Noticia
El pasado mes de julio comenzó la décima legislatura del Parlamento Europeo, un nuevo ciclo institucional que abarcará el periodo 2024-2029. La Presidenta de la Comisión Europea, Ursula von der Leyen, fue elegida para un segundo mandato, tras presentar al Parlamento Europeo sus Orientaciones Políticas para la próxima Comisión Europea 2024-2029.
Estas orientaciones establecen las prioridades que guiarán las políticas europeas en los próximos años. Entre los objetivos generales, encontramos que se invertirán esfuerzos en:
- Facilitar los negocios y fortalecer el mercado único.
- Descarbonizar y reducir los precios de la energía.
- Hacer que la investigación y la innovación sean los motores de la economía.
- Impulsar la productividad mediante la difusión de la tecnología digital.
- Invertir masivamente en competitividad sostenible.
- Subsanar la brecha en materia de capacidades y mano de obra.
En este artículo, nos vamos a centrar en desgranar el punto 4, centrado en combatir la insuficiente difusión de las tecnologías digitales. El desconocimiento de las posibilidades tecnológicas al alcance de la ciudadanía limita la capacidad de desarrollar nuevos servicios y modelos de negocio competitivos a nivel mundial.
Impulsar la productividad con la difusión de la tecnología digital
El mandato anterior estuvo marcado por la aprobación de nuevas regulaciones encaminadas a impulsar una economía digital justa y competitiva a través de un mercado único digital, donde la tecnología se situase al servicio de las personas. Ahora, es el momento de poner el foco en la aplicación y el cumplimiento de las leyes digitales adoptadas.
Una de las normativas de más reciente aprobación ha sido el Reglamento de Inteligencia Artificial (IA), un marco de referencia para el desarrollo de cualquier sistema IA. En esta norma, el foco estaba puesto en garantizar la seguridad y fiabilidad de la inteligencia artificial, evitando sesgos a través de diversas medidas entre las que se encontraba una gobernanza sólida de datos.
Una vez que ya contamos con este marco, ha llegado el momento de impulsar el uso de esta tecnología en pro de la innovación. Para ello, en este nuevo ciclo, se fomentarán los siguientes aspectos:
- Factorías de inteligencia artificial. Se trata de ecosistemas abiertos que ofrecen una infraestructura de servicios de supercomputación de inteligencia artificial. De esta forma se ponen grandes capacidades tecnológicas a disposición de empresas emergentes y comunidades de investigación.
- Estrategia de uso de la inteligencia artificial. Se busca impulsar usos industriales en diversos sectores, incluyendo la prestación de servicios públicos en áreas como la atención sanitaria. Para elaborar esta estrategia se contará con la visión de la industria y la sociedad civil.
- Consejo europeo de investigación sobre inteligencia artificial. Este organismo ayudará a poner en común los recursos de la Unión Europea (UE), facilitando el acceso a los mismos.
Pero para que sea posible desarrollar estas medidas, primero es necesario garantizar el acceso a datos de calidad. Estos datos no solo favorecen el entrenamiento de los sistemas IA y el desarrollo de productos y servicios tecnológicos de vanguardia, sino que también ayudan a la toma de decisiones informada y a la elaboración de estrategias políticas y económicas más certeras. Como dice el propio documento “el acceso a los datos no solo es un motor importante de la competitividad que representa casi el 4 % del PIB de la UE, sino que también es esencial para la productividad y las innovaciones sociales, desde la medicina personalizada hasta el ahorro de energía”.
Para mejorar el acceso a los datos de las empresas europeas y mejorar su capacidad competitiva con respecto a los grandes actores tecnológicos mundiales, la Unión Europea apuesta por la “mejora del acceso a los datos abiertos”, garantizando, al mismo tiempo, la más estricta protección de datos.
La revolución de los datos europea
“Europa necesita una revolución de los datos”. Así de tajante se muestra la Presidenta ante la situación actual. Por ello, una de las medidas en las que se trabajará es en una nueva Estrategia de datos de la Unión Europea. Esta estrategia se basará en las normas existentes actualmente. Es previsible que se tome como referencia la actual estrategia, entre cuyas líneas de acción se encuentra el fomento del intercambio de información a través de la creación de un mercado único de datos donde los datos puedan fluir entre países y sectores económicos de la UE.
En este marco seguirán muy presentes los avances legislativos que vimos en la última legislatura:
- Directiva (UE) 2019/1024 relativa a los datos abiertos y la reutilización de la información del sector público, que establece el marco jurídico para la reutilización de la información del sector público, puesta a disposición del público como datos abiertos, incluyendo el fomento de los datos de alto valor.
- Reglamento (UE) 2022/868 relativo a la gobernanza europea de datos (DGA en sus siglas en inglés), que regula el intercambio seguro y voluntario de conjuntos de datos que están bajo el poder de organismos públicos sobre los que concurren derechos de terceros, así como los servicios de intermediación de datos y su cesión altruista.
- Reglamento (UE) 2023/2854 sobre normas armonizadas para un acceso justo a los datos y su utilización (Data Act), que impulsa reglas armonizadas relativas al acceso y uso equitativo de los datos en el marco de la Estrategia Europea.
Con todo ello, se busca garantizar un “marco simplificado, claro y coherente para que las empresas y las administraciones compartan datos sin fisuras y a gran escala, respetando al mismo tiempo normas estrictas de privacidad y seguridad”.
Además de intensificar la inversión en tecnologías punteras, como la supercomputación, el internet de las cosas o la computación cuántica, la Unión Europea tiene entre sus planes continuar impulsando el acceso a datos de calidad que ayuden a generar un ecosistema tecnológico sostenible y solvente, capaz de competir con las grandes empresas mundiales. En este espacio iremos informando de las medidas tomadas con este fin.
Blog
El Informe Europeo sobre Drogas proporciona una visión actual de la situación de las drogas en la región, analizando las principales tendencias y amenazas emergentes. Se trata de una publicación de gran valor, con un alto número de descargas, que se cita en múltiples medios de comunicación.
El informe se realiza de forma anual por la Agencia de la Unión Europea sobre Drogas (EUDA en sus siglas en inglés), nombre actual del antiguo Observatorio Europeo de las Drogas y las Toxicomanías. Este organismo recopila y analiza datos de los Estados miembros de la Unión Europea, junto con otros países asociados, como son Turquía y Noruega, para proporcionar una visión integral del consumo y oferta de drogas, los daños que producen y las intervenciones de reducción de daños. El informe contiene conjuntos completos de datos sobre estos temas desagregados a nivel nacional, e incluso, en algunos casos, a nivel de ciudad (como Barcelona o Palma de Mallorca).
Este estudio lleva realizándose desde 1993 y traduciéndose a más de 20 idiomas oficiales de la Unión Europea. No obstante, en los dos últimos años ha presentado una novedad: un cambio en los procesos internos para mejorar la visualización de los datos obtenidos. Un proceso que han explicado en el reciente webinar “El Informe Europeo sobre las Drogas: uso de un enfoque de datos abiertos para mejorar la visualización de datos”, organizado por el Portal de Datos Abiertos Europeo (data.europa.eu) el pasado 25 de junio. A continuación, se resume lo que contaron los representantes del Observatorio en esta cita.
La necesidad de un cambio
El Observatorio siempre ha trabajado con datos abiertos, pero el proceso presentaba ineficiencias. Hasta ahora el Informe Europeo sobre Drogas se había publicado siempre en formato PDF, poniendo el foco en conseguir un producto visualmente llamativo. El proceso interno previo a la publicación del informe consistía en varias etapas que involucraban a diversos equipos:
- Un equipo del Observatorio comprobaba el formato de los datos recibidos por parte del proveedor y, si era necesario, los adaptaba.
- Un equipo especializado en análisis de datos creaba visualizaciones a partir de los datos.
- Un equipo especializado en redacción redactaba el informe. El equipo que había creado las visualizaciones podía colaborar en esta fase.
- Un equipo interno validaba el contenido del reporte.
- El proveedor de los datos revisaba que el Observatorio había intepretado los datos correctamente.
A pesar del buen recibimiento del informe y su formato, en 2022 el Observatorio decidió cambiar completamente el formato de publicación por los siguientes motivos:
- Una vez iniciados los distintos pasos del proceso de publicación, los datos se formateban y dejaban de ser legibles por una máquina. Esto reducía la acessibilidad de los datos, por ejemplo, para lectores de pantalla, y limitaba su capacidad de reutilización.
- Si en los distintos pasos del proceso se detectaban errores, se corregían directamente sobre el formato que tenían los datos en este paso. Es decir, si en la fase de revisión se detectaba un error en un gráfico, se corregía directamente sobre dicho gráfico. Este procedimiento podía causar errores y opacar la trazabilidad de los datos, limitando la eficiencia: un mismo gráfico estático podía estar presente varias veces en el documento y cada mención se tenía que corregir individualmente.
- Al final del proceso se tenía que ajustar el formato de los datos de origen, por los cambios realizados en el procedimiento de publicación.
- Muchos de los usuarios que consultaban el informe lo hacían desde un dispositivo móvil, para el cual el formato del PDF no siempre era adecuado.
- Al no ser accesibles ni aptos para dispositivos moviles, los documentos en formato PDF no solían aparecer como primer resultado en los motores de búsqueda. Este punto es importante para el Observatorio, ya que muchos de los usuarios encuentran el informe a través de buscadores.
Era necesario un formato web responsive, que ajustara automáticamente el sitio web al tamaño y disposición de los dispositivos de sus usuarios. Con ello se buscaba:
- Una mejora de la accesibilidad.
- Un proceso de creación de visualizaciones más ágil.
- Un proceso de traducción más fácil.
- Un aumento de visitantes procedentes de motores de búsqueda.
- Un mayor modularidad.
El proceso detrás del nuevo informe
Con el fin de transformar por completo el formato de publicación del informe, se ha llevado a cabo un proceso de visualización diseñado ad hoc, resumido en la siguiente imagen:
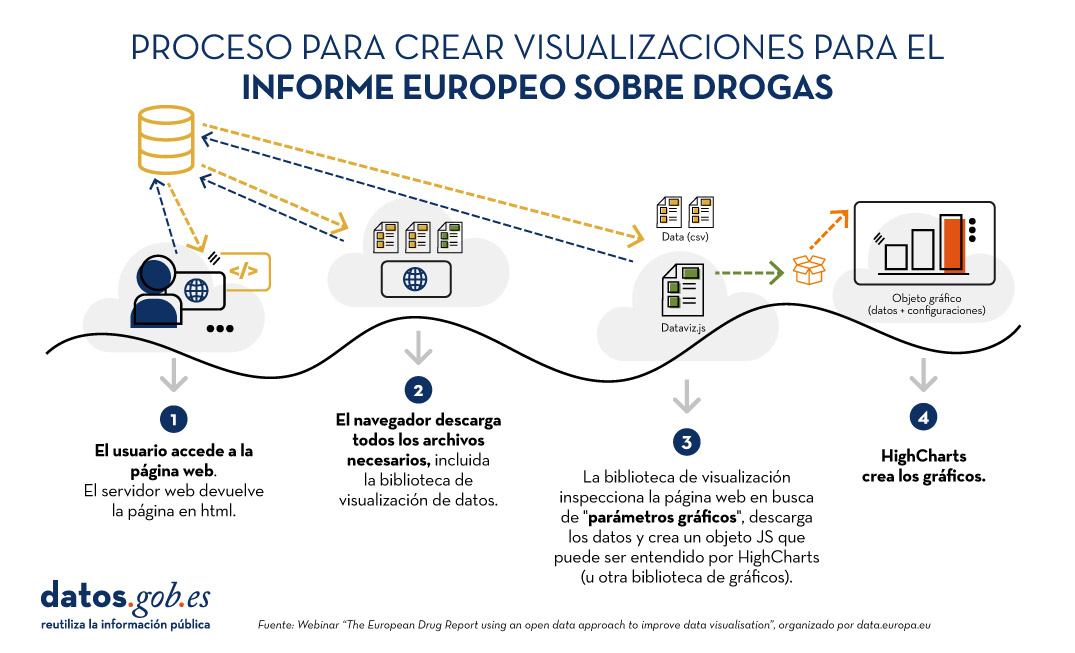
Figura 1. Proceso para crear visualizaciones para el Informe Europeo sobre Drogas. Fuente ES: Webinar “The European Drug Report using an open data approach to improve data visualisation”, organizado por data.europa.eu.
