Blog
La construcción del ecosistema de uso secundario de los datos de salud electrónica en el Espacio Europeo de Datos de Salud (EEDS) plantea un escenario significativo de oportunidades para la investigación española, para la innovación y el emprendimiento. Para ello, la Unión Europea está impulsando multitud de proyectos estratégicos en los que participan hospitales, fundaciones de investigación sanitaria, universidades, centros de investigación y empresas españolas. La lista de proyectos es extensa y atiende a satisfacer al menos dos objetivos: potenciar la generación de infraestructuras capaces de generar conjuntos de datos de calidad y promover condiciones para su reutilización.
El papel de España. Fortalezas en el despliegue del Espacio Europeo de Salud
España ofrece condiciones significativamente favorables no sólo para participar sino también para contribuir significativamente a las tareas de creación del EEDS:
- En primer lugar, nuestro sistema público de salud se caracteriza por un alto nivel de integración y estructuración. A diferencia de los sistemas basados en mecanismos de reembolso, en los que puede existir una atomización en el ámbito de la provisión de servicios, en nuestro sistema disponemos de un marco de referencia clara en atención primaria, especialidades médicas y servicios hospitalarios.
- Por otra parte, la experiencia desplegada por nuestros entornos de salud a partir del Reglamento General de Protección de Datos (RGPD) y, particularmente, las lecciones aprendidas a partir de la disposición adicional decimoséptima sobre tratamientos de datos de salud de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD) constituyen una experiencia valiosa.
- La apertura del Espacio Nacional de Datos de Salud promovido por el Gobierno de España e impulsado por el Ministerio para la Transformación Digital y de la Función Pública, el Ministerio de Sanidad y las Comunidades Autónomas permite el despliegue de una infraestructura esencial para el EEDS.
El Espacio Nacional de Datos de Salud se presentó el pasado 29 de enero. En el evento se resaltó cómo este proyecto representa un cambio de paradigma que revoluciona la gestión del dato sanitario, impulsando un modelo federado, seguro y ético que preserva la soberanía y privacidad de la información mientras facilita su uso para investigación, innovación y políticas públicas. Su funcionamiento se basa en un catálogo federado de metadatos y un riguroso proceso de acceso y análisis en entornos seguros, que busca potenciar la ciencia abierta y los avances científicos y tecnológicos, beneficiando a pacientes, investigadores, gestores e industria.
Lecciones aprendidas desde los Proyectos Europeos
El camino que arranca el Reglamento (UE) 2025/327 del Parlamento Europeo y del Consejo, de 11 de febrero de 2025, relativo al Espacio Europeo de Datos de Salud, y por el que se modifican la Directiva 2011/24/UE y el Reglamento (UE) 2024/2847 (EEDSR) plantea retos significativos que se abordan en los proyectos de investigación financiados con fondos europeos y nacionales. Las lecciones aprendidas en algunos de ellos pueden ser de extraordinaria utilidad para la comunidad investigadora y de emprendimiento en nuestro país. No podemos olvidar que partimos de fortalezas significativas.
1.-Cumplimiento desde el diseño
La existencia de una nueva normativa obliga a desplegar un análisis riguroso del estado del arte en nuestras organizaciones, no sólo para implementar su despliegue sino también para asegurar las condiciones previas de confiabilidad legal de los conjuntos de datos y de la investigación que se proponga.
2.-Accountability: responsabilidad proactiva y solidez documental
En nuestro país venimos de una larga tradición de “accountability”. El EEDSR va a imponer al solicitante de datos un conjunto de requisitos documentales relevantes, como, por ejemplo, haber previsto las garantías para prevenir cualquier uso indebido de los datos de salud electrónicos. Esta cuestión tampoco podrá descuidarse desde el punto de vista de los tenedores de datos, quienes también tendrán que cumplir algunos requisitos. Por ejemplo, demostrar que los datos son legítimos y reutilizables es una cuestión ética y jurídicamente documentable; y el procedimiento simplificado para el acceso a los datos de salud electrónicos a través de un tenedor fiable de datos de salud obliga a este a documentar la seguridad de su espacio de datos o las capacidades para evaluar las solicitudes de acceso a datos de salud.
Uno de los principales escollos a los que nos enfrentamos en este periodo intermedio de implantación del EEDS reside precisamente en la cultura organizativa para la generación de evidencias verificables. A medida que la estandarización y el conjunto de reglas comunes del EEDS escalen será necesario profundizar en la dinámica de la responsabilidad proactiva entendida como responsabilidad demostrada.
3. Entornos seguros de procesamiento
En nuestro país, los entornos de salud por su propia definición deben ser entornos seguros. El despliegue del Esquema Nacional de Seguridad (ENS) y el del RGPD, han permitido que la totalidad del sistema de salud, público o privado, haya adoptado modelos de madurez perfectamente coherentes con las condiciones de los entornos de procesamiento seguro que define el EEDSR.
Retos del sistema español
Junto a las fortalezas inherentes a nuestro sistema, es necesario considerar aquellos aspectos que se presentan como retos.
1. Anonimización y seudonimización
En el contexto nacional la citada disposición adicional decimoséptima de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales, define condiciones específicas para la seudonimización. Estas consisten en la separación funcional entre los equipos que seudonimizan y los que reutilizan los datos, y en la definición de un entorno seguro que prevenga cualquier intento de reidentificación. A ello se suman garantías jurídicas en términos de compromisos individuales de no reidentificación, despliegue de la herramienta de la evaluación de impacto relativa a la protección de datos y supervisión por comités de ética. El reto de la anonimización se muestra más exigente, ya que implica la imposibilidad de vincular bajo ninguna condición los datos de salud con los del paciente original.
2. Reeskilling de los equipos
El Espacio Europeo de Datos de Salud (EEDS) planteará un desafío formativo sin precedentes que atravesará todos los sectores implicados en el ecosistema de datos sanitarios. Los comités de ética de investigación deberán familiarizarse no solo con los usos secundarios admisibles de los datos de salud, sino también con la integración del Reglamento de Inteligencia Artificial y con los principios éticos del marco ALTAI (Assessment List for Trustworthy Artificial Intelligence). Esta necesidad de reeskilling se extenderá igualmente a los sistemas de salud y la administración sanitaria, donde los organismos de acceso a datos (Health Data Access Bodies) requerirán personal altamente cualificado en estos nuevos marcos éticos y regulatorios, al igual que los tenedores fiables de datos que custodiarán la información sensible. El personal de desarrollo y los equipos de tecnologías de la información también deberán adquirir nuevas competencias en ámbitos técnicos críticos, como la catalogación, validación y curación de datos, así como en los estándares de interoperabilidad que permitan la comunicación efectiva entre sistemas. Quizás el reto de capacitación más delicado recaerá sobre los nuevos operadores, que podrán aprovechar las oportunidades de acceso a conjuntos de datos para usos secundarios innovadores. Esto concierne especialmente a las startups tecnológicas del sector salud. Para enfrentar un marco normativo muy exigente, (RGPD, Regalmento de IA, EEDSR), los recursos y capacidades para el cumplimiento legal (compliance) en las pymes españolas es notablemente limitado. Por ello será necesario construir desde el inicio una cultura sólida de protección de datos y desarrollo ético de sistemas de inteligencia artificial confiables.
3. Catalogación de datos: el desafío de la calidad y la estandarización
En el contexto del Espacio Europeo de Datos de Salud, profundizar en la estandarización de los datos mediante las metodologías más funcionales —como OMOP CDM para datos clínicos observacionales, HL7 FHIR para el intercambio dinámico de información, DICOM para imágenes médicas, o terminologías de referencia como SNOMED CT, LOINC y RxNorm— se presenta como un elemento estratégico fundamental para la creación y reutilización de conjuntos de datos de alta calidad. Sin embargo, la adopción de estos estándares no es suficiente por sí sola: los procesos de validación, anotación semántica y enriquecimiento de datos requieren de recursos humanos altamente cualificados capaces de garantizar la coherencia, completitud y precisión de la información, convirtiéndose esta capacitación en una auténtica precondición para la participación efectiva en el ecosistema europeo de datos de salud. El alineamiento con la catalogación estandarizada de conjuntos de datos siguiendo el estándar HealthDCAT-AP (Health Data Catalog Application Profile), que permite describir de manera homogénea los metadatos descriptivos de los recursos de datos sanitarios, se presenta como uno de los retos inmediatos, junto con la implementación de los trabajos que se vienen desplegando en relación con el data utility quality label, una etiqueta de calidad que evalúa la utilidad real de los datos para usos secundarios y que se está convirtiendo en un sello de confianza para usuarios e investigadores.
Si anteriormente en este artículo se subrayaron las altísimas capacidades del sistema sanitario español para generar datos de salud de manera sistemática y en volúmenes significativos, estos aspectos de catalogación, estandarización y certificación de calidad ocuparán un lugar absolutamente central para diseñar condiciones óptimas de competitividad europea en su reutilización, transformando la abundancia de datos en una verdadera ventaja estratégica que permita a España posicionarse como un actor relevante en el panorama de la investigación y la innovación con datos de salud electrónicos.
La experiencia del proyecto EUCAIM (Cancer Image EU)
El Reglamento del Espacio Europeo de Datos de Salud tiene por objeto permitir el uso secundario de los datos sanitarios electrónicos en toda Europa mediante normas armonizadas en un ecosistema federado. En el ámbito del cáncer, el acceso fragmentado a conjuntos de datos de alta calidad ralentiza la investigación, limita la reproducibilidad y socava la capacidad de Europa para desarrollar y validar herramientas de IA fiables para la oncología.
EUCAIM demuestra la viabilidad de un ecosistema para el uso secundario del cáncer a través de un modelo federado que permite el acceso transfronterizo bajo normas armonizadas garantizando un control adecuado de los recursos a nivel local. Y ello se despliega mediante un conjunto de componentes habilitadores:
1) Un entorno de procesamiento seguro (SPE) federado a nivel europeo
EUCAIM está creando un SPE federado para hacer cumplir las condiciones de acceso a los datos, controlar el procesamiento y apoyar el análisis transfronterizo seguro bajo las restricciones del EEDS. Este SPE se ajusta plenamente a los requisitos y medidas que establece el artículo 73 EEDSR en materia de entornos seguros.
