Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
Captura del vídeo que muestra la interacción con el dashboard de la caracterización de la demanda de empleo y la contratación registrada en España disponible al final de este artículo
2. Objetivos
El objetivo principal de este post es realizar una visualización interactiva partiendo de datos abiertos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre la evolución de la demanda de empleo en España a lo largo de los últimos años. A partir de estos datos se determina el perfil que representa la demanda de empleo en nuestro país, estudiando específicamente cómo afecta la brecha de género al colectivo y la incidencia de variables como la edad, la prestación por desempleo o la región.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se han seleccionado conjuntos de datos publicados por el Servicio Público de Empleo Estatal (SEPE), coordinado por el Ministerio de Trabajo y Economía Social, que recogen series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presentan los demandantes de empleo. Estos datasets se encuentran disponibles en datos.gob.es con las siguientes características:
- Demandantes de empleo por municipio: contiene el número de demandantes de empleo desagregado por municipio, edad y sexo, desde 2006 hasta 2020.
- Gasto de prestaciones por desempleo por Provincia: serie temporal desde 2010 hasta 2020 sobre el gasto en prestaciones por desempleo, desagregado por provincia y el tipo de prestación.
- Contratos registrados por el Servicio Público de Empleo Estatal (SEPE) por municipio: estos conjuntos de datos contienen el número de contratos registrados tanto a demandantes como a no demandantes de empleo, desagregados por municipio, sexo y tipo de contrato, desde 2006 hasta 2020.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
RStudio es un entorno de desarrollo open source integrado para el lenguaje de programación R, dedicado al análisis estadístico y la creación de gráficos.
RMarkdown permite la realización de informes integrando texto, código y resultados dinámicos en un único documento.
Para la creación de los gráficos interactivos se ha utilizado la herramienta Kibana.
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstasg y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch. Las principales ventajas de esta herramienta son:
- Presenta la información de manera visual a través de dashboards interactivos y personalizables mediante intervalos temporales, filtros facetados por rango, cobertura geoespacial, entre otros.
- Dispone de un catálogo de herramientas de desarrollo (Dev Tools) para interactuar con los datos almacenados en Elasticsearch.
- Cuenta con una versión gratuita para utilizar en tu propio ordenador y una versión enterprise que se desarrolla en un cloud propio de Elastic u otras infraestructuras en cloud como Amazon Web Service (AWS).
En la propia web de Elastic encontramos manuales de usuario para la descarga e instalación de la herramienta, o cómo crear gráficos o dashboards, entre otros. Además ofrece vídeos cortos en su canal de youtube y organiza webinars donde explican diversos aspectos relacionados con Elastic Stack.
Si quieres saber más sobre estas herramientas u otras que pueden ayudarte en el procesado de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Para la realización una visualización, es necesario preparar los datos de la forma adecuada realizando una serie de tareas que incluyen el preprocesado y el análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer la realidad de los datos a los que nos enfrentamos. El objetivo es identificar características de los datos y detectar las posibles anomalías o errores que pudieran afectar a la calidad de los resultados. Un tratamiento previo de los datos es esencial para que los análisis o las visualizaciones que se realicen posteriormente sean consistentes y efectivas.
Para favorecer el entendimiento de los lectores no especialistas en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo clik en \"Código\", no está diseñado para su eficiencia sino para su fácil comprensión, por lo que es posible que lectores más avanzados en este lenguaje de programación consideren una forma de codificar algunas funcionalidades de forma alternativa. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en cuenta en Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de RMarkdown. Una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
El paquete base de R, siempre disponible desde que abrimos la consola en RStudio, incorpora un amplio conjunto de funcionalidades para cargar datos de fuentes externas, llevar a cabo análisis estadísticos y obtener representaciones gráficas. No obstante, hay multitud de tareas para las que necesitamos recurrir a paquetes adicionales incorporando al entorno de trabajo las funciones y objetos definidos en ellas. Algunos de ellos ya están instalados en el sistema, pero otros será preciso descargarlos e instalarlos.
#Instalación de paquetes \r\n #El paquete dplyr presenta una colección de funciones para realizar de manera sencilla operaciones de manipulación de datos \r\n if (!requireNamespace(\"dplyr\", quietly = TRUE)) {install.packages(\"dplyr\")}\r\n #El paquete lubridate para el manejo de variables tipo fecha \r\n if (!requireNamespace(\"lubridate\", quietly = TRUE)) {install.packages(\"lubridate\")}\r\n#Carga de paquetes en el entorno de desarrollo \r\nlibrary (dplyr)\r\nlibrary (lubridate)\r\n4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros .CSV y .XLS. Debemos cargar en nuestro entorno de desarrollo todos los ficheros que nos interesan. El siguiente código muestra como ejemplo la carga de un único fichero .CSV en una tabla de datos para que la lectura de este post sea más comprensible.
Para agilizar el proceso de carga en el entorno de desarrollo, es necesario descargar en el directorio de trabajo los conjuntos de datos necesarios para esta visualización, que se encuentran disponibles en la cuenta de Github de datos.gob.es.
#Carga del datasets de demandantes de empleo por municipio de 2020. \r\n Demandantes_empleo_2020 <- \r\n read.csv(\"Conjuntos de datos/Demandantes de empleo por Municipio/Dtes_empleo_por_municipios_2020_csv.csv\",\r\n sep=\";\", skip = 1, header = T)\r\nUna vez que tenemos todos los conjuntos de datos cargados como tablas en el entorno de desarrollo, debemos unificarlos para así tener un único dataset que integre todos los años de la serie temporal, por cada una de las características relacionadas con los demandantes de empleo que se quiere analizar: número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados por el SEPE.
#Dataset de demandantes de empleo\r\nDatos_desempleo <- rbind(Demandantes_empleo_2006, Demandantes_empleo_2007, Demandantes_empleo_2008, Demandantes_empleo_2009, \r\n Demandantes_empleo_2010, Demandantes_empleo_2011,Demandantes_empleo_2012, Demandantes_empleo_2013,\r\n Demandantes_empleo_2014, Demandantes_empleo_2015, Demandantes_empleo_2016, Demandantes_empleo_2017, \r\n Demandantes_empleo_2018, Demandantes_empleo_2019, Demandantes_empleo_2020) \r\n#Dataset de gasto en prestaciones por desempleo\r\ngasto_desempleo <- rbind(gasto_2010, gasto_2011, gasto_2012, gasto_2013, gasto_2014, gasto_2015, gasto_2016, gasto_2017, gasto_2018, gasto_2019, gasto_2020)\r\n#Dataset de nuevos contratos a demandantes de empleo\r\nContratos <- rbind(Contratos_2006, Contratos_2007, Contratos_2008, Contratos_2009,Contratos_2010, Contratos_2011, Contratos_2012, Contratos_2013, \r\n Contratos_2014, Contratos_2015, Contratos_2016, Contratos_2017, Contratos_2018, Contratos_2019, Contratos_2020)b. Selección de variables
Una vez que tenemos las tablas con las tres series temporales (número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados), crearemos una nueva tabla que incluirá las variables que interesan de cada una de ellas.
