Blog
Europa está desarrollando un espacio común de datos para el turismo, que busca integrar a múltiples actores, incluyendo autoridades locales y regionales, el sector privado y varios Estados miembro. Entre ellos podemos encontrar también a España, donde ya se han llevado a cabo varios talleres de trabajo como parte del proceso de dinamización del espacio de datos de turismo nacional y con el objetivo de debatir los retos y oportunidades o los casos de uso del sector.
El futuro espacio de datos de turismo está en el centro de la transición hacia una mayor sostenibilidad y una profunda digitalización en el sector. Esta actuación se enmarca también dentro de la estrategia europea de datos, que tiene como visión común la creación de un mercado único donde la información pueda ser compartida libremente, buscando impulsar la innovación en diferentes sectores económicos y en ciertas áreas de interés público. Así mismo, los futuros espacios de datos tienen también gran importancia dentro de la necesidad de recuperar la soberanía digital de Europa, recuperando el control sobre nuestros datos, nuestra capacidad de innovación y la capacidad de elaborar y aplicar nuestra propia legislación en el entorno digital.
Ya en la conferencia del año pasado sobre el Futuro de la Unión Europea se destacó la importancia de los espacios de datos en áreas como el turismo y la movilidad, reconociéndolos como sectores clave para considerar en la transformación digital. El turismo, en particular, se considera un sector especialmente beneficiado por este tipo de iniciativas, dada su naturaleza basada en las experiencias de los usuarios –que son dinámicas y en constante evolución– y en donde el acceso a la información necesaria en el momento adecuado será por tanto clave.
Así pues, el espacio común Europeo de datos para el turismo busca aumentar el intercambio y la reutilización de datos, estableciendo para ello un modelo de gobernanza que respete la legislación existente. El objetivo final es que todos los interesados se puedan beneficiar de esos datos compartidos de múltiples formas:
- Fomentando la innovación en el sector, mejorando y personalizando los servicios gracias a contar con más información de calidad;
- Ayudando a las autoridades públicas en la toma de decisiones para la sostenibilidad de su oferta turística que estén basadas en datos relevantes;
- Apoyando a las empresas especializadas para que puedan proporcionar mejores servicios basados en el análisis de los datos y de las tendencias del mercado;
- Consiguiendo que las empresas del sector tengan mayor facilidad de acceso al mercado Europeo;
- Mejorando la disponibilidad de fuentes de datos para la elaboración de estadísticas oficiales de calidad.
Sin embargo, existen también varios desafíos que se deben afrontar a la hora de compartir los datos existentes dentro del sector turístico, debido principalmente a reticencias respecto a la reciprocidad y la reutilización de la información. Estos desafíos se podrían resumir como:
- Interoperabilidad de los datos: Diseñar y gestionar una experiencia turística en Europa implica gestionar una gran diversidad de datos no personales en dominios tan diversos como la movilidad, la gestión medioambiental o el patrimonio cultural, que servirán para enriquecer la experiencia turística. El principal desafío en este ámbito radica en poder compartir y contrastar información de distintas fuentes sin duplicidades, con un marco de referencia que promueva la interoperabilidad entre diferentes sectores, y utilizando estándares ya existentes en la medida de los posible.
- Acceso a los datos: A diferencia de otros sectores, el ecosistema turístico de la Unión Europea carece de una plataforma única de mercado. Las distintas ofertas son modeladas y catalogadas por diferentes actores, tanto públicos como privados, ya sea a nivel nacional como regional o local. Este enfoque da lugar a un panorama diverso, rico y multilingüe. Aunque el espacio de datos de turismo no pretende servir como nodo de centralización de las reservas, puede contribuir enormemente proporcionando herramientas eficaces de búsqueda de información, facilitando el acceso a los datos necesarios, la toma de decisiones y también la innovación en el sector.
- Provisión de datos por parte de entidades públicas y privadas: Existe una variedad de datos en este sector, desde datos abiertos como horarios y condiciones climáticas, hasta otros privados y comerciales como datos de búsquedas, reservas y pagos. Una gran parte de estos datos comerciales son gestionados por un pequeño grupo de grandes entidades privadas, por lo que será necesario establecer un diálogo inclusivo para establecer reglas justas y adecuadas sobre el acceso a estos datos dentro del espacio de datos compartido.
Con el objetivo de poder consolidar esta iniciativa, la Senda de la Transición para el Turismo, introdujo la necesidad de avanzar en la creación y optimización de un espacio de datos específico para el sector turístico, buscando modernizar y potenciar este importante sector económico en Europa a través de las siguientes acciones clave:
- Gobernanza: La gobernanza del espacio de datos turísticos determinará cómo se relacionarán los principales habilitadores necesarios para garantizar la interoperabilidad. El objetivo es conseguir que los datos se accedan, compartan y utilicen de manera lícita, justa, transparente, proporcional y no discriminatoria para generar confianza, apoyar la investigación y la innovación dentro del sector.
- Semántica para la interoperabilidad: Se necesitan modelos y vocabularios de datos comunes para conseguir una interoperabilidad efectiva. Tanto las agencias nacionales de estadística como el Eurostat cuentan ya con ciertas definiciones consensuadas, pero su adopción por parte del sector turísticos es todavía irregular. Es por ello crucial aclarar las definiciones dentro del universo multilingüe de la Unión para conseguir un modelo de datos común Europeo que cuente también con guías para su implementación. En nuestro país se han llevado ya a cabo actividades pioneras en relación a la interoperabilidad semántica, como por ejemplo el desarrollo de la Ontología del Turismo, la norma técnica de semántica aplicada a destinos turísticos inteligentes o el modelo de recogida, explotación y análisis de datos turísticos.
- Estándares técnicos para la interoperabilidad: El Centro de Soporte para los Espacios de Datos (DSSC) está ya trabajando para poder identificar estándares técnicos comunes que puedan ser reutilizados, teniendo en cuenta las iniciativas y los marcos regulatorios ya existentes o en marcha. Además, todos los espacios de datos se beneficiarán también de Simpl, un middleware para federaciones en la nube que servirá de base para las principales iniciativas de datos financiadas por la Comisión Europea. Por otro lado, existen también otros estándares técnicos específicos del sector, como los desarrollados por Eurostat para poder compartir datos de alojamientos.
- Definición del papel del sector privado: El espacio común de datos europeo para el turismo se beneficiará claramente de la cooperación con el sector privado y del mercado de nuevos servicios y herramientas que éste podrá ofrecer. Algunas plataformas ya comparten datos con Eurostat y se están desarrollando también nuevos acuerdos para compartir otros datos no personales del sector turismo, además de la elaboración de un nuevo código de conducta para fomentar la confianza entre los diversos actores.
- Apoyo a las PYMEs en la transición hacia un espacio de datos: La Comisión Europea brinda desde hace tiempo apoyo específico a las PYMEs a través de los Centros de Innovación Digital (EDIH) y de la Red Europea de Empresas (EEN) – que vienen ofreciendo apoyo técnico y financiero, además de soporte en el desarrollo de nuevas habilidades digitales. Incluso algunos de estos centros están especializados en el área del turismo. Además, la Red Europea de Empresas de Turismo (SGT) – con 61 miembros en 23 países – ofrece también apoyo en materia de digitalización e internacionalización. Este apoyo las PYMES cobra especial relevancia cuando tenemos en cuenta que éstas representan casi la totalidad de las empresas en el sector turístico – concretamente el 99,9%; de las cuales el 91% son microempresas.
- Apoyo a los destinos turísticos en la transición hacia un espacio de datos: Los destinos turísticos deben integrar el turismo en sus planes urbanos para poder garantizar un turismo sostenible y beneficioso para sus residentes y el entorno en el que habitan. Varias iniciativas de la Comisión fortalecen la disponibilidad de la información necesaria para la gestión turística y el intercambio de buenas prácticas, promoviendo la cooperación entre destinos y proponiendo acciones para mejorar los servicios digitales.
- Prueba de concepto para el espacio de datos turísticos: La Comisión Europea, junto con varios estados miembros y otros actores privados, está ya en la actualidad llevando a cabo una serie de pruebas piloto para los espacios de datos de turismo a través de las acciones de coordinación y apoyo (CSAs) DSFT y DATES. El objetivo principal de estas pruebas es alinearse con los estándares técnicos existentes para los datos de alojamiento y mostrar el valor de la interoperabilidad y los modelos de negocio que surgen gracias a poder compartir los datos mediante un enfoque realista e inclusivo, centrado en alquileres a corto plazo y alojamiento. En España, el informe sobre la radiografía del espacio de datos de turismo explica el momento en el que se encuentra actualmente el diseño del espacio de datos nacional.
En definitiva, la Comisión Europea se compromete firmemente a apoyar la creación de un espacio donde los datos relacionados con el turismo fluyan respetando los principios de equidad, accesibilidad, seguridad y privacidad – en línea con la estrategia europea de datos y con el Pacto por el desarrollo de nuevas competencias. Con ello lo que se persigue es poder construir un espacio común de datos para el turismo que sea progresivo, sólido, e integrado en el marco de interoperabilidad ya existente. Para ello la Comisión insta a todos los actores a compartir datos para el mutuo beneficio de todos los actores involucrados en un ecosistema que será clave para el conjunto de la economía Europea.
