Blog
Durante años, el debate sobre la reutilización de datos se ha centrado principalmente en los procesos de publicación, es decir, en cómo exponer más y mejores conjuntos de datos desde las entidades proveedoras. En cambio, ha quedado con frecuencia en un segundo plano el apoyo a quienes deben localizarlos, comprenderlos, combinarlos y convertirlos en productos o servicios de valor añadido.
Con la irrupción de la inteligencia artificial (IA), esta mirada empezó a cambiar. La cuestión ya no era solo cuántos datos existen, sino cómo transformar datos dispersos, heterogéneos y sujetos a reglas distintas en materia prima útil para innovar (usando, entre otras, técnicas de analítica avanzada e IA). En ese contexto, la Unión Europea ha empezado a perfilar los data labs como una pieza clave de su Estrategia para una Unión de Datos: una iniciativa orientada a aumentar la disponibilidad de datos de calidad para la IA, simplificar las reglas aplicables y conectar mejor las fuentes de datos existentes (espacios de datos, portales de datos abiertos, portales estadísticos, etc.) con los ecosistemas de innovación.
Data labs, el nuevo concepto que aglutina servicios para la reutilización de datos
¿Y qué son exactamente los data labs? La Unión Europea los describe como centros operativos especializados que darán a empresas e investigadores acceso a conjuntos de datos diversos y ofrecerán servicios relacionados con la aplicación de técnicas de IA sobre esos datos.
Esto supone un cambio de enfoque relevante porque el foco, además de ayudar al proveedor para que publique los datos, está en acompañar al consumidor para que pueda encontrar, preparar y reutilizar los datos con mayor facilidad. En este sentido, uno de los aportes más interesantes de los data labs es que desplazan el foco desde la simple acumulación de datos hacia su calidad, preparación y reutilización efectiva.
En los proyectos de ciencia de datos e IA, desde hace años se repite una versión de la regla de Pareto que establece que alrededor del 80% del tiempo se dedica a localizar, limpiar, integrar, documentar y preparar los datos, mientras que solo el 20% restante se reserva para analizarlos o entrenar modelos. No es una ley matemática, pero sí una realidad que estudios recientes siguen situando en ese mismo orden de magnitud.
Y, precisamente, ahí es donde los data labs pueden marcar la diferencia, dándole la vuelta a estos porcentajes, ya que ayudan a descubrir fuentes relevantes, mejorar metadatos, armonizar formatos, resolver problemas de acceso y avanzar en tareas de curación que convierten el dato bruto en un activo realmente utilizable. En otras palabras, no se trata solo de tener más datos, sino de tener mejores datos.
Alcance y valor añadido de los data labs
La UE sitúa a los data labs en un contexto muy concreto: aumentar el acceso a datos de calidad para IA, simplificar el marco regulatorio y reforzar la posición europea en la economía global del dato. Visto desde la perspectiva de la reutilización, esto se traduce en tres necesidades muy reconocibles: encontrar y acceder al dato adecuado, operar con seguridad jurídica y confianza, y preparar los datos con la calidad suficiente para que generen impacto. Específicamente, el alcance de los data labs abarca seis ámbitos:
- Infraestructura y herramientas técnicas: aportan entornos seguros y herramientas para gestionar datos (desde anonimización hasta generación de datos sintéticos).
- Data pooling: ponen en común datos heterogéneos de diversas fuentes, combinándolos conforme a las reglas aplicables.
- Curación y etiquetado: ayudan a enriquecer conjuntos de datos para que sean más representativos y útiles para la IA.
- Guía regulatoria y formación: proporcionan orientación práctica sobre cómo cumplir la normativa europea aplicable a los datos y la IA.
- Conexión entre espacios de datos y ecosistemas de IA: actúan como puente entre los espacios europeos de datos y quienes desarrollan soluciones de IA.
- Facilitación del acceso a datos: ayudan a localizar conjuntos de datos relevantes y a superar barreras técnicas, legales o administrativas para utilizarlos.
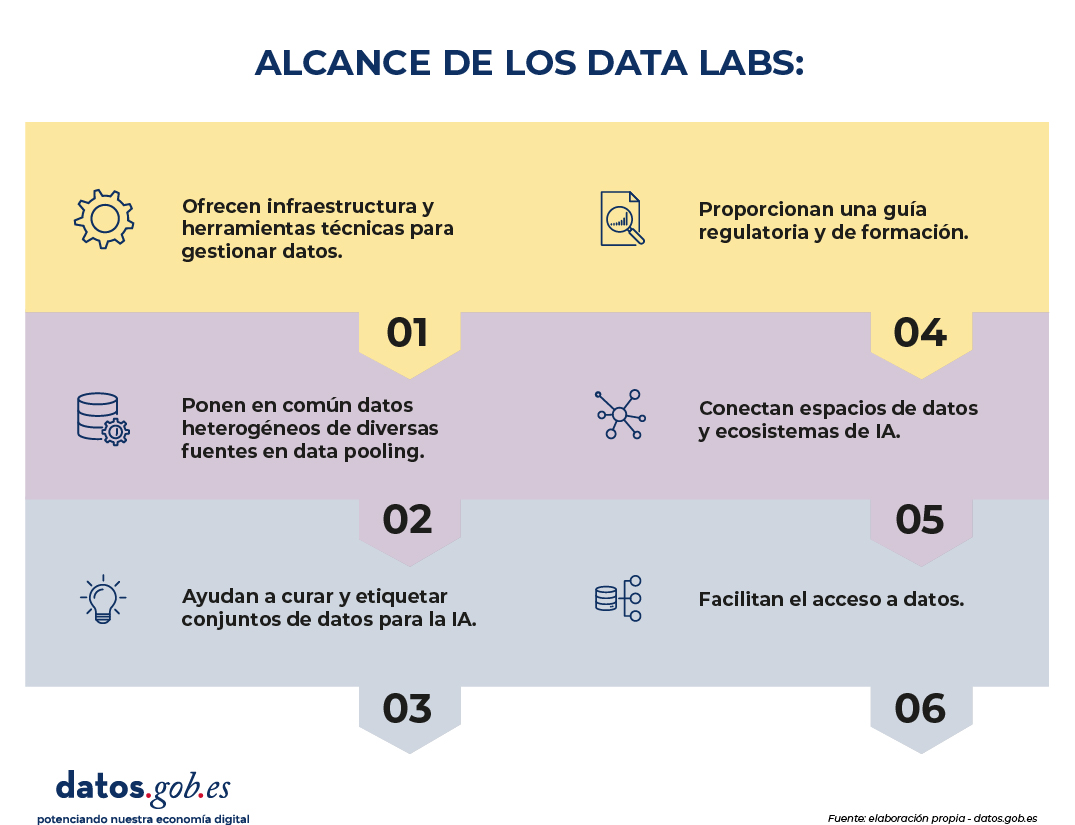
Figura 1. Alcance de los datalabs. Fuente: elaboración propia - datos.gob.es
Por todo ello, el valor de los data labs no está en “dar acceso” a los datos (de hecho, esto ya lo hacen los espacios de datos o los portales de datos abiertos), sino en hacer operativo el dato. Los data labs podrán ofrecer servicios como limpieza y enriquecimiento de conjuntos de datos, normalización, anonimización, generación de datos sintéticos y servicios de data pooling compatibles con la normativa de competencia. Por lo tanto, ofrecen menos fricción para pasar del dato bruto al dato listo para entrenar, probar o desplegar soluciones de IA.
Relación de data labs con datos abiertos y con espacios de datos
En el marco europeo, los datos abiertos siguen siendo la capa más accesible del ecosistema, especialmente cuando proceden del sector público. Destaca el concepto de datos de alto valor (high-value datasets o HVD) porque la propia normativa europea subraya que estos conjuntos son fuentes clave para el desarrollo de la IA. De hecho, la Estrategia para una Unión de Datos prevé ampliar durante 2026 la lista de datos de alto valor a ámbitos como los datos legales, judiciales y administrativos, así como, hacer disponibles 30 millones de objetos culturales digitalizados para entrenamiento de IA a través de Europeana. Por ello, los data labs añaden una capa adicional a los portales de datos abiertos, encargada de la búsqueda y combinación de datos (entre conjuntos de datos abiertos de diferentes fuentes, pero también entre conjuntos de datos abiertos y datos procedentes de otras fuentes), así como de su preparación.
Los data labs no sustituyen a las iniciativas de datos abiertos ni a las de espacios de datos, sino que las complementan.
Por otra parte, la UE define explícitamente que los data labs deben actuar como el puente entre los espacios de datos y el ecosistema de IA. Podría decirse, de manera simplificada, que los espacios de datos ponen orden en la disponibilidad del dato mientras que los data labs convierten esa disponibilidad en un recurso utilizable para innovar mediante el uso de IA. Es decir, los espacios de datos disponen de infraestructura y una gobernanza adecuada para compartir y reutilizar datos y los data labs convierten esa disponibilidad de datos en uso efectivo, ayudando a localizar, reunir, organizar, curar, etiquetar y preparar esos datos para casos de uso de IA y analítica avanzada.
Uniendo ambos escenarios (datos abiertos y espacios de datos), los data labs podrían servir para detectar qué nuevos conjuntos de datos del sector público merecería abrir o reforzar a partir de los conjuntos de datos disponibles en un espacio de datos.
Data labs y factorías de IA: el binomio perfecto
Las factorías de IA se conciben como ecosistemas que reúnen capacidad de cómputo, datos y talento para desarrollar modelos de IA y aplicaciones avanzadas. Los data labs se desplegarán precisamente en ese entorno, como una especie de capa de servicios de datos para esas factorías. La complementariedad es clara: una factoría de IA sin datos de calidad corre el riesgo de quedarse en capacidad de cómputo infrautilizada, mientras que un data lab sin acceso a infraestructuras de IA tiene más difícil cerrar el ciclo desde el dato hasta el modelo.
¿Qué no es un data lab?
Conviene aclarar, además, una posible confusión en cuanto al término data lab. No estamos hablando aquí de las “salas seguras” o entornos controlados para acceso a datos protegidos con fines de investigación, como ES_Datalab, que incluye datos del INE o del Banco de España. Esos entornos están pensados para el acceso controlado a microdatos y otra información sensible con fines de investigación, preservando confidencialidad y privacidad.
Los data labs europeos tienen un alcance distinto y más amplio, ya que son un instrumento para conectar datos públicos y privados (incluyendo espacios de datos) e innovación en IA mediante servicios de acceso, preparación, curación y apoyo regulatorio. Pueden incorporar técnicas de protección, pero no equivalen a una sala segura.
En conclusión, la apuesta europea de los data labs consiste en pasar de hablar solo de publicación de datos a hablar de activación del dato para la innovación a partir de su reutilización. Esto es muy útil para diferentes perfiles:
- Para los perfiles técnicos, los data labs prometen más datos preparados y mejor documentados.
- Para las empresas del sector infomediario, abren oportunidades en servicios de descubrimiento, calidad, metadatos, etiquetado, integración o cumplimiento de normativa.
- Para la administración pública, pueden convertirse en un mecanismo muy útil para orientar qué publicar en abierto, con qué calidad y para qué usos.
- Para la comunidad investigadora, ofrecen la posibilidad de acercar mejor el acceso al dato, la gobernanza y la infraestructura de computación.
Por lo tanto, los data labs no compiten con los datos abiertos ni con los espacios de datos, sencillamente ayudan a que ambos generen más valor en la práctica.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial está cambiando a gran velocidad la forma en que tomamos decisiones personales y profesionales, el modo en que gestionamos los servicios que prestan nuestras empresas y los criterios con los que procesamos la información en nuestro día a día. En la actualidad, ya convivimos con sistemas capaces de ayudar a priorizar listas de espera o analizar pruebas diagnósticas en el ámbito sanitario, detectar riesgo de abandono escolar o personalizar itinerarios de aprendizaje en educación y evaluar operaciones sospechosas en banca, además de resumir expedientes, clasificar documentos, recomendar actuaciones y generar borradores o incluso interactuar con nosotros en lenguaje natural en un servicio de atención al cliente. En muchos casos, sin que realmente seamos conscientes de ello, ya que estos procesos residen en el interior de las compañías y administraciones públicas con las que tenemos interacciones.
