Blog
Today's industry is facing one of the biggest challenges in its recent history. Market demands, pressure to meet climate targets, consumer demand for transparency and technological acceleration are converging in a profound transformation of the production model. This transformation is not only aimed at greater competitiveness, but also at more resilient, flexible, efficient and sustainable production.
In this context, industrial digitisation - driven by technologies such as the Internet of Things (IoT), artificial intelligence, edge computing, or cyber-physical systems - is generating massive amounts of operational, environmental and logistical data. However, the mere existence of this data does not in itself guarantee value. The key is to govern it properly, i.e. to establish principles, processes, roles and technologies that ensure that this data is reliable, accessible, useful and secure. In other words, that the data is fit to be harnessed to improve industrial processes.
This is why industrial data governance is positioned as a strategic factor. It is not just a matter of ‘having data’, but of turning it into a critical infrastructure for decision-making, resource optimisation, intelligent automation and ecological transition. Without data governance, there is no Industry 4.0. And without Industry 4.0, the challenges of sustainability, energy efficiency or full traceability are intractable.
In this article we explore why data governance is essential in industry, what concrete benefits it brings to production processes and how initiatives such as the National Industry Data Space can accelerate this transformation.
We then analyse its impact at different levels, from the most relevant use cases to the collaborative frameworks that are emerging in Spain.
Why is data governance key in industry?
Industrial data comes from a multitude of distributed sources: IoT sensors, SCADA systems, automated assembly lines, maintenance platforms, ERP or Manufacturing Execution Systems (MES), among others. This heterogeneity, if not properly managed, can become a barrier to the integration and useful analysis of information.
Data governance overcomes these barriers by establishing the rules of the game for data capture, storage, quality, interoperability, use, protection and disposal. This enables not only operational efficiency but also long-term sustainability. How?
- Reducing operational inefficiencies: by having accurate, up-to-date and well-integrated data between systems, tasks can be automated, rework avoided, and unplanned downtime reduced. For example, a plant can adjust the speed of its production lines in real time based on the analysis of performance and demand data.
- Improving sustainability: robust data management can identify patterns of energy consumption, materials or emissions. With this information, processes can be redesigned to be more sustainable, eco-design can be applied and the environmental footprint can be reduced. Data, in this case, acts as a compass towards decarbonisation.
- Ensuring regulatory compliance and traceability: from ISO 9001 to the new circular economy regulations or the Digital Product Passport, industries must demonstrate compliance. This is only possible with reliable, traceable and auditable data.
- Facilitating interoperability between systems: data governance acts as the ‘glue’ that binds together the different technological silos of an organisation: quality, production, logistics, maintenance, purchasing, etc. The standardisation and semantic alignment of data allows for more agile flows and better informed decisions.
- Boosting the circular economy: thanks to the full traceability of a product's life cycle, from design to recycling, it is possible to identify opportunities for reuse, material recovery and sustainable design. This is supported by data that follows the product throughout its life.
What should data governance look like in the industrial environment?
A data governance model adapted to this context should include:
▸Specific roles: it is necessary to have a defined team, where everyone's responsibility and tasks are clear. Some of the roles that cannot be missing are:
- Data owners: responsible for the use of the data in their area (production, quality, maintenance...).
- Data stewards: ensure the consistency, completeness and accuracy of the information.
- Data governance team: coordinates the strategy, defines common policies and evaluates compliance.
▸Structured processes: Like the roles, it is necessary to define the various phases and operations to be carried out. These include the following:
- Classification and cataloguing of data assets (by type, criticality, use).
- Data quality control: definition of validation rules, cleaning of duplicates, exception management.
- Data life cycle: from its creation on the machine to its archiving or destruction.
- Access and security: privilege management, usage audits, traceability.
▸Organisational policies: to ensure interoperability and data quality it is necessary to have standards, norms and guidelines to guide users. Some examples are:
- Standards for nomenclature, formats, encoding and synchronisation.
- Standards for interoperability between systems (e.g. use of standards such as OPC UA or ISA-95).
- Guidelines for ethical and legally compliant use (such as Data Regulation, GDPR or environmental legislation).
This approach makes industrial data an asset managed with the same rigour as any physical infrastructure.
Industrial use cases enabled by data governance
The benefits of data governance in industry are realised in multiple practical applications. Some of the most representative use cases are:
1.Predictive maintenance
One of the great classics of Industry 4.0. By combining historical maintenance data with real-time sensors, organisations can anticipate machine failures and avoid unexpected downtime. But this is only possible if the data is governed: if its capture frequency, format, responsible parties, quality and availability have been defined.
2. Complete product traceability
From raw material to end customer, every event in the value chain is recorded and accessible. This is vital for sectors such as food, automotive or pharmaceuticals, where traceability is both an added value and a regulatory obligation. Data governance ensures that this traceability is not lost, is verifiable and meets the required interoperability standards.
3. Digital twins and process simulation
For a digital twin - a virtual replica of a physical process or system - to work, it needs to be fed with accurate, up-to-date and consistent data. Data governance ensures synchronisation between the physical and virtual worlds, and allows the generation of reliable simulation scenarios, from the design of a new production line to the optimisation of the factory layout, i.e. of the different elements within the plant.
4. Energy monitoring and emission control
Real-time monitoring of energy, water or gas consumption can reveal hidden inefficiencies and opportunities for savings. Through intelligent dashboards and KPIs defined on governed data, industrial plants can reduce their costs and advance their environmental sustainability goals.
5. Automation and intelligent quality control
Machine vision systems and machine learning algorithms trained with production data allow to detect defects in real time, adjust parameters automatically and improve final quality. Without good data quality (accuracy, completeness, consistency), these algorithms can fail or generate unreliable results.
The National Industry Data Space: key to collaboration and competitiveness
For industrial data governance to transcend the scope of each company and become a real lever for sectoral transformation, it is necessary to have infrastructures that facilitate the secure, reliable and efficient sharing of data between organisations. The National Data Space for Industry, framed within the Plan for the Promotion of Sectoral Data Spaces promoted by the Ministry for Digital Transformation and the Civil Service, is in this line.
This space aims to create an environment of trust where companies, associations, technology centres and administrations can share and reuse industrial data in an interoperable manner, in accordance with ethical, legal and technical principles. Through this framework, the aim is to enable new forms of collaboration, accelerate innovation and reinforce the strategic autonomy of the national productive fabric.
The industrial sector in Spain is enormously diverse, with an ecosystem made up of large corporations, SMEs, suppliers, subcontractors, clusters and R&D centres. This diversity can become a strength if it is articulated through a common data infrastructure that facilitates the integration and exchange of information in an orderly and secure manner. Moreover, these industrial data can be complemented with open data published by public bodies, such as those available in the National Catalogue of Open Data, thus extending the value and possibilities of reuse for the sector as a whole.
The strengths of this common infrastructure allow:
- Detect synergies along the value chain, such as industrial recycling opportunities between different sectors (e.g. plastic waste from one chemical industry as raw material in another).
- Reducing entry barriers to digitisation, especially for SMEs that do not have the resources to deploy advanced data analytics solutions, but could access shared services or data within the space.
- Encourage open innovation models where companies share data in a controlled way for the joint development of solutions based on artificial intelligence or predictive maintenance.
- Promote sectoral aggregate indicators, such as shared carbon footprints, energy efficiency levels or industrial circularity indices, which allow the country as a whole to make more coordinated progress towards sustainability and competitiveness objectives.
The creation of the National Industrial Data Space can be a true lever for modernization for the Spanish industrial fabric:
- Increased international competitiveness, by facilitating compliance with European market requirements, such as the Data Regulation, the Digital Product Passport, and sustainability standards.
- Regulatory agility and improved traceability, allowing industries to respond quickly to audits, certifications, or regulatory changes.
