Blog
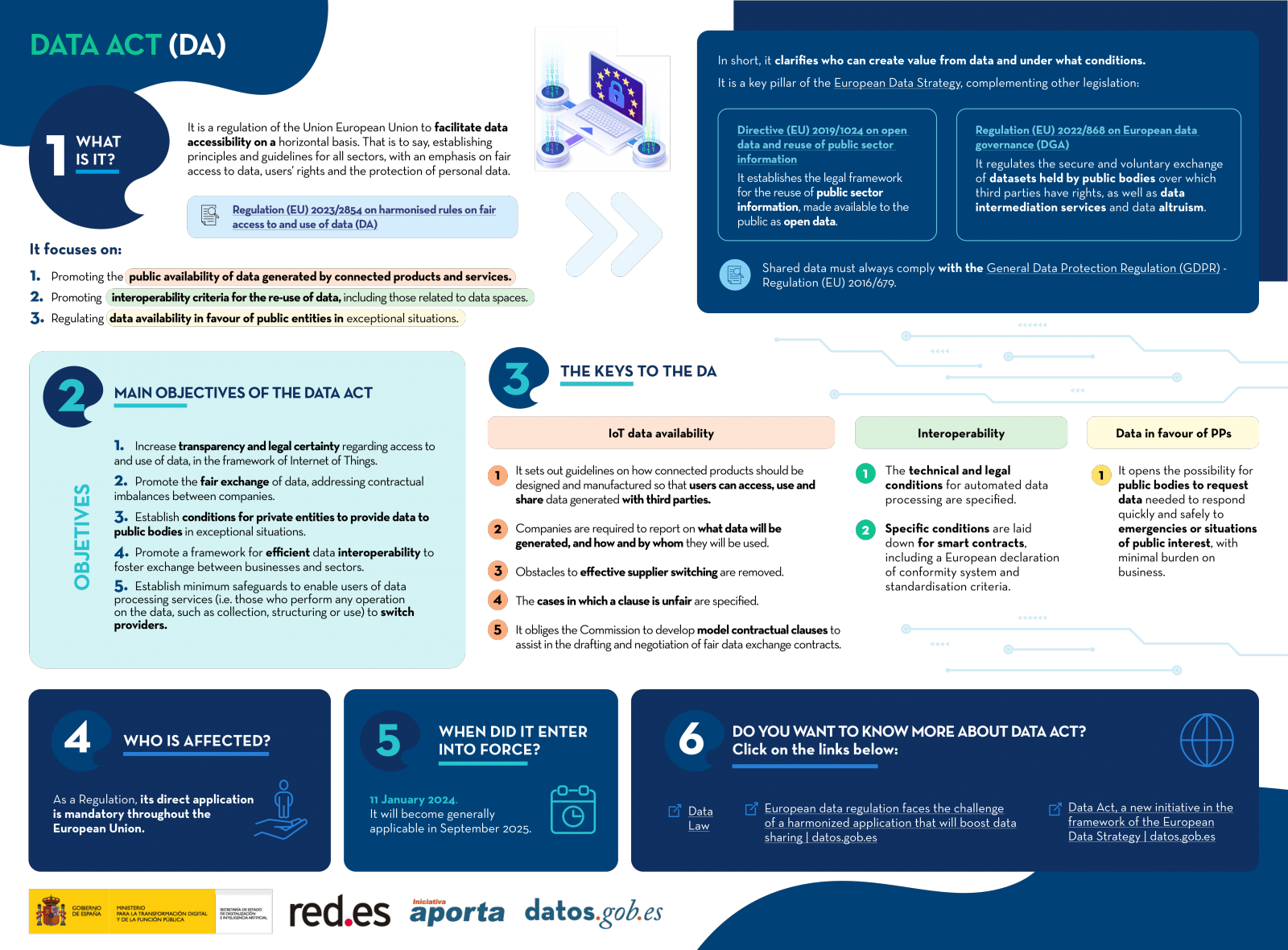
The adoption of the Regulation (EU) of the European Parliament and of the Council of 13 December 2023 on harmonised rules for fair access to and use of data (Data Law) is an important step forward in the regulation of the European Union to facilitate data accessibility. This is an initiative already included in the European Data Strategy , the main aims of which are:
- Regulate the provision of data topublic entities in exceptional situations.
- Promote the development of interoperability criteria for data spaces, data processing services and smart contracts.
- And, from the perspective that interests us now, to promote the provision of the data generated by connected products and services, either to those who use them or to the third parties they indicate.
In this respect, in view of users' difficulties in accessing data, the Regulation seeks to facilitate their free choice of providers of repair and other services, as it has been found that in many areas manufacturers try to reserve their use on an exclusive basis. Among other issues, it is intended to promote the user's right to decide for what purposes and by whom the data may be used, without prejudice to the existence of a series of limitations and conditions that are provided for in the Regulation itself.
A major shift in regulatory focus
While the Open Data and Re-use of Public Sector Information Directive and the Data Governance Regulation focus on establishing rules and safeguards to promote access to data held by public bodies, the new regulation pays special attention to relations between private parties. In other words, it allows public bodies to demand data from certain private subjects under exceptional conditions and for reasons of public interest.
One of the main objectives of the Data Regulation is to encourage not only "the development of new and innovative connected products or related services and to stimulate innovation in the aftermarkets, but also to stimulate the development of entirely new services using the data inquestion, including those based on data from a variety of connected products or related services".
To this end, it has been considered essential to establish clear and precise obligations for manufacturers of connected products, suppliers of connected products and related service providers to share the data generated with users.
What obligations are in place?
