses o años. No es el objetivo de este ejercicio explicar en detalle las características de las series temporales, ya que nos centramos en explicar brevemente el modelo de predicción. No obstante, si quieres saber más al respecto, puedes consultar el siguiente manual.
Este tipo de análisis se basa en el supuesto de que los valores futuros de una variable estarán correlacionados con los valores históricos. Utilizando técnicas estadísticas y de aprendizaje automático, se pueden identificar patrones en los datos históricos y utilizarlos para predecir valores futuros.
El análisis predictivo realizado en el ejercicio ha sido dividido en cinco fases; preparación de los datos, análisis exploratorio de los datos, entrenamiento del modelo, validación del modelo y predicción de valores futuros), las cuales se explicarán en los próximos apartados.
Los procesos que te describimos a continuación los encontrarás desarrollados y comentados en el siguiente Notebook ejecutable desde Google Colab junto al código fuente que está disponible en nuestra cuenta de Github.
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
4.1 Preparación de los datos
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este apartado se importan los conjuntos de datos abiertos descritos en los puntos anteriores que utilizaremos en el ejercicio, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores que puedan condicionar los pasos futuros.
4.2 Análisis exploratorio de los datos (EDA)
Este apartado podrás encontrarlo en el punto 2 del Notebook.
En este apartado realizaremos un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de origen, detectar anomalías, datos ausentes, errores u outliers que pudieran afectar a la calidad de los procesos posteriores y resultados.
A continuación, en la siguiente visualización interactiva, podrás inspeccionar la tabla de datos con los valores de consumo históricos generada en el punto anterior pudiendo filtrar por periodo temporal concreto. De esta forma podemos comprender, de una forma visual, la principal información de la serie de datos.
Una vez inspeccionada la visualización interactiva de la serie temporal, habrás observado diversos valores que potencialmente podrían ser considerados como outliers, como se muestra en la siguiente figura. También podemos calcular de forma numérica estos outliers, como se muestra en el notebook.

