Blog
A data space is a development framework that enables the creation of a complete ecosystem by providing an organisational, regulatory, technical and governance structure with the objective of facilitating the reliable and secure exchange of different data assets for the common benefit of all actors involved and ensuring compliance with all applicable laws and regulations. Data spaces are also a key element of the European Union's new data strategy and an essential building block in realising the goal of the European single data market.
As part of this strategy, the EU is currently exploring the creation of several data space pilots in a number of strategic sectors and domains: health, industry, agriculture, finance, mobility, Green Pact, energy, public administration and skills. These data spaces offer great potential to help organisations improve decision-making, increase innovation, develop new products, services and business models, reduce costs and avoid duplication of efforts. However, creating a successful data space is not a trivial activity and requires first carefully analysing the use cases and then facing major business, legal, operational, functional, technological and governance challenges.
This is why, as a support measure, the Data Spaces Support Centre (DSSC) has also been created to provide guidance, tools and resources to organisations interested in creating or participating in new data spaces. One of the first resources developed by the DSSC was the Data Spaces Starter Kit, the final version of which has recently been published and which provides a basic initial guide to understanding the basic elements of a data space and how to deal with the different challenges that arise when building them. We review below some of the main guidelines and recommendations offered by this starter kit.
The value of data spaces and their business models
Data spaces can be a real alternative to current unidirectional platforms, generating business models based on network effects that respond to both the supply and demand of data. Among the different business model patterns existing in data spaces, we can find:
- Cost sharing: all participants save time and money by sharing data for a common purpose, such as the smart network of connected SCSN providers.
- Joint innovation: innovation is only possible if data is shared as none of the participants have the complete data individually, e.g., the Eona-X platform for mobility, transport and tourism.
- Combined forces: different actors join forces to prevent a single actor from dominating a certain space, as in the EuPro Gigant manufacturing data network.
- Shared market: actors with common interests share data with each other in order to benefit each other, such as the Catena-X automotive network.
- Greater common good: when the public and private sectors share data for a social purpose, as for example in the mobility data space developed in Spain through the Mobility Working Group of the Gaia-X Hub.
The legal aspects
The legal side of data spaces can be a major challenge as they necessarily move between multiple legal frameworks and regulations, both national and European. To address this challenge, the Data Spaces Support Centre proposes the elaboration of a reference framework composed of three main instruments:
- The cross-cutting legal frameworks that will apply to all data spaces, such as contract law, data protection, intellectual property, competition or cybersecurity laws.
- The organisational aspects to consider when establishing models and mechanisms for data governance in each specific case.
- The contractual dimension to be taken into account when exchanging data and the agreements and terms of use to be established to make this possible.
Operational activities
The design of operational activities should address the arrangements that enable the organisational functioning of the data space, such as guidelines for onboarding new participants, decision-making and conflict resolution.
In addition, consideration should also be given to business operations, such as process streamlining and automation, marketing tasks and awareness-raising activities, which are also important components of operational activities.
Functionality of data spaces
Data spaces shall share a number of basic components (or building blocks) that will provide the minimum functionality expected of them, including at least the following elements:
- Interoperability: data models and formats, data exchange interfaces and origin and traceability.
- Trust: identity management, access and usage control and secure data exchanges.
- Data value: metadata and location protocols, data usage accounting, publishing and commercial services.
- Governance: cooperation and service level agreements and continuity models.
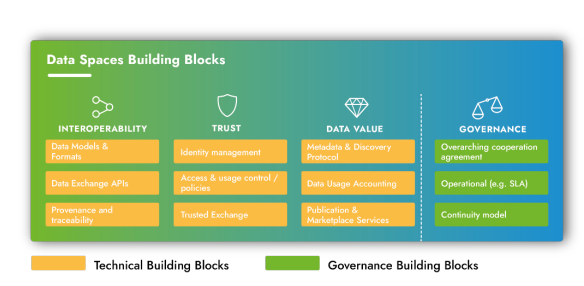
While these components can be expected to be common to all data spaces and provide similar functionality, each individual data space can make its own design choices in implementing and realising them.
Technological aspects
Data spaces are designed to be technology agnostic, i.e., defined solely in terms of functionality and with freedom in the choice of specific technologies for implementation. In this scenario it will be important to establish clear references in terms of:
- A formal basis of de facto standards to be followed.
- Specifications to serve as a reference for the different implementations.
- Open source implementations of the basic components carried out by other actors.
Governance of data spaces
Designing, implementing and maintaining a data space requires multiple organisations to collaborate together across different functions. This requires these entities to build a common vision of the key aspects of such collaboration through a governance framework.
This will require a joint design exercise through which stakeholders formalise a set of agreements defining key strategic and operational aspects, such as legal issues, description of the network of participants, code of conduct, terms and conditions of use, data space incorporation and membership agreements, and governance model.
In the near future the DSSC support centre will identify the core components of each of the dimensions described above and provide additional guidance for each of them through the development of a common blueprint for data spaces. So, if you are considering participating in any of the data spaces initiatives that are being launched, but are not quite sure where to start, then this basic starter kit will certainly be a valuable resource in understanding the basic concepts - along with the glossary that explains all the related terminology. Also, don't forget to subscribe to the support centre's newsletter to keep up to date with all the latest news, documentation and support services on offer.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
We live in the era of data, a lever of digital transformation and a strategic asset for innovation and the development of new technologies and services. Data, beyond the skills it brings to the generator and/or owner of the same, also has the peculiarity of being a non-rival asset. This means that it can be reused without detriment to the owner of the original rights, which makes it a resource with a high degree of scalability in its sharing and exploitation.
