Noticia
Un año más, la Comisión Europea organizó los EU Open Data Days, uno de los eventos de referencia sobre datos abiertos e innovación a nivel mundial. Los pasados días 19 y 20 de marzo, el Centro Europeo de Convenciones de Luxemburgo reunió a expertos, funcionarios públicos y representantes del ámbito académico para compartir conocimientos, experiencias y avances en materia de datos abiertos en Europa.
Durante estas dos intensas jornadas, que también pudieron seguirse online, se exploraron temas cruciales como la gobernanza, la calidad, la interoperabilidad y el impacto de la inteligencia artificial (IA) en los datos abiertos. Este evento se ha convertido en un foro esencial para impulsar el desarrollo de políticas y prácticas que fomenten la transparencia y la innovación basada en datos en toda la Unión Europea. En este post, repasamos cada una de las ponencias del evento.
Apertura e historia de los datos
Para empezar, la Directora General de la Oficina de Publicaciones de la Unión Europea, Hilde Hardeman, inauguró el evento dando la bienvenida a los asistentes y estableciendo el tono para las discusiones que seguirían. A continuación, Helena Korjonen y Emma Schymanski, dos expertas de la Universidad de Luxemburgo, presentaron una retrospectiva titulada "Un viaje de datos: de la oscuridad a la iluminación", donde exploraron la evolución del almacenamiento y compartición de datos a lo largo de 18.000 años. Desde las pinturas rupestres hasta los servidores modernos, este recorrido histórico destacó cómo muchos de los desafíos actuales en materia de datos abiertos, como la propiedad, la preservación y la accesibilidad, tienen raíces profundas en la historia de la humanidad.
A continuación, Slava Jankin, profesor del Centro de IA en Gobierno de la Universidad de Birmingham, presentó una ponencia sobre gemelos digitales impulsados por IA y datos abiertos para crear simulaciones dinámicas de sistemas de gobernanza, que permiten a los responsables políticos probar reformas y predecir resultados antes de implementarlos.
Casos de uso entre los datos abiertos y la IA
Por otro lado, también se presentaron varios casos de uso, como la experiencia práctica de Lituania en la catalogación exhaustiva de datos públicos. Milda Aksamitauskas de la Universidad de Wisconsin, abordó los desafíos de gobernanza y las estrategias de comunicación empleadas en el proyecto y presentó lecciones sobre cómo otros países podrían adaptar métodos similares para mejorar la transparencia y la toma de decisiones basadas en datos.
En relación, el coordinador científico Bastiaan van Loenen presentó las conclusiones del proyecto en el que trabaja, ODECO de Horizon 2020, centrado en la creación de ecosistemas sostenibles de datos abiertos. Tal y como explicó van Loenen, la investigación, que ha sido desarrollada durante cuatro años por 15 investigadores, ha explorado las necesidades de los usuarios y las estructuras de gobernanza para siete grupos distintos, destacando cómo los enfoques circulares, inclusivos y basados en habilidades pueden proporcionar valor económico y social a los ecosistemas de datos abiertos.
Además, la inteligencia artificial fue protagonista durante todo el evento. La profesora asistente Anastasija Nikiforova de la Universidad de Tartu ofreció una visión reveladora sobre cómo la inteligencia artificial puede transformar los ecosistemas de datos abiertos gubernamentales. En su presentación, "Datos para IA o IA para datos" exploró ocho roles distintos que la IA puede desempeñar. Por ejemplo, la IA puede servir de ‘limpiador’ de un portal de open data e incluso recuperar datos del ecosistema, proporcionando valiosas perspectivas para los responsables políticos y los investigadores sobre cómo aprovechar eficazmente la IA en las iniciativas de datos abiertos.
También utilizando herramientas impulsadas por IA, encontramos el EU Open Research Repository lanzado por Zenodo en 2024, una iniciativa de ciencia abierta que proporciona un repositorio de investigación adaptado para los beneficiarios de financiación de investigación de la UE. La presentación de Lars Holm Nielsen destacó cómo las herramientas impulsadas por IA y los conjuntos de datos abiertos de alta calidad reducen el coste y el esfuerzo de limpieza de datos, al tiempo que garantizan la adherencia a los principios FAIR.
La jornada continuó con la intervención de Maroš Šefčovič, Comisario Europeo de Comercio y Seguridad Económica, Relaciones Interinstitucionales y Transparencia, quien subrayó el compromiso de la Comisión Europea con los datos abiertos como pilar fundamental para la transparencia y la innovación en la Unión Europea.
Interoperabilidad y calidad de datos
Después de una pausa, Georges Lobo y Pavlina Fragkou coordinador de programa y de proyecto del SEMIC, respectivamente, explicaron cómo el Centro de Interoperabilidad Semántica de Europa (SEMIC) mejora el intercambio interoperable de datos en Europa a través del perfil de aplicación del vocabulario de catálogo de datos (DCAT-AP) y las secuencias de eventos de datos vinculados (LDES). Su presentación destacó cómo estos estándares facilitan la publicación y el consumo eficientes de datos, con casos prácticos como el Rijksmuseum y la Agencia Ferroviaria de la Unión Europea, demostrando su valor para fomentar ecosistemas de datos interoperables y sostenibles.
A continuación, Barbara Šlibar, de la Universidad de Zagreb, ofreció un análisis detallado de la calidad de los metadatos en los conjuntos de datos abiertos europeos, revelando disparidades significativas en cinco dimensiones clave. Su estudio, basado en muestras aleatorias de data.europa.eu, subrayó la importancia de mejorar las prácticas de metadatos y aumentar la concienciación entre las partes interesadas para mejorar la usabilidad y el valor de los datos abiertos en Europa.
Después, Bianca Sammer, de Bavarian Agency for Digital Affairs compartió su experiencia creando el portal de datos abiertos de Alemania en solo un año. Su presentación "Desbloqueando el potencial" destacó soluciones innovadoras para superar los desafíos en la gestión de datos abiertos. Por ejemplo, consiguieron una mejora automatizada de la calidad de los metadatos, una infraestructura de código abierto reutilizable y estrategias de participación para administraciones públicas y usuarios.
Actualidad y horizonte respecto a los datos abiertos
El segundo día comenzó con las intervenciones de Rafał Rosiński, Subsecretario de Estado del Ministerio de Asuntos Digitales de Polonia, quien presentó la perspectiva de la Presidencia polaca sobre datos abiertos y transformación digital, y Roberto Viola, Director General de la Dirección General de Redes de Comunicación, Contenido y Tecnología de la Comisión Europea, que habló sobre el camino europeo hacia la innovación digital.
Después de la presentación de la jornada, empezaron las ponencias sobre casos de uso y propuestas innovadoras en open data. En primer lugar, Stefaan Verhulst, cofundador del laboratorio de gobernanza neoyorquino GovLab, bautizó al momento histórico que estamos viviendo como la "cuarta ola de datos abiertos" caracterizada por la integración de la inteligencia artificial generativa con datos abiertos para abordar desafíos sociales. Su presentación planteó preguntas cruciales sobre cómo las interfaces conversacionales basadas en IA pueden mejorar la accesibilidad, qué significa que los datos abiertos estén "preparados para la IA" y cómo construir soluciones basadas en datos sostenibles que equilibren la apertura y la confianza.
A continuación, Christos Ellinides, Director General de Traducción de la Comisión Europea, destacó la importancia de los datos lingüísticos para la IA en el continente. Con 25 años de datos que abarcan múltiples idiomas y la experiencia para desarrollar servicios multilingües basados en inteligencia artificial, la Comisión está a la vanguardia en el ámbito de los espacios de datos lingüísticos y en el uso de infraestructuras europeas de computación de alto rendimiento para explotar datos e IA.
Casos de uso de reutilización de datos abiertos
La reutilización aporta múltiples beneficios. Kjersti Steien, de la agencia de digitalización noruega, presentó el portal nacional de datos de Noruega, data.norge.no, que emplea un motor de búsqueda impulsado por IA para mejorar la capacidad de descubrimiento de datos. Utilizando Google Vertex, el motor permite a los usuarios encontrar conjuntos de datos relevantes sin necesidad de conocer los términos exactos utilizados por los proveedores de datos, demostrando cómo la IA puede mejorar la reutilización de datos y adaptarse a los modelos de lenguaje emergentes.
Más allá de Noruega, también se pusieron en la mesa casos de uso de otras ciudades y países. Sam Hawkins, Director del programa de datos de Ember en el Reino Unido, subrayó la importancia de los datos energéticos abiertos para avanzar en la transición hacia energías limpias y garantizar la flexibilidad del sistema.
Otro caso fue el que presentó Marika Eik de la Universidad de Estonia, que aprovecha datos urbanos y la colaboración intersectorial para mejorar la sostenibilidad y el impacto comunitario. Su sesión examinó un enfoque a nivel de ciudad para las métricas de sostenibilidad y los cálculos de huella de CO2, basándose en datos de municipios, operadores inmobiliarios, instituciones de investigación y análisis de movilidad para ofrecer modelos replicables que mejoren la responsabilidad ambiental.
Por otro lado, Raphaël Kergueno, de Transparency International EU, explicó cómo Integrity Watch EU aprovecha los datos abiertos para mejorar la transparencia y la rendición de cuentas en la Unión. Esta iniciativa reutiliza conjuntos de datos como el Registro de Transparencia de la UE y los registros de reuniones de la Comisión Europea para aumentar la conciencia pública sobre las actividades de lobby y mejorar la supervisión legislativa, demostrando el potencial de los datos abiertos para fortalecer la gobernanza democrática.
También, Kate Larkin del Observatorio Marino Europeo, presentó la Red Europea de Observación y Datos Marinos, destacando cómo los servicios paneuropeos de datos marinos, que se adhieren a los principios FAIR contribuyen a iniciativas como el Pacto Verde Europeo, la planificación espacial marítima y la economía azul. Su presentación mostró casos de uso prácticos que demuestran la integración de datos marinos en ecosistemas de datos más amplios como el European Digital Twin Ocean.
Visualización y comunicación de datos
Además de casos de uso, los EU Open Data Days 2025 pusieron en valor la visualización de datos como mecanismo para acercar el open data a la gente. En este sentido, Antonio Moneo, CEO de Tangible Data, exploró cómo transformar conjuntos de datos complejos en esculturas físicas fomenta la alfabetización de datos y la participación comunitaria.
Por otro lado, Jan Willem Tulp, fundador de TULP interactive, examinó cómo el diseño visual influye en la percepción de los datos. Su sesión exploró cómo elementos de diseño como el color, la escala y el enfoque pueden dar forma a narrativas e introducir potencialmente sesgos, destacando las responsabilidades de los visualizadores de datos para mantener la transparencia mientras elaboran narrativas visuales convincentes.
