Blog
The Spanish Data Protection Agency (AEPD), through its own Innovation and Technology section, carries out an essential didactic task by providing a documentary corpus that translates the legal obligations of the General Data Protection Regulation (GDPR) into specific technological realities. Its value lies in its ability to offer legal certainty and technical guidelines in areas where regulations are still finding their practical fit, such as artificial intelligence or biometrics.
These are reference guides, articles and other teaching materials aimed especially at SMEs and entrepreneurs. In this post we present some of the most recent, ordered by sector and subject.
The new trends in artificial intelligence and its secure deployment
The evolution of artificial intelligence towards increasingly autonomous systems poses new challenges in terms of data protection. For this reason, the Spanish Data Protection Agency has developed various guides and documents aimed at facilitating a secure and responsible deployment of this technology. In general, AI is one of the areas of greatest document activity of the AEPD due to its transversal impact. The Agency's resources range from internal management to state-of-the-art technologies.
- Guide to agentric artificial intelligence from the perspective of data protection: theso-called agentric AI is one capable of making decisions and acting with a certain degree of independence. Unlike purely reactive models, an agent AI can carry out multiple tasks autonomously and make intermediate decisions during complex processes. This guide discusses the risks of loss of human control and sets out criteria to ensure that decision traceability is not lost in automation.
- General policy for the use of generative AI in AEPD administrative processes: generative artificial intelligence (IAG or GenAI) is a type of AI capable of producing new content, such as text, images, audio or code from learned patterns. This document establishes an internal policy for its responsible use in administrative processes.
- Implementation annex of the AEPD's general IAG policy: this annex to the above document includes the permitted use cases, the type of systems recommended (external, internal or ad hoc), the level of risk associated with each application and the specific obligations of review, human control, security and data protection.
- Basic summary of obligations and recommendations for the management of generative AI: this is a synthesized outline on aspects of governance, design and development of use cases, processing of personal data and sensitive information, transparency and explainability, and responsible use of tools, among others.
- Federated Learning Report: Federated learning is an AI approach that allows models to be trained collaboratively without centralizing data, improving privacy, and aligning with GDPR. This guide explains what it consists of, where personal data can be processed and what are the benefits and challenges in data protection.
To complement this information, users can also visit the AEPD's blog, which serves as a trend observatory where the visible and invisible risks of consumer technologies are analyzed. Some of the topics covered are:
- Image and voice processing: Analyses have been published on AI voice transcription and the use of services that convert photos to other formats (such as animations). These articles warn about the processing of biometric data and the ownership of data in the cloud.
- Algorithmic literacy: resources such as "Addressing AI Misconceptions" seek to raise the level of critical judgment of users and managers in the face of the opacity of algorithms.
- Balance of rights: the analysis of the protection of minors in the digital environment and the design of public contracts that integrate privacy by design stands out.
European Digital Identity Wallet
The evolution towards an interconnected Europe requires robust identity standards and security measures accessible to all levels of business.
Building a secure, interoperable and trustworthy digital identity is one of the pillars of digital transformation in Europe. The future European Digital Identity Portfolio is a project that aims to allow citizens to identify themselves electronically and share personal attributes in a controlled way across multiple services, both public and private.
To analyse its implications from the point of view of privacy, the Spanish Data Protection Agency has published a series of four monographic articles throughout 2025. In them, the Agency breaks down the relationship between the new digital identity wallet and the GDPR.
These contents address key issues such as:
- Data minimisation and the principle of proportionality in information exchange: explains how the eIDAS2 Regulation boosts the European digital identity portfolio. This regulation establishes a framework for secure, interoperable and user-centric electronic identification, aligned with the GDPR to ensure the control and protection of personal data across the EU.
- The risks associated with interoperability between systems: delves into how to prevent the use of the European Digital Identity Wallet from tracking citizens when they present credentials in different public or private services, highlighting the need for advanced cryptographic solutions.
- The need to ensure user control over their credentials: examines identification threats in digital identity wallets under eIDAS2, highlighting that, without strong safeguards such as pseudonymization and non-bonding, even selective disclosure of data can allow for the improper identification and profiling of users.
- The security measures needed to prevent misuse or data breaches: Raises the threats of inaccuracy in digital identity wallets under eIDAS2, highlighting how outdated data or linkable cryptographic mechanisms can lead to erroneous decisions and compromise privacy. To solve this, it stresses the need for solutions that guarantee both reliability and plausible deniability (that there is no technical evidence to prove that a person has carried out a specific action with their wallet or digital credential).
This series provides a progressive overview that helps to understand both the potential of European digital identity and the challenges posed by its implementation from a data protection perspective.
Personal Data Protection Encryption in SMBs
For many small and medium-sized businesses, ensuring the security of personal data remains a challenge, especially due to a lack of technical resources or specialized knowledge. In this context, encryption is presented as a fundamental tool to protect the confidentiality and integrity of information.
With the aim of bringing this concept closer to a non-expert audience, the Spanish Data Protection Agency has published the Encryption Guide for the self-employed and SMEs, accompanied by an explanatory infographic.
These resources explain in a clear and practical way:
- What is encryption and why is it important in data protection?
- What types of encryption exist and in which cases they are applied.
- How to implement encryption measures in common situations, such as sending emails or storing information.
- Which tools can be used without the need for advanced knowledge.
Scientific research and the European legal framework
For profiles that require a more in-depth and academic analysis, the Agency has promoted the publication of scientific articles in various international media, which connect technology with ethics and law. Some examples are:
- Addictive patterns: analysis of how interface design affects human behavior.
- Neurotechnology: study on the risks of brain-computer interfaces.
- Algorithmic governance: A comprehensive analysis that aligns the GDPR with the European Artificial Intelligence Regulation (AI Act), the Digital Services Act (DSA), and the Cyber Resilience Act.
The didactic value of these materials lies in their ability to offer a 360-degree view of the data. From cutting-edge academic research to encryption infographics for a small business, the AEPD provides the building blocks for innovation that doesn't sacrifice privacy.
Together, these materials shared by the Spanish Data Protection Agency help to incorporate effective security measures and comply with the requirements of the General Data Protection Regulation in a proportionate and accessible way. All of them, and some others, are compiled and ordered by theme in its website, available here.
Documentación
The Spanish Data Protection Agency has recently published the Spanish translation of the Guide on Synthetic Data Generation, originally produced by the Data Protection Authority of Singapore. This document provides technical and practical guidance for data protection officers, managers and data protection officers on how to implement this technology that allows simulating real data while maintaining their statistical characteristics without compromising personal information.
The guide highlights how synthetic data can drive the data economy, accelerate innovation and mitigate risks in security breaches. To this end, it presents case studies, recommendations and best practices aimed at reducing the risks of re-identification. In this post, we analyse the key aspects of the Guide highlighting main use cases and examples of practical application.
What are synthetic data? Concept and benefits
Synthetic data is artificial data generated using mathematical models specifically designed for artificial intelligence (AI) or machine learning (ML) systems. This data is created by training a model on a source dataset to imitate its characteristics and structure, but without exactly replicating the original records.
