Noticia
The European Parliament's tenth parliamentary term started on July, a new institutional cycle that will run from 2024-2029. The President of the European Commission, Ursula von der Leyen, was elected for a second term, after presenting to the European Parliament her Political Guidelines for the next European Commission 2024-2029.
These guidelines set out the priorities that will guide European policies in the coming years. Among the general objectives, we find that efforts will be invested in:
- Facilitating business and strengthening the single market.
- Decarbonise and reduce energy prices.
- Make research and innovation the engines of the economy.
- Boost productivity through the diffusion of digital technology.
- Invest massively in sustainable competitiveness.
- Closing the skills and manpower gap.
In this article, we will explain point 4, which focuses on combating the insufficient diffusion of digital technologies. Ignorance of the technological possibilities available to citizens limits the capacity to develop new services and business models that are competitive on a global level.
Boosting productivity with the spread of digital technology
The previous mandate was marked by the approval of new regulations aimed at fostering a fair and competitive digital economy through a digital single market, where technology is placed at the service of people. Now is the time to focus on the implementation and enforcement of adopted digital laws.
One of the most recently approved regulations is the Artificial Intelligence (AI) Regulation, a reference framework for the development of any AI system. In this standard, the focus was on ensuring the safety and reliability of artificial intelligence, avoiding bias through various measures including robust data governance.
Now that this framework is in place, it is time to push forward the use of this technology for innovation. To this end, the following aspects will be promoted in this new cycle:
- Artificial intelligence factories. These are open ecosystems that provide an infrastructure for artificial intelligence supercomputing services. In this way, large technological capabilities are made available to start-up companies and research communities.
- Strategy for the use of artificial intelligence. It seeks to boost industrial uses in a variety of sectors, including the provision of public services in areas such as healthcare. Industry and civil society will be involved in the development of this strategy.
- European Research Council on Artificial Intelligence. This body will help pool EU resources, facilitating access to them.
But for these measures to be developed, it is first necessary to ensure access to quality data. This data not only supports the training of AI systems and the development of cutting-edge technology products and services, but also helps informed decision-making and the development of more accurate political and economic strategies. As the document itself states " Access to data is not only a major driver for competitiveness, accounting for almost 4% of EU GDP, but also essential for productivity and societal innovations, from personalised medicine to energy savings”.
To improve access to data for European companies and improve their competitiveness vis-à-vis major global technology players, the European Union is committed to "improving open access to data", while ensuring the strictest data protection.
The European data revolution
"Europe needs a data revolution. This is how blunt the President is about the current situation. Therefore, one of the measures that will be worked on is a new EU Data Strategy. This strategy will build on existing standards. It is expected to build on the existing strategy, whose action lines include the promotion of information exchange through the creation of a single data market where data can flow between countries and economic sectors in the EU.
In this framework, the legislative progress we saw in the last legislature will continue to be very much in evidence:
- Directive (EU) 2019/1024 on open data and re-use of public sector information, which establishes the legal framework for the re-use of public sector information, made available to the public as open data, including the promotion of high-value data.
- Regulation (EU) 2022/868 on European Data Governance (EDG), which regulates the secure and voluntary exchange of data sets held by public bodies over which third party rights concur, as well as data brokering services and the altruistic transfer of data.
- Regulation (EU) 2023/2854 on harmonised rules for fair access to and use of data (Data Act), which promotes harmonised rules on fair access and use of data in the framework of the European Strategy.
The aim is to ensure a "simplified, clear and coherent legal framework for businesses and administrations to share data seamlessly and at scale, while respecting high privacy and security standards".
In addition to stepping up investment in cutting-edge technologies, such as supercomputing, the internet of things and quantum computing, the EU plans to continue promoting access to quality data to help create a sustainable and solvent technological ecosystem capable of competing with large global companies. In this space we will keep you informed of the measures taken to this end.
Blog
The European Drug Report provides a current overview of the drug situation in the region, analysing the main trends and emerging threats. It is a valuable publication, with a high number of downloads, which is quoted in many media outlets.
