Blog
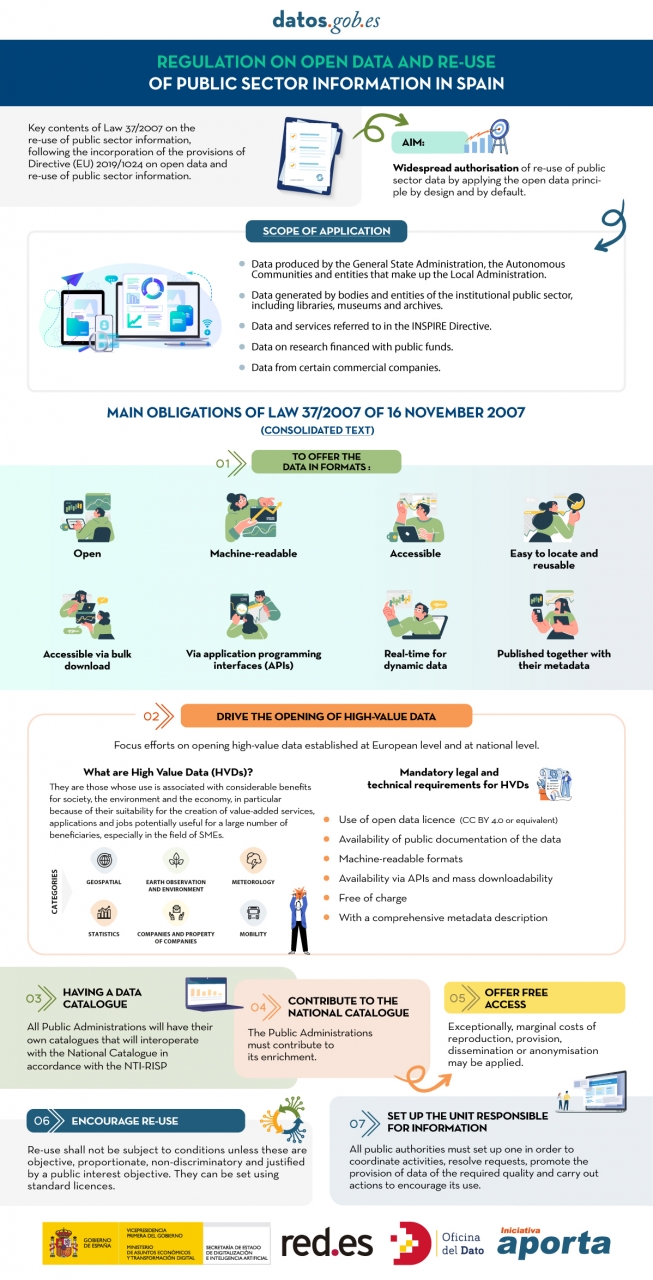
The public sector in Spain will have the duty to guarantee the openness of its data by design and by default, as well as its reuse. This is the result of the amendment of Law 37/2007 on the reuse of public sector information in application of European Directive 2019/1024.
This new wording of the regulation seeks to broaden the scope of application of the Law in order to bring the legal guarantees and obligations closer to the current technological, social and economic context. In this scenario, the current regulation takes into account that greater availability of public sector data can contribute to the development of cutting-edge technologies such as artificial intelligence and all its applications.
Moreover, this initiative is aligned with the European Union's Data Strategy aimed at creating a single data market in which information flows freely between states and the private sector in a mutually beneficial exchange.
From high-value data to the responsible unit of information: obligations under Law 37/2007
In the following infographic, we highlight the main obligations contained in the consolidated text of the law. Emphasis is placed on duties such as promoting the opening of High Value Datasets (HVDS), i.e. datasets with a high potential to generate social, environmental and economic benefits. As required by law, HVDS must be published under an open data attribution licence (CC BY 4.0 or equivalent), in machine-readable format and accompanied by metadata describing the characteristics of the datasets. All of this will be publicly accessible and free of charge with the aim of encouraging technological, economic and social development, especially for SMEs.
In addition to the publication of high-value data, all public administrations will be obliged to have their own data catalogues that will interoperate with the National Catalogue following the NTI-RISP, with the aim of contributing to its enrichment. As in the case of HVDS, access to the datasets of the Public Administrations must be free of charge, with exceptions in the case of HVDS. As with HVDS, access to public authorities' datasets should be free of charge, except for exceptions where marginal costs resulting from data processing may apply.
To guarantee data governance, the law establishes the need to designate a unit responsible for information for each entity to coordinate the opening and re-use of data, and to be in charge of responding to citizens' requests and demands.
In short, Law 37/2007 has been modified with the aim of offering legal guarantees to the demands of competitiveness and innovation raised by technologies such as artificial intelligence or the internet of things, as well as to realities such as data spaces where open data is presented as a key element.
Click on the infographic to see it full size:
Documentación
1. Introduction
Visualizations are graphical representations of data that allows comunication in a simple and effective way the information linked to it. The visualization possibilities are very wide, from basic representations, such as a graph of lines, bars or sectors, to visualizations configured on dashboards or interactive dashboards. Visualizations play a fundamental role in drawing conclusions using visual language, also allowing to detect patterns, trends, anomalous data or project predictions, among many other functions.
In this section of "Step-by-Step Visualizations" we are periodically presenting practical exercises of open data visualizations available in datos.gob.es or other similar catalogs. They address and describe in a simple way the necessary stages to obtain the data, perform the transformations and analysis that are relevant to it and finally, the creation of interactive visualizations. From these visualizations we can extract information to summarize in the final conclusions. In each of these practical exercises, simple and well-documented code developments are used, as well as free to use tools. All generated material is available for reuse in the Github data lab repository belonging to datos.gob.es.
In this practical exercise, we have carried out a simple code development that is conveniently documented based on free to use tool.
Access the data lab repository on Github.
Run the data pre-processing code on Google Colab.
2. Objetive
The main objective of this post is to show how to make an interactive visualization based on open data. For this practical exercise we have used a dataset provided by the Ministry of Justice that contains information about the toxicological results made after traffic accidents that we will cross with the data published by the Central Traffic Headquarters (DGT) that contain the detail on the fleet of vehicles registered in Spain.
From this data crossing we will analyze and be able to observe the ratios of positive toxicological results in relation to the fleet of registered vehicles.
It should be noted that the Ministry of Justice makes available to citizens various dashboards to view data on toxicological results in traffic accidents. The difference is that this practical exercise emphasizes the didactic part, we will show how to process the data and how to design and build the visualizations.
