Documentación
The digital ecosystem around data has evolved rapidly in recent years. While the debate once focused mainly on volume and speed, today we face a far more complex landscape in which generative artificial intelligence, governance, ethics, and interoperability have become central priorities.
This report identifies and analyses four major trends that are currently shaping the data ecosystem, along with the challenges they present and the key lines of action needed to address them.

Figura 1. Four key trends in the world of data. Source: own elaboration - datosgob.es.
Each of these is summarized below.
1. Generative artificial intelligence: a new paradigm in the use of data
The emergence of generative AI has redefined the role of data, not only as raw material for training models, but also as a product. This transformation poses great opportunities when it comes to automating tasks or enriching public services but also challenges in terms of quality and possible ethical biases, as well as in terms of traceability and human monitoring capacity. The new European legislation, especially the AI Act, establishes a robust regulatory framework that classifies systems according to their level of risk and imposes minimum requirements such as impact assessments, or obligations in terms of transparency and human control. Spain reinforces this approach with initiatives such as the creation of the Spanish Agency for the Supervision of AI (AESIA) and the adoption of new quality guidelines and standards.
2. Ethics and digital rights: placing people at the center
In a context where personal data feeds a large part of digital systems, the protection of fundamental rights becomes an unavoidable obligation. The General Data Protection Regulation (GDPR) continues to be the main regulatory pillar, promoting good practices in terms of data minimisation, portability or algorithmic transparency. In addition to this, there are other initiatives such as the EU Declaration of Digital Rights and Principles and the Charter of Digital Rights in Spain, which strengthen the social and humanistic approach to digital transformation. Thanks to all this, a new organisational culture is beginning to consolidate where ethical aspects are integrated in a transversal way in the processes of design, development and deployment of digital solutions.
3. Data spaces: building the new information ecosystems
The European Data Spaces represent a strategic commitment to build a common data ecosystem in key sectors such as health, energy, mobility or tourism. These spaces facilitate controlled and secure access to public and private data, expanding on the traditional model of open data portals. The ultimate goal is to achieve an interconnected data environment that allows the development of innovative services, activating a more dynamic data economy. However, technical and organizational challenges, such as semantic and technical interoperability, inclusive participation, or the protection of security and privacy, remain significant. Initiatives such as the Data Spaces Support Centre or the Data Space Reference Centre (CRED) in Spain are driving its practical implementation.
4. Data governance: the new high-value asset in organizations
Data governance has ceased to be a purely technical issue and has become an institutional priority. In order to achieve this, public and private organisations are adapting their organisational structures and adopting new regulatory and technical frameworks. Proper governance must cover the entire life cycle of the data, from its creation to the final archive, and involves carrying out actions in several areas, such as cataloguing, interoperability, traceability and security. In addition, a series of human, technological and evaluation capacities will need to be developed in order to respond to these new needs. In general, both Spain and other European countries are moving towards more mature and better articulated data governance models, understanding data as a strategic infrastructure.
The role of the regulatory framework
The report concludes with an overview of the related regulatory framework, which acts as a lever for progress and a generator of trust. The European Union has succeeded in positioning itself as a global reference in digital regulation, with an approach grounded in rights and sustainability. Integration between the various existing standards, such as the GDPR, the AI Act and the DGA, helps to create a more secure, transparent and innovative environment for the use of data, albeit complex. For this reason, the regulatory simplification expected under the new Digital Omnibus is anticipated to bring greater coherence and clarity, making adoption and compliance easier.dopción y cumplimiento.
Blog
Massive, superficial AI-generated content isn't just a problem, it's also a symptom. Technology amplifies a consumption model that rewards fluidity and drains our attention span.
We listen to interviews, podcasts and audios of our family at 2x. We watch videos cut into highlights, and we base decisions and criteria on articles and reports that we have only read summarized with AI. We consume information in ultra-fast mode, but at a cognitive level we give it the same validity as when we consumed it more slowly, and we even apply it in decision-making. What is affected by this process is not the basic memory of contents, which seems to be maintained according to controlled studies, but the ability to connect that knowledge with what we already had and to elaborate our own ideas with it. More than superficiality, it is worrying that this new way of thinking is sufficient in so many contexts.
What's new and what's not?
We may think that generative AI has only intensified an old dynamic in which content production is infinite, but our attention spans are the same. We cannot fool ourselves either, because since the Internet has existed, infinity is not new. If we were to say that the problem is that there is too much content, we would be complaining about a situation in which we have been living for more than twenty years. Nor is the crisis of authority of official information or the difficulty in distinguishing reliable sources from those that are not.
However, the AI slop, which is the flood of AI-generated digital content on the Internet, brings its own logic and new considerations, such as breaking the link between effort and content, or that all that is generated is a statistical average of what already existed. This uniform and uncontrolled flow has consequences: behind the mass-generated content there may be an orchestrated intention of manipulation, an algorithmic bias, voluntary or not, that harms certain groups or slows down social advances, and also a random and unpredictable distortion of reality.