La principal novedad es que las visualizaciones se crean dinámicamente a partir de los datos fuente. De esta forma, si se modifica algo en dichos datos, automáticamente se cambia en todas las visualizaciones que se alimentan de ellos. Mediante el sistema de gestión de contenidos Drupal, en el que está basada gran parte de la web, los administradores pueden registrar cambios que automáticamente se reflejarán en el HTML y, por lo tanto, en las visualizaciones. Además, los administradores de la página disponen de un generador de visualizaciones que crea visualizaciones sin necesidad de tocar código, a partir de los datos e indicaciones -que equivalen a instrucciones sencillas como “ordenar de mayor a menor”, expresados mediante HTML-.
El mismo procedimiento dinámico de actualización se aplica al PDF que el usuario puede descargar. Si hay cambios en los datos, en las visualizaciones o se corrigen errores tipográficos, el PDF se genera nuevamente a través de un proceso de compilación que el Observatorio ha creado específicamente para esta tarea.
El informe después del cambio
Actualmente el informe se publica en versión HTML, con la posibilidad de descargar capítulos o el informe completo en formato PDF. Está estructurado por módulos temáticos y también permite la consulta de anexos.
Además, los datos siempre se publican en formato CSV y se indica en la misma página las condiciones de licencia de los datos (CC-BY-4.0). La referencia de la fuente de los datos siempre se pone a disposición del lector en la misma página en la que está una visualización.
Con este cambio de procedimiento y formato, se han conseguido beneficios para todos. Desde el punto de vista de los lectores, se ha mejorado la experiencia del usuario. Para la organización, se ha agilizado el proceso de publicación.
En cuanto a datos abiertos, este nuevo enfoque permite una mayor trazabilidad, ya que se puede consultar en cada momento los datos en su formato actual. Además, según los ponentes del Observatorio, este nuevo formato del informe, junto con el hecho de que los datos y visualizaciones siempre están actualizados, ha aumentado la accesibilidad de los datos para medios de comunicación.
Puedes acceder a los materiales del webinar aquí:
Blog
La publicación el viernes 12 de julio de 2024 del Reglamento de Inteligencia Artificial (RIA o AIA en sus siglas en inglés) abre una nueva etapa en el marco regulatorio europeo y global. La norma se caracteriza por tratar de conjugar dos almas. De un lado se trata de asegurar que la tecnología no genere riesgos sistémicos para la democracia, la garantía de nuestros derechos y el ecosistema socioeconómico en su conjunto. De otro lado, se busca un enfoque orientado al desarrollo de producto de modo que responda a los altos estándares de fiabilidad, seguridad y cumplimiento normativo definidos por la Unión Europea.
Ámbito de aplicación de la norma
La norma permite diferenciar entre sistemas de bajo y medio riesgo, sistemas de alto riesgo y modelos de IA de uso general. Para calificar los sistemas, el RIA define criterios relacionados con el sector regulado por la Unión Europea (Anexo I) y define el contenido y alcance de aquellos sistemas que por su naturaleza y finalidad podrían generar riesgos (Anexo III). Los modelos son altamente dependientes del volumen de datos, sus capacidades y la carga operacional.
El RIA solo afecta a los dos últimos casos: sistemas de alto riesgo y modelos de IA de uso general. Los sistemas de alto riesgo exigen la evaluación de la conformidad a través de organismos notificados. Estos son entidades ante las que se presentan evidencias de que el desarrollo se ajusta al RIA. En este sentido, los modelos están sujetos a fórmulas de control por la Comisión que aseguran la prevención de riesgos sistémicos. No obstante, estamos ante un marco normativo flexible que favorece la investigación, relajando su aplicación en entornos de experimentación, así como mediante el despliegue de sandboxes para el desarrollo.
La norma establece una serie de “requisitos de los sistemas de IA de alto riesgo” (sección segunda del capítulo tercero) que deberían constituir un marco de referencia para el desarrollo de cualquier sistema e inspirar los códigos de buenas prácticas, normas técnicas y esquemas de certificación. Entre ellos, ocupa un lugar central el artículo 10 sobre “datos y gobernanza de datos”. Este proporciona indicaciones muy precisas sobre las condiciones de diseño de los sistemas de IA, particularmente cuando supongan tratar datos personales o cuando se proyecten sobre personas físicas.
Esta gobernanza debería considerarse por quienes proporcionen la infraestructura básica y/o los conjuntos de datos, gestionen espacios de datos o los llamados Digital Innovation Hubs, que ofrezcan servicios de soporte. En nuestro ecosistema, caracterizado por una alta prevalencia de PYMEs y/o equipos de investigación, la gobernanza de datos se proyecta sobre la calidad, seguridad y fiabilidad en sus acciones y resultados. Por ello es necesario asegurar los valores que el RIA impone a los conjuntos de datos de entrenamiento, validación y prueba en sistemas de alto riesgo y, en su caso, cuando se empleen técnicas que impliquen el entrenamiento de modelos de IA.
Estos valores pueden alinearse con los principios del artículo 5 del Reglamento General de Protección de Datos (RGPD) y los enriquecen y complementan. A ellos se añade el enfoque de riesgo y la protección de datos desde el diseño y por defecto. Relacionar unos y otros constituye un ejercicio sin duda interesante.
Garantizar el origen legítimo de los datos: Lealtad y licitud
Junto a la referencia común a la cadena de valor asociada a los datos, hay que referirse a una cadena de custodia que garantice la legalidad en los procesos de recogida de datos. El origen de los datos, particularmente en el caso de los datos personales, debe ser lícito, legítimo y su uso coherente con la finalidad original de su recogida. Por ello es indispensable una adecuada catalogación de los conjuntos de datos en origen que asegure una correcta descripción de su legitimidad y condiciones de uso.
Esta es una cuestión que afecta a los entornos de open data, a los organismos y servicios de acceso a datos detallados en el Reglamento de gobernanza de datos (DGA en sus siglas en inglés) o el Espacio Europeo de Datos de Salud (EHDS) y a buen seguro inspirará futuras regulaciones. Lo usual será combinar fuentes externas de datos con la información que maneja la PYME.
Minimización de los datos, exactitud y limitación de finalidad
El RIA ordena, de una parte, realizar una evaluación de la disponibilidad, la cantidad y la adecuación de los conjuntos de datos necesarios. De otra, exige que los conjuntos de datos de entrenamiento, validación y prueba sean pertinentes, suficientemente representativos y posean las propiedades estadísticas adecuadas. Esta tarea es muy relevante para los derechos de las personas o los colectivos afectados por el sistema. Además, en la mayor medida posible, carecerán de errores y estarán completos en vista de su finalidad prevista. RIA predica estas propiedades para cada conjunto de datos individualmente o para una combinación de estos.
Para la consecución de tales objetivos resulta necesario asegurar el despliegue de las técnicas adecuadas:
- Realizar las operaciones de tratamiento oportunas para la preparación de los datos, como la anotación, el etiquetado, la depuración, la actualización, el enriquecimiento y la agregación.
- Formular supuestos, en particular en lo que respecta a la información que se supone que miden y representan los datos. O, dicho en un lenguaje más coloquial, definir los casos de uso.
- Tener en cuenta, en la medida necesaria para la finalidad prevista, las características o elementos particulares del entorno geográfico, contextual, conductual o funcional específico en el que está previsto que se utilice el sistema de IA de alto riesgo.
Gestionar el riesgo: evitar el sesgo
En el ámbito de la gobernanza de los datos se atribuye un papel esencial a la evitación del sesgo cuando pueda generar riesgos para la salud y la seguridad de las personas, afectar negativamente a los derechos fundamentales o dar lugar a algún tipo de discriminación prohibida por el Derecho de la Unión, especialmente cuando las salidas de datos influyan en las informaciones de entrada de futuras operaciones. Para ello procede adoptar las medidas adecuadas para detectar, prevenir y mitigar posibles sesgos detectados.
El RIA habilita excepcionalmente el tratamiento de categorías especiales de datos personales siempre que ofrezcan las garantías adecuadas en relación con los derechos y las libertades fundamentales de las personas físicas. Pero impone condiciones adicionales:
- que el tratamiento de otros datos, como los sintéticos o los anonimizados, no permita efectuar de forma efectiva la detección y corrección de sesgos;
- que las categorías especiales de datos personales estén sujetas a limitaciones técnicas relativas a la reutilización de los datos personales y a medidas punteras en materia de seguridad y protección de la intimidad, incluida la seudonimización;
- que las categorías especiales de datos personales estén sujetas a medidas para garantizar que los datos personales tratados estén asegurados, protegidos y sujetos a garantías adecuadas, incluidos controles estrictos y documentación del acceso, a fin de evitar el uso indebido y garantizar que solo las personas autorizadas tengan acceso a dichos datos personales con obligaciones de confidencialidad adecuadas;
- que las categorías especiales de datos personales no se transmitan ni transfieran a terceros y que estos no puedan acceder de ningún otro modo a ellos;
- que las categorías especiales de datos personales se eliminen una vez que se haya corregido el sesgo o los datos personales hayan llegado al final de su período de conservación, si esta fecha es anterior;
- que los registros de las actividades de tratamiento con arreglo a los Reglamentos (UE) 2016/679 y (UE) 2018/1725 y la Directiva (UE) 2016/680 incluyan las razones por las que el tratamiento de categorías especiales de datos personales era estrictamente necesario para detectar y corregir sesgos, y por las que ese objetivo no podía alcanzarse mediante el tratamiento de otros datos.
Las previsiones normativas resultan extraordinariamente interesantes. RGPD, DGA o EHDS apuestan por tratar datos anonimizados. RIA establece una excepción en aquellos casos en los que se generan conjuntos de datos inadecuados o de baja calidad desde el punto de vista del sesgo.
Tanto los desarrolladores individuales, como los espacios de datos y los servicios de intermediación que proporcionen conjuntos de datos y/o plataformas para el desarrollo deben ser particularmente diligentes a la hora de definir su seguridad. Esta previsión es coherente con la exigencia de disponer de espacios seguros de procesamiento en EHDS, implica una apuesta por estándares certificables en seguridad, públicos o privados, y aconseja una relectura de la disposición adicional decimoséptima sobre tratamientos de datos en nuestra Ley orgánica de protección de datos en materia de seudonimización, en la medida en la que añade garantías éticas y jurídicas a las propiamente técnicas. Además, se subraya la necesidad de garantizar una adecuada trazabilidad en los usos. Adicionalmente será necesario integrar en el registro de actividades de tratamiento una mención específica a este tipo de usos y a su justificación.