Una vez evaluados los outliers, para este ejercicio se ha decidido modificar únicamente el registrado en la fecha "2022-12-05". Para ello se sustituirá el valor por la media del registrado el día anterior y el día siguiente.
La razón de no eliminar el resto de outliers es debido a que son valores registrados en días consecutivos, por lo que se presupone que son valores correctos afectados por variables externas que se escapan del alcance del ejercicio. Una vez solucionado el problema detectado con los outliers, esta será la serie temporal de datos que utilizaremos en los siguientes apartados.
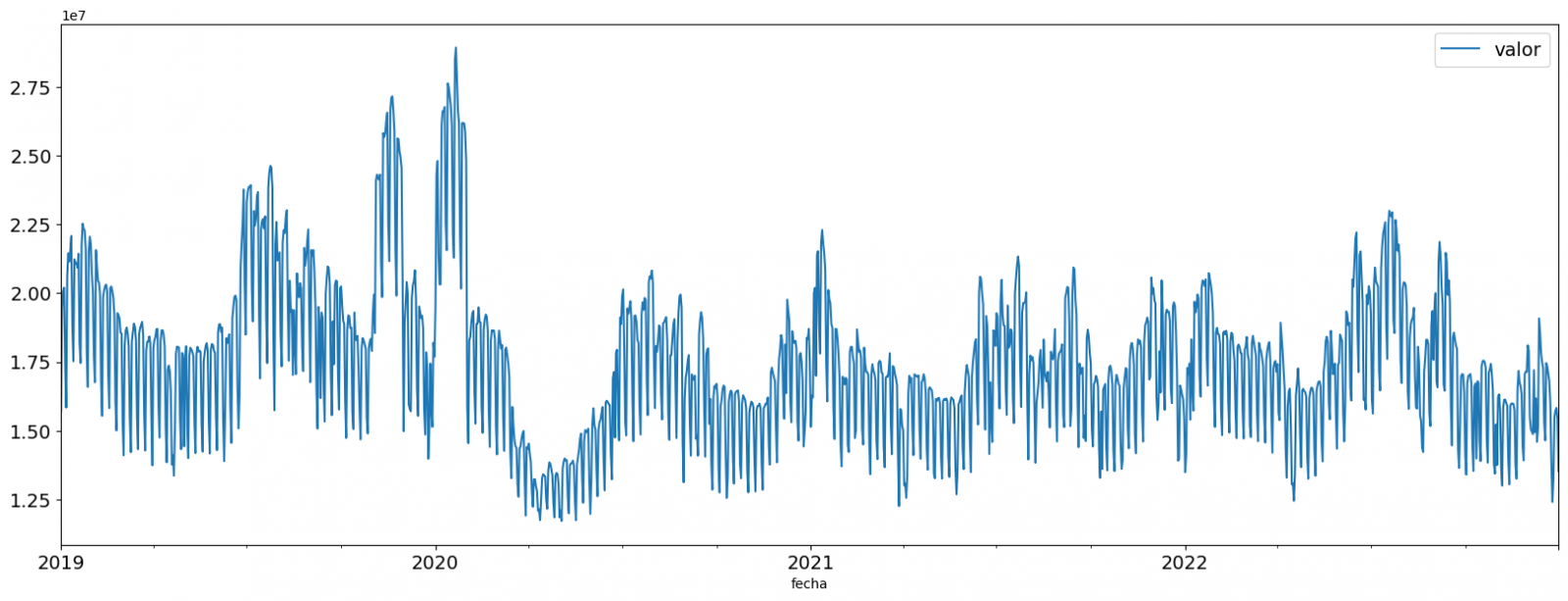
Figura 2. Serie temporal de datos históricos una vez tratados los outliers
Si quieres conocer más sobre estos procesos puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
4.3 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 3 del Notebook.
En primer lugar, creamos dentro de la tabla de datos los atributos temporales (año, mes, día de la semana y trimestre). Estos atributos son variables categóricas que ayudan a garantizar que el modelo sea capaz de capturar con precisión las características y patrones únicos de estas variables. Mediante las siguientes visualizaciones de diagramas de cajas, podemos ver su relevancia dentro de los valores de la serie temporal.
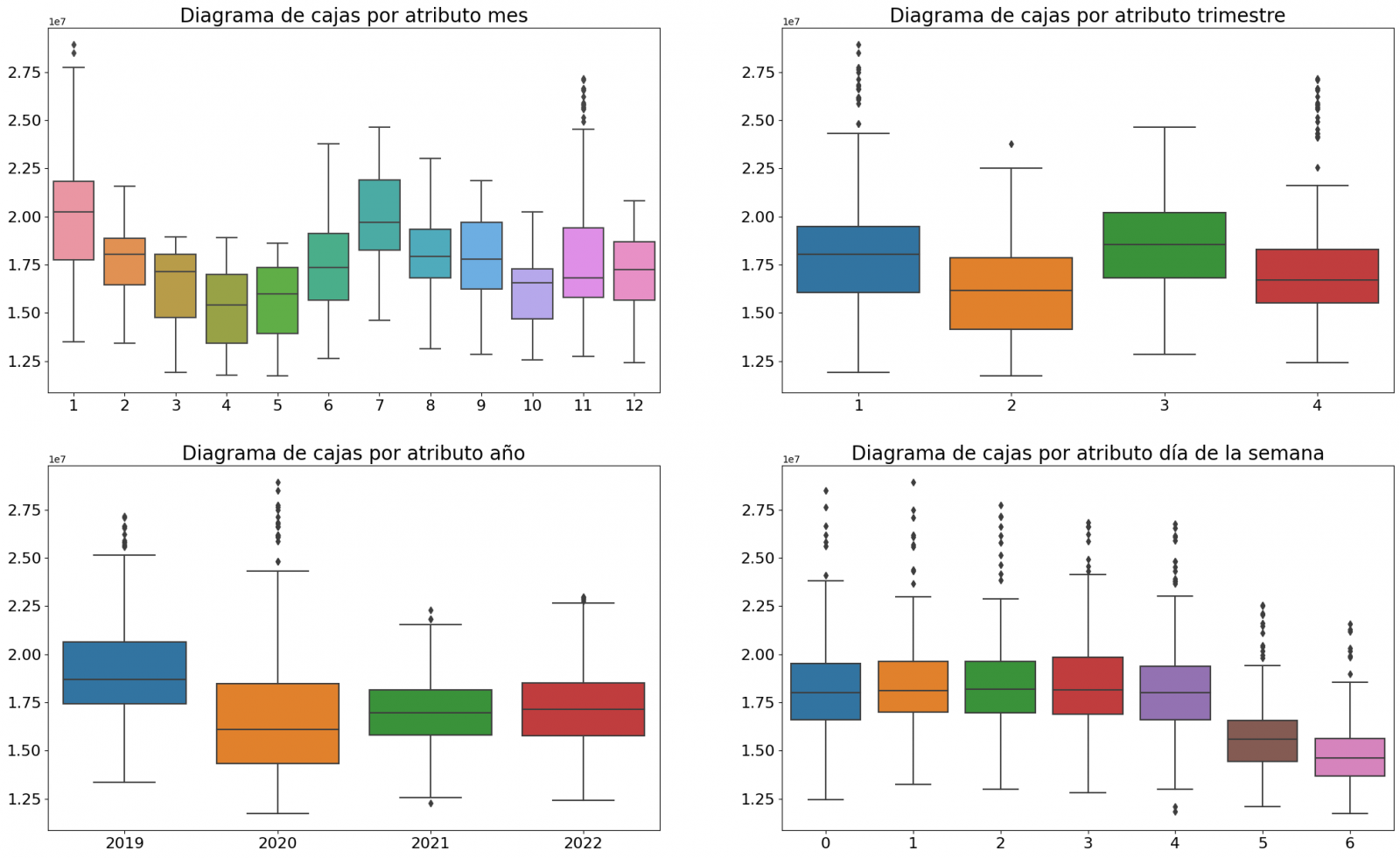
Figura 3. Diagramas de cajas de los atributos temporales generados
Podemos observar ciertos patrones en las gráficas anteriores como los siguientes:
- Los días laborales (lunes a viernes) presentan un mayor consumo que los fines de semana.
- El año que valores de consumo más bajos presenta es el 2020, esto entendemos que se debe a la reducción de actividad servicios e industrial durante la pandemia.
- El mes que mayor consumo presenta es julio, lo cual es entendible debido al uso de aparatos de aire acondicionado.
- El segundo trimestre es el que presenta valores más bajos de consumo, destacando abril como el mes con valores más bajos.
A continuación, dividimos la tabla de datos en set de entrenamiento y en set de validación. El set de entrenamiento se utiliza para entrenar el modelo, es decir, el modelo aprende a predecir el valor de la variable objetivo a partir de dicho set, mientras que el set de validación se utiliza para evaluar el rendimiento del modelo, es decir, el modelo se evalúa con los datos de dicho set para determinar su capacidad para predecir los nuevos valores.