But how much of what I read is AI?
By 2025, it has been estimated that a large portion of online content incorporates synthetic text: an Ahrefs analysis of nearly one million web pages published in the first half of the year found that 74.2% of new pages contained signals of AI-generated content. Graphite research from the same year cites that, during the first year of ChatGPT alone, 39% of all online content was already generated with AI. Since November 2024, that figure has remained stable at around 52%, meaning that since then AI content outnumbers human content.
However, there are two questions we should ask ourselves when we come across estimates of this type:
1. Is there a reliable mechanism to distinguish a written text from a generated text? If the answer is no, no matter how striking and coherent the conclusions are, we cannot give them value, because they could be true or not. It is a valuable quantitative data, but one that does not yet exist.
With the information we currently have, we can say that "AI-generated text" detectors fail as often as a random model would, so we cannot attribute reliability to them. In a recent study cited by The Guardian, detectors were correct about whether the text was generated with AI or not in less than 40% of cases. On the other hand, in the first paragraph of Don Quixote, certain detectors have also returned an 86% probability that the text was created by AI.
2. What does it mean that a text is generated with AI? On the other hand, the process is not always completely automatic (what we call copying and pasting) but there are many grays in the scale: AI inspires, organizes, assists, rewrites or expands ideas, and denying, delegitimizing or penalizing this writing would be ignoring an installed reality.
The two nuances above do not cancel out the fact that the AI slop exists, but this does not have to be an inevitable fate. There are ways to mitigate its effects on our abilities.
What are the antidotes?
We may not contribute to the production of synthetic content, but we cannot slow down what is happening, so the challenge is to review the criteria and habits of mind with which we approach both reading and writing content.
1. Prioritize what clicks: one of the few reliable signals we have left is that clicking sensation at the moment when something connects with a previous knowledge, an intuition that we had diffused or an experience of our own, and reorganizes it or makes it clear. We also often say that it "resonates". If something clicks, it's worth following, confirming, researching, and briefly elaborating on a personal level.
2. Look for friction with data: anchoring content in open data and verifiable sources introduces healthy friction against the AI slop. It reduces, above all, arbitrariness and the feeling of interchangeable content, because the data force us to interpret and put it in context. It is a way of putting stones in the excessively fluid river that is the generation of language, and it works when we read and when we write.
3. Who is responsible? The text exists easily now, the question is why it exists or what it wants to achieve, and who is ultimately responsible for that goal. It seeks the signature of people or organizations, not so much for authorship but for responsibility. He is wary of collective signatures, also in translations and adaptations.
4. Change the focus of merit: evaluate your inertia when reading, because perhaps one day you learned to give merit to texts that sounded convincing, used certain structures or went up to a specific register. It shifts value to non-generatable elements such as finding a good story, knowing how to formulate a vague idea or daring to give a point of view in a controversial context.
On the other side of the coin, it is also a fact that content created with AI enters with an advantage in the flow, but with a disadvantage in credibility. This means that the real risk now is that AI can create high-value content, but people have lost the ability to concentrate on valuing it. To this we must add the installed prejudice that, if it is with AI, it is not valid content. Protecting our cognitive abilities and learning to differentiate between compressible and non-compressible content is therefore not a nostalgic gesture, but a skill that in the long run can improve the quality of public debate and the substrate of common knowledge.
Content created by Carmen Torrijos, expert in AI applied to language and communication. The content and views expressed in this publication are the sole responsibility of the author.
Blog
We live in an age where more and more phenomena in the physical world can be observed, measured, and analyzed in real time. The temperature of a crop, the air quality of a city, the state of a dam, the flow of traffic or the energy consumption of a building are no longer data that are occasionally reviewed: they are continuous flows of information that are generated second by second.
This revolution would not be possible without cyber-physical systems (CPS), a technology that integrates sensors, algorithms and actuators to connect the physical world with the digital world. But CPS does not only generate data: it can also be fed by open data, multiplying its usefulness and enabling evidence-based decisions.
In this article, we will explore what CPS is, how it generates massive data in real time, what challenges it poses to turn that data into useful public information, what principles are essential to ensure its quality and traceability, and what real-world examples demonstrate the potential for its reuse. We will close with a reflection on the impact of this combination on innovation, citizen science and the design of smarter public policies.
What are cyber-physical systems?
A cyber-physical system is a tight integration between digital components – such as software, algorithms, communication and storage – and physical components – sensors, actuators, IoT devices or industrial machines. Its main function is to observe the environment, process information and act on it.
