Blog
Invitamos a presentar la candidatura a los Premios Aporta a todas las empresas que hayan realizado con éxito proyectos con datos reutilizables generados por las administraciones públicas españolas
Los Premios Aporta 2017, una iniciativa promovida por la Secretaría de Estado para la Sociedad de la Información y la Agenda Digital, la Entidad Pública Empresarial Red.es y la Secretaría General de Administración Digital, nacen con la pretensión de divulgar y reconocer casos de éxito que sirvan a otros profesionales del sector público para innovar y apostar por la reutilización de datos abiertos como motor de transformación digital y la innovación.
Las empresas que deseen participar tienen hasta el próximo 12 de septiembre para presentar proyectos desarrollados en los dos últimos años en los que la reutilización de datos haya contribuido a generar valor social, nuevos negocios y/o mejoras para la sociedad.
Las candidaturas, que habrán de referir iniciativas que hayan hecho uso de datos abiertos públicos generados por las AA.PP. o de datos ofrecidos por entidades privadas, deberán presentarse a través del formulario disponible en la sede electrónica de Red.es.
Los proyectos serán evaluados durante el mes de septiembre por representantes de la Iniciativa Aporta. Se tendrá en cuenta la originalidad, la utilidad y el impacto de la iniciativa en términos de destinatarios beneficiados.
Las dos mejores iniciativas recibirán un reconocimiento en el Encuentro Aporta que tendrá lugar a finales de octubre de 2017.
Esperamos que nuestra labor de difusión y reconocimiento de casos de éxito en la reutilización de datos públicos sirva a muchos otros profesionales del sector privado para innovar y apostar por el uso de datos generados por las Administraciones Públicas como fuente de ventajas competitivas.
Toda la información en datos.gob.es y en Bases de los Premios Aporta 2017.
Blog
En demasiadas ocasiones las iniciativas de publicación de datos abiertos nacen en los gobiernos como proyectos puramente técnicos cuya finalidad es simplemente la de crear un catálogo de datos, cuando en realidad deberían ser vistas como proyectos colaborativos de transformación que se llevan a cabo dentro de entornos complejos y muy variables, en los que la finalidad última no está del todo clara y las entidades coordinadoras – la administración pública en este caso – no tiene todos los recursos para generar el cambio necesario por sí mismas.
En realidad, para poder explotar todo su potencial los datos abiertos deben poder contar con un ecosistema saludable y equilibrado que lo sostenga y le de vida. Los datos no serán más que la plataforma común sobre la que soporta este ecosistema y que proporciona la materia prima necesaria para que se nutra y evolucione.
Por tanto, una de las claves para el éxito (o fracaso) de cualquier iniciativa de datos abiertos será su capacidad para crear y evolucionar una comunidad activa de usuarios en torno a los datos publicados, estableciendo mecanismos de comunicación y colaboración permanentes que permitan habilitar procesos de retroalimentación y co-creación durante todo el proceso.

Es importante también que estos procesos se establezcan para los múltiples actores que deben formar parte de ese ecosistema:
-
Sector público: incluyendo todos los niveles de la administración y cuyo papel consistirá en proporcionar una soporte político, garantizar la sostenibilidad a largo plazo, proporcionar la dirección estratégica al más alto nivel, guiar la implementación, crear normas, establecer la agenda o dar soporte.
-
Organizaciones no gubernamentales: centradas principalmente en usar los datos como herramienta para sus distintas actividades, concienciar acerca del valor real que se oculta detrás de los datos, monitorizar las políticas relevantes y exigir una mayor disponibilidad de datos y garantías de participación.
-
Hackers cívicos: que utilizarán sus conocimientos más técnicos para transformar los datos y darle sentido para las distintas audiencias.
-
Medios de comunicación y difusión: cuyo rol consiste en utilizar los datos para informar, hacer periodismo de investigación y contar historias a través de los datos que lleguen más directamente a los ciudadanos.
-
Universidad e instituciones de Investigación: usando los datos no sólo para desarrollar conceptos teóricos y frameworks, sino también investigación aplicada para dar lugar a nuevos productos y servicios a través de los datos y la innovación.
-
Sector privado: generando valor y negocio en base a los datos, proporcionar las infraestructuras de datos necesarias, colaborando para facilitar los procesos de apertura y aportando sus propios datos para enriquecer el ecosistema.
Y dado que la clave está en el ecosistema, ¿cómo conseguiremos entonces fomentar una ecosistema exitoso? Podemos fijarnos por ejemplo en las diez lecciones que comparten con nosotros los pioneros de Internet, el mayor y más exitoso ecosistema social existente hasta la fecha gracias a la colaboración:
-
Deja que todo el mundo juegue: atrae nuevos recursos y genera nuevas ideas.