3. Resources
3.1. Datasets
For this case study, a dataset provided by the Ministry of Justice has been used, which contains information on the toxicological results carried out in traffic accidents. This dataset is in the following Github repository:
The datasets of the fleet of vehicles registered in Spain have also been used. These data sets are published by the Central Traffic Headquarters (DGT), an agency under the Ministry of the Interior. They are available on the following page of the datos.gob.es Data Catalog:
3.2. Tools
To carry out the data preprocessing tasks it has been used the Python programming language written on a Jupyter Notebook hosted in the Google Colab cloud service.
Google Colab (also called Google Colaboratory), is a free cloud service from Google Research that allows you to program, execute and share code written in Python or R from your browser, so it does not require the installation of any tool or configuration.
For the creation of the interactive visualization, the Google Data Studio tool has been used.
Google Data Studio is an online tool that allows you to make graphs, maps or tables that can be embedded in websites or exported as files. This tool is simple to use and allows multiple customization options.
If you want to know more about tools that can help you in the treatment and visualization of data, you can use the report "Data processing and visualization tools".
4. Data processing or preparation
Before launching to build an effective visualization, we must carry out a previous treatment of the data, paying special attention to obtaining it and validating its content, ensuring that it is in the appropriate and consistent format for processing and that it does not contain errors.
The processes that we describe below will be discussed in the Notebook that you can also run from Google Colab. Link to Google Colab notebook
As a first step of the process, it is necessary to perform an exploratory data analysis (EDA) in order to properly interpret the starting data, detect anomalies, missing data or errors that could affect the quality of subsequent processes and results. Pre-processing of data is essential to ensure that analyses or visualizations subsequently created from it are reliable and consistent. If you want to know more about this process, you can use the Practical Guide to Introduction to Exploratory Data Analysis.
The next step to take is the generation of the preprocessed data tables that we will use to generate the visualizations. To do this we will adjust the variables, cross data between both sets and filter or group as appropriate.
The steps followed in this data preprocessing are as follows:
- Importing libraries
- Loading data files to use
- Detection and processing of missing data (NAs)
- Modifying and adjusting variables
- Generating tables with preprocessed data for visualizations
- Storage of tables with preprocessed data
You will be able to reproduce this analysis since the source code is available in our GitHub account. The way to provide the code is through a document made on a Jupyter Notebook that once loaded into the development environment you can execute or modify easily. Due to the informative nature of this post and favor the understanding of non-specialized readers, the code does not intend to be the most efficient, but to facilitate its understanding, so you will possibly come up with many ways to optimize the proposed code to achieve similar purposes. We encourage you to do so!
5. Generating visualizations
Once we have done the preprocessing of the data, we go with the visualizations. For the realization of these interactive visualizations, the Google Data Studio tool has been used. Being an online tool, it is not necessary to have software installed to interact or generate any visualization, but it is necessary that the data tables that we provide are properly structured, for this we have made the previous steps for the preparation of the data.
The starting point is the approach of a series of questions that visualization will help us solve. We propose the following:
- How is the fleet of vehicles in Spain distributed by Autonomous Communities?
- What type of vehicle is involved to a greater and lesser extent in traffic accidents with positive toxicological results?
- Where are there more toxicological findings in traffic fatalities?
Let''s look for the answers by looking at the data!
5.1. Fleet of vehicles registered by Autonomous Communities
This visual representation has been made considering the number of vehicles registered in the different Autonomous Communities, breaking down the total by type of vehicle. The data, corresponding to the average of the month-to-month records of the years 2020 and 2021, are stored in the "parque_vehiculos.csv" table generated in the preprocessing of the starting data.
Through a choropleth map we can visualize which CCAAs are those that have a greater fleet of vehicles. The map is complemented by a ring graph that provides information on the percentages of the total for each Autonomous Community.
As defined in the "Data visualization guide of the Generalitat Catalana" the choropletic (or choropleth) maps show the values of a variable on a map by painting the areas of each affected region of a certain color. They are used when you want to find geographical patterns in the data that are categorized by zones or regions.
Ring charts, encompassed in pie charts, use a pie representation that shows how the data is distributed proportionally.
Once the visualization is obtained, through the drop-down tab, the option to filter by type of vehicle appears.
View full screen visualization
5.2. Ratio of positive toxicological results for different types of vehicles
This visual representation has been made considering the ratios of positive toxicological results by number of vehicles nationwide. We count as a positive result each time a subject tests positive in the analysis of each of the substances, that is, the same subject can count several times in the event that their results are positive for several substances. For this purpose, the table "resultados_vehiculos.csv” has been generated during data preprocessing.
Using a stacked bar chart, we can evaluate the ratios of positive toxicological results by number of vehicles for different substances and different types of vehicles.
As defined in the "Data visualization guide of the Generalitat Catalana" bar graphs are used when you want to compare the total value of the sum of the segments that make up each of the bars. At the same time, they offer insight into how large these segments are.
When stacked bars add up to 100%, meaning that each segmented bar occupies the height of the representation, the graph can be considered a graph that allows you to represent parts of a total.
The table provides the same information in a complementary way.
Once the visualization is obtained, through the drop-down tab, the option to filter by type of substance appears.
View full screen visualization
5.3. Ratio of positive toxicological results for the Autonomous Communities
This visual representation has been made taking into account the ratios of the positive toxicological results by the fleet of vehicles of each Autonomous Community. We count as a positive result each time a subject tests positive in the analysis of each of the substances, that is, the same subject can count several times in the event that their results are positive for several substances. For this purpose, the "resultados_ccaa.csv" table has been generated during data preprocessing.
It should be noted that the Autonomous Community of registration of the vehicle does not have to coincide with the Autonomous Community where the accident has been registered, however, since this is a didactic exercise and it is assumed that in most cases they coincide, it has been decided to start from the basis that both coincide.
Through a choropleth map we can visualize which CCAAs are the ones with the highest ratios. To the information provided in the first visualization on this type of graph, we must add the following.
As defined in the "Data Visualization Guide for Local Entities" one of the requirements for choropleth maps is to use a numerical measure or datum, a categorical datum for the territory, and a polygon geographic datum.
The table and bar chart provides the same information in a complementary way.
Once the visualization is obtained, through the peeling tab, the option to filter by type of substance appears.
View full screen visualization
6. Conclusions of the study
Data visualization is one of the most powerful mechanisms for exploiting and analyzing the implicit meaning of data, regardless of the type of data and the degree of technological knowledge of the user. Visualizations allow us to build meaning on top of data and create narratives based on graphical representation. In the set of graphical representations of data that we have just implemented, the following can be observed:
- The fleet of vehicles of the Autonomous Communities of Andalusia, Catalonia and Madrid corresponds to about 50% of the country''s total.
- The highest positive toxicological results ratios occur in motorcycles, being of the order of three times higher than the next ratio, passenger cars, for most substances.
- The lowest positive toxicology result ratios occur in trucks.