Unlike traditional monitoring systems, a CPS is not limited to measuring: it closes a complete loop between perception, decision, and action. This cycle can be understood through three main elements:
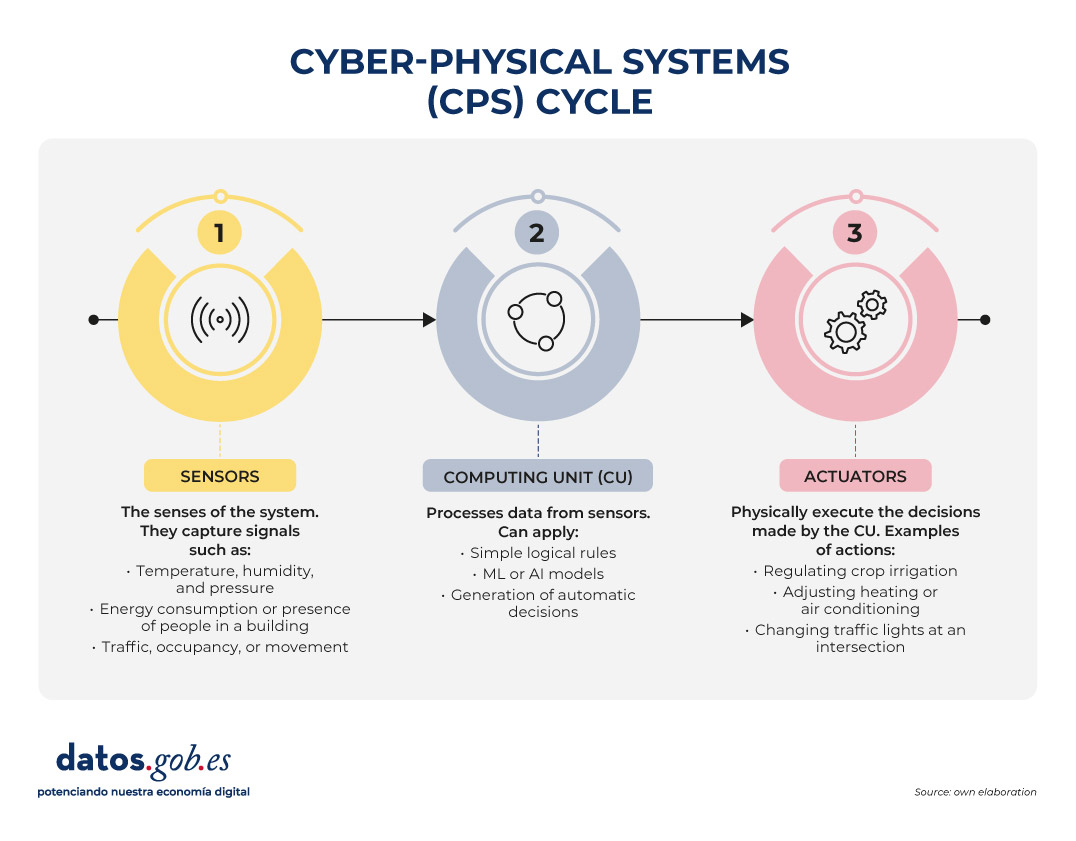
Figure 1. Cyber-physical systems cycle. Source: own elaboration
An everyday example that illustrates this complete cycle of perception, decision and action very well is smart irrigation, which is increasingly present in precision agriculture and home gardening systems. In this case, sensors distributed throughout the terrain continuously measure soil moisture, ambient temperature, and even solar radiation. All this information flows to the computing unit, which analyzes the data, compares it with previously defined thresholds or with more complex models – for example, those that estimate the evaporation of water or the water needs of each type of plant – and determines whether irrigation is really necessary.
When the system concludes that the floor has reached a critical level of dryness, the third element of CPS comes into play: the actuators. They are the ones who open the valves, activate the water pump or regulate the flow rate, and they do so for the exact time necessary to return the humidity to optimal levels. If conditions change—if it starts raining, if the temperature drops, or if the soil recovers moisture faster than expected—the system itself adjusts its behavior accordingly.
This whole process happens without human intervention, autonomously. The result is a more sustainable use of water, better cared for plants and a real-time adaptability that is only possible thanks to the integration of sensors, algorithms and actuators characteristic of cyber-physical systems.
CPS as real-time data factories
One of the most relevant characteristics of cyber-physical systems is their ability to generate data continuously, massively and with a very high temporal resolution. This constant production can be seen in many day-to-day situations:
- A hydrological station can record level and flow every minute.
- An urban mobility sensor can generate hundreds of readings per second.
- A smart meter records electricity consumption every few minutes.
- An agricultural sensor measures humidity, salinity, and solar radiation several times a day.
- A mapping drone captures decimetric GPS positions in real time.
Beyond these specific examples, the important thing is to understand what this capability means for the system as a whole: CPS become true data factories, and in many cases come to function as digital twins of the physical environment they monitor. This almost instantaneous equivalence between the real state of a river, a crop, a road or an industrial machine and its digital representation allows us to have an extremely accurate and up-to-date portrait of the physical world, practically at the same time as the phenomena occur.