Quizá por ello, a medida que los sistemas de IA adquieren mayor autonomía y pasamos de modelos de lenguaje que responden a nuestras preguntas hacia agentes autónomos capaces de resolver nuestras tareas de forma completa, surgen dudas y preguntas acerca del papel que deben desempeñar los humanos en estos nuevos procesos y sistemas; y más importante aún, sobre la responsabilidad de las decisiones que se toman.
Ese salto ha hecho que la conversación ya no gire solo en torno a si es conveniente usar IA en un determinado proceso, sino sobre cómo se reparte la responsabilidad entre las “máquinas” y las personas. No es casual que el primer principio de la Guía Ética para una IA confiable de la Comisión Europea sea el de autonomía y supervisión humana (human agency and oversight). Esto es, que la IA debe estar al servicio de las personas reforzando su capacidad de decisión y por supuesto siempre contando con mecanismos efectivos de supervisión.
Entre la seguridad del control total y la eficiencia de la autonomía
En este contexto cobran sentido enfoques como human-in-the-loop (HITL), human-on-the-loop (HOTL) y human-in-command (HIC), que describen distintas maneras de articular esa intervención humana según el contexto y el nivel de riesgo de cada sistema. No son por tanto etiquetas equivalentes, sino que describen las distintas maneras en que las personas pueden intervenir en la supervisión y la toma de decisiones asociadas a los sistemas de inteligencia artificial.
- En el caso de Human in the Loop (HITL), el ser humano interviene directamente en el ciclo de decisión del sistema. Es decir, la inteligencia artificial sugiere, pero es un agente humano quien valida o corrige antes de que la acción se ejecute. Podría ser el caso, por ejemplo, de un sistema que analizase solicitudes de prestaciones sociales. Diseñaríamos un proceso en el que la IA extraería datos de documentos, los cruzaría con información de otros sistemas para validarlos y prepararía un borrador de resolución. Sin embargo, en la parte final del proceso sería un empleado quien decidiría y firmaría después de validar la propuesta realizada por el sistema automatizado. Sería, por tanto, el modelo más conservador y, también, el más utilizado cuando las decisiones pueden tener consecuencias significativas sobre las personas o sus derechos.
- En el modelo Human on the Loop (HOTL), el sistema puede actuar de forma autónoma, pero un agente humano monitoriza el proceso en tiempo real y tiene la capacidad de intervenir si detecta un problema. A diferencia del enfoque HITL, una persona no participa necesariamente en cada decisión individual, sino que mantiene una función de vigilancia sobre el conjunto de la operación. Es el modelo que se utiliza, por ejemplo, en sistemas de detección de fraude o en el filtrado automatizado de contenidos, donde la IA analiza grandes volúmenes de información y genera alertas o ejecuta acciones preliminares de forma continua. Se trata de encontrar un equilibrio entre eficiencia y control, y es especialmente adecuado para entornos de alto volumen de operaciones donde la intervención humana en cada caso individual no sería viable.
- En el enfoque Human in Command (HIC), la intervención humana no se sitúa necesariamente en cada decisión individual ni en la supervisión continua del sistema, sino en un plano superior de dirección o gobernanza. Son las personas quienes definen para qué puede utilizarse la IA y definen límites, criterios de calidad, el nivel de riesgo aceptable y en qué circunstancias debe revisarse su funcionamiento. Sería el caso, por ejemplo, de una administración que utilizase IA para priorizar inspecciones o para clasificar incidencias: el sistema podría operar con bastante autonomía, pero serían los responsables quienes determinarían su propósito y validarían sus reglas de funcionamiento. Además, auditarían los resultados obtenidos y gestionarían las incidencias producidas, e incluso podrían llegar a suspender el sistema en caso de detectar efectos no deseados. Más que intervenir caso por caso, aquí la función humana consiste en asegurar que la IA permanezca alineada con los objetivos del servicio y el marco normativo.
Frente a estos modelos de gobernanza de la supervisión de los sistemas de IA, también suele mencionarse el enfoque Human out of the Loop (HOOTL), que es aquel en el que el sistema funciona sin intervención humana directa. Se trata del grado más alto de automatización y, por tanto, del escenario que mayores precauciones exige, ya que el margen de corrección humana durante la ejecución es muy reducido o incluso inexistente, como ocurre en algunos sistemas de gestión inteligente de infraestructuras. Por ejemplo, un sistema de IA puede regular automáticamente la climatización de edificios a partir de sensores de temperatura, ocupación, consumo energético, etc, sin que una persona tenga que validar cada decisión. Este modelo puede resultar razonable en tareas muy acotadas y con bajo riesgo de error, como pueden ser procesos de automatización sin efectos relevantes sobre derechos o intereses de las personas. Sin embargo, su aplicación resulta mucho más problemática cuando la IA influye en decisiones sensibles. Por eso, más que como una opción generalizable, el modelo HOOTL debe entenderse como una posibilidad limitada a contextos muy específicos en los que además existan salvaguardas robustas.
El siguiente visual resume estos cuatro tipos de enfoques:
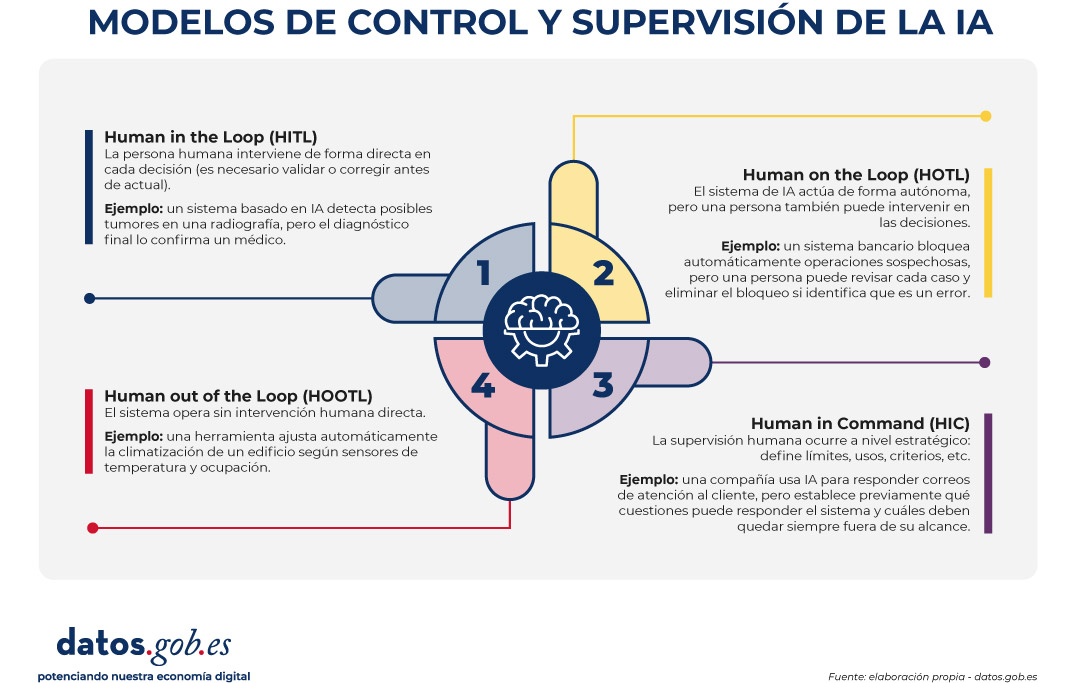
Figura 1. cuatro enfoques de intervención humana en la IA. Fuente: elaboración propia - datos.gob.es.
Por qué importa la elección del enfoque de supervisión humana
La paradoja central de la supervisión humana en los sistemas de IA es que, a medida que estos sistemas mejoran, en parte gracias a esta supervisión, la presión para reducir la intervención humana aumenta. Si un modelo tiene una precisión del 99%, ¿tiene sentido supervisar el sistema o es mejor aceptar los errores? Esta pregunta es legítima desde el punto de vista de la eficiencia, pero encierra sin embargo un riesgo que los especialistas en IA responsable han denominado el problema del "sesgo de automatización". Este sesgo es la tendencia humana a confiar en exceso en sistemas que, en general, funcionan bien, pero que pueden esconder errores difíciles de detectar o, en el peor de los casos, manipulaciones interesadas. Por otra parte, un 1% puede parecer mínimo, pero el porcentaje podría esconder un número muy elevado de errores o pocos errores con un coste inaceptable.
Por ello, la elección entre los diferentes modelos de supervisión no es únicamente técnica, ni está basada en la búsqueda de la eficiencia, ya que tiene implicaciones éticas y legales, y no solo operativas. En particular, el Reglamento Europeo de Inteligencia Artificial (AI Act) dedica su artículo 14 a los requisitos de supervisión humana para los sistemas de IA de alto riesgo, estableciendo que estos deben diseñarse de manera que puedan ser "vigilados de manera efectiva por personas físicas durante el período que estén en uso". Esto convierte el despliegue de un modelo de supervisión en una obligación normativa para numerosas aplicaciones.
La Guía española de supervisión humana, elaborada en el marco del sandbox regulatorio de IA, lo explica detalladamente, desarrollando las cinco grandes exigencias del artículo 14 del Reglamento de IA: vigilancia efectiva durante el uso, mecanismos para minimizar riesgos, fijación de responsabilidades, transparencia y trazabilidad, y garantías adicionales en ciertos sistemas. La Guía también subraya que “la responsabilidad final de las acciones realizadas por un sistema de IA es competencia de las personas de la entidad proveedora y usuaria responsables del mismo” por lo que para que la “vigilancia sea efectiva, las personas deben tener el control sobre el sistema y poder gestionar los riesgos que pueden derivarse de su uso”. Dicho de otro modo, poner a una persona “en el circuito” no basta por sí solo, ya que, si esa persona no comprende el sistema o no tiene autoridad para intervenir, la supervisión será meramente formal, pero no efectiva.
La supervisión humana en el entrenamiento de los sistemas de IA
Hay otra dimensión de la supervisión humana que tiene relevancia en los sistemas de inteligencia artificial y es el papel de esta supervisión en los procesos de entrenamiento de dichos sistemas. Y es que, antes de que un sistema entre en producción, los humanos ya han intervenido en múltiples decisiones que condicionan su comportamiento posterior:
- Por una parte, tenemos la intervención humana en el ciclo de vida de los datos de entrenamiento. La anotación humana integra la inteligencia humana directamente en el ciclo de desarrollo de la IA. Las personas deciden qué datos se recogen, cuáles se descartan, cómo se estructuran y qué variables se consideran relevantes. También intervienen en tareas de depuración, anonimización, control de calidad o revisión de sesgos de los conjuntos de datos. Todo ello tiene una gran influencia porque un modelo no aprende sin más de grandes volúmenes de información, sino de la forma concreta en que esos conjuntos de datos han sido preparados.
- Y, por otra parte, tenemos la intervención humana en la validación del comportamiento los modelos de IA con técnicas como el aprendizaje por refuerzo con retroalimentación humana (RLHF). En esta técnica, anotadores humanos evalúan pares de respuestas generadas por el modelo, indicando cuál es mejor. Con esas evaluaciones se entrena un modelo de recompensa, que, a su vez, guía el ajuste fino del modelo principal. Se trata, en esencia, de una supervisión Human in the Loop en el proceso de entrenamiento: los humanos no solo validan los resultados finales, sino que moldean activamente los valores del sistema. Por tanto, la diversidad de los anotadores, en términos culturales o sociales, tiene impacto directo en el comportamiento del modelo resultante.
En ambos procesos la intervención humana es esencial tanto para garantizar la calidad de los datos de entrenamiento como para asegurar el alineamiento de los modelos con los valores que se desean.
Casos de uso en el sector público
Uno de los primeros casos documentados en el sector público es el de la oficina estadística de Australia (ABS), presentado ya en 2020 en el artículo Human-in-the-Loop AI in Government: A Case Study. El trabajo explica cómo una agencia pública puede aplicar un enfoque Human in the Loop para automatizar parte de la producción de estadísticas oficiales, utilizando como ejemplo la Encuesta de presupuestos familiares. El objetivo no era eliminar la intervención humana, sino ahorrar tiempo y recursos en tareas intensivas en trabajo manual, de manera que los profesionales pudieran concentrarse en actividades de mayor valor añadido. Precisamente ahí reside el interés del caso, ya que demuestra que la IA puede incorporarse a procesos muy exigentes en calidad gracias a la validación humana.