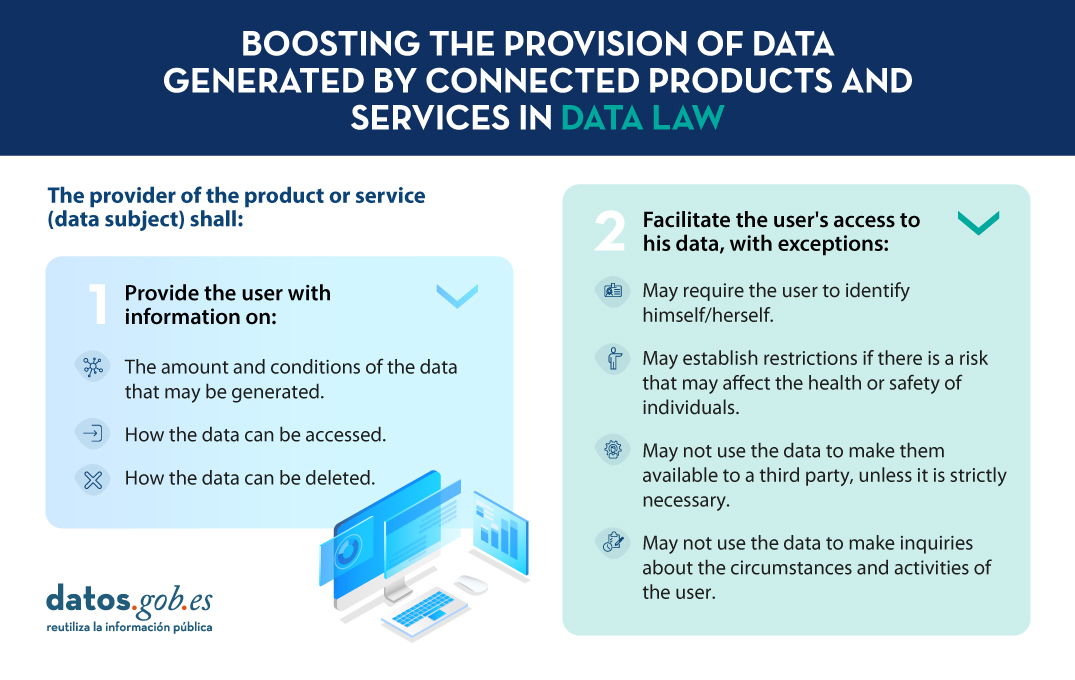
Prior to contracting the products and services, the owner of the data - i.e. the supplier of the product or service, which may also be the manufacturer -‑‑, shall provide the user with information on:
- The amount and conditions of the data that can be generated
- How this data can be accessed
- How they can be suppressed
In this respect, the design of products and services is required to take appropriate measures to ensure that, by default, data are accessible, free of charge and directly, in particular in a structured, machine-readable format.
However, this right is subject to certain conditions and limitations in order to ensure that other legal interests and interests are not affected:
- The data subject may not make it difficult for the user to access his or her data, but may require the user to identify himself or herself, even if he or she is prohibited from keeping the information generated indefinitely.
- It may establish restrictions in the contract when, as a result of the user's access to the data, there is a risk to the functioning of the product that may affect the health or safetyof persons.
- Under no circumstances may you use the data obtained during the use of the product or the provision of the service to make them available to a third party, unless it is strictly essential for the fulfilment of the contract.
- It is also expressly forbidden to use the data to make enquiries about the user's circumstances and activity, such as, for example, the user's financial situation.
For his part, the user is also subject to a number of obligations specifically aimed at ensuring the good faith of his legal relationship with the holder:
- You are not allowed to use the data to compete with the latter, either directly or through a third party to whom you may provide it,
- You may not use access to them to make enquiries about the activity of the manufacturer of the product or, where applicable, of the data subject.
- In addition to these obligations, you have the right to share the data with a third party, who may only use it for the purposes for which you authorise them to do so. In particular, it may not create profiles unless this is necessary to provide the service, make them available to another party or develop a product that competes with the one from which the data originally originated.
In any case, the regulation establishes an important limitation to be taken into account by users, as micro and small enterprises are excluded from this regime. With one exception: they have been commissioned to develop the product or provide the service by a subject that falls within the scope of the Regulation.
what safeguards are in place to ensure the effectiveness of this regulation?
As is generally the case in any area, the user may bring the matter before a judicial body to enforce his or her rights. In addition, the new regulation establishes the possibility of approaching the designated authority at State level to ensure the application and enforcement of the provisions of the Regulation. If the problem concerns the processing of personal data, you may also exercise your rights before the competent authority in this area.
In this respect, the European Commission will have to make public a list of the relevant authorities on the basis of the information provided by the States. They may designate more than one authority, indicating which one has the coordinating role. These authorities shall have sufficient means: their members shall have the expertise required for the performance of their duties and their impartiality shall be guaranteed, so that they may not receive instructions from other entities.
Apart from this channel, the data subject and the user - or, where appropriate, the third party to whom the user permits the use of the data - may voluntarily agree to submit to a certified dispute resolution body, whose decision must be taken within a maximum of 90 days. Such a body shall be accredited to the State where it is established. To this end, he or she must justify his or her impartiality, capacity and independence. It must also demonstrate that it has adequate procedural rules and that it is easily accessible by electronic means.
In short, the new Data Law has not only established a regulatory framework that reinforces users' access to the data generated by the connected products they acquire and the related services they enjoy, but it has also enshrined a series of guarantees specifically aimed at ensuring effective compliance.
Download the infographic in PDF here
This infographic is also available in two pages
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec). The contents and points of view reflected in this publication are the sole responsibility of its author.
Noticia
The concept of High-Value data (High-Value datasets) was introduced by the European Parliament and the Council of the European Union 4 years ago, in Directive (EU) 2019/1024. In it, they were defined as a series of datasets with a high potential to generate "benefits for society, the environment and the economy". Therefore, member states were to push for their openness for free, in machine-readable formats, via APIs, in the form of bulk download and comprehensively described by metadata.
Initially, the directive proposed in its annex six thematic categories to be considered as high value: geospatial, earth observation and environmental, meteorological, statistical, business records and transport network data. These categories were subsequently detailed in an implementing regulation published in December 2022. In addition, to facilitate their openness, a document with guidelines on how to use DCAT-AP for publication was published in June 2023.
New categories of data to be considered of high value
These initial categories were always open to extension. In this sense, the European Commission has just published the report "Identification of data themes for the extensions of public sector High-Value Datasets" which includes seven new categories to be considered as high-value data
-
Climate loss: This refers to data related to approaches and actions needed to avoid, minimize and address damages associated with climate change. Examples of datasets in this category are economic and non-economic losses from extreme weather events or slow-onset changes such as sea level rise or desertification. It also includes data related to early warning systems for natural disasters, the impact of mitigation measures, or research data on the attribution of extreme events to climate change.
-
Energy: This category includes comprehensive statistics on the production, transport, trade and final consumption of primary and secondary energy sources, both renewable and non-renewable. Examples of data sets to consider are price and consumption indicators or information on energy security.
-
Finance: This is information on the situation of private companies and public administrations, which can be used to assess business performance or economic sustainability, as well as to define spending and investment strategies. It includes datasets on company registers, financial statements, mergers and acquisitions, as well as annual financial reports.
-
Government and public administration: This theme includes data that public services and companies collect to inform and improve the governance and administration of a specific territorial unit, be it a state, a region or a municipality. It includes data relating to government (e.g. minutes of meetings), citizens (census or registration in public services) and government infrastructures. These data are then reused to inform policy development, deliver public services, optimize resources and budget allocation, and provide actionable and transparent information to citizens and businesses.
-
Health: This concept identifies data sets covering the physical and mental well-being of the population, referring to both objective and subjective aspects of people's health. It also includes key indicators on the functioning of health care systems and occupational safety. Examples include data relating to Covid-19, health equity or the list of services provided by health centers.
-
Justice and legal affairs: Identifies datasets to strengthen the responsiveness, accountability and interoperability of EU justice systems, covering areas such as the application of justice, the legal system or public security, i.e. that which ensures the protection of citizens. The data sets on justice and legal matters include documentation of national or international jurisprudence, decisions of courts and prosecutors general, as well as legal acts and their content.
