Noticia
Once again this year, the European Commission organised the EU Open Data Day, one of the world's leading open data and innovation events. On 19-20 March, the European Convention Centre in Luxembourg brings together experts, government officials and academics to share knowledge, experience and progress on open data in Europe.
During these two intense days, which also could be followed online explored crucial topics such as governance, quality, interoperability and the impact of artificial intelligence (AI) on open data. This event has become an essential forum for fostering the development of policies and practices that promote transparency and data-driven innovation across the European Union. In this post, we review each of the presentations at the event.
Openness and data history
To begin with, the Director General of the European Union Publications Office, Hilde Hardeman, opened the event by welcoming the attendees and setting the tone for the discussions to follow. Helena Korjonen and Emma Schymanski, two experts from the University of Luxembourg, then presented a retrospective entitled "A data journey: from darkness to enlightenment", exploring the evolution of data storage and sharing over 18,000 years. From cave paintings to modern servers, this historical journey highlighted how many of today's open data challenges, such as ownership, preservation and accessibility, have deep roots in human history.
This was followed by a presentation by Slava Jankin, Professor at the Centre for AI in Government at the University of Birmingham, on AI-driven digital twins and open data to create dynamic simulations of governance systems, which allow policymakers to test reforms and predict outcomes before implementing them.
Use cases between open data and AI
On the other hand, several use cases were also presented, such as Lithuania's practical experience in the comprehensive cataloguing of public data. Milda Aksamitauskas of the University of Wisconsin, addressed the governance challenges and communication strategies employed in the project and presented lessons on how other countries could adapt similar methods to improve transparency and data-driven decision-making.
In relation, scientific coordinator Bastiaan van Loenen presented the findings of the project he is working on, ODECO of Horizon 2020, focusing on the creation of sustainable open data ecosystems. As van Loenen explained, the research, which has been conducted over four years by 15 researchers, has explored user needs and governance structures for seven different groups, highlighting how circular, inclusive and skills-based approaches can provide economic and social value to open data ecosystems.
In addition, artificial intelligence was at the forefront throughout the event. Assistant Professor Anastasija Nikiforova from the University of Tartu offered a revealing insight into how artificial intelligence can transform government open data ecosystems. In his presentation, "Data for AI or AI for data" he explored eight different roles that AI can play. For example, AI can serve as a open data portal 'cleanser' and even retrieve data from the ecosystem, providing valuable insights for policymakers and researchers on how to effectively leverage AI in open data initiatives.
Also using AI-powered tools, we find the EU Open Research Repository launched by Zenodo in 2024, an open science initiative that provides a tailored research repository for EU research funding recipients. Lars Holm Nielsen's presentation dhighlighted how AI-driven tools and high-quality open datasets reduce the cost and effort of data cleaning, while ensuring adherence to the FAIR principles.
The day continued with a speech by Maroš Šefčovič, European Commissioner for Trade and Economic Security, Inter-institutional Relations and Transparency, who underlined the European Commission's commitment to open data as a key pillar for transparency and innovation in the European Union.
Interoperability and data quality
After a break, Georges Lobo and Pavlina Fragkou, programme and project coordinator of SEMIC respectively, explained how the Semantic Interoperability Centre Europe (SEMIC) improves interoperable data exchange in Europe through theData Catalogue Vocabulary Application Profile (DCAT-AP) and Linked Data Event Streams (LDES). His presentation highlighted how these standards facilitate the efficient publication and consumption of data, with case studies such as the Rijksmuseum and the European Union Railway Agency demonstrating their value in fostering interoperable and sustainable data ecosystems.
Barbara Šlibar from the University of Zagreb then provided a detailed analysis of metadata quality in European open datasets, revealing significant disparities in five key dimensions. His study, based on random samples from data.europa.eu, underlined the importance of improving metadata practices and raising awareness among stakeholders to improve the usability and value of open data in Europe.
Then, Bianca Sammer, from Bavarian Agency for Digital Affairs shared her experience creating Germany's open data portal in just one year. His presentation "Unlocking the Potential" highlighted innovative solutions to overcome challenges in open data management. For example, they achieved an automated improvement of metadata quality, a reusable open source infrastructure and participation strategies for public administrations and users.
Open data today and on the horizon
The second day started with interventions by Rafał Rosiński, Undersecretary of State at the Ministry of Digital Affairs of Poland, who presented the Polish Presidency's perspective on open data and digital transformation, and Roberto Viola, Director General of the European Commission's Directorate-General for Communication Networks, Content and Technology, who spoke about the European path to digital innovation.
After the presentation of the day, the presentations on use cases and innovative proposals in open databegan. First, Stefaan Verhulst, co-founder of the New York governance lab GovLab, dubbed the historic moment we are living through as the "fourth wave of open data" characterised by the integration of generative artificial intelligence with open data to address social challenges.. His presentation raised crucial questions about how AI-based conversational interfaces can improve accessibility, what it means for open data to be "AI-ready" and how to build sustainable data-driven solutions that balance openness and trust.
Christos Ellinides, Director General for Translation at the European Commission, then highlighted the importance of language data for AI on the continent. With 25 years of data spanning multiple languages and the expertise to develop multilingual services based on artificial intelligence, the Commission is at the forefront in the field of linguistic data spaces and in the use of European high-performance computing infrastructures to exploit data and AI.
Open data re-use use cases
Reuse brings multiple benefits. Kjersti Steien, from the Norwegian digitisation agency, presented Norway's national data portal, data.norge.no, which employs an AI-powered search engine to improve data discoverability. Using Google Vertex, the engine allows users to find relevant datasets without needing to know the exact terms used by data providers, demonstrating how AI can improve data reuse and adapt to emerging language models.
Beyond Norway, use cases from other cities and countries were also discussed. Sam Hawkins, Ember's UK Data Programme Manager, underlined the importance of open energy data in advancing the clean energy transition and ensuring system flexibility.
Another case was presented by Marika Eik from the University of Estonia, which leverages urban data and cross-sector collaboration to improve sustainability and community impact. His session examined a city-level approach to sustainability metrics and CO2 footprint calculations, drawing on data from municipalities, real estate operators, research institutions and mobility analysts to provide replicable models for improving environmental responsibility.
Raphaël Kergueno of Transparency International EU explained how Integrity Watch EU leverages open data to improve transparency and accountability in the Union. This initiative re-uses datasets such as the EU Transparency Register and the European Commission's meeting records to increase public awareness of lobbying activities and improve legislative oversight, demonstrating the potential of open data to strengthen democratic governance.
Also, Kate Larkin of the European Marine Observatory, presented the European Marine Observation and Data Network, highlighting how pan-European marine data services, which adhere to the FAIR principles contribute to initiatives such as the European Green Pact, maritime spatial planning and the blue economy. His presentation showed practical use cases demonstrating the integration of marine data into wider data ecosystems such as the European Digital Twin Ocean.
Data visualisation and communication
In addition to use cases, the EU Open Data Days 2025 highlighted data visualisation as a mechanism to bring open data to the people. In this vein, Antonio Moneo, CEO of Tangible Data, explored how transforming complex datasets into physical sculptures fosters data literacy and community engagement.
On the other hand, Jan Willem Tulp, founder of TULP interactive, examined how visual design influences the perception of data. His session explored how design elements such as colour, scale and focus can shape narratives and potentially introduce bias, highlighting the responsibilities of data visualisers to maintain transparency while crafting compelling visual narratives.
Education and data literacy
Davide Taibi, researcher at the Italian National Research Council, shared experiences on the integration of data literacy and AI in educational pathways, based on EU-funded projects such as DATALIT, DEDALUS and SMERALD. These initiatives piloted digitally enhanced learning modules in higher education, secondary schools and vocational training in several EU Member States, focusing on competence-oriented approaches and IT-based learning systems.