Esta división de los datos es importante para evitar el sobreajuste siendo la proporción típica de los datos que se utilizan para el set de entrenamiento de un 70 % y el set de validación del 30% aproximadamente. Para este ejercicio hemos decidido generar el set de entrenamiento con los datos comprendidos entre el "01-01-2019" hasta el "01-10-2021", y el set de validación con los comprendidos entre el "01-10-2021" y el "31-12-2022" como podemos apreciar en la siguiente gráfica.
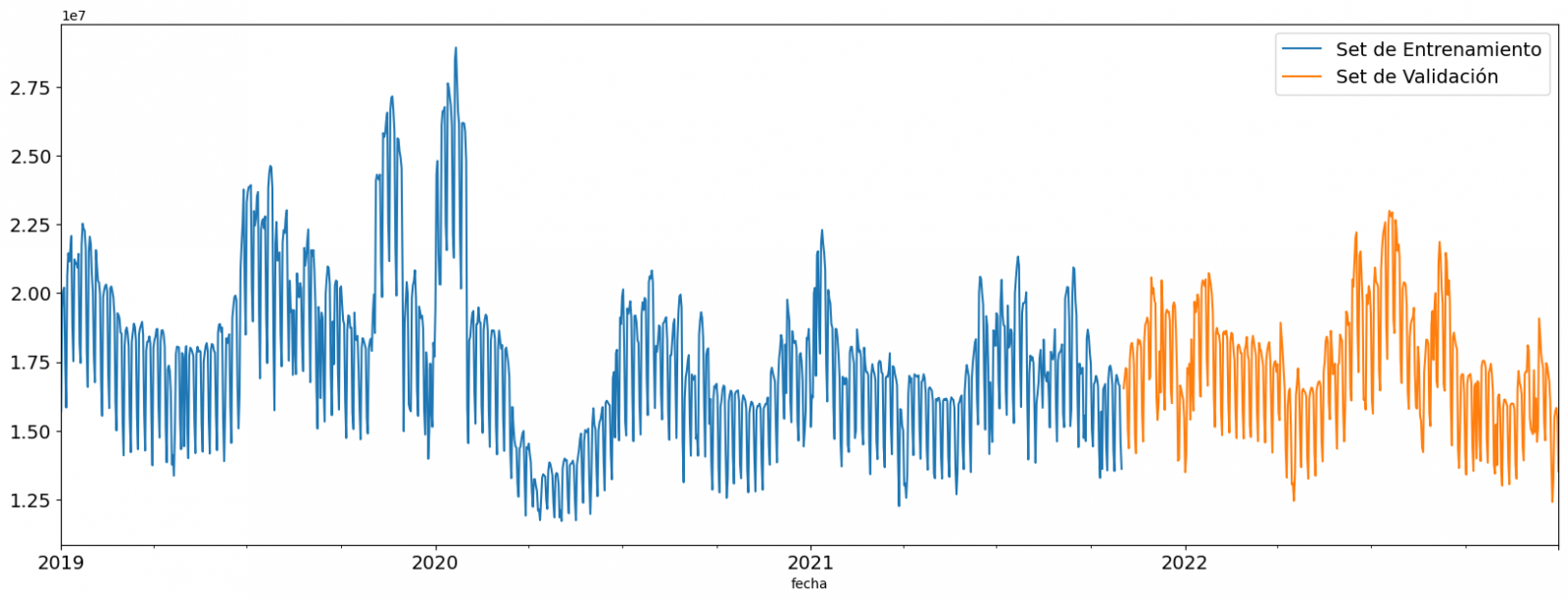
Figura 4. Serie temporal de datos históricos dividida en set de entrenamiento y set de validación
Para este tipo de ejercicio, tenemos que utilizar algún algoritmo de regresión. Existen diversos modelos y librerías que pueden utilizarse para predicción de series temporales. En este ejercicio utilizaremos el modelo “Gradient Boosting”, modelo de regresión supervisado que se trata de un algoritmo de aprendizaje automático utilizado para predecir un valor continúo basándose en el entrenamiento de un conjunto de datos que contienen valores conocidos para la variable objetivo (en nuestro ejemplo la variable “valor”) y los valores de las variables independientes (en nuestro ejercicio los atributos temporales).
Está basado en árboles de decisión y utiliza una técnica llamada "boosting" para mejorar la precisión del modelo siendo conocido por su eficiencia y capacidad para manejar una variedad de problemas de regresión y clasificación.
Sus principales ventajas son el alto grado de precisión, su robustez y flexibilidad, mientras que alguna de sus desventajas son la sensibilidad a valores atípicos y que requiere una optimización cuidadosa de los parámetros.
Utilizaremos el modelo de regresión supervisado ofrecido en la librería XGBBoost, el cuál puede ajustarse con los siguientes parámetros:
- n_estimators: parámetro que afecta al rendimiento del modelo indicando el número de árboles utilizados. Un mayor número de árboles generalmente resulta un modelo más preciso, pero también puede llevar más tiempo de entrenamiento.
- early_stopping_rounds: parámetro que controla el número de rondas de entrenamiento que se ejecutarán antes de que el modelo se detenga si el rendimiento en el conjunto de validación no mejora.
- learning_rate: controla la velocidad de aprendizaje del modelo. Un valor más alto hará que el modelo aprenda más rápido, pero puede provocar un sobreajuste.
- max_depth: controla la profundidad máxima de los árboles en el bosque. Un valor más alto puede proporcionar un modelo más preciso, pero también puede provocar un sobreajuste.
- min_child_weight: controla el peso mínimo de una hoja. Un valor más alto puede ayudar a prevenir el sobreajuste.
- gamma: controla la cantidad de reducción de la pérdida esperada que se necesita para dividir un nodo. Un valor más alto puede ayudar a prevenir el sobreajuste.
