Blog
La aprobación del Reglamento (UE), del Parlamento Europeo y del Consejo de 13 de diciembre de 2023 sobre normas armonizadas para un acceso justo a los datos y su utilización (Ley de Datos) supone un importante avance en la regulación que la Unión Europea para facilitar la accesibilidad de los datos. Se trata de una iniciativa ya contemplada en la Estrategia Europea de Datos que tiene como principales finalidades:
- Regular la puesta a disposición de datos a favor de las entidades públicas en situaciones excepcionales.
- Promover el desarrollo de criterios de interoperabilidad en los espacios de datos, los servicios de tratamiento de datos y los contratos inteligentes.
- Y, desde la perspectiva que ahora nos interesa, impulsar la puesta a disposición de los datos que generan los productos y servicios conectados, ya sea a favor de quienes los utilizan o de los terceros que estos indiquen.
A este respecto, ante las dificultades de los usuarios en el acceso a los datos, el Reglamento trata de facilitar que puedan elegir libremente los proveedores de servicios de reparación y otros servicios, ya que se ha detectado que en muchos ámbitos los fabricantes intentan reservarse su utilización en condiciones de exclusividad. Entre otras cuestiones, se pretende impulsar el derecho del usuario a decidir para qué fines y por quién se pueden utilizar los datos, sin perjuicio de la existencia de una serie de limitaciones y condicionantes que se contemplan en el propio Reglamento.
Un importante cambio de orientación en la regulación
Mientras que la Directiva de datos abiertos y reutilización de la información del sector público y el Reglamento sobre Gobernanza de Datos se centran en establecer reglas y garantías que promuevan el acceso a los datos en poder de las entidades públicas, la nueva regulación presta una especial atención a las relaciones entre sujetos privados. Es decir, permite a los organismos públicos exigir datos a ciertos sujetos privados en condiciones excepcionales y por razones de interés público.
Uno de los principales objetivos del Reglamento de Datos consiste en fomentar no solo “el desarrollo de productos conectados o servicios relacionados nuevos e innovadores y estimular la innovación en los mercados de posventa, sino también en estimular el desarrollo de servicios totalmente novedosos que utilicen los datos en cuestión, incluso los basados en datos procedentes de diversos productos conectados o servicios relacionados”.
A tal efecto, se ha considerado esencial establecer obligaciones claras y precisas para que los fabricantes de los productos conectados, quienes los suministren y los prestadores de servicios vinculados tengan que compartir con los usuarios los datos generados.
¿Qué obligaciones se han establecido?
Con carácter previo a la contratación de los productos y servicios, el titular de los datos –esto es, el suministrador del producto o servicio, que puede ser también el fabricante –‑‑, deberá proporcionar al usuario información sobre:
- La cantidad y las condiciones de los datos que se pueden generar
- Cómo se puede acceder a dichos datos
- Cómo se pueden suprimir
A este respecto, se exige que en el diseño de los productos y los servicios se adopten medidas adecuadas para que, por defecto, los datos sean accesibles, de manera gratuita y directa, sobre todo, en un formato estructurado que permita su lectura mecánica.
Sin embargo, este derecho está sometido a ciertas condiciones y limitaciones con el fin de garantizar que no se ven afectados otros bienes e intereses jurídicos:
- El titular de los datos no podrá dificultar que el usuario acceda a sus datos, pero sí podrá exigirle que se identifique, aun cuando tenga prohibido conservar la información generada de manera indefinida.
- Podrá establecer restricciones en el contrato cuando, a consecuencia del acceso del usuario a los datos, exista un riesgo para el funcionamiento del producto que pueda afectar a la salud o la seguridad de las personas.
- En ningún caso podrá utilizar los datos que se obtengan durante el uso del producto o la prestación del servicio para ponerlos a disposición de un tercero, salvo que sea estrictamente imprescindible para el cumplimiento del contrato.
- También tiene prohibido de manera expresa utilizar los datos para hacer averiguaciones acerca de las circunstancias y la actividad del usuario, como, por ejemplo, su situación económica.

Por su parte, el usuario también se ve condicionado por una serie de obligaciones específicamente dirigidas a garantizar la buena fe de su relación jurídica con el titular:
- No tiene permitido utilizar los datos para competir con este último, ya sea de manera directa o a través de un tercero a quien pueda proporcionárselos,
- No puede aprovechar el acceso a los mismos para realizar averiguaciones acerca de la actividad del fabricante del producto o, en su caso, del titular de los datos.
- Junto con estas obligaciones se le reconoce el derecho a compartir los datos con un tercero, que sólo podrá utilizarlos para las finalidades que le autorice. En concreto, no podrá elaborar perfiles salvo que sea necesario para prestar el servicio, ni ponerlos a disposición de otro sujeto o desarrollar un producto que compita con aquel del que procedan originariamente los datos.
En todo caso, la regulación establece una importante limitación a tener en cuenta por los usuarios, ya que se excluye de este régimen a las microempresas y pequeñas empresas. Con una excepción: que hubieran recibido el encargo de desarrollar el producto o prestar el servicio por parte de un sujeto que sí estuviera incluido en el ámbito de aplicación del Reglamento.
¿Qué garantías se contemplan para asegurar la efectividad de esta regulación?
Como sucede con carácter general en cualquier ámbito, el usuario podrá acudir ante un órgano judicial para exigir el respeto de sus derechos. Además, adicionalmente, la nueva regulación establece la posibilidad de dirigirse a la autoridad designada a nivel estatal para garantizar la aplicación y ejecución de las previsiones del Reglamento. En el caso de que la problemática se refiera al tratamiento de datos personales, también podrá ejercer sus derechos ante la autoridad competente en este ámbito.
A este respecto, la Comisión Europea tendrá que hacer público un listado de las correspondientes autoridades a partir de la información proporcionada por los Estados. Estos podrán designar más de una autoridad, indicando a cuál le corresponde la función de coordinación. Dichas autoridades contarán con los medios suficientes: sus integrantes habrán de tener la especialización requerida para el desempeño de sus funciones y se garantizará su imparcialidad, de manera que no podrán recibir instrucciones de otras entidades.
Al margen de esta vía, el titular de los datos y el usuario –o, en su caso el tercero a quien este permita su utilización—podrán acordar voluntariamente someterse a un órgano de resolución de litigios certificado, cuya decisión habrá de adoptarse en un plazo máximo de 90 días. Dicho órgano deberá acreditarse ante el Estado donde esté establecido. Para ello deberá justificar su imparcialidad, capacidad e independencia. También deberá demostrar que dispone de unas normas procedimentales adecuadas y que es fácilmente accesible por medios electrónicos.
En definitiva, con la nueva Ley de Datos no sólo se ha establecido un marco normativo que refuerza el acceso de los usuarios a los datos que se generan por los productos conectados que adquieren y los servicios vinculados de los que disfrutan, sino que, además, se han consagrado una serie de garantías específicamente dirigidas a asegurar su efectivo cumplimiento.

Descarga la infografía en PDF aquí
Esta infografía también está disponible en dos páginas
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El concepto de datos de alto valor (High-Value datasets) fue introducido por el Parlamento Europeo y el Consejo de la Unión Europea hace 4 años, en la Directiva (UE) 2019/1024. En ella se definían como una serie de conjuntos de datos con un gran potencial para generar “beneficios para la sociedad, el medio ambiente y la economía”. Por ello, los estados miembro debían impulsar su apertura de manera gratuita, en formatos legibles por máquinas, a través de APIs, en forma de descarga masiva y descritos de forma exhaustiva mediante metadatos.
De manera inicial, la directiva proponía en su anexo seis categorías temáticas a considerar como de alto valor: datos geoespaciales, observación de la tierra y medioambientales, meteorológicos, estadísticos, registros empresariales y datos sobre redes de transporte. Estas categorías fueron detalladas posteriormente en un reglamento de ejecución publicado en diciembre de 2022. Además, para facilitar su apertura, en junio de 2023 se editó un documento con pautas sobre cómo usar DCAT-AP para su publicación.
