Evento
Aragón Open Data, the open data portal of the Government of Aragón, will present its most recent work on 15 March 2023 to present its lines of action and progress in the field of open data and linked data.
What does 'Aragón Open Data: Open and connect data' consist of?
In this meeting, which is part of the events framed in the Open Data Days 2023, Aragón Open Data will take the opportunity to talk about the evolution of its open data platform and the improvement of the quality of the data offered.
In this line, the conference 'Aragón Open Data: Open and connect data' will also focus on detailing the functioning of Aragopedia, its new linked data strategy.
Through a series of technical explanations, supported by a demo, attendees will learn how this service works, based on the new structure of Interoperable Information of Aragon (EI2A) that allows sharing, connecting and relating certain data available on the Aragon Open Data portal.
In order to detail as precisely as possible, the approach of the conference, we share the programme below:
- Welcome to the conference. Julián Moyano, coordinator of Aragón Open Data.
- Introduction to Aragón Open Data (Marc Garriga, Desidedatum)
- Improving the quality of the data and its semantisation (Koldo Z. / Susana G.)
- Previous situation and current situation
- New navigation focused on Aragón Open Data and Aragopedia data (Pedro M. / Beni)
- Explanation and Demo
- My experience with Aragopedia (Sofía Arguís, Documentalist and user of Aragón Open Data )
- Process of identification, processing and opening of new data (Cristina C.)
- Starting point and challenges encountered to achieve openness.
- Conclusions (Marc Garriga)
- Question/Comment Time
Where and when is it being held?
The technical conference 'Aragón Open Data: Open and connect data' will be held on 15 March from 12:00 to 13:30 online. Therefore, in order to attend it, interested users must fill in the form available at the following point.
How can I register?
To attend and access the online session you can fill in the following form and if you have any questions, do not hesitate to write to us at opendata@aragon.es.
Aragón Open Data is co-financed by the European Union, European Regional Development Fund (ERDF) "Building Europe from Aragon.
Noticia
On 21 February, the winners of the 6th edition of the Castilla y León Open Data Competition were presented with their prizes. This competition, organised by the Regional Ministry of the Presidency of the Regional Government of Castilla y León, recognises projects that provide ideas, studies, services, websites or mobile applications, using datasets from its Open Data Portal.
The event was attended, among others, by Jesús Julio Carnero García, Minister of the Presidency, and Rocío Lucas Navas, Minister of Education of the Junta de Castilla y León.
In his speech, the Minister Jesús Julio Carnero García emphasised that the Regional Government is going to launch the Data Government project, with which they intend to combine Transparency and Open Data, in order to improve the services offered to citizens.
In addition, the Data Government project has an approved allocation of almost 2.5 million euros from the Next Generation Funds, which includes two lines of work: both the design and implementation of the Data Government model, as well as the training for public employees.
This is an Open Government action which, as the Councillor himself added, "is closely related to transparency, as we intend to make Open Data freely available to everyone, without copyright restrictions, patents or other control or registration mechanisms".
Nine prize-winners in the 6th edition of the Castilla y León Open Data Competition
It is precisely in this context that initiatives such as the 6th edition of the Castilla y León Open Data Competition stand out. In its sixth edition, it has received a total of 26 proposals from León, Palencia, Salamanca, Zamora, Madrid and Barcelona.
In this way, the 12,000 euros distributed in the four categories defined in the rules have been distributed among nine of the above-mentioned proposals. This is how the awards were distributed by category:
Products and Services Category: aimed at recognising projects that provide studies, services, websites or applications for mobile devices and that are accessible to all citizens via the web through a URL.
- First prize: 'Oferta de Formación profesional de Castilla y León. An attractive and accessible alternative with no-cod tools'". Author: Laura Folgado Galache (Zamora). 2,500 euros.
- Second prize: 'Enjoycyl: collection and exploitation of assistance and evaluation of cultural activities'. Author: José María Tristán Martín (Palencia). 1,500 euros.
- Third prize: 'Aplicación del problema de la p-mediana a la Atención Primaria en Castilla y León'. Authors: Carlos Montero and Ernesto Ramos (Salamanca) 500 euros.
- Student prize: 'Play4CyL'. Authors: Carlos Montero and Daniel Heras (Salamanca) 1,500 euros.
Ideas category: seeks to reward projects that describe an idea for developing studies, services, websites or applications for mobile devices.
- First prize: 'Elige tu Universidad (Castilla y León)'. Authors: Maite Ugalde Enríquez and Miguel Balbi Klosinski (Barcelona) 1,500 euros.
- Second prize: 'Bots to interact with open data - Conversational interfaces to facilitate access to public data (BODI)'. Authors: Marcos Gómez Vázquez and Jordi Cabot Sagrera (Barcelona) 500 euros
Data Journalism Category: awards journalistic pieces published or updated (in a relevant way) in any medium (written or audiovisual).
- First prize: '13-F elections in Castilla y León: there will be 186 fewer polling stations than in the 2019 regional elections'. Authors: Asociación Maldita contra la desinformación (Madrid) 1,500 euros.
- Second prize: 'More than 2,500 mayors received nothing from their city council in 2020 and another 1,000 have not reported their salary'. Authors: Asociación Maldita contra la desinformación (Madrid). 1,000 euros.
Didactic Resource Category: recognises the creation of new and innovative open didactic resources (published under Creative Commons licences) that support classroom teaching.
In short, and as the Regional Ministry of the Presidency itself points out, with this type of initiative and the Open Data Portal, two basic principles are fulfilled: firstly, that of transparency, by making available to society as a whole data generated by the Community Administration in the development of its functions, in open formats and with a free licence for its use; and secondly, that of collaboration, allowing the development of shared initiatives that contribute to social and economic improvements through joint work between citizens and public administrations.
Blog
There is such a close relationship between data management, data quality management and data governance that the terms are often used interchangeably or confused. However, there are important nuances.
The overall objective of data management is to ensure that data meets the business requirements that will support the organisation's processes, such as collecting, storing, protecting, analysing and documenting data, in order to implement the objectives of the data governance strategy. It is such a broad set of tasks that there are several categories of standards to certify each of the different processes: ISO/IEC 27000 for information security and privacy, ISO/IEC 20000 for IT service management, ISO/IEC 19944 for interoperability, architecture or service level agreements in the cloud, or ISO/IEC 8000-100 for data exchange and master data management.
Data quality management refers to the techniques and processes used to ensure that data is fit for its intended use. This requires a Data Quality Plan that must be in line with the organisation's culture and business strategy and includes aspects such as data validation, verification and cleansing, among others. In this regard, there is also a set of technical standards for achieving data quality] including data quality management for transaction data, product data and enterprise master data (ISO 8000) and data quality measurement tasks (ISO 25024:2015).
