Evento
Los datos espaciales y geoespaciales son esenciales en la toma de decisiones, la planificación territorial y la gestión de recursos. La capacidad de visualizar y analizar datos en un contexto espacial ofrece herramientas valiosas para enfrentar desafíos complejos en diversas áreas, desde la defensa hasta la sostenibilidad. Participar en eventos que abordan estas temáticas no solo amplía nuestros conocimientos, sino que también fomenta la colaboración y la innovación en el sector.
En este post, presentamos dos eventos próximos que versan sobre datos geoespaciales y sus usos más innovadores. ¡No te los pierdas!
II Jornada de Inteligencia Geoespacial: Territorio y Defensa
El Instituto Geográfico de Aragón (IGEAR) en colaboración con la Academia General Militar, el Centro Universitario de la Defensa y Telespazio Ibérica, ha organizado la segunda edición de la Jornada de Inteligencia Geoespacial: Territorio y Defensa, un evento que reunirá a profesionales del sector para explorar cómo los datos geoespaciales pueden optimizar las estrategias en el ámbito de la seguridad y la gestión del territorio.
Durante el próximo 21 de noviembre, la sala de la corona del Edificio Pignatelli en Zaragoza reunirá ponentes y asistentes para debatir sobre el impacto de la inteligencia geoespacial en España. El evento acogerá a un máximo de 100 asistentes que podrán acudir por invitación.
La inteligencia geoespacial, o GEOINT por su abreviatura en inglés (Geospatial Intelligence), se enfoca en comprender las dinámicas que ocurren dentro de un determinado espacio geográfico. Para lograr esto, GEOINT se apoya en el análisis detallado de imágenes, bases de datos y otra información relevante, partiendo de la idea de que, aunque las circunstancias que rodean cada situación puedan variar, existe una característica común: toda acción tiene lugar en coordenadas geográficas específicas.
La GEOINT es un campo muy amplio que se puede aplicar tanto al ámbito militar, para ejecutar movimientos analizando el terreno, como en el científico, para estudiar entornos, o incluso en el ámbito empresarial, para ayudar a adaptar información censal, histórica, meteorológica, agrícola y geológica hacia usos comerciales.
En la II Jornada de Inteligencia Geoespacial se presentarán casos prácticos y avances tecnológicos y se promoverán debates sobre el futuro de la inteligencia geoespacial en contextos de defensa. Para más detalles, puedes visitar el sitio web del evento.
- ¿Cuándo? El próximo 21 de noviembre de 2024 a las 8:00h.
- ¿Dónde? Sala de la Corona del Edificio Pignatelli. Paseo María Agustín, 36. Zaragoza.
- ¿Cómo acceder? A través de este enlace
XV Edición de las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) y III geoEuskadi
Este año, el Consejo Directivo de la Infraestructura de Información Geográfica de España (CODIIGE) organiza de manera conjunta las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) y el III Congreso geoEuskadi Kongresua. Ambos eventos pretenden potenciar y promover las actividades vinculadas a la información geográfica en diversos sectores, abarcando tanto la publicación y accesibilidad normalizada de datos geográficos como su producción, procesamiento y explotación.
Por un lado, en las JIIDE colaboran la Direção-Geral do Território de Portugal, el Instituto Geográfico Nacional de España, a través del Centro Nacional de Información Geográfica, y el Govern d’Andorra.
Por su parte, el geoEuskadi Kongresua es organizado por la Dirección de Planificación Territorial y Agenda Urbana del Gobierno Vasco. Este año, todas estas entidades se unirán para llevar a cabo un único evento bajo el lema “El valor del dato geoespacial”.
Las jornadas se centrarán en las nuevas tendencias tecnológicas relacionadas con la accesibilidad y reutilización de datos, así como en las técnicas actuales de observación y representación de la Tierra.
Los datos geoespaciales digitales son un motor clave para el crecimiento económico, la competitividad, la innovación, la creación de empleo y el progreso social. Por ello, III geoEuskadi y la XV edición JIIDE 2024 enfatizarán la importancia de tecnologías, como el big data y la inteligencia artificial, para generar ideas que mejoren la toma de decisiones empresariales y la creación de sistemas que realicen tareas que tradicionalmente requieren intervención humana.
Además, se pondrá en valor la colaboración para la coproducción y armonización de datos entre diferentes administraciones y organizaciones, algo que sigue siendo esencial para generar datos geoespaciales de valor, que puedan convertirse en verdaderas referencias. Este es un momento de renovación, impulsado por la revisión de la Directiva INSPIRE, la actualización de las normativas sobre datos espaciales medioambientales y las nuevas regulaciones sobre datos abiertos y gobernanza de datos que propician una modernización en la publicación y reutilización de estos datos.
Durante el evento, también se presentarán ejemplos de reutilización de conjuntos de datos de alto valor, tanto a través de las OGC API como mediante servicios de descarga y formatos interoperables.
La combinación de estos eventos representará un espacio privilegiado para reflexionar sobre la información geográfica y será un escaparate de los proyectos más innovadores en la península ibérica. Además, se llevarán a cabo talleres técnicos para compartir conocimientos específicos y mesas redondas que promoverán el debate. Para conocer más sobre este evento, visita el portal de JIIDE.
- ¿Cuándo? Del 13 al 15 de noviembre.
- ¿Dónde? Palacio de Congresos Europa (Vitoria-Gasteiz).
- ¿Cómo me inscribo? A través de este enlace.
No pierdas la oportunidad de participar en estos eventos que promueven el avance en el uso de datos espaciales y geoespaciales. Te animamos a unirte a estas jornadas para aprender, colaborar y contribuir al desarrollo de este sector en constante evolución.
Blog
Muchas personas utilizan aplicaciones para desplazarse en su día a día. Apps como Google Maps, Moovit o CityMapper facilitan la ruta más rápida y eficaz para llegar a un destino. Sin embargo, lo que muchos usuarios desconocen es que tras estas plataformas se encuentra una valiosa fuente de información: los datos abiertos. Gracias a la reutilización de conjuntos de datos públicos, como los relacionados con la calidad del aire, el tráfico o el transporte público, estas aplicaciones pueden ofrecer un mejor servicio.
En este post, exploraremos cómo la reutilización de datos abiertos por parte de estas plataformas potencia un ecosistema urbano más inteligente y sostenible.
Google Maps: agrega información de calidad del aire y datos de transporte en GTFS.
Más de mil millones de personas utilizan Google Maps mensualmente alrededor del mundo. El gigante tecnológico ofrece un mapa mundial actualizado y gratuito que obtiene sus datos de diferentes fuentes, algunas de ellas, abiertas.
Una de las funciones que brinda la app es la información sobre la calidad del aire en la ubicación en la que se encuentra el usuario. El Índice de Calidad del Aire (ICA) es un parámetro que viene determinado por cada país o región. La referencia europea se puede consultar en este mapa que muestra calidad del aire por zonas geolocalizadas en tiempo real.
Para mostrar la calidad de aire de la ubicación del usuario, Google Maps aplica un modelo basado en un enfoque multicapa conocido como “enfoque de fusión”. Este método combina datos de varias fuentes de entrada y pondera las capas con un procedimiento sofisticado. Las capas de entrada son:
- Estaciones de monitorización de referencia de los gobiernos
- Redes de sensores comerciales
- Modelos de dispersión mundiales y regionales
- Modelos de polvo y humo de incendios
- Información obtenida por satélite
- Datos del tráfico
- Información auxiliar como la superficie
- Meteorología
En el caso de España, esta información se obtiene de fuentes de datos abiertos como el Ministerio de Transición Ecológica y Reto Demográfico, el Instituto Geográfico Nacional (que le permite obtener la cartografía con nombres oficiales de carreteras, poblaciones, etc.) la Conselleria de Medio Ambiente, Territorio y Vivienda de la Xunta de Galicia o la Comunidad de Madrid. Puedes consultar aquí las fuentes de datos abiertos que se utilizan en otros países del mundo.
Otra funcionalidad que ofrece Google Maps para planificar las mejores rutas para llegar a un destino es la información sobre el transporte público. Estos datos son proporcionados de manera voluntaria por las empresas públicas que ofrecen el servicio de transporte en cada ciudad. Para que estos datos abiertos estén a disposición del usuario, primero se vuelcan en Google Transit y deben cumplir el estándar abierto de transporte público GTFS (General Transit Feed Specification). Además, Google Maps también integra datos de transporte en GTFS del Punto de Acceso Nacional.
Moovit: reutiliza datos abiertos para ofrecer información en tiempo real
Moovit es otra de las aplicaciones de movilidad urbana, que utiliza datos abiertos y colaborativos para facilitar a los usuarios la planificación de sus desplazamientos en transporte público.
