Blog
A data space is the place where value is generated around data through voluntary sharing in an environment of sovereignty, trust and security. The data space enables you to determine who accesses what data and under what conditions, thus facilitating the deployment of different use cases to meet different business needs. The data space functions as an open and heterogeneous environment of providers and consumers of data products, with no dominant players and no disproportionate barriers to entry and exit.
The data space is the place for sustainable value generation around data, a catalyst for innovation and business growth, allowing to identify market opportunities, anticipate trends, make better informed decisions, increase operational efficiency, develop transformative products and services or personalise customer experiences.
Within the concept of data space, and beyond a bilateral exchange of information, there is room for both centralised environments of information aggregation and generation of value-added services, with or without financial compensation, and more innovative data sharing environments (typically federated and distributed). The former can be seen as fundamental building blocks for the latter, and in any case, full interoperability of the deployed solutions and their future scalability should be sought.
The data space is the ideal scenario for deploying a variety of advanced technologies to efficiently explore data sets and turn them into information. This creates an environment conducive to innovation and process optimisation, resulting in a landscape in which information becomes a strategic resource for growth and informed decision-making. The data space enables the use of advanced analytics tools (business intelligence, big data, machine learning, deep learning, etc.), generative algorithms (LLM, GPT), process automation (RPA), and/or advanced data preservation techniques (DLTs).
In practice, a data provider (formally incorporated in the corresponding data space) will make its data products accessible through a catalogue, managed according to the indications of the data space promoter. When a participant wishes to access a product, it will look for the availability of such information, studying its conditions of access and use, as well as the appropriateness of its semantics and vocabulary. If the characteristics detailed in the catalogue meet his/her expectations, he/she will establish the appropriate negotiation and proceed to establish an effective transfer between supplier and consumer, in accordance with the technical conditions set out in the catalogue.
What does the data space offer to each type of participant?
There are four types of participants in a data space:
1) Data space promoter:
It is the driver of the sharing and operating environment, and will therefore be responsible for its governance and management (and may delegate some operational parts). It will therefore be the guarantor of the generation of community around the data space, articulating different business models and seeking and attracting new participants, thus dynamising innovation and the development of new value-added services.
Different business models can be generated within the data space. These include:
- Monetisation of data on a bilateral basis.
- Markets as a meeting point between suppliers and consumers.
- The marketing of software products or services for data analysis and exploitation.
- The facilitation of technological solutions to mediate the identification of participants or the exchange between them.
- The development of industrial platforms integrating the value chain.
- Making data openly available altruistically.
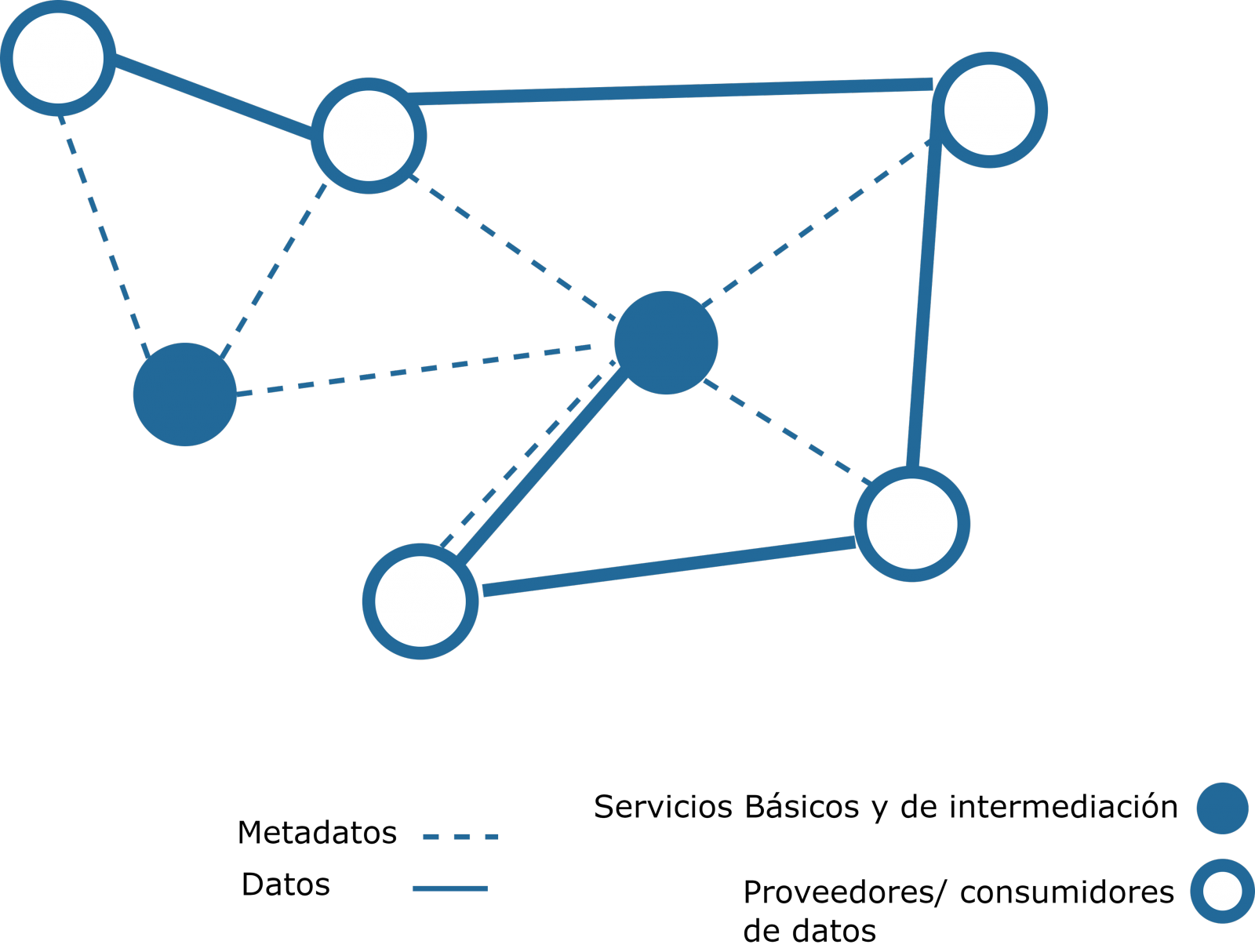
2) Providers of data sets and services:
They offer data products (both sets and services) within the contours of rights and obligations defined by the data space developer .