Educación y alfabetización en datos
Davide Taibi, investigador del Consejo Nacional de Investigación de Italia, compartió experiencias sobre la integración de la alfabetización en datos e IA en los itinerarios educativos, basadas en proyectos financiados por la UE como DATALIT, DEDALUS y SMERALD. Estas iniciativas pilotaron módulos de aprendizaje digitalmente mejorados en educación superior, escuelas secundarias y formación profesional en varios Estados miembros de la UE, centrándose en enfoques orientados a competencias y sistemas de aprendizaje basados en TI.
Nadieh Bremer, fundadora de Visual Cinnamon, exploró cómo los enfoques creativos para la visualización de datos pueden revelar los intrincados vínculos entre personas, culturas y conceptos. Los ejemplos incluyeron un árbol genealógico de 3.000 personas de la realeza europea, las relaciones en el Patrimonio Cultural Inmaterial de la UNESCO y constelaciones interculturales en el cielo nocturno, demostrando cómo los procesos de diseño iterativo pueden descubrir patrones ocultos en redes complejas.
El artista digital Andreas Refsgaard cerró las presentaciones con una reflexión sobre la intersección de la IA generativa, el arte y la ciencia de datos. A través de ejemplos artísticos y atractivos, invitó a la audiencia a reflexionar sobre el vasto potencial y los dilemas éticos que surgen de la creciente influencia de las tecnologías digitales en nuestra vida cotidiana.
En resumen, los EU Open Data Days 2025 han demostrado, una vez más, la importancia de estos encuentros para impulsar la evolución del ecosistema de datos abiertos en Europa. Los debates, presentaciones y casos prácticos compartidos durante estas dos jornadas no solo han puesto de manifiesto los avances logrados, sino también los desafíos pendientes y las oportunidades emergentes. En un contexto donde la inteligencia artificial, la sostenibilidad y la participación ciudadana están transformando la manera en que utilizamos y valoramos los datos, eventos como este resultan fundamentales para fomentar la colaboración, compartir conocimientos y desarrollar estrategias que maximicen el valor social y económico de los datos abiertos. El compromiso continuo de las instituciones europeas, los gobiernos nacionales, la academia y la sociedad civil será esencial para construir un ecosistema de datos abiertos más robusto, accesible e impactante que responda a los desafíos del siglo XXI y contribuya al bienestar de todos los ciudadanos europeos.
Puedes volver las grabaciones de cada ponencia aquí.
Blog
La crisis climática y los desafíos ambientales actuales demandan respuestas innovadoras y efectivas. En este contexto, la iniciativa Destination Earth (DestinE) de la Comisión Europea es un proyecto pionero que tiene como objetivo desarrollar un modelo digital y altamente preciso de nuestro planeta.
A través de este gemelo digital de la Tierra se podrá monitorear y prevenir posibles desastres naturales, adaptar las estrategias de sostenibilidad y coordinar esfuerzos humanitarios, entre otras funciones. En este post, analizamos en qué consiste el proyecto y en qué estado se encuentra su desarrollo.
Características y componentes de Destination Earth
Alineado con el Pacto Verde Europeo y la Estrategia de Europa Digital, Destination Earth integra el modelado digital y las ciencias climáticas para ofrecer una herramienta que sea de utilidad a la hora de abordar retos ambientales. Para ello, cuenta con un enfoque orientado hacia la precisión, el detalle local y la rapidez en el acceso a la información.
En general, la herramienta permite:
- Monitorear y simular los desarrollos del sistema terrestre, que incluyen la tierra, el mar, la atmósfera y la biosfera, así como las intervenciones humanas.
- Anticipar desastres ambientales y crisis socioeconómicas, permitiendo así la salvaguarda de vidas y la prevención de recesiones económicas significativas.
- Generar y probar escenarios que promuevan un desarrollo más sostenible en el futuro.
Para llevar esto a cabo, DestinE se subdivide en tres componentes principales que son:
- Lago de datos:
- ¿Qué es? Un repositorio centralizado que permite almacenar datos de diversas fuentes, como la Agencia Espacial Europea (ESA), EUMETSAT y Copernicus, así como de los nuevos gemelos digitales.
- ¿Qué ofrece? Esta infraestructura permite el descubrimiento y acceso a datos, así como el procesamiento de grandes volúmenes de información en la nube.
- ·La Plataforma de DestinE:
- ¿Qué es? Un ecosistema digital que integra servicios, herramientas de toma de decisiones basadas en datos y una infraestructura de computación abierta en la nube, flexible y segura.
- ¿Qué ofrece? Los usuarios tienen acceso a información temática, modelos, simulaciones, pronósticos y visualizaciones que facilitarán una comprensión más profunda del sistema terrestre.
- Gemelos digitales e ingeniería:
- ¿Qué son? Son varias réplicas digitales que cubren diferentes aspectos del sistema terrestre. Ya están desarrollados los dos primeros, uno relacionado con la adaptación al cambio climático y, el otro, sobre eventos climáticos extremos.
- ¿Qué ofrecen? Estos gemelos ofrecen simulaciones multidecadales (variación de la temperatura) y pronósticos de alta resolución.
Descubre los servicios y contribuye a mejorar DestinE
La plataforma de DestinE ofrece un recopilatorio de aplicaciones y casos de uso desarrollados en el marco de la iniciativa, como, por ejemplo:
- Gemelo digital del turismo (Beta): permite revisar y anticipar la viabilidad de las actividades turísticas en función de las condiciones medioambientales y meteorológicas de su territorio.
- VizLab: ofrece una interfaz gráfica de usuario intuitiva y tecnologías avanzadas de renderizado en 3D para proporcionar una experiencia narrativa haciendo que conjuntos de datos complejos sean accesibles y comprensibles para un público amplio.
- miniDEA: es una app de visualización web interactiva y fácil de usar, basado en DEA, para previsualizar datos de DestinE.
- GeoAI: es una plataforma de IA geoespacial para casos de uso de observación de la Tierra.
- Global Fish Tracking System (GFTS): es un proyecto para ayudar a obtener información precisa sobre las poblaciones de peces para elaborar políticas de conservación basadas en datos.
- Planificación urbana más resiliente: es una solución que proporciona un índice de estrés térmico que permite a los planificadores urbanos conocer cuáles son las mejores prácticas de adaptación contra las temperaturas extremas en entornos urbanos.
- Monitoreo de la reserva de agua del Delta del Danubio: es un análisis exhaustivo y preciso basado en el lago de datos DestinE para informar sobre los esfuerzos de conservación del Delta del Danubio, una de las regiones con mayor biodiversidad de Europa.
Desde octubre de este año la plataforma de DestinE acepta registros, una posibilidad que permite explorar todo el potencial de la herramienta y acceder a recursos exclusivos. Esta opción sirve para recabar feedback y mejorar el sistema del proyecto.
Para convertirte en usuario y poder generar servicios, debes seguir estos pasos.
Hoja de ruta del proyecto:
La Unión Europea plantea una serie de hitos ubicados en el tiempo que marcarán el desarrollo de la iniciativa:
- 2022 – Lanzamiento oficial del proyecto.
- 2023 – Inicio del desarrollo de los principales componentes.
- 2024 – Desarrollo de todos los componentes del sistema. Puesta en marcha de la plataforma de DestinE y el lago de datos. Demostración.
- 2026 - Mejora del sistema DestinE, integración de gemelos digitales adicionales y servicios relacionados.
- 2030 - Réplica digital completa de la Tierra.
Destination Earth no solo representa un avance tecnológico, sino que también es una herramienta poderosa para la sostenibilidad y la resiliencia frente a los desafíos climáticos. Al proporcionar datos precisos y accesibles, DestinE permite tomar decisiones basadas en datos y crear estrategias de adaptación y mitigación efectivas.
Blog
La Infraestructura de Pruebas para el Análisis de Datos (BDTI, por sus siglas en inglés, Big Data Test Infrastructure) es una herramienta financiada por el Programa Digital Europeo, que permite a las administraciones públicas realizar análisis con datos abiertos y herramientas de código abierto con el fin de impulsar la innovación.
Esta herramienta, alojada en la nube y de uso gratuito, se creó en 2019 para acelerar la transformación digital y social. Con este planteamiento y siguiendo también la Directiva Europea de Datos Abiertos, la Comisión Europea llegó a la conclusión de que, para lograr un impulso digital y económico, debía aprovecharse el poder de los datos de las administraciones públicas; es decir, aumentar su disponibilidad, calidad y usabilidad. Es así como nace BDTI, con el propósito de fomentar la reutilización de esta información proporcionando un entorno de prueba de análisis gratuito que permite a las administraciones públicas crear prototipos de soluciones en la nube antes de implementarlas en el entorno de producción de sus propias instalaciones.
¿Qué herramientas ofrece BDTI?
Big Data Test Infrastructure ofrece a las administraciones públicas europeas un conjunto de herramientas estándar de código abierto para el almacenamiento, procesamiento y análisis de sus datos. La plataforma consta de máquinas virtuales, clústeres de análisis e instalaciones de almacenamiento y de red. Las herramientas que ofrece son:
- Bases de datos: para almacenar datos y realizar consultas sobre los datos almacenados. El BDTI incluye actualmente una base de datos relacional (PostgreSQL), una base de datos orientada a documentos (MongoDB) y una base de datos gráfica (Virtuoso).
- Lago de datos: para almacenar grandes cantidades de datos estructurados y sin estructurar (MinIO). Los datos en bruto no estructurados se pueden procesar con configuraciones desplegadas de otros bloques de construcción (componentes BDTI) y almacenarse en un formato más estructurado dentro de la solución de lago de datos.
- Entornos de desarrollo: proporcionan las capacidades informáticas y las herramientas necesarias para realizar actividades estándar de análisis de datos sobre datos que provienen de fuentes externas, como lagos de datos y bases de datos.
- JupyterLab, un entorno de desarrollo interactivo y online para crear cuadernos Jupyter, código y datos.
- Rstudio, un entorno de desarrollo integrado para R, un lenguaje de programación para computación estadística y gráficos.
- KNIME, una plataforma de análisis, informes e integración de datos de código abierto que cuenta con componentes para el aprendizaje automático y la minería de datos, que se puede utilizar para todo el ciclo de vida de la ciencia de datos.
- H2O.ai, una plataforma de aprendizaje automático (machine learning o ML) e inteligencia artificial (IA) de código abierto diseñada para simplificar y acelerar la creación, el funcionamiento y la innovación con ML e IA en cualquier entorno.
- Procesamiento avanzado: también se pueden crear clústeres y herramientas para procesar grandes volúmenes de datos y realizar operaciones de búsqueda en tiempo real (Apache Spark, Elasticsearch y Kibana
- Visualización: BDTI también ofrece aplicaciones para visualizar datos como Apache Superset, capaz de manejar datos a escala de petabytes o Metabase.