The report is produced annually by the European Union Drugs Agency (EUDA), the current name of the former European Monitoring Centre for Drugs and Drug Addiction. It collects and analyses data from EU Member States, together with other partner countries such as Turkey and Norway, to provide a comprehensive picture of drug use and supply, drug harms and harm reduction interventions. The report contains comprehensive datasets on these issues disaggregated at the national level, and even, in some cases, at the city level (such as Barcelona or Palma de Mallorca).
This study has been carried out since 1993 and translated into more than 20 official languages of the European Union. However, in the last two years it has introduced a new feature: a change in internal processes to improve the visualisation of the data obtained. A process they explained in the recent webinar "The European Drug Report: using an open data approach to improve data visualisation", organised by the European Open Data Portal (data.europa.eu) on 25 June. The following is a summary of what the Observatory's representatives had to say at this event.
The need for change
The Observatory has always worked with open data, but there were inefficiencies in the process. Until now, the European Drug Report has always been published in PDF format, with the focus on achieving a visually appealing product. The internal process leading up to the publication of the report consisted of several stages involving various teams:
- A team from the Observatory checked the format of the data received from the supplier and, if necessary, adapted it.
- A specialised data analysis team created visualisations from the data.
- A specialised drafting team drafted the report. The team that had created the visualisations could collaborate in this phase.
- An internal team validated the content of the report.
- The data provider checked that the Observatory had interpreted the data correctly.
Despite the good reception of the report and its format, in 2022 the Observatory decided to completely change the publication format for the following reasons:
- Once the various steps of the publication process had been initiated, the data were formatted and were no longer machine-readable. This reduced the accessibility of the data, e.g. for screen readers, and limited its reusability.
- If errors were detected in the different steps of the process, they were corrected directly on the format of the data in this step. In other words, if an error was detected in a chart during the revision phase, it was corrected directly on that chart. This procedure could cause errors and dull the traceability of data, limiting efficiency: the same static graph could be present several times in the document and each mention had to be corrected individually.
- At the end of the process, the format of the source data had to be adjusted due to changes in the publication procedure.
- Many of the users who consulted the report did so from a mobile device, for which the PDF format was not always suitable.
- Because they are neither accessible nor mobile-friendly, PDF documents did not usually appear as the first result in search engines. This point is important for the Observatory, as many users find the report through search engines.
A responsive web format was needed, which automatically adjusts a website to the size and layout of its users' devices. The aim was to:
- Improved accessibility.
- A more streamlined process for creating visualisations.
- An easier translation process.
- An increase in visitors from search engines.
- Greater modularity.
The process behind the new report
In order to completely transform the publication format of the report, an ad hoc visualisation process has been carried out, summarised in the following image:
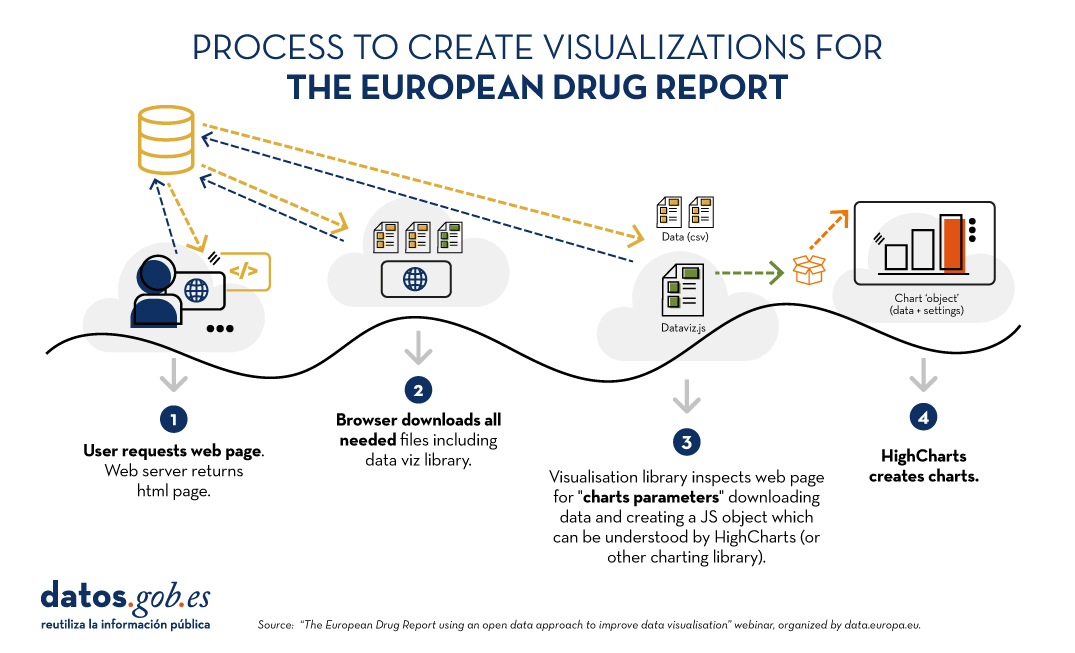
Figure 1. Process for creating visualizations for the European Drug Report. Source EN: Webinar “The European Drug Report using an open data approach to improve data visualisation”, organized by data.europa.eu.
