Blog
Los libros son una fuente inagotable de conocimientos y de experiencias vividas por otros antes que nosotros, que podemos reutilizar para avanzar en nuestras vidas. Las bibliotecas, por tanto, son lugares donde los lectores que buscan libros, los toman prestados y una vez usados y extraído de ellos lo que necesitan, los devuelven. Resulta curioso imaginar las razones por las que un lector necesita encontrar un libro concreto que trate de un determinado tema.
En caso de que haya varios libros que cumplan con las características requeridas, cuáles pueden ser los criterios que pesen más para elegir el libro que el lector considera que mejor contribuye a su tarea. Y una vez finalizado el periodo de préstamo del libro, la labor de los bibliotecarios para hacer que todo vuelva a un estado inicial resulta casi mágica. El proceso de dejar los libros de vuelta en las estanterías se puede repetir indefinidamente.
Tanto en esas estanterías inmensas que están a disposición pública de todos los lectores en las salas, como esas otras más pequeñas, fuera de la vista de todos, donde descansan bajo custodia los libros que, debido a alguna razón no pueden estar públicamente disponibles. Este proceso lleva pasando siglos desde que el hombre empezó a escribir y a compartir su conocimiento entre coetáneos y entre generaciones.
En cierto sentido, los datos son como los libros. Y los repositorios de datos son como las bibliotecas: en nuestro día a día, tanto a nivel profesional como a nivel personal, necesitamos datos que están en las “estanterías” de numerosas “bibliotecas”. Algunos, que están abiertos, muy pocos aún, se pueden usar; otros están restringidos, y necesitamos permisos para usarlos.
En cualquier caso, contribuyen a desarrollar proyectos personales y profesionales; y por eso, estamos entendiendo que los datos son el pilar de la nueva economía del dato, lo mismo que los libros llevan siendo el pilar del conocimiento desde hace miles de años.
Los cuatro principios FAIR
Tal como ocurre con las bibliotecas, para poder elegir y usar los datos más adecuados para nuestras tareas, necesitamos que “los bibliotecarios de los datos hagan su magia” para ordenarlo todo de tal manera que sea fácil encontrar, acceder, interoperar y reutilizar los datos. Ese es el secreto de los “magos de los datos”: algo que ellos, recelosamente, llaman principios FAIR para que el resto de los humanos no podamos descubrirlos. No obstante, siempre es posible dar algunas pistas, para que podamos sacar mejor partido de su magia:

- Tiene que poder ser fácil encontrar los datos. De aquí viene la “F” de los principios FAIR, de “findable” (localizable, en español). Para ello, es importante que los datos estén suficientemente descritos mediante una colección adecuada de metadatos, de tal manera que se puedan realizar búsquedas de manera sencilla. Del mismo modo que en las bibliotecas se establece un tejuelo para etiquetar los libros, los datos necesitan su propia etiqueta. Los “magos de los datos” tienen que encontrar, por un lado, formas de escribir las etiquetas para que sea fácil localizar los libros, y por otro proporcionar herramientas (como buscadores) para que los usuarios puedan hacer búsquedas. Los usuarios, por nuestra parte, tenemos que conocer y saber interpretar lo que significan las distintas etiquetas de los libros, y saber cómo funcionan las herramientas de búsqueda (imposible no acordarse aquí de los protagonistas de “Ángeles y demonios” de Dan Brown buscando en la Biblioteca del Vaticano).
- Una vez localizados los datos que se pretenden utilizar, tiene que ser fácil poder acceder a ellos para utilizarlos. Esta es la A de “accessible” de FAIR. Lo mismo que para tomar prestado un libro de una biblioteca hay que hacerse socio y te dan un carné, con los datos pasa lo mismo: hay que conseguir una licencia para acceder a los datos. En este sentido, sería ideal poder acceder a cualquier libro sin tener ningún tipo de traba previa como ocurre con los datos abiertos licenciados por CC BY 4.0 o equivalente. Pero el hecho de ser socio de la “biblioteca de datos”, no tiene por qué conferirte acceso a toda la biblioteca. Quizás para ciertos datos que descansan en esas estanterías custodiadas fuera del alcance de todas las miradas, necesites ciertos permisos (imposible no acodarse aquí de “El nombre de la rosa” de Umberto Eco).
- No es suficiente con poder acceder a los datos, tiene que ser fácil poder interoperar con ellos, entendiendo su significado y sus descripciones. Este principio se representa con la “I” de “interoperable” en FAIR. Así, los “magos de los datos” tienen que conseguir, mediante las correspondientes técnicas, que los datos estén descritos y puedan ser entendidos para poder ser usados en el contexto de uso de los usuarios; aunque en, no pocas ocasiones, serán los usuarios los que tengan que adaptarse para poder operar con los datos (imposible no acordarse de las runas élficas de “El Señor de los Anillos” de J.R.R. Tolkien).
- Finalmente, los datos, al igual que los libros, tienen que poder ser reutilizados para ayudar una y otra vez a que otros puedan cubrir sus propias necesidades. De aquí la “R” de “reusable” en FAIR. Para ello, los “magos de los datos” tiene que establecer los mecanismos para asegurar que, tras su uso, todo puede volver a ese estado inicial, que será el punto de partida desde el que otros empezarán sus propios caminos.
A medida que nuestra sociedad va avanzando en esto de la economía digital, nuestras necesidades de datos van cambiando. Y no es que necesitemos más datos, sino que necesitamos disponer de forma distinta de los datos que se tienen, de los que se producen y de los que se ponen a disposición de los usuarios. Además, necesitamos ser más respetuosos con los datos que se generan, y con cómo usamos esos datos para no violar los derechos ni las libertades de los ciudadanos. Así que puede decirse, que nos enfrentamos a nuevos retos, lo que requiere nuevas soluciones. Esto obliga a nuestros “magos de datos” a perfeccionar sus trucos, pero siempre manteniendo la esencia de su magia, esto es, de los principios FAIR.