- Orquestación: para la automatización de los procesos basados en datos durante todo su ciclo de vida, desde la preparación de datos hasta la toma de decisiones basadas en ellos y la realización de acciones basadas en esas decisiones, se ofrece:
- Apache Airflow, una plataforma de gestión de flujos de trabajo de código abierto que permite programar y ejecutar fácilmente canalizaciones de datos complejas.
A través de estas herramientas que se encuentran en entorno nube, los trabajadores públicos de países de los países de la UE pueden crear sus propios proyectos piloto para demostrar el valor que los datos pueden aportar a la innovación. Una vez finalizado el proyecto, los usuarios tienen la posibilidad descargar el código fuente y los datos para continuar el trabajo por sí mismos, utilizando entornos de su elección. Además, la sociedad civil, la academia y el sector privado pueden participar en estos proyectos piloto, siempre y cuando haya una entidad pública involucrada en el caso de uso.
Casos de éxito
Estos recursos han posibilitado la creación de proyectos diversos en diferentes países de la UE. En la web de BDTI, se recogen algunos ejemplos de casos de uso. Por ejemplo, Eurostat llevó a cabo un proyecto piloto en el que se utilizaron datos abiertos de anuncios de empleo en internet para mapear la situación de los mercados laborales europeos. Otros casos de éxito fue la optimización de la contratación pública por parte de la Agencia Noruega de Digitalización, los esfuerzos de intercambio de datos por parte de la European Blood Alliance y el trabajo para facilitar la comprensión del impacto de COVID-19. sobre la ciudad de Florencia .
En España, BDTI hizo posible un proyecto de minería de datos en la Conselleria de Sanitat de la Comunidad Valenciana. Gracias a BDTI se pudieron extraer conocimientos de la enorme cantidad de artículos clínicos científicos; una tarea que apoyó a clínicos y gestores en sus prácticas clínicas y en su trabajo diario.

Cursos, boletín y otros recursos
Además de publicar casos de uso, la web Big Data Test Infrastructure ofrece un curso online y gratuito para aprender a sacar el máximo partido a BDTI. Este curso se centra en un caso de uso altamente práctico: analizar la financiación de proyectos verdes e iniciativas en regiones contaminadas de la UE, utilizando datos abiertos de data.europa.eu y otras fuentes abiertas.
Por otro lado, recientemente se ha lanzado una newsletter de envío mensual sobre las últimas noticias de BDTI, buenas prácticas y oportunidades de análisis de datos para el sector público.
En definitiva, la reutilización de los datos del sector público (RISP) es una prioridad para la Comisión Europea y BDTI (Big Data Test Infrastructure) una de las herramientas que contribuyen a su desarrollo. Si trabajas en la administración pública y te interesa utilizar BDTI regístrate aquí.
Blog
El pasado noviembre de 2023, Crue Universidades Españolas publicó el informe TIC360 “Analítica de datos en la Universidad”. El informe es una iniciativa del grupo de trabajo de Dirección de TI Crue-Digitalización y tiene como objetivo exponer cómo la optimización en los procesos de extracción y tratamiento de los datos es clave para la generación del conocimiento en entornos de la universidad pública española. Para ello se incluyen cinco capítulos en los que se abordan determinados aspectos relacionados con la tenencia de datos y las capacidades analíticas de las universidades para generar conocimiento sobre su funcionamiento.
A continuación, presentamos un resumen de los capítulos explicando al lector qué puede encontrar en cada uno de ellos.
¿Por qué es importante la analítica de datos y cuáles son sus retos?
En la introducción, se recuerda el concepto de analítica de datos como la extracción de conocimiento a partir de datos disponible, resaltando su importancia creciente en la era actual. La analítica de datos es el instrumento adecuado para obtener la información necesaria que sirva de base para tomar decisiones en distintos campos. Entre otras cuestiones, ayuda a optimizar los procesos de gestión o mejorar la eficiencia energética de la organización, por poner algunos ejemplos. Aunque es fundamental para todos los sectores, el documento se centra en el potencial impacto de los datos en la economía y la educación, enfatizando la necesidad de un enfoque ético y responsable.
El informe explora el desarrollo acelerado de esta disciplina, impulsado por la abundancia de datos y la avanzada capacidad de cómputo; no obstante, también se alerta sobre los riesgos inherentes de unas herramientas basadas en técnicas y algoritmos que están en fase de desarrollo, y que además pueden introducir sesgos basados en edad, procedencia, sexo, estatus socioeconómico, etc. En este sentido, es importante tener en cuenta la importancia de la privacidad, la protección de datos personales, la transparencia y la explicabilidad, es decir, que cuando un algoritmo genera un resultado, debe ser posible explicar cómo se ha llegado a ese resultado.
Un buen resumen de este capítulo es la siguiente frase del autor: “El buen uso de los datos no nos llevará al paraíso, pero sí puede construir una sociedad más sostenible, justa e inclusiva. Por el contrario, su mal uso sí podría acercarnos a un infierno digital”.
¿Qué beneficio aportaría a las universidades participar en los Espacios de Datos?
El primer capítulo, partiendo de la base de que el dato es el gran protagonista y el activo vertebrador de la transformación digital, aborda el concepto de Espacio de Datos, destacando su relevancia en la estrategia de la Comisión Europea como el activo más importante de la economía del dato.
Tras resaltar los potenciales beneficios de compartir datos, el capítulo destaca cómo la economía del dato, impulsada por un mercado único de datos compartidos, puede ajustarse a los valores europeos y contribuir a una economía digital más justa e inclusiva. A ello pueden contribuir iniciativas como la Estrategia España Digital 2026, donde se destaca el papel del dato como un activo clave en la transformación digital.
La participación del mundo universitario en los espacios de datos presenta múltiples ventajas, como la compartición, el acceso y la reutilización de recursos de datos generados por otras comunidades universitarias. Esto permite avanzar más rápidamente en las investigaciones, optimizando los recursos públicos dedicados anteriormente la investigación. Una iniciativa que pone de manifiesto dichos beneficios es el Espacio Europeo de Ciencia Abierta (EOSC), que persigue establecer vínculos entre investigadores y profesionales en ciencia y tecnología en un entorno virtual con servicios abiertos y sin fisuras para el almacenamiento, gestión, análisis y reutilización de datos científicos, más allá de fronteras físicas y de disciplinas científicas. El capítulo también introduce diferentes aspectos relacionados con los espacios de datos como sus principios rectores, la legislación, los participantes y los roles a considerar. También resalta algunos aspectos relacionados con el gobierno de los espacios de datos y con las tecnologías necesarias para su despliegue.
¿En qué consiste el Espacio Europeo de Datos de Habilidades (European Skill Data Space)?
Este segundo capítulo explora la creación de un espacio común europeo de datos, enfocado en las habilidades. Este espacio busca reducir la brecha entre habilidades educativas y necesidades del mercado laboral, aumentando la productividad y competitividad gracias a un acceso transfronterizo a datos clave para la creación de aplicaciones y otros usos innovadores. En este sentido, es fundamental tener en cuenta la liberación de la versión 3.1 del European Learning Model (ELM), que pasa a consolidarse como el modelo europeo único de datos para cualquier tipo de aprendizaje (formal, no formal, informal) base para el Espacio Europeo de Datos de Habilidades.
El informe define las fases y los elementos clave para la creación e integración en el Espacio Europeo de Datos de Habilidad, destacando qué contribuciones podrían aportar y qué podrían esperar los distintos roles (proveedor de educación y capacitación, demandante de empleo, ciudadano, estudiante y empleador).
¿Cuál es el rol de la universidad española en el contexto de los Espacios Europeos de Datos?
Este capítulo se centra en el rol de las universidades españolas dentro de los espacios de datos europeos como un agente fundamental para la transformación digital del país. Para conseguir esos resultados y obtener los beneficios que aporta la analítica de datos y la interacción con espacios europeos de datos, las instituciones deben pasar de un modelo estático, basado en criterios de planificación a medio y largo plazo, a modelos flexibles más adecuados a la realidad líquida en la que vivimos, de tal forma que se puedan aprovechar los datos para mejorar la educación y la investigación.
En este contexto, es fundamental la importancia de la colaboración y el intercambio de datos a nivel europeo, pero teniendo en cuenta la legislación vigente, tanto la genérica como la específica de un dominio particular. En este sentido, estamos asistiendo a una revolución para la cual el cumplimiento normativo y el compromiso por parte de la organización universitaria es crucial. Se corre el riesgo de que organizaciones que no sean capaces de cumplir con el bloque normativo, no podrán generar conjuntos de datos de alta calidad.
Finalmente, el capítulo ofrece una serie de indicaciones sobre el tipo de plantilla que deberían tener las universidades para no verse privadas de la creación de un cuerpo de analistas y expertos en computación, vitales para el futuro.
¿Qué tipo de certificaciones existen en el ámbito de los datos?
Para poder abordar los retos introducidos en los capítulos del informe, se necesita que las universidades cuenten con: (1) datos con niveles adecuados; (2) buenas prácticas con respecto a su gobierno, gestión y calidad; y (3) profesionales suficientemente cualificados y capacitados para desempeñar las distintas tareas. Para transmitir confianza en estos elementos este capítulo justifica la importancia de tener certificaciones para los tres elementos presentados:
- Certificaciones del nivel de calidad de productos de datos como ISO/IEC 25012, ISO/IEC 25024 e ISO/IEC 25040.
- Certificaciones del nivel de madurez organizacional con respecto al gobierno del dato, gestión del dato y gestión de la calidad del dato, basadas en el modelo MAMD.
- Certificaciones de competencias personales de datos, como las referidas a conocimientos tecnológicos o las certificaciones de competencia profesionales, entre las que se incluyen las expedidas por CDMP o la Certificación CertGed.
¿En qué estado está la Universidad en la era del dato?
Aunque se ha avanzado en la materia, las universidades españolas todavía tienen un camino por delante para adaptarse y transformarse en organizaciones dirigidas por datos, y así poder obtener el máximo beneficio de las analíticas de datos. En este sentido, es necesario una actualización de la forma de operar en todas las áreas que abarca la universidad, lo cual requiere actuar y liderar los cambios necesarios para poder ser competitivos en la nueva realidad en la que estamos ya viviendo.
El objetivo es que la analítica genere impacto en la mejora de la docencia universitaria para lo que es fundamental la digitalización de los procesos de docencia y aprendizaje. Con ello se generarán beneficios también en la personalización del aprendizaje y la optimización de los procesos administrativos y de gestión.
En resumen, el análisis de datos es área de gran importancia para mejorar la eficiencia del sector universitario, pero para alcanzar todos sus beneficios es necesario continuar trabajando tanto en el desarrollo de espacios de datos, como en la capacitación del personal. Este informe busca proporcionar información para avanzar en la materia en ambos sentidos.