- colsample_bytree: controla la proporción de las características que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
- subsample: controla la proporción de los datos que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
Estos parámetros se pueden ajustar para mejorar el rendimiento del modelo en un conjunto de datos específico. Se recomienda experimentar con diferentes valores de estos parámetros para encontrar el valor que proporciona el mejor rendimiento en tu conjunto de datos.
Por último, mediante una gráfica de barras observaremos de forma visual la importancia de cada uno de los atributos durante el entrenamiento del modelo. Se puede utilizar para identificar los atributos más importantes en un conjunto de datos, lo que puede ser útil para la interpretación del modelo y la selección de características.
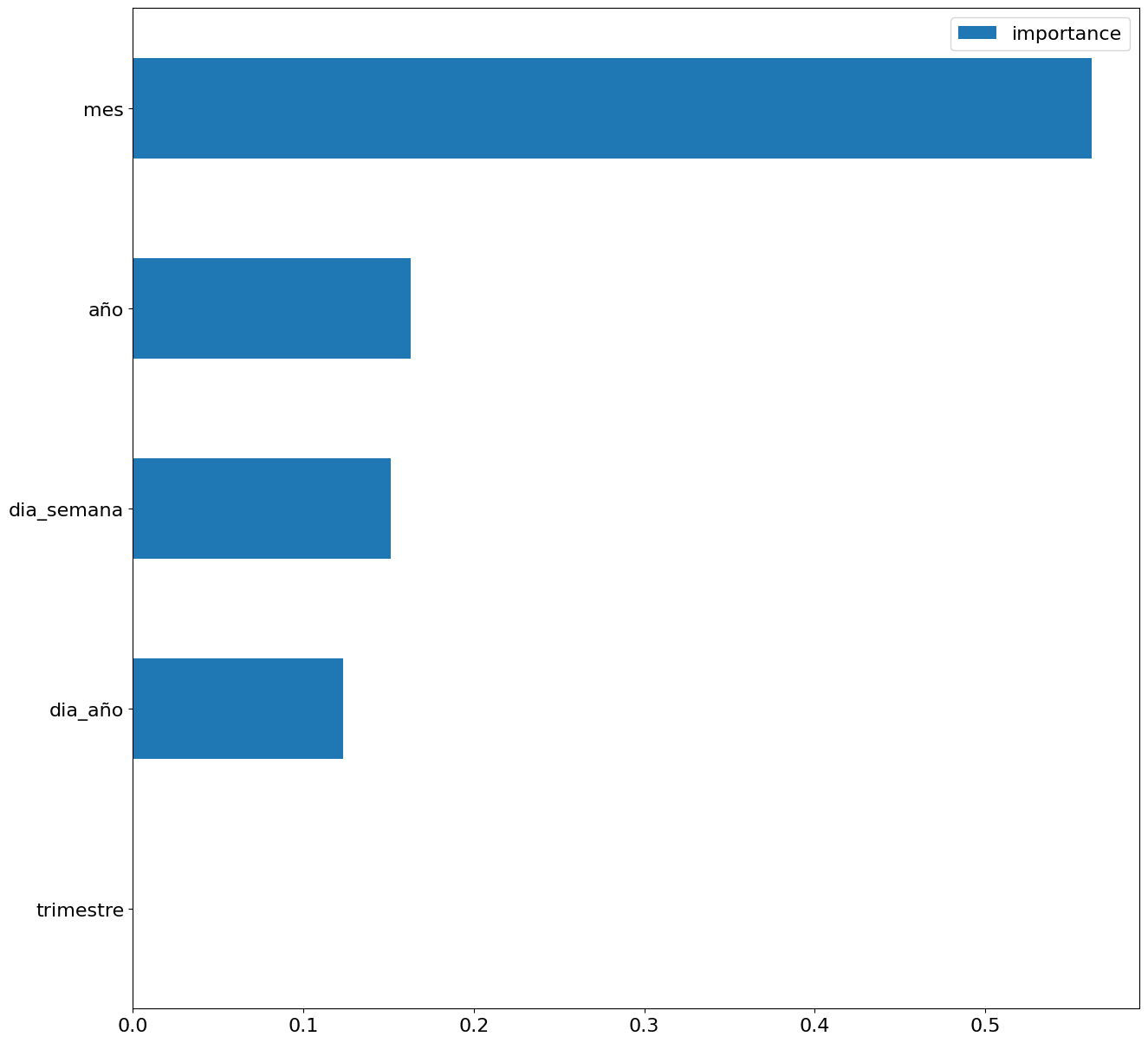
Figura 5. Gráfica de barras con importancia de los atributos temporales
4.4 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 4 del Notebook.
Una vez entrenado el modelo, evaluaremos cómo de preciso es para los valores conocidos del set de validación.
Podemos evaluar de forma visual el modelo ploteando la serie temporal con los valores conocidos junto a las predicciones realizadas para el set de validación como se muestra en la siguiente figura.
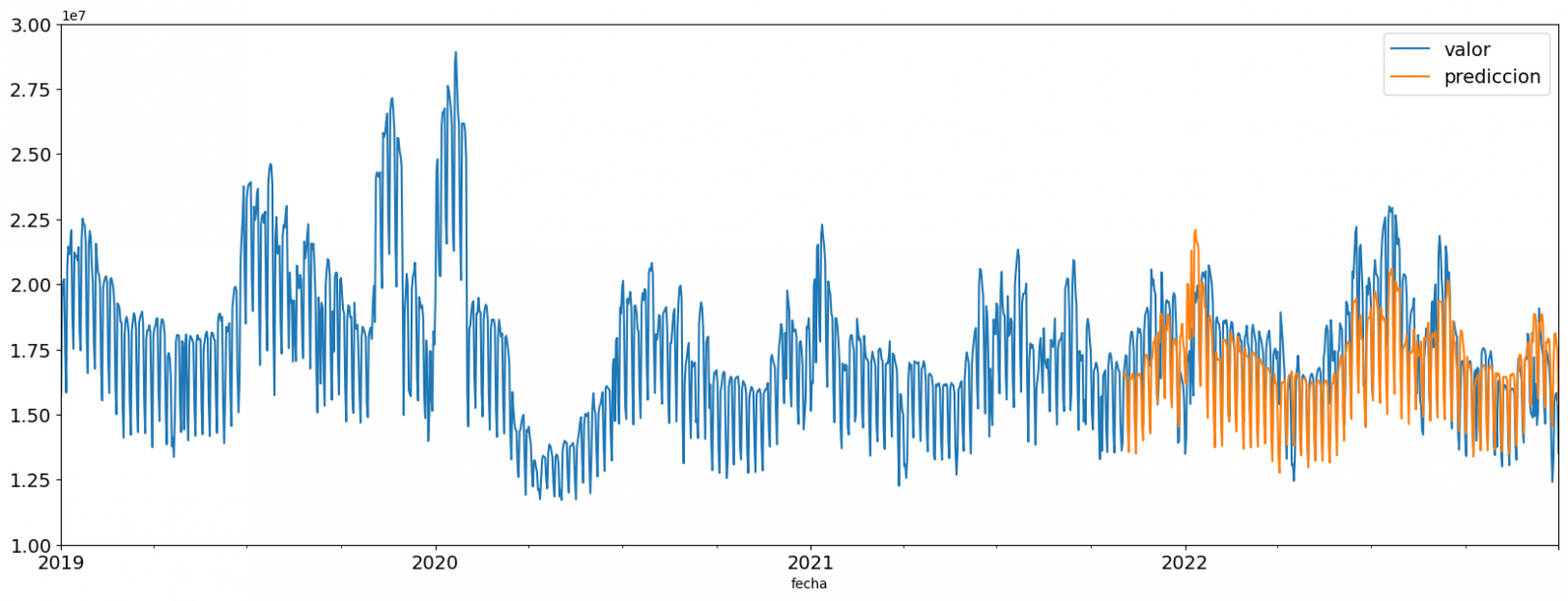
Figura 6. Serie temporal con los datos del set de validación junto a los de la predicción
También podemos evaluar de forma numérica la precisión del modelo mediante distintas métricas. En este ejercicio hemos optado por utilizar la métrica del error porcentual absoluto medio (MAPE), el cuál ha sido de un 6,58%. La precisión del modelo se considera alta o baja dependiendo del contexto y de las expectativas en dicho modelo, generalmente un MAPE se considera bajo cuando es inferior al 5%, mientras que se considera alto cuando es superior al 10%. En este ejercicio, el resultado de la validación del modelo puede ser considerado un valor aceptable.
Si quieres consultar otro tipo de métricas para evaluar la precisión de modelos aplicados a series temporales, puedes consultar el siguiente enlace.
4.5 Predicciones valores futuros
Este apartado podrás encontrarlo en el punto 5 del Notebook.
Una vez generado el modelo y evaluado su rendimiento MAPE = 6,58 %, pasamos a aplicar dicho modelo al total de datos conocidos, con la finalidad de predecir los valores de consumo eléctrico no conocidos del 2023.
En primer lugar, volvemos a entrenar el modelo con los valores conocidos hasta finales del 2022, sin dividir en set de entrenamiento y validación. Por último, calculamos los valores futuros para el año 2023.

