Blog
Open data plays a relevant role in technological development for many reasons. For example, it is a fundamental component in informed decision making, in process evaluation or even in driving technological innovation. Provided they are of the highest quality, up-to-date and ethically sound, data can be the key ingredient for the success of a project.
In order to fully exploit the benefits of open data in society, the European Union has several initiatives to promote the data economy, a single digital model that encourages data sharing, emphasizing data sovereignty and data governance, the ideal and necessary framework for open data.
In the data economy, as stated in current regulations, the privacy of individuals and the interoperability of data are guaranteed. The regulatory framework is responsible for ensuring compliance with this premise. An example of this can be the modification of Law 37/2007 for the reuse of public sector information in compliance with European Directive 2019/1024. This regulation is aligned with the European Union's Data Strategy, which defines a horizon with a single data market in which a mutual, free and secure exchange between the public and private sectors is facilitated.
To achieve this goal, key issues must be addressed, such as preserving certain legal safeguards or agreeing on common metadata description characteristics that datasets must meet to facilitate cross-industry data access and use, i.e. using a common language to enable interoperability between dataset catalogs.
What are metadata standards?
A first step towards data interoperability and reuse is to develop mechanisms that enable a homogeneous description of the data and that, in addition, this description is easily interpretable and processable by both humans and machines. In this sense, different vocabularies have been created that, over time, have been agreed upon until they have become standards.
Standardized vocabularies offer semantics that serve as a basis for the publication of data sets and act as a "legend" to facilitate understanding of the data content. In the end, it can be said that these vocabularies provide a collection of metadata to describe the data being published; and since all users of that data have access to the metadata and understand its meaning, it is easier to interoperate and reuse the data.
W3C: DCAT and DCAT-AP Standards
At the international level, several organizations that create and maintain standards can be highlighted:
- World Wide Web Consortium (W3C): developed the Data Catalog Vocabulary (DCAT): a description standard designed with the aim of facilitating interoperability between catalogs of datasets published on the web.
- Subsequently, taking DCAT as a basis, DCAT-AP was developed, a specification for the exchange of data descriptions published in data portals in Europe that has more specific DCAT-AP extensions such as:
- GeoDCAT-AP which extends DCAT-AP for the publication of spatial data.
- StatDCAT-AP which also extends DCAT-AP to describe statistical content datasets.
- Subsequently, taking DCAT as a basis, DCAT-AP was developed, a specification for the exchange of data descriptions published in data portals in Europe that has more specific DCAT-AP extensions such as:
ISO: Organización de Estandarización Internacional
Además de World Wide Web Consortium, existen otras organizaciones que se dedican a la estandarización, por ejemplo, la Organización de Estandarización Internacional (ISO, por sus siglas en inglés Internacional Standarization Organisation).
- Entre otros muchos tipos de estándares, ISO también ha definido normas de estandarización de metadatos de catálogos de datos:
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
- ISO 19115-2 para datos ráster e imágenes.
- ISO 19139 proporciona una implementación en XML del vocabulario.
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
The horizon in metadata standards: challenges and opportunities
Both W3C and ISO are working on the development and maintenance of standardized vocabularies adapted to the needs of users. Their work contributes to achieving an interoperable open data ecosystem that facilitates reuse. However, interoperability often encounters obstacles arising from quality weaknesses, such as outdated data, difficulties in accessing and interoperating with it, or incomplete metadata.
However, as has been demonstrated, data sharing is a fundamental mechanism in the data economy. So ensuring the interoperability and reuse of data is a key action to address the development of the data economy in line with the expectations of organizations in terms of innovation.
Among the multiple advantages offered by the reuse of datasets and their interoperability, we can highlight the creation of applications and services that bring value to society or help in the evaluation of policies, for example.
In addition, the reuse and interoperability of datasets favors economic development in general, and the data economy in particular. It is estimated that this industry will reach a value of 829 billion euros by 2025, according to European Union forecasts. In order to reap the benefits of data sharing, common description standards must first be agreed upon and adhered to: the standards for describing dataset catalog metadata.