2) Superación de la «barrera de la anonimización»
EUCAIM promueve una estrategia de anonimización por capas que combina procesos de anonimización local autónoma por el tenedor de datos con controles de la plataforma para permitir que los conjuntos de datos sigan siendo útiles para la investigación y el desarrollo de la IA. La importancia de este enfoque radica en que pretende conciliar la protección de la privacidad con la necesidad práctica de disponer de conjuntos con grandes volúmenes de datos caracterizados por su diversidad.
3) Catalogación y estandarización de datos
EUCAIM alinea la catalogación con los principios HealthDCAT-AP cuyo objetivo principal es aplicar los principios FAIR, esto es asegurar que los datos sean encontrables, accesibles, interoperables y reutilizables.
4) Reducción de costes legales
EUCAIM ha desplegado un marco de cumplimiento propio orientado al Reglamento General de Protección de Datos y el Reglamento de Inteligencia Artificial. Para ello, se dispone de un marco sólido de cumplimiento a nivel de una plataforma que se despliega en ecosistemas complejos de datos. Este se basa en evaluaciones de impacto en la protección de datos (incluidas en el RGPD) con especial atención a los derechos fundamentales. También incorpora la formación y el reciclaje profesional de los usuarios como requisito funcional, de modo que la capacidad de cumplimiento se convierta en una característica esencial.
5) Apoyo a los usuarios de datos
EUCAIM ofrece ventajas significativas a los usuarios de datos, incluidos los investigadores y los desarrolladores de IA, al establecer un entorno transparente y bien gobernado para el acceso a los datos. La adopción de criterios de gobernanza transparentes, obligaciones claramente definidas y su aplicación técnica por la plataforma, proporcionan a los usuarios de datos la garantía de que su acceso es adecuado y lícito, totalmente auditable y se mantiene estable a lo largo del tiempo. El diseño de la plataforma garantiza que los usuarios puedan aprovechar datos de gran utilidad para análisis avanzados, incluido el procesamiento federado en un entorno seguro. A través de la formación obligatoria y la implementación de procedimientos estandarizados, los equipos se benefician de una menor incertidumbre y están mejor equipados para alinearse con los requisitos de cumplimiento establecidos por el EEDSR, el RGPD y los marcos de gobernanza de la IA.
6) Garantía de los derechos de los pacientes
El enfoque de EUCAIM se basa en la protección de datos desde el diseño y por defecto que une las salvaguardias organizativas con controles técnicos sólidos. Este marco se ha construido expresamente para minimizar el riesgo de uso indebido de los datos, al tiempo que apoya la investigación y la innovación transfronterizas seguras y eficaces en materia de cáncer. El resultado es un sistema en el que la protección de la privacidad no es un obstáculo sino un elemento fundamental que permite el uso responsable de los datos en beneficio de la sociedad y la ciencia. El modelo refuerza la responsabilidad por el uso secundario de los datos sanitarios mediante la combinación de una sólida supervisión de la gobernanza, un registro exhaustivo de las acciones y obligaciones estrictas y exigibles para todas las entidades participantes. Todas las acciones realizadas con los datos de los pacientes se registran y se someten a revisión, lo que garantiza que todos los usos sean totalmente auditables. Esta trazabilidad garantiza que el tratamiento de los datos se mantenga dentro de los límites del uso permitido y que cualquier desviación pueda identificarse y abordarse rápidamente.
Gobernanza multinivel: la clave del éxito sostenible
La lección aprendida más relevante en EUCAIM se refiere a la necesidad imperiosa de una gobernanza multinivel articulada, coherente y operativa. En sentido amplio, resulta indispensable proporcionar herramientas y marcos de gobierno efectivos sobre tres dimensiones fundamentales:
- En primer lugar, sobre los procesos de generación de conjuntos de datos y sus condiciones de compartición, estableciendo criterios claros sobre qué datos se generan, cómo se estandarizan, quién ostenta derechos sobre ellos y bajo qué licencias y restricciones pueden ser compartidos con terceros.
- En segundo lugar, sobre los procesos de solicitud de acceso a datos, definiendo procedimientos transparentes y eficientes para que investigadores, innovadores y responsables de políticas públicas puedan identificar, solicitar y obtener acceso a los datos necesarios para sus proyectos, minimizando las cargas administrativas sin comprometer las garantías éticas y legales.
- En tercer lugar, sobre los procesos de validación de la corrección de los conjuntos de datos y de adhesión al sistema, así como los procedimientos de autorización de acceso a datos, asegurando que solo datos de calidad certificada alimenten la infraestructura y que únicamente usuarios autorizados y con propósitos legítimos accedan a información sensible.
Esta gobernanza procedimental no puede funcionar sin decisiones estratégicas y operativas en relación con la definición de roles y funciones en materia de recursos humanos. Para ello, es necesario contar con perfiles profesionales necesarios como gestores de datos, expertos en ética de la investigación, especialistas en ciberseguridad, curadores de datos y responsables de calidad. En segundo lugar, será fundamental la definición de los entornos seguros de procesamiento donde se ejecutan análisis sobre datos sensibles, garantizando que estos espacios cumplan con los más altos estándares técnicos de seguridad, trazabilidad, auditoría y preservación de la privacidad, y que estén diseñados para operar bajo el principio de confianza cero (zero trust) adaptado al contexto sanitario. Solo mediante esta arquitectura de gobernanza multinivel, que integre dimensiones técnicas, organizativas, éticas y legales en todos los niveles de decisión —desde el diseño de políticas nacionales hasta la gestión operativa diaria de las plataformas—, será posible construir infraestructuras de datos de salud verdaderamente sostenibles, confiables y capaces de generar valor social, científico y económico a largo plazo, posicionando al sistema sanitario español como un actor estratégico en el ecosistema europeo de innovación en salud.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos de salud son uno de los activos más valiosos de nuestra sociedad. Bien gestionados y compartidos de forma responsable, pueden salvar vidas, impulsar descubrimientos médicos o incluso optimizar recursos hospitalarios. Sin embargo, durante décadas, estos datos han permanecido fragmentados en silos institucionales, con formatos incompatibles y barreras técnicas y legales que dificultaban su reutilización. Ahora, la Unión Europea está cambiando radicalmente el panorama con una estrategia ambiciosa que combina dos enfoques complementarios:
- Facilitar el acceso abierto a estadísticas y datos agregados no sensibles.
- Crear infraestructuras seguras para compartir datos personales de salud bajo estrictas garantías de privacidad.
En España, esta transformación ya está en marcha a través del Espacio Nacional de Datos de Salud o grupos de investigación que están a la vanguardia en el uso innovador de datos de salud. Iniciativas como IMPACT-Data, que integra datos médicos para impulsar la medicina de precisión, demuestran el potencial de trabajar con datos de salud de manera estructurada y segura. Y para facilitar que todos estos datos sean fáciles de encontrar y reutilizar se implementan estándares como HealthDCAT-AP.
Todo ello está perfectamente alineado con la estrategia europea del Reglamento del Espacio Europeo de Datos de Salud (EHDS), publicado oficialmente en marzo de 2025 que se integra también con la Directiva de Datos Abiertos (ODD), en vigor desde 2019. Aunque ambos marcos regulatorios tienen alcances distintos, su interacción ofrece oportunidades extraordinarias para la innovación, la investigación y la mejora de la atención sanitaria en toda Europa.
Un reciente informe elaborado por Capgemini Invent para data.europa.eu analiza estas sinergias. En este post, exploramos las principales conclusiones de este trabajo y reflexionamos sobre su relevancia para el ecosistema español de datos abiertos.
Dos marcos complementarios para un objetivo común
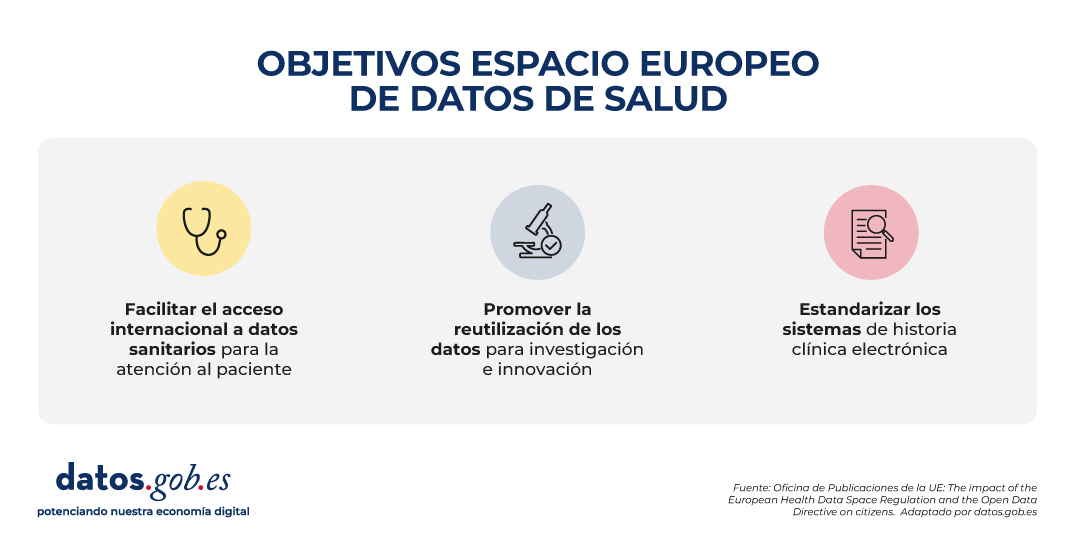
Por un lado, el Espacio Europeo de Datos de Salud se centra específicamente en datos de salud y persigue tres objetivos fundamentales:
- Facilitar el acceso internacional a datos sanitarios para la atención al paciente (uso primario).
- Promover la reutilización de estos datos para investigación, políticas públicas e innovación (uso secundario).
- Estandarizar técnicamente los sistemas de historia clínica electrónica (HCE) para mejorar la interoperabilidad transfronteriza.
Por su parte, la Directiva de Datos Abiertos tiene un alcance más amplio: promueve que el sector público ponga a disposición de cualquier usuario datos gubernamentales para su reutilización libre. Esto incluye los conjuntos de datos de alto valor (High-Value Datasets) que deben publicarse gratuitamente, en formatos legibles por máquina y a través de API en seis categorías entre las que no se encontraba “salud” originalmente. Sin embargo, en la propuesta de ampliación de las nuevas categorías que publicó la UE sí aparece la categoría de salud.