Más reciente es la iniciativa impulsada por el London Office of Technology and Innovation (LOTI), que en marzo de 2025 lanzó un proyecto de investigación específicamente orientado a analizar cuál debe ser el papel de los funcionarios como supervisores de sistemas de IA en los servicios públicos locales. El punto de partida es la constatación de que muchos ayuntamientos ya designan a una persona para revisar o aprobar las salidas de los sistemas automatizados. Sin embargo, esto no significa que exista una supervisión verdaderamente efectiva y, por ello, se busca generar recomendaciones prácticas para que ayuntamientos y otras organizaciones públicas puedan diseñar adecuadamente estos roles de supervisión. El valor de esta iniciativa está en que desplaza el debate: desde la necesidad de que exista la presencia de un humano hacia la definición de las condiciones que hacen esa intervención realmente efectiva.
En definitiva, hablar de Human in the Loop, Human on the Loop o Human in Command es abordar uno de los elementos centrales de la adopción responsable de la inteligencia artificial. Por eso, más que plantear una discusión entre automatización y control humano, el verdadero reto consiste en encontrar el equilibrio adecuado entre ambos. La IA puede aportar eficiencia, pero solo genera verdadero valor si se integra en procesos con mecanismos efectivos de supervisión. En ese sentido, el futuro no parece apuntar aún a sistemas sin personas, sino más bien a organizaciones capaces de combinar de forma excelente el potencial de la IA con el juicio y la responsabilidad que de momento solo pueden aportar los humanos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En los últimos años, la inteligencia artificial ha pasado de ser una tecnología emergente a convertirse en una realidad cotidiana en administraciones públicas, empresas y organizaciones de todo tipo. Se habla de sistemas que predicen la demanda sanitaria, optimizan rutas de transporte o detectan anomalías en el gasto público. Pero detrás de cada uno de estos casos de uso existe una pregunta que rara vez ocupa el primer plano del debate: ¿en qué se apoya realmente esa inteligencia artificial?
La respuesta no está solo en los algoritmos. Está en los datos. Y, más concretamente, en cómo las organizaciones se estructuran, y los estructuran, para gestionarlos.
En este post abordaremos:
-
Por qué los datos son la base real de cualquier sistema de IA y qué riesgos implica ignorarlos
-
Qué estructuras organizativas permiten gobernarlos de forma efectiva
-
El papel estratégico del dato abierto en este ecosistema
-
Las diferencias y sinergias entre gobierno del dato y gobierno de la IA
-
Los estándares y marcos de referencia disponibles en España y a nivel internacional
Los datos como base de la inteligencia artificial
El aprendizaje automático ha transformado el paradigma del desarrollo tecnológico. Donde antes los sistemas seguían reglas fijas y explícitas, hoy aprenden de patrones que emergen de los datos. Esto supone un cambio de enorme relevancia: el comportamiento de un modelo de IA no depende tanto de la lógica con la que fue programado como de la calidad, representatividad y coherencia de los datos con los que fue entrenado.
Aquí reside uno de los riesgos más subestimados de la IA: el espejismo del dato neutral. Los datos no son verdades objetivas; son representaciones de la realidad capturadas en un contexto concreto (procesos de negocio), con sus propias limitaciones y sesgos. Un sistema entrenado con datos incompletos o sesgados no solo replicará esos sesgos, sino que los amplificará. Los ejemplos son numerosos: desde modelos de reconocimiento facial con peor rendimiento en determinados grupos poblacionales hasta sistemas de priorización que reproducen desigualdades históricas.
Además, los datos envejecen. Lo que hoy es un conjunto de entrenamiento representativo puede dejar de serlo mañana si la realidad cambia y el modelo no se actualiza. Este fenómeno, conocido como data drift, es uno de los principales motivos por los que sistemas de IA inicialmente exitosos acaban degradando su rendimiento a lo largo del tiempo si no se sigue un adecuado mantenimiento. Un caso ilustrativo fue el de varios modelos predictivos desplegados durante la pandemia de COVID-19: entrenados con patrones de comportamiento previos, su precisión se deterioró cuando la realidad cambió de forma drástica y repentina, evidenciando que un modelo es tan vigente como los datos que lo sustentan.
Por todo ello, la calidad de los datos no puede dejarse al azar. Requiere una gestión activa, sistemática y con responsabilidades claramente asignadas.
Estructuras organizativas para gobernar el dato
Reconocer que los datos son un activo estratégico es el primer paso. El segundo, y más difícil, es organizarse para gestionarlos como tal.
Gobernar el dato significa establecer quién decide sobre los datos, cómo se gestionan y bajo qué reglas se utilizan. No es una cuestión puramente técnica; es, sobre todo, organizativa. Implica:
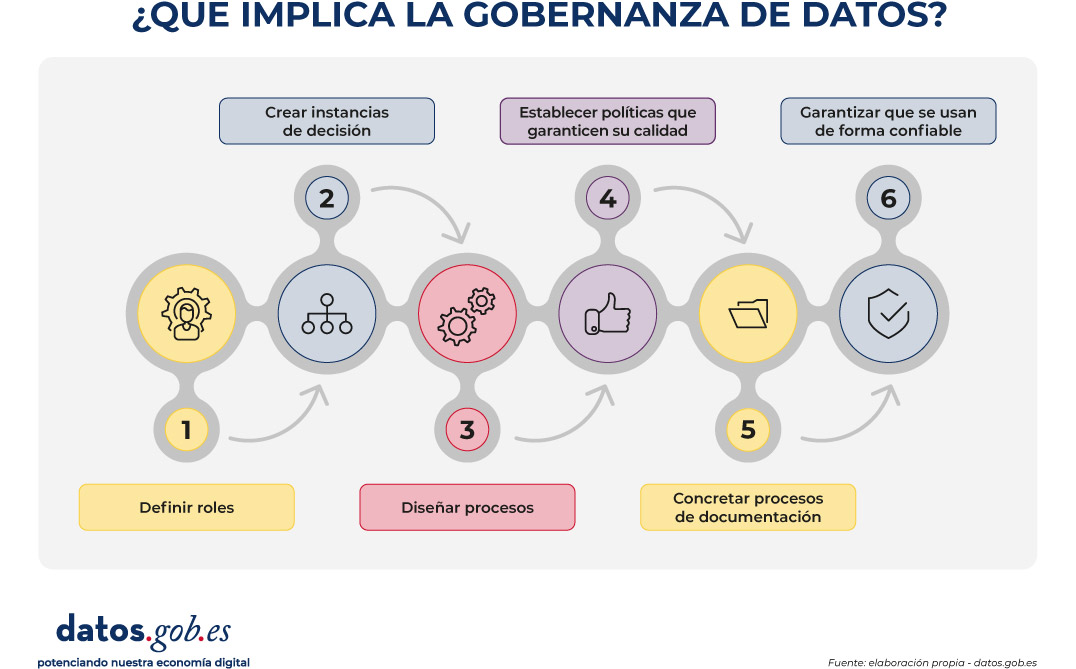
Figura 1. Visual sobre las implicaciones de la gobernanza de datos. Fuente: elaboración propia - datos.gob.es
Las organizaciones más maduras en este ámbito suelen articular su gobernanza en torno a tres niveles:
-
En el nivel estratégico, se sitúan figuras como el Chief Data Officer (CDO) y órganos colegiados de supervisión, cuya función es definir el papel que juegan los datos en la estrategia de la organización y asegurar que las decisiones de alto nivel estén alineadas con esa visión.
-
En el nivel operativo, una Oficina de Gobierno del Dato traduce esa estrategia en políticas concretas: estándares de calidad, catálogos de metadatos, procedimientos de gestión del ciclo de vida del dato, normas de seguridad y privacidad.
-
En el nivel de dominio, los data owners (responsable del dato) y data stewards (gestor del dato) son los responsables de que los datos se gestionen correctamente en el día a día: los primeros con responsabilidad formal sobre determinados conjuntos de datos; los segundos garantizando su calidad, consistencia y correcta documentación.
Cuando la IA entra en escena, esta estructura no cambia en esencia, pero sí se amplía. Aparecen nuevos perfiles como los científicos de datos o ingenieros de modelos, responsables de cumplimiento algorítmico, y nuevas necesidades: documentar los conjuntos de entrenamiento, garantizar la trazabilidad de las decisiones del modelo, gestionar el riesgo de sesgos. Todo ello debe integrarse en el marco de gobernanza existente, no añadirse como una capa separada, y teniendo en cuenta regulaciones como el Reglamento de Inteligencia Artificial de la UE (AI Act).
El dato abierto dentro del gobierno del dato
En el contexto del sector público español, el gobierno del dato no puede disociarse de la política de datos abiertos. Ambas dimensiones se refuerzan mutuamente.
El dato abierto aporta valor mucho más allá de la transparencia. En el contexto de la inteligencia artificial, sus aportaciones son múltiples.
Primero, como materia prima para la innovación: muchos proyectos de IA, especialmente en sus fases iniciales, se apoyan en datasets abiertos para entrenar y validar modelos. Portales como datos.gob.es ponen a disposición de investigadores, empresas y administraciones miles de conjuntos de datos reutilizables sobre movilidad, demografía, medio ambiente o gasto público, entre otros sectores. Un ejemplo concreto es el uso de datos abiertos de tráfico y transporte público para entrenar modelos de predicción de demanda o de optimización de rutas: sin esa capa de información pública, estructurada y de calidad, muchas de estas iniciativas simplemente no despegan.
En segundo lugar, como mecanismo de auditoría y confianza: cuando los datos que alimentan un sistema de IA son accesibles, la comunidad puede analizarlos, identificar posibles sesgos y cuestionar los resultados. Esto es especialmente relevante en decisiones de alto impacto, donde la explicabilidad y la rendición de cuentas son exigencias ineludibles.
Y, tercero, como catalizador de ecosistemas de datos: el dato abierto es uno de los pilares de los espacios de datos compartidos, donde múltiples organizaciones intercambian información bajo reglas comunes. Iniciativas como el Espacio Nacional de Datos de Salud (ENDS) o los espacios europeos sectoriales se apoyan en esta lógica. Para que funcionen, necesitan una gobernanza sólida que garantice la interoperabilidad, el control de acceso y la confianza entre los participantes.
Gobierno del dato y gobierno de la IA: diferencias y complementariedad
Es frecuente que ambos conceptos se confundan o se usen de forma intercambiable, pero tienen alcances distintos, aunque profundamente relacionados.
-
El gobierno del dato tiene como objeto el activo en sí mismo. Se pregunta: ¿son los datos de calidad? ¿Están bien definidos? ¿Se gestionan con seguridad? ¿Quién es responsable de ellos? Su horizonte es la integridad, la disponibilidad y el uso apropiado de la información.
-
El gobierno de la IA, en cambio, tiene como objeto el sistema algorítmico. Se pregunta: ¿es el modelo explicable? ¿Introduce sesgos? ¿Cumple con los requisitos éticos y legales? ¿Cómo se supervisa su funcionamiento a lo largo del tiempo? Su horizonte es la responsabilidad, la transparencia y la mitigación de riesgos.
La relación entre ambos no es de sustitución sino de dependencia: no puede haber un gobierno efectivo de la IA sin un gobierno previo y sólido del dato. Si no sabemos de dónde viene el dato que alimenta un modelo, si no podemos garantizar su calidad o su representatividad, cualquier sistema de gestión de IA se construye sobre arena. El gobierno del dato es, en este sentido, la infraestructura invisible sobre la que descansa la confianza en la inteligencia artificial.
Estándares y marcos de referencia
Para que estas estructuras organizativas no queden en una declaración de intenciones, es fundamental apoyarse en marcos normativos y estándares que ofrezcan orientación práctica y permitan comparar, evaluar e incluso certificar el nivel de madurez alcanzado.
En España, la familia de especificaciones UNE impulsadas desde la Dirección del Dato ofrece una guía completa y cohesionada. La UNE 0077 aborda el gobierno del dato; la UNE 0078, su gestión; la UNE 0079, la calidad; la UNE 0080, la evaluación de madurez; y la UNE 0085, la implantación progresiva de estas capacidades. A estas se suma la UNE 0081, que establece criterios específicos para la evaluación de la calidad de datasets, pieza crítica cuando hablamos de entrenamiento y validación de modelos de IA.