En primer lugar, agregaremos por provincia las tablas de demandantes de empleo (“datos_desempleo”) y contratos nuevos contratos registrados (“contratos”) para facilitar la visualización y que coincidan con la desagregación por provincia de la tabla de gasto en prestaciones por desempleo (“gasto_desempleo”). En este paso, seleccionamos únicamente las variables que interesen de los tres conjuntos de datos.
#Realizamos un group by al dataset de \"datos_desempleo\", agruparemos las variables numéricas que nos interesen, en función de varias variables categóricas\r\nDtes_empleo_provincia <- Datos_desempleo %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(total.Dtes.Empleo = (sum(total.Dtes.Empleo)), Dtes.hombre.25 = (sum(Dtes.Empleo.hombre.edad...25)), \r\n Dtes.hombre.25.45 = (sum(Dtes.Empleo.hombre.edad.25..45)), Dtes.hombre.45 = (sum(Dtes.Empleo.hombre.edad...45)),\r\n Dtes.mujer.25 = (sum(Dtes.Empleo.mujer.edad...25)), Dtes.mujer.25.45 = (sum(Dtes.Empleo.mujer.edad.25..45)),\r\n Dtes.mujer.45 = (sum(Dtes.Empleo.mujer.edad...45)))\r\n#Realizamos un group by al dataset de \"contratos\", agruparemos las variables numericas que nos interesen en función de las varibles categóricas.\r\nContratos_provincia <- Contratos %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(Total.Contratos = (sum(Total.Contratos)),\r\n Contratos.iniciales.indefinidos.hombres = (sum(Contratos.iniciales.indefinidos.hombres)), \r\n Contratos.iniciales.temporales.hombres = (sum(Contratos.iniciales.temporales.hombres)), \r\n Contratos.iniciales.indefinidos.mujeres = (sum(Contratos.iniciales.indefinidos.mujeres)), \r\n Contratos.iniciales.temporales.mujeres = (sum(Contratos.iniciales.temporales.mujeres)))\r\n#Seleccionamos las variables que nos interesen del dataset de \"gasto_desempleo\"\r\ngasto_desempleo_nuevo <- gasto_desempleo %>% select(Código.mes, Comunidad.Autónoma, Provincia, Gasto.Total.Prestación, Gasto.Prestación.Contributiva)En segundo lugar, procedemos a unir las tres tablas en una que será con la que trabajemos a partir de este punto.
Caract_Dtes_empleo <- Reduce(merge, list(Dtes_empleo_provincia, gasto_desempleo_nuevo, Contratos_provincia))
c. Transformación de variables
Una vez tengamos la tabla con las variables de interés para el análisis y la visualización, debemos transformar algunas de ellas a otros tipos más adecuados para futuras agregaciones.
#Transformación de una variable fecha\r\nCaract_Dtes_empleo$Código.mes <- as.factor(Caract_Dtes_empleo$Código.mes)\r\nCaract_Dtes_empleo$Código.mes <- parse_date_time(Caract_Dtes_empleo$Código.mes(c(\"200601\", \"ym\")), truncated = 3)\r\n#Transformamos a variable numérica\r\nCaract_Dtes_empleo$Gasto.Total.Prestación <- as.numeric(Caract_Dtes_empleo$Gasto.Total.Prestación)\r\nCaract_Dtes_empleo$Gasto.Prestación.Contributiva <- as.numeric(Caract_Dtes_empleo$Gasto.Prestación.Contributiva)\r\n#Transformación a variable factor\r\nCaract_Dtes_empleo$Provincia <- as.factor(Caract_Dtes_empleo$Provincia)\r\nCaract_Dtes_empleo$Comunidad.Autónoma <- as.factor(Caract_Dtes_empleo$Comunidad.Autónoma)d. Análisis exploratorio
Veamos qué variables y estructura presenta el nuevo conjunto de datos.
str(Caract_Dtes_empleo)\r\nsummary(Caract_Dtes_empleo)La salida de esta porción de código se omite para facilitar la lectura. Las características principales que presenta el conjunto de datos son:
- El rango temporal abarca desde enero de 2010 hasta diciembre de 2020.
- El número de columnas (variables) es de 17.
- Presenta dos variables categóricas (“Provincia” y “Comunidad.Autónoma”), una variable tipo fecha (“Código.mes”) y el resto son variables numéricas.
e. Detección y tratamiento de datos perdidos
Seguidamente analizaremos si el dataset presenta valores perdidos (NAs). El tratamiento o la eliminación de los NAs es esencial, ya que si no es así no será posible procesar adecuadamente las variables numéricas.
any(is.na(Caract_Dtes_empleo)) \r\n#Como el resultado es \"TRUE\", eliminamos los datos perdidos del dataset, ya que no sabemos cual es la razón por la cual no se encuentran esos datos\r\nCaract_Dtes_empleo <- na.omit(Caract_Dtes_empleo)\r\nany(is.na(Caract_Dtes_empleo))4.3. Creación de nuevas variables
Para realizar la visualización, vamos a crear una nueva variable a partir de dos variables que se encuentran en la tabla de datos. Esta acción es muy común en el análisis de datos ya que en ocasiones interesa trabajar con datos calculados (por ejemplo, la suma o la media de diferentes variables) en lugar de los datos de origen. En este caso vamos a calcular el gasto medio en prestaciones por desempleo para cada demandante de empleo. Para ello utilizaremos las variables de gasto total por prestación (“Gasto.Total.Prestación”) y el total de demandantes de empleo (“total.Dtes.Empleo”).
Caract_Dtes_empleo$gasto_desempleado <-\r\n (1000 * (Caract_Dtes_empleo$Gasto.Total.Prestación/\r\n Caract_Dtes_empleo$total.Dtes.Empleo))4.4. Guardar el dataset
Una vez que tenemos la tabla con las variables que nos interesan para los análisis y las visualizaciones, la guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos. Es importante utilizar la codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta.
write.csv(Caract_Dtes_empleo,\r\n file=\"Caract_Dtes_empleo_UTF8.csv\",\r\n fileEncoding= \"UTF-8\")5. Creación de la visualización sobre la caracterización de la demanda de empleo en España usando Kibana
El desarrollo de esta visualización interactiva se ha realizado usando Kibana en nuestro entorno local. Tanto para la descarga del software, como para la instalación del mismo, hemos recurrido al tutorial realizado por la propia compañía, Elastic.