Aplicar las lecciones aprendidas desde la protección de datos, desde el diseño y por defecto
El artículo 10 de RIA obliga a documentar las decisiones pertinentes relativas al diseño y a detectar lagunas o deficiencias pertinentes en los datos que impidan el cumplimiento del RIA y la forma de subsanarlas. En resumen, no basta con garantizar la gobernanza de datos, también es necesario proporcionar evidencia documental y mantener una actitud proactiva y vigilante durante todo el ciclo de vida de los sistemas de información.
Estas dos obligaciones integran la clave de bóveda del sistema. Y su lectura debería ser incluso mucho más amplia en la dimensión jurídica. Las lecciones aprendidas en el RGPD enseñan que existe una doble condición para la responsabilidad proactiva y la garantía de los derechos fundamentales. La primera es intrínseca y material: el despliegue de la ingeniería de la privacidad al servicio de la protección de datos desde el diseño y por defecto asegura el cumplimiento del RGPD. La segunda es contextual: los tratamientos de datos personales no se dan en el vacío, sino en un contexto amplio y complejo regulado por otros sectores del Ordenamiento.
La gobernanza de datos opera estructuralmente desde los cimientos a la bóveda de los sistemas de información basados en IA. Asegurar que exista, sea adecuada y funcional es esencial. Así lo ha entendido la Estrategia de Inteligencia Artificial 2024 del Gobierno de España que trata de dotar al país de esas palancas que dinamicen nuestro desarrollo.
RIA plantea un salto cualitativo y subraya el enfoque funcional desde el que deben leerse los principios de protección de datos subrayando la dimensión poblacional. Ello obliga a repensar las condiciones en las que se ha venido cumpliendo el RGPD en la Unión Europea. Urge abandonar los modelos basados en plantillas que la empresa de consultoría copia-pega. Es evidente que las listas de control y la estandarización son imprescindibles. Sin embargo, su efectividad es altamente dependiente del ajuste fino. Y ello obliga a apelar particularmente a los profesionales que soportan el cumplimiento de este objetivo a dedicar sus mayores esfuerzos para dotar de sentido profundo al cumplimiento del Reglamento de Inteligencia Artificial.
Puedes ver un resumen del reglamento en la siguiente infografía:

Puedes accerder a la versión accesible e interactiva aquí
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Desde hace un tiempo venimos escuchando hablar de los datos de alto valor (High value datasets en inglés o HVD), esos conjuntos de datos cuya reutilización está asociada a considerables beneficios para la sociedad, el medio ambiente y la economía. Se dieron a conocer en la Directiva (UE) 2019/1024 del Parlamento Europeo y del Consejo, de 20 de junio de 2019, relativa a los datos abiertos y la reutilización de la información del sector público, para posteriormente quedar definidos en el Reglamento de ejecución (UE) 2023/138 de la Comisión de 21 de diciembre de 2022 por el que se establecen una lista de conjuntos de datos específicos de alto valor y modalidades de publicación y reutilización.
En concreto se trata de seis categorías de datos: geoespacial, observación terrestre y medio ambiente, meteorología, estadística, sociedades y propiedad de sociedades, y movilidad. El detalle de estas categorías y cómo deben abrirse estos conjuntos de datos está resumido en la siguiente infografía:
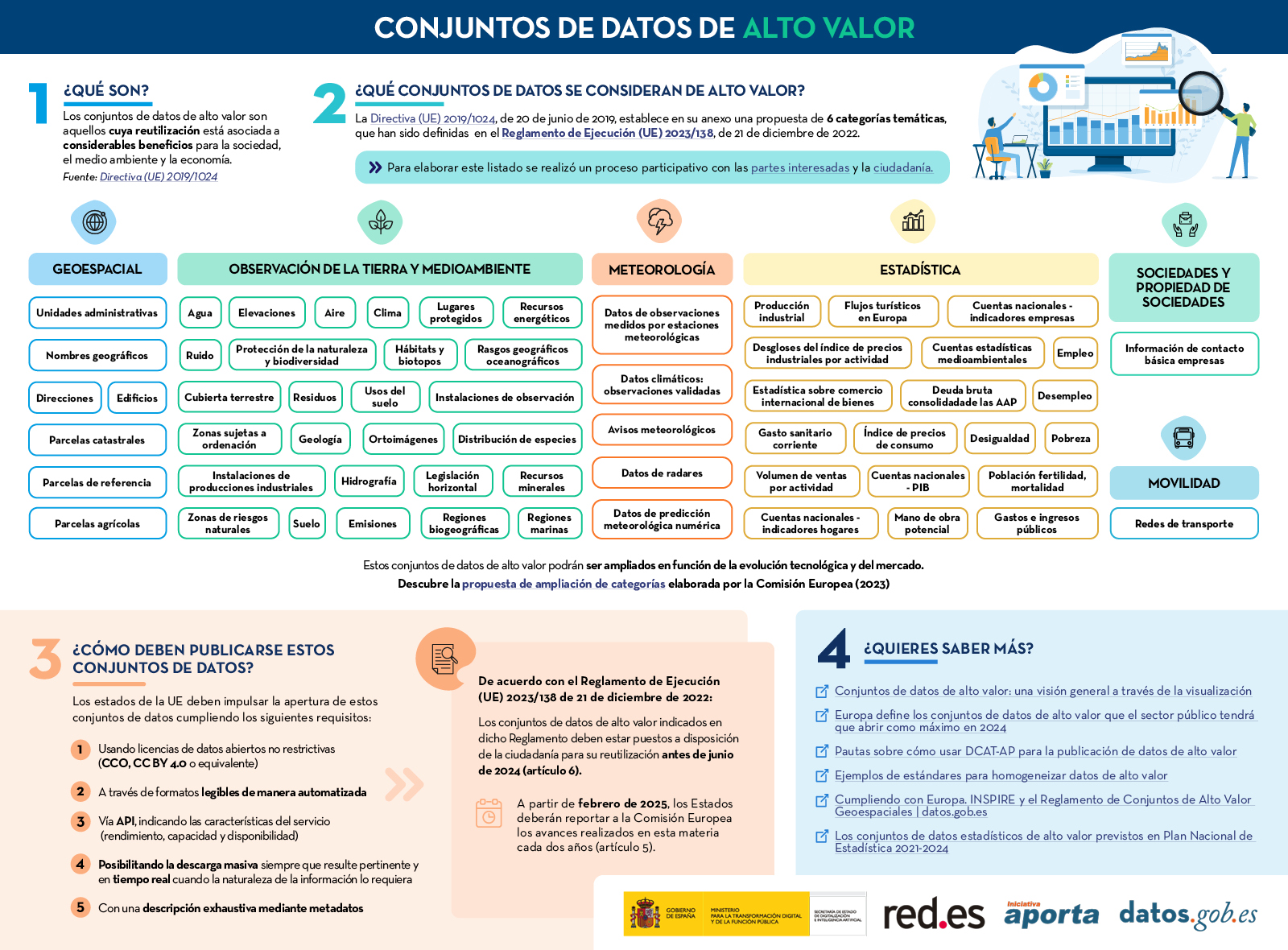
Haz clic en la imagen o aquí para ampliar y acceder a la versión accesible
Desde hace años, incluso antes de la publicación de la Directiva (UE) 2019/1024, los organismos españoles trabajan para que esta tipología de conjuntos de datos esté a disposición de desarrolladores, empresas y cualquier ciudadano que quiera hacer uso de ellos, con unas características técnicas que faciliten su reutilización. Sin embargo, el Reglamento ha fijado una serie de requisitos específicos a cumplir. A continuación, resumimos los avances llevados a cabo en cada categoría.
Datos geoespaciales
En el caso de los datos geoespaciales, el Reglamento de ejecución (UE) 2023/138 tiene en cuenta las categorías indicadas en la Directiva 2007/2/CE del Parlamento Europeo y del Consejo, de 14 de marzo de 2007, por la que se establece una infraestructura de información espacial en la Comunidad Europea (INSPIRE), a excepción de parcelas agrícolas y de referencia, para las que se aplica el Reglamento (UE) 2021/2116 del Parlamento Europeo y del Consejo, de 2 de diciembre de 2021.
La Directiva INSPIRE se cumple en España desde hace años, gracias a la Ley 14/2010 de 5 de julio sobre las infraestructuras y los servicios de información geográfica en España (LISIGE), que transpone dicha Directiva. Los ciudadanos tienen a su disposición el Catálogo Oficial de Datos y Servicios INSPIRE de España, así como los catálogos de las Infraestructuras de Datos Espaciales de las Comunidades Autónomas. Gracias a ello se ha logrado una cobertura geográfica integral, con metadatos exhaustivos, que cumple con los requisitos europeos.
- Puedes ver los datos actualmente publicados por nuesto país en esta categoría en el Geoportal de INSPIRE. En este post tienes más información al respecto.
Datos de observación de la Tierra y medio ambiente
Para la categoría de datos de observación de la Tierra y medio ambiente se tienen en cuenta, tanto los conjuntos de datos medioambientales y climáticos recogidos en los anexos de la Directiva INSPIRE, como los producidos en el contexto de una serie de actos jurídicos conocidos como datos prioritarios, detallados en el Reglamento de ejecución.
Al igual que sucedía con la categoría anterior, el hecho de contar con la ley LISIGE, que desarrolla INSPIRE y va más allá en las obligaciones marcadas, ha hecho que muchos de estos conjuntos de datos ya estuvieran disponibles antes de la aplicación del Reglamento de ejecución.
- Puedes ver los datos actualmente publicados por España en esta categoría en el Geoportal de INSPIRE y profundizar en este contenido sobre su publicación en España.
Datos meteorológicos
La categoría temática meteorológica engloba colecciones de datos sobre observaciones medidas por diversos elementos, como estaciones meteorológicas, radares, etc.
En España, la Agencia Estatal de Meteorología (AEMET) cuenta con un portal, AEMET OpenData, que fue pionero en Europa en cuanto a la disponibilidad de datos meteorológicos abiertos. En dicho portal encontramos que buena parte de los conjuntos de datos de alto valor ya están disponibles, agrupados en las 14 categorías de AEMET OpenData. Una tarea en la que se sigue trabajando para ampliar tanto los datasets disponibles como su granularidad y otros aspectos técnicos que impulsen aún más su usabilidad.
- Puedes ver una revisión más detallada de la situación actual del estado de publicación de los conjuntos de datos de esta categoría en este post.
Datos estadísticos
Los conjuntos de datos de alto valor estadístico están contemplados en una serie de actos jurídicos detallados en el anexo del Reglamento de ejecución. Esta categoría se basa en el Sistema Estadístico Europeo, que garantiza la calidad e interoperabilidad entre estados.
Alineado con dicho sistema, en España contamos con el Plan Estadístico Nacional, Este plan se desarrolla y ejecuta mediante programas anuales específicos que detallan las operaciones estadísticas, sus objetivos, organismos involucrados y créditos presupuestarios, muchas de las cuales están alineadas con los conjuntos estadísticos detallados en el Reglamento de ejecución.
- Puedes ver el detalle de la equivalencia entre los datos de alto valor y los conjuntos de datos publicados fruto del Plan Estadístico Nacional en este artículo. Además, puedes ver el detalle de los datos publicados por el Instituto Nacional de Estadística (INE) aquí.
Datos de sociedades y propiedad de sociedades
Los datos de sociedades y propiedades de sociedades hacen referencia a conjuntos de datos que contienen información básica de empresas, incluyendo documentos y cuentas de las mismas.