High-quality synthetic data retain the statistical properties and patterns of the original data. They therefore allow for analyses that produce results similar to those that would be obtained with real data. However, being artificial, they significantly reduce the risks associated with the exposure of sensitive or personal information.
For more information on this topic, you can read this Monographic report on synthetic data:. What are they and what are they used for? with detailed information on the theoretical foundations, methodologies and practical applications of this technology.
The implementation of synthetic data offers multiple advantages for organisations, for example:
- Privacy protection: allow data analysis while maintaining the confidentiality of personal or commercially sensitive information.
- Regulatory compliance: make it easier to follow data protection regulations while maximising the value of information assets.
- Risk reduction: minimise the chances of data breaches and their consequences.
- Driving innovation: accelerate the development of data-driven solutions without compromising privacy.
- Enhanced collaboration: Enable valuable information to be shared securely across organisations and departments.
Steps to generate synthetic data
To properly implement this technology, the Guide on Synthetic Data Generation recommends following a structured five-step approach:
- Know the data: cClearly understand the purpose of the synthetic data and the characteristics of the source data to be preserved, setting precise targets for the threshold of acceptable risk and expected utility.
- Prepare the data: iidentify key insights to be retained, select relevant attributes, remove or pseudonymise direct identifiers, and standardise formats and structures in a well-documented data dictionary .
- Generate synthetic data: sselect the most appropriate methods according to the use case, assess quality through completeness, fidelity and usability checks, and iteratively adjust the process to achieve the desired balance.
- Assess re-identification risks: aApply attack-based techniques to determine the possibility of inferring information about individuals or their membership of the original set, ensuring that risk levels are acceptable.
- Manage residual risks: iImplement technical, governance and contractual controls to mitigate identified risks, properly documenting the entire process.
Practical applications and success stories
To realise all these benefits, synthetic data can be applied in a variety of scenarios that respond to specific organisational needs. The Guide mentions, for example:
1 Generation of datasets for training AI/ML models: lSynthetic data solves the problem of the scarcity of labelled (i.e. usable) data for training AI models. Where real data are limited, synthetic data can be a cost-effective alternative. In addition, they allow to simulate extraordinary events or to increase the representation of minority groups in training sets. An interesting application to improve the performance and representativeness of all social groups in AI models.
2 Data analysis and collaboration: eThis type of data facilitates the exchange of information for analysis, especially in sectors such as health, where the original data is particularly sensitive. In this sector as in others, they provide stakeholders with a representative sample of actual data without exposing confidential information, allowing them to assess the quality and potential of the data before formal agreements are made.
3 Software testing: sis very useful for system development and software testing because it allows the use of realistic, but not real data in development environments, thus avoiding possible personal data breaches in case of compromise of the development environment..
The practical application of synthetic data is already showing positive results in various sectors:
I. Financial sector: fraud detection. J.P. Morgan has successfully used synthetic data to train fraud detection models, creating datasets with a higher percentage of fraudulent cases that significantly improved the models' ability to identify anomalous behaviour.
II. Technology sector: research on AI bias. Mastercard collaborated with researchers to develop methods to test for bias in AI using synthetic data that maintained the true relationships of the original data, but were private enough to be shared with outside researchers, enabling advances that would not have been possible without this technology.
III. Health sector: safeguarding patient data. Johnson & Johnson implemented AI-generated synthetic data as an alternative to traditional anonymisation techniques to process healthcare data, achieving a significant improvement in the quality of analysis by effectively representing the target population while protecting patients' privacy.
The balance between utility and protection
It is important to note that synthetic data are not inherently risk-free. The similarity to the original data could, in certain circumstances, allow information about individuals or sensitive data to be leaked. It is therefore crucial to strike a balance between data utility and data protection.
This balance can be achieved by implementing good practices during the process of generating synthetic data, incorporating protective measures such as:
- Adequate data preparation: removal of outliers, pseudonymisation of direct identifiers and generalisation of granular data.
- Re-identification risk assessment: analysis of the possibility that synthetic data can be linked to real individuals.
- Implementation of technical controls: adding noise to data, reducing granularity or applying differential privacy techniques.
Synthetic data represents a exceptional opportunity to drive data-driven innovation while respecting privacy and complying with data protection regulations. Their ability to generate statistically representative but artificial information makes them a versatile tool for multiple applications, from AI model training to inter-organisational collaboration and software development.
By properly implementing the best practices and controls described in Guide on synthetic data generation translated by the AEPD, organisations can reap the benefits of synthetic data while minimising the associated risks, positioning themselves at the forefront of responsible digital transformation. The adoption of privacy-enhancing technologies such as synthetic data is not only a defensive measure, but a proactive step towards an organisational culture that values both innovation and data protection, which are critical to success in the digital economy of the future.
Blog
As organisations seek to harness the potential of data to make decisions, innovate and improve their services, a fundamental challenge arises: how can data collection and use be balanced with respect for privacy? PET technologies attempt to address this challenge. In this post, we will explore what they are and how they work.
What are PET technologies?
PET technologies are a set of technical measures that use various approaches to privacy protection. The acronym PET stands for "Privacy Enhancing Technologies" which can be translated as "privacy enhancing technologies".
According to the European Union Agency for Cibersecurity this type of system protects privacy by:
- The deletion or reduction of personal data.
- Avoiding unnecessary and/or unwanted processing of personal data.
All this, without losing the functionality of the information system. In other words, they make it possible to use data that would otherwise remain unexploited, as they limit the risks of disclosure of personal or protected data, in compliance with current legislation.
Relationship between utility and privacy in protected data
To understand the importance of PET technologies, it is necessary to address the relationship between data utility and data privacy. The protection of personal data always entails a loss of usefulness, either because it limits the use of the data or because it involves subjecting them to so many transformations to avoid identification that it perverts the results. The following graph shows how the higher the privacy, the lower the usefulness of the data.

Figure 1. Relationship between utility and privacy in protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
PET techniques allow a more favourable privacy-utility trade-off to be achieved. However, it should be borne in mind that there will always be some limitation of usability when exploiting protected data.