Data governance, according to Deloitte's definition, consists of an organisation's set of rules, policies and processes to ensure that the organisation's data is correct, reliable, secure and useful. In other words, it is the strategic, high-level planning and control to create business value from data. In this case, open data governance has its own specificities due to the number of stakeholders involved and the collaborative nature of open data itself.
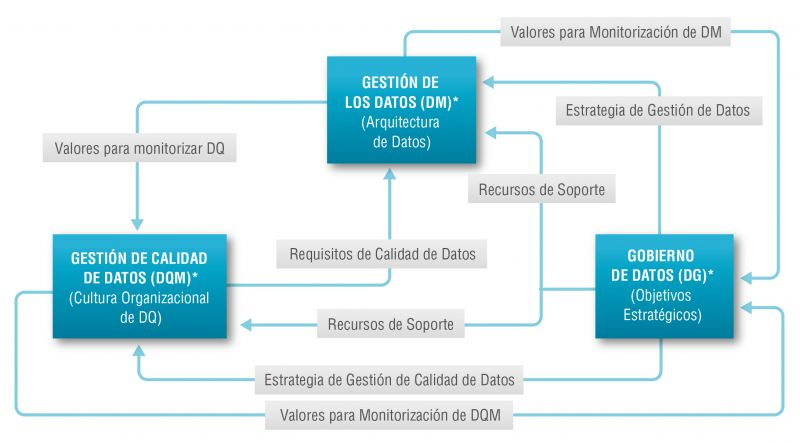
The Alarcos Model
In this context, the Alarcos Model for Data Improvement (MAMD), currently in its version 3, aims to collect the necessary processes to achieve the quality of the three dimensions mentioned above: data management, data quality management and data governance. This model has been developed by a group of experts coordinated by the Alarcos research group of the University of Castilla-La Mancha in collaboration with the specialised companies DQTeam and AQCLab.
The MAMD Model is aligned with existing best practices and standards such as Data Management Community (DAMA), Data management maturity (DMM) or the ISO 8000 family of standards, each of which addresses different aspects related to data quality and master data management from different perspectives. In addition, the Alarcos model is based on the family of standards to define the maturity model so it is possible to achieve AENOR certification for ISO 8000-MAMD data governance, management and quality.
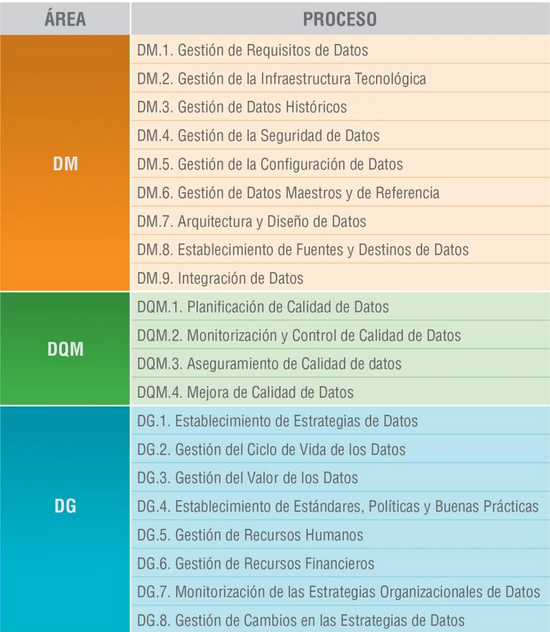
The MAMD model consists of 21 processes, 9 processes correspond to data management (DM), data quality management (DQM) includes 4 more processes and data governance (DG), which adds another 8 processes.
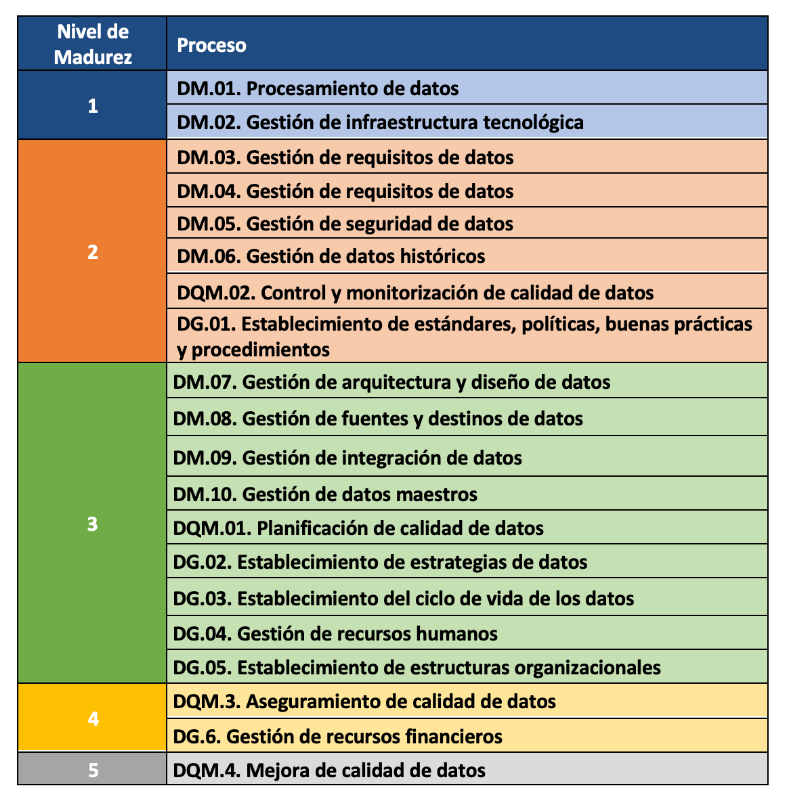
The progressive incorporation of the 21 processes allows the definition of 5 maturity levels that contribute to the organisation improving its data management, data quality and data governance. Starting with level 1 (Performed) where the organisation can demonstrate that it uses good practices in the use of data and has the necessary technological support, but does not pay attention to data governance and data quality, up to level 5 (Innovative) where the organisation is able to achieve its objectives and is continuously improving.
The model can be certified with an audit equivalent to that of other AENOR standards, so there is the possibility of including it in the cycle of continuous improvement and internal control of regulatory compliance of organisations that already have other certificates.
Practical exercises
The Library of the University of Castilla-La Mancha (UCLM), which supports more than 30,000 students and 3,000 professionals including teachers and administrative and service staff, is one of the first organisations to pass the certification audit and therefore obtain level 2 maturity in ISO/IEC 33000 - ISO 8000 (MAMD).
The strengths identified in this certification process were the commitment of the management team and the level of coordination with other universities. As with any audit, improvements were proposed such as the need to document periodic data security reviews which helped to feed into the improvement cycle.
The fact that organisations of all types place an increasing value on their data assets means that technical certification models and standards have a key role to play in ensuring the quality, security, privacy, management or proper governance of these data assets. In addition to existing standards, a major effort continues to be made to develop new standards covering aspects that have not been considered central until now due to the reduced importance of data in the value chains of organisations. However, it is still necessary to continue with the formalisation of models that, like the Alarcos Data Improvement Model, allow the evaluation and improvement process of the organisation in the treatment of its data assets to be addressed holistically, and not only from its different dimensions.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Public administration is working to ensure access to open data, in order to empowering citizens in their right to information. Aligned with this objective, the European open data portal (data.europa.eu) references a large volume of data on a variety of topics.
However, although the data belong to different information domains or are in different formats, it is complex to exploit them together to maximise their value. One way to achieve this is through the use of RDF (Resource Description Framework), a data model that enables semantic interoperability of data on the web, standardised by the W3C, and highlighted in the FAIR principles. RDF occupies one of the top levels of the five-star schema for open data publishing, proposed by Tim Berners-Lee, the father of the web.
In RDF, data and metadata are automatically interconnected, generating a network of Linked Open Data (LOD) by providing the necessary semantic context through explicit relationships between data from different sources to facilitate their interconnection. This model maximises the exploitation potential of linked data.
It is a data sharing paradigm that is particularly relevant within the EU data space initiative explained in this post.
RDF offers great advantages to the community. However, in order to maximise the exploitation of linked open data it is necessary to know the SPARQL query language, a technical requirement that can hinder public access to the data.
An example of the use of RDF is the open data catalogues available on portals such as datos.gob.es or data.europa.eu that are developed following the DCAT standard, which is an RDF data model to facilitate their interconnection. These portals have interfaces to configure queries in SPARQL language and retrieve the metadata of the available datasets.
A new app to make interlinked data accessible: Vinalod.
Faced with this situation and with the aim of facilitating access to linked data, Teresa Barrueco, a data scientist and visualisation specialist who participated in the 2018 EU Datathon, the EU competition to promote the design of digital solutions and services related to open data, developed an application together with the European Publications Office.
The result is a tool for exploring LOD without having to be familiar with SPARQL syntax, called Vinalod: Visualisation and navigation of linked open data. The application, as its name suggests, allows you to navigate and visualise data structures in knowledge graphs that represent data objects linked to each other through the use of vocabularies that represent the existing relationships between them. Thus, through a visual and intuitive interaction, the user can access different data sources:
- EU Vocabularies. EU reference data containing, among others, information from Digital Europa Thesaurus, NUTS classification (hierarchical system to divide the economic territory of the EU) and controlled vocabularies from the Named Authority Lists.
- Who's Who in the EU. Official EU directory to identify the institutions that make up the structure of the European administration.
- EU Data. Sets and visualisations of data published on the EU open data portal that can be browsed according to origin and subject.
- EU publications. Reports published by the European Union classified according to their subject matter.
- EU legislation. EU Treaties and their classification.
The good news is that the BETA version of Vinalod is now available for use, an advance that allows for temporary filtering of datasets by country or language.
To test the tool, we tried searching for data catalogues published in Spanish, which have been modified in the last three months. The response of the tool is as follows:

And it can be interpreted as follows:

Therefore, the data.europa.eu portal hosts ("has catalog") several catalogues that meet the defined criteria: they are in Spanish language and have been published in the last three months. The user can drill down into each node ("to") and find out which datasets are published in each portal.
In the example above, we have explored the 'EU data' section. However, we could do a similar exercise with any of the other sections. These are: EU Vocabularies; Who's Who in the EU; EU Publications and EU Legislation.
All of these sections are interrelated, that means, a user can start by browsing the 'EU Facts', as in the example above, and end up in 'Who's Who in the EU' with the directory of European public officials.

As can be deduced from the above tests, browsing Vinalod is a practical exercise in itself that we encourage all users interested in the management, exploitation and reuse of open data to try out.
To this end, in this link we link the BETA version of the tool that contributes to making open data more accessible without the need to know SPARQL, which means that anyone with minimal technical knowledge can work with the linked open data.
This is a valuable contribution to the community of developers and reusers of open data because it is a resource that can be accessed by any user profile, regardless of their technical background. In short, Vinalod is a tool that empowers citizens, respects their right to information and contributes to the further opening of open data.
Blog
Talking about GPT-3 these days is not the most original topic in the world, we know it. The entire technology community is publishing examples, holding events and predicting the end of the world of language and content generation as we know it today. In this post, we ask ChatGPT to help us in programming an example of data visualisation with R from an open dataset available at datos.gob.es.
Introduction
Our previous post talked about Dall-e and GPT-3's ability to generate synthetic images from a description of what we want to generate in natural language. In this new post, we have done a completely practical exercise in which we ask artificial intelligence to help us make a simple program in R that loads an open dataset and generates some graphical representations.
We have chosen an open dataset from the platform datos.gob.es. Specifically, a simple dataset of usage data from madrid.es portals. The description of the repository explains that it includes information related to users, sessions and number of page views of the following portals of the Madrid City Council: Municipal Web Portal, Sede Electrónica, Transparency Portal, Open Data Portal, Libraries and Decide Madrid.
The file can be downloaded in .csv or .xslx format and if we preview it, it looks as follows:

OK, let's start co-programming with ChatGPT!
First we access the website and log in with our username and password. You need to be registered on the openai.com website to be able to access GPT-3 capabilities, including ChatGPT.
We start our conversation:

During this exercise we have tried to have a conversation in the same way as we would have with a programming partner. So the first step we do is to say ‘hello’ and mention the problem we have. When we ask the AI to help us create a small program in R that graphically represents some data, it gives us some examples and helps us with the explanation of the program:

Since we have no data, we cannot do anything practical at the moment, so we ask it to help us generate some synthetic data.
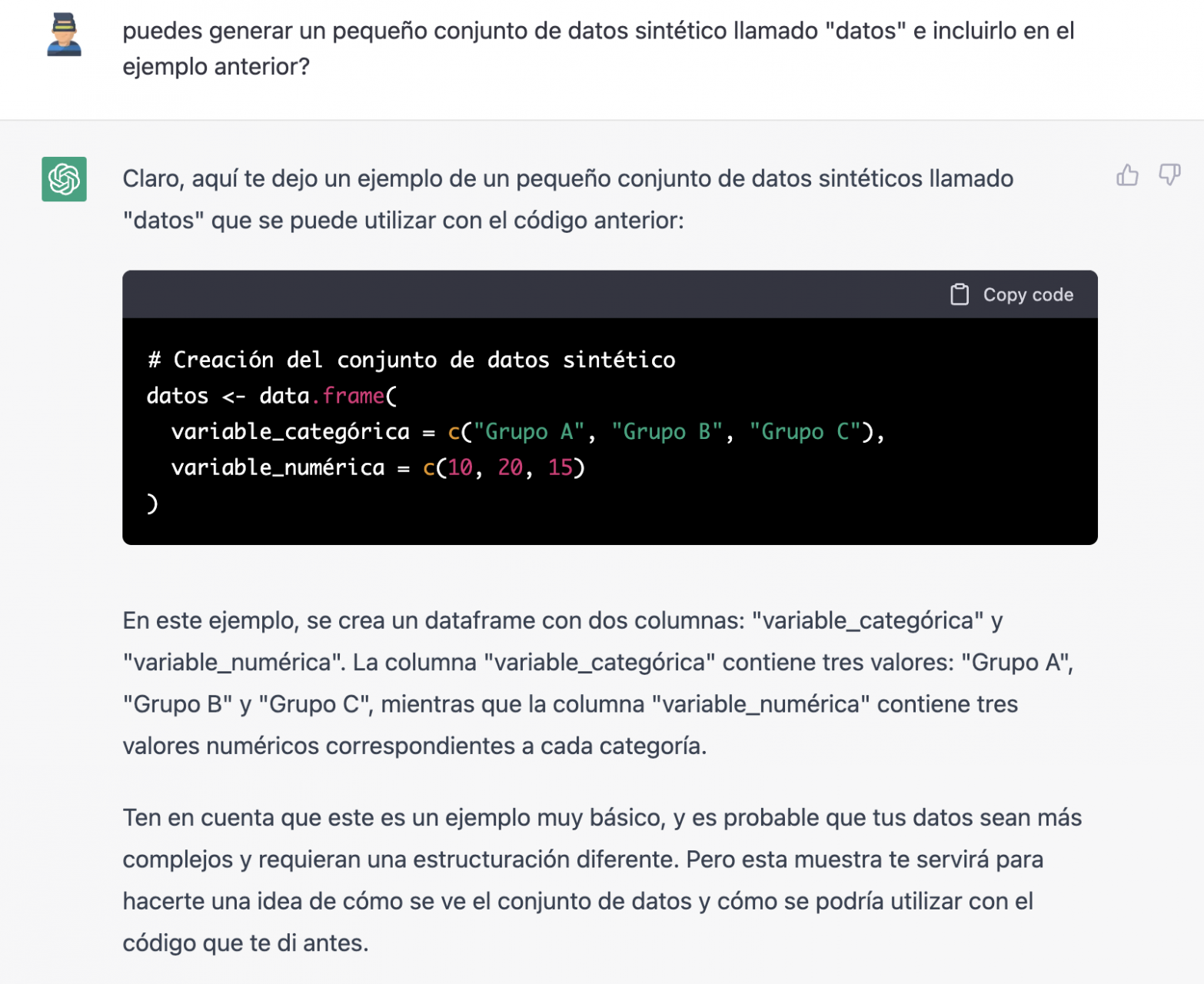
As we say, we behave with the AI as we would with a person (it looks good).