Nadieh Bremer, founder of Visual Cinnamon, explored how creative approaches to data visualisation can reveal the intricate bonds between people, cultures and concepts. Examples included a family tree of 3,000 European royals, relationships in UNESCO's Intangible Cultural Heritage and cross-cultural constellations in the night sky, demonstrating how iterative design processes can uncover hidden patterns in complex networks.
Digital artist Andreas Refsgaard closed the presentations with a reflection on the intersection of generative AI, art and data science. Through artistic and engaging examples, he invited the audience to reflect on the vast potential and ethical dilemmas arising from the growing influence of digital technologies in our daily lives.
In summary, the EU Open Data Day 2025 has once again demonstrated the importance of these meetings in driving the evolution of the open data ecosystem in Europe. The discussions, presentations and case studies shared during these two days have highlighted not only the progress made, but also the remaining challenges and emerging opportunities. In a context where artificial intelligence, sustainability and citizen participation are transforming the way we use and value data, events like this one are essential to foster collaboration, share knowledge and develop strategies that maximise the social and economic value of open data. The continued engagement of European institutions, national governments, academia and civil society will be essential to build a more robust, accessible and impactful open data ecosystem that responds to the challenges of the 21st century and contributes to the well-being of all European citizens.
You can return to the recordings of each lecture here.
Blog
Today's climate crisis and environmental challenges demand innovative and effective responses. In this context, the European Commission's Destination Earth (DestinE) initiative is a pioneering project that aims to develop a highly accurate digital model of our planet.
Through this digital twin of the Earth it will be possible to monitor and prevent potential natural disasters, adapt sustainability strategies and coordinate humanitarian efforts, among other functions. In this post, we analyse what the project consists of and the state of development of the project.
Features and components of Destination Earth
Aligned with the European Green Pact and the Digital Europe Strategy, Destination Earth integrates digital modeling and climate science to provide a tool that is useful in addressing environmental challenges. To this end, it has a focus on accuracy, local detail and speed of access to information.
In general, the tool allows:
- Monitor and simulate Earth system developments, including land, sea, atmosphere and biosphere, as well as human interventions.
- To anticipate environmental disasters and socio-economic crises, thus enabling the safeguarding of lives and the prevention of significant economic downturns.
- Generate and test scenarios that promote more sustainable development in the future.
To do this, DestinE is subdivided into three main components :
- Data lake:
- What is it? A centralised repository to store data from a variety of sources, such as the European Space Agency (ESA), EUMETSAT and Copernicus, as well as from the new digital twins.
- What does it provide? This infrastructure enables the discovery and access to data, as well as the processing of large volumes of information in the cloud.
·The DestinE Platform:.
- What is it? A digital ecosystem that integrates services, data-driven decision-making tools and an open, flexible and secure cloud computing infrastructure.
- What does it provide? Users have access to thematic information, models, simulations, forecasts and visualisations that will facilitate a deeper understanding of the Earth system.
- Digital cufflinks and engineering:
- What are they? There are several digital replicas covering different aspects of the Earth system. The first two are already developed, one on climate change adaptation and the other on extreme weather events.
- WHAT DOES IT PROVIDE? These twins offer multi-decadal simulations (temperature variation) and high-resolution forecasts.
Discover the services and contribute to improve DestinE
The DestinE platform offers a collection of applications and use cases developed within the framework of the initiative, for example:
- Digital twin of tourism (Beta): it allows to review and anticipate the viability of tourism activities according to the environmental and meteorological conditions of its territory.
- VizLab: offers an intuitive graphical user interface and advanced 3D rendering technologies to provide a storytelling experience by making complex datasets accessible and understandable to a wide audience..
- miniDEA: is an interactive and easy-to-use DEA-based web visualisation app for previewing DestinE data.
- GeoAI: is a geospatial AI platform for Earth observation use cases.
- Global Fish Tracking System (GFTS): is a project to help obtain accurate information on fish stocks in order to develop evidence-based conservation policies.
- More resilient urban planning: is a solution that provides a heat stress index that allows urban planners to understand best practices for adapting to extreme temperatures in urban environments..
- Danube Delta Water Reserve Monitoring: is a comprehensive and accurate analysis based on the DestinE data lake to inform conservation efforts in the Danube Delta, one of the most biodiverse regions in Europe.
Since October this year, the DestinE platform has been accepting registrations, a possibility that allows you to explore the full potential of the tool and access exclusive resources. This option serves to record feedback and improve the project system.
To become a user and be able to generate services, you must follow these steps..
Project roadmap:
The European Union sets out a series of time-bound milestones that will mark the development of the initiative:
- 2022 - Official launch of the project.
- 2023 - Start of development of the main components.
- 2024 - Development of all system components. Implementation of the DestinE platform and data lake. Demonstration.
- 2026 - Enhancement of the DestinE system, integration of additional digital twins and related services.
- 2030 - Full digital replica of the Earth.
Destination Earth not only represents a technological breakthrough, but is also a powerful tool for sustainability and resilience in the face of climate challenges. By providing accurate and accessible data, DestinE enables data-driven decision-making and the creation of effective adaptation and mitigation strategies.
Blog
The Big Data Test Infrastructure (BDTI) is a tool funded by the European Digital Agenda, which enables public administrations to perform analysis with open data and open source tools in order to drive innovation.
This free-to-use, cloud-based tool was created in 2019 to accelerate digital and social transformation. With this approach and also following the European Open Data Directive, the European Commission concluded that in order to achieve a digital and economic boost, the power of public administrations' data should be harnessed, i.e. its availability, quality and usability should be increased. This is how BDTI was born, with the purpose of encouraging the reuse of this information by providing a free analysis test environment that allows public administrations to prototype solutions in the cloud before implementing them in the production environment of their own facilities.
What tools does BDTI offer?
Big Data Test Infrastructure offers European public administrations a set of standard open source tools for storing, processing and analysing their data. The platform consists of virtual machines, analysis clusters, storage and network facilities. The tools it offers are:
- Databases: to store data and perform queries on the stored data. The BDTI currently includes a relational database(PostgreSQL), a document-oriented database(MongoDB) and a graph database(Virtuoso).
- Data lake: for storing large amounts of structured and unstructured data (MinIO). Unstructured raw data can be processed with deployed configurations of other building blocks (BDTI components) and stored in a more structured format within the data lake solution.
- Development environments: provide the computing capabilities and tools necessary to perform standard data analysis activities on data from external sources, such as data lakes and databases.
- JupyterLab, an interactive, online development environment for creating Jupyter notebooks, code and data.
- Rstudio, an integrated development environment for R, a programming language for statistical computing and graphics.
- KNIME, an open source data integration, reporting and analytics platform with machine learning and data mining components, can be used for the entire data science lifecycle.
- H2O.ai, an open sourcemachine learning ( ML) and artificial intelligence (AI) platform designed to simplify and accelerate the creation, operation and innovation with ML and AI in any environment.
- Advanced processing: clusters and tools can also be created to process large volumes of data and perform real-time search operations(Apache Spark, Elasticsearch and Kibana)
- Display: BDTI also offers data visualisation applications such as Apache Superset, capable of handling petabyte-scale data, or Metabase.
- Orchestration: for the automation of data-driven processes throughout their lifecycle, from preparing data to making data-driven decisions and taking actions based on those decisions, is offered:
- Apache Airflow, an open source workflow management platform that allows complex data pipelines to be easily scheduled and executed.
Through these cloud-based tools, public workers in EU countries can create their own pilot projects to demonstrate the value that data can bring to innovation. Once the project is completed, users have the possibility to download the source code and data to continue the work themselves, using environments of their choice. In addition, civil society, academia and the private sector can participate in these pilot projects, as long as there is a public entity involved in the use case.
Success stories
These resources have enabled the creation of various projects in different EU countries. Some examples of use cases can be found on the BDTI website. For example, Eurostat carried out a pilot project using open data from internet job advertisements to map the situation of European labour markets. Other success stories included the optimisation of public procurement by the Norwegian Agency for Digitisation, data sharing efforts by the European Blood Alliance and work to facilitate understanding of the impact of COVID-19 on the city of Florence .