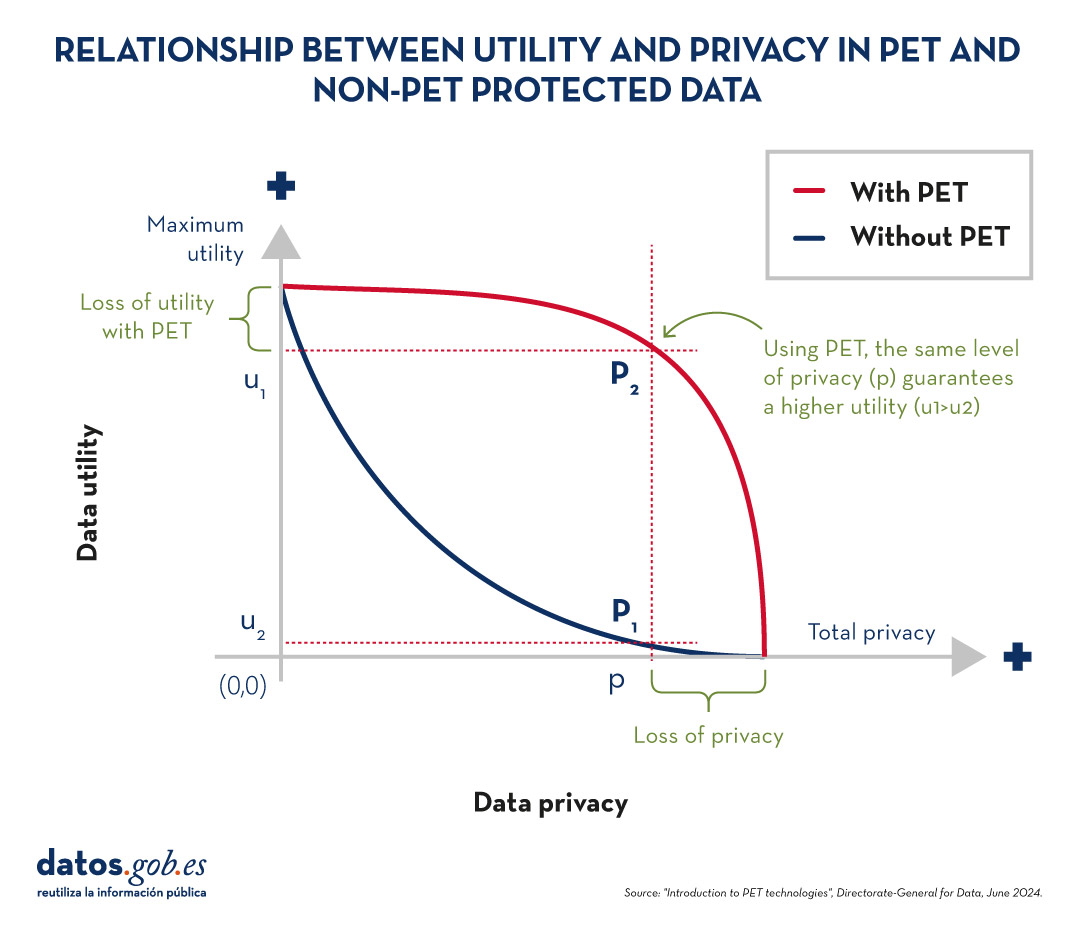
Figure 2. Relationship between utility and privacy in PET and non-PET protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
Most popular PET techniques
In order to increase usability and to be able to exploit protected data while limiting risks, a number of PET techniques need to be applied. The following diagram shows some of the main ones:
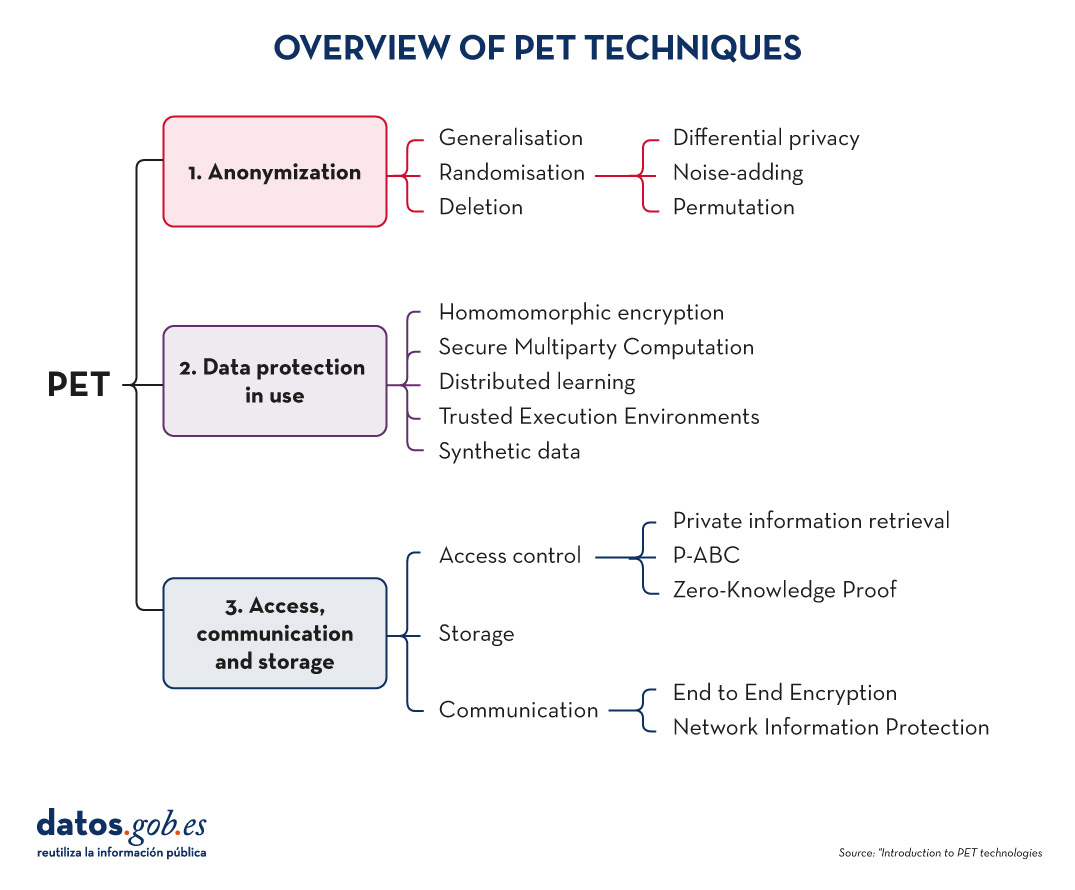
Figure 3. Overview of PET techniques. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
As we will see below, these techniques address different phases of the data lifecycle.
Before data mining: anonymisation
Anonymisation is the transformation of private data sets so that no individual can be identified. Thus, the General Data Protection Regulation (GDPR) no longer applies to them.
It is important to ensure that anonymisation has been done effectively, avoiding risks that allow re-identification through techniques such as linkage (identification of an individual by cross-referencing data), inference (deduction of additional attributes in a dataset), singularisation (identification of individuals from the values of a record) or compounding (cumulative loss of privacy due to repeated application of treatments). For this purpose, it is advisable to combine several techniques, which can be grouped into three main families:
- Randomisation: involves modifying the original data by introducing an element of chance. This is achieved by adding noise or random variations to the data, so that general patterns and trends are preserved, but identification of individuals is made more difficult.
- Generalisation: is the replacement or hiding of specific values in a data set with broader or less precise values. For example, instead of recording the exact age of a person, a range of ages (such as 35-44 years) could be used.
- Deletion: implies the complete removal of certain data from the set, especially those that can identify a person directly. This is the case for names, addresses, identification numbers, etc.
You can learn more about these three general approaches and the various techniques involved in the practical guide "Introduction to data anonymisation: techniques and practical cases". We also recommend reading the article Common misunderstandings in data anonymisation.
Data protection in use
This section deals with techniques that safeguard data privacy during the implementation of operational processing.
-
Homomomorphic encryption: is a cryptographic technique which allows mathematical operations to be performed on encrypted data without first decrypting it. For example, a cipher will be homomorphic if it is true that, if two numbers are encrypted and a sum is performed in their encrypted form, the encrypted result, when decrypted, will be equal to the sum of the original numbers.