Desde su lanzamiento en 2012, la app de descarga gratuita ofrece información en tiempo real de las distintas opciones de transporte, sugiere las mejores rutas para llegar al destino indicado, guía al usuario durante su recorrido (cuánto tiene que esperar, cuántas paradas faltan, cuándo tiene que bajar, etc.) y realiza actualizaciones constantes ante cualquier alteración en el servicio.
Como otras apps de movilidad, también está disponible en modalidad offline y permite guardar las rutas y líneas frecuentes en “Favoritos”. Además, se trata de una solución inclusiva ya que integra VoiceOver (iOs) o TalkBack (Android) para personas invidentes.
La plataforma no solo aprovecha datos abiertos proporcionados por gobiernos y autoridades locales, sino que también recopila información de sus usuarios, lo que le permite ofrecer un servicio dinámico y constantemente actualizado.
CityMapper: nace como reutilizador de datos abiertos de movilidad
El equipo de desarrollo de CityMapper reconoce que la aplicación nació con un ADN abierto que todavía se mantiene. Reutilizan conjuntos de datos abiertos de, por ejemplo, OpenStreetMap a nivel global o RENFE y Cercanías Bilbao a nivel nacional. A medida que la aplicación está disponible en más ciudades, mayor es la lista de fuentes de referencia de datos abiertos de las que obtiene información.
La plataforma ofrece información en tiempo real sobre rutas de transporte público, incluyendo autobuses, trenes, metro o bicicletas compartidas. También añade opciones para desplazarse a pie, en bici o en sistemas de transporte compartido. Está diseñada para proporcionar la ruta más eficiente y rápida para llegar a un destino, integrando datos de diferentes medios de transporte en una sola interfaz.
Tal y como publicamos en el informe monográfico “Innovación municipal a través de datos abiertos” CityMapper utiliza principalmente open data de las autoridades de transporte locales normalmente utilizando el estándar GTFS (General Transit Feed Specification). No obstante, cuando estos datos no son suficientes o no son suficientemente precisos, CityMapper los combina con conjuntos de datos generados por los propios usuarios de la aplicación que colaboran voluntariamente. También utiliza datos mejorados y gestionados por el trabajo de los propios empleados locales de la empresa. Todos estos datos se combinan con algoritmos de inteligencia artificial desarrollados para optimizar las rutas y ofrecer recomendaciones ajustadas a las necesidades de los usuarios.
En conclusión, el uso de datos abiertos en el transporte impulsa una transformación significativa en el sector de la movilidad en ciudades. Gracias al aporte que ofrecen a las aplicaciones, los usuarios pueden acceder a datos actualizados y precisos, planificar sus viajes de manera eficiente y tomar decisiones informadas. Los gobiernos, por su parte, han asumido el rol de facilitadores al hacer posible la difusión de datos mediante plataformas abiertas, optimizando recursos y fomentando la colaboración entre distintos sectores. Además, los datos abiertos han creado nuevas oportunidades para los desarrolladores y el sector privado, quienes han contribuido con soluciones tecnológicas, como pueden ser Google Maps, Moovit o CityMapper. En definitiva, el potencial de los datos abiertos para transformar el futuro de la movilidad urbana es algo innegable.
Aplicación
Es una web que recopila información pública sobre el estado de los diferentes embalses que hay en España. El usuario puede filtrar la información por cuencas hidrográficas y unidades administrativas como provincias o comunidades autónomas.
Los datos se actualizan diariamente y se muestran con porcentajes y gráficas. Además, también ofrece información sobre pluviómetros y la comparación entre el porcentaje de agua embasada actual y la que había hace un año y hace 10 años.
Embales.net comparte de manera clara y entendible datos abiertos que obtiene de AEMET y el Ministerio de Transición Ecológica y Reto Demográfico.
Blog
En la era digital actual, la compartición de datos y los datos abiertos (open data) han emergido como pilares fundamentales para la innovación, la transparencia y el desarrollo económico. Diversas compañías y organizaciones alrededor del mundo están adoptando estos enfoques para fomentar el acceso abierto a la información y potenciar la toma de decisiones basada en datos. A continuación, exploramos algunos ejemplos internacionales y nacionales de cómo estas prácticas están siendo implementadas.
Casos de éxito globales
Uno de los referentes globales en la compartición de datos es LinkedIn con su programa Data for Impact. Este programa facilita a gobiernos y organizaciones el acceso a datos económicos agregados y anonimizados, basados en el Economic Graph de LinkedIn, el cual representa la actividad profesional global. Es importante aclarar que los datos solo pueden utilizarse con fines de investigación y desarrollo. El acceso debe solicitarse vía email, adjuntando una propuesta para su evaluación, y se priorizan propuestas de gobiernos y organizaciones multilaterales. Estos datos han sido utilizados por entidades como el Banco Mundial y el Banco Central Europeo para informar de políticas y decisiones económicas clave. El enfoque de LinkedIn en la privacidad y la calidad de los datos asegura que estas colaboraciones beneficien tanto a las organizaciones como a los ciudadanos, promoviendo un crecimiento económico inclusivo, verde y alineado con las tecnologías digitales.
Por otro lado, el Registry of Open Data on AWS (RODA) es un repositorio gestionado Amazon Web Services (AWS) que alberga conjuntos de datos públicos. Los datasets no son proporcionados directamente por AWS, sino que son mantenidos por organizaciones gubernamentales, investigadores, empresas y particulares. Podemos encontrar, en el momento de escribir este post, más de 550 conjuntos de datos publicados por diferentes organizaciones, incluyendo algunas como el Allen Institute for Artificial Intelligence (AI2) o la propia NASA. Esta plataforma facilita que los usuarios aprovechen los servicios de computación en la nube de AWS para su análisis.
En el ámbito del periodismo de datos, FiveThirtyEight, propiedad de ABC News, ha adoptado un enfoque de transparencia radical al compartir públicamente los datos y códigos detrás de sus artículos y visualizaciones. Estos se encuentran accesibles a través de GitHub en formatos fácilmente reutilizables como CSV. Esta práctica no solo permite la verificación independiente de su trabajo, sino que también impulsa la creación de nuevas historias y análisis por parte de otros investigadores y periodistas. FiveThirtyEight se ha convertido en un modelo a seguir en lo relativo a cómo los datos abiertos pueden mejorar la calidad y la credibilidad del periodismo.
Casos de éxito en España
España no se queda atrás en cuanto a iniciativas de compartición de datos y open data por parte de compañías privadas. Varias empresas españolas están liderando iniciativas que promueven la accesibilidad y transparencia de los datos en diferentes sectores. Veamos algunos ejemplos.
Idealista, uno de los portales inmobiliarios más importantes del país, ha publicado un conjunto de datos abiertos que incluye información detallada sobre más de 180,000 viviendas en Madrid, Barcelona y Valencia. Este conjunto de datos proporciona las coordenadas geográficas y los precios de venta de cada propiedad, junto con sus características internas y la información oficial del catastro español. Este conjunto de datos está disponible para su acceso a través de GitHub como un paquete en R y se ha convertido en una gran herramienta para el análisis del mercado inmobiliario, permitiendo a investigadores y profesionales del sector desarrollar modelos de valoración automática y realizar estudios detallados sobre la segmentación del mercado. Cabe destacar que Idealista también reutiliza datos públicos de organismos como el catastro o el INE para ofrecer servicios de datos que dan soporte a las decisiones en el mercado inmobiliario, como contratación de hipotecas, estudios de mercado, valoración de carteras, etc.Por su parte BBVA, a través de su Fundación, ofrece acceso a un extenso fondo estadístico con bases de datos que incluyen cuadros, tablas y gráficos dinámicos. Estas bases de datos, de descarga libre, cubren temas como la productividad, la competitividad, el capital humano o la desigualdad en España, entre otros. Además, proporcionan series históricas sobre la economía española, inversiones, actividades culturales y gasto público. Estas herramientas están diseñadas para complementar publicaciones impresas y ofrecer una visión profunda sobre la evolución económica y social del país.
Además, Esri España habilita su Portal de Datos Abiertos, que pone a disposición de los usuarios una amplia variedad de contenidos que pueden ser consultados, analizados y descargados. Este portal incluye datos gestionados por Esri España, junto con una recopilación de otros portales de datos abiertos desarrollados con tecnología Esri. Esto amplía significativamente las posibilidades para investigadores, desarrolladores y profesionales que buscan aprovechar los datos geoespaciales en sus proyectos. Podemos encontrar conjuntos de datos en las categorías de salud, ciencia y tecnología o economía, entre otros.
En el ámbito de las empresas públicas, España también cuenta con ejemplos destacados de compromiso con los datos abiertos. Renfe, la principal operadora ferroviaria, y Red Eléctrica Española (REE), la entidad responsable de la operación del sistema eléctrico, han desarrollado programas de open data que facilitan el acceso a información relevante para la ciudadanía y para el desarrollo de aplicaciones y servicios que mejoren la eficiencia y la sostenibilidad. Destaca, en el caso de REE, la posibilidad de consumo de los datos disponibles a través de APIs REST, que facilitan la integración de aplicaciones sobre conjuntos de datos que reciben continuas actualizaciones sobre el estado de los mercados eléctricos.