-
Linguistic data: Refers to written or spoken expressions that are at the basis of artificial intelligence, natural language processing and the development of related services. The Commission provides a fairly broad definition of this category of data, all of which are grouped under the term "multimodal linguistic data". They may include repositories of text collections, corpora of spoken languages, audio resources, or video recordings.

To make this selection, the authors of the report conducted desk research as well as consultations with public administrations, data experts and private companies through a series of workshops and surveys. In addition to this assessment, the study team mapped and analyzed the regulatory ecosystem around each category, as well as policy initiatives related to their harmonization and sharing, especially in relation to the creation of European Common Data Spaces.
Potential for SMEs and digital platforms
In addition to defining these categories, the study also provides a high-level estimate of the impact of the new categories on small and medium-sized companies, as well as on large digital platforms. One of the conclusions of the study is that the cost-benefit ratio of data openness is similar across all new topics, with those relating to the categories "Finance" and "Government and public administration" standing out in particular.
Based on the publicly available datasets, an estimate was also made of the current degree of maturity of the data belonging to the new categories, according to their territorial coverage and their degree of openness (taking into account whether they were open in machine-readable formats, with adequate metadata, etc.). To maximize the overall cost-benefit ratio, the study suggests selecting a different approach for each thematic category: based on their level of maturity, it is recommended to indicate a higher or lower number of mandatory criteria for publication, thus ensuring to avoid overlaps between new topics and existing high-value data.
You can read the full study at this link.
Blog
Since 24 September last year, the Regulation (EU) 2022/868 of the European Parliament and of the Council of 30 May 2022, on European Data Governance (Data Governance Regulation) has been applicable throughout the European Union. Since it is a Regulation, its provisions are directly effective without the need for transposing State legislation, as is the case with directives. However, with regard to the application of its regulation to Public Administrations, the Spanish legislator has considered it appropriate to make some amendments to the Law 37/2007, of 16 November 2007, on the re-use of public sector information. Specifically:
- A specific sanctioning regime has been incorporated within the scope of the General State Administration for cases of non-compliance with its provisions by re-users, as will be explained in detail below;
- Specific criteria have been established on the calculation of the fees that may be charged by public administrations and public sector entities that are not of an industrial or commercial nature;
- And finally, some singularities have been established in relation to the administrative procedure for requesting re-use, in particular a maximum period of two months is established for notifying the corresponding resolution -which may be extended to a maximum of thirty days due to the length or complexity of the request-, after which the request will be deemed to have been rejected.
What is the scope of this new regulation?
As is the case with the Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on open data and the reuse of public sector informationthis Regulation applies to data generated in the course of the "public service remit" in order to facilitate its re-use. However, the former did not contemplate the re-use of those data protected by the concurrence of certain legal assets, such as confidentiality, trade secrets, the intellectual property or, singularly, the protection of personal data.
You can see a summary of the regulations in this infographic.
Indeed, one of the main objectives of the Regulation is to facilitate the re-use of this type of data held by administrations and other public sector entities for research, innovation and statistical purposes, by providing for enhanced safeguards for this purpose. It is therefore a matter of establishing the legal conditions that allow access to the data and their further use without affecting other rights and legal interests of third parties. Consequently, the Regulation does not establish new obligations for public bodies to allow access to and re-use of information, which remains a competence reserved for Member States. It simply incorporates a number of novel mechanisms aimed at making access to information compatible, as far as possible, with respect for the confidentiality requirements mentioned above. In fact, it is expressly warned that, in the event of a conflict with the Regulation (EU) 2016/679 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data (GDPR), the latter shall in any case prevail (GDPR), the latter shall in any case prevail.
Apart from the regulation referring to the public sector, to which we will refer below, the Regulation incorporates specific provisions for certain types of services which, although they could also be provided by public entities in some cases, will normally be assumed by private entities. Specifically, intermediation services and the altruistic transfer of data are regulated, establishing a specific legal regime for both cases. The Ministry of Economic Affairs and Digital Transformation will be in charge of overseeing this process in Spain
As regards, in particular, the impact of the Regulation on the public sector, its provisions do not apply to public undertakings , i.e. those in which there is a dominant influence of a public sector body, to broadcasting activities and, inter alia, to cultural and educational establishments. Nor to data which, although generated in the performance of a public service mission, are protected for reasons of public security, defence or national security.
Under what conditions can information be re-used?
In general, the conditions under which re-use is authorised must preserve the protected nature of the information. For this reason, as a general rule, access will be to data that are anonymised or, where appropriate, aggregated, modified or subject to prior processing to meet this requirement. In this respect, public bodies are authorised to charge fees which, among other criteria, are to be calculated on the basis of the costs necessary for the anonymisation of personal data or the adaptation of data subject to confidentiality.
It is also expressly foreseen that access and re-use take place in a secure environment controlled by the public body itself, be it a physical or virtual environment. In this way, direct supervision can be carried out, which could consist not only in verifying the activity of the re-user, but also in prohibiting the results of processing operations that jeopardise the rights and interests of third parties whose integrity must be guaranteed. Precisely, the cost for the maintenance of these spaces is included among the criteria that can be taken into account when calculating the corresponding fee that can be charged by the public body.
In the case of personal data, the Regulation does not add a new legal basis to legitimise the re-use of personal data other than those already established by the general rules on re-use. Public bodies are therefore encouraged to provide assistance to re-usersin such cases to help them obtain permission from stakeholders. However, this is a support measure that can in no way place disproportionate burdens on the agencies. In this respect, the possibility to re-use pseudonymised data should be covered by some of the cases provided for in the GDPR. Furthermore, as an additional guarantee, the purpose for which the data are intended to be re-used must be compatible with the purpose for which the data were originally intended justified the processing of the data by the public body in the exercise of its main activity, and appropriate safeguards must be adopted.
A practical example of great interest concerns the re-use of health data for biomedical research purposes reuse of health data for biomedical research purposes, which the Spanish legislator which has been established by the Spanish legislator under the provisions of the latter precept. Specifically, the 17th additional provision of Organic Law 3/2018, of 5 December, on the Protection of Personal Data and the Guarantee of Digital Rightsallows the reuse of pseudonymised data in this area when certain specific guarantees are established, which could be reinforced with the use of the aforementioned secure environments in the case of the use of particularly incisive technologies, such as artificial intelligence. This is without prejudice to compliance with other obligations which must be taken into account depending on the conditions of the data processing, in particular the carrying out of impact assessments.
What instruments are foreseen to ensure effective implementation?
From an organisational perspective, States need to ensure thatinformation is easily accessible through a single point. In the case of Spain, this point is available through the platform enabled through the platform datos.gob.esplatform, although there may also be other access points for specific sectors and different territorial levels, in which case they must be linked. Re-users may contact this point in order to make enquiries and requests, which shall be forwarded to thethese will be forwarded to the competent body or entity for processing and response.