- Two-wheeled vehicles (motorcycles and mopeds) have higher "cannabis" ratios than those obtained in "cocaine", while four-wheeled vehicles (cars, vans and trucks) have higher "cocaine" ratios than those obtained in "cannabis"
- The Autonomous Community where the ratio for the total of substances is highest is La Rioja.
It should be noted that in the visualizations you have the option to filter by type of vehicle and type of substance. We encourage you to do so to draw more specific conclusions about the specific information you''re most interested in.
We hope that this step-by-step visualization has been useful for learning some very common techniques in the treatment and representation of open data. We will return to show you new reuses. See you soon!
Blog
Over the past year, the academic section of data.europa.eu expanded its open data training offer by publishing new conferences, courses and workshops. Thus, data.europa.academy shared a total of 15 webinars related to open data, data spaces and other topics and technical issues around the data economy.
In line with the online training philosophy of this area of expertise, professionals and users interested in open data were able to attend the conferences from anywhere in the EU by filling in a web-based registration form.
Among the webinars of the recently concluded 2022 were workshops and seminars on open data quality and metadata, the legal and technical perspective of open data openness, the potential of open data in real time or the opportunities it offers to citizens when developing solutions and services.
In this way, the range of content is very broad in terms of subject matter and level of technical accessibility, which makes it easy to filter the webinars according to interests. In addition, as many of the training sessions are based on reports previously published by the European data portal, they have very useful supporting documentation to complete the knowledge acquired.
In order to bring together this valuable source of knowledge in an orderly fashion, below you can access the 15 lectures published over the past year, as well as their respective supporting presentations.
Data quality and metadata
- Description: This webinar focuses on explaining why high quality data and metadata are the basis for beneficial production outcomes and for fostering informed decision making.
- Viewing link: https://www.youtube.com/watch?v=PcyJX8xbyik
Best practices of open data: the case of Estonia, Slovenia and Ukraine
- Description: Through this conference, the European portal tries to explain the importance and impact that the reuse of open data can have. To do so, they use the presentation of good practices and use cases of several European portals based on this type of data.
- Link to viewing: https://www.youtube.com/watch?v=mTVayKTUC-s
Real-time data
- Description: This course explains what real-time data is and which standards and technologies are most commonly used with this type of data.
- Link to viewer: https://www.youtube.com/watch?v=yl4ZotQQfuk
Demand and reuse of data in the public sector
- Description: This webinar provides an introduction to the re-use of data by public institutions, while focusing on the importance of meeting and measuring the demand for data by this specific user group.
- Viewing link: https://www.youtube.com/watch?v=uTd7Ti0aQNA&t=752s
Opportunities and challenges of citizen-generated data.
- Description: This seminar explores how citizen-generated data is currently available in open data portals of different levels of public administrations in Europe.
- Link to viewing: https://www.youtube.com/watch?v=4FHaerYTFmc&t=1801s
The role of data.europa.eu in the context of EU data spaces
- Description: This webinar enables data providers to understand how they can make better use of different infrastructures and thus provide more visibility to open data assets by assessing the role of data.europa.eu in contexts of common European data spaces.
- Link to view: https://www.youtube.com/watch?v=DjhGkGMoKso
Eurostat's regional yearbook goes digital
- Description: This is a conference dedicated to the evolution of Eurostat's regional yearbook from a printed publication to a digital publication that functions as a modern interactive tool.
- Viewing link: https://www.youtube.com/watch?v=q0mgg4IbXUY
Data.europa.eu - The official European data portal (webinar for data providers)
- Description: This webinar provides an overview of data.europa.eu, a portal that acts as a gateway to public sector information on different open data portals of EU institutions, agencies and bodies and national and international organisations around the world. The training provides an overview of the services provided through the portal.
- Link to view: https://www.youtube.com/watch?v=4s9Yol8GsSc
Measuring the impact of open data in Europe.
- Description: The aim of this conference is to provide an overview of the methods to assess the impact of open data. After a short introduction, guest speakers from the national open data teams of Poland and France presented real examples of how they measure the impact of open data in these countries.
- Link to viewing: https://www.youtube.com/watch?v=Cp7-qSNLR1U
Data visualisation
- Description: To highlight the potential behind data visualisations, through this webinar, and additional training materials, users can learn how to get the most out of open data catalogues through different ways of visualising them.
- Viewing link: https://www.youtube.com/watch?v=XY91H9TcO1A
- Supporting documents: https://data.europa.eu/en/academy/data-visualisation
Use Case Observatory Stories - Volume I
- Description: This webinar is part of a series of three sessions dedicated to the research project "Use Case Observatory" and its publications. In the first part of this training, an overview of the project, its methodology and the findings of the publication in 2022 are given. During the second part of the webinar, four of the managers of the thirty reuse cases participating in the research take the floor to present their open data solutions.
- Viewing link: https://www.youtube.com/watch?v=-FT0OxfgF0M
Trends in Geospatial Data
- Description: This seminar focuses on emerging trends in the geospatial community and how these along with standards and new ideas can be relevant to data.europa.eu.
- Link to view: https://www.youtube.com/watch?v=Hyt1MNm9l00
Federation of geospatial data on data.europa.eu
- Description: This training aims to present the geospatial data that can be found on data.europa.eu, as well as to explain the process of federating this type of data. The speakers took a close look at a geospatial dataset on data.europa.eu and explored the journey of its metadata from the source geo-catalogue to the portal.
- Link to viewing: https://www.youtube.com/watch?v=7UPneA4QOoo
Understanding open data from the perspective of legal openness (webinar for data providers)
- Description: This webinar aims to explain and discuss what openness means from a legal perspective and how it can best be achieved. The aim is not to provide purely theoretical legal training, but to identify best practices and resources that data providers can use to achieve openness and to realise when openness cannot be achieved.
- Link to viewing: https://www.youtube.com/watch?v=53QdDf4LJN0&t=1s
Understanding the technical openness of open data (webinar for data providers)
- Description: The aim of this training is to guide data providers through the principle of technical openness and the data management process of moving from closed to open data formats. An open format is one in which the programme specifications are freely available to anyone, free of charge and without limitations on re-use imposed by intellectual property rights.
- Viewing link: https://www.youtube.com/watch?v=cQMwMXd4n9I&t=17s
For the new year that is already underway, data.europa.eu aims to continue to expand the training resources of its academic section with the programming of seminars such as Data and Competition Law or another linked to the recent publication of the Open Data Maturity 2022 report.
For more information on future seminars, follow the link below to the European open data portal and stay tuned for news on this topic from datos.gob.es.
Noticia
Data science has a key role to play in building a more equitable, fair and inclusive world. Open data related to justice and society can serve as the basis for the development of technological solutions that drive a legal system that is not only more transparent, but also more efficient, helping lawyers to do their work in a more agile and accurate way. This is what is known as LegalTech, and includes tools that make it possible to locate information in large volumes of legal texts, perform predictive analyses or resolve legal disputes easily, among other things.