El documento está disponible públicamente para su lectura en: https://www.crue.org/wp-content/uploads/2023/10/TIC-360_2023_WEB.pdf
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Nunca se acaban las oportunidades para debatir, aprender y compartir experiencias sobre datos abiertos y tecnologías relacionadas. En este post, seleccionamos algunas de las que tendrán lugar próximamente, y te contamos todo lo que tienes que saber: de qué va, cuándo y dónde se celebra y cómo puedes inscribirte.
No te pierdas esta selección de eventos sobre temáticas de vanguardia como los datos geoespaciales, las estrategias de reutilización de datos accesibles e incluso las tendencias innovadoras de periodismo de datos. ¿Lo mejor? Todos son gratuitos.
Hablemos del dato en Alicante
La Asociación Nacional de Big Data y Analytics (ANBAN) organiza un evento abierto y gratuito en Alicante para debatir e intercambiar opiniones sobre datos e inteligencia artificial. Durante el encuentro no solo se presentarán casos de uso que relacionen datos con IA, sino que también se dedicará una parte a incentivar el networking entre los asistentes.
- ¿De qué trata?: 'Hablemos del dato’ empezará con dos charlas sobre proyectos de inteligencia artificial que ya estén creando impacto. Posteriormente, se explicará en qué va a consistir el curso sobre IA que ha organizado la Universidad de Alicante junto a ANBAN. La parte final del evento será más distendida para animar a los asistentes a establecer conexiones de valor.
- ¿Cuándo y dónde?: El jueves 29 de febrero a las 20.30h en ULAB (Pza. San Cristóbal, 14) en Alicante.
- ¿Cómo me inscribo?: Reserva tu lugar apuntándote aquí: https://www.eventbrite.es/e/entradas-hablemos-del-dato-beers-alicante-823931670807?aff=oddtdtcreator&utm_source=rrss&utm_medium=colaborador&utm_campaign=HDD-ALC-2902
Open Data Day en Barcelona: Reutilización de datos para mejorar la ciudad
El Open Data Day es un evento internacional que agrupa actividades sobre los datos abiertos alrededor del mundo. En este marco, la iniciativa Barcelona Open Data ha organizado un acto para dialogar sobre proyectos y estrategias de publicación y reutilización de datos abiertos para hacer posible una ciudad limpia, segura, amigable y accesible.
- ¿De qué trata?: A través de proyectos con datos abiertos y estrategias basadas en ellos, se abordará el reto de la seguridad, la coexistencia de usos y el mantenimiento de espacios compartidos en los municipios. El objetivo es generar diálogo entre las organizaciones que publican datos y los reutilizan para aportar valor y desarrollar estrategias de manera conjunta.
- ¿Cuándo y dónde?: El día 6 de marzo de 17h a 19.30h en Ca l’Alier (C/ de Pere IV, 362).
- ¿Cómo me inscribo?: A través de este enlace: https://www.eventbrite.es/e/entradas-open-data-day-2024-819879711287?aff=oddtdtcreator
Presentación de la “Guía de Buenas Prácticas para Periodistas de Datos”
El Observatori Valencià de Dades Obertes i Transparència de la Universitat Politècnica de València ha creado una guía dirigida a periodistas y profesionales del dato con consejos prácticos para convertir los datos en historias periodísticas atractivas y relevantes para la sociedad. La autora de este material de referencia dialogará con un periodista de datos sobre los retos y oportunidades que los datos ofrecen en el ámbito periodístico.
- ¿De qué trata?: Es un evento que abordará conceptos clave de la Guía de Buenas Prácticas para Periodistas de Datos mediante ejemplos prácticos y casos para analizar y visualizar datos correctamente. La ética también será un tema que se abordará durante la presentación.
- ¿Cuándo y dónde?: El viernes 8 de marzo de 12h a 13h en el Salón de Actos de la Facultad de ADE de la UPV (Avda. Tarongers s/n) en Valencia.
- ¿Cómo me inscribo?: Más información e inscripción aquí: https://www.eventbrite.es/e/entradas-presentacion-de-la-guia-de-buenas-practicas-para-periodistas-de-datos-835947741197
Jornadas de Geodatos del Geoportal del Ayuntamiento de Madrid
Madrid acoge la sexta edición de este evento que reúne responsables de instituciones y empresas de referencia en cartografía, sistemas de información geográfica, gemelo digital, BIM, Big Data e inteligencia artificial. También se aprovechará el evento para hacer entrega de los premios del Estand del Geodato.
- ¿De qué trata?: Siguiendo la estela de otros años, las Jornadas de Geodatos de Madrid presentan casos prácticos y novedades sobre cartografía, gemelo digital, reutilización de datos georreferenciados, así como los mejores trabajos presentados al Estand del Geodato.
- ¿Cuándo y dónde?: El evento empieza el día 12 de marzo a las 9h en Auditorio de La Nave en Madrid y durará hasta las 14h. El día siguiente, 13 de marzo la sesión será virtual y se presentarán los proyectos y las novedades de la producción de geo información y de la distribución a través del Geoportal de Madrid.
- ¿Cómo me inscribo?: A través del portal del evento. Las plazas son limitadas https://geojornadas.madrid.es/
III Jornadas de Cultura Libre de la URJC
Las Jornadas de Cultura Libre de la Universidad Rey Juan Carlos son un punto de encuentro, aprendizaje e intercambio de experiencias en torno a la cultura libre en la universidad. Se abordarán temas como la publicación abierta de materiales docentes e investigativos, la ciencia abierta, los datos abiertos, y el software libre.
- ¿De qué trata?: Son dos días durante los que se ofrecerán presentaciones a cargo de expertos, talleres sobre temas específicos y se dará la oportunidad a la comunidad universitaria de presentar ponencias. Además, habrá un espacio ferial donde se compartirán herramientas y novedades relacionadas con la cultura y el software libre, así como un área de exposición de poster
- ¿Cuándo y dónde?: El 20 y 21 de marzo en el Campus de Fuenlabrada de la URJC
- ¿Cómo me inscribo?: La inscripción es gratuita mediante este enlace: https://eventos.urjc.es/109643/tickets/iii-jornadas-de-cultura-libre-de-la-urjc.html
Estos son algunos de los eventos que sucederán próximamente. De todas formas, no olvides seguirnos en redes sociales para no perderte ninguna novedad sobre innovación y datos abiertos. Estamos en Twitter y LinkedIn, también nos puedes escribir a dinamizacion@datos.gob.es si quieres que incluyamos algún otro evento a la lista o si necesitas información extra.
Blog
Vivimos un momento histórico en el que los datos son un activo clave, del que dependen cada día multitud de pequeñas y grandes decisiones de empresas, organismos públicos, entidades sociales y ciudadanos. Por ello, es importante conocer de donde proviene cada dato, para garantizar que las cuestiones que afectan a nuestra vida están basadas en información veraz.
¿Qué es la citación de datos?
Cuando hablamos de “citar” nos referimos al proceso de indicar qué fuentes externas se han utilizado para crear contenidos. Una cuestión ampliamente recomendable que afecta a todos los datos, incluidos los datos públicos como está recogido en nuestro ordenamiento jurídico. En el caso de los datos ofrecidos por las adminstraciones, el Real Decreto 1495/2011 incluye la necesidad del reutilizador de citar la fuente de origen de la información.
Para ayudar a los usuarios en esta tarea, la Oficina de Publicaciones de la Unión Europea editó Data Citation: A guide to best practice, donde se habla de la importancia de la citación de datos y se recogen recomendaciones de buenas prácticas, así como los retos a superar para citar conjuntos de datos de manera correcta.
¿Por qué es importante la citación de datos?
La guía menciona las razones más relevantes por las que es recomendable llevar a cabo esta práctica:
- El crédito. Crear conjuntos de datos conlleva trabajo. Citar al autor o autores les permite recibir feedback y saber que su trabajo es útil, lo que les anima a seguir trabajando en nuevos conjuntos de datos.
- La transparencia. Cuando los datos se citan, el lector puede acudir a ellos para revisarlos, comprender mejor su alcance y evaluar su idoneidad.
- La integridad. Los usuarios no deben de caer en el plagio. No deben atribuirse el mérito de la creación de conjuntos de datos que no son suyos..
- La reproducibilidad. La citación de los datos permite que una tercera persona pueda intentar reproducir los mismos resultados, utilizando la misma información.
- La reutilización. La citación de datos facilita que cada vez más conjuntos de datos se den a conocer y, por tanto, aumente su uso.
- Minería de textos. Los datos no solo son consumidos por humanos, también pueden serlo por máquinas. Una correcta citación ayudará a las máquinas a comprender mejor el contexto de los conjuntos de datos, amplificando los beneficios de su reutilización.
Buenas prácticas generales
De entre todas las buenas prácticas generales incluidas en la guía, a continuación destacamos algunas de las más relevantes:
- Sé preciso. Es necesario que los datos citados estén definidos con exactitud. La citación de datos debe indicar qué datos concretos se han utilizado de cada conjunto de datos. También es importante señalar si han sido procesados y si provienen directamente del creador o de algún agregador (como un observatorio que ha tomado datos de diversas fuentes).
- Utiliza "identificadores persistentes" (persistent identifiers o PID). Al igual que cada libro que encontramos en una biblioteca tiene su identificador, los conjuntos de datos también pueden (y deben) tenerlo. Los identificadores persistentes son esquemas formales que proporcionan una nomenclatura común, que identifican de manera única los conjuntos de datos, evitando ambigüedades. A la hora de citar conjuntos de datos, es necesario localizarlos y escribirlos como un hipervínculo accionable, sobre el que se puede hacer clic para acceder al conjunto de datos citado y a sus metadatos. Existen diferentes familias de PID, pero la guía destaca dos de las más comunes: el sistema Handle y el identificador de objeto digital (DOI).
- Indica el momento en el que se ha accedido a los datos. Esta cuestión es de gran importancia cuando trabajamos con datos dinámicos (que se actualizan y cambian periódicamente) o continuos (sobre los que se añaden datos adicionales sin modificar los antiguos). En estos casos, es importante citar la fecha de acceso. Además, si es necesario, el usuario puede añadir “snapshots” o instantáneas del conjunto de datos, es decir, copias tomadas en momentos concretos.
- Consulta los metadatos del conjunto de datos utilizado y las funcionalidades del portal en que se ubica. En los metadatos se encuentra gran cantidad de la información necesaria para la cita.
Además, los portales de datos pueden incluir herramientas que ayuden a la citación. Es el caso del Portal de datos abiertos de la Unión Europea en cuyo menú superior se puede encontrar el botón de citación.