The following must also be designated and notified to the notify to the European Commission one or more specialised entities with the appropriate technical and human resources, which could be some of the existing ones, that perform the function of assisting public bodies in granting or refusing re-use. However, if foreseen by European or national regulations, these bodies could assume decision-making functions and not only mere assistance. In any case, it is foreseen that the administrations and, where appropriate, the entities of the institutional public sector, according to the ‑‑according to the terminology of article 2 of Law 27/2007‑‑who make this designation and communicate it to the Ministry of Economic Affairs and Digital Transformationwhich, for its part, will be responsible for the corresponding notification at European level.
Finally, as indicated at the beginning, the following have been classified as specific infringements for the scope of the General Administration of the State certain conducts of re-users which are punishable by fines ranging from 10,001 to 100,000 euros. Specifically, it concerns conduct that, either deliberately or negligently, involves a breach of the main guarantees provided for in European legislation: in particular, failure to comply with the conditions for access to data or to secure areas, re-identification or failure to report security problems.
In short, as pointed out in the European Data Strategyif the European Union wants to play a leading role in the data economy , it is essential, among other measures, to improve governance structures and increase repositories of quality data , which are often affected by significant legal obstacles. With the Data Governance Regulation an important step has been taken at the regulatory level, but it now remains to be seen whether public bodies are able to take a proactive stance to facilitate the implementation of its measures, which ultimately imply important challenges in the digital transformation of their document management.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the "Innovation, Law and Technology" Research Group (iDerTec).
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Data activism is an increasingly significant citizen practice in the platform era for its growing contribution to democracy, social justice and rights. It is an activism that uses data and data analysis to generate evidence and visualisations with the aim of revealing injustices, improving people's lives and promoting social change.
In the face of the massive use of surveillance data by certain corporations, data activism is exercised by citizens and non-governmental organisations. For example, the organisation Forensic Architecture (FA)a centre at Goldsmiths under the University of London, investigates human rights violations, including state violence, using public, citizen and satellite data, and methodologies such as open source intelligence (known as OSINT). The analysis of data and metadata, the synchronisation of video footage taken by witnesses or journalists, as well as official recordings and documents, allows for the reconstruction of facts and the generation of an alternative narrative about events and crises.
Data activism has attracted the interest of research centres and non-governmental organisations, generating a line of work within the discipline of critical studies. This has allowed us to reflect on the effect of data, platforms and their algorithms on our lives, as well as on the empowerment that is generated when citizens exercise their right to data and use it for the common good.

Image 1: Ecocide in Indonesia (2015)
Source: Forensic Architecture (https://forensic-architecture.org/investigation/ecocide-in-indonesia)
Research centres such as Datactive o Data + Feminism Lab have created theory and debates on the practice of data activism. Likewise, organisations such as Algorights -a collaborative network that encourages civil society participation in the field of aI technologies- y AlgorithmWatch -a human rights organisation - generate knowledge, networks and arguments to fight for a world in which algorithms and artificial Intelligence (AI) contribute to justice, democracy and sustainability, rather than undermine them.
This article reviews how data activism emerged, what interest it has sparked in social science, and its relevance in the age of platforms.
History of a practice
The production of maps using citizen data could be one of the first manifestations of data activism as it is now known. A seminal map in the history of data activism was generated by victims and activists with data from the 2010 Haiti earthquakeon the Kenyan platform Ushahidi ("testimony" in Swahili). A community of digital humanitarianscreated the map from other countries and called on victims and their families and acquaintances to share data on what was happening in real time. Within hours, the data was verified and visualised on an interactive map that continued to be updated with more data and was instrumental in assisting the victims on the ground. Today, such mapsare generated whenever a crisis arises, and are enriched with citizen, satellite and camera-equipped drone data to clarify events and generate evidence.
Emerging from movements known as cypherpunk and technopositivism or technoptimism (based on the belief that technology is the answer to humanity's challenges), data activism has evolved as a practice to adopt more critical stances towards technology and the power asymmetries that arise between those who originate and hand over their data, and those who capture and analyse it.
Today, for example, the Ushahidi community map production platform has been used to create data on gender-based violence in Egypt and Syria, and on trusted gynaecologists in India, for example. Today, the invisibilisation and silencing of women is the reason why some organisations are fighting for recognition and a policy of visibility, something that became evident with the #MeToo movement. Feminist data practices seek visibility and critical interpretations of datification(or the transformation of all human and non-human action into measurable data that can be transformed into value). For example, Datos Contra el Feminicidio or Feminicidio.net offer maps and data analysis on femicide in various parts of the world.
The potential for algorithmic empowerment offered by these projects removes barriers to equality by improving the conditions conditions that enable women to solve problems, determine how data is collected and used, and exercise power.
Birth and evolution of a concept
In 2015, Citizen Media Meets Big Data: The Rise of Data Activismwas published, in which, for the first time, data activism was coined and defined as a concept based on practices observed in activists who engage politically with data infrastructure. Data infrastructure includes the data, software, hardware and processes needed to turn data into value. Later, Data activism and social change (London, Palgrave) and Data activism and social change. Alliances, maps, platforms and action for a better world (Madrid: Dykinson) develop analytical frameworks based on real cases that offer ways to analyse other cases.
Accompanying the varied practices that exist within data activism, its study is creating spaces for feminist and post-colonialist research on the consequences of datification. Whereas the chroniclers of history (mainly male sources) defined technology in relation to the value of their productsfeminist data studies consider women as users and designers of technology as users and designers of algorithmic systems and seek to use data for equality, and to move away from capitalist exploitation and its structures of domination.
Data activism is now an established concept in social science. For example, Google Scholar offers more than 2,000 results on "data activism". Several researchers use it as a perspective to analyse various issues. For example, Rajão and Jarke explore environmental activism in Brazil; Gezgin studies critical citizenship and its use of data infrastructure; Lehtiniemi and Haapoja explore data agency and citizen participation; and Scott examines the need for platform users to develop digital surveillance and care for their personal data.
At the heart of these concerns is the concept of data agency, which refers to people not only being aware of the value of their data, but also exercising control over it, determining how it is used and shared. It could be defined as actions and practices related to data infrastructure based on individual and collective reflection and interest. That is, while liking a post would not be considered an action with a high degree of data agency, participating in a hackathon - a collective event in which a computer programme is improved or created - would be. Data agency is based on data literacy, or the degree of knowledge, access to data and data tools, and opportunities for data literacy that people have. Data activism is not possible without a data agency.
In the rapidly evolving landscape of the platform economy, the convergence of data activism, digital rights and data agency has become crucial. Data activism, driven by a growing awareness of the potential misuse of personal data, encourages individuals and collectives to use digital technology for social change, as well as to advocate for greater transparency and accountability on the part of tech giants. As more and more data generation and the use of algorithms shape our lives in areas such as education, employment, social services and health, data activism emerges as a necessity and a right, rather than an option.
