Blog
Europe is developing a common data space for tourism, aiming to integrate various stakeholders, including local and regional authorities, the private sector, and multiple member states. Spain is among them, where several workshops have already been conducted as part of the process to energize the national tourism data space, focusing on discussing the challenges, opportunities, and use cases in the sector.
The future tourism data space is at the core of the transition towards greater sustainability and profound digitization in the tourism sector. This initiative is also aligned with the European data strategy, which envisions creating a single market where information can be freely shared, promoting innovation across different economic sectors and certain areas of public interest. Furthermore, future data spaces hold significant importance in Europe's quest to regain digital sovereignty, reasserting control over data, fostering innovation, and the ability to develop and implement its own legislation in the digital environment.
Even in last year's conference on the Future of the European Union, the importance of data spaces in sectors like tourism and mobility was highlighted, recognizing them as key sectors in the digital transformation. Tourism, in particular, stands to benefit greatly from such initiatives due to its dynamic and ever-evolving nature, heavily reliant on user experiences and the timely access to necessary information.
Therefore, the European common data space for tourism aims to boost data exchange and reuse, establishing a governance model that respects existing legislation. The ultimate goal is to benefit all stakeholders in various ways, including:
- Promoting innovation in the sector by enhancing and personalizing services through access to high-quality information.
- Assisting public authorities in making data-driven decisions for the sustainability of their tourism offerings.
- Supporting specialized businesses in providing better services based on data analysis and market trends.
- Facilitating market access for sector businesses in Europe.
- Improving data availability for the creation of high-quality official statistics.
However, there are several challenges in sharing existing data in the tourism sector, primarily stemming from concerns regarding reciprocity and data reuse. These challenges can be summarized as follows:
- Data interoperability: Designing and managing a European tourist experience involves handling a wide array of non-personal data across various domains like mobility, environmental management, or cultural heritage, all of which enrich the tourist experience. The primary challenge in this regard is the ability to share and cross-reference information from different sources without duplications, with a reference framework that promotes interoperability between different sectors, utilizing existing standards where possible.
- Data access: Unlike other sectors, the European Union's tourism ecosystem lacks a single marketplace platform. Various offerings are modeled and cataloged by different actors, both public and private, at national, regional, or local levels. While the tourism data space does not aim to serve as a central booking node, it can greatly contribute by providing effective information search tools, facilitating access to necessary data, decision-making, and fostering innovation in the sector.
- Data provision by public and private entities: There is a wide variety of data in this sector, from open data like schedules and weather conditions to private and commercial data such as search, bookings, and payments. A significant portion of these commercial data are managed by a small group of large private entities, making it necessary to establish inclusive dialogue for fair and appropriate rules on data access within the shared data space.
To consolidate this initiative, the Transition Path for Tourism emphasizes the need to advance in the creation and optimization of a specific data space for the tourism sector. This aims to modernize and enhance this crucial economic sector in Europe through key actions:
- Governance: The governance of the tourism data space will determine how the main enablers will relate to ensure interoperability. The goal is to ensure that data is accessed, shared, and used lawfully, fairly, transparently, proportionally, and without discrimination to build trust, support research, and foster innovation within the sector.
- Semantics for interoperability: Common data models and vocabularies are needed for effective interoperability. National statistical agencies and Eurostat already have some consensus definitions, but their adoption within the tourism sector remains uneven. Therefore, clarifying definitions within the multilingual European context is crucial to establish a common European data model, accompanied by implementation guidelines. Spain has already made pioneering efforts in semantic interoperability, such as the development of the Tourism Ontology, technical standards for semantic applied to smart tourism destinations, or the model for collecting, exploiting, and analyzing tourism data.
- Technical standards for interoperability: The Data Spaces Support Center (DSSC) is already working to identify common technical standards that can be reused, taking into account existing or ongoing initiatives and regulatory frameworks. Additionally, all data spaces will also benefit from Simpl, a cloud federation middleware that will serve as a foundation for major data initiatives funded by the European Commission. Furthermore, there are specific technical standards in the sector, such as those developed by Eurostat for sharing accommodation data.
- Defining the role of the private sector: The European common data space for tourism will clearly benefit from cooperation with the private sector and the market for new services and tools it can offer. Some platforms already share data with Eurostat, and new agreements are being developed to share other non-personal tourism data, along with the creation of a new code of conduct to foster trust among various stakeholders.
- Supporting SMEs in the transition to a data space: The European Commission has long provided specific support to SMEs through Digital Innovation Hubs (DIHs) and the Enterprise Europe Network (EEN), offering technical and financial support, as well as assistance in developing new digital skills. Some of these centers specialize in tourism. Additionally, the European Tourism Enterprises Network (SGT), with 61 members in 23 countries, also provides support for digitalization and internationalization. This support for SMEs is particularly relevant given that they represent nearly all of the companies in the tourism sector, specifically 99.9%, of which 91% are microenterprises.
- Supporting tourism destinations in the transition to a data space: Tourism destinations must integrate tourism into their urban plans to ensure sustainable and beneficial tourism for residents and the environment. Several Commission initiatives enhance the availability of necessary information for tourism management and the exchange of best practices, promoting cooperation among destinations and proposing actions to improve digital services.
- Proof of concept for the tourism data space: The European Commission, along with several member states and private actors, is currently conducting a series of pilot tests for tourism data spaces through the DSFT and DATES coordination and support actions (CSAs). The main goal of these tests is to align with existing technical standards for accommodation data and demonstrate the value of interoperability and business models that arise from data sharing through a realistic and inclusive approach, focusing on short-term rentals and accommodation. In Spain, the report on the state of the tourism data space explains the current status of the national data space design.
In conclusion, the European Commission is firmly committed to supporting the creation of a space where tourism-related data flows while respecting the principles of fairness, accessibility, security, and privacy, in line with the European data strategy and the Pact for Skills development. The goal is to build a common data space for tourism that is progressive, robust, and integrated within the existing interoperability framework. To achieve this, the Commission urges all stakeholders to share data for the mutual benefit of everyone involved in an ecosystem that will be crucial for the entire European economy.