Nuevas categorías de datos a considerar de alto valor
Estas categorías iniciales siempre estuvieron abiertas a su ampliación. En este sentido, la Comisión Europea acaba de publicar el informe “Identification of data themes for the extensions of public sector High-Value Datasets” donde se incluyen siete nuevas categorías que se estudia considerar como datos de alto valor
-
Pérdida climática: Hace referencia a los datos relacionados con los enfoques y acciones necesarios para evitar, minimizar y abordar los daños asociados al cambio climático. Ejemplos de conjuntos de datos de esta categoría son las pérdidas económicas y no económicas derivadas de los fenómenos meteorológicos extremos o los cambios de evolución lenta, como el aumento del nivel del mar o la desertificación. También incluye datos relacionados con los sistemas de alerta temprana ante desastres naturales, la repercusión de las medidas de mitigación o datos de investigación sobre la atribución de fenómenos extremos al cambio climático.
-
Energía: Esta categoría incluye estadísticas completas sobre la producción, transporte, comercio y consumo final de fuentes de energía primarias y secundarias, tanto renovables como no renovables. Algunos ejemplos de conjuntos de datos a considerar son los indicadores de precios y consumo o la información sobre seguridad energética.
-
Finanzas: Se trata de información sobre la situación de las empresas privadas y las administraciones públicas, que puede utilizarse para evaluar el rendimiento empresarial o la sostenibilidad económica, así como para definir estrategias de gasto e inversión. Incluye conjuntos de datos sobre registros de empresas, estados financieros, fusiones y adquisiciones, así como informes financieros anuales.
-
Gobierno y administración pública: Esta temática incluye aquellos datos que los servicios y empresas públicas recopilan para informar y mejorar la acción de gobierno y la administración de una unidad territorial específica, ya sea un estado, una región o un municipio. Incluye datos relativos al gobierno (por ejemplo, actas de reuniones), los ciudadanos (censos o registro en los servicios públicos) y las infraestructuras gubernamentales. Estos datos se reutilizan posteriormente para fundamentar la elaboración de políticas, prestar servicios públicos, optimizar los recursos y la asignación presupuestaria, así como proporcionar información procesable y transparente a ciudadanos y empresas.
-
Salud: Este concepto identifica los conjuntos de datos que cubren el bienestar físico, y mental de la población, haciendo referencia tanto a aspectos objetivos como subjetivos de la salud de las personas. También incluye indicadores clave sobre el funcionamiento de los sistemas de asistencia sanitaria y la seguridad en el trabajo. Algunos ejemplos son los datos relativos a la Covid-19, la equidad sanitaria o el listado de servicios prestados por los centros sanitarios.
-
Justicia y asuntos jurídicos: Identifica conjuntos de datos que permiten reforzar la capacidad de respuesta, la rendición de cuentas y la interoperabilidad de los sistemas judiciales de la UE, cubriendo ámbitos como la aplicación de la justicia, el sistema jurídico o la seguridad pública, es decir, aquella que garantiza la protección de los ciudadanos. Los conjuntos de datos sobre justicia y asuntos jurídicos incluyen documentación de jurisprudencia nacional o internacional, decisiones de tribunales y fiscales generales, así como actos jurídicos y su contenido.
-
Datos lingüísticos: Hace referencia a expresiones escritas u orales que están en la base de la inteligencia artificial, el procesamiento del lenguaje natural y el desarrollo de servicios relacionados. La Comisión ofrece una definición bastante amplia de esta categoría de datos, todos ellos agrupados bajo la denominación de "datos lingüísticos multimodales". Pueden incluir repositorios de colecciones de textos, corpus de lenguas habladas, recursos de audio, o grabaciones de vídeo.

Para realizar esta selección, los autores del informe llevaron a cabo una investigación documental, así como consultas a administraciones públicas, expertos en datos y empresas privadas mediante una serie de talleres y encuestas. Además de esta evaluación, el equipo del estudio cartografió y analizó el ecosistema normativo en torno a cada categoría, así como las iniciativas políticas relacionadas con su armonización y puesta en común, especialmente en relación con la creación de Espacios Comunes Europeos de Datos.
Potencial para las PYMEs y las plataformas digitales
Además de definir estas categorías, el estudio también ofrece una estimación de alto nivel sobre el impacto de las nuevas categorías en las pequeñas y medianas empresas, así como en las grandes plataformas digitales. Una de las conclusiones del estudio es que la relación coste-beneficio de la apertura de datos es similar en todos los nuevos temas, destacando especialmente aquellos relativos a las categorías "Finanzas" y "Gobierno y administración pública".
Basándose en los conjuntos de datos disponibles públicamente, también se realizó una estimación del grado de madurez actual de los datos pertenecientes a las nuevas categorías, según su cobertura territorial y su grado de apertura (teniendo en cuenta si estaban abiertos en formatos leíbles por máquinas, con metadatos adecuados, etc.). Para maximizar la relación coste-beneficio global, el estudio sugiere seleccionar para cada categoría temática una aproximación distinta: en base a su nivel de madurez, se recomienda indicar un mayor o menor número de criterios obligatorios para su publicación, asegurándose así el evitar solapamientos entre los nuevos temas y con los datos de alto valor ya existentes.
Puedes leer el estudio completo en este enlace.
Blog
Desde el pasado 24 de septiembre el Reglamento (UE) 2022/868 del Parlamento Europeo y del Consejo, de 30 de mayo de 2022, relativo a la gobernanza europea de datos (Reglamento de Gobernanza de Datos) resulta de aplicación en toda la Unión Europea. Al tratarse de un Reglamento, sus previsiones son directamente eficaces sin necesidad de una normativa estatal de transposición, como sucede por el contrario en el caso de las directivas. Sin embargo, por lo que se refiere a la aplicación de su regulación a las Administraciones Públicas, el legislador español ha considerado oportuno realizar algunas modificaciones en la Ley 37/2007, de 16 de noviembre, sobre reutilización de la información del Sector Público. En concreto:
- Se ha incorporado un régimen sancionador específico en el ámbito de la Administración General del Estado para los supuestos de incumplimiento de sus previsiones por parte de los reutilizadores, tal y como se explicará en detalle más adelante;
- Se han establecido criterios específicos sobre el cálculo de las tasas que pueden cobrar las Administraciones Públicas y entidades del sector público que no tengan carácter industrial o mercantil;
- Y, finalmente, se ha fijado algunas singularidades con relación al procedimiento administrativo para solicitar la reutilización, en particular se establece un plazo máximo de dos meses para notificar la correspondiente resolución –que se podrá ampliar hasta un máximo de treinta días debido a la extensión o complejidad de la solicitud–, transcurrido el cual se entenderá desestimada la petición.
¿Cuál es el ámbito de aplicación de esta nueva regulación?
Al igual que sucede con la Directiva (UE) 2019/1024 del Parlamento Europeo y del Consejo, de 20 de junio de 2019, relativa a los datos abiertos y la reutilización de la información del sector público, este Reglamento se aplica a los datos que se generen con ocasión de la “misión de servicio público” con el fin de facilitar su reutilización. Sin embargo, aquella no contemplaba la reutilización de aquellos datos protegidos por la concurrencia de ciertos bienes jurídicos, como es el caso de la confidencialidad, los secretos comerciales, la propiedad intelectual o, singularmente, la protección de los datos de carácter personal.
Puedes ver un resumen del reglamento en esta infografía.
Precisamente, uno de los principales objetivos del Reglamento consiste en facilitar la reutilización de este tipo de datos en manos de las Administraciones y otras entidades del sector público con fines de investigación, innovación y estadísticos, contemplando unas garantías reforzadas para ello. Se trata, por tanto, de establecer las condiciones jurídicas que permitan el acceso a los datos y su uso posterior sin que, por ello, se vean afectados otros derechos y bienes jurídicos de terceros. En consecuencia, el Reglamento no establece nuevas obligaciones para que los organismos públicos permitan el acceso a la información y su posterior reutilización, competencia que sigue reservada para los Estados miembros. Simplemente se incorporan una serie de mecanismos novedosos que tienen por finalidad hacer compatibles, en la medida de lo posible, el acceso a la información con el respeto a las exigencias de confidencialidad antes aludidas. De hecho, se advierte expresamente que, en caso de conflicto con el Reglamento (UE) 2016/679 relativo a la protección de las personas físicas en lo que respecta al tratamiento de datos personales y a la libre circulación de estos datos (RGPD), en todo caso habrá de prevalecer este último.