Thanks to cybersecurity and the sovereignty capabilities it provides, the barriers and risks associated with sharing are lowered, thus facilitating the generation of value and the return on the investment involved in making resources available. Moreover, the technological uncertainties linked to the deployment of innovative business models are partially mitigated by the use of standard frameworks and solutions (provided by the technology specifier and the technology provider, respectively).
Providers of data sets and services can opt for different revenue generation models, such as:
- Provide free access to the data, thus seeking to generate a high volume of traffic to attract sponsors or advertisers.
- Deploy a type of freemiun access free of charge for specific data and services, but at a cost for specific or higher quality services and data.
- Establish temporary or continuous licensing agreements.
- Define dynamic costing systems linked to timely demand or complexity of access
- Deploy a collaborative sharing system where access to other people's data is linked to sharing one's own data ( quid-pro-quomodel).
3) Consumers of data sets and services:
They consume data products within the contours of rights and obligations defined by the data space developer.
It allows them to benefit by incorporating the value of third-party data (from different suppliers) into their system by consolidating or combining it with their own data. The information and knowledge generated from this shared data makes it possible to solve business problems that would be unmanageable on an individual basis, adding value to the business itself.
The value proposition of the data consumer can go through:
- Acting on one's own behalf, for personal consumption and profit.
- Acting as a data broker, connecting organisations with fewer resources or maturity, and thus offering trust.
- It plays the role of a reuser, which is able to generate value-added services on the data space by reworking the information provided.
Precisely in the sense of risk mitigation and confidence building, the use of standard solutions (provided by the technology provider of the data space, which we will see below) serves to ensure service levels(business continuity) and the reduction of technological risks, as well as to avoid registration on multiple platforms or the management of complex and diverse authorisation and access processes.
4) Technology provider:
It is in charge of integrating and operating the technical solution that enables the deployment of the data space infrastructure (on behalf of, under the governance and management of the developer). This provider will carry out the development, configuration and parameterisation to implement the technical solution to deploy the data space, practically as a service ready for consumption. For this purpose, a basic physical infrastructure will be used, on top of which technological components will be added to enable adequate management of participants' identities, as well as all other functionalities that characterise the data space in question (and which will typically follow a reference architecture).
The provider will therefore make precise use of different enabling technologies for the governance and management of the data space, from the deployment of privacy-enhancing technologies to ensure the proper treatment of protected information, to tools to automate contractual compliance and guarantee sovereignty.
It is important to note that this figure of the "data space technology provider" does not coincide with that of the data technology service provider within the already operational data space itself. The former deploys and operates the technologies necessary to shape the ecosystem, within which the latter operates, offering ad-hoc solutions (which could in any case include the former organisation, as permitted by the competition regulations of the sector in which the data space operates, as well as its specific governance).
Blog
Data has become the great transforming power of society. Beyond the more mercantilist view, its capacity to generate knowledge, drive innovation and empower individuals and communities is undeniable. Indeed, it is a resource with which to address, from an innovative perspective, major environmental, social and health challenges, enabling collaboration between actors, driving innovation and improving accountability.
Following European guidelines such as the European Data Strategy, the challenge now is to promote the circulation of data for the benefit of all, by pooling data in key sectors with the creation of common and interoperabledata spaces. A data space is an ecosystem where the voluntary sharing of its participants' data takes place within an environment of sovereignty, trust and security, established through integrated governance, organisational, regulatory and technical mechanisms. Data spaces are key to the development of the data economy, enabling access, exchange and legitimate re-use, positioning data as a non-rivalrous resource, whose utility grows as its use becomes more widespread, in a clear example of the network effect.
What are the Coordinated Support Actions (CSA)?
In order to foster the development of data spaces, the European Commission's Digital Europe Programme (DIGITAL) is funding a series of Coordinated Support Actions (CSA) to foster their development. Most of these actions have a funding of around one million euros per project and a duration of approximately one year, with an expected completion date in the fourth quarter of 2023. Their results should contribute to the objectives of the DIGITAL programme, which aims to bridge the gap between research and deployment of digital technologies, and to facilitate the transfer of research results to the market, to the benefit of European citizens and businesses, especially small and medium-sized ones.
Each concrete action focuses on a particular sector of economic activity seeking, based on a mapping of the data landscape of each sector concerned, to contact and connect relevant stakeholders, seeking to collaboratively develop a shared strategic roadmap. This shared roadmap ultimately aims to eventually build up the corresponding sectoral data spacesin subsequent phases. During the process, clear objectives and key results are defined to inspire, support and motivate all stakeholders to contribute and use high quality sectoral data as a basis for innovation and value generation.
In order to carry out this roadmap, a comprehensive inventory of existing platforms that already share relevant data has been drawn up. In addition, each CSA project has focused, through different working groups and stakeholder workshops, on developing recommendations on governance models for data spaces and digital business models for their sector. The aim is to identify key success factors and outline how a data space can create value and benefits not only for the sector in question but also for other sectors with which it is interlinked. In addition, plans to address the technical and organisational challenges that drive the use of interoperability standards are made in the different projects in close collaboration with the Data Spatial Support Centre (DSSC) in order to align with the European Technological Framework for Data Spaces.