At the end of October, there will also be a new opportunity to learn more about the tourism data space and the challenges associated with data spaces in general, through the European Big Data Value Forum in Valencia.
Content created by Carlos Iglesias, Open Data Researcher and Consultant, World Wide Web Foundation.
The content and viewpoints reflected in this publication are the sole responsibility of the author.
Blog
In the era dominated by artificial intelligence that we are just beginning, open data has rightfully become an increasingly valuable asset, not only as a support for transparency but also for the progress of innovation and technological development in general.
The opening of data has brought enormous benefits by providing public access to datasets that promote government transparency initiatives, stimulate scientific research, and foster innovation in various sectors such as health, education, agriculture, and climate change mitigation.
However, as data availability increases, so does concern about privacy, as the exposure and mishandling of personal data can jeopardize individuals' privacy. What tools do we have to strike a balance between open access to information and the protection of personal data to ensure people's privacy in an already digital future?
Anonymization and Pseudonymization
To address these concerns, techniques like anonymization and pseudonymization have been developed, although they are often confused. Anonymization refers to the process of modifying a dataset to eliminate a reasonable probability of identifying an individual within it. It is important to note that, in this case, after processing, the anonymized dataset would no longer fall under the scope of the General Data Protection Regulation (GDPR). This data.gob.es report analyzes three general approaches to data anonymization: randomization, generalization, and pseudonymization.
On the other hand, pseudonymization is the process of replacing identifiable attributes with pseudonyms or fictitious identifiers in a way that data cannot be attributed to the individual without using additional information. Pseudonymization generates two new datasets: one containing pseudonymized information and the other containing additional information that allows the reversal of anonymization. Pseudonymized datasets and the linked additional information fall under the scope of the General Data Protection Regulation (GDPR). Furthermore, this additional information must be separated and subject to technical and organizational measures to ensure that personal data cannot be attributed to an individual.
Consent
Another key aspect of ensuring privacy is the increasingly prevalent "unambiguous" consent of individuals, where people express awareness and agreement on how their data will be treated before it is shared or used. Organizations and entities that collect data need to provide clear and understandable privacy policies, but there is also a growing need for more education on data handling to help people better understand their rights and make informed decisions.
In response to the growing need to properly manage these consents, technological solutions have emerged that seek to simplify and enhance the process for users. These solutions, known as Consent Management Platforms (CMPs), originally emerged in the healthcare sector and allow organizations to collect, store, and track user consents more efficiently and transparently. These tools offer user-friendly and visually appealing interfaces that facilitate understanding of what data is being collected and for what purpose. Importantly, these platforms provide users with the ability to modify or withdraw their consent at any time, giving them greater control over their personal data.
Artificial Intelligence Training
Training artificial intelligence (AI) models is becoming one of the most challenging areas in privacy management due to the numerous dimensions that need to be considered. As AI continues to evolve and integrate more deeply into our daily lives, the need to train models with large amounts of data increases, as evidenced by the rapid advances in generative AI over the past year. However, this practice often faces profound ethical and privacy dilemmas because the most valuable data in some scenarios is not open at all.
Advancements in technologies like federated learning, which allows AI algorithms to be trained through a decentralized architecture composed of multiple devices containing their own local and private data, are part of the solution to this challenge. This way, explicit data exchange is avoided, which is crucial in applications such as healthcare, defense, or pharmacy.
Additionally, techniques like differential privacy are gaining traction. Differential privacy ensures, through the addition of random noise and mathematical functions applied to the original data, that there is no loss of utility in the results obtained from the data analysis to which this technique is applied.
Web3
But if any advancement promises to revolutionize our interaction on the internet, providing greater control and ownership of user data, it would be web3. In this new paradigm, privacy management is inherent in its design. With the integration of technologies like blockchain, smart contracts, and decentralized autonomous organizations (DAOs), web3 seeks to give individuals full control over their identity and all their data, eliminating intermediaries and potentially reducing privacy vulnerabilities.
Unlike current centralized platforms where user data is often "owned" or controlled by private companies, web 3.0 aspires to make each person the owner and manager of their own information. However, this decentralization also presents challenges. Therefore, while this new era of the web unfolds, robust tools and protocols must be developed to ensure both freedom and privacy for users in the digital environment.
Privacy in the era of open data, artificial intelligence, and web3 undoubtedly requires working with delicate balances that are often unstable. Therefore, a new set of technological solutions, resulting from collaboration between governments, companies, and citizens, will be essential to maintain this balance and ensure that, while enjoying the benefits of an increasingly digital world, we can also protect people's fundamental rights.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The content and views reflected in this publication are the sole responsibility of the author.
Blog
The INSPIRE (Infrastructure for Spatial Information in Europe) Directive sets out the general rules for the establishment of an Infrastructure for Spatial Information in the European Community based on the Infrastructures of the Member States. Adopted by the European Parliament and the Council on 14 March 2007 (Directive 2007/2/EC), it entered into force on 25 April 2007.
INSPIRE makes it easier to find, share and use spatial data from different countries. The information is available through an online portal where it can be found broken down into different formats and topics of interest.
To ensure that these data are compatible and interoperable in a Community and cross-border context, the Directive requires the adoption of common Implementing Rules specific to the following areas:
- Metadata
- Data sets
- Network services
- Data sharing and services
- Spatial data services
- Monitoring and reporting
The technical implementation of these standards is done through Technical Guidelines, technical documents based on international standards and norms.
Inspire and semantic interoperability
These rules are considered Commission decisions or regulations and are therefore binding in each EU country. The transposition of this Directive into Spanish law is developed through Law 14/2010 of 5 July, which refers to the infrastructures and geographic information services of Spain (LISIGE) and the IDEE portal, both of which are the result of the implementation of the INSPIRE Directive in Spain.
Semantic interoperability plays a decisive role in INSPIRE. Thanks to this, there is a common language in spatial data, as the integration of knowledge is only possible when a homogenisation or common understanding of the concepts that constitute a domain or area of knowledge is achieved. Thus, in INSPIRE, semantic interoperability is responsible for ensuring that the content of the information exchanged is understood in the same way by any system.