A finales de octubre podremos contar también con una nueva oportunidad para saber más sobre el espacio de datos de turismo, y sobre los retos asociados a los espacios de datos en general, a través del European Big Data Value Forum en Valencia.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En la etapa protagonizada por la inteligencia artificial que estamos comenzando, los datos abiertos se han convertido por derecho propio en un activo cada vez más valioso no sólo como soporte a la transparencia, sino también para el progreso de la innovación y el desarrollo tecnológico en general.
La apertura de datos ha traído enormes beneficios al brindar acceso público a conjuntos de datos que habilitan el impulso de iniciativas de transparencia gubernamental, que estimulan investigaciones científicas y que promueven la innovación en sectores tan variados como la salud, la educación, la agricultura, o la lucha contra el cambio climático.
Sin embargo, a medida que aumenta la disponibilidad de datos, también lo hace la preocupación por la privacidad ya que la exposición y tratamiento indebido de datos personales puede poner en peligro la privacidad de las personas. ¿Qué herramientas tenemos para mantener el equilibrio entre el acceso abierto a la información y la protección de los datos personales para garantizar la privacidad de las personas en un futuro que ya es digital?
Anonimización y pseudonimización
Para abordar estas preocupaciones, se han desarrollado técnicas como la anonimización y pseudonimización que con frecuencia se confunden. La anonimización se refiere al proceso por el que se modifica un conjunto de datos para que no exista una probabilidad razonable de que pueda identificarse a una persona física en el mismo. Es importante destacar que, en este caso, después del tratamiento, el conjunto de datos anonimizado ya no estaría bajo el ámbito de aplicación del Reglamento General de Protección de Datos (RGPD). En este informe de datos.gob.es se analizan tres enfoques generales para la anonimización de datos: aleatorización, generalización y seudonimización.
Por su parte, la pseudonimización es el proceso de reemplazar atributos identificables con pseudónimos o identificadores ficticios de forma que los datos no puedan atribuirse a la persona física sin utilizar información adicional. El tratamiento de pseudonimización genera dos nuevos conjuntos de datos: el que contiene la información pseudonimizada y el que contiene la información adicional que permite revertir la anonimización. El conjunto de datos pseudonimizados y la información adicional vinculada con dicho conjunto de datos sí están bajo el ámbito de aplicación del Reglamento General de Protección de Datos (RGPD). Además, se requiere que dicha información adicional esté independizada y sujeta a medidas técnicas y organizativas destinadas a garantizar que los datos personales no se atribuyan a una persona física.
Consentimiento
Otro aspecto clave para garantizar la privacidad es el cada vez más presente consentimiento “inequívoco” de los interesados por el que las personas manifiestan ser conscientes y estar de acuerdo con cómo se tratarán sus datos antes de que estos se compartan o utilicen. Es necesario que las organizaciones y las entidades que recopilan datos proporcionen políticas de privacidad claras y comprensibles pero cada vez más se pone de manifiesto la necesidad de una mayor educación en materia de tratamiento de datos que ayude a las personas a comprender mejor sus derechos y que garantice decisiones más informadas.
En respuesta a la creciente necesidad de gestionar adecuadamente estos consentimientos, han surgido soluciones tecnológicas que buscan simplificar y mejorar el proceso para los usuarios. Estas soluciones conocidas como plataformas de gestión de los consentimientos (CMP, por sus siglas en inglés), nacieron originalmente en el ámbito del sector salud y permiten a las organizaciones recopilar, almacenar y rastrear los consentimientos de los usuarios de una manera más eficiente y transparente. Estas herramientas ofrecen interfaces amigables y visualmente atractivas que facilitan la comprensión de qué datos se están recopilando y con qué propósito. Pero, sobre todo, estas plataformas proporcionan a los usuarios la posibilidad de modificar o retirar su consentimiento en cualquier momento, otorgándoles un mayor control sobre sus datos personales.
Entrenamientos de inteligencia artificial
El entrenamiento de modelos de inteligencia artificial (IA) se perfila como uno de los campos más desafiantes en materia de gestión de la privacidad por la multitud de dimensiones que es necesario tener en cuenta. A medida que la IA continúa evolucionando y se integra más profundamente en nuestra vida cotidiana, la necesidad de entrenar modelos con grandes cantidades de datos aumenta, como han puesto de manifiesto los vertiginosos avances en materia de IA generativa del último año. Sin embargo, esta práctica a menudo se enfrenta a profundos dilemas éticos y de privacidad ya que los datos de mayor valor en algunos escenarios no son en absoluto abiertos.
Los avances en tecnologías como el aprendizaje federado, que permite entrenar algoritmos de IA a través de una arquitectura descentralizada formada por múltiples dispositivos los cuales contienen sus propios datos locales y privados, son parte de la solución a este desafío. De este modo, no se intercambian datos de forma explícita, algo que es clave en aplicaciones de salud, defensa o farmacia.
Asimismo, están ganando tracción técnicas como la privacidad diferencial que permite garantizar, mediante la incorporación de ruido aleatorio, aplicando funciones matemáticas a la información original, que en el resultado del proceso de análisis de los datos a los que se ha aplicado esta técnica no hay pérdida en la utilidad de los resultados obtenidos.
Web3
Pero si algún avance promete revolucionar nuestra interacción en internet, otorgando mayor control y propiedad a los usuarios sobre sus datos, este sería la web3 ya que, en este nuevo paradigma, la gestión de la privacidad es inherente a su propio diseño. Con la integración de tecnologías como la cadena de bloques (blockchain), los contratos inteligentes (smart contracts) y las organizaciones autónomas descentralizadas, la web3 busca proporcionar a los individuos un control total sobre su identidad y todos sus datos, eliminando intermediarios y potencialmente reduciendo puntos de vulnerabilidad a la privacidad.
A diferencia de las plataformas centralizadas actuales, donde los datos de los usuarios a menudo son “propiedad” o están controlados por empresas privadas, la web 3.0 aspira a que cada persona sea dueña y gestora de su propia información. No obstante, esta descentralización también plantea desafíos por lo que es esencial que, mientras se despliega esta nueva era de la web, se desarrollen herramientas y protocolos robustos que garanticen tanto la libertad como la privacidad de los usuarios en el entorno digital.
La privacidad en la era de los datos abiertos, la inteligencia artificial y la web3 obliga, sin duda, a trabajar con equilibrios delicados que a menudo son inestables. Por ello, un nuevo conjunto de soluciones tecnológicas, fruto de la colaboración entre gobiernos, empresas y ciudadanos, será esencial para mantener este equilibrio y garantizar que, mientras disfrutamos de los beneficios de un mundo cada vez más digital, también seamos capaces de proteger los derechos fundamentales de las personas.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Directiva INSPIRE (Infrastructure for Spatial Information in Europe) establece las reglas generales para el establecimiento de una Infraestructura de Información espacial en la Comunidad Europea basada en las Infraestructuras de los Estados miembro. Aprobada por el Parlamento Europeo y el Consejo el 14 de marzo de 2007 (Directiva 2007/2/CE), esta entró en vigor el 25 de abril de 2007.
INSPIRE permite encontrar, compartir y utilizar con más facilidad los datos espaciales de diferentes países. La información está disponible a través de un portal online desde el que se pueden encontrar desglosados en distintos formatos y temáticas de interés.
Para asegurar que estos datos sean compatibles e interoperables en un contexto comunitario y transfronterizo, la Directiva exige que se adopten Normas de Ejecución comunes (Implementing Rules) específicas para las siguientes áreas:
- Metadatos
- Conjuntos de datos
- Servicios de red
- Uso compartido de datos y servicios
- Servicios de datos espaciales
- Monitoreo e informes
La implementación técnica de estas normas se realiza mediante las Guías Técnicas o Directrices (Technical Guidelines), documentos técnicos basados en estándares y normas internacionales.
Inspire e interoperabilidad semántica
Estas normas se consideran decisiones o reglamentos de la Comisión y, por lo tanto, son de obligado cumplimiento en cada uno de los países de la Unión. La transposición de esta Directiva al ordenamiento jurídico español se desarrolla a través de la Ley 14/2010 de 5 de julio, la cual hace referencia a las infraestructuras y los servicios de información geográfica de España (LISIGE) y el portal IDEE, ambos son el resultado de la implementación de la Directiva INSPIRE en España.
En INSPIRE juega un papel decisivo la interoperabilidad semántica. Gracias a esta, existe un lenguaje común en los datos espaciales, pues la integración del conocimiento solo es posible cuando se logra una homogenización o entendimiento común de los conceptos que constituyen un dominio o área de conocimiento. Así, en INSPIRE, la interoperabilidad semántica es la encargada de asegurar que el contenido de la información intercambiada sea entendido de la misma manera por cualquier sistema.
Por ello, en la implementación de los modelos de datos espaciales en INSPIRE, en formato de intercambio GML, podemos encontrar los codelist que son una parte importante de las especificaciones de datos de INSPIRE y contribuyen sustancialmente a la interoperabilidad.
En general, una codelist o lista de códigos contiene varios términos cuyas definiciones son universalmente aceptadas y comprendidas. Las listas de códigos favorecen la interoperabilidad de los datos y constituyen un vocabulario compartido por una comunidad. Incluso pueden ser multilingües.