Conclusión
La compartición de datos y el open data representan una evolución crucial en la forma en que las organizaciones gestionan y aprovechan la información. Desde gigantes tecnológicos internacionales como LinkedIn y AWS hasta innovadores nacionales como Idealista y BBVA, están proporcionando acceso abierto a los datos con el fin de impulsar un cambio significativo en cómo se toman decisiones, el desarrollo de políticas y la creación de nuevas oportunidades económicas. En España, tanto las empresas privadas como las públicas están mostrando un fuerte compromiso con estas prácticas, posicionando al país como un líder en la adopción de modelos de datos abiertos y de compartición de datos que beneficien a toda la sociedad.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El Gobierno Vasco convoca la quinta edición de los premios a los mejores proyectos de reutilización de datos abiertos de Euskadi. Una iniciativa que nace con el objetivo de premiar las mejores ideas y aplicaciones/servicios creados a partir del catálogo de datos abiertos de Euskadi (Open Data Euskadi) para mostrar su potencial y fomentar la cultura open data.
Como ya venía sucediendo en ediciones anteriores, existen dos modalidades de premios: un concurso de ideas y otro de aplicaciones. En el primero, se repartirá una suma de 13.500 euros en premios. En el segundo, la cifra asciende a 21.000€ en premios.
A continuación, presentamos los detalles de la convocatoria para cada una de las modalidades:
Concurso de ideas
Se valorarán propuestas de servicios, estudios, visualizaciones y aplicaciones (web y móvil) que reutilicen conjuntos de datos abiertos del portal Open Data Euskadi para proporcionar valor a la sociedad. Las ideas podrán ser de utilidad general o centrarse en alguno de estos dos sectores: sanitario y social o medio ambiente y sostenibilidad.
- ¿A quién va dirigido? A todas aquellas personas o empresas de dentro y fuera del País Vasco que quieran presentar ideas y proyectos de reutilización de datos abiertos de Euskadi. Esta modalidad no requiere de conocimientos técnicos de programación o desarrollo informático.
- ¿Cómo participar? Será necesario explicar la idea en un documento de texto y adjuntarlo al realizar la inscripción. La inscripción podrá realizarse tanto online como de manera presencial.
- ¿Qué premios se ofrecen? Se elegirá dos proyectos ganadores por cada categoría, que se dividirán en un primer premio de 3.000 euros y otro segundo premio de 1.500 euros. Es decir, en resumen, los premios son:
- Categoría sanitaria y social
- Primer premio: 3.000 €
- Segundo premio: 1.500 €
- Categoría de medio ambiente y sostenibilidad
- Primer premio: 3.000 €
- Segundo premio: 1.500 €
- Categoría general
- Primer premio: 3.000 €
- Segundo premio: 1.500 €
Aquí puedes leer las bases del concurso de ideas de Open Data Euskadi: https://www.euskadi.eus/servicios/1028505
Concurso de aplicaciones
Esta modalidad sí requiere de cierto conocimiento técnico de programación o desarrollo informático, ya que se debe presentar soluciones ya desarrolladas que utilicen conjuntos de datos abiertos de Open Data Euskadi. Las aplicaciones podrán presentarse a la categoría general o a la categoría específica de servicios web.
- ¿A quién va dirigido? A aquellas personas o empresas capaces de crear servicios, estudios, visualizaciones, aplicaciones web o para dispositivos móviles que utilicen, como mínimo, un conjunto de datos abiertos de alguno de los catálogos de datos abiertos de Euskadi.
- ¿Cómo participar? Será necesario explicar el proyecto en un documento de texto y que el proyecto desarrollado (servicio, estudio, visualización, aplicación web o para dispositivos móviles) sea accesible mediante una URL. Al realizar la inscripción se adjuntará tanto el documento explicativo como la URL del proyecto.
- ¿Qué premios se ofrecen? En esta modalidad se ofrece un único premio de 8.000 euros para la categoría de servicios web y dos premios para la categoría general de 8.000 y 5.000 euros.
- Categoría servicios web
- Único premio: 8.000 €
- Categoría general
- Primer premio: 8.000 €
- Segundo premio: 5.000 €
Consulta aquí las bases del concurso en modalidad desarrollo de aplicaciones: https://www.euskadi.eus/servicios/1028605
Plazo de inscripción:
El concurso acepta propuestas desde el 31 de julio y el plazo cerrará el próximo 10 de octubre. Síguenos en redes sociales para no perderte ninguna novedad sobre eventos y concursos de reutilización de datos abiertos: @datosgob
¡Anímate y participa!
Noticia
La Junta de Castilla y León acaba de lanzar una nueva edición de su concurso de datos abiertos. Con ello, busca reconocer la realización de proyectos que utilicen conjuntos de datos de su Portal Open Data. La convocatoria estará abierta hasta finales de septiembre, así que puedas aprovechar las semanas que quedan de verano para presentar tu solicitud.
¿En qué consiste la competición?
El objetivo del VIII Concurso de Datos Abiertos es reconocer la realización de proyectos que utilicen datos abiertos en cuatro categorías:
- Categoría “Ideas”: los participantes tendrán que describir una idea para crear estudios, servicios, sitios web o aplicaciones para dispositivos móviles.
- Categoría “Productos y Servicios”: se premiarán estudios, servicios, sitios web o aplicaciones para dispositivos móviles, los cuales deben estar accesibles para toda la ciudadanía vía web mediante una URL.
- Categoría “Recurso Didáctico”: consiste en la creación de recursos didácticos abiertos nuevos e innovadores, que sirvan de apoyo a la enseñanza en el aula. Estos recursos deben ser publicados con licencias Creative Commons.
- Categoría “Periodismo de Datos”: se buscan piezas periodísticas publicadas o actualizadas (de forma relevante) tanto en soporte escrito como audiovisual.
Todas las categorías tienen algo en común: es necesario que el proyecto utilice, al menos, un conjunto de datos del portal de Datos Abiertos de la Junta de Castilla y León. Estos datasets se puede combinar, si así lo desean los autores, con otras fuentes de datos, privadas o públicas, de cualquier nivel de la administración.
¿Quién puede participar?
La competición está abierta a cualquier persona física o jurídica, que haya realizado un proyecto y que cumpla los requisitos de cada categoría. No podrán participar administraciones públicas ni aquellas personas que hayan colaborado directa o indirectamente en la elaboración de las bases reguladoras y la convocatoria.
Se puede participar de manera individual o en grupo. Además, una misma persona puede presentar más de una candidatura a la misma o diferentes categorías. También un mismo proyecto se puede presentar a diversas categorías, aunque solo podrá ser premiado en una.
¿En qué consisten los premios?
Un jurado valorará las propuestas recibidas en base a una serie de requisitos, entre los que se encuentra su utilidad, valor económico, originalidad, calidad etc. Una vez valorados todos los proyectos, se anunciarán una serie de ganadores, que recibirán un diploma, asesoría en materia de datos abiertos y la siguiente dotación económica:
- Categoría Ideas.
- Primer premio 1.500€.
- Segundo premio 500€.
- Categoría Productos y servicios. En este caso, se ha creado también un premio especial para estudiantes dirigido a personas matriculadas en los cursos lectivos 2023/2024 y 2024/2025, tanto en enseñanza universitaria como no universitaria siempre que sea oficial.
- Primer premio 2.500€.
- Segundo premio: 1.500€.
- Tercer premio: 500€.
- Premio estudiantes: 1.500€.
- Categoría Recurso didáctico.
- Primer premio: 1.500€.
- Categoría Periodismo de datos.
- Primer premio: 1.500€.
- Segundo premio : 1.000€.
Además, las candidaturas premiadas se difundirán y promocionarán a través del Portal de Datos Abiertos de Castilla y León y otros medios de la Administración.
¿Cuáles son los plazos?
El plazo para recibir las candidaturas se abrió el pasado 23 de julio de 2024, un día después de la publicación de las bases en el Boletín Oficial de Castilla y León. Los participantes tendrán hasta el 23 de septiembre de 2024 para presentar sus solicitudes.
¿Cómo puedo participar?
Las candidaturas se pueden presentar de manera presencial o electrónica.
- Presencial: en el Registro General de la Consejería de la Presidencia , las Oficinas de asistencia en materia de registros de la Junta de Castilla y León o en cualquiera de los lugares establecidos en el artículo 16.4 de la Ley 39/2015.
- Electrónica: a través de la sede electrónica.
Las solicitudes deberán incluir información sobre:
- Autor o autores del proyecto.
- Título del proyecto.
- Categoría o categorías a las que se presenta.
- Memoria del proyecto, con una extensión máxima de mil palabras.
Tienes toda la información detallada en la sede electrónica, donde se incluyen las bases del concurso.