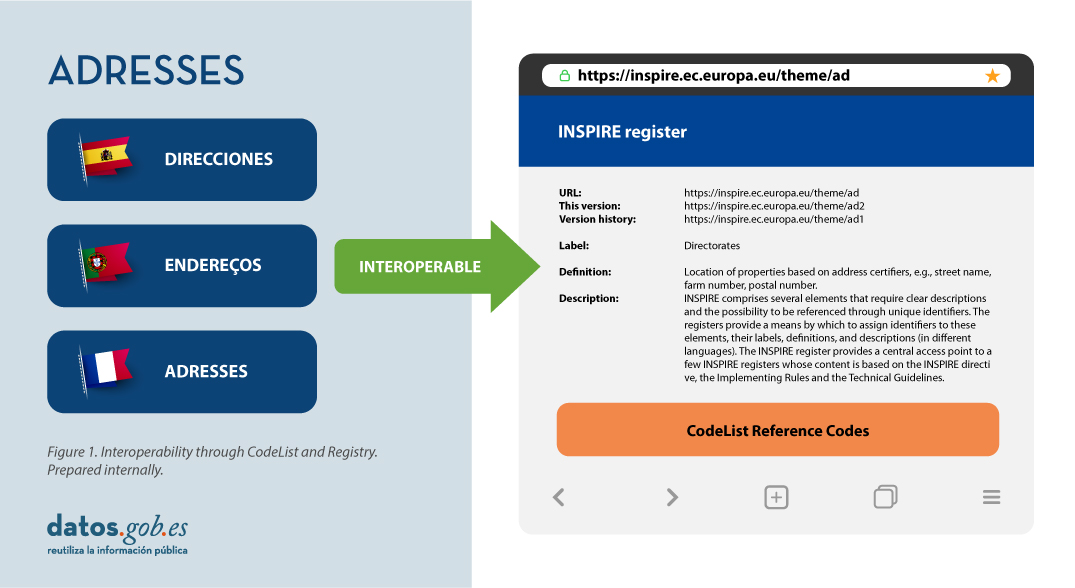
Therefore, in the implementation of spatial data models in INSPIRE, in GML exchange format, we can find codelists that are an important part of the INSPIRE data specifications and contribute substantially to interoperability.
In general, a codelist (or code list) contains several terms whose definitions are universally accepted and understood. Code lists promote data interoperability and constitute a shared vocabulary for a community. They can even be multilingual.
INSPIRE code lists are commonly managed and maintained in the central Federated INSPIRE Registry (ROR) which provides search capabilities, so that both end-users and client applications can easily access code list values for reference.
Registers are necessary because:
- They provide the codes defined in the Technical Guidelines, Regulations and Technical Specifications necessary to implement the Directive.
- They allow unambiguous references of the elements.
- Provides unique and persistent identifiers for resources.
- Enable consistent management and version control of different elements
The code lists used in INSPIRE are maintained at:
- The Inspire Central Federated Registry (ROR).
- The register of code lists of a member state,
- The list registry of a recognised external third party that maintains a domain-specific code list.
To add a new code list, you will need to set up your own registry or work with the administration of one of the existing registries to publish your code list. This can be quite a complicated process, but a new tool helps us in this task.
Re3gistry is a reusable open-source solution, released under EUPL, that allows companies and organisations to manage and share \"reference codes\" through persistent URIs, ensuring that concepts are unambiguously referenced in any domain and facilitating the management of these resources graphically throughout their lifecycle.
Funded by ELISE, ISA2 is a solution recognised by the Europeans in the Interoperability Framework as a supporting tool.
Illustration 3: Image of the Re3gister interface
Re3gistry is available for both Windows and Linux and offers an easy-to-use Web Interface for adding, editing, and managing records and reference codes. In addition, it allows the management of the complete lifecycle of reference codes (based on ISO 19135: 2005 Integrated procedures for the registration of reference codes)
The editing interface also provides a flag to allow the system to expose the reference code in the format that allows its integration with RoR, so that it can eventually be imported into the INSPIRE registry federation. For this integration, Reg3gistry makes an export in a format based on the following specifications:
- The W3C Data Catalogue (DCAT) vocabulary used to model the entity registry (dcat:Catalog).
- The W3C Simple Knowledge Organisation System (SKOS) which is used to model the entity registry (skos:ConceptScheme) and the element (skos:Concept).
Other notable features of Re3gistry
- Highly flexible and customisable data models
- Multi-language content support
- Support for version control
- RESTful API with content negotiation (including OpenAPI 3 descriptor)
- Free-text search
- Supported formats: HTML, ISO 19135 XML, JSON
- Service formats can be easily added or customised (default formats): JSON and ISO 19135 XML
- Multiple authentication options
- Externally governed elements referenced through URIs
- INSPIRE record federation format support (option to automatically create RoR format)
- Easy data export and re-indexing (SOLR)
- Guides for users, administrators, and developers
- RSS feed
Ultimately, Re3gistry provides a central access point where reference code labels and descriptions are easily accessible to both humans and machines, while fostering semantic interoperability between organisations by enabling:
- Avoid common mistakes such as misspellings, entering synonyms or filling in online forms.
- Facilitate the internationalisation of user interfaces by providing multilingual labels.
- Ensure semantic interoperability in the exchange of data between systems and applications.
- Tracking changes over time through a well-documented version control system.
- Increase the value of reference codes if they are widely reused and referenced.
More about Re3gistry:




References
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Content prepared by Mayte Toscano, Senior Consultant in Technologies linked to the data economy.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Image segmentation is a method that divides a digital image into subgroups (segments) to reduce its complexity, thus facilitating its processing or analysis. The purpose of segmentation is to assign labels to pixels to identify objects, people, or other elements in the image.
Image segmentation is crucial for artificial vision technologies and algorithms, but it is also used in many applications today, such as medical image analysis, autonomous vehicle vision, face recognition and detection, and satellite image analysis, among others.