Las listas de códigos INSPIRE se administran y mantienen comúnmente en Registro Inspire Central Federado (ROR) que proporciona capacidades de búsqueda, de modo que tanto los usuarios finales como las aplicaciones cliente pueden acceder fácilmente a los valores de la lista de códigos como referencia.
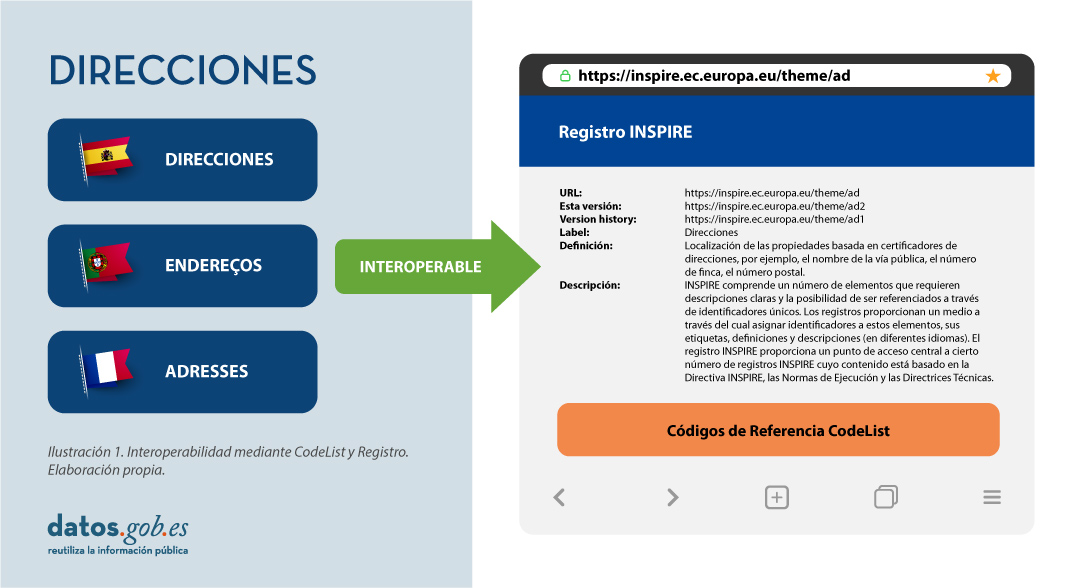
Los registros son necesarios porque:
- Proporcionan los códigos definidos en las Directrices Técnicas (Guidelines), Reglamentos y Especificaciones técnicas necesarios para implementar la Directiva
- Permiten referencias inequívocas de los elementos
- Proporcionna identificadores únicos y persistentes para los recursos
- Permiten una gestión y control de versiones coherentes de los diferentes elementos
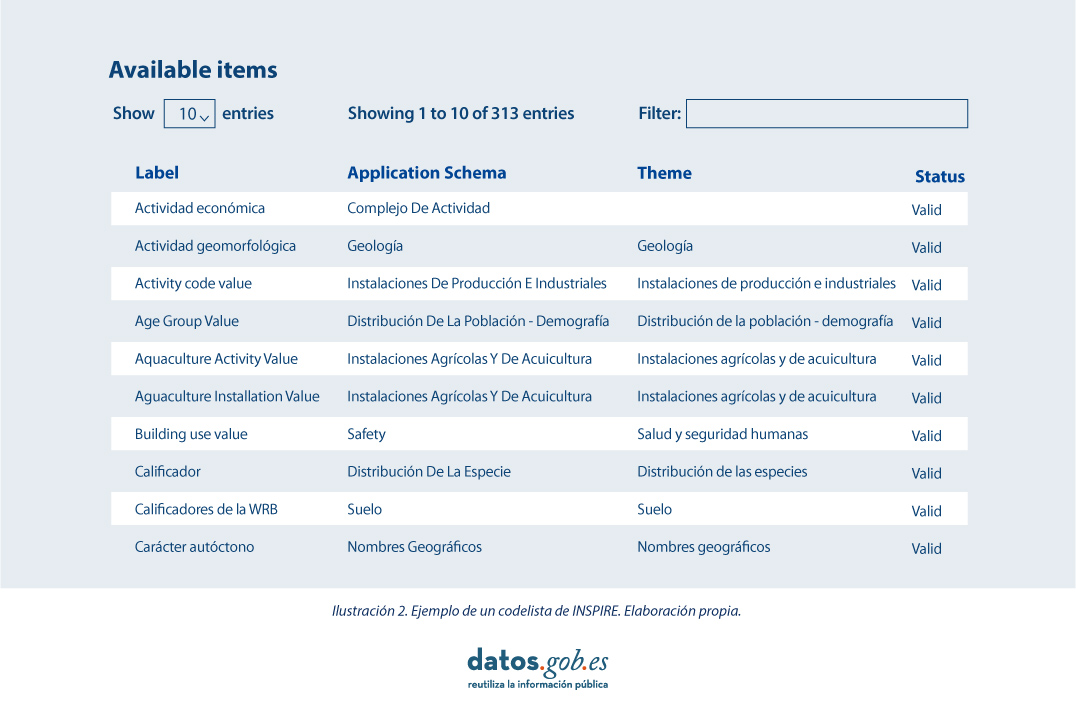
Las listas de códigos utilizados en INSPIRE se mantienen en:
- El Registro Inspire Central Federado (ROR)
- El registro de listas de códigos de un estado miembro
- El registro de listas de un tercero externo reconocido que mantiene una lista de códigos específica de dominio.
Para agregar una nueva lista de códigos, tendrá que configurar su propio registro o trabajar con la administración de uno de los registros existentes para publicar su lista de códigos. Este puede ser un proceso bastante complicado pero una nueva herramienta nos ayuda en esta labor.
Re3gistry es una solución de código abierto reutilizable y publicado bajo licencia EUPL, que permite a las empresas y organizaciones administrar y compartir \"códigos de referencia\" a través de URI persistentes, asegurando que los conceptos se referencian inequívocamente en cualquier dominio y facilitando la gestión de estos recursos gráficamente durante todo su ciclo de vida.
Financiado por ELISE, ISA2 es una solución reconocida por los europeos en el Marco de interoperabilidad como una herramienta de apoyo.Ilustración 3 Imagen de la interface de Re3gister.
Ilustración 3: Imagen de la interface de Re3gister
Re3gistry está disponible tanto para Windows como para Linux y ofrece una Interfaz Web fácil de usar para agregar, editar y administrar los registros y códigos de referencia. Además, permite la gestión del ciclo de vida completo de los códigos de referencia (basado en la norma ISO 19135: 2005 Procedimientos integrados para el registro de códigos de referencia)
La interfaz de edición también proporciona un indicador para permitir que el sistema exponga el código de referencia en el formato que permite su integración con RoR, de esta manera, eventualmente se puede importar en la federación de registro INSPIRE. Para esta integración, Reg3gistry hace una exportación en un formato basado en las siguientes especificaciones:
- El vocabulario del Catálogo de datos del W3C (DCAT) que se utiliza para modelar el registro de entidades (dcat:Catalog).
- El Sistema de Organización Simple del Conocimiento (SKOS) del W3C que se utiliza para modelar el registro de entidades (skos:ConceptScheme) y el elemento (skos:Concept).
Otras características destacables de Re3gistry
- Modelos de datos altamente flexibles y personalizables
- Soporte de contenido en varios idiomas
- Soporte para el control de versiones
- API RESTful con negociación de contenido (incluido el descriptor OpenAPI 3)
- Búsqueda de texto-libre
- Formatos soportados: HTML, ISO 19135 XML, JSON
- Los formatos de servicio se pueden agregar o personalizar fácilmente (formatos predeterminados: JSON e ISO 19135 XML)
- Múltiples opciones de autentificación
- Elementos gobernados externamente a los que se hace referencia a través de URIs
- Soporte de formato de federación de registro INSPIRE (opción para crear automáticamente el formato RoR)
- Fácil exportación y reindexación de datos (SOLR)
- Guías para usuarios, administradores y desarrolladores
- Fuente RSS
En definitiva, Re3gistry proporciona un punto de acceso central donde las etiquetas y descripciones de los códigos de referencia son fácilmente accesibles tanto para humanos como para máquinas, al tiempo que fomenta la interoperabilidad semántica entre organizaciones ya que permite:
- Evitar errores comunes como faltas de ortografía, ingresar sinónimos o completar formularios en línea.
- Facilitar la internacionalización de las interfaces de usuario proporcionando etiquetas multilingües.
- Garantizar la interoperabilidad semántica en el intercambio de datos entre sistemas y aplicaciones.
- El rastreo de los cambios a lo largo del tiempo a través de un sistema de control de versiones bien documentado.
- Aumentar el valor de los códigos de referencia, si se reutilizan y referencian ampliamente.
Más acerca de Re3gistry:
|
|
Soporte | https://github.com/ec-jrc/re3gistry |
|
|
Manual de usuario | https://github.com/ec-jrc/re3gistry/blob/master/documentation/user-manual.md |
|
|
Manual de administrador | https://github.com/ec-jrc/re3gistry/blob/master/documentation/administrator-manual.md |
|
|
Manual de desarrollador |
https://github.com/ec-jrc/re3gistry/blob/master/documentation/developer-manual.md
|




Referencias
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La segmentación de imágenes es un método que divide una imagen digital en subgrupos (segmentos) para reducir la complejidad de esta y, así, poder facilitar su procesamiento o análisis. La finalidad de la segmentación es asignar etiquetas a píxeles para identificar objetos, personas u otros elementos en la imagen.