La complementariedad entre ambos marcos regulatorios es evidente: mientras la ODD facilita el acceso abierto a estadísticas sanitarias agregadas y no sensibles, el EHDS regula el acceso controlado a datos individuales de salud bajo condiciones estrictas de seguridad, consentimiento y gobernanza. Juntos, conforman un sistema escalonado de compartición de datos que maximiza su valor social sin comprometer la privacidad, en total cumplimiento con el Reglamento General de Protección de Datos (RGPD).
Principales beneficios ordenador por grupos de usuarios
El informe analiza cuatro grupos de usuarios principales y examina tanto los beneficios potenciales como los desafíos que enfrentan al combinar datos del EHDS con datos abiertos.
-
Pacientes: empoderamiento informado con barreras prácticas
Los pacientes europeos obtendrán acceso más rápido y seguro a sus propias historias clínicas electrónicas, especialmente en contextos transfronterizos gracias a infraestructuras como MyHealth@EU. Este proyecto resulta especialmente útil para ciudadanos europeos que se encuentren desplazados en otro país europeo. .
Otro proyecto interesante que informa a la ciudadanía es PatientsLikeMe que reúne a más 850.000 pacientes con enfermedades raras o crónicas en una comunidad online que comparte información de interés sobre tratamientos y otras cuestiones.
-
Profesionales de la salud potencial subordinado a la integración
Por otro lado, los profesionales sanitarios podrán acceder antes y de manera más sencilla a datos clínicos de pacientes, incluso a través de fronteras, mejorando la continuidad asistencial y la calidad del diagnóstico y tratamiento.
La combinación con datos abiertos podría amplificar estos beneficios si se desarrollan herramientas que integren ambas fuentes de información directamente en los sistemas de historia clínica electrónica.
3. Responsables políticos: datos para mejores decisiones
Los cargos públicos son beneficiarios naturales de la convergencia entre EHDS y datos abiertos. La posibilidad de combinar datos salud detallados (previa solicitud y autorización a través de los Organismos de Acceso a Datos Sanitarios que cada Estado miembro debe establecer) con información estadística y contextual abierta permitiría desarrollar políticas basadas en evidencia mucho más sólida.
El informe menciona casos de uso como la combinación de datos de salud con información medioambiental para evaluar impactos sanitarios. Un ejemplo real es el proyecto francés Green Data for Health, que cruza datos abiertos sobre contaminación acústica con información sobre prescripciones de medicamentos para el sueño de más de 10 millones de habitantes, investigando correlaciones entre ruido ambiental y trastornos del sueño.
4. Investigadores y reutilizadores: los principales beneficiarios inmediatos
Los investigadores, académicos e innovadores constituyen el grupo que más directamente se beneficiará de la sinergia EHDS-ODD ya que disponen de las habilidades y herramientas necesarias para localizar, acceder, combinar y analizar datos de múltiples fuentes. Además, su trabajo ya implica habitualmente la integración de diversos conjuntos de datos.
Un estudio reciente publicado en PLOS Digital Health sobre el caso de Andalucía demuestra cómo los datos abiertos en salud pueden democratizar la investigación en IA sanitaria y mejorar la equidad en el tratamiento.
El desarrollo del EHDS está siendo apoyado por programas europeos como EU4Health, Horizon Europe y proyectos específicos como TEHDAS2, que ayudan a definir estándares técnicos y pilotar aplicaciones reales.
Recomendaciones para maximizar el impacto
El informe concluye con cuatro recomendaciones clave que resultan particularmente relevantes para el ecosistema español de datos abiertos:
- Estimular la investigación en la intersección EHDS-datos abiertos mediante financiación específica. Es fundamental incentivar que los investigadores que combinan estas fuentes traduzcan sus hallazgos en aplicaciones prácticas: protocolos clínicos mejorados, herramientas de decisión, estándares de calidad actualizados.
- Evaluar y facilitar el uso directo por profesionales y pacientes. Promover la alfabetización en datos y desarrollar aplicaciones intuitivas integradas en los sistemas existentes (como las historias clínicas electrónicas) podría cambiar esta situación.
- Fortalecer la gobernanza mediante educación y marcos regulatorios claros. A medida que se vayan operativizando las entidades técnicas del EHDS , será esencial contar con una regulación clara que defina unos marcos regulatorios comunes..
- Monitorizar, evaluar y adaptar. El período 2025-2031 verá la entrada en vigor gradual de los distintos requisitos del EHDS. Se recomienda realizar evaluaciones periódicas para valorar cómo se está utilizando realmente el EHDS, qué combinaciones con datos abiertos están generando más valor, y qué ajustes son necesarios.
Además, para que todo esto funcione, el informe sugiere que portales como data.europa.eu (y por extensión, datos.gob.es) deberían destacar ejemplos prácticos que demuestren cómo se complementan los datos abiertos con los datos protegidos de espacios sectoriales, inspirando así nuevas aplicaciones.
En general, el papel de los portales de datos abiertos será fundamental en este ecosistema emergente: no solo como proveedores de conjuntos de datos de calidad, sino también como facilitadores de conocimiento, espacios de encuentro entre comunidades y catalizadores de innovación. El futuro de la sanidad europea se está escribiendo ahora, y los datos abiertos tienen un papel protagonista en esa historia.
Blog
Los datos son el motor de la innovación, y su potencial transformador se refleja en todos los ámbitos, destacando especialmente en el de la salud. Desde diagnósticos más rápidos hasta tratamientos personalizados y políticas públicas más eficaces, el uso inteligente de la información sanitaria tiene el poder de cambiar vidas de forma profunda y significativa.
Pero, para que estos datos desplieguen todo su valor y se conviertan en una fuerza real para el progreso, es fundamental que "hablen el mismo idioma". Es decir, que estén bien organizados, sean fáciles de encontrar y puedan compartirse de forma segura y coherente entre distintos sistemas, países y profesionales.
Aquí es donde entra en juego HealthDCAT-AP, una nueva especificación europea que, aunque suene técnico, tiene mucho que ver con nuestro bienestar como ciudadanos. HealthDCAT-AP está diseñado para describir los datos de salud —desde estadísticas agregadas hasta registros clínicos anonimizados— de manera homogénea, clara y reutilizable, a través de metadatos. En definitiva, no actúa sobre los datos clínicos en sí, sino que facilita que puedan localizarse y comprenderse mejor gracias a una descripción estandarizada.
HealthDCAT-AP se ocupa exclusivamente de los metadatos, es decir, de cómo se describen y organizan los conjuntos de datos en los catálogos, diferenciándose de HL7, FHIR y DICOM que estructuran el intercambio de información clínica e imágenes; CDA que describe la arquitectura de los documentos; y SNOMED CT, LOINC y CIE-10 que estandarizan la semántica de diagnósticos, procedimientos y observaciones para garantizar que los datos tengan el mismo significado en cualquier contexto
Este artículo explora cómo HealthDCAT-AP, en el contexto del Espacio Europeo de Datos Sanitarios (EHDS) y del Espacio Nacional de Datos Sanitarios (ENDS), aporta valor principalmente a quienes reutilizan los datos —como investigadores, innovadores o responsables de políticas públicas— y, en última instancia, beneficia también a la ciudadanía a través de los avances que estos generan.
¿Qué es HealthDCAT-AP y cuál es su relación con DCAT-AP?
Imagina una biblioteca enorme llena de libros sobre salud, pero sin ningún sistema para organizarlos. Buscar una información concreta sería una tarea caótica. Con los datos de salud ocurre algo similar: si no están bien descritos, localizarlos y reutilizarlos es prácticamente imposible.
HealthDCAT-AP nace para resolver este reto. Es una especificación técnica europea que permite describir de forma clara y uniforme los conjuntos de datos sanitarios dentro de catálogos de datos a, facilitando su búsqueda, acceso, comprensión y reutilización. En otras palabras, hace que la descripción de los datos sanitarios hable el mismo idioma en toda Europa, lo que resulta clave para mejorar la atención, la investigación y las políticas de salud.
Esta especificación técnica se basa en DCAT-AP, la especificación general utilizada para describir catálogos de conjuntos de datos del sector público en Europa. Mientras que DCAT-AP proporciona una estructura común para todo tipo de datos, HealthDCAT-AP es su extensión especializada en salud, que adapta y amplía ese modelo para cubrir las particularidades de los datos clínicos, epidemiológicos o biomédicos.
HealthDCAT-AP fue desarrollado en el marco del proyecto piloto europeo EHDS2 (European Health Data Space 2) y continúa evolucionando gracias al apoyo de proyectos como HealthData@EU Pilot, que trabajan en el despliegue de la futura infraestructura europea de datos sanitarios. La especificación está en desarrollo activo y su versión más reciente, junto con documentación y ejemplos, puede consultarse públicamente en su repositorio oficial de GitHub.
Así mismo, HealthDCAT-AP está diseñado para aplicar los principios FAIR que los datos sean Encontrables, Accesibles, Interoperables y Reutilizables. Esto significa que, aunque los datos sanitarios puedan ser complejos o sensibles, su descripción (metadatos) es clara, estandarizada y útil. Cualquier profesional o institución —ya sea en España o en otro país europeo— puede saber qué datos existen, cómo acceder a ellos y con qué condiciones. Esto fomenta la confianza, la transparencia y el uso responsable de los datos sanitarios. HealthDCAT-AP es además una piedra angular del EHDS y por ende del ENDS. Su adopción permitirá que hospitales, centros de investigación o administraciones compartan información de forma coherente y segura a lo largo de toda Europa. Así, se impulsa la colaboración entre países y se maximiza el valor de los datos para beneficio de toda la ciudadanía.
Para facilitar su uso y adopción, desde Europa, bajo las iniciativas mencionadas anteriormente, se han creado herramientas como el editor y el validador HealthDCAT-AP, que permiten a cualquier organización generar descripciones de conjuntos de datos a través de los metadatos que sean compatibles sin necesidad de conocimientos técnicos avanzados. Esto elimina barreras y anima a más entidades a participar en este ecosistema de datos de salud en red.
¿Cómo contribuye HealthDCAT-AP al valor público de los datos de salud?