-
Juega limpio: un error común será reducir la participación potencial poniendo serias barreras de entrada para evitar aportaciones de baja calidad, vandalismo, etc.
-
Cuenta lo que está haciendo mientras lo haces: mejora la comprensión y participación, evita solapamientos y genera confianza.
-
Utiliza múltiples canales de comunicación: no centrarse únicamente en la Web.
-
Comparte: no te reserves lo que sabes y aprendes.
-
Busca los límites: necesitarás esa visión cuando aparezcan los problemas más complicados.
-
Saca ventaja de todos: necesitarás de la participación de todo el mundo con distintos intereses e incentivos.
-
Diseña para la participación: divide el trabajo en tareas manejables que sean fáciles de realizar e inviten a involucrarse.
-
Maximiza el efecto de red: un modelo de comunidad basado en una red de nodos que interactúan entre ellos dará lugar a un crecimiento exponencial.
-
Construye plataformas: ayuda a la gente y las organizaciones a coordinarse para que juntos sean más productivos.
“Si te centras en evitar que la gente pueda hacer cosas malas [con los datos], también estarás evitando que puedan hacer cualquier cosa buena” – Jimmy Wales, co-fundador de la Wikipedia.
Blog
El impacto final que se puede obtener a través de una iniciativa de datos abiertos dependerá finalmente de múltiples factores interrelacionados que estarán presentes (o ausentes) en dichas iniciativas. Es por ello que el GovLab de la New York University ha analizado estos factores gracias al estudio de los varios casos de usos recopilados por su proyecto acerca del impacto del open data a lo largo del mundo llegando a elaborar una tabla periódica de los elementos habilitadores del impacto.
Estos elementos de impacto han sido finalmente clasificados en cinco categorías principales por las que haremos un rápido recorrido en las diferentes secciones a continuación.
Definición del problema y de la demanda de datos asociada
Obtener un mayor conocimiento anticipado de los problemas que deseamos resolver y la demanda de datos necesarios para poder darles solución es un primer paso lógico para la obtención del impacto deseado. Los elementos que entran en acción en esta categoría son:
-
Análisis en profundidad de los futuros usuarios y optimización con respecto a sus necesidades desde el comienzo del proyecto.
-
Definición de las causas y el contexto, distinguiendo claramente entre las causas del origen de los problemas que pretendemos atajar y los simples síntomas ocasionados por estos mismos problemas.
-
Refinamiento a través de la descomposición del problema en cada uno de los factores que lo definen.
-
Definición de los beneficios y objetivos esperados para poder proceder a la posterior medición de su grado de consecución.
-
Auditoría de los datos necesarios para llevar a cabo la proposición de valor planteada e inventario de los datos realmente existentes al respecto.
Capacidad y cultura civil e institucional
La falta de conocimientos o de las capacidades mínimas tecnológicas y de gestión podría dar lugar a una barrera difícil de franquear a la hora de obtener el impacto esperado. Los elementos que forman parte de esta categoría incluyen:
-
Los elementos mínimos de hardware y software que constituyen las infraestructuras de datos necesarias para poder proporcionar el acceso y habilitar su uso.
-
El capital humano, los servicios públicos y los elementos de la sociedad civil que constituyen la Infraestructura pública imprescindible para garantizar la disponibilidad de los datos en un ecosistema saneado.
-
El nivel de alfabetización digital y el grado de penetración de internet necesarios para poder sacar provecho de los datos disponibles.
-
Las barreras culturales o institucionales con respecto a la apertura y que podrían actuar como freno de la publicación o expansión de los datos abiertos.
-
La existencia de las capacidades y conocimientos técnicos necesarios para poder sacar partido de los datos.
-
Los canales de retroalimentación habilitados a la hora de recoger las experiencias de los usuarios y beneficiarios finales de los datos.
-
Disponibilidad de los recursos necesarios para poder garantizar la sostenibilidad y disponibilidad en el largo plazo de los datos ya compartidos.
Gobernanza de los datos
La diversidad existente entre los distintos modelos de gobernanza con respecto a los estándares y políticas de publicación es otra variable claramente diferenciadora a la hora de hablar de impacto. Los elementos que forman parte de esta categoría incluyen:
-
Elaboración de métricas de rendimiento que informen las decisiones a tomar en los proyectos de apertura a través de las diferentes iteraciones.
-
Control de riesgos que pudiesen afectar a la privacidad de los datos o a información sensible para prevenir una exposición no deseada.
-
Apertura por defecto como principio director de la estrategia y políticas existentes para garantizar el compromiso político al más alto nivel.
-
Libre acceso a la información y otras políticas que funcionen como pilares necesarios sobre los que edificar los proyectos de apertura de datos.