Con esta nueva edición, el Portal de datos de Castilla y León reafirma su compromiso no solo con la publicación de datos abiertos, sino también con el impulso de su reutilización. Este tipo de acciones son un escaparate para promocionar ejemplos del uso de datos abiertos en diferentes campos. Puedes ver los proyectos ganadores del año pasado en este artículo.
¡Anímate y participa!
Aplicación
AUVASA Pay es una aplicación móvil que ofrece información en tiempo real sobre la red pública de autobuses de Valladolid. A través de AUVASA Pay se pueden consultar detalles como los tiempos de espera en parada o incluso comprar títulos de transporte en formato QR y recargar la tarjeta de transporte para utilizarla en los autobuses.
Esta aplicación utiliza datos abiertos de Open Street Map para mostrar los mapas de la ciudad. Además, ofrece conjuntos de datos abiertos sobre el transporte público en Valladolid disponibles para su descarga y reutilización bajo licencia Creative Commons en Datos abiertos - AUVASA
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos, se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos los flujos de turistas a nivel nacional, creando visualizaciones de los turistas que se mueven entre las comunidades autónomas (CCAA) y provincias.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
Analizar los flujos de turistas nacionales nos permite observar ciertos movimientos ya muy conocidos, como, por ejemplo, que la provincia de Alicante es un destino muy popular del turismo veraniego. Además, este análisis es interesante para observar tendencias en el impacto económico que el turismo pueda tener, año tras año, en ciertas CCAA o provincias. El artículo sobre experiencias para la gestión de los flujos de visitantes en destinos turísticos ilustra el impacto de los datos en el sector.
3. Objetivo
El objetivo principal del ejercicio es crear visualizaciones interactivas en Python que permitan visualizar información compleja de manera comprensible y atractiva. Se cumplirá este objetivo usando un conjunto de datos abiertos que contiene información sobre flujos de turistas nacionales, planteando varias preguntas sobre los datos y contestándolas gráficamente. Podremos responder a preguntas como las que se plantean a continuación:
- ¿En qué CCAA hay más turismo procedente de la misma CA?
- ¿Cuál es la CA que más sale de su propia CA?
- ¿Qué diferencias hay entre los flujos de turistas a lo largo del año?
- ¿Cuál es la provincia valenciana que más turistas recibe?
La comprensión de las herramientas propuestas aportará al lector la capacidad para poder modificar el código contenido en el notebook que acompaña a este ejercicio para seguir explorando los datos por su cuenta y detectar más comportamientos interesantes a partir del conjunto de datos utilizado.
Para poder crear visualizaciones interactivas y contestar a las preguntas sobre los flujos de turistas, será necesario un proceso de limpieza y reformateado de datos que está descrito en el notebook que acompaña este ejercicio.
4. Recursos
Conjunto de datos
El conjunto de datos abiertos utilizado contiene información sobre los flujos de turistas en España a nivel de CCAA y provincias, indicando también los valores totales a nivel nacional. El conjunto de datos ha sido publicado por el Instituto Nacional de Estadística, a través de varios tipos de ficheros. Para el presente ejercicio utilizamos únicamente el fichero .csv separado por “;”. Los datos datan de julio de 2019 a marzo de 2024 (a la hora de redactar este ejercicio) y se actualizan mensualmente.
Número de turistas por CCAA y provincia de destino desagregados por PROVINCIA de origen
El conjunto de datos también se encuentra disponible para su descarga en este repositorio de Github.
Herramientas analíticas
Para la limpieza de los datos y la creación de las visualizaciones se ha utilizado el lenguaje de programación Python. El código creado para este ejercicio se pone a disposición del lector a través de un notebook de Google Colab.
Las librerías de Python que utilizaremos para llevar a cabo el ejercicio son:
- pandas: es una librería que se utiliza para el análisis y manipulación de datos.
- holoviews: es una librería que permite crear visualizaciones interactivas, combinando las funcionalidades de otras librerías como Bokeh y Matplotlib.
5. Desarrollo del ejercicio
Para visualizar los datos sobre flujos de turistas interactivamente crearemos dos tipos de diagramas, los diagramas de cuerdas y los diagramas de Sankey.
Los diagramas de cuerdas son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 1. Los nodos se sitúan en un círculo y las aristas simbolizan las relaciones entre los nodos del círculo. Estos diagramas suelen utilizarse para mostrar tipos de flujos, por ejemplo, flujos migratorios o monetarios. El volumen diferente de las aristas se visualiza de manera comprensible y refleja la importancia de un flujo o de un nodo. Por su forma de círculo, el diagrama de cuerdas es una buena opción para visualizar las relaciones entre todos los nodos de nuestro análisis (relación del tipo “varios a varios”).
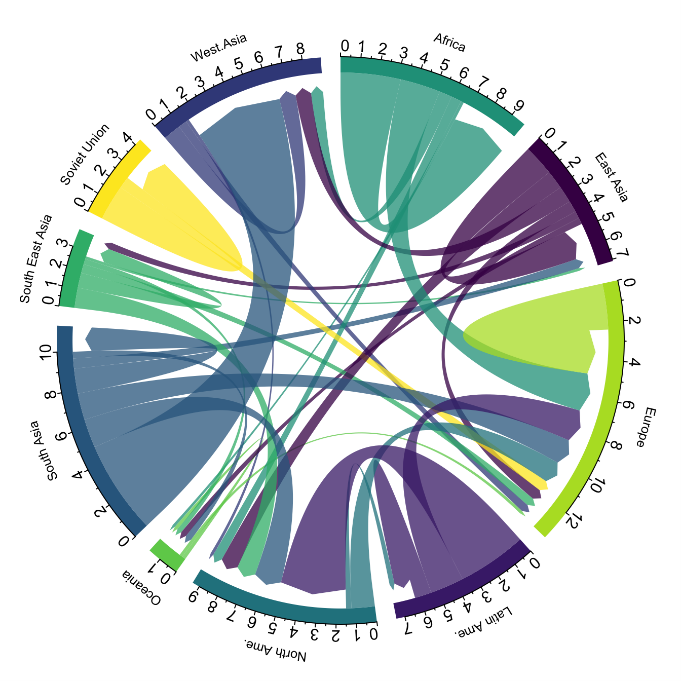
Figura 1. Diagrama de cuerdas (Migración global). Fuente.
Los diagramas de Sankey, igual que los diagramas de cuerdas, son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 2. Los nodos se representan en los márgenes de la visualización, estando las aristas entre los márgenes. Por esta agrupación lineal de los nodos, los diagramas de Sankey son mejores que los diagramas de cuerdas para análisis en los cuales queramos visualizar la relación entre:
- varios nodos y otros nodos (tipo varios a varios, o varios a pocos, o viceversa)
- varios nodos y un solo nodo (varios a uno, o viceversa)

Figura 2. Diagrama de Sankey (Migración interna Reino Unido). Fuente.
El ejercicio está dividido en 5 partes, siendo la parte 0 (“configuración inicial”) solo de montar el entorno de programación. A continuación, describimos las cinco partes y los pasos que se llevan a cabo.
5.1. Cargar datos
Este apartado podrás encontrarlo en el punto 1 del notebook.
En este parte cargamos el conjunto de datos para poder procesarlo en el notebook. Comprobamos el formato de los datos cargados y creamos un pandas.DataFrame que utilizaremos para el procesamiento de los datos en los siguientes pasos.
5.2. Exploración inicial de los datos
Este apartado podrás encontrarlo en el punto 2 del notebook.
En esta parte realizamos un análisis exploratorio de los datos para entender el formato del conjunto de datos que hemos cargado y para tener una idea más clara de la información que contiene. Mediante esta exploración inicial, podemos definir los pasos de limpieza que tenemos que llevar a cabo para poder crear las visualizaciones interactivas.
Si quieres aprender más sobre cómo abordar esta tarea, tienes a tu disposición esta guía introductoria sobre análisis exploratorio de datos.
5.3. Análisis del formato de los datos
Este apartado podrás encontrarlo en el punto 3 del notebook.
En esta parte resumimos las observaciones que hemos podido hacer durante la exploración inicial de los datos. Recapitulamos aquí las observaciones más importantes:
| Provincia de origen | Provincia de origen | CCAA y provincia de destino | CCAA y provincia de destino | CCAA y provincia de destino | Concepto turístico | Periodo | Total |
|---|---|---|---|---|---|---|---|
| Total Nacional | Total Nacional | Turistas | 2024M03 | 13.731.096 | |||
| Total Nacional | Ourense | Total Nacional | Andalucía | Almería | Turistas | 2024M03 | 373 |
Figura 3. Fragmento del conjunto de datos original.
Podemos observar en las columnas uno a cuatro que los orígenes de los flujos de turistas están desagregados por provincia mientras que, para los destinos, las provincias están agregadas por CCAA. Aprovecharemos el mapeado de las CCAA y de sus provincias que podemos extraer de la cuarta y quinta columna para agregar las provincias de origen por CCAA.