This wealth of data opens up a huge field of opportunity when published as open information. Data from CPS can drive innovative services developed by companies, fuel high-impact scientific research, empower citizen science initiatives that complement institutional data, and strengthen transparency and accountability in the management of public resources.
However, for all this value to really reach citizens and the reuse community, it is necessary to overcome a series of technical, organisational and quality challenges that determine the final usefulness of open data. Below, we look at what those challenges are and why they are so important in an ecosystem that is increasingly reliant on real-time generated information.
The challenge: from raw data to useful public information
Just because a CPS generates data does not mean that it can be published directly as open data. Before reaching the public and reuse companies, the information needs prior preparation , validation, filtering and documentation. Administrations must ensure that such data is understandable, interoperable and reliable. And along the way, several challenges appear.
One of the first is standardization. Each manufacturer, sensor and system can use different formats, different sample rates or its own structures. If these differences are not harmonized, what we obtain is a mosaic that is difficult to integrate. For data to be interoperable, common models, homogeneous units, coherent structures, and shared standards are needed. Regulations such as INSPIRE or the OGC (Open Geospatial Consortium) and IoT-TS standards are key so that data generated in one city can be understood, without additional transformation, in another administration or by any reuser.
The next big challenge is quality. Sensors can fail, freeze always reporting the same value, generate physically impossible readings, suffer electromagnetic interference or be poorly calibrated for weeks without anyone noticing. If this information is published as is, without a prior review and cleaning process, the open data loses value and can even lead to errors. Validation – with automatic checks and periodic review – is therefore indispensable.
Another critical point is contextualization. An isolated piece of information is meaningless. A "12.5" says nothing if we don't know if it's degrees, liters or decibels. A measurement of "125 ppm" is useless if we do not know what substance is being measured. Even something as seemingly objective as coordinates needs a specific frame of reference. And any environmental or physical data can only be properly interpreted if it is accompanied by the date, time, exact location and conditions of capture. This is all part of metadata, which is essential for third parties to be able to reuse information unambiguously.
It's also critical to address privacy and security. Some CPS can capture information that, directly or indirectly, could be linked to sensitive people, property, or infrastructure. Before publishing the data, it is necessary to apply anonymization processes, aggregation techniques, security controls and impact assessments that guarantee that the open data does not compromise rights or expose critical information.
Finally, there are operational challenges such as refresh rate and robustness of data flow. Although CPS generates information in real time, it is not always appropriate to publish it with the same granularity: sometimes it is necessary to aggregate it, validate temporal consistency or correct values before sharing it. Similarly, for data to be useful in technical analysis or in public services, it must arrive without prolonged interruptions or duplication, which requires a stable infrastructure and monitoring mechanisms.
Quality and traceability principles needed for reliable open data
Once these challenges have been overcome, the publication of data from cyber-physical systems must be based on a series of principles of quality and traceability. Without them, information loses value and, above all, loses trust.
The first is accuracy. The data must faithfully represent the phenomenon it measures. This requires properly calibrated sensors, regular checks, removal of clearly erroneous values, and checking that readings are within physically possible ranges. A sensor that reads 200°C at a weather station or a meter that records the same consumption for 48 hours are signs of a problem that needs to be detected before publication.
The second principle is completeness. A dataset should indicate when there are missing values, time gaps, or periods when a sensor has been disconnected. Hiding these gaps can lead to wrong conclusions, especially in scientific analyses or in predictive models that depend on the continuity of the time series.
The third key element is traceability, i.e. the ability to reconstruct the history of the data. Knowing which sensor generated it, where it is installed, what transformations it has undergone, when it was captured or if it went through a cleaning process allows us to evaluate its quality and reliability. Without traceability, trust erodes and data loses value as evidence.
Proper updating is another fundamental principle. The frequency with which information is published must be adapted to the phenomenon measured. Air pollution levels may need updates every few minutes; urban traffic, every second; hydrology, every minute or every hour depending on the type of station; and meteorological data, with variable frequencies. Posting too quickly can generate noise; too slow, it can render the data useless for certain uses.
The last principle is that of rich metadata. Metadata explains the data: what it measures, how it is measured, with what unit, how accurate the sensor is, what its operating range is, where it is located, what limitations the measurement has and what this information is generated for. They are not a footnote, but the piece that allows any reuser to understand the context and reliability of the dataset. With good documentation, reuse isn't just possible: it skyrockets.
Examples: CPS that reuses public data to be smarter
In addition to generating data, many cyber-physical systems also consume public data to improve their performance. This feedback makes open data a central resource for the functioning of smart territories. When a CPS integrates information from its own sensors with external open sources, its anticipation, efficiency, and accuracy capabilities are dramatically increased.