This possibility of non-rival sharing, in addition to opening potential new lines of business for the original owners, also carries a huge latent value for the development of new business models. And although sharing is not new, it is still very limited to niche contexts of sector specialisation, mediated either by trust between parties (usually forged in advance), or tedious and disciplined contractual conditions. This is why the innovative concept of data space has emerged, which in its most simplified sense is nothing more than the modelling of the general conditions under which to deploy a voluntary, sovereign and secure sharing of data. Once modelled, the prescription of considerations and methodologies (technological, organisational and operational) allows to make such sharing tangible based on peer-to-peer interactions, which together shape federated ecosystems of data sets and services.
Therefore, and given the distributed nature of data spaces (they are not a monolithic computer system, nor a centralised platform), an optimal way to approach their construction is through the creation and deployment of use cases.
The Data Office has created this infographic of a 'Model of use case development within data spaces', with the objective of synthetically defining the phases of this iterative journey, which progressively shapes a data space. This model also serves as a general framework for other technical and methodological deliverables to come, such as the 'Use Case Feasibility Assessment Guide', or the 'Use Case Design Guide', elements with which to facilitate the implementation of practical (and scalable by design) data sharing experiences, a sine qua non condition to articulate the longed-for European single data market.
The challenge of building a data space
To make the process of developing a data space more accessible, we could assimilate the definition and construction of a use case as a construction project, in which from an initial business problem (needs or challenges, desires, or problems to be solved) a goal is reached in which value is added to the business, providing a solution to those initial needs. This infographic offers a synthesis of that journey.

These are the phases of the model:
PHASE 1: Definition of the business problem. In this phase a group of potential participants detects an opportunity around the sharing of their data (hitherto siloed) and its corresponding exploitation. This opportunity can be new products or services (innovation), efficiency improvements, or the resolution of a business problem. In other words, there is a business objective that the group can solve jointly, by sharing data.
PHASE 2: Data-driven modelling. In this phase, those elements that serve to structure and organise the data for strategic decision-making based on its exploitation will be identified. It involves defining a model that possibly uses multidisciplinary tools to achieve business results. This is the part traditionally associated with data science tasks.
PHASE 3: Consensus on requirements specification. Here, the actors sponsoring the use case must establish the relationship model to have during this collaborative project around the data. Such a formula must: (i) define and establish the rules of engagement, (ii) define a common set of policies and governance model, and (iii) define a trust model that acts as the root of the relationship.
PHASES 4 and 5: Use case mapping. As in a construction project, the blueprint is the means of expressing the ideas of those who have defined and agreed the use case, and should explicitly capture the solutions proposed for each part of the use case development. This plan is unique for each use case, and phase 5 corresponds to its construction. However, it is not created from scratch, but there are multiple references that allow the use of previously identified materials and techniques. For example, models, methodologies, artefacts, templates, technological components or solutions as a service. Thus, just as an architect designing a building can reuse recognised standards, in the world of data spaces there are also models on which to paint the components and processes of a use case. The analysis and synthesis of these references is phase 4.
PHASE 6: Technology selection, parameterisation and/or development. The technology enables the deployment of the transformation and exploitation of the data, favouring the entire life cycle, from its collection to its valorisation. In this phase, the infrastructure that supports the use case is implemented, understood as the collection of tools, platforms, applications and/or pieces of software necessary for the operation of the application.
PHASE 7: Integration, testing and deployment. Like any technological construction process, the use case will go through the phases of integration, testing and deployment. The integration work and the functional, usability, exploratory and acceptance tests, etc. will help us to achieve the desired configuration for the operational deployment of the use case. In the case of wanting to incorporate a use case into a pre-existing data space, the integration would seek to fit within its structure, which means modelling the requirements of the use case within the processes and building blocks of the data space.
PHASE 8: Operational data space. The end point of this journey is the operational use case, which will employ digital services deployed on top of the data space structure, and whose architecture supports different resources and functionalities federated by design. This implies that the value creation lifecycle would have been efficiently articulated based on the shared data, and business returns are achieved according to the original approach. However, this does not prevent the data space from continuing to evolve a posteriori, as its vocation is to grow either with the entry of new challenges, or actors to existing use cases. In fact, the scalability of the model is one of its unique strengths.
In essence, the data shared through a federated and interoperable ecosystem is the input that feeds a layer of services that will generate value and solve the original needs and challenges posed, in a journey that goes from the definition of a business problem to its resolution.
Noticia
Open data is the highest level of data sharing, as it is freely available and accessible to all. Properly processed and with full respect for the protection of personal data, it can help citizens, businesses and the public sector to make better decisions.
Open data, together with other data, play a key role in the creation of data spaces, as referred to in the European Data Strategy. As stated in the document, the implementation of common and interoperable data spaces in strategic sectors is set up with the aim of "overcoming technical and legal barriers to data sharing between organisations, combining the necessary tools and infrastructures and addressing trust issues", for example through common standards developed for the space.
In view of its relevance, the European Data Portal Academy has organised a series of webinars on data spaces. The first of these was held on 12 May in an online format and can be viewed here. In it, the new developments and progress being made regarding data spaces were mentioned, developments that in Spain are being carried out by the Data Office.
We summarise below the main aspects addressed in this first seminar, in which Daniele Rizzi, Principal administrator and policy officer and Johan Bodenkamp, Policy and project officer at the Directorate General for Communication Networks, Content and Technologies of the European Commission, participated, with the moderation of Giulia Carsaniga, Research and Policy Lead Consultant at Capgemini.
Data spaces and the EU's digital strategy
The first part of the seminar, which was held online, highlighted how digital transformation is one of the European Union's top priorities. In fact, Europe has a specific strategy to advance in this aspect, i.e. to achieve 'A Europe fit for the digital age', and it is one of the six 2019-24 priorities of the European Commission.
The European Union's digital strategy aims to make digital transformation benefit people and businesses, a context in which the European Data Strategy of February 2020 is framed, which includes a series of measures for the promotion of a European data market, similar to the European Common Market, the seed of the current EU.
The creation of this European data market requires the establishment of a series of actions and standards with a focus on data, technology and infrastructure. A collective effort, including public programmes such as DIGITAL Europe and private programmes such as Gaia-X, is also contributing to this.