Hace poco, al final de febrero de 2023, tuvo lugar una Asamblea de estos magos de datos. Y estuvieron discutiendo sobre cómo revisar los principios FAIR para perfeccionar estos trucos de magia para escenarios tan relevantes como los espacios europeos de datos, los datos geoespaciales, o incluso cómo medir lo bien que se aplican los principios FAIR para estos nuevos retos. Si quieres ver de lo que hablaron, puedes ver los videos y el material en el siguiente enlace: https://www.go-peg.eu/2023/03/07/go-peg-final-workshop-28-february-20203-1030-1300-cet/
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La crisis humanitaria que se originó tras el terremoto de Haití en 2010 fue el punto de partida de una iniciativa voluntaria para crear mapas que identificaran el nivel de daño y vulnerabilidad por zonas, y así, poder coordinar los equipos de emergencia. Desde entonces, el proyecto de mapeo colaborativo conocido como Hot OSM (OpenStreetMap) realiza una labor clave en situaciones de crisis y desastres naturales.
Ahora, la organización ha evolucionado hasta convertirse en una red global de voluntarios que aportan sus habilidades de creación de mapas en línea para ayudar en situaciones de crisis por todo el mundo. La iniciativa es un ejemplo de colaboración en torno a los datos para resolver problemas de la sociedad, tema que desarrollamos en este informe de datos.gob.es.
Hot OSM trabaja para acelerar la colaboración con organizaciones humanitarias y gubernamentales en torno a los datos, así como con comunidades locales y voluntarios de todo el mundo, para proporcionar mapas precisos y detallados de áreas afectadas por desastres naturales o crisis humanitarias. Estos mapas se utilizan para ayudar a coordinar la respuesta de emergencia, identificar necesidades y planificar la recuperación.
En su trabajo, Hot OSM prioriza la colaboración y el empoderamiento de las comunidades locales. La organización trabaja para garantizar que las personas que viven en las áreas afectadas tengan voz y poder en el proceso de mapeo. Esto significa que Hot OSM trabaja en estrecha colaboración con las comunidades locales para asegurarse de que se mapeen áreas importantes para ellos. De esta manera, se tienen en cuenta las necesidades de las comunidades a la hora de planificar respuesta de emergencia y la recuperación.
Labor didáctica de Hot OSM
Además de su trabajo en situaciones de crisis, Hot OSM dedica esfuerzos a la promoción del acceso a datos geoespaciales abiertos y libres, y trabaja en colaboración con otras organizaciones para construir herramientas y tecnologías que permitan a las comunidades de todo el mundo aprovechar el poder del mapeo colaborativo.
A través de su plataforma en línea, Hot OSM proporciona acceso gratuito a una amplia gama de herramientas y recursos para ayudar a los voluntarios a aprender y participar en la creación de mapas colaborativos. La organización también ofrece capacitación para aquellos interesados en contribuir a su trabajo.
Un ejemplo de proyecto de HOT es el trabajo que la organización realizó en el contexto del ébola en África Occidental. En 2014, un brote de ébola afectó a varios países de África Occidental, incluidos Sierra Leona, Liberia y Guinea. La falta de mapas precisos y detallados en estas áreas dificultó la coordinación de la respuesta de emergencia.
En respuesta a esta necesidad, HOT inició un proyecto de mapeo colaborativo que involucró a más de 3.000 voluntarios en todo el mundo. Los voluntarios utilizaron herramientas en línea para mapear áreas afectadas por el ébola, incluidas carreteras, pueblos y centros de tratamiento.
Este mapeo permitió a los trabajadores humanitarios coordinar mejor la respuesta de emergencia, identificar áreas de alto riesgo y priorizar la asignación de recursos. Además, el proyecto también ayudó a las comunidades locales a comprender mejor la situación y a participar en la respuesta de emergencia.
Este caso en África Occidental es solo un ejemplo del trabajo que HOT realiza en todo el mundo para ayudar en situaciones de crisis humanitarias. La organización ha trabajado en una variedad de contextos, incluidos terremotos, inundaciones y conflictos armados, y ha ayudado a proporcionar mapas precisos y detallados para la respuesta de emergencia en cada uno de estos contextos.
Por otro lado, la plataforma también está involucrada en zonas en las que no hay cobertura de mapas, como en muchos países africanos. En estas zonas los proyectos de ayuda humanitaria muchas veces tienen un gran reto en las primeras fases, ya que es muy difícil cuantificar qué población vive en una zona y donde está emplazada. Poder tener la ubicación esas personas y que muestre vías de acceso las “pone en el mapa” y permite que puedan llegar a acceder a los recursos.
En el artículo The evolution of humanitarian mapping within the OpenStreetMap community de Nature, podemos ver gráficamente algunos de los logros de la plataforma.