A continuación se adjunta un vídeo tutorial donde se muestra todo el proceso de realización de la visualización. En el vídeo podrás ver la creación de un cuadro de mando (dashboard) con diferentes indicadores interactivos mediante la generación de representaciones gráficas de diferentes tipos. Los pasos para obtener el dashboard son los siguientes:
- Cargamos los datos en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos en los archivos cargados, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
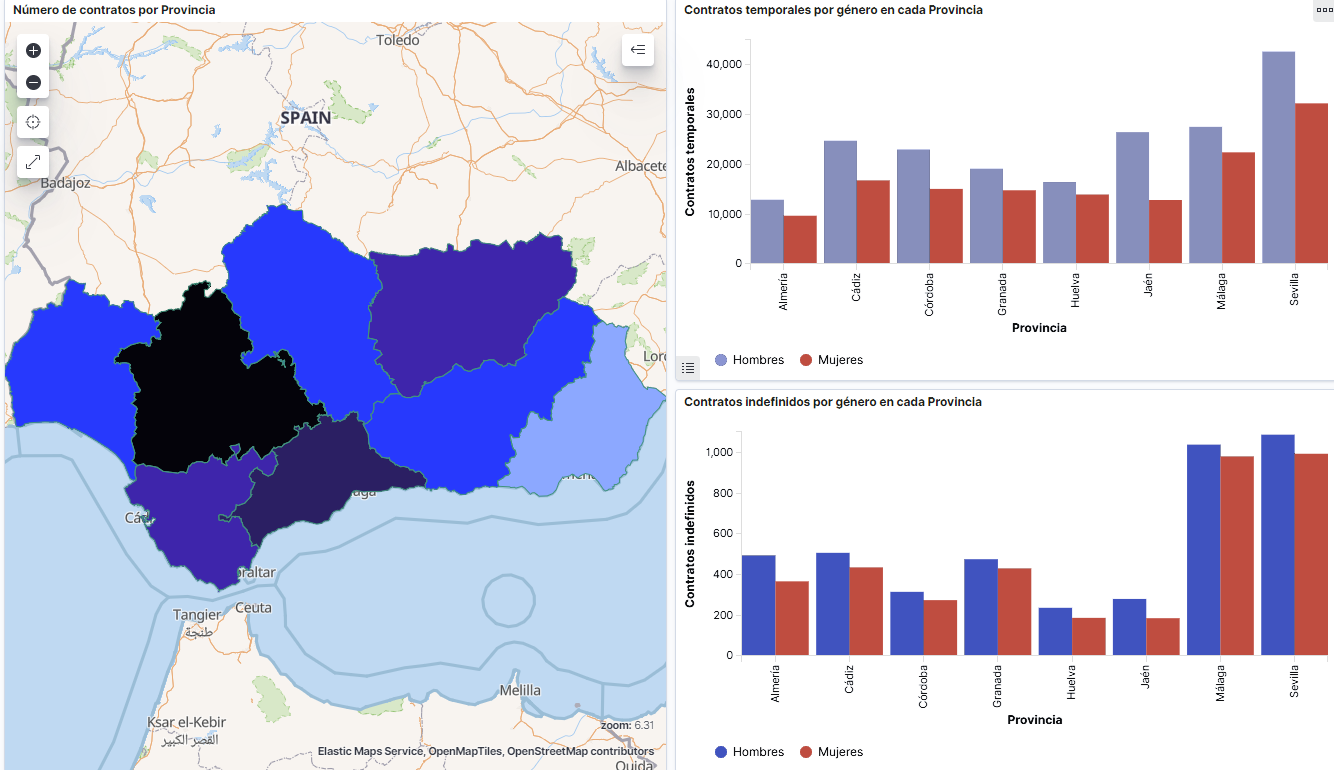
- Gráfico de líneas para representar la serie temporal sobre los demandantes de empleo en España desde 2006 hasta 2020.
- Gráfico de sectores de los demandantes de empleo desagregados por Provincia y Comunidad Autónoma.
- Mapa temático, mostrando el número de contratos nuevos registrados en cada Provincia del territorio. Para la creación de este visual es necesaria la descarga de un dataset de la georeferenciación de las Provincias publicado en el portal de datos abiertos Open Data Soft.
- Construcción del dashboard.
Seguidamente mostraremos un vídeo tutorial interactuando con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre el perfil de los demandantes de empleo en España en el periodo 2010 hasta 2020, se pueden obtener, entre otras, las siguientes conclusiones:
- Existen dos incrementos significativos en el número de demandantes de empleo. El primero aproximadamente en 2010, que coincide con la crisis económica. El segundo, mucho más pronunciado en 2020, que coincide con la crisis derivada de la pandemia.
- Se observa que existe una brecha de género en el colectivo de demandantes de empleo: el número de mujeres demandantes de empleo es mayor a lo largo de toda la serie temporal, principalmente en los grupos de edad de mayores de 25.
- A nivel regional, Andalucía, seguida de Cataluña y Comunidad Valenciana, son las Comunidades Autónomas con mayor número de demandantes de empleo. En contraste, Andalucía, es la Comunidad Autónoma con menor gasto por desempleo, mientras que Cataluña, es la que presenta mayor gasto por desempleo.
- Los contratos de tipo temporal son los prioritarios y las provincias que generan mayor número de contratos son Madrid y Barcelona, que coinciden con las provincias con mayor número de habitantes, mientras que en el lado opuesto, las provincias que menos número de contratos realizan son Soria, Ávila, Teruel o Cuenca, que coincide con las zonas más despobladas de España.
Esta visualización nos ha ayudado a sintetizar gran cantidad de información y darle sentido pudiendo obtener unas conclusiones y si fuera necesario tomar decisiones en función de los resultados. Esperemos que os haya gustado este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!
Documentación
En el Plan de Acción de la Conferencia Internacional de Datos Abiertos, el desarrollo de capacidades se ha convertido en un aspecto prioritario dentro del movimiento open data internacional. Al fin y al cabo la necesidad de herramientas formativas es imprescindible para los líderes responsables de las políticas RISP, los productores y reutilizadores de datos, el sector público y privado, e incluso, los ciudadanos. Por ello, facilitar herramientas formativas que permitan a los diferentes agentes avanzar en la apertura y reutilización constituye una tarea prioritaria.
Con este objetivo, desde la línea de difusión, sensibilización y formación de Iniciativa Aporta, se han elaborado ocho unidades didácticas, dirigidas a todo tipo de público: desde ciudadanos que se acercan por primera vez a los datos abiertos hasta reutilizadores y empleados públicos, responsables de iniciativas de apertura de la información, que deseen ampliar sus conocimientos.
Las unidades formativas están diseñada para entender los conceptos básicos del movimiento open data, para conocer buenas prácticas en la implementación de políticas de datos abiertos y su reutilización, pautas metodológicas para la apertura, normativas técnicas como DCAT-AP y NTI-RISP o además del uso de herramientas de tratamiento de datos, entre otros aspectos.