In addition, this type of data drives the development of solutions aimed at responding to the great social challenges facing humanity, helping to promote the common good, such as the inclusion of certain groups, aid for refugees and people in conflict zones or the fight against gender-based violence.
When we talk about open data related to justice and society, we refer both to legal data and to other data that can have an impact on universalising access to basic services, achieving equity, ensuring that all people have the same opportunities for development and promoting collaboration between different social agents.
What types of data on justice and society can I find in datos.gob.es?
On our portal you can access a wide catalogue of data that is classified by different sectors. The Legislation and Justice category currently has more than 5,000 datasets of different types, including information related to criminal offences, appeals or victims of certain crimes, among others. For its part, the Society and Welfare category has more than 8,000 datasets, including, for example, lists of aid, associations or information on unemployment.
Of all these datasets, here are some examples of the most outstanding ones, together with the format in which you can consult them:
At state level
- Spanish Statistical Office (INE). Offences according to sex by Autonomous Communities and cities. CSV, XLSX, XLS, JSON, PC-Axis, HTML (landing page for data download)
- Spanish Statistical Office (INE). 2030 Agenda SDG - Population at risk of poverty or social exclusion: AROPE indicator. CSV, XLS, XLSX, HTML (landing page for data download)
- Spanish Statistical Office (INE). Internet use by demographic characteristics and frequency of use. CSV, XLSX, XLS, JSON, PC-Axis, HTML (landing page for data download)
- Spanish Statistical Office (INE). Average expenditure according to size of the municipality of residence. CSV, XLSX, XLS, JSON, PC-Axis, HTML (landing page for data download)
- Spanish Statistical Office (INE). Retirement age in access to Benefit. CSV, XLSX
- Ministry of Justice. Judicial Census. XLSX, PDF, HTML (landing page for data download
At Autonomous Community level
- Cantabrian Institute of Statistics. Statistics on annulments, separations and divorces. RDF-XML, XLS, JSON, ZIP, PC-Axis, HTML (landing page for data download).
- Basque Government. Standards and laws in force applicable in the Basque Country. JSON, JSON-P, XML, XLSX.
- Basque Government. Locating mass graves from the Civil War and Francoism. CSV, XLS, XML.
- Generalitat Catalana. Minstry of Justice resources statistics. XLSX, HTML (landing page for data download).
- Government of Catalonia. Youth justice statistics. XLSX, HTML (landing page de descarga de datos).
- Autonomous Community of Navarre. Statistics on Transfer of Property Rights. XLSX, HTML (landing page for data download).
- Principality of Asturias. Sustainable Development Goals indicators in Asturias. HTML, XLSX, ZIP.
- Principality of Asturias. Justice in Asturias: staffing levels of the judicial bodies of the Principality of Asturias according to type. HTML (landing page for data download).
- Cantabrian Institute of Statistics. Judges and magistrates active in the Canary Islands. HTML, JSON, PC-Axis.
A the local level
- Santa Cruz de Tenerife City Council. Parking spaces for people with reduced mobility. SHP, KML, KMZ, RDF-XML, CSV, JSON, XLS
- Madrid City Council. Justice Administration Offices in the city of Madrid. CSV, XML, RSS, RDF-XML, JSON, HTML (landing page for data download)
- Gijón City Council. Security forces. JSON, CSV, XLS, PDF, HTML, TSV, texto, XML, HTML (landing page for data download)
- Madrid City Council. Child and Family Care Centres. CSV, JSON, RDF-XML, XML, RSS, HTML (landing page for data download).
- Zaragoza City Council. List of police stations. CSV, JSON.
Some examples of re-use of justice and social good related data
In the companies and applications section of datos.gob.es you can find some examples of solutions developed with open data related to justice and social good. One example is Papelea, a company that provides answers to users' legal and administrative questions. To this end, it draws on public information such as administrative procedures of the main administrations, legal regulations, jurisprudence, etc. Another example is the ISEAK Foundation, which specialises in the evaluation of public policies on employment, inequality, inclusion and gender, using public data sources such as the National Institute of Statistics, Social Security, Eurostat and Opendata Euskadi.
Internationally, there are also examples of initiatives created to monitor procedural cases or improve the transparency of police services. In Europe, there is a boom in the creation of companies focused on legal technology that seek to improve the daily life of citizens, as well as initiatives that seek to use data for equity. Concrete examples of solutions in this area are miHub for asylum seekers and refugees in Cyprus, or Surviving in Brussels, a website for the homeless and people in need of access to services such as medical help, housing, job offers, legal help or financial advice.
Do you know of a company that uses this kind of data or an application that relies on it to contribute to the advancement of society? Then do not hesitate to leave us a comment with all the information or send us an email to dinamizacion@datos.gob.es.
Noticia
The University of Salamanca (USAL) hosted the symposium "Justice and Law in Data: The role of Data as a change enabler and driver for the transformation of Justice and Law". The meeting was organised by the University itself, in collaboration with the Ministry of Justice, with the aim of reflecting on data as a public good.
The first day had an institutional and academic character, with keynote lectures by experts in law and competitiveness in the country.
Opening of the event
The symposium was inaugurated by Fernando Carbajo Cascón, Dean of the Faculty of Law, María Encarnación Pérez Álvarez, Deputy Delegate of the Government in Salamanca, Federico Bueno de Mata, Academic Director of the symposium and Fabiola Solino, Head of the Support Unit of the Directorate General of Digital Transformation of the Ministry of Justice. Fabiola Solino began by highlighting how "data is a fundamental resource in all current societies and plays an essential role in the way in which public services are administered, to the point of being at the centre of any public agenda with a transformative vocation". She also highlighted how the conference would show the willingness of administrations, academia and private sector to "promote data and the application of new techniques such as robotisation and artificial intelligence in order to offer citizens a closer, more transparent, innovative and efficient public service". All of this with an inclusive and sustainable approach.
Federico Bueno de Mata highlighted three key elements of the conference: modernity, humanism - since behind the data there are people - and knowledge transfer between the different agents of public administrations, academia and companies. María Encarnación Pérez Álvarez highlighted the importance of addressing digital advances to guarantee the sustainability of the system, paying special attention to security and the guarantee of fundamental rights. Finally, Fernando Carbajo Cascón focused on the importance of data for the functioning of society and the economy: "a responsible and transparent policy of generation, transfer and access to data is fundamental for the creation, dissemination and access to knowledge, for the development of dynamic innovation for the benefit of society and the better provision of public services". In his speech, he highlighted the importance of data for the development of public policies, decision-making by public and private agents, and as a driver of solutions -many linked to artificial intelligence- that help legal operators to carry out their work in a more transparent, simple and agile way.
After the inauguration, there were several keynote speeches, focusing on the situation of justice and data in Spain, Big Data, artificial intelligence and the digitisation of justice, among other issues.