Once the AI seems to easily answer our questions, we go to the next step, we are going to give it the data. And here the magic begins... We have opened the data file that we have downloaded from datos.gob.es and we have copied and pasted a sample.
| Note: ChatGPT has no internet connection and therefore cannot access external data, so all we can do is give it an example of the actual data we want to work with. |


With the data copied and pasted as we have given it to it, the AI writes the code in R to load it manually into a dataframe called \"data\". It then gives us the code for ggplot2 (the most popular graphics library in R) to plot the data along with an explanation of how the code works.

Great! This is a spectacular result with a totally natural language and not at all adapted to talk to a machine. Let's see what happens next:
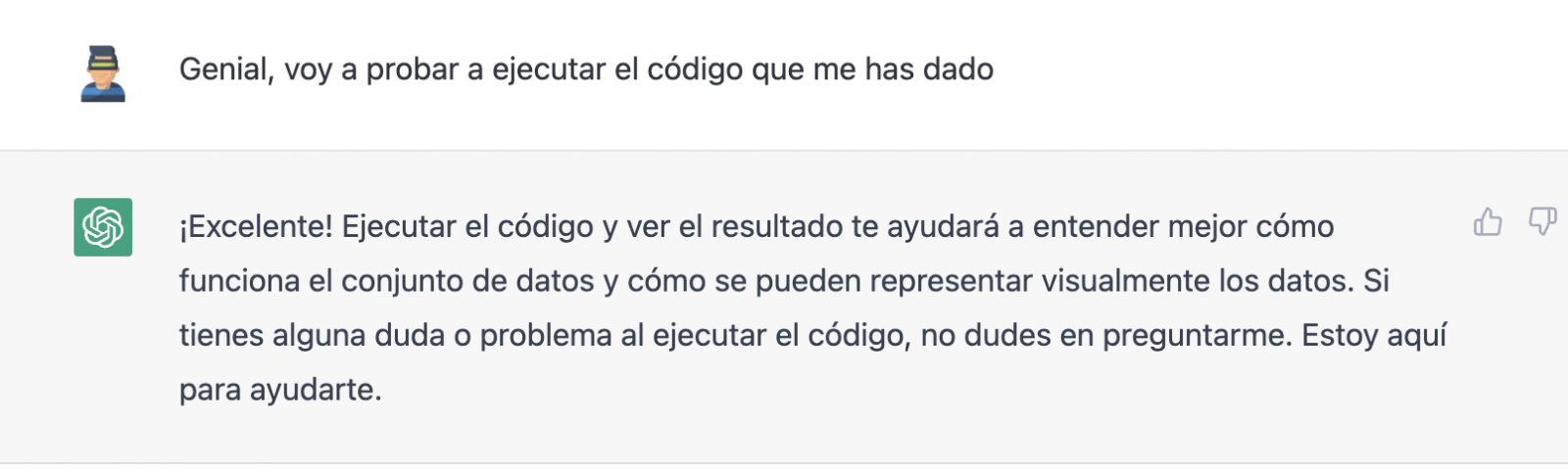
But it turns out that when we copy and paste the code into an RStudio environment it is no running.

So, we tell to it what's going on and ask it to help us to solve it.

We tried again and, in this case, it works!
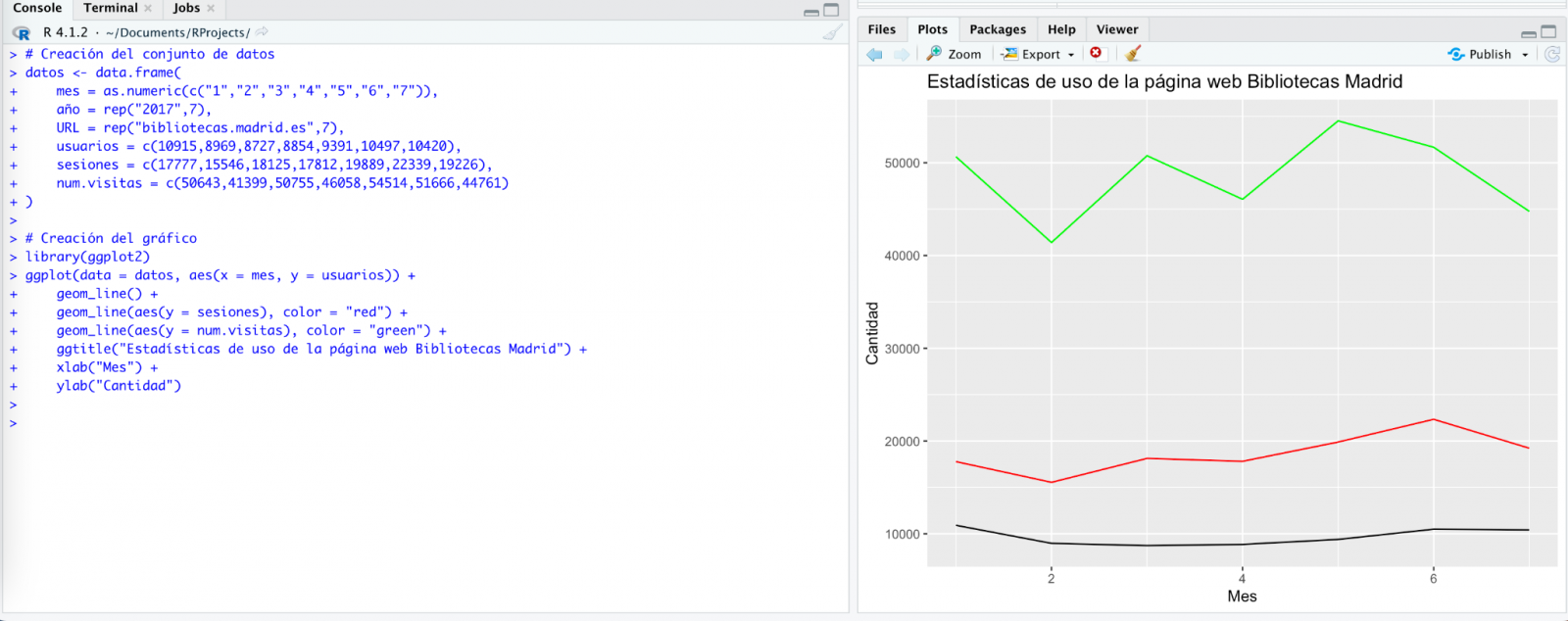
However, the result is a bit clumsy. So, we tell it.