Noticia
The European Directive 2019/1024 on open data and re-use of public sector information emphasises, among many other aspects, the importance of publishing data in real time. In fact, the document talks about dynamic data, which it defines as "documents in digital format, subject to frequent or real-time updates due to their volatility or rapid obsolescence". According to the Directive, public bodies must make this data available for re-use by citizens immediately after collection, through appropriate APIs and, where possible, as a bulk download.
To explore this further, the European Data Portal, Data.europa.eu, has published the report “Real-time data 2022: Approaches to integrating real-time data sources in data.europa.eu” which analyses the potential of real-time data. It draws on the results of a webinar held by data.europa.eu on 5 April 2022, a recording of which is available on its website.
In addition to detailing the conclusions of the event, the report provides a brief summary of the information and technologies presented at the event, which are useful for real-time data sharing.
The importance of real-time data
The report begins by explaining what real-time data are: data that are frequently updated and delivered immediately after collection, as mentioned above. These data can be of a very heterogeneous nature. The following table gives some examples:

This type of data is widely used to shape applications that report traffic, energy prices, weather forecasts or flows of people in certain spaces. You can find out more about the value of real-time data in this other article.
Real-time data sharing standards
La interoperabilidad es uno de los factores más importantes a tener en cuenta a la hora de seleccionar la tecnología más adecuada para el intercambio de datos en tiempo real. Se precisa un lenguaje común, es decir, formatos de datos comunes e interfaces de acceso a datos que permitan el flujo de datos en tiempo real. Dos estándares que ya son muy utilizados en el ámbito del Internet de las cosas (IoT en sus siglas en inglés) y que pueden ayudar en este sentido son:
SensorThings API (STA)
SensorThings API, from the Open Geospatial Consortium, emerged in 2016 and has been considered a best practice for data sharing in compliance with the INSPIRE Directive.
This standard provides an open and unified framework for encoding and providing access to sensor-generated data streams. It is based on REST and JSON specifications and follows the principles of the OData (OASIS Open Data Protocol) standard.
STA provides common functionalities for creating, reading, updating and deleting sensor resources. It enables the formulation of complex queries tailored to the underlying data model, allowing more direct access to the specific data the user needs. Query options include filtering by time period, observed parameters or resource properties to reduce the volume of data downloaded. It also allows sorting the content of a result by user-specified criteria and provides direct integration with the MQTT standard, which is explained below.
Message Queuing Telemetry Transport (MQTT)
MQTT was invented by Dr. Andy Stanford-Clark of IBM and Arlen Nipper of Arcom (now Eurotech) in 1999. Like STA, it is also an OASIS standard.
The MQTT protocol allows the exchange of messages according to the publish/subscribe principle. The central element of MQTT is the use of brokers, which take incoming messages from publishers and distribute them to all users who have a subscription for that type of data. In this type of environment, data is organised by topics, which are freely defined and allow messages to be grouped into thematic channels to which users subscribe.
The advantages of this system include reduced latency, simplicity and agility, which facilitates its implementation and use in constrained environments (e.g. with limited bandwidth or connectivity).
In the case of the European portal, users can already find real-time datasets based on MQTT. However, there is not yet a common approach to providing metadata on brokers and the topics they offer, and work is still ongoing.
Other conclusions of the report
As mentioned at the beginning, the webinar on 5 April also served to gather participants' views on the use of real-time data, current challenges in data availability and needs for future improvements. These views are also reflected in this report.
Among the most valued categories of real-time data, users highlighted traffic information and weather data. Data on air pollution, allergens, flood monitoring and stock market information were also mentioned. In this respect, more and more detailed data were requested, especially in the field of mobility and energy in order to be able to compare commodity prices. Users also highlighted some drawbacks in locating real-time data on the European portal, including the heterogeneity of the information, which requires the use of common standards and formats across countries.
Finally, the report provides a set of recommendations on how to improve the ability to locate real-time data sources through data.europa.eu. To this end, a series of short and medium-term actions have been established, including the collection of use cases, support for data providers and the development of best practices to unify metadata.
You can read the full report here.