-
Medidas para asegurar una mínima calidad de los datos publicados de forma que sean suficientemente precisos y actualizados para poder sacarles provecho.
-
Capacidad auténtica de respuesta ante las reacciones y necesidades cambiantes de los usuarios de los datos.
Colaboraciones con otros actores del ecosistema
Las colaboraciones con todo tipo de organizaciones e individuos que formen parte del ecosistema de los datos juegan un papel fundamental a la hora de afrontar un proceso de apertura con garantías de éxito. Los elementos que forman parte de esta categoría incluyen:
-
Establecer conexiones cercanas con los gestores de los datos, tanto públicos como privados, es una buena estrategia a la hora de afrontar las carencias existentes en los datos con su ayuda.
-
La actuación de los intermediarios y su rol a la hora de hacer llegar los beneficios de la apertura de datos a los usuarios finales puede llegar a marcar la diferencia respecto al éxito o fracaso de una iniciativa.
-
Expertos de dominio que proporciones el conocimiento específico requerido a la hora de trabajar en sectores específicos y bien definidos.
-
Colaboraciones con otros individuos y organizaciones afines en cuanto a la filosofía de apertura.
Gestión de riesgos
Un proceso de apertura de datos siempre estará expuesto a un cierto nivel de riesgos que se deben identificar y afrontar adecuadamente. Los elementos que forman parte de esta categoría incluyen:
-
Problemas de privacidad para los que será necesario garantizar la anonimización de los datos frente a las distintas técnicas de identificación individual.
-
Técnicas de seguridad de los datos no intrusivas para proteger la información sensible frente a una exposición no deseada pero sin comprometer la apertura del resto de datos.
-
Problemas en la toma de decisiones debido a fundamentarse en información incorrecta o incompleta.
-
Profundización en la asimetría de poder ante la imposibilidad de poder acceder a los datos por parte de algunos grupos marginados en beneficio de una minoría privilegiada.
-
Uso del open data como simple lavado de imagen en lugar de perseguir un verdadero cambio transformador.
Aunque obviamente existen otras variables de contexto que afectarán a nuestras posibilidades de éxito en cada caso específico, trabajar sobre los elementos anteriormente vistos tendrá sin duda un efecto positivo sobre el impacto final de nuestras iniciativas de apertura de datos.

Blog
Una de las principales barreras para el despliegue de los datos enlazados (Linked Data) es la dificultad que tienen los editores de datos para determinar qué vocabularios usar para describir la semántica de los mismos. Estos vocabularios proporcionan el “pegamento semántico” (semantic glue) que permite que unos simples datos se conviertan en “datos con significado” (meaningful data).
Linked Open Vocabularies (LOV) es un catálogo de vocabularios disponibles para reutilizar con el objetivo de describir de datos en la Web. LOV recopila metadatos y visibiliza indicadores como la conexión entre diferentes vocabularios, el historial de versiones, las políticas de mantenimiento, junto con referencias pasadas y actuales (tanto a individuos como a organizaciones). El nombre de esta iniciativa (Linked Open Vocabularies - LOV) tiene su raíz en el término Linked Open Data - LOD.

El objetivo principal de LOV es ayudar a los editores de datos enlazados (Linked Data) y vocabularios a evaluar los recursos (vocabularios, clases, propiedades y agentes) ya disponibles y promover así la mayor reutilización posible, además de proporcionar una vía para que los editores añadan sus propias creaciones.
LOV comenzó en el año 2011 bajo el proyecto de investigación Datalift y albergado por Open Knowledge International (anteriormente conocida como Open Knowledge Foundation). Actualmente la iniciativa cuenta con el apoyo de un pequeño equipo de conservadores/revisores de datos y programadores.
Para facilitar la reutilización de los vocabularios bien documentados (con metadatos), se proporcionan varias formas de acceder a los datos:
-
Mediante un interfaz de usuario, con un entorno de navegación y búsquedas (la propia página web).
-
Mediante un SPARQL endpoint para realizar consultas al grafo de conocimiento.
-
Mediante un API REST.
-
Mediante un volcado de los datos, tanto de la base de conocimiento de LOV (en formato Notation3), como de la base de conocimiento más los propios vocabularios (en formato N-Quads).
Actualmente, el registro identifica y enumera:
-
621 vocabularios (vocabularios RDF -RDFS/OWL- definidos como esquemas (T-Box) para la descripción de Linked Data)
-
cerca de 60.000 términos (entre clases y propiedades)
-
Cerca de 700 agentes (creadores, contribuyentes o publicadores, y tanto personas como organizaciones)
Entre todos los vocabularios, 34 tiene algún término en idioma español, lo cual permite un amplio campo de trabajo para la comunidad en español.