- Proactive capacity, thanks to the joint analysis of production, consumption, or market data that allows for the prediction of disruptions in supply chains or the demand for critical resources.
- Creation of new business models, based on the provision of products as a service, the reuse of materials, or the shared leasing of industrial capacities.
The deployment of this national data space not only seeks to improve the efficiency of industrial processes. It also aims to strengthen the country's technological and data sovereignty, enabling a model where the value generated by data remains within the companies, regions, and sectors themselves. In this sense, the National Industrial Data Space aligns with European initiatives such as GAIA-X and Manufacturing-X, but with an approach adapted to the context and needs of the Spanish industrial ecosystem.
Conclusions
Data governance is a fundamental pillar for the industry to move toward more efficient, sustainable, and resilient models. Having large volumes of information is not enough: it must be managed properly to generate real value.
The benefits are clear: operational optimization, improved traceability, a boost to the circular economy, and support for technologies such as artificial intelligence and digital twins. But the real leap forward comes when data is no longer managed in isolation and becomes part of a shared ecosystem.
The National Industrial Data Space offers this framework for collaboration and trust, facilitating innovation, competitiveness, and technological sovereignty. Investing in its development means investing in a more connected, intelligent industry that is prepared for the challenges of the future.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The content and point of view reflected in this publication are the sole responsibility of its author.
Blog
With 24 official languages and more than 60 regional and minority languages, the European Union is proud of its cultural and linguistic diversity. However, this richness also represents a significant challenge in the digital and technological sphere. Advances in artificial intelligence (AI) and natural language processing have been dominated by English, creating a noticeable imbalance in the availability of language resources for most European languages.
This imbalance has direct consequences, for example:
- Asymmetric technology development: Companies and researchers have difficulty creating AI solutions adapted to specific languages because resources are limited.
- Technological dependence: Europe risks becoming dependent on language solutions developed outside its cultural and normative context.
Addressing this gap is not only a matter of inclusion, but also represents a large-scale economic opportunity, capable of generating huge gains in both trade and technological innovation. To address these challenges, the European Commission has launched the European Language Data Space (LDS), a decentralised infrastructure that promotes the secure and controlled exchange of language data among multiple actors in the European ecosystem.
Unlike a simple centralised repository, the LDS functions as a language data marketplace that allows participants to share, sell or license their data under clearly defined conditions and with full control over the use of the data.
The European Language Data Space (LDS), with a beta version operational, represents a decisive step towards democratising language technologies across all languages of the European Union. We tell you the keys to this project and the next steps.
How does this platform work?
LDS is based on a decentralised peer-to-peer (P2P) architecture that allows users to interact directly with each other, without the need for a central server or single authority, where each participant maintains control of its own data. The key elements of LDS operation are:
1. Decentralised and sovereign architecture
Each participant (whether data provider or data consumer) can locally install the LDS Connector, a software that allows interacting directly with other participants without the need for a central server.. This approach ensures:
-
Data sovereignty: owners retain full control over who can access their data and under what conditions of use.
-
Trust and security: Only eligible and authorised participants, legal entities registered in the EU, can be part of the ecosystem.
- Interoperability: is compatible with other European data spaces, following common standards.
2. Data exchange flow
The exchange process follows a structured flow between two main actors:
- The providers describe their linguistic datasets, establish access policies (licences, prices) and publish these offers in the catalogue.
- The consumers explore the catalogue, identify resources of interest and, through their connectors, initiate negotiations on the terms of use.
If both parties reach an agreement, a contract is established and the data transfer takes place securely between the connectors.
3 Supporting infrastructure
Although the exchange is decentralised, the LDS includes supporting elements such as:
-
Participant registration: ensures that only verified entities participate in the ecosystem.
-
Optional catalogue: facilitates the publication and discovery of available resources
-
Hub of vocabularies: is a service that centralises controlled vocabularies, and allows maintaining lists of values, definitions, relationships between terms, mappers between lists, etc.
- Monitoring service: allows you to monitor the overall operation of the system.
Added value for the European data ecosystem
The LDS brings significant benefits to the European digital landscape:
-
Boosting multilingual AI
By facilitating access to quality linguistic data in all European languages, the LDS contributes directly to the development of more inclusive AI models adapted to Europe's multilingual reality. This is especially relevant at a time when large language models (LLMs) are transforming human-machine interaction.
-
Strengthening the data economy
It is estimated that true digital language integration could generate enormous economic benefits in both trade and technological innovation. The LDS creates a marketplace where language data becomes valuable by incentivising its collection, processing and availability under fair and transparent conditions.
-
Preservation of linguistic diversity
By promoting technological development in all European languages, the LDS contributes to preserving and revitalising the continent's linguistic heritage, ensuring that no language is left behind in the digital revolution.
-
The crucial role of industry and public administrations
The success of the LDS depends crucially on the active participation of various actors:
-
Fresh, quality data
The platform seeks to attract especially "fresh" data from the industry (media, publishing, customer services) and the public sector, necessary to train and improve current language models. They are particularly valued:
-
Multimodal data (text, audio, video).
-
Specific content from various professional domains.
- Up-to-date and relevant language resources.
-
Participation open to all ecosystem actors
The LDS is designed to be inclusive, allowing both private organisations and public entities to participate, as long as they are legal entities registered in the EU. Both types of organisations can act as providers and/or consumers of data.
Participation is formalised through a validation process by the governance board, ensuring that all eligible organisations can benefit from this common language data marketplace.
How can you take part?
The beta version of the LDS is now operational and open to new participants. Organisations interested in participating in this initiative can:
- Join the test and focus groups: to contribute to the development and improvement of the platform, here.
- Testing the LDS connector: experimenting with the technology in controlled environments.
- Provide technical feedback : helping to define key aspects such as metadata, licensing or exchange mechanisms.
- Identify relevant data: assessing which language resources could be shared through the platform.
The future of the LDS
While LDS currently focuses on data exchange, its medium-term vision envisages the possibility of integrating language services and AI model hosting within the same ecosystem, thus reinforcing Europe's role in the development of language technologies . A pre-final version of LDS is expected to be available in July 2025 and the finalised version of LDS is expected in January 2026.
All these aspects were discussed at a free online seminar held by the European open data portal "Data spaces: experience from the European Language Data Space". You can go back to watch the webinar here.
In a global context where technological sovereignty has become a strategic priority, the European Language Data Space represents a decisive step towards ensuring that the AI revolution does not leave Europe's linguistic richness behind.
Blog
Access to financial and banking data is revolutionising the sector, promoting transparency, financial inclusion and innovation in economic services. However, the management of this data faces regulatory challenges in balancing openness with security and privacy.
For this reason, there are different ways of accessing this type of data, as we will see below.
Open Banking and Open Finance versus Open Data.
These terms, although related, have important differences.
The term Open Banking refers to a system that allows banks and other financial institutions to securely and digitally share customer financial data with third parties. This requires the customers' express approval of the data sharing conditions . This consent can be cancelled at any time according to the customer's wishes.
Open Finance, on the other hand, is an evolution of Open Banking which embraces a broader range of financial products and services. When we talk about Open Finance, in addition to banking data, data on insurance, pensions, investments and other financial services are included.
In both Open Banking and Open Finance, the data is not open (Open Data), but can only be accessed by those previously authorised by the customer. The exchange of data is done through an application programming interface or API , which guarantees the agility and security of the process. All of this is regulated by the European directive on payment services in the internal market (known as PSD2), although the European Commission is working on updating the regulatory framework.
-
Applications of Open Banking and Open Finance:
The purpose of these activities is to provide access to new services based on information sharing. For example, they facilitate the creation of apps that unify access to all the bank accounts of a customer, even if they are from different providers. This improves the management and control of income and expenditure by providing an overview in a single environment.