Al margen de la regulación referida al sector público, –a la que nos referiremos más adelante–, el Reglamento incorpora previsiones específicas para cierto tipo de servicios que, si bien podrían prestar también las entidades públicas en algún caso, normalmente serán asumidos por sujetos privados. En concreto, se regulan los servicios de intermediación y la cesión altruista de datos, estableciendo un régimen jurídico específico para ambos supuestos. El Ministerio de Asuntos Económicos y Transformación Digital será el encargado en España de supervisar este proceso
Por lo que se refiere, en concreto, a la incidencia del Reglamento en el sector público, sus previsiones no resultan aplicables a las empresas públicas –esto es, aquellas en las que exista una influencia dominante de un organismo del sector público–, a las actividades de radiodifusión ni, entre otros supuestos, a los centros culturales y de enseñanza. Tampoco a los datos que, aun siendo generados en ejecución de una misión de servicio público, se encuentren protegidos por motivos de seguridad pública, defensa o seguridad nacional.
¿En qué condiciones se puede reutilizar la información?
Con carácter general, las condiciones en que se autorice la reutilización han de preservar la naturaleza protegida de la información. Por esta razón, como regla general, el acceso tendrá lugar a datos anonimizados o, en su caso, agregados, modificados o sometidos a un tratamiento previo que permita cumplir con dicha exigencia. A este respecto, se autoriza a los organismos públicos para que cobren tasas que, entre otros criterios, habrán de calculase en función de los costes necesarios para la anonimización de los datos personales o la adaptación de los sometidos a confidencialidad.
Asimismo, se contempla expresamente que el acceso y la reutilización tengan lugar en un entorno seguro controlado por la propia entidad pública, ya sea un entorno físico o virtual. De esta manera, se puede realizar una supervisión directa que podría consistir, no sólo en verificar la actividad del reutilizador, sino incluso, en prohibir los resultados de aquellos tratamientos que pongan en peligro los derechos e intereses de terceros cuya integridad debe garantizarse. Precisamente, el coste por el mantenimiento de estos espacios se incluye entre los criterios que se pueden tener en cuenta a la hora de calcular la correspondiente tasa que puede cobrar el organismo público.
Cuando se trate de datos de carácter personal, el Reglamento no añade una nueva base jurídica que legitime su reutilización distinta de las que ya establece la normativa general en dicha materia. Por ello, se insta a los organismos públicos a que, en este tipo de supuestos, presten asistencia a los reutilizadores para ayudarles a obtener el permiso de los interesados. Ahora bien, se trata de una medida de apoyo que en ningún caso puede suponer cargas desproporcionadas para los organismos. A este respecto, la posibilidad de reutilizar datos seudonimizados debe encontrar amparo en algunos de los supuestos que contempla el RGPD. Asimismo, como garantía adicional, la finalidad para la que se pretendan reutilizar los datos habrá de ser compatible con la que inicialmente justificara el tratamiento de los datos por parte de la entidad pública en el ejercicio de su actividad principal, debiendo adoptarse las garantías adecuadas.
Un ejemplo práctico de gran interés es el relativo a la reutilización de datos de salud con fines de investigación biomédica que ha establecido el legislador español al amparo de lo previsto en este último precepto. En concreto, la disposición adicional 17ª de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos de Carácter Personal y Garantía de los Derechos Digitales, admite la reutilización de datos seudonimizados en este ámbito cuando se establezcan ciertas garantías específicas, que podrían reforzarse con el uso de los referidos entornos seguros en el caso de que se empleen tecnologías especialmente incisivas, como podría ser la inteligencia artificial. Todo ello sin perjuicio de cumplir, asimismo, con otras obligaciones que deban tenerse en cuenta en función de las condiciones del tratamiento de los datos, singularmente la realización de evaluaciones de impacto.
¿Qué instrumentos se prevén para garantizar la efectividad de su aplicación?
Desde una perspectiva organizativa, los Estados han de garantizar que la información se encuentre fácilmente accesible a través de un punto único. En el caso de España, este punto se encuentra habilitado a través de la plataforma datos.gob.es, si bien pueden existir también otros puntos de acceso para sectores concretos y diferentes niveles territoriales, en cuyo caso deberán estar vinculados. Los reutilizadores podrán dirigirse a dicho punto para formular consultas y solicitudes, que se remitirán a la entidad o al órgano competente para su tramitación y respuesta.
Asimismo, se han de designar y notificar a la Comisión Europea una o varias entidades especializadas que cuenten con los medios técnicos y personales adecuados, que podrían ser algunas de las ya existentes, que desarrollan la función de prestar asistencia a los organismos públicos a la hora de conceder o denegar la reutilización. No obstante, si lo previera la regulación europea o de los Estados, dichos organismos podrían asumir funciones decisorias y no únicamente de mera asistencia. En todo caso, se prevé que sean las Administraciones y, en su caso, las entidades del sector público institucional ‑‑según la terminología del artículo 2 de la Ley 27/2007‑‑ quienes realicen esta designación y la comuniquen al Ministerio de Asuntos Económicos y Transformación Digital, que por su parte se encargará de la correspondiente notificación a nivel europeo.
Finalmente, como se indicaba al principio, se han tipificado como infracciones específicas para el ámbito de la Administración General del Estado algunas conductas de los reutilizadores que se sancionan con multas que van desde los 10.001 a los 100.000 euros. En concreto, se trata de conductas que, de forma deliberada o por negligencia, supongan el incumplimiento de las principales garantías que contempla la normativa europea: en concreto, el incumplimiento de las condiciones de acceso a los datos o a los espacios seguros, la reidentificación o la falta de comunicación de problemas de seguridad.
En definitiva, como señalaba la Estrategia Europea de Datos, si la Unión Europea quiere desempeñar un papel de liderazgo en la economía de los datos resulta imprescindible, entre otras medidas, mejorar las estructuras de gobernanza e incrementar los repositorios de datos de calidad que, con frecuencia, se encuentran afectados por relevantes obstáculos jurídicos. Con el Reglamento de Gobernanza de Datos se ha dado un paso importante a nivel regulatorio, pero ahora resta por comprobar si los organismos públicos son capaces de asumir una posición proactiva para facilitar la puesta en marcha de sus medidas que, en última instancia, implica importantes desafíos en la transformación digital de su gestión documental.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El activismo de datos es una práctica ciudadana cada vez más significativa en la era de las plataformas por su creciente contribución a la democracia, la justicia social y los derechos. Se trata de un activismo que utiliza los datos y su análisis para generar evidencias y visualizaciones con el objetivo de revelar injusticias, mejorar la vida de las personas y fomentar el cambio social.
Frente al uso masivo de datos de vigilancia por parte de determinadas corporaciones, el activismo de datos es ejercido por la ciudadanía y organizaciones no gubernamentales. Por ejemplo, la organización Forensic Architecture (FA), un centro de Goldsmiths dependiente de la Universidad de Londres, investiga violaciones de derechos humanos, incluidas las violencias de Estado, usando datos públicos, ciudadanos y satelitales, y metodologías como la inteligencia de fuentes abiertas (conocida como OSINT). El análisis de datos y metadatos, la sincronización de vídeos tomados por testigos o periodistas, así como de grabaciones y documentos oficiales, permiten reconstruir los hechos y generar un relato alternativo acerca de eventos y crisis.
El activismo de datos ha suscitado el interés de centros de investigación y organizaciones no gubernamentales, generando una línea de trabajo dentro de la disciplina de los estudios críticos. Esto ha permitido reflexionar sobre el efecto de los datos, las plataformas y sus algoritmos en nuestras vidas, así como acerca del empoderamiento que se genera cuando la ciudadanía ejerce su derecho a los datos y los usa para el bien común.

Imagen 1: Ecocidio en Indonesia (2015)
Fuente: Forensic Architecture (https://forensic-architecture.org/investigation/ecocide-in-indonesia)
Centros de investigación como Datactive o Data + Feminism Lab han creado teoría y debates sobre la práctica del activismo de datos. Asimismo, organizaciones como Algorights –una red colaborativa que fomenta la participación de la sociedad civil en el campo de las tecnologías de IA- y AlgorithmWatch -organización de derechos humanos- generan conocimiento, redes y argumentos para luchar por un mundo donde los algoritmos y la Inteligencia Artificial (IA)contribuyan a la justicia, la democracia y la sostenibilidad, en vez de debilitarlas.