Precision agriculture: In agriculture, sensors installed in the field allow variables such as soil moisture, temperature or solar radiation to be measured. However, smart irrigation systems do not rely solely on this local information: they also incorporate weather forecasts from AEMET, open IGN maps on slope or soil types, and climate models published as public data. By combining their own measurements with these external sources, agricultural CPS can determine much more accurately which areas of the land need water, when to plant, and how much moisture should be maintained in each crop. This fine management allows water and fertilizer savings that, in some cases, exceed 30%.
Water management: Something similar happens in water management. A cyber-physical system that controls a dam or irrigation canal needs to know not only what is happening at that moment, but also what may happen in the coming hours or days. For this reason, it integrates its own level sensors with open data on river gauging, rain and snow predictions, and even public information on ecological flows. With this expanded vision, the CPS can anticipate floods, optimize the release of the reservoir, respond better to extreme events or plan irrigation sustainably. In practice, the combination of proprietary and open data translates into safer and more efficient water management.
Impact: innovation, citizen science, and data-driven decisions
The union between cyber-physical systems and open data generates a multiplier effect that is manifested in different areas.
- Business innovation: Companies have fertile ground to develop solutions based on reliable and real-time information. From open data and CPS measurements, smarter mobility applications, water management platforms, energy analysis tools, or predictive systems for agriculture can emerge. Access to public data lowers barriers to entry and allows services to be created without the need for expensive private datasets, accelerating innovation and the emergence of new business models.
- Citizen science: the combination of SCP and open data also strengthens social participation. Neighbourhood communities, associations or environmental groups can deploy low-cost sensors to complement public data and better understand what is happening in their environment. This gives rise to initiatives that measure noise in school zones, monitor pollution levels in specific neighbourhoods, follow the evolution of biodiversity or build collaborative maps that enrich official information.
- Better public decision-making: finally, public managers benefit from this strengthened data ecosystem. The availability of reliable and up-to-date measurements makes it possible to design low-emission zones, plan urban transport more effectively, optimise irrigation networks, manage drought or flood situations or regulate energy policies based on real indicators. Without open data that complements and contextualizes the information generated by the CPS, these decisions would be less transparent and, above all, less defensible to the public.
In short, cyber-physical systems have become an essential piece of understanding and managing the world around us. Thanks to them, we can measure phenomena in real time, anticipate changes and act in a precise and automated way. But its true potential unfolds when its data is integrated into a quality open data ecosystem, capable of providing context, enriching decisions and multiplying uses.
The combination of SPC and open data allows us to move towards smarter territories, more efficient public services and more informed citizen participation. It provides economic value, drives innovation, facilitates research and improves decision-making in areas as diverse as mobility, water, energy or agriculture.
For all this to be possible, it is essential to guarantee the quality, traceability and standardization of the published data, as well as to protect privacy and ensure the robustness of information flows. When these foundations are well established, CPS not only measure the world: they help it improve, becoming a solid bridge between physical reality and shared knowledge.
Content created by Dr. Fernando Gualo, Professor at UCLM and Government and Data Quality Consultant. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Artificial intelligence (AI) has become a central technology in people's lives and in the strategy of companies. In just over a decade, we've gone from interacting with virtual assistants that understood simple commands, to seeing systems capable of writing entire reports, creating hyper-realistic images, or even writing code.
This visible leap has made many wonder: is it all the same? What is the difference between what we already knew as AI and this new "Generative AI" that is so much talked about?
In this article we are going to organize those ideas and explain, with clear examples, how "Traditional" AI and Generative AI fit under the great umbrella of artificial intelligence.
Traditional AI: analysis and prediction
For many years, what we understood by AI was closer to what we now call "Traditional AI". These systems are characterized by solving concrete, well-defined problems within a framework of available rules or data.
Some practical examples:
-
Recommendation engines: Spotify suggests songs based on your listening history and Netflix adjusts its catalog to your personal tastes, generating up to 80% of views on the platform.
-
Prediction systems: Walmart uses predictive models to anticipate the demand for products based on factors such as weather or local events; Red Eléctrica de España applies similar algorithms to forecast electricity consumption and balance the grid.
- Automatic recognition: Google Photos classifies images by recognizing faces and objects; Visa and Mastercard use anomaly detection models to identify fraud in real time; Tools like Otter.ai automatically transcribe meetings and calls.
In all these cases, the models learn from past data to provide a classification, prediction, or decision. They do not invent anything new, but recognize patterns and apply them to the future.
Generative AI: content creation
The novelty of generative AI is that it not only analyzes, but also produces (generates) from the data it has.
In practice, this means that:
-
You can generate structured text from a couple of initial ideas.
-
You can combine existing visual elements from a written description.
-
You can create product prototypes, draft presentations, or propose code snippets based on learned patterns.
The key is that generative models don't just classify or predict, they generate new combinations based on what they learned during their training.
The impact of this breakthrough is enormous: in the development world, GitHub Copilot already includes agents that detect and fix programming errors on their own; in design, Google's Nano Banana tool promises to revolutionize image editing with an efficiency that could render programs like Photoshop obsolete; and in music, entirely AI-created bands like Velvet Velvet Sundown they already exceed one million monthly listeners on Spotify, with songs, images and biography fully generated, without real musicians behind them.