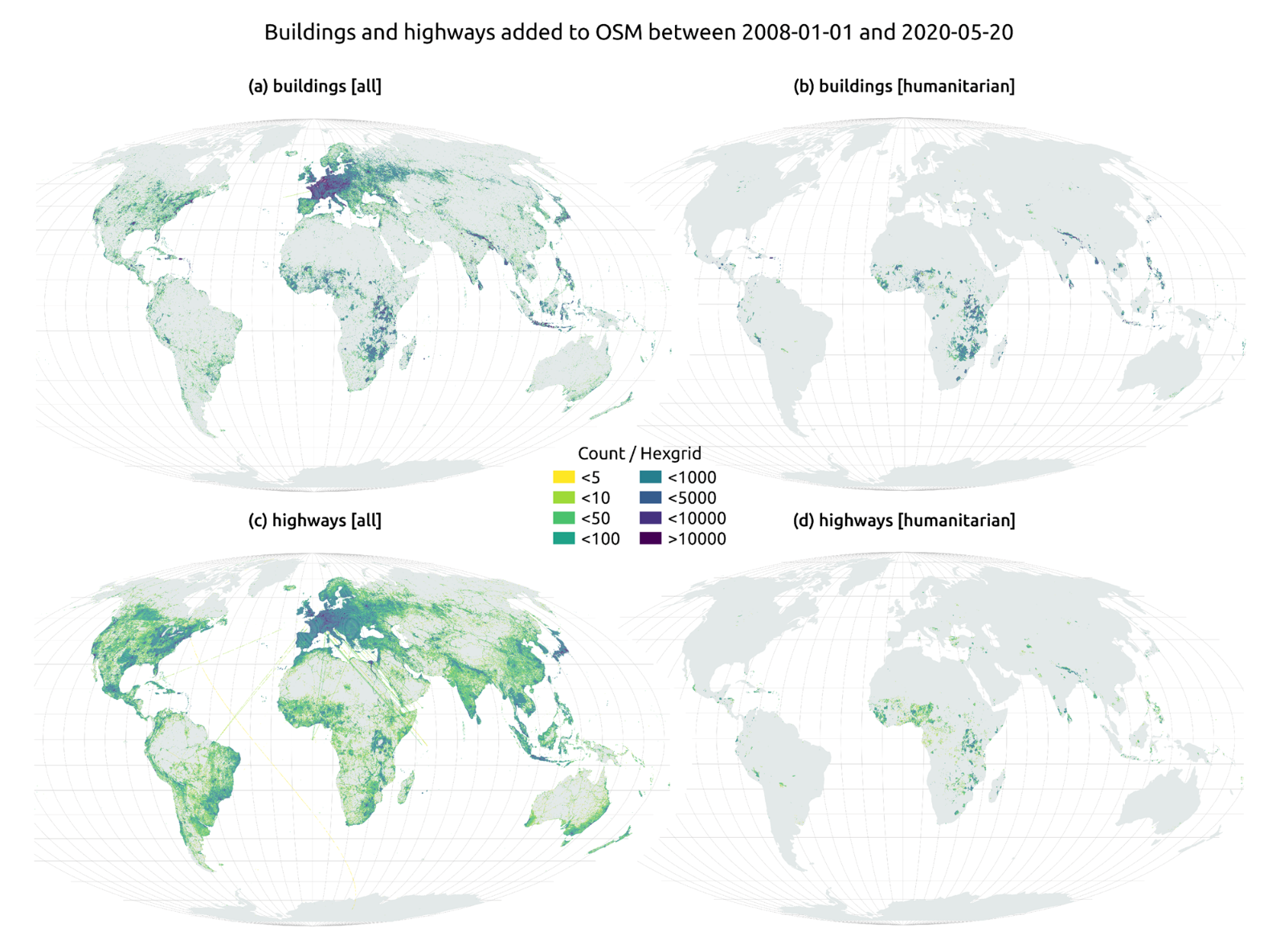
Como colaborar
Empezar a colaborar con Hot OSM es fácil, basta con ir a la página https://tasks.hotosm.org/explore y ver los proyectos abiertos que necesitan colaboración.
Esta pantalla nos permite una gran cantidad de opciones a la hora de buscar los proyectos, seleccionado por nivel de dificultad, organización, ubicación o intereses entre otros.
Para participar, basta con pulsar el botón Registrese.
Dar un nombre y un e-mail y en la siguiente pantalla:

Nos preguntará si tenemos creada una cuenta en Open Street Maps o queremos crear una.
Si queremos ver más en detalle el proceso, esta página nos lo pone muy fácil.
Una vez creado el usuario, en la página aprender encontramos ayuda de cómo participar en el proyecto.
Es importante destacar que las contribuciones de los voluntarios se revisan y validan y existe un segundo nivel de voluntarios, los validadores, que dan por bueno el trabajo de los principiantes. Durante el desarrollo de la herramienta, el equipo de HOT ha cuidado mucho que sea una aplicación sencilla de utilizar para no limitar su uso a personas con conocimientos informáticos.
Además, organizaciones como Cruz Roja o Naciones unidas organizan regularmente mapatones con el objetivo de reunir grupos de personas para proyectos específicos o enseñar a nuevos voluntarios el uso de la herramienta. Estas reuniones sirven, sobre todo, para quitar el miedo de los nuevos usuarios a “romper algo” y para que puedan ver cómo su labor de voluntariado sirve para cosas concretas y ayuda a otras personas.
Otra de las grandes fortalezas del proyecto es que está basado en software libre y permite la reutilización del mismo. En el repositorio Github del proyecto MissingMaps podemos encontrar el código y si queremos crear una comunidad basada en el software, la organización Missing Maps nos facilita el proceso y dará visibilidad a nuestro grupo.
En definitiva, Hot OSM es un proyecto de ciencia ciudadana y altruismo de datos que contribuye a aportar beneficios a la sociedad mediante la elaboración de mapas colaborativos muy útiles en situaciones de emergencia. Este tipo de iniciativas están alineadas con el concepto europeo de gobernanza de datos que busca impulsar el altruismo para facilitar voluntariamente el uso de los datos para el bien común.
Contenido elaborado por Santiago Mota, senior data scientist.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
Portal web con diversos cuadros de mandos interactivos de acceso libre dedicado a la gobernanza climática.
La aplicación agrupa ocho conjuntos de datos del portal de datos del Gobierno de Canarias, MITECO, ITC, ISTAC y GRAFCAN:
1. Inventario de emisiones
2. Huella de carbono
3. Contaminantes emitidos a la atmósfera
4. Incendios forestales
5. Proyecciones climáticas
6. PIMA
7. Producción de energía en Canarias
8. Producción neta de electricidad
Noticia
La Asociación Multisectorial de la Información (ASEDIE) ha publicado la undécima edición de su Informe sobre el Sector Infomediario, en el que hace un repaso a la salud de las empresas que generan aplicaciones, productos y/o servicios a partir de información del sector público, teniendo en cuenta que es el poseedor de los datos más valiosos.