Another example of use is that they allow providers to cross-check information more quickly. For example, by allowing access to a customer's financial data, a dealer could provide information on financing options more quickly.
Open data platforms on banking
While private banking data, like all types of personal data, is strictly regulated and cannot be openly published due to privacy protection regulations, there are sets of financial data that can be freely shared. For example, aggregate information on interest rates, economic indicators, historical stock market data, investment trends and macroeconomic statistics, which are accessible through open sources.
This data, in addition to boosting transparency and confidence in markets, can be used to monitor economic trends, prevent fraud and improve risk management globally. In addition, fintechcompanies, developers and entrepreneurs can take advantage of them to create solutions such as financial analysis tools, digital payment systems or automated advice.
Let's look at some examples of places where open data on the banking and financial sector can be obtained.
International sources
Some of the most popular international sources are:
-
European Central Bank: provides statistics and data on euro area financial markets, through various platforms. Among other information, users can download datasets on inflation, bank interest rates, balance of payments, public finances, etc.
-
World Bank: provides access to global economic data on financial development, poverty and economic growth.
-
International Monetary Fund: provides simplified access to macroeconomic and financial data, such as the outlook for the global or regional economy. It also provides open data from reports such as its Fiscal Monitor, which analyses the latest developments in public finances.
- Federal Reserve Economic Data (FRED): focuses on US economic data, including market indicators and interest rates. This repository is created and maintained by the Research Department of the Federal Reserve Bank of St. Louis.
National sources
Through the National Open Data Catalogue of datos.gob.es a large number of datasets related to the economy can be accessed. One of the most prominent publishers is the Instituto Nacional de Estadística (INE), which provides data on defaults by financial institution, mortgages, etc.
In addition, the Banco de España offers various products for those interested in the country's economic data:
- Statistics: the Banco de España collects, compiles and publishes a wide range of economic and financial statistics. It includes information on interest and exchange rates, financial accounts of the institutional sectors, balances of payments and even household financial surveys, among others.
- Dashboard: the Banco de España has also made available to the public an interactive viewer that allows quarterly and annual data on external statistics to be consumed in a more user-friendly way.
In addition, Banco de España has set up asecure room for researchers to access data that is valuable but cannot be opened to the general public due to its nature. In this sense we find:
- BELab: the secure data laboratory managed by the Banco de España, offering on-site (Madrid) and remote access. These data have been used in various projects.
- ES_DataLab: restricted microdata laboratory for researchers developing projects for scientific and public interest purposes. In this case, it brings together micro-data from various organisations, including the Bank of Spain.
Data spaces: an opportunity for secure and controlled exchange of financial data
As we have just seen, there are also options to facilitate access to financial and banking data in a controlled and secure manner. This is where data spaces come into play, an ecosystem where different actors share data in a voluntary and secure manner, following common governance, regulatory and technical mechanisms.
In this respect, Europe is pushing for a European Financial Data Facility (EEDF), a key initiative within the European Data Strategy. The EEDF consists of three main pillars:
- Public reporting data ("public disclosures"): collects financial reporting data (balance sheets, revenues, income statements), which financial firms are required by law to disclose on a regular basis. In this area is the European Single Access Point (ESAP)initiative, a centralised platform for accessing data from over 200 public reports from more than 150,000 companies.
- Private customer data of financial service providers: encompasses those data held by financial service providers such as banks. In this area is the framework for access to financial data, which covers data such as investments, insurance, pensions, loans and savings.
- Data from supervisory reports: for this type of data, the supervisory strategy, which covers data from different sectors (banks, insurance, pension funds...) has to be taken into account in order to promote digital transformation in the financial sector.
In conclusion, access to financial and banking data is evolving significantly thanks to various initiatives that have enabled greater transparency and that will encourage the development of new services, while ensuring the security and privacy of shared data. The future of the financial sector will be shaped by the ability of institutions and regulators to foster data ecosystems that drive innovation and trust in the market.
Blog
A Smart Tourism Destination (ITD) is based on a management model based on innovation and the use of advanced technology to optimise the visitor experience and improve the sustainability of the destination, while strengthening the quality of life of residents. The DTI model is based on a series of indicators that allow the state of the tourism destination to be analysed, areas for improvement to be diagnosed and strategic action plans to be developed. This approach, promoted by SEGITTUR (Sociedad Estatal para la Gestión de la Innovación y las Tecnologías Turísticas) and other regional public entities (e.g. the DTI-CV model of the Comunitat Valenciana defined by INVATTUR - Instituto Valenciano de Tecnologías Turísticas), has been consolidated as a key pillar in the digital transformation of tourism. This intensive use of technologies in ITDs has transformed them into true data-generating centres, which - combined with external sources - can be used to optimise decision-making and improve destination management.
Data provenance in an ITD and its use
In an ITD, data are basically generated from two main areas:
- Data generated by visitors or tourists: they create a digital footprint as they interact with different technologies. This footprint includes comments, ratings, images, spending records, locations and preferences, which are reflected in mobile apps, social media or booking platforms. In addition, data is generated passively through electronic payment systems or urban mobility systems, as well as traffic measurement devices, among others.
- Data generated by the tourist destination: thanks to the sensorisation and implementation of IoT networks (Internet of Things ), destinations collect real-time information on traffic management, energy consumption, environmental quality and use of services (public or private). In addition, the destination generates essential data on its tourism offer, such as updated lists of accommodation or hospitality establishments, places or events of tourist interest and complementary services.
The combination of these data sources in a Intelligent Destination Platform (IDP) such as the one proposed by SEGITTUR, allows ITDs to use them to facilitate a more innovative and experience-oriented management.
Title: Areas of data generation in an ITD
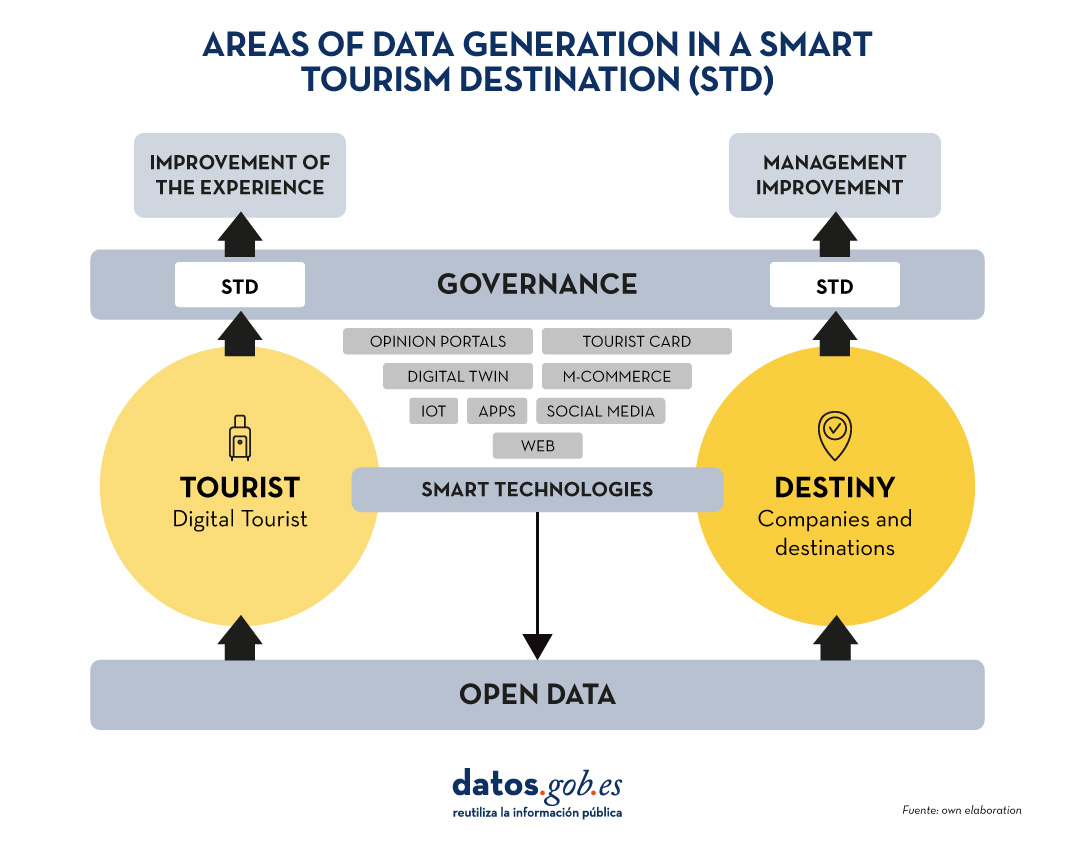
Source: own elaboration
There are numerous examples and good practices in the use of these tourism data, implemented by various European destinations, whose description is documented in the report Study on mastering data for tourism by EU destinations. This report provides a detailed insight into the opportunities that the use of data offers to improve the competitiveness of the tourism ecosystem. Furthermore, this report does not ignore the importance of tourist destinations as data generators, formulating a series of recommendations for public administrations, including the development of a cross-cutting data management plan - i.e. involving not only the area of tourism, but also other areas such as urban planning and the environment-, guaranteeing an integrated approach. This plan should promote the availability of open data, with a special focus on data related to sustainability, accessibility and specialised tourism offer.