En España se ofrece en abierto la información del Boletín Oficial del Registro Mercantil (BORME), con cobertura temporal desde 2009. No obstante, se continúa trabajando en la apertura de más datos de esta categoría.
Datos de movilidad
La categoría de movilidad incluye conjuntos de datos que caen bajo el dominio “Redes de Transporte”, incluido en el Anexo I de la Directiva INSPIRE, junto con aquellos mencionados en la Directiva 2005/44/CE del Parlamento Europeo y del consejo, de 7 de septiembre de 2005, relativa a los servicios de información fluvial (SIF) armonizados en las vías navegables interiores de la Comunidad.
Al igual que pasaba con otras categorías donde los datos de alto valor ya estaban recogidos en la Directiva INSPIRE, España cuenta con gran cantidad de datos disponible en el Geoportal de la Infraestructura de Datos Espaciales de España (IDEE) y las infraestructuras de las Comunidades Autónomas.
- Puedes ver los datos publicados en el Geoportal de INSPIRE y el detalle de la situación actual en este contenido.
La gran cantidad de datos publicados refleja el compromiso de nuestro país con la transparencia y el acceso a datos de alto valor. Se trata de un esfuerzo continuo, fruto de la colaboración e implicación de diversos organismos. Una tarea en la que se sigue trabajando para dotar a la ciudadanía de la mayor cantidad de datos de calidad posible.
Blog
La transversalidad de los datos abiertos sobre el tiempo y el clima ha favorecido su uso en ámbitos tan diversos como la agricultura de precisión, la prevención de incendios o la industria forestal de precisión. Pero la relevancia de estos conjuntos de datos radica no solo en su aplicabilidad directa en múltiples industrias, sino también en su contribución a los retos relacionados con el cambio climático y la sostenibilidad ambiental sobre los que pretenden actuar las diferentes líneas de acción del Pacto Verde Europeo.
Los datos meteorológicos están considerados por la Comisión europea, datos de alto valor, de acuerdo con el anexo del Reglamento 2023/138. En este post te explicamos cuáles son los conjuntos de datos concretos que se consideran de alto valor y el nivel de disponibilidad de este tipo de datos en España.
La Agencia Estatal de Meteorología
En España, corresponde a la Agencia Estatal de Meteorología (AEMET) la misión de proporcionar servicios meteorológicos y climatológicos en el ámbito nacional. Como parte del Ministerio para la Transición Ecológica y el Reto Demográfico, AEMET lidera las actividades relacionadas de observación, predicción y estudio de las condiciones meteorológicas y climáticas, así como la investigación relacionada con estos ámbitos. Su misión incluye el suministro y difusión de información y predicciones esenciales de interés general. Una información que también puede servir de apoyo en ámbitos tan relevantes como la protección civil, la navegación aérea, la defensa nacional u otros sectores de actividad.
Para cumplir esta misión, la AEMET gestiona un portal de datos abiertos que habilita la reutilización por parte de personas físicas o jurídicas, con fines comerciales o no comerciales, de una parte de los datos que genera, elabora y custodia en el cumplimiento de sus funciones. Este portal, conocido como AEMET OpenData, ofrece actualmente dos modalidades que posibilitan el acceso y la descarga de los datos en formatos reutilizables:
- Acceso general, que consiste en un acceso gráfico destinado al público en general a través de interfaces amigables para los humanos.
- AEMET OpenData API, pensado para interacciones periódicas o programadas en cualquier lenguaje de programación y que permite a los desarrolladores incluir los datos de AEMET en sus propios sistemas de información y aplicaciones.
Adicionalmente, atendiendo a la Reglamento 2023/138, se contempla habilitar una tercera vía de acceso que permitiría a los reutilizadores obtener datasets empaquetados para la descarga masiva en los casos que fuera posible.
Para acceder a cualquiera de los conjuntos de datos, es necesario disponer de una clave de acceso (API Key) que se puede obtener a través de una sencilla solicitud en la que sólo se requiere un correo electrónico, sin ningún otro dato adicional del solicitante, para el envío de la clave de acceso. Se trata de una medida de control para garantizar que el servicio se preste con la calidad adecuada y de forma no discriminatoria para todos los usuarios.
AEMET OpenData, además, fue pionero en Europa en cuanto a la disponibilidad de datos meteorológicos abiertos, reflejando el compromiso de AEMET con la mejora continua de los servicios meteorológicos, el apoyo a la comunidad científica y tecnológica, y el fomento de una sociedad más informada y resiliente frente a los desafíos climáticos.
Los conjuntos de datos de alto valor sobre meteorología
El Anexo del Reglamento (UE) 2023/138 detalla cinco conjuntos de datos meteorológicos de alto valor: observaciones de estaciones meteorológicas, observaciones validadas de datos climáticos, avisos meteorológicos, datos de radar y datos de modelo de predicción numérica (conocidos como predicción meteorológica numérica o PMN). Para cada uno de los conjuntos, el reglamento especifica la granularidad y los principales atributos que deben publicarse.
Si analizamos la correspondencia de los conjuntos de datos que están actualmente disponibles agrupados en 14 categorías en el portal AEMET OpenData, con los cinco conjuntos de datos que pasarán a ser obligatorios en los próximos meses, obtenemos las conclusiones que resumimos en la siguiente tabla:
| Conjuntos de datos meteorológicos de alto valor | Equivalencia en los conjuntos de datos de AEMET OpenData |
|---|---|
| Datos de observaciones medidos por estaciones meteorológicas | El conjunto de datos “Observación convencional”, generado por el Servicio de Observación, proporciona un elevado número de variables horarias sobre precipitación líquida y sólida, velocidad y dirección del viento, humedad, presión, temperatura del aire, suelo y subsuelo, visibilidad, etc. La actualización se realiza dos veces por hora. Atendiendo al Reglamento se incluirán datos diezminutales con actualización continua. |
| Datos climáticos: observaciones validadas | Dentro de la categoría “Valores Climatológicos”, se proporcionan cuatro conjuntos de datos sobre observaciones de datos climáticos: “Climatologías diarias”, “Climatologías mensuales/anuales”, “Valores normales” y “Extremos registrados”. El conjunto de datos validados proporcionado por el Servicio del Banco Nacional de Datos Climatológicos se actualiza normalmente una vez al día con un retardo de cuatro días debido a los procesos de validación. Entre los atributos disponibles están la temperatura media diaria, la precipitación diaria en su forma estándar de medición de 07 a 07 horas, la humedad relativa media diaria, la dirección de la racha máxima, etc. Atendiendo al Reglamento está planificada la inclusión de climatología horarias. |
| Avisos meteorológicos | Se proporcionan “Avisos de fenómenos meteorológicos adversos” para toda España, o segmentados por provincia o CCAA. Tanto los últimos emitidos como los históricos desde 2018. En ellos, se ofrecen datos de los fenómenos meteorológicos adversos observados y/o previstos, desde el momento actual hasta las siguientes 72 horas. Estos avisos se refieren a cada parámetro meteorológico por nivel de aviso, para cada zona meteorológica definida en el Plan Meteoalerta. Está generado por los Grupos Funcionales de Fenómenos Adversos y la información está disponible en cualquier momento en el que se emite un fenómeno meteorológico adverso, en línea con lo especificado en el Reglamento, que requiere que el conjunto de datos se publique “tal como se expidió o cada hora”. En este caso la AEMET anuncia unas horas preferentes de emisión: 09:00, 11:30, 23:00 y 23:50. |
| Datos de radar | Existen dos conjuntos de datos: “Imagen gráfica radar regional” e “Imagen de la composición nacional de radares”, que proporcionan imágenes de reflectividad, aunque no los otros descritos en el Reglamento (retrodispersión, polarización, precipitaciones, viento y echotop). El conjunto de datos está generado por el grupo de Teledetección Terrestre y la información está disponible con una periodicidad de 10 minutos en vez de los 5 recomendados en el Reglamento. Sin embargo, de acuerdo al Plan Estratégico 2022-2025 de la AEMET, está prevista la actualización de los 15 radares meteorológicos y la incorporación de nuevos radares de mayor resolución, de modo que además de fortalecer el sistema de alerta temprana puedan cumplirse con las obligaciones del Reglamento. |
| Datos del modelo PMN | Existen varios conjuntos de datos con información sobre predicciones, algunos disponibles para descarga y otros disponibles en web: predicción climática, predicción normalizada en texto, predicciones específicas, predicción marítima y mapas de variables meteorológicas de los modelos numéricos HARMONIE-AROME para distintos ámbitos geográficos y periodos de tiempo. Sin embargo, la AEMET, de acuerdo con su documento de preguntas frecuentes, no considera actualmente datos abiertos las salidas de modelos numéricos. La AEMET ofrece la posibilidad de solicitar este o cualquier otro conjunto de datos a través del registro general o de la sede electrónica, pero esta no es una opción contemplada en el Reglamento. Atendiendo a este, está prevista la inclusión de salidas de modelos numéricos atmosféricos y de oleaje. |
Figura 1: Tabla con la equivalencia entre los conjuntos de datos de alto valor y los conjuntos de datos de AEMET OpenData.
El reglamento establece además una serie de requisitos para la publicación en cuanto a formato, licencia otorgada, frecuencia de actualización y puntualidad, medio de acceso y metadatos ofrecidos.
En el caso de los metadatos, la AEMET publica, en formato legible por máquina, las características principales del fichero descargado: quién lo elabora, cada cuánto tiempo se prepara, qué contiene y su formato, además de información sobre los campos de datos (variable meteorológica, unidad de medida, etc.). También se especifica el copyright y las condiciones de uso mediante la nota legal. En este sentido, está previsto que se revisen las licencias actuales para que los conjuntos de datos estén disponibles en un esquema de licenciamiento conforme al Reglamento y posiblemente se seguirá la recomendación adoptando la licencia CC BY-SA 4.0.
En definitiva, parece que la larga trayectoria de la Agencia Estatal de Meteorología, ofreciendo datos abiertos de calidad, le ha situado en una buena posición para cumplir con los requisitos del nuevo reglamento, haciendo algunos ajustes en los conjuntos de datos que ya ofrece a través de AEMET OpenData para alinearlos con las nuevas obligaciones. AEMET contempla ir incluyendo en dicho servicio los conjuntos de datos requeridos en el Reglamento y que actualmente no están disponibles, esto a medida que adapte su normativa respecto a precios públicos, así como la infraestructura y sistemas que lo posibiliten. Los conjuntos de datos adicionales que estarán disponibles serán los datos de observación diezminutales, las climatologías horarias y algunos parámetros de datos de los radares regionales y de los modelos numéricos de predicción y oleaje.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El portal europeo de datos abiertos (data.europa.eu) organiza regularmente sesiones formativas virtuales sobre cuestiones de actualidad en el sector de los datos abiertos, regulaciones que afectan y tecnologías relacionadas. En este post, repasamos las claves del último webinar sobe los conjuntos de datos de alto valor (HVD, por sus siglas en inglés, High Value Datasets)
Entre otras cuestiones, este seminario se centró en transmitir buenas prácticas, así como explicar las experiencias de dos países, Finlandia y Chequia, que formaron parte del informe “High-value Datasets Best Practices in Europe”, publicado por data.europa.eu, junto con Dinamarca, Estonia, Italia, Países Bajos y Rumania. El estudio se realizó inmediatamente después de la publicación del reglamento de implementación de HVDS, en febrero de 2023.
Buenas prácticas ligadas a la puesta a disposición de datos de alto valor
Tras una introducción donde se explicó qué son y qué requisitos tienen que cumplir los datos de alto valor, durante el webinar, se detalló el alcance del informe. Concretamente, se identificaron retos, buenas prácticas y recomendaciones por parte de los estados miembros, como se detalla a continuación.