Manuel Olmedo Palacios, Secretary General for Innovation and Quality of the Public Justice Service, addressed data within the context of co-governance in the field of Justice, a system that represents a positive experience for the Ministry, insofar as it facilitates a dialogue-based ecosystem for the provision of the public service of Justice in Spain, where decisions can be taken with greater accuracy and in which one can learn from the experiences of others. He explained that the plurality of decision-making actors within the justice ecosystem is a strength for coordinated decision-making, and it is in this context that data must be managed. The need for a correct management of data is raised, without ceasing to pursue the placement and situation of the person, the citizen, at the centre of all justice policies as the only way to reduce the gaps and protect their fundamental rights in the best way possible.
The Data Manifesto, a document drawn up within the State Technical Committee for e-Justice Administration, was also discussed, where the need to reinforce the importance of data in the process of digital transformation of justice is raised. Tontxu Rodríguez Esquerdo, Secretary of State for Justice, officially presented the Data Manifesto, explaining the relevance of this document aimed at identifying the principles on which to build a public data space for the Justice sector: to define, generate, maintain, preserve, guarantee and respect the principles that must govern the processing of public data related to the activity of Justice. He also informed that access to the data by citizens and other public and private political actors is now a right, which implies the possibility of demanding from the body responsible for the elaboration and dissemination of the data as part of its activities.
Open data in the justice sector
In the afternoon, the session focused on "Open Data, AI and the Administration of Justice", first from the perspective of Constitutional Law and Administrative Law, and then from the perspective of Procedural Law.
Various speakers talked about the guarantees of rights in the framework of open data and the protection of personal data. The governance of artificial intelligence in the public legal sphere was also addressed, highlighting the importance of looking at the risks associated with three elements: the input data, what the system does with it and the output decision. To provide greater safeguards, there is a need to develop risk reviews and promote transparency. The need to have specific rules for the use of AI in the sector, to always work with human supervision and to respect fundamental rights, including procedural rights such as effective judicial protection or the presumption of innocence, was also highlighted.
Another issue highlighted was the need for data management professionals who are aware of the importance of data. These professionals must be aware of the relevance that each piece of data may have not only individually, but also when combined with other data. Furthermore, they must take into account the nature of each piece of data, especially in those areas, such as the university, where information of a different nature coexists, such as academic, health, economic data, etc.
Examples of use cases
Examples of open data reuse in the legal sector were then presented in several parallel rooms. Examples are:
- The National Institute of Toxicology and Forensic Sciences spoke about digital transformation in forensic medicine and the work they carry out in the area of data-driven justice and prevention. To this end, they use tools that allow combined analysis from multiple data sources, as well as the visualisation and comprehensive exploration of data in an interactive and simple way, facilitating the creation of collaborative content in which different working groups participate. An example of its data processing work is the report on "Technological findings in traffic accident fatalities", which brings together data from different laboratories, the results of which can also be viewed on the "Justice in data" portal.
- Representatives of the Autonomous University of Madrid commented on how since 2015 they have been analysing judgments (more than 2,000 per year) from various bodies: the contentious-administrative courts, the High Courts of Justice, the National High Court and the Supreme Court. Through the analysis of this data, they try to answer questions such as at what territorial level of the administration litigiousness is concentrated, what factors influence the estimation of appeals or whether there are territorial differences in management. Thanks to these data, the aim is to improve three facets: regulatory quality, administrative activity and the jurisdictional function.
- From the Universitat Politècnica de València (UPV) they spoke about the application of artificial intelligence and georeferencing, using the cadastre and the land registry, to carry out municipal genealogies, to generate a correspondence of names and surnames and to be able to more easily resolve disputes related to these matters.
- The representative of the Universitat de Barcelona-Universitat de Girona talk about AI and predictive justice, focusing on the incorporation of the future behaviour of the accused as a parameter to be considered in decision-making related to the penal system through risk assessment. One example is the RisCanvi protocol, used by the Catalan Department of Justice to assess the risk of recidivism based on a series of parameters (economic capacity, beliefs, family support, etc.). In the US, in Pennsylvania, they go a step further and apply algorithms to determine the sentences to be served. The risk lies in preventing this type of solution from being discriminatory and in the importance of being transparent.
- The massive analysis of data and Artificial Intelligence to improve the control and audit of public procurement was another of the topics discussed, in this case by the representative of the University of Oviedo and NTT Data. Through the analysis of data from the Public Sector Procurement Platform and the Commercial Register, together with data from the European platform TED Tender, a search engine/recommender of companies for tenders has been created, as well as a software application to detect irregular tenders, among others.
Other talks were focused on the automation of robotic processes (RPA) to improve the efficiency of justice in tasks such as the return of economic income, the need to improve interoperability and the importance of transparency and good information management to promote competitive bidding in electronic judicial auctions.
Sharing experiences
The second day focused on sharing experiences from the public and private sector in the legal field related to data, including international experiences.
There were also parallel rooms where the ethical use of AI, the importance of universal interoperability in Justice, the use of biometric systems in Justice or the application of Machine learning for judicial notifications were discussed.
All the presentations, both those held in the auditorium and in the parallel rooms, are available through the Youtube channel of the University of Salamanca.
In short, during the two days, the willingness of all members of the legal sector, including public administrations, private organisations and academic centres, to promote the transformation of the sector, implementing innovations to improve effectiveness and efficiency, was evident. A task for which it is necessary to have quality open data that shows the reality of the sector, respecting all legal guarantees.
Blog
The Manifesto for a public data space has recently been published. The document raises the need to reinforce the importance of data in the current digital transformation process in this area. The document has been drawn up within the State Technical Committee of the Electronic Judicial Administration and was subsequently ratified by the competent Public Administrations in matters of Justice, i.e. the General State Administration through the Ministry of Justice and the Autonomous Communities that have assumed competence in this field, as well as the General Council of the Judiciary and the General State Prosecutor's Office.
Specifically, as is expressly recognised, it is "an instrument that seeks to improve the efficiency of Justice through data processing and to design public policies in the field of Justice, based on the consideration of data as a public good, in such a way as to guarantee both its production and its free access".
What are the main objectives to be achieved?
The document is part of a wider initiative called Data-driven Justice which, within the broader framework of the transformation of the public service of Justice, is conceived as a priority project for the Administration of Justice. Its main purpose is the creation of a secure, interoperable and reuse-oriented public data space. Specifically, it aims to:
- Promote a data-driven management model underpinning the transformation of Justice.
- Given that data must be considered a public good, it is considered a priority to guarantee free access to them.
- To promote a secure, interoperable and reuse-oriented public data space, which implies the need to address technical, organisational and, ultimately, legal challenges and problems. To this end, a governance model is proposed based on the configuration of access to data as a right, the promotion of interoperability, as well as, among other principles, the promotion of data literacy and the rejection of practices that prevent the re-use of data or, where appropriate, imply the recognition of exclusive rights.