LOV es un claro ejemplo de la importancia de documentar correctamente los vocabularios con metadatos. El valor de los metadatos radica en su capacidad para clasificar y organizar información de la manera más eficiente, proporcionando mayor inteligencia y conocimiento de superior calidad, lo que facilita e impulsa iniciativas de automatización, revisión de conformidades, colaboración, apertura de datos y mucho más.
Blog
Los datos abiertos tienen un gran potencial para mejorar la transparencia y la rendición de cuentas o para la mejora de los servicios públicos y la creación de nuevos servicios, pero al mismo tiempo muestran también una cara menos amigable al aumentar nuestra vulnerabilidad y exponer información cada vez más detallada que no siempre es utilizada en nuestro beneficio. Esta cada vez más abundante información personal convenientemente combinada puede a su vez llevar a la identificación personal final o incluso a sofisticadas herramientas de control masivo si no se toman las medidas necesarias para evitarlo. Prácticamente cada aspecto de nuestras vidas ofrece muestras ya de esa doble vertiente positiva y negativa:
-
Por un lado la medicina de precisión nos ofrece grandes avances en el diagnóstico y tratamiento de las enfermedades, pero para ello será necesario recopilar y analizar una gran cantidad de información sobre los pacientes.
-
Los datos han revolucionado también la forma en la que nos desplazamos por las ciudades gracias a la multitud de aplicaciones disponibles y esos mismos datos son de gran utilidad también en la planificación urbana, pero por lo general al coste de compartir prácticamente todos nuestros movimientos a lo largo del día.
-
En el entorno educativo los datos pueden ofrecer experiencias de aprendizaje más adaptadas a los distintos perfiles y necesidades, aunque para ello será nuevamente necesario exponer datos sensibles sobre los expedientes académicos.
En definitiva, los datos personales están en todas partes: cada vez que usamos las redes sociales, cuando hacemos nuestras compras ya sea online o en una gran superficie, cuando hacemos una búsqueda online, cada vez que enviamos un correo electrónico o un mensaje o simplemente navegando por la red… Hoy en día guardamos mucha más información íntima en nuestros móviles que la que solíamos guardar en nuestros diarios personales. Nuevos retos como la gran cantidad de datos que las ciudades digitales gestionan sobre sus ciudadanos necesitan también de nuevos enfoques prácticos para garantizar la seguridad y privacidad de esos datos.
A todo lo anterior hay que sumar que, al ritmo al que sigue avanzado la tecnología hoy en día, puede llegar a ser realmente difícil el garantizar que la privacidad futura de nuestros datos se seguirá manteniendo inalterada, debido a las múltiples posibilidades que ofrece la interconexión de todos estos datos. Parece pues que en este nuevo mundo dirigido por los datos en el que nos adentramos será necesario también empezar a replantearnos el futuro de una nueva economía basada en los datos personales, una nueva forma de gestionar nuestras identidades y datos digitales y los nuevos mercados de datos asociados.
El problema de la privacidad en la gestión de los datos personales no ha hecho más que empezar y está aquí para quedarse como parte de nuestras identidades digitales. No sólo necesitamos un nuevo marco legal y nuevos estándares que se adapten a los tiempos actuales y protejan nuestros datos, sino que también debemos esforzarnos en concienciar y educar a toda una nueva generación sobre la importancia de la privacidad online. Nuestros datos nos pertenecen y debemos ser capaces de retomar y mantener el pleno control sobre ellos y poder así garantizar que se usarán únicamente bajo nuestro consentimiento explícito. Algunas iniciativas pioneras están trabajando ya en áreas clave como la sanidad, la energía o las redes sociales para devolver el control de los datos a sus verdaderos dueños.
Blog
Personas, gobiernos, economía, infraestructuras, medio ambiente… todos estos elementos confluyen en nuestras ciudades y hacen que para poder ser más eficientes éstas tengan que sacar el máximo potencial del flujo de datos constante que fluye a través de sus calles. Análisis de eficiencia de los servicios, seguimiento de la inversión, mejora del transporte público, participación y colaboración con los ciudadanos, reducción de los residuos o prevención de desastres naturales son sólo algunos de los múltiples ejemplos de innovación en las ciudades dirigidas por datos que nos muestran cómo los gobiernos locales están consiguiendo mejorar los servicios y la calidad de vida de sus ciudadanos gracias a la apertura y mejor explotación de sus datos.
Desde encontrar una plaza de aparcamiento a descubrir nuevos lugares de ocio o simplemente movernos por la ciudad. Las aplicaciones que nos facilitan el día a día ya forman parte del paisaje habitual de las ciudades. Al mismo tiempo, los datos están también transformando las ciudades poco a poco delante de nuestros propios ojos y nos ofrecen una visión alternativa de las mismas a través de la definición de nuevos barrios virtuales en función de la huella que vamos dejando con nuestras acciones y nuestros datos.