Este artículo revisa cómo surgió el activismo de datos, qué interés ha suscitado en la ciencia social y su relevancia en la era de las plataformas.
Historia de una práctica
La producción de mapas usando datos ciudadanos podría ser de las primeras manifestaciones del activismo de datos tal y como se conoce ahora. Un mapa fundamental en la historia del activismo de datos fue el generado por víctimas y activistas con datos sobre el terremoto de Haití en 2010, sobre la plataforma keniata Ushahidi (“testimonio”, en Suajili). Una comunidad de humanitaristas digitales creó el mapa desde otros países y convocó a las víctimas y a sus familiares y conocidos para que compartieran datos de lo que estaba ocurriendo en tiempo real. En cuestión de pocas horas, los datos se verificaron y se visualizaron en un mapa interactivo que continuó actualizándose con más datos, y que fue decisivo a la hora de asistir a las víctimas en el terreno. Hoy en día se generan mapas de este tipo cada vez que surge una crisis, y se enriquecen con datos ciudadanos, satelitales y generados por drones dotados de cámaras para esclarecer hechos y generar evidencias.
Emergiendo de movimientos conocidos como cypherpunk y el tecnopositivismo o tecnoptimismo (basado en la confianza en que la tecnología es la respuesta a los retos de la humanidad), el activismo de datos ha ido evolucionando como práctica para adoptar posturas más críticas frente a la tecnología y a las asimetrías de poder que surgen entre quienes originan y ceden sus datos, y quienes los captan y analizan.
Hoy día, por ejemplo, la plataforma de producción de mapas comunitarios Ushahidi se ha empleado para crear datos sobre la violencia machista en Egipto y en Siria, y sobre ginecólogos confiables en India, por ejemplo. Actualmente, la invisibilización y el silenciamiento de las mujeres es la razón por la cual algunas organizaciones luchan por el reconocimiento y una política de visibilidad, algo que se hizo evidente con el movimiento #MeToo (#Cuéntalo en español). Las prácticas de datos feministas buscan visibilidad e interpretaciones críticas de la datificación (o la transformación de toda acción humana y no humana en datos mesurables y transformables en valor). Por ejemplo, Datos Contra el Feminicidio o Feminicidio.net ofrecen mapas y análisis de datos sobre el feminicidio en varios lugares del mundo.
El potencial para el empoderamiento algorítmico que ofrecen estos proyectos elimina las barreras a la igualdad, mejorando las condiciones que permiten a las mujeres resolver problemas, determinar cómo se recaban y se usan los datos y ejercer el poder.
Nacimiento y evolución de un concepto
En 2015 se publicó Los medios ciudadanos se encuentran con los grandes datos: el surgimiento del activismo de datos, en el que, por primera vez, se acuñaba y definía el activismo de datos como un concepto basado en prácticas observadas en activistas que se involucran políticamente con la infraestructura de datos. La infraestructura de datos incluye los datos, el software, el hardware y los procesos necesarios para convertir los datos en valor. Más adelante, Data activism and social change (London, Palgrave) y Activismo de datos y cambio social. Alianzas, mapas, plataformas y acción para un mundo mejor (Madrid: Dykinson) desarrollan marcos analíticos basados en casos reales que ofrecen formas de analizar otros casos.
Acompañando las variadas prácticas que existen dentro de activismo de datos, su estudio está creando espacios para la investigación feminista y postcolonialista sobre las consecuencias de la datificación. Mientras que los cronistas de la historia (principalmente fuentes masculinas) definieron la tecnología en relación con el valor sus productos, los estudios de datos feministas consideran a las mujeres como usuarias y diseñadoras de sistemas algorítmicos y buscan utilizar los datos para la igualdad, y alejarse de la explotación capitalista y sus estructuras de dominación.
El activismo de datos es hoy un concepto establecido en la ciencia social. Por ejemplo, Google Scholar ofrece más de 2.000 resultados sobre “data activism”. Varios investigadores e investigadoras lo emplean como perspectiva para analizar diversos asuntos. Por ejemplo, Rajão y Jarke exploran el activismo ambiental en Brasil; Gezgin estudia la ciudadanía crítica y el uso que hace esta de la infraestructura de datos; Lehtiniemi y Haapoja explora la agencia de datos y la participación ciudadana; y Scott examina la necesidad de los usuarios y usuarias de plataformas de desarrollar una vigilancia digital y cuidar de sus datos personales.
En el centro de estas preocupaciones se encuentra el concepto de agencia de datos, que se refiere a que las personas no sólo son conscientes del valor de sus datos, sino que también ejercen control sobre ellos, determinando cómo se usan y comparten. Se podría definir como acciones y prácticas relacionadas con la infraestructura de datos basadas en la reflexión y el interés individual y colectivo. Es decir, mientras darle un like a un post no se consideraría una acción con un alto grado de agencia de datos, participar en un hackaton –un evento colectivo en el que se mejora un programa informático o se crea— sí lo sería. La agencia de datos se basa en la alfabetización en datos, o el grado de conocimientos, acceso a los datos y a sus herramientas, y a las oportunidades para ejercerla que tienen las personas. El activismo de datos no es posible sin agencia de datos.
En el panorama en rápida evolución de la economía de plataformas, la convergencia del activismo de datos, los derechos digitales y la agencia de datos se ha vuelto crucial. El activismo de datos, impulsado por una creciente conciencia del posible uso indebido de los datos personales, alienta a individuos y colectivos a utilizar la tecnología digital para el cambio social, así como a abogar por una mayor transparencia y responsabilidad por parte de las gigantes tecnológicas. Dado que cada vez más la generación de datos y el uso de algoritmos determinan nuestras vidas en áreas como la educación, el empleo, los servicios sociales y la salud, el activismo de datos emerge como una necesidad y un derecho, más que como una opción.
____________________________________________________________________________
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Documentación
La digitalización en el sector público en España también llegó al ámbito judicial. La primera regulación para establecer un marco legal en este sentido fue la reforma que tuvo lugar a través de la Ley 18/2011, de 5 de julio (LUTICAJ). Desde entonces, se han producido avances en la modernización tecnológica de la Administración de Justicia. El año pasado, el Consejo de Ministros aprobó un nuevo paquete legislativo para abordar de manera definitiva la transformación digital del servicio público de justicia, el Proyecto de Ley sobre Eficiencia Digital.
Este proyecto incorpora diversas medidas específicamente dirigidas a impulsar la gestión basada en datos, en coherencia con el planteamiento general que se ha formulado a través del denominado Manifiesto del Dato de Justicia.
Una vez decidida la apuesta por la gestión basada en datos, ésta debe afrontarse teniendo en cuenta las exigencias e implicaciones del Gobierno Abierto, de manera que no sólo se refuercen las posibilidades de mejora en la gestión interna de la actividad judicial sino, asimismo, las posibilidades de reutilización de la información que se genera como consecuencia del desarrollo de dicho servicio público (RISP).
Los datos abiertos: premisa para la transformación digital de justicia
Para afrontar el desafío de la transformación digital de la justicia, la apertura de los datos es una exigencia fundamental. En esta línea, los datos abiertos requieren de unas condiciones que permitan su integración de manera automatizada en el ámbito judicial. En primer lugar, se debe llevar a cabo una mejora de las condiciones de accesibilidad de los conjuntos de datos que deben estar en formato interoperable y reutilizable. De hecho, existe una necesidad de impulsar un modelo institucional basado la interoperabilidad y el establecimiento de condiciones homogéneas que, desde la normalización adaptada a las singularidades del ámbito judicial, faciliten su integración de manera automatizada.
Con el objetivo de profundizar en la sinergia entre datos abiertos y justicia, el informe elaborado por el experto Julián Valero identifica las claves de la transformación digital en el ámbito judicial, así como una serie de fuentes de datos abiertos de valor en el sector.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.