____________________________________________________________________
Content prepared by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy and gender disinformation.
The contents and views reflected in this publication are the sole responsibility of its author.
Documentación
The digitalization in the public sector in Spain has also reached the judicial field. The first regulation to establish a legal framework in this regard was the reform that took place through Law 18/2011, of July 5th (LUTICAJ). Since then, there have been advances in the technological modernization of the Administration of Justice. Last year, the Council of Ministers approved a new legislative package to definitively address the digital transformation of the public justice service, the Digital Efficiency Bill.
This project incorporates various measures specifically aimed at promoting data-driven management, in line with the overall approach formulated through the so-called Data Manifesto promoted by the Data Office.
Once the decision to embrace data-driven management has been made, it must be approached taking into account the requirements and implications of Open Government, so that not only the possibilities for improvement in the internal management of judicial activity are strengthened, but also the possibilities for reuse of the information generated as a result of the development of said public service (RISP).
Open data: a premise for the digital transformation of justice
To address the challenge of the digital transformation of justice, data openness is a fundamental requirement. In this regard, open data requires conditions that allow their automated integration in the judicial field. First, an improvement in the accessibility conditions of the data sets must be carried out, which should be in interoperable and reusable formats. In fact, there is a need to promote an institutional model based on interoperability and the establishment of homogeneous conditions that, through standardization adapted to the singularities of the judicial field, facilitate their automated integration.
In order to deepen the synergy between open data and justice, the report prepared by expert Julián Valero identifies the keys to digital transformation in the judicial field, as well as a series of valuable open data sources in the sector.
If you want to learn more about the content of this report, you can watch the interview with its author.
Below, you can download the full report, the executive summary, and a summary presentation.
Blog
The combination and integration of open data with artificial intelligence (AI) is an area of work that has the potential to achieve significant advances in multiple fields and bring improvements to various aspects of our lives. The most frequently mentioned area of synergy is the use of open data as input for training the algorithms used by AI since these systems require large amounts of data to fuel their operations. This makes open data an essential element for AI development and utilizing it as input brings additional advantages such as increased equality of access to technology and improved transparency regarding algorithmic functioning.
Today, we can find open data powering algorithms for AI applications in diverse areas such as crime prevention, public transportation development, gender equality, environmental protection, healthcare improvement, and the creation of more friendly and liveable cities. All of these objectives are more easily attainable through the appropriate combination of these technological trends.
However, as we will see next, when envisioning the joint future of open data and AI, the combined use of both concepts can also lead to many other improvements in how we currently work with open data throughout its entire lifecycle. Let's review step by step how artificial intelligence can enrich a project with open data.
Utilizing AI to Discover Sources and Prepare Data Sets
Artificial intelligence can assist right from the initial steps of our data projects by supporting the discovery and integration of various data sources, making it easier for organizations to find and use relevant open data for their applications. Furthermore, future trends may involve the development of common data standards, metadata frameworks, and APIs to facilitate the integration of open data with AI technologies, further expanding the possibilities of automating the combination of data from diverse sources.
In addition to automating the guided search for data sources, AI-driven automated processes can be helpful, at least in part, in the data cleaning and preparation process. This can improve the quality of open data by identifying and correcting errors, filling gaps in the data, and enhancing its completeness. This would free scientists and data analysts from certain basic and repetitive tasks, allowing them to focus on more strategic activities such as developing new ideas and making predictions.
Innovative Techniques for Data Analysis with AI
One characteristic of AI models is their ability to detect patterns and knowledge in large amounts of data. AI techniques such as machine learning, natural language processing, and computer vision can easily be used to extract new perspectives, patterns, and knowledge from open data. Moreover, as technological development continues to advance, we can expect the emergence of even more sophisticated AI techniques specifically tailored for open data analysis, enabling organizations to extract even more value from it.
Simultaneously, AI technologies can help us go a step further in data analysis by facilitating and assisting in collaborative data analysis. Through this process, multiple stakeholders can work together on complex problems and find answers through open data. This would also lead to increased collaboration among researchers, policymakers, and civil society communities in harnessing the full potential of open data to address social challenges. Additionally, this type of collaborative analysis would contribute to improving transparency and inclusivity in decision-making processes.
The Synergy of AI and Open Data
In summary, AI can also be used to automate many tasks involved in data presentation, such as creating interactive visualizations simply by providing instructions in natural language or a description of the desired visualization.
On the other hand, open data enables the development of applications that, combined with artificial intelligence, can provide innovative solutions. The development of new applications driven by open data and artificial intelligence can contribute to various sectors such as healthcare, finance, transportation, or education, among others. For example, chatbots are being used to provide customer service, algorithms for investment decisions, or autonomous vehicles, all powered by AI. By using open data as the primary data source for these services, we would achieve higher
Finally, AI can also be used to analyze large volumes of open data and identify new patterns and trends that would be difficult to detect through human intuition alone. This information can then be used to make better decisions, such as what policies to pursue in each area to bring about the desired changes.
These are just some of the possible future trends at the intersection of open data and artificial intelligence, a future full of opportunities but at the same time not without risks. As AI continues to develop, we can expect to see even more innovative and transformative applications of this technology. This will also require closer collaboration between artificial intelligence researchers and the open data community in opening up new datasets and developing new tools to exploit them. This collaboration is essential in order to shape the future of open data and AI together and ensure that the benefits of AI are available to all in a fair and equitable way.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Open data is a highly valuable source of knowledge for our society. Thanks to it, applications can be created that contribute to social development and solutions that help shape Europe's digital future and achieve the Sustainable Development Goals (SDGs).
The European Open Data portal (data.europe.eu) organizes online events to showcase projects that have been carried out using open data sources and have helped address some of the challenges our society faces: from combating climate change and boosting the economy to strengthening European democracy and digital transformation.
In the current year, 2023, four seminars have been held to analyze the positive impact of open data on each of the mentioned themes. All the material presented at these events is published on the European data portal, and recordings are available on their YouTube channel, accessible to any interested user.
In this post, we take a first look at the showcased use cases related to boosting the economy and democracy, as well as the open data sets used for their development.
Solutions Driving the European Economy and Lifestyle
In a rapidly evolving world where economic challenges and aspirations for a prosperous lifestyle converge, the European Union has demonstrated an unparalleled ability to forge innovative solutions that not only drive its own economy but also elevate the standard of living for its citizens. In this context, open data has played a pivotal role in the development of applications that address current challenges and lay the groundwork for a prosperous and promising future. Two of these projects were presented in the second webinar of the series "Stories of Use Cases”, an event focused on "Open Data to Foster the European Economy and Lifestyle": UNA Women and YouthPOP.