The main new feature is that visualisations are created dynamically from the source data. In this way, if something is changed in these data, it is automatically changed in all visualisations that feed on it. Using the Drupal content management system, on which much of the site is based, administrators can register changes that will automatically be reflected in the HTML and therefore in the displays. In addition, site administrators have a visualisation generator which, based on data and indications - equivalent to simple instructions such as "sort from highest to lowest" expressed in HTML - creates visualisations without the need to touch code.
The same dynamic update procedure applies to the PDF that the user can download. If there are changes in the data, in the visualisations or if typographical errors are corrected, the PDF is generated again through a compilation process that the Observatory has created specifically for this task.
The report after the change
The report is currently published in HTML version, with the possibility to download chapters or the full report in PDF format. It is structured by thematic modules and also allows the consultation of annexes.
Furthermore, the data are always published in CSV format and the licensing conditions of the data (CC-BY-4.0) are indicated on the same page. The reference to the source of the data is always made available to the reader on the same page as a visualisation.
With this change in procedure and format, benefits for all have been achieved. From the readers' point of view, the user experience has been improved. For the organisation, the publication process has been streamlined.
In terms of open data, this new approach allows for greater traceability, as the data can be consulted at any time in its current format. Moreover, according to the Observatory speakers, this new format of the report, together with the fact that the data and visualisations are always up-to-date, has increased the accessibility of the data for the media.
You can access the webinar materials here:
Blog
The publication on Friday 12 July 2024 of the Artificial Intelligence Regulation (AIA) opens a new stage in the European and global regulatory framework. The standard is characterised by an attempt to combine two souls. On the one hand, it is about ensuring that technology does not create systemic risks for democracy, the guarantee of our rights and the socio-economic ecosystem as a whole. On the other hand, a targeted approach to product development is sought in order to meet the high standards of reliability, safety and regulatory compliance defined by the European Union.
Scope of application of the standard
The standard allows differentiation between low-and medium-risk systems, high-risk systems and general-purpose AI models. In order to qualify systems, the AIA defines criteria related to the sector regulated by the European Union (Annex I) and defines the content and scope of those systems which by their nature and purpose could generate risks (Annex III). The models are highly dependent on the volume of data, their capacities and operational load.
AIA only affects the latter two cases: high-risk systems and general-purpose AI models. High-risk systems require conformity assessment through notified bodies. These are entities to which evidence is submitted that the development complies with the AIA. In this respect, the models are subject to control formulas by the Commission that ensure the prevention of systemic risks. However, this is a flexible regulatory framework that favours research by relaxing its application in experimental environments, as well as through the deployment of sandboxes for development.
The standard sets out a series of "requirements for high-risk AI systems" (section two of chapter three) which should constitute a reference framework for the development of any system and inspire codes of good practice, technical standards and certification schemes. In this respect, Article 10 on "data and data governance" plays a central role. It provides very precise indications on the design conditions for AI systems, particularly when they involve the processing of personal data or when they are projected on natural persons.
This governance should be considered by those providing the basic infrastructure and/or datasets, managing data spaces or so-called Digital Innovation Hubs, offering support services. In our ecosystem, characterised by a high prevalence of SMEs and/or research teams, data governance is projected on the quality, security and reliability of their actions and results. It is therefore necessary to ensure the values that AIA imposes on training, validation and test datasets in high-risk systems, and, where appropriate, when techniques involving the training of AI models are employed.