Ciudades hiperconectadas, dirigidas por los datos, gestionadas por inteligencia artificial y habitadas por un mayor número de robots que de humanos ya no serán una exclusiva de las películas y series de ciencia ficción, sino proyectos reales en mitad del desierto y con planes ya definidos que han sido puestos en marcha en busca de la diversificación y con el objetivo de transformar y renovar economías demasiado dependientes del viejo petróleo irónicamente gracias al supuesto nuevo petróleo de los datos. Volviendo por un momento al presente, encontramos también ya ejemplos de cómo esa transformación a través de los datos es real y está sucediendo en casos tan tangibles como la prevención de crímenes y disminución de la violencia en las favelas de Rio de Janeiro.
Pero no todas las expectativas son tan optimistas, ya que la visión transformadora que tienen algunas empresas tecnológicas para nuestros barrios genera también serias dudas fundadas, no sólo sobre cómo se gestionarán nuestros datos más personales y quiénes serán realmente los que tendrán acceso y control sobre ellos, sino también sobre el supuesto poder transformador de los propios datos.
Por el momento lo único que parece estar totalmente claro es que el papel de los datos en la transformación de las ciudades y ciudadanos del futuro inmediato será clave y deberemos encontrar nuestro propio camino a medias entre las visiones más optimistas y las más pesimistas para definir entre todos qué entendemos como el nuevo paradigma de las Smart Cities, pero siempre con el foco puesto en el elemento humano y no únicamente en los aspectos puramente tecnológicos y con la participación y la co-creación como elementos clave.
Blog
Con toda la probabilidad la mayoría de nosotros conoceremos, o habremos al menos oído hablar de la tecnología blockchain, por su relación con la criptomoneda más popular del momento – Bitcoin. Sin embargo, blockchain no es una tecnología nacida únicamente para sostener esta nueva economía digital, sino que como otras muchas tecnologías de cadenas de bloques su principal finalidad es almacenar y gestionar cadenas de datos de forma descentralizada y distribuida.
Blockchain cuenta con una serie de características que serán en definitiva las que nos proporcionen las ventajas la convertirán en una tecnología de utilidad en varios campos de aplicación: privacidad, (cuasi) anonimato, integridad, distribución de la confianza, transparencia, seguridad, sostenibilidad y código abierto. Si bien está claro que su aplicación más extendida hasta el momento está en el campo de las finanzas, y más concretamente las criptomonedas, también puede resultar de gran utilidad para muchos otros campos fuera y dentro de los gobiernos, particularmente todo aquello relacionado con la identificación personal o la protección de los datos personales mediante la descentralización de la privacidad.