The first project focuses on tackling one of the most relevant challenges we must overcome to achieve a just society: gender inequality. Closing the gender gap is a complex social and economic issue. According to estimates from the World Economic Forum, it will take 132 years to achieve full gender parity in Europe. The UNA Women application aims to reduce that figure by providing guidance to young women so they can make better decisions regarding their education and early career steps. In this use case, the company ITER IDEA has used over 6 million lines of processed data from various sources, such as data.europa.eu, Eurostat, Censis, Istat (Italy's National Institute of Statistics), and NUMBEO.
The second presented use case also targets the young population. This is the YouthPOP application (Youth Public Open Procurement), a tool that encourages young people to participate in public procurement processes. For the development of this app, data from data.europa.eu, Eurostat, and ESCO, among others, have been used. YouthPOP aims to improve youth employment and contribute to the proper functioning of democracy in Europe.
Open Data for Boosting and Strengthening European Democracy
In this regard, the use of open data also contributes to strengthening and consolidating European democracy. Open data plays a crucial role in our democracies through the following avenues:
- Providing citizens with reliable information.
- Promoting transparency in governments and public institutions.
- Combating misinformation and fake news.
The theme of the third webinar organized by data.europe.eu on use cases is "Open Data and a New Impetus for European Democracy". This event presented two innovative solutions: EU Integrity Watch and the EU Institute for Freedom of Information.
Firstly, EU Integrity Watch is a platform that provides online tools for citizens, journalists, and civil society to monitor the integrity of decisions made by politicians in the European Union. This website offers visualizations to understand the information and provides access to collected and analyzed data. The analyzed data is used in scientific disclosures, journalistic investigations, and other areas, contributing to a more open and transparent government. This tool processes and offers data from the Transparency Register.
The second initiative presented in the democracy-focused webinar with open data is the EU Institute for Freedom of Information (IDFI), a Georgian non-governmental organization that focuses on monitoring and supervising government actions, revealing infractions, and keeping citizens informed.
The main activities of the IDFI include requesting public information from relevant bodies, creating rankings of public bodies, monitoring the websites of these bodies, and advocating for improved access to public information, legislative standards, and related practices. This project obtains, analyzes, and presents open data sets from national public institutions.
In conclusion, open data makes it possible to develop applications that reduce the gender wage gap, boost youth employment, or monitor government actions. These are just a few examples of the value that open data can offer to society.

Learn more about these applications in their seminars -> Recordings here.
Noticia
Open data is the highest level of data sharing, as it is freely available and accessible to all. Properly processed and with full respect for the protection of personal data, it can help citizens, businesses and the public sector to make better decisions.
Open data, together with other data, play a key role in the creation of data spaces, as referred to in the European Data Strategy. As stated in the document, the implementation of common and interoperable data spaces in strategic sectors is set up with the aim of "overcoming technical and legal barriers to data sharing between organisations, combining the necessary tools and infrastructures and addressing trust issues", for example through common standards developed for the space.
In view of its relevance, the European Data Portal Academy has organised a series of webinars on data spaces. The first of these was held on 12 May in an online format and can be viewed here. In it, the new developments and progress being made regarding data spaces were mentioned, developments that in Spain are being carried out by the Data Office.
We summarise below the main aspects addressed in this first seminar, in which Daniele Rizzi, Principal administrator and policy officer and Johan Bodenkamp, Policy and project officer at the Directorate General for Communication Networks, Content and Technologies of the European Commission, participated, with the moderation of Giulia Carsaniga, Research and Policy Lead Consultant at Capgemini.
Data spaces and the EU's digital strategy
The first part of the seminar, which was held online, highlighted how digital transformation is one of the European Union's top priorities. In fact, Europe has a specific strategy to advance in this aspect, i.e. to achieve 'A Europe fit for the digital age', and it is one of the six 2019-24 priorities of the European Commission.
The European Union's digital strategy aims to make digital transformation benefit people and businesses, a context in which the European Data Strategy of February 2020 is framed, which includes a series of measures for the promotion of a European data market, similar to the European Common Market, the seed of the current EU.
The creation of this European data market requires the establishment of a series of actions and standards with a focus on data, technology and infrastructure. A collective effort, including public programmes such as DIGITAL Europe and private programmes such as Gaia-X, is also contributing to this.
One year after the approval of the European Data Strategy, the European Council acknowledged in March 2021 "the need to accelerate the creation of common data spaces and ensure access and interoperability of data" and invited the Commission to "present the progress made and the remaining measures necessary to establish the sectoral data spaces announced in the European Data Strategy of February 2020." Subsequently, in February 2022, the European Commission published a working document on the European data market.
After contextualizing the development of the concept of data spaces within the European framework, the webinar presenters went on to explain the key components that will be part of the data spaces, some of which are already operational and others are still in development. The seminar provided an overview of what the European data space is expected to be like, highlighting the following aspects:
Firstly, there was a discussion about high-value datasets from the public sector. In January of this year, the European Commission published a list of high-value datasets, which are understood as those that provide added value and significant benefits to society. There is a wide variety of high-value data in different areas (health, agriculture, mobility, energy, etc.) that stakeholders make available with varying degrees of openness. As explained in the webinar, the idea is to start creating common high-value data spaces in more homogeneous areas, although the ultimate goal is for data to be shared across all sectors within the European market, as most applications will require data from different domains.
To support the creation of these data spaces, the first initiative launched in Europe is the establishment of the Data Spaces Support Centre. This center explores the needs of data space initiatives, defines common requirements, establishes best practices to accelerate the formation of sovereign data spaces as a crucial element of digital transformation in all areas, and ensures interoperability through compliance with common standards.
In order for all of this to be developed, a technical infrastructure for data spaces is necessary, which facilitates cloud and edge-cloud services, intelligent middleware solutions (Simpl), a digital marketplace, high-performance computing, on-demand artificial intelligence platform, and AI testing and experimentation facilities.
Differences and similarities between data spaces and datalakes
After providing an overview of data spaces in Europe, the seminar addressed their main characteristics. In this regard, a data space was presented as a secure and privacy-respecting IT infrastructure for aggregating, accessing, processing, using, and sharing data. It was also defined as a data governance mechanism that comprises a set of administrative and contractual rules that determine the rights of access, processing, use, and sharing of data in a reliable, transparent, and compliant manner with applicable legislation.
One of the features highlighted in the webinar regarding this type of infrastructure is that data owners have control over who can access which data, for what purpose, and under what conditions they can be used. Additionally, there is a large amount of voluntarily available data that can be reused either for free or in exchange for compensation, depending on the decisions of the data owners.
Furthermore, it was emphasized that data spaces involve the participation of an open number of organizations/individuals, respecting competition rules and ensuring non-discriminatory access for all participants.
Another concept discussed in the seminar was that of datalakes, in comparison to data spaces. Datalakes were defined as repositories that allow storing structured and unstructured data at any scale. In a datalake, as explained in the seminar, data can be stored as is, without the need for prior structuring, and different types of analyses can be performed, ranging from dashboards and visualizations to real-time data processing and machine learning for more informed decision-making. Accessing the datalake implies the possibility of accessing all the contained data, not necessarily in an organized manner.