Figura 7. Serie temporal con los datos históricos y la predicción para el 2023
En la siguiente visualización interactiva puedes observar los valores predichos para el año 2023 junto a sus principales métricas, pudiendo filtrar por periodo temporal.
Mejorar los resultados de los modelos predictivos de series temporales es un objetivo importante en la ciencia de datos y el análisis de datos. Varias estrategias que pueden ayudar a mejorar la precisión del modelo del ejercicio son el uso de variables exógenas, la utilización de más datos históricos o generación de datos sintéticos, optimización de los parámetros, …
Debido al carácter divulgativo de este ejercicio y para favorecer el entendimiento de los lectores menos especializados, nos hemos propuesto explicar de una forma lo más sencilla y didáctica posible el ejercicio. Posiblemente se te ocurrirán muchas formas de optimizar el modelo predictivo para lograr mejores resultados, ¡Te animamos a que lo hagas!
5. Conclusiones ejercicio
Una vez realizado el ejercicio, podemos apreciar distintas conclusiones como las siguientes:
- Los valores máximos para las predicciones de consumo en el 2023 se dan en la última quincena de julio superando valores de 22.500.000 MWh
- El mes con un mayor consumo según las predicciones del 2023 será julio, mientras que el mes con un menor consumo medio será noviembre, existiendo una diferencia porcentual entre ambos del 25,24%
- La predicción de consumo medio diario para el 2023 es de 17.259.844 MWh, un 1,46% inferior a la registrada entre los años 2019 y 2022.
Esperemos que este ejercicio te haya resultado útil para el aprendizaje de algunas técnicas habituales en el estudio y análisis de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
La UNESCO (Organización de las Naciones Unidas para la Educación, la Ciencia y la Cultura) es un organismo de las Naciones Unidas cuyo objeto es el de contribuir a la paz y a la seguridad en el mundo mediante la educación, la ciencia, la cultura y las comunicaciones. Para cumplir con su objetivo esta organización suele establecer guías y recomendaciones como la que ha publicado este 5 de Julio del 2023 titulado ‘Open data for AI: what now?’
Tras la pandemia del COVID-19 la UNESCO destaca una serie de lecciones aprendidas:
- Deben desarrollarse marcos normativos y modelos de gobernanza de datos, respaldados por infraestructuras, recursos humanos y capacidades institucionales suficientes para abordar los retos relacionados con los datos abiertos, con el fin de estar mejor preparados para las pandemias y otros retos mundiales.
- Es necesario especificar más la relación entre los datos abiertos y la IA, incluyendo qué características de los datos abiertos son necesarias para que sean "AI-Ready".
- Debe establecerse una política de gestión, colaboración e intercambio de datos para la investigación, así como para las instituciones gubernamentales que posean o procesen datos relacionados con la salud, al tiempo que se debe garantizar la privacidad de los datos mediante la anonimización.
- Los funcionarios públicos que manejan datos que son o pueden llegar a ser de utilidad para las pandemias pueden necesitar formación para reconocer la importancia de dichos datos, así como el imperativo de compartirlos.
- Deben recopilarse y recogerse tantos datos de alta calidad como sea posible. Los datos tienen que proceder de una variedad de fuentes creíbles, que, sin embargo, también deben ser éticas, es decir, no deben incluir conjuntos de datos con sesgos y contenido perjudicial, y tienen que recopilarse únicamente con consentimiento y no de forma invasiva para la privacidad. Además, las pandemias suelen ser procesos que evolucionan rápidamente, por lo que la actualización continua de los datos es esencial.
- Estas características de los datos son especialmente obligatorias para mejorar en el futuro las inadecuadas herramientas de diagnóstico y predicción de la IA. Es necesario realizar un esfuerzo para convertir los datos pertinentes en un formato legible por máquina, lo que implica la conservación de los datos recopilados, es decir, su limpieza y etiquetado.
- Debe abrirse una amplia gama de datos relacionados con las pandemias, adhiriéndose a los principios FAIR.
- El público objetivo de los datos abiertos relacionados con la pandemia incluye la investigación y el mundo académico, los responsables de la toma de decisiones en los gobiernos, el sector privado para el desarrollo de productos relevantes, pero también el público, todos los cuales deben ser informados sobre los datos disponibles.
- Las iniciativas de datos abiertos relacionadas con pandemias deberían institucionalizarse en lugar de formarse ad hoc, y por tanto deberían ponerse en marcha para la preparación ante futuras pandemias. Estas iniciativas también deberían ser integradoras y reunir a distintos tipos de productores y usuarios de datos.
- Asimismo, debería regularse el uso beneficioso de los datos relacionados con pandemias para las técnicas de aprendizaje automático de IA con el objetivo de evitar el uso indebido para el desarrollo de pandemias artificiales, es decir, armas biológicas, con la ayuda de sistemas de IA.
La UNESCO se basa en estas lecciones aprendidas para establecer unas Recomendaciones sobre la Ciencia Abierta facilitando el intercambio de datos, mejorando la reproducibilidad y la transparencia, promoviendo la interoperabilidad de los datos y las normas, apoyando la preservación de los datos y el acceso a largo plazo.
A medida que reconocemos cada vez más el papel de la Inteligencia Artificial (IA), la disponibilidad y el acceso a los datos son más cruciales que nunca, por ello la UNESCO lleva a cabo investigaciones en el ámbito de la IA para proporcionar conocimientos y soluciones prácticas que fomenten la transformación digital y construyan sociedades del conocimiento inclusivas.
Los datos abiertos son el principal objetivo de estas recomendaciones, ya que se consideran un requisito previo para la elaboración de planes, la toma de decisiones y las intervenciones con conocimiento de causa. Por ello, el informe afirma que los Estados miembros deben compartir los datos y la información, garantizando la transparencia y la rendición de cuentas, así como las oportunidades para que cualquiera pueda hacer uso de los datos.
La UNESCO ofrece una guía en la que pretende dar a conocer el valor de los datos abiertos y especifican los pasos concretos que los Estados miembros pueden dar para abrir sus datos. Son pasos prácticos, pero de alto nivel sobre cómo abrir datos, basándose en las directrices existentes. Se distinguen tres fases: preparación, apertura de los datos y seguimiento para su reutilización y sostenibilidad, y se presentan cuatro pasos para cada fase.
Es importante señalar que varios de los pasos pueden realizarse simultáneamente, es decir, no necesariamente de forma consecutiva.