Muchos de los conjuntos de datos que permiten al sector infomediario desarrollar soluciones están incluidos en las listas de conjuntos de datos de alto valor (HVDS, por sus siglas en inglés) que la Unión Europea ha publicado recientemente. Una iniciativa que reconoce el potencial de la información pública y se suma al propósito de impulsar la economía del dato en línea con la propuesta de Ley de Datos del Parlamento Europeo.
ASEDIE agrupa a empresas de diferentes sectores que impulsan la economía del dato, que se nutren fundamentalmente de los datos que proporciona el sector público. Entre sus objetivos se encuentra impulsar el sector y contribuir a concienciar a la sociedad de sus beneficios e impacto. No en vano, se estima que la economía del dato genere 270.000 millones de euros de PIB adicional para los Estados miembros de la UE en 2028.
La presentación de esta edición del informe, bajo el título ‘Economía del Dato en el ámbito infomediario’ tuvo lugar el pasado 22 de marzo en la sala Enredadera de Red.es. En la edición del informe presentada este año han sido identificadas 710 empresas activas, con una facturación de más de 2.278 millones de euros. Hay que destacar que el primer informe en 2013 contó con 444 empresas. Por tanto, el sector ha crecido un 60% en una década.
Principales conclusiones del informe
- El sector infomediario ha crecido un 12,1%, un dato por encima del crecimiento del PIB nacional que fue de un 7,6%. Estos datos se extraen del análisis de las 472 empresas (un 66% de la muestra) que presentaron sus cuentas en los ejercicios anteriores.
- El número de empleados es de 22.663. Los trabajadores se encuentran muy concentrados en pocas empresas: el 62% de ellas tiene menos de 10 trabajadores. El subsector que aglutina un mayor número de profesionales es el de Información geográfica, con un 30% del total. Junto con los subsectores Económico financiero, Consultoría técnica y Estudios de mercado, agrupan al 75% de los empleados.
- El empleo en las empresas del Sector Infomediario crece un 1,7%, frente a la caída de 1,1% en el año anterior. Todos los subsectores han crecido, excepto Turismo y Cultura que se mantienen, y Consultoría técnica y Estudios de mercado, que decrecen.
- La facturación media por empleado supera los 100.00 euros, incrementándose un 6,6% respecto al ejercicio previo. Por otra parte, el gasto medio por empleado fue de 45.000 euros.
- El importe de la cifra de negocio agregada es de 2.279.613.288 euros. Los subsectores de Información geográfica y Económico Financiero aglutinan el 46% de las ventas.
- El capital suscrito agregado es de 250.115.989 euros. Los tres subsectores más capitalizados son Estudios de mercado, Económico Financiero e Información geográfica, que aglutinan el 66% de la capitalización.
- El resultado neto supera los 180 millones de euros, 70 millones más que el año pasado. El subsector Económico financiero reúne un 66% del total de beneficios.
- Los subsectores de Información geográfica, Estudios de mercado, Económico financiero e Informática de Infomediación aglutinan al 76% de las empresas infomediarias, contabilizando un total de 540 empresas de las 710 activas.
- La Comunidad de Madrid es la que acoge a un mayor número de empresas del sector, con un 39%, seguida de Cataluña (13%), Andalucía (11%) y Comunidad Valenciana (9%).
Tal y como recoge el informe, la llegada de nuevas empresas impulsa el desarrollo de un sector que factura ya cerca de 2.300 millones de euros al año, y que crece a un ritmo superior al de otros indicadores macroeconómicos del país. De estos datos se desprende no solo que el Sector Infomediario goza de buena salud, sino también su capacidad de resiliencia y potencial de crecimiento.
Avances del Estudio del impacto de los datos abiertos en España
El informe recoge también los resultados de una encuesta realizada a los diferentes actores que conforman el ecosistema de los datos, en colaboración con la Facultad de Ciencias de la Información de la Universidad Complutense de Madrid. Esta encuesta se presenta como el primer ejercicio de un estudio más ambicioso que pretende conocer el impacto de los datos abiertos en España e identificar las principales barreras en su acceso y puesta a disposición. Para ello, se ha enviado un cuestionario a miembros del sector público, sector privado y sector académico. Entre las principales conclusiones de este primer sondeo, podemos destacar:
- Como principales barreras a la hora de publicar información, el 65% de los encuestados del sector público menciona la falta de recursos humanos, el 39% la falta de liderazgo político y el 38% la poca calidad de los datos.
- El mayor obstáculo en el acceso a los datos públicos para su reutilización es para los encuestados del sector público que la información proporcionada en los datos no es homogénea (41,9%). Los encuestados del sector académico señalan la falta de calidad de los datos (43%) y desde el sector privado se cree que la principal barrera es la falta de actualización (49%).
- En cuanto a la frecuencia de utilización de los datos públicos, el 63% de los participantes asegura usar los datos todos los días o al menos una vez a la semana.
- El 61% de los encuestados utiliza los datos publicados en el portal datos.gob.
- Los encuestados creen de forma mayoritaria que el impacto de la apertura de los datos en el sector privado es positivo. Así, el 77% de los encuestados del sector privado indica que acceder a los datos públicos es económicamente viable y el 89% de ellos manifiesta que los datos públicos les permiten desarrollar soluciones útiles.
- El 95% de los encuestados reclama un compendio de las normativas que afectan al acceso, publicación y reutilización de los datos del sector público.
- El 27% de los encuestados del sector público afirma no conocer las seis categorías de datos de alto valor establecidas en el Reglamento de ejecución (EU) 20137138 de la Comisión.
Vemos así que la mayoría de los encuestados son conscientes del potencial del sector y del impacto de los datos del sector público, aunque indican que es necesario salvar algunos obstáculos para su reutilización y creen que un compendio de las diferentes normativas existentes facilitaría su puesta en práctica y ayudaría al desarrollo del sector.