On the other hand, a data space, according to the presenters, can be defined as a federated data ecosystem based on shared policies and rules. Users of data spaces have the ability to securely, transparently, reliably, easily, and uniformly access data. In a data space, data owners have control over the access and use of their data. From a technical perspective, a data space can be seen as a data integration concept that does not require common database schemas or physical data integration but is based on distributed and integrated data stores as needed.
Using a fishing analogy, in a datalake, the user has to catch the fish themselves, while a data space would be like going to a fish market.
Next steps: Governance framework and European actors
Once the difference between dataspaces and datalakes was presented, the webinar addressed the paradigm shift in data sharing that is currently taking place. Until now, bilateral data exchange based on contractual agreements has been common. However, a new model of data exchange infrastructure with centralized data hosting and/or data markets is gaining momentum, which reduces transaction costs when data is not maintained in a central repository.
According to the presenters, the next step in the evolution of data spaces would be the creation of links between participants in a model where data is federated and stored in a distributed manner, with tools that enable search, access, and analysis across multiple industries, companies, and entities.

To make this process happen, as explained by the presenters, the support and coordinated work of different actors are necessary. On one hand, it would be essential to establish common rules that facilitate data exchange and bring the different stakeholders closer to a common data policy in the EU. Similarly, providing technical solutions and financial support is indispensable.
In this regard, the webinar highlighted an important milestone: the establishment of the European Data Innovation Board (EDIB), which will support the Commission in publishing guidelines to facilitate the development of common European data spaces and identifying the necessary standards and interoperability requirements for data exchange.
As mentioned earlier, the implementation of data spaces requires technical architecture, and the webinar highlighted two free technical solutions:
-
Building Blocks: Open and reusable digital solutions based on standards that enable basic functionalities, such as reliable authentication and secure data exchange.
-
Simpl: The intelligent middleware that will enable cloud-based federations and edge-cloud. It will support major data initiatives funded by the European Commission, such as the common European data spaces.
The key role of the Data Spaces Support Centre
Towards the end of the seminar, the Data Spaces Support Centre (DSCC) initiative was presented in more detail. This center, established in October 2022, provides support to various initiatives in the creation of data spaces and is expected to conclude its activities in March 2026. It consists of twelve partners and also has sixteen collaborating partners, including important associations and companies with expertise in the field of data exchange.
The main mission of the DSCC is to create a network of partners and a community to provide tools for the creation of data spaces. It focuses particularly on interoperability and aims to generate synergies at the European level for the development of data spaces.
The webinar reviewed the collaborations and initiatives in which the Data Spaces Support Centre participates, and it was highlighted that the starter kit, a starting point for building data spaces, is available on its website.
In the final stretch of the seminar, an overview of the relevant actors in the European common data space was provided:
-
Data Spaces Support Centre (DSSC): Responsible for coordinating relevant actions in data spaces.
-
Data Space Coordination and Support Actions (CSAs): Focused on sectoral data spaces.
-
European Data Innovation Board: Starting from September 2023, it will be responsible for setting guidelines to achieve interoperability in data spaces.
If you want to know more about the concept of data spaces and their relevance today, you can watch the full seminar in the following video:
The following training material is now available on data.europa academy:
- The recording of the session;
- The slide deck presented during the webinar.
Blog
The emergence of artificial intelligence (AI), and ChatGPT in particular, has become one of the main topics of debate in recent months. This tool has even eclipsed other emerging technologies that had gained prominence in a wide range of fields (legal, economic, social and cultural). This is the case, for example, of web 3.0, the metaverse, decentralised digital identity or NFTs and, in particular, cryptocurrencies.
There is an unquestionable direct relationship between this type of technology and the need for sufficient and appropriate data, and it is precisely this last qualitative dimension that justifies why open data is called upon to play a particularly important role. Although, at least for the time being, it is not possible to know how much open data provided by public sector entities is used by ChatGPT to train its model, there is no doubt that open data is a key to improving their performance.
Regulation on the use of data by AI
From a legal point of view, AI is arousing particular interest in terms of the guarantees that must be respected when it comes to its practical application. Thus, various initiatives are being promoted that seek to specifically regulate the conditions for its use, among which the proposal being processed by the European Union stands out, where data are the object of special attention.
At the state level, Law 15/2022, of 12 July, on equal treatment and non-discrimination, was approved a few months ago. This regulation requires public administrations to promote the implementation of mechanisms that include guarantees regarding the minimisation of bias, transparency and accountability, specifically with regard to the data used to train the algorithms used for decision-making.
There is a growing interest on the part of the autonomous communities in regulating the use of data by AI systems, in some cases reinforcing guarantees regarding transparency. Also, at the municipal level, protocols are being promoted for the implementation of AI in municipal services in which the guarantees applicable to the data, particularly from the perspective of their quality, are conceived as a priority requirement.
The possible collision with other rights and legal interests: the protection of personal data
Beyond regulatory initiatives, the use of data in this context has been the subject of particular attention as regards the legal conditions under which it is admissible. Thus, it may be the case that the data to be used are protected by third party rights that prevent - or at least hinder - their processing, such as intellectual property or, in particular, the protection of personal data. This concern is one of the main motivations for the European Union to promote the Data Governance Regulation, a regulation that proposes technical and organisational solutions that attempt to make the re-use of information compatible with respect for these legal rights.
Precisely, the possible collision with the right to the protection of personal data has motivated the main measures that have been adopted in Europe regarding the use of ChatGPT. In this regard, the Garante per la Protezione dei Dati Personali has ordered a precautionary measure to limit the processing of Italian citizens' data, the Spanish Data Protection Agency has initiated ex officio inspections of OpenAI as data controller and, with a supranational scope, the European Data Protection Supervisor (EDPB) has created a specific working group.
The impact of the regulation on open data and re-use
The Spanish regulation on open data and re-use of public sector information establishes some provisions that must be taken into account by IA systems. Thus, in general, re-use will be admissible if the data has been published without conditions or, in the event that conditions are set, when they comply with those established through licences or other legal instruments; although, when they are defined, the conditions must be objective, proportionate, non-discriminatory and justified by a public interest objective.
As regards the conditions for re-use of information provided by public sector bodies, the processing of such information is only allowed if the content is not altered and its meaning is not distorted, and the source of the data and the date of its most recent update must be mentioned.
On the other hand, high-value datasets are of particular interest for these AI systems characterised by the intense re-use of third-party content given the massive nature of the data processing they carry out and the immediacy of the requests for information made by users. Specifically, the conditions established by law for the provision of these high-value datasets by public bodies mean that there are very few limitations and also that their re-use is greatly facilitated by the fact that the data must be freely available, be susceptible to automated processing, be provided through APIs and be provided in the form of mass downloading, where appropriate.