Paso 1: Preparación
- Elaborar una política de gestión y puesta en común de datos: Una política de gestión y puesta en común de datos es un requisito importante previo a la apertura de los datos, ya que dicha política define el compromiso de los gobiernos de compartir los datos. El Instituto de Datos Abiertos sugiere los siguientes elementos de una política de datos abiertos:
- Una definición de datos abiertos, una declaración general de principios, un esquema de los tipos de datos y referencias a cualquier legislación, política u otra orientación pertinente.
- Se anima a los gobiernos a adherirse al principio "tan abierto como sea posible, tan cerrado como sea necesario". Si los datos no pueden abrirse por motivos legales, de privacidad o de otro tipo, por ejemplo, datos personales o sensibles, debe explicarse claramente.
Además, los gobiernos también deberían animar a los investigadores y al sector privado de sus países a desarrollar políticas de gestión e intercambio de datos que se adhieran a los mismos principios.
- Reunir y recopilar datos de alta calidad: Los datos existentes deben recopilarse y almacenarse en el mismo repositorio, por ejemplo, de varios departamentos gubernamentales donde pueden haber estado almacenados en silos. Los datos deben ser precisos y no estar desfasados. Además, los datos deben ser exhaustivos y no deben, por ejemplo, descuidar a las minorías o la economía informal. Los datos sobre las personas deben desglosarse cuando sea pertinente, incluso por ingresos, sexo, edad, raza, origen étnico, situación migratoria, discapacidad y ubicación geográfica.
- Desarrollar capacidades de datos abiertos: Estas capacidades se dirigen a dos grupos:
- Para los funcionarios públicos, incluye la comprensión de los beneficios de los datos abiertos potenciando y propiciando el trabajo que conlleva la apertura de los datos.
- Para los usuarios potenciales, incluye la demostración de las oportunidades de los datos abiertos, como su reutilización, y cómo tomar decisiones informadas.
- Preparar los datos para la IA: Si los datos no van a ser utilizados únicamente por humanos, sino que también pueden alimentar sistemas de IA, deben cumplir algunos criterios más para estar preparados para la IA.
- El primer paso en este sentido es preparar los datos en un formato legible por máquinas.
- Algunos formatos favorecen más que otros la legibilidad por parte de los sistemas de inteligencia artificial.
- Los datos también deben limpiarse y etiquetarse, lo que a menudo lleva mucho tiempo y, por tanto, es costoso.
- El éxito de un sistema de IA depende de la calidad de los datos de entrenamiento, incluida su coherencia y pertinencia. La cantidad necesaria de datos de entrenamiento es difícil de conocer de antemano y debe controlarse mediante comprobaciones de rendimiento. Los datos deben abarcar todos los escenarios para los que se ha creado el sistema de IA.
Paso 2: Abrir los datos
- Seleccionar los conjuntos de datos que se van a abrir: El primer paso para abrir los datos es decidir qué conjuntos de datos se van a abrir. Los criterios a favor de la apertura son:
- Si ha habido solicitudes previas de apertura de estos datos
- Si otros gobiernos han abierto estos datos y si ello ha dado lugar a usos beneficiosos de los datos.
La apertura de los datos no debe violar las leyes nacionales, como las leyes de privacidad de datos.
- Abrir los conjuntos de datos legalmente: Antes de abrir los conjuntos de datos, el gobierno correspondiente tiene que especificar exactamente en qué condiciones, en su caso, se pueden utilizar los datos. A la hora de publicar los datos, los gobiernos podrán optar por la licencia que mejor se adapte a sus objetivos, como son por ejemplo las licencias Creative Commons y Open. Para dar soporte a la selección de licencia la comisión europea pone a disposición JLA - Compatibility Checker, una herramienta que da apoyo para esta decisión
- Abrir los conjuntos de datos técnicamente: La forma más habitual de abrir los datos es publicarlos en formato electrónico para su descarga en un sitio web, además se debe contar con APIs para el consumo de estos datos, ya sea el del propio Gobierno o el de un tercero.
Los datos deben presentarse en un formato que permita su localización, accesibilidad, interoperabilidad y reutilización, cumpliendo así los principios FAIR.
Además, los datos también podrían publicarse en un archivo o repositorio de datos, que debería ser, según la Recomendación de la UNESCO, apoyado y mantenido por una institución académica, una sociedad académica, una agencia gubernamental u otra organización sin ánimo de lucro bien establecida y dedicada al bien común que permita el acceso abierto, la distribución sin restricciones, la interoperabilidad y la preservación y el archivo digital a largo plazo.
- Crear una cultura impulsada por los datos abiertos: La experiencia ha demostrado que, además de la apertura legal y técnica de los datos, hay que lograr al menos dos cosas más para alcanzar una cultura de datos abiertos:
- A menudo los departamentos gubernamentales no están acostumbrados a compartir datos y ha sido necesario crear una mentalidad y educarles en esta finalidad.
- Además, los datos deben convertirse, si es posible, en la base exclusiva para la toma de decisiones; en otras palabras, las decisiones deben estar basadas en los datos.
- Además se requieren cambios culturales por parte de todo el personal implicado, fomentando la divulgación proactiva de datos, lo que puede asegurar que los datos estén disponibles incluso antes de que se soliciten.
Paso 3: Seguimiento de la reutilización y la sostenibilidad
- Apoyar la participación ciudadana: Una vez abiertos los datos, deben ser descubiertos por los usuarios potenciales. Para ello hay que desarrollar una estrategia de promoción, que puede comprender anunciar la apertura de los datos en comunidades de datos abiertos y los canales de medios sociales pertinentes.
Otra actividad importante es la consulta y el compromiso tempranos con los usuarios potenciales, a los que, además de informar sobre los datos abiertos, se debe animar a utilizarlos y reutilizarlos y a seguir participando.
- Apoyar el compromiso internacional: Las asociaciones internacionales aumentarían aún más los beneficios de los datos abiertos, por ejemplo, mediante la colaboración sur-sur y norte-sur. Especialmente importantes son las asociaciones que apoyan y crean capacidades para la reutilización de los datos, ya sea mediante el uso de IA o sin ella.
- Apoyar la participación beneficiosa de la IA: Los datos abiertos ofrecen muchas oportunidades a los sistemas de IA. Para aprovechar todo el potencial de los datos, es necesario potenciar que los desarrolladores hagan uso de ellos y desarrollen sistemas de IA en consecuencia. Al mismo tiempo, hay que evitar el abuso de los datos abiertos para aplicaciones de IA irresponsables y perjudiciales. Una práctica recomendada es mantener un registro público de qué datos han utilizado los sistemas de IA y cómo lo han hecho.
- Mantener datos de alta calidad: Muchos datos quedan obsoletos rápidamente. Por lo tanto, los conjuntos de datos deben actualizarse con regularidad. El paso "Mantener datos de alta calidad" convierte esta directriz en un bucle, ya que enlaza con el paso "Reunir y recopilar datos de alta calidad".
Conclusiones
Estas directrices sirven como una llamada a la acción por parte de la UNESCO sobre la ética de la inteligencia artificial. Los datos abiertos son un requisito previo y necesario para el seguimiento y la consecución del desarrollo sostenible.
Debido a la magnitud de las tareas, los gobiernos no sólo deben adoptar la apertura de los datos, sino también crear condiciones favorables para una participación beneficiosa de la IA que cree nuevos conocimientos a partir de los datos abiertos, para una toma de decisiones basada en pruebas.
Si los Estados Miembros de la UNESCO siguen estas directrices y abren sus datos de manera sostenible, crean capacidades, así como una cultura impulsada por los datos abiertos, podremos conseguir un mundo en el que los datos no sólo sean más éticos, sino que las aplicaciones sobre estos datos sean más certeras y beneficiosas para la humanidad.
Referencias
https://www.unesco.org/en/articles/open-data-ai-what-now
Autor : Ziesche, Soenke , ISBN : 978-92-3-100600-5
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
El Estudio de Madurez de Datos Abiertos 2022 nos ofrece una visión del nivel de desarrollo de las políticas que promueven los datos abiertos en los países, así como una evaluación del impacto esperado de las mismas. Entre sus hallazgos destaca que la medición del impacto de los datos abiertos es una prioridad, pero también un gran desafío en toda Europa.
En esta edición se ha registrado una disminución del 7% en el nivel de madurez promedio en la dimensión de impacto para los países de UE27 que coincide con la reestructuración de los indicadores de la dimensión impacto. Sin embargo, no se puede considerar tanto una disminución en el nivel de madurez, sino una imagen más precisa de la dificultad en evaluar el impacto resultante de la reutilización de los datos abiertos.
Es por ello, que con el fin de comprender mejor cómo progresar en el desafío de medir el impacto de los datos abiertos, hemos analizado las mejores prácticas existentes para la medición del impacto de los datos abiertos en Europa. Para conseguir este objetivo se ha trabajado con los datos proporcionados por los países en las respuestas al cuestionario del estudio y en particular con las de los once países que han tenido una puntuación superior a los 500 puntos en la dimensión de Impacto, independientemente de su puntuación global y de su posición en el ranking: Francia, Irlanda, Chipre, Estonia y República Checa que obtienen la máxima puntuación de 600 puntos; y Polonia, España, Italia, Dinamarca y Suecia que puntuaron por encima de los 510 puntos.
En el informe proporcionamos un perfil de cada uno de los diez países en el que se analizan de forma general los resultados del país en todas las dimensiones del estudio y de forma detallada los diferentes componentes de la dimensión impacto en la que resumen las prácticas que han llevado a su alta puntuación a partir del análisis de las respuestas al cuestionario.
A través de esta estructura de fichas el documento permite una comparación directa entre los indicadores de los países y ofrece una visión detallada de las mejores prácticas y los desafíos en el uso de datos abiertos en lo que se refiere a la medición del impacto a través de los siguientes indicadores:
-
“Conciencia estratégica”: Cuantifica la conciencia y preparación de los países para entender el nivel de reutilización y el impacto de los datos abiertos dentro de su territorio.
-
“Midiendo la reutilización”: Se centra en cómo los países miden la reutilización de datos abiertos y en qué métodos utilizan.
-
“Impacto creado”: Recopila datos sobre el impacto creado dentro de cuatro áreas de impacto: impacto gubernamental (anteriormente impacto político), impacto social, impacto ambiental e impacto económico.
Para finalizar el informe proporciona un análisis comparativo de estos países y extrae una serie de recomendaciones y buenas prácticas que tienen como objetivo de proporcionar ideas sobre cómo mejorar el impacto de la apertura de datos en cada uno de los tres indicadores medidos en el estudio.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar cómo realizar un análisis de redes o de grafos partiendo de datos abiertos sobre viajes en bicicleta de alquiler en la ciudad de Madrid. Para ello, realizaremos un preprocesamiento de los datos con la finalidad de obtener las tablas que utilizaremos a continuación en la herramienta generadora de la visualización, con la que crearemos las visualizaciones del grafo.
Los análisis de redes son métodos y herramientas para el estudio y la interpretación de las relaciones y conexiones entre entidades o nodos interconectados de una red, pudiendo ser estas entidades personas, sitios, productos, u organizaciones, entre otros. Los análisis de redes buscan descubrir patrones, identificar comunidades, analizar la influencia y determinar la importancia de los nodos dentro de la red. Esto se logra mediante el uso de algoritmos y técnicas específicas para extraer información significativa de los datos de red.
Una vez analizados los datos mediante esta visualización, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la estación de la red con mayor tráfico de entrada y de salida?
- ¿Cuáles son las rutas entre estaciones más frecuentes?
- ¿Cuál es el número medio de conexiones entre estaciones para cada una de ellas?
- ¿Cuáles son las estaciones más interconectadas dentro de la red?
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre los viajes en bicicleta de préstamo realizados en la ciudad de Madrid. La información que aportan se trata de la estación de origen y de destino, el tiempo del trayecto, la hora del trayecto, el identificador de la bicicleta, …
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Madrid, mediante ficheros que recogen los registros de forma mensual.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de la visualización interactiva se ha usado la herramienta Gephi
"Gephi" es una herramienta de visualización y análisis de redes. Permite representar y explorar relaciones entre elementos, como nodos y enlaces, con el fin de entender la estructura y patrones de la red. El programa precisa descarga y es gratuito.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Debido al alto volumen de viajes registrados en los conjuntos de datos, definimos los siguientes puntos de partida a la hora de analizarlos:
- Analizaremos la hora del día con mayor tráfico de viajes
- Analizaremos las estaciones con un mayor volumen de viajes
Antes de lanzarnos a analizar y construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, es necesario realizar un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de análisis de redes (Gephi) que de forma visual nos ayudará a comprender la información. Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en este Notebook de Google Colab, son los siguientes:
- Instalación de librerías y carga de los conjuntos de datos
- Análisis exploratorio de los datos (EDA)
- Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que, una vez cargado en el entorno de desarrollo, podrás ejecutar o modificar de manera sencilla.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente sino facilitar su comprensión, por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Análisis de la red
5.1. Definición de la red
La red analizada se encuentra formada por los viajes entre distintas estaciones de bicicletas en la ciudad de Madrid, teniendo como principal información de cada uno de los viajes registrados la estación de origen (denominada como “source”) y la estación de destino (denominada como “target”).
La red está formada por 253 nodos (estaciones) y 3012 aristas (interacciones entre las estaciones). Se trata de un grafo dirigido, debido a que las interacciones son bidireccionales y ponderado, debido a que cada arista entre los nodos tiene asociado un valor numérico denominado "peso" que en este caso corresponde al número de viajes realizados entre ambas estaciones.
5.2. Carga de la tabla preprocesada en Gephi
Mediante la opción “importar hoja de cálculo” de la pestaña archivo, importamos en formato CSV la tabla de datos previamente preprocesada. Gephi detectará que tipo de datos se están cargando, por lo que utilizaremos los parámetros predefinidos por defecto.