From here (and after several attempts to copy and paste more and more rows of data) the AI changes the approach slightly and provides me with instructions and code to load my own data file from my computer instead of manually entering the data into the code.

We take its opinion into account and copy a couple of years of data into a text file on our computer. Watch what happens next:
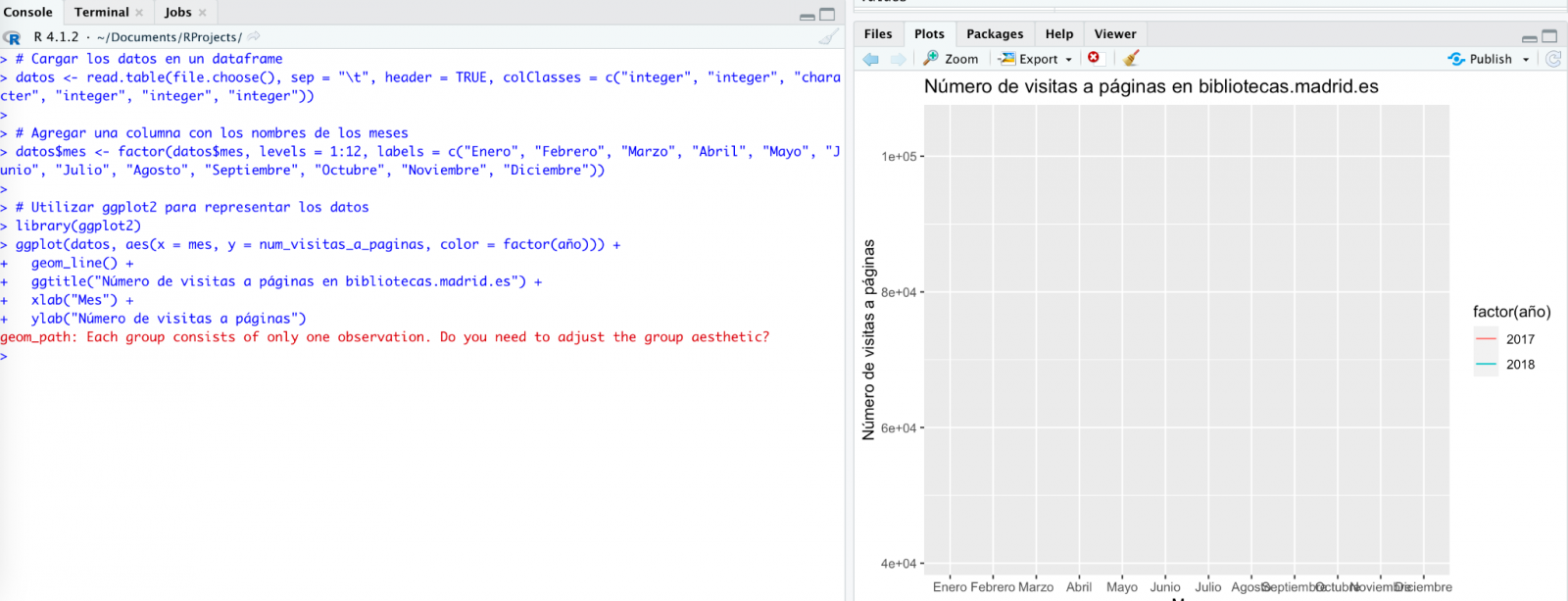

We try again:
As you can see, it works, but the result is not quite right.
And let's see what happens.

Finally, it looks like it has understood us! That is, we have a bar chart with the visits to the website per month, for the years 2017 (blue) and 2018 (red). However, I am not convinced by the format of the axis title and the numbering of the axis itself.

Let's look at the result now.

It looks much better, doesn't it? But what if we give it one more twist?
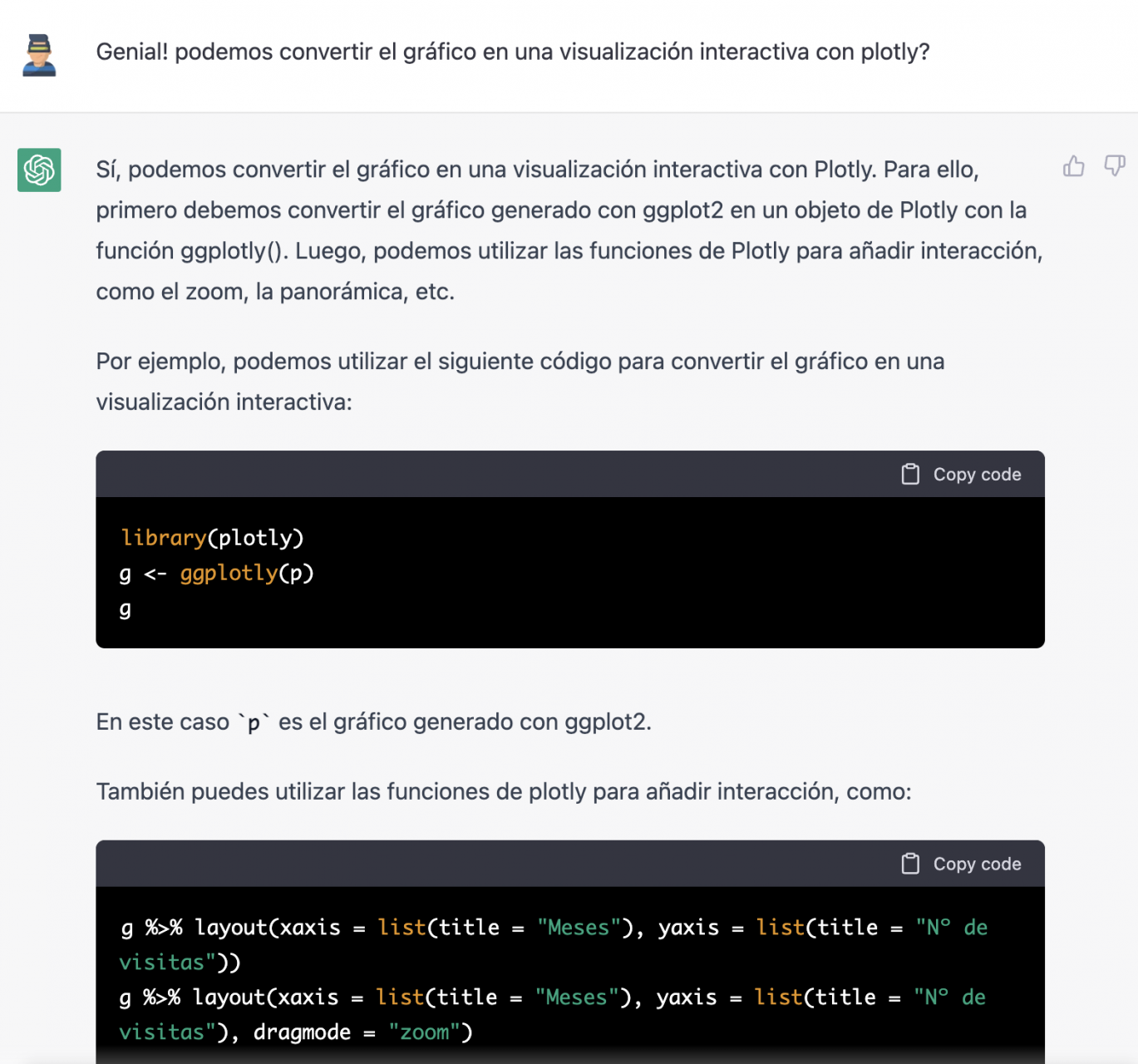
However, it forgot to tell us that we must install the plotly package or library in R. So, we remind it.
Let's have a look at the result:

As you can see, we have now the interactive chart controls, so that we can select a particular year from the legend, zoom in and out, and so on.
Conclusion
You may be one of those sceptics, conservatives or cautious people who think that the capabilities demonstrated by GPT-3 so far (ChatGPT, Dall-E2, etc) are still very infantile and impractical in real life. All considerations in this respect are legitimate and, many of them, probably well-founded.
However, some of us have spent a good part of our lives writing programs, looking for documentation and code examples that we could adapt or take inspiration from; debugging bugs, etc. For all of us (programmers, analysts, scientists, etc.) to be able to experience this level of interlocution with an artificial intelligence in beta mode, made freely available to the public and being able to demonstrate this capacity for assistance in co-programming, is undoubtedly a qualitative and quantitative leap in the discipline of programming.
We don't know what is going to happen, but we are probably on the verge of a major paradigm shift in computer science, to the point that perhaps the way we program has changed forever and we haven't even realised it yet.
Content prepared by Alejandro Alija, Digital Transformation expert.
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Generative artificial intelligence refers to machine’s ability to generate original and creative content, such as images, text or music, from a set of input data. As far as text generation is concerned, these models have been accessible, in an experimental format, for some time, but began to generate interest in mid-2020 when Open AI, an organisation dedicated to research in the field of artificial intelligence, published access to its GPT-3 language model via an API.
The GPT-3's architecture is composed of 175 billion parameters, comparing to its predecessor GPT-2 was 1.5 billion parameters, i.e. more than 100 times more. Therefore, GPT-3 represents a huge change in scale as it was also trained with a much larger corpus of data and a much larger token size, which allowed it to acquire a deeper and more complex understanding of the human language.
Although it was in 2022 when OpenAI announced the launch of chatGPT, which provides a conversational interface to a language model based on an improved version of GPT-3, it has only been in the last two months that the chat has attracted massive public attention, thanks to extensive media coverage that tries to respond to the emerging general interest.
In fact, ChatGPT is not only able to generate text from a set of characters (prompt) like GPT-3, but also it is able to respond to natural language questions in several languages including English, Spanish, French, German, Italian or Portuguese. This specific updated issue in the access interface from an API to a chatbot that has made the AI accessible to any type of user.
Maybe for this reason, more than a million people registered to use it in just five days, which has led to the multiplication of examples in which chatGPT produces software code, university-level essays, poems and even jokes. Not to mention the fact that it has been able to ace an history SAT or pass the final MBA exam at the prestigious Wharton School.
All of this has put generative AI at the centre of a new wave of technological innovation that promises to revolutionise the way we relate to the internet and the web through AI-powered searches or browsers capable of summarising the results of these searches.
Just a few days ago, we heard the news that Microsoft is working on the implementation of a conversational system within its own search engine, which has been developed based on the well-known Open AI language model and whose news has put Google in check.
As a result of this new reality in which AI is here to stay, the technological giants have gone a step further in the battle to make the most of the benefits it brings. Along these lines, Microsoft has presented a new strategy aimed at optimising the way in which we interact with the internet, introducing AI to improve the results offered by browser search engines, applications, social networks and, in short, the entire web ecosystem.
However, although the path in the development of new and future services offered by Open AI's remains to be seen, advances such as the mentioned above, offer a small hint of the browser war that is coming and that will probably change the way we create and find content on the web in the short term.
The open data
GPT-3, like other models that have been generated with the techniques described in the original GTP-3 scientific publication, is a pre-trained language model, which means that it has been trained with a large dataset, in total about 45 terabytes of text data. According to the paper, the training dataset was composed of 60% of data obtained directly from the internet containing millions of documents of all kinds, 22% from the WebText2 corpus built from Reddit, and the rest from a combination of books (16%) and Wikipedia (3%).
However, it is not known exactly how much open datasets GPT-3 uses, as OpenAI does not provide more specific details about the dataset used to train the model. What we can ask chatGPT itself are some questions that can help us draw interesting conclusions about its use of open data.
For example, if we ask chatGPT what was the population of Spain between 2015 and 2020 (we cannot ask for more recent data), we get an answer like this:

As we can see in the image above, although the question is the same, the answer may vary in both the wording and the information it contains. The variations can be even greater if we ask the question on different days or in different threads:
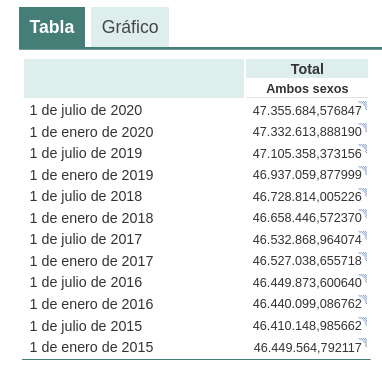
Small variations in the wording of the text, generating the question at different times in the conversation thread (remember that it saves the context) or in different threads or on different days may lead to slightly different results. Moreover, the answer is not completely accurate, as the tool itself warns us if we compare it with the INE's own series on the resident population in Spain, where it recommends us to consult. The data that we would ideally have expected in the response could be obtained in an open INE dataset:
Such responses suggest that open data has not been used as an authoritative source for answering factual questions, or at least that the model is not yet fully refined on this matter. Doing some basic tests with questions about other countries we have observed similar errors, so this does not seem to be a problem only with questions referring to Spain.
If we ask more specific questions, such as asking for a list of the municipalities in the province of Burgos that begin with the letter "G", we get answers that are not completely correct, as is typical of a technology that is still in its infancy.
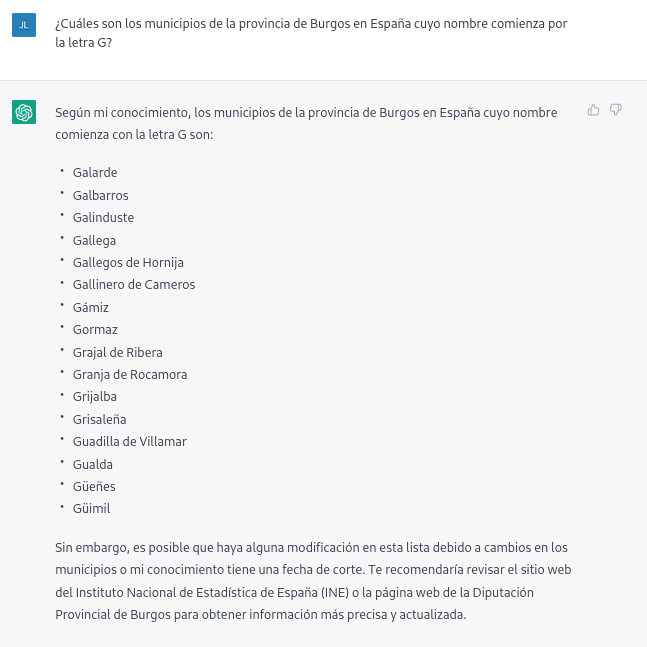
The correct answer should contain six municipalities: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán and Gumiel del Mercado. However, the answer we have obtained only contains the first four and includes localities in the province of Guadalajara (Gualda), municipalities in the province of Valladolid (Gallegos de Hornija) or localities in the province of Burgos that are not municipalities (Galarde). In this case, we can also turn to the open dataset to get the correct answer.
Next, we ask ChatGPT for the list of municipalities beginning with the letter Z in the same province. ChatGPT tells us that there are none, reasoning the answer, when in fact there are four:
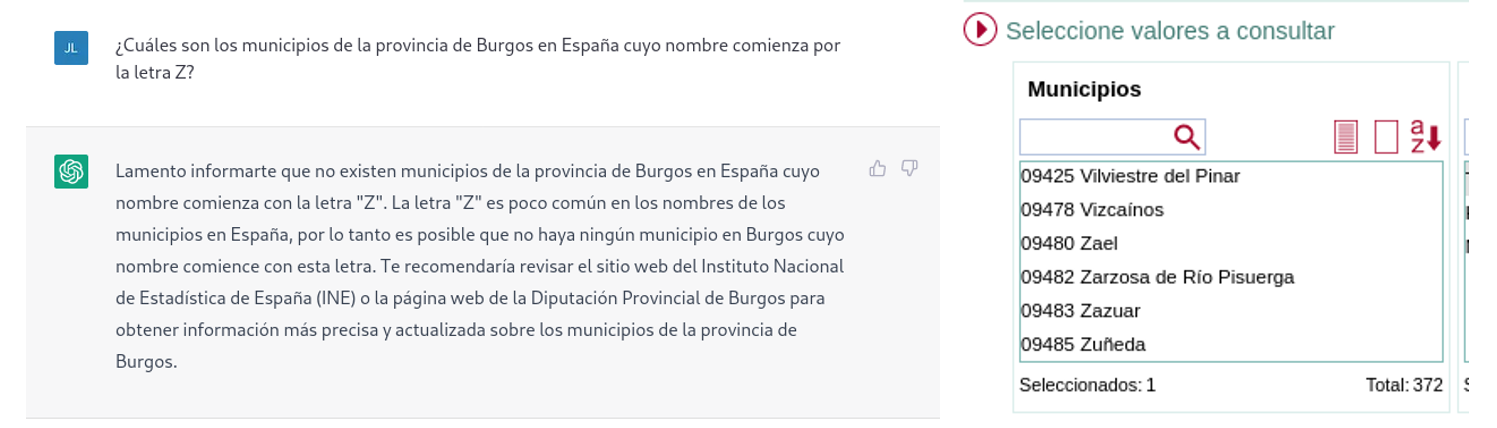
As can be seen from the examples above, we can see how open data can indeed contribute to technological evolution and thus improve the performance of Open AI's artificial intelligence. However, given its current state of maturity, it is still too early to see the optimal use of open data to answer more complex questions.
Therefore, for a generative AI model to be effective, it is necessary to have a large amount of high quality and diverse data, and open data is a valuable source of knowledge for this purpose.
In future versions of the model, we will probably be able to see how open data will acquire a much more important role in the composition of the training corpus, achieving a significant improvement in the quality of the factual answers.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
The Plenary Session of the Council of the Valencian Community has approved a collaboration agreement between the Ministry of Participation, Transparency, Cooperation and Democratic Quality and the Polytechnic University of Valencia (UPV) with the aim of promoting the development of activities in the field of transparency and open data during 2023.
Thus, the Transparency Ministry will allocate 65,000 euros to promote the activities of the agreement focused on the opening and reuse of data present at different levels of public administrations.
Among the planned actions, the third edition of the Open Data Datathon stands out, an event that seeks to encourage the use of open data to develop applications and services that provide benefits to citizens. This collaboration will also promote the reuse of data related to the business sector, promoting innovation, dissemination, and awareness in various fields.
In parallel, it is planned to work jointly with different entities from civil society to establish a series of intelligent sensors for collecting data, while also promoting workshops and seminars on data journalism.
In turn, a series of informative sessions are included aimed at disseminating knowledge on the use and sharing of open data, the presentation of the Datos y Mujeres project, or the dissemination of open data repositories for research or transparency in algorithms.
Likewise, the collaboration includes the programming of talks and workshops to promote the use of open data in high schools, the integration of open data in different subjects of the PhD, bachelor's, and master's degrees on Public Management and Administration, the Master's degree in Cultural Management, and some transversal doctoral subjects.
Finally, this collaboration between the university and the administration also seeks to promote and mentor a large part of the work on transparency and open data, including the development of a guide to the reuse of open data aimed at reuse organizations, as well as activities to disseminate the Open Government Alliance (OGP) and action plans of the Valencian Community.
Previous projects related to open data
Apart from the plan of activities designed for this 2023 and detailed in the previous lines, this is not the first time that the Polytechnic University of Valencia and the Department of Participation and Transparency have worked together in the dissemination and promotion of open data. In fact, to be exact, they have been actively working through the Open Data and Transparency Observatory, belonging to the same university, to promote the value and sharing of data both in the academic and social spheres.
For instance, in line with this dissemination work, last year 2022, they promoted the 'Women and Data' initiative from the same entity, a project that brought together several women from the data field to talk about their professional experience, the challenges and opportunities addressed in the sector.
Among the interviewees, prominent names included Sonia Castro, coordinator of datos.gob.es, Ana Tudela, co-founder of Datadista, or Laura Castro, data visualization designer at Affective Advisory, among many other professionals.
Likewise, last spring and coinciding with the International Open Data Day, the second edition of Datathon took place, whose purpose was to promote the development of new tools from open data linked to responsible consumption, the environment or culture.
Thus, this particular alliance between the Department of Participation and Transparency and the Polytechnic University of Valencia demonstrates that not only is it possible to showcase the potential of open data, but also that dissemination opportunities are multiplied when institutions and the academic sphere work together in a coordinated and planned manner towards the same objectives.
Noticia
Updated: 21/03/2024
On January 2023, the European Commission published a list of high-value datasets that public sector bodies must make available to the public within a maximum of 16 months. The main objective of establishing the list of high-value datasets was to ensure that public data with the highest socio-economic potential are made available for re-use with minimal legal and technical restriction, and at no cost. Among these public sector datasets, some, such as meteorological or air quality data, are particularly interesting for developers and creators of services such as apps or websites, which bring added value and important benefits for society, the environment or the economy.
The publication of the Regulation has been accompanied by frequently asked questions to help public bodies understand the benefit of HVDS (High Value Datasets) for society and the economy, as well as to explain some aspects of the obligatory nature of HVDS (High Value Datasets) and the support for publication.
In line with this proposal, Executive Vice-President for a Digitally Ready Europe, Margrethe Vestager, stated the following in the press release issued by the European Commission:
"Making high-value datasets available to the public will benefit both the economy and society, for example by helping to combat climate change, reducing urban air pollution and improving transport infrastructure. This is a practical step towards the success of the Digital Decade and building a more prosperous digital future".
In parallel, Internal Market Commissioner Thierry Breton also added the following words on the announcement of the list of high-value data: "Data is a cornerstone of our industrial competitiveness in the EU. With the new list of high-value datasets we are unlocking a wealth of public data for the benefit of all”. Start-ups and SMEs will be able to use this to develop new innovative products and solutions to improve the lives of citizens in the EU and around the world.
Six categories to bring together new high-value datasets
The regulation is thus created under the umbrella of the European Open Data Directive, which defines six categories to differentiate the new high-value datasets requested:
- Geospatial
- Earth observation and environmental
- Meteorological
- Statistical
- Business
- Mobility
However, as stated in the European Commission's press release, this thematic range could be extended at a later stage depending on technological and market developments. Thus, the datasets will be available in machine-readable format, via an application programming interface (API) and, if relevant, also with a bulk download option.
In addition, the reuse of datasets such as mobility or building geolocation data can expand the business opportunities available for sectors such as logistics or transport. In parallel, weather observation, radar, air quality or soil pollution data can also support research and digital innovation, as well as policy making in the fight against climate change.
Ultimately, greater availability of data, especially high-value data, has the potential to boost entrepreneurship as these datasets can be an important resource for SMEs to develop new digital products and services, which in turn can also attract new investors.
Find out more in this infographic:


Access the accessible version on two pages.
Empresa reutilizadora
Digital Earth Solutions is a technology company whose aim is to contribute to the conservation of marine ecosystems through innovative ocean modelling solutions.
Based on more than 20 years of CSIC studies in ocean dynamics, Digital Solutions has developed a unique software capable of predicting in a few minutes and with high precision the geographical evolution of any spill or floating body (plastics, people, algae...), forecasting its trajectory in the sea for the following days or its origin by analysing its movement back in time.
Thanks to this technology, it is possible to minimise the impact of oil and other waste spills on coasts, seas and oceans.
Blog
For years now we have been announcing that Artificial Intelligence is undergoing one of its most prolific, exciting periods. A time when applications and use cases begin to be seen in which human intelligence merges with artificial intelligence. Some occupations are changing forever. Journalists and writers now have software tools that can write for them. Content creators - images or video - can ask the machine to create for them just by saying a phrase. In this post we have taken a closer look at this last example. We have been able to test Dall-e 2 and the results have left us speechless.
Introduction
Nowadays, in the technological community worldwide, there is an underlying buzz, a collective excitement of all lovers of digital technologies and in particular of artificial intelligence. On several occasions we have mentioned the innovations of the company Open AI in this communication space. We have written several articles where we talk about the GPT-3 algorithm and what it is capable of in the field of natural language processing. Recently, OpenAI has been doing away with the waiting lists (on which many of us had been enrolled for a long time) to allow us to test in a limited way the capabilities of the GPT-3 algorithm implemented in different types of applications.
Example of the multiple applications of GPT-3 in the field of natural language.
We recommend our readers to try out the text completion tool with which, merely by providing a short sentence, the AI completes the text with several paragraphs indistinguishable from human writing. The last few days have been hectic with crowds of people testing the ChatGPT-3 tool. The degree of naturalness with which AI can have a conversation is simply amazing. The results are having an impact on a wide variety of use cases, such as support for software developers. ChatGPT-3 has been able to programme simple code routines or algorithms just from a description in natural language of what you want to programme. However, the result is even more impressive when we realise that AI is capable of correcting its own programming errors.
DALL-E
Leaving aside the capabilities of generating natural language indistinguishable from that written by a human, now let's take a look the main theme of this post. One of the most amazing applications of the AI of OpenAI is the solution known as DALL-E. What better way to introduce DALL-E than ask ChatGPT-3 what DALL-E is.
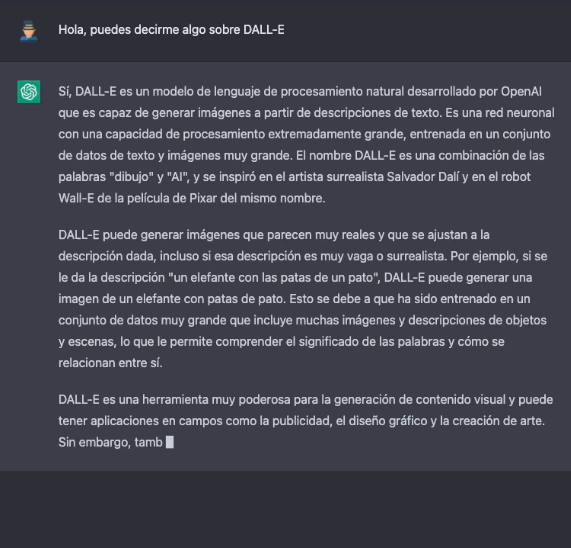
The more formal description of DALL-E, according to its own website, is as follows:
DALL·E is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions. DALL-E has a diverse set of capabilities, including creating anthropomorphised versions of animals and objects, combining unrelated concepts in plausible ways, rendering text, and applying transformations to existing images..
There is currently a second version of the algorithm. DALL-E 2 capable of generating more realistic and precise images with a resolution 4 times higher. The tool for trying out DALL-E is available here https://labs.openai.com/. To use it, we first need to create an OpenAI account that will allow us to play with all the tools of the company. When we access the test website we can write our own text or ask the tool to generate random descriptions of images in natural language to create images. For example, by clicking the Surprise me button:

The web generates this random description for us: an astronaut lounging in a tropical resort in space, pixel art
And this is the result:

We repeat: An expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula
We can assure you that the exercise is somewhat addictive and we admit that some of us have spent hours of our weekends playing with the descriptions and waiting, over and over again, for the amazing result.
About DALL-E 2 training
DALL-E 2 (arXiv:2204.06125) is a refined version of the original DALL-E system (arXiv:2102.12092). To train the original DALL-E model, which contains 12 billion parameters, a set of 250 million text-image pairs was used (publicly available online). This data set is a mixture of several prior datasets comprising: Conceptual Captions by Google; Wikipedia's text-image pairs and a filtered subset of YFCC100M.
DALL-E 2 trivia
Some interesting things besides the tests that we can do to generate our own images. OpenAI has created a specific Github repository which describes the risks and limitations of DALL-E. At the site it is reported, for example, that, for the time being, the use of DALL-E is limited to non-commercial purposes. So it is not possible to make any commercial use of the images generated. In other words, they cannot be sold or licensed under any circumstances. In this regard, all the images generated by DALL-E include a distinctive mark that lets you know that they have been generated by AI. At the Github site we can find loads of information about the generation of explicit content, the risks related with the bias that AI can introduce into the generation of images and the inappropriate uses of DALL-E such as the harassment, bullying or exploitation of individuals.

Along national lines, MarIA
Along national lines, after months of tests and adjustments, MarIA, the first supermassive artificial intelligence, has seen the light of day, trained with open data from the web archives of the National Library of Spain (BNE) and thanks to the computing resources of the National Supercomputing Centre. With regard to this post, MarIA has been trained using the GPT-2 algorithm which we have talked about many months ago in this space. To carry out the MarIA training, 135 billion previous words from the National Library's documentary bank have been used with a total volume of 570 Gigabytes of information.
Conclusions
As the days and weeks go by since the general opening of the APIs and the OpenIA tools, there has been a torrent of publications on all kinds of media, social media and specialised blogs about the capabilities and possibilities of Chat GPT-3 and DALL-E. I don't think that at this time anyone is capable of predicting the potential commercial, scientific and social applications of this technology. What is clear is that many of us think that OpenAI has shown only a sample of what it is capable of and it seems that we may be on the verge of a historic milestone in the development of AI after many years of overexpectations and unfulfilled promises. We will continue to report on the progress of GTP-3, but for the time being, all we can do is to keep enjoying, playing and learning with the simple tools that we have at our disposal!
Content prepared by Alejandro Alija, an expert in Digital Transformation.
The contents and points of view reflected in this publication are the sole responsibility of its author.