In Spain, BDTI enabled a data mining project atthe Conselleria de Sanitat de la Comunidad Valenciana. Thanks to BDTI, knowledge could be extracted from the enormous amount of scientific clinical articles, a task that supported clinicians and managers in their clinical practices and daily work.

Courses, newsletter and other resources
In addition to publishing use cases, theBig Data Test Infrastructure website offers an free online course to learn how to get the most out of BDTI. This course focuses on a highly practical use case: analysing the financing of green projects and initiatives in polluted regions of the EU, using open data from data.europa.eu and other open sources.
In addition, a monthly newsletter on the latest BDTI news, best practices and data analytics opportunities for the public sector has recently been launched .
In short, the re-use of public sector data (RISP) is a priority for the European Commission and BDTI(Big Data Test Infrastructure) is one of the tools contributing to its development. If you work in the public administration and you are interested in using BDTI register here.
Blog
Last November 2023, Crue Spanish Universities published the report TIC360 "Data Analytics in the University". The report is an initiative of the Crue-Digitalisation IT Management working group and aims to show how the optimisation of data extraction and processing processes is key to the generation of knowledge in Spanish public university environments. To this end, five chapters address certain aspects related to data holdings and the analytical capacities of universities to generate knowledge about their functioning.
The following is a summary of the chapters, explaining to the reader what can be found in each chapter.
Why is data analytics important and what are the challenges?
In the introduction, the concept of data analytics is recalled as the extraction of knowledge from available data, highlighting its growing importance in the current era. Data analytics is the right tool to obtain the necessary information to support decision-making in different fields. Among other things, it helps to optimise management processes or improve the energy efficiency of the organisation, to give a few examples. While fundamental to all sectors, the paper focuses on the potential impact of data on the economy and education, emphasising the need for an ethical and responsible approach.
The report explores the accelerated development of this discipline, driven by the abundance of data and advanced computing power; however, it also warns about the inherent risks of tools based on techniques and algorithms that are still under development, and that may introduce biases based on age, background, gender, socio-economic status, etc.In this regard, it is important to bear in mind the importance of privacy, personal data protection, transparency and explainability, i.e. when an algorithm generates a result, it must be possible to explain how that result has been arrived at.
A good summary of this chapter is the following sentence by the author: "Good use of data will not lead us to paradise, but it can build a more sustainable, just and inclusive society. On the contrary, its misuse could bring us closer to a digital hell.
How would universities benefit from participating in Data Spaces?
The first chapter, starting from the premise that data is the main protagonist and the backbone asset of the digital transformation, addresses the concept of the Data Spacehighlighting its relevance in the European Commission's strategy as the most important asset of the data economy.
Highlighting the potential benefits of data sharing, the chapter highlights how the data economy, driven by a single market for shared data, can be aligned with European values and contribute to a fairer and more inclusive digital economy. Initiatives such as the Digital Spain Strategy 2026which highlights the role of data as a key asset in digital transformation.
There are many advantages to university participation in data spaces, such as sharing, accessing and reusing data resources generated by other university communities. This allows for faster progress in research, optimising the public resources previously dedicated to research. One initiative that demonstrates these benefits is the European Open Science Space (EOSC)which aims to link researchers and practitioners in science and technology in a virtual environment with open and seamless services for the storage, management, analysis and re-use of scientific data, across physical boundaries and scientific disciplines. The chapter also introduces different aspects related to data spaces such as guiding principles, legislation, participants and roles to be considered. It also highlights some issues related to the governance of data spaces and the technologies needed for their deployment.
What is the European Skill Data Space (ESDS)?
This second chapter explores the creation of a common European data space, with a focus on skills. This space aims to reduce the gap between educational skills and labour market needs, increasing productivity and competitiveness through cross-border access to key data for the creation of applications and other innovative uses. In this respect, it is essential to take into account the release of the version 3.1 of the European Learning Model (ELM)which is to be consolidated as the single European data model for all types of learning (formal, non-formal, informal) as the basis for the European Skills Data Space.
The report defines the key phases and elements for the creation and integration into the European Skills Data Space, highlighting what contributions the different roles (education and training provider, jobseeker, citizen, learner and employer) could make and expect.
what is the role of the Spanish university in the context of European Data Spaces?
This chapter focuses on the role of Spanish universities within European data spaces as a key agent for the country's digital transformation. To achieve these results and reap the benefits of data analytics and interaction with European data spaces, institutions must move from a static model, based on medium- and long-term planning criteria, to flexible models more suited to the liquid reality in which we live, so that data can be harnessed to improve education and research.
In this context, the importance of collaboration and data exchange at European level is crucial, but taking into account existing legislation, both generic and domain-specific. In this sense, we are witnessing a revolution for which compliance and commitment on the part of the university organisation is crucial. There is a risk that organisations that are not able to comply with the regulatory block will not be able to generate high quality datasets.
Finally, the chapter offers a number of indications as to what kind of staff universities should have in order not to be deprived of creating a corps of analysts and computer experts, vital for the future.
What kind of certifications exist in the field of data?
In order to address the challenges introduced in the chapters of the report, universities need to have in place: (1) data with adequate standards; (2) good practices with regard to governance, management and quality; and (3) sufficiently qualified and skilled professionals to perform the different tasks. To convey confidence in these elements, this chapter justifies the importance of having certifications for the three elements presented:
- Data product quality level certifications such as ISO/IEC 25012, ISO/IEC 25024 and ISO/IEC 25040.
- Organisational maturity level certifications with respect to data governance, data management and data quality management, based on the MAMD model.
- Certifications of personal data competences, such as those related to technological skills or professional competence certifications, including those issued by CDMP or the CertGed Certification.
What is the state of the University in the data age?
Although progress has been made in this area, Spanish universities still have a long way to go to adapt and transform themselves into data-driven organisations in order to get the maximum benefit from data analytics. In this sense, it is necessary to update the way of operating in all the areas covered by the university, which requires acting and leading the necessary changes in order to be competitive in the new reality in which we are already living.
The aim is for analytics to have an impact on the improvement of university teaching, for which the digitisation of teaching and learning processesis fundamental. This will also generate benefits in the personalisation of learning and the optimisation of administrative and management processes.
In summary, data analytics is an area of great importance for improving the efficiency of the university sector, but to achieve its full benefits, further work is needed on both the development of data spaces and staff training. This report seeks to provide information to move the issue forward in both directions.
The document is publicly available for reading at: https://www.crue.org/wp-content/uploads/2023/10/TIC-360_2023_WEB.pdf
Content prepared by Dr. Ismael Caballero, Full Professor at UCLM
The contents and points of view reflected in this publication are the sole responsibility of its author.
Evento
There is never an end to opportunities to discuss, learn and share experiences on open data and related technologies. In this post, we select some of the upcoming ones, and tell you everything you need to know: what it's about, when and where it takes place and how you can register.
Don't miss this selection of events on cutting-edge topics such as geospatial data, accessible data reuse strategies and even innovative trends in data journalism. the best thing? All are free of charge.
Let's talk about data in Alicante
The National Association of Big Data and Analytics (ANBAN) is organising an open and free event in Alicante to debate and exchange views on data and artificial intelligence. During the meeting, not only will use cases that relate data with AI be presented, but also a part of the event will be dedicated to encourage networking among the attendees.
- What is it about? let's talk about data' will start with two talks on artificial intelligence projects that are already making an impact. Afterwards, the course on AI organised by the University of Alicante together with ANBAN will be explained. The final part of the event will be more relaxed to encourage attendees to make valuable connections.
- When and where? Thursday 29 February at 20.30h at ULAB (Pza. San Cristóbal, 14) in Alicante.