One year after the approval of the European Data Strategy, the European Council acknowledged in March 2021 "the need to accelerate the creation of common data spaces and ensure access and interoperability of data" and invited the Commission to "present the progress made and the remaining measures necessary to establish the sectoral data spaces announced in the European Data Strategy of February 2020." Subsequently, in February 2022, the European Commission published a working document on the European data market.
After contextualizing the development of the concept of data spaces within the European framework, the webinar presenters went on to explain the key components that will be part of the data spaces, some of which are already operational and others are still in development. The seminar provided an overview of what the European data space is expected to be like, highlighting the following aspects:
Firstly, there was a discussion about high-value datasets from the public sector. In January of this year, the European Commission published a list of high-value datasets, which are understood as those that provide added value and significant benefits to society. There is a wide variety of high-value data in different areas (health, agriculture, mobility, energy, etc.) that stakeholders make available with varying degrees of openness. As explained in the webinar, the idea is to start creating common high-value data spaces in more homogeneous areas, although the ultimate goal is for data to be shared across all sectors within the European market, as most applications will require data from different domains.
To support the creation of these data spaces, the first initiative launched in Europe is the establishment of the Data Spaces Support Centre. This center explores the needs of data space initiatives, defines common requirements, establishes best practices to accelerate the formation of sovereign data spaces as a crucial element of digital transformation in all areas, and ensures interoperability through compliance with common standards.
In order for all of this to be developed, a technical infrastructure for data spaces is necessary, which facilitates cloud and edge-cloud services, intelligent middleware solutions (Simpl), a digital marketplace, high-performance computing, on-demand artificial intelligence platform, and AI testing and experimentation facilities.
Differences and similarities between data spaces and datalakes
After providing an overview of data spaces in Europe, the seminar addressed their main characteristics. In this regard, a data space was presented as a secure and privacy-respecting IT infrastructure for aggregating, accessing, processing, using, and sharing data. It was also defined as a data governance mechanism that comprises a set of administrative and contractual rules that determine the rights of access, processing, use, and sharing of data in a reliable, transparent, and compliant manner with applicable legislation.
One of the features highlighted in the webinar regarding this type of infrastructure is that data owners have control over who can access which data, for what purpose, and under what conditions they can be used. Additionally, there is a large amount of voluntarily available data that can be reused either for free or in exchange for compensation, depending on the decisions of the data owners.
Furthermore, it was emphasized that data spaces involve the participation of an open number of organizations/individuals, respecting competition rules and ensuring non-discriminatory access for all participants.
Another concept discussed in the seminar was that of datalakes, in comparison to data spaces. Datalakes were defined as repositories that allow storing structured and unstructured data at any scale. In a datalake, as explained in the seminar, data can be stored as is, without the need for prior structuring, and different types of analyses can be performed, ranging from dashboards and visualizations to real-time data processing and machine learning for more informed decision-making. Accessing the datalake implies the possibility of accessing all the contained data, not necessarily in an organized manner.
On the other hand, a data space, according to the presenters, can be defined as a federated data ecosystem based on shared policies and rules. Users of data spaces have the ability to securely, transparently, reliably, easily, and uniformly access data. In a data space, data owners have control over the access and use of their data. From a technical perspective, a data space can be seen as a data integration concept that does not require common database schemas or physical data integration but is based on distributed and integrated data stores as needed.
Using a fishing analogy, in a datalake, the user has to catch the fish themselves, while a data space would be like going to a fish market.
Next steps: Governance framework and European actors
Once the difference between dataspaces and datalakes was presented, the webinar addressed the paradigm shift in data sharing that is currently taking place. Until now, bilateral data exchange based on contractual agreements has been common. However, a new model of data exchange infrastructure with centralized data hosting and/or data markets is gaining momentum, which reduces transaction costs when data is not maintained in a central repository.
According to the presenters, the next step in the evolution of data spaces would be the creation of links between participants in a model where data is federated and stored in a distributed manner, with tools that enable search, access, and analysis across multiple industries, companies, and entities.

To make this process happen, as explained by the presenters, the support and coordinated work of different actors are necessary. On one hand, it would be essential to establish common rules that facilitate data exchange and bring the different stakeholders closer to a common data policy in the EU. Similarly, providing technical solutions and financial support is indispensable.
In this regard, the webinar highlighted an important milestone: the establishment of the European Data Innovation Board (EDIB), which will support the Commission in publishing guidelines to facilitate the development of common European data spaces and identifying the necessary standards and interoperability requirements for data exchange.
As mentioned earlier, the implementation of data spaces requires technical architecture, and the webinar highlighted two free technical solutions:
-
Building Blocks: Open and reusable digital solutions based on standards that enable basic functionalities, such as reliable authentication and secure data exchange.
-
Simpl: The intelligent middleware that will enable cloud-based federations and edge-cloud. It will support major data initiatives funded by the European Commission, such as the common European data spaces.
The key role of the Data Spaces Support Centre
Towards the end of the seminar, the Data Spaces Support Centre (DSCC) initiative was presented in more detail. This center, established in October 2022, provides support to various initiatives in the creation of data spaces and is expected to conclude its activities in March 2026. It consists of twelve partners and also has sixteen collaborating partners, including important associations and companies with expertise in the field of data exchange.
The main mission of the DSCC is to create a network of partners and a community to provide tools for the creation of data spaces. It focuses particularly on interoperability and aims to generate synergies at the European level for the development of data spaces.
The webinar reviewed the collaborations and initiatives in which the Data Spaces Support Centre participates, and it was highlighted that the starter kit, a starting point for building data spaces, is available on its website.
In the final stretch of the seminar, an overview of the relevant actors in the European common data space was provided:
-
Data Spaces Support Centre (DSSC): Responsible for coordinating relevant actions in data spaces.
-
Data Space Coordination and Support Actions (CSAs): Focused on sectoral data spaces.