Where can I find up-to-date information on CSAs?
Concrete information on the state of play of the different coordination and support actions can be found on their websites through the following links:
 |
DATES (Tourism) |
 |
Tourism Data Space (Tourism) |
 |
DS4SKills (Skills) |
 |
PrepDSpace4Mobility (Mobility) |
 |
AgriDataSpace (Agri-food) |
 |
Great (Environmental) |
 |
DataSp4ce (Industrial) |
 |
DS4SSCC (Smarts Cities) |
The outcome of these coordinated support actions will provide the information and the basis for the correct execution of the projects for the development and implementation (\"deployments\") of the Common European Data Spaces, which will be supported by different European programmes. This will catalyse the creation of a single data market, based on reliable and quality data, which will enable the digitisation of industries' value chains. Moreover, its effective development will support the European Union's objectives of achieving a green transition and a digital transformation, and of strengthening its resilience and strategic autonomy.
Blog
Building Europe's digital infrastructure of tomorrow
As a global technology race unfolds, Europe is deploying the regulatory framework and investments needed to foster innovation and technological leadership in areas such as online platforms, artificial intelligence, data, cloud, quantum technologies and virtual worlds. In today's rapidly changing economic context, a state-of-the-art telecommunications infrastructure is a key pillar for growth, innovation and job creation.
For this technological revolution to succeed, says EC Internal Market Commissioner Thierry Breton, it must be ensured that European networks are up to the task in terms of transmission speed, storage capacity, computing power and interoperability. To this end, it will seek to promote a Digital Networks Act that will serve to redefine the DNA of Europe's telecommunications sector.
Exploratory consultation on the future of the electronic communications sector and its infrastructure
From 23 February to 19 May 2023, the European Commission conducted an exploratory consultation on the future of the electronic communications sector and its infrastructure. The aim was to gather views from different stakeholders, in particular on the technological and market changes affecting the sector, as well as the types of infrastructure and investments that Europe is expected to need to lead the digital transformation in the coming years. The consultation was divided into four areas: (i) technological and market developments, (ii) fairness for consumers, (iii) barriers to the single market and (iv) fair contribution of all digital actors.
The Commission received close to 500 responses to the consultation from different interest groups such as companies (including network providers as well as large traffic generators), business associations, citizens, non-governmental organisations, academic institutions, consumer organisations and trade unions, as well as comments from public authorities. Most of the responses came from the EU, although there were also participants from other invited countries such as the United States and the United Kingdom.
From the exploratory consultation on the future of the electronic communications sector and its infrastructure, the following conclusions can be drawn:
- The need for innovation and efficient investment in technologies such as network virtualisation, artificial intelligence, open networks and perimeter cloud (in that order of importance), recognising that these will have a substantial impact on the sector in the coming years by driving cost reductions. Network virtualisation is expected to be the technology with the greatest impact by enabling greater flexibility and improved network efficiency, offering a great opportunity to develop new business models. In terms of investment, most respondents expect that a significant part of their annual revenues in the coming years (up to 50% of revenues) will have to be spent on investments in connectivity infrastructure and replacement of devices from providers considered high risk. Public funding is seen as crucial, but questions remain as to whether it will be enough and how to attract more private investment.
- The second conclusion, relating to consumer equity, is that the majority of respondents indicate that overall broadband access prices will decrease in the coming years, although there is more discrepancy when considering high transmission speeds. There is also no consensus among respondents on the effectiveness/efficiency of the Universal Service Obligation rules to protect consumers with special needs, and there is also disagreement on whether it should continue to be financed by the public budget or by network providers.
- It also points to the importance of harnessing the single market to drive investment and innovation, cooperating on key technology developments, and standardising technologies and platform building, so as to support the deployment of initiatives based on federated, interoperable and open source models. The majority of responses indicate that streamlining and simplifying regulation by harmonising best practices at EUlevel would serve to reduce administrative burdens, supply chain and/or regulatory costs, thereby increasing efficiency and speed of infrastructure deployment.
- The fourth conclusion focuses on the need to protect EU networks. In an interconnected world with growing geopolitical tensions, security is critical. Despite advances in the security of 5G networks, gaps remain in the protection of network infrastructure. A more coordinated European approach, especially with regard to further integration of radio spectrum, and with a better aligned auction model and licensing conditions between regions, could improve coverage in border areas and strengthen the EU against harmful external interference.
- Finally, as regards the contribution of digital players to network roll-out, several telco providers anticipate a negative outlook for the next 5 years, driven by the continued fall in unit prices (in terms of EUR/Mbps), which offset the potential revenues from increased data traffic and, therefore, to the detriment of the investments needed to support such traffic. More than half of the respondents answered in the affirmative on the question of whether large digital players should contribute in a fair and proportionate way to the costs of public goods, services and infrastructure, and on the potential introduction of a mandatory mechanism for direct payments from content application providers.
The role of communications networks in the development of data spaces
The data spaces are ecosystems from which to realise the voluntary sharing of data among their participants, based on the creation of an environment of sovereignty, trust and cybersecurity. In contrast to traditional monolithic models, data spaces are virtual, federated environmentsand are therefore established through integrated governance, organisational, regulatory and technical mechanisms.
Data spaces ensure that a large amount of data and algorithms are available for use in the economy and society, while the companies, organisations and individuals that generate these resources retain control over them. As such, these data sets and algorithms will aspire to maintain their residence in the computer systems of their respective owners, connecting with others on an ad hoc basis according to precise needs, which is why data spaces require a renewed infrastructure of communication networks. Based on 5G (or even 6G) technology, data transmission with lower latency and higher capacity is enabled, and also drives the development of edge computing solutions (edge computing), which allow added flexibility for the emerging European Data Economy.