Segmenting an image is a slow and costly process. Therefore, instead of processing the entire image, a common practice is image segmentation using the mean-shift approach. This procedure employs a sliding window that progressively traverses the image, calculating the average pixel values within that region.
This calculation is done to determine which pixels should be incorporated into each of the delineated segments. As the window advances along the image, it iteratively recalibrates the calculation to ensure the suitability of each resulting segment.
When segmenting an image, the factors or characteristics primarily considered are:
-
Color: Graphic designers have the option to use a green-toned screen to ensure chromatic uniformity in the background of the image. This practice enables the automation of background detection and replacement during the post-processing stage.
-
Edges: Edge-based segmentation is a technique that identifies the edges of various objects in a given image. These edges are identified based on variations in contrast, texture, color, and saturation.
-
Contrast: The image is processed to distinguish between a dark figure and a light background based on high-contrast values.
These factors are applied in different segmentation techniques:
-
Thresholds: Divide the pixels based on their intensity relative to a specified threshold value. This method is most suitable for segmenting objects with higher intensity than other objects or backgrounds.
-
Regions: Divide an image into regions with similar characteristics by grouping pixels with similar features.
-
Clusters: Clustering algorithms are unsupervised classification algorithms that help identify hidden information in the images. The algorithm divides the images into groups of pixels with similar characteristics, separating elements into groups and grouping similar elements in these groups.
-
Watersheds: This process transforms grayscale images, treating them as topographic maps, where the brightness of pixels determines their height. This technique is used to detect lines forming ridges and watersheds, marking the areas between watershed boundaries.
Machine learning and deep learning have improved these techniques, such as cluster segmentation, and have also generated new segmentation approaches that use model training to enhance program capabilities in identifying important features. Deep neural network technology is especially effective for image segmentation tasks.
Currently, there are different types of image segmentation, with the main ones being:
- Semantic Segmentation: Semantic image segmentation is a process that creates regions within an image and assigns semantic meaning to each of them. These objects, also known as semantic classes, such as cars, buses, people, trees, etc., have been previously defined through model training, where these objects are classified and labeled. The result is an image where pixels are classified into each located object or class.
- Instance Segmentation: Instance segmentation combines the semantic segmentation method (interpreting the objects in an image) with object detection (locating them within the image). As a result of this segmentation, objects are located, and each of them is individualized through a bounding box and a binary mask, determining which pixels within that window belong to the located object.
- Panoptic Segmentation: This is the most recent type of segmentation. It combines semantic segmentation and instance segmentation. This method can determine the identity of each object because it locates and distinguishes different objects or instances and assigns two labels to each pixel in the image: a semantic label and an instance ID. This way, each object is unique.

In the image, you can observe the results of applying different segmentations to a satellite image. Semantic segmentation returns a category for each type of identified object. Instance segmentation provides individualized objects along with their bounding boxes, and in panoptic segmentation, we obtain individualized objects and also differentiate the context, allowing for the detection of the ground and street regions.
Meta's New Model: SAM
In April 2023, Meta's research department introduced a new Artificial Intelligence (AI) model called SAM (Segment Anything Model). With SAM, image segmentation can be performed in three ways:
-
By selecting a point in the image, SAM will search for and distinguish the object intersecting with that point and find all identical objects in the image.
-
Using a bounding box, a rectangle is drawn on the image, and all objects found in that area are identified.
-
By using keywords, users can type a word in a console, and SAM can identify objects that match that word or explicit command in both images and videos, even if that information was not included in its training.
SAM is a flexible model that was trained on the largest dataset to date, called SA-1B, which includes 11 million images and 1.1 billion segmentation masks. Thanks to this data, SAM can detect various objects without the need for additional training.
Currently, SAM and the SA-1B dataset are available for non-commercial use and research purposes only. Users who upload their images are required to commit to using it solely for academic purposes. To try it out, you can visit this GitHub link.
In August 2023, the Image and Video Analysis Group of the Chinese Academy of Sciences released an update to their model called FastSAM, significantly reducing processing time with a 50 times faster execution speed compared to the original SAM model. This makes the model more practical for real-world usage. FastSAM achieved this acceleration by training on only 2% of the data used to train SAM, resulting in lower computational requirements while maintaining high accuracy.
SAMGEO: The Version for Analyzing Geospatial Data
The segment-geospatial package developed by Qiusheng Wu aims to facilitate the use of the Segment Anything Model (SAM) for geospatial data. For this purpose, two Python packages, segment-anything-py and segment-geospatial, have been developed, and they are available on PyPI and conda-forge.
The goal is to simplify the process of leveraging SAM for geospatial data analysis, allowing users to achieve it with minimal coding effort. These libraries serve as the basis for the QGIS Geo-SAM plugin and the integration of the model in ArcGIS Pro.
En la imagen se pueden observar los resultados de aplicar las distintas segmentaciones a una imagen satelital. La segmentación semántica devuelve una categoría por cada tipo de objeto identificado. La segmentación por instancia devuelve los objetos individualizados y la caja delimitadora y, en la segmentación panóptica, obtenemos los objetos individualizados y el contexto también diferenciado, pudiendo detectar el suelo y la región de calles.

Conclusions
In summary, SAM represents a significant revolution not only for the possibilities it opens in terms of editing photos or extracting elements from images for collages or video editing but also for the opportunities it provides to enhance computer vision when using augmented reality glasses or virtual reality headsets.
SAM also marks a revolution in spatial information acquisition, improving object detection through satellite imagery and facilitating the rapid detection of changes in the territory.
Content created by Mayte Toscano, Senior Consultant in Data Economy Technologies.
The content and viewpoints reflected in this publication are the sole responsibility of the author.
Blog
The "Stories of Use Cases" series, organized by the European Open Data portal (data.europe.eu), is a collection of online events focused on the use of open data to contribute to common European Union objectives such as consolidating democracy, boosting the economy, combating climate change, and driving digital transformation. The series comprises four events, and all recordings are available on the European Open Data portal's YouTube channel. The presentations used to showcase each case are also published.