La segmentación de las imágenes es clave para las tecnologías y algoritmos de visión artificial, pero también se utiliza hoy en día para muchas aplicaciones como, por ejemplo, el análisis de imágenes médicas, la visión de los vehículos autónomos, el reconocimiento y la detección de rostros o el análisis de imágenes satelitales, entre otras.
Segmentar una imagen es un proceso lento y costoso, por eso en lugar de procesar la imagen completa, una práctica común es la segmentación de imágenes mediante el enfoque de desplazamiento medio. Este procedimiento emplea una ventana desplazable que atraviesa progresivamente la imagen, calculando el promedio de los valores de píxeles contenidos en dicha región.
Este cálculo se efectúa con el propósito de establecer los píxeles que han de ser incorporados a cada uno de los segmentos delineados. Conforme la ventana avanza a lo largo de la imagen, lleva a cabo de manera iterativa una recalibración del cálculo para garantizar la idoneidad de cada uno de los segmentos resultantes.
A la hora de segmentar una imagen los factores o características que se tienen en cuenta son principalmente:
- El color: Los diseñadores gráficos tienen la posibilidad de emplear una pantalla de tonalidad verdosa con el fin de asegurar una uniformidad cromática en el fondo de la imagen. Esta práctica posibilita la automatización de la detección y sustitución del fondo durante la etapa de postprocesamiento.
- Bordes: La segmentación basada en bordes es una técnica que identifica los bordes de varios objetos en una imagen determinada. Estos se identifican en función de las variaciones de contraste, textura, color y saturación.
- Contraste: Se procesa la imagen distinguiendo entre una figura oscura y un fondo claro basándose en valores de alto contraste.
Estos factores se aplican en distintas técnicas de segmentación:
- Umbrales: Divide los píxeles en función de su intensidad en relación con un valor o umbral determinado. Este método es el más adecuado para segmentar objetos con mayor intensidad que otros objetos o fondos.
- Regiones: Consiste en dividir una imagen en regiones con características semejantes agregando los píxeles con características similares.
- Clústeres: Los algoritmos de agrupamiento son algoritmos de clasificación no supervisados que ayudan a identificar información oculta en las imágenes. El algoritmo divide las imágenes en grupos de píxeles con características similares, separando los elementos en grupos y agrupando elementos similares en estos grupos.
- Cuencas hidrográficas: Se trata de un proceso que transforma las imágenes a escala de grises, tratándolas como mapas topográficos, donde el brillo de los píxeles determina la altura. Esta técnica sirve para detectar líneas que forman crestas y cuencas. marcando las áreas entre las líneas divisorias de aguas.
El aprendizaje automático y el aprendizaje profundo (Deep learning) han mejorado estas técnicas, como la segmentación de clústeres, pero también han generado nuevos enfoques de segmentación que utilizan el entrenamiento de modelos para mejorar la capacidad de los programas a la hora de identificar características importantes. La tecnología de redes neuronales profundas es especialmente efectiva para las tareas de segmentación de imágenes.
En la actualidad encontramos distintos tipos de segmentación de imágenes, siendo las principales:
- Segmentación Semántica: La segmentación semántica de imágenes es un proceso que permite crear regiones dentro de una imagen y atribuir significado semántico a cada una de ellas. Estos objetos o también conocidas como clases semánticas, por ejemplo: coche, autobús, persona, árbol, etc., han sido previamente definidas mediante el entrenamiento de modelos en los que se clasifican y etiquetan estos objetos. El resultado es una imagen en lo que se han clasificado los pixeles en cada objeto o clase localizado.
- Segmentación de instancias: La segmentación de instancias combina el método de segmentación semántica (interpretando los objetos de una imagen) y la detección de objetos (al localizarlos dentro de la imagen). Como resultado de esta segmentación, se localizan los objetos, para que cada uno de ellos sea singularizado por medio de una ventana delimitadora (bounding box) y una máscara binaria, las cuales determinan qué píxeles de dicha ventana pertenecen al objeto localizado.
- Segmentación panóptica: Es el tipo más actual de segmentación. Se trata de una combinación de segmentación semántica y de instancias. Este método sí puede determinar la identidad de cada objeto porque esta técnica de segmentación localiza y distingue los diferentes objetos o instancias y asigna dos etiquetas a cada píxel de la imagen: una etiqueta semántica y una ID de instancia. De esta forma cada objeto es único.

En la imagen se pueden observar los resultados de aplicar las distintas segmentaciones a una imagen satelital. La segmentación semántica devuelve una categoría por cada tipo de objeto identificado. La segmentación por instancia devuelve los objetos individualizados y la caja delimitadora y, en la segmentación panóptica, obtenemos los objetos individualizados y el contexto también diferenciado, pudiendo detectar el suelo y la región de calles.
El nuevo modelo de Meta: SAM
En abril del 2023, el departamento de investigación de Meta presentó un nuevo modelo de Inteligencia Artificial (IA) al que llamaron SAM (Segment Anything Model). Con SAM se puede realizar la segmentación de una imagen mediante tres formas:
- Seleccionando un punto en la imagen, se buscará y distinguirá el objeto que intersecta con ese punto y se buscará todos los objetos iguales encontrados en la imagen.
- Por ventana delimitadora o bounding box, sobre la imagen se dibuja un rectángulo y se identifican todos los objetos encontrados en esa área.
- Por palabras, mediante una consola se escribe una palabra y SAM puede identificar los objetos que coincidan con esa palabra u orden explícita tanto en imágenes o videos, incluso si ese dato no fue incluido en su entrenamiento.
SAM es un modelo flexible que fue entrenado con el conjunto de datos más grande hasta la fecha, llamado SA-1B y que cuenta con 11 millones de imágenes y 1.1 mil millones de máscaras en segmentación. Gracias a estos datos, SAM es capaz de detectar todo tipo de objetos sin necesidad de un entrenamiento adicional.
Por ahora, el modelo SAM y el conjunto de datos SA-1B está disponible para su uso no comercial y con fines de investigación. De este modo, los usuarios que suban sus imágenes tendrán que comprometerse a utilizarlo únicamente con fines de académicos. Para probarla, ingresa a este enlace de GitHub.
En agosto del 2023, el Grupo de Análisis de Imagen y Vídeo de la Academia China de las Ciencias, lanza una actualización de su modelo llamado FastSAM que reduce considerablemente el tiempo de procesado, se consigue una velocidad de ejecución 50 veces mayor, haciendo que el modelo sea más práctico de ejecutar que el modelo SAM original. Esta aceleración la consiguen habiendo entrenado el modelo con el 2% de los datos utilizados para entrenar SAM. FastSAM tiene menos requisitos computacionales que SAM, sin dejar de alcanzar una gran precisión.
SAMGEO: la versión que permite analizar datos geoespaciales
El paquete segment-geospatial desarrollado por Qiusheng Wu tiene como finalidad facilitar el uso de Segment Anything Model (SAM) para datos geoespaciales, para ello se he desarrollado los paquetes de Python segment-anything-py y segment-geospatial , que están disponibles en PyPI y conda-forge.
El objetivo es simplificar el proceso de aprovechamiento de SAM para el análisis de datos geoespaciales al permitir que los usuarios lo logren con un mínimo esfuerzo de codificación. A partir de estas librerías, se desarrolla el plugin de QGIS Geo-SAM y se desarrolla el uso del modelo en ArcGIS Pro.

Conclusiones
En definitiva, SAM supone una gran revolución no sólo por las posibilidades que abre a la hora de editar fotografías o extraer elementos de imágenes para collages o edición de video, sino también por las oportunidades de mejora que permiten aumentar la visión por computadora, a la hora de usar lentes de realidad aumentada o cascos de realidad virtual.
También SAM supone una revolución para la obtención de información espacial, mejorando la detención de objetos mediante imágenes satelitales y facilitando la detección de cambios en el territorio de forma rápida.
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La serie “Stories of use cases”, organizada por el portal de datos abiertos europeo (data.europe.eu), es un conjunto de eventos online sobre el uso de los datos abiertos para contribuir a la consecución de objetivos comunes de la Unión Europea como la consolidación de la democracia, el impulso de la economía, la lucha contra el cambio climático o la transformación digital. La serie consta de cuatro eventos y todas las grabaciones están disponibles en el canal de Youtube del portal europeo de datos abiertos. También están publicadas las presentaciones que se utilizaron para exponer cada caso.
En un post anterior de datos.gob.es, explicamos las aplicaciones que se presentaron en dos de los eventos de la serie, en concreto, sobre economía y democracia. Ahora, nos centramos en los casos de uso relacionados con clima y tecnología, así como los conjuntos de datos abiertos que se emplearon para su desarrollo.
Los datos abiertos han permitido el desarrollo de aplicaciones que ofrecen información y servicios variados. En materia de clima, algunos ejemplos logran identificar la trazabilidad del proceso de gestión de residuos o visualizar datos relevantes sobre agricultura ecológica. Mientras que la aplicación de los datos abiertos en el ámbito tecnológico facilita la gestión de procesos. ¡Descubre los ejemplos destacados por el portal de datos abiertos europeo!