- How do I register? Book your place by signing up here: https://www.eventbrite.es/e/entradas-hablemos-del-dato-beers-alicante-823931670807?aff=oddtdtcreator&utm_source=rrss&utm_medium=colaborador&utm_campaign=HDD-ALC-2902
Open Data Day in Barcelona: Re-using data to improve the city
Open Data Day is an international event that brings together open data activities around the world. Within this framework, the barcelona Open Data initiative initiative has organised an event to discuss projects and strategies for the publication and reuse of open data to make a clean, safe, friendly and accessible city possible.
- What is it about? Through open data projects and data-driven strategies, the challenge of security, coexistence of uses and maintenance of shared spaces in municipalities will be addressed. The aim is to generate dialogue between organisations that publish and reuse data to add value and develop strategies together.
- When and where? On 6 March from 5 to 7.30 p.m. at Ca l'Alier (C/ de Pere IV, 362).
- How do I register? Through this link: https://www.eventbrite.es/e/entradas-open-data-day-2024-819879711287?aff=oddtdtcreator
Presentation of the "Good Practice Guide for Data Journalists"
The Valencian Observatory of Open Data and Transparency of the Universitat Politècnica de València has created a guide for journalists and data professionals with practical advice on how to turn data into attractive and relevant journalistic stories for society. The author of this reference material will talk to a data journalist about the challenges and opportunities that data offers in journalism.
- What is it about? It is an event that will address key concepts of the Good Practice Guide for Data Journalists through practical examples and cases to analyse and visualise data correctly. Ethics will also be a theme of the presentation.
- When and where? Friday 8th March from 12h to 13h in the Assembly Hall of the Faculty of ADE of the UPV (Avda. Tarongers s/n) in Valencia.
- How do I register? More information and registration here: https://www.eventbrite.es/e/entradas-presentacion-de-la-guia-de-buenas-practicas-para-periodistas-de-datos-835947741197
Geodata Conference of the Madrid City Council Geoportal
Madrid hosts the sixth edition of this event which brings together heads of institutions and benchmark companies in cartography, geographic information systems, digital twin, BIM, Big Data and artificial intelligence. The event will also be used as an opportunity to award the prizes of the Geodata Stand.
- What is it about? Followingin the footsteps of previous years, the Madrid Geodata Conference will present case studies and new developments in cartography, digital twinning, reuse of georeferenced data, as well as the best papers presented at the Geodata Stand.
- When and where? The event starts on 12 March at 9am in the Auditorio de La Nave in Madrid and will last until 2pm. The following day, 13 March, the session will be virtual and will present the projects and new developments in geo-information production and distribution via the Madrid Geoportal.
- How do I register? Through the event portal. Places are limited https://geojornadas.madrid.es/
3rd URJC Free Culture Conference
The Free Culture Conference of the Universidad Rey Juan Carlos is a meeting point, learning and exchange of experiences about free culture in the university. Topics such as open publishing of teaching and research materials, open science, open data, and free software will be addressed.
- What is it about? The two-day event will feature presentations by experts, workshops on specific topics and an opportunity for the university community to present papers. In addition, there will be an exhibition space where tools and news related to culture and free software will be shared, as well as a poster exhibition area
- When and where? 20 and 21 March at the Fuenlabrada Campus of the URJC
- How do I register? Registration is free of charge via this link: https://eventos.urjc.es/109643/tickets/iii-jornadas-de-cultura-libre-de-la-urjc.html
These are some of the upcoming events. In any case, don't forget to follow us on social media so you don't miss any news about innovation and open data. We are on Twitter y LinkedIn you can also write to us at dinamizacion@datos.gob.es if you would like us to add another event to the list or if you need extra information.
Blog
We are living in a historic moment in which data is a key asset, on which many small and large decisions of companies, public bodies, social entities and citizens depend every day. It is therefore important to know where each piece of information comes from, to ensure that the issues that affect our lives are based on accurate information.
What is data subpoena?
When we talk about "citing" we refer to the process of indicating which external sources have been used to create content. This is a highly commendable issue that affects all data, including public data as enshrined in our legal system. In the case of data provided by administrations, Royal Decree 1495/2011 includes the need for the reuser to cite the source of origin of the information.
To assist users in this task, the Publications Office of the European Union published Data Citation: A guide to best practice, which discusses the importance of data citation and provides recommendations for good practice, as well as the challenges to be overcome in order to cite datasets correctly.
Why is data citation important?
The guide mentions the most relevant reasons why it is advisable to carry out this practice:
- Credit. Creating datasets takes work. Citing the author(s) allows them to receive feedback and to know that their work is useful, which encourages them to continue working on new datasets.
- Transparency. When data is cited, the reader can refer to it to review it, better understand its scope and assess its appropriateness.
- Integrity. Users should not engage in plagiarism. They should not take credit for the creation of datasets that are not their own.
- Reproducibility. Citing the data allows a third party to attempt to reproduce the same results, using the same information.
- Re-use. Data citation makes it easier for more and more datasets to be made available and thus to increase their use.
- Text mining. Data is not only consumed by humans, it can also be consumed by machines. Proper citation will help machines better understand the context of datasets, amplifying the benefits of their reuse.
General good practice
Of all the general good practices included in the guide, some of the most relevant are highlighted below:
- Be precise. It is necessary that the data cited are precisely defined. The data citation should indicate which specific data have been used from each dataset. It is also important to note whether they have been processed and whether they come directly from the originator or from an aggregator (such as an observatory that has taken data from various sources).
- It uses "persistent identifiers" (PIDs). Just as every book in a library has an identifier, so too can (and should) have an identifier. Persistent identifiers are formal schemes that provide a common nomenclature, which uniquely identify data sets, avoiding ambiguities. When citing datasets, it is necessary to locate them and write them as an actionable hyperlink, which can be clicked on to access the cited dataset and its metadata. There are different families of PIDs, but the guide highlights two of the most common: the Handle system and the Digital Object Identifier (DOI).
- Indicates the time at which the data was accessed. This issue is of great importance when working with dynamic data (which are updated and changed periodically) or continuous data (on which additional data are added without modifying the old data). In such cases, it is important to cite the date of access. In addition, if necessary, the user can add "snapshots" of the dataset, i.e. copies taken at specific points in time.
- Consult the metadata of the dataset used and the functionalities of the portal in which it is located. Much of the information necessary for the citation is contained in the metadata.
In addition, data portals can include tools to assist with citation. This is the case of data.europa.ue, where you can find the citation button in the top menu.