Smart destination models and open data
SEGITTUR's DTI model (recently described in its practical guide) establishes as a requirement the creation of an open data portal in tourist destinations to facilitate the publication of data in the place where tourism activity takes place and its access in reusable formats, enabling the development of different products and services. No specific themes are established, but information of interest such as public transport, shops, job offers, cultural agenda or environmental sensors are highlighted. Interesting is the definition of indicators to assess the quality of the portal such as compliance with open data standards, the existence of systems to automate the publication of data or the number of datasets available per 100,000 inhabitants. It is also indicated that new datasets should be added progressively as their usefulness is identified.
It should be noted that in other DTI models, such as INVATTUR's DTI-CV model mentioned above, it is also proposed that destinations should have a tourism open data portal in order to promote tourism innovation.
High-value tourism data
The European Union, through Directive (EU) 2019/1024 on open data and re-use of public sector information and Implementing Regulation (EU) 2023/138, has defined high value datasets in various areas, including tourism within the category of statistical data. These are data on tourism flows in Europe:
- Overnight stays in tourist accommodation establishments, at national level, at NUTS 2 level (autonomous communities and cities), NUTS 3 level (provinces) and for some specific cities.
- Tourist arrivals and departures, tourist expenditure, hotel occupancy, demand for tourist services, at national level.
It is interesting to note that these and other data have been collected in Dataestur, the data platform for tourism in Spain. Dataestur organises its data in different categories:
- Travel and leisure: statistics on tourist arrivals, attraction ratings, museum visits and leisure spending.
- Economy: data on employment in the tourism sector, active businesses and spending by international visitors.
- Transport: data on mobility, including air traffic, bus and rail transport, roads and ports.
- Accommodation: information on hotel occupancy, rural tourism, campsites and tourist accommodation, as well as prices, profitability and hotel satisfaction.
- Sustainability: indicators on air quality, water and nature conservation in tourist destinations.
- Knowledge: analysis of visitor perception, security, digital connectivity, tourism studies and reports.
Most of these data are collected at provincial level (NUTS 3) and are therefore not published at destination level. In this sense, the Spanish Federation of Municipalities and Provinces (FEMP) proposes 80 datasets to be published openly by the local administration which, in addition, take into account high-value data, bringing them down to the local level. Among all these data sets, the following are explicitly defined as data within the tourism category: cultural agenda, tourist accommodation, census of commercial and leisure premises, tourist flows, tourist attractions and monuments.
Barriers and opportunities in the publication of open data by ITDs
After analysing the current state of data management in the field of tourism, a series of opportunities for tourism destinations as generators of open data are proposed:
-
Provision of data for internal consumption: tourism data covers multiple themes and is generated in different departments within the local administration, such as tourism, urban planning, mobility, environment or economy. Given this scenario of diversity of sources and decision-makers, working on the publication of data in reusable formats not only facilitates its reuse by external agents, but also optimises its use within the local administration itself, allowing for a more efficient and data-based management.
-
Fostering innovation in tourism: open data from tourism destinations is an excellent raw material on which to develop intelligent products and services with added value for the sector. This facilitates public-private collaboration, promoting the creation of a technology industry around tourism destinations and the open data they generate.
- Facilitating the participation of tourism destinations in data spaces: the publication of open data allows the managing bodies of tourism destinations to join data spaces in a more robust way. On the one hand, having open data facilitates interoperability between actors in the sector. On the other hand, tourism open data initiatives increase the data culture in tourism destinations, boosting the perception of the usefulness of data-driven tourism management.
Despite these clear opportunities, there are a number of barriers that make it difficult for tourism destinations to publish data in open format effectively:
- Necessity of sufficient budget and technical resources: the publication of open data requires investments in technological platforms and in the training of specialised teams. This is even more important in the field of tourism, where data are heterogeneous, subject-matter diverse and fragmented, requiring additional efforts in their collection, standardisation and coordinated publication.
- Small business dominance in tourism destinations: tourism businesses need to be supported to incorporate the use of open destination data, as well as the development of data-driven solutions tailored to the needs of the destination.
- Awareness of the usefulness of open data: there is a risk that open data will be seen as a trend rather than a strategic resource that enables tangible benefits. In this sense, data is perceived as an internal resource rather than an asset that can be shared to multiply its value. There is a lack of clear references and examples of the impact of the reuse of open data in tourist destinations that would allow for a deeper incorporation of a data culture at the tourist destination level.
- Difficulty in operationalising data strategies: Tourism destinations have incorporated the publication of open data in their strategic plans, but it is necessary to push for its effective implementation. One of the key issues in this regard is the fear of loss of competitive advantage, as the publication of open data related to a destination's tourism activity could reduce its differentiation from other destinations. Another concern relates to legal and personal data protection aspects, especially in areas such as mobility and tourism consumption.
Conclusions: the future of open data in ITD models
In relation to data management, it is necessary to address aspects that are still not sufficiently developed in the DTI models, such as data exchange at the destination, rather than the mere purchase of information; the transversal integration of data on a local scale, allowing the cross-referencing of information from different areas (urban planning, environment, tourism, etc.).); obtaining a greater level of detail in the data, both in terms of time (specific events) and space (areas or points of interest within destinations), safeguarding privacy; and the development of an effective open data strategy.
Focusing on this last point, ITD strategies should include the publication of open data. To this end, it is a priority to define a data management plan that allows each destination to determine what data is produced, how it can be shared and under what conditions, ensuring that the opening of data does not negatively affect the competitiveness of the destination or conflict with current data protection and privacy legislation.
A key tool in this process is the definition of a catalogue, which makes it possible to organise, prioritise and classify the available data (and their metadata) according to their value and usefulness for the different actors in the tourism ecosystem. This catalogue should enable ITD data to comply with the FAIR principles (Findable, Accessible, Interoperable, Reusable), facilitating their open publication or allowing their integration in data spaces (such as the European tourism data space developed in the DeployTour project). In this context, each identified and catalogued dataset should have two versions:
- An open version, accessible to any user and in a reusable format, with an unrestricted licence (i.e. an open dataset).
- A version that allows specific agreements for use in data spaces, where the sovereignty and control of the destination is maintained, establishing access restrictions and conditions of use.