- Secure Multiparty Computation or SMPC: is an approach that allows multiple parties to collaborate to perform computations on private data without revealing their information to the other participants. In other words, it allows different entities to perform joint operations and obtain a common result, while maintaining the confidentiality of their individual data.
- Distributed learning: traditionally, machine learning models learn centrally, i.e., they require gathering all training data from multiple sources into a single dataset from which a central server builds the desired model. In el distributed learning, data is not concentrated in one place, but remains in different locations, devices or servers. Instead of moving large amounts of data to a central server for processing, distributed learning allows machine learning models to be trained at each of these locations, integrating and combining the partial results to obtain a final model.
- Trusted Execution Environments or TEE: trusted computing refers to a set of techniques and technologies that allow data to be processed securely within protected and certified hardware environments known as trusted computing environments.
- Synthetic data: is artificially generated data that mimics the characteristics and statistical patterns of real data without representing specific people or situations. They reproduce the relevant properties of real data, such as distribution, correlations and trends, but without information to identify specific individuals or cases. You can learn more about this type of data in the report Synthetic data:. What are they and what are they used for?
3. Access, communication and storage
PET techniques do not only cover data mining. These also include procedures aimed at ensuring access to resources, communication between entities and data storage, while guaranteeing the confidentiality of the participants. Some examples are:
Access control techniques
-
Private information retrieval or PIR: is a cryptographic technique that allows a user to query a database or server without the latter being able to know what information the user is looking for. That is, it ensures that the server does not know the content of the query, thus preserving the user's privacy.
-
Privacy-Attribute Based Credentials or P-ABC: is an authentication technology that allows users to demonstrate certain personal attributes or characteristics (such as age of majority or citizenship) without revealing their identity. Instead of displaying all his personal data, the user presents only those attributes necessary to meet the authentication or authorisation requirements, thus maintaining his privacy.
- Zero-Knowledge Proof or ZKP: is a cryptographic method that allows one party to prove to another that it possesses certain information or knowledge (such as a password) without revealing the content of that knowledge itself. This concept is fundamental in the field of cryptography and information security, as it allows the verification of information without the need to expose sensitive data.
Communication techniques
-
End to End Encryption or E2EE: This technique protects data while it is being transmitted between two or more devices, so that only authorised participants in the communication can access the information. Data is encrypted at the origin and remains encrypted all the way to the recipient. This means that, during the process, no intermediary individual or organisation (such as internet providers, application servers or cloud service providers) can access or decrypt the information. Once they reach their destination, the addressee is able to decrypt them again.
- Network Information Protection (Proxy & Onion Routing): a proxy is an intermediary server between a user's device and the connection destination on the Internet. When someone uses a proxy, their traffic is first directed to the proxy server, which then forwards the requests to the final destination, allowing content filtering or IP address change. The Onion Routing method protects internet traffic over a distributed network of nodes. When a user sends information using Onion Routing, their traffic is encrypted multiple times and sent through multiple nodes, or "layers" (hence the name "onion", meaning "onion").
Storage techniques
- Privacy Preserving Storage (PPS): its objective is to protect the confidentiality of data at rest and to inform data custodians of a possible security breach, using encryption techniques, controlled access, auditing and monitoring, etc.
These are just a few examples of PET technologies, but there are more families and subfamilies. Thanks to them, we have tools that allow us to extract value from data in a secure way, guaranteeing users' privacy. Data that can be of great use in many sectors, such as health, environmental care or the economy.
Documentación
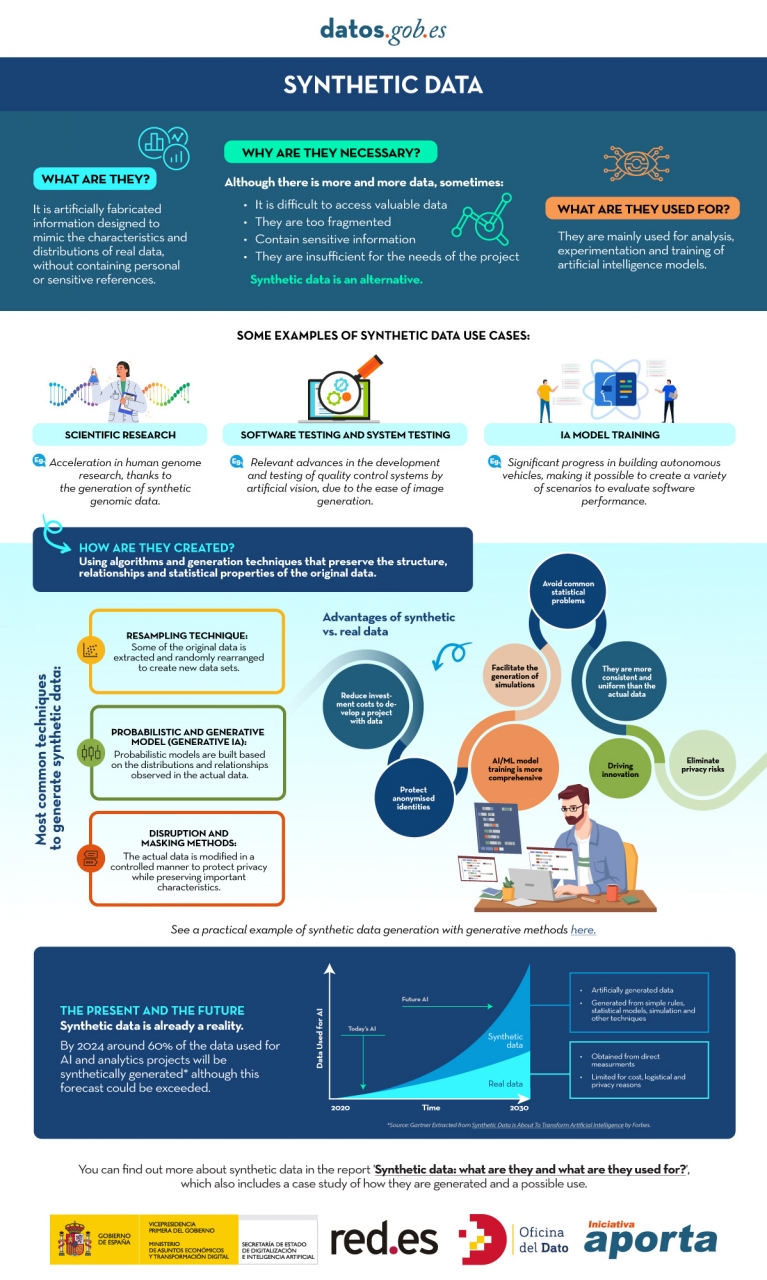
In the era of data, we face the challenge of a scarcity of valuable data for building new digital products and services. Although we live in a time when data is everywhere, we often struggle to access quality data that allows us to understand processes or systems from a data-driven perspective. The lack of availability, fragmentation, security, and privacy are just some of the reasons that hinder access to real data.
However, synthetic data has emerged as a promising solution to this problem. Synthetic data is artificially created information that mimics the characteristics and distributions of real data, without containing personal or sensitive information. This data is generated using algorithms and techniques that preserve the structure and statistical properties of the original data.