-
European Data Innovation Board: Starting from September 2023, it will be responsible for setting guidelines to achieve interoperability in data spaces.
If you want to know more about the concept of data spaces and their relevance today, you can watch the full seminar in the following video:
The following training material is now available on data.europa academy:
- The recording of the session;
- The slide deck presented during the webinar.
Blog
As technology and connectivity have advanced in recent years, we have entered a new era in which data never sleeps and the amount of data circulating is greater than ever. Today, we could say that we live enclosed in a sphere surrounded by data and this has made us more and more dependent on it. On the other hand, we have also gradually become both producers and collectors of data.
The term datasphere has historically been used to define the set of all the information existing in digital spaces, also including other related concepts such as data flows and the platforms involved. But this concept has been developing and gaining more and more relevance in parallel with the growing weight of data in our society today, becoming an important concept in defining the future of the relationship between technology and society.
In the early days of the digital era we could consider that we lived in our own data bubbles that we fed little by little throughout our lives until we ended up totally immersed in the data of the online world, where the distinction between the real and the virtual is increasingly irrelevant. Today we live in a society that is interconnected through data and also through algorithms that link us and establish relationships between us. All that data we share more or less consciously no longer affects only ourselves as individuals, but can also have its effect on the rest of society, even in sometimes totally unpredictable ways - like a digital version of the butterfly effect.
Governance models that are based on working with data and its relationship to people, as if it were simply isolated instances that we can work with individually, will therefore no longer serve us well in this new environment.
The need for a systems-based approach to data
Today, that relatively simple concept of the data sphere has evolved into a complete, highly interconnected and complex digital ecosystem - made up of a wide range of data and technologies - that we inhabit and that affects the way we live our lives. It is a system in which data has value only in the context of its relationship with other data, with people and with the rules that govern those relationships.
Effective management of this new ecosystem will therefore require a better understanding of how the different components of the datasphere relate to each other, how data flows through these components, and what the appropriate rules will be needed to make this interconnected system work.
Data as an active component of the system
In a systems-based approach, data is considered as an active component within the ecosystem. This means that data is no longer just static information, but also has the capacity to influence the functioning of the ecosystem itself and will therefore be an additional component to be considered for the effective management of the ecosystem.
For example, data can be used to fine-tune the functioning of algorithms, improving the accuracy and efficiency of artificial intelligence and machine learning systems. Similarly, it could also be used to adjust the way decisions are made and policies implemented in different sectors, such as healthcare, education and security.
The data sphere and the evolution of data governance
It will therefore be necessary to explore new collective data governance frameworks that consider all elements of the ecosystem in their design, controlling how information is accessed, used and protected across the data sphere.
This could ensure that data is used securely, ethically and responsibly for the whole ecosystem and not just in individual or isolated cases. For example, some of the new data governance tools that have been experimented with for some time now and can help us to manage the data sphere collectively are data commons or digital data assets, data trusts, data cooperatives, data collaboratives or data collaborations, among others.
The future of the data sphere
The data sphere will continue to grow and evolve in the coming years, driven once again by new technological advances and the increasing connectivity and ubiquity of systems. It will be important for governments and organisations to keep abreast of these changes and adapt their data governance and management strategies accordingly through robust regulatory frameworks, accompanied by ethical guidelines and responsible practices that ensure that the benefits that data exploitation promises us can finally be realised while minimising risks.
In order to adequately address these challenges, and thus harness the full potential of the data sphere for positive change and for the common good, it will be essential to move away from thinking of data as something we can treat in isolation and to adopt a systems-based approach that recognises the interconnected nature of data and its impact on society as a whole.
Today, we could consider data spaces, which the European Commission has been developing for some time now as a key part of its new data strategy, as precisely a logical evolution of the data sphere concept adapted to the particular needs of our time and acting on all components of the ecosystem simultaneously: technical, functional, operational, legal and business.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
Last March 13th, a session of the Mobility Working Group of the Gaia-X Spain Hub was held, addressing the main challenges of the sector regarding projects related to data sharing and exploitation. The session, which took place at the Technical School of Civil Engineers of the Polytechnic University of Madrid, allowed attendees to learn firsthand about the main challenges of the sector, as well as some of the cutting-edge data projects in the mobility industry. The event was also a meeting point where ideas and reflections were shared among key actors in the sector.
The session began with a presentation from the Ministry of Transport, Mobility, and Urban Agenda, which highlighted the great importance of the National Access Point for Multimodal Transport, a European project that allows all information on passenger transport services in the country to be centralized in a single national point, with the aim of providing the foundation for driving the development of future mobility services.
Next, the Data Office of the State Secretariat for Artificial Intelligence (SEDIA) provided their vision of the Data Spaces development model and the design principles of such spaces aligned with European values. The importance of business networks based on data ecosystems, the intersectoral nature of the Mobility industry, and the significant role of open data in the sector's data spaces were highlighted.
Next, use cases were presented by Vicomtech, Amadeus, i2CAT, and the Alcobendas City Council, which allowed attendees to learn firsthand about some examples of technology use for data sharing projects (both data spaces and data lakes).
Finally, an initial study by the i2CAT Foundation, FACTUAL Consulting, and EIT Urban Mobility on the basic components of future mobility data spaces in Spain was presented. The study, which can be downloaded here in Spanish, addresses the potential of mobility data spaces for the Spanish market. Although it focuses on Spain, it takes a national and international research approach, framed in the European context to establish standards, develop the technical components that enable data spaces, the first flagship projects, and address common challenges to achieve milestones in sustainable mobility in Europe.
The presentations used in the session are available at this link.
Blog
The European Commission's 'European Data Strategy' states that the creation of a single market for shared data is key. In this strategy, the Commission has set as one of its main objectives the promotion of a data economy in line with European values of self-determination in data sharing (sovereignty), confidentiality, transparency, security and fair competition.