Aunque HealthDCAT-AP es una especificación técnica centrada en la descripción de conjuntos de datos de salud, su adopción tiene implicaciones prácticas que van más allá del ámbito tecnológico. Al ofrecer una forma común y estructurada de documentar qué datos existen, cómo pueden utilizarse y en qué condiciones, contribuye a que distintos actores —desde hospitales y administraciones hasta centros de investigación o startups— puedan acceder, combinar y reutilizar mejor la información disponible, habilitando el denominado uso secundario de la misma, más allá del uso primario asistencial.
A continuación, se detallan algunos de los ámbitos donde su contribución técnica se traduce en beneficios concretos para el conjunto de la sociedad.
- Diagnósticos más rápidos y tratamientos personalizados: cuando los datos están bien organizados y son accesibles para quienes los necesitan, los avances en investigación médica se aceleran. Esto permite desarrollar herramientas de inteligencia artificial que detectan enfermedades antes, identificar patrones en grandes poblaciones y adaptar tratamientos al perfil de cada paciente. Es la base de la medicina personalizada, que mejora resultados y reduce riesgos.
- Mejor acceso al conocimiento sobre qué datos existen: HealthDCAT-AP permite a investigadores, gestores sanitarios o autoridades localizar más fácilmente conjuntos de datos útiles, gracias a su descripción estandarizada. Esto puede facilitar, por ejemplo, el análisis de desigualdades en salud o la planificación de recursos en situaciones de crisis.
- Mayor transparencia y trazabilidad: El uso de metadatos permite saber quién es responsable de cada conjunto de datos, con qué finalidad se puede usar y en qué condiciones. Esto fortalece la confianza en el ecosistema de reutilización de datos.
- Servicios sanitarios más eficientes: la estandarización de los metadatos mejora los flujos de información entre centros, regiones y sistemas. Esto reduce la burocracia, evita duplicidades, optimiza el uso de recursos y libera tiempo y dinero que pueden reinvertirse en mejorar la atención directa a los pacientes.
- Más innovación y nuevas soluciones para el ciudadano: al facilitar el acceso a mayores conjuntos de datos, HealthDCAT-AP impulsa el desarrollo de nuevas herramientas digitales centradas en el paciente: apps de autocuidado, sistemas de seguimiento remoto, comparadores de servicios, etc. Muchas de estas soluciones nacen fuera del sistema sanitario —en universidades, startups o asociaciones— pero benefician directamente a la ciudadanía.
- Una Europa conectada en torno a la salud: al compartir una forma común de describir los datos, HealthDCAT-AP hace posible que un conjunto de datos creado en España pueda ser comprendido y utilizado en Alemania o Finlandia, y viceversa. Esto favorece la colaboración internacional, refuerza la cohesión europea y garantiza que los ciudadanos se beneficien de avances científicos independientemente de su país.
¿Y qué papel juega España en todo esto?
España no solo está alineada con el futuro del dato sanitario en Europa: está participando activamente en su construcción. Gracias a una sólida base legal, un sistema sanitario ampliamente digitalizado, la experiencia acumulada en la compartición segura de información de salud dentro del SNS, y una larga trayectoria en datos abiertos —a través de iniciativas como datos.gob.es—, nuestro país se encuentra en una posición privilegiada para contribuir y beneficiarse del Espacio Europeo de Datos Sanitarios (EHDS).
Desde hace años, España ha desarrollado marcos legales y capacidades técnicas que anticipan muchos de los requisitos del Reglamento EHDS. La digitalización generalizada de la atención sanitaria y la experiencia en el uso de datos de forma segura y responsable permiten avanzar hacia un modelo interoperable, ético y orientado al bien común.
En este contexto, el proyecto del Espacio Nacional de Datos de Salud supone un paso decisivo. Esta iniciativa tiene como objetivo, convertirse en la plataforma nacional de referencia para el análisis y explotación de datos sanitarios para uso secundario., concibiéndose como catalizador de la investigación e innovación en salud, referente en la aplicación de soluciones disruptivas y puerta de acceso a diferentes orígenes de datos. Todo ello se realiza bajo condiciones estrictas de anonimización, seguridad, transparencia y protección de derechos, garantizando que los datos solo se utilicen con fines legítimos y con pleno respeto a la normativa vigente.
La familiaridad de España con estándares como DCAT-AP facilita el despliegue de HealthDCAT-AP. Plataformas como datos.gob.es, que ya actúan como punto de referencia en la publicación de datos abiertos, serán clave en su despliegue y difusión.
Conclusiones
HealthDCAT-AP puede sonar a algo técnico, pero en realidad es una especificación que puede llegar a repercutir en nuestra vida diaria. Al ayudar a describir mejor los datos de salud, facilita que esa información se utilice de forma útil, segura y responsable.
Esta especificación permite que la descripción de conjuntos de datos hable el mismo idioma en toda Europa. Así, se pueden encontrar más fácilmente, compartir con quien corresponde y reutilizar para fines que nos benefician a todos: diagnósticos más rápidos, tratamientos más personalizados, decisiones de salud pública más acertadas o nuevas herramientas digitales que mejoran nuestra calidad de vida.
España, gracias a su experiencia en datos abiertos y a su sistema sanitario digitalizado, está participando activamente en esta transformación realizando un esfuerzo conjunto entre profesionales, instituciones, empresas, investigadores, etc. y también ciudadanos. Porque cuando los datos se entienden y se gestionan bien, pueden marcar la diferencia. Pueden salvar tiempo, recursos, e incluso vidas.
HealthDCAT-AP no es solo una especificación técnica: es un paso adelante hacia una salud más conectada, transparente y centrada en las personas. Una especificación pensada para maximizar el uso secundario de la información de salud, y para que, con ello, todos como ciudadanos podamos salir beneficiados.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial ya no es cosa del futuro: está aquí y puede convertirse en una aliada en nuestro día a día. Desde facilitarnos tareas en el trabajo, como redactar correos o resumir documentos, hasta ayudarnos a organizar un viaje, aprender un nuevo idioma o planificar nuestros menús semanales, la IA se adapta a nuestras rutinas para hacernos la vida más fácil. No hace falta ser un experto en tecnología para sacarle partido; si bien las herramientas actuales son muy accesibles, comprender sus capacidades y saber cómo formular las preguntas adecuadas maximizará su utilidad.
Sujetos pasivos y activos de la IA
Las aplicaciones de la inteligencia artificial en el día a día están transformando nuestra vida cotidiana. La IA abarca ya múltiples campos de nuestras rutinas. Los asistentes virtuales, como Siri o Alexa, se encuentran entre las herramientas más conocidas que incorporan inteligencia artificial, y se utilizan para responder preguntas, programar citas o controlar dispositivos.
Muchas personas usan a diario herramientas o aplicaciones con inteligencia artificial, aunque esta opere de forma imperceptible para al usuario y no requiera su intervención. Google Maps, por ejemplo, utiliza IA para optimizar rutas en tiempo real, predecir el estado del tráfico, sugerir caminos alternativos o estimar la hora de llegada. Spotify la aplica para personalizar las listas de reproducción o sugerir canciones, y Netflix para realizar recomendaciones y adaptar el contenido que se muestra a cada usuario.
Pero también es posible ser un usuario activo de la inteligencia artificial utilizando herramientas que interactúan directamente con los modelos. Así, podemos hacer preguntas, generar textos, resumir documentos o planificar tareas. La IA deja de ser un mecanismo oculto para convertirse en una especie de copiloto digital que nos asiste en nuestro día a día. ChatGPT, Copilot o Gemini son herramientas que nos permiten usar la IA sin necesidad de ser expertos. Esto nos facilita la automatización de tareas cotidianas, liberando tiempo para dedicarlo a otras actividades.
IA en el hogar y la vida personal
Los asistentes virtuales responden a comandos de voz y nos informan de qué hora es, el tiempo que va a hacer o nos ponen la música que queremos escuchar. Pero sus posibilidades van mucho más allá, ya que son capaces de aprender de nuestros hábitos para anticiparse a nuestras necesidades. Pueden controlar diferentes dispositivos que tenemos en el hogar de manera centralizada, como la calefacción, el aire acondicionado, las luces o los dispositivos de seguridad. También es posible configurar acciones personalizadas que se activen a través de un comando de voz. Por ejemplo, una rutina “buenos días” que encienda las luces, nos informe del pronóstico del tiempo y del estado del tráfico.
Cuando hemos perdido el manual de alguno de los electrodomésticos o aparatos electrónicos que tenemos en casa, la inteligencia artificial es una buena aliada. Enviando una foto del dispositivo, nos ayudará a interpretar las instrucciones, configurarlo o solucionar problemas básicos.
Si quieres ir más allá, la IA puede hacer por ti algunas tareas de la vida cotidiana. A través de estas herramientas podemos planificar nuestros menús semanales, indicando necesidades o preferencias, como platos aptos para celiacos o vegetarianos, preparar la lista de la compra y obtener las recetas. También nos puede ayudar a elegir entre los platos de la carta de un restaurante teniendo en cuenta nuestras preferencias y restricciones alimentarias, como alergias o intolerancias. A través de una simple foto de la carta, la IA nos ofrecerá sugerencias personalizadas.
El ejercicio físico es otro ámbito de nuestra vida personal en el que estos copilotos digitales son muy valiosos. Podemos pedirle, por ejemplo, que cree rutinas de ejercicios adaptadas a diferentes condiciones físicas, objetivos y material disponible.
La planificación de unas vacaciones es otra de las funcionalidades más interesantes de estos asistentes digitales. Si les proporcionamos un destino, un número de días, intereses e incluso presupuesto, tendremos un plan completo para nuestro próximo viaje.
Aplicaciones de la IA en los estudios
La IA está transformando profundamente la forma de estudiar, ofreciendo herramientas que personalizan el aprendizaje. Ayudar a los más pequeños de la casa en sus tareas escolares, aprender un idioma o adquirir nuevas habilidades para nuestro desarrollo profesional son solo algunas de las posibilidades.
Existen plataformas que generan contenidos personalizados en apenas unos minutos y material didáctico realizado a partir de datos abiertos que se puede utilizar tanto en el aula como en casa para repasar. Entre los universitarios o los estudiantes de secundaria y bachillerato, algunas de las opciones más populares son las aplicaciones que resumen o hacen esquemas a partir de textos más largos. Incluso es posible generar un pódcast desde un fichero, lo que nos puede ayudar a entender y familiarizarnos con un tema mientras hacemos deporte o cocinamos.