Este enfoque está plenamente alineado con las recomendaciones publicadas en datos.gob.es sobre gobernanza del datos, donde se insiste en la necesidad de definir roles claros, establecer políticas y asegurar la calidad como elementos estructurales para generar confianza y valor a partir de los datos. En este sentido, la gobernanza no es solo una capa organizativa, sino un habilitador de todo el ciclo de vida del dato., donde se insiste en la necesidad de definir roles claros, establecer políticas y asegurar la calidad como elementos estructurales para generar confianza y valor a partir de los datos. En este sentido, la gobernanza no es solo una capa organizativa, sino un habilitador de todo el ciclo de vida del dato.
En el plano internacional, este marco se amplía y se conecta directamente con la inteligencia artificial. La ISO/IEC 38507 proporciona directrices para el gobierno de la IA, mientras que la ISO/IEC 42001 define el primer sistema de gestión específico para IA, estableciendo requisitos organizativos, de control y mejora continua. Estas normas dejan claro que no puede existir una gestión efectiva de la IA sin una base sólida de gobernanza y gestión del dato.
A su vez, la calidad de la IA se articula sobre tres pilares fundamentales: datos, modelos y software, cada uno respaldado por estándares específicos. La calidad del dato se apoya en normas como la ISO/IEC 5259, mientras que la seguridad y la protección se vinculan a estándares como ISO/IEC 27090 o ISO/IEC 27563. En el ámbito del software y los productos de IA, destacan referencias como ISO/IEC 25059, y en procesos, estándares como ISO/IEC 5338, junto con normas de seguridad específicas como ISO/IEC 5469 o ISO/IEC 22440.
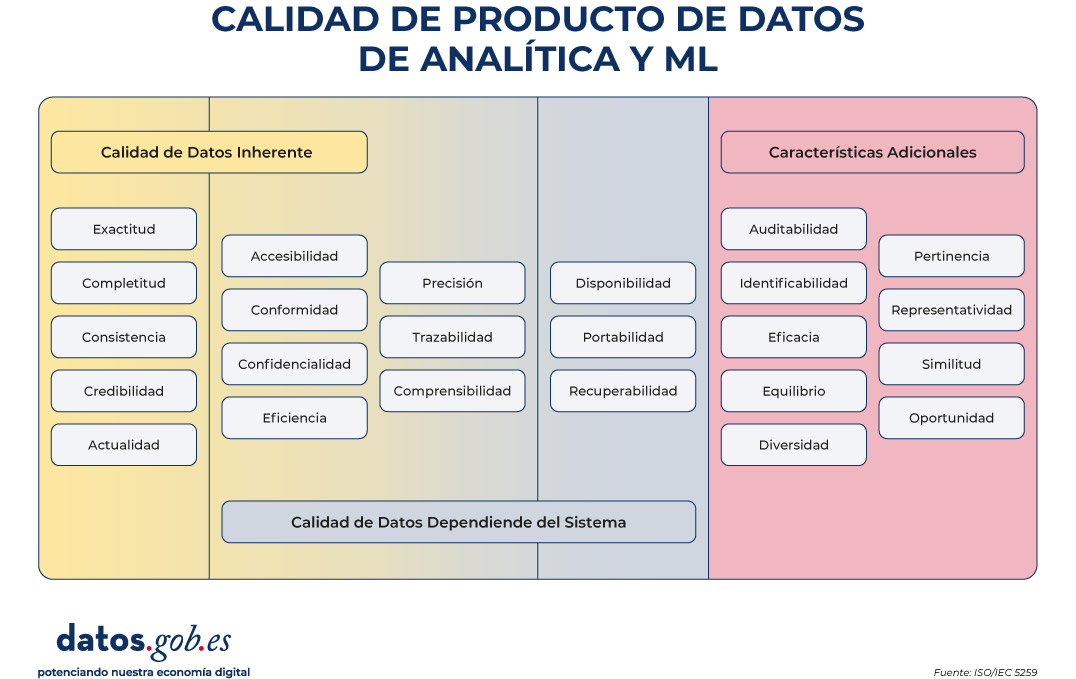
Figura 2. Visual sobre la calidad de producto de datos de analítica y machine learning (ML)
Todos estos marcos apuntan en la misma dirección: la gobernanza del dato no es un requisito burocrático, sino la base sobre la que se construye la calidad, la seguridad y, en última instancia, la confianza en los sistemas de inteligencia artificial. Sin ella, ni la gestión ni la calidad de la IA pueden sostenerse de forma fiable ni escalable.
Conclusión: gobernar el dato es gobernar el futuro
La inteligencia artificial ha puesto de relieve algo que existía pero que no siempre resultaba visible: la calidad de cualquier decisión basada en datos depende, en última instancia, de cómo esos datos se gestionan.
En este sentido, las organizaciones que mejor aprovecharán las oportunidades que ofrece la IA serán las que hayan construido estructuras organizativas capaces de garantizar que sus datos son de calidad, están bien documentados, cuentan con responsables claros y se gestionan bajo políticas coherentes.
Y, en definitiva, gobernar el dato con rigor es la condición que hace posible una innovación sostenible, responsable y digna de confianza. Porque, en un entorno donde la IA aprende de aquello que le damos, la pregunta más importante no es qué modelo usamos, sino qué datos lo alimentan y cómo los hemos cuidado.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
La gobernanza de datos es un elemento central de cualquier estrategia digital. Gobiernos, empresas, organizaciones sociales e instituciones internacionales coinciden en que, sin reglas claras sobre cómo se recopilan, gestionan, comparten y utilizan los datos, es imposible aprovechar todo su valor.
Este artículo busca aclarar este concepto, aportando información sobre sus principios básicos. Para ello, nos hemos basado en dos informes: Data Governance Toolkit: Navigating Data in the digital era de la Broadband Commission, cofundada por la UNESCO y la Unión Internacional de Telecomunicaciones (ITU en sus siglas en inglés), y What is Data Governance: 30 Questions and Answers, elaborado por The Govlab. El segundo informe profundiza en las definiciones y conceptos incluidos en el primero. Ambos documentos coinciden en que la gobernanza de datos no es solo un conjunto de normas, sino un marco integral que orientan todo el ciclo de vida de los datos.
A continuación, se recoge un resumen de lo que dicen ambos informes.
¿Qué es la gobernanza de datos?
La gobernanza de datos puede definirse como el conjunto de procesos, personas, políticas, prácticas y tecnologías que guían cómo se generan, gestionan y reutilizan los datos a lo largo de todo su ciclo de vida. Su objetivo es aumentar la confianza, el valor y la equidad, al tiempo que se minimizan los riesgos y los perjuicios, de conformidad con un conjunto de principios fundamentales.
Las 4P del Data Governance Toolkit
La Broadband Commission subraya cuatro elementos esenciales de la gobernanza de datos:
Por qué: definir la visión y el propósito de los datos y de su gobernanza.
- Cómo: establecer los principios que guiarán las decisiones y prácticas.
- Quién: identificar los roles, responsabilidades y procesos institucionales.
- Qué: concretar las políticas, mecanismos y tecnologías que se aplicarán en cada fase del ciclo de vida del dato.
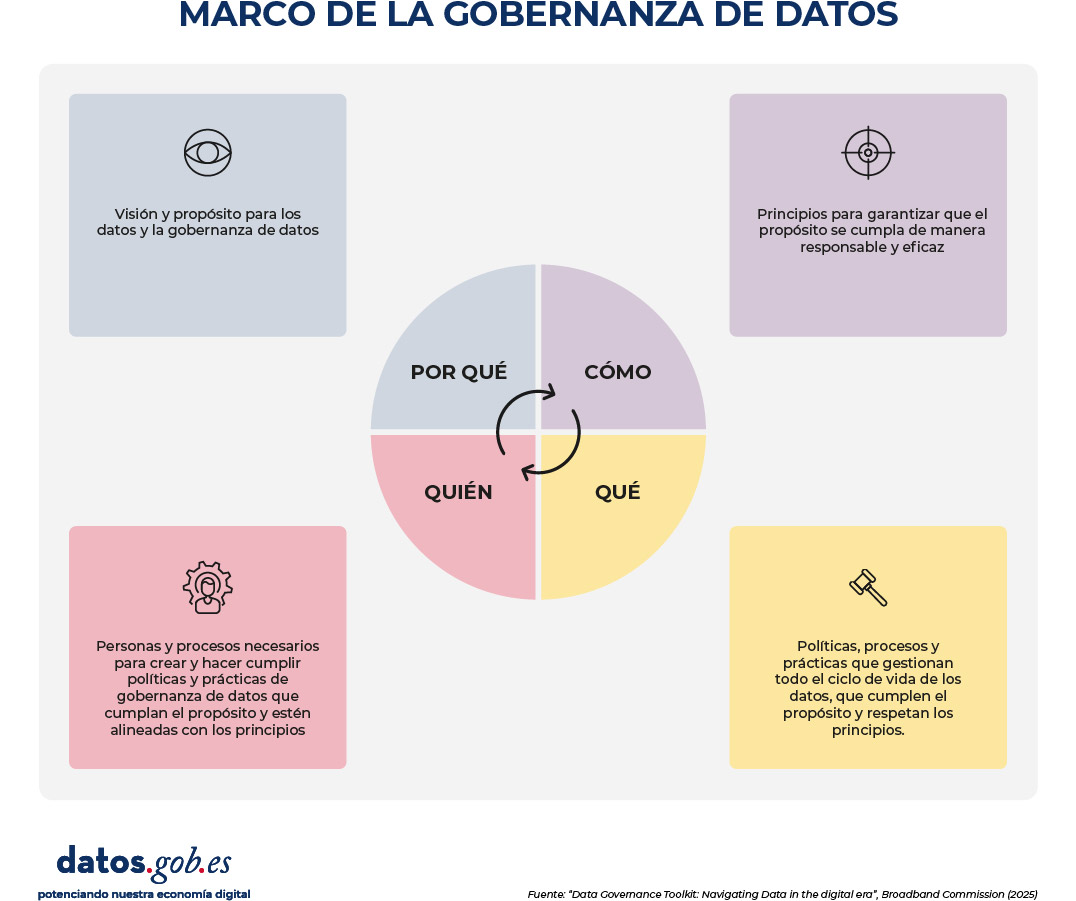
Figura 1. Marco de la gobernanza de datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Esta estructura -conocida como los 4P del Toolkit por sus nombres en inglés (Purpose, Principles, People, and Practices)- permite que la gobernanza no sea un ejercicio abstracto, sino una práctica operativa y medible. Funciona como bloques (building blocks) que pueden aprovecharse y adaptarse para orientar el desarrollo de nuevas estrategias de gobernanza de datos.
A continuación, se detallan cada uno de ellos:
1. ¿Por qué? (Purpose)
- El propósito y la visión son esenciales para orientar la gobernanza de los datos, dar coherencia a las iniciativas y garantizar una gestión responsable a lo largo de todo el ciclo de vida del dato.
- Un buen propósito de gobernanza debe reflejar valores y prioridades sociales, ser accionable y equilibrar oportunidades (como innovación o reutilización de datos) con riesgos (como sesgos, exclusión o daños).
- Los propósitos más habituales incluyen maximizar el valor de los datos, fomentar la innovación y el desarrollo sostenible, promover la equidad, apoyar objetivos de política pública y reforzar la participación y la agencia de las personas.
Un propósito bien formulado actúa como marco de referencia para asegurar alineación, coherencia y rendición de cuentas. Además, ayuda a evitar usos indebidos, duplicidades o esfuerzos desconectados. Para que sea eficaz, este propósito debe:
- Reflejar los valores fundamentales de la organización y las prioridades sociales (por ejemplo, la equidad, la innovación y los derechos humanos).
- Ser aplicables y estar en consonancia con los objetivos de la empresa.
- Abordar tanto las oportunidades (por ejemplo, la reutilización de datos o la implementación de la inteligencia artificial) como los riesgos (por ejemplo, los perjuicios, la exclusión o los sesgos).