También podemos ver que la información contenida en la primera columna a veces es superflua, por lo cual, la combinaremos con la segunda columna. Además, hemos constatado que la quinta y sexta columna no aportan valor para nuestro análisis, por lo cual, las eliminaremos. Renombraremos algunas columnas para tener un pandas. DataFrame más comprensible.
5.4. Limpieza de los datos
Este apartado podrás encontrarlo en el punto 4 del notebook.
En esta parte llevamos a cabo los pasos necesarios para darle mejor formato a nuestros datos. Para ello aprovechamos varias funcionalidades que nos ofrece pandas, por ejemplo, para renombrar las columnas. También definimos una función reutilizable que necesitamos para concatenar los valores de la primera y segunda columna con el objetivo de no tener una columna que exclusivamente indique “Total Nacional” en todas las filas del pandas.DataFrame. Además, extraeremos de las columnas de destino un mapeado de CCAA a provincias que aplicaremos a las columnas de origen.
Queremos obtener una versión del conjunto de datos más comprimida con mayor transparencia de los nombres de las columnas y que no contenga información que no vamos a procesar. El resultado final del proceso de limpieza de datos es el siguiente:
| Origen | Provincia de origen | Destino | Provincia de destino | Periodo | Total |
|---|---|---|---|---|---|
| Total Nacional | Total Nacional | 2024M03 | 13731096.0 | ||
| Galicia | Ourense | Andalucía | Almería | 2024M03 | 373.0 |
Figura 4. Fragmento del conjunto de datos limpio.
5.5. Crear visualizaciones
Este apartado podrás encontrarlo en el punto 5 del notebook
En esta parte creamos nuestras visualizaciones interactivas utilizando la librería Holoviews. Para poder dibujar gráficos de cuerdas o de Sankey que visualicen el flujo de personas entre CCAA y CCAA y/o provincias, tenemos que estructurar la información de nuestros datos de tal forma que dispongamos de nodos y aristas. En nuestro caso, los nodos son los nombres de CCAA o provincia y las aristas, es decir, la relación entre los nodos, son el número de turistas. En el notebook definimos una función para obtener los nodos y aristas que podemos reutilizar para los diferentes diagramas que queramos realizar, cambiando el período de tiempo según la estación del año que nos interese analizar.
Vamos a crear primero un diagrama de cuerdas usando exclusivamente los datos sobre flujos de turistas de marzo de 2024. En el notebook, este diagrama de cuerdas es dinámico. Te animamos a probar su interactividad.
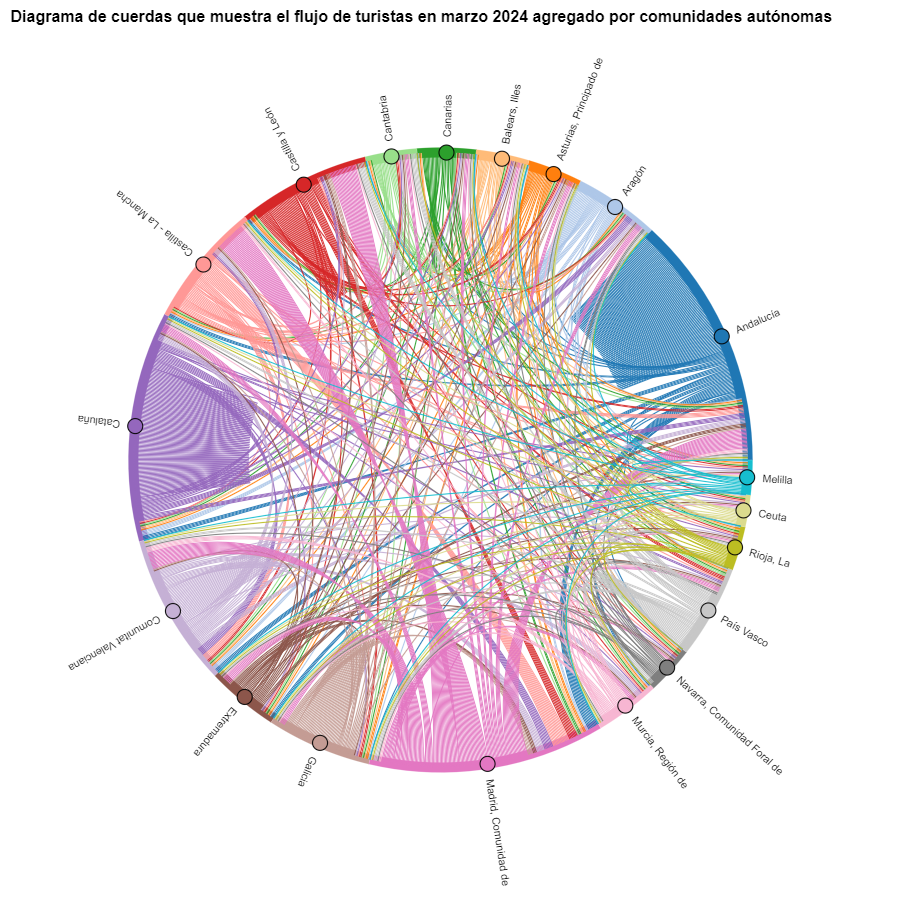
Figura 5. Diagrama de cuerdas que muestra el flujo de turistas en marzo 2024 agregado por comunidades autónomas.
En el diagrama de cuerdas se visualizan los flujos de turistas entre todas las CCAA. Cada CA tiene un color y los movimientos que hacen los turistas provenientes de esta CA se simbolizan con el mismo color. Podemos observar que los turistas de Andalucía y Cataluña viajan mucho dentro de sus propias CCAA. En cambio, los turistas de Madrid salen mucho de su propia CA.
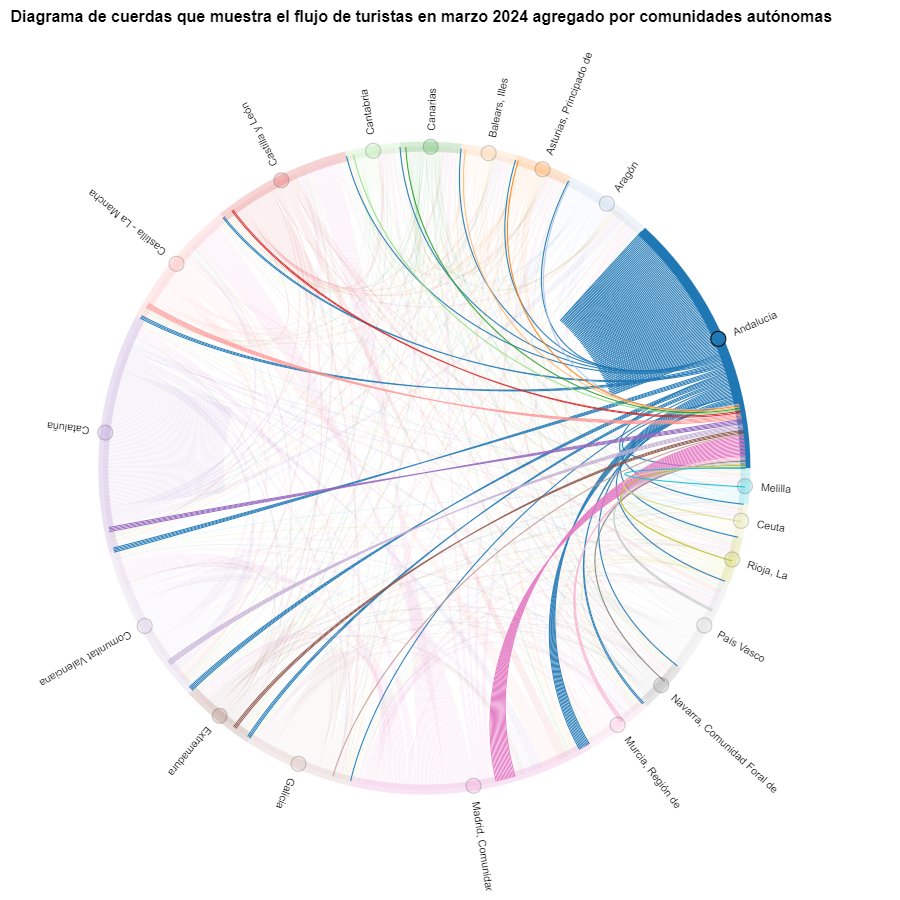
Figura 6. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de Andalucía en marzo 2024 agregado por comunidades autónomas.
Creamos otro diagrama de cuerdas utilizando la función que hemos creado y visualizamos los flujos de turistas en agosto de 2023.