Pero también podemos crear nuestras aplicaciones para estudiar o incluso simular exámenes. Sin tener conocimientos de programación, es posible generar una aplicación para aprender las tablas de multiplicar, los verbos irregulares en inglés o lo que se nos ocurra.
Cómo usar la IA en el trabajo y las finanzas personales
En el ámbito profesional la inteligencia artificial ofrece herramientas que aumentan la productividad. De hecho, se estima que en España un 78% de los trabajadores utilizan ya herramientas de IA en el ámbito laboral. Al automatizar procesos, ahorramos tiempo para centrarnos en tareas de más valor. Estos asistentes digitales resumen documentos largos, generan informes especializados en un campo, redactan correos electrónicos o toman notas en las reuniones.
Algunas plataformas incorporan ya la transcripción de las reuniones en tiempo real, algo que puede resultar muy útil si no dominamos el idioma. Microsoft Teams, por ejemplo, ofrece a través de Copilot opciones útiles desde la pestaña “Resumen” de la propia reunión, como la transcripción, un resumen o la posibilidad de agregar notas.
El manejo de las finanzas personales ha evolucionado igualmente gracias a aplicaciones que utilizan IA, permitiendo controlar gastos y gestionar un presupuesto. Pero también podemos crear nuestro propio asesor financiero personal utilizando alguna herramienta de IA, como ChatGPT. Al proporcionarle información sobre ingresos, gastos fijos, variables y objetivos de ahorro, analiza los datos y crea planes financieros personalizados.
Prompts y creación de aplicaciones útiles para el día a día
Hemos visto las grandes posibilidades que nos brinda la inteligencia artificial como copiloto en nuestro día a día. Pero para lograr que sea un buen asistente digital, debemos saber cómo preguntarle y darle las instrucciones precisas.
Un prompt es una instrucción básica o petición que se realiza a un modelo de IA para guiarlo, con el objetivo de que nos proporcione una respuesta coherente y de calidad. Un buen prompting es la clave para sacar el máximo rendimiento de la IA. Es fundamental preguntar bien y proporcionar la información necesaria.
Para escribir prompts efectivos tenemos que ser claros, específicos y evitar ambigüedades. Debemos indicar cuál es el objetivo, es decir, qué queremos que la IA haga: resumir, traducir, generar una imagen, etc. Igualmente es clave proporcionarle el contexto, explicando a quién se dirige o por qué lo necesitamos, además de cómo esperamos que sea la respuesta. Esto puede incluir el tono del mensaje, el formato, las fuentes que se utilicen para generarla, etc.
A continuación, te dejamos algunos consejos para crear prompts efectivos:
- Utiliza frases cortas, directas y concretas. Cuanto más clara sea la petición, más precisa será la respuesta. Evita expresiones como “por favor” o “gracias”, ya que lo único que hacen es añadir ruido innecesario y consumir más recursos. Por el contrario, utiliza palabras como “debes”, “haz”, “incluye” o “enumera”. Para reforzar la petición puedes usar mayúsculas en esas palabras. Estas expresiones son especialmente útiles para afinar una primera respuesta del modelo que no cumple con tus expectativas.
- Indica el público al que se dirige. Especifica si la respuesta va dirigida a un público experto, inexperto, niños, adolescentes, adultos, etc. Cuando queremos una respuesta sencilla podemos, por ejemplo, pedirle a la IA que nos lo explique como si tuviéramos diez años.
- Usa delimitadores. Separa las instrucciones mediante algún símbolo, como unas barras (//) o comillas para que el modelo comprenda mejor la instrucción. Por ejemplo, si quieres que haga una traducción, usa delimitadores para separar la orden (“Traduce al inglés”) de la frase que debe traducir.
- Indica la función que debe adoptar el modelo. Especifica el rol que debe asumir el modelo para generar la respuesta. Indicarle si debe actuar como un experto en finanzas o en nutrición, por ejemplo, ayudará a generar respuestas más especializadas ya que adaptará tanto el contenido como el tono.
- Divide las peticiones completas en solicitudes sencillas. Si vas a hacer una petición compleja que requiere un prompt excesivamente largo, es recomendable que la desgloses en pasos más sencillos. Si necesitas explicaciones detalladas utiliza expresiones como “Piensa a paso” para que te dé una respuesta más estructurada.
- Usa ejemplos. Incluye en el prompt ejemplos de lo que buscas para guiar al modelo hacia la respuesta.
- Proporciona instrucciones en positivo. En lugar de pedir que no haga o incluya algo, expresa la petición de forma afirmativa. Por ejemplo, en vez de “No uses frases largas”, dile: “Utiliza frases breves y concisas”. Las instrucciones en positivo evitan ambigüedades y facilitan que la IA entienda lo que debe hacer. Esto sucede porque los prompts negativos suponen un esfuerzo extra para el modelo, al tener que deducir cuál es la acción contraria.
- Ofrece propinas o penalizaciones. Esto sirve para reforzar comportamientos deseados y coartar respuesta inadecuadas. Por ejemplo, “Si usas frases vagas o ambiguas, perderás 100 euros”.
- Pide que te pregunte lo que necesite. Si le indicamos que nos pida información adicional, reducimos la posibilidad de las alucinaciones, ya que estamos mejorando el contexto de nuestra petición.
- Solicita que responda como un humano. Si los textos te parecen demasiado artificiales o mecánicos, especifica en el prompt que la respuesta sea más natural o que parezca elaborada por un humano.
- Proporciona el inicio de la respuesta. Este simple truco resulta muy útil para guiar al modelo hacia la respuesta que esperamos.
- Delimita las fuentes que debe utilizar. Si acotamos el tipo de información que debe utilizar para generar la respuesta, obtendremos respuestas más afinadas. Pide, por ejemplo, que utilice solo datos posteriores a un año concreto.
- Solicita que imite un estilo. Podemos proporcionarle un ejemplo para que su respuesta sea coherente con el estilo de la referencia o pedirle que siga el estilo de un autor famoso.
Si bien es posible generar código funcional para tareas y aplicaciones sencillas sin conocimientos de programación, es importante notar que el desarrollo de soluciones más complejas o robustas a nivel profesional sigue requiriendo experiencia en programación y desarrollo de software. Para crear, por ejemplo, una aplicación que nos ayude a gestionar nuestras tareas pendientes, le pedimos a las herramientas de IA que generen el código, explicando de manera detallada qué queremos que haga, cómo esperamos que se comporte y qué aspecto debe tener. A partir de estas instrucciones, la herramienta generará el código y nos irá guiando para probarlo, modificarlo y ponerlo en marcha. Podemos preguntarle cómo y dónde ejecutarlo de manera gratuita y pedirle ayuda para realizar mejoras.
Como hemos visto, el potencial de estos asistentes digitales es enorme, pero su verdadero poder reside en gran parte en cómo nos comunicamos con ellos. Los prompts claros y bien estructurados son la clave para obtener respuestas precisas sin necesidad de ser expertos en tecnología. La IA no solo nos ayuda a automatizar tareas rutinarias, sino que amplía nuestras capacidades, permitiéndonos hacer más en menos tiempo. Estas herramientas están redefiniendo nuestro día a día, haciéndolo más eficiente y dejándonos tiempo para otras cosas. Y lo mejor de todo: ya está a nuestro alcance.
Aplicación
Más Datos Cáncer es una iniciativa que agrupa a 24 entidades científicas y asociaciones de pacientes, con el objetivo de desarrollar un modelo integrado de conocimiento sobre el cáncer. Este proyecto pone a disposición pública 69 indicadores clave, organizados en seis dimensiones fundamentales del itinerario de la persona con cáncer: promoción de la salud y prevención primaria, prevención secundaria, detección precoz, diagnóstico, atención sanitaria, seguimiento y final de vida.
La aplicación tiene como propósito principal promover la equidad en el acceso a la información sobre el cáncer en todo el territorio nacional. A través del uso de datos abiertos, busca mejorar la accesibilidad, homogeneidad y calidad de la información disponible, facilitando así una toma de decisiones más informada tanto para profesionales como para pacientes.
Los indicadores se han elaborado a partir de fuentes primarias y oficiales, lo que garantiza la fiabilidad y calidad de los datos. Entre las fuentes utilizadas destacan el Instituto Nacional de Estadística (INE), el sistema de información del Ministerio de Hematología y Hemoterapia (SEHH), la Sociedad Española de Cuidados Paliativos (SECPAL), así como otros datos procedentes del Observatorio de la Asociación Española Contra el Cáncer y literatura gris. Todos estos recursos permiten generar un panorama amplio y detallado de la situación del cáncer en España, que está accesible a través de este portal de datos abiertos.
Consulta aquí el informe de resultados del proyecto y aquí la información metodológica.
Noticia
Impulsar la cultura del dato es un objetivo clave a nivel nacional que también comparten las administraciones autonómicas. Uno de los caminos para llevar a cabo este propósito es premiar aquellas soluciones que han sido desarrolladas con conjuntos de datos abiertos, una iniciativa que potencia su reutilización e impacto en la sociedad.
En esta misión, la Junta de Castilla y León y el Gobierno Vasco llevan años organizando concursos de datos abiertos, temática de la que hablamos en nuestro primer episodio del pódcast de datos.gob.es que puedes escuchar aquí.
En este post, repasamos cuáles han sido los proyectos premiados en las últimas ediciones de los concursos de datos abiertos de Euskadi y Castilla y León.
Premiados en el VIII Concurso de Datos Abiertos de Castilla y León
En la octava edición de esta competición anual, que suele abrir su plazo a finales de verano, se presentaron 35 candidaturas, de las cuales se han escogido 8 ganadores divididos en diferentes categorías.
Categoría Ideas: los participantes tenían que describir una idea para crear estudios, servicios, sitios web o aplicaciones para dispositivos móviles. Se repartían un primer premio de 1.500€ y un segundo premio de 500€.
- Primer premio: Guardianes Verdes de Castilla y León presentado por Sergio José Ruiz Sainz. Se trata de una propuesta para desarrollar una aplicación móvil que oriente a los visitantes de los parques naturales de Castilla y León. Los usuarios pueden acceder a información (como mapas interactivos con puntos de interés) a la vez que pueden contribuir con datos útiles de su visita, que enriquecen la aplicación.