Documentación
A data space is an ecosystem where, on a voluntary basis, the data of its participants (public sector, large and small technology or business companies, individuals, research organizations, etc.) are pooled. Thus, under a context of sovereignty, trust and security, products or services can be shared, consumed and designed from these data spaces.
This is especially important because if the user feels that he has control over his own data, thanks to clear and concise communication about the terms and conditions that will mark its use, the sharing of such data will become effective, thus promoting the economic and social development of the environment.
In line with this idea and with the aim of improving the design of data spaces, the Data Office establishes a series of characteristics whose objective is to record the regulations that must be followed to design, from an architectural point of view, efficient and functional data spaces.
We summarize in the following visual some of the most important characteristics for the creation of data spaces. To consult the original document and all the standards proposed by the Data Office, please download the attached document at the end of this article.
(You can download the accessible version in word here)

Documentación
This report published by the European Data Portal (EDP) explores existing and emerging developments and initiatives around data sharing using data spaces.
The objective is twofold: to identify the owners of open data involved in the implementation of data spaces and to reflect on the role that open data portals (with special attention to data.europa.eu) could play in this implementation.
After documentary research and interviews with the promoters of data spaces, it is analyzed how data.europa.eu could be positioned in the common European data spaces that are emerging.
The report is available at this link: "Data.europa.eu y los espacios comunes de datos europeos: un informe sobre retos y oportunidades"
Documentación
This report published by the European Data Portal (EDP) aims to advance the debate on the medium and long-term sustainability of open data portal infrastructures.
It provides recommendations to open data publishers and data publishers on how to make open data available and how to promote its reuse. It is based on the previous work done by the data.europa.eu team, on research on open data management, and on the interaction between humans and data.
Considering the conclusions, 10 recommendations are proposed for increasing the reuse of data.
The report is available at this link: " Principles and recommendations to make data.europa.eu data more reusable: A strategy mapping report "
Documentación
By analysing data, we can discover meaningful patterns and gain insights that lead to informed decision making. But good data analysis needs to be methodical and follow a series of steps in an orderly fashion. In this video (in Spanish) we give you some tips on the steps to follow:
The importance of pre-analysis work
The first step is to be clear about the final objective. It should be concrete, clear and straightforward and identify a problem to be solved. One way to set the objective is to shape a concrete question to be answered, such as how many traffic accidents there are or how air quality will evolve.
It is also important to know the prior state of the issue. It is likely that other people and organisations have asked the same questions before. It is therefore important to find out what previous projects exist on the chosen topic. On platforms such as data.europa.eu or datos.gob.es you have sections where use cases such as applications and companies are collected. It is also advisable to examine the proposals submitted to hackathons, challenges and competitions, both national and international, as well as to closely follow the activity of companies and start-ups focused on the field of study.
To be able to cover so many fronts, it is advisable to have a multidisciplinary team with different points of view, including data scientists, engineers, business analysts, communicators, etc. Soft skills, such as critical thinking, effective communication and industry knowledge, are as important as technical skills for success.
Where to locate the data?
With the end goal clear, it will be easier to determine what data we need to answer the initial question. It is most common to combine different sources of information, public and/or private, to enrich the analysis and reach an appropriate level of depth.
In addition to the multitude of existing national data catalogues, you can also search specialised repositories in specific fields such as environment, health and welfare or economics.