Likewise, operators, through initiatives such as Open Gateway, will also be able to transform their telecommunication networks into value-added platforms, making their capabilities more flexible and available through standardised APIs, with which to develop new applications and digital solutions of greater complexity and scope. Such developments may encourage the participation, collaboration and interoperability of the different actors in the data spaces, with telecommunications operators also playing an important role as facilitators, not only in the development of use cases, but also in the implementation and operation of these use cases.
Blog
The regulatory approach in the European Union has taken a major turn since the first regulation on the reuse of public sector information was promoted in 2003. Specifically, as a consequence of the European Data Strategy approved in 2020, the regulatory approach is being expanded from at least two points of view:
-
on the one hand, governance models are being promoted that take into account the need to integrate, from the design and by default, respect for other legally relevant rights and interests, such as the protection of personal data, intellectual property or commercial secrecy, as has happened in particular through the Data Governance Regulation;
-
on the other hand, extending the subjective scope of the rules to go beyond the public sector, so that obligations specifically aimed at private entities are also beginning to be contemplated, as shown by the approval in November 2023 of the Regulation on harmonized rules for fair access to and use of data (known as the Data Act).
In this new approach, data spaces take on a singular role, both in terms of the importance of the sectors they deal with (health, mobility, environment, energy...) and, above all, because of the important role they are called upon to play in facilitating the availability of large amounts of data, specifically in overcoming the technical and legal obstacles that hinder their sharing. In this regard, in Spain we already have a legal provision in this regard, which has materialized with the creation of a specific section in the Public Sector Procurement Platform.
The Strategy itself envisages the creation of "a common European data space for public administrations, in order to improve transparency and accountability of public spending and the quality of spending, fight corruption at both national and EU level, and address compliance needs, as well as support the effective implementation of EU legislation and encourage innovative applications". At the same time, however, it is recognized that "data concerning public procurement are disseminated through various systems in the Member States, are available in different formats and are not user-friendly", concluding the need, in many cases, to "improve the quality of the data".
Why a data space in the field of public procurement?
Within the activity carried out by public entities, public procurement stands out, whose relevance in the economy of the EU as a whole reaches almost 14% of GDP, so it is a strategic pole to boost a more innovative, competitive and efficient economy. However, as expressly recognized in the Commission's Communication Public Procurement: A Data Space to improve public spending, boost data-driven policy making and improve access to tenders for SMEs published in March 2023, although there is a large amount of data on public procurement, however "at the moment its usefulness for taxpayers, public decision-makers and public purchasers is scarce".
The regulation on public procurement approved in 2014 incorporated a strong commitment to the use of electronic media in the dissemination of information related to the call for tenders and the awarding of procedures, although this regulation suffers from some important limitations:
-
refers only to contracts that exceed certain minimum thresholds set at European level, which limits the measure to 20% of public procurement in the EU, so that it is up to the States themselves to promote their own transparency measures for the rest of the cases;
-
does not affect the contractual execution phase, so that it does not apply to such relevant issues as the price finally paid, the execution periods actually consumed or, among other issues, possible breaches by the contractor and, if applicable, the measures adopted by the public entities in this respect;
-
although it refers to the use of electronic media when complying with the obligation of transparency, it does not, however, contemplate the need for it to be articulated on the basis of open formats that allow the automated reuse of the information.
Certainly, since the adoption of the 2014 regulation, significant progress has been made in facilitating the standardization of the data collection process, notably by imposing the use of electronic forms for the above-mentioned thresholds as of October 25, 2023. However, a more ambitious approach was needed to "fully leverage the power of procurement data". To this end, this new initiative envisages not only measures aimed at decisively increasing the quantity and quality of data available, but also the creation of an EU-wide platform to address the current dispersion, as well as the combination with a set of tools based on advanced technologies, notably artificial intelligence.
The advantages of this approach are obvious from several points of view:
-
on the one hand, it could provide public entities with more accurate information for planning and decision-making;
-
on the other hand, it would also facilitate the control and supervision functions of the competent authorities and society in general;
-
and, above all, it would give a decisive boost to the effective access of companies and, in particular, of SMEs to information on current or future procedures in which they could compete.
What are the main challenges to be faced from a legal point of view?
The Communication on the European Public Procurement Data Space is an important initiative of great interest in that it outlines the way forward, setting out the potential benefits of its implementation, emphasizing the possibilities offered by such an ambitious approach and identifying the main conditions that would make it feasible. All this is based on the analysis of relevant use cases, the identification of the key players in this process and the establishment of a precise timetable with a time horizon up to 2025.
The promotion of a specific European data space in the field of public procurement is undoubtedly an initiative that could potentially have an enormous impact both on the contractual activity of public entities and also on companies and, in general, on society as a whole. But for this to be possible, major challenges would also have to be addressed from a legal perspective:
Firstly, there are currently no plans to extend the publication obligation to contracts below the thresholds set at European level, which would mean that most tenders would remain outside the scope of the area. This limitation poses an additional consequence, as it means leaving it up to the Member States to establish additional active publication obligations on the basis of which to collect and, if necessary, integrate the data, which could pose a major difficulty in ensuring the integration of multiple and heterogeneous data sources, particularly from the perspective of interoperability. In this respect, the Commission intends to create a harmonized set of data which, if they were to be mandatory for all public entities at European level, would not only allow data to be collected by electronic means, but also to be translated into a common language that facilitates their automated processing.