Synthetic data is useful in various situations where the availability of real data is limited or privacy needs to be protected. It has applications in scientific research, software and system testing, and training artificial intelligence models. It enables researchers to explore new approaches without accessing sensitive data, developers to test applications without exposing real data, and AI experts to train models without the need to collect all the real-world data, which is sometimes simply impossible to capture within reasonable time and cost.
There are different methods for generating synthetic data, such as resampling, probabilistic and generative modeling, and perturbation and masking methods. Each method has its advantages and challenges, but overall, synthetic data offers a secure and reliable alternative for analysis, experimentation, and AI model training.
It is important to highlight that the use of synthetic data provides a viable solution to overcome limitations in accessing real data and address privacy and security concerns. Synthetic data allows for testing, algorithm training, and application development without exposing confidential information. However, ensuring the quality and fidelity of synthetic data is crucial through rigorous evaluations and comparisons with real data.
In this report, we provide an introductory overview of the discipline of synthetic data, illustrating some valuable use cases for different types of synthetic data that can be generated. Autonomous vehicles, DNA sequencing, and quality controls in production chains are just a few of the cases detailed in this report. Furthermore, we highlight the use of the open-source software SDV (Synthetic Data Vault), developed in the academic environment of MIT, which utilizes machine learning algorithms to create tabular synthetic data that imitates the properties and distributions of real data. We present a practical example in a Google Colab environment to generate synthetic data about fictional customers hosted in a fictional hotel. We follow a workflow that involves preparing real data and metadata, training the synthesizer, and generating synthetic data based on the learned patterns. Additionally, we apply anonymization techniques to protect sensitive data and evaluate the quality of the generated synthetic data.
In summary, synthetic data is a powerful tool in the data era, as it allows us to overcome the scarcity and lack of availability of valuable data. With its ability to mimic real data without compromising privacy, synthetic data has the potential to transform the way we develop AI projects and conduct analysis. As we progress in this new era, synthetic data is likely to play an increasingly important role in generating new digital products and services.
If you want to know more about the content of this report, you can watch the interview with its author.
Below, you can download the full report, the executive summary and a presentation-summary.
Blog
In the era dominated by artificial intelligence that we are just beginning, open data has rightfully become an increasingly valuable asset, not only as a support for transparency but also for the progress of innovation and technological development in general.
The opening of data has brought enormous benefits by providing public access to datasets that promote government transparency initiatives, stimulate scientific research, and foster innovation in various sectors such as health, education, agriculture, and climate change mitigation.
However, as data availability increases, so does concern about privacy, as the exposure and mishandling of personal data can jeopardize individuals' privacy. What tools do we have to strike a balance between open access to information and the protection of personal data to ensure people's privacy in an already digital future?
Anonymization and Pseudonymization
To address these concerns, techniques like anonymization and pseudonymization have been developed, although they are often confused. Anonymization refers to the process of modifying a dataset to eliminate a reasonable probability of identifying an individual within it. It is important to note that, in this case, after processing, the anonymized dataset would no longer fall under the scope of the General Data Protection Regulation (GDPR). This data.gob.es report analyzes three general approaches to data anonymization: randomization, generalization, and pseudonymization.
On the other hand, pseudonymization is the process of replacing identifiable attributes with pseudonyms or fictitious identifiers in a way that data cannot be attributed to the individual without using additional information. Pseudonymization generates two new datasets: one containing pseudonymized information and the other containing additional information that allows the reversal of anonymization. Pseudonymized datasets and the linked additional information fall under the scope of the General Data Protection Regulation (GDPR). Furthermore, this additional information must be separated and subject to technical and organizational measures to ensure that personal data cannot be attributed to an individual.
Consent
Another key aspect of ensuring privacy is the increasingly prevalent "unambiguous" consent of individuals, where people express awareness and agreement on how their data will be treated before it is shared or used. Organizations and entities that collect data need to provide clear and understandable privacy policies, but there is also a growing need for more education on data handling to help people better understand their rights and make informed decisions.
In response to the growing need to properly manage these consents, technological solutions have emerged that seek to simplify and enhance the process for users. These solutions, known as Consent Management Platforms (CMPs), originally emerged in the healthcare sector and allow organizations to collect, store, and track user consents more efficiently and transparently. These tools offer user-friendly and visually appealing interfaces that facilitate understanding of what data is being collected and for what purpose. Importantly, these platforms provide users with the ability to modify or withdraw their consent at any time, giving them greater control over their personal data.
Artificial Intelligence Training
Training artificial intelligence (AI) models is becoming one of the most challenging areas in privacy management due to the numerous dimensions that need to be considered. As AI continues to evolve and integrate more deeply into our daily lives, the need to train models with large amounts of data increases, as evidenced by the rapid advances in generative AI over the past year. However, this practice often faces profound ethical and privacy dilemmas because the most valuable data in some scenarios is not open at all.
Advancements in technologies like federated learning, which allows AI algorithms to be trained through a decentralized architecture composed of multiple devices containing their own local and private data, are part of the solution to this challenge. This way, explicit data exchange is avoided, which is crucial in applications such as healthcare, defense, or pharmacy.
Additionally, techniques like differential privacy are gaining traction. Differential privacy ensures, through the addition of random noise and mathematical functions applied to the original data, that there is no loss of utility in the results obtained from the data analysis to which this technique is applied.
Web3
But if any advancement promises to revolutionize our interaction on the internet, providing greater control and ownership of user data, it would be web3. In this new paradigm, privacy management is inherent in its design. With the integration of technologies like blockchain, smart contracts, and decentralized autonomous organizations (DAOs), web3 seeks to give individuals full control over their identity and all their data, eliminating intermediaries and potentially reducing privacy vulnerabilities.
Unlike current centralized platforms where user data is often "owned" or controlled by private companies, web 3.0 aspires to make each person the owner and manager of their own information. However, this decentralization also presents challenges. Therefore, while this new era of the web unfolds, robust tools and protocols must be developed to ensure both freedom and privacy for users in the digital environment.
Privacy in the era of open data, artificial intelligence, and web3 undoubtedly requires working with delicate balances that are often unstable. Therefore, a new set of technological solutions, resulting from collaboration between governments, companies, and citizens, will be essential to maintain this balance and ensure that, while enjoying the benefits of an increasingly digital world, we can also protect people's fundamental rights.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The content and views reflected in this publication are the sole responsibility of the author.
Blog
Data anonymisation is a complex process and often prone to misunderstandings. In the worst case, these misconceptions lead to data leakage, directly affecting the guarantees that should be offered to users regarding their privacy.
Anonymisation aims at rendering data anonymous, avoiding the re-identification of individuals. However, the mere application of anonymisation techniques does not guarantee the anonymisation of data. The main risk is measured precisely by the probability of re-identification, i.e. the probability that an individual is identified within a dataset.
Most attacks on anonymised datasets try to exploit common weaknesses in the process, usually through the use of complementary data. A well-known example is the case of the dataset released by Netflix in 2007, where, using data obtained from the Internet Movie Database (IMDb), two researchers from the University of Texas were able to identify users and link them to their possible political preferences and other sensitive data.