The analysis process
Once the data is available, it is time to start the analysis, following the workflow below:
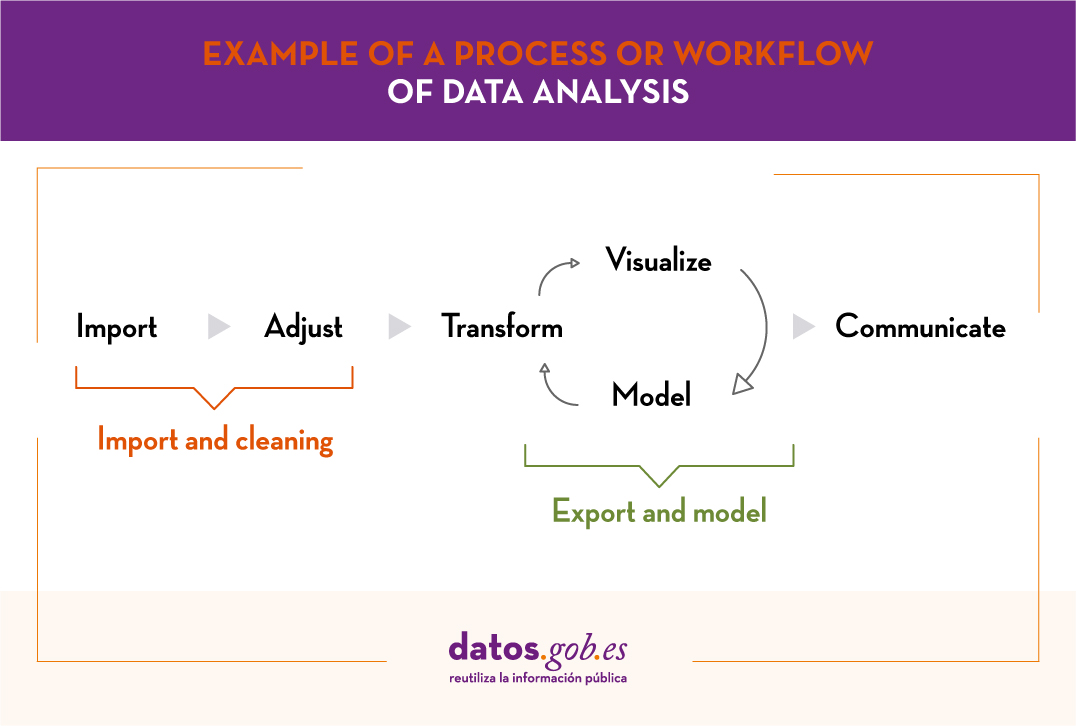
- Phase 1: Import and cleaning. Before the analysis, the data must be cleaned in order to achieve a homogeneous structure, free of errors and in the right format. For this purpose, it is recommended to perform an Exploratory Data Analysis (EDA). This will result in clean, error-free and homogeneous data.
- Phase 2: Export and modelling. Depending on the question to be answered, we will determine the type of analysis to be carried out: descriptive analysis (what has happened?), diagnostic (why has it happened?), predictive (what is going to happen?) or prescriptive (what should I do to make it happen again -or not?).
- Phase 3: Communicate. Once the data has been analysed, we will have obtained new knowledge, which we must communicate to our target audience in a way that is easy to understand. This can be done using data storytelling techniques, visualisations, web or mobile applications, services or commercial products, depending on the initial objectives.
In order to carry out these 3 phases, we have different tools at our disposal. You can see some examples in the report "Data processing and visualisation tools".
From datos.gob.es we encourage you to practice with the data in our catalogue and put different analyses into practice. You can share the results of your analyses with us through the e-mail box dinamizacion@datos.god.es.
Documentación
It is important to publish open data following a series of guidelines that facilitate its reuse, including the use of common schemas, such as standard formats, ontologies and vocabularies. In this way, datasets published by different organizations will be more homogeneous and users will be able to extract value more easily.
One of the most recommended families of formats for publishing open data is RDF (Resource Description Framework). It is a standard web data interchange model recommended by the World Wide Web Consortium, and highlighted in the F.A.I.R. principles or the five-star schema for open data publishing.
RDFs are the foundation of the semantic web, as they allow representing relationships between entities, properties and values, forming graphs. In this way, data and metadata are automatically interconnected, generating a network of linked data that facilitates their exploitation by reusers. This also requires the use of agreed data schemas (vocabularies or ontologies), with common definitions to avoid misunderstandings or ambiguities.
In order to promote the use of this model, from datos.gob.es we provide users with the "Practical guide for the publication of linked data", prepared in collaboration with the Ontology Engineering Group team - Artificial Intelligence Department, ETSI Informáticos, Polytechnic University of Madrid-.
The guide highlights a series of best practices, tips and workflows for the creation of RDF datasets from tabular data, in an efficient and sustainable way over time.
Who is the guide aimed at?