In a previous post on datos.gob.es, we explained the applications presented in two of the series' events, specifically those related to the economy and democracy. Now, we focus on use cases related to climate and technology, as well as the open datasets used for their development.
Open data has enabled the development of applications offering diverse information and services. In terms of climate, some examples can trace waste management processes or visualize relevant data about organic agriculture. Meanwhile, the application of open data in the technological sphere facilitates process management. Discover the highlighted examples by the European Open Data portal!
Open Data for Fulfilling the European Green Deal
The European Green Deal is a strategy by the European Commission aiming to achieve climate neutrality in Europe by 2050 and promote sustainable economic growth. To reach this objective, the European Commission is working on various actions, including reducing greenhouse gas emissions, transitioning to a circular economy, and improving energy efficiency. Under this common goal and utilizing open datasets, three applications have been developed and presented in one of the webinars of the series on data.europe.eu use cases: Eviron Mate, Geofluxus, and MyBioEuBuddy.
- Eviron Mate: It's an educational project aimed at raising awareness among young people about climate change and related data. To achieve this goal, Eviron Mate utilizes open data from Eurostat, the Copernicus Program and data.europa.eu.
- Geofluxus: This initiative tracks waste from its origin to its final destination to promote material reuse and reduce waste volume. Its main objective is to extend material lifespan and provide businesses with tools for better waste management decisions. Geofluxus uses open data from Eurostat and various national open data portals.
- MyBioEuBuddy is a project offering information and visualizations about sustainable agriculture in Europe, using open data from Eurostat and various regional open data portals.
The Role of Open Data in Digital Transformation
In addition to contributing to the fight against climate change by monitoring environment-related processes, open data can yield interesting outcomes in other digitally-operating domains. The combination of open data with innovative technologies provides valuable results, such as natural language processing, artificial intelligence, or augmented reality.
Another online seminar from the series, presented by the European Data Portal, delved into this theme: driving digital transformation in Europe through open data. During the event, three applications that combine cutting-edge technology and open data were presented: Big Data Test Infrastructure, Lobium, and 100 Europeans.
- "Big Data Test Infrastructure (BDTI)": This is a European Commission tool featuring a cloud platform to facilitate the analysis of open data for public sector administrations, offering a free and ready-to-use solution. BDTI provides open-source tools that promote the reuse of public sector data. Any public administration can request the free advisory service by filling out a form. BDTI has already aided some public sector entities in optimizing procurement processes, obtaining mobility information for service redesign, and assisting doctors in extracting knowledge from articles.
- Lobium: A website assisting public affairs managers in addressing the complexities of their tasks. Its aim is to provide tools for campaign management, internal reporting, KPI measurement, and government affairs dashboards. Ultimately, its solution leverages digital tools' advantages to enhance and optimize public management.
- 100 Europeans: An application that simplifies European statistics, dividing the European population into 100 individuals. Through scrolling navigation, it presents data visualizations with figures related to healthy habits and consumption in Europe.
These six applications are examples of how open data can be used to develop solutions of societal interest. Discover more use cases created with open data in this article we have published on datos.gob.es

Learn more about these applications in their seminars -> Recordings here
Blog
The combination and integration of open data with artificial intelligence (AI) is an area of work that has the potential to achieve significant advances in multiple fields and bring improvements to various aspects of our lives. The most frequently mentioned area of synergy is the use of open data as input for training the algorithms used by AI since these systems require large amounts of data to fuel their operations. This makes open data an essential element for AI development and utilizing it as input brings additional advantages such as increased equality of access to technology and improved transparency regarding algorithmic functioning.
Today, we can find open data powering algorithms for AI applications in diverse areas such as crime prevention, public transportation development, gender equality, environmental protection, healthcare improvement, and the creation of more friendly and liveable cities. All of these objectives are more easily attainable through the appropriate combination of these technological trends.
However, as we will see next, when envisioning the joint future of open data and AI, the combined use of both concepts can also lead to many other improvements in how we currently work with open data throughout its entire lifecycle. Let's review step by step how artificial intelligence can enrich a project with open data.
Utilizing AI to Discover Sources and Prepare Data Sets
Artificial intelligence can assist right from the initial steps of our data projects by supporting the discovery and integration of various data sources, making it easier for organizations to find and use relevant open data for their applications. Furthermore, future trends may involve the development of common data standards, metadata frameworks, and APIs to facilitate the integration of open data with AI technologies, further expanding the possibilities of automating the combination of data from diverse sources.
In addition to automating the guided search for data sources, AI-driven automated processes can be helpful, at least in part, in the data cleaning and preparation process. This can improve the quality of open data by identifying and correcting errors, filling gaps in the data, and enhancing its completeness. This would free scientists and data analysts from certain basic and repetitive tasks, allowing them to focus on more strategic activities such as developing new ideas and making predictions.
Innovative Techniques for Data Analysis with AI
One characteristic of AI models is their ability to detect patterns and knowledge in large amounts of data. AI techniques such as machine learning, natural language processing, and computer vision can easily be used to extract new perspectives, patterns, and knowledge from open data. Moreover, as technological development continues to advance, we can expect the emergence of even more sophisticated AI techniques specifically tailored for open data analysis, enabling organizations to extract even more value from it.
Simultaneously, AI technologies can help us go a step further in data analysis by facilitating and assisting in collaborative data analysis. Through this process, multiple stakeholders can work together on complex problems and find answers through open data. This would also lead to increased collaboration among researchers, policymakers, and civil society communities in harnessing the full potential of open data to address social challenges. Additionally, this type of collaborative analysis would contribute to improving transparency and inclusivity in decision-making processes.
The Synergy of AI and Open Data
In summary, AI can also be used to automate many tasks involved in data presentation, such as creating interactive visualizations simply by providing instructions in natural language or a description of the desired visualization.