Secondly, although the Communication urges States to "endeavor to collect data at both the pre-award and post-award stages", it nevertheless makes contract completion notices voluntary. If they were mandatory, it would be possible to "achieve a much more detailed understanding of the entire public procurement cycle", as well as to encourage corrective action in legally questionable situations, both as regards the legal position of the companies that were not awarded the contracts and of the authorities responsible for carrying out audit functions.
Another of the main challenges for the optimal functioning of the European data space is the reliability of the data published, since errors can often slip in when filling in the forms or, even, this task can be perceived as a routine activity that is sometimes carried out without paying due attention to its execution, as has been demonstrated by administrative practice in relation to the CPVs. Although it must be recognized that there are currently advanced tools that could help to correct this type of dysfunction, the truth is that it is essential to go beyond the mere digitization of management processes and make a firm commitment to automated processing models that are based on data and not on documents, as is still common in many areas of the public sector. Based on these premises, it would be possible to move forward decisively from the interoperability requirements referred to above and implement the analytical tools based on emerging technologies referred to in the Communication.
The necessary adaptation of European public procurement regulations
Given the relevance of the objectives proposed and the enormous difficulty involved in the challenges indicated above, it seems justified that such an ambitious initiative with such a significant potential impact should be articulated on the basis of a solid regulatory foundation. It is essential to go beyond recommendations, establishing clear and precise legal obligations for the Member States and, in general, for public entities, when managing and disseminating information on their contractual activity, as has been proposed, for example, in the health data space.
In short, almost ten years after the approval of the package of directives on public procurement, perhaps the time has come to update them with a more ambitious approach that, based on the requirements and possibilities of technological innovation, will allow us to really make the most of the huge amount of data generated in this area. Moreover, why not configure public procurement data as high-value data under the regulation on open data and reuse of public sector information?
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec). The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Two of the European Union's most relevant data regulations will soon articulate the legal contours that will delineate the development of the data economy in the coming years. The Data Governance Act (DGA) has been fully applicable since September 24, 2023, while the wording of the Data Act (DA) was approved on November 27.
They are not the only ones, as the legal framework already includes other important rules that regulate interconnected matters, thus revealing the proactive approach of the European Union in establishing rules of the game in line with the needs of European citizens and businesses. These guidelines provide the necessary legal security environment to achieve the ultimate goal of promoting a European Digital Single Market.
In the case of the DGA and the DA, the negotiations for their approval have shown that their objectives were shared by the stakeholders concerned. For both, data is a central element for digital transformation, and they share an interest in eliminating or reducing the barriers and obstacles to its sharing. They thus assume that data-driven innovation will bring enormous benefits to citizens and the economy. Therefore, creating legal frameworks that facilitate such processes is a common goal for companies, institutions and citizens.
The contributions from the academic, business and associative worlds have been abundant and enriching, both for the drafting phase of the standards and for what will be their implementation and development in practice. One of the most reiterated questions is the concern about how the different standards of this 'digital regulatory package' will interact. Particularly important is the interaction with the General Data Protection Regulation, which is why DGA and DA have established general guidelines on the pre-eminence of said regulation in case of conflict. In this regard, the increase in regulation does not prevent specific situations from arising in practice around key concepts in the field of personal data, such as consent, purposes of processing, anonymization, or portability.
Another of the issues highlighted has to do with the search for synergies between this regulation and current or future data business models. The recognized overall goal is to boost the development of data spaces and the data economy as a whole. This goal will be closer to the extent that the 'regulatory burden' does not reduce the incentives for companies to invest in collecting and managing data; that it does not weaken the competitive position of European companies (by adequately protecting trade secrets, intellectual property rights and confidentiality); and that there is an appropriate balance between general and business interests.
The case of the Data Governance Act
In the case of the DGA, the provisions related to data brokering services ––one of the central parts of the regulation–– occupied a significant part of the previous analyses carried out. For example, the question was raised as to what extent SMEs and start-ups could compete with large technology companies in the provision of these services; or whether, by requiring the structural separation required of data brokering service providers (through a separate legal entity), there could be problems related to other functionalities of the same companies.
Along the same lines, the question arises as to whether a more decentralized data economy requires new intermediaries, or whether under the new legal formulation, they can successfully compete in data markets through alternative, non-vertically integrated business models.
Considerations on the deployment of the Data Act
With regard to the DA, the final wording of the regulation clarified its scope, the definition of concepts and the categorization of data, as suggested by the industry. The specific sectoral application to be developed subsequently will further define those concepts and interpretations that provide the desirable legal certainty.
This legal certainty has also been argued in relation to trade secrets, intellectual property rights and confidentiality; an aspect that the Regulation seeks to address with safeguards aimed at preventing misuse and fraud.
Other aspects that attracted attention were compensation for making data available; dispute resolution procedures; provisions on unfair contract terms (aimed at compensating for imbalances in bargaining power); making data available in case of exceptional need; and, finally, provisions on switching from one data processing service provider to another.
A positive starting point
The starting point, in any case, is positive. The data economy in the European Union is taking hold on the basis of the European Data Strategy and the regulatory package that develops it. There are also practical examples of the potential of the industrial ecosystems that are being deployed around the Common European Data Spaces in sectors such as tourism, mobility and logistics, and agri-food, among others. In addition, initiatives that bring together public and private interests in this area are making significant progress in the deployment of technical and governance foundations, strengthening the competitive position of European companies, and achieving the ultimate goal of a single data market in the European Union.
Click here for an extended version of this note.
Blog
The European Union aims to boost the Data Economy by promoting the free flow of data between member states and between strategic sectors, for the benefit of businesses, researchers, public administrations and citizens. Undoubtedly, data is a critical factor in the industrial and technological revolution we are experiencing, and therefore one of the EU's digital priorities is to capitalise on its latent value, relying on a single market where data can be shared under conditions of security and, above all, sovereignty, as this is the only way to guarantee indisputable European values and rights.