- Segundo premio: ParkNature: sistema inteligente de gestión de aparcamientos en espacios naturales presentado por Víctor Manuel Gutiérrez Martín. Consiste en una idea para la crear una aplicación que optimice la experiencia de los visitantes de los espacios naturales de Castilla y León, mediante la integración en tiempo real de datos sobre aparcamientos y la conexión con eventos culturales y turísticos cercanos.
Categoría Productos y Servicios: premiaba estudios, servicios, sitios web o aplicaciones para dispositivos móviles, los cuales deben estar accesibles para toda la ciudadanía vía web mediante una URL. En esta categoría se repartieron un primer, segundo y tercer premio de 2.500€, 1.500€ y 500€, respectivamente, además de un premio específico de 1.500€ para estudiantes.
- Primer premio: AquaCyL de Pablo Varela Vázquez. Es una aplicación que ofrece información sobre las zonas de baño en la comunidad autónoma.
- Segundo premio: ConquistaCyL presentado por Markel Juaristi Mendarozketa y Maite del Corte Sanz. Es un juego interactivo pensado para hacer turismo en Castilla y León y aprender a través de un proceso gamificado.
- Tercer premio: Todo el deporte de Castilla y León presentado por Laura Folgado Galache. Es una app que presenta toda la información de interés asociada a un deporte según la provincia.
- Premio estudiantes: Otto Wunderlich en Segovia por Jorge Martín Arévalo. Es un repositorio fotográfico ordenado según tipo de monumentos y localización de las fotografías de Otto Wunderlich.
Categoría Recurso Didáctico: consistía en la creación de recursos didácticos abiertos nuevos e innovadores, que sirvieran de apoyo a la enseñanza en el aula. Estos recursos debían ser publicados con licencias Creative Commons. En esta categoría se otorgaba un único primer premio de 1.500€.
- Primer premio: StartUp CyL: Creación de empresas a través de la Inteligencia Artificial y Datos Abiertos presentado por José María Pérez Ramos. Es un chatbot que utiliza la API de ChatGPT para asistir en la creación de una empresa utilizando datos abiertos.
Categoría Periodismo de Datos: premiaba piezas periodísticas publicadas o actualizadas (de forma relevante), tanto en soporte escrito como audiovisual, y ofrecía un premio de 1.500€.
- Primer premio: Codorniz, perdiz y paloma torcaz son las especies más cazadas en Burgos, presentado por Sara Sendino Cantera, que analiza datos sobre la caza en Burgos.
Premiados de la 5ª edición del Concurso de Datos Abiertos de Open Data Euskadi
Como ya venía sucediendo en ediciones anteriores, el portal de datos abiertos de Euskadi abrió dos modalidades de premios: un concurso de ideas y otro de aplicaciones, cada uno de los cuales estaba dividido en varias categorías. En esta ocasión, se presentaron 41 candidaturas en el concurso de ideas y 30 para el de aplicaciones
Concurso de ideas: en esta modalidad se han repartido dos premios por categoría, el primero de 3.000€ y el segundo de 1.500€.
Categoría Sanitaria y Social
- Primer premio: Desarrollo de un Modelo de Predicción de Volumen de Pacientes que acudirán al Servicio de urgencias de Osakidetza de Miren Bacete Martínez. Propone el desarrollo de un modelo predictivo usando series temporales capaz de anticipar tanto el volumen de personas que acudirán a urgencias, como el nivel de gravedad de los casos.
- Segundo premio: Euskoeduca de Sandra García Arias. Es una propuesta de solución digital diseñada para brindar orientación académica y profesional personalizada a estudiantes, padres y tutores.
Categoría Medio ambiente y Sostenibilidad
- Primer premio: Baratzapp de Leire Zubizarreta Barrenetxea. La idea consiste en el desarrollo de un software que facilita y asiste en la planificación de un huerto mediante algoritmos que buscan potenciar el conocimiento relacionado con la huerta de autoconsumo, a la vez que integra, entre otras, la información climatológica, medioambiental y parcelaria de una manera personalizada para el usuario.
- Segundo premio: Euskal Advice de Javier Carpintero Ordoñez. El objetivo de esta propuesta es definir un recomendador turístico basado en inteligencia artificial.
Categoría General
- Primer premio: Lanbila de Hodei Gonçalves Barkaiztegi. Es una propuesta de app que utiliza IA generativa y datos abiertos para emparejar curriculum vitae con ofertas de empleo de forma semántica. Proporciona recomendaciones personalizadas, alertas proactivas de empleo y formación, y permite decisiones informadas a través de indicadores laborales y territoriales.
- Segundo premio: Desarrollo de un LLM para la consulta interactiva de Datos Abiertos del Gobierno Vasco de Ibai Alberdi Martín. La propuesta consiste en el desarrollo de un Modelo de Lenguaje a Gran Escala (LLM) similar a ChatGPT, entrenado específicamente con datos abiertos, enfocado en proporcionar una interfaz conversacional y gráfica que permita a los usuarios obtener respuestas precisas y visualizaciones dinámicas.
Concurso de aplicaciones: esta modalidad ha seleccionado un proyecto en la categoría de servicios web, premiado con 8.000€, y dos más en la Categoría General que han recibido un primer premio de 8.000€ y 5.000€ como segundo premio.
Categoría Servicios web
- Primer premio: Bizidata: Plataforma de visualización del uso de bicicletas en Vitoria-Gasteiz de Igor Díaz de Guereñu de los Ríos. Es una plataforma que visualiza, analiza y permite descargar datos del uso de bicicletas en Vitoria-Gasteiz, y explorar cómo factores externos, como la climatología y el tráfico, influyen en el uso de la bicicleta.
Categoría General
- Primer premio: Garbiñe AI de Beatriz Arenal Redondo. Es un asistente inteligente que combina la inteligencia artificial (IA) con datos abiertos de Open Data Euskadi para promover la economía circular y mejorar los ratios de reciclaje en Euskadi.
- Segundo premio: Vitoria-Gasteiz Businessmap de Zaira Gil Ozaeta. Es una herramienta de visualización interactiva basada en datos abiertos, diseñada para mejorar las decisiones estratégicas en el ámbito del emprendimiento y la actividad económica en Vitoria-Gasteiz.
Todas estas soluciones premiadas reutilizan conjuntos de datos abiertos del portal autonómico de Castilla y León o Euskadi, según el caso. Te animamos a que eches un vistazo a las propuestas que pueden inspirarte de cara a participar en la próxima edición de estos concursos. ¡Síguenos en redes sociales para no perderte las convocatorias de este año!
Blog
IMPaCT, la Infraestructura de Medicina de Precisión asociada a la Ciencia y la Tecnología, es un programa innovador que busca revolucionar la atención médica. Coordinado y financiado por el Instituto de Salud de Carlos III su objetivo es impulsar el despliegue efectivo de la medicina personalizada de precisión.
La medicina personalizada es un enfoque médico que reconoce que cada paciente es único. A través del análisis de las características genéticas, fisiológicas y de estilo de vida de cada persona, se realizan tratamientos a medida más eficientes y seguros, con menos efectos secundarios. El acceso a esta información, además, es clave para avanzar en prevención y detección temprana, así como en investigación y avances médicos.
IMPaCT consta de 3 ejes estratégicos:
- Eje 1 Medicina predictiva: Programa COHORTE. Es un proyecto de investigación epidemiológica que consiste en el desarrollado y puesta en marcha de una estructura para el reclutamiento de 200.000 personas para que participen en un estudio prospectivo.
- Eje 2 Ciencia de datos: Programa DATA. Es un programa enfocado en el desarrollo de un sistema común, interoperable e integrado, de recogida y análisis de datos clínicos y moleculares. A través de él se elaboran criterios, técnicas y buenas prácticas para la recolección de información de historias clínicas electrónicas, imágenes médicas y datos genómicos.
- Eje 3 Medicina genómica: Programa GENÓMICA. Es una infraestructura cooperativa para el diagnóstico de enfermedades raras y genéticas. Entre otras cuestiones, elabora procedimientos normalizados para el correcto desarrollo de los análisis genómicos y la gestión de los datos obtenidos, así como para la estandarización y homogeneización de la información y los criterios empleados.
Además de estos ejes, existen dos líneas estratégicas transversales: una centrada en la ética e integridad científica y otra en la internacionalización, como se resume en el siguiente visual.

Fuente: IMPaCT-Data
A continuación, nos vamos a centrar en el funcionamiento y resultados de IMPaCT-Data, el proyecto ligado al eje 2.
IMPaCT-Data, un entorno integrado para el análisis de datos interoperables
IMPaCT-Data se orienta al desarrollo y validación de un entorno de integración y análisis conjunto de datos clínicos, moleculares y genéticos, para su uso secundario, con el objetivo final de facilitar la implementación eficaz y coordinada de la medicina personalizada de precisión en el Sistema Nacional de Salud. Actualmente está formado por un consorcio de 45 entidades asociadas por un convenio con vigencia hasta el 31 de diciembre de 2025.
A través de este programa, se busca la creación de una infraestructura en la nube de datos médicos para investigación, así como de los protocolos necesarios para coordinar, integrar, gestionar y analizar dichos datos. Para ello se sigue una hoja de ruta con los siguientes objetivos técnicos:

Fuente: IMPaCT-Data.
Resultados de IMPaCT-Data
Como vemos, esta infraestructura, aún en desarrollo, ofrecerá un entorno de investigación virtual para el análisis de los datos a través de diversos servicios y productos:
- Nube federada IMPaCT-Data. Incluye el acceso a datos públicos y de acceso controlado, así como herramientas y flujos de trabajo para el análisis de datos genómicos, historias clínicas e imágenes. En este vídeo se muestra cómo se realiza el acceso de usuarios federado y la ejecución de trabajos mediante el uso de recursos computacionales compartidos. Esto permite visualizar y acceder a los resultados en formato HTML y en crudo, así como a sus metadatos. Aquellos que quieran profundizar en las opciones de acceso de usuario, pueden ver este otro vídeo, donde se muestra la vinculación de las cuentas institucionales a la cuenta IMPaCT-Data y el uso de pasaportes y visados para el acceso local a datos protegidos.
- Recopilación de herramientas software para el análisis de los datos de IMPaCT-Data. Estas herramientas son de acceso público a través del dominio IMPaCT-Data en bio.tools, un registro de componentes software y bases de datos dirigido a investigadores en el campo de las ciencias biológicas y biomédicas. Incluye herramientas muy diversas. Por un lado, encontramos soluciones generales, por ejemplo, enfocadas en la privacidad a través de acciones relacionadas con la desidentificación y anonimización de datos (FAIR4Health Data Privacy Tool). Por otro, hay herramientas concretas, centradas en cuestiones muy específicas, como el metaanálisis de la expresión génica (ImaGEO).