Blog
La combinación e integración de los datos abiertos con la inteligencia artificial (IA) es un área de trabajo que cuenta con el potencial de lograr avances significativos en múltiples campos y conseguir mejoras en varios aspectos de nuestras vidas. El área de sinergia que más frecuentemente se menciona suele ser la utilización de los datos abiertos como datos de entrada para el entrenamiento de los algoritmos utilizados por la IA, ya que estos sistemas necesitan devorar grandes cantidades de datos para alimentar su funcionamiento. Esto convierte a los datos abiertos en un elemento ya de por sí esencial para el desarrollo de la IA, pero su utilización como datos de entrada conlleva además otras múltiples ventajas como una mayor igualdad de acceso a la tecnología o una mejora de la transparencia sobre el funcionamiento de los algoritmos.
Así pues, hoy en día podemos encontrar datos abiertos alimentando algoritmos para la aplicación de la IA en áreas tan variadas como la prevención de crímenes, el desarrollo del transporte público, la igualdad de género, la protección del medioambiente, la mejora de la sanidad o la búsqueda de ciudades más amigables y habitables. Todos ellos son ya objetivos más fácilmente alcanzables gracias a la adecuada combinación de ambas tendencias tecnológicas.
Sin embargo, como veremos a continuación, puestos a imaginar el futuro conjunto de los datos abiertos y la IA, el uso combinado de ambos conceptos puede dar lugar también a muchas otras mejoras en la forma en que trabajamos actualmente con los datos abiertos y a lo largo de todo el ciclo de vida de los mismos. Repasamos, paso a paso, cómo la inteligencia artificial puede enriquecer un proyecto con datos abiertos.
Utilizar la IA para descubrir fuentes y preparar conjuntos de datos
La inteligencia artificial puede ayudar ya desde los primeros pasos de nuestros proyectos de datos mediante el apoyo en la fase de descubrimiento e integración de diversas fuentes de datos, facilitando a las organizaciones encontrar y usar datos abiertos de relevancia para sus aplicaciones. Además, las tendencias futuras pueden incluir el desarrollo de estándares comunes de datos, marcos de metadatos y APIs para facilitar la integración de los datos abiertos con tecnologías de IA, lo que ampliaría aún más las posibilidades de automatizar la combinación de datos de diversas fuentes.
Además de la automatización en la búsqueda guiada de fuentes de datos, los procesos automáticos de la inteligencia artificial pueden ser de utilidad, al menos en parte, en el proceso de limpieza y preparación de los datos. De esta forma se puede mejorar la calidad de los datos abiertos al identificar y corregir los errores, rellenar los vacíos existentes en los datos y mejorar así su completitud. Esto contribuiría a liberar a los científicos y analistas de datos de ciertas tareas básicas y repetitivas para que puedan centrarse en otras tareas más estratégicas, como desarrollar nuevas ideas y hacer predicciones.
Técnicas innovadoras para el análisis de datos con IA
Una de las características de los modelos de IA es su facilidad para detectar patrones y conocimiento en grandes cantidades de datos. Técnicas de IA como el aprendizaje automático, el procesamiento del lenguaje natural y la visión por computador se pueden usar fácilmente para extraer nuevas perspectivas, patrones y conocimiento de los datos abiertos. Por otro lado, a medida que el desarrollo tecnológico continúa avanzando, podremos ver el desarrollo de técnicas de IA aún más sofisticadas y especialmente adaptadas para el análisis de datos abiertos, permitiendo a las organizaciones extraer todavía más valor de los mismos.
Paralelamente, las tecnologías de IA pueden ayudarnos a ir un paso más allá en el análisis de los datos facilitando y asistiendo en el análisis de datos colaborativo. Mediante este proceso, las múltiples partes interesadas pueden trabajar juntas en problemas complejos y darles respuesta a través de los datos abiertos. Esto daría lugar también a una mayor colaboración entre investigadores, formuladores de políticas públicas y comunidades de la sociedad civil a la hora de sacar el mayor provecho de los datos abiertos para abordar los desafíos sociales. Además, este tipo de análisis colaborativo también contribuiría a mejorar la transparencia y la inclusividad en los procesos de toma de decisiones.
La sinergia de la IA y los datos abiertos
En definitiva, la IA también se puede utilizar para automatizar muchas de las tareas involucradas en la presentación de los datos, como por ejemplo crear visualizaciones interactivas proporcionando simplemente instrucciones en lenguaje natural o una descripción de la visualización deseada.
Por otro lado, los datos abiertos permiten desarrollar aplicaciones que, combinadas con la inteligencia artificial, pueden resultar soluciones innovadoras. El desarrollo de nuevas aplicaciones impulsadas por los datos abiertos y la inteligencia artificial puede contribuir en diversos sectores como la atención sanitaria, finanzas, transporte o educación entre otros. Por ejemplo, se están utilizando chatbots para proporcionar servicio al cliente, algoritmos para tomar decisiones de inversión o coches autónomos, todos ellos impulsados por la IA. Lo que conseguiríamos además si estos servicios utilizaran los datos abiertos como fuente principal de datos sería una mayor calidad y veracidad, gracias a un mejor entrenamiento de los modelos de IA. Además, cuanta mayor sea la disponibilidad de los datos abiertos, mayor será también el número de personas que tendrán estas aplicaciones a su alcance.
Finalmente, la IA se puede utilizar también para analizar grandes volúmenes de datos abiertos e identificar nuevos patrones y tendencias que serían difíciles de detectar únicamente a través de la intuición humana. Esta información puede utilizarse luego para tomar mejores decisiones, como por ejemplo qué políticas llevar a cabo en un área determinada para poder obtener los cambios deseados.
Estas son solo algunas de las posibles tendencias futuras en la intersección de los datos abiertos y la inteligencia artificial, un futuro lleno de oportunidades pero al mismo tiempo no exento de riesgos. A medida que la IA continúa desarrollándose, podemos esperar ver aplicaciones aún más innovadoras y transformadoras de esta tecnología. Para ello será también necesaria una colaboración más cercana entre investigadores de inteligencia artificial y la comunidad de los datos abiertos a la hora de abrir nuevos conjuntos de datos y desarrollar nuevas herramientas para explotarlos. Esta colaboración es esencial para poder darle forma al futuro conjunto de los datos abiertos y la IA y garantizar que los beneficios de la IA estén disponibles para todos de forma justa y equitativa.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos son una fuente de conocimiento muy valiosa para nuestra sociedad. Gracias a ellos, se pueden crear aplicaciones que contribuyen al desarrollo social y soluciones que ayudan a configurar el futuro digital de Europa y alcanzar los Objetivos de Desarrollo Sostenible (ODS).
El portal de datos abiertos europeo (data.europe.eu) organiza eventos en línea para poner en valor aquellos proyectos que se han llevado a cabo con fuentes de datos abiertos y han ayudado a hacer frente a alguno de los retos a los que nos enfrentamos como sociedad: desde la lucha contra el cambio climático, el impulso de la economía, la consolidación de la democracia europea o la transformación digital.
En lo que llevamos de año, en 2023 se han celebrado cuatro seminarios para analizar el impacto positivo que tienen los datos abiertos en cada una de las temáticas mencionadas. Todo el material que se presentó en los eventos está publicado en el portal europeo y las grabaciones están disponibles en su canal de Youtube, al alcance de cualquier usuario interesado.