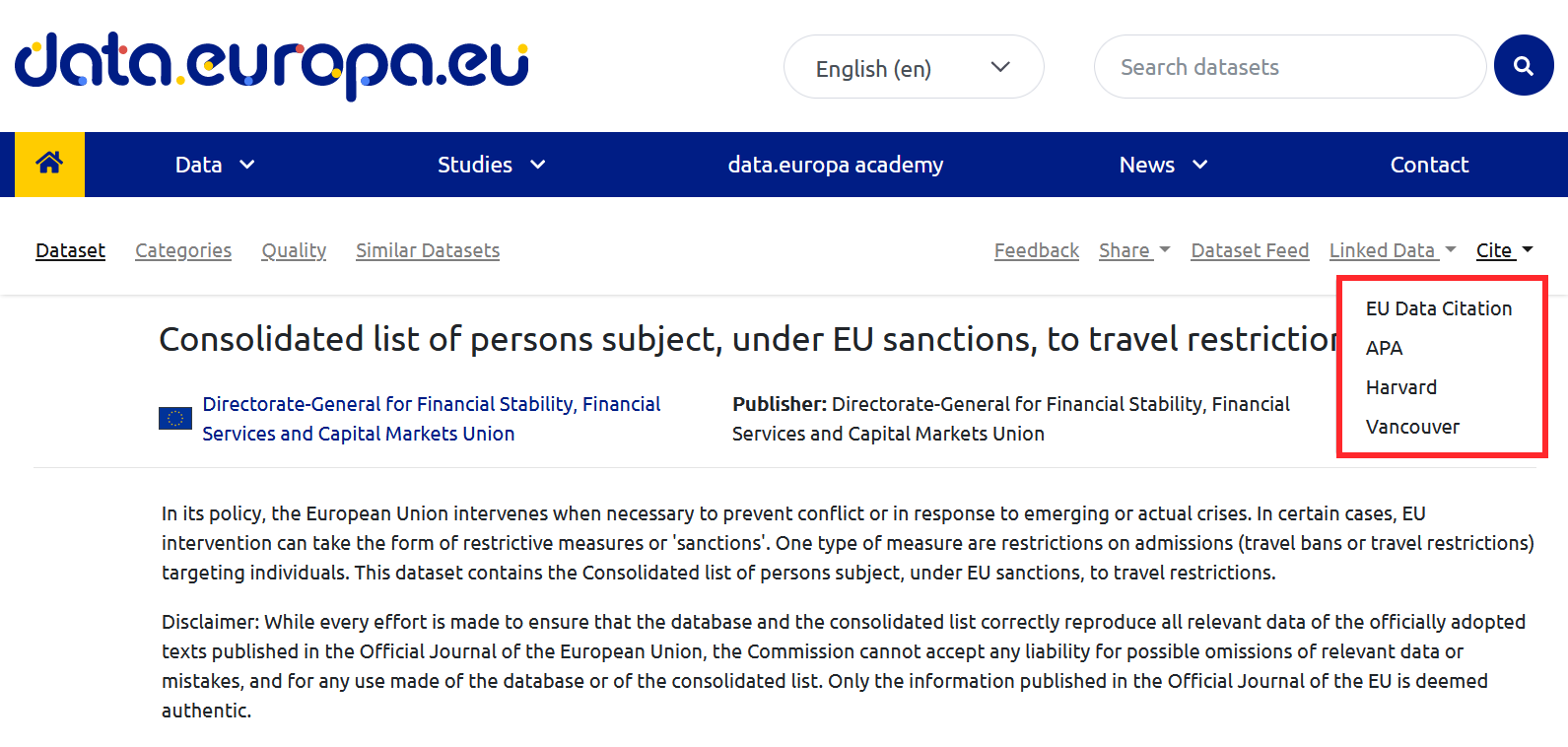
- Rely on software tools. Most of the software used to create documents allows for the automatic creation and formatting of citations, ensuring their formatting. In addition, there are specific citation management tools such as BibTeX or Mendeley, which allow the creation of citation databases taking into account their peculiarities, a very useful function when it is necessary to cite numerous datasets in multiple documents
With regard to the order of all this information, there are different guidelines for the general structure of citations. The guide shows the most appropriate forms of citation according to the type of document in which the citation appears (journalistic documents, online, etc.), including examples and recommendations. One example is the Interinstitutional Style Guide (ISG), which is published by the EU Publications Office. This style guide does not contain specific guidance on how to cite data, but it does contain a general citation structure that can be applied to datasets, shown in the image below.
How to cite correctly
The second part of the report contains the technical reference material for creating citations that meet the above recommendations. It covers the elements that a citation should include and how to arrange them for different purposes.
Elements that should be included in a citation include:
- Author, can refer to either the individual who created the dataset (personal author) or the responsible organisation (corporate author).
- Title of the dataset.
- Version/edition.
- Publisher, which is the entity that makes the dataset available and may or may not coincide with the author (in case of coincidence it is not necessary to repeat it).
- Date of publication, indicating the year in which it was created. It is important to include the time of the last update in brackets.
- Date of citation, which expresses the date on which the creator of the citation accessed the data, including the time if necessary. For date and time formats, the guide recommends using the DCAT specification , as it offers greater accuracy in terms of interoperability.
- Persistent identifier.

The guide ends with a series of annexes containing checklists, diagrams and examples.
If you want to know more about this document, we recommend you to watch this webinar where the most important points are summarised.
Ultimately, correctly citing datasets improves the quality and transparency of the data re-use process, while at the same time stimulating it. Encouraging the correct citation of data is therefore not only recommended, but increasingly necessary.
Blog
It is now almost five years since the publication of the study on the first decade of open data by the Open Data for Development (OD4D) network and more than 60 expert authors from around the world. This first edition of the study highlighted the importance of open data in socio-economic development and global problem solving. It also highlighted progress in making data more accessible and reusable , and at the same time began to elaborate on the need to take into account other key issues such as data justice, the need for responsible AI and privacy challenges.
Over the last year and a half, the new Data for Development (D4D) network has been organising a series of discussions to analyse the evolution of the open data movement in recent years and to publish an update of the previous study. Preliminary general conclusions from these discussions include:
- The need to make impact stories more visible as a way to encourage greater openness and availability of data.
- The desirability of opening up data in a way that meets the needs of potential users and beneficiaries, and that is done in a collaborative way with the community.
- Advocate for donor organisations to add as part of their grant programmes a requirement for grantees to develop and implement open data plans.
- Prioritise the need for interoperable data sharing.
- Publish more data focused on improving the situation of historically marginalised groups.
- Increase efforts to further develop the technical capacities required for the implementation of open data.
- Delve into the creation, evolution and implementation of the legal and policy frameworks necessary to support all of the above.
At the same time, there was a process of updating the study underway, analysing the progress made over the last few years in each of the sectors and communities covered by the original study. As a result of this process, we can already see some previews of the most important developments over the last few years, as well as the remaining challenges in various areas, which we review below. The 2nd Edition of the State of Open Data in a brand new online format with 30 new chapter updates and a renewed vision to guide open data agendas in the years to come.
Sectoral developments
Some of the most relevant developments in different key sectors over the last five years include the following:
Accountability and anti-corruption: There has been a rapid increase in the use of data in this area, although its impact is not well documented and the use of open data in this area should focus more on the problems identified and work more collaboratively with all stakeholders.
Agriculture: The agri-food sector has focused on facilitating the secure and efficient sharing of data by applying the principles of the FAIR (Findable, Accessible, Interoperable and Reusable) data model , mainly due to reluctance to share some of the more personal data.
Shipping: This is a sector where public authorities clearly recognise the importance of open data in building transport ecosystems that contribute to addressing global issues such as sustainable development and climate change. The main challenges identified in this case are interoperability and data privacyprotection.
Health: The practice of collecting, sharing and using health-related data has accelerated considerably due to the effects of the Covid-19 pandemic . At the same time, the containment measures carried out during this period in terms of contact tracing and quarantines have contributed to increased recognition of the importance of digital rights for health data.
National statistics: Open data has established itself as an integral part of national statistics, but there is a significant risk of regression. International organisations are no longer so much focused on disseminating data as on encouraging its use to generate value and impact. Therefore, it is now necessary to focus on the sustainability of initiatives in order to ensure equitable access and enhance the social good.
Action on climate change: In recent years, the quality and availability of climate data has improved in some very specific sectors, such as energy. However, there are still large gaps in other areas, for example in cities or the private sector. On the other hand, the available climate datasets present other challenges such as being often too technical, poorly formatted or not addressing specific use cases and problems.
Urban development: Open data is playing an increasingly important role in the context of urban development globally through its promotion of equity, its contribution to climate change mitigation and the improvement of crisis response systems. In addition, the continuous development and growth of urban technologies such as the Internet of Things (IoT), digitalsandboxes or digital twins is creating the need to improve data quality and interoperability - which at the same time pushes the development of open data. The task ahead in this sector is to achieve greater citizen participation.
Cross-cutting developments
In addition to sectoral developments, we must also take into account those cross-cutting trends that have the potential to affect all sectors, which are described below:
Artificial Intelligence: AI applications have an increasing influence on what data is published and how it is structured. Governments and others are striving to complete the open data available for AI training that is necessary to avoid the biases that currently exist . To make this possible, new mechanisms are also being developed to enable access to sensitive data that cannot be published directly under open licences.