- Ensure innovation in the field of Justice with a solution-oriented approach to concrete problems, in particular to promote cohesion and equality.
Difficulties and challenges from an open data and re-use perspective
This is undoubtedly a suggestive approach which, nevertheless, faces important challenges that go beyond the mere approval of formal documents and the promotion of legislative reforms.
Firstly, it is necessary to start from the existence of a plurality of subjects involved. To this end, the existence of a dual perspective in the public management of the judicial sphere must be emphasised. On the one hand, the Ministry of Justice or, as the case may be, the Autonomous Communities with transferred powers are the administrations that provide the material and personal resources to support management and, therefore, are responsible for exercising the powers relating to access and re-use of the information linked to their own sphere of competence. On the other hand, the Constitution reserves the exercise of the judicial function exclusively to judges and courts, which implies a significant role in the processing and management of documents. In this respect, the legislation grants an important role to the General Council of the Judiciary as regards access to and re-use of judicial decisions. Undoubtedly, the fact that the judicial governing body has ratified the Manifesto represents an important commitment beyond the legal regulation.
Secondly, although there has been significant progress since the approval in 2011 of a legislative framework aimed at promoting the digitisation of Justice, nevertheless, the daily reality of courts and tribunals often demonstrates the continued importance of paper-based management. Furthermore, major interoperability problems sometimes persist and, ultimately, the interconnection of the different technological tools and information systems is not always guaranteed in practice.
In order to address these challenges, two major initiatives have been promoted in recent months. On the one hand, the reform intended to be carried out by the Draft Act on Procedural Efficiency Measures in the Public Justice Service shows, in short, that the modernisation of the judiciary is still a pending objective. However, it should be borne in mind that this is not simply a purely technological challenge, but also requires important reforms in the organisational structure, document management and, in short, the culture that pervades a highly formalised area of the public sector. A major effort is therefore needed to manage the change that the Manifesto aims to promote.
With regard to open data and the re-use of public sector information, it is necessary to distinguish between purely administrative management, where the competence corresponds to the public administrations, as mentioned above, and judicial decisions, the latter being in the hands of the General Council of the Judiciary. In this respect, the important effort made by the judges' governing body to facilitate access to statistical information must be acknowledged. However, access to judicial decisions for re-use has significant restrictions which should be reconsidered in the light of European regulation. Even taking into account the progress made at the time with the implementation of the service of access to judicial decisions available through the CENDOJ, it is true that this is a model with significant limitations that may hinder the promotion of advanced digital services based on the use of data.
Even though the last attempt to regulate the singularities of the re-use of judicial information by the General Council of the Judiciary ended up being annulled by the Supreme Court, the aforementioned Draft Act contemplates a relevant measure in this respect. Specifically, within the framework of the electronic archiving of documents and files, it entrusts the General Council of the Judiciary with the regulation of "the re-use of judgments and other judicial decisions by digital means of reference or forwarding of information, whether or not for commercial purposes, by natural or legal persons to facilitate access to them by third parties".
More recently, at the end of July, the Council of Ministers approved a second legislative initiative that is already being processed in the Spanish Parliament and which incorporates some measures specifically dedicated to the promotion of digital efficiency. Specifically, in relation to the electronic judicial file, the reform aims to go beyond the document-based management model and proposes a paradigm shift based on the establishment of the general principle of a data-based justice system that, among other possibilities, facilitates "automated, proactive and assisted actions". With regard to open data and the reuse of information, the draft legislation includes a specific title that provides for the publication of open data on the Justice Administration Portal according to interoperability criteria and, whenever possible, in formats that allow automatic processing.
In short, data-driven management in the judicial sphere and, in particular, access to judicial information for reuse purposes requires a process of in-depth reflection in which not only the competent public bodies and legal publishers offering access to jurisprudence but, with a broader scope, the various legal professions and society in general can participate. Beyond the promotion of suggestive initiatives such as the Forum on the Digital Transformation of Justice, the first edition of which took place a few months ago, and the timely organisation of academic events where this debate can take place, such as the one held last October, ultimately we must start from an elementary principle: the need to promote a management model based on the opening up of information by default and by design. Only on this premise can the effective re-use of information in the public service of Justice be promoted definitively and with the appropriate legal guarantees.
Therefore, in view of the important legal reforms that are being processed, the time seems to have come to make a definitive commitment to the value of data in the judicial sphere under the protection of the objectives that the aforementioned Manifesto intends to address.
Content prepared by Julián Valero, professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec).
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Documentación
This report published by the European Data Portal explores the so-called Citizen Generated Data (CGD). This category of data refers to those generated by citizens. There is a lack of this type of data within European open data portals, mainly due to the lack of publication and management of CGDs by public administrations.
The document analyzes various open data portals, whose main objective is to provide a vision of the CGDs that can be part of these portals and how to include them by public administrations. It should be noted that during the analysis, a framework is established for the description, reference, and characterization of the CGDs.
Finally, based on the conclusions of the previous analysis, the document offers a series of recommendations and guidelines for data publishers. The objective is to increase and improve the presence of CGDs in the publication of open data, involving citizens in the design of policy, processes and governance.
This report is available at the following link: "Data.europa.eu and citizen-generated data"
Evento
Data has become one of the pillars of society's digital transformation process, which also challenges sectors such as justice and law enforcement. Thanks to them, access to information and statistics has been improved, allowing decision-making to be based on objective figures to which new techniques such as automation and artificial intelligence can be applied.
Thus, and with the aim of continuing to delve into the advantages derived from the data ecosystem, on 17 and 18 October, the University of Salamanca is organising, in collaboration with the Ministry of Justice, a symposium on Justice and Data.
What will be the themes to be addressed?
During the two days of the event and through the various presentations, the aim will be to discuss "the role of data for the proper functioning of public services". In other words, how open data can help to improve the efficiency and effectiveness with regard to citizens and the services offered to them.
In line with this idea, the questions that will form part of the symposium will revolve around the following themes:
- Personalised assistants
- Data Analytics
- Designing Data Visualisations
- Governance, Transparency and Open Data
- AI - NLP
- AI - Other
- Robotisation
- Data Sharing Spaces
- Data, AI, RPA Training
Thus, while the first day will be made up of conferences by relevant people from the Justice, Law and academic sectors, the second day will showcase the different initiatives of the international technology sector and the legal-tech sector related to data.
Likewise, in simultaneous rooms, public and private projects in which technology is applied to the services of Justice and Law will be analysed.
In conclusion, it is an event that seeks to become a meeting point for innovation in the field of justice. So that, through the exchange of experiences and success stories, between the administration, institutions and private companies in any field, it will be possible to guide the use of data to provide and give solutions to specific problems.