When is it best to use each type of AI?
The choice between Traditional and Generative AI is not a matter of fashion, but of what specific need you want to solve. Each shines in different situations:
Traditional AI: the best option when...
-
You need to predict future behaviors based on historical data (sales, energy consumption, predictive maintenance).
-
You want to detect anomalies or classify information accurately (transaction fraud, imaging, spam).
-
You are looking to optimize processes to gain efficiency (logistics, transport routes, inventory management).
-
You work in critical environments where reliability and accuracy are a must (health, energy, finance).
Use it when the goal is to make decisions based on real data with the highest possible accuracy.
Generative AI: the best option when...
-
You need to create content (texts, images, music, videos, code).
-
You want to prototype or experiment quickly, exploring different scenarios before deciding (product design, R+D testing).
-
You are looking for more natural interaction with users (chatbots, virtual assistants, conversational interfaces).
-
You require large-scale personalization, generating messages or materials adapted to each individual (marketing, training, education).
-
You are interested in simulating scenarios that you cannot easily obtain with real data (fictitious clinical cases, synthetic data to train other models).
Use it when the goal is to create, personalize, or interact in a more human and flexible way.
An example from the health field illustrates this well:
-
Traditional AI can analyze thousands of clinical records to anticipate the likelihood of a patient developing a disease.
-
Generative AI can create fictional scenarios to train medical students, generating realistic clinical cases without exposing real patient data.
Do they compete or complement each other?
In 2019, Gartner introduced the concept of Composite AI to describe hybrid solutions that combined different AI approaches to solve a problem more comprehensively. Although it was a term that was not very widespread then, today it is more relevant than ever thanks to the emergence of Generative AI.
Generative AI does not replace Traditional AI, but rather complements it. When you integrate both approaches into a single workflow, you achieve much more powerful results than if you used each technology separately.
Although, according to Gartner, Composite AI is still in the Innovation Trigger phase, where an emerging technology begins to generate interest, and although its practical use is still limited, we already see many new trends being generated in multiple sectors:
-
In retail: A traditional system predicts how many orders a store will receive next week, and generative AI automatically generates personalized product descriptions for customers of those orders.
-
In education: a traditional model assesses student progress and detects weak areas, while generative AI designs exercises or materials tailored to those needs.
-
In industrial design: a traditional algorithm optimizes manufacturing logistics, while a generative AI proposes prototypes of new parts or products.
Ultimately, instead of questioning which type of AI is more advanced, the right thing to do is to ask: what problem do I want to solve, and which AI approach is right for it?
Content created by Juan Benavente, senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsability of the author.
Documentación
The Sustainable Development Goals (SDGs) are a set of targets adopted by the international community aimed at addressing the most pressing challenges of our time. These goals were born simultaneously with the Global Partnership for Sustainable Development Data and the International Open Data Charter, which provided a coalition of experts willing to harness the benefits of open data for the new development agenda.
In this regard, open data plays a very relevant role within the development agenda as indicators of progress towards the SDGs, as they allow measuring and evaluating their progress, as well as improving accountability through sharing that data with the rest of the community, providing great value in multiple ways:
- Facilitating decision-making when designing policies and strategies to help meet the objectives;
- Identifying inequalities and specific challenges among different regions or population groups;
- Improving efficiency in policy and program implementation;
- As an engine of innovation through research and development.
Today, there are large global databases, both generalist and thematic, that we can use for these purposes, in addition to all the national data sources available in our own country. However, there is still a long way to go in this regard: the proportion of SDG indicators that are conceptually clear and have good national coverage is still 66%, according to the latest SDG progress report published in 2023. This leads us to continue facing data gaps in vital areas such as poverty, hunger, education, equality, sustainability, climate, seas, and justice, among others. Additionally, there is also a fairly general and significant lack of data disaggregated by age and/or sex, making it very difficult to properly monitor the potential progress of the objectives regarding the most vulnerable population groups.
This report takes a journey through the dual role that open data plays in supporting national and global progress in achieving the SDGs. The first part of the report focuses on the better-known role of open data as mere indicators when measuring progress towards the objectives, while the second part addresses its role as a key tool and fundamental raw material for the development of society in general and for the achievement of the objectives themselves in particular. To this end, it explores which datasets could have the greatest potential in each case, showing some practical examples, both national and at the European level, in various specific development objectives.
If you want to learn more about the content of this report, you can watch the interview with its author.
Blog
It is now almost five years since the publication of the study on the first decade of open data by the Open Data for Development (OD4D) network and more than 60 expert authors from around the world. This first edition of the study highlighted the importance of open data in socio-economic development and global problem solving. It also highlighted progress in making data more accessible and reusable , and at the same time began to elaborate on the need to take into account other key issues such as data justice, the need for responsible AI and privacy challenges.