Regardless of the approach taken, all published data should comply with the FAIR principles, ensuring that it is findable, accessible, interoperable and reusable, promoting its use in both the public and private sectors and facilitating the development of innovative data-driven solutions in the field of tourism.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
The European Green Deal (Green Deal) is the European Union's (EU) sustainable growth strategy, designed to drive a green transition that transforms Europe into a just and prosperous society with a modern and competitive economy. Within this strategy, initiatives such as Target 55 (Fit for 55), which aims to reduce EU emissions by at least 55% by 2030, stand out, and the Nature Restoration Regulation(, which sets binding targets to restore ecosystems, habitats and species.
The European Data Strategy positions the EU as a leader in data-driven economies, promoting fundamental values such as privacy and sustainability. This strategy envisages the creation of data spaces sectoral spaces to encourage the availability and sharing of data, promoting its re-use for the benefit of society and various sectors, including the environment.
This article looks at how environmental data spaces, driven by the European Data Strategy, play a key role in achieving the goals of the European Green Pact by fostering the innovative and collaborative use of data.
Green Pact data space from the European Data Strategy
In this context, the EU is promoting the Green Deal Data Space, designed to support the objectives of the Green Deal through the use of data. This data space will allow sharing data and using its full potential to address key environmental challenges in several areas: preservation of biodiversity, sustainable water management, the fight against climate change and the efficient use of natural resources, among others.
In this regard, the European Data Strategy highlights two initiatives:
- On the one hand, the GreenData4all initiative which carries out an update of the INSPIRE directive to enable greater exchange of environmental geospatial data between the public and private sectors, and their effective re-use, including open access to the general public.
- On the other hand, the Destination Earth project proposes the creation of a digital twin of the Earth, using, among others, satellite data, which will allow the simulation of scenarios related to climate change, the management of natural resources and the prevention of natural disasters.
Preparatory actions for the development of the Green Pact data space
As part of its strategy for funding preparatory actions for the development of data spaces, the EU is funding the GREAT project (The Green Deal Data Space Foundation and its Community of Practice). This project focuses on laying the foundations for the development of the Green Deal data space through three strategic use cases: climate change mitigation and adaptation, zero pollution and biodiversity. A key aspect of GREAT is the identification and definition of a prioritised set of high-value environmental data (minimum but scalable set). This approach directly connects this project to the concept of high-value data defined in the European Open Data Directive (i.e. data whose re-use generates not only a positive economic impact, but also social and environmental benefits).. The high-value data defined in the Implementing Regulation include data related to Earth observation and the environment, including data obtained from satellites, ground sensors and in situ data.. These packages cover issues such as air quality, climate, emissions, biodiversity, noise, waste and water, all of which are related to the European Green Pact.
Differentiating aspects of the Green Pact data space
At this point, three differentiating aspects of the Green Pact data space can be highlighted.
- Firstly, its clearly multi-sectoral nature requires consideration of data from a wide variety of domains, each with their own specific regulatory frameworks and models.
- Secondly, its development is deeply linked to the territory, which implies the need to adopt a bottom-up approach (bottom-up) starting from concrete and local scenarios.
- Finally, it includes high-value data, which highlights the importance of active involvement of public administrations, as well as the collaboration of the private and third sectors to ensure its success and sustainability.
Therefore, the potential of environmental data will be significantly increased through European data spaces that are multi-sectoral, territorialised and with strong public sector involvement.
Development of environmental data spaces in HORIZON programme
In order to develop environmental data spaces taking into account the above considerations of both the European Data Strategy and the preparatory actions under the Horizon Europe (HORIZON) programme, the EU is funding four projects:
- Urban Data Spaces for Green dEal (USAGE).. This project develops solutions to ensure that environmental data at the local level is useful for mitigating the effects of climate change. This includes the development of mechanisms to enable cities to generate data that meets the FAIR principles (Findable, Accessible, Interoperable, Reusable) enabling its use for environmentally informed decision-making.
- All Data for Green Deal (AD4GD).. This project aims to propose a set of mechanisms to ensure that biodiversity, water quality and air quality data comply with the FAIR principles. They consider data from a variety of sources (satellite remote sensing, observation networks in situ, IoT-connected sensors, citizen science or socio-economic data).
- F.A.I.R. information cube (FAIRiCUBE). The purpose of this project is to create a platform that enables the reuse of biodiversity and climate data through the use of machine learning techniques. The aim is to enable public institutions that currently do not have easy access to these resources to improve their environmental policies and evidence-based decision-making (e.g. for the adaptation of cities to climate change).
- Biodiversity Building Blocks for Policy (B-Cubed).. This project aims to transform biodiversity monitoring into an agile process that generates more interoperable data. Biodiversity data from different sources, such as citizen science, museums, herbaria or research, are considered; as well as their consumption through business intelligence models, such as OLAP cubes, for informed decision-making in the generation of adequate public policies to counteract the global biodiversity crisis.
Environmental data spaces and research data
Finally, one source of data that can play a crucial role in achieving the objectives of the European Green Pact is scientific data emanating from research results. In this context, the European Union's European Open Science Cloud (EOSC) initiativeis an essential tool. EOSC is an open, federated digital infrastructure designed to provide the European scientific community with access to high quality scientific data and services, i.e. a true research data space. This initiative aims to facilitate interoperability and data exchange in all fields of research by promoting the adoption of FAIR principles, and its federation with the Green Pact data space is therefore essential.
Conclusions
Environmental data is key to meeting the objectives of the European Green Pact. To encourage the availability and sharing of this data, promoting its re-use, the EU is developing a series of environmental data space projects. Once in place, these data spaces will facilitate more efficient and sustainable management of natural resources, through active collaboration between all stakeholders (both public and private), driving Europe's ecological transition.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
The Ministry for the Digital Transformation and Civil Service, on 17 December, announced the publication of the call for proposals for products and services for data spaces, an initiative that seeks to promote innovation and development in various sectors through financial aid. These grants are designed to support companies and organisations in the implementation of advanced technological solutions, thus promoting competitiveness and digital transformation in Spain.
In addition, on 30 December, the Ministry also launched the second call for proposals for demonstrators and use cases. This call aims to encourage the creation and development of sectoral data spaces, promoting collaboration and the exchange of information between the different actors in the sector.
The Ministry has been conducting promotions through online workshops to inform and prepare stakeholders about the opportunities and benefits of the data space sector. It is expected that these events will continue throughout January, providing further opportunities for stakeholders to inform themselves and participate.
The following material is of interest to you:
Call for demonstrators and use cases


- Data space demonstrators and use cases (2nd call for proposals).
- Enquiry mailbox: dcu2.espaciosdedatos@digital.gob.es
- Presentations and helpful videos:
Products and services


- Call for proposals for products and services for data spaces.
- Consultation mailbox: ps.espaciosdedatos@digital.gob.es
- Presentations and helpful videos:
Noticia
Researchers and students from various centers have also reported advances resulting from working with data:The last days of the year are always a good time to look back and assess the progress made. If a few weeks ago we took stock of what happened in the Aporta initiative, now it is time to compile the news related to data sharing, open data and the technologies linked to them.
Six months ago, we already made a first collection of milestones in the sector. On this occasion, we will summarise some of the innovations, improvements and achievements of the last half of the year.
Regulating and driving artificial intelligence
La inteligencia artificial (IA) continúa siendo uno de los campos donde cada día se aprecian nuevos avances. Se trata de un sector cuyo auge es relativamente nuevo y que necesita regulación. Por ello, la Unión Europea publicó el pasado julio el Reglamento de inteligencia artificial, una norma que marcará el entorno regulatorio europeo y global. Alineada con Europa, España ya presentó unos meses antes su nueva Estrategia de inteligencia artificial 2024, con el fin de establecer un marco para acelerar el desarrollo y expansión de la IA en España.