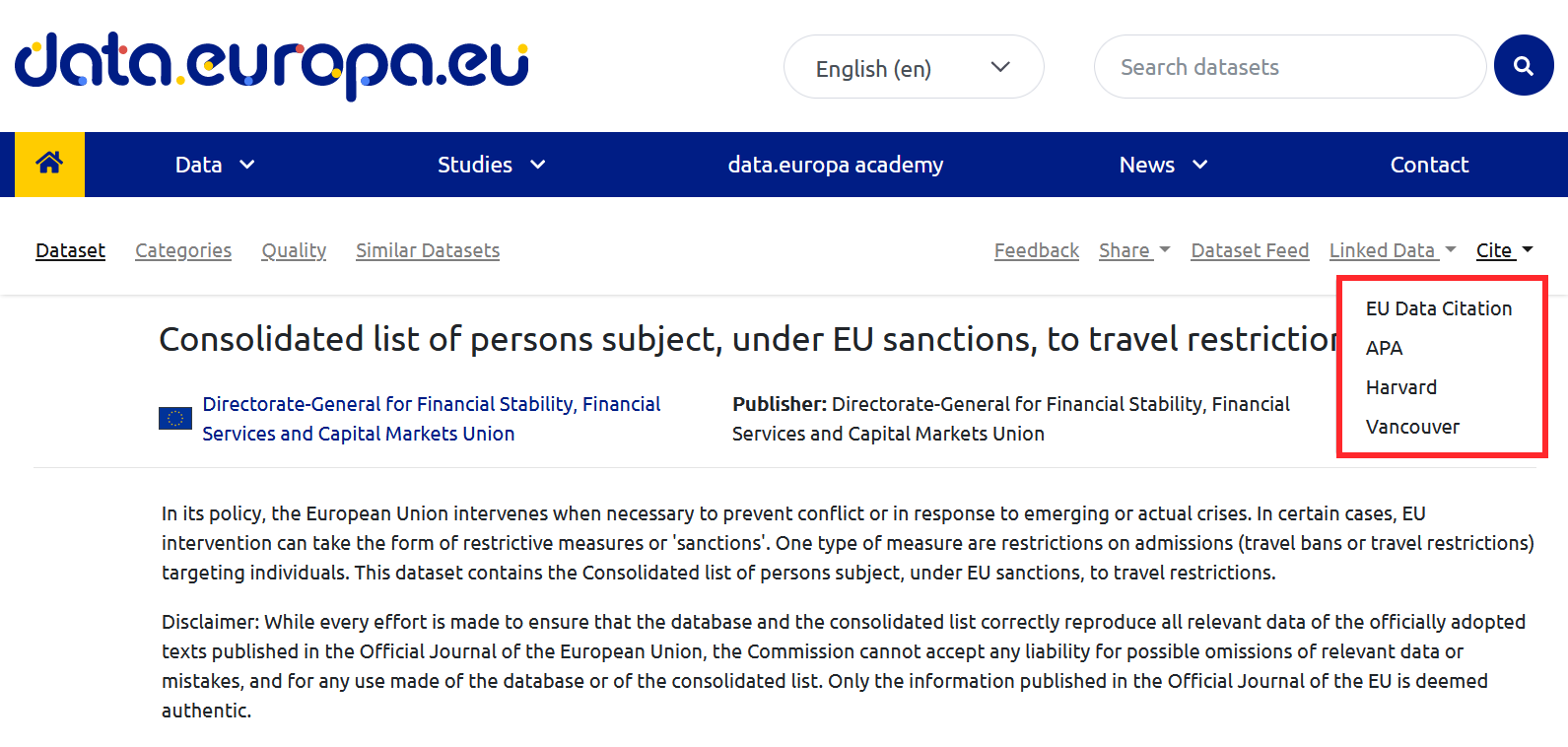
- Apóyate en herramientas de software. La mayoría de los programas informáticos utilizados para crear documentos permiten crear y formatear citas automáticamente, asegurando su formato. Además, existen herramientas específicas de gestión de citas como BibTeX o Mendeley, que permiten crear bases de datos de citas teniendo en cuenta sus peculiaridades, una función de gran utilidad cuando es necesario citar numerosos conjuntos de datos en múltiples documentos.
Cómo citar correctamente
La segunda parte del informe contiene el material técnico de referencia para crear citas que cumplan las recomendaciones indicadas. Abarca los elementos que debe incluir una cita y cómo ordenarlos para distintos fines.
Entre los elementos que debe incluir una cita se encuentran:
- Autor, puede referir tanto al individuo que ha creado el conjunto de datos (autor personal) como a la organización responsable (autor corporativo).
- Título del dataset.
- Versión/edición.
- Publicador, que es la entidad que hace disponible el conjunto de datos y puede coincidir o no con el autor (en caso de que coincidan no es necesario repetirlo).
- Fecha de publicación, donde se indica el año en que se creó. Es importante incluir entre paréntesis el momento de la última actualización.
- Fecha de citación, que expresa la fecha en la que el creador de la cita accedió a los datos, incluyendo la hora si es necesario. Para los formatos de fechas y horas, la guía recomienda acudir a la especificación DCAT, ya que ofrece una precisión mayor en términos de interoperabilidad.
- Identificador persistente.
Respeto al orden de toda esa información, existen diferentes directrices en relación con la estructura general de las citas. La guía muestra las diferentes formas más adecuadas de citar según el tipo de documento en el que aparece la cita (documentos periodísticos, online, etc.), incluyendo ejemplos y recomendación. Entre otros, destaca el ejemplo del Libro de estilo interinstitucional (ISG), que edita la Oficina de Publicaciones de la UE. Este libro de estilo no contiene orientaciones específicas sobre cómo citar datos, pero sí una estructura general para citas que puede aplicarse a los conjuntos de datos, recogida en la siguiente imagen.

La guía finaliza con una serie de anexos con listas de control, diagramas y ejemplos.
Si quieres saber más sobre este documento, te recomendamos ver este seminario online donde se resumen los puntos más importantes.
En definitiva, citar correctamente los conjuntos de datos mejora la calidad y la transparencia del proceso de reutilización de los datos, estimulándolo al mismo tiempo. Por tanto, fomentar la citación correcta de los datos es una práctica no solo recomendable, sino cada vez más necesaria.
Blog
Hace ya casi cinco años de la publicación del estudio sobre la primera década de los datos abiertos llevado a cabo por la red de los datos abiertos para el desarrollo (OD4D) y más de 60 autores de todo el mundo expertos en la materia. En esta primera edición del estudio se destacaba la importancia de los datos abiertos en el desarrollo socioeconómico y en la resolución de problemas a nivel mundial. También se recalcaban los avances para conseguir que los datos fuesen más accesibles y reutilizables y al mismo tiempo se comenzaba a profundizar en la necesidad de tener en cuenta otras cuestiones clave como la justicia de datos, la necesidad de una IA responsable y los retos de la privacidad.
Durante el último año y medio la nueva red de los datos para el desarrollo (D4D) ha estado organizando una serie de debates con el objetivo de analizar la evolución del movimiento de los datos abiertos en estos últimos años y poder así publicar una actualización del estudio anterior. Entre las conclusiones generales preliminares de esos debates se encuentran:
- La necesidad de hacer las historias de impacto más visibles como una forma de incentivar una mayor apertura y disponibilidad de datos.
- La conveniencia de abrir los datos de manera que satisfagan las necesidades de los potenciales usuarios y beneficiarios, y que se haga de forma colaborativa con la comunidad.
- Abogar para que las organizaciones donantes añadan como parte de sus programas de subvenciones el requisito de que los beneficiarios deban elaborar y llevar a cabo planes de datos abiertos.
- Dar prioridad a la necesidad de compartir datos de forma interoperable.
- Publicar más datos enfocados a mejorar la situación de los grupos históricamente marginados.
- Aumentar los esfuerzos para un mayor desarrollo de las capacidades técnicas requeridas para la implantación de los datos abiertos.
- Ahondar en la creación, evolución e implementación de los marcos legales y políticos necesarios para dar soporte a todo lo anterior.
Al mismo tiempo, se ha llevado a cabo un proceso de actualización del estudio mediante el cual se analizan los progresos conseguidos durante los últimos años en cada una de los sectores y comunidades analizados por el estudio original. Gracias a este proceso podemos conocer ya algunos adelantos de las novedades más destacadas durante los últimos años, así como los retos pendientes en varios ámbitos que pasamos a repasar a continuación.
Novedades a nivel sectorial
Algunas de las novedades más relevantes que se han dado en distintos sectores clave durante los últimos cinco años son las siguientes:
Rendición de cuentas y lucha contra la corrupción: Se ha incrementado rápidamente el uso de datos en esta área, aunque su impacto no está bien documentado y el uso de datos abiertos en este ámbito debería centrarse más en los problemas detectados y trabajar de forma más colaborativa con todos los actores implicados.
Agricultura: El sector agroalimentario se ha centrado en facilitar el intercambio seguro y eficaz de los datos aplicando los principios del modelo de datos FAIR (Encontrables, Accesibles, Interoperables y Reutilizables), debido principalmente a las reticencias a la hora de compartir algunos datos de ámbito más personal.
Transporte: Este es un sector en que las autoridades públicas reconocen claramente la importancia de los datos abiertos a la hora de construir ecosistemas de transporte que contribuyan a abordar problemas globales como el desarrollo sostenible y el cambio climático. Los principales desafíos detectados en este caso son la interoperabilidad y la protección de la privacidad de los datos.
Sanidad: La práctica de recolectar, compartir y usar datos relacionados con la salud se ha acelerado considerable debido a los efectos de la pandemia de Covid-19. Al mismo tiempo, las medidas de contención llevadas a cabo durante este periodo en cuanto al rastreo de contactos y las cuarentenas, han contribuido a aumentar el reconocimiento de la importancia de los derechos digitales en cuanto a los datos sanitarios.
Estadísticas nacionales: Los datos abiertos se han consolidado como parte integral de las estadísticas nacionales, pero hay un riesgo significativo de retroceso. Las organizaciones internacionales ya no se centran tanto en la difusión de los datos como en fomentar su uso para generar valor e impacto. Por ello, ahora es necesario centrarse en la sostenibilidad de las iniciativas para poder asegurar un acceso equitativo y mejorar el bien social.
Acción por el cambio climático: En los últimos años, la calidad y disponibilidad de datos climáticos ha mejorado en algunos sectores muy concretos, como por ejemplo en el de la energía. Sin embargo, existen todavía grandes vacíos en otras áreas, como por ejemplo en las ciudades o el sector privado. Por otro lado, los conjuntos de datos climáticos disponibles presentan otros retos como que suelen ser demasiado técnicos, estar mal formateados o que no abordan casos de uso y problemas específicos.
Desarrollo urbano: Los datos abiertos juegan un papel cada vez más importante en el contexto del desarrollo urbano a nivel global a través de la promoción de la equidad, su contribución a mitigar el cambio climático y a la mejora de los sistemas de respuesta a crisis. Además, el continuo desarrollo y crecimiento de tecnologías urbanas como el Internet de las Cosas (IoT), las sandboxes digitales o los gemelos digitales está creando la necesidad de mejorar la calidad e interoperabilidad de los datos – lo que al mismo tiempo empuja el desarrollo de los datos abiertos. La tarea pendiente en este sector es conseguir una mayor participación ciudadana.