Data literacy: Low data literacy remains one of the main factors delaying the exploitation of open data, although there have also been some important developments at the level of industry, civil society, government and educational institutions - particularly in the context of the urgent need to counter the growing amount of misinformation being misused.
Gender equality: In recent years the Covid-19 pandemic and other global political events have compounded the challenges for women and other marginalised groups. Progress in the publication and use of open data on gender has been generally slow and more resources would need to be made available to improve this situation.
Privacy: The growing demand for personal data and the increasing use of multiple data sources in combination has increased privacy risks. Group privacy is also an emerging concern and some debate has also formed about the necessary balance between transparency and privacy protection in some cases. In addition, there is also a demand for better data governance and oversight mechanisms for adequate data protection.
What's New Geographically
Finally, we will review some of the trends observed at the regional level:
South and East Asia: There has been little change in the region's open data landscape with several countries experiencing a decline in their open data practices after facing changes in their governments. At a general level, improvements can be seen in a more conducive bureaucratic environment and in data-related skills. However, all this is not yet translating into real impact due to lack of re-use.
Sub-Saharan Africa: The open data movement has expanded considerably in the region in recent years, involving new actors from the private sector and civil society. This dynamisation has been made possible mainly by following an approach based on addressing the challenges stemming from the Sustainable Development Goals. However, there are still significant gaps in the capacity to collect data and to ensure its ethical treatment.
Latin America: As in other parts of the world, open data agendas are not advancing at the same pace as a few years ago. Some progress can be seen in some types of data such as public finance, but also large gaps in other areas such as business information or data on climate action. In addition, there is still a lot of basic work to be done in terms of data openness and availability.
North America and Oceania: There is a shift towards institutionalising data policies and the structures needed to integrate open data into the culture of public governance more broadly. The use of open data during Covid-19 to facilitate transparency, communication, research and policy-making served to demonstrate its multi-purpose nature in this area.
These are just a few previews of what we will see in the next edition of the study on the evolution of the open data movement. In the 2nd Edition of the State of Open Data we can know in detail all the progress of the last five years, the new challenges and the challenges that remain. As we enter a new phase in the evolution of open data, it will also be interesting to see how these lessons and recommendations are put into practice, and at the same time also to begin to imagine how open data will be positioned on the global agenda in the coming years.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
What challenges do data publishers face?
In today's digital age, information is a strategic asset that drives innovation, transparency and collaboration in all sectors of society. This is why data publishing initiatives have developed enormously as a key mechanism for unlocking the potential of this data, allowing governments, organisations and citizens to access, use and share it.
However, there are still many challenges for both data publishers and data consumers. Aspects such as the maintenance of APIs(Application Programming Interfaces) that allow us to access and consume published datasets or the correct replication and synchronisation of changing datasets remain very relevant challenges for these actors.
In this post, we will explore how Linked Data Event Streams (LDES), a new data publishing mechanism, can help us solve these challenges. what exactly is LDES? how does it differ from traditional data publication practices? And, most importantly, how can you help publishers and consumers of data to facilitate the use of available datasets?
Distilling the key aspects of LDES
When Ghent University started working on a new mechanism for the publication of open data, the question they wanted to answer was: How can we make open data available to the public? What is the best possible API we can design to expose open datasets?
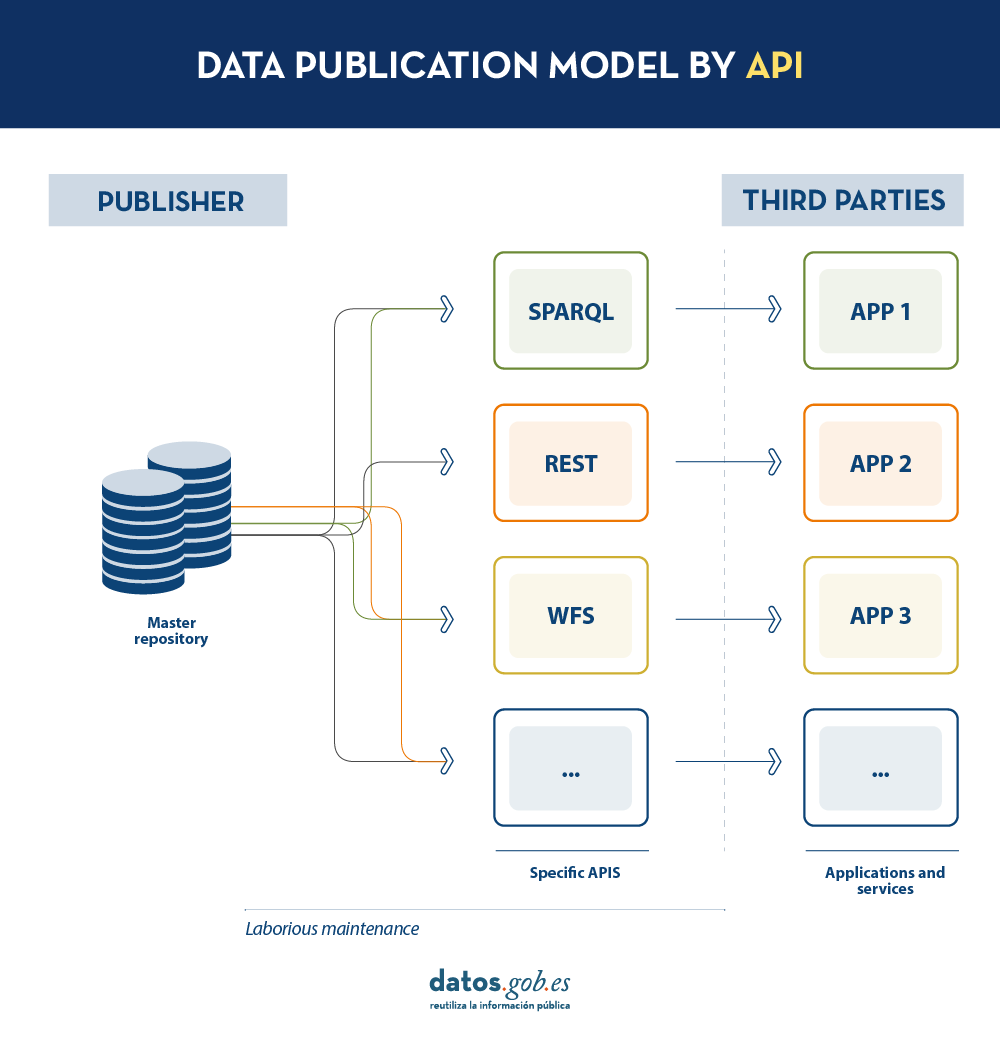
Today, data publishers use multiple mechanisms to publish their different datasets. On the one hand, it is easy to find APIs. These include SPARQL, a standard for querying linked data(Link Data), but also REST or WFS, for accessing datasets with a geospatial component. On the other hand, it is very common that we find the possibility to access data dumps in different formats (i.e. CSV, JSON, XLS, etc.) that we can download for use.
In the case of data dumps, it is very easy to encounter synchronisation problems. This occurs when, after a first dump, a change occurs that requires modification of the original dataset, such as changing the name of a street in a previously downloaded street map. Given this change, if the third party chooses to modify the street name on the initial dump instead of waiting for the publisher to update its data in the master repository to perform a new dump, the data handled by the third party will be out of sync with the data handled by the publisher. Similarly, if it is the publisher that updates its master repository but these changes are not downloaded by the third party, both will handle different versions of the dataset.
On the other hand, if the publisher provides access to data through query APIs, rather than through data dumps to third parties, synchronisation problems are solved, but building and maintaining a high and varied volume of query APIs is a major effort for data publishers.
LDES seeks to solve these different problems by applying the concept of Linked Data to an event stream . According to the definition in its own specification, a Linked Data Event Stream (LDES) is a collection of immutable objects where each object is described in RDF terns.