5.3. Opciones de visualización de la red
5.3.1 Ventana de distribución
En primer lugar, aplicamos en la ventana de distribución, el algoritmo Force Atlas 2. Este algoritmo utiliza la técnica de repulsión de nodos en función del grado de conexión de tal forma que los nodos escasamente conectados se separan respecto a los que tiene una mayor fuerza de atracción entre sí.
Para evitar que los componentes conexos queden fuera de la vista principal, fijamos el valor del parámetro "Gravedad en Puesta a punto" a un valor de 10 y para evitar que los nodos queden amontonados, marcamos la opción “Disuadir Hubs” y “Evitar el solapamiento”.

Dentro de la ventana de distribución, también aplicamos el algoritmo de Expansión con la finalidad de que los nodos no se encuentren tan juntos entre sí mismos.

Figura 3. Ventana distribución - algoritmo de Expansión
5.3.2 Ventana de apariencia
A continuación, en la ventana de apariencia, modificamos los nodos y sus etiquetas para que su tamaño no sea igualitario, sino que dependa del valor del grado de cada nodo (nodos con un mayor grado, mayor tamaño visual). También modificaremos el color de los nodos para que los de mayor tamaño sean de un color más llamativo que los de menor tamaño. En la misma ventana de apariencia modificamos las aristas, en este caso hemos optado por un color unitario para todas ellas, ya que por defecto el tamaño va acorde al peso de cada una de ellas.
Un mayor grado en uno de los nodos implica un mayor número de estaciones conectadas con dicho nodo, mientras que un mayor peso de las aristas implica un mayor número de viajes para cada conexión.

5.3.3 Ventana de grafo
Por último, en la zona inferior de la interfaz de la ventana de grafo, tenemos diversas opciones como activar/desactivar el botón para mostrar las etiquetas de los distintos nodos, adecuar el tamaño de las aristas con la finalizad de hacer más limpia la visualización, modificar el tipo de letra de las etiquetas, …

A continuación, podemos ver la visualización del grafo que representa la red una vez aplicadas las opciones de visualización mencionadas en los puntos anteriores.

Figura 6. Visualización del grafo
Activando la opción de visualizar etiquetas y colocando el cursor sobre uno de los nodos, se mostrarán los enlaces que corresponden al nodo y el resto de los nodos que están vinculados al elegido mediante dichos enlaces.
A continuación, podemos visualizar los nodos y enlaces relativos a la estación de bicicletas “Fernando el Católico". En la visualización se distinguen con facilidad los nodos que poseen un mayor número de conexiones, ya que aparecen con un mayor tamaño y colores más llamativos, como por ejemplo "Plaza de la Cebada" o "Quevedo".

5.4 Principales medidas de red
Junto a la visualización del grafo, las siguientes medidas nos aportan la principal información de la red analizada. Estas medias, que son las métricas habituales cuando se realiza analítica de redes, podremos calcularlas en la ventana de estadísticas.