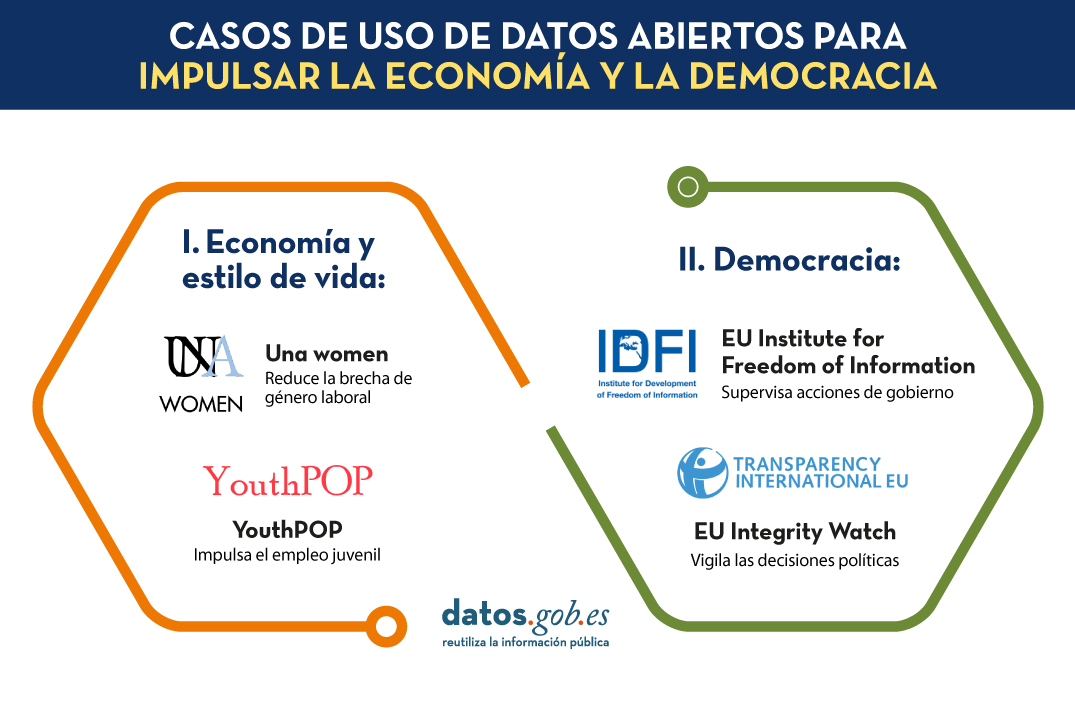
En este post, realizamos un primer repaso de los casos de uso presentados en materia de impulso a la economía y a la democracia, así como los conjuntos de datos abiertos que se emplearon para su desarrollo.
Soluciones que impulsan la economía y el estilo de vida europeo
En un mundo en constante evolución, donde los desafíos económicos y las aspiraciones de un estilo de vida próspero convergen, la Unión Europea ha demostrado una capacidad inigualable para forjar soluciones innovadoras que no solo impulsan su propia economía, sino que también elevan el estándar de vida de sus ciudadanos. En este contexto, los datos abiertos han jugado un papel fundamental en el desarrollo de aplicaciones que han dado respuesta a desafíos actuales y han sentado las bases para un futuro próspero y prometedor. Dos de estos proyectos se presentaron en el segundo webinar de la serie “Stories of use cases”, un evento sobre “Datos abiertos para fomentar la economía y el estilo de vida europeo”: UNA WOMEN y YouthPOP.
El primero de ellos se centra en solucionar uno de los retos más relevantes que debemos superar para lograr una sociedad justa: la desigualdad de género. La eliminación de la brecha de género es un problema social y económico muy complejo. Según estimaciones del Foro Económico Mundial, se necesitarán 132 años para lograr la paridad de género total en Europa. La aplicación UNA Women nace con el propósito de reducir esa cifra, asesorando a las mujeres jóvenes para que puedan tomar mejores decisiones a la hora de elegir su futuro en cuanto a educación y primeros pasos en sus carreras profesionales. En este caso de uso, la empresa ITER IDEA ha utilizado más de 6 millones de líneas de datos procesados de distintas fuentes, como data.europa.eu, Eurostat, Censis, Istat (Instituto nacional de estadística de Italia) o NUMBEO.
El segundo caso de uso presentado también va dirigido a la población joven. Se trata de la aplicación YouthPOP (Youth Públic Open Procurement), una herramienta que anima a los jóvenes a participar en procesos de contratación pública. Para el desarrollo de esta app se han utilizado datos de data.europa.eu, Eurostat y ESCO, entre otros. Youth POP tiene entre sus objetivos mejorar el empleo juvenil y contribuir al correcto funcionamiento de la democracia en Europa.
Datos abiertos para impulsar y consolidar la democracia europea
En esta línea, el uso de los datos abiertos también contribuye a fortalecer y consolidar la democracia europea. Los datos abiertos desempeñan un papel fundamental en nuestras democracias a través de las siguientes vías:
- Proporcionando a los ciudadanos información confiable.
- Fomentando la transparencia en los gobiernos e instituciones públicas.
- Combatiendo la desinformación y las noticias falsas.
El tema del tercer webinar organizado por datos.europa.eu sobre casos de uso es “Datos abiertos y un nuevo impulso a la democracia europea”, evento en el que se presentaron dos soluciones innovadoras: EU Integrity Watch y EU Institute For Freedom of Information.
En primer lugar, EU Integrity Watch es una plataforma que proporciona herramientas en línea para que los ciudadanos, periodistas y la sociedad civil monitoricen la integridad de las decisiones tomadas por los políticos en la Unión Europea. Esta web ofrece visualizaciones para comprender la información y pone a disposición los datos recopilados y analizados. Los datos analizados se utilizan en divulgaciones científicas, investigaciones periodísticas y otros ámbitos, lo que contribuye a un gobierno más abierto y transparente. Esta herramienta procesa y ofrece datos de Transparency register.
La segunda iniciativa presentada en el webinar sobre democracia con datos abiertos es el EU Institute For Freedom of Information (IDFI), una organización no gubernamental georgiana que se centra en actividades de vigilancia y supervisión de las acciones del gobierno, revelando infracciones y manteniendo informada a la ciudadanía.
Las principales actividades del IDFI incluyen solicitar información pública a los organismos pertinentes, elaborar clasificaciones de organismos públicos, monitorizar los sitios web de dichos organismos y abogar por la mejora del acceso a la información pública, los estándares legislativos y las prácticas relacionadas. Este proyecto obtiene, analiza y presenta conjuntos de datos abiertos procedentes de instituciones públicas nacionales.
En definitiva, los datos abiertos hacen posible el desarrollo de aplicaciones para reducir la brecha laboral de género, impulsar el empleo juvenil o vigilar las acciones de gobierno. Estos son solo algunos ejemplos del valor que pueden ofrecer los datos abiertos a la sociedad.
Conoce más sobre estas aplicaciones en sus seminarios -> Grabaciones aquí
Noticia
Los datos abiertos suponen el nivel más alto de intercambio de datos, ya que están disponibles de manera gratuita y son accesibles para todos. Procesados de manera adecuada y garantizando un pleno respeto a la protección de datos personales, pueden ayudar a los ciudadanos, empresas y sector público a tomar mejores decisiones.
Los datos abiertos, junto con el resto de datos, juegan un papel clave la creación de espacios de datos, tal y como refiere la Estrategia Europea de Datos. Como recoge el documento, la puesta en marcha de espacios de datos comunes e interoperables en sectores estratégicos se constituye con el objetivo de “superar los obstáculos técnicos y jurídicos a la puesta en común de datos entre organizaciones, combinando las herramientas e infraestructuras necesarias y abordando cuestiones de confianza”, por ejemplo, mediante normas comunes desarrolladas para el espacio”.
Teniendo en cuenta su relevancia, la Academia del Portal de Datos Europeo ha organizado una serie de seminarios web sobre espacios de datos. El primero de ellos se celebró el pasado 12 de mayo en formato online y se puede ver aquí. En él, se mencionaron las novedades y progresos que se están llevando a cabo respecto a los data spaces, avances que en España se vienen realizando desde la Oficina del Dato.
Resumimos a continuación los principales aspectos abordados en este primer seminario, en el que participaron Daniele Rizzi, Principal administrator and policy officer y Johan Bodenkamp, Policy and project officer en la Dirección General de Redes de Comunicación, Contenido y Tecnologías de la Comisión Europea, con la moderación de Giulia Carsaniga, Research and Policy Lead Consultant en Capgemini.
Los espacios de datos y la estrategia digital de la UE
En la primera parte del seminario, que se celebró de manera online, se destacó cómo la transformación digital es una de las grandes prioridades de la Unión Europea. De hecho, Europa cuenta con una estrategia específica para avanzar en este aspecto, es decir, lograr ‘Una Europa adaptada a la era digital’, y es una de las seis prioridades 2019-24 de la Comisión Europea.