Con respecto a la mejora de los gobiernos blockchain puede contribuir en muy diversas áreas tales como la prestación de servicios públicos, la autenticidad de los registros públicos, la gestión de los datos del sector público, la lucha contra la corrupción o las garantías en los procesos electorales entre otros. Son también ya decenas los ejemplos de emprendedores aplicando la tecnología para innovar en campos tan importantes como la sanidad o la agricultura.
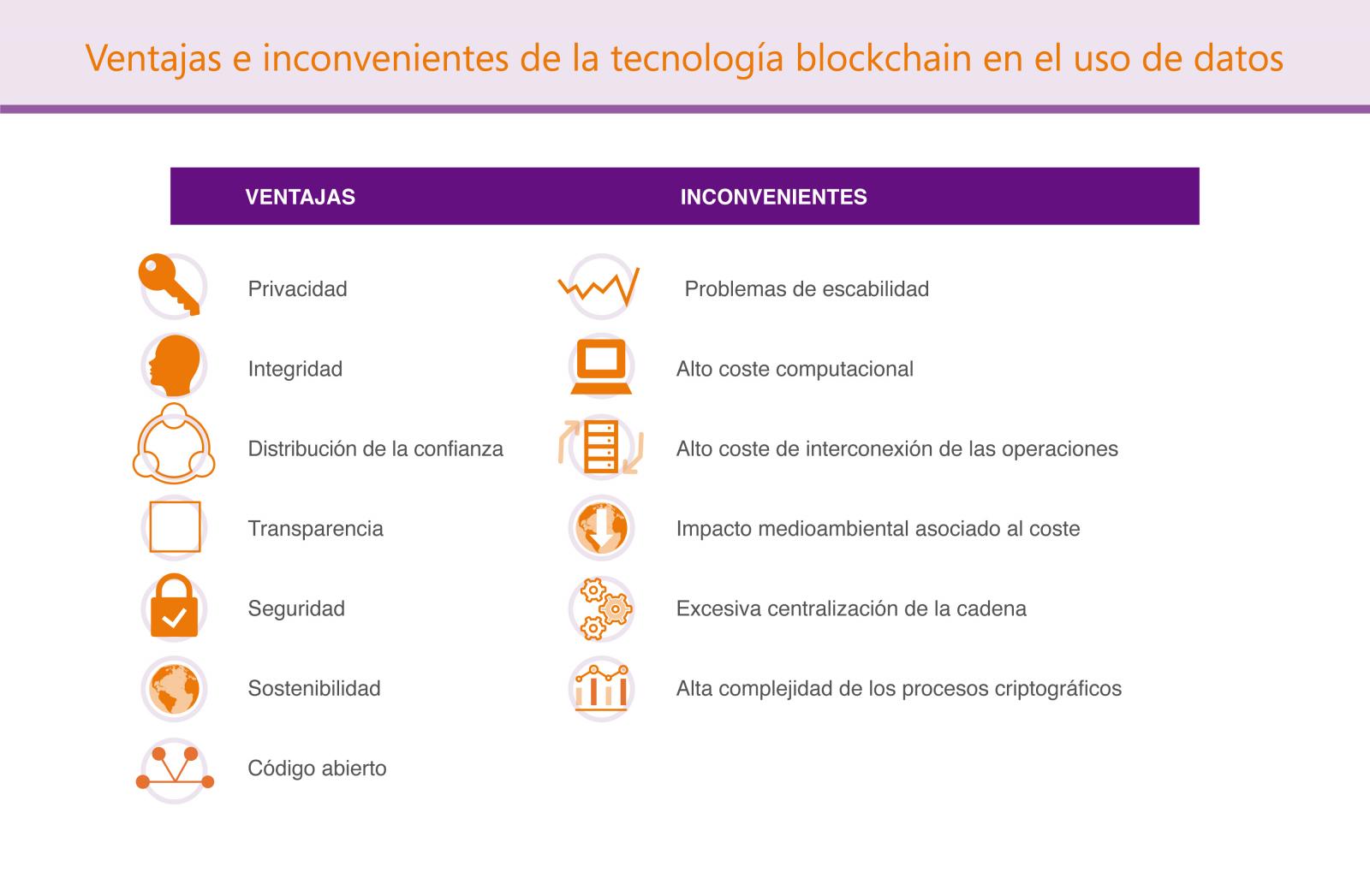
En definitiva, blockchain es una tecnología con el potencial de transformar nuestros sistemas políticos y al mismo tiempo habilitar cambios sociales relevantes. Pero, como pasa también con cualquier otra tecnología disruptiva y todavía en fase de maduración, no todo son ventajas y nos encontraremos también algunos inconvenientes y limitaciones que también habrá que superar, como por ejemplo los problemas de escalabilidad, el alto coste computacional y de interconexión que soportan las operaciones, el impacto medioambiental asociado a ese coste, la excesiva centralización de cada cadena o la alta complejidad de los procesos criptográficos.
Por otro lado, aun cuando blockchain se ha convertido rápidamente en la tecnología de moda y a pesar de la aparente simplicidad del concepto subyacente, sigue siendo al mismo tiempo una de las tecnologías más crípticas e incomprendidas por parte de sus potenciales beneficiarios en la actualidad. Por tanto, para que estas tecnologías de gestión de datos descentralizadas se puedan popularizar en un futuro próximo será también necesario afrontar otro tipo de barreras de entrada de tipo más estructural relacionadas con la necesidad de más formación, una mejora en la usabilidad, mayor capacidad de adaptación institucional o el desarrollo de los cambios regulatorios necesarios para darle soporte.
Si quieres saber más de blockchain, puedes leer nuestro informe Descubriendo las claves de blockchain.
Blog
El uso de RDF y de los datos enlazados (Linked Data) se está extendido a múltiples campos, desde la agricultura a la medicina. Y en todos los campos de conocimiento es necesario la validación de los datos RDF generados, aunque las condiciones sean diferentes para cada caso. Esta era una de las asignaturas pendientes de la pila de tecnologías de la Web Semántica, una tecnología para validar un grafo RDF frente a una estructura definida. Para poder solucionar esta brecha, el World Wide Web Consortium (W3C) creó un grupo de trabajo denominado RDF Data Shapes, cuyo objetivo era producir un estándar a tal efecto.
Y el resultado ha sido la publicación, en julio de 2017, del Lenguaje de Restricción de Formas (Shapes Constraint Language - SHACL), un lenguaje para validar grafos RDF contra un conjunto de condiciones. Estas condiciones se proporcionan como “formas” (shapes) y otras construcciones, todo ello expresado como un grafo RDF. A estos grafos RDF se les denominan en SHACL "grafos de formas" (shapes graphs). Y los grafos RDF a validar contra un grafo de formas se les denomina "grafos de datos" (data graphs).