- Servir de referencia para las decisiones de gobernanza, los indicadores de éxito y la mejora continua.
En la práctica, las organizaciones suelen orientar su gobernanza hacia metas como maximizar el valor económico y social del dato, fomentar la innovación y el desarrollo sostenible, promover la equidad, apoyar objetivos de política pública (como resultados en salud o protección ambiental) o fortalecer la participación y la autodeterminación digital. Estas finalidades no son excluyentes. Al combinarse permiten construir ecosistemas de datos más responsables, útiles y legítimos.
2. ¿Cómo? (Principles)
Es necesario desarrollar principios de gobernanza de datos mediante un proceso estructurado que parta de definir objetivos y alcance. Estos principios deben:
- Incorporar marcos de derechos humanos y principios básicos como transparencia, responsabilidad, proporcionalidad, equidad, participación, legalidad, seguridad, privacidad, calidad, etc.
- Anclarse en estándares internacionales ligados a la interoperabilidad, la ética de la IA o la protección de datos.
- Tener en cuenta el contexto cultural y los valores sociales locales mediante la participación de actores diversos y pruebas basadas en escenarios concretos.
- Revisarse y actualizarse de forma continua para mantener su relevancia ante cambios legales y tecnológicos.
3. ¿Quién? (People)
La creación de marcos eficaces de gobernanza de datos requiere involucrar a múltiples actores mediante procesos colaborativos que garanticen inclusión, transparencia y coherencia con estándares legales y éticos. Este bloque conlleva identificar a las principales partes interesadas, sus roles y responsabilidades, y establecer mecanismos eficaces de coordinación y rendición de cuentas. Para ello, se recomienda:
- Desarrollar talleres, consultas y mecanismos de retroalimentación para que gobiernos, empresas, sociedad civil y expertos técnicos contribuyan a definir principios y responsabilidades.
- Implementar herramientas como el mapeo de actores, la revisión de políticas y la comparación con marcos globales, incluidos derechos humanos, estándares de procedencia de datos o guías de IA ética.
- Realizar pruebas basadas en escenarios concretos para identificar brechas y fortalecer la resiliencia de los marcos de gobernanza.
- Desarrollar capacidades en gobernanza de datos combinando formación continua, estructuras claras y herramientas de gestión.
- Diseñar estructuras de responsabilidad y mecanismos de supervisión transparentes para garantizar el cumplimiento.
- Implementar acuerdos contractuales, políticas institucionales, enfoques de gobernanza por diseño y medidas de seguridad, como cifrado o controles de acceso.
Es importante tener en cuenta modelos como RACI. Así mismo, las evaluaciones de madurez y las auditorías ayudan a revisar y mejorar las prácticas.
4. ¿Qué? (Practices)
Antes de abordar este apartado, es necesario comprender en qué consiste el ciclo de vida del dato. El ciclo de vida del dato describe las distintas etapas por las que atraviesa la información, desde que se concibe su necesidad hasta que se utiliza para generar conocimiento o apoyar decisiones. Aunque existen múltiples marcos y cada uno puede emplear terminologías ligeramente distintas, la mayoría coincide en seis fases fundamentales: planificación, recogida, procesamiento, compartición, análisis y uso.
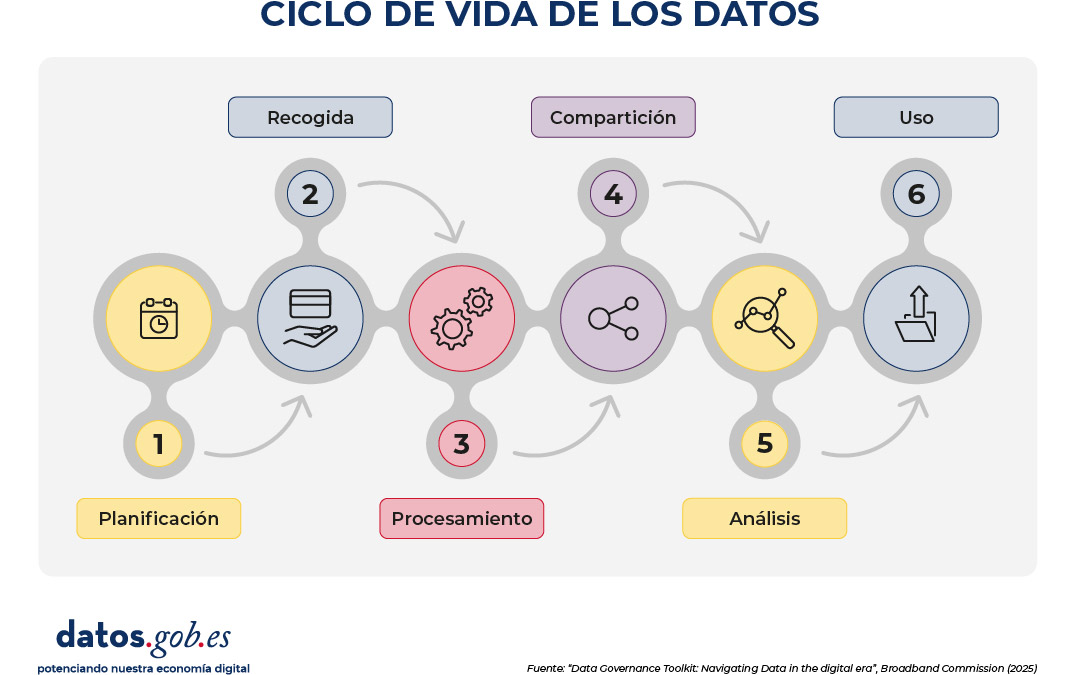
Figura 2. Ciclo de vida de los datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Estas fases consisten en:
1. Planificación. En esta fase se definen las necesidades de datos, los usos previstos y los requisitos de gobernanza que se aplicarán posteriormente. Es el momento de aclarar el propósito, alcance, viabilidad, identificar riesgos, establecer criterios de calidad y determinar quién será responsable de cada decisión. Una planificación deficiente -por ejemplo, un propósito ambiguo- puede comprometer todo el ciclo posterior.
2. Recogida. Consiste en obtener los datos mediante encuestas, sensores, transacciones, registros administrativos u otros mecanismos. Aquí se decide qué datos son realmente necesarios, cómo se obtienen de forma equitativa y ética, y cómo se garantiza que su captura respete principios como la privacidad o la minimización. Una fase de recogida desordenada o excesiva puede generar riesgos y costes innecesarios.
3. Procesamiento. Incluye todas las tareas de limpieza, validación, organización, almacenamiento y preservación de los datos. También abarca la eliminación cuando ya no son necesarios. La fase de procesamiento es crítica para asegurar la calidad, la trazabilidad y el manejo adecuado de la información. Un procesamiento deficiente puede introducir sesgos, errores o pérdidas de integridad que afectarán al análisis posterior.
4. Compartición. En esta etapa los datos se ponen a disposición de terceros para su reutilización, ya sea a través de plataformas, API, acuerdos de intercambio o espacios colaborativos. La gobernanza determina quién puede acceder, bajo qué condiciones, con qué salvaguardas y con qué mecanismos de control. Una compartición bien diseñada multiplica el valor del dato; una mal gestionada puede generar riesgos de seguridad o uso indebido.
5. Análisis. Aquí los datos se interpretan para generar conocimiento, mediante estadísticas, visualizaciones, modelos o técnicas avanzadas como la inteligencia artificial. La gobernanza influye en cómo se documentan los métodos, cómo se gestionan los sesgos y cómo se garantiza la reproducibilidad. Un análisis sin controles puede conducir a conclusiones erróneas o discriminatorias.
6. Uso. Finalmente, los resultados del análisis se aplican para informar decisiones, diseñar políticas, mejorar servicios o crear productos. Esta fase debe estar alineada con el propósito definido al inicio y con los principios éticos y legales establecidos. Un uso inadecuado puede generar impactos negativos, incluso si las fases anteriores se realizaron correctamente.
En cada una de estas etapas se toman decisiones clave: quién accede a los datos, cómo se garantiza su calidad, qué salvaguardas se aplican, cómo se documentan los procesos o qué mecanismos de supervisión existen. Estas decisiones no son independientes: se acumulan y condicionan lo que es posible en las fases posteriores.
Aplicar los principios y decisiones de gobernanza de datos a lo largo de todo el ciclo de vida del dato requiere integrarlos en procesos, herramientas y marcos de cumplimiento alineados con requisitos normativos. Además, es necesario adaptarse a las necesidades de cada sector, apoyándose en estándares globales o jurisdiccionales. Algunos aspectos a consideran son:
- Definir roles y requisitos legales desde la planificación.
- Usar marcos como DAMA‑DMBOK o acuerdos de intercambio, apoyándose en metadatos, trazabilidad y estándares de interoperabilidad para garantizar la transparencia y el uso responsable.
- Apoyarse en acuerdos legales, cooperación regulatoria y tecnologías de mejora de la privacidad para garantizar flujos correctos de datos.
- Garantizar un uso seguro y responsable de la inteligencia artificial mediante datos fiables, bien documentados y gestionados con transparencia y supervisión.
- Medir el éxito de la iniciativa evaluando el cumplimiento, la calidad, la seguridad y la madurez.
La guía de la Broadband Commission incluye un mecanismo de autoevaluación con diversas listas de validación (checklist). El objetivo es que gobiernos, instituciones públicas y organizaciones puedan conocer el estado actual de sus sistemas de gobernanza de datos e identificar oportunidades de mejora. Estas listas abarcan tanto las actividades del resto de bloques como los procesos recomendados en cada fase del ciclo de vida de los datos.
Otros marcos a considerar
La Broadband Commission no es la única organización que ha elaborado un marco de referencia. La siguiente tabla recoge otras iniciativas que también pueden ser de interés.
| Toolkit | Autor | Audiencia |
|---|---|---|
| Data Governance Toolkit | Gobierno del estado de Nueva Gales del Sur (Australia) | Sector público |
| Data Innovation Toolkit | Laboratorio de Innovación Digital de la Comisión Europea | Sector público |
| OECD Data Governance | Organización para la Cooperación y el Desarrollo Económicos (OECD, en inglés) | Sector público |
| Data to Policy Navigator | Iniciativa Data4Policy de la GIZ y la Oficina Digital del Programa de las Naciones Unidas para Desarrollo (PNUD, en inglés) | Sector público |
| Data policy Framework | Unión Africana (AU, en inglés) | Sector público |
| Data Management Framework | Asociación de Naciones de Asia Sudoriental (ASEAN, en inglés) | Sector público |
| Navigating Data Governance | Unión Internacional de Telecomunicaciones (ITU, en inglés) | Reguladores |
| The Data Playbook | Federación Internacional de Sociedades de la Cruz Roja y de la Media Luna Roja (IFRC, en inglés) y Solferimo Academy | Sector humanitario |
| Data Responsability Journey | The GovLab | Sector público y privado |
| Data Governance and Management Toolkit | Miembros del Comité de Dirección de Datos de los Gobiernos Indígenas Autónomos (SGIG DSC Members, en inglés) | Gobiernos indígenas |
Figura 2. Mapeo de conjuntos de herramientas para la gobernanza de datos. Fuente: Data Governance Toolkit: Navigating Data in the digital era, Broadband Commission (2025).
Todos los marcos coinciden en un aspecto: la clave de la gobernanza de datos está en combinar un propósito claro, principios sólidos, mecanismos de participación y legitimidad y procesos aplicables a todo el ciclo de vida del dato.
En España contamos con la familia de normas UNE de gobierno, gestión y calidad del dato 0077, 0078, 0079 0080 y 0085, concebidas para aplicarse de manera conjunta y ofrecer un marco de referencia sólido que impulse la adopción de prácticas sostenibles y efectivas en torno al dato.
En un momento en que los datos impulsan desde la IA hasta los servicios públicos digitales, avanzar hacia una gobernanza responsable es una oportunidad para reforzar la confianza, potenciar la innovación y garantizar que los beneficios del dato se distribuyan de forma equitativa. Por ello es importante que todas las organizaciones apliquen un marco claro que garantice una gobernanza sólida de los datos.