Datos abiertos para cumplir con el European Green Deal
El European Green Deal es una estrategia de la Comisión Europea que tiene como objetivo lograr la neutralidad climática en Europa para el año 2050 y fomentar el crecimiento económico sostenible. Para alcanzar este objetivo, la Comisión Europea está trabajando en varias líneas de acción, como la reducción de emisiones de gases de efecto invernadero, la transición hacia una economía circular y la mejora de la eficiencia energética. Bajo esta meta común y empleando conjuntos de datos abiertos, se han desarrollado las tres aplicaciones que se presentan en uno de los webinars de la serie sobre casos de uso de datos.europe.eu: Eviron mate, Geofluxus y MyBioEuBuddy.
-
Eviron mate: Es un proyecto educativo que tiene como objetivo concienciar a los jóvenes sobre el cambio climático y los datos relacionados con él. Para lograr este objetivo, Eviron mate utiliza datos abiertos de Eurostat, el programa Copernicus y data.europa.eu.
- Geofluxus: Es una iniciativa que realiza un seguimiento de los residuos desde su punto de origen hasta su destino final, para fomentar la reutilización de materiales y reducir la cantidad de residuos. Su principal objetivo es extender la vida útil de los materiales y ofrecer herramientas a las empresas para tomar mejores decisiones con sus desechos. Para ello, Geofluxus utiliza datos abiertos de Eurostat y de diferentes portales de datos abiertos nacionales.
- MyBioEuBuddy es un proyecto que ofrece información y visualizaciones sobre la agricultura sostenible en Europa, utilizando datos abiertos de Eurostat y de diferentes portales de datos abiertos regionales.
El papel de los datos abiertos en la transformación digital
Además de contribuir a la lucha contra el cambio climático permitiendo monitorizar procesos relacionados con el medio ambiente, los datos abiertos pueden ofrecer resultados interesantes en otros ámbitos que también operan en la era digital. La combinación del uso de datos abiertos con tecnologías innovadoras ofrece un resultado muy valioso, por ejemplo, en procesamiento de lenguaje natural, inteligencia artificial o realidad aumentada, entre otras.
Otro de los seminarios online de la serie sobre casos de uso presentado por el European Data Portal se adentró en este tema: el impulso de la transformación digital en Europa mediante datos abiertos. Durante el evento, se presentaron tres aplicaciones que combinan tecnología puntera y datos abiertos: Big Data Test Infrastructure, Lobium y 100 europeans.
- "Big Data Test Infrastructure (BDTI)": Es una herramienta de la Comisión Europea que cuenta con una plataforma en la nube para facilitar el análisis de datos abiertos para las administraciones del sector público, brindando una solución gratuita y lista para usar. BDTI ofrece herramientas de código abierto que fomentan la reutilización de datos del sector público. Desde cualquier administración pública, se puede solicitar el servicio de asesoramiento gratuito rellenando este formulario. El BDTI ya ha ayudado a algunas entidades del sector público a optimizar procesos de contratación, obtener información sobre movilidad para rediseñar servicios o apoyar a los médicos extrayendo conocimiento de artículos.
- Lobium: Web que ayuda a los gerentes de asuntos públicos a abordar las complejidades de sus tareas. Su objetivo es proporcionar herramientas para la administración de campañas, informes internos, medición de KPI y paneles de control de asuntos gubernamentales. En definitiva, su solución permite aprovechar las ventajas de las herramientas digitales para mejorar y optimizar las gestiones públicas.
- 100 europeans: Es una aplicación que visualiza estadísticas europeas de manera sencilla, dividiendo la población europea en 100 personas. Mediante una navegación de scrolling presenta visualizaciones de datos con cifras sobre los hábitos saludables y de consumo en Europa.
Las seis aplicaciones son ejemplos de cómo los datos abiertos pueden servir para desarrollar soluciones de interés para la sociedad. Descubre más casos de uso creados con datos abiertos en este artículo que hemos publicado en datos.gob.es.

Conoce más sobre estas aplicaciones en sus seminarios -> Grabaciones aquí
Blog
La combinación e integración de los datos abiertos con la inteligencia artificial (IA) es un área de trabajo que cuenta con el potencial de lograr avances significativos en múltiples campos y conseguir mejoras en varios aspectos de nuestras vidas. El área de sinergia que más frecuentemente se menciona suele ser la utilización de los datos abiertos como datos de entrada para el entrenamiento de los algoritmos utilizados por la IA, ya que estos sistemas necesitan devorar grandes cantidades de datos para alimentar su funcionamiento. Esto convierte a los datos abiertos en un elemento ya de por sí esencial para el desarrollo de la IA, pero su utilización como datos de entrada conlleva además otras múltiples ventajas como una mayor igualdad de acceso a la tecnología o una mejora de la transparencia sobre el funcionamiento de los algoritmos.
Así pues, hoy en día podemos encontrar datos abiertos alimentando algoritmos para la aplicación de la IA en áreas tan variadas como la prevención de crímenes, el desarrollo del transporte público, la igualdad de género, la protección del medioambiente, la mejora de la sanidad o la búsqueda de ciudades más amigables y habitables. Todos ellos son ya objetivos más fácilmente alcanzables gracias a la adecuada combinación de ambas tendencias tecnológicas.
Sin embargo, como veremos a continuación, puestos a imaginar el futuro conjunto de los datos abiertos y la IA, el uso combinado de ambos conceptos puede dar lugar también a muchas otras mejoras en la forma en que trabajamos actualmente con los datos abiertos y a lo largo de todo el ciclo de vida de los mismos. Repasamos, paso a paso, cómo la inteligencia artificial puede enriquecer un proyecto con datos abiertos.
Utilizar la IA para descubrir fuentes y preparar conjuntos de datos
La inteligencia artificial puede ayudar ya desde los primeros pasos de nuestros proyectos de datos mediante el apoyo en la fase de descubrimiento e integración de diversas fuentes de datos, facilitando a las organizaciones encontrar y usar datos abiertos de relevancia para sus aplicaciones. Además, las tendencias futuras pueden incluir el desarrollo de estándares comunes de datos, marcos de metadatos y APIs para facilitar la integración de los datos abiertos con tecnologías de IA, lo que ampliaría aún más las posibilidades de automatizar la combinación de datos de diversas fuentes.
Además de la automatización en la búsqueda guiada de fuentes de datos, los procesos automáticos de la inteligencia artificial pueden ser de utilidad, al menos en parte, en el proceso de limpieza y preparación de los datos. De esta forma se puede mejorar la calidad de los datos abiertos al identificar y corregir los errores, rellenar los vacíos existentes en los datos y mejorar así su completitud. Esto contribuiría a liberar a los científicos y analistas de datos de ciertas tareas básicas y repetitivas para que puedan centrarse en otras tareas más estratégicas, como desarrollar nuevas ideas y hacer predicciones.
Técnicas innovadoras para el análisis de datos con IA
Una de las características de los modelos de IA es su facilidad para detectar patrones y conocimiento en grandes cantidades de datos. Técnicas de IA como el aprendizaje automático, el procesamiento del lenguaje natural y la visión por computador se pueden usar fácilmente para extraer nuevas perspectivas, patrones y conocimiento de los datos abiertos. Por otro lado, a medida que el desarrollo tecnológico continúa avanzando, podremos ver el desarrollo de técnicas de IA aún más sofisticadas y especialmente adaptadas para el análisis de datos abiertos, permitiendo a las organizaciones extraer todavía más valor de los mismos.
Paralelamente, las tecnologías de IA pueden ayudarnos a ir un paso más allá en el análisis de los datos facilitando y asistiendo en el análisis de datos colaborativo. Mediante este proceso, las múltiples partes interesadas pueden trabajar juntas en problemas complejos y darles respuesta a través de los datos abiertos. Esto daría lugar también a una mayor colaboración entre investigadores, formuladores de políticas públicas y comunidades de la sociedad civil a la hora de sacar el mayor provecho de los datos abiertos para abordar los desafíos sociales. Además, este tipo de análisis colaborativo también contribuiría a mejorar la transparencia y la inclusividad en los procesos de toma de decisiones.
La sinergia de la IA y los datos abiertos
En definitiva, la IA también se puede utilizar para automatizar muchas de las tareas involucradas en la presentación de los datos, como por ejemplo crear visualizaciones interactivas proporcionando simplemente instrucciones en lenguaje natural o una descripción de la visualización deseada.
Por otro lado, los datos abiertos permiten desarrollar aplicaciones que, combinadas con la inteligencia artificial, pueden resultar soluciones innovadoras. El desarrollo de nuevas aplicaciones impulsadas por los datos abiertos y la inteligencia artificial puede contribuir en diversos sectores como la atención sanitaria, finanzas, transporte o educación entre otros. Por ejemplo, se están utilizando chatbots para proporcionar servicio al cliente, algoritmos para tomar decisiones de inversión o coches autónomos, todos ellos impulsados por la IA. Lo que conseguiríamos además si estos servicios utilizaran los datos abiertos como fuente principal de datos sería una mayor calidad y veracidad, gracias a un mejor entrenamiento de los modelos de IA. Además, cuanta mayor sea la disponibilidad de los datos abiertos, mayor será también el número de personas que tendrán estas aplicaciones a su alcance.