Top 3 ASEDIE
Como en ediciones anteriores, el informe incluye la situación del Top 3 ASEDIE, una iniciativa que pretende que todas las Comunidades Autónomas abran de manera completa tres conjuntos de datos, siguiendo unos criterios unificados que faciliten su reutilización, y que se incluye en el IV plan de Gobierno Abierto. En 2019, se propuso la apertura de las bases de datos de Cooperativas, Asociaciones y Fundaciones y actualmente ya hay 16 Comunidades Autónomas en las que se puede acceder de manera completa. Además, en ocho de ellas es posible acceder al NIF con identificador único, algo que permite mejorar la transparencia y que la información sea más veraz.
Teniendo en cuenta los buenos resultados de la primera propuesta, en 2020 se lanzó una nueva petición de apertura de datos, el Segundo Top 3 ASEDIE, en este caso de Certificados de Eficiencia Energética, Registros SAT (Sociedades Agrarias de Transformación) y Polígonos Industriales, cuya evolución ha sido también muy positiva. En el siguiente mapa se puede ver la situación de apertura de estas tres nuevas bases de datos en 2023.
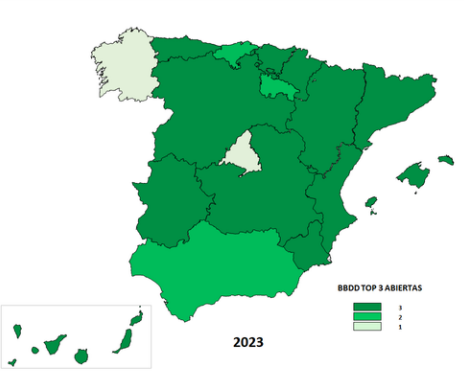
La iniciativa del Top 3 ASEDIE ha sido un éxito y se ha convertido en una referencia en el sector, impulsando la apertura de bases de datos de una manera conjunta y demostrando que es posible armonizar fuentes de datos públicas para ponerlas al servicio de la sociedad.
Los siguientes pasos en este sentido serán hacer un seguimiento de las bases de datos ya abiertas y realizar una difusión a todos los niveles, incluyendo la identificación de buenas prácticas de la Administración y la selección de ejemplos para incentivar la colaboración público-privada en datos abiertos. Además, se identificará un nuevo top 3 para avanzar en la apertura de nuevas bases de datos, y se lanzará una nueva iniciativa que alcance a los organismos de la Administración General del Estado, con la identificación de un nuevo Top 3 AGE.
Casos de éxito
El informe incluye también una serie de casos de éxito de productos y servicios desarrollados con datos del sector público, como API Market de Iberinform que facilita el acceso y la integración de 52 conjuntos de datos de empresas y autónomos en los sistemas de gestión de las empresas. Otro caso exitoso es el de Geocode, una solución centrada en procesos de estandarización, validación, corrección, codificación y geolocalización de direcciones postales en España y Portugal.
Geomarketing permite aumentar la velocidad de cálculo de datos geoespaciales e Infoempresa.com ha mejorado sus informes de actividad de las empresas españolas, haciéndolos más visuales, completos e intuitivos. Por último, Pyramid Data posibilita el acceso a los Certificados de Eficiencia Energética (CEE) de una cartera inmuebles determinada.
Como ejemplos de buenas prácticas en el sector público, el informe de ASEDIE destaca los datos estadísticos abiertos como motor de la Economía del Dato del Instituto Canario de Estadística (ISTAC) y la tecnología para la apertura de datos del Portal de Datos Abiertos de la Junta de Andalucía.
Como novedad, se ha incorporado la categoría de ejemplos de buenas prácticas en el sector académico, que reconoce el trabajo realizado por el Código Geoespacial y el Informe sobre el estado de los datos abiertos en España III, de la Universidad Rey Juan Carlos y Fundación FIWARE.
El 11º Informe ASEDIE sobre la Economía del Dato en el ámbito infomediario se puede descargar en la web de Asedie en español. También están disponibles las presentaciones de los indicadores económicos y el Top 3 y del Ecosistema de Datos.
En resumen, el informe recoge la buena salud de la industria que confirma su recuperación tras la pandemia, su capacidad de resiliencia y el potencial de crecimiento y, además, se observan los buenos resultados de la colaboración público-privada y su impacto en la economía del dato.
Aplicación
Hablando en data es el primer proyecto de visualización de datos de la Biblioteca y Centro de Documentación del Museo Reina Sofía, en colaboración con la Facultad de Ciencias Sociales de la Universidad de Salamanca. Su objetivo es analizar y visualizar la presencia de mujeres artistas, críticas de arte, comisarias, escritoras y autoras que integran su catálogo bibliográfico. El proyecto busca conectar y recopilar la información disponible sobre estas creadoras en otras bases de datos y dar acceso a estos resultados a través de su página web. Toda la información recopilada está disponible para su consulta, uso o descarga, dejando abierta la posibilidad a otros enfoques y visualizaciones.
Financiado con fondos del Plan de Recuperación, Transformación y Resiliencia de la UE
Noticia
Durante los últimos años estamos asistiendo a una revolución tecnológica que nos empuja cada vez más a ampliar nuestra formación para adaptarnos a los nuevos dispositivos, herramientas y servicios digitales que ya forman parte de nuestro día a día. En este contexto, la formación en competencias digitales cobra más relevancia que nunca.
El pasado mes de octubre, la Comisión Europea, con su presidenta Ursula Von Der Leyen a la cabeza, puso de manifiesto su intención de hacer de este 2023 el “Año Europeo de las Habilidades”, incluidas las digitales. La razón se encuentra en las dificultades que se han identificado entre la ciudadanía europea para adaptarse a las nuevas tecnologías y aprovechar todo su potencial, especialmente en el ámbito profesional.