Blog
Los datos abiertos tienen un gran potencial para transformar la forma en que interactuamos con nuestras ciudades. Al estar disponibles para toda la ciudadanía, permiten desarrollar aplicaciones y herramientas que dan respuesta a retos urbanos como la accesibilidad, la seguridad vial o la participación ciudadana. Facilitar el acceso a esta información no solo impulsa la innovación, sino que también contribuye a mejorar la calidad de vida en los entornos urbanos.
Este potencial cobra aún más relevancia si consideramos el contexto actual. El crecimiento urbano acelerado ha traído consigo nuevos desafíos, especialmente en materia de salud pública. Según datos de las Naciones Unidas, se estima que para 2050 más del 68% de la población mundial vivirá en ciudades. Por lo tanto, el diseño de entornos urbanos saludables es una prioridad en la que los datos abiertos se consolidan como una herramienta clave: permiten planificar ciudades más resilientes, inclusivas y sostenibles, poniendo el bienestar de las personas en el centro de las decisiones. En este post, te contamos qué son los entornos urbanos saludables y cómo pueden los datos abiertos ayudar a construirlos y mantenerlos.
¿Qué son los Entornos urbanos saludables? Usos y ejemplos
Los entornos urbanos saludables van más allá de la simple ausencia de contaminación o ruido. Según la Organización Mundial de la Salud (OMS), estos espacios deben promover activamente estilos de vida saludables, facilitar la actividad física, fomentar la interacción social y garantizar el acceso equitativo a servicios básicos. Como establece la "Guía para planificar ciudades saludables" del Ministerio de Sanidad, estos entornos se caracterizan por tres elementos clave:
-
Ciudades pensadas para caminar: deben ser espacios que prioricen la movilidad peatonal y ciclista, con calles seguras, accesibles y confortables que inviten al desplazamiento activo.
-
Incorporación de la naturaleza: integran zonas verdes, infraestructura azul y elementos naturales que mejoran la calidad del aire, regulan la temperatura urbana y ofrecen espacios de recreo y descanso.
-
Espacios de encuentro y convivencia: cuentan con áreas que facilitan la interacción social, reducen el aislamiento y fortalecen el tejido comunitario.
El papel de los datos abiertos en entornos urbanos saludables
En este escenario, los datos abiertos actúan como el sistema nervioso de las ciudades inteligentes, proporcionando información valiosa sobre patrones de uso, necesidades ciudadanas y efectividad de las políticas públicas. En concreto, en el ámbito de los espacios urbanos saludables son especialmente útiles los datos de:
-
Análisis de patrones de actividad física: los datos de movilidad, uso de instalaciones deportivas y frecuentación de espacios verdes revelan dónde y cuándo los ciudadanos son más activos, identificando oportunidades para optimizar la infraestructura existente.
-
Monitorización de la calidad ambiental: los sensores urbanos que miden la calidad del aire, los niveles de ruido y la temperatura proporcionan información en tiempo real sobre las condiciones de salubridad de diferentes áreas urbanas.
-
Evaluación de accesibilidad: el transporte público, la infraestructura peatonal y la distribución de servicios permiten identificar barreras al acceso y diseñar soluciones más inclusivas.
-
Participación ciudadana informada: las plataformas de datos abiertos facilitan procesos participativos donde los ciudadanos pueden contribuir con información local y colaborar en la toma de decisiones.
El ecosistema español de datos abiertos cuenta con sólidas plataformas que alimentan proyectos de espacios urbanos saludables. Por ejemplo, el Portal de Datos Abiertos del Ayuntamiento de Madrid ofrece información en tiempo real sobre la calidad del aire así como un inventario completo de zonas verdes. También Barcelona publica datos sobre calidad del aire, incluyendo las ubicaciones y características de las estaciones de medida.
Estos portales no solo almacenan información, sino que la estructuran de manera que desarrolladores, investigadores y ciudadanos puedan crear aplicaciones y servicios innovadores.
Casos de uso: aplicaciones que reutilizan datos abiertos
Varios proyectos demuestran cómo los datos abiertos se traducen en mejoras tangibles para la salud urbana. Por un lado, podemos destacar algunas aplicaciones o herramientas digitales como:
-
AQI Air Quality Index: utiliza datos gubernamentales para ofrecer información en tiempo real sobre la calidad del aire en diferentes ciudades españolas.
-
GV Aire: procesa datos oficiales de calidad atmosférica para generar alertas y recomendaciones ciudadanas.
-
Índice de Calidad del Aire Nacional: centraliza información de estaciones de medición de todo el país.
-
Valencia Verde: utiliza datos municipales para mostrar ubicación y características de parques y jardines de Valencia.
Por otro lado, existen iniciativas que combinan datos abiertos multisectoriales para ofrecer soluciones que mejoran la interacción entre urbe y ciudadanía. Por ejemplo:
-
Programa Supermanzanas: utiliza mapas que muestran los niveles de contaminación de calidad del aire y datos de tráfico disponibles en formatos abiertos como CSV y GeoPackage de Barcelona Open Data y el Ajuntament de Barcelona para identificar calles donde la reducción del tráfico rodado puede maximizar los beneficios para la salud, creando espacios seguros para peatones y ciclistas.
-
La plataforma DataActive: busca establecer una infraestructura internacional en la que participen investigadores, entidades deportivas públicas y privadas. Las temáticas que aborda incluyen la gestión del territorio, el urbanismo, la sostenibilidad, la movilidad, la calidad del aire y la justicia ambiental. Su objetivo es promover entornos urbanos más activos, saludables y accesibles mediante la implementación de estrategias basadas en el open data y la investigación.
La disponibilidad de datos se complementa con herramientas avanzadas de visualización. La Infraestructura de Datos Espaciales de Madrid (IDEM) ofrece visores geográficos especializados en calidad del aire y el Instituto Geográfico Nacional (IGN) ofrece el callejero nacional CartoCiudad con información de todas las ciudades de España.
Gobernanza efectiva y ecosistema de innovación
No obstante, la efectividad de estas iniciativas depende de nuevos modelos de gobernanza que integren múltiples actores. Para lograr una correcta coordinación entre administraciones públicas de diferentes niveles, empresas privadas, organizaciones del tercer sector y ciudadanía es esencial contar con datos abiertos de calidad.
Los datos abiertos no solo alimentan aplicaciones específicas, sino que crean un ecosistema completo de innovación. Desarrolladores independientes, startups, centros de investigación y organizaciones ciudadanas utilizan estos datos para:
-
Desarrollar estudios de impacto en salud urbana.
-
Crear herramientas de planificación participativa.
-
Generar alertas tempranas sobre riesgos ambientales.
-
Evaluar la efectividad de políticas públicas.
-
Diseñar servicios personalizados según las necesidades de diferentes grupos poblacionales.
Los proyectos de espacios urbanos saludables basados en datos abiertos generan múltiples beneficios tangibles:
-
Eficiencia en la gestión pública: los datos permiten optimizar la asignación de recursos, priorizar intervenciones y evaluar su impacto real sobre la salud ciudadana.
-
Innovación y desarrollo económico: el ecosistema de datos abiertos estimula la creación de startups y servicios innovadores que mejoran la calidad de vida urbana, como demuestran las múltiples aplicaciones disponibles en datos.gob.es.
-
Transparencia y participación: la disponibilidad de datos facilita el control ciudadano y fortalece los procesos democráticos de toma de decisiones.
-
Evidencia científica: los datos sobre salud urbana contribuyen al desarrollo de políticas públicas basadas en evidencia y al avance del conocimiento científico.
-
Replicabilidad: las soluciones exitosas pueden adaptarse y replicarse en otras ciudades, acelerando la transformación hacia entornos urbanos más saludables.
En definitiva, el futuro de nuestras ciudades depende de nuestra capacidad para integrar tecnología, participación ciudadana y políticas públicas innovadoras. Los ejemplos analizados demuestran que los datos abiertos no son solo información; son la base para construir entornos urbanos que promuevan activamente la salud, la equidad y la sostenibilidad.
Noticia
No hay duda de que la inteligencia artificial se ha convertido en un pilar fundamental de la innovación tecnológica. Hoy en día, mediante inteligencia artificial (IA) se pueden crear chatbots especializados en datos abiertos, aplicaciones que faciliten el trabajo profesional e incluso un gemelo digital de la Tierra para anticiparse a desastres naturales.
Las posibilidades son infinitas, sin embargo, el futuro de la IA también tiene retos a superar para que los modelos sean más inclusivos, accesibles y transparentes. En este sentido, la Unión Europea está desarrollando diversas iniciativas para conseguir avanzar en este campo.
Marco regulatorio europeo a favor de una IA más abierta y transparente
El planteamiento de la UE en materia de IA busca ofrecer a los ciudadanos la confianza necesaria para adoptar estas tecnologías y animar a las empresas a desarrollarlas. Para ello, el Reglamento Europeo de IA establece unas pautas de desarrollo de la inteligencia artificial alineadas con los valores europeos de privacidad, seguridad y diversidad cultural. Por otro lado, el Reglamento de Gobernanza de Datos (DGA) define que se debe garantizar un acceso amplio a los datos sin comprometer derechos de propiedad intelectual, privacidad y equidad.
Junto con la Ley de Inteligencia Artificial, la actualización del Plan Coordinado sobre la IA garantiza la seguridad y los derechos fundamentales de las personas y las empresas, reforzando al mismo tiempo la inversión y la innovación en todos los países de la UE. La Comisión también ha puesto en marcha un paquete de innovación en materia de inteligencia artificial para ayudar a las empresas emergentes y pymes europeas a que desarrollen una IA fiable que respete los valores y normas de la UE.
Otras instituciones también están trabajando en el impulso de una inteligencia impulsando los modelos de IA de código abierto como una solución muy interesante. Un informe reciente de Open Future y Open Source Initiative (OSI) define cómo debería ser la gobernanza de datos en los modelos de IA open source. Uno de los desafíos que destaca el informe es, precisamente, lograr un equilibrio entre apertura de datos y derechos sobre los mismos, conseguir más transparencia y evitar sesgos culturales. De hecho, los expertos en la materia Ricard Martínez y Carmen Torrijos debatieron sobre este tema en el pódcast de datos.gob.es.
El proyecto OpenEuroLLM
Con el objetivo de solventar los posibles desafíos y planteándose como una solución innovadora y abierta, la Unión Europea, a través del programa Europa Digital ha presentado A través de este proyecto de inteligencia artificial de código abierto se esperan crear modelos de lenguaje eficientes, transparentes y alineados con la normativa europea de IA.
El proyecto OpenEuroLLM tiene como meta principal el desarrollo de modelos de lenguaje de última generación que sirvan para una amplia variedad de aplicaciones tanto públicas como privadas. Entre los objetivos más destacados, podemos mencionar:
- Extender las capacidades multilingües de los modelos existentes: esto incluye no solo las lenguas oficiales de la Unión Europea, sino también otras lenguas que son de interés social y económico. Europa es un continente rico en diversidad lingüística, y el proyecto busca reflejar esa diversidad en los modelos de IA.
- Acceso sostenible a modelos fundamentales: los modelos desarrollados dentro del proyecto serán fáciles de acceder y estarán listos para ser ajustados a diversas aplicaciones. Esto no solo beneficiará a grandes empresas, sino también a pequeñas y medianas empresas (PYMES) que deseen integrar la IA en sus procesos sin enfrentar barreras tecnológicas.
- Evaluación de resultados y alineación con la normativa europea: los modelos serán evaluados de acuerdo con rigurosos estándares de seguridad y alineación con el Reglamento Europeo de IA y otros marcos regulatorios europeos. Esto garantizará que las soluciones de IA sean seguras y respetuosas con los derechos fundamentales.
- Transparencia y accesibilidad: una de las premisas del proyecto es compartir de manera abierta las herramientas, procesos y resultados intermedios de los procesos de entrenamiento. Esto permitirá que otros investigadores y desarrolladores puedan reproducir, mejorar y adaptar los modelos para sus propios propósitos.
- Fomento de la comunidad: OpenEuroLLM no se limita a la creación de modelos, sino que también tiene como objetivo construir una comunidad activa y comprometida, tanto en el sector público como en el privado, que pueda colaborar, compartir conocimientos y trabajar en conjunto para avanzar en la investigación de IA.