The guide is aimed at those responsible for open data portals and those preparing data for publication on such portals. No prior knowledge of RDF, vocabularies or ontologies is required, although a technical background in XML, YAML, SQL and a scripting language such as Python is recommended.
What does the guide include?
After a short introduction, some necessary theoretical concepts (triples, URIs, controlled vocabularies by domain, etc.) are addressed, while explaining how information is organized in an RDF or how naming strategies work.
Next, the steps to be followed to transform a CSV data file, which is the most common in open data portals, into a normalized RDF dataset based on the use of controlled vocabularies and enriched with external data that enhance the context information of the starting data are described in detail. These steps are as follows:

The guide ends with a section oriented to more technical profiles that implements an example of the use of RDF data generated using some of the most common programming libraries and databases for storing triples to exploit RDF data.
Additional materials
The practical guide for publishing linked data is complemented by a cheatsheet that summarizes the most important information in the guide and a series of videos that help to understand the set of steps carried out for the transformation of CSV files into RDF. The videos are grouped in two series that relate to the steps explained in the practical guide:
1) Series of explanatory videos for the preparation of CSV data using OpenRefine. This series explains the steps to be taken to prepare a CSV file for its subsequent transformation into RDF:
- Video 1: Pre-loading tabular data and creating an OpenRefine project.
- Video 2: Modifying column values with transformation functions.
- Video 3: Generating values for controlled lists or SKOS.
- Video 4: Linking values with external sources (Wikidata) and downloading the file with the new modifications.
2) Series of explanatory videos for the construction of transformation rules or CSV to RDF mappings. This series explains the steps to be taken to transform a CSV file into RDF by applying transformation rules.
- Video 1: Downloading the basic template for the creation of transformation rules and creating the skeleton of the transformation rules document.
- Video 2: Specifying the references for each property and how to add the Wikidata reconciled values obtained through OpenRefine.
Below you can download the complete guide, as well as the cheatsheet. To watch the videos you must visit our Youtube channel.
Documentación
These infographics show examples of the use of open data in certain sectors, as well as data from studies on its impact. New content will be published periodically.
Learning with open data: training resources for secondary school students
 |
Published: November 2025 This compilation of educational resources serves as a guide to learning more about open data and related technologies. Specially designed for students, it compiles tips for harnessing the potential of data sets, videos, and much more. |
Open science and citizen science: the combination that transforms research
 |
Published: July 2025 Planning the publication of open data from the outset of a citizen science project is key to ensuring the quality and interoperability of the data generated, facilitating its reuse, and maximizing the scientific and social impact of the project. |
Open Data and Urban Management: Innovative Use Cases
 |
Published: July 2024 Municipal innovation through the use of open data presents a significant opportunity to improve the accessibility and efficiency of municipal services. In this infographic, we collect examples of applications that contribute to the improvement of urban sectors such as transport and mobility, organisation of basic public services, environment and sustainability, and citizen services. |
Open data for Sustainable City Development
 |
Published: August 2023 In this infographic, we have gathered use cases that utilize sets of open data to monitor and/or enhance energy efficiency, transportation and urban mobility, air quality, and noise levels. Issues that contribute to the proper functioning of urban centers. |
Open data, a key tool for promoting knowledge and education
 |
Published: May 2023 Open data is a key for the strengthening and progress of education and we must no forget thatbsp;education is a universal right and one of the main tools for the progress of humanity. In this infographic we summarize the benefits of utilizing open data in education |
LegalTech: Transformative potencial of legal services
 |
Published: August 2022 The LegalTech concept refers to the use of new technological processes and tools to offer more efficient legal services. For all these tools to work properly, it is necessary to have valuable data. In this sense, open data is a great opportunity. Find out more information in this inforgraphic. |
How is open data used in the health and welfare sector?