La estrategia digital de la Unión Europea tiene como objetivo hacer que la trasformación digital beneficie a las personas y las empresas, contexto en el que se enmarca la Estrategia Europea de Datos de febrero de 2020, que recoge una serie de medidas para el impulso de un mercado europeo del dato, a semejanza del Mercado Común Europeo, germen de la actual UE.
La creación de este mercado europeo del dato requiere del establecimiento de una serie de acciones y estándares con un enfoque basado en los datos, la tecnología y la infraestructura. A ello, contribuye además el esfuerzo colectivo, en el que se encuadran programas públicos como DIGITAL Europe o privados como Gaia-X.
Un año después de la aprobación de la Estrategia Europea del Dato, el Consejo Europeo reconocía, en marzo de 2021, “la necesidad de acelerar la creación de espacio de datos comunes y asegurar el acceso e interoperabilidad de los datos” e invitaba a la Comisión a “presentar el progreso realizado y las medidas restantes necesarias para establecer los espacios de datos sectoriales anunciados en la Estrategia Europea de Datos de febrero de 2020”. Posteriormente, en febrero de 2022 la Comisión Europea publicó un documento de trabajo sobre el mercado europeo del dato.
Tras contextualizar en el marco europeo el desarrollo del concepto de espacios de datos, los ponentes del webinar pasaron a explicar aquellas piezas fundamentales que formarán parte de los espacios de datos, algunas de ellas ya están operativas y otras se encuentran en desarrollo. En el seminario se dio una visión general de cómo se espera que sea el espacio de datos europeo, y se destacaron las siguientes partes:
En primer lugar, se habló sobre los datasets de alto valor del sector público. En enero de este año la Comisión Europea publicó el listado de conjuntos de datos de alto valor entendido como aquellos que aportan valor añadido e importantes beneficios para la sociedad. Existe una amplia variedad de datos de alto valor englobados en diferentes áreas (salud, agricultura, movilidad, energía, etc.) que las partes interesadas ponen a disposición con diferentes grados de apertura. Tal y como se explicó en el webinar, la idea es comenzar a crear espacios de datos de alto valor comunes en áreas más homogéneas, aunque el objetivo final es que en ese mercado europeo se compartan datos entre todas ellas, ya que la mayoría de las aplicaciones requerirán datos de diferentes ámbitos.
Para apoyar la creación de esos espacios de datos, la primera iniciativa que se ha puesto en marcha en Europa es la creación del Data Spaces Support Centre. Este centro explora las necesidades de las iniciativas de los espacios de datos, define requisitos comunes, establece las mejores prácticas para acelerar la formación de espacios de datos soberanos como un elemento crucial de la transformación digital en todas las áreas y se encarga de garantizar su interoperabilidad mediante el cumplimiento de unos estándares comunes.
Para que todo esto se pueda desarrollar, es necesario contar con una infraestructura técnica para los espacios de datos, que se encarga de facilitar servicios cloud y edge-cloud, soluciones de middleware inteligente (Simpl), mercado digital, computación de alto rendimiento, plataforma de inteligencia artificial bajo demanda e instalaciones de prueba y experimentación de IA.
Diferencias y similitudes entre los espacios de datos y los datalakes
Tras repasar la visión general de los espacios de datos en Europa, en el seminario se abordaron sus principales características. De esta forma, se presentó un espacio de datos como una infraestructura de TI segura y respetuosa con la privacidad para agrupar, acceder, procesar, usar y compartir datos. Además, se definió como un mecanismo de gobernanza de datos que comprende un conjunto de reglas de naturaleza administrativa y contractual que determinan los derechos de acceso, procesamiento, uso y compartición de datos de manera confiable, transparente y en cumplimiento de la legislación vigente.
Una de las características que se destacaron en el webinar sobre este tipo de infraestructura es que en ella los titulares de los datos tienen el control sobre quién puede acceder a qué datos, con qué propósito y bajo qué condiciones pueden ser utilizados, Además, hay una gran cantidad de datos disponibles de forma voluntaria que pueden ser reutilizados de forma gratuita o a cambio de una remuneración, dependiendo de la decisión de los titulares de los datos.
Finalmente, se subrayó el hecho de que los espacios de datos cuentan con la participación de un número abierto de organizaciones/individuos, respetando las normas de competencia y garantizando un acceso no discriminatorio para todos los participantes.
Otro de los conceptos que se abordó en el seminario fue el de datalake, para compararlo con el de un espacio de datos. Así, se definieron los lagos de datos como repositorios que permiten almacenar datos estructurados y no estructurados a cualquier escala. En un datalake, según explicaron en el seminario, es posible almacenar datos tal y como están, sin necesidad de estructurarlos previamente y ejecutar diferentes tipos de análisis, desde paneles de control y visualizaciones hasta realizar procesamiento de big data, análisis en tiempo real y aprendizaje automático para tomar decisiones más acertadas. El acceso al datalake implica la posibilidad de acceder a todos los datos contenidos que se albergan en él, no necesariamente de manera ordenada.
Por otra parte, un espacio de datos, en palabras de los ponentes, se puede definir como un ecosistema de datos federado basado en políticas y reglas compartidas. Los usuarios de dichos espacios de datos tienen la capacidad de acceder a los datos de manera segura, transparente, confiable, fácil y unificada. En un espacio de datos los titulares de los datos tienen el control sobre el acceso y uso de sus datos. Desde una perspectiva técnica, se puede ver un espacio de datos como un concepto de integración de datos que no requiere esquemas de bases de datos comunes ni integración física de datos, sino que se basa en almacenes de datos distribuidos e integrados según sea necesario.
Haciendo un símil con la acción de conseguir peces, en el datalake el usuario tiene que pescarlos por sí mismo, y un espacio de datos sería como ir a un mercado de peces.
Próximos pasos: Marco de gobernanza y actores europeos
Una vez presentada la diferencia entre dataspaces y datalakes, en el webinar se abordó el cambio de paradigma de intercambio de datos que está sucediendo en la actualidad. Hasta ahora, se empleaba un intercambio bilateral de datos basado en acuerdos contractuales, sin embargo, va tomando fuerza un nuevo modelo de infraestructuras de intercambio de datos con alojamiento centralizado de datos y/o mercados de datos que permiten reducir los costes de transacción cuando los datos no se mantienen en un repositorio central.
El siguiente paso en la evolución de los espacios de datos sería, según los ponentes, la creación de enlaces entre los participantes, en un modelo en el que los datos se federasen y se almacenasen de manera distribuida con herramientas que permitan la búsqueda, el acceso y el análisis en múltiples industrias, empresas y entidades.

Para que este proceso ocurra, tal y como los ponentes explicaron, es necesario el apoyo y trabajo coordinado de diferentes actores. Por un lado, sería fundamental establecer unas normas comunes que faciliten el intercambio de datos y acercar a los diferentes actores implicados a una política común de datos en la UE. Igualmente es indispensable ofrecer soluciones técnicas y apoyo financiero.
En esta línea, en el webinar se destacó un importante hito: la puesta en marcha del European Data Innovation Board (EDIB) que apoyará a la Comisión en la publicación de directrices para facilitar el desarrollo de los espacios comunes europeos de datos y la identificación de las normas y los requisitos de interoperabilidad necesarios para el intercambio de datos.
Como se indicó anteriormente, la puesta en marcha del espacio de datos precisa de arquitectura técnica, por lo que en el webinar se destacaron dos soluciones técnicas gratuitas:
- Los Building Blocks: Soluciones digitales abiertas y reutilizables basadas en estándares que permiten funcionalidades básicas, como la autenticación confiable y el intercambio seguro de datos.
- Simpl: El middleware inteligente que permitirá federaciones basadas en la nube y nube en el borde. Apoyará las principales iniciativas de datos financiadas por la Comisión Europea, como los espacios de datos europeos comunes.
El papel clave del Data Spaces Support Centre
Al final del seminario se presentó con más detalle la iniciativa Data Spaces Support Centre (DSCC). Este centro, creado en octubre de 2022, da apoyo a las diferentes iniciativas en la creación de espacios de datos y está previsto que finalice su actividad en marzo de 2026. Está formado por doce socios y cuenta además con dieciséis socios colaboradores, entre los que se encuentran importantes asociaciones y empresas con experiencia en el ámbito del intercambio de datos.