On the other hand, open data enables the development of applications that, combined with artificial intelligence, can provide innovative solutions. The development of new applications driven by open data and artificial intelligence can contribute to various sectors such as healthcare, finance, transportation, or education, among others. For example, chatbots are being used to provide customer service, algorithms for investment decisions, or autonomous vehicles, all powered by AI. By using open data as the primary data source for these services, we would achieve higher
Finally, AI can also be used to analyze large volumes of open data and identify new patterns and trends that would be difficult to detect through human intuition alone. This information can then be used to make better decisions, such as what policies to pursue in each area to bring about the desired changes.
These are just some of the possible future trends at the intersection of open data and artificial intelligence, a future full of opportunities but at the same time not without risks. As AI continues to develop, we can expect to see even more innovative and transformative applications of this technology. This will also require closer collaboration between artificial intelligence researchers and the open data community in opening up new datasets and developing new tools to exploit them. This collaboration is essential in order to shape the future of open data and AI together and ensure that the benefits of AI are available to all in a fair and equitable way.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Open data is a highly valuable source of knowledge for our society. Thanks to it, applications can be created that contribute to social development and solutions that help shape Europe's digital future and achieve the Sustainable Development Goals (SDGs).
The European Open Data portal (data.europe.eu) organizes online events to showcase projects that have been carried out using open data sources and have helped address some of the challenges our society faces: from combating climate change and boosting the economy to strengthening European democracy and digital transformation.
In the current year, 2023, four seminars have been held to analyze the positive impact of open data on each of the mentioned themes. All the material presented at these events is published on the European data portal, and recordings are available on their YouTube channel, accessible to any interested user.
In this post, we take a first look at the showcased use cases related to boosting the economy and democracy, as well as the open data sets used for their development.
Solutions Driving the European Economy and Lifestyle
In a rapidly evolving world where economic challenges and aspirations for a prosperous lifestyle converge, the European Union has demonstrated an unparalleled ability to forge innovative solutions that not only drive its own economy but also elevate the standard of living for its citizens. In this context, open data has played a pivotal role in the development of applications that address current challenges and lay the groundwork for a prosperous and promising future. Two of these projects were presented in the second webinar of the series "Stories of Use Cases”, an event focused on "Open Data to Foster the European Economy and Lifestyle": UNA Women and YouthPOP.
The first project focuses on tackling one of the most relevant challenges we must overcome to achieve a just society: gender inequality. Closing the gender gap is a complex social and economic issue. According to estimates from the World Economic Forum, it will take 132 years to achieve full gender parity in Europe. The UNA Women application aims to reduce that figure by providing guidance to young women so they can make better decisions regarding their education and early career steps. In this use case, the company ITER IDEA has used over 6 million lines of processed data from various sources, such as data.europa.eu, Eurostat, Censis, Istat (Italy's National Institute of Statistics), and NUMBEO.
The second presented use case also targets the young population. This is the YouthPOP application (Youth Public Open Procurement), a tool that encourages young people to participate in public procurement processes. For the development of this app, data from data.europa.eu, Eurostat, and ESCO, among others, have been used. YouthPOP aims to improve youth employment and contribute to the proper functioning of democracy in Europe.
Open Data for Boosting and Strengthening European Democracy
In this regard, the use of open data also contributes to strengthening and consolidating European democracy. Open data plays a crucial role in our democracies through the following avenues:
- Providing citizens with reliable information.
- Promoting transparency in governments and public institutions.
- Combating misinformation and fake news.
The theme of the third webinar organized by data.europe.eu on use cases is "Open Data and a New Impetus for European Democracy". This event presented two innovative solutions: EU Integrity Watch and the EU Institute for Freedom of Information.
Firstly, EU Integrity Watch is a platform that provides online tools for citizens, journalists, and civil society to monitor the integrity of decisions made by politicians in the European Union. This website offers visualizations to understand the information and provides access to collected and analyzed data. The analyzed data is used in scientific disclosures, journalistic investigations, and other areas, contributing to a more open and transparent government. This tool processes and offers data from the Transparency Register.
The second initiative presented in the democracy-focused webinar with open data is the EU Institute for Freedom of Information (IDFI), a Georgian non-governmental organization that focuses on monitoring and supervising government actions, revealing infractions, and keeping citizens informed.
The main activities of the IDFI include requesting public information from relevant bodies, creating rankings of public bodies, monitoring the websites of these bodies, and advocating for improved access to public information, legislative standards, and related practices. This project obtains, analyzes, and presents open data sets from national public institutions.
In conclusion, open data makes it possible to develop applications that reduce the gender wage gap, boost youth employment, or monitor government actions. These are just a few examples of the value that open data can offer to society.

Learn more about these applications in their seminars -> Recordings here.
Blog
In the digital age, technological advancements have transformed the field of medical research. One of the factors contributing to technological development in this area is data, particularly open data. The openness and availability of information obtained from health research provide multiple benefits to the scientific community. Open data in the healthcare sector promotes collaboration among researchers, accelerates the validation process of study results, and ultimately helps save lives.
The significance of this type of data is also evident in the prioritized intention to establish the European Health Data Space (EHDS), the first common EU data space emerging from the European Data Strategy and one of the priorities of the Commission for the 2019-2025 period. As proposed by the European Commission, the EHDS will contribute to promoting better sharing and access to different types of health data, not only to support healthcare delivery but also for health research and policymaking.
However, the handling of this type of data must be appropriate due to the sensitive information it contains. Personal data related to health is considered a special category by the Spanish Data Protection Agency (AEPD), and a personal data breach, especially in the healthcare sector, has a high personal and social impact.
To avoid these risks, medical data can be anonymized, ensuring compliance with regulations and fundamental rights, thereby protecting patient privacy. The Basic Anonymization Guide developed by the AEPD based on the Personal Data Protection Commission Singapore (PDPC) defines key concepts of an anonymization process, including terms, methodological principles, types of risks, and existing techniques.
Once this process is carried out, medical data can contribute to research on diseases, resulting in improvements in treatment effectiveness and the development of medical assistance technologies. Additionally, open data in the healthcare sector enables scientists to share information, results, and findings quickly and accessibly, thus fostering collaboration and study replicability.