- Guías con recomendaciones y buenas prácticas para la recolección de información médica. Actualmente hay tres guías disponibles: “Recomendaciones de IMPaCT-Data sobre datos y software”, “Consideraciones adicionales de IMPaCT-Data a la convocatoria para proyectos IMPaCT 2022” y “Recomendaciones de IMPaCT-Data sobre datos y software”.
A ellos hay que sumar diversos entregables relacionados con aspectos técnicos del proyecto, como comparaciones de técnicas o pruebas de concepto, así como publicaciones científicas.
Impulsando casos de uso a través de demostradores
Uno de los objetivos de IMPaCT-Data es contribuir a la evaluación de tecnologías asociadas a los desarrollos del proyecto, a través de un ecosistema de demostradores. Con ello se busca favorecer las aportaciones de empresas, entidades y grupos académicos para impulsar mejoras y conseguir la implementación del proyecto a gran escala.
Para cumplir este objetivo, se organizan distintas actividades donde se evalúan componentes concretos en colaboración con miembros de IMPaCT-Data. Un ejemplo es el servidor de terminologías ORBITS para la codificación de fenotipos clínicos en códigos HPO (Human Phenotype Ontology), dirigido a extraer y codificar de manera automática información contenida en reportes clínicos no estructurados usando procesamiento del lenguaje natural. Para ello utiliza la terminología HPO, cuyo objetivo es estandarizar la recopilación de datos fenotípicos, haciéndolos accesibles para el posterior análisis.
Otro ejemplo de demostradores hace referencia a la compartición de datos médicos virtualizados entre diferentes centros para proyectos de investigación, dentro de un entorno gobernado, eficiente y seguro, donde se cumplen todos los estándares de calidad de datos definidos por cada entidad.
Un proyecto estratégico alineado con Europa
IMPaCT-Data se enmarca directamente en la Estrategia nacional para el uso secundario de los datos del sistema de salud nacional, descrita en el PERTE de salud (Proyectos estratégicos para la recuperación y transformación económica), siendo sus conocimientos, experiencia y aportaciones muy valiosa de cara al desarrollo del Espacio Nacional de datos de Salud.
Además, los desarrollos de IMPaCT-Data está directamente alineados con las líneas maestras propuestas por GAIA-X, tanto a nivel general como en el entorno específico de salud.
El impacto del proyecto en Europa queda patente, también, en su participación en el proyecto Europeo GDI (Genomic Data Infrastructure), que busca facilitar el acceso a datos genómicos, fenotípicos y clínicos en toda Europa, donde se está usando IMPaCT-Data como instrumento a nivel nacional.
Todo ello pone de manifiesto que gracias a IMPaCT-Data se podrán impulsar proyectos de investigación en biomedicina no solo en España, sino también en Europa, contribuyendo de este modo a la mejorar la salud pública y el tratamiento individualizado de los pacientes.
Blog
En el sector médico, el acceso a la información puede transformar vidas. Este es uno de los principales motivos por los que las comunidades de compartición y apertura de datos o la ciencia abierta ligada a la investigación médica se han convertido en un recurso muy valioso. Los grupos de investigación médica que abogan por el uso y reutilización de datos dirigen esta transformación, impulsando la innovación, mejorando la colaboración y acelerando el avance de la ciencia.
Como vimos en el caso de la Fundación FISABIO los datos abiertos en el sector salud fomentan la colaboración entre investigadores, aceleran el proceso de validación de resultados en estudios y, en definitiva, ayudan a salvar vidas. Esta tendencia no solo facilita descubrimientos más rápidos, sino que también ayuda a crear soluciones más eficaces. En España, el Consejo Superior de Investigación Científicas (CSIC) apuesta por la apertura de datos y algunos reconocidos hospitales también comparten los resultados de sus investigaciones protegiendo los datos sensibles de sus pacientes.
En este post, exploraremos cómo los grupos de investigación y comunidades de salud están compartiendo y reutilizando datos para impulsar investigaciones pioneras y expondremos casos de uso más inspiradores. Desde el desarrollo de nuevos tratamientos hasta la identificación de tendencias en salud pública, los datos están redefiniendo el panorama de la investigación médica y abriendo nuevas oportunidades para mejorar la salud global.
Grupos de investigación médica que apuestan el trabajo con datos compartidos
En España, existen diversos grupos de investigación y comunidades que comparten sus descubrimientos de manera más libre a través de plataformas y bases de datos que facilitan la colaboración global y la reutilización de datos en el campo de la salud. A continuación, destacamos algunos de los casos más influyentes, demostrando cómo el acceso a la información puede acelerar el progreso científico y mejorar los resultados en salud.
-
H2O – Health Outcomes Observatory: repositorio de datos clínicos
H2O es una asociación estratégica entre el sector público y privado para crear un sólido modelo de infraestructura y gobernanza de datos que permita recopilar e incorporar los resultados de los pacientes a escala en la toma de decisiones sanitarias a nivel individual y poblacional. El enfoque de H2O otorga a los pacientes el control definitivo de sus y garantiza que solo ellos ejerzan ese control. En este consorcio participan hospitales de todo el mundo, entre los que se encuentran los españoles Hospital Universitario Fundación Jiménez Díaz o el Hospital Vall d’Hebron. La Unidad de investigación de España recoge los resultados de salud que reportan los pacientes y otros datos clínicos para construir un observatorio que mejore la atención al paciente.
-
Instituto de Salud Carlos III: IMPaCT: proyectos de investigación de ciencia abierta
En el marco de la infraestructura IMPaCT se desarrollan diferentes proyectos aprobados en las ayudas para Proyectos de Investigación de Medicina Personalizada de Precisión de la Acción en Salud:
- Programa COHORTE – Medicina predictiva
- Programa DATA: Ciencia de datos
- Programa GENÓMICA - Medicina genómica
La información, datos, metadatos y productos científicos generados en IMPaCT son de acceso abierto, para hacer la ciencia más accesible, eficiente, democrática y transparente. En este proyecto, participan hospitales e institutos de investigación de toda España.
-
Datos POP Salud: proyecto de investigación médica del Instituto de Salud Carlos III (ISCIII) y la Plataforma de Organizaciones de Pacientes (POP)
Es un proyecto de datos desarrollado colaborativamente entre ISCIII y POP para mejorar el conocimiento y evidencia sobre la realidad clínica, laboral y social de los pacientes crónicos, sin duda algo crucial para nosotros. En esta iniciativa participan 36 organizaciones nacionales de pacientes, 16 sociedades científicas y 3 administraciones públicas, entre los que destacan el Ministerio de Derechos Sociales y Agenda 2030, el Instituto de Salud Carlos III y la Agencia Española de Medicamentos y Productos Sanitarios.
-
Iniciativa Europea de Imagen de Cáncer: proyecto europeo para obtener imágenes oncológicas y apoyar en la investigación contra el cáncer.
Uno de los objetivos del Plan Europeo de Lucha contra el Cáncer es aprovechar al máximo el potencial de los datos y las tecnologías digitales como la inteligencia artificial (IA) o la informática de alto rendimiento (HPC). La piedra angular de la iniciativa será una infraestructura europea federada para datos de imágenes de cáncer, desarrollada por la Federación Europea de IMages CAncer (EUCAIM). El proyecto comienza con 21 centros clínicos de 12 países entre los que se encuentran 4 centros españoles situados en Valencia, Barcelona, Sevilla y Madrid.
-
4CE: Consorcio de investigación
Es un consorcio internacional para el estudio de la pandemia de COVID-19 a partir de los datos de la historia clínica electrónica (HCE). El objetivo del proyecto -dirigido por el grupo internacional de usuarios académicos i2b2 -es informar a médicos, epidemiólogos y al público en general sobre los pacientes de COVID-19 con datos adquiridos a través del proceso de atención sanitaria. La plataforma ofrece datos agregados que están disponibles en la propia web del proyecto divididos entre datos de adultos y datos pediátricos. En ambos casos, los datos deben de ser utilizados con fines académicos y de investigación; el proyecto no permite el uso de los datos para orientación médica o diagnóstico clínico.
En conclusión, la apuesta por la compartición y reutilización de datos en la investigación médica está demostrando ser un catalizador fundamental para el avance científico y la mejora de la salud pública. A través de iniciativas como H2O, IMPaCT, y la Iniciativa Europea de Imagen de Cáncer, vemos cómo la accesibilidad en la gestión de datos está redefiniendo la forma en que abordamos la investigación y el tratamiento de enfermedades.
La integración de prácticas de análisis de datos promete un futuro donde la innovación en salud se logre de manera más rápida, equitativa y eficiente, ofreciendo así mejores resultados para los pacientes a nivel global.
Blog
Construir el Espacio Europeo de Datos de Salud constituye uno de los retos de nuestra generación. La pandemia de COVID 19 nos sitúo frente al espejo y nos devolvió al menos dos imágenes. La primera no era otra que el resultado de la aplicación de modelos formalistas, burocratizados y avejentados a la hora de gestionar los datos. La segunda, el enorme potencial que ofrece la compartición de datos, la colaboración de equipos interdisciplinares y el uso de la información sanitaria al servicio del bien común. La Unión Europea apuesta claramente por la segunda estrategia. En este artículo se examinan desde diversos enfoques los retos que plantea la construcción de un Espacio Nacional de Datos de Salud como instrumento que potencie la reutilización de dichos datos para usos secundarios.
El error de apostar por visiones formalistas
El escenario de tratamiento y compartición de datos anterior al despliegue de la estrategia europea del dato y su apuesta por los espacios de datos produjo efectos no sólo contraintuitivos, también contrafactuales. El marco del Reglamento General de Protección de Datos (RGPD) en lugar de favorecer el tratamiento operó como barrera. Se optó por una aplicación estricta, basada en la prevalencia de la privacidad. En lugar de buscar cómo gobernar el riesgo mediante soluciones jurídicas y técnicas se decidió por no tratar datos o por anonimizaciones técnicamente complejas e inviables en la práctica.