En la elaboración de los recursos, se han tenido en cuenta dos tipos de aprendizaje. El aprendizaje por descubrimiento, orientado a ampliar los conocimientos para resolver las dudas y reflexiones planteadas y el aprendizaje significativo basado en el conocimiento previo, a través del uso de ejemplos prácticos para contextualizar y aplicar los conceptos tratados.
Además, los módulos formativos contienen materiales complementarios a través de enlaces a páginas externas y documentos para su descarga sin necesidad de conexión. De esta forma, se le brinda la oportunidad al alumno de ampliar sus conocimientos y familiarizarse con fuentes relevantes donde obtener información fiable y actualizada sobre el sector open data.
Todas las unidades se distribuyen bajo la licencia Creative Commons Share-Alike Attribution Licence (CC-BY-SA) que permite copiar, distribuir el material en cualquier medio o formato y adaptarlo para crear nuevos recursos a partir de él.
 ¿Qué contenidos están disponibles?
¿Qué contenidos están disponibles?
El material formativo elaborado por Iniciativa Aporta consta de ocho unidades didácticas que abordan los siguientes contenidos del sector de la apertura y reutilización de la información del sector público:
- Conceptos básicos, beneficios del Open Data y Barreras
- Marco Normativo
- Tendencias y buenas prácticas en la implementación de políticas de datos abiertos
- La reutilización de datos públicos en su papel transformador
- Pautas metodológicas para la apertura de datos
- DCAT-AP y la Norma Técnica de Interoperabilidad de Reutilización de Recursos de Información (NTI-RISP)
- Uso de herramientas básicas de tratamiento de datos
- Buenas prácticas en el diseño de APIs y Linked Data
 ¿En qué consisten las unidades didácticas?
¿En qué consisten las unidades didácticas?
Cada unidad está diseñada para que el alumno adquiera o amplíe sus conocimientos sobre el sector de la apertura y reutilización del sector público. Con el fin de facilitar su comprensión, todas ellas cuentan con una estructura similar que incluye objetivos, contenidos, actividades de evaluación, ejemplos prácticos, información complementaria y conclusiones.
Todas las unidades didácticas puede realizarse de forma online, directamente desde el portal de datos.gob.es o, en su defecto, también es posible su descarga en el equipo del usuario e, incluso, su carga en una plataforma LMS.
 ¿Es necesario realizar todas las unidades didácticas?
¿Es necesario realizar todas las unidades didácticas?
Cada unidad independiente en sí misma; permitiendo al alumno adquirir los conocimientos necesarios en una materia específica acorde a sus necesidades formativas. No obstante, aquellos alumnos que deseen poseer una visión más completa del sector RISP, tienen la oportunidad de realizar la serie completa de ocho unidades didácticas para conocer en profundidad los aspectos más relevantes de las iniciativas de datos abiertos.
 ¿Dónde están publicadas las unidades didácticas?
¿Dónde están publicadas las unidades didácticas?
Las unidades didácticas están disponibles dentro de la sección web “Documentación” bajo la categoría “Materiales formativos” para su realización a través del portal online o para su descarga en el equipo del alumno.
Materiales formativos de la Iniciativa Aporta
Blog
La primera fase del Desafío Aporta 2017: El valor del dato para la Administración ha llegado a su fin. El concurso “Cómo reutilizar datos abiertos para mejorar la eficiencia en las administraciones públicas”, promovido por la Secretaría de Estado para la Sociedad de la Información y la Agenda Digital, la Entidad Pública Empresarial Red.es, y la Secretaría General de Administración Digital, ha recibido un total de 45 ideas procedentes de grupos de trabajo de los ámbitos académico y empresarial, así como de particulares. Diez de ellas han sido seleccionadas y pasan a la segunda fase. El jurado, que ha evaluado las ideas presentadas teniendo en cuenta su relevancia, calidad y utilidad, ha destacado la alta calidad de todas las propuestas recibidas.
Las diez propuestas que han resultado finalistas en esta primera fase son las siguientes:
-
qMe-aporta: guiado NL en consultas de datos.gob.es
Buscador basado en lenguaje natural guiado que busca facilitar el descubrimiento de los datos ofrecidos por las administraciones públicas y su reutilización entre ellas. -
Licitalio: tu comparador de contratos públicos
Herramienta web que, mediante técnicas de datamining y clusterización, plantea mejorar el acceso a los contratos del sector público para facilitar la selección y reutilización de las mejores licitaciones según las necesidades de la administración interesada. -
Análisis informal de licencias
Mecanismo de caracterización de licencias que, utilizando técnicas de procesamiento del lenguaje natural, pretende detectar de forma ágil qué recursos de las administraciones están debidamente licenciados para su reutilización y cuáles cuentan con condiciones de uso que precisan ser reajustadas. -
Anfitrión
Sistema cliente servidor que plantea actuar a modo de intérprete para la transformación de conjuntos de datos en diferentes formatos al formato JSON, fácilmente reutilizable por las empresas y por otras administraciones -
Light
Aplicación móvil que, introduciendo mecánicas de gamificación, propone incentivar a las personas que contribuyen con las administraciones a hacer posible un entorno más sostenible, premiando hábitos y acciones como el uso del servicio público de transporte. -
Plataforma PLAN
Proyecto dirigido a la publicación de anuncios previos al lanzamiento de licitaciones nacionales al que podrán suscribirse todos los operadores económicos, favoreciendo así la concurrencia y la transparencia. -
Análisis de contenido de comunicación ciudadana
Iniciativa dirigida a agilizar la respuesta de las administraciones a la ciudadanía a través del análisis de los canales de comunicación ciudadano-ayuntamiento, y la identificación de los intereses de forma previa a la solicitud de información. -
Noticias abiertas
Sistema dirigido a recomendar conjuntos de datos abiertos públicos relacionados con contenidos generados por medios digitales, con el objetivo de favorecer la participación activa del ciudadano y la transparencia de las administraciones públicas. -
Funding analytucs for innovation projects
Propuesta de desarrollo de una herramienta analítica web basada en datos abiertos de proyectos I+D+i dirigida a analizar y visualizar concesiones de subvenciones y a detectar tendencias de investigación que ayuden a las administraciones públicas a evaluar y crear nuevas líneas de negocio a las empresas. -
Mi turno
Aplicación móvil que, reflejando el número de personas que hay esperando turno en las oficinas asociadas a un servicio que ofrece la administración, ofrecería analizar y gestionar los tiempos de espera del ciudadano y, en consecuencia, mejorar la eficiencia de la Administración.
Comienza ahora segunda fase de Desafío Aporta, en la que los responsables de las ideas ganadoras tienen un plazo de dos meses y medio para desarrollar sus prototipos, que presentarán el próximo día 23 de octubre a los miembros del jurado.
Cuantías de 3.000, 2.000 y 1.000 euros serán los premios que recibirán los tres mejores prototipos, que se darán a conocer durante el Encuentro Aporta 2017 el próximo 24 de octubre .