Artificial intelligence (AI) continues to be one of the fields where new advances are being made every day. This is a relatively new and booming sector in need of regulation. Therefore, last July, the European Union published the Artificial Intelligence Regulation, a standard that will shape the European and global regulatory environment. Aligned with Europe, Spain had already presented its new Artificial Intelligence Strategy 2024 a few months earlier, with the aim of establishing a framework to accelerate the development and expansion of AI in Spain.
On the other hand, in October, Spain took over the co-presidency of the Open Government Partnership. Its roadmap includes promoting innovative ideas, taking advantage of the opportunities offered by open data and artificial intelligence. As part of the position, Spain will host the next OGP World Summit in Vitoria.
Innovative new data-driven tools
Data drives a host of disruptive technological tools that can generate benefits for all citizens. Some of those launched by public bodies in recent months include:
- The Ministry of Transport and Sustainable Mobility has started to use Big Data technology to analyse road traffic and improve investments and road safety.
- The Principality of Asturias announces a plan to use Artificial Intelligence to end traffic jams during the summer, through the development of a digital twin.
- The Government of Aragon presented a new tourism intelligence system, which uses Big Data and AI to improve decision-making in the sector.
- The Region of Murcia has launched “Murcia Business Insight”, a business intelligence application that allows dynamic analysis of data on the region's companies: turnover, employment, location, sector of activity, etc.
- The Granada City Council has used Artificial Intelligence to improve sewerage. The aim is to achieve "more efficient" maintenance planning and execution, with on-site data.
- The Segovia City Council and Visa have signed a collaboration agreement to develop an online tool with real, aggregated and anonymous data on the spending patterns of foreign Visa cardholders in the capital. This initiative will provide relevant information to help tailor strategies to promote international tourism.
Researchers and students from various centers have also reported advances resulting from working with data:
- Researchers from the Center for Genomic Regulation (CRG) in Barcelona, the University of the Basque Country (UPV/EHU), the Donostia International Physics Center (DIPC) and the Fundación Biofísica Bizkaia have trained an algorithm to detect tissue alterations in the early stages and improve cancer diagnosis.
- Researchers from the Spanish National Research Council (CSIC) and KIDO Dynamics have launched a project to extract metadata from mobile antennas to understand the flow of people in natural landscapes. The objective is to identify and monitor the impact of tourism.
- A student at the University of Valladolid (UVa) has designed a project to improve the management and analysis of forest ecosystems in Spain at the local level, by converting municipal boundaries into a linked open data format. The results are available for re-use.
Advances in data spaces
The Ministry for Digital Transformation and the Civil Service and, specifically, the Secretariat of State for Digitalisation and Artificial Intelligence continues to make progress in the implementation of data spaces, through various actions:
- A Plan for the Promotion of Sectoral Data Spaces has been presented to promote secure data sharing.
- The development of Data Spaces for Intelligent Urban Infrastructures (EDINT) has been launched. This project, which will be carried out through the Spanish Federation of Municipalities and Provinces (FEMP), contemplates the creation of a multi-sectoral data space that will bring together all the information collected by local entities.
- In the field of digitalisation, aid has been launched for the digital transformation of strategic productive sectors through the development of technological products and services for data spaces.
Functionalities that bring data closer to reusers
The open data platforms of the various agencies have also introduced new developments, as new datasets, functionalities, strategies or reports:
- The Ministry for Ecological Transition and the Demographic Challenge has launched a new application for viewing the National Air Quality Index (AQI) in real time. It includes health recommendations for the general population and the sensitive population.
- The Andalusian Government has published a "Guide for the design of Public Policy Pilot Studies". It proposes a methodology for designing pilot studies and a system for collecting evidence for decision-making.
- The Government of Catalonia has initiated steps to implement a new data governance model that will improve relations with citizens and companies.
- The Madrid City Council is implementing a new 3D cartography and thermal map. In the Blog IDEE (Spatial Data Infrastructure of Spain) they explain how this 3D model of the capital was created using various data capture technologies.
- The Canary Islands Statistics Institute (ISTAC) has published 6,527 thematic maps with labor indicators on the Canary Islands in its open data catalog.
- Open Data Initiative and the Democratic Union of Pensioners and Retirees of Spain, with support from the Ministry of Social Rights, Consumption and Agenda 2030, presented the first Data website of the Data Observatory x Seniors. Its aim is to facilitate the analysis of healthy ageing in Spain and strategic decision-making. The Barcelona Initiative also launched a challenge to identify 50 datasets related to healthy ageing, a project supported by the Barcelona Provincial Council.
- The Centre for Technological Development and Innovation (CDTI) has presented a dashboard in beta phase with open data in exploitable format.
In addition, work continues to promote the opening up of data from various institutions:
- Asedie and the King Juan Carlos University (Madrid) have launched the Open Data Reuse Observatory to promote the reuse of open data. It already has the commitment of the Madrid City Council and they are looking for more institutions to join their Manifesto.
- The Cabildo of Tenerife and the University of La Laguna have developed a Sustainable Mobility Strategy in the Macizo de Anaga Biosphere Reserve. The aim is to obtain real-time data in order to take measures adapted to demand.
Data competitions and events to encourage the use of open data
Summer was the time chosen by various public bodies to launch competitions for products and/or services based on open data. This is the case of:
- The Community of Madrid held DATAMAD 2024 at the Universidad Rey Juan Carlos de Madrid. The event included a workshop on how to reuse open data and a datathon.
- More than 200 students registered for the I Malackathon, organised by the University of Malaga, a competition that awarded projects that used open data to propose solutions for water resource management.
- The Junta de Castilla y León held the VIII Open Data Competition, whose winners were announced in November.
- The II UniversiData Datathon was also launched. 16 finalists have been selected. The winners will be announced on 13 February 2025.
- The Cabildo of Tenerife also organised its I Open Data Competition: Ideas for reuse. They are currently evaluating the applications received. They will later launch their 2nd Open Data Competition: APP development.
- The Government of Euskadi held its V Open Data Competition. The finalists in both the Applications and Ideas categories are now known.
Also in these months there have been multiple events, which can be seen online, such as:
- The III GeoEuskadi Congress and XVI Iberian Conference on Spatial Data Infrastructures (JIIDE).
- DATAforum Justice 2024.
Other examples of events that were held but are not available online are the III Congress & XIV Conference of R Users, the Novagob 2024 Public Innovation Congress, DATAGRI 2024 or the Data Governance for Local Entities Conference, among others.
These are just a few examples of the activity carried out during the last six months in the Spanish data ecosystem. We encourage you to share other experiences you know of in the comments or via our email address dinamizacion@datos.gob.es.
Noticia
TheMinistry for the Digital Transformation and Civil Service has presented an ambitious Plan for the Promotion of Sectorial Data Spaces. Its objective is to foster innovation and improve competitiveness and added-value in all economic sectors, promoting the deployment of data spaces where data can be securely shared. Thanks to them, companies, and the economy in general, will be able to benefit from the full potential of a European data single market.
The Plan has a 500 million euros budget from the Recovery, Transformation and Resilience Plan, and will be developed in 6 axes and 11 initiatives with a planned duration until 2026.
Data spaces
Data sharing in data spaces offers enormous benefits to all the participating companies, both individually and collectively. These benefits include improved efficiency, cost reduction, increased competitiveness, innovation in business models and better adaptation to regulations. These benefits cannot be achieved by companies in isolation but requires the sharing of data among all the actors involved.