How can I attend?
Attendance at the conference will be free of charge and will take place at the Hospederia Arzobispo Fonseca in Salamanca. In order to attend, it will be necessary to fill in the following registration form. As with other similar events, this one will also be broadcast live online.
Entrevista
Today, data drives the world. It conditions public policies, the behaviour of algorithms and the decision-making of many companies. That is why it is important to have figures that correctly represent reality, i.e. that take into account all variables, including gender.
Thais Ruiz de Alda is founder and CEO of Digital Fems, an entity that designs projects to increase the presence of women in technological environments. In addition to consultancy tasks and the design of equality policies, Digital Fems carries out projects based on data science with a gender perspective. In this interview, Thais talks about the current situation and the challenges in this field (video only available in Spanish).
Full interview:
1. Why is it important to have gender-sensitive data?
Gender-sensitive data is a tool to measure various aspects, in a differentiated way between men and women, between different sexes.
It also serves to measure reality in terms of gender identity, if information is available. Finally, there are subjects, areas of data processing, where it is essential to include intersectional perspectives, such as gender or origin. For example, when data is collected on the use of health services, we can see differentiated effects depending on whether the patients are of different sexes, or for example in the use of public transport, it is important to identify the sex of the person using the service, in order to design a service in accordance with the needs of the passengers: space for breastfeeding, space for carrying children, safety and avoidance of sexual harassment or other types of aggression. The problem we still have today is the lack or non-existence of this type of data. The famous gender data gap. That is why many organisations say that without data with a gender perspective, equality is not possible. Without GenderData , equality is not.
2. What is the current status of this type of data? You indicate that there is a gender gap in the data…
There is a tremendous gender gap in data. In general, and since the era of open government began in 2007, public administrations have been the ones that started opening data. This makes sense, given that administrations have been the generators of official statistics and the owners and guardians of some of the data that citizens create through the use of public services. According to the United Nations, by December 2020, we had only 39% of the gender-sensitive data we need to monitor the SDGs. So, from the public authorities' side, we still have some way to go. I think the future outlook for this kind of data is positively good, because we are on the right track, making progress in creating this kind of data. This is where we can say that, in parallel, there are civil society organisations that are also working on the generation of gender-sensitive data. Many women's organisations have realised the need to create and collect this data in order to alleviate this gap. In fact, right now, civil society organisations are the ones that should be pushing and lobbying to show the value of this type of data and pushing for public authorities to generate it. Now we need other stakeholders such as companies or academic environments to prioritise this need and generate data with a gender perspective in order to understand issues that affect men and women differently. The topic could be the subject of a doctoral thesis... but in short, the first stumbling block to be resolved is to produce data with this perspective, which has been ignored, and once we have these data, we will be able to read reality, measure it and draw conclusions that will allow us to make decisions with much greater precision.
According to the United Nations, by December 2020, we had only 39% of the gender-sensitive data we need to monitor the SDGs
3. Digital Fems, together with other organisations, has set up GenderDataLab.org, a repository of open data with a gender perspective. What kind of information can users find there? What are the challenges you have encountered in collecting and making this kind of data public?
Genderdatalab is a recently created space for experimentation and publication of datasets with a gender perspective, where visitors can choose to:
- Learn through articles, recommendations, guides or best practices and information collected on the discipline of data with a gender perspective. It is a space of common use because after registering, users can create datasets and publish them, with open licenses to publish their study reports, etc.
- Register and publish datasets; it is a space of common use because after registering, users can create and publish datasets, with open licenses to publish their study reports, etc.
- Download or use the API of the datasets, or simply visit the datasets and visualise them...
Despite our "youth" we have had diverse experiences: we have convinced organisations to publish their data, which contained the gender perspective, in open format and they have had some fears that open data is susceptible to manipulation. Therefore, we have evangelised about open data to non-digitised communities. On the other hand, we have seen how, on the contrary, organisations that wanted to publish gender-inclusive reports, opened up to do so, and asked us for help and support in implementation. We have also detected some fears in the use of the platform, i.e. resistance to publish datasets for "fear" that they are not well designed, etc. and that is why we are now going to publish mini training courses to familiarise users with the functionalities of the platform, as well as with the contents and encourage the members of the platform, which already has a few hundred people registered.
4. One of the areas where data can also help us is in the fight against gender violence. This is the field of work of your project DatosContraelRuido.org, where you use Big Data techniques to analyse thousands of data files on the subject. How have you developed the project and what has been its impact?
The DatosContraElRuido.org project was the first project that we launched at Digitalfems in terms of gender data activism. We developed the project so that, through the application of our methodology, complex legal concepts could be understood in data visualisations, processed and analysed from a gender perspective, which could explain the presence of male violence in Spain, or the typology of violence that is exercised with the data that the Ministry of Justice and the General Council of the Judiciary publish. With all these thousands of lines of information, we have been able to create an understandable story for ordinary people, and to design communication campaigns that allow us to understand the dimension of male violence.
Each time we publish an update of the data, we achieve a relatively important media impact, which has allowed us to be invited to many forums, especially in the context of male violence, to explain three issues:
- Creating technology or technological solutions with a gender perspective helps to broaden the field of vision of the problems. We need more women technologists who can address social issues.
- GenderData is a discipline of data science that is not only concerned with data collection, but also applies to the way data is structured and processed for analysis.
- All data can be downloaded from GenderDataLab.org so that anyone can in turn process the data and expand the scope of analysis.
The social impact we are aiming for is to clarify the high prevalence of male violence, based on official, undeniable data.... and to raise social awareness about it. For us, DatosContraelRuido.org is an open and accessible tool for society to know the reality of a type of violence that needs to be spoken out loud and clear. If drugs, traffic accidents and public safety are areas of public interest, so too is the violence that some men inflict on women. Seventy per cent of complaints are filed away...
DatosContraelRuido makes it possible to understand complex legal concepts in data visualisations, processed and analysed from a gender perspective. The aim is to explain the presence of male violence in Spain, or the typology of violence that is exercised with the data published by the Ministry of Justice and the General Council of the Judiciary.
5. In your opinion, what should be the strategic actions to generate gender-sensitive data from an institutional perspective?
We live in data-driven societies, and we are getting more and more... so it would make perfect sense to take into account the different tools, methodologies and processes that help to generate the best possible quality data. Here it is very clear that we need an action plan to make this possible.
First and foremost, training must be provided to individuals, departments and teams responsible for maintaining datasets or with the potential to create datasets within the public administration. It is necessary to invest in training the people who manage data generation. In fact, it is a "leg" of what is meant by digitising or digitally transforming public administration.
The second is to promote the creation of this type of data through administrative instruments. For example, the European Commission announced in 2020 that beneficiaries of its research grants would have to incorporate sex and gender analysis in the design of their studies, probably due to the experience of COVID-19 and vaccines.