Marco político y legal
- Existe la necesidad de fomentar una cultura gubernamental prioritariamente práctica y enfocada a objetivos alcanzables, aprovechando valores culturales arraigados en los sistemas gubernamentales, como la transparencia.
- Se recomienda un enfoque estratégico basado en una perspectiva más amplia de la regulación, aprovechando esfuerzos realizados anteriormente para la implementación de directivas trascendentes como INSPIRE o DCAT como estándar para la publicación de datos. En este sentido, es oportuno priorizar acciones que se superponen con estas iniciativas existentes.
- Se recomienda utilizar licencias Creative Commons (CC).
- A nivel transversal, otro de los retos es combinar el cumplimiento de los requisitos de los conjuntos de datos de alto valor con las disposiciones del Reglamento General de Protección de Datos (RGPD), cuando hablamos de datos sensibles o personales.
Gobernanza y procesos
- Se anima a participar en asociaciones estratégicas y fomentar la colaboración a nivel nacional. Entre otras cuestiones se recomienda coordinar esfuerzos entre ministerios, agencias responsables de diferentes categorías de HVD y otros actores relacionados, especialmente en los Estados miembros con estructuras de gobernanza descentralizadas. Para ello, es relevante crear grupos de trabajo interdisciplinarios que faciliten la realización de un inventario de datos completo y aclaren qué agencia es responsable de cada conjunto de datos. Estos grupos permitirán compartir conocimiento y fomentar un sentido de comunidad y responsabilidad compartida, lo que contribuye al éxito general de los esfuerzos de gobernanza de datos.
- Se recomienda participar en intercambios periódicos con otros Estados miembros, para compartir ideas y soluciones a desafíos comunes.
- Es necesario promover la sostenibilidad a través de la responsabilidad individual de las agencias por sus respectivos conjuntos de datos. Garantizar la sostenibilidad de los portales nacionales de datos significa asegurarse de que los metadatos se mantengan con los recursos disponibles.
- Se aconseja desarrollar un marco integral de gobernanza de datos evaluando primero los recursos disponibles, incluida la experiencia técnica, las herramientas de gestión de datos y los aportes clave de las partes interesadas. Este proceso de evaluación permite una comprensión clara de las reglas, procesos y responsabilidades necesarias para una implementación efectiva de la gobernanza de datos.
Aspectos técnicos, calidad de los metadatos y nuevos requisitos
- Se propone desarrollar una comprensión integral de los requisitos específicos para los HVD. Esto implica identificar conjuntos de datos existentes para determinar su cumplimiento con los estándares descritos en el reglamento de implementación para los HVD. Es necesario constituir una base sistémica para identificar, mejorar la calidad y disponibilidad de los datos potenciando el valor general de los conjuntos de datos de alto valor.
- Se recomienda mejorar la calidad de los metadatos directamente en la fuente de datos antes de publicarlos en portales, siguiendo las pautas de publicación de conjuntos de datos de alto valor del DCAT-AP y los vocabularios controlados para las seis categorías de HVD. También es necesario mejorar la implementación de API y descargas masivas desde cada origen de datos. Su implementación presenta desafíos importantes debido a la escasez de recursos y experiencia, por lo que resulta imprescindible el fortalecimiento de capacidades y la dotación de recursos.
- Se sugiere fortalecer la disponibilidad de conjuntos de datos de alto valor a través de financiación externa o planificación estratégica. El reglamento exige que todos los HVD sean accesibles de forma gratuita por lo que algunos Estados miembros diversifican las fuentes de financiación buscando apoyo financiero por medio de vías externas, por ejemplo, aprovechando proyectos europeos. En este sentido, se recomienda adaptar los modelos de negocio progresivamente para ofrecer datos gratuitos.
Por último, el informe destaca una hoja de ruta de cumplimiento del reglamento de implementación de HVD, sugerida en base a ocho pasos:
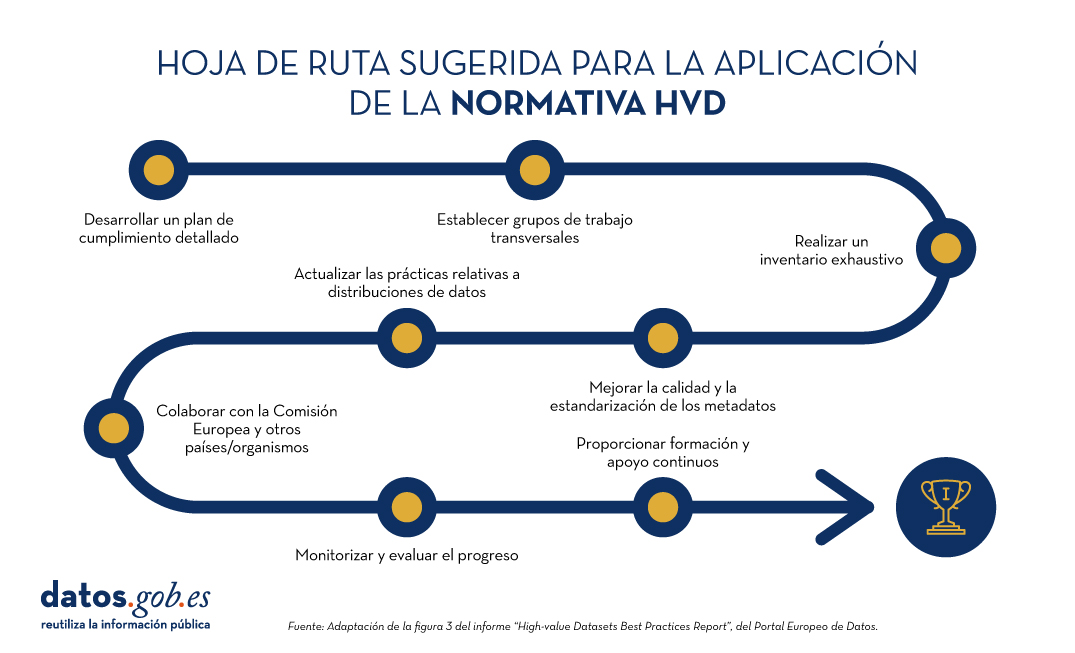
Figura 1: Hoja de ruta sugerida para la aplicación de la normativa HVD. Adaptación de la figura 3 del informe “High-value Datasets Best Practices Report”, del Portal Europeo de Datos.
El ejemplo de la República Checa
En una segunda parte del webinar, República Checa presentó su caso de implementación, que están abordando desde cuatro tareas principales: motivación, implementación regulatoria, responsabilidad de las agencias públicas proveedoras de datos y requerimientos técnicos.
- La motivación entre los diferentes agentes se está articulando a través de la constitución de grupos de trabajo.
- La implementación regulatoria se concentra en el análisis de datasets y la consistencia o inconsistencia con INSPIRE.
- Para impulsar la responsabilidad de las agencias públicas, se están llevando a cabo seminarios para compartir conocimiento en torno a la vinculación entre INSPIRE y HVD utilizando como vía de publicación el estándar DCAT-AP.
- Respecto a los requerimientos técnicos, se están integrando los requisitos de DCAT-AP e INSPIRE en las prácticas de metadatos adaptadas a su contexto nacional. Chequia ha desarrollado especificaciones para catálogos locales de datos abiertos, con el fin de garantizar la compatibilidad con el Catálogo Nacional de Datos Abiertos. No obstante, su mayor reto es una fuerte dependencia derivada de la falta de capacidades técnicas.
El ejemplo de Finlandia
A continuación, tomó la palabra Finlandia. Al contar con una legislación preexistente (INSPIRE y otras normas específicas sobre apertura de datos y gestión de información en administraciones públicas), Finlandia requirió solo ajustes menores para alinearse con la transposición nacional de la directiva de los HVD. El reto está en entender y hacer coexistir INSPIRE y los HVD.
Su estrategia principal se basa en el mapa sobre gestión de información en administraciones públicas, que asegura la armonización, interoperabilidad, gestión de alta calidad y seguridad para implementar los principios de apertura de datos. Además, han establecido dos grupos de trabajo para abordar la implementación de HVD:
- El primer grupo, que es un grupo coordinador de promotores de datos, se centró en cuestiones prácticas y técnicas. Como expertos legales, también brindaron orientación para comprender la regulación HVD desde una perspectiva legal.
- El segundo grupo, un grupo de coordinación interministerial, es un grupo de trabajo que garantiza que no haya conflictos ni superposiciones entre la regulación HVD y la legislación nacional. Este grupo administra el inventario, en formato hoja de cálculo, que contiene todos los elementos necesarios para un catálogo de HVD. Al identificar áreas donde los conjuntos de datos no cumplen con estos requisitos, las organizaciones pueden establecer una hoja de ruta para abordar las brechas y garantizar el cumplimiento total a lo largo del tiempo.
El secretariado de los grupos recae en un comité de datos geoespaciales. Ambos cuentan con una amplia red de partes interesadas para articular la discusión y el feedback de las medidas adoptadas.
De cara a futuro, destacan como reto la necesidad de ir alcanzando mayor experiencia técnica y a nivel ejecutivo.
Fin de la sesión
El webinar continuó con la participación de la empresa Compass Gruppe (Alemania) que comercializa, entre otros, datos procedentes del registro mercantil de Austria. Disponen de un portal que ofrece dichos datos vía API a través de un modelo de negocio freemium.
Además, se recordó la obligación que tienen los Estados miembros de reportar a Europa cada dos años los avances en HVD, una actividad con la que se espera impulsar la disponibilidad de metadatos armonizados federados sobre el portal europeo de datos. La idea es que los usuarios puedan encontrar todos los HVD de la Unión Europea, utilizando el filtrado disponible en el portal o a través de consultas SPARQL.
La combinación de las conclusiones del informe y las experiencias de los países ponentes, nos dan buenas pistas para orientar la implementación de los HVD, cumpliendo con la normativa europea. En resumen, la implementación de los HVD plantea los siguientes desafíos:
- Respaldar con la financiación necesaria el abordaje del proceso de apertura.
- Superar los retos técnicos para desarrollar accesos eficientes (API).
- Lograr una correcta convivencia entre INSPIRE y el reglamento de HVD.
- Consolidar grupos de trabajo que funcionen como un mecanismo robusto de avance y convergencia.
- Monitorizar los avances y realizar un seguimiento continuo del proceso.
- Invertir en la capacitación técnica del personal.
- Crear y mantener una fuerte coordinación ante la diversidad compleja de data holders.
- Potencial el aseguramiento de la calidad de los conjuntos de datos de alto valor.
- Acordar una estandarización necesaria desde el punto de vista empresarial.
Dando respuesta a estos retos, conseguiremos una apertura exitosa de los datos de alto valor, impulsando su reutilización en beneficio de toda la sociedad.
Puedes volver a ver la grabación de la sesión aquí
Blog
España, como parte de la Unión Europea, está comprometida con la implementación de las directivas europeas sobre datos abiertos y reutilización de la información del sector público. Esto incluye la adopción de iniciativas como el Reglamento de Implementación (UE) 2023/138, emitido por la Comisión Europea, que define directrices específicas para las entidades gubernamentales con respecto a la disponibilidad de conjuntos de datos de alto valor (High value datasets en inglés o HVD) . Estos datos se categorizan en temáticas previamente detalladas en discusiones anteriores: Geoespacial, Observación de la Tierra y Medio Ambiente, Meteorología, Estadística, Sociedades y Propiedades de Sociedades, y Movilidad. En este artículo nos centraremos en el último grupo mencionado.