Además, los grafos de formas SHACL pueden verse como la descripción de la estructura de los grafos de datos que satisfacen estas condiciones. Asimismo, dichas descripciones pueden usarse para una variedad de propósitos además de la validación, como la construcción de interfaces de usuario, la generación de código o la integración de datos.
Un ejemplo sencillo del uso de SHACL para validar un grafo RDF podría el siguiente: en un grafo de datos enlazados (Linked Data) de una biblioteca que contiene información sobre los documentos depositados, donde se quiere comprobar que todos los libros (bibo:Book) tengan asociados uno y solo un identificador (dc:identifier).
En este caso, el grafo de formas (shapes graph), expresado en Turtle, con las condiciones expuestas sería el siguiente:
ex:BookShape
a sh:NodeShape ;
sh:targetClass bibo:Book ;
sh:property [
sh:path dc:identifier ;
sh:minCount 1 ;
sh:maxCount 1 ;
rdfs:comment "Condición: El libro tiene uno y solo un identificador."@es ;
sh:message "El libro NO tiene uno y solo un identificador"@es ;
] .
Si por ejemplo se tuviera el grafo de datos (data graph)
ex:AmigoArbol a bibo:Book;
dc:title "Mi amigo el árbol"@es ;
dc:creator "Martín Chico"@es;
dc:contributor "Seminiano Alonso"@es;
dc:identifier "Villacarralon-1933" .
ex:ElQuixote a bibo:Book;
dc:title "El Ingenioso Hidalgo Don Quijote de la Mancha"@es ;
dc:creator "Miguel de Cervantes"@es.
El validador informaría que el recurso ex:ElQuixote no posee un identificador, como indican la condición del grafo de formas previamente definido.

Actualmente, el conjunto de herramientas que dan soporte a esta tecnología es reducido.
Dentro del grupo de desarrollos informáticos distribuidos bajo la marca TopBraid, se puede nombrar TopBraid SHACL API, un componente software, diseñado en Java (usando la librería Apache Jena) y disponible bajo licencia abierta, para chequear condiciones SHACL mediante llamadas a un API software. Otro validador disponible es SHACL.js , software diseñado en JavaScript y disponible bajo licencia abierta, y del cual está desplegada una instancia en SHACL Playground, que ofrece un interfaz web de usuario donde, tras rellenar el “grafo de formas” y el “grafo de datos”, se genera un informe de validación, así como una estructura visual con la estructura de los grafos de formas.
SHACL seguramente va a ser un paso significativo para que los datos enlazados sean más utilizados en todos los ámbitos. Es por ello, que muchas personas creen que SHACL va a cambiar las reglas de juego en la administración de datos y la gestión de los metadatos de datos, conjuntos de datos (datasets) y Big Data.
Nota: Por simplicidad de lectura, en el ejemplo no se ha incluido los prefijos.
@prefix sh: <http://www.w3.org/ns/shacl#> .
@prefix ex: <http://example.org/ns#> .
@prefix bibo: <http://purl.org/ontology/bibo/> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
Evento
Los ayuntamientos de Barcelona y de la ciudad japonesa de Kobe han lanzado una nueva edición del concurso de análisis y visualización de datos World Data Viz Challenge 2019 Barcelona-Kobe. Este concurso nació el año pasado con motivo de la celebración de los 25 años de hermanamiento de las dos ciudades. La gran cantidad de participantes y la calidad de los trabajos presentados, que se pueden consultar aquí, han llevado a los organizadores a impulsar esta nueva convocatoria.
¿En qué consiste?
El concurso se realiza en paralelo en las ciudades de Barcelona y Kobe. En ambas ciudades, los participantes tendrán que analizar datos y generar visualizaciones con el objetivo de mejorar aspectos concretos de la ciudad. En el caso de Barcelona, los participantes tendrán que utilizar al menos un conjunto de datos del portal Open Data BCN. Se pueden presentar las visualizaciones en forma de infografías, gráficos, mapas interactivos, etc.
Aunque se aceptan visualizaciones de cualquier temática relacionada con la ciudad, este año se prestará especial atención a los trabajos relacionados con la emergencia climática. De esta forma, el World Data Viz Challenge 2019 Barcelona-Kobe se alinea con el Plan Clima, que integra todas las líneas de actuación que el Ayuntamiento de Barcelona lleva a cabo en relación con esta materia.
¿Quiénes pueden participar?
Cualquier persona que tenga habilidades y capacidades para trabajar con datos abiertos, analizarlos y visualizarlos.