La brecha europea de las competencias digitales
Según datos ofrecidos por Eurostat, más del 75% de las empresas de la Unión Europea han informado sobre las dificultades que encuentran a la hora de conseguir profesionales que cuenten con las habilidades necesarias para desarrollar el trabajo que demandan. Es más, la Agencia Laboral Europea alerta de la gran escasez que existe en Europa de especialistas en TIC y trabajadores con formación cualificada en STEM. Este dato se agudiza al observar que actualmente tan solo 1 de cada 6 especialistas en TI pertenece al género femenino.
En lo que respecta a las habilidades digitales, las cifras tampoco son halagüeñas. Y es que, tal y como se apunta en el Índice de Economía y Sociedad Digital (DESI), basado en datos de 2021, solo el 56% de la población europea posee competencias digitales básicas, entre las que se incluyen: habilidades de alfabetización de información y datos, de comunicación y colaboración, de creación de contenido digital, de seguridad y de resolución de problemas.
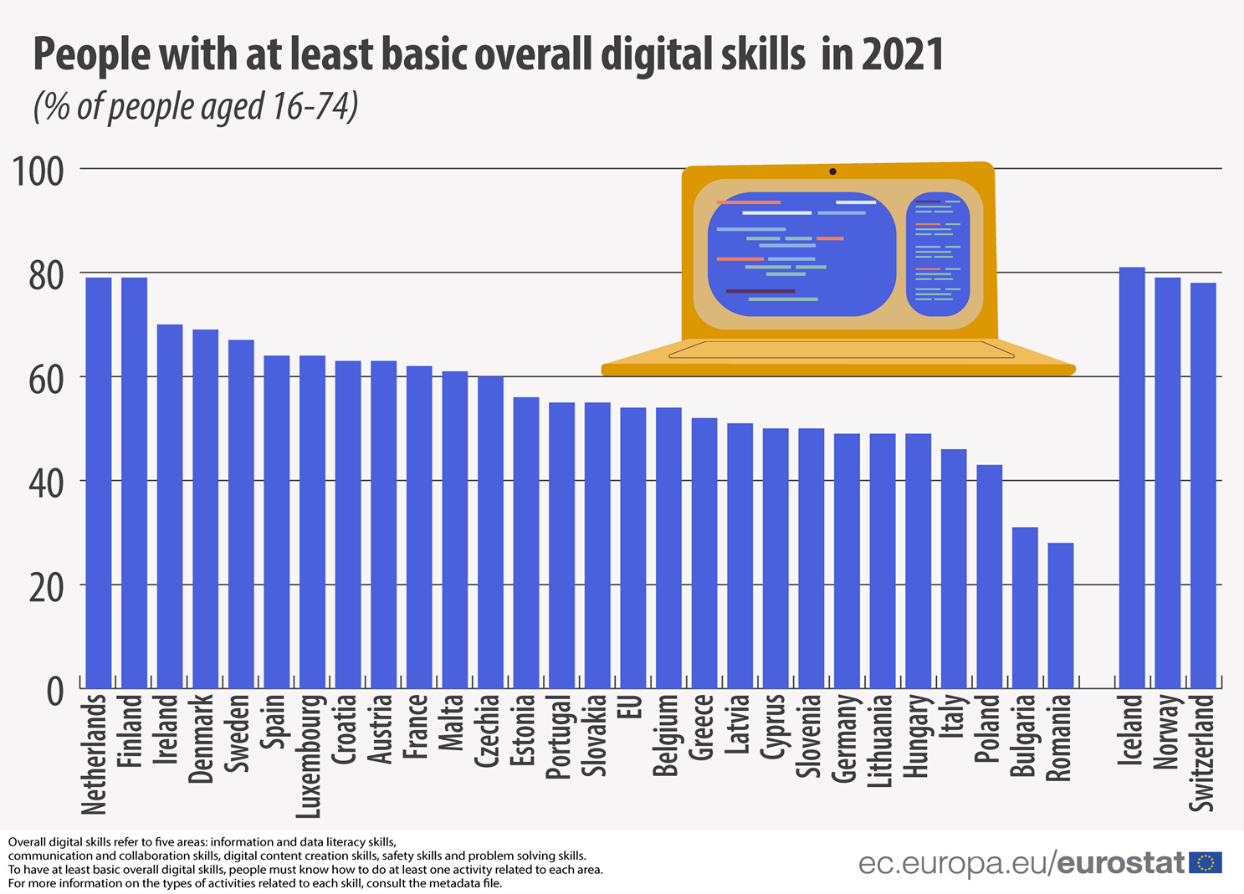
Ciudadanos de la UE con menos habilidades digitales básicas por país. Fuente: Eurostat, 2022.
Iniciativas europeas para fomentar el desarrollo de competencias digitales
Como mencionamos anteriormente, mejorar la educación y las habilidades digitales es uno de los grandes objetivos que se ha marcado la Comisión Europea para este 2023. Si miramos a largo plazo, el objetivo es más ambicioso: La UE pretende que en 2030 al menos el 80% de los adultos de la UE cuenten con habilidades digitales básicas como las mencionadas anteriormente. En lo que respecta al sector profesional, el objetivo se centra en contar con alrededor de 20 millones de profesionales especialistas en TIC, con un número destacado de mujeres en el sector.
Para llevar a cabo estos objetivos, existe una serie de medidas e iniciativas que se han puesto en marcha a nivel europeo. Una de ellas parte de la Agencia Europea de Habilidades, cuyos puntos de acción 6 y 7 están enfocados a mejorar todas las habilidades relevantes para las transiciones verde y digital, así como a aumentar el número de graduados en TIC.
A través de los fondos NextGenerationEU y su Mecanismo de Recuperación y Resiliencia, los estados miembros de la UE podrán optar a ayudas destinadas a financiar reformas relacionadas con las competencias digitales, ya que se habilitarán 560.00 millones de euros para este cometido.