Some examples of these benefits would be:
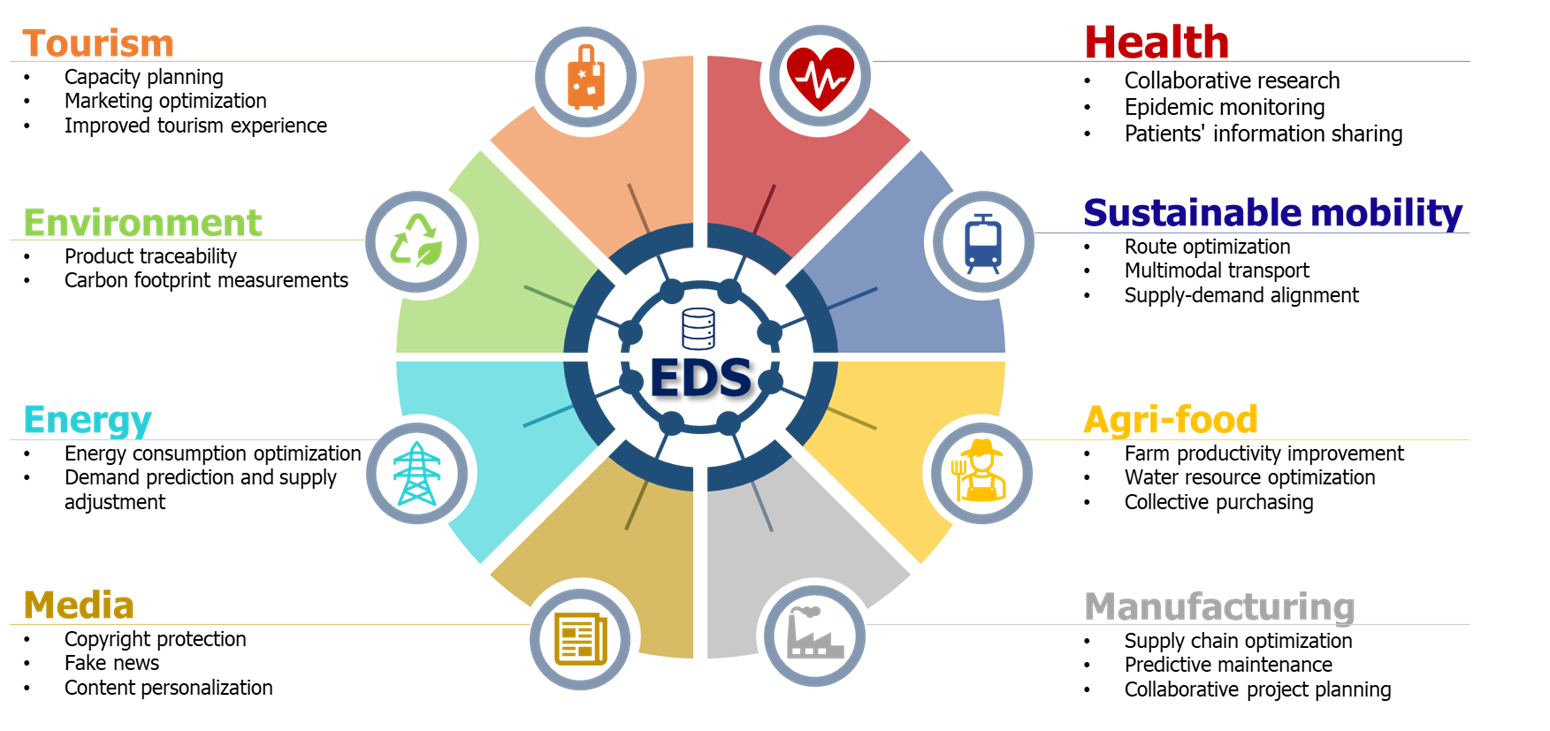
Figure 1. Impact of data spaces on various sectors.
Some specific initiatives include:
- The AgriDataSpace project ensures food quality and safety through full traceability of products.
- The Mobility Data Space project improves urban planning and transportation efficiency by integrating mobility data.
Benefits of the Plan for the Promotion of Sectorial Data Spaces
The Plan will offer more than €287 million in grants for the creation and maintenance of data spaces, the development of high-value use cases and the reduction of costs for participating companies when consuming, sharing or providing data. It will also offer up to 44 million euros in grants to the technology industry to facilitate the adaptation of their digital products and services to the needs of data spaces and the entities that participate in them by sharing data and making our industry more competitive in data technologies.
Finally, with a budget of up to 169 million euros, several unique projects of public interest will be developed that will act as enablers for digital transformation focused on data and data spaces in all economic sectors. These enablers will contribute to accelerate the process of deploying use cases and data spaces, as well as stimulate companies to actively share data and obtain the expected benefits. To this end, a network of common infrastructures and data space demonstrators will be developed, a National Reference Center for data spaces will be set up, and the entire non-open public data sets held by public administrations which are of high interest to businesses will be made available to the economic sectors.
Learn more about the Plan and its measures


The set of initiatives to be developed by the Plan is summarized in the following table:

Figure 2. Summary table with the initiatives included in the Plan for the Promotion of Sectorial Data Spaces.
Discover the grants that are currently active, and the planned schedule to benefit from them:

More information about data spaces here.
Links of interest




Noticia
Tourism is one of Spain's economic engines. In 2022, it accounted for 11.6% of Gross Domestic Product (GDP), exceeding €155 billion, according to the Instituto Nacional de Estadística (INE). A figure that grew to 188,000 million and 12.8% of GDP in 2023, according to Exceltur, an association of companies in the sector. In addition, Spain is a very popular destination for foreigners, ranking second in the world and growing: by 2024 it is expected to reach a record number of international visitors, reaching 95 million.
In this context, the Secretariat of State for Tourism (SETUR), in line with European policies, is developing actions aimed at creating new technological tools for the Network of Smart Tourist Destinations, through SEGITTUR (Sociedad Mercantil Estatal para la Gestión de la Innovación y las Tecnologías Turísticas), the body in charge of promoting innovation (R&D&I) in this industry. It does this by working with both the public and private sectors, promoting:
- Sustainable and more competitive management models.
- The management and creation of smart destinations.
- The export of Spanish technology to the rest of the world.
These are all activities where data - and the knowledge that can be extracted from it - play a major role. In this post, we will review some of the actions SEGITTUR is carrying out to promote data sharing and openness, as well as its reuse. The aim is to assist not only in decision-making, but also in the development of innovative products and services that will continue to position our country at the forefront of world tourism.
Dataestur, an open data portal
Dataestur is a web space that gathers in a unique environment open data on national tourism. Users can find figures from a variety of public and private information sources.
The data are structured in six categories:
- General: international tourist arrivals, tourism expenditure, resident tourism survey, world tourism barometer, broadband coverage data, etc.
- Economy: tourism revenues, contribution to GDP, tourism employment (job seekers, unemployment and contracts), etc.
- Transport: air passengers, scheduled air capacity, passenger traffic by ports, rail and road, etc.
- Accommodation: hotel occupancy, accommodation prices and profitability indicators for the hotel sector, etc.
- Sustainability: air quality, nature protection, climate values, water quality in bathing areas, etc.
- Knowledge: active listening reports, visitor behaviour and perception, scientific tourism journals, etc.
The data is available for download via API.
Dataestur is part of a more ambitious project in which data analysis is the basis for improving tourist knowledge, through actions with a wide scope, such as those we will see below.
Developing an Intelligent Destination Platform (IDP)
Within the fulfillment of the milestones set by the Next Generation funds, and corresponding to the development of the Digital Transformation Plan for Tourist Destinations, the Secretary of State for Tourism, through SEGITTUR, is developing an Intelligent Destination Platform (PID). It is a platform-node that brings together the supply of tourism services and facilitates the interoperability of public and private operators. Thanks to this platform it will be possible to provide services to integrate and link data from both public and private sources.
Some of the challenges of the Spanish tourism ecosystem to which the IDP responds are:
- Encourage the integration and development of the tourism ecosystem (academia, entrepreneurs, business, etc.) around data intelligence and ensure technological alignment, interoperability and common language.