Finalmente, la IA se puede utilizar también para analizar grandes volúmenes de datos abiertos e identificar nuevos patrones y tendencias que serían difíciles de detectar únicamente a través de la intuición humana. Esta información puede utilizarse luego para tomar mejores decisiones, como por ejemplo qué políticas llevar a cabo en un área determinada para poder obtener los cambios deseados.
Estas son solo algunas de las posibles tendencias futuras en la intersección de los datos abiertos y la inteligencia artificial, un futuro lleno de oportunidades pero al mismo tiempo no exento de riesgos. A medida que la IA continúa desarrollándose, podemos esperar ver aplicaciones aún más innovadoras y transformadoras de esta tecnología. Para ello será también necesaria una colaboración más cercana entre investigadores de inteligencia artificial y la comunidad de los datos abiertos a la hora de abrir nuevos conjuntos de datos y desarrollar nuevas herramientas para explotarlos. Esta colaboración es esencial para poder darle forma al futuro conjunto de los datos abiertos y la IA y garantizar que los beneficios de la IA estén disponibles para todos de forma justa y equitativa.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos son una fuente de conocimiento muy valiosa para nuestra sociedad. Gracias a ellos, se pueden crear aplicaciones que contribuyen al desarrollo social y soluciones que ayudan a configurar el futuro digital de Europa y alcanzar los Objetivos de Desarrollo Sostenible (ODS).
El portal de datos abiertos europeo (data.europe.eu) organiza eventos en línea para poner en valor aquellos proyectos que se han llevado a cabo con fuentes de datos abiertos y han ayudado a hacer frente a alguno de los retos a los que nos enfrentamos como sociedad: desde la lucha contra el cambio climático, el impulso de la economía, la consolidación de la democracia europea o la transformación digital.
En lo que llevamos de año, en 2023 se han celebrado cuatro seminarios para analizar el impacto positivo que tienen los datos abiertos en cada una de las temáticas mencionadas. Todo el material que se presentó en los eventos está publicado en el portal europeo y las grabaciones están disponibles en su canal de Youtube, al alcance de cualquier usuario interesado.
En este post, realizamos un primer repaso de los casos de uso presentados en materia de impulso a la economía y a la democracia, así como los conjuntos de datos abiertos que se emplearon para su desarrollo.
Soluciones que impulsan la economía y el estilo de vida europeo
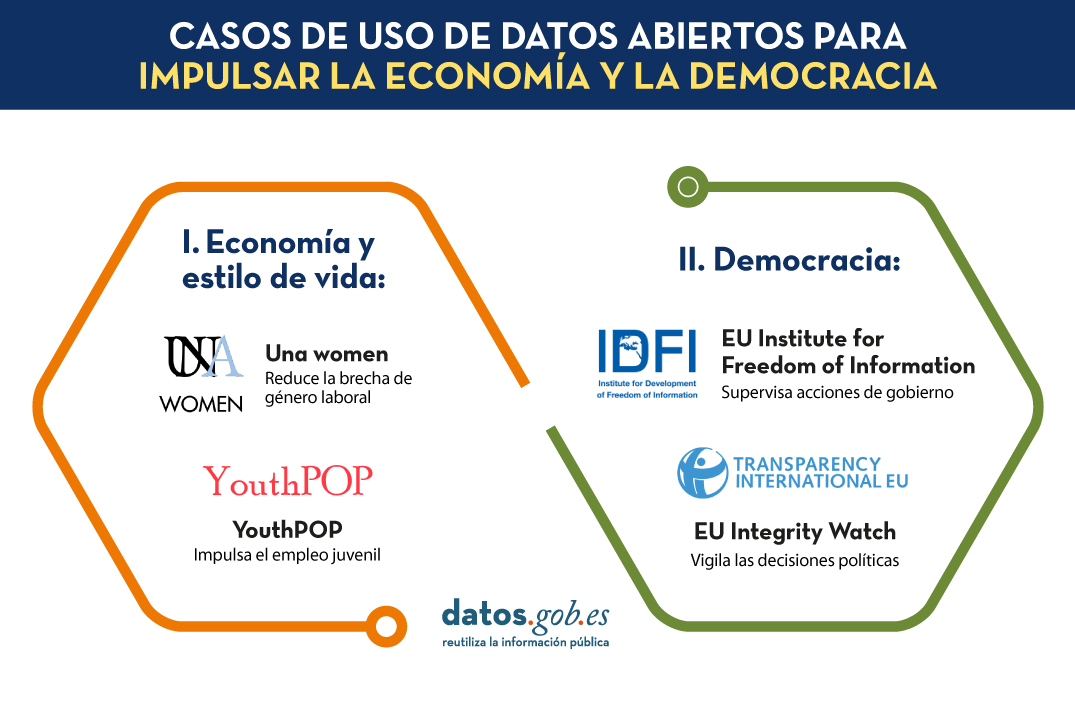
En un mundo en constante evolución, donde los desafíos económicos y las aspiraciones de un estilo de vida próspero convergen, la Unión Europea ha demostrado una capacidad inigualable para forjar soluciones innovadoras que no solo impulsan su propia economía, sino que también elevan el estándar de vida de sus ciudadanos. En este contexto, los datos abiertos han jugado un papel fundamental en el desarrollo de aplicaciones que han dado respuesta a desafíos actuales y han sentado las bases para un futuro próspero y prometedor. Dos de estos proyectos se presentaron en el segundo webinar de la serie “Stories of use cases”, un evento sobre “Datos abiertos para fomentar la economía y el estilo de vida europeo”: UNA WOMEN y YouthPOP.
El primero de ellos se centra en solucionar uno de los retos más relevantes que debemos superar para lograr una sociedad justa: la desigualdad de género. La eliminación de la brecha de género es un problema social y económico muy complejo. Según estimaciones del Foro Económico Mundial, se necesitarán 132 años para lograr la paridad de género total en Europa. La aplicación UNA Women nace con el propósito de reducir esa cifra, asesorando a las mujeres jóvenes para que puedan tomar mejores decisiones a la hora de elegir su futuro en cuanto a educación y primeros pasos en sus carreras profesionales. En este caso de uso, la empresa ITER IDEA ha utilizado más de 6 millones de líneas de datos procesados de distintas fuentes, como data.europa.eu, Eurostat, Censis, Istat (Instituto nacional de estadística de Italia) o NUMBEO.
El segundo caso de uso presentado también va dirigido a la población joven. Se trata de la aplicación YouthPOP (Youth Públic Open Procurement), una herramienta que anima a los jóvenes a participar en procesos de contratación pública. Para el desarrollo de esta app se han utilizado datos de data.europa.eu, Eurostat y ESCO, entre otros. Youth POP tiene entre sus objetivos mejorar el empleo juvenil y contribuir al correcto funcionamiento de la democracia en Europa.
Datos abiertos para impulsar y consolidar la democracia europea
En esta línea, el uso de los datos abiertos también contribuye a fortalecer y consolidar la democracia europea. Los datos abiertos desempeñan un papel fundamental en nuestras democracias a través de las siguientes vías:
- Proporcionando a los ciudadanos información confiable.
- Fomentando la transparencia en los gobiernos e instituciones públicas.
- Combatiendo la desinformación y las noticias falsas.
El tema del tercer webinar organizado por datos.europa.eu sobre casos de uso es “Datos abiertos y un nuevo impulso a la democracia europea”, evento en el que se presentaron dos soluciones innovadoras: EU Integrity Watch y EU Institute For Freedom of Information.
En primer lugar, EU Integrity Watch es una plataforma que proporciona herramientas en línea para que los ciudadanos, periodistas y la sociedad civil monitoricen la integridad de las decisiones tomadas por los políticos en la Unión Europea. Esta web ofrece visualizaciones para comprender la información y pone a disposición los datos recopilados y analizados. Los datos analizados se utilizan en divulgaciones científicas, investigaciones periodísticas y otros ámbitos, lo que contribuye a un gobierno más abierto y transparente. Esta herramienta procesa y ofrece datos de Transparency register.
La segunda iniciativa presentada en el webinar sobre democracia con datos abiertos es el EU Institute For Freedom of Information (IDFI), una organización no gubernamental georgiana que se centra en actividades de vigilancia y supervisión de las acciones del gobierno, revelando infracciones y manteniendo informada a la ciudadanía.
Las principales actividades del IDFI incluyen solicitar información pública a los organismos pertinentes, elaborar clasificaciones de organismos públicos, monitorizar los sitios web de dichos organismos y abogar por la mejora del acceso a la información pública, los estándares legislativos y las prácticas relacionadas. Este proyecto obtiene, analiza y presenta conjuntos de datos abiertos procedentes de instituciones públicas nacionales.
En definitiva, los datos abiertos hacen posible el desarrollo de aplicaciones para reducir la brecha laboral de género, impulsar el empleo juvenil o vigilar las acciones de gobierno. Estos son solo algunos ejemplos del valor que pueden ofrecer los datos abiertos a la sociedad.
Conoce más sobre estas aplicaciones en sus seminarios -> Grabaciones aquí
Blog
En la era digital, los avances tecnológicos han transformado el sector de la investigación médica. Uno de los factores que contribuyen al desarrollo tecnológico en este ámbito son los datos y, en especial, los datos abiertos. La apertura y disponibilidad de la información que se obtiene de investigaciones sanitarias aporta múltiples beneficios a la comunidad científica. Los datos abiertos en el sector salud fomentan la colaboración entre investigadores, aceleran el proceso de validación de resultados en estudios y, en definitiva, ayudan a salvar vidas.