Thus, the European Data Strategy seeks to enhance the exchange of data on a large scale, under distributed and federated environments, while ensuring cybersecurity and transparency. To achieve scale, and to unlock the full potential of data in the digital economy, a key element is building trust. This, as a basic element that conditions the liquidity of the ecosystem, must be developed coherently across different areas and among different actors (data providers, users, intermediaries, service platforms, developers, etc.). Therefore, their articulation affects different perspectives, including business and functional, legal and regulatory, operational, and even technological. Therefore, success in these highly complex projects depends on developing strategies that seek to minimise barriers to entry for participants, and maximise the efficiency and sustainability of the services offered. This in turn translates into the development of data infrastructures and governance models that are easily scalable, and that provide the basis for effective data exchange to generate value for all stakeholders.
A methodology to boost data spaces
Spain has taken on the task of putting this European strategy into practice, and has been working for years to create an environment conducive to facilitating the deployment and establishment of a Sovereign Data Economy, supported, among other instruments, by the Recovery, Transformation and Resilience Plan. In this sense, and from its coordinating and enabling role, the Data Office has made efforts to design a general conceptual methodology , agnostic to a specific sector. It shapes the creation of data ecosystems around practical projects that bring value to the members of the ecosystem.
Therefore, the methodology consists of several elements, one of them being experimentation. This is because, by their flexible nature, data can be processed, modelled and thus interpreted from different perspectives. For this reason, experimentation is key to properly calibrate those processes and treatments needed to reach the market with pilots or business cases already close to the industries, so that they are closer to generating a positive impact. In this sense, it is necessary to demonstrate tangible value and underpin its sustainability, which implies, as a minimum, having:
- Frameworks for effective data governance
- Actions to improve the availability and quality of data, also seeking to increase their interoperability by design
- Tools and platforms for data exchange and exploitation.
Furthermore, given that each sector has its own specificity in terms of data types and semantics, business models, and participants' needs, the creation of communities of experts, representing the voice of the market, is another key element in generating useful projects. Based on this active listening, which leads to an understanding of the dynamics of data in each sector, it is possible to characterise the market and governance conditions necessary for the deployment of data spaces in strategic sectors such as tourism, mobility, agri-food, commerce, health and industry.
In this process of community building, data co-operatives play a fundamental role, as well as the more general figure of the data broker, which serves to raise awareness of the existing opportunity and favour the effective creation and consolidation of these new business models.
All these elements are different pieces of a puzzle with which to explore new business development opportunities, as well as to design tangible projects to demonstrate the differential value that data sharing will bring to the reality of industries. Thus, from an operational perspective, the last element of the methodology is the development of concrete use cases. These will also allow the iterative deployment of a catalogue of reusable experience and data resources in each sector to facilitate the construction of new projects. This catalogue thus becomes the centrepiece of a common sectoral and federated platform, whose distributed architecture also facilitates cross-sectoral interconnection.
On the shoulders of giants
It should be noted that Spain is not starting from scratch, as it already has a powerful ecosystem of innovation and experimentation in data, offering advanced services. We therefore believe it would be interesting to make progress in the harmonisation or complementarity of their objectives, as well as in the dissemination of their capacities in order to gain capillarity. Furthermore, the proposed methodology reinforces the alignment with European projects in the same field, which will serve to connect learning and progress from the national level to those made at EU level, as well as to put into practice the design tasks of the "cyanotypes" promulgated by the European Commission through the Data Spaces Support Centre.
Finally,the promotion of experimental or pilot projects also enables the development of standards for innovative data technologies, which is closely related to the Gaia-X project. Thus, the Gaia-X Hub Spain has an interoperability node, which serves to certify compliance with the rules prescribed by each sector, and thus to generate the aforementioned digital trust based on their specific needs.
At the Data Office, we believe that the interconnection and future scalability of data projects are at the heart of the effort to implement the European Data Strategy, and are crucial to achieve a dynamic and rich Data Economy, but at the same time a guarantor of European values and where traceability and transparency help to collectivise the value of data, catalysing a stronger and more cohesive economy.
Noticia
Under the Spanish Presidency of the Council of the European Union, the Government of Spain has led the Gaia-X Summit 2023, held in Alicante on November 9 and 10. The event aimed to review the latest advances of Gaia-X in promoting data sovereignty in Europe. As presented on datos.gob.es, Gaia-X is a European private sector initiative for the creation of a federated, open, interoperable, and reversible data infrastructure, fostering digital sovereignty and data availability.
The summit has also served as a space for the exchange of ideas among the leading voices in the European data spaces community, culminating in the presentation of a statement to boost strategic autonomy in cloud computing, data, and artificial intelligence—considered crucial for EU competitiveness. The document, promoted by the State Secretariat for Digitization and Artificial Intelligence, constitutes a joint call for a "more coherent and coordinated" response in the development of programs and projects, both at the European and member state levels, related to data and sector technologies.
To achieve this, the statement advocates for interoperability supported by a robust cloud services infrastructure and the development of high-quality data-based artificial intelligence with a robust governance framework in compliance with European regulatory frameworks. Specifically, it highlights the possibilities offered by Deep Neural Networks, where success relies on three main factors: algorithms, computing capacity, and access to large amounts of data. In this regard, the document emphasizes the need to invest in the latter factor, promoting a neural network paradigm based on high-quality, well-parameterized data in shared infrastructures, not only saving valuable time for researchers but also mitigating environmental degradation by reducing computing needs beyond the brute force paradigm.
For this reason, another aspect addressed in the document is the stimulation of access to data sources from different complementary domains. This would enable a "flexible, dynamic, and highly scalable" data economy to optimize processes, innovate, and/or create new business models.