Common data spaces at European level are a fundamental resource in the data strategy because they act as enablers for driving the data economy. Indeed, pooling European data in key sectors, fostering data circulation and creating collective and interoperable data spaces are actions that contribute to the benefit of society.
Although data sharing environments have existed for a long time, the creation of data spaces that guarantee EU values and principles is an issue. Developing enabling legislative initiatives is not only a technological challenge, but also one of coordination among stakeholders, governance, adoption of standards and interoperability.
To address a challenge of this magnitude, the Commission plans to invest close to €8 billion by 2027 in the deployment of Europe's digital transformation. Part of the project includes the promotion of infrastructures, tools, architectures and data sharing mechanisms. For this strategy to succeed, a data space paradigm that is embedded in the industry needs to be developed, based on the fulfilment of European values. This data space paradigm will act as a de facto technology standard and will advance social awareness of the possibilities of data, which will enable the economic return on the investments required to create it.
In order to make the data space paradigm a reality, from the convergence of current initiatives, the European Commission has committed to the development of the Simpl project.
What exactly is Simpl?
Simpl is a €150 million project funded by the European Commission's Digital Europe programme with a three-year implementation period. Its objective is to provide society with middleware for building data ecosystems and cloud infrastructure services that support the European values of data sovereignty, privacy and fair markets.
The Simpl project consists of the delivery of 3 products:
- Simpl-Open: Middleware itself. This is a software solution to create ecosystems of data services (data and application sharing) and cloud infrastructure services (IaaS, PaaS, SaaS, etc). This software must include agents enabling connection to the data space, operational services and brokerage services (catalogue, vocabulary, activity log, etc.). The result should be delivered under an open source licence and an attempt will be made to build an open source community to ensure its evolution.
- Simpl-Labs: Infrastructure for creating test bed environments so that interested users can test the latest version of the software in self-service mode. This environment is primarily intended for data space developers who want to do the appropriate technical testing prior to a deployment.
- Simpl-Live: Deployments of Simpl-open in production environments that will correspond to sectorial spaces contemplated in the Digital Europe programme. In particular, the deployment of data spaces managed by the European Commission itself (Health, Procurement, Language) is envisaged.
The project is practically oriented and aims to deliver results as soon as possible. It is therefore intended that, in addition to supplying the software, the contractor will provide a laboratory service for user testing. The company developing Simpl will also have to adapt the software for the deployment of common European data spaces foreseen in the Digital Europe programme.
The Gaia-X partnership is considered to be the closest in its objectives to the Simpl project, so the outcome of the project should strive for the reuse of the components made available by Gaia-X.
For its part, the Data Space Support Center, which involves the main European initiatives for the creation of technological frameworks and standards for the construction of data spaces, will have to define the middleware requirements by means of specifications, architectural models and the selection of standards.
Simpl's preparatory work was completed in May 2022, setting out the scope and technical requirements of the project which have been the subject of detail in the currently open contractual process. The tender was launched on 24 February 2023. All information is available on TED eTendering, including how to ask questions about the tendering process. The deadline for applications is 24 April 2023 at 17:00 (Brussels time).
Simpl expects to have a minimum viable platform published in early 2024. In parallel, and as soon as possible, the open test environment (Simpl-Labs) will be made available for interested parties to experiment. This will be followed by the progressive integration of different use cases, helping to tailor Simpl to specific needs, with priority being given to cases otherwise funded under the Europe DIGITAL work programme.
In conclusion, Simpl is the European Commission's commitment to the deployment and interoperability of the different sectoral data space initiatives, ensuring alignment with the specifications and requirements emanating from the Data Space Support Center and, therefore, with the convergence process of the different European initiatives for the construction of data spaces (Gaia-X, IDSA, Fiware, BDVA).
Noticia
Gaia-X represents an innovative paradigm for linking data more closely to the technological infrastructure underneath, so as to ensure the transparency, origin and functioning of these resources. This model allows us to deploy a sovereign and transparent data economy, which respects European fundamental rights, and which in Spain will take shape around the sectoral data spaces (C12.I1 and C14.I2 of the Recovery, Transformation and Resilience Plan). These data spaces will be aligned with the European regulatory framework, as well as with governance and instruments designed to ensure interoperability, and on which to articulate the sought-after single data market.
In this sense, Gaia-X interoperability nodes, or Gaia-X Digital Clearing House (GXDCH), aim to offer automatic validation services of interoperability rules to developers and participants of data spaces. The creation of such nodes was announced at the Gaia-X Summit 2022 in Paris last November. The Gaia-X architecture, promoted by the Gaia-X European Association for Data & Cloud AISBL, has established itself as a promising technological alternative for the creation of open and transparent ecosystems of data sets and services.
These ecosystems, federated by nature, will serve to develop the data economy at scale. But in order to do so, a set of minimum rules must be complied with to ensure interoperability between participants. Compliance with these rules is precisely the function of the GXDCH, serving as an "anchor" to deploy certified market services. Therefore, the creation of such a node in Spain is a crucial element for the deployment of federated data spaces at national level, which will stimulate development and innovation around data in an environment of respect for data sovereignty, privacy, transparency and fair competition.
The GXDCH is defined as a node where operational services of an ecosystem compliant with the Gaia-X interoperability rules are provided. Operational services" should be understood as services that are necessary for the operation of a data space, but are not in themselves data sharing services, data exploitation applications or cloud infrastructures. Gaia-X defines six operational services, of which at least two must be part of the mandatory nodes hosting the GXDCHs:
Mandatory services
- Gaia-X Registry: Defined as an immutable, non-repudiable, distributed database with code execution capabilities. Typically it would be a blockchain infrastructure supporting a decentralised identity service ('Self Sovereign Identity') in which, among others, the list of Trust Anchors or other data necessary for the operation of identity management in Gaia-X is stored.