Los participantes pueden presentar sus proyectos de manera individual o en equipo, el cual deberá estar integrado por un máximo de tres personas.
¿Cómo se puede participar?
El plazo para presentar los trabajos realizados acaba el 31 de octubre de 2019. Las candidaturas deben presentarse a través de este formulario de participación.
¿Cómo se selecciona a los ganadores?
Un jurado formado por profesionales especializados en análisis de datos y tecnologías de la información revisará los trabajos presentados y elegirá a 6 finalistas, cuyo nombre se conocerá el 11 de noviembre de 2019. En paralelo, en la ciudad de Kobe también se seleccionarán otros 6 finalistas.
Todos ellos, entre otros beneficios, serán obsequiados con una entrada 3-DAY CONGRESS PAS además de poder presentar su trabajo el día 19 de Noviembre en el marco del Smart City Expo World Congress que se celebrará en Barcelona entre los días 19 y 21.
Para más información, puedes consultar las condiciones de participación aquí.
Evento
Comienza un año nuevo y es el momento de apuntar en nuestra agenda todas aquellas citas que no queremos perdernos durante los próximos 12 meses. Hay de todos los tipos: grandes eventos internacionales, concursos y hackatones, talleres... todo pensado para que los amantes de los datos y las nuevas tecnologías podamos estar al día de las nuevas tendencias y retos a superar en estas materias.
Al igual que en años anteriores nuestro país acogerá varios eventos de gran tamaño. Barcelona volverá a ser la sede mundial de la tecnología con 3 citas ineludibles: el Mobile World Congress (del 25 al 28 de febrero), el IOT Solutions World congress (del 29 al 31 de octubre) y el Smartcity Expo (del 19 al 21 de noviembre). Los datos tienen un papel fundamental en todas estas tecnologías: Smartphones, dispositivos IoT o los sensores de las ciudades inteligentes generan un gran volumen de información, cuyo análisis es fundamental para la toma de decisiones. Por ello no es de extrañar que encontremos espacios dedicados a la gestión o la analítica de datos en cada uno de estos eventos. Por ejemplo, en el Mobile World Congress, tendrán lugar datathones y conferencias centradas en cómo impulsar un futuro dirigido por los datos. La agenda del OT Solutions World Congress y el Smartcity Expo no está aún disponible, pero no dudamos de que seguirán la misma línea, al igual que sucedió el año pasado.
Madrid, por su parte acogerá el Digital Enterprise Show, conocido como DES (del 21 al 23 de mayo) o el South summit (del 2 al 4 de octubre), que el año pasado reunió a más de 100 start-ups con ganas de innovar. También en Madrid se celebrará el Open Expo Europe (6 de junio), una feria profesional sobre Open Source, Software Libre y Open World Economy (Open Data y Open Innovation), y el T3chFest 2019 (del 14 al 15 de marzo), una feria de informática y nuevas tecnologías celebrada en la Universidad Carlos III donde entre otras cuestiones se hablará de ciencia de datos, desarrollos y formatos abiertos.
Otras citas a tener en cuenta son el Greencities (del 27 al 28 de marzo en Málaga), centrado en la inteligencia y sostenibilidad urbana, y el Alldata 2019 (del 24 al 28 de marzo en Valencia), una conferencia internacional sobre Big Data, Small Data, Linked Data y Open Data.
El buen momento de los datos abiertos también queda patente en la gran cantidad de concursos y hackatones que se esperan durante los próximos meses. Actualmente se encuentra abierto el periodo de inscripción para el Concurso de datos abiertos de Castilla y León.
Además, vuelve el taller de Periodismo de datos, organizado por Medialab Prado, que se celebrará del 25 al 29 de marzo. Bajo el título, sigue el rastro de la comida, el taller se centrará en el mundo de la alimentación y su relación con los Objetivos de Desarrollo Sostenible (ODS). El pasado 9 de enero se cerró la convocatoria de proyectos y ahora es el momento para que aquellos que quieran participar se apunten como colaboradores.
Otro taller, este sobre Gestión de datos abiertos, se celebrará en la ciudad de Burgos el 13 de febrero. En él se abordará desde el marco legal y ético de los datos abiertos, hasta las herramientas para hacer accesibles los datos de investigación.
Además de estos ejemplos, durante el año se irán dando a conocer nuevas citas y eventos relacionados con el mundo de los datos. Por ejemplo, tendremos una nueva edición del Encuentro Aporta. Y no hay que olvidar que el próximo 2 de marzo se celebra el Open Data Day, un marco en el que tendrán lugar diversas actividades que poco a poco se irán publicando en su web.
Desde datos.gob.es os iremos informando de todas estas novedades, para que no os perdáis ninguna cita.