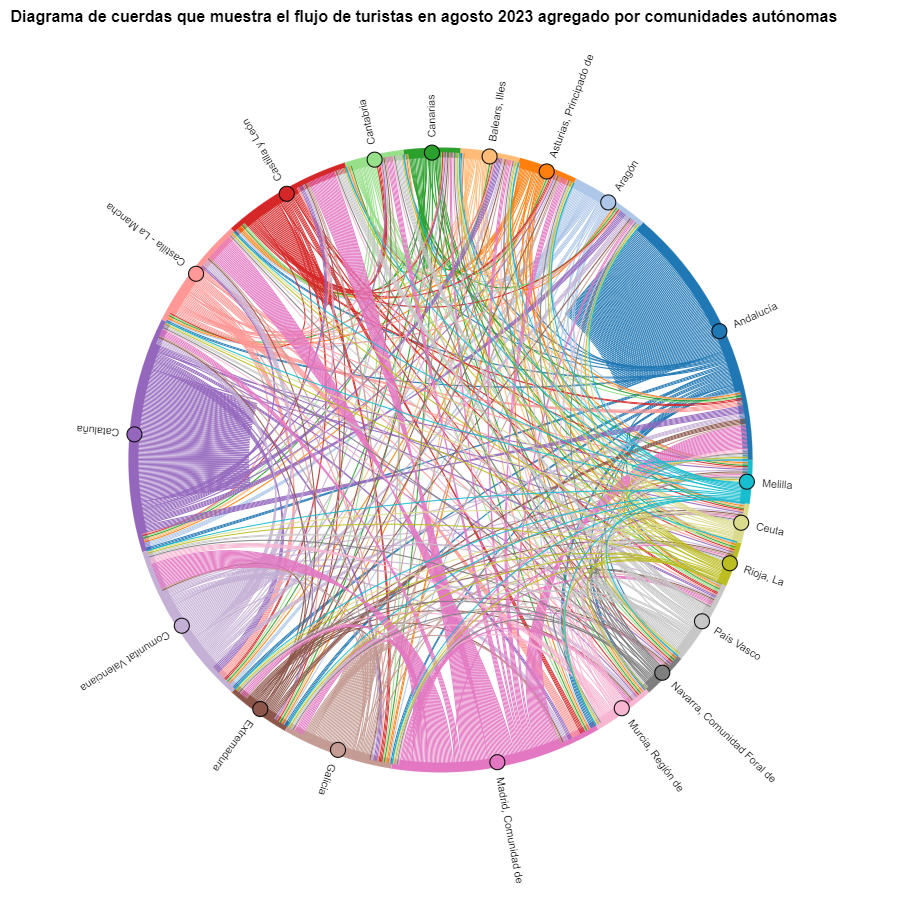
Figura 7. Diagrama de cuerdas que muestra el flujo de turistas en agosto 2023 agregado por comunidades autónomas.
Podremos observar que, a grandes rasgos, no cambian los movimientos de los turistas, solo que se intensifican los movimientos que ya hemos podido observar para marzo 2024.
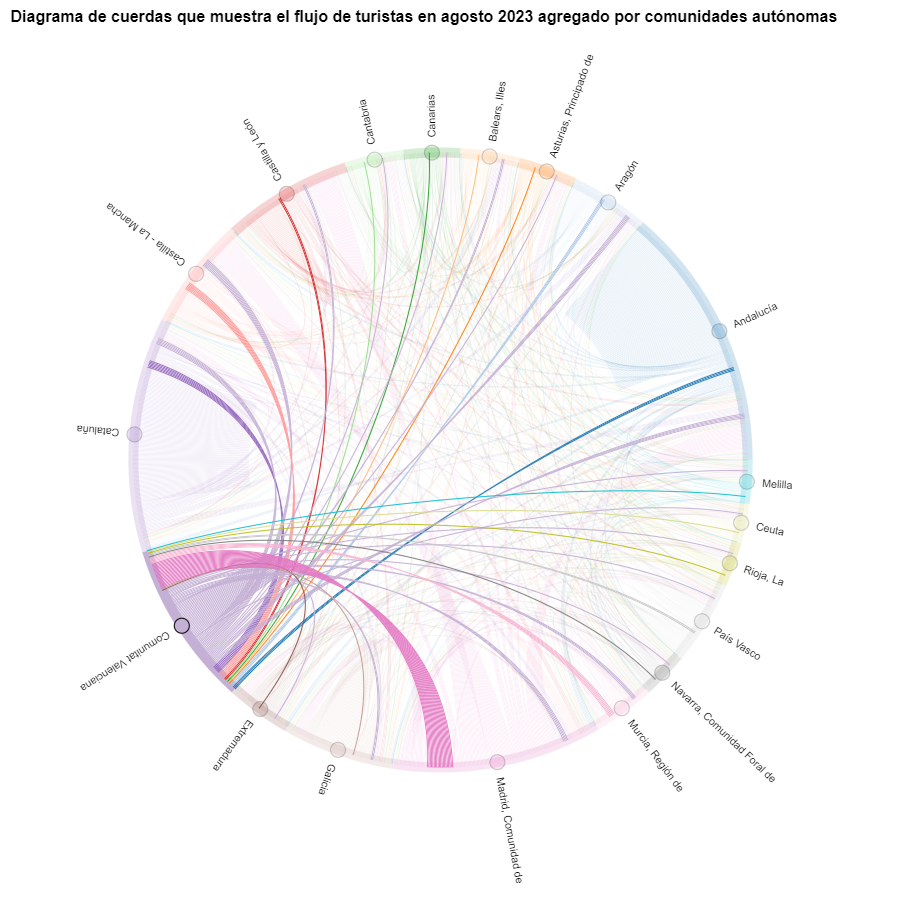
Figura 8. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de la Comunitat Valenciana en agosto 2023 agregado por comunidades autónomas.
El lector puede crear el mismo diagrama para otros períodos de tiempo, por ejemplo, para el verano del año 2020, con el fin de visualizar el impacto de la pandemia en el turismo veraniego, reutilizando la función que hemos creado.
Para los diagramas de Sankey nos vamos a centrar en la Comunitat Valenciana, ya que es un destino vacacional popular. Filtramos las aristas que hemos creado para el diagrama de cuerdas anterior de manera que solo contengan flujos que terminen en la Comunitat Valenciana. El mismo procedimiento se podría aplicar para estudiar cualquier otra CA o se podría invertir para analizar dónde van a veranear los valencianos. Visualizamos el diagrama de Sankey que, igual que los diagramas de cuerdas, es interactivo dentro del notebook. El aspecto visual quedaría así:
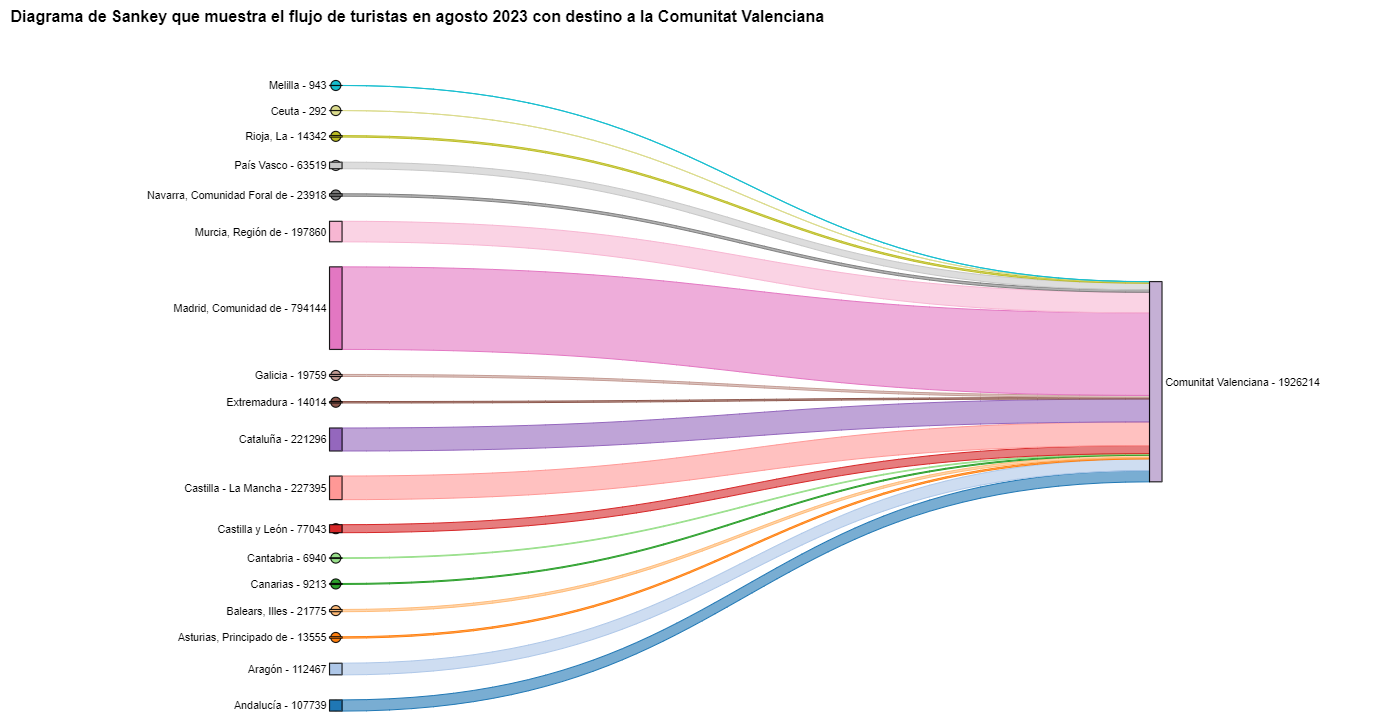
Figura 9. Diagrama de Sankey que muestra el flujo de turistas en agosto 2023 con destino a la Comunitat Valenciana.