Firstly, the fact that the LDES are committed to Linked Data provides design principles that allow combining diverse data and/or data from different sources, as well as their consultation through semantic mechanisms that allow readability by both humans and machines. In short, it provides interoperability and consistency between datasets, thus facilitating search and discovery.
On the other hand, the event streams or data streams, allow consumers to replicate the history of datasets, as well as synchronise recent changes. Any new record added to a dataset, or any modification of existing records (in short, any change), is recorded as a new incremental event in the LDES that will not alter previous events. Therefore, data can be published and consumed as a sequence of events, which is useful for frequently changing data, such as real-time information or information that undergoes constant updates, as it allows synchronisation of the latest updates without the need for a complete re-download of the entire master repository after each modification.
In such a model, the publisher will only need to develop and maintain one API, the LDES, rather than multiple APIs such as WFS, REST or SPARQL. Different third parties wishing to use the published data will connect (each third party will implement its LDES client) and receive the events of the streams to which they have subscribed. Each third party will create from the information collected the specific APIs it deems appropriate based on the type of applications they want to develop or promote. In short, the publisher will not have to solve all the potential needs of each third party in the publication of data, but by providing an LDES interface (minimum base API), each third party will focus on its own problems.
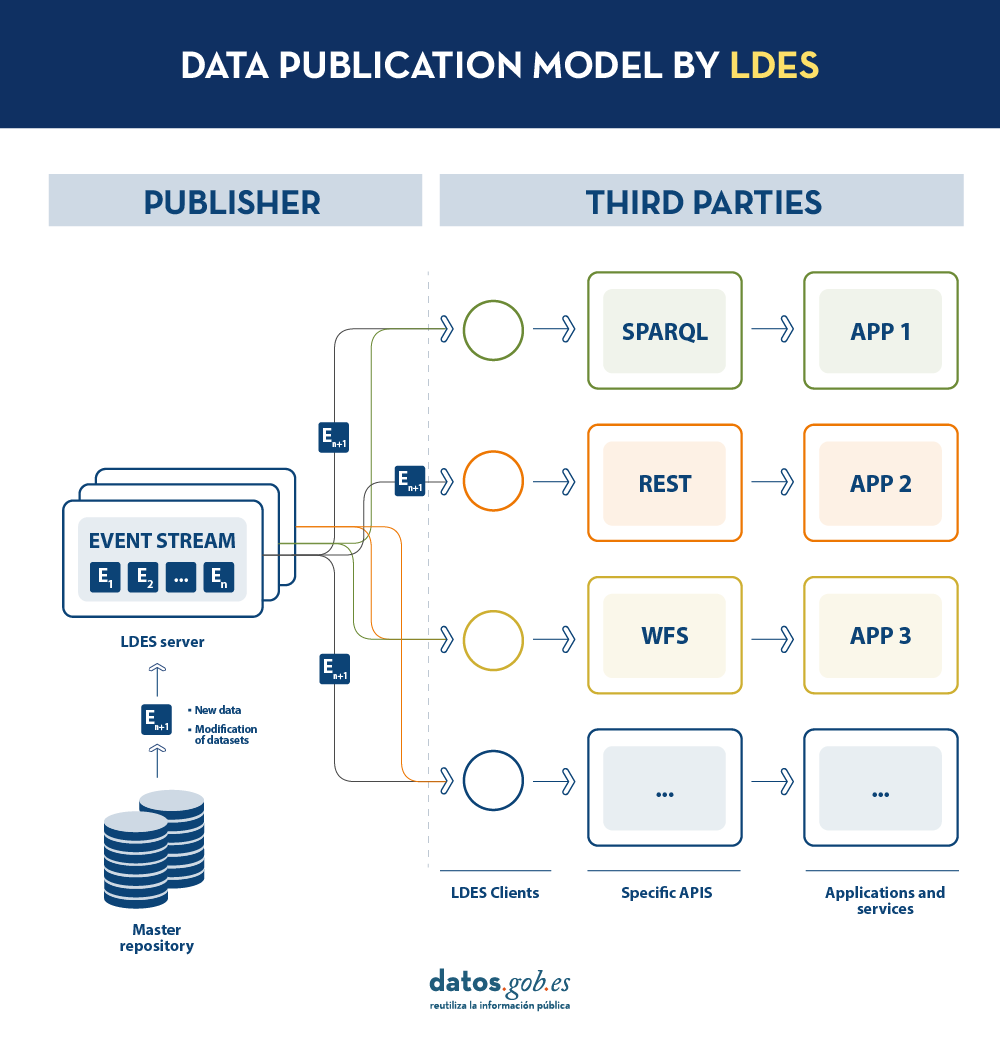
In addition, to facilitate access to large volumes of data or to data that may be distributed across different sources, such as an inventory of electric charging points in Europe, LDES provides the ability to fragment datasets. Through the TREE specification, LDES allows different types of relationships between data fragments to be established. This specification allows publishing collections of entities, called members, and provides the ability to generate one or more representations of these collections. These representations are organised as views, distributing the members through pages or nodes interconnected by relationships. Thus, if we want the data to be searchable through temporal indexes, it is possible to set a temporal fragmentation and access only the pages of a temporal interval. Similarly, alphabetical or geospatial indexes can be provided and a consumer can access only the data needed without the need to 'dump' the entire dataset.
What conclusions can we draw from LDES?
In this post we have looked at the potential of LDES as a mechanism for publishing data. Some of the most relevant learnings are:
- LDES aims to facilitate the publication of data through minimal base APIs that serve as a connection point for any third party wishing to query or build applications and services on top of datasets.
- The construction of an LDES server, however, has a certain level of technical complexity when it comes to establishing the necessary architecture for the handling of published data streams and their proper consultation by data consumers.
- The LDES design allows the management of both high rate of change data (i.e. data from sensors) and low rate of change data (i.e. data from a street map). Both scenarios can handle any modification of the dataset as a data stream.
- LDES efficiently solves the management of historical records, versions and fragments of datasets. This is based on the TREE specification, which allows different types of fragmentation to be established on the same dataset.
Would you like to know more?
Here are some references that have been used to write this post and may be useful to the reader who wishes to delve deeper into the world of LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
The European Open Science Cloud (EOSC) is a European Union initiative that aims to promote open science through the creation of an open, collaborative and sustainabledigital research infrastructure. EOSC's main objective is to provide European researchers with easier access to the data, tools and resources they need to conduct quality research.
EOSC on the European Research and Data Agenda
EOSC is part of the 20 actions of the European Research Area (ERA) agenda 2022-2024 and is recognised as the European data space for science, research and innovation, to be integrated with other sectoral data spaces defined in the European data strategy. Among the expected benefits of the platform are the following:
- An improvement in the confidence, quality and productivity of European science.
- The development of new innovative products and services.
- Improving the impact of research in tackling major societal challenges.
The EOSC platform
EOSC is in fact an ongoing process that sets out a roadmap in which all European states participate, based on the central idea that research data is a public good that should be available to all researchers, regardless of their location or affiliation. This model aims to ensure that scientific results comply with the FAIR (Findable, Accessible, Interoperable, Reusable) Principles to facilitate reuse, as in any other data space.
However, the most visible part of EOSC is its platform that gives access to millions of resources contributed by hundreds of content providers. This platform is designed to facilitate the search, discovery and interoperability of data and other content such as training resources, security, analysis, tools, etc. To this end, the key elements of the architecture envisaged in EOSC include two main components:
- EOSC Core: which provides all the basic elements needed to discover, share, access and reuse resources - authentication, metadata management, metrics, persistent identifiers, etc.
- EOSC Exchange: to ensure that common and thematic services for data management and exploitation are available to the scientific community.
In addition, the ESOC Interoperability Framework (EOSC-IF)is a set of policies and guidelines that enable interoperability between different resources and services and facilitate their subsequent combination.