Over the last year and a half, the new Data for Development (D4D) network has been organising a series of discussions to analyse the evolution of the open data movement in recent years and to publish an update of the previous study. Preliminary general conclusions from these discussions include:
- The need to make impact stories more visible as a way to encourage greater openness and availability of data.
- The desirability of opening up data in a way that meets the needs of potential users and beneficiaries, and that is done in a collaborative way with the community.
- Advocate for donor organisations to add as part of their grant programmes a requirement for grantees to develop and implement open data plans.
- Prioritise the need for interoperable data sharing.
- Publish more data focused on improving the situation of historically marginalised groups.
- Increase efforts to further develop the technical capacities required for the implementation of open data.
- Delve into the creation, evolution and implementation of the legal and policy frameworks necessary to support all of the above.
At the same time, there was a process of updating the study underway, analysing the progress made over the last few years in each of the sectors and communities covered by the original study. As a result of this process, we can already see some previews of the most important developments over the last few years, as well as the remaining challenges in various areas, which we review below. The 2nd Edition of the State of Open Data in a brand new online format with 30 new chapter updates and a renewed vision to guide open data agendas in the years to come.
Sectoral developments
Some of the most relevant developments in different key sectors over the last five years include the following:
Accountability and anti-corruption: There has been a rapid increase in the use of data in this area, although its impact is not well documented and the use of open data in this area should focus more on the problems identified and work more collaboratively with all stakeholders.
Agriculture: The agri-food sector has focused on facilitating the secure and efficient sharing of data by applying the principles of the FAIR (Findable, Accessible, Interoperable and Reusable) data model , mainly due to reluctance to share some of the more personal data.
Shipping: This is a sector where public authorities clearly recognise the importance of open data in building transport ecosystems that contribute to addressing global issues such as sustainable development and climate change. The main challenges identified in this case are interoperability and data privacyprotection.
Health: The practice of collecting, sharing and using health-related data has accelerated considerably due to the effects of the Covid-19 pandemic . At the same time, the containment measures carried out during this period in terms of contact tracing and quarantines have contributed to increased recognition of the importance of digital rights for health data.
National statistics: Open data has established itself as an integral part of national statistics, but there is a significant risk of regression. International organisations are no longer so much focused on disseminating data as on encouraging its use to generate value and impact. Therefore, it is now necessary to focus on the sustainability of initiatives in order to ensure equitable access and enhance the social good.
Action on climate change: In recent years, the quality and availability of climate data has improved in some very specific sectors, such as energy. However, there are still large gaps in other areas, for example in cities or the private sector. On the other hand, the available climate datasets present other challenges such as being often too technical, poorly formatted or not addressing specific use cases and problems.
Urban development: Open data is playing an increasingly important role in the context of urban development globally through its promotion of equity, its contribution to climate change mitigation and the improvement of crisis response systems. In addition, the continuous development and growth of urban technologies such as the Internet of Things (IoT), digitalsandboxes or digital twins is creating the need to improve data quality and interoperability - which at the same time pushes the development of open data. The task ahead in this sector is to achieve greater citizen participation.
Cross-cutting developments
In addition to sectoral developments, we must also take into account those cross-cutting trends that have the potential to affect all sectors, which are described below:
Artificial Intelligence: AI applications have an increasing influence on what data is published and how it is structured. Governments and others are striving to complete the open data available for AI training that is necessary to avoid the biases that currently exist . To make this possible, new mechanisms are also being developed to enable access to sensitive data that cannot be published directly under open licences.
Data literacy: Low data literacy remains one of the main factors delaying the exploitation of open data, although there have also been some important developments at the level of industry, civil society, government and educational institutions - particularly in the context of the urgent need to counter the growing amount of misinformation being misused.
Gender equality: In recent years the Covid-19 pandemic and other global political events have compounded the challenges for women and other marginalised groups. Progress in the publication and use of open data on gender has been generally slow and more resources would need to be made available to improve this situation.
Privacy: The growing demand for personal data and the increasing use of multiple data sources in combination has increased privacy risks. Group privacy is also an emerging concern and some debate has also formed about the necessary balance between transparency and privacy protection in some cases. In addition, there is also a demand for better data governance and oversight mechanisms for adequate data protection.
What's New Geographically
Finally, we will review some of the trends observed at the regional level:
South and East Asia: There has been little change in the region's open data landscape with several countries experiencing a decline in their open data practices after facing changes in their governments. At a general level, improvements can be seen in a more conducive bureaucratic environment and in data-related skills. However, all this is not yet translating into real impact due to lack of re-use.
Sub-Saharan Africa: The open data movement has expanded considerably in the region in recent years, involving new actors from the private sector and civil society. This dynamisation has been made possible mainly by following an approach based on addressing the challenges stemming from the Sustainable Development Goals. However, there are still significant gaps in the capacity to collect data and to ensure its ethical treatment.