These values can be aligned with the principles of Article 5 of the General Data Protection Regulation (GDPR) and enrich and complement them. To these are added the risk approach and data protection by design and by default. Relating one to the other is ancertainly interesting exercise.
Ensure the legitimate origin of the data. Loyalty and lawfulness
Alongside the common reference to the value chain associated with data, reference should be made to a 'chain of custody' to ensure the legality of data collection processes. The origin of the data, particularly in the case of personal data, must be lawful, legitimate and its use consistent with the original purpose of its collection. A proper cataloguing of the datasets at source is therefore indispensable to ensure a correct description of their legitimacy and conditions of use.
This is an issue that concerns open data environments, data access bodies and services detailed in the Data Governance Regulation (DGA ) or the European Health Data Space (EHDS) and is sure to inspire future regulations. It is usual to combine external data sources with the information managed by the SME.
Data minimisation, accuracy and purpose limitation
AIA mandates, on the one hand, an assessment of the availability, quantity and adequacy of the required datasets. On the other hand, it requires that the training, validation and test datasets are relevant, sufficiently representative and possess adequate statistical properties. This task is highly relevant to the rights of individuals or groups affected by the system. In addition, they shall, to the greatest extent possible, be error-free and complete in view of their intended purpose. AIA predicates these properties for each dataset individually or for a combination of datasets.
In order to achieve these objectives, it is necessary to ensure that appropriate techniques are deployed:
- Perform appropriate processing operations for data preparation, such as annotation, tagging, cleansing, updating, enrichment and aggregation.
- Make assumptions, in particular with regard to the information that the data are supposed to measure and represent. Or, to put it more colloquially, to define use cases.
- Take into account, to the extent necessary for the intended purpose, the particular characteristics or elements of the specific geographical, contextual, behavioural or functional environment in which the high-risk AI system is intended to be used.
Managing risk: avoiding bias
In the area of data governance, a key role is attributed to the avoidance of bias where it may lead to risks to the health and safety of individuals, adversely affect fundamental rights or give rise to discrimination prohibited by Union law, in particular where data outputs influence incoming information for future operations. To this end, appropriate measures should be taken to detect, prevent and mitigate possible biases identified.
The AIA exceptionally enables the processing of special categories of personal data provided that they offer adequate safeguards in relation to the fundamental rights and freedoms of natural persons. But it imposes additional conditions:
- the processing of other data, such as synthetic or anonymised data, does not allow effective detection and correction of biases;
- that special categories of personal data are subject to technical limitations concerning the re-use of personal data and to state-of-the-art security and privacy protection measures, including the pseudonymisation;
- that special categories of personal data are subject to measures to ensure that the personal data processed are secured, protected and subject to appropriate safeguards, including strict controls and documentation of access, to prevent misuse and to ensure that only authorised persons have access to such personal data with appropriate confidentiality obligations;
- that special categories of personal data are not transmitted or transferred to third parties and are not otherwise accessible to them;
- that special categories of personal data are deleted once the bias has been corrected or the personal data have reached the end of their retention period, whichever is the earlier;
- that the records of processing activities under Regulations (EU) 2016/679 and (EU) 2018/1725 and Directive (EU) 2016/680 include the reasons why the processing of special categories of personal data was strictly necessary for detecting and correcting bias, and why that purpose could not be achieved by processing other data.
The regulatory provisions are extremely interesting. RGPD, DGA or EHDS are in favour of processing anonymised data. AIA makes an exception in cases where inadequate or low-quality datasets are generated from a bias point of view.
Individual developers, data spaces and intermediary services providing datasets and/or platforms for development must be particularly diligent in defining their security. This provision is consistent with the requirement to have secure processing spaces in EHDS, implies a commitment to certifiable security standards, whether public or private, and advises a re-reading of the seventeenth additional provision on data processing in our Organic Law on Data Protection in the area of pseudonymisation, insofar as it adds ethical and legal guarantees to the strictly technical ones. Furthermore, the need to ensure adequate traceability of uses is underlined. In addition, it will be necessary to include in the register of processing activities a specific mention of this type of use and its justification.