Animamos a la comunidad de datos abiertos a asistir de forma gratuita a dicho Encuentro que este año llega a su séptima edición.
Blog
El próximo día 12 de septiembre concluye el plazo para que empresas y entidades que han desarrollado proyectos con datos públicos se presenten a la primera edición de los Premios Aporta 2017. Unos premios enfocados a divulgar y reconocer a profesionales que han apostado por la reutilización de datos abiertos y la innovación como motor de transformación digital y que son promovidos por la Secretaría de Estado para la Sociedad de la Información y la Agenda Digital, la Entidad Pública Empresarial Red.es y la Secretaría General de Administración Digital.
Con esta iniciativa, se pretende impulsar y visibilizar el valor de los datos generados por las administraciones públicas españolas, así como reutilización de los mismos. Los proyectos y trabajos que pueden optar a dichos premios han tenido que ser desarrollados en los dos últimos años, reutilizando datos públicos y contribuyendo a generar valor social, nuevos negocios y/o mejoras para la sociedad.
Las candidaturas serán evaluadas durante el mes de septiembre por representantes de Iniciativa Aporta. Se tendrá en cuenta la originalidad, la utilidad y el impacto de la iniciativa en términos de destinatarios beneficiados. Las dos mejores iniciativas recibirán un reconocimiento en el Encuentro Aporta que tendrá lugar a finales de octubre de 2017.
Convocamos y animamos a los profesionales del sector y empresas innovadoras para que presenten su candidatura a los Premios Aporta, a través del formulario disponible en la sede electrónica de Red.es. La fecha límite es el próximo 12 de septiembre. ¡Participa!
Toda la información en datos.gob.es y en Bases de los Premios Aporta 2017.
Blog
A la hora de planificar nuestras vacaciones, todos buscamos el destino perfecto que cumpla con nuestras expectativas: playa, montaña, ciudad... Pero una vez que ya sabemos dónde ir, todavía nos quedan muchas decisiones que tomar: ¿cómo voy a organizar mi viaje para que todo salga perfecto? Por suerte, contamos con cientos de aplicaciones que nos hacen la vida mucho más fácil.
Hoy en día puedes utilizar algún tipo de app para calcular cuál es la ruta más adecuada para llegar a tu destino o decidir dónde echar gasolina durante el trayecto sin dañar el bolsillo. También puedes mirar las opciones de alojamiento o restauración con mejor calidad/precio desde el móvil. O consultar las actividades culturales de la zona, buscando actividades que puedan emocionar a los más pequeños de la casa. Y si quieres ir a la playa, puedes comprobar fácilmente el estado del mar, el viento o la temperatura del agua sin salir del hotel.
Todas estas aplicaciones, además de ayudarnos a organizar nuestras vacaciones de manera sencilla, tienen algo en común: basan su funcionamiento en datos abiertos procedentes de administraciones públicas.
El hecho de que cada vez más administraciones locales estén abriendo sus datos relacionados con el turismo permite generar servicios que ayudan a gestionar nuestros viajes de una forma más eficiente, integrando información a la que no siempre es fácil acceder. Como ejemplo, Asturias o Aragón están fomentado catálogos de datasets concretos centrados en este ámbito.
Muchas de estas aplicaciones han sido diseñadas por particulares y empresas, reutilizando los datos abiertos disponibles, pero otras han sido promovidas por las propias administraciones. Esto se debe a que los datos abiertos turísticos no solo ayudan a los visitantes, sino que también tienen grandes ventajas para los ayuntamientos.
El turismo es una actividad económica fundamental para nuestro país. Durante los 5 primeros meses de 2018, España superó los 28,6 millones de turistas internacionales, lo que supone un aumento del 2% con respecto al mismo periodo del año anterior. Estos turistas son una gran fuente de ingresos económicos: sólo en el mes de mayo el gasto medio por turista fue de 1.009 euros, un 1,8% más que en 2017. No es de extrañar, por tanto, que cualquier ayuntamiento quiera difundir los servicios que ofrece y atraer visitantes.
Las aplicaciones turísticas basadas en datos abiertos pueden favorecer la interacción entre los visitantes y la comunidad local, promoviendo servicios locales y favoreciendo el crecimiento económico. Además, algunas aplicaciones permiten incluso recolectar información de los usuarios bajo su consentimiento. El análisis de dicha información anonimizada, combinada con otros conjuntos de datos como el gasto total en viajes de turistas internacionales según el motivo del viaje o los turistas alojados por municipios permite conocer los patrones de comportamiento de los turistas y diseñar políticas específicas con el foco puesto en la innovación y la gestión inteligente de los destinos turísticos.
Tradicionalmente, el sector turismo ha tenido un gran peso en España, pero como todos los sectores tiene que seguir renovándose para no quedarse atrás, integrando nuevos elemento que ayuden a mejorar la experiencia de los visitantes. Los datos abiertos ligados al uso de nuevas tecnologías como el análisis Big data y la inteligencia artificial son una buena opción - por ejemplo para realizar recomendaciones y personalizaciones basadas en el comportamiento de los usuarios -. El objetivo final es proporcionar un servicio global de alta calidad, que nos permita continuar siendo líderes y recibir millones de visitantes año tras año.
Blog
En las políticas que está impulsando la Unión Europea se ha planteado la existencia de una íntima conexión entre la inteligencia artificial y los datos abiertos. A este respecto, como se ha destacado, los datos abiertos son esenciales para el correcto funcionamiento de la inteligencia artificial, ya que los algoritmos han de ser alimentados por datos cuya calidad y disponibilidad resulta imprescindible para su continua mejora y, asimismo, para auditar su correcto funcionamiento.
La inteligencia artificial conlleva un incremento de la sofisticación en los tratamientos de los datos, ya que requiere de una mayor precisión, actualización y calidad de los mismos que, por otro lado, han de ser obtenidos de fuentes muy diversas para incrementar la calidad del resultado final de los algoritmos. Asimismo, el hecho de que los tratamientos se realicen de forma automatizada y deban ofrecer respuestas precisas de manera inmediata ante circunstancias cambiantes supone una dificultad añadida. Se precisa, por tanto, una perspectiva dinámica que justifica la necesidad de que los datos no sólo se ofrezcan en formato abierto y legible por máquinas, sino también con los niveles más elevados de precisión y desagregación.
Esta exigencia adquiere una especial importancia por lo que se refiere a la accesibilidad de los datos generados por parte del sector público, sin duda una de las principales fuentes de donde se nutren los algoritmos debido tanto al elevado número de conjunto de datos disponibles como, asimismo, por el especial interés de las materias a las que se refiere su actividad, en especial los servicios públicos. En este sentido, al margen de la necesidad de superar las insuficiencias del marco legal vigente en cuanto al limitado alcance de las obligaciones que se imponen a las entidades públicas, resulta conveniente valorar en qué medida las condiciones jurídicas en que se ofrecen los datos sirven para dinamizar el desarrollo de aplicaciones basadas en la inteligencia artificial.