- To promote the use of the data economy to improve the generation, aggregation and sharing of knowledge in the Spanish tourism sector, driving its digital transformation.
- To contribute to the correct management of tourist flows and tourist hotspots in the citizen space, improving the response to citizens' problems and offering real-time information for tourist management.
- Generate a notable impact on tourists, residents and companies, as well as other agents, enhancing the brand "sustainable tourism country" throughout the travel cycle (before, during and after).
- Establish a reference framework to agree on targets and metrics to drive sustainability and carbon footprint reduction in the tourism industry, promoting sustainable practices and the integration of clean technologies.

Figure 1. Objectives of the Intelligent Destination Platform (IDP).
New use cases and methodologies to implement them
To further harmonise data management, up to 25 use cases have been defined that enable different industry verticals to work in a coordinated manner. These verticals include areas such as wine tourism, thermal tourism, beach management, data provider hotels, impact indicators, cruises, sports tourism, etc.
To implement these use cases, a 5-step methodology is followed that seeks to align industry practices with a more structured approach to data:
- Identify the public problems to be solved.
- Identify what data are needed to be available to be able to solve them.
- Modelling these data to define a common nomenclature, definition and relationships.
- Define what technology needs to be deployed to be able to capture or generate such data.
- Analyse what intervention capacities, both public and private, are needed to solve the problem.
Boosting interoperability through a common ontology and data space
As a result of this definition of the 25 use cases, a ontology of tourism has been created, which they hope will serve as a global reference. The ontology is intended to have a significant impact on the tourism sector, offering a series of benefits:
- Interoperability: The ontology is essential to establish a homogeneous data structure and enable global interoperability, facilitating information integration and data exchange between platforms and countries. By providing a common language, definitions and a unified conceptual structure, data can be comparable and usable anywhere in the world. Tourism destinations and the business community can communicate more effectively and agilely, fostering closer collaboration.
- Digital transformation: By fostering the development of advanced technologies, such as artificial intelligence, tourism companies, the innovation ecosystem or academia can analyse large volumes of data more efficiently. This is mainly due to the quality of the information available and the systems' better understanding of the context in which they operate.
- Tourism competitiveness: Aligned with the previous question, the implementation of this ontology contributes to eliminating inequalities in the use and application of technology within the sector. By facilitating access to advanced digital tools, both public institutions and private companies can make more informed and strategic decisions. This not only raises the quality of the services offered, but also boosts the productivity and competitiveness of the Spanish tourism sector in an increasingly demanding global market.
- Tourist experience: Thanks to ontology, it is possible to offer recommendations tailored to the individual preferences of each traveller. This is achieved through more accurate profiling based on demographic and behavioural characteristics as well as specific motivations related to different types of tourism. By personalising offers and services, customer satisfaction before, during and after the trip is improved, and greater loyalty to tourist destinations is fostered.
- Governance: The ontology model is designed to evolve and adapt as new use cases emerge in response to changing market demands. SEGITTUR is actively working to establish a governance model that promotes effective collaboration between public and private institutions, as well as with the technology sector.
In addition, to solve complex problems that require the sharing of data from different sources, the Open Innovation Platform (PIA) has been created, a data space that facilitates collaboration between the different actors in the tourism ecosystem, both public and private. This platform enables secure and efficient data sharing, empowering data-driven decision making. The PIA promotes a collaborative environment where open and private data is shared to create joint solutions to address specific industry challenges, such as sustainability, personalisation of the tourism experience or environmental impact management.
Building consensus
SEGITTUR is also carrying out various initiatives to achieve the necessary consensus in the collection, management and analysis of tourism-related data, through collaboration between public and private actors. To this end, the Ente Promotor de la Plataforma Inteligente de Destinoswas created in 2021, which plays a fundamental role in bringing together different actors to coordinate efforts and agree on broad lines and guidelines in the field of tourism data.
In summary, Spain is making progress in the collection, management and analysis of tourism data through coordination between public and private actors, using advanced methodologies and tools such as the creation of ontologies, use cases and collaborative platforms such as PIA that ensure efficient and consensual management of the sector.
All this is not only modernising the Spanish tourism sector, but also laying the foundations for a smarter, more intelligent, connected and efficient future. With its focus on interoperability, digital transformation and personalisation of experiences, Spain is positioned as a leader in tourism innovation, ready to face the technological challenges of tomorrow.
Noticia
The Ministry for Digital Transformation and Public Administration has launched a grant for the development of Data Spaces for Intelligent Urban Infrastructures (EDINT). This project envisages the creation of a multi-sectoral data space that will bring together all the information collected by local authorities. The project will be carried out through the Spanish Federation of Municipalities and Provinces (FEMP) and will receive a subsidy of 13 million euros, as stated in the Official State Gazette published on Wednesday 16 October.
A single point of access to smart urban infrastructure data
Thanks to this action, it will be possible to finance, develop and manage a multisectoral data space that will bring together all the information collected by the different Spanish municipalities in an aggregated and centralized manner. It should be recalled that data spaces enable the voluntary sharing of information in an environment of sovereignty, trust and security, established through integrated governance, organisational, regulatory and technical mechanisms.
EDINT will act as a single neutral point of access to smart city information, enabling companies, researchers and administrations to access information without the need to visit the data infrastructure of each municipality, increasing agility and reducing costs. In addition, it will allow connection with other sectoral data spaces.
The sharing of this data will help to accelerate technological innovation processes in smart city products and services. Businesses and organisations will also be able to use the data for the improvement of processes and efficiency of their activities.
The Spanish Federation of Municipalities and Provinces (FEMP) will implement the project.
The EDINT project will be articulated through the Spanish Federation of Municipalities and Provinces.The FEMP reaches more than 95% of the Spanish population, which gives it a deep and close knowledge of the needs and challenges of data management in Spanish municipalities and provinces.
Among the actions to be carried out are:
- Development and implementation of the data infrastructure and platform, which will store data from existing Smart City systems.
- Incorporation of local entities and companies interested in accessing the data space.
- Development of three use cases on the data space, focusing on the following areas: "smart mobility", "managed cities and territories" and "mapping the economic and social activity of cities and territories".
- Definition of the governance schemes that will regulate the operation of the project, guaranteeing the interoperability of the data, as well as the management of the complex network of stakeholders (companies, academic institutions and governmental organisations).
- Setting up Centres of Excellence and Data Offices, with physical workspaces. These centres will be responsible for the collection of lessons learned and the development of new use cases.
It is a ongoing and sustainable long-term project that will be open to the participation of new actors, be they data providers or data consumers, at any time.
A project aligned with Europe
This assistance is part of the Recovery, Transformation and Resilience Plan, funded by the European Union-Next Generation EU. The creation of data spaces is envisaged in the European Data Strategy, as a mechanism to establish a common data market to ensure the European Union's leadership in the global data economy. In particular, it aims to achieve the free flow of information for the benefit of businesses, researchers and public administrations.
Moreover, data spaces are a key area of the Digital Spain 2026 Agenda, which is driving, among other issues, the acceleration of the digitalisation processes of the productive fabric. To this end, sectoral and data-intensive digitalisation projects are being developed, especially in strategic economic sectors for the country, such as agri-food, mobility, health, tourism, industry, commerce and energy.
The launch of the EDINT project joins other previously launched initiatives such as funding and development grants for use cases and data space demonstrators, which encourage the promotion of public-private sectoral innovation ecosystems.
Sharing data under conditions of sovereignty, control and security not only allows local governments to improve efficiency and decision-making, but also drives the creation of creative solutions to various urban challenges, such as optimising traffic or improving public services. In this sense, actions such as the Data Spaces for Smart Urban Infrastructures represent a step forward in achieving smarter, more sustainable and efficient cities for all citizens.