Apply lessons learned from data protection, by design and by default
Article 10 of AIA requires the documentation of relevant design decisions and the identification of relevant data gaps or deficiencies that prevent compliance with AIA and how to address them. In short, it is not enough to ensure data governance, it is also necessary to provide documentary evidence and to maintain a proactive and vigilant attitude throughout the lifecycle of information systems.
These two obligations form the keystone of the system. And its reading should even be much broader in the legal dimension. Lessons learned from the GDPR teach that there is a dual condition for proactive accountability and the guarantee of fundamental rights. The first is intrinsic and material: the deployment of privacy engineering in the service of data protection by design and by default ensures compliance with the GDPR. The second is contextual: the processing of personal data does not take place in a vacuum, but in a broad and complex context regulated by other sectors of the law.
Data governance operates structurally from the foundation to the vault of AI-based information systems. Ensuring that it exists, is adequate and functional is essential. This is the understanding of the Spanish Government's Artificial Intelligence Strategy 2024 which seeks to provide the country with the levers to boost our development.
AIA makes a qualitative leap and underlines the functional approach from which data protection principles should be read by stressing the population dimension. This makes it necessary to rethink the conditions under which the GDPR has been complied with in the European Union. There is an urgent need to move away from template-based models that the consultancy company copies and pastes. It is clear that checklists and standardisation are indispensable. However, its effectiveness is highly dependent on fine tuning. And this calls particularly on the professionals who support the fulfilment of this objective to dedicate their best efforts to give deep meaning to the fulfilment of the Artificial Intelligence Regulation.
You can see a summary of the regulations in the following infographic:

You can access the accessible and interactive version here
Content prepared by Ricard Martínez, Director of the Chair of Privacy and Digital Transformation. Professor, Department of Constitutional Law, Universitat de València. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
For some time now we have been hearing about high-value dataset, those datasets whose re-use is associated with considerable benefits for society, the environment and the economy. They were announced in Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on open data and the re-use of public sector information, and subsequently defined in Commission Implementing Regulation (EU) 2023/138 of 21 December 2022 establishing a list of specific high-value datasets and modalities for publication and re-use.
In particular, six categories of dataset are concerned: geospatial, Earth observation and environment, meteorology, statistics, companies and company ownership, and mobility. The detail of these categories and how these datasets should be opened is summarised in the following infographic:

Click on the image or here to expand and access the accessible version
For years, even before the publication of Directive (EU) 2019/1024,Spanish organisations have been working to make this type of datasets available to developers, companies and any citizen who wants to use them, with technical characteristics that facilitate their reuse. However, the Regulation has laid down a number of specific requirements to be met. Below is a summary of the progress made in each category.
Geospatial data
For geospatial data, the implementing regulation (EU) 2023/138 takes into account the categories indicated in Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE), with the exception of agricultural and reference parcels, for which Regulation (EU) 2021/2116 of the European Parliament and of the Council of 2 December 2021applies.
Spain has complied with the INSPIRE Directive for years, thanks to the Law 14/2010 of 5 July 2010 on geographic information infrastructures and services in Spain (LISIGE), which transposes the Directive. Citizens have at their disposal the Official Catalogue of INSPIRE Data and Services of Spain, as well as the catalogues of the Spatial Data Infrastructures of the Autonomous Communities. This has resulted in comprehensive geographical coverage, with exhaustive metadata, which complies with European requirements.
- You can see the dataset currently published by our country in this category on the INSPIRE Geoportal. You can read more about it in this post.
Earth observation and environmental data
For the category of Earth observation and environment data, both the environmental and climate datasets listed in the annexes of the INSPIRE Directive and those produced in the context of a number of legal acts known as priority data, detailed in the Implementing Regulation, are taken into account.
As with the previous category, the fact of having the LISIGE law, which develops INSPIRE and goes further in the obligations set out, has meant that many of these datasets were already available prior to the Implementing Regulation.
- You can see the dataset currently published by Spain in this category in the INSPIRE Geoportal and read more about its publication in Spain here.
Meteorological data
The meteorological thematic category encompasses collections of data on observations measured by various elements, such as weather stations, radars, etc.