In short, considering the particularities of this technology and, therefore, the very unique circumstances in which the data are processed, it seems appropriate that the licences and, in general, the conditions under which public entities allow their re-use be reviewed and, where appropriate, updated to meet the legal challenges that are beginning to arise.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the "Innovation, Law and Technology" Research Group (iDerTec).
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
The European Data Strategy envisages, among other measures, the implementation of a series of sectoral data spaces, in strategic areas and areas of particular public interest, with the aim of facilitating the "availability of large data repositories in these sectors, together with the necessary tools and technical infrastructures to use and exchange data, as well as appropriate governance mechanisms".
Specifically, according to the European Commission's working document on data spaces, they are promoted with the aim of "overcoming legal and technical barriers to data sharing, combining the necessary tools and infrastructures and addressing trust issues through common standards".
As recognised in the document, such spaces require not only the implementation of adequate infrastructures, but also the design of enabling governance frameworks, the latter of which poses significant challenges from a legal perspective. Although there is no normative definition of data spaces, according to the document, at EU level they are considered as ecosystems where data from the public sector, businesses and individuals, as well as research institutions and other types of organisations, are available and exchanged in a reliable and secure way.
Beyond the initiatives being promoted at European level and, specifically, their institutional and legal configuration, the creation of data spaces is also being promoted at state level in Spain, in particular by the Data Office, an administrative body directly under the Secretary of State for Digitalisation and Artificial Intelligence. In this respect, the Office's main functions include "the creation of spaces for data sharing between companies, citizens and public administrations in a secure and governed manner (sandboxes, national and European data spaces, data ecosystems for both public and private sector use, etc.)", as well as "the development of secure access mechanisms to these data platforms, for data-based public decision-making or for business use".
These spaces are set to play an essential role in the context of the Recovery, Transformation and Resilience Plan, particularly in the industrial sphere, one of whose main objectives is to facilitate the modernisation and productivity of the Spanish industry-services ecosystem through the digitisation of the value chain and, specifically, by boosting business innovation based on the intensive use of data. Among the main areas where the creation of these spaces, identified in the Digital Agenda 2025 and the aforementioned Plan, is planned, are important sectors such as agri-food, sustainable mobility, health, trade and tourism. In particular, their implementation will be carried out "through the development of use cases, demonstrators and pilots, and public-private sectoral innovation ecosystems around these data spaces".
The configuration of data spaces
Given the absence of a specific regulation on data spaces, their specific configuration will depend both on the singularities of the sector to which they refer and on the objectives pursued by their constitution. Nevertheless, we can start from a general characterisation that serves to delimit their main implications from a legal perspective.
- Thus, in the first place, each participant must retain control over the data contributed to the common space, which in principle implies the freedom to decide freely not only on their incorporation but even on their withdrawal, with the nuances that may derive from the existence of regulatory obligations in this respect, as may be the case with public entities. On the other hand, it is essential to ensure conditions of technological neutrality, so that there is no linkage to a specific tool or solution. This premise allows the space to move to other environments and use other infrastructures freely. In this respect, it is particularly important that the different spaces are built on the basis of parameters that allow for their interoperability, so that, if necessary, they can be interconnected and, if necessary, data migration between different infrastructures can be facilitated.
- Adequate conditions for access to data and for their subsequent use must also be guaranteed. Specifically, this requirement has important consequences from the perspective of the rules on free competition, so that, on the one hand, undue situations of prevalence and/or concentration in a specific market are not generated and, on the other hand, those cases of re-use of data that are illegal or, where appropriate, contrary to the principles and objectives that were previously established when the corresponding space was created, are avoided.
- Particularly important is the design of a governance model that precisely establishes the conditions for the participation of the various actors involved, in particular their rights and obligations, who will be responsible for adopting the decisions relating to the design of the space and its subsequent practical execution, also contemplating the mechanisms for the resolution of potential conflicts that may arise beyond the unquestionable judicial route that, in principle, would always be available.
Legal implications of data spaces
Since the approval of Directive (EU) 2019/1024 on open data and the re-use of public sector information, there have been important regulatory developments affecting data spaces, including Regulation (EU) 2022/868 on European data governance, which provides for a specific regime for intermediation services and altruism in the transfer of data.
Thus, recently, Implementing Regulation (EU) 2023/138 has been published, establishing the high-value datasets that public sector entities have to make available under technical and legal conditions that facilitate their re-use. Other initiatives of general scope are also in the pipeline that are set to have a major direct impact on data spaces, including the proposal for harmonised rules for fair access to and use of data (Data Act).
Beyond this transversal regulatory framework, it is necessary to distinguish those spaces that have a specific regulation from those that, on the contrary, do not, since in the latter case the determination of the applicable legal rules will have to be made using other non-regulatory legal instruments, i.e. mainly through the agreement - whether in the form of a contract, agreement, etc. - between the subjects that participate in the creation of the space and decide on its initial configuration.
It is also decisive whether a public sector entity is involved in the area, since, if so, it could join the area on an equal footing with the rest of the private parties or, as the case may be, adopt a management, control or supervisory role that would be incompatible with its participation under the first modality insofar as such a position could interfere with the normal functioning of the area. If this is the case, an appropriate functional and organisational separation should be envisaged, so that different entities would be in charge of carrying out both tasks, i.e. providing data to the site and using them and, on the other hand, managing the operation of the site.
On the other hand, it could be the case that there is a separate regulatory framework for the space in question, as is being considered at European level in the area of health data. In this case, it is the sectoral regulations themselves that would establish the conditions for participation in the area, which could even be compulsory; the technical, organisational, legal and economic premises applicable, both as regards the parties that provide the data and those that intend to re-use them; the assumptions or, where appropriate, the conditions under which the re-use of the information would not be admissible; or, among other things, the institutional guarantees to be taken into account and, above all, the organisational structures in charge of enforcing compliance with the regulatory provisions governing the corresponding area.
In short, sectoral spaces constitute a model that goes beyond the mere exchange of data between various subjects and that also goes beyond -although it may include, depending on the case- the re-use of public sector information. Specifically, these are ecosystems in which, in general, private entities are called upon to play an important role, which does not necessarily mean that the public sector is excluded from active participation. However, this type of initiative is highly complex, not only because of the configuration of the sectoral space itself but, above all, because of the ambitious approach involved in the future integration of several spaces, whether at national or, to an even greater extent, European level, which reinforces the importance of initiatives such as Gaia-X.
In the absence of a specific regulatory framework for data spaces, it is essential to establish the appropriate conditions for the design and implementation of these spaces to be carried out with the greatest legal guarantees, taking into account the ultimate objective pursued: to facilitate the creation of value-added digital services based on technological innovation.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the "Innovation, Law and Technology" Research Group (iDerTec).
The contents and points of view reflected in this publication are the sole responsibility of the author.