Este modelo no es sostenible. La aceleración tecnológica obliga a trasladar el centro de gravedad de la prohibición a la gestión del riesgo y a la gobernanza de los datos. Y esta es la apuesta del Reglamento del Parlamento Europeo y del Consejo sobre el Espacio Europeo de Datos de Salud (EHDS): encontrar soluciones y definir garantías para proteger a las personas. Y esta transformación encuentra al sector sanitario de España ante una situación inmejorable desde cualquier punto de vista, aunque no exenta de riesgos.
España, pionera en el cambio de enfoque
Nuestro país hizo los deberes con la Disposición adicional decimoséptima sobre tratamientos de datos de salud de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD). La regulación soslayó la mayor parte de problemas que afectan al uso secundario de datos de salud y lo hizo con la metodología que deriva del RGPD y la jurisprudencia del Tribunal Constitucional. Para ello apostó por:
- Una clara sistematización y predeterminación normativa de los casos de uso.
- Una definición precisa de las habilitaciones para el tratamiento.
- Unas garantías procedimentales, contractuales y de seguridad.
La Disposición se adelantó cinco años al EHDS en cuanto a sus fines, objetivos y garantías. Y no sólo esto, sitúa a nuestro sistema sanitario en una posición de ventaja competitiva desde un punto de vista jurídico y material.
Desde este punto de vista el Espacio Nacional de Datos de Salud como eje vertebrador es un proyecto tan imprescindible como inaplazable, tal y como refleja la estrategia de Salud Digital del Sistema Nacional de Salud y el Plan de Recuperación, Transformación y Resiliencia. Sin embargo, esta afirmación no puede sustentarse en un entusiasmo acrítico. Queda mucho trabajo por hacer.
Lecciones aprendidas y retos a superar
Los proyectos europeos de investigación gestionados por el ecosistema de fundaciones sanitarias en el Instituto Carlos Tercero, la universidad y la empresa, proporcionan lecciones interesantes. En nuestro país se trabaja en medicina de precisión, en la construcción de data lakes, en aplicaciones móviles, en altas capacidades de seudonimización y anonimización, en imagen médica, en inteligencia artificial predictiva …, y podríamos seguir. Este ecosistema necesita una capa de innovación en materia de gobernanza. Una parte de ella será proporcionada directamente por el EHDS. Los organismos de acceso a datos, la autoridad de control y las estructuras de acceso transfronterizo asegurarán el ciclo de vida desde la conformación de conjuntos de datos catalogados y confiables a su tratamiento efectivo. Estas infraestructuras de gobierno requieren de un despliegue organizativo y humano que los soporte. La experiencia previa ayuda a prever los riesgos que pueden suponer una prueba de esfuerzo para el conjunto de la cadena de valor:
- La formación de los recursos humanos en aspectos cruciales en materia de protección de datos, seguridad de la información y nuevas exigencias éticas no es siempre la adecuada ni en su formato, ni en su volumen, ni en la segmentación de perfiles. No se forma al 100% de la plantilla, mientras la formación continua voluntaria para profesionales de la salud es de alto nivel jurídico, causando un efecto tan contraproducente como perverso: cercenar la capacidad de innovar. Si en lugar de empoderar y generar compromiso ofrecemos una interminable lista de obligaciones del RGPD, el personal investigador acaba por autocensurar su capacidad de imaginar. Se confunde el contenido y el target formativo. La formación de alto nivel debería centrarse en los project manager y en el personal de soporte técnico y jurídico. Y en estos, cumplen una función vehicular, la persona delegada de protección de datos que es quien debe prestar un asesoramiento no binario, - del tipo legal o no legal-, y no puede trasladar toda la responsabilidad al equipo investigador.
- La gobernanza de los recursos de tratamiento y de los procesos debe mejorar. En determinadas áreas de investigación, y las universidades son el mejor ejemplo de ello, los sistemas de información se segmentan y manejan en el nivel más reducido de proyecto o equipo de investigación. Son recursos insuficientes, con escaso nivel de control en la gestión del riesgo y la monitorización de la seguridad, incluido el soporte a la gestión y mantenimiento del entorno de tratamiento. Por otra parte, los procedimientos de acceso a los datos se basan en modelos rígidos, anclados en el estudio de caso o el ensayo clínico. Así, en no pocas ocasiones, manejamos conjuntos de datos en entornos muy específicos ajenos a los centros de proceso de datos principales. Ello multiplica el riesgo, y los costes en materias como las evaluaciones de impacto relativas a la protección de datos o el despliegue de medidas de seguridad.
- La carencia de personas expertas puede plantear riesgos sistémicos. Para empezar, los Comités de Ética se enfrentan a cuestiones de protección de datos y ética de la inteligencia artificial que desbordan sus hábitos, costumbres y conocimientos, y apolillan sus procesos. De otro, lo que vulgarmente hemos denominado big data no es algo que se realice por arte de magia. La seudonimización o la anonimización, la anotación, el enriquecimiento y la validación del conjunto de datos y de los procesos que sobre ellos se implementan, exigen profesionales con altas capacidades.
Efectos del EHDS
Deberíamos reflexionar si nuestra posición destacada en digitalización pudiera a la vez ser nuestro talón de Aquiles. Pocos países poseen un alto grado de digitalización de cada uno de los niveles de atención sanitaria, de la primaria a la hospitalaria. Prácticamente ninguno ha regulado el uso de datos seudonimizados sin consentimiento, ni tampoco el modelo de consentimiento amplio de nuestra LOPDGDD. En este sentido, bajo el paraguas del EHDS podrían producirse dos efectos que debemos manejar:
- Nuevas oportunidades en proyectos de investigación. En primer lugar, tan pronto como las instituciones sanitarias españolas publiquen sus catálogos de datos a nivel europeo, las peticiones de acceso desde otros países podrían multiplicarse. Y con ello las oportunidades de participación en proyectos de investigación como proveedores de información, data holders, o como usuarios de datos.
- Impulso del ecosistema de empresas innovadoras. Por otra parte, el amplio abanico de usos secundarios que prevé el EHDS, ampliará el perfil de los agentes que presentarán solicitudes de acceso a datos. Ello apunta la posibilidad de alumbrar un ecosistema propio de empresas innovadoras para el despliegue de soluciones de salud desde el wellness (bienestar) al diagnóstico médico asistido por una inteligencia artificial.
Esto obliga a los responsables del sistema público de salud a hacerse una pregunta más bien sencilla: ¿qué nivel de disponibilidad, capacidad de proceso, seguridad e interoperabilidad pueden ofrecer los sistemas de información disponibles? No olvidemos que detrás de muchos proyectos de investigación transeuropeos, o del despliegue de herramientas de Inteligencia Artificial en el sector sanitario, existen presupuestos millonarios. Y ello presenta enormes oportunidades para profundizar en el despliegue de nuevos modelos de prestación de servicios de salud que, además, retroalimenten la investigación, la innovación y el emprendimiento. Pero también el riesgo de no ser capaces de aprovechar los recursos disponibles por carencias en el diseño de los repositorios y de sus capacidades de proceso.
¿Qué modelo de espacio de datos perseguimos?
La respuesta a esta pregunta se encuentra de modo muy claro tanto en la estrategia de espacios de datos de la Unión Europea, como en la propia estrategia del Gobierno de España. La tarea que el EHDS atribuye a los organismos de acceso a datos, más allá de la mera concesión de un permiso de acceso, es la de soporte y apoyo al desarrollo del tratamiento. Y para ello, se necesita de un Espacio Nacional de Datos de Salud que asegure el nivel de servicio, los estándares de anonimización o seudonimización, la interoperabilidad y la seguridad de la información.
En este contexto, los investigadores individuales en entornos ajenos a la salud, pero sobre todo las pequeñas y medianas empresas innovadoras, no poseen el músculo y la experiencia necesaria para satisfacer los requerimiento éticos y normativos. Por ello, no debería desdeñarse la necesidad de proporcionarles apoyo desde el punto de vista del diseño de modelos de compliance normativo y ético, si no se desea que estos operen como barrera de entrada o exclusión.
Y ello no excluye ni precluye los esfuerzos autonómicos, los que realizan fundaciones u hospitales de referencia o las infraestructuras de datos nacientes en el ámbito de la imagen médica de cáncer o la genómica. Precisamente, la idea de federación de espacios de datos que inspira la legislación europea puede rendir aquí frutos de una altísima calidad. El Ministerio de Sanidad y las Consejerías de Salud deben avanzar en esa dirección, con el apoyo del nuevo Ministerio de Transformación Digital y Función Pública. En las comunidades autónomas se reflexiona y actúa para el desarrollo de modelos gobernables y se participa, junto con el Ministerio de Sanidad, en el modelo de gobernanza que debe regir en el marco nacional. Reguladores como la Agencia Española de Protección de Datos están ofreciendo marcos de referencia viables para el desarrollo de los espacios de datos. Hospitales enteros diseñan, implementan y despliegan sistemas de información que buscan la integración de centenares de fuentes de datos y la generación de data lakes para la investigación. Infraestructuras de datos como EUCAIM abren el camino y generan know how de alta calidad en ámbitos altamente especializados.
Los trabajos para el despliegue de un Espacio Nacional de Datos de Salud, y todas y cada una de las iniciativas singulares en marcha, nos muestran un camino a seguir en el que la federación del esfuerzo, la solidaridad y la compartición de datos aseguren que nuestra posición de privilegio en digitalización sanitaria estimule el liderazgo en la investigación, la innovación y el emprendimiento digital en la salud. El Espacio Nacional de Datos de Salud podrá ofrece un valor diferencial a los partícipes. Proporcionará calidad y volumen de datos, soportará herramientas avanzadas de analítica de datos e IA intensivas en cómputo y podrá proveer seguridad en los procesos de intermediación de software para el tratamiento de datos seudonimizados con altos requerimientos.
Es necesario recordar un valor central para la Unión Europea: la garantía de los derechos fundamentales y el enfoque centrado en el ser humano. La Carta de derechos Digitales impulsada por el Gobierno de España propone sucesivamente el derecho de acceso a datos con fines de investigación científica, innovación y desarrollo, así como el derecho a la protección de la salud en el entorno digital. El Espacio Nacional de Datos de Salud está llamado a ser el instrumento indispensable para alcanzar una salud digital sostenible, inclusiva y al servicio del bien común, que a la vez impulse esta dimensión de la economía del dato, promoviendo la investigación y el emprendimiento en nuestro país.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.