But these flaws do not only affect private companies; in the mid-1990s, Dr Sweeney was able to re-identify medical records of the Governor of Massachusetts, who had assured that the published dataset was secure. Later, in 2000, the same researcher demonstrated that he could re-identify 87% of the inhabitants of the United States just knowing their postcode, date of birth and gender.
Here are some common examples of misunderstandings that we should avoid if we want to approach an anonymisation process properly.
Anonymising a dataset is not always possible
Data anonymisation is a tailor-made process, designed for each data source and for each study or use case to be developed. Sometimes, the risk of re-identification may be unaffordable or the resulting dataset may not be sufficiently useful. Depending on the specific context and requirements, anonymisation may not be feasible.
However, a common misconception is that it is always feasible to anonymise a dataset, when it really depends on the level of assurance required or the utility needed for the case study.
Automation and reuse of anonymisation processes is Limited
Although it is possible to automate some parts of the process, other steps require manual intervention by an expert. In particular, there are no tools to reliably assess the usefulness of the resulting dataset for a given scenario, or the detection of possible indirect identifiers from external data sources.
Similarly, it is not advisable to reuse anonymisation processes applied on different data sources. The constraints vary from case to case, and it is critical to assess the volume of data available, the existence of complementary data sources and the target audience.
Anonymisation is neither permanent nor absolute.
Due to the possible emergence of new data or the development of new techniques, the risk of re-identification increases over time. The level of anonymisation must be measured on a scale, it is not a binary concept, where anonymisation cannot normally be considered absolute, because it is not possible to assume zero level of risk.
Pseudonymisation is not the same as anonymisation
Specifically, this technique consists of modifying the values of key attributes (such as identifiers) by other values that are not linked to the original record.
The main problem is that there is still a possibility to link the natural person indirectly from additional data, making it a reversible process. In fact, the data controller normally preserves the ability to undo such a process.
Encryption is not an anonymisation technique, but a pseudonymisation technique.
Data encryption is framed within the framework of pseudonymisation, in this case replacing key attributes with encrypted versions. The additional information would be the encryption key, held by the data controller.
The best known example is the dataset released in 2013 by the New York City Taxi and Limousine Commission. Among other data, it contained pick-up and drop-off locations, schedules and especially the encrypted licence number. It was later discovered that it was relatively easy to undo the encryption and identify the drivers.
Conclusions
There are other common misunderstandings about anonymisation, such as the widespread misunderstanding that an anonymised dataset is completely useless, or the lack of interest in re-identification of personal data.
Anonymisation is a technically complex process, requiring the involvement of specialised profesionals and advanced data analysis techniques. A robust anonymisation process assesses the risk of re-identification and defines guidelines for managing it over time.
In return, anonymisation allows more data sources to be shared, more securely and preserving their usefulness in a multitude of scenarios, with particular emphasis on health data analysis and research studies that enable the science advancement to new levels.
If you want to learn more about this subject, we invite you to read the guide Introduction to Data Anonymisation: Techniques and Case Studies, which includes a set of practical examples. The code and data used in the exercise are available on Github.
Content prepared by José Barranquero, expert in Data Science and Quantum Computing.
The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
Data anonymization defines the methodology and set of best practices and techniques that reduce the risk of identifying individuals, the irreversibility of the anonymization process, and the auditing of the exploitation of anonymized data by monitoring who, when, and for what purpose they are used.
This process is essential, both when we talk about open data and general data, to protect people's privacy, guarantee regulatory compliance, and fundamental rights.
The report "Introduction to Data Anonymization: Techniques and Practical Cases," prepared by Jose Barranquero, defines the key concepts of an anonymization process, including terms, methodological principles, types of risks, and existing techniques.
The objective of the report is to provide a sufficient and concise introduction, mainly aimed at data publishers who need to ensure the privacy of their data. It is not intended to be a comprehensive guide but rather a first approach to understand the risks and available techniques, as well as the inherent complexity of any data anonymization process.
What techniques are included in the report?
After an introduction where the most relevant terms and basic anonymization principles are defined, the report focuses on discussing three general approaches to data anonymization, each of which is further integrated by various techniques:
- Randomization: data treatment, eliminating correlation with the individual, through the addition of noise, permutation, or Differential Privacy.
- Generalization: alteration of scales or orders of magnitude through aggregation-based techniques such as K-Anonymity, L-Diversity, or T-Closeness.
- Pseudonymization: replacement of values with encrypted versions or tokens, usually through HASH algorithms, which prevent direct identification of the individual unless combined with additional data, which must be adequately safeguarded.
The document describes each of these techniques, as well as the risks they entail, providing recommendations to avoid them. However, the final decision on which technique or set of techniques is most suitable depends on each particular case.
The report concludes with a set of simple practical examples that demonstrate the application of K-Anonymity and pseudonymization techniques through encryption with key erasure. To simplify the execution of the case, users are provided with the code and data used in the exercise, available on GitHub. To follow the exercise, it is recommended to have minimal knowledge of the Python language.
You can now download the complete report, as well as the executive summary and a summary presentation.
Entrevista
A few months ago, Facebook surprised us all with a name change: it became Meta. This change alludes to the concept of "metaverse" that the brand wants to develop, uniting the real and virtual worlds, connecting people and communities.
Among the initiatives within Meta is Data for Good, which focuses on sharing data while preserving people's privacy. Helene Verbrugghe, Public Policy Manager for Spain and Portugal at Meta spoke to datos.gob.es to tell us more about data sharing and its usefulness for the advancement of the economy and society.
Full interview:
1. What types of data are provided through the Data for Good Initiative?
Meta's Data For Good team offers a range of tools including maps, surveys and data to support our 600 or so partners around the world, ranging from large UN institutions such as UNICEF and the World Health Organization, to local universities in Spain such as the Universitat Poliècnica de Catalunya and the University of Valencia.
To support the international response to COVID-19, data such as those included in our Range of Motion Maps have been used extensively to measure the effectiveness of stay-at-home measures, and in our COVID-19 Trends and Impact Survey to understand issues such as reluctance to vaccinate and inform outreach campaigns. Other tools, such as our high-resolution population density maps, have been used to develop rural electrification plans and five-year water and sanitation investments in places such as Rwanda and Zambia. We also have AI-based poverty maps that have helped extend social protection in Togo and an international social connectivity index that has been useful for understanding cross-border trade and financial flows. Finally, we have recently worked to support groups such as the International Federation of the Red Cross and the International Organization for Migration in their response to the Ukraine crisis, providing aggregated information on the volumes of people leaving the country and arriving in places such as Poland, Germany and the Czech Republic.
Privacy is built into all our products by default; we aggregate and de-identify information from Meta platforms, and we do not share anyone's personal information.
2. What is the value for citizens and businesses? Why is it important for private companies to share their data?
Decision-making, especially in public policy, requires information that is as accurate as possible. As more people connect and share content online, Meta provides a unique window into the world. The reach of Facebook's platform across billions of people worldwide allows us to help fill key data gaps. For example, Meta is uniquely positioned to understand what people need in the first hours of a disaster or in the public conversation around a health crisis - information that is crucial for decision-making but was previously unavailable or too expensive to collect in time.