El Consorcio OpenEuroLLM: un proyecto colaborativo y multinacional
El proyecto OpenEuroLLM está siendo desarrollado por un consorcio de 20 instituciones europeas de investigación, empresas tecnológicas y centros de supercomputación, bajo la coordinación de la Universidad de Charles (República Checa) y la colaboración de Silo GenAI (Finlandia). El consorcio reúne a algunas de las instituciones y empresas líderes en el campo de la inteligencia artificial en Europa, creando una colaboración multinacional para desarrollar modelos de lenguaje de código abierto.
Entre las principales instituciones que participan en el proyecto se encuentran universidades de renombre como la Universidad de Helsinki (Finlandia) o la Universidad de Oslo (Noruega), así como empresas tecnológicas como Aleph Alpha Research (Alemania) o la empresa ilicitana prompsit (España), entre otras. Además, los centros de supercomputación como Barcelona Supercomputing Center (España) o SURF (Países Bajos) proporcionan la infraestructura necesaria para entrenar modelos a gran escala.
Diversidad lingüística, transparencia y conformidad con las normas de la UE
Uno de los mayores desafíos de la inteligencia artificial globalizada es la inclusión de múltiples idiomas y la preservación de las diferencias culturales. Europa, con su vasta diversidad lingüística, presenta un entorno único para abordar estos problemas. OpenEuroLLM se compromete a preservar esa diversidad y garantizar que los modelos de IA desarrollados sean sensibles a las variaciones lingüísticas y culturales de la región.
Como hemos visto al inicio del post, el desarrollo tecnológico debe ir de la mano de los valores éticos y responsables. En este sentido, una de las características clave del proyecto OpenEuroLLM es su enfoque en la transparencia. Los modelos, los datos, la documentación, el código de entrenamiento y las métricas de evaluación estarán completamente disponibles para el público. Esto permitirá que investigadores y desarrolladores puedan auditar, modificar y mejorar los modelos, garantizando un enfoque abierto y colaborativo.
Además, el proyecto se alinea con las estrictas normativas europeas de IA. OpenEuroLLM está diseñado para cumplir con la Ley de IA de la UE, que establece criterios rigurosos para garantizar la seguridad, la equidad y la privacidad en los sistemas de inteligencia artificial.
Democratización del acceso a la IA
Uno de los logros más importantes de OpenEuroLLM es la democratización del acceso a la IA de alto rendimiento. Los modelos de código abierto permitirán que empresas, instituciones académicas y organizaciones del sector público de toda Europa tengan acceso a tecnología de vanguardia, independientemente de su tamaño o presupuesto.
Esto es especialmente relevante para las pequeñas y medianas empresas (PYMES), que a menudo enfrentan dificultades para acceder a soluciones de IA debido a los altos costos de licencias o las barreras tecnológicas. OpenEuroLLM eliminará estas barreras y permitirá que las empresas desarrollen productos y servicios innovadores utilizando IA, lo que contribuirá al crecimiento económico de Europa.
El proyecto OpenEuroLLM también es una apuesta de la UE por la soberanía digital que está invirtiendo de manera estratégica en el desarrollo de infraestructura tecnológica que reduzca la dependencia de actores globales y refuerce la competitividad europea en el ámbito de la inteligencia artificial. Este es un paso importante hacia una inteligencia artificial que no solo sea más avanzada, sino también más justa, segura y responsable.
Blog
No hay duda de que la formación en competencias digitales es necesaria hoy en día. Los conocimientos digitales básicos son fundamentales para poder interactuar en una sociedad en la que la tecnología ya juega un papel transversal. En concreto, es importante conocer aspectos básicos de la tecnología para trabajar con datos.
En este contexto, las trabajadoras y trabajadores del sector público también deben mantenerse en constante actualización. Capacitarse en este ámbito es clave para optimizar procesos, garantizar la seguridad de la información y fortalecer la confianza en las instituciones.
En este post, identificamos habilidades digitales relacionadas con los datos abiertos tanto dirigidas a la publicación como al uso de estos. No solo identificamos las competencias profesionales que deben tener y mantener los empleados públicos que trabajan con open data, también recopilamos una serie de recursos formativos que están a su disposición.
Competencias profesionales para trabajar con datos
En el Encuentro Nacional de Datos Abiertos de 2024 se constituyó un grupo de trabajo con un objetivo: identificar las competencias digitales que debían tener los profesionales de la administración pública que trabajasen con datos abiertos. Más allá de las conclusiones de este evento de relevancia nacional, el grupo de trabajo definió perfiles y roles necesarios para la apertura de datos, recogiendo información sobre sus funciones y las capacidades y conocimientos necesarios. Los principales roles identificados fueron:
- Rol responsable: tiene funciones de responsabilidad técnica en el impulso de políticas de datos abiertos y organiza actividades de definición de las políticas y modelos de datos. Algunos conocimientos necesarios son:
- Liderazgo en el impulso de estrategias para impulsar la apertura del dato.
- Impulsar la estrategia del dato para impulsar la apertura con propósito.
- Comprender el marco normativo relacionado con los datos para actuar dentro de la legalidad en todo el ciclo de vida del dato.
- Fomentar el uso de herramientas y procesos para la gestión del dato.
- Capacidad de generar sinergias para consensuar instrucciones transversales a toda la organización.
- Rol técnico de apertura de datos (perfil TIC): desarrolla actividades de ejecución más vinculadas con la gestión de los sistemas, los procesos de extracción, limpieza de datos, etc. Este perfil debe conocer, por ejemplo:
- Cómo estructurar el conjunto de datos, el vocabulario de metadatos, calidad del dato, estrategia a seguir...
- Ser capaz de analizar un conjunto de datos e identificar los procesos de depuración y limpieza de manera rápida e intuitiva.
- Generar visualizaciones de datos, conectando bases de datos de diferentes formatos y orígenes, y así obtener gráficos, indicadores y mapas dinámicos e interactivos.
- Dominar las funcionalidades de la plataforma, es decir, saber aplicar soluciones tecnológicas para la gestión de datos abiertos o conocer técnicas y estrategias para acceder, extraer e integrar datos de diferentes plataformas.
- Rol funcional de apertura de datos (técnico de un servicio): ejecuta actividades más vinculadas con la selección de datos a publicar, la calidad, promoción de los datos abiertos, visualización, analítica de datos, etc. Por ejemplo:
- Manejar herramientas de visualización y dinamización.
- Conocer la economía del dato y conocer la información referente al dato en toda su extensión (generación por las AAPP, datos abiertos, infomediarios, reutilización de la información pública, Big Data, Data Driven, roles implicados, etc.).
- Conocer y aplicar los aspectos éticos y de protección de datos de carácter personal que aplican a la apertura de datos.
- Uso de datos por parte de los trabajadores públicos: este perfil lleva a cabo actividades sobre el uso de los datos para la toma de decisiones, analítica básica de datos, entre otros. Para ello, deberá tener estas competencias:
- Navegación, búsqueda y filtrado de datos.
- Evaluación de datos.
- Almacenamiento y explotación de datos.
- Análisis y explotación de datos.
Además, como parte de este reto para incrementar las capacidades para la apertura de datos, se elaboró un listado de formaciones y guías gratuitas en materia de datos abiertos y análisis de datos. Recopilamos algunas de ellas que están disponibles online y en formato abierto.
| Institución | Recurso | Enlace | Nivel |
|---|---|---|---|
| Centro Knight para el Periodismo en las Américas | Periodismo de datos y visualización con herramientas gratuitas | https://journalismcourses.org/es/course/dataviz/ | Principiante |
| Data Europa Academy | Introducción a los datos abiertos | https://data.europa.eu/en/academy/introducing-open-data | Principiante |
| Data Europa Academy | Comprender el lado legal de los datos abiertos | https://data.europa.eu/en/academy/understanding-legal-side-open-data | Principante |
| Data Europa Academy | Mejorar la calidad de los datos abiertos y los metadatos | https://data.europa.eu/en/academy/improving-open-data-and-metadata-quality | Avanzado |
| Data Europa Academy | Medir el éxito en las iniciativas de datos abiertos | https://data.europa.eu/en/training/elearning/measuring-success-open-data-initiatives | Avanzado |
| Escuela de Datos | Curso de tubería de datos – Data Pipeline | https://escueladedatos.online/curso/curso-tuberia-de-datos-data-pipeline/ | Intermedio |
| FEMP | Guía estratégica para su puesta en marcha – Conjuntos de datos mínimos a publicar | https://redtransparenciayparticipacion.es/download/guia-estrategica-para-su-puesta-en-marcha-conjuntos-de-datos-minimos-a-publicar/ | Intermedio |
| Datos.gob.es | Pautas metodológicas para la apertura de datos | /es/conocimiento/pautas-metodologicas-para-la-apertura-de-datos | Principiante |
| Datos.gob.es | Guía práctica para la publicación de datos abiertos usando APIs | /es/conocimiento/guia-practica-para-la-publicacion-de-datos-abiertos-usando-apis | Intermedio |
| Datos.gob.es | Guía práctica para la publicación de datos espaciales | /es/conocimiento/guia-practica-para-la-publicacion-de-datos-espaciales | Intermedio |
| Junta de Andalucía | Tratar conjuntos de datos con Open Refine | https://www.juntadeandalucia.es/datosabiertos/portal/tutoriales/usar-openrefine.html | Principiante |
Figura 1. Tabla de elaboración propia con recursos formativos. Fuente: https://encuentrosdatosabiertos.es/wp-content/uploads/2024/05/Reto-2.pdf
El Instituto Nacional de Administración Pública (INAP) cuenta con un Programa de Actividades Formativas para 2025, enmarcado en la Estrategia de Aprendizaje del INAP 2025-2028. Este catálogo formativo incluye más de 180 actividades organizadas en diferentes programas de aprendizaje, que se desarrollarán a lo largo del año con el objetivo de fortalecer las competencias del personal público en ámbitos clave como la gestión de datos abiertos y el uso de tecnologías relacionadas.
En el programa formativo de INAP para 2025 se ofrece una amplia variedad de cursos orientados a mejorar las capacidades digitales y la alfabetización en datos abiertos. Algunas de las formaciones destacadas incluyen:
- Fundamentos y herramientas del análisis de datos.
- Introducción a SQL de Oracle.
- Datos abiertos y reutilización de la información.
- Análisis y visualización de datos con Power BI.
- Blockchain: aspectos técnicos.
- Programación en Python avanzado.
Estos cursos, dirigidos a distintos perfiles de empleados públicos, desde responsables de datos abiertos hasta técnicos en gestión de información, permiten adquirir conocimientos sobre extracción, tratamiento y visualización de datos, así como sobre estrategias para la apertura y reutilización de datos abiertos en la Administración Pública. Puedes consultar el catálogo completo aquí.
Otras referencias formativas
Algunas administraciones públicas o entidades disponen de oferta de cursos de formación vinculadas a los datos abiertos. Para más información de su oferta formativa, se facilita el catálogo con la oferta de cursos programados.
- Red de entidades locales por la Transparencia y la Participación Ciudadana de la FEMP: https://redtransparenciayparticipacion.es/
- Gobierno de Aragón. Aragón Open Data: https://opendata.aragon.es/informacion/eventos-de-datos-abiertos
- Escuela de Administración Pública de Catalunya (EAPC): https://eapc.gencat.cat/ca/inici/index.html
- Diputació de Barcelona: http://aplicacions.diba.cat/gestforma/public/cercador_baf_ens_locals
- Instituto Geográfico Nacional (IGN): https://cursos.cnig.es/
En resumen, la formación en competencias digitales, en general, y en datos abiertos, en particular, es una práctica que recomendamos desde datos.gob.es. ¿Necesitas algún recurso formativo en específico? Escríbenos en comentarios, ¡te leemos!
Blog
La inteligencia artificial (IA) de código abierto es una oportunidad para democratizar la innovación y evitar la concentración de poder en la industria tecnológica. Sin embargo, su desarrollo depende en gran medida de la disponibilidad de conjuntos de datos de alta calidad y de la implementación de marcos sólidos de gobernanza de datos. Un informe reciente de Open Future y la Open Source Initiative (OSI) analiza los desafíos y oportunidades en esta intersección, proponiendo soluciones para una gobernanza de datos equitativa y responsable. Puedes leer aquí el informe completo.