In Spain, the State Meteorological Agency (AEMET) has a portal, AEMET OpenData, which was a pioneer in Europe in terms of the availability of open meteorological data. In this portal we find that most of the high-value datasets are already available, grouped in the 14 categories of AEMET OpenData. Work is ongoing to expand the available datasets, their granularity and other technical aspects to further enhance their usability.
- You can see a more detailed review of the current status of the publication status of the datasets in this category in this post.
Statistical data
High statistical value data are covered by a number of legal acts detailed in the Annex to the Implementing Regulation. This category is based on the European Statistical System, which ensures quality and interoperability between states.
In line with this system, Spain has the National Statistical Plan. This plan is developed and implemented through specific annual programmes detailing statistical operations, their objectives, bodies involved and budget appropriations, many of which are aligned with the statistical packages detailed in the Implementing Regulation.
- You can see the detail of the equivalence between the high value data and the datasets published as the result of the National Statistical Plan in this article. You can also see the details of the data published by the National Statistics Institute (INE) here.
Company data and company ownership
Company and company ownership data refer to datasets containing basic company information, including company documents and accounts.
In Spain, information from the Official Gazette of the Mercantile Registry (BORME in Spanish acronyms) is offered openly, with temporal coverage since 2009. However, work continues on opening up more datasets in this category.
Mobility data
The mobility category includes datasets falling under the domain "Transport Networks", included in Annex I of the INSPIRE Directive, together with those referred to in Directive 2005/44/EC of the European Parliament and of the Council of 7 September 2005 on harmonised River Information Services (RIS) on inland waterways in the Community.
As was the case for other categories where high value dataset were already covered by the INSPIRE Directive, Spain has a large amount of dataset available on the Geoportal of the Spatial Data Infrastructure of Spain (IDEE) and the infrastructures of the Autonomous Communities and the infrastructures of the Autonomous Communities.
- You can see the dataset published in the INSPIRE Geoportal and the details of the current situation in this content.
The large amount of dataset published reflects our country's continued commitment to transparency and access to high-value dataset. This is an ongoing effort, the result of the collaboration and involvement of various organisations. Work continues to provide the public with as much quality data as possible.
Blog
The cross-cutting nature of open data on weather and climate data has favoured its use in areas as diverse as precision agriculture, fire prevention or the precision forestry. But the relevance of these datasets lies not only in their direct applicability across multiple industries, but also in their contribution to the challenges related to climate change and environmental sustainability challenges related to climate change and environmental sustainability, which the different action lines of the which the different action lines of the European Green Pact seek to address.
Meteorological data are considered by the European Commission, high value data in accordance with the annex to Regulation 2023/138. In this post we explain which specific datasets are considered to be of high value and the level of availability of this type of data in Spain.
The State Meteorological Agency
In Spain, it corresponds to the State Agency for Meteorology (AEMET) the mission of providing meteorological and climatological services at national level. As part of the Ministry for Ecological Transition and the Demographic Challenge. AEMET leads the related activities of observation, prediction and study of meteorological and climatic conditions, as well as research related to these fields. Its mission includes the provision and dissemination of essential information and forecasts of general interest. This information can also support relevant areas such as civil protection, air navigation, national defence and other sectors of activity.
In order to fulfil this mission, AEMET manages an open data portal that enables the reuse by natural or legal persons, for commercial or non-commercial purposes, of part of the data it generates, prepares and safeguards in the performance of its functions. This portal, known as AEMET OpenData currently offers two modalities for accessing and downloading data in reusable formats:
- General access, which consists of graphical access for the general public through human-friendly interfaces.
- AEMET OpenData API, designed for periodic or scheduled interactions in any programming language, which allows developers to include AEMET data in their own information systems and applications.
In addition, in accordance with Regulation 2023/138, it is envisaged to enable a third access route that would allow re-users to obtain packaged datasets for mass downloading where possible.
In order to access any of the datasets, an access key (API Key) which can be obtained through a simple request in which only an e-mail address is required, without any additional data from the applicant, for the sending of the access key. This is a control measure to ensure that the service is provided with adequate quality and in a non-discriminatory manner for all users.