For example, to support the response to the crisis in Ukraine, we can provide up-to-date information on population changes in neighbouring countries in near real-time, faster than other estimates. We can also collect data at scale by promoting Facebook surveys such as our COVID-19 Trends and Impact Survey, which has been used to better understand how mask-wearing behaviour will affect transmission in 200 countries and territories around the world.
3. The information shared through Data for Good is anonymised, but what is the process like? How is the security and privacy of user data guaranteed?
Data For Good respects the choices of Facebook users. For example, all Data For Good surveys are completely voluntary. For location data used for Data For Good maps, users can choose whether they want to share that information from their location history settings.
We also strive to share how we protect privacy by publishing blogs about our methods and approaches. For example, you can read about our differential privacy approach to protecting mobility data used in the response to COVID-19 here.
4. What other challenges have you encountered in setting up an initiative of this kind and how have you overcome them?
When we started Data For Good, the vast majority of our datasets were only available through a licensing agreement, which was a cumbersome process for some partners and unfeasible for many governments. However, at the onset of the COVID-19 pandemic, we realised that, in order to operate at scale, we would need to make more of our work publicly available, while incorporating stringent measures, such as differential privacy, to ensure security. In recent years, most of our datasets have been made public on platforms such as the Humanitarian Data Exchange, and through this tool and other APIs, our public tools have been queried more than 55 million times in the past year. We are proud of the move towards open source sharing, which has helped us overcome early difficulties in scaling up and meeting the demand for our data from partners around the world.
5. What are Meta's future plans for Data for Good?
Our goal is to continue to help our partners get the most out of our tools, while continuing to evolve and create new ways to help solve real-world problems. In the past year, we have focused on growing our toolkit to respond to issues such as climate change through initiatives such as our Climate Change Opinion Survey, which will be expanded this year; as well as evolving our knowledge of cross-border population flows, which is proving critical in supporting the response to the crisis in Ukraine.
Blog
We are in a historical moment, where data has become a key asset for almost any process in our daily lives. There are more and more ways to collect data and more capacity to process and share it, where new technologies such as IoT, Blockchain, Artificial Intelligence, Big Data and Linked Data play a crucial role.
Both when we talk about open data, and data in general, it is critical to be able to guarantee the privacy of users and the protection of their personal data, understood as Fundamental rights. An aspect that sometimes does not receive special attention despite the rigorous existing regulations, such as the GDPR.
What is anonymization and what techniques are there?
The anonymization of data defines the methodology and the set of good practices and techniques that reduce the risk of identifying persons, the irreversibility of the anonymization process and the audit of the exploitation of the anonymized data, monitoring who, when and what they are used for. In other words, it covers both the objective of anonymization and that of mitigating the risk of re-identification, the latter being a key aspect.
To understand it well, it is necessary to speak of the confidentiality chain, a term that includes the analysis of specific risks for the purpose of the treatment to be carried out. The breaking of this chain implies the possibility of re-identification, that is, of identifying the specific people to whom it belongsns
Anonymization techniques are focused on identifying and obfuscating microdata, indirect identifiers and other sensitive data. When we talk about obfuscating, we refer to changing or altering sensitive data or data that identifies a person (personally identifiable information or PII, in English), in order to protect confidential information. In this case, lMicrodata are unique data for each individual, which can allow direct identification (ID, medical record code, full name, etc.). Indirect identification data can be crossed with the same or different sources to identify an individual (sociodemographic, browser configuration, etc.). It should be noted that sensitive data are those referred to in article 9 of the RGPD (especially financial and medical data).
In general, they can be considered various anonymization techniques, without European legislation contains any prescriptive rules, there are 4 general approaches:
- Randomization: alteration of the data, eliminating the correlation with the individual, by adding noise, permutation, or differential privacy (that is, collecting data from global users without knowing who each data corresponds to).
- Generalization: alteration of scales or orders of magnitude through techniques such as Aggregation / Anonymity-K or Diversity-l/Proximity-t.
- Encryption: obfuscation via HASH algorithms, with key erasure, or direct processing of encrypted data through homomorphic techniques. Both techniques can be complemented with time stamps or electronic signature.
- Pseudonymisation: replacement of attributes by encrypted versions or tokens that prevents direct identification of the individual. The set continues to be considered as personal data, because re-identification is possible through guarded keys. prevents direct identification of the individual. The set continues to be considered as personal data, because re-identification is possible through guarded keys.
Basic principles of anonymization
Like other data protection processes, anonymization must be governed by the concept of privacy by design and by default (Art. 25 of the RGPD), taking into account 7 principles:
- Proactive: the design must be considered from the initial stages of conceptualization, identifying microdata, indirect identification data and sensitive data, establishing sensitivity scales that are informed to all those involved in the anonymization process.
- Privacy by default: it is necessary to establish the degree of detail or granularity of the anonymized data in order to preserve confidentiality, eliminating non-essential variables for the study to be carried out, taking into account risk and benefit factors.
- Objective: Given the impossibility of absolute anonymization, it is critical to assess the level of risk of re-identification assumed and to establish adequate contingency policies.
- Functional: To guarantee the usefulness of the anonymized data set, it is necessary to clearly define the purpose of the study and inform users of the distortion processes used so that they are taken into account during their exploitation.
- Integral: the anonymization process goes beyond the generation of the data set, being applicable also during the study of these, through confidentiality and limited use contracts, validated through the relevant audits throughout the life cycle.
- Informative: this is a key principle, being necessary that all the participants in the life cycle are properly trained and informed regarding their responsibility and the associated risks.
- Atomic It is recommended, as far as possible, that the work team be defined with independent people for each function within the process.
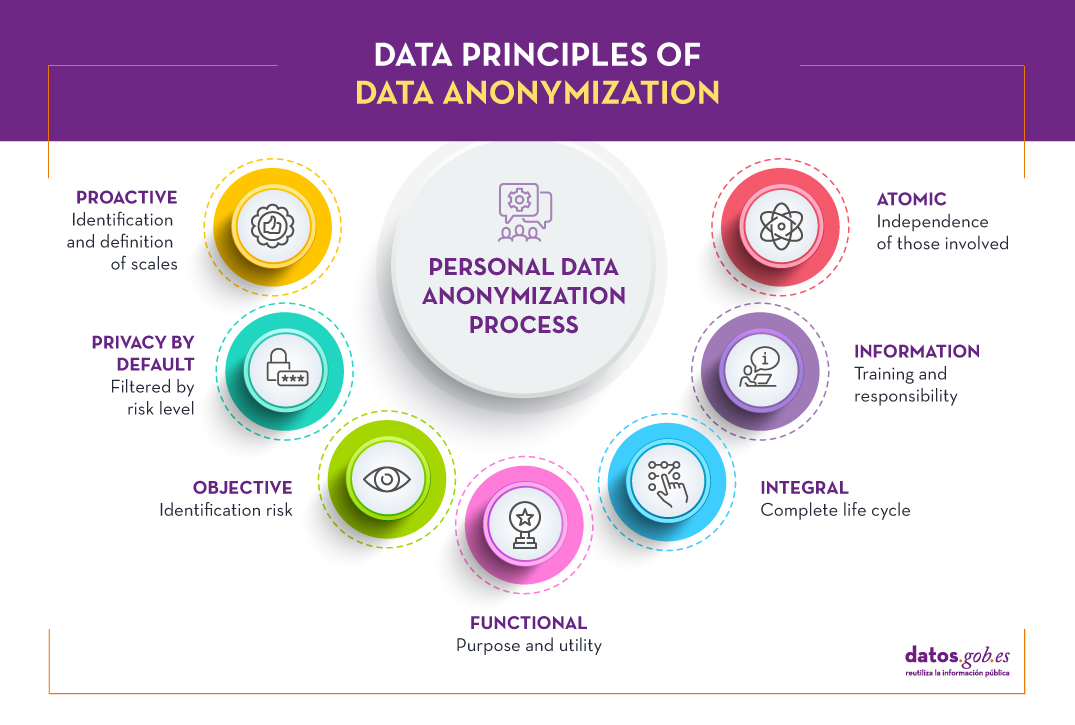
In an anonymization process, an essential task is to define a scheme based on the three levels of identification of people: microdata, indirect identifiers and sensitive data (principle of proactivity), where a quantitative value is assigned to each of the variables. This scale must be known to all the personnel involved (information principle) and is critical for the Impact Assessment on the Protection of Personal Data (EIPD).