Novedades a nivel transversal
Además de las novedades sectoriales, debemos también tener en cuenta aquellas tendencias transversales que cuentan con el potencial de afectar a todos los sectores y que se describen a continuación:
Inteligencia Artificial: Las aplicaciones de IA tienen una creciente influencia con respecto a cuáles son los datos que se publican y cómo se estructuran. Gobiernos y otras entidades se esfuerzan por completar los datos abiertos disponibles para el entrenamiento de las IA que son necesarios para evitar los sesgos existentes en la actualidad. Para que esto sea posible se están desarrollando además nuevos mecanismos para habilitar el acceso a aquellos datos sensibles que no puedan publicarse directamente bajo licencias abiertas.
Alfabetización de datos: La escasa alfabetización en esta materia continúa siendo uno de los factores que más retrasa la explotación de los datos abiertos, aunque también se han producido algunos avances importantes a nivel de industria, sociedad civil, gobierno e instituciones educativas – particularmente en el contexto de la urgente necesidad de contrarrestar la creciente cantidad de desinformación utilizada de forma malintencionada.
Igualdad de género: En los últimos años la pandemia de Covid-19 y otros eventos políticos globales han agravado los desafíos para las mujeres y otros grupos marginados. El progreso en cuanto a la publicación y uso de datos abiertos sobre género ha sido en general lento y sería necesario aumentar los recursos disponibles para poder mejorar esta situación.
Privacidad: La creciente demanda de datos personales y el cada vez mayor uso de múltiples fuentes de datos combinadas ha incrementado los riesgos de privacidad. La privacidad grupal es también una preocupación emergente y se ha formado también cierto debate acerca del balance necesario entre la transparencia y la protección de la privacidad en algunos casos. Además, existe también una demanda por mejores mecanismos de gobierno y supervisión de los datos para una adecuada protección.
Novedades a nivel Geográfico
Por último, repasaremos algunas de las tendencias observadas a nivel regional:
Sur y Este Asiático: Ha habido pocos cambios en el panorama de datos abiertos de la región con varios países que han experimentado un declive en sus prácticas de apertura de datos después de afrontar cambios en sus gobiernos. A nivel general se observan mejoras con un entorno burocrático más propicio y en las capacidades relacionas con los datos. Sin embargo, todo esto no se está traduciendo todavía en un impacto real debido a la falta de reutilización.
África Subsahariana: El movimiento de datos abiertos se ha expandido considerablemente en la región durante los últimos años, involucrando a nuevos actores del sector privado y la sociedad civil. Esta dinamización ha sido posible principalmente gracias a seguir un enfoque basado en la resolución de los desafíos provenientes de los Objetivos de Desarrollo Sostenible. Sin embargo, todavía existen carencias significativas en la capacidad para recolectar datos y para asegurar un tratamiento ético de los mismos.
América Latina: Al igual que en otras partes del mundo, las agendas de datos abiertos no están avanzando al mismo ritmo que hace unos años. Se puede ver cierto progreso en algunos tipos de datos como por ejemplo en las finanzas públicas, pero también grandes lagunas en otras áreas como la información empresarial o los datos sobre acción climática. Además, aún hay muchas tareas básicas pendientes relacionadas con la apertura de datos y su disponibilidad.
Norte América y Oceanía: Se observa un cambio hacia la institucionalización de las políticas de datos y las estructuras necesarias para integrar los datos abiertos en la cultura de la gobernanza pública de manera más amplia. El uso de datos abiertos durante la Covid-19 para facilitar la transparencia, comunicación, investigación y formulación de políticas sirvió para demostrar su naturaleza multipropósito en este ámbito.
Estos son tan solo algunas conclusiones de lo que podemos ver en la segunda edición del estudio sobre la evolución del movimiento de los datos abiertos. La 2ª edición del Estado de los Datos Abiertos presenta 30 nuevos capítulos actualizados y una visión renovada para guiar las agendas de los datos abiertos en los próximos años, los avances de los últimos cinco años, los nuevos retos y los retos que continúan pendientes. A medida que entramos ya en una nueva fase de evolución de los datos abiertos será interesante también poder ver cómo se ponen en práctica estos aprendizajes y recomendaciones, y empezar al mismo tiempo también a imaginar cómo se posicionarán los datos abiertos en la agenda global para los próximos años.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
¿Qué retos afrontan los publicadores de datos?
En la era digital actual, la información es un activo estratégico que impulsa la innovación, la transparencia y la colaboración en todos los sectores de la sociedad. Es por ello por lo que las iniciativas de publicación de datos han experimentado un enorme desarrollo como mecanismo fundamental para desbloquear el potencial de estos datos, permitiendo que gobiernos, organizaciones y ciudadanos accedan, utilicen y compartan.
No obstante, existen aún muchos retos tanto para publicadores de datos como para consumidores de los mismos. Aspectos como el mantenimiento de las APIs (Application Programming Interfaces) que nos permiten acceder y consumir los conjuntos de datos publicados o la correcta replicación y sincronización de conjuntos de datos cambiantes siguen siendo desafíos muy relevantes para estos actores.
En este post, exploraremos cómo los Linked Data Event Streams (LDES), un nuevo mecanismo de publicación de datos, pueden ayudarnos a solventar estos retos. ¿Qué es exactamente LDES? ¿Cómo difiere de las prácticas tradicionales de publicación de datos? Y, lo más importante, ¿cómo puede ayudar a publicadores y consumidores de datos a facilitar el uso de los conjuntos de datos disponibles?
Destilando los aspectos claves de LDES
Cuando desde la Universidad de Gante se comenzó a trabajar en un nuevo mecanismo para la publicación de datos abiertos, la pregunta a la que pretendían dar respuesta era: ¿Cuál es la mejor API posible que podemos diseñar para exponer conjuntos de datos abiertos?
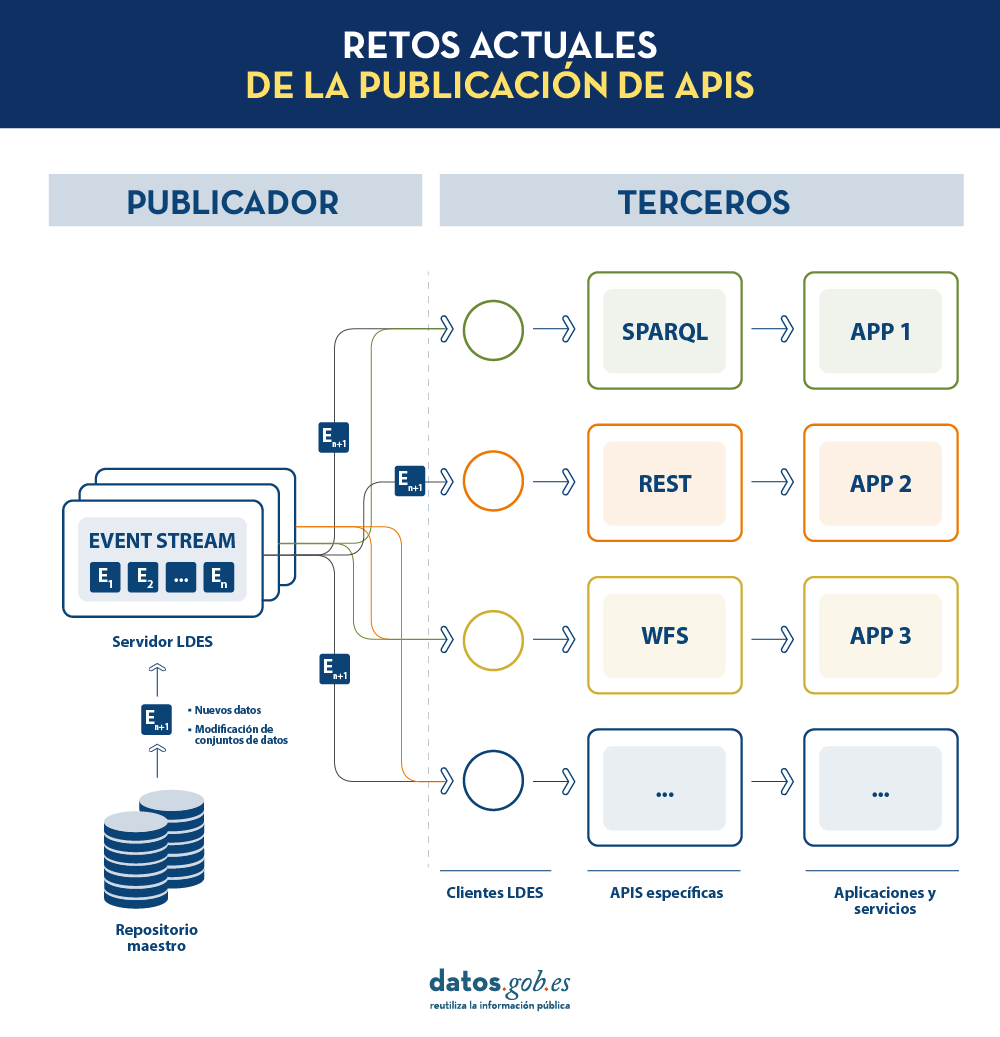
En la actualidad, los organismos publicadores de datos recurren a múltiples mecanismos para publicar sus diferentes conjuntos de datos. Por un lado, es fácil encontrarnos APIs. Destacan las de tipo SPARQL, estándar para consulta de datos enlazados (Link Data), pero también de tipo REST o de tipo WFS, para el acceso a conjuntos de datos con componente geoespacial. Por otro lado, es muy común que encontremos la posibilidad de acceder a volcados de datos en diferentes formatos (i.e. CSV, JSON, XLS, etc.) que podamos descargar para su utilización.
En el caso de los volcados de datos, es muy fácil encontrarnos con problemas de sincronización. Esto ocurre cuando, tras un primer volcado, se produce un cambio que requiere la modificación del conjunto de datos original como, por ejemplo, el cambio del nombre de una calle en un callejero previamente descargado. Ante este cambio, si el tercero opta por modificar el nombre de la calle sobre el volcado inicial en lugar de esperar a que el publicador actualice sus datos en el repositorio maestro para realizar un nuevo volcado, los datos manejados por el tercero quedarán desincronizados frente a los manejados por el publicador. De igual forma, si es el publicador el que actualiza su repositorio maestro pero estos cambios no son descargados por el tercero, ambos manejarán diferentes versiones del conjunto de datos.
Por otra parte, si el publicador ofrece el acceso a los datos a través de APIs de consulta, en lugar de mediante volcados de los datos a los terceros, se solucionan los problemas de sincronización, pero la construcción y mantenimiento de un alto y variado volumen de las mismas supone un elevado esfuerzo a los publicadores de datos.