En este post, analizaremos las ideas más relevantes del documento, así como los consejos que ofrece para garantizar una correcta y efectiva gobernanza de datos en la inteligencia artificial open source y aprovechar todas sus ventajas.
Los retos de la gobernanza de datos en la IA
A pesar de la gran cantidad de datos disponibles en la web, su acceso y uso para entrenar modelos de IA plantean importantes desafíos éticos, legales y técnicos. Por ejemplo:
- Equilibrio entre apertura y derechos: en línea con el Reglamento de Gobernanza de Datos (DGA), se debe garantizar un acceso amplio a los datos sin comprometer derechos de propiedad intelectual, privacidad y equidad.
- Falta de transparencia y estándares de apertura: es importante que los modelos etiquetados como “abiertos” cumplan con criterios claros de transparencia en el uso de datos.
- Sesgos estructurales: muchos conjuntos de datos reflejan sesgos lingüísticos, geográficos y socioeconómicos que pueden perpetuar desigualdades en los sistemas de IA.
- Sostenibilidad ambiental: el uso intensivo de recursos para entrenar modelos de IA plantea desafíos de sostenibilidad que deben abordarse con prácticas más eficientes.
- Involucrar a más actores: actualmente, los desarrolladores y las grandes corporaciones dominan la conversación sobre IA, dejando fuera a comunidades afectadas y organizaciones públicas.
Una vez identificados los retos, el informe propone una estrategia para alcanzar el objetivo principal: una gobernanza de datos adecuada en los modelos de IA de código abiertos. Este enfoque está basado en dos pilares fundamentales.
Hacia un nuevo paradigma de gobernanza de datos
En la actualidad, el acceso y la gestión de los datos para entrenar modelos de IA están marcados por una creciente desigualdad. Mientras algunas grandes corporaciones tienen acceso exclusivo a vastos repositorios de datos, muchas iniciativas de código abierto y comunidades marginadas carecen de los recursos para acceder a datos representativos y de calidad. Para abordar este desequilibrio es necesario un nuevo enfoque en la gestión y uso de los datos en la IA de código abierto. El informe destaca dos cambios fundamentales en la manera en que se concibe la gobernanza de datos:
Por un lado, adoptar un enfoque de data commons que no es más que un modelo de acceso que garantiza el equilibrio entre la apertura de datos y la protección de derechos. Para ello, sería importante utilizar licencias innovadoras que permitan compartir datos sin explotación indebida. También es relevante crear estructuras de gobernanza que regulen el acceso y uso de datos. Y, por último, implementar mecanismos de compensación para comunidades cuyos datos son utilizados en inteligencia artificial.
Por otro lado, es necesario trascender la visión centrada en desarrolladores de IA e incluir a más actores en la gobernanza de datos, como:
- Propietarios de los datos y comunidades que generan contenido.
- Instituciones públicas que pueden promover estándares de apertura.
- Organizaciones de la sociedad civil que velen por la equidad y el acceso responsable a los datos.
Al adoptar estos cambios, la comunidad de IA podrá establecer un sistema más inclusivo, en el que los beneficios del acceso a datos se distribuyan de manera equitativa y respetuosa con los derechos de todas las partes interesadas. Según el informe, la implementación de estos modelos no solo aumentará la cantidad de datos disponibles para la IA de código abierto, sino que también fomentará la creación de herramientas más justas y sostenibles para la sociedad en su conjunto.
Consejos y estrategia
Para hacer efectiva una gobernanza de datos robusta en la IA de código abierto, el informe propone seis áreas de acción prioritarias:
- Preparación y trazabilidad de datos: mejorar la calidad y documentación de los conjuntos de datos.
- Mecanismos de licenciamiento y consentimiento: permitir a los creadores de datos definir su uso de manera clara.
- Custodia de datos: fortalecer la figura de intermediarios que gestionen datos de forma ética.
- Sostenibilidad ambiental: reducir el impacto del entrenamiento de IA con prácticas eficientes.
- Compensación y reciprocidad: garantizar que los beneficios de la IA lleguen a quienes contribuyen con datos.
- Intervenciones de política pública: promover regulaciones que incentiven la transparencia y el acceso equitativo a datos.

La inteligencia artificial de código abierto puede impulsar la innovación y la equidad, pero para lograrlo es necesario un enfoque de gobernanza de datos más inclusivo y sostenible. Adoptar modelos de datos comunes y ampliar el ecosistema de actores permitirá construir sistemas de IA más justos, representativos y responsables con el bien común.
El informe que publican Open Future y Open Source Initiative hace una llamada a la acción a desarrolladores, legisladores y sociedad civil para establecer normas compartidas y soluciones que equilibren la apertura de datos con la protección de derechos. Con una gobernanza de datos sólida, la IA de código abierto podrá cumplir su promesa de servir al interés público.
Noticia
El Encuentro Nacional de Datos Abiertos (ENDA) es una iniciativa que nace en 2022 del esfuerzo conjunto de la Diputación de Barcelona, el Gobierno de Aragón y la Diputación de Castellón. Su objetivo es ser un espacio para el intercambio de ideas y reflexiones de las administraciones para identificar y elaborar propuestas concretas con el fin de fomentar una reutilización de los datos abiertos de calidad que permita aportar un valor concreto en la mejora de las condiciones de vida de los ciudadanos.
Una peculiaridad importante que hay que destacar de la iniciativa de Encuentros es que fomenta un ciclo anual de trabajo colaborativo, donde se plantean retos y se trabaja en conjunto para encontrar soluciones. Estos retos, propuestos por los organizadores, se desarrollan a lo largo del año de la mano de voluntarios ligados al ámbito de los datos, la mayoría pertenecientes al mundo académico y de la Administración pública.
Hasta el momento se han trabajado tres retos. Las conclusiones de los retos trabajados son presentadas durante cada evento anual y la documentación generada es pública.
RETO 1.- Generar intercambios de datos y facilitar su apertura
En el primer ENDA (celebrado en Barcelona, noviembre 2022) se realizó una votación sobre los datos cuya apertura debería ser prioritaria. A partir de los resultados de esta votación, el grupo de trabajo del Reto 1 realizó un esfuerzo para recoger estándares, normativas, fuentes de los datos y sus responsables, así como casos de publicación y reutilización.
El objetivo de este reto era favorecer la colaboración interadministrativa para generar intercambios de datos y facilitar su apertura, identificando conjuntos de datos sobre los que trabajar para impulsar su calidad, el uso de estándares y sus posibilidades de reutilización.
- Material del Reto 1: Favorecer la colaboración interadministrativa para generar intercambios de datos y facilitar su apertura presentado en el segundo ENDA (Zaragoza, septiembre 2023)
RETO 2.- Incrementar las capacidades para la apertura de datos
El Reto 2 tenía por objetivo conseguir que los trabajadores y trabajadoras del sector público desarrollen conocimientos y habilidades necesarias para impulsar la divulgación de los datos abiertos. El objetivo final era mejorar las políticas públicas incorporando a la ciudadanía y a las empresas en todo el proceso de apertura.
Por ello, el grupo de trabajó definió perfiles y roles necesarios para la apertura de datos, recogiendo información sobre sus funciones y las capacidades y conocimientos necesarios.
Además, se recogió un listado de formaciones gratuitas en materia de datos abiertos y análisis de datos, enlazando estas con los perfiles para los que podrían estar orientadas.
- Documento del Reto 2: Capacidades para la apertura de datos
RETO 3.- Cómo medir el impacto de los datos abiertos
El reto 3 quería dar respuesta a la necesidad de conocer el impacto de los datos abiertos. Por ello, a lo largo del año, se trabajó en una propuesta metodológica para la realización de un mapeo sistemático de iniciativas que traten de medir el impacto de los datos abiertos.
En el tercer ENDA (Peñíscola, mayo 2024) se presentó, como resultado del grupo de trabajo, un auto test para que las entidades locales midan el impacto de la publicación de datos abiertos.
Las respuestas a estos retos han sido posibles gracias a la colaboración y el trabajo conjunto, que ha dado como resultado documentos y herramientas concretas de gran ayuda para otros organismos públicos que quieran avanzar en su estrategia de datos abiertos. Durante los próximos años se seguirá trabajando en nuevos retos, con el fin de impulsar aún más la apertura de datos de calidad y su reutilización en beneficio de toda la sociedad.
Evento
Alicante acogerá los próximos días 9 y 10 de noviembre el Summit 2023 de Gaia-X, en el que se llevará a cabo un repaso sobre los últimos progresos realizados por esta iniciativa en la promoción de la soberanía de datos en Europa. La interoperabilidad, transparencia y el cumplimiento normativo adquieren una dimensión práctica a través del intercambio y explotación de datos articulados bajo un entorno de nube confiable.
También se abordarán las relaciones establecidas con líderes del sector, expertos, empresas, gobiernos, instituciones académicas y organizaciones varias, facilitando el intercambio de ideas y experiencias entre los diversos grupos de interés involucrados en la transformación digital europea. El evento contará con conferencias magistrales, talleres interactivos y mesas redondas, en las que se explorarán las posibilidades ilimitadas de los ecosistemas digitales cooperativos, y de un futuro próximo en el que los datos se hayan convertido en un activo de alto valor añadido.
Este evento está organizado por la asociación europea Gaia-X, en colaboración con el Hub español de Gaia-X. Cuenta también con la participación de la Oficina del Dato, dependiente de la Secretaría de Estado de Digitalización e Inteligencia Artificial, y se desarrolla bajo los auspicios de la presidencia española del Consejo de la Unión Europea.
La iniciativa Gaia-X busca garantizar que los datos sean almacenados y procesados de manera segura y soberana, respetando las regulaciones europeas, además de fomentar la colaboración entre diferentes y heterogéneos actores, como empresas, gobiernos y organizaciones. Así, Gaia-X promueve la innovación y el desarrollo económico basado en datos en Europa. Por tanto, la relación abierta en colaboración con la Unión Europea resulta fundamental para la consecución de sus objetivos.
La soberanía digital: una Europa adaptada a la era de los datos
Como para Gaia-X, uno de los grandes objetivos de la Unión Europea es el de fomentar la soberanía digital a lo largo de todo su territorio. Para ello, promueve el desarrollo de industrias y tecnologías clave para su competitividad y seguridad, fortalece sus relaciones comerciales y cadenas de suministro, y mitiga dependencias externas, concentrándose en la reindustrialización de su territorio y en asegurar su autonomía digital estratégica.
El concepto de soberanía digital abarca distintas dimensiones: tecnológica, regulatoria y socioeconómica. La dimensión tecnológica se refiere al hardware, software, nube e infraestructura de redes utilizados para acceder, procesar y almacenar datos. Mientras, la dimensión regulatoria se refiere a las normas que proporcionan seguridad jurídica a los ciudadanos, empresas e instituciones que operan en un ámbito digital. Finalmente, la dimensión socioeconómica se enfoca en las iniciativas empresariales y los derechos individuales en el nuevo entorno digital global. Para avanzar en todas estas dimensiones, la UE se apoya en proyectos como Gaia-X.
La iniciativa busca crear ecosistemas federados, abiertos, seguros y transparentes, donde los conjuntos y servicios de datos cumplen una serie mínima de reglas comunes que les permiten así ser reutilizables bajo entornos de confianza y transparencia. A su vez, esto habilita la creación de ecosistemas de datos confiables de alta calidad, con que las organizaciones europeas podrán impulsar su proceso de digitalización, mejorando las cadenas de valor a lo largo de diferentes sectores industriales. Estas cadenas de valor, desplegadas digitalmente sobre entornos de nube federada y confiable (“Trusted Cloud”), gozan de trazabilidad y transparencia, y sirven por tanto para impulsar los esfuerzos de cumplimiento normativo y soberanía digital.
En resumen, este enfoque se basa en aprovechar y reforzar unos valores reflejados en un marco regulatorio en desarrollo que busca incorporar conceptos como la confianza y la gobernanza en los entornos de datos. Esto busca convertir la UE en líder de una sociedad y economía donde la digitalización sea vector para reindustrializarnos y prosperar, pero siempre bajo el marco de unos valores que nos definen.
Se puede acceder al programa completo de este Summit desde la página oficial de la asociación europea: https://gaia-x.eu/summit-2023/agenda/.