Así, en primer lugar, el artículo 5.3 de la Ley señala con rotundidad que “no podrá exigirse a las Administraciones y organismos del sector público que mantengan la producción y el almacenamiento de un determinado tipo de documento con vistas a su reutilización”. Teniendo en cuenta esta previsión legal, las referidas entidades pueden apoyarse en la inexistencia de una obligación de garantizar indefinidamente el suministro de los datos. También en la limitación de responsabilidad que contemplan algunas disposiciones al afirmar que el uso de los datos se realizará bajo la responsabilidad y riesgo de los usuarios o agentes de la reutilización o, incluso, la exoneración por cualquier error u omisión que venga determinado por la incorrección de los propios datos. Ahora bien, se trata de una interpretación cuyo efectivo alcance en cada caso concreto ha de contrastarse con la exigente regulación europea en la materia por lo que se refiere al alcance de las obligaciones y las vías de tutela, en particular tras la reforma que tuvo lugar en el año 2013.
Más allá de un planteamiento basado en el estricto cumplimiento normativo desde una interpretación restrictiva, lo cierto es que la necesidad de ofrecer políticas de apertura de datos del sector público para hacer frente a las singulares exigencias de la inteligencia artificial precisa de una aproximación proactiva que adopte una visión de mayor alcance. En este sentido, la interacción entre sujetos públicos y privados en contextos de mediciones y obtenciones sistemáticas de datos, continuamente actualizados a partir de conexiones generalizadas - como sucede en las iniciativas de ciudades inteligentes -, nos sitúa ante un escenario tecnológico donde las políticas activas de gestión contractual adquieren una especial importancia a fin de superar las barreras y dificultades jurídicas para su apertura. En efecto, en ocasiones los servicios públicos municipales son prestados con frecuencia por sujetos privados que se encuentran al margen de la normativa sobre reutilización y, además, los datos no siempre se obtienen de servicios u objetos gestionados por entidades públicas o con ocasión de actividades cuya gestión les corresponda; incluso a pesar del interés general subyacente en ámbitos como el suministro eléctrico, la prestación de servicios de telefonía y comunicaciones electrónicas o, incluso, los servicios financieros.
Por esta razón la iniciativa que puso en marcha la Unión Europea en 2017 adquiere una singular importancia desde la perspectiva de la inteligencia artificial, ya que pretende superar buena parte de las restricciones jurídicas actualmente existentes para la apertura de los datos. En el mismo sentido, la Estrategia española de I+D+I en Inteligencia Artificial, presentada recientemente por el Ministerio de Ciencia, Innovación y Universidades, sienta como una de sus prioridades el desarrollo de un ecosistema digital de datos entre cuyas medidas destacan la necesidad de garantizar un uso óptimo de los datos abiertos, así como la creación de un Instituto Nacional de Datos encargado de la gobernanza de los datos procedentes de los diferentes niveles de la Administración Pública. Asimismo, en la misma línea de la iniciativa europea antes referida, entre otras medidas se plantea la necesidad de ampliar las obligaciones de apertura a ciertas entidades privadas y a los datos científicos, lo que sin duda tendría un impacto relevante para el mejor funcionamiento de los algoritmos.
La singularidad tecnológica que plantea la Inteligencia Artificial requiere, sin duda, un marco ético y jurídico adecuado, que permita hacer frente a los desafíos que conlleva. La nueva Directiva sobre datos abiertos y reutilización de la información del sector público recientemente aprobada por el Parlamento Europeo supondrá un decidido impulso para la inteligencia artificial en la medida que dicha iniciativa ampliará tanto los sujetos obligados como el tipo de datos que habrán de estar disponibles. Sin duda una medida ciertamente relevante, a la que seguirán otras muchas en marco de la estrategia de la Unión Europea sobre Inteligencia Artificial, una de cuyas principales premisas es asegurar un marco normativo adecuado para facilitar la innovación tecnológica desde el respeto a los derechos fundamentales y los principios éticos.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hace unos meses los datos del Open Data Climático, realizado por la Agencia Estatal de Meteorología, protagonizaron un gran número de noticias, con titulares como “El cambio climático afecta ya a un 70% de los españoles”, “Los veranos son cinco semanas más largos que en los años ochenta” o “El clima semiárido avanza hacia Galicia”.
Nuestro planeta se enfrenta a grandes retos en los próximos años: deforestación, altos niveles de contaminación, deshielo de los polos, desertización… Todo ello pone en peligro la vida de las distintas especies que vivimos en él, llevando a algunas incluso a la extinción. Además, puede generar grandes daños al desarrollo económico: si no se mitigan los efectos del cambio climático, el mercado mundial podría sufrir una recesión de hasta el 20% del PIB global, tal y como dice Carmen Parra, Directora de la Cátedra de Economía Solidaria de la Universidad Abat Oliba CEU, en base al Informe Stern sobre impacto del cambio climático sobre la economía.
Los seres humanos tenemos la responsabilidad de intentar revertir esta situación, y la tecnología y los datos abiertos pueden ayudarnos a ello. Proporcionar información detallada y actualizada a la población ayuda a concienciar a los ciudadanos sobre la realidad que nos rodea, así como a buscar soluciones al cambio climático y al resto de retos medioambientales que nos afectan.
Aprovechando el Día Mundial del Medio Ambiente, en datos.gob.es hemos querido recopilar algunos ejemplos de aplicaciones que reutilizan datos abiertos generados por organismos públicos y cuyo objetivo es impulsar la sostenibilidad y la mejora del medio ambiente.
Luchar contra la contaminación
Nueve de cada diez personas en todo el mundo están expuestas a niveles de contaminación que superan las cuotas de seguridad señaladas por la Organización Mundial de la Salud (OMS). Cada vez más ciudades, regiones y países ponen en marcha mecanismos para tratar de limitar la cantidad de partículas y gases contaminantes que se emiten. En este sentido, también han surgido aplicaciones para informar en tiempo real del estado del aire o de nuestros ríos.
- airACT. Esta aplicación, desarrollada por la Universidad Politécnica de Cataluña junto a Ecologistas en Acción y el CSIC, entre otros, busca informar a la población de la calidad del aire en tiempo real. A través de un sistema de alertas, basados en las recomendaciones de la OMS, los usuarios pueden conocer los niveles de los principales contaminantes del aire, así como el nivel de riesgo al que nos exponen.
-
Riu Net. Además del aire que respiramos, también es importante concienciar sobre la calidad del agua. Riu Net es una herramienta educativa interactiva que permite evaluar el estado ecológico de los ríos y, al mismo tiempo, proporciona datos científicos que podrán ser consultados tanto por expertos y gestores ambientales como por el público en general.