La relevancia de este tipo de datos también se manifiesta en la intención prioritaria de constituir el proyecto de espacio europeo de datos sanitarios (EEDS), el primer espacio común de datos de la UE que surge de la Estrategia Europea de Datos y una de las prioridades de la Comisión para el período 2019-2025. Tal y como plantea la Comisión Europea en su propuesta, el EEDS este espacio contribuirá a promover un mejor intercambio y acceso a diferentes tipos de datos sanitarios, no solo para apoyar la prestación de asistencia médica sino también para la investigación sanitaria y la elaboración de políticas en el ámbito de la salud.
Sin embargo, el tratamiento de este tipo de datos debe de ser adecuado, debido a la información sensible que albergan. Los datos personales relativos a la salud están considerados como una categoría especial por la Agencia Española de Protección de Datos (AEPD) y una brecha de datos personales, especialmente, en el sector de la salud, tiene un alto impacto personal y social.
Para evitar estos riesgos, los datos médicos se pueden anonimizar garantizando el cumplimiento normativo y de los derechos fundamentales y, así, proteger la privacidad de los pacientes. La Guía básica de anonimización elaborada por la AEPD a partir de la Personal Data Protection Commission Singapore (PDPC) define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
Una vez se realiza ese proceso, los datos médicos pueden contribuir a la investigación sobre enfermedades, lo que se traduce en mejoras en la eficacia de tratamientos y en el desarrollo de tecnologías de asistencia médica. Además, los datos abiertos en el sector salud permiten que los científicos compartan información, resultados y hallazgos de manera rápida y accesible, fomentando así la colaboración y la replicabilidad de los estudios.
En este sentido, existen diversas instituciones que comparten sus datos anonimizados para contribuir a la investigación sanitaria y el desarrollo de la ciencia. Una de ellas es la Fundación FISABIO (Fundación para el Fomento de la Investigación Sanitaria y Biomédica de la Comunitat Valenciana) que se ha convertido en un referente en el campo de la medicina gracias a su compromiso con la apertura y compartición de datos médicos. Como parte de esta institución, ubicada en la Comunidad Valenciana, existe la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) que se dedica, entre otras tareas, al estudio y desarrollo de técnicas avanzadas de imagen médica para mejorar el diagnóstico y tratamiento de enfermedades.
Este grupo de investigación ha desarrollado diferentes proyectos sobre análisis de imagen médica. El resultado de todo su trabajo se publica bajo licencias de código abierto: desde el resultado de sus investigaciones hasta los repositorios de datos que emplean para entrenar modelos de inteligencia artificial y machine learning.
Para proteger los datos sensibles de los pacientes, también han desarrollado sus propias técnicas de anonimización y seudonimización de imágenes e informes médicos mediante un modelo de Procesamiento del Lenguaje Natural (NLP) por el que los datos anonimizados se pueden sustituir por valores sintéticos. Siguiendo su técnica, se puede borrar la información facial de resonancias magnéticas cerebrales empleando un software libre de deep learning.
BIMCV: Banco de imágenes médicas de la Comunidad Valenciana
Uno de los mayores hitos de la Conselleria de Sanidad Universal y Salud Pública, a través de la Fundación y el hospital San Juan de Alicante, es la creación y mantenimiento del Banco de Imágenes Médicas de la Comunidad Valenciana, BIMCV (por sus siglas en inglés, Medical Imaging Databank of the Valencia Region), un repositorio de conocimiento para lograr “avances tecnológicos en imágenes médicas y proporcionar servicios de cobertura tecnológica para apoyar proyectos de I+D”, tal y como explican en su web.
BIMCV se aloja en XNAT, una plataforma que contiene imágenes de código abierto para la investigación basada en imágenes, y que es accesible bajo previo registro y/o bajo demanda. Actualmente, el Banco de Imágenes Médicas de la Comunidad Valenciana incluye datos abiertos procedentes de investigaciones realizada en diversos centros sanitarios de la región: alberga datos de más de 90.000 sujetos recogidos en más de 150.000 sesiones.
Nuevo conjunto de datos de imágenes radiológicas
Recientemente, la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) ha publicado en abierto la tercera y última iteración de datos del proyecto BIMCV-COVID-19: iniciativa con la que liberaron datos de imagen de radiologías de tórax realizadas a pacientes con COVID-19, así como los modelos que habían entrenado para detección de diferentes patologías de Rx tórax, gracias al apoyo de la Conselleria de Innovación, la Conselleria de Sanidad y los Fondos de la Unión Europea REACT-UE. Todo ello, “para que pueda ser utilizado por empresas del sector o simplemente para investigación”, explica María de la Iglesia, directora de la Unidad. “Creemos que la reproducibilidad es de gran relevancia e importancia en el sector salud", añade. Los conjuntos de datos y el resultado de sus investigaciones se pueden consultar aquí.
Los hallazgos están mapeados en terminología estándar del Sistema Unificado de Lenguaje Médico (UMLS) (como propuesta de los resultados de la tesis doctoral de la Oncóloga e Ingeniera Informática Dra. Aurelia Bustos)y almacenados en alta resolución con etiquetas anatómicas en un formato de Estructura de Datos de Imágenes Médicas (MIDS). Entre la información almacenada, se encuentran datos demográficos del paciente, el tipo de proyección y los parámetros de adquisición del estudio de imagen, entre otros, todo ello anonimizado.
La contribución que este tipo de proyectos sobre datos abiertos aportan a la sociedad, no solo beneficia a los investigadores y profesionales de la salud, sino que también permite el desarrollo de soluciones que pueden tener un impacto relevante en la mejora de la atención médica. Una de ellas puede ser la IA generativa que proporciona interesantes resultados que los profesionales sanitarios, priorizando su criterio, pueden tomar en consideración para personalizar el diagnóstico y proponer un tratamiento más eficaz.
Por otro lado, la digitalización de los sistemas sanitarios ya es una realidad: impresión 3D, gemelos digitales aplicados a la medicina, consultas telemáticas o dispositivos médicos portátiles. En este contexto, la colaboración y compartición de datos médicos, siempre y cuando se garantice su protección, contribuye a impulsar la investigación e innovación en el sector. Es decir, las iniciativas de datos abiertos para la investigación médica estimulan este avance tecnológico en la salud.
Por todo ello, la Fundación FISABIO conjuntamente con el Centro de Investigación Príncipe Felipe en donde se ubica la plataforma que alberga BIMCV, se destaca como un ejemplo destacado al promover la apertura y compartición de datos en el campo de la medicina. A medida que avanza la era digital, es fundamental seguir fomentando la apertura de datos y promoviendo su uso responsable en la investigación médica, en beneficio de toda la sociedad.
Blog
Detrás de un asistente virtual de voz, la recomendación de una película en una plataforma de streaming o el desarrollo de algunas vacunas contra el covid-19 existen modelos de machine learning. Esta rama de la inteligencia artificial permite que los sistemas aprendan y mejoren su funcionamiento.
El machine learning (ML) o aprendizaje automático es uno de los campos que impulsa el avance tecnológico del presente y sus aplicaciones crecen cada día. Como ejemplos de soluciones desarrolladas con machine learning podemos mencionar DALL-E, el conjunto de modelos del lenguaje en español MarIA o incluso Chat GPT-3, herramienta de IA generativa que es capaz de crear contenido de todo tipo, como, por ejemplo, código para programar visualizaciones con datos del catálogo datos.gob.es.
Todas estas soluciones funcionan gracias a grandes repositorios de datos que hacen posible el aprendizaje de los sistemas. Entre estos, los datos abiertos juegan un papel fundamental para el desarrollo de la inteligencia artificial ya que pueden servir de entrenamiento para los modelos de aprendizaje automático.
Bajo esta premisa, sumado al esfuerzo permanente de las administraciones por la apertura de datos, existen organizaciones no gubernamentales y asociaciones que contribuyen desarrollando aplicaciones que usan técnicas de machine learning dirigidas a mejorar la vida de la ciudadanía. Destacamos tres de ellas:
ML Commons impulsa un sistema de aprendizaje automático mejor para todos
Esta iniciativa pretende mejorar el impacto positivo del aprendizaje automático en la sociedad y acelerar la innovación ofreciendo herramientas como conjuntos de datos, mejores prácticas y algoritmos abiertos. Entre sus miembros fundadores se encuentran empresas como Google, Microsoft, DELL, Intel AI, Facebook AI, entre otras.
Según ML Commons, en torno al 80% de las investigaciones realizadas en el ámbito del machine learning se basan en datos abiertos. Por lo tanto, los datos abiertos son vitales para acelerar la innovación en esta materia. Sin embargo, hoy en día, “la mayoría de los ficheros de datos públicos disponibles son pequeños, estáticos, tienen restricciones legales y no son redistribuibles”, tal y como asegura David Kanter, director de ML Commons.
En esta línea, las tecnologías innovadoras de ML necesitan grandes conjuntos de datos con licencias que permitan su reutilización, que puedan ser redistribuibles y que estén en continua mejora. Por ello, la misión de ML Commons es contribuir a mitigar esa brecha y para así impulsar la innovación en machine learning.