 |
Published: September 2021 Open health data is essential for management and decision making by our governments, but it is also fundamental as a basis for solutions that help both patients and doctors. This infographic shows several examples, both of applications that collect health services and of tools for forecasting and diagnosing diseases, among others. |
Open data use cases to care for the environment and fight climate change
 |
Published: November 2020 This interactive infographic shows the strategic, regulatory and political situation affecting the world of open data in Spain and Europe. It includes the main points of the European Data Strategy, the Regulation on Data Governance in Europe or the Spain Digital 2025 plan, among others. |
Public administrations faced with the reuse of public information
 |
Published: August 2020 Public administrations play an important role in the open data ecosystem, both as information providers and consumers. This infographic contains a series of examples of success stories and best practices, compiled in the report "Las Administraciones Públicas ante la reutilización de la información pública" by the National Observatory of Telecommunications and the Information Society (ONTSI). |
The importance of opening cultural data
 |
Published: June 2020 Did you know that 90% of the world''s cultural heritage has not yet been digitized? Discover in this infographic the benefits of open cultural data, as well as examples of the products that can be created through its reuse, and success stories of museums that share open collections. |
Open data, especially valuable for small and medium-sized companies
 |
Published: March 2020 This infographic shows the results of the study "The Impact of open data: opportunities for value creation in Europe", conducted by the European Data Portal. Find out what the expected annual growth rate is, both in terms of turnover and jobs.(only available in Spanish). |
Documentación
A spatial data or geographical data is that which has a geographical reference associated with it, either directly, through coordinates, or indirectly, such as a postal code. Thanks to these geographical references it is possible to locate its exact location on a map. The European Union includes spatial data among the datasets that can be considered of high value, due to their "considerable benefits for society, the environment and the economy, in particular due to their suitability for the creation of value-added services, applications and new jobs". There are many examples of the potential for re-use of this type of data. For example, the data provided by the Copernicus Earth Observation system has been used to create tools for monitoring areas susceptible to fire or to help stop drug trafficking. It is therefore important that spatial data is created in a way that facilitates its availability, access, interoperability and application.
A large amount of the open data managed by public administrations can be geo-referenced, thus maximising its value. To help public administrations publish this type of information in open format, this "Practical Guide to the Publication of Spatial Data" has been produced within the framework of the Aporta Initiative. It has been developed by Carlos de la Fuente García, an expert in open data, with the collaboration of the National Centre for Geographic Information (National Geographic Institute), as well as contributions and suggestions from a large number of experts in the field.
Who is the guide for?
The guide is primarily aimed at Open Data developers whose goal is to publish spatial data sets. It is preferable that the reader be familiar with basic knowledge about the fundamental elements that make up geospatial information, spatial context metadata and geographic web services.
What can I find in the guide?
The guide begins with a section that addresses the essential concepts needed to understand the nature of spatial data. This section includes explanations of the visual representation of geographic information, as well as details of the tools required for spatial data analysis and transformation, and the recommended formats and metadata. There are specific sections on Geographic Information Systems (GIS) and the role of geographic web services and Spatial Data Infrastructures (SDIs) in facilitating access to and management of geographic data sets and services is discussed.
It then compiles a set of guidelines to facilitate the efficient publication of spatial data on the Internet, taking into account the international standards of the International Organization for Standardization (ISO). The guidelines detailed in this guide are:
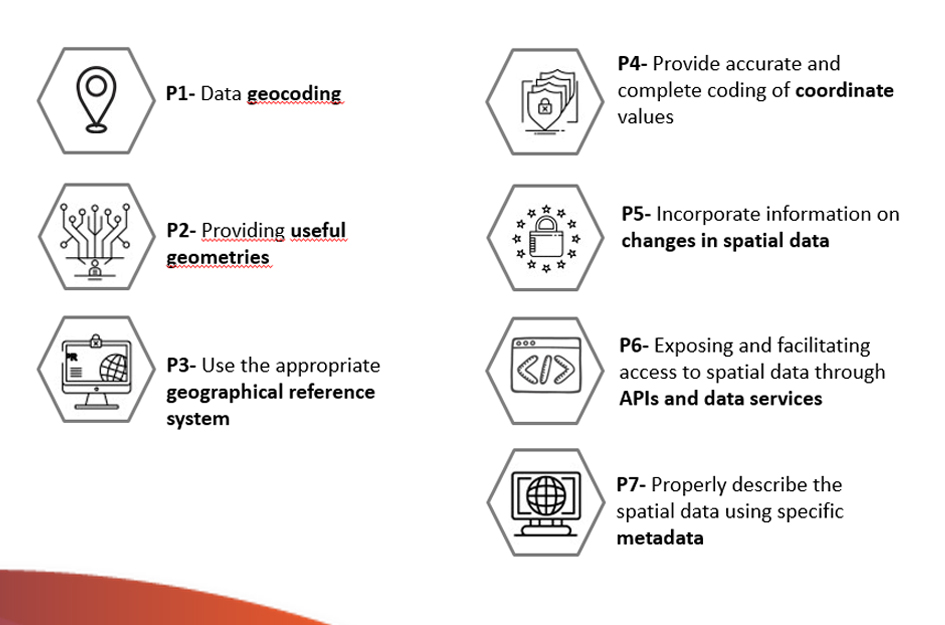
Finally, a series of references, specifications, formats, standards and tools of direct application for the publication of Spatial Data are included.