Mejorar la gestión de residuos
8 millones de toneladas de plásticos llegan cada año a nuestros océanos. Para acabar con esta situación es necesario fomentar la reutilización y el reciclaje de materiales. Las aplicaciones que muestran los puntos de recolección de residuos ayudan a crear conciencia y educar al público sobre el reciclaje, la clasificación y eliminación de residuos. Algunos ejemplos de estas aplicaciones son:
-
Contenedores de basura en Cáceres. Esta aplicación permite visualizar la ubicación de todos los contenedores de la ciudad de Cáceres. El usuario puede filtrar por tipos de contenedor (orgánico, plásticos, papel, etc.) para mejorar la búsqueda y localizar el contenedor más cercano.
-
CleanSpotApp - Tu punto limpio más cercano!. Algunos residuos necesitan de contenedores especializados (puntos limpios). Gracias a aplicaciones como esta podemos saber cuál es el punto limpio más cercano para depositar pilas, aparatos eléctricos, bombillas, aceite usado, ropa y zapatos, juguetes, libros y material escolar, cápsulas de café, etc.
Promover medios de transporte sostenibles
Los automóviles son responsables del 83% de las emisiones de CO2 del transporte. Algunas aplicaciones basadas en datos abiertos buscan evitar o reducir el uso individual de coches particulares e impulsar el uso de otros medios de transporte más sostenible (transporte público, bicicletas, patinetes eléctricos).
-
dBizi++. Los usuarios de dBizi pueden conocer con una frecuencia de 5-6 minutos, la disponibilidad de bicicletas en las 16 estaciones de la ciudad de San Sebastián. Además, La aplicación informa al usuario de la viabilidad de su trayecto, empleando datos históricos y en tiempo real.
-
Puedo circular. Esta aplicación proporciona información personalizada sobre los protocolos de contaminación en la ciudad de Madrid. El usuario solo tiene que introducir la matrícula de su vehículo en la web/aplicación y obtendrá información sobre cuál es el distintivo ambiental que corresponde al vehículo, cuál es el escenario activado de acuerdo con el protocolo de contaminación de la capital y cómo le afecta dicho escenario: si puede circular o no por la ciudad, dónde puede aparcar o qué velocidad debe mantener para reducir el impacto ambiental.
Luchar contra la contaminación acústica
La contaminación acústica suele ser una de las grandes olvidadas cuando hablamos de medio ambiente, pero sus efectos pueden ser muy nocivos para la salud: puede generar desde estrés y trastornos del sueño hasta pérdida de atención o afecciones cardiovasculares. En España se calcula que al menos 9 millones de personas soportan niveles medios de 65 decibelios, el límite aceptado por la OMS.
-
ComfortUP!: Se trata de una aplicación móvil de colaboración ciudadana, a través de la cual las personas que están usando los espacios públicos pueden valorar la confortabilidad de estos lugares desde el punto de vista acústico y térmico, basándose en su propia experiencia. La aplicación también permite realizar observaciones y medidas de las condiciones ambientales en una selección de parques de la ciudad.
-
Noise Capture: Esta aplicación sirve de soporte a un proyecto de ciencia ciudadana cuyo objetivo es registrar los niveles de ruido soportados por los usuarios. Además de descubrir la contaminación sonora que sufren los ciudadanos, permite compartir esa información y contribuir a la creación de mapas colaborativos de ruido de forma voluntaria y anónima.
La protección y mejora del medio ambiente es una cuestión fundamental que afecta al bienestar de los pueblos y a su desarrollo tanto social como económico. Por ello debe ser una de las prioridades no solo de los gobiernos, sino también de los ciudadanos. Gracias a los datos abiertos, y a los servicios creados en base a ellos, los ciudadanos pueden ser más conscientes de su entorno y actuar consecuentemente para reducir su huella ambiental.
Empresa reutilizadora
Grupo de profesionales especializados en el manejo y uso de datos en diferentes niveles.
Un equipo referente en el desarrollo, extracción y tratamiento de la información convirtiéndola en estrategia y valor para sus clientes.
Documentación
¿Por qué son importantes los datos abiertos? ¿Cuál es su relación con el gobierno abierto? ¿Cómo puedo poner en marcha una iniciativa de este tipo? ¿A quién puedo tomar cómo referente? Estas son algunas de las preguntas que trata de responder la Guía Open Data: Publicación y reutilización de Datos Abiertos como iniciativa de Gobierno Abierto en la Administración.
Elaborada por la Consejería de Fomento y Medio Ambiente de la Junta de Castilla y León, esta guía se enmarca en la Comunidad Rural Digital (CRD), un proyecto de colaboración entre Administraciones Públicas de Portugal y España. El objetivo del proyecto es mejorar la innovación tecnológica de las instituciones del medio rural, fomentando la cooperación y su competitividad.
La guía se divide en 5 secciones: introducción a los datos abiertos, situación actual del gobierno abierto y el open data, implantación de datos abiertos, soluciones innovadoras y casos de éxito, y conclusiones.
En la primera sección de introducción, perfecta para aquellos poco familiarizados con el mundo de los datos abiertos, se repasan algunos conceptos básicos. El informe se centra en el gobierno abierto como un modo de interacción sociopolítico basado en 4 pilares - transparencia, rendición de cuentas, participación y colaboración-, los cuales pueden ser impulsados y mejorados gracias a los datos abiertos. Todo ello se explica en esta sección, que también describe los principios que deben cumplir los datos para considerarse abiertos.
A continuación, se aborda la situación actual del gobierno abierto y el open data en España, Portugal y Europa incluyendo la normativa existente. En el caso de España, el informe destaca la existencia de casi 300 iniciativas, incluidas en el mapa de iniciativas de datos.gob.es, así como la existencia de más de 660 empresas que reutilizan información, beneficiándose de ello con un volumen de negocio superior a los 1.700 millones de euros anuales. Estos datos, unidos a la buena posición de España en el informe European Open Data Maturity Landscaping 2018, demuestran el buen momento de los datos abiertos en nuestro país.