In this regard, various institutions share their anonymized data to contribute to health research and scientific development. One of them is the FISABIO Foundation (Foundation for the Promotion of Health and Biomedical Research of the Valencian Community), which has become a reference in the field of medicine thanks to its commitment to open data sharing. As part of this institution, located in the Valencian Community, there is the FISABIO-CIPF Biomedical Imaging Unit, which is dedicated, among other tasks, to the study and development of advanced medical imaging techniques to improve disease diagnosis and treatment.
This research group has developed different projects on medical image analysis. The outcome of all their work is published under open-source licenses: from the results of their research to the data repositories they use to train artificial intelligence and machine learning models.
To protect sensitive patient data, they have also developed their own techniques for anonymizing and pseudonymizing images and medical reports using a Natural Language Processing (NLP) model, whereby anonymized data can be replaced by synthetic values. Following their technique, facial information from brain MRIs can be erased using open-source deep learning software.
BIMCV: Medical Imaging Bank of the Valencian Community
One of the major milestones of the Regional Ministry of Universal Health and Public Health, through the Foundation and the San Juan de Alicante Hospital, is the creation and maintenance of the Medical Imaging Bank of the Valencian Community, BIMCV (Medical Imaging Databank of the Valencia Region in English), a repository of knowledge aimed at achieving "technological advances in medical imaging and providing technological coverage services to support R&D projects," as explained on their website.
BIMCV is hosted on XNAT, a platform that contains open-source images for image-based research and is accessible by prior registration and/or on-demand. Currently, the Medical Imaging Bank of the Valencian Community includes open data from research conducted in various healthcare centers in the region, housing data from over 90,000 subjects collected in more than 150,000 sessions.
New Dataset of Radiological Images
Recently, the FISABIO-CIPF Biomedical Imaging Unit and the Prince Felipe Research Center (FISABIO-CIPF) released in open access the third and final iteration of data from the BIMCV-COVID-19 project. They released image data of chest radiographs taken from patients with and without COVID-19, as well as the models they had trained for the detection of different chest X-ray pathologies, thanks to the support of the Regional Ministry of Innovation, the Regional Ministry of Health and the European Union REACT-EU Funds. All of this was made available "for use by companies in the sector or simply for research purposes," explains María de la Iglesia, director of the unit. "We believe that reproducibility is of great relevance and importance in the healthcare sector," she adds. The datasets and the results of their research can be accessed here.
The findings are mapped using the standard terminology of the Unified Medical Language System (UMLS), as proposed by the results of Dr. Aurelia Bustos' doctoral thesis, an oncologist and computer engineer. They are stored in high resolution with anatomical labels in a Medical Image Data Structure (MIDS) format. Among the stored information are patient demographic data, projection type, and imaging study acquisition parameters, among others, all anonymized.
The contribution that such open data projects make to society not only benefits researchers and healthcare professionals but also enables the development of solutions that can have a significant impact on improving healthcare. One of these solutions can be generative AI, which provides interesting results that healthcare professionals can consider in personalized diagnosis and propose more effective treatment, prioritizing their own judgment.
On the other hand, the digitization of healthcare systems is already a reality, including 3D printing, digital twins applied to medicine, telemedicine consultations, or portable medical devices. In this context, the collaboration and sharing of medical data, provided their protection is ensured, contribute to promoting research and innovation in the sector. In other words, open data initiatives for medical research stimulate technological advancements in healthcare.
Therefore, the FISABIO Foundation, together with the Prince Felipe Research Center, where the platform hosting BIMCV is located, stands out as an exemplary case in promoting the openness and sharing of data in the field of medicine. As the digital age progresses, it is crucial to continue promoting data openness and encouraging its responsible use in medical research, for the benefit of society.
Blog
Behind a voice-enabled virtual assistant, a movie recommendation on a streaming platform, or the development of some COVID-19 vaccines, there are machine learning models. This branch of artificial intelligence enables systems to learn and improve their performance.
Machine learning (ML) is one of the fields driving technological progress today, and its applications are growing every day. Examples of solutions developed with machine learning include DALL-E, the set of language models in Spanish known as MarIA, and even Chat GPT-3, a generative AI tool capable of creating content of all types, such as code for programming data visualizations from the datos.gob.es catalog.
All of these solutions work thanks to large data repositories that make system learning possible. Among these, open data plays a fundamental role in the development of artificial intelligence as it can be used to train machine learning models.
Based on this premise, along with the ongoing effort of governments to open up data, there are non-governmental organizations and associations that contribute by developing applications that use machine learning techniques aimed at improving the lives of citizens. We highlight three of them:
ML Commons is driving a better machine learning system for everyone
This initiative aims to improve the positive impact of machine learning on society and accelerate innovation by offering tools such as open datasets, best practices, and algorithms. Its founding members include companies such as Google, Microsoft, DELL, Intel AI, Facebook AI, among others.
According to ML Commons, around 80% of research in the field of machine learning is based on open data. Therefore, open data is vital to accelerate innovation in this field. However, nowadays, "most public data files available are small, static, legally restricted, and not redistributable," as David Kanter, director of ML Commons, assures.
In this regard, innovative ML technologies require large datasets with licenses that allow their reuse, that can be redistributed, and that are continually improving. Therefore, ML Commons' mission is to help mitigate that gap and thus promote innovation in machine learning.
The main goal of this organization is to create a community of open data for the development of machine learning applications. Its strategy is based on three pillars:
Firstly, creating and maintaining comprehensive open datasets, including The People's Speech, with over 30,000 hours of speech in English to train natural language processing (NLP) models, Multilingual Spoken Words, with over 23 million expressions in 50 different languages, or Dollar Street, with over 38,000 images of homes from around the world in various socio-economic situations. The second pillar involves promoting best practices that facilitate standardization, such as the MLCube project, which proposes standardizing the container process for ML models to facilitate shared use. Lastly, benchmarking in study groups to define benchmarks for the developer and research community.