El principal objetivo de esta organización es crear una comunidad de datos abiertos para el desarrollo de aplicaciones machine learning. Su estrategia se basa en tres pilares:
En primer lugar, crear y mantener conjuntos de datos abiertos completos. Entre otros: The People’s Speech, con más de 30.000 horas de discurso en inglés para entrenar modelos de procesamiento del lenguaje natural (PLN), Multilingual Spoken Words, con más de 23 millones de expresiones en 50 idiomas diferentes o Dollar Street, con más de 38.000 imágenes de hogares de todo el mundo en situaciones socioeconómicas variadas. El segundo pilar consiste en impulsar buenas prácticas que faciliten la estandarización. Ejemplo de ello es el proyecto MLCube que propone estandarizar el proceso de contenedores para modelos ML para facilitar su uso compartido. Y, por último, realizar benchmarking en grupos de estudios para definir puntos de referencia para la comunidad desarrolladora e investigadora.
Aprovechar las ventajas y formar parte de la comunidad ML Commons es gratuito para las instituciones académicas y las empresas pequeñas (menos de diez trabajadores).
Datacommons sintetiza diferentes fuentes de datos abiertos en un único portal
Datacommons busca potenciar los flujos democráticos de datos dentro de la economía cooperativa y solidaria y tiene como objetivo principal ofrecer datos depurados, normalizados e interoperables.
La variedad de formato e información que ofrecen los portales públicos de datos abiertos puede llegar a ser un obstáculo para la investigación. El objetivo de Datacommons es compilar datos abiertos en una web enciclopédica que ordena todos los dataset mediante nodos. De esta manera, el usuario puede acceder a la fuente que más le interesa.
Esta plataforma, que fue diseñada con fines educativos y de investigación periodística, funciona como herramienta de referencia para navegar entre distintas fuentes de datos. El equipo de colaboradores trabaja para mantener la información actualizada e interactúa con la comunidad a través de su e-mail (support@datacommons.org) o foro de GitHub.
Papers with Code: el repositorio de materiales en abierto para alimentar modelos machine learning
Se trata de un portal que ofrece código, informes, datos, métodos y tablas de evaluación en formato abierto y gratuito. Todo el contenido de la web está bajo licencia CC-BY-SA, es decir, permite copiar, distribuir, exhibir y modificar la obra incluso con fines comerciales compartiendo las contribuciones realizadas con la misma licencia original.
Cualquier usuario puede contribuir aportando contenido e, incluso, participar en el canal de Slack de la comunidad que está moderado por responsables que protegen la política de inclusión definida por la plataforma.
A día de hoy, Papers with Code aloja 7806 conjuntos de datos que se pueden filtrar según formato (gráfico, texto, imagen, tabular etc.), tarea (detección de objeto, consultas, clasificación de imágenes etc.) o idioma. El equipo que mantiene Papers with Code pertenece al instituto de investigación de Meta.
El objetivo de ML Commons, Data Commons y Papers with Code es mantener y hacer crecer comunidades de datos abiertos que contribuyan al desarrollo de tecnologías innovadoras. Entre ellas, la inteligencia artificial (machine learning, deep learning etc.) con todas las posibilidades que su desarrollo puede llegar a ofrecer a la sociedad.
Como parte de este proceso, las tres organizaciones desarrollan un papel fundamental: ofrecen repositorios de datos en formato estándar y redistribuible para entrenar modelos machine learning. Son recursos útiles para realizar ejercicios académicos, impulsar la investigación y, al fin y al cabo, facilitar la innovación de tecnologías que cada día están más presentes en nuestra sociedad.
Evento
El próximo 5 de marzo, comunidades de todo el mundo se unen para celebrar el Día de los Datos Abiertos (Open Data Day 2022). Se trata de una celebración anual que busca mostrar los beneficios y fomentar la adopción de políticas de datos abiertos en gobiernos, empresas y sociedad civil.
Durante todo el día -y en fechas próximas- grupos locales de todos los rincones del mundo organizan distintas acciones ligadas a la publicación y reutilización de datos. En España también se celebran algunas actividades, como por ejemplo:
DATATHON 2022
- Fecha: Del 4 de marzo al 30 de abril de 2022.
- Formato: Online
- Organizadores: Universidad de Alicante, Universidad Miguel Hernández, PAGODA, Dades Valencia, Cátedra Transició energética, Catedrades, Generalitat Valenciana, Universidad Politécnica de Valencia, Universidad de Valencia, ACICOM y MESURA.
El próximo 4 de marzo arranca el Datathon 2022, en el que los participantes tendrán que utilizar herramientas de aprendizaje automático, inteligencia artificial o ciencia de datos para dar respuesta a un reto de su elección relacionado con los siguientes campos:
A) Producción y consumo responsable.
B) Aspectos medioambientales (agricultura, residuos, transición energética…).
C) Cultura.
Se trata de un evento gratuito. Pueden participar todas aquellas personas físicas mayores de edad que lo deseen, en equipos de 2 a 6 personas. Para ello es necesario inscribirse previamente antes del 4 de marzo a través de eventbritte.
Se otorgarán premios en dos categorías: alumnado de grado (750€ por cada reto) y alumnado de máster, doctorado y empresas (500€ por cada reto). Además, en ambas categorías se otorgarán a los vencedores de cada reto tres accésits de 350€.
La competición irá acompañada de diversas sesiones informativas y talleres dirigidos a los participantes, que tendrán lugar durante toda la competición (del 4 de marzo al 30 de abril de 2022). Algunos ejemplos de estos talleres son: “Cómo solicitar información a la administración y legalidad del uso de los datos”, “Minería de datos y visualización” o “Contar historias con datos”.
Open Data Day 2022
- Fecha: Del 4 al 8 de marzo de 2022.
- Formato: Presencial y online.
- Organizadores: Generalitat de Catalunya
La Secretaría de Gobierno Abierto de la Generalitat de Catalunya también se suma a la celebración del Día Internacional de los Datos Abiertos, con actividades, la mayoría en catalán, que abarcarán del 4 al 8 de marzo.
- 4 de marzo, a las 9:30h (presencial y online). El valor del open data. La jornada estará dedicada a los reutilizadores de datos abiertos. Se realizará una mesa redonda con expertos en el campo de la reutilización y se presentarán dos documentos de interés: el nuevo volumen de la colección Gobierno Abierto, "El valor de los datos abiertos y los casos de uso", de la consultora Alícia León Molina, que recoge ejemplos de uso relacionados con los datos abiertos en diferentes países, y el III informe sobre reutilización de datos elaborado por la Fundación COTEC. Se retransmite vía Youtube.
- 7 de marzo, a las 10h (online). Ciencia Abierta y Ciencia Ciudadana. Le lunes se dedicará al uso de los datos abiertos en el mundo de la investigación. Participará la Dirección General de Investigación presentará el CORA - Catalan Open Research y se presentarán experiencias del sector privado por parte de Ideas for Change.
- 8 de marzo, a las 13:30h (online). ¿Cuál puede ser el papel de los gobiernos locales en una economía de datos emergente? Representantes de la ciudad de Rennes, Francia, y de Cataluña, explicarán el proyecto RUDI data Rennes, liderado por Rennes Métropole y financiado por la Unión Europea: una "red de datos sociales". Este evento se celebrará en inglés y francés.
Open Data Day 2022: Por una reutilización más efectiva de los datos abiertos
- Fecha: 9 marzo de 2022, 17h
- Formato: Presencial
- Organizadores: Iniciativa Open Data Barcelona
Justo dos años después de su último evento presencial, Iniciativa Open Data Barcelona recupera las reuniones “cara a cara” con una conferencia dirigida a divulgar conocimiento y experiencias sobre los datos abiertos públicos y su reutilización. El evento, que durará de 17 a 19 de la tarde, se estructurará en torno a dos mesas redondas:
- Oportunidades ligadas a los datos abiertos de las instituciones, donde se hablará de las novedades de los portales de datos institucionales, destacando los datasets que se ofrecen y las nuevas funcionalidades que impulsan su reutilización.
- Proyectos basados en la reutilización de datos abiertos, centrada en cómo usar dichos datos en un proyecto, resaltando su potencial como fuente de conocimiento para resolver los retos a los que hacen frente diversos colectivos.
El evento es gratuito, pero es necesaria inscripción previa.
Otros eventos internacionales
Además de las actividades celebradas en nuestro país, en otros lugares del mundo también tienen lugar eventos, algunos de los cuales se pueden seguir online.
Por ejemplo, la ciudad de Nueva York celebra del 5 al 13 de marzo de 2022 su semana de los datos abiertos, organizada por la Oficina de Análisis de Datos de la Alcaldía de Nueva York y BetaNYC. Esta celebración se produce cada año coincidiendo no solo con el Open Data Day, sino también con la Ley de Datos Abiertos de la ciudad de Nueva York, que se promulgó el 7 de marzo de 2012. Este año, la semana de los datos abiertos de NY se celebra con un formato híbrido con actividades presenciales y online. Todas las actividades están relacionadas directamente con los datos abiertos disponibles públicamente sobre Nueva York.
Otro ejemplo de evento online es el OSM Africa March Mapathon: Map Sierra Leone, una iniciativa que busca apoyar el desarrollo de la comunidad OpenStreetMap en África.
Si quieres conocer otras actividades que se celebrarán con motivo del Open Data Day 2022, puedes visitar su página web.