- Nodos (N): son los distintos elementos individuales que componen una red, representando entidades diversas. En este caso las distintas estaciones de bicicletas. Su valor en la red es de 243
- Enlaces (L): son las conexiones que existen entre los nodos de una red. Los enlaces representan las relaciones o interacciones entre los elementos individuales (nodos) que componen la red. Su valor en la red es de 3014
- Número máximo de enlaces (Lmax): es el máximo posible de enlaces en la red. Se calcula mediante la siguiente fórmula Lmax= N(N-1)/2. Su valor en la red es de 31878
- Grado medio (k): es una medida estadística para cuantificar la conectividad promedio de los nodos de la red. Se calcula promediando los grados de todos los nodos de la red. Su valor en la red es de 23,8
- Densidad de la red (d): indica la proporción de conexiones existentes entre los nodos de la red con respecto al total de conexiones posibles. Su valor en la red es de 0,047
- Diámetro (dmax ): es la distancia de grafo más larga entre dos nodos cualquiera de la res, es decir, cómo de lejos están los 2 nodos más alejados. Su valor en la red es de 7
- Distancia media (d): es la distancia de grafo media promedio entre los nodos de la red. Su valor en la red es de 2,68
- Coeficiente medio de clustering (C): Índica cómo los nodos están incrustados entre sus nodos vecinos. El valor medio da una indicación general de la agrupación en la red. Su valor en la red es de 0,208
- Componente conexo: grupo de nodos que están directa o indirectamente conectados entre sí, pero no están conectados con los nodos fuera de ese grupo. Su valor en la red es de 24
5.5 Interpretación de los resultados
La probabilidad de grados sigue de forma aproximada una distribución de larga cola, donde podemos observar que existen unas pocas estaciones que interactúan con un gran número de ellas mientras que la mayoría interactúa con un número bajo de estaciones.
El grado medio es de 23,8 lo que indica que cada estación interacciona de media con cerca de otras 24 estaciones (entrada y salida).
En el siguiente gráfico podemos observar que, aunque tengamos nodos con grados considerados como altos (80, 90, 100, …), se observa que el 25% de los nodos tienen grados iguales o inferiores a 8, mientras que el 75% de los nodos tienen grados inferiores o iguales a 32.

La gráfica anterior se puede desglosar en las dos siguientes correspondientes al grado medio de entrada y de salida (ya que la red es direccional). Vemos que ambas tienen distribuciones de larga cola similares, siendo su grado medio el mismo de 11,9.
Su principal diferencia es que la gráfica correspondiente al grado medio de entrada tiene una mediana de 7 mientras que la de salida es de 9, lo que significa que existe una mayoría de nodos con grados más bajos en los de entrada que los de salida.


El valor del grado medio con pesos es de 346,07 lo cual nos indica la media de viajes totales de entrada y salida de cada estación.

La densidad de red de 0,047 es considerada una densidad baja indicando que la red es dispersa, es decir, contiene pocas interacciones entre distintas estaciones en relación con las posibles. Esto se considera lógico debido a que las conexiones entre estaciones estarán limitadas a ciertas zonas debido a la dificultad de llegar a estaciones que se encuentra a largas distancias.
El coeficiente medio de clustering es de 0,208 significando que la interacción de dos estaciones con una tercera no implica necesariamente la interacción entre sí, es decir, no implica necesariamente transitividad, por lo que la probabilidad de interconexión de esas dos estaciones mediante la intervención de una tercera es baja.
Por último, la red presenta 24 componentes conexos, siendo 2 de ellos componentes conexos débiles y 22 componentes conexos fuertes.
5.6 Análisis de centralidad
Un análisis de centralidad se refiere a la evaluación de la importancia de los nodos en una red utilizando diferentes medidas. La centralidad es un concepto fundamental en el análisis de redes y se utiliza para identificar nodos clave o influyentes dentro de una red. Para realizar esta tarea se parte de las métricas calculadas en la ventana de estadísticas.
- La medida de centralidad de grado indica que cuanto más alto es el grado de un nodo, más importante es. Las cinco estaciones con valores más elevados son: 1º Plaza de la Cebada, 2º Plaza de Lavapiés, 3º Fernando el Católico, 4º Quevedo, 5º Segovia 45.

- La media de centralidad de cercanía indica que cuanto más alto sea el valor de cercanía de un nodo, más central es, ya que puede alcanzar cualquier otro nodo de la red con el menor esfuerzo posible. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico 2º General Pardiñas, 3º Plaza de la Cebada, 4º Plaza de Lavapiés, 5º Puerta de Madrid.

Figura 13. Distribución medida centralidad de cercanía

- La medida de centralidad de intermediación indica que cuanto mayor sea la medida de intermediación de un nodo, más importante es dado que está presente en más rutas de interacción entre nodos que el resto de los nodos de la red. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico, 2º Plaza de Lavapiés, 3º Plaza de la Cebada, 4º Puerta de Madrid, 5º Quevedo.

 FIgura 16. Visualización grafo centralidad de intermediación
FIgura 16. Visualización grafo centralidad de intermediación
Con la herramienta Gephi se pueden calcular gran cantidad de métricas y parámetros que no se reflejan en este estudio ,como por ejemplo, la medida de vector propio o distribucción de centralidad "eigenvector".
5.7 Filtros
Mediante la ventana de filtrado, podemos seleccionar ciertos parámetros que simplifiquen las visualizaciones con la finalidad de mostrar información relevante del análisis de redes de una forma más clara visualmente.

A continuación, mostraremos varios filtrados realizados:
- Filtrado de rango (grado), en el que se muestran los nodos con un rango superior a 50, suponiendo un 13,44% (34 nodos) y un 15,41% (464 aristas)

- Filtrado de aristas (peso de la arista), en el que se muestran las aristas con un peso superior a 100, suponiendo un 0,7% (20 aristas)

Figura 19. VIsualización grafo filtrado de arista (peso)
Dentro de la ventana de filtros, existen muchas otras opciones de filtrado sobre atributos, rangos, tamaños de particiones, las aristas, … con los que puedes probar a realizar nuevas visualizaciones para extraer información del grafo. Si quieres conocer más sobre el uso de Gephi, puedes consultar los siguientes cursos y formaciones sobre la herramienta.
6. Conclusiones del ejercicio
Una vez realizado el ejercicio, podemos apreciar las siguientes conclusiones:
- Las tres estaciones más interconectadas con otras estaciones son Plaza de la Cebada (133), Plaza de Lavapiés (126) y Fernando el Católico (114).
- La estación que tiene un mayor número de conexiones de entrada es la Plaza de la Cebada (78), mientras que la que tiene un mayor número de conexiones de salida es la Plaza de Lavapiés con el mismo número que Fernando el Católico (57)
- Las tres estaciones con un mayor número de viajes totales son Plaza de la Cebada (4524), Plaza de Lavapiés (4237) y Fernando el Católico (3526).
- Existen 20 rutas con más de 100 viajes. Siendo las 3 rutas con un mayor número de ellos: Puerta de Toledo – Plaza Conde Suchil (141), Quintana Fuente del Berro – Quintana (137), Camino Vinateros – Miguel Moya (134).
- Teniendo en cuenta el número de conexiones entre estaciones y de viajes, las estaciones de mayor importancia dentro de la red son: Plaza la Cebada, Plaza de Lavapiés y Fernando el Católico.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!