LDES busca solventar estas diferentes problemáticas aplicando el concepto de Linked Data a un event stream o flujo de datos. Según la definición que aparece en su propia especificación, un Linked Data Event Stream (LDES) es una colección de objetos inmutables donde cada objeto está descrito en ternas RDF.
En primer lugar, el hecho de que los LDES apuesten por Linked Data aporta principios de diseño que permiten combinar datos diversos y/o pertenecientes a diferentes fuentes, así como su consulta a través de mecanismos semánticos que permiten legibilidad tanto por humanos como por máquinas. En resumen, aporta interoperabilidad y consistencia entre conjuntos de datos, y facilita por tanto su búsqueda y descubrimiento.
Por otro lado, los event streams o flujos de datos, permiten a los consumidores replicar la historia de los conjuntos de datos, así como sincronizar los cambios recientes. Cualquier nuevo registro añadido a un conjunto de datos o cualquier modificación de los registros existentes (en definitiva, cualquier cambio), se registra como un nuevo evento incremental en el LDES que no alterará los eventos anteriores. Por tanto, pueden publicarse y consumirse datos como una secuencia de eventos, lo cual es útil para datos que cambian con frecuencia, como información en tiempo real o información que sufre actualizaciones constantes, ya que permite la sincronización de las últimas actualizaciones sin necesidad de hacer una nueva descarga completa de todo el repositorio maestro tras cada modificación.
En un modelo de este tipo, el editor solo necesitará desarrollar y mantener una API, el LDES, en lugar de múltiples APIs como WFS, REST o SPARQL. Los diferentes terceros que deseen utilizar los datos publicados se conectarán (cada tercero implementará su cliente LDES) y recibirán los eventos de los streams a los que se hayan suscrito. Cada tercero creará a partir de la información recabada las APIs específicas que considere oportunas en base al tipo de aplicaciones que quieran desarrollar o fomentar. En definitiva, el publicador no tendrá que resolver todas las potenciales necesidades que tenga cada tercero en la publicación de datos, sino que dando un interfaz LDES (API base mínima) cada tercero se centrará en su problemática.
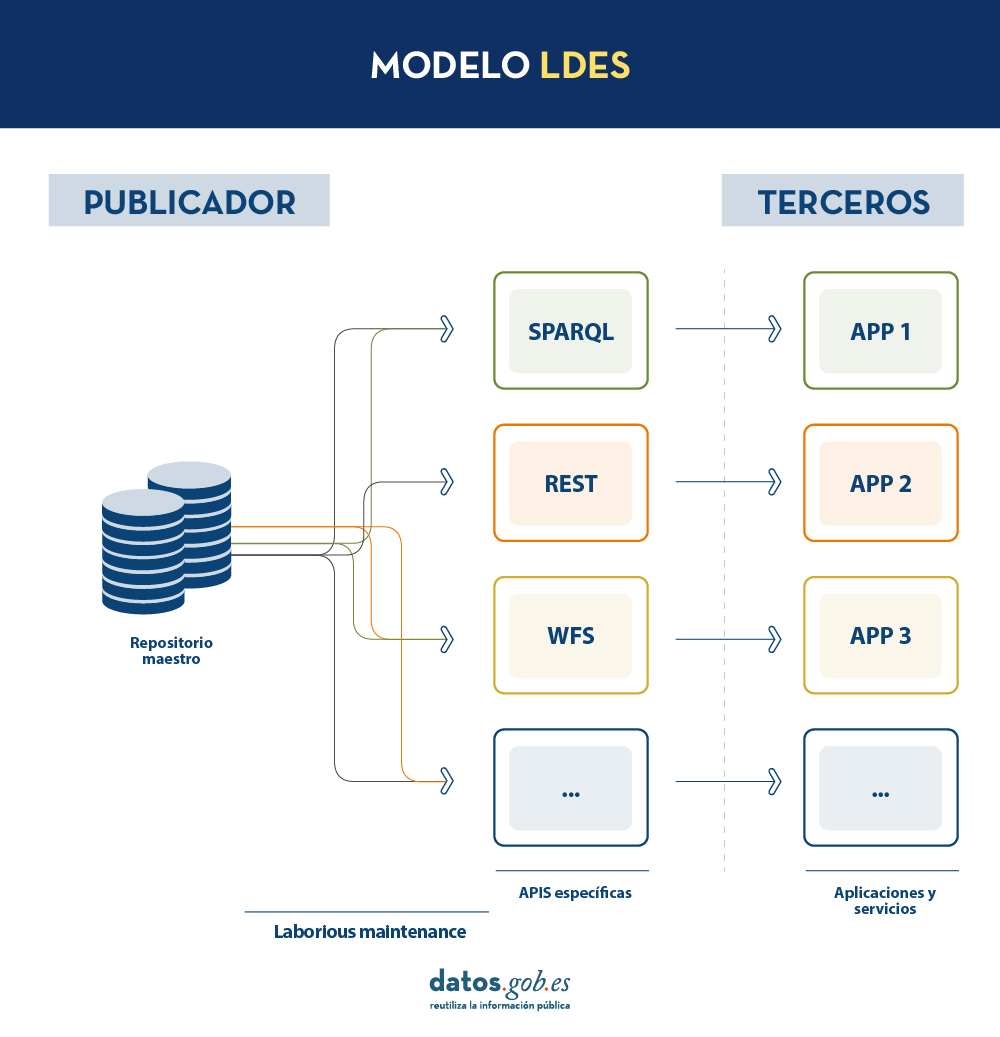
Además, para facilitar el acceso en grandes volúmenes de datos o a datos que pueden estar distribuidos en diferentes fuentes, como un inventario de puntos de recarga eléctrica en Europa, LDES aporta la capacidad de fragmentación de los conjuntos de datos. A través de la especificación TREE (en inglés, árbol), LDES permite establecer diferentes tipos de relaciones entre fragmentos de datos. Esta especificación permite publicar colecciones de entidades, llamados miembros, y ofrece la capacidad de generar una o más representaciones de estas colecciones. Estas representaciones se organizan como vistas, distribuyendo los miembros a través de páginas o nodos interconectados mediante relaciones. Así, si deseamos que los datos se puedan consultar a través de índices temporales, se podrá establecer una fragmentación temporal y acceder solo a las páginas de un intervalo temporal. De igual forma, se podrán plantear índices alfabéticos o geoespaciales y así un consumidor podrá acceder sólo a aquellos datos necesarios sin la necesidad de realizar el “volcado” del conjunto de datos completo.
¿Qué conclusiones podemos extraer de LDES?
En este post hemos observado el potencial de LDES como mecanismo para la publicación de datos. Algunos de los aprendizajes más relevantes son:
- LDES persigue facilitar la publicación de datos a través de APIs base mínimas que sirvan como punto de conexión para cualquier tercero que desee consultar o construir aplicaciones y servicios sobre conjuntos de datos.
- La construcción de un servidor LDES, no obstante, tiene cierto nivel de complejidad técnica a la hora de establecer la arquitectura necesaria para el manejo de los flujos de datos publicados y su adecuada consulta por parte de consumidores de datos.
- El diseño de LDES permite la gestión tanto de datos con una elevada tasa de cambios (i.e. datos provenientes de sensores), como datos con una baja tasa de cambios (i.e. datos provenientes de un callejero). Ambos escenarios pueden manejar cualquier modificación del conjunto de datos como un flujo de datos.
- LDES soluciona de forma eficiente la gestión de registros históricos, versiones y fragmentos de conjuntos de datos. Para ello se apoya en la especificación TREE pudiendo establecer diferentes tipos de fragmentación sobre el mismo conjunto de datos.
¿Te gustaría saber más?
Dejamos a continuación algunas referencias que han servido para redactar este post y pueden servir al lector que desee profundizar en el mundo de LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La European Open Science Cloud (EOSC) es una iniciativa de la Unión Europea que tiene como objetivo promover la ciencia abierta a través de la creación de una infraestructura digital de investigación abierta, colaborativa y sostenible. El objetivo principal de EOSC es el de proporcionar a los investigadores europeos un acceso más fácil a los datos, las herramientas y los recursos necesarios para poder llevar a cabo investigaciones de calidad.
EOSC en la agenda europea de investigación y datos
EOSC forma parte de las 20 acciones de la agenda 2022-2024 del Espacio Europeo de Investigación (ERA) y se reconoce como el espacio europeo de datos de ciencia, investigación e innovación, llamado a integrarse con otros espacios de datos sectoriales definidos en la estrategia europea para los datos. Entre los beneficios que se esperan obtener gracias a esta plataforma se encuentran:
-
Una mejora en la confianza, calidad y productividad de la ciencia europea.
- El desarrollo de nuevos productos y servicios innovadores.
- Una mejora en el impacto de la investigación a la hora de afrontar los mayores desafíos sociales.
La plataforma EOSC
EOSC es en realidad un proceso continuo que marca una hoja de ruta en la que todos los Estados Europeos participan, basándose en la idea central de que los datos de investigación son un bien público que debe estar disponible para todos los investigadores, independientemente de su ubicación o afiliación. Mediante este modelo se persigue que los resultados científicos cumplan con los Principios FAIR (Findable, Accesible, Interoperable, Reusable) para facilitar la reutilización, al igual que en cualquier otro espacio de datos.
No obstante, la parte más visible de ESCO es su plataforma que da acceso a millones de recursos aportados por cientos de proveedores de contenido. Dicha plataforma está diseñada para facilitar la búsqueda, el descubrimiento y la interoperabilidad de los datos y otros contenidos como recursos formativos, de seguridad, de análisis, herramientas, etc. Para ello, entre los elementos clave de la arquitectura prevista en EOSC encontramos dos componentes principales:
- EOSC Core: que proporciona todos los elementos básicos necesarios para descubrir, compartir, acceder y reutilizar recursos – autenticación, gestión de metadatos, métricas, identificadores persistentes, etc.
- EOSC Exchange: para asegurar que los servicios comunes y temáticos para la gestión y explotación de los datos estén disponibles a la comunidad científica.
A lo anterior hay que sumar el Framework de interoperabilidad de ESOC (EOSC-IF), un conjunto de políticas y directrices que habilitan la interoperabilidad entre distintos recursos y servicios y facilitan su posterior combinación.
En la actualidad la plataforma está disponible en 24 idiomas y se actualiza continuamente para añadir nuevos datos y servicios. Para los próximos siete años se prevé una inversión conjunta por parte de los socios de la Unión Europea de al menos 1.000 millones de euros para continuar con su desarrollo.
Participación en EOSC
La evolución de EOSC está siendo guiada por un organismo de coordinación tripartito formado por la propia Comisión Europea, los países participantes representados en la Junta Directiva de EOSC y la comunidad de investigación representada mediante la Asociación EOSC. Además, para poder formar parte de la comunidad ESCO tan sólo hay que seguir una serie de reglas mínimas de participación:
-
Todo el concepto de EOSC se basa en el principio general de apertura.