Como ya hemos podido intuir por el diagrama de cuerdas de arriba, véase la figura 8 el mayor grupo de turistas que llegan a la Comunitat Valenciana proviene de Madrid. Vemos que también hay un elevado número de turistas que visitan la Comunitat Valenciana desde las CCAA vecinas como Murcia, Andalucía y Cataluña.
Para comprobar que estas tendencias se dan en las tres provincias de la Comunitat Valenciana, vamos a crear un diagrama de Sankey que muestre en el margen izquierdo todas las CCAA y en el margen derecho las tres provincias de la Comunitat Valenciana.
Para crear este diagrama de Sankey a nivel de provincias tenemos que filtrar nuestro pandas. DataFrame inicial para extraer de él las filas que contienen la información relevante. Los pasos en el notebook se pueden adaptar para realizar este análisis a nivel de provincias para cualquier otra CA. Aunque no estamos reutilizando la función que hemos usado anteriormente, también podemos cambiar el período de análisis.
El diagrama de Sankey que visualiza los flujos de turistas que llegaron en agosto de 2023 a las tres provincias valencianas quedaría así:
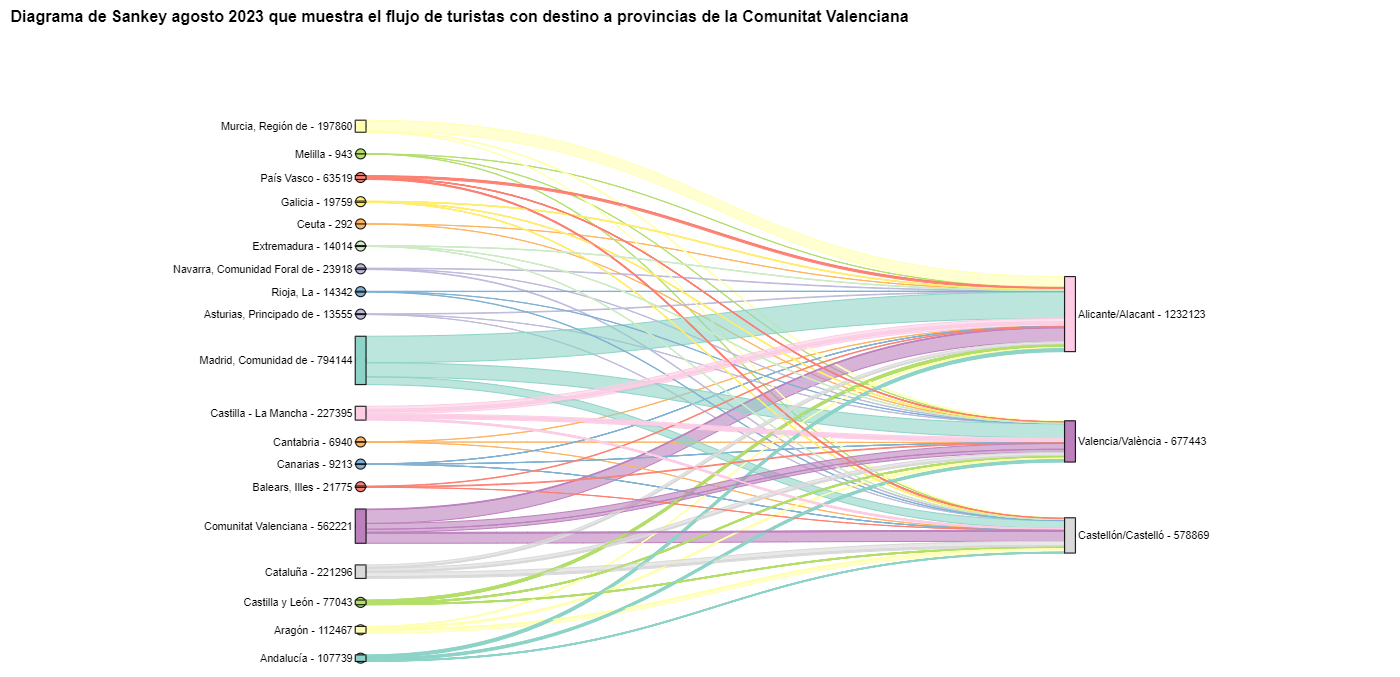
Figura 10. Diagrama de Sankey agosto 2023 que muestra el flujo de turistas con destino a provincias de la Comunitat Valenciana.
Podemos observar que, como ya suponíamos, el mayor número de turistas que llega a la Comunitat Valenciana en agosto proviene de la Comunidad de Madrid. Sin embargo, podemos comprobar que esto no es cierto para la provincia de Castellón, donde en agosto de 2023 la mayoría de los turistas fueron valencianos que se desplazaron dentro de su propia CA.
6. Conclusiones del ejercicio
Gracias a las técnicas de visualización empleadas en este ejercicio, hemos podido observar los flujos de turistas que se desplazan dentro del territorio nacional, enfocándonos en hacer comparaciones entre diversas épocas del año y tratando de identificar patrones. Tanto en los diagramas de cuerdas como en los diagramas de Sankey que hemos creado, hemos podido observar la afluencia de los turistas madrileños en las costas valencianas en verano. También hemos podido identificar las comunidades autónomas donde los turistas salen menos de su propia comunidad autónoma, como Cataluña y Andalucía.
7. ¿Quieres realizar el ejercicio?
Invitamos al lector a ejecutar el código contenido en el notebook de Google Colab que acompaña a este ejercicio para seguir con el análisis de los flujos de turistas. Dejamos aquí algunas ideas de posibles preguntas y de cómo se podrían contestar:
- El impacto de la pandemia: ya lo hemos mencionado brevemente arriba, pero una pregunta interesante sería medir el impacto que ha tenido la pandemia del coronavirus sobre el turismo. Podemos comparar los datos de los años anteriores con el 2020 y también analizar los años siguientes para detectar tendencias de estabilización. Visto que la función que hemos creado permite cambiar fácilmente el período de tiempo bajo análisis, te proponemos hacer este análisis por tu cuenta.
- Intervalos de tiempo: también es posible modificar la función que hemos estado usando de tal manera que no solo permita seleccionar un periodo de tiempo concreto, sino que también permita intervalos de tiempos.
- Análisis a nivel de provincias: igualmente, un lector avanzado con Pandas puede imponerse el reto de crear un diagrama de Sankey que visualice a qué provincias viajan los habitantes de una determinada región, por ejemplo, Ourense. Para no tener demasiadas provincias de destino que podrían hacer ilegible el diagrama de Sankey, se podrían visualizar solo las 10 más visitadas. Para obtener los datos para crear esta visualización, el lector tendría que jugar con los filtros que pone sobre el dataset y con el método de groupby de pandas, dejándose inspirar por el código ya ejecutado.
Esperamos que este ejercicio práctico te haya aportado conocimiento suficiente para desarrollar tus propias visualizaciones. Si tienes algún tema sobre ciencia de datos que quieras que tratemos próximamente, no dudes en proponer tu interés a través de nuestros canales de contacto.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Ejercicios de ciencia de datos”.
Documentación
La revolución digital está transformando los servicios municipales, impulsada por la creciente adopción de tecnologías de inteligencia artificial (IA) que también se benefician de los datos abiertos. Estos avances tienen potencial para redefinir la manera en que los municipios ofrecen servicios a sus ciudadanos, proporcionando herramientas para mejorar la eficiencia, accesibilidad y sostenibilidad. El presente informe analiza casos de éxito en el despliegue de aplicaciones y plataformas que buscan mejorar diversos aspectos de la vida en los municipios, destacando su potencial para liberar algo más del vasto potencial aún por explotar de los datos abiertos y las tecnologías asociadas a la inteligencia artificial.
Las aplicaciones y plataformas descritas en este informe tienen un alto potencial de replicabilidad en diferentes contextos municipales, ya que abordan problemas que son comunes. La replicación de estas soluciones puede llevarse a cabo mediante la colaboración entre municipios, empresas y desarrolladores, así como a través de la liberación y estandarización de datos abiertos.