The call is optimistic about existing European initiatives and programs, starting with the Gaia-X project itself. Other projects highlighted include IPCEI-CIS or the Simpl European project. It also emphasizes the need for "broader and more effective coordination to drive industrial projects, advance the standardization of cloud and reliable data tags, ensuring high levels of cybersecurity, data protection, algorithmic transparency, and portability."
The statement underscores the importance of achieving a single data market that includes data exchange processes under a common governance framework. It values the innovative set of digital and data legislation, such as the Data Act, with the goal of promoting data availability across the Union. The statement is open to new members seeking to advance the promotion of a flexible, dynamic, and highly scalable data economy.
You can read the full document here: The Trinity of Trusted Cloud Data and AI as a Gateway to EU's Competitiveness
Blog
Trust, as a key factor in unlocking the potential of data in the digital economy, is an increasingly central element in all data regulations. The European General Data Protection Regulation, in 2016 already recognised that if individuals have more control over their own personal data, this will improve trust and contribute to the positive impact on the development of the digital economy. The European Commission's European Data Law 2022 European Commission proposal puts even greater emphasis on the targets themselves, stating that "low trust prevents the full potential of data-driven innovation from being realised".
Among the findings of the World Data Regulation Survey published by the World Bank in 2021, highlights the need to strengthen regulatory frameworks around the world to build greater citizen trust. This would contribute to more effective effectiveness of government initiatives that use data and that aim, in many cases, to generate value forsociety. As an example, he cites the limited impact of contact-tracking applications around the world during the COVID-19 pandemic, largely due to a lack of public confidence in the potential use of the data provided.
If we really believe that trust in data is so critical to creating value for society and the economy, we need to pay close attention both to the mechanisms we have at our disposal to enhance that trustworthiness, and to the strategies for building and maintaining that trust, beyond the regulatory frameworks themselves.
Quality and transparency
Trust in data starts with quality and transparency. When users understand how data are collected, processed and maintained, they are more likely to trust them to use them use it, and even be more willing to contribute their own data.
A fundamental mechanism for ensuring quality and transparency is the implementation of rigorous standards, such as the UNE specifications for Data Governance UNE 0077:2023, Data Management UNE 0078:2023, and Data Quality Management UNE 0079:2023 at each stage of the data lifecycle. On the one hand, quality is enhanced through the deployment of robust validation and verification practices that ensure the accuracy and integrity of the data, and on the other hand, transparency is improved through, for example, descriptive metadata that provide detailed information about the data, including its origin, collection methodology and any transformation it has undergone.
European Data Spaces
The European Data Spaces is an ambitious EU initiative aimed at building trust and facilitating the exchange and use of data between countries and sectors in a secure and regulated environment. The central idea behind the European Data Spaces is to create environments in which the availability, accessibility and interoperability of data are maximised, while the risks associated with data handling are minimised. Initially the European data strategy initially envisaged 10 data spaces in strategic areas such as health, energy or public administration. Since then this number has grown and other data spaces have been launched in important areas such as media and cultural heritage, or in strategic sectors for Spain such as tourism.
In order to bet on the leadership in data spaces in strategic sectors for Spain, the government is promoting the Gaia-X Spanish Hub the Spanish government is promoting a new initiative, comprised of companies of all sizes, aimed at deploying a solid ecosystem in the field of industrial data sharing
Improving cyber security
The increasing number of cyber security incidents media headlines, some of which have even brought private companies and public bodies to a standstill, has made cyber security a primary concern for users and organisations in the digital age.
Robust cyber security involves organisations deploying advanced technologies and best practices to protect systems and data from unauthorised access and malicious manipulation through measures such as firewalls, two-factor authentication, and real-time threat monitoring and detection, encryption two-factor authentication, and real-time threat monitoring and detection. However, improving users' education and cybersecurity awareness is also vital to help them recognise and avoid potential threats.
European digital identity
The European Digital Identity is being developed in the framework of the European Union with the aim of providing citizens and businesses with a secure and unified way of accessing services, public and private, online and offline, across the EU. The idea is that, with a European digital identity, people would be able to identify themselves or confirm data in services such as banking, education or health, among others, in a secure and frictionless way, providing a high level of security and privacy protection.
This deepens the framework of trust and confidence created by the EIDAS Regulation on electronic identification and trust services for electronic transactions in the internal market, which already contributes significantly to increasing consumer confidence phishing or improving confidence in the origin of documents.
Building a culture of trust and responsibility in the handling of data and digital infrastructures is the focus of the actions of EU governments, including Spain. In this context, the intersection between data quality and transparency, robust cybersecurity that reduces cybercrime, European Data Spaces, and European digital identity stand out as key mechanisms to cultivate this trust and propose a route towards greater innovation that ultimately generates social and economic value through data.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
On September 11th, a webinar was held to review Gaia-X, from its foundations, embodied by its architecture and trust model called Trust Framework, to the Federation Services that aim to facilitate and speed up access to the infrastructure, to the catalogue of services that some users (providers) will be able to make available to others (consumers).
The webinar, led by the manager of the Spanish Gaia-X Hub, was led by two experts from the Data Office, who guided the audience through their presentations towards a better understanding of the Gaia-X initiative. At the end of the session, there was a dynamic question and answer session to go into more detail. A recording of this seminar can be accessed from the Hub's official website,[Forging the Future of Federated Data Spaces in Europe | Gaia-X (gaiax.es)]
Gaia-X as a key building block for forging European Data Spaces
Gaia-X emerges as an innovative paradigm to facilitate the integration of IT resources. Based on Web 3.0 technology models, the identification and traceability of different data resources is enabled, from data sets, algorithms, different semantic or other conceptual models, to even underlying technology infrastructure (cloud resources). This serves to make the origin and functioning of these entities visible, thus facilitating transparency and compliance with European regulations and values.