The third is to raise awareness of this new discipline, and the benefits it would bring, but this without the other actions is useless. And most importantly, without budgets to incentivise change or put in place elements of innovation, we do nothing....
First and foremost, training must be provided to individuals, departments and teams responsible for maintaining datasets or with the potential to create datasets within the public administration.
6. Although it is a sector in constant growth, women are still a minority in work environments linked to the technological field. What are the reasons behind this situation? What measures should be taken to change it?
It is complex because this reality is found all over the planet, countries and territories. One of the strongest reasons is that there is a strong presence of gender stereotypes about "technology". There are many, many studies that show how even from an early age, girls and boys associate technology with masculine skills. Let's be aware that in the cradle of tech culture, Silicon Valley, there is a term that is constantly used to define traits of corporate cultures: Brogrammer, a fusion between brother and programmer.
Stereotypes operate invisibly, and are one of the reasons why there are no women university students in specific engineering-related fields, and therefore there are also low rates into professional environments. It is said that women represent approximately 30% of the total number of employees in the tech sector, in a sector whose growth rate is 10% per year, vs. 0.4%, which is the rate of growth of the employment rate in the Eurozone. So the recruitment rate of female technologists is low because there are few of them, but this rate continues to fall as careers develop and the retention of female talent is an unresolved issue in the tech sector.
The solution to this is complex, because it implies that on the one hand, public policies must be activated to generate actions that promote a greater female presence. For example, Barcelona City Council has been a pioneer in regulating and setting criteria and means to change the trend of the sector (the government measure is called BcnFemTech). On the other hand, corporate policies must also and above all be activated among the companies that form part of the sector through the creation of measures that encourage the entry of more women, and the retention of this talent, which also has a direct impact on the company's profits: the more diverse people who design software, the better and more effective it will be, as the Bill and Melinda Gates Foundation says.
The recruitment rate of female technologists is low because there are few of them, but it is also because this rate continues to fall as careers develop and the retention of female talent is a pending issue in the tech sector.
7. Can you tell us about Digital Fems' next lines of work in the field of open data?
Well, we continue to work with data from some of the organisations we collaborate with, for example with CIMA, where we follow up on their reports on the presence of women in film, and we monitor the evolution of the number of women working in the industry, directing films or scriptwriting them, and we calculate the gender gap. We are also going to publish openly two works we have done this year: a survey of companies based in Catalonia about women's roles and tasks in technological environments, and a report and dataset about women in tech environments in Spain. We are very happy because these two reports will shed light on the reality of women technologists in Spain. By the last quarter of 2022 we will probably be working on a data and music project as well, through EllesMusic: the music sector works with non-standardised metadata, and gender should be incorporated as an element of metadata.
Noticia
Last December, the Congress of Deputies validated Royal Decree-Law 24/2021, which transposed several European directives, including Directive (EU) 2019/1024 on open data and the re-use of public sector information. This directive seeks to broaden the scope of application of the previous regulation, bringing legal guarantees and obligations in line with the current innovation landscape, where technologies such as Artificial Intelligence (AI) could benefit from increased availability of public sector data. This initiative is aligned with the European Union's Data Strategy for the creation of a single data market where information flows freely between States and between sectors.
With this Royal Decree-Law, the provisions of Act 37/2007, of 16 November, on the re-use of public sector information were amended, providing new features regarding obligated parties, types of data to be considered of special interest or procedures for processing requests, among other aspects. As the Directive points out, the aim of this new regulation is to promote the re-use of public sector information in a context of digital transformation, seeking to promote the "intelligent use of data", as well as the "creation of new services and applications based on the use, aggregation or combination of data". It was therefore essential to update the regulatory framework as the previous provisions were "outdated with respect to these rapid changes and, as a result, the economic and social opportunities offered by the re-use of public data may be lost".
These new developments have been analysed by a team coordinated by researchers Julián Valero and Rubén Martínez, as part of the project "Open data and reuse of public sector information in the context of its digital transformation: adapting to the new regulatory framework of the European Union (ref. PID2019-105736GB-I00)", funded by the Ministry of Science and Innovation.
Main findings of the study
Based on these premises, the study undertakes a systematic analysis of the new regulatory framework, highlighting the following conclusions:
- The European regulation is limited in its ability to establish clear and precise obligations to facilitate access to public sector information for re-use. In this regard, the referral to the Member States' regulation constitutes an added difficulty in facilitating a European market for re-use.
- The subjective scope of application of the rules on re-use has been extended to include new subjects to which the rules apply. Consequently, these entities have to adjust the management of the data they generate to the new regulation, which is a major challenge insofar as it does not always coincide with the scope of application of the regulation on common administrative procedure and the legal regime of the public sector, a regulation that has served to boost technological modernisation in this area.
- The new category of high-value data is one of the main novelties of the new regulation. Beyond the measures to be adopted at the European level, the study suggests that the States adopt a broader perspective than that envisaged in the Directive. Thus, it is proposed not only to include certain private subjects but also to establish new sets of data outside those established by the European Union, such as those referring to public sector procurement.
- The Directive also establishes that "Member States should ensure that practical arrangements are in place that help re-users in their search for documents available for re-use". In this sense, the study suggests taking advantage of the current parliamentary procedure of the draft act to establish a specific regulation in Spanish legislation, since these are instruments of great relevance for the achievement of the objectives set by the European Union, especially with regard to Artificial Intelligence.
- It is essential to promote a regulation that adequately addresses the issue of the liability of public sector entities. In particular, the study considers that the current regulation may generate legal uncertainty for re-users, who will not find an adequate legal framework to promote digital transformation initiatives based on the re-use of public sector information.
- Although the new regulation allows public bodies to continue to set conditions that restrict the re-use of data or limit competition, this possibility is conditional on the respect of certain safeguards. This has given an important boost to the use of open licences. However, the fact that there is a wide diversity in the conditions set by each agency creates significant dysfunctions for re-users, which would justify, according to the study, the creation of an open governmental licensing model based on legal regulation.
- A more precise regulation of the administrative procedure to be followed by public bodies when dealing with requests for access for re-use should be established. According to the study, special attention should be paid to the grounds for refusal, as they are too generic in their current wording. It is also considered necessary to review the regulation of administrative silence from the perspective of European legislation, which is particularly demanding with regard to the reasons for refusing access. Finally, it is proposed that an independent control body be set up, so that complaints lodged with this body can replace ordinary administrative appeals, a possibility expressly permitted by the legislation on common administrative procedure.
These are some of the main contributions of the study, the final result of which has materialised in the book "Datos abiertos y reutilización de la información del sector público", published by the Comares publishing house, the first book in Spain to comprehensively study the new legal regime in this area, integrating European regulations and state legislation.