Latin America: As in other parts of the world, open data agendas are not advancing at the same pace as a few years ago. Some progress can be seen in some types of data such as public finance, but also large gaps in other areas such as business information or data on climate action. In addition, there is still a lot of basic work to be done in terms of data openness and availability.
North America and Oceania: There is a shift towards institutionalising data policies and the structures needed to integrate open data into the culture of public governance more broadly. The use of open data during Covid-19 to facilitate transparency, communication, research and policy-making served to demonstrate its multi-purpose nature in this area.
These are just a few previews of what we will see in the next edition of the study on the evolution of the open data movement. In the 2nd Edition of the State of Open Data we can know in detail all the progress of the last five years, the new challenges and the challenges that remain. As we enter a new phase in the evolution of open data, it will also be interesting to see how these lessons and recommendations are put into practice, and at the same time also to begin to imagine how open data will be positioned on the global agenda in the coming years.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views reflected in this publication are the sole responsibility of the author.
Documentación
"Information and data are more valuable when they are shared and the opening of government data could allow [...] to examine and use public information in a more transparent, collaborative, efficient and productive way". This was, in general terms, the idea that revolutionized more than ten years ago a society for which the opening of government data was a totally unknown action. It is from this moment that different trends began to emerge that will mark the evolution of the open data movement around the world.
This report, written by Carlos Iglesias, analyzes the main trends in the still incipient history of global open data, paying special attention to open data within public administrations. To this end, this analysis reflects the main problems and opportunities that have arisen over the years, as well as the trends that will help to continue driving the movement forward:
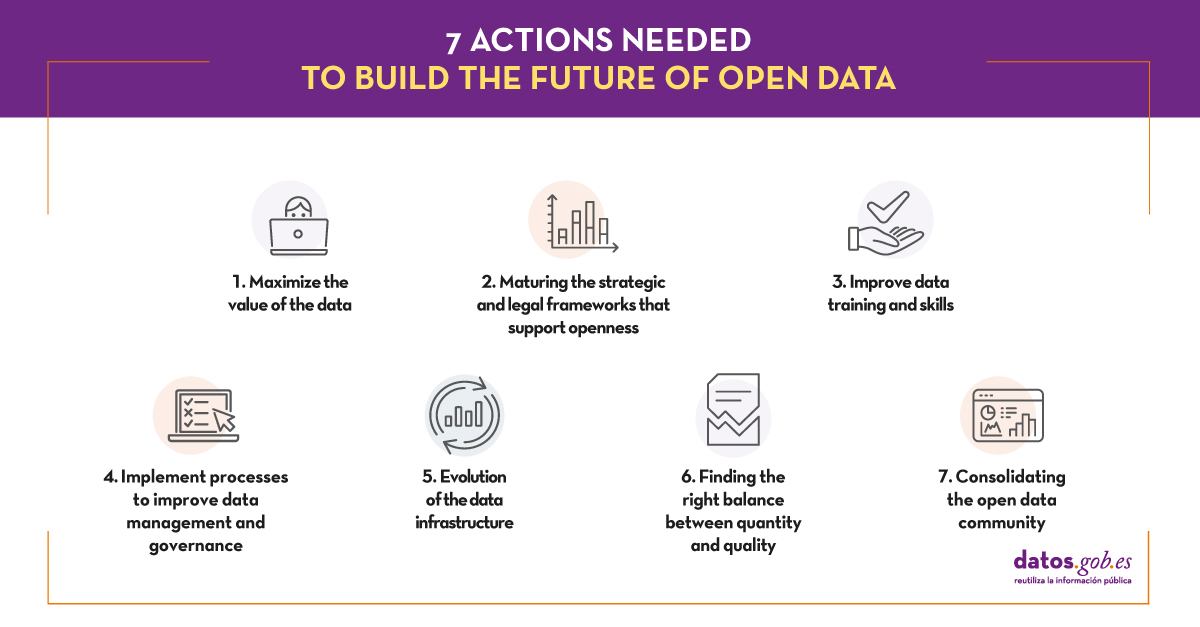
For the preparation of this report, we have used as a reference the report "“The Emergence of a Third Wave of Open Data”, which analyses the new stage that is opening up in the world of open data, published by the Open Data Policy Lab. This analysis serves as a reference to present both the current trends and the most important challenges associated with open data.
The final part of this report presents some of the actions that will play a key role in strengthening and consolidating the future of open data over the next ten years. These actions have been adapted to the European Union environment, and specifically to Spain (including its regulatory framework).
Below, you can download the full report, as well as its executive summary and a summary presentation in power point format.
Noticia
The following infographic shows the strategic, regulatory and political situation that will affect the world of open data in Spain and Europe. To deepen its content you can read the following articles:
- The data-related strategies that will mark 2021 in Europe
- The data-related strategies that will mark 2021 in Spain