A pesar de los beneficios, la adopción de datos abiertos para la innovación municipal también presenta importantes desafíos. Debe garantizarse la calidad, actualización y estandarización de los datos publicados por las entidades locales, así como la interoperabilidad entre diferentes plataformas y sistemas. Además, es necesario reforzar la cultura de datos abiertos entre todos los actores implicados, incluidos los ciudadanos, los desarrolladores, las empresas y las propias administraciones públicas.
Los casos de uso analizados se dividen en cuatro secciones. A continuación, se describen cada una de estas secciones y se muestran algunos ejemplos de las soluciones incluidas en el informe.
Transporte y Movilidad
Uno de los desafíos más significativos en las áreas urbanas es la gestión del transporte y la movilidad. Las aplicaciones que utilizan datos abiertos han demostrado ser efectivas en la mejora de estos servicios. Por ejemplo, aplicaciones como Park4Dis facilitan la localización de plazas de aparcamiento para persona con movilidad reducida, utilizando datos de múltiples municipios y contribuciones de voluntarios. CityMapper, que ha alanzado escala global, por otro lado, ofrece rutas de transporte público optimizadas en tiempo real, integrando datos de diversos modos de transporte para proporcionar la ruta más eficiente. Estas aplicaciones no solo mejoran la movilidad, sino que también contribuyen a la sostenibilidad al reducir la congestión y las emisiones de carbono.
Medio Ambiente y Sostenibilidad
La creciente conciencia sobre la sostenibilidad ha impulsado el desarrollo de aplicaciones que promueven prácticas ecológicas. CleanSpot, por ejemplo, facilita la localización de puntos de reciclaje y la gestión de residuos urbanos. La aplicación incentiva la participación ciudadana en la limpieza y el reciclaje, contribuyendo a la reducción de la huella ecológica. Liight, por su parte, gamifica comportamientos sostenibles, recompensando a los usuarios por acciones como reciclar o usar el transporte público. Estas aplicaciones no solo mejoran la gestión ambiental, sino que también educan y motivan a los ciudadanos a adoptar hábitos más sostenibles.
Optimización de Servicios Públicos Básicos
Las plataformas de gestión de servicios urbanos, como Gestdropper, utilizan datos abiertos para monitorizar y controlar infraestructuras urbanas en tiempo real. Estas herramientas permiten una gestión más eficiente de recursos como el alumbrado público, redes de agua y mobiliario urbano, optimizando el mantenimiento, la respuesta ante incidencias y reduciendo costes operativos. Por otra parte, el despliegue de sistemas de gestión de citas previas, como CitaME, ayuda a reducir los tiempos de espera y mejorar la eficiencia en la atención al ciudadano.
Agregadores de Servicios a los Ciudadanos
Las aplicaciones que centralizan información y servicios públicos, como Badajoz Es Más y AppValencia, mejoran la accesibilidad y la comunicación entre las administraciones y los ciudadanos. Estas plataformas proporcionan datos en tiempo real sobre transporte público, eventos culturales, turismo y trámites administrativos, facilitando la vida en el municipio tanto a los residentes como a los turistas. Por ejemplo, al integrar múltiples servicios en una sola aplicación, se mejora la eficiencia y se reduce la necesidad de desplazamientos innecesarios. Estas herramientas también apoyan a las economías locales al promover eventos culturales y servicios comerciales.
Conclusiones
La utilización de datos abiertos y tecnologías de inteligencia artificial está transformando la gestión municipal, mejorando la eficiencia, accesibilidad y sostenibilidad de los servicios públicos. Los casos de éxito presentados en este informe describen cómo estas herramientas pueden beneficiar tanto a los ciudadanos como a las administraciones públicas convirtiendo las ciudades en entornos más inteligentes, inclusivos y sostenibles, y respondiendo mejor a las necesidades y bienestar de sus habitantes y visitantes.
Para profundizar en el contenido del informe, hemos grabado un pódcast y una video-entrevista donde el autor nos cuenta las claves de esta guía. Además, se ha elaborado una infografía y un resumen ejecutivo.
Escucha el pódcast con el autor
Mira la vídeo-entrevista con el autor
Noticia
Uno de los objetivos de datos.gob.es es divulgar la cultura del dato. Para ello utilizamos diferentes canales de difusión de contenidos como un blog de contenidos especializados, un boletín de envío quincenal o perfiles en redes sociales como X (antiguo Twitter) o LinkedIn. Las redes sociales nos sirven, tanto como canal de divulgación, como espacio de contacto con la comunidad reutilizadora de datos abiertos. En nuestra misión didáctica de dar a conocer la cultura del dato, ahora también estaremos presentes en Instagram.
Esta plataforma visual y dinámica se convertirá en un nuevo punto de encuentro donde nuestros seguidores podrán descubrir, explorar y aprovechar el valor de los datos abiertos y las tecnologías relacionadas.
En nuestra cuenta de Instagram (@datosgob), ofreceremos una variedad de contenidos:
- Conceptos clave: definiciones de conceptos del mundo de los datos y tecnologías relacionadas explicadas de manera clara y concisa para crear un glosario a tu alcance.
- Infografías informativas: cuestiones complejas como leyes, casos de uso o aplicación de tecnologías innovadoras explicadas gráficamente y de una forma más sencilla.
- Historias de impacto: proyectos inspiradores que utilizan datos abiertos para generar un impacto positivo en la sociedad.
- Tutoriales y consejos: para que aprendas a usar nuestra plataforma de manera más efectiva, ejercicios de ciencia de datos y visualizaciones paso a paso, entre otros.
- Eventos y novedades: actividades importantes, lanzamientos de nuevos conjuntos de datos y las últimas novedades en el mundo de los datos abiertos.
Formatos variados de contenidos de valor
Además, toda esta información de interés irá presentada en formatos adecuados a la plataforma como son:
- Publicaciones: posts de píldoras informativas, infografías, monográficos, entrevistas, piezas audiovisuales y casos de éxito que te ayudarán a conocer cómo diferentes herramientas y metodologías digitales son tus aliadas. Podrás disfrutar de distintos tipos de publicaciones (fijas, carruseles, colaborativas con otras cuentas de referencia, etc.), donde tendrás la posibilidad de compartir tus opiniones, dudas y experiencias, y conectar con otros profesionales.
- Stories: anuncios, encuestas o calendarios para que puedas estar al tanto de todo lo que sucede en el ecosistema de los datos y formar parte de él compartiendo tus impresiones.
- Historias destacadas: en la parte superior de nuestro perfil, dejaremos seleccionada y ordenada la información más relevante sobre los diferentes ámbitos e iniciativas de datos.gob.es, en tres temáticas: formación, eventos y novedades.
Una plataforma participativa y colaborativa
Tal y como venimos haciendo en las otras redes sociales en las que tenemos presencia, queremos que nuestra cuenta sea un espacio de diálogo y colaboración. Por ello, invitamos a toda la ciudadanía, investigadores, periodistas, desarrolladores y cualquier persona interesada en los datos abiertos a que se unan a la comunidad datos.gob.es. Aquí hay algunas maneras en las que puedes participar:
- Comenta y comparte: queremos escuchar tus opiniones, preguntas y sugerencias. Interactúa en nuestras publicaciones y comparte nuestro contenido con tu red para ayudar a difundir la importancia de los datos abiertos.
- Etiquétanos: si estás trabajando en un proyecto que utiliza datos abiertos, ¡muéstranos! Etiquétanos en tus publicaciones y usa el hashtag #datosgob para que podamos ver y compartir tu trabajo con nuestra comunidad.
- Historias destacadas: ¿tienes una historia interesante que contar sobre cómo has utilizado los datos abiertos? Envíanos un mensaje directo y podríamos destacarla en nuestra cuenta para inspirar a otros.
¿Por qué Instagram?
En un mundo donde la información visual se ha convertido en una herramienta poderosa para la comunicación y el aprendizaje, hemos decidido dar el salto a Instagram. Esta plataforma no solo nos permitirá hacernos eco de las novedades del ecosistema de los datos de manera más atractiva y comprensible, sino que también nos ayudará a conectar con una audiencia más amplia y diversa. Queremos que la información pública sea accesible y relevante para todos, y creemos que Instagram es el lugar perfecto para hacerlo.
En resumen, el lanzamiento de nuestra cuenta de Instagram marca un paso importante en nuestra misión de hacer que los datos abiertos sean más accesibles y útiles para todos.
Síguenos en Instagram en @datosgob y únete a una comunidad creciente de personas interesadas en la transparencia, la innovación y el conocimiento compartido. Al seguirnos, tendrás acceso inmediato a una fuente constante de información y recursos que te ayudarán a aprovechar al máximo los datos abiertos. Además, no olvides seguirnos en nuestras otras redes sociales X o LinkedIn.