- Gaia-X Compliance Service or Gaia-X Compliance Service: Belongs to the so-called Gaia-X Federation Services and its function is to verify compliance with the minimum interoperability rules defined by the Gaia-X Association (e.g. the Trust Framework).
Optional services
- Self-Descriptions (SDs) or Wizard Edition Service: SDs are verifiable credentials according to the standard defined by the W3C by means of which both the participants of a Gaia-X ecosystem and the products made available by the providers describe themselves. The aforementioned compliance service consists of validating that the SDs comply with the interoperability standards. The Wizard is a convenience service for the creation of Self-Descriptions according to pre-defined schemas.
- Catalogue: Storage service of the service offer available in the ecosystem for consultation.
- e-Wallet: For the management of verifiable credentials (SDs) by participants in a system based on distributed identities.
- Notary Service: Service for issuing verifiable credentials signed by accreditation authorities (Trust Anchors).
What is the Gaia-X Compliance Service (i.e. Compliance Service)?
The Gaia-X Compliance Service belongs to the so-called Gaia-X Federation Services and its function is to verify compliance with the minimum interoperability rules defined by the Gaia-X Association. Gaia-X calls these minimum interoperability rules (Trust Framework). It should be noted that the establishment of the Trust Framework is one of the differentiating contributions of the Gaia-X technology framework compared to other solutions on the market. But the objective is not just to establish interoperability standards, but to create a service that is operable and, as far as possible, automated, that validates compliance with the Trust Framework. This service is the Gaia-X Compliance Service.
The key element of these rules are the so-called "Self-Descriptions" (SDs). SDs are verifiable credentials according to the standard defined by the W3C by which both the participants of a data space and the products made available by the providers describe themselves. The Gaia-X Compliance service validates compliance with the Trust Framework by checking the SDs from the following points of view:
- Format and syntax of the SDs
- Validation of the SDs schemas (vocabulary and ontology)
- Validation of the cryptography of the signatures of the issuers of the SDs
- Attribute consistency
- Attribute value veracity.
Once the Self-Descriptions have been validated, the compliance service operator issues a verifiable credential that attests to compliance with interoperability standards, providing confidence to ecosystem participants. Gaia-X AISBL provides the necessary code to implement the Compliance Service and authorises the provision of the service to trusted entities, but does not directly operate the service and therefore requires the existence of partners to carry out this task.

Blog
The Spanish Hub of Gaia-X (Gaia-X Hub Spain), a non-profit association whose aim is to accelerate Europe's capacity in data sharing and digital sovereignty, seeks to create a community around data for different sectors of the economy, thus promoting an environment conducive to the creation of sectoral data spaces. Framed within the Spain Digital 2026 strategy and with the Recovery, Transformation and Resilience Plan as a roadmap for Spain's digital transformation, the objective of the hub is to promote the development of innovative solutions based on data and artificial intelligence, while contributing to boosting the competitiveness of our country's companies.
The hub is organized into different working groups, with a specific one dedicated to analyzing the challenges and opportunities of data sharing and exploitation spaces in the tourism sector. Tourism is one of the key productive sectors in the Spanish economy, reaching a volume of 12.2% of the national GDP.
Tourism, given its ecosystem of public and private participants of different sizes and levels of technological maturity, constitutes an optimal environment to contrast the benefits of these federated data ecosystems. Thanks to them, the extraction of value from non-traditional data sources is facilitated, with high scalability, and ensuring robust conditions of security, privacy, and thus data sovereignty.
Thus, with the aim of producing the first X-ray of this dataspace in Spain, the Data Office, in collaboration with the Spanish Hub of Gaia-X, has developed the report 'X-ray of the Tourism Dataspace in Spain', a document that seeks to summarize and highlight the current status of the design of this dataspace, the different opportunities for the sector, and the main challenges that must be overcome to achieve its deployment, offering a roadmap for its construction and deployment.
Why is a tourism data space necessary?
If something became clear after the outbreak of the COVID-19 pandemic, it is that tourism is an interdependent activity with other industries, so when it was paused, sectors such as mobility, logistics, health, agriculture, automotive, or food, among others, were also affected.
Situations like the one mentioned above highlight the possibilities offered by data sharing between sectors, as they can help improve decision-making. However, achieving this in the tourism sector is not an easy task since deploying a data space for this sector requires coordinated efforts among the different parts of society involved.
Thus, the objective and challenge is to create intelligent "spaces" capable of providing a context of security and trust that promotes the exchange and combination of data. In this way, and based on the added value generated by data, it would be possible to solve some of the existing problems in the sector and create new strategies focused on better understanding the tourist and, therefore, improving their travel experience.
The creation of these data sharing and exploitation spaces will bring significant benefits to the sector, as it will facilitate the creation of more personalized offers, products, and services that provide an enhanced and tailored experience to meet the needs of customers, thus improving the capacity to attract tourists. In addition, it will promote a better understanding of the sector and informed decision-making by both public and private organizations, which can more easily detect new business opportunities.
Challenges of security and data governance to take advantage of digital tourism market opportunities
One of the main obstacles to developing a sectoral data space is the lack of trust in data sharing, the absence of shared data models, or the insufficient interoperability standards for efficient data exchange between different existing platforms and actors in the value chain.
Moving to more specific challenges, the tourism sector also faces the need to combine B2B data spaces (sharing between private companies and organizations) with C2B and G2B spaces (sharing between users and companies, and between the public sector and companies, respectively). If we add to this the ideal need to land the tourism sector's datasets at the national, regional, and local levels, the challenge becomes even greater.
To design a sector data space, it is also important to take into account the differences in data quality among the aforementioned actors. Due to the lack of specific standards, there are differences in the level of granularity and quality of data, semantics, as well as disparity in formats and licenses, resulting in a disconnected data landscape.
Furthermore, it is essential to understand the demands of the different actors in the industry, which can only be achieved by listening and taking notes on the needs present at the different levels of the industry. Therefore, it is important to remember that tourism is a social activity whose focus should not be solely on the destination. The success of a tourism data space will also rely on the ability to better understand the customer and, consequently, offer services tailored to their demands to improve their experience and incentivize them to continue traveling.