La categoría de Movilidad engloba colecciones de datos que caen bajo el dominio de la "Redes de Transporte", como se demarca en el Anexo I de la Directiva 2007/2/CE del Parlamento Europeo y del Consejo, de 14 de marzo de 2007, por la que se establece una infraestructura de información espacial en la Comunidad Europea (INSPIRE). En concreto, esta Directiva hace referencia a que se deben poner a disposición de los usuarios los conjuntos de datos relativos a redes de carreteras, ferrocarril, transporte aéreo y vías navegables, con sus correspondientes infraestructuras, las conexiones entre redes diferentes y la red transeuropea de transporte, según la definición de la Decisión no 1692/96/CE del Parlamento Europeo y del Consejo, de 23 de julio de 1996, sobre las orientaciones comunitarias para el desarrollo de la red transeuropea de transporte.
Además, se incluyen los conjuntos de datos tal como se describe en la Directiva 2005/44/CE del Parlamento Europeo y del Consejo, de 7 de septiembre de 2005, relativa a los servicios de información fluvial (SIF) armonizados en las vías navegables interiores de la Comunidad. Esta Directiva establece un marco armonizado para la creación de una red transeuropea de información fluvial (RIS, por sus siglas en inglés). El objetivo principal de la Directiva es mejorar el tráfico y el transporte fluvial y se aplican a los canales, ríos, lagos y puertos capaces de albergar buques de entre 1.000 y 1.500 toneladas. Estos conjuntos de datos incluyen:
| Conjunto de datos | Conjuntos de datos sobre vías navegables interiores |
|---|---|
| Datos estáticos |
|
| Datos dinámicos |
|
| Cartas electrónicas y de navegación interior (ENC Fluvial según la norma SIVCE Fluvial) |
|
Figura 1: Tabla con los conjuntos de datos de alto valor relativos a la Directiva 2005/44/CE para la creación de una red transeuropea de información fluvial.
Para que todos podamos aprovechar al máximo la información disponible, el Reglamento define algunas reglas básicas sobre cómo se comparten estos datos:
- Uso libre y fácil. Los datos tienen que estar listos para usarse y compartirse con todos y para cualquier fin reconociendo y citando la fuente de los datos, tal como prescribe la licencia tipo Creative Commons BY 4.0.
- Fácil de leer y usar. Se presentarán de una manera que tanto las personas como las computadoras puedan entenderlos fácilmente y estará todo explicado en público.
- Acceso directo y sencillo. Habrá maneras especiales (llamadas APIs) que permiten a los programas acceder a los datos automáticamente. Además, el usuario podrá alternativamente descargar mucha información de una vez.
- Siempre al día. Es importante que los datos estén actualizados, así que existirá el acceso a la versión más reciente. Pero si el usuario necesita acceder a los datos previos, también se podrá ver las versiones anteriores.
- Detallados y precisos. Los datos se compartirán con tanto detalle como sea posible, hasta un nivel muy fino de precisión, de manera que se cubra todo el territorio al combinarse.
- Información sobre la información. Habrá "información sobre la información" (metadatos) que contará todo sobre los datos. Los elementos de metadatos contendrán como mínimo los recogidos en el anexo del Reglamento (CE) nº 1205/2008 de la Comisión, de 3 de diciembre de 2008.
- Entendible y ordenado: Se explicará bien cómo están organizados los datos y qué significa todo, de manera que sea fácil de entender para todos (estructura y semántica).
- Lenguaje común. Los datos usarán vocabularios, listas controladas y categorías que sean reconocidos y aceptados a nivel europeo o mundial.
¿En España quién es el responsable de la creacion y mantenimiento de los datos de movilidad?
En España, la responsabilidad de la creación y mantenimiento de los datos de movilidad recae generalmente en distintas entidades gubernamentales, dependiendo del tipo de movilidad y del ámbito territorial:
- Nivel nacional. El Ministerio de Transportes y Movilidad Sostenible es el organismo principal encargado de la movilidad en cuanto a infraestructuras y transportes a nivel nacional. Este incluiría datos sobre carreteras, ferrocarriles, transporte aéreo y marítimo.
- Nivel autonómico y local. Las comunidades autónomas y los ayuntamientos también desempeñan un papel importante en la movilidad urbana y regional. Se encargan de la movilidad urbana, el transporte público y las vías públicas, dentro de sus respectivas jurisdicciones.
- Entidades públicas empresariales. Hay entidades como ADIF (acrónimo de Administrador de Infraestructuras Ferroviarias), AENA (acrónimo de Aeropuertos Españoles y Navegación Aérea), Puertos del Estado y otras que gestionan datos específicos relacionados con su campo de acción en el transporte ferroviario, aéreo y marítimo, respectivamente.
En España, el Ministerio de Transportes y Movilidad Sostenible, en colaboración con las comunidades autónomas, juega un rol clave en proporcionar acceso a una amplia gama de datos de movilidad. En conformidad con INSPIRE y LISIGE (la Ley 14/2010 de 5 de julio sobre las infraestructuras y los servicios de información geográfica en España, que transpone la Directiva INSPIRE), ofrece recursos como el Geoportal de la Infraestructura de Datos Espaciales de España (IDEE), donde la ciudadanía y los profesionales pueden acceder a datos y servicios geográficos, especialmente en lo referente a movilidad.
¿Cumple España con el Reglamento de los HVD de movilidad?
Para resolver esta pregunta nos tenemos que ir al el Geoportal de INSPIRE que es donde se encuentra disponible la información oficial clasificada como conjuntos de datos de alto valor en Europa. En concreto en la categoría de movilidad.

Figura 2: Captura del Geoportal Inspire.
A abril de 2024 España tiene publicado en el Geoportal de INSPIRE la siguiente información:
- Zonas de servicio portuarias de España. Las zonas de servicio portuarias de los puertos de interés general del Estado, incluyen la información cartográfica y alfanumérica de la zona de servicio terrestre y de la zona I y II de aguas. El Sistema Portuario español de titularidad estatal está integrado por 46 puertos de interés general, gestionados por 28 Autoridades Portuarias.
- Redes de Transporte de España. La Red de Transporte de la Información Geográfica de Referencia del Sistema Cartográfico Nacional de España, es una red tridimensional de cobertura nacional, definida y publicada en conformidad con la Directiva INSPIRE, que contempla cinco modos de transporte: red viaria, raíl, vías navegables, aéreo y cable, junto con sus respectivas conexiones intermodales y las infraestructuras asociadas a cada modo. Dicha información tiene la geometría lineal de los viales y la puntual de los portales y puntos kilométricos.
- Red de Transporte Ferroviario de ADIF de España. Conjunto de datos geográficos de carácter público sobre la adaptación de la Tramificación Común de ADIF a la normativa INSPIRE (Redes de Transporte Anexo I).
La publicación de estos conjuntos de datos de alto valor responde positivamente a la pregunta de si España cumple con el reglamento de HVD, y supone un logro que refleja el compromiso continuo de nuestro país con la transparencia y el acceso a datos de movilidad.
El esfuerzo conjunto entre el Ministerio de Transportes, Movilidad y Agenda Urbana, el Sistema Cartográfico Nacional y las Comunidades Autónomas y las Entidades Públicas Empresariales subraya la importancia de un enfoque colaborativo para la gestión de la información de movilidad.
La disponibilidad de estos datos destaca el compromiso de España en publicar datos de alto valor y subraya la importancia de mejorar continuamente el acceso a la información para optimizar la navegación interior y los datos de movilidad.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El Observatorio de Casos de Uso (Use Case Observatory, en inglés) es una iniciativa liderada por data.europa.eu, el Portal Europeo de Datos Abiertos. Se trata de un proyecto de investigación sobre el impacto económico, gubernamental, social y medioambiental de los datos abiertos. El proyecto se prolongará durante tres años, desde 2022 hasta 2025, en los que el Portal Europeo de Datos realizará el seguimiento de 30 casos de reutilización de datos abiertos e irá publicando conclusiones en entregas periódicas.
En 2022 hizo un primer informe y ahora, en abril de 2024, ha presentado el volumen 2 del análisis exploratorio en torno al uso de los datos abiertos. En esta segunda entrega, analiza trece de los casos de uso iniciales que permanece en estudio, tres de ellos españoles, y expone, a modo de conclusiones, los siguientes puntos:
- El documento subraya en primer lugar el alto potencial de la reutilización de datos abiertos.
- Destaca que muchas organizaciones y aplicaciones deben su propia existencia a los datos abiertos.
- Asimismo, señala la necesidad de liberar de forma más amplia, el impacto potencial de los datos abiertos en la economía, la sociedad y el medio ambiente.
- Para lograr el punto anterior, señala el apoyo continuo a la comunidad de reutilización como crucial para identificar oportunidades de crecimiento financiero.
Los tres casos españoles: UniversiDATA-Lab, Tangible Data y Planttes
Para seleccionar los casos de uso, el Observatorio realizó un inventario basado en tres fuentes: los ejemplos recogidos en los estudios de madurez que realiza cada año el portal europeo, las soluciones participantes en el EU Datathon y los ejemplos de reutilización disponibles en el repositorio de casos de uso de data.europa.eu. Solo se tuvieron en cuenta aquellos proyectos desarrollados en Europa, intentando mantener un equilibrio entre los distintos países.
Además, se destacaron aquellos proyectos que hubiesen obtenido algún premio o que estuviesen alineados con las prioridades de la Comisión Europea para 2019 a 2024. Para finalizar la selección, desde data.europa.eu se realizaron entrevistas con representantes de los casos de uso que cumplían los requisitos y que estaban interesados en participar en el proyecto.
En esta segunda ocasión, el nuevo informe reseña un proyecto del área de impacto económico, tres del ámbito gubernamental, seis del área social y cuatro medioambientales.
Tanto en el primer volumen como en este, destaca tres casos españoles: UniversiDATA-Lab y Tangible Data, del ámbito social y Planttes, en la categoría de medioambiente.
UniversiDATA-Lab, la unión de seis universidades en torno a los datos abiertos
En el caso de UniversiDATA-Lab está enfocado en la educación superior. Es un portal público para el análisis avanzado y automático de los conjuntos de datos publicados por las seis universidades españolas que forman parte del portal UniversiDATA: la Universidad Autónoma de Madrid (UAM), la Universidad Carlos III de Madrid, la Universidad Complutense de Madrid (UCM), la Universidad de Huelva, la Universidad de Valladolid (UVa) y la Universidad Juan Carlos I.
El objetivo de UniversiDATA-Lab es transformar los análisis estáticos de la sección del portal en resultados dinámicos. El informe del Observatorio señala que este proyecto “fomenta el uso de recursos compartidos” entre los distintos centros universitarios. También destaca como impacto reseñable la puesta en marcha de aplicaciones web dinámicas que leen en tiempo real el catálogo de UniversiDATA, obtienen todos los datos disponibles y realizan análisis de datos en línea.
Respecto al informe anterior, elogia su “esfuerzo considerable para convertir datos intrincados en información de fácil manejo”, además de señalar que este proyecto proporciona documentación detallada para ayudar a los usuarios a comprender la naturaleza de los datos analizados.
Tangible Data, haciendo comprensibles los datos espaciales
En el caso de Tangible Data, se trata de un proyecto que transforma los datos de su contexto digital a un contexto físico mediante la creación de esculturas de datos en el espacio público. Estas esculturas de datos ayudan a las personas que carecen de ciertas competencias digitales a comprenderlos. Para ello, utiliza como fuentes de datos los de organismos internacionales (por ejemplo, NASA, Banco Mundial) y otras plataformas similares.