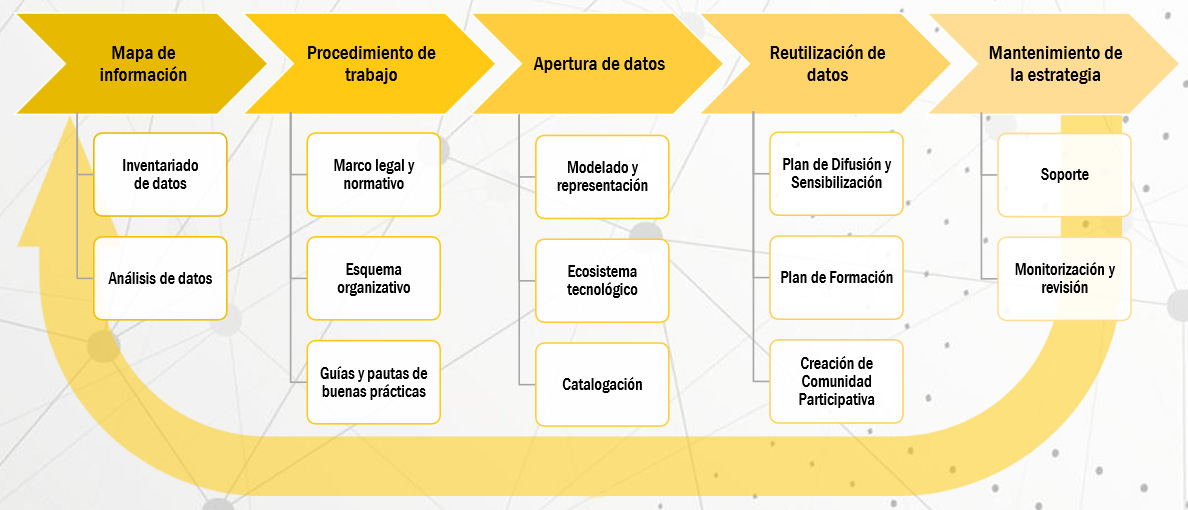
La tercera sección del informe se centra en la implantación de datos abiertos en una organización. Para facilitar este proceso, los autores de la guía han elaborado un plan con una serie de etapas que son detalladas en el informe:
Por último, el informe muestra varios ejemplos de soluciones innovadoras y casos de éxito, basándose en 2 criterios:
-
Ejemplos de portales de datos abiertos de referencia, que destaquen por su funcionalidad, como el portal de datos abiertos Aragon Open Data o el centro de descargas del Instituto Geográfico Nacional (IGN), entre otros.
-
Ejemplos de buenas prácticas en materia de reutilización, por su carácter innovador y el valor económico o social que generan. Se incluyen ejemplos de distintos sectores, como el inmobiliario (TerceroB), meteorológico (Meteogrid), la contratación pública (EuroAlert) o el periodismo de datos y la transparencia pública (Civio).
El informe acaba recogiendo una serie de conclusiones, como la necesidad de ampliar la formación tanto de los empleados públicos que están inmersos en la apertura de datos abiertos como de las empresas y particulares para impulsar el uso y análisis de los datos.
A continuación puedes descargar el informe completo y profundizar en todos estos apartados.
Evento
El próximo 28 de noviembre tendrá lugar la 8ª Edición del Encuentro Aporta, que en esta ocasión se centrará en el poder de los datos públicos para impulsar la innovación y el emprendimiento. Bajo el lema “Emprendiendo con datos públicos”, empresas consolidadas, startups y organismos públicos nos contarán su experiencia a la hora de aprovechar las oportunidades de mejora y de negocio ligadas a los datos abiertos y los nuevos paradigmas tecnológicos, como el Big Data o la Inteligencia Artificial.
Gracias a estos testimonios, los asistentes podrán conocer de primera mano qué retos se pueden encontrar al abordar un proyecto innovador con datos abiertos, y podrán descubrir posibles soluciones. El objetivo es crear un evento inclusivo y dinámico, donde los asistentes también puedan transmitir sus preocupaciones y contar su propia experiencia a través de mesas redondas colaborativas.
El Encuentro comenzará a las 9:30 en el Salón de actos de la Secretaría de Estado para el Avance Digital (Ministerio de Economía y Empresa).
-
Mesa I: El valor para las Administraciones Públicas de la reutilización de sus datos.
La primera mesa estará centrada en las administraciones públicas y en cómo la reutilización de sus datos permite optimizar los servicios que ofrecen a los ciudadanos.
Son múltiples los ejemplos de entidades locales, autonómicas o estatales que han puesto en marcha servicios y aplicaciones basadas en datos públicos para mejorar su agilidad y eficiencia. Estos servicios permiten una comunicación más directa, impulsando la transparencia y la rendición de cuentas, así como una mayor participación de los ciudadanos en la vida política de su localidad o región. Además, a través del análisis de estos datos, también se pueden identificar patrones de comportamiento que favorezcan una mejor planificación de recursos y una mayor personalización en los servicios ofrecidos.
Para abordar esta temática contaremos con la presencia de representantes del Ayuntamiento de Madrid –que moderará la mesa-, el Ministerio de Agricultura, Pesca y Alimentación, la Junta de Castilla y León, la Comunidad Autónoma de la Región de Murcia, Renfe y la Diputación Foral de Vizcaya.
-
Mesa II: La información del sector público y el emprendimiento
De acuerdo a los últimos datos del Observatorio Nacional de las Telecomunicaciones y para la Sociedad de la Información (ONTSI), actualmente existen más de 530 pequeñas y medianas empresas que tienen como fin la creación de ideas y de nuevos productos a partir de información y datos públicos. Estas empresas generaron un volumen de negocio de entre 1.500 y 1.750 millones de euros y más de 5.000 empleos directos en 2016.
La innovación en torno a los datos públicos es especialmente notable cuando hablamos de emprendedores y start-ups, ya que la disponibilidad de datos públicos gratuitos o con un coste marginal hace que el riesgo de empezar un nuevo negocio sea menor.
Por ello, la segunda mesa estará formada por emprendedores y startups de distintos sectores que están desarrollando nuevos productos y servicios basados en la reutilización y el análisis de datos públicos. Es el caso de VisualNACert, desarrolladora de un software que mejora la gestión de fincas agrícolas, Piperlab, que utiliza tecnologías Big Data y ciencias de datos para desarrollar algoritmos que mejoran la toma de decisiones o Naru Intelligence, que aplica la analítica de datos al sector de la biomedicina. Esta mesa estará moderada por Iniciativa Barcelona Open Data.
-
Mesa III: Datos públicos y desarrollo de negocio
Pero los datos abiertos no son solo útiles para emprendedores. Cada vez más entidades privadas utilizan datos públicos para afrontar los retos de negocio y mejorar su competitividad. Para estas compañías los datos públicos se han convertido en un recurso empresarial más que contribuye a mantener el liderazgo en su sector de actividad, a reducir costes corporativos, adaptarse y evolucionar ágilmente en los entornos en lo que operan y colaborar con clientes e, incluso, competidores para enfrentarse a los desafíos de la industria.
Por ello, la tercera mesa estará integrada por cuatro compañías internacionales que comentarán cómo el uso de datos públicos ha permitido mejorar sus productos o servicios, adaptarse a nuevos mercados y ampliar el radio de influencia en la industria. Estas empresas son Informa, Syngenta, GMV y Esri, que nos contarán su experiencia bajo la moderación de la Secretaría de Estado para el Avance Digital.
La agenda completa está disponible en este enlace. Aunque el evento es gratuito, las plazas son limitadas. Por ello, aquellos interesados en asistir deben inscribirse en este enlace.