Thus, as stated in the report prepared by the Data Office, in collaboration with the Spanish hub of Gaia-X, it is interesting to redirect the focus and shift it from the destination to the tourist, in line with the discovery and generation of use cases by SEGITTUR. While it is true that focusing on the destination has helped develop digital platforms that have driven competitiveness, efficiency, and tourism strategy, a strategy that pays the same attention to the tourist would allow for expanding and improving the available data catalogs.
Measuring the factors that condition tourists' experience during their visit to our country allows for optimizing their satisfaction throughout the entire travel circuit, while also contributing to creating increasingly personalized marketing campaigns, based on the analysis of the interests of different market segments.
Current status of the construction of the Spanish Tourism data space and next steps
The lack of maturity of the market in the creation of data spaces as a solution makes an experimental approach necessary, both for the consolidation of the technological components and for the validation of the different facets (soft infrastructure) present in the data spaces.
Currently, the Tourism Working Group of the Spanish Gaia-X Hub is working on the definition of the key elements of the tourism data space, based on use cases aligned with the sector's challenges. The objective is to answer some key questions, using existing knowledge in the field of data spaces:
- What are the key characteristics of the tourism environment and what business problems can be addressed?
- What data-oriented models can be worked on in different use cases?
- What requirements exist and what governance model is necessary? What types of participants should be considered?
- What business, legal, operational, functional, and technological components are necessary?
- What reference technology architecture can be used?
- What development, integration, testing, and technology deployment processes can be employed?
Blog
The promotion of the so-called data economy is one of the main priorities on which the European Union, in general, and Spain, in particular, are currently working. Having a single digital market for data exchange is one of the keys to achieving this momentum among the Member States, and data spaces come into play for this purpose.
Data Spaces Business Alliance (DSBA)
A data space is an ecosystem capable of realising the voluntary sharing of data among its participants, while respecting their sovereignty over it, i.e. being able to set the conditions for its access and use. The DSBA, founded in 2021, is composed of the main actors in the definition of standards, models and technological frameworks for the construction and operation of data spaces. Specifically, the alliance is composed of the Big Data Value Association (BDVA), the FIWARE Foundation and the Gaia-X European Association for Data and Cloud AISBL and the International Data Spaces Association (IDSA). The purpose of the alliance is to agree on a common technological framework that avoids technological fragmentation of the activity, as well as harmonisation in messaging and dissemination activities.
Technical Convergence Discussion Document
On the technological side, the DSBA published in September 2022 a first approximation of the desired technological convergence.
The document technically analyses the anchor points for creating trusted data spaces, federated catalogues and shared markets, and the ability to define data use policies (based on the use of a common language). This ability to share while respecting the sovereignty of the data owner is what makes these spaces novel and truly disruptive, offering for the first time technical elements with which to control the risks associated with information sharing.
The document explains, step by step and from a purely technical perspective, the actions to be addressed by each of the identified roles, with the purpose of guiding potential scenarios that could occur in reality.
To achieve technical convergence, the partnership agreed on the development of a minimum viable framework (MVF) based on three pillars:
- Interoperability in data exchange through the use of the standard NGSI-LD data exchange protocol/API and the extended Smart Data Models for the adoption of the information model defined by the IDS architecture.
- Sovereignty and trust in data exchange through the adoption of a decentralised model (Self-Sovereign Identity) as proposed by Gaia-X (with its Trust Framework) that would use the DLT (Distributed Ledger Technologies) promoted by the European Commission (EBSI). The result will be a trust environment compatible with the EU's eIDAS 2.0 regulation.
- Value creation (brokering) services consisting of a decentralised data catalogue and trading services based on TM Forum standards.
The alliance believes that this MVF would be a good starting point from which to work towards the desired technological convergence, counting and reusing parts of the current solutions provided by the different suppliers.
Example of a public data marketplace
The paper gives the example of a data service provider offering its service in a public data marketplace, so that consumers can easily access this offer. In addition, providers can also delegate access to their users to modify attributes of the service they contract.
This is an example that can be seen in detail in the document, which is interesting because different authentication systems, security and access policies and, in short, different systems that must interoperate with each other come into play.

Additionally, an example of integration between the Data Marketplace and a data catalogue is presented using the approach followed by the European Horizon 2020 project 'Digital Open Marketplace Ecosystem' (DOME). In this way, offers are created in the shared catalogue and can be subsequently consulted following the defined access policies.
The future of the DSBA
The DSBA considers that the aforementioned MVF is only the first step towards the convergence of the different existing architectures and technologies in the construction of data spaces. The next steps of the alliance will take into account the roles assigned to each of the participants. More specifically:
-
IDSA: Develops data space architectures and standards. In particular, a model for connectors to ensure sovereign data sharing in a scalable way.
-
Gaia-X: Develops and deploys an architecture, a governance model according to business specifications for sectoral data spaces, as well as a toolkit (Gaia-X Federation Services toolkit) to instantiate interoperability, composability and transparency of infrastructure and cloud data services.
- FIWARE: With a technology stack that comes from the world of Digital Twins, the community develops software components that allow to implement the construction of data spaces.
The DSBA has also set itself the following priority objectives:
- The compatibility of the IDS architecture with an identity management mechanism based on decentralised identifiers.
- The integration of a federated catalogue such as the one proposed with the metadata broker proposed in the IDS architecture.
- The definition of a common vocabulary.
- Advancing jointly with the work of the Data Space Support Center (a programme funded by the European Commission, where these associations play a leading role), as well as with the standardisation efforts based on the EC's Smart Middleware Platform (SIMPL) project.
Content prepared by Juan Mañes, expert in Data Governance.
The contents and views expressed in this publication are the sole responsibility of the author.