En este segundo volumen destacan su evolución “significativa”, ya que desde el pasado año el proyecto ha pasado de realizar pruebas de producto mínimo viable a la entrega de proyectos integrales. Esto les ha permitido “explorar oportunidades comerciales y educativas, como exposiciones, talleres, etc.”, tal y como se extrapola de las entrevistas realizadas. Además, los cuatro procesos clave (diseño, creación, entrega y medición) se han estandarizado y han hecho que el proyecto sea globalmente accesible y rápidamente desplegable.
Planttes, iniciativa medioambiental que se cuela en el Observatorio
El tercer ejemplo español, Planttes, es una aplicación de ciencia ciudadana que informa a los usuarios sobre qué plantas están en flor y si esto puede afectar a las personas alérgicas al polen. Utiliza los datos abiertos del Punto de información sobre aerobiología (PIA-UAB), entre otros, que complementa con datos que aportan los usuarios para crear mapas personalizados.
De este proyecto, el Observatorio señala que, aprovechando la participación de la comunidad y la tecnología, “la iniciativa ha logrado avances significativos en la comprensión y mitigación del impacto de las alergias al polen con el compromiso de fomentar la concienciación y la educación en los años venideros”.
Respecto al trabajo desarrollado, señala que Planttes ha evolucionado pasando de ser una aplicación móvil a una aplicación web con el fin de mejorar la accesibilidad. El objetivo de esta transición es facilitar a los usuarios el uso de la plataforma sin las limitaciones de las aplicaciones móviles.
El Observatorio de Casos de Uso entregará su tercer volumen en el año 2025. Su razón de ser se enmarca más allá de analizar y reseñar los logros alcanzados y los retos presentes. Al tratarse de un proyecto continuo durante tres años, permitirá extrapolar ideas concretas para mejorar las metodologías de evaluación del impacto de los datos abiertos.
Blog
El Reglamento de ejecución (UE) 2023/138 de la Comisión Europea establece pautas claras para los organismos públicos en la disponibilidad de conjuntos de datos de alto valor en un plazo de 16 meses. Estos conjuntos de datos de alto valor (High value datasets o HVD) se agrupan en los siguientes temas, los cuales ya se describían en este post:

Este artículo se centra en la categoría geoespacial, denominada Conjuntos de Datos de Alto Valor Geoespacial (HVDG).
Para todos los HVDG se deberá aplicar lo indicado en la Directiva 2007/2/CE del Parlamento Europeo y del Consejo, de 14 de marzo de 2007, por la que se establece una infraestructura de información espacial en la Comunidad Europea (INSPIRE), a excepción de parcelas agrícolas y de referencia, para las que se aplica el Reglamento (UE) 2021/2116 del Parlamento Europeo y del Consejo, de 2 de diciembre de 2021.
Tal y como se refleja en la tabla siguiente, el reglamento proporciona información detallada sobre los requisitos a tener en cuenta para estos HVDG, tales como escalas o granularidad y atributos de cada conjunto de datos. Estos complementan a los atributos definidos en el Reglamento Europeo (nº 1089/2010), que establece la interoperabilidad de los conjuntos y los servicios de datos espaciales.
| Conjunto de datos | Escala | Atributos |
|---|---|---|
| Unidades administrativas |
Niveles de generalización disponibles con una granularidad hasta la escala de 1:5 000. De municipios a países; unidades marítimas. |
|
| Nombres geográficos | No se aplica |
|
| Direcciones | No se aplica |
|
| Edificios | Niveles de generalización disponibles con una granularidad hasta la escala de 1:5 000 |
|
| Parcelas catastrales | Niveles de generalización disponibles con una granularidad hasta la escala de 1:5 000 |
|
| Parcelas de referencia |
Niveles de generalización disponibles con una granularidad hasta la escala de 1:5 000 |
|
| Parcelas agrícolas |
Nivel de precisión equivalente a la escala 1:10 000 y a partir de 2016, a escala de 1:5 000 |
|
Para garantizar la accesibilidad y la reutilización de todos estos valiosos conjuntos de datos, es imperativo seguir ciertas disposiciones que faciliten su publicación. Aquí están los requisitos clave:
- Licencia Abierta: Todos los conjuntos de datos deben estar disponibles para su reutilización bajo una licencia Creative Commons BY 4.0, o cualquier licencia abierta equivalente menos restrictiva. Esto fomenta la libertad de compartir y adaptar la información.
- Formato Abierto y Legible por Máquina: Los datos deben presentarse en un formato abierto, legible por máquina y estar documentados públicamente. Esto asegura que la información sea fácilmente comprensible y accesible para cualquier persona o sistema automatizado.
- Interfaces de Programación de Aplicaciones (API) y Descarga Masiva: Se deben proporcionar interfaces de programación de aplicaciones (API) para facilitar el acceso programático a los datos. Además, la descarga masiva directa de conjuntos de datos debe ser posible, permitiendo opciones flexibles para los usuarios según sus necesidades.
- Versión Actualizada: La disponibilidad de los conjuntos de datos en su versión más actualizada es esencial. Esto garantiza que los usuarios accedan a la información más reciente, promoviendo la relevancia y la precisión de los datos.
- Metadatos: La descripción de los datos también se cuidará de manera minuciosa mediante el uso de metadatos. Estos metadatos, como mínimo, incluirán los elementos definidos en el Reglamento (CE) nº 1205/2008 de la Comisión, de 3 de diciembre de 2008. Este reglamento ejecuta la Directiva 2007/2/CE del Parlamento Europeo y del Consejo, y establece los estándares para los metadatos asociados a los conjuntos de datos. El uso de metadatos estandarizados proporciona información adicional esencial para entender, interpretar y utilizar los conjuntos de datos de manera efectiva. Al seguir estos estándares, se facilita la interoperabilidad y la coherencia en la presentación de información, promoviendo así una comprensión más completa y precisa de los datos disponibles.
Estas disposiciones no solo promueven la transparencia y la apertura, sino que también facilitan la colaboración y el uso efectivo de la información en diversos contextos.
¿Cumple España con el Reglamento de los HVD geoespaciales?
La Directiva INSPIRE (Infrastructure for Spatial Information in Europe) determina las reglas generales para el establecimiento de una Infraestructura de Información espacial en la Comunidad Europea basada en las Infraestructuras de los Estados miembros. Aprobada por el Parlamento Europeo y el Consejo el 14 de marzo de 2007 (Directiva 2007/2/CE), entró en vigor el 25 de abril de 2007.
INSPIRE permite encontrar, compartir y utilizar con más facilidad los datos espaciales de diferentes países y en cada una de las regiones, estando los HVD disponibles en el nuevo catálogo de la Comisión de los HVD y en cada uno de los catálogos de las Infraestructuras de Datos Espaciales de las Comunidades Autónomas, así como en el Catálogo Oficial de Datos y Servicios INSPIRE de España. La información está disponible a través de una plataforma online desde la que se puede encontrar datos de distintos países.
ADVERTENCIA: En la actualidad están trabajando en este Geoportal realizando las tareas de volcado de datos, por lo tanto, puede existir alguna incongruencia temporal con los datos aportados, que se corresponden del Catalogo Oficial de Datos y Servicios INSPIRE (CODSI).
En España existe la Ley 14/2010 de 5 de julio sobre las infraestructuras y los servicios de información geográfica en España (LISIGE), que transpone la Directiva 2007/2/CE INSPIRE. Esta ley enmarca los trabajos para poner a disposición todos los datos espaciales nacionales y obliga a adaptarlos a las Guías Técnicas o Directrices recogidos por la Directiva INSPIRE, asegurando así que estos datos sean compatibles e interoperables en un contexto comunitario y transfronterizo.
La LISIGE se aplica a los datos geográficos que cumplan estas condiciones:
- Referirse a una zona geográfica del territorio nacional, el mar territorial, la zona contigua, la plataforma continental y la zona económica exclusiva.
- Haber sido generados por o bajo la responsabilidad de las Administraciones públicas.
- Estar en formato electrónico.
- Ser su producción y mantenimiento competencia de una Administración u organismo del sector público.
- Estar dentro de los temas de los anexos I (Información Geográfica de Referencia), II (Datos Temáticos Fundamentales) o III (Datos Temáticos Generales) referidos en mencionada ley
Además, se aclara que los datos y servicios geográficos regulados por la LISIGE estarán disponibles en el Geoportal de la IDEE y en el CODSI, así como en el resto de los catálogos de las CC. AA., cuyo mantenimiento es responsabilidad del Instituto Geográfico Nacional (IGN).
Gracias a los incansables esfuerzos realizados por toda la administración española desde la publicación de la LISIGE, España ha logrado un hito notable. En la actualidad, se encuentra disponible en el Geoportal de INSPIRE una amplia gama de información clasificada como HVDG. Este logro refleja el compromiso continuo de nuestro país con la transparencia y el acceso a datos geoespaciales de alta calidad.
A enero de 2024, España tiene publicado en el Geoportal de INSPIRE y en el CODSI la siguiente información relacionada con los conjuntos de alto valor geoespacial:
- 31 conjuntos de datos asociados a sus metadatos
- 34 servicios de descarga (WFS, ATOM Feed, OGC Api Feature)
- 28 servicios de visualización (WMS, WMTS)
Analizando los conjuntos de alto valor geoespaciales, vemos que según las temáticas se han publicado en la actualidad:
| HVDG España | Conjuntos de datos |
Servicios de descarga |
Servicios de visualización | Recubre el territorio español |
|---|---|---|---|---|
| Unidades administrativas | 5 | 7 | 7 | Sí |
| Nombres geográficos | 7 | 8 | 8 | Sí |
| Direcciones | 6 | 5 | 7 | Sí |
| Edificios | 5 | 3 | 4 | Sí |
| Parcelas catastrales | 3 | 3 | 3 | Sí |
| Parcelas de referencia |
3 | 0 | 3 | Sí |
| Parcelas agrícolas |
2 | 2 | 2 | Sí |
En la actualidad España cumple con el Reglamento de los HVDG en todas las categorías. En concreto, cumple con la legislación establecida a nivel de escala o granularidad, atributos, licencia, formato, disponibilidad de los datos en API o descarga máxima, con ser la versión más actualizada y con los metadatos.
Al realizar un análisis detallado de los conjuntos de datos publicados en el marco de los HVD, se destacan varios aspectos clave:
- Cobertura Geográfica Integral: Se ha logrado poner a disposición al menos un conjunto de datos que abarca la totalidad del territorio español.
- Metadatos Exhaustivos: Se han generado metadatos para todos los Conjuntos de Alto Valor Geoespacial (HVDG). Estos metadatos se encuentran publicados en el Catálogo Oficial de Datos y Servicios INSPIRE (CODSI),validados para cumplir con los estándares del Reglamento (CE) nº 1205/2008 de la Comisión.
- Servicios de Visualización y Descarga: Todos los HVDG cuentan con servicios de visualización y de descarga. Los servicios de descarga pueden ser de descarga masiva o API de descarga y en estos momentos son WFS y ATOM y en un futuro pueden ser OGC API Feature o API Coverage.
- Licencias y Formatos Abiertos: Todos los servicios publicados están bajo licencia Creative Commons BY 4.0, y los servicios de descarga utilizan formatos estándares y abiertos como el formato GML documentado por la norma internacional ISO 19136.