What are the main risks and challenges associated with anonymization?
Given the advancement of technology, it is especially complex to be able to guarantee absolute anonymization, so the risk of re-identification is approached as a residual risk, assumed and managed, and not as a breach of regulations. That is, it is governed by the principle of objectivity, being necessary to establish contingency policies. These policies must be considered in terms of cost versus benefit, making the effort required for re-identification unaffordable or reasonably impossible.
It should be noted that the risk of re-identification increases with the passage of time, due to the possible appearance of new data or the development of new techniques, such as future advances in quantum computing, which could lead to the encryption key break.
Specifically, three specific risk vectors associated with re-identification are established, defined in the Opinion 05/2014 on anonymization techniques:
- Singling out: risk of extracting attributes that allow an individual to be identified.
- Linkability: risk of linking at least two attributes to the same individual or group, in one or more data sets.
- Inference: risk of deducing the value of a critical attribute from other attributes.
The following table, proposed
| Is there a risk of singularization? | Is there a risk of linkability? | Is there a risk of inference? | |
|---|---|---|---|
| Pseudonymisation | Yes | Yes | Yes |
| Adding noise | Yes | Maybe not | Maybe not |
| Substitution | Yes | Yes | Maybe not |
| Aggregation and anonymity K | No | Yes | Yes |
| Diversity l | No | Yes | Maybe not |
| Differential privacy | Maybe not | Maybe not | Maybe not |
| Hash/Tokens | Yes | Yes | Maybe not |
Another important factor is the quality of the resulting data for a specific purpose, also called utility, since sometimes it is necessary to sacrifice part of the information (privacy principle by default). This entails an inherent risk for which it is necessary to identify and propose mitigation measures to avoid the loss of informative potential of the anonymized data set, focused on a specific use case (principle of functionality).
Ultimately, the challenge lies in ensuring that the analysis of the anonymized data does not differ significantly from the same analysis performed on the original data set, thus minimizing the risk of re-identification by combining various anonymization techniques and monitoring of everything. the process; from anonymization to exploitation for a specific purpose.
References and regulations
- REGULATION (EU) 2016/679 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of April 27, 2016
- DIRECTIVE (EU) 2019/1024 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of 20 June 2019
- Organic Law 3/2018, of December 5, on Protection of Personal Data and guarantee of digital rights
- Guidelines 03/2020 on the processing of data concerning health for the purpose of scientific research in the context of the COVID-19 outbreak - European Data Protection Board
Content written by Jose Barranquero, expert in data science and quantum computing.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Young people have consolidated in recent years as the most connected demographic group in the world and are now also the most relevant actors in the new digital economy. One in three internet users across the planet is a child. Furthermore, this trend has been accelerating even more in the current context of health emergencies, in which young people have exponentially increased the time they spend online while being much more active and sharing much more information on social networks. A clear example of the consequences of this incremental use is the need of online teaching, where new challenges are posed in terms of student privacy, while we already know of some initial cases related to problems in the management of fairly worrying data.
On the other hand, young people are more concerned about their privacy than we might initially think. However, they recognise that they have many problems in understanding how and for what purpose the various online services and tools collect and reuse their personal information.
For all these reasons, although in general legislation related to online privacy is still developing throughout the world, there are already several governments that now recognise that children - and minors in general - require special treatment with regard to the privacy of their data as a particularly vulnerable group in the digital context.
Therefore, minors already have a degree of special protection in some of the legislative frameworks of reference in terms of privacy at a global level, as the European (GDPR) or US (COPPA) regulations. For example, both set limits on the general age of legal consent for the processing of personal data (16 years in the GDPR and 13 years in COPPA), as well as providing additional protection measures such as requiring parental consent, limiting the scope of use of such data or using simpler language in the information provided about privacy.
However, the degree of protection we offer children and young people in the online world is not yet comparable to the protection they have in the offline world, and we must therefore continue to make progress in creating safe online spaces that have strong privacy measures and specific features so that minors can feel safe and be truly protected - in addition to continuing to educate both young people and their guardians in good practice in terms of managing personal data.
The Responsible Management of Children's Data (RD4C) initiative, promoted by UNICEF and The GovLab, was born with this objective in mind. The aim of this initiative is to raise awareness of the need to pay special attention to data activities involving children, helping us to better understand the potential risks and improve practices around data collection and analysis in order to mitigate them. To this end, they propose a number of principles that we should follow in the handling of such data:

- Participatory processes: Involving and informing people and groups affected by the use of data for and about children
- Responsibility and accountability: Establishing institutional processes, roles and responsibilities for data processing.
- People-centred: Prioritising the needs and expectations of children and young people, their guardians and their social circles.
- Damage prevention: Assessing potential risks in advance during the stages of the data lifecycle, including collection, storage, preparation, sharing, analysis and use.
- Proportional: Adjusting the extent of data collection and the length of data retention to the purpose initially intended.
- Protection of children's rights: Recognizing the different rights and requirements needed to help children develop to their full potential.
- Purpose-driven: specifying what the data is needed for and how its use can potentially benefit children's lives.
Some governments have also begun to go a step further and favour a higher degree of protection for minors by developing their own guidelines aimed at improving the design of online services. A good example is the code of conduct developed by the UK which - similarly to the R4DC - also calls for the best interests of children themselves, but also introduces a number of service design patterns that include recommendations such as the inclusion of parental controls, limitations on the collection of personal data or restrictions on the use of misleading design patterns that encourage data sharing. Another good example is the technical note published by the Spanish Data Protection Agency (AEPD) for the protection of children on the Internet, which provides detailed recommendations to facilitate parental control in access to online services and applications.
At datos.gob.es, we also want to contribute to the responsible use of data affecting young people, and we also believe in participatory processes. That is why we have included data security and/or privacy issues in the field of education as one of the challenges to be resolved in the next Aporta Challenge. We hope that you will be encouraged to participate and send us all your ideas in this and other areas related to digital education before 18 November.
Content prepared by Carlos Iglesias, Open data Researcher and consultan, World Wide Web Foundation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.