El DSCC tiene como misión principal la creación de una red de socios y una comunidad, a la que proporciona las herramientas para la creación de los espacios de datos. Se centra de manera especial en la interoperabilidad y pretende generar sinergias a nivel europeo para el desarrollo de espacios de datos.
En el webinar se hizo un repaso de las colaboraciones y las iniciativas en las que participa el Data spaces support centre y se destacó que en su web está disponible el kit de inicio, un punto de partida para la construcción de los espacios de datos.
En la recta final del seminario, para dar una visión general de los espacios de datos, se detallaron cuáles son los actores relevantes del espacio común de datos europeo:
- Data Spaces Support Centre (DSSC): Encargado de coordinar las acciones relevantes en los espacios de datos.
- Data Space Coordination and Support Actions (CSAs): Se centra en los espacios de datos sectoriales.
- European Data Innovation Board: A partir de septiembre de 2023, se ocupará de fijar las directrices para lograr la interoperabilidad en los espacios de datos.
Si quieres saber más sobre el concepto de los espacios de datos y su relevancia en la actualidad, puedes ver el seminario completo en el siguiente vídeo:
Los materiales formativos están disponibles en https://data.europa.eu/en/academy:
- La sesión grabada: https://www.youtube.com/watch?v=L9U-eKVtspA
- La presentación de apoyo del webinar: https://data.europa.eu/en/academy/role-dataeuropaeu-eu-data-spaces
Blog
La irrupción de la inteligencia artificial (IA) y, en particular ChatGPT, se ha convertido en uno de los principales temas de debate en los últimos meses. Esta herramienta ha eclipsado incluso otras tecnologías emergentes que habían adquirido un protagonismo en los más diversos ámbitos (jurídicos, económicos, sociales o culturales). Caso, por ejemplo, la web 3.0, el metaverso, la identidad digital descentralizada o los NFT y, en particular, las criptomonedas.
Resulta incuestionable la relación directa que existe entre este tipo de tecnología y la necesidad de disponer de datos suficientes y adecuados, siendo precisamente esta última dimensión cualitativa la que justifica que los datos abiertos estén llamados a desempeñar un papel de especial importancia. Aunque, al menos de momento, no es posible saber cuántos datos abiertos proporcionados por las entidades del sector público utiliza ChatGPT para entrenar su modelo, no hay duda de que los datos abiertos son una fuente especialmente significativa a la hora de mejorar su funcionamiento.
La regulación sobre el uso de los datos por la IA
Desde el punto de vista jurídico, la IA está despertando un especial interés por lo que se refiere a las garantías que deben respetarse a la hora de su aplicación práctica. Así, se están impulsando diversas iniciativas que pretenden regular específicamente las condiciones para proceder a su utilización, entre las que destaca la propuesta que está tramitando la Unión Europea, donde los datos son objeto de especial atención.
Ya en el ámbito estatal, hace unos meses se aprobó la Ley 15/2022, de 12 de julio, integral para la igualdad de trato y la no discriminación. Esta normativa exige a las Administraciones Públicas que favorezcan la implantación de mecanismos que contemplen garantías relativas a la minimización de sesgos, transparencia y rendición de cuentas, en concreto por lo que respecta a los datos utilizados para el entrenamiento de los algoritmos que se empleen para la toma de decisiones.
Por parte de las comunidades autónomas existe un creciente interés a la hora de regular el uso de los datos por parte de los sistemas de IA, reforzándose en algún caso las garantías relativas a la transparencia. También, a nivel municipal se están promoviendo protocolos para la implantación de la IA en los servicios municipales en los que las garantías aplicables a los datos, en particular desde la perspectiva de su calidad, se conciben como una exigencia prioritaria.
La posible colisión con otros derechos y bienes jurídicos: la protección de datos de carácter personal
Más allá de las iniciativas regulatorias, el uso de los datos en este contexto ha sido objeto de una especial atención por lo que se refiere a las condiciones jurídicas en que resulta admisible. Así, puede darse el caso de que los datos que se utilicen estén protegidos por derechos de terceros que impidan —o al menos dificulten— su tratamiento, tal y como sucede con la propiedad intelectual o, singularmente, la protección de datos de carácter personal. Esta inquietud constituye una de las principales motivaciones de la Unión Europea a la hora de promover el Reglamento de Gobernanza de Datos, regulación donde se plantean soluciones técnicas y organizativas que intentan compatibilizar la reutilización de la información con el respeto de tales bienes jurídicos.
Precisamente, la posible colisión con el derecho a la protección de datos de carácter personal ha motivado las principales medidas que se han adoptado en Europa respecto del uso de ChatGPT. En este sentido, el Garante per la Protezione dei Dati Personali ha acordado cautelarmente la limitación del tratamiento de datos de ciudadanos italianos, la Agencia Española de Protección de Datos ha iniciado de oficio actuaciones de inspección frente a OpenAI como responsable del tratamiento y, con una proyección supranacional, el Supervisor Europeo de Protección de Datos (EDPB) ha creado un grupo de trabajo específico.
La incidencia de la regulación sobre datos abiertos y reutilización
La regulación española sobre datos abiertos y reutilización de la información del sector público establece algunas previsiones que han de tenerse en cuenta por los sistemas de IA. Así, con carácter general, la reutilización será admisible si los datos se hubieren publicado sin sujeción a condiciones o, en el caso de que se fijen, cuando se ajuste a las establecidas a través de licencias u otros instrumentos jurídicos; si bien, cuando se definan, las condiciones han de ser objetivas, proporcionadas, no discriminatorias y estar justificadas por un objetivo de interés público.
Por lo que se refiere a las condiciones de reutilización de la información proporcionada por las entidades del sector público, su tratamiento sólo se permitirá si no se altera el contenido ni se desnaturaliza su sentido, debiéndose citar la fuente de la que se hubieren obtenido los datos y la fecha de su actualización más reciente.
Por otra parte, los conjuntos de datos de alto valor adquieren un especial interés para estos sistemas de IA caracterizados por la intensa reutilización de contenidos de terceros dado el carácter masivo de los tratamientos de datos que llevan a cabo y la inmediatez de las peticiones de información que formulan quienes las utilizan. En concreto, las condiciones establecidas legalmente para la puesta a disposición de estos conjuntos de datos de alto valor por parte de las entidades públicas determinan que existan muy pocas limitaciones y, asimismo, que se facilite enormemente su reutilización al tratarse de datos que han de estar disponibles de manera gratuita, ser susceptibles de tratamiento automatizado, suministrarse a través de API y proporcionarse en forma de descarga masiva, siempre que proceda.
En definitiva, teniendo en cuenta las particularidades de esta tecnología y, por tanto, las circunstancias tan singulares en las que tratan los datos, parece oportuno que las licencias y, en general, las condiciones en las que las entidades públicas permiten su reutilización sean revisadas y, en su caso, actualizadas para hacer frente a los retos jurídicos que se están empezando a plantear.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
Gardena-Transparencia es una Plataforma de Transparencia y Buen Gobierno que aglutina toda la información pública relevante:
- Registro Mercantil: Permite realizar una búsqueda filtrada de toda la información del Boletín Oficial del Registro Mercantil (BORME) y fichas completas de todas las empresas registradas y de sus empresarios.
-Contratación Pública: En este apartado, el usuario puede acceder a todas las licitaciones y contratos menores de la Administración Pública, tanto a nivel estatal como local. La aplicación emplea analítica avanzada de datos e inteligencia artificial para identificar desviaciones.
-Altos Cargos: Todo el histórico de cargos políticos de la democracia y más de una década de altos cargos. Se trata de un conjunto de datos de Personas con Responsabilidad Pública (PRPs) muy completo. El apartado recoge también un ranking de retribuciones: salarios de alcaldes y presidentes/as autonómicos.
En la home de la plataforma se puede apreciar un resumen de los datos más destacados como puede ser el presupuesto general licitado el último mes, la evolución de las licitaciones adjudicadas o las empresas con más adjudicaciones de licitaciones en el mes.
La aplicación ha sido desarrolla de forma voluntaria y procuran mantener una periodicidad diaria en la carga de licitaciones y contratos menores. Para ello, se han implementado algoritmos de inteligencia artificial para la mejora de la calidad de la información.