Noticia
On 20 October, Madrid hosted a new edition of the Data Management Summit Spain, an international summit that this year also took place in Italy (7 July) and Latam (20 September). The event brought together CiOs, CTOs, CDOs, Business Intelligence Officers and Data Scientists in charge of implementing emerging technologies in order to solve new technological challenges aligned with new business opportunities.
This event was preceded by a prologue held the previous evening, in collaboration with DAMA Spain and the Data Office. This was a session aimed exclusively at representatives of different levels of public administration and focused on open data and information sharing between administrations. During the day, participants discussed the transformative role of data and how its intensive use and enhancement are essential to achieve the digital transformation of public administrations.
As was mentioned in the session, data plays an essential role in the development of disruptive technologies such as Artificial Intelligence, and is a differential factor when it comes to launching an industrial and technological revolution that allows for the consolidation of a fairer, more inclusive digital economy in line with the SDGs and the 2030 Agenda. A true data economy with the vocation to nurture the development of two key and strategic processes for the reconstruction of our country: the digital transformation and the ecological transition.
Data spaces and open data, key to achieving data-driven government
The institutional opening was given by Carlos Alonso, Director of the Data Office Division. His speech focused on highlighting how the achievement of a data-oriented administration, an inseparable part of its digital transformation process, depends on the development of public sector data spaces, which enable data sharing with sovereignty and its large-scale exploitation. Data is a public good, to be preserved and processed in order to implement quality public services and policies. The aim is to achieve a data-driven, citizen-centred, open, transparent, inclusive, participatory and egalitarian administration, ensuring ethical, secure and responsible use of data.
In this process of designing public and private sector data spaces, open data is fundamental, as Carlos Alonso highlighted during his speech: "Data spaces are major consumers and generators of open data, and their availability must be ensured. That is, it is necessary to establish certain service level agreements to ensure access".
Sharing experiences between administrations
After this institutional opening, the conference addressed the opportunity provided by the creation of spaces for sharing and exploiting data in public administrations, and allowed for the dissemination of different data-related projects by representatives of the different administrative levels, including autonomous communities and local entities.
Andreu Francisco, Director General of the Localret consortium, formed by the local administrations of Catalonia for the development of telecommunications services and networks and the application of ICT, presented a digital metamodel, which aims to structure the technological architecture and services required in a digital city. It is a comprehensive solution that can be implemented in different territories and personalised according to the singularities of each city, making it easier for the inhabitants of the 877 Catalan municipalities to develop professionally and personally.
César Priol, Director General of Digitalisation and Citizen Services, of Bizkaiko Foru Aldundia (Basque Country) shared his experience in the creation of the Data Office, highlighting the importance of self-organising on an organisational, regulatory and legal level in order to have the capacity to transform not only the organisation, but also the territory with data.
Magda Lorente, Head of the Local Information Systems Assistance Section, and Sara Aguilar, Head of the Service of the Official Gazette of the Province of Barcelona and other Official Publications of the Barcelona Provincial Council, spoke of good practices in data management. Magda Lorente highlighted the importance of the Diputacions becoming data-oriented in order to assume their relevant role in the promotion of municipal data governance. According to a study carried out by the Diputació de Barcelona, which will be published at the end of November, 85% of municipalities could be left out of artificial intelligence and intelligent administration because their technical capacities do not allow them to materialise the necessary data orientation.
Sara Aguilar, for her part, presented an example of how the administrations are consolidating the way in decision-making based on quality data: the CIDO, a search engine for official information and documentation. This tool was created in 2000 with the aim of bringing government information closer to citizens in a user-friendly way. It provides access, for example, to more than 2,600 selection processes with open calls for applications and 1,600 open subsidies, thanks to the open data offered by the different municipalities of Catalonia. CIDO is based on a tag reader model and the use of artificial intelligence algorithms, which classify the information collected from the municipalities. They have more than 2 million ads, structured and documented open data that they serve through an API that can be integrated into any platform.
Roundtables and group dynamics to promote debate
During the course of the day, attendees were able to participate in different dynamics for the exchange of experiences. The first dynamic focused on open data and the second on interoperability.
In addition, two round tables were held, which allowed the subject to be approached from different points of view:
- The first round table, moderated by Carlos Alonso, focused on the challenges and barriers to data exchange in the public sector. Current methodologies, specifications and practices related to the processing of information, in order to achieve a fluid and continuous exchange of data between administrations, industrial sectors and citizens, were projected on a larger scale. The round table was attended by: Carlos Alonso, Jose Antonio Eusamio (General Secretariat for Digital Government), César Priol (Vizcaya Provincial Council), Miguel Angel Martinez Vidal (INE) and Magda Lorente.
- The second round table focused on how to accelerate the adoption of Open Linked Data in the public administration domain, moderated in this case by Oscar Alonso (IBM Consulting & DAMA Spain). Participants included Sara Aguilar (Barcelona Provincial Council), Oscar Alonso (DAMA Spain & IBM), Sonia Castro (datos.gob.es), Juan José Alonso (Orange) and Olga Quiros (ASEDIE). The conversation revolved around EU initiatives, such as the Data Governance Act, which are acting as a turning point in data policies. The act seeks to establish robust mechanisms to facilitate the re-use of certain categories of protected public sector data, increase trust in data brokering services and promote data altruism across the EU. This highlights how the EU is working to strengthen various data sharing mechanisms to promote the availability of data that can be used to drive advanced applications and solutions in artificial intelligence, personalised medicine, green mobility, smart manufacturing and many other areas. The importance of data ethics was also highlighted during the debate.
Materials available on the day
If you missed the session, the video is available on Youtube. The recording of the summit on the 20th has also been made public, a session that had a more business-oriented approach, with expert presentations and group dynamics focused on data governance, data quality, master data and data architecture, among other topics. Photos from the event are also available.
In addition, interviews with some of the speakers have been published on the summit's website, allowing a deeper insight into the projects they are carrying out.