More specifically, Gaia-X provides different services in charge of automatically verifying compliance with minimum interoperability rules, which then allows defining more abstract rules with a business focus, or even as a basis for defining and instantiating the Trusted Cloud and sovereign data spaces. These services will be operationalised through different Gaia-X interoperability nodes, or Gaia-X Digital Clearing Houses.
Using Gaia-X as a tool, we will be able to publish, discover and exploit a catalogue of services that will cover different services according to the user's requirements. For instance, in the case of cloud infrastructure, these offerings may include features such as residence in European territory or compliance with EU regulations (such as eIDAS or GDPR, or data intermediation rules outlined in the Data Governance Regulation). It will also enable the creation of combinable services by aggregating components from different providers (which is complex now). Moreover, specific datasets will be available for training Artificial Intelligence models, and the owner of these datasets will maintain control thanks to enabled traceability, up to the execution of algorithms and apps on the consumer's own data, always ensuring privacy preservation.
As we can see, this novel traceability capability, based on cutting-edge technologies, serves as a driver for compliance, and is therefore a fundamental building block in the deployment of interoperable data spaces at European level and the digital single market.
Noticia
Mark them on your calendar, make a note in your agenda, or set reminders on your mobile to not forget about this list of events on data and open government taking place this autumn. This time of year brings plenty of opportunities to learn about technological innovation and discuss the transformative power of open data in society.
From practical workshops to congresses and keynote speeches, in this post, we present some of the standout events happening in October and November. Sign up before the slots fill up!
Data spaces in the EU: synergies between data protection and data spaces
At the beginning of the tenth month of the year, the Spanish Data Protection Agency (AEPD) and the European Cybersecurity Agency (ENISA) will hold an event in English to address the challenges and opportunities of implementing the provisions of the General Data Protection Regulation (GDPR) in EU data spaces.
During the conference, the conference will review best practices of existing EU data spaces, analyse the interaction between EU legislation and policies on data exchange and present data protection engineering as an integral element in the structure of data spaces, as well as its legal implications.
- Who is it aimed at? This event promises to be a platform for knowledge and collaboration of interest to anyone interested in the future of data in the region.
- When and where is it? On October 2nd in Madrid from 9:30 AM to 6:00 PM and available for streaming with prior registration until 2:45 PM.
- Registration: link no longer available
SEMIC Conference 'Interoperable Europe in the age of AI'
Also in October, the annual SEMIC conference organised by the European Commission in collaboration with the Spanish Presidency of the Council of the European Union returns. This year's event takes place in Madrid and will explore how interoperability in the public sector and artificial intelligence can benefit each other through concrete use cases and successful projects.
Sessions will address the latest trends in data spaces, digital governance, data quality assurance and generative artificial intelligence, among others. In addition, a proposal for an Interoperable Europe Act will be presented.
- Who is it aimed at? Public or private sector professionals working with data, governance and/or technology. Last year's edition attracted more than 1,000 professionals from 60 countries.
- When and where is it? The conference will be held on October 18th at the Hotel Riu Plaza in Madrid and can also be followed online. Pre-conference workshops will take place on October 17th at the National Institute of Public Administration
- Registration: https://semic2023.eu/registration/

Data and AI in action: sustainable impact and future realities
From October 25th to 27th, an event on the value of data in artificial intelligence is taking place in Valencia, with the collaboration of the European Commission and the Spanish Presidency of the Council of the European Union, among others.
Over the course of the three days, approximately one-hour presentations will be given on a variety of topics such as sectoral data spaces, the data economy and cybersecurity.
- Who is it aimed at? Members of the European Big Data Value Forum will receive a discounted entrance fee and associate members receive three tickets per organisation. The ticket price varies from 120 to 370 euros.
- When and where is it? It will take place on October 25th, 26th and 27th in Valencia.
- Registration: bipeek.
European Webinars: open data for research, regional growth with open data and data spaces
The European Open Data Portal organises regular webinars on open data projects and technologies. In datos.gob.es we report on this in summary publications on each session or in social networks. In addition, once the event is over, the materials used to carry out the didactic session are published. The October events calendar is now available on the portal's website. Sign up to receive a reminder of the webinar and, subsequently, the materials used.
Data spaces: Discovering block architecture
- When? On October 6th from 10:00 AM to 11:30 AM
- Registration: data.europa academy 'Data spaces: Discovering the building blocks' (clickmeeting.com)
How to use open data in your research?
- When? On October 19th from 10:00 AM to 11:30 AM
- Registration: How to use open data for your research (clickmeeting.com)
Open Data Maturity Report: The in-depth impact dimension
- When? On October 27th from 10:00 AM to 11.30 AM
- Registration: data.europa academy 'Open Data Maturity 2022: Diving deeper into the impact dimension' (clickmeeting.com)
ODI SUMMIT 2023: Changes in data
November starts with an Open Data Institute (ODI) event that poses the following question by way of introduction: how does data impact on technology development to address global challenges? For society to benefit from such innovative technologies as artificial intelligence, data is needed.
This year's ODI SUMMIT features speakers of the calibre of World Wide Web founder Tim Berners-Lee, Women Income Network co-founder Alicia Mbalire and ODI CEO Louise Burke. It is a free event with prior registration.
- Who is it aimed at? Teachers, students, industry professionals and researchers are welcome to attend the event.
- When and where is it? It is on November 7th, online.
- Entry: Form (hsforms.com)
These are some of the events that are scheduled for this autumn. Anyway, don't forget to follow us on social media so you don't miss any news about innovation and open data. We are on Twitter and LinkedIn; you can also write to us at dinamizacion@datos.gob.es if you want us to add any other event to the list or if you need extra information.