Además, otros programas de financiación de la Unión Europea como el Programa Europa Digital (DEP) o el Mecanismo Conectar Europa (CEF) ofrecerán respectivamente apoyo económico destinado al desarrollo de programas de educación especializados en habilidades digitales o el lanzamiento de la Plataforma Europea de Empleos y Habilidades Digitales para poner a disposición de la ciudadanía información y recursos relacionados.
Junto a ellas, encontramos también otras iniciativas dedicadas a la formación en habilidades digitales en el Plan de Acción de Educación Digital, que ha creado el Centro Europeo de Educación Digital, o en la misión de la Coalición de Empleos y Habilidades Digitales, cuyo objetivo es concienciar y abordar la brecha de habilidades digitales junto a administraciones públicas, empresas y ONG.
La importancia de los datos abiertos en el ‘Año Europeo de las Habilidades Digitales’
A la hora de fomentar el desarrollo de las competencias digitales por parte de la ciudadanía europea, el portal de datos abiertos europeo lleva a cabo diversas acciones que contribuyen a este fin y donde los datos abiertos juegan un papel fundamental. En esta línea, Data Europa mantiene firme su compromiso por impulsar la formación y la divulgación de los datos abiertos. Así, junto a los objetivos que enumeraremos a continuación, conviene subrayar también el valor a nivel conocimiento que encontramos detrás de cada uno de los talleres y seminarios que programan desde su sección académica, a lo largo del año.
- Apoyar a los Estados miembros en la recopilación de datos y estadísticas sobre la demanda de competencias digitales para desarrollar medidas y políticas específicas.
- Trabajar junto a los portales de datos abiertos nacionales para que los datos estén disponibles y sean fácilmente accesibles y comprensibles.
- Ofrecer apoyo a portales de datos abiertos regionales y locales que presenten una mayor necesidad de ayuda en labores de digitalización.
- Fomentar la alfabetización de datos, así como la recopilación de casos de uso de interés que puedan ser reutilizados.
- Desarrollar entornos colaborativos que faciliten a los proveedores de datos públicos la creación de una sociedad inteligente basada en datos.
Así, del mismo que data.europa academy funciona como un centro de conocimiento creado para que las comunidades de datos abiertos pueden encontrar seminarios web y formaciones relevantes para mejorar sus habilidades digitales, en España, el Instituto Nacional de Formación Pública, incluye entre sus opciones formativas varios cursos sobre datos cuyo cometido es mantener al día de las últimas tendencias en este ámbito, a los trabajadores de las administraciones públicas.
En esta línea, durante la primavera del 2023, tendrá lugar una formación sobre Datos abiertos y Reutilización de la Información, a través de la cual se realizará una aproximación al ecosistema de los datos abiertos y los principios generales de reutilización. Igualmente, desde el 24 de mayo al 5 de junio, el INAP organiza otro curso sobre Fundamentos de Big Data donde se abordarán bloques de conocimiento como la visualización de datos, la computación en la nube, la inteligencia artificial o las distintas estrategias en materia de Gobierno del Dato.
Asimismo, si no eres un trabajador perteneciente al sector público, pero tienes interés en ampliar tus conocimientos sobre datos abiertos, inteligencia artificial, machine learning u otras temáticas vinculadas a la economía del dato, en el blog y la sección de documentación de datos.gob.es podrás encontrar materiales formativos adaptados, monográficos sobre diversas temáticas, casos prácticos, infografías y visualizaciones paso a paso que te ayudarán a comprender de forma más tangible las diferentes aplicaciones teóricas que implican a los datos abiertos.
En datos.gob.es, hemos elaborado publicaciones que recopilan diferentes formaciones gratuitas sobre temáticas y especializaciones diversas. Como, por ejemplo, sobre inteligencia artificial o visualizaciones de datos.
Por último, si conoces más ejemplos u otras iniciativas dedicadas a fomentar las habilidades digitales tanto en el ámbito estatal o europeo, no dudes en hacérnoslo saber a través de nuestro buzón de correo electrónico dinamizacion@datos.gob.es. ¡Esperamos todas tus sugerencias!
Blog
El sector público en España tendrá el deber de garantizar la apertura de sus datos desde el diseño y por defecto, así como su reutilización. Así lo recoge la modificación de la Ley 37/2007 sobre la reutilización de la información del sector público en aplicación de la Directiva Europea 2019/1024.
Esta nueva redacción de la norma busca ampliar el ámbito de aplicación de la Ley para acercar las garantías y obligaciones jurídicas al contexto tecnológico, social y económico actual. En este escenario, la normativa vigente tiene en cuenta que una mayor disponibilidad de los datos del sector público puede contribuir al desarrollo de tecnologías tan punteras como la inteligencia artificial y todas sus aplicaciones.
Además, esta iniciativa está alineada con la Estrategia de datos de la Unión Europea dirigida a la creación de un mercado único de datos en el que la información fluya libremente entre los estados y el sector privado en un intercambio que beneficie ambas partes.
De los datos de alto valor a la unidad responsable de información: obligaciones de la Ley 37/2007
En la siguiente infografía, destacamos las principales obligaciones que recoge el texto consolidado de la ley. Se enfatiza en deberes como impulsar la apertura de datos de alto valor (HVDS, por sus siglas en inglés, High Value Datasets), es decir, conjuntos de datos con un gran potencial para generar beneficios sociales, medioambientales y económicos. Tal y como dicta la Ley, los HVDS deberán publicarse con licencia de atribución de datos abiertos (CC BY 4.0 o equivalente), en formato legible por máquinas y acompañados de metadatos que describan las características de los conjuntos de datos. Todo ello será de acceso público y gratuito con el objetivo de incentivar el desarrollo tecnológico, económico y social, especialmente de las PYMEs.