The platform is currently available in 24 languages and is continuously updated to add new data and services. Over the next seven years, a joint investment by the EU partners of at least EUR 1 billion is foreseen for its further development.
Participation in EOSC
The evolution of EOSC is being guided by a tripartite coordinating body consisting of the European Commission itself, the participating countries represented on the EOSC Steering Board and the research community represented through the EOSC Association. In addition, in order to be part of the ESCO community, you only have to follow a series of minimum rules of participation:
- The whole EOSC concept is based on the general principle of openness.
- Existing EOSC resources must comply with the FAIR principles.
- Services must comply with the EOSC architecture and interoperability guidelines.
- EOSC follows the principles of ethical behaviour and integrity in research.
- EOSC users are also expected to contribute to EOSC.
- Users must comply with the terms and conditions associated with the data they use.
- EOSC users always cite the sources of the resources they use in their work.
- Participation in EOSC is subject to applicable policies and legislation.
EOSC in Spain
The Consejo Superior de Investigaciones Científicas (CSIC) of Spain was one of the 4 founding members of the association and is currently a commissioned member of the association, in charge of coordination at national level.
CSIC has been working for years on its open access repository DIGITAL.CSIC as a step towards its future integration into EOSC. Within its work in open science we can highlight for example the adoption of the Current Research Information System (CRIS), information systems designed to help research institutions to collect, organise and manage data on their research activity: researchers, projects, publications, patents, collaborations, funding, etc.
CRIS are already important tools in helping institutions track and manage their scientific output, promoting transparency and open access to research. But they can also play an important role as sources of information feeding into the EOSC, as data collected in CRIS can also be easily shared and used through the EOSC.
The road to open science
Collaboration between CRIS and ESCO has the potential to significantly improve the accessibility and re-use of research data, but there are also other transitional actions that can be taken on the road to producing increasingly open science:
- Ensure the quality of metadata to facilitate open data exchange.
- Disseminate the FAIR principles among the research community.
- Promote and develop common standards to facilitate interoperability.
- Encourage the use of open repositories.
- Contribute by sharing resources with the rest of the community.
This will help to boost open science, increasing the efficiency, transparency and replicability of research.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
IATE, which stands for Interactive Terminology for Europe, is a dynamic database designed to support the multilingual drafting of European Union texts. It aims to provide relevant, reliable and easily accessible data with a distinctive added value compared to other sources of lexical information such as electronic archives, translation memories or the Internet.
This tool is of interest to EU institutions that have been using it since 2004 and to anyone, such as language professionals or academics, public administrations, companies or the general public. This project, launched in 1999 by the Translation Center, is available to any organization or individual who needs to draft, translate or interpret a text on the EU.
Origin and usability of the platform
IATE was created in 2004 by merging different EU terminology databases.The original Eurodicautom, TIS, Euterpe, Euroterms and CDCTERM databases were imported into IATE. This process resulted in a large number of duplicate entries, with the consequence that many concepts are covered by several entries instead of just one. To solve this problem, a cleaning working group was formed and since 2015 has been responsible for organizing analyses and data cleaning initiatives to consolidate duplicate entries into a single entry. This explains why statistics on the number of entries and terms show a downward trend, as more content is deleted and updated than is created.
In addition to being able to perform queries, there is the possibility to download your datasets together with the IATExtract extraction tool that allows you to generate filtered exports.
This inter-institutional terminology base was initially designed to manage and standardize the terminology of EU agencies. Subsequently, however, it also began to be used as a support tool in the multilingual drafting of EU texts, and has now become a complex and dynamic terminology management system. Although its main purpose is to facilitate the work of translators working for the EU, it is also of great use to the general public.
IATE has been available to the public since 2007 and brings together the terminology resources of all EU translation services. The Translation Center manages the technical aspects of the project on behalf of the partners involved: European Parliament (EP), Council of the European Union (Consilium), European Commission (COM), Court of Justice (CJEU), European Central Bank (ECB), European Court of Auditors (ECA), European Economic and Social Committee (EESC/CoR), European Committee of the Regions (EESC/CoR), European Investment Bank (EIB) and the Translation Centre for the Bodies of the European Union (CoT).
The IATE data structure is based on a concept-oriented approach, which means that each entry corresponds to a concept (terms are grouped by their meaning), and each concept should ideally be covered by a single entry. Each IATE entry is divided into three levels:
-
Language Independent Level (LIL)
-
Language Level (LL)
-
Term Level (TL) For more information, see Section 3 ('Structure Overview') below.
Reference source for professionals and useful for the general public
IATE reflects the needs of translators in the European Union, so that any field that has appeared or may appear in the texts of the publications of the EU environment, its agencies and bodies can be covered. The financial crisis, the environment, fisheries and migration are areas that have been worked on intensively in recent years. To achieve the best result, IATE uses the EuroVoc thesaurus as a classification system for thematic fields.
As we have already pointed out, this database can be used by anyone who is looking for the right term about the European Union. IATE allows exploration in fields other than that of the term consulted and filtering of the domains in all EuroVoc fields and descriptors. The technologies used mean that the results obtained are highly accurate and are displayed as an enriched list that also includes a clear distinction between exact and fuzzy matches of the term.
The public version of IATE includes the official languages of the European Union, as defined in Regulation No. 1 of 1958. In addition, a systematic feed is carried out through proactive projects: if it is known that a certain topic is to be covered in EU texts, files relating to this topic are created or improved so that, when the texts arrive, the translators already have the required terminology in IATE.
How to use IATE
To search in IATE, simply type in a keyword or part of a collection name. You can define further filters for your search, such as institution, type or date of creation. Once the search has been performed, a collection and at least one display language are selected.
To download subsets of IATE data you need to be registered, a completely free option that allows you to store some user preferences in addition to downloading. Downloading is also a simple process and can be done in csv or tbx format.
The IATE download file, whose information can also be accessed in other ways, contains the following fields:
-
Language independent level:
-
Token number: the unique identifier of each concept.
-
Subject field: the concepts are linked to fields of knowledge in which they are used. The conceptual structure is organized around twenty-one thematic fields with various subfields. It should be noted that concepts can be linked to more than one thematic field.
-
Language level:
-
Language code: each language has its own ISO code.
-
Term level
-
Term: concept of the token.
-
Type of term. They can be: terms, abbreviation, phrase, formula or short formula.
-
Reliability code. IATE uses four codes to indicate the reliability of terms: untested, minimal, reliable or very reliable.
-
Evaluation. When several terms are stored in a language, specific evaluations can be assigned as follows: preferable, admissible, discarded, obsolete and proposed.
A continuously updated terminology database
The IATE database is a document in constant growth, open to public participation, so that anyone can contribute to its growth by proposing new terminologies to be added to existing files, or to create new files: you can send your proposal to iate@cdt.europa.eu, or use the 'Comments' link that appears at the bottom right of the file of the term you are looking for. You can provide as much relevant information as you wish to justify the reliability of the proposed term, or suggest a new term for inclusion. A terminologist of the language in question will study each citizen's proposal and evaluate its inclusion in the IATE.
In August 2023, IATE announced the availability of version 2.30.0 of this data system, adding new fields to its platform and improving functions, such as the export of enriched files to optimize data filtering. As we have seen, this EU inter-institutional terminology database will continue to evolve continuously to meet the needs of EU translators and IATE users in general.
Another important aspect is that this database is used for the development of computer-assisted translation (CAT) tools, which helps to ensure the quality of the translation work of the EU translation services. The results of translators' terminology work are stored in IATE and translators, in turn, use this database for interactive searches and to feed domain- or document-specific terminology databases for use in their CAT tools.
IATE, with more than 7 million terms in over 700,000 entries, is a reference in the field of terminology and is considered the largest multilingual terminology database in the world. More than 55 million queries are made to IATE each year from more than 200 countries, which is a testament to its usefulness.