Taking advantage of the benefits and being part of the ML Commons community is free for academic institutions and small companies (less than ten workers).
Datacommons synthesizes different sources of open data into a single portal
Datacommons aims to enhance democratic data flows within the cooperative and solidarity economy and its main objective is to offer purified, normalized, and interoperable data.
The variety of formats and information offered by public portals of open data can be a hindrance to research. The goal of Datacommons is to compile open data into an encyclopedic website that organizes all datasets through nodes. This way, users can access the source that interests them the most.
This platform, designed for educational and journalistic research purposes, functions as a reference tool for navigating through different sources of data. The team of collaborators works to keep the information up-to-date and interacts with the community through its email (support@datacommons.org) or GitHub forum.
Papers with Code: the open repository of materials to feed machine learning models
This is a portal that offers code, reports, data, methods, and evaluation tables in open and free format. All content on the website is licensed under CC-BY-SA, meaning it allows copying, distributing, displaying, and modifying the work, even for commercial purposes, by sharing the contributions made with the same original license.
Any user can contribute by providing content and even participate in the community's Slack channel, which is moderated by responsible individuals who protect the platform's defined inclusion policy.
As of today, Papers with Code hosts 7806 datasets that can be filtered by format (graph, text, image, tabular, etc.), task (object detection, queries, image classification, etc.), or language. The team maintaining Papers with Code belongs to the Meta Research Institute.
The goal of ML Commons, Data Commons, and Papers with Code is to maintain and grow open data communities that contribute to the development of innovative technologies, including artificial intelligence (machine learning, deep learning, etc.) with all the possibilities its development can offer to society.
As part of this process, the three organizations play a fundamental role: they offer standard and redistributable data repositories to train machine learning models. These are useful resources for academic exercises, promoting research, and ultimately facilitating the innovation of technologies that are increasingly present in our society.
Evento
On March 5, communities around the world will join together to celebrate Open Data Day 2022. It is an annual celebration that seeks to showcase the benefits and encourage the adoption of open data policies in governments, businesses and civil society.
Throughout the day -and on upcoming dates- local groups from all corners of the world organize different actions related to the publication and reuse of data. In Spain, some activities are also being held, such as:
DATATHON 2022
- Date: From March 4 to April 30, 2022.
- Format: Online
- Organizers: University of Alicante, Miguel Hernández University, PAGODA, Dades Valencia, Cátedra Transició energética, Catedrades, Valencian Government, Polytechnic University of Valencia, University of Valencia, ACICOM and MESURA.
The Datathon 2022 kicks off on March 4, in which participants will have to use machine learning, artificial intelligence or data science tools to respond to a challenge of their choice related to the following fields:
A) Responsible production and consumption.
B) Environmental aspects (agriculture, waste, energy transition...).
C) Culture.
This is a free event. All natural persons of legal age can participate, in teams of 2 to 6 people. It is necessary to register before March 4 through eventbritte.
Prizes will be awarded in two categories: undergraduate students (€750 for each challenge) and master's, doctoral and corporate students (€500 for each challenge). In addition, in both categories, three runners-up prizes of €350 will be awarded to the winners of each challenge.
The competition will be accompanied by various informative sessions and workshops aimed at participants, which will take place throughout the competition (from March 4 to April 30, 2022). Some examples of these workshops are: "How to request information from the administration and legality of data use", "Data mining and visualization" or "Telling stories with data".
Open Data Day 2022
- Date: 4-8 March 2022.
- Format: Face-to-face and online.
- Organizers: Government of Catalonia.
The Open Government Secretariat of the Government of Catalonia also joins the celebration of the International Open Data Day, with activities from March 4 to 8.
- March 4, at 9:30 am (fase-to-face and online). The value of open data. The day will be dedicated to open data reusers. There will be a round table with experts in the field of reuse and two documents of interest will be presented: the new volume of the Open Government collection, "The value of open data and use cases", by the consultant Alícia León Molina, which collects examples of use related to open data in different countries, and the III report on data reuse prepared by the COTEC Foundation. It will be broadcasted via youtube.
- March 7, at 10h (online). Open Science and Citizen Science. Monday will be dedicated to the use of open data in the world of research. The Directorate General for Research will present CORA - Catalan Open Research and experiences from the private sector will be presented by Ideas for Change.
- March 8, at 13:30h (online): What can be the role of local governments in an emerging data economy? Representatives from the city of Rennes, France, and Catalonia will explain the RUDI data Rennes project, led by Rennes Métropole and funded by the European Union: a "social data network". This event will be held in English and French.
Open Data Day 2022: For a more effective reuse of open data
- Date: March 9, 2022, 17h
- Format: Face-to-face
- Organizers: Open Data Barcelona Initiative
Just two years after its last face-to-face event, Open Data Barcelona Initiative brings back the "face-to-face" meetings with a conference aimed at disseminating knowledge and experiences about public open data and its reuse. The evento will last from 5pm to 7pm and will be structured around two round tables:
- Opportunities linked to open data in institutions, where the new features of institutional data portals will be discussed, highlighting the datasets offered and the new functionalities that boost their reuse.
- Projects based on the reuse of open data, focusing on how to use such data in a project, highlighting its potential as a source of knowledge to solve the challenges faced by various groups.
The event is free of charge, but prior registration is required.
Other international events
In addition to the activities held in our country, events are also taking place in other parts of the world, some of which can be followed online.
For example, New York City celebrates from March 5 to 13, 2022 its Open Data Week, organized by the Office of Data Analytics of the New York City Mayor's Office and BetaNYC. This celebration occurs each year to coincide not only with Open Data Day, but also with the New York City Open Data Act, which was enacted on March 7, 2012. This year, NY Open Data Week is being celebrated in a hybrid format with both in-person and online activities. All activities are directly related to publicly available open data about New York.
Another example of an online event is the OSM Africa March Mapathon: Map Sierra Leone, an initiative that seeks to support the development of the OpenStreetMap community in Africa.
If you want to know about other activities that will be held on the occasion of Open Data Day 2022, you can visit their website.