Además de la publicación de los datos de alto valor, todas las administraciones públicas tendrán la obligación de disponer de catálogos propios de datos que interoperarán con el Catálogo Nacional siguiendo la NTI-RISP, con el objetivo de contribuir a su enriquecimiento. Como ocurre con los HVDS, el acceso a los conjuntos de datos de las AA. PP. deberá ser gratuito salvo excepciones en las que se podrían aplicar costes marginales resultado del tratamiento de los datos.
Para garantizar la gobernabilidad del dato, la ley establece la necesidad de designar una unidad responsable de información para cada entidad que coordine la apertura y reutilización de los datos, y que se encargue de responder a las solicitudes y demandas ciudadanas.
En definitiva, la Ley 37/2007, ha sido modificada con el objetivo de ofrecer garantías jurídicas a las exigencias de competitividad e innovación que suscitan tecnologías como la inteligencia artificial o el internet de las cosas, así como a realidades como los espacios de datos donde los datos abiertos se presentan como una pieza clave.
Haz clic en la infografía para verla a tamaño real:

Evento
Aragón Open Data, portal de datos abiertos del Gobierno de Aragón, presentará el próximo 15 de marzo de 2023 sus trabajos más recientes para dar a conocer sus líneas de acción y avances en materia de apertura de datos y datos enlazados.
¿En qué consiste ‘Aragón Open Data: Abre y conecta datos’?
En este encuentro, que forma parte de los actos enmarcados en los Open Data Days 2023, Aragón Open Data aprovechará la ocasión para hablar de la evolución de su plataforma de datos abiertos y de la mejora de la calidad de los datos ofrecidos.
En esta línea, la jornada ‘Aragón Open Data: Abre y conecta datos’ pondrá además la sílaba tónica en detallar el funcionamiento de Aragopedia, su nueva estrategia de datos enlazados.
A través de una serie de explicaciones técnicas, apoyadas por una demo, los asistentes podrán conocer cómo funciona este servicio, basado en la nueva estructura de Información Interoperable de Aragón (EI2A) que permite compartir, conectar y relacionar determinados datos disponibles en el portal Aragón Open Data.
A continuación, y con el objetivo de detallar con la mayor precisión posible el planteamiento de la jornada, compartimos el programa de la misma:
- Bienvenida a la jornada. Julián Moyano, coordinador de Aragón Open Data.
- Introducción a Aragón Open Data (Marc Garriga, Desidedatum)
- Mejora de la calidad de los datos y de su semantización (Koldo Z. / Susana G.)
- Situación previa y situación actual
- Nueva navegación centrada en los datos de Aragón Open Data y Aragopedia (Pedro M. / Beni)
- Explicación y Demo
- Mi experiencia con la Aragopedia. (Sofía Arguís, Documentalista y usuaria de Aragón Open Data )
- Proceso de identificación, procesado y apertura de nuevos datos (Cristina C.)
- Punto de partida y Retos encontrados para lograr la apertura
- Conclusiones (Marc Garriga )
- Turno de preguntas/comentarios
¿Dónde y cuándo se celebra?
La jornada técnica ‘Aragón Open Data: Abre y conecta datos’ se celebrará el próximo 15 de marzo de 12:00 a 13:30 horas de forma online. Por ello, para poder asistir a la misma, los usuarios interesados deberán rellenar el formulario disponible en el siguiente punto.
¿Cómo puedo inscribirme?
Para asistir y acceder a la sesión online puedes completar el siguiente formulario y para cualquier cuestión no dudes en escribirnos opendata@aragon.es
Aragón Open Data está cofinanciado por la Unión Europea, Fondo Europeo de Desarrollo Regional (FEDER) "Construyendo Europa desde Aragón.
Aplicación
Urban3r es una aplicación que permite visualizar diferentes indicadores sobre el estado actual de la edificación, los datos de demanda energética de los edificios residenciales en su estado actual y tras someterlos a una rehabilitación energética, así como los costes estimados de estas intervenciones.
Para facilitar la toma de decisiones a escala urbana, la herramienta permite filtrar por temáticas de estudio específicas y consultar los datos individualmente a escala de edificio. A este nivel hay que tener en cuenta que se trata de una primera aproximación orientativa.
Para las personas registradas, la herramienta dispone de un sistema de descarga de datos en formato CSV y GeoPackage de aquellos municipios de España de los que dispone de información. Los municipios de los que no tiene información, pueden ser procesados automáticamente mediante la subida del fichero urbano en formato CAT disponible en la Sede Electrónica del Catastro.
La información relacionada con la rehabilitación energética de los edificios procede de una aplicación a escala de referencia catastral de los datos elaborados en el marco de la ERESEE 2020 (Estrategia a largo plazo para la rehabilitación energética en el sector de la edificación en España).
En definitiva, es una plataforma de datos abiertos para impulsar la regeneración urbana en España que utiliza los conjuntos de datos de la Sede Electrónica del Catastro y permite la descarga de los datos por municipio en formato CSV.
Aplicación
El Sistema de Observación Meteorológica del Gobierno de Canarias es una infraestructura promovida por la Consejería de Transición Ecológica, Lucha contra el Cambio Climático y Planificación Territorial, que integra una red de estaciones equipadas con sensores meteorológicos y servidores encargados de la administración de la red y el almacenamiento, control de calidad y difusión de los datos registrados.
Se trata de una red que se concibe como una infraestructura complementaria a las ya existentes y esencial para el ejercicio de competencias como las relacionadas con el Cambio Climático o el seguimiento de Fenómenos Meteorológicas Adversos (FMA).
Conforme a la Directiva (UE) 2019/1024, este sistema gestiona un conjunto de datos de alto valor que está disponible para su reutilización. Por ello, desde su web es posible realizar los siguientes servicios:
- Consultar la ubicación de las estaciones y los últimos datos registrados.
- Descargar las series históricas de observaciones registradas por las estaciones en datos abiertos.
- Visualizar en tiempo real las observaciones registradas por las estaciones meteorológicas.
- Integrar, mediante una API, los datos registrados en cualquier sistema.