- Cumplimiento con Modelos de Datos INSPIRE: Casi todos los conjuntos de datos cumplen con los modelos de datos INSPIRE, garantizando así la coherencia y calidad de los atributos establecidos en el reglamento de HVDG.
- Datos Actualizados y Mantenidos: Los servicios de descarga garantizan la disponibilidad de datos en su versión más actualizada. Cada administración pública responsable de los datos se encarga del mantenimiento y la actualización de la información.
Este análisis resalta el compromiso y la eficiencia en la gestión de datos geoespaciales en España, contribuyendo a la transparencia, accesibilidad y calidad en la información proporcionada a la comunidad.
Se debe resaltar que, en España, se cumple con todos los requisitos de los HVDG. Organismos como el CNIG y el ICGC o el Gob. de Navarra, además de publicar a través de servicios WFS o ATOM, está ya trabajando en tener publicados estos conjuntos de datos con las API de OGC.
El Geoportal de INSPIRE se ha convertido en una valiosa fuente de información, gracias a la dedicación y colaboración de diversas entidades gubernamentales, entre ellas las españolas. Este avance no solo resalta el progreso en la implementación de estándares geoespaciales, sino que también fortalece la base para el desarrollo sostenible y la toma de decisiones informadas en España. ¡Un logro significativo para el país en el ámbito geoespacial!
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La transición energética es también una transición de materias primas. Cuando nos imaginamos un futuro sostenible, lo concebimos fundado en una serie de sectores estratégicos como son los de las energías renovables o la movilidad eléctrica. De igual forma, nos imaginamos un futuro conectado y digital, donde nuevas innovaciones y modelos de negocio relacionados con la cuarta revolución industrial nos permiten resolver retos globales como la escasez de alimento o el acceso a la educación. En definitiva, nos centramos en tecnologías que nos ayudan a mejorar nuestra calidad de vida.
¿Por qué son importantes los minerales críticos?
Estos sectores dependen de una serie de tecnologías clave, como las baterías de almacenamiento energético, los aerogeneradores, las placas solares, los electrolizadores, los drones, los robots, las redes de transmisión de datos, los dispositivos electrónicos o satélites espaciales. Unas tecnologías que en los últimos años han experimentado una gran evolución tecnológica y un enorme crecimiento en su demanda a nivel mundial. Si analizamos las previsiones de desarrollo a 2030, podemos esperar crecimientos anuales de al menos dos dígitos para muchas de ellas, como se observa en la figura 1.

Figura 1: Crecimiento esperado hasta 2030 de algunas de las tecnologías clave para sectores estratégicos. Fuente: McKinsey (imagen 1, imagen 2, imagen 3)
Ahora bien, como puede observarse en la figura 2, muchas de estas tecnologías de futuro tienen una gran dependencia de un conjunto de materias primas críticas necesarias para su desarrollo. El indio y el galio son claves para la fabricación de iluminación LED de bajo consumo, el silicio es indispensable para la fabricación de microchips y semiconductores, y el grupo de metales del platino (como iridio, paladio, platino rodio o rutenio) son utilizados en catalizadores para electrolizadores de hidrógeno.

Figura 2: Representación semicuantitativa de flujos de materias primas hacia las quince tecnologías clave y cinco sectores estratégicos. Fuente: JRC Study.
Así pues, ¿cuándo entenderemos que un material sea crítico? Existen varios factores que nos permiten determinar si una materia prima pasa a ser considerada como crítica:
- Sus reservas mundiales son escasas
- No existen materiales alternativos que puedan ejercer su función (sus propiedades son únicas o muy singulares)
- Son materiales indispensables para sectores económicos clave de futuro, y/o su cadena de suministro es de elevado riesgo
Según las propias palabras de Margrethe Vestager, vicepresidenta ejecutiva de la Comisión Europea, “sin un suministro seguro y sostenible de materias primas críticas, no habrá una transición verde (sostenible) e industrial”.
Investigación de fuentes de datos de minerales críticos
Para poder conocer con detalle la situación de estos minerales en Europa, necesitamos localizar datos de calidad. Una tarea para la que tendremos que acudir a diversas fuentes.
En primer lugar, acudimos al portal europeo de datos abiertos. Desde su buscador, en una primera iteración, observamos que existen más de 46.000 conjuntos de datos ante la consulta “materias primas críticas” (figura 3).
Figura 3: Primera búsqueda de materias primas críticas en el portal de datos europeo
Tras un primer análisis de las categorías de datos disponibles, ajustamos los filtros hasta reducir los conjuntos de datos de interés a 190 (figura 4). Nos llaman especial atención los datos publicados por el JRC (European Comission Joint Research Center) y, en particular, el conjunto de datos titulado Materias primas críticas (CRM), evaluación de 2020.
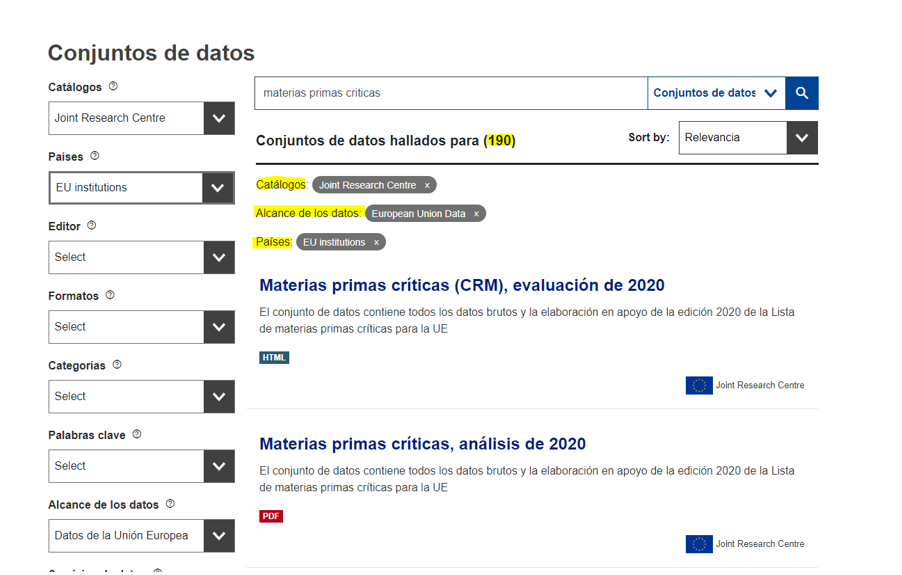
Figura 4: Segunda búsqueda de materias primas críticas en el portal de datos europeo
Este conjunto de datos contiene un enlace directo a un portal web, el RMIS (Raw Material Information System), que es en realidad la base de conocimiento de referencia en torno a materias primas de la Comisión Europea a través de la cual podemos acceder a datos y análisis muy relevantes.

Figura 5: RMIS – base de conocimiento de la Comisión Europea para materias primas
A través del RMIS, encontramos una publicación muy interesante para cualquier estudio sobre la materia. Aunque esta publicación se encuentra en formato PDF, nos permite acceder al listado de materiales estratégicos, críticos y no críticos identificados por la Comisión Europea indicando su nivel de criticidad y su uso en diferentes tecnologías clave como se muestra en la figura 6.

Figura 6: Tabla de materias primas estratégicas, críticas y no críticas utilizadas diferentes tecnologías clave contenida en el fichero PDF. Fuente: Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU – A foresight study, JRC 2023.
Continuando nuestra exploración, en este caso en busca de datos sobre reservas minerales en el continente europeo, encontramos la plataforma European Gelological Data Infrastructure (EDGI), la cual dispone de un amplio catálogo con más de 5.700 conjuntos de datos y servicios geológicos. En nuestro caso, tras realizar una búsqueda en su catálogo de datos, seleccionamos tres conjuntos de datos que contienen información interesante en cuanto a hallazgos de minerales críticos de litio, cobalto y grafito (figura 7).

Figura 7: Búsqueda de conjuntos de datos en el catálogo de EDGI
Desde el visualizador de EDGI, podemos ver el contenido de estos tres datasets antes de descargarlo en formato GeoJSON (figura 8). Los tres conjuntos de datos han sido originados desde el proyecto FRAME (Forecasting And Assessing Europe’s Strategic Raw Materials Needs), en el cual participan múltiples entidades europeas entre las que encontramos al Instituto Geológico y Minero de España (IGME).
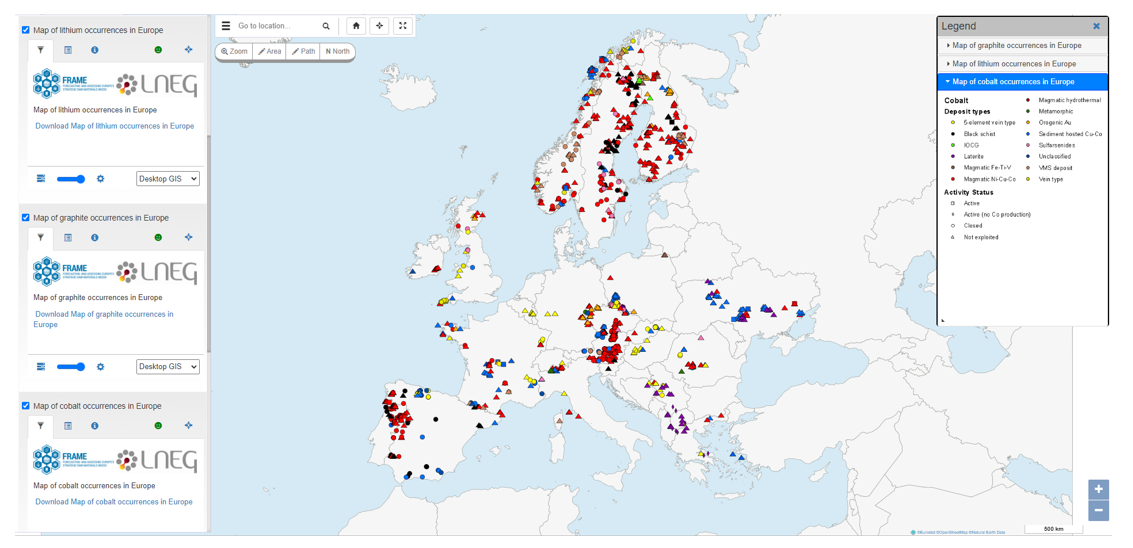
Figura 8: Consulta de conjuntos de datos seleccionados a través de plataforma de visualización EDGI. Fuente: Map of cobalt occurrences in Europe, Map of graphite occurrences in Europe, Map of lithium occurrences in Europe, proyecto FRAME.
En último lugar, acudimos al portal de datos de la International Energy Agency (IEA) (figura 9). En este caso, encontramos, entre sus más de 70 conjuntos de datos, uno directamente relacionado con nuestro ámbito de investigación, titulado Critical Minerals Demand Dataset, el cual procedemos a descargar para su posterior análisis en formato excel.
Figura 9: Captura del portal de datos de la International Energy Agency (IEA)
Tras esta búsqueda, hemos localizado algunos datos de interés que nos pueden servir a la hora de realizar diversos análisis
Aunque este ejercicio se ha realizado bajo la temática de minerales críticos, los portales de datos abiertos europeos proporcionan una gran cantidad de información y conjuntos de datos diversos sobre multitud de áreas de interés que nos pueden ayudar a comprender los retos a afrontar como sociedad, desde la transición energética a la lucha contra la pobreza o el despilfarro de alimentos. Unos datos que permitirán realizar análisis encaminados a tomar mejores decisiones para avanzar hacia un futuro más próspero y sostenible.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.