- Los recursos existentes en EOSC deben cumplir con los principios FAIR.
- Los servicios deben cumplir con la arquitectura y pautas de interoperabilidad de EOSC.
- EOSC sigue los principios de comportamiento ético e integridad en la investigación.
- Se espera que los usuarios de EOSC también contribuyan a EOSC.
- Los usuarios deben cumplir los términos y condiciones asociados a los datos que usen.
- Los usuarios de EOSC siempre citan las fuentes de los recursos que usen en su trabajo.
- La participación en EOSC está sujeta a las políticas y legislaciones aplicables.
EOSC en España
El Consejo Superior de Investigaciones Científicas (CSIC) de España fue uno de los 4 miembros fundadores de la asociación y actualmente es miembro encomendado de la misma, encargado de la coordinación a nivel nacional.
El CSIC lleva ya años trabajando en su repositorio de acceso abierto DIGITAL.CSIC como paso previo a su futura integración en EOSC. Dentro de su trabajo en ciencia abierta podemos señalar por ejemplo la adopción de los Current Research Information System (CRIS), sistemas de información diseñados para ayudar a las instituciones de investigación a recopilar, organizar y gestionar datos sobre su actividad investigadora: investigadores, proyectos, publicaciones, patentes, colaboraciones, financiación, etc.
Los CRIS son ya de por sí herramientas importantes a la hora de ayudar a las instituciones a rastrear y administrar su producción científica, promoviendo la transparencia y el acceso abierto a la investigación. Pero, además, pueden también desempeñar un papel relevante como fuentes de información que alimentan la EOSC, ya que los datos recopilados en los CRIS pueden ser también fácilmente compartidos y utilizados a través de la EOSC.
El camino hacia la ciencia abierta
La colaboración entre los CRIS y la EOSC tiene el potencial de mejorar significativamente la accesibilidad y la reutilización de los datos de investigación, pero hay también otras acciones de transición que se pueden adoptar en el camino hacia la producción de una ciencia cada vez más abierta:
-
Garantizar la calidad de los metadatos para facilitar el intercambio abierto de datos.
- Divulgar los principios FAIR entre la comunidad investigadora.
- Promover y desarrollar estándares comunes para facilitar la interoperabilidad.
- Fomentar la utilización de repositorios abiertos.
- Contribuir compartiendo recursos con el resto de la comunidad.
Todo ello ayudará a impulsar la ciencia abierta, aumentando la eficiencia, transparencia y replicabilidad de las investigaciones.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
IATE, acrónimo en inglés de Interactive Terminology for Europe (Terminología Interactiva para Europa), es una base de datos dinámica diseñada para respaldar la redacción multilingüe de textos de la Unión Europea. Su objetivo es proporcionar datos relevantes, confiables y de fácil acceso con un valor añadido distintivo en comparación con otras fuentes de información léxica como pueden ser archivos electrónicos, memorias de traducción o internet.
Esta herramienta es de interés para las instituciones de la UE que la utilizan desde 2004 y para cualquier persona, como profesionales de la lengua o del mundo académico, administraciones públicas, empresas o público en general Este proyecto, puesto en marcha en 1999 por el Centro de Traducción, está disponible para cualquier organización o persona que necesite redactar, traducir o interpretar un texto sobre la UE.
Origen y usabilidad de la plataforma
IATE se creó en 2004 mediante la fusión de diferentes bases de datos terminológicas de la UE. Para su creación se importaron a IATE las bases de datos originales de Eurodicautom, TIS, Euterpe, Euroterms y CDCTERM. Este proceso originó una gran cantidad de entradas duplicadas, lo que tiene como consecuencia que muchos conceptos estén cubiertos por varias entradas en lugar de una sola. Para solucionar este problema, se constituyó un grupo de trabajo de limpieza que desde 2015 se encarga de organizar análisis e iniciativas de limpieza de datos para consolidar entradas duplicadas en una sola entrada. Esto explica por qué las estadísticas sobre el número de entradas y términos muestran una tendencia a la baja, ya que se eliminan y actualizan más contenidos de los que se crean.
Además de poder realizar consultas, existe la posibilidad de descargar sus ficheros de datos junto con la herramienta de extracción IATExtract que permite generar exportaciones filtradas.
Esta base terminológica interinstitucional fue inicialmente diseñada para gestionar y normalizar la terminología de las agencias de la UE. No obstante, posteriormente, también se empezó a utilizar como herramienta de apoyo en la redacción multilingüe de los textos de la UE, hasta llegar a convertirse en la actualidad en un sistema complejo y dinámico de gestión terminológica. Aunque su principal objetivo es facilitar la labor de los traductores que trabajan para la UE, también es de gran utilidadl para el público en general. .
IATE lleva a disposición del público desde 2007, y reúne los recursos terminológicos de todos los servicios de traducción de la UE. El Centro de Traducción gestiona los aspectos técnicos del proyecto en nombre de los socios que participan en él: el Parlamento Europeo (EP), el Consejo de la Unión Europea (Consilium), la Comisión Europea (COM), el Tribunal de Justicia (CJUE), el Banco Central Europeo (ECB), el Tribunal de Cuentas Europeo (ECA), el Comité Económico y Social Europeo (EESC/CoR), el Comité Europeo de las Regiones (EESC/CoR), el Banco Europeo de Inversiones (EIB) y el Centro de Traducción de los Órganos de la Unión Europea (CdT).
La estructura de datos de IATE se basa en un enfoque orientado a conceptos, lo que significa que cada entrada corresponde a un concepto (los términos se agrupan por su significado), y cada concepto idealmente debería estar cubierto por una sola entrada. Cada entrada de IATE se divide en tres niveles:
-
Nivel independiente del idioma (LIL)
-
Nivel de idioma (LL)
-
Nivel de término (TL) Para obtener más información, consulte la Sección 3 ('Visión general de la estructura') a continuación.
Fuente de referencia para profesionales y útil para el público en general
En IATE se reflejan las necesidades de los traductores de la Unión Europea, por lo que puede cubrirse cualquier ámbito que haya aparecido o pueda aparecer en los textos de las publicaciones del entorno de la UE, sus agencias y organismos. La crisis financiera, el medio ambiente, la pesca y la migración son ámbitos en los que se ha trabajado de forma intensa durante los últimos años. Para conseguir el mejor resultado, IATE utiliza el tesauro EuroVoc como sistema de clasificación de campos temáticos.
Como ya hemos señalado, esta base de datos puede ser utilizada por cualquier persona que esté buscando el término adecuado sobre la Unión Europea. IATE permite explorar en campos diferentes al del término consultado y filtrar los dominios en todos los ámbitos y descriptores de EuroVoc. Las tecnologías utilizadas hacen que los resultados obtenidos tengan una gran precisión, mostrándose como una lista enriquecida que incluye además una clara distinción entre las coincidencias exactas y difusas del término.
La versión pública de IATE incluye las lenguas oficiales de la Unión Europea, que se definen en el Reglamento n.º 1 de 1958. . Además, se efectúa una alimentación sistemática a través de proyectos anticipativos: si se sabe que va a tratarse en textos de la UE un tema determinado, se crean o mejoran las fichas que guardan relación con ese tema para que, cuando lleguen los textos, los traductores dispongan ya en IATE de la terminología precisada.
Cómo utilizar IATE
Para realizar una búsqueda en IATE simplemente se debe escribir una palabra clave o parte del nombre de una colección. Se pueden definir más filtros para su búsqueda, como institución, tipo o fecha de creación. Una vez que se ha realizado la búsqueda, se selecciona una colección y al menos una lengua de visualización.
Para descargar subconjuntos de datos de IATE es necesario estar registrado, una opción totalmente gratuita que permite además de la descarga, almacenar algunas preferencias de usuario. La descarga es también un proceso sencillo y se puede realizar en formato csv o tbx.
El archivo de descarga de IATE, a cuya información se puede también acceder de otras formas, contiene los siguientes campos:
-
Nivel independiente de la lengua:
-
Número de ficha: el identificador único de cada concepto.
-
Campo temático: los conceptos están vinculados a ámbitos de conocimiento en los que se utilizan. La estructura conceptual se organiza en torno a veintiún campos temáticos con diversos subcampos. Hay que señalar que los conceptos pueden estar vinculados a más de un campo temático.
-
Nivel de la lengua:
-
Código de la lengua: cada idioma tiene su propio código ISO.
-
Nivel del término
-
Término: concepto de la ficha.
-
Tipo de término. Pueden ser: términos, abreviatura, frase, fórmula o fórmula corta.
-
Código de fiabilidad. IATE utiliza cuatro códigos para indicar la fiabilidad de los términos: sin comprobar, mínima, fiable o muy fiable.
-
Evaluación. Cuando se almacenan varios términos en una lengua, se pueden asignar evaluaciones específicas del siguiente modo: preferible, admisible, desechado, obsoleto y propuesto.
Una base de datos terminológica en continua actualización
La base de datos IATE es un documento en permanente crecimiento, abierto a la participación ciudadana, de forma que cualquier persona puede contribuir a su crecimiento proponiendo nuevas terminologías para añadir a fichas existentes, o para crear fichas nuevas: puede enviar su propuesta a iate@cdt.europa.eu, o bien utilizar el enlace ‘Observaciones’ que aparece en la parte inferior derecha de la ficha del término buscado. Se puede facilitar cuanta información pertinente se desee para justificar la fiabilidad del término propuesto, o plantear un nuevo término a incluir. Un terminólogo de la lengua en cuestión estudiará cada propuesta ciudadana y valorará su incorporación al IATE.
En agosto de 2023, la IATE anunciaba la disponibilidad de la versión 2.30.0 de este sistema de datos, añadiendo nuevos campos en su plataforma y la mejora de funciones, como la exportación de archivos enriquecidos para optimizar el filtrado de datos. Como hemos visto, esta base de datos terminológica interinstitucional de la UE seguirá evolucionando de manera continua para satisfacer las necesidades de los traductores de la UE y los usuarios de IATE en general.
Otro aspecto importante es que esta base de datos sirve para el desarrollo de herramientas de traducción asistida por ordenador (TAO), lo que contribuye a garantizar la calidad de los trabajos de traducción de los servicios de traducción de la UE. Los resultados de la labor de terminología de los traductores se almacenan en IATE y éstos, a su vez, utilizan esta base de datos para realizar búsquedas interactivas y para alimentar bases de datos terminológicas específicas para un ámbito o documento que utilizan en sus herramientas TAO.
IATE, con más de 7 millones de términos en más de 700.000 entradas, es una referencia en el ámbito de la terminología y está considerada como la mayor base de datos terminológica multilingüe del mundo. Cada año se realizan en IATE más de 55 millones de consultas desde más de 200 países, lo que da buena cuenta de su utilidad.