The following elements are also included throughout the guide: references to the European INSPIRE Directive as a catalyst for sharing geographic resources in Europe and guidelines for describing spatial information derived from the Open Data metadata standards, DCAT and GeoDCAT-AP.
Other materials of interest
Although the primary scope of this document is oriented towards the publication of spatial data, it should not be forgotten that the application of all good practices linked to data quality in general is essential for their effective re-use. In this sense, it is advisable to complement this guide with the reading and application of other guides that provide guidance on the application of guidelines to ensure the publication of structured quality data, such as the Practical Guide for the publication of tabular data in CSV files and or using APIs.
You can download the Practical Guide for the Publication of Spatial Data from the following links:
Documentación
In the Action Plan of the International Open Data Conference, capacity development has become a priority within the international open data movement. After all, the need for training tools is essential for leaders responsible for PSI policies, data producers and reusers, public and private sector, and even citizens. For this reason, providing training tools that allow the different agents to advance in the openness and re-use of public data is a priority task.
To this end, eight training units have been developed within the dissemination, awareness raising and training line of Iniciativa Aporta, aimed at all types of public: from citizens who read for the first time about open data to public employees, responsible for open information initiatives who want to expand their knowledge in the field.
The training units are designed to understand the basic concepts of the open data movement, to know best practices in the implementation of open data policies and their re-use, methodological guidelines for open data, technical regulations such as DCAT-AP and NTI-RISP, in addition to the use of data processing tools, among other aspects.
In the development of resources, two types of learning have been taken into account. Learning by discovery, oriented to extend the knowledge to solve the doubts and reflections raised, and significant learning based on prior knowledge, through the use of practical examples to contextualize and apply the concepts treated.
In addition, the training modules contain complementary materials through links to external pages and documents to be downloaded without connection. In this way, the student is given the opportunity to enhance his knowledge and familiarize himself with relevant sources to obtain reliable and up-to-date information about the open data sector.
All units are distributed under the Creative Commons Share-Alike Attribution Licence (CC-BY-SA) which allows copying, distributing the material in any medium or format and adapting it to create new resources from it.

The training material developed by Iniciativa Aporta consists of eight didactic units that address the following contents of the open data sector:
- Basic concepts, benefits and barriers of open data
- Legal framework
- Trends and best practices on the implementation of open data practices
- The re-use of public data on its transformative role
- Methodological guidelines for open data
- DCAT-AP and NTI-RISP
- Use of basic tools for data treatment
- Best practices in the design of APIs and Linked Data

Each unit is designed in a way the student expands his knowledge on the open data sector. In order to facilitate their understanding, all of them have a similar structure that includes objectives, contents, evaluation activities, practical examples, complementary information and conclusions.
All the training units can be done online, directly from the datos.gob.es or, in its absence, it is also possible to download them on the user's device and even load it on an LMS platform.

Each unit is independent; enabling the student to acquire the necessary knowledge in a specific subject according to their training needs. However, those students who wish to have a more complete view of the PSI sector have the opportunity to perform the complete series of eight training units in order to know in depth the most relevant aspects of open data initiatives.

The training units are available in the "Documentation" section under the category "Training materials" to be carried out through the online portal or to be downloaded.