AEMET OpenData also pioneered the availability of open meteorological data in Europe, reflecting AEMET''s commitment to the continuous improvement of meteorological services, support to the scientific and technological community, and the promotion of a more informed and resilient society in the face of climate challenges.
High-value meteorological datasets
The Annex to Regulation (EU) 2023/138 details five high-value meteorological data sets: weather station observations, validated weather data observations, weather warnings, radar data and numerical prediction model (NMP) data. For each of the sets, the regulation specifies the granularity and the main attributes to be published.
If we analyse the correspondence of the datasets that are currently available grouped in 14 categories in the portal AEMET OpenData portal, with the five datasets that will become mandatory in the coming months, we obtain the conclusions summarised in the following table:
| High-value meteorological datasets | Equivalence in the AEMET OpenData datasets |
|---|---|
| Observation data measured by meteorological stations | The "Conventional Observation" dataset, generated by the Observing Service, provides a large number of hourly variables on liquid and solid precipitation, wind speed and direction, humidity, pressure, air, soil and subsoil temperature, visibility, etc. It is updated twice an hour. In accordance with the Regulation, ten-minute data shall be included with continuous updating. |
| Climate data: validated observations | Within the category "Climatological Values", four datasets on climate data observations are provided: "Daily climatologies", "Monthly/annual climatologies", "Normal values" and "Recorded extremes". The validated dataset provided by the National Climatological Data Bank Service is normally updated once a day with a delay of four days due to validation processes. Attributes available include daily mean temperature, daily precipitation in its standard 07:00 to 07:00 measurement form, daily mean relative humidity, maximum gust direction, etc. In accordance with the Regulation, the inclusion of hourly climatology is planned. |
| Weather warnings | Adverse weather warnings" are provided for the whole of Spain, or segmented by province or Autonomous Community. Both the latest issued and the historical ones since 2018. They provide data on observed and/or forecast severe weather events, from the present time until the next 72 hours. These warnings refer to each meteorological parameter by warning level, for each weather zone defined in the Meteoalert Plan. It is generated by the Adverse Events Functional Groups and the information is available any time an adverse weather event is issued, in line with the Regulation, which requires the dataset to be published "as issued or hourly". In this case, AEMET announces preferential broadcasting hours: 09:00, 11:30, 23:00 y 23:50. |
| Radar data | There are two sets of data: "Regional radar graphic image" and "National radar composition image", which provide reflectivity images, but not the others described in the Regulation (backscatter, polarisation, precipitation, wind and echotop). The dataset is generated by the Land Remote Sensing group and the information is available at a periodicity of 10 minutes instead of the 5 minutes recommended in the Regulation. However, according to the Strategic Plan 2022-2025 of the AEMET the updating of the 15 weather radars and the incorporation of new radars with higher resolution is foreseen, so that in addition to strengthening the early warning system, the obligations of the Regulation can be fulfilled. |
| PMN model data | There are several datasets with forecast information, some available for download and some available on the web: weather forecast, normalised text forecast, specific forecasts, maritime forecast and maps of weather variables maps of the HARMONIE-AROME numerical models for different geographical areas and time periods. However, the AEMET, according to their frequently asked questions document does not currently consider numerical model outputs as open data. AEMET offers the possibility of requesting this or any other dataset through the general register or through the electronic site but this is not an option provided for in the Regulation. In line with this, the inclusion of numerical atmospheric and wave model outputs is foreseen. |
Figure 1: Table showing the equivalence between high value datasets and AEMET OpenData datasets.
The regulation also sets out a number of requirements for publication in terms of format, licence granted, frequency of updating and timeliness, means of access and metadata provided.
In the case of metadata, AEMET publishes, in machine-readable format, the main characteristics of the downloaded file: who prepares it, how often it is prepared, what it contains and its format, as well as information on the data fields (meteorological variable, unit of measurement, etc.). The copyright and terms of use are also specified by means of the legal notice. In this regard, it is foreseen that the current licences will be reviewed to make the datasets available under a licensing scheme compliant with the Regulation, possibly following the recommendation by adopting the license CC BY-SA 4.0.
All in all, it seems that the long track record of the State Meteorological Agency (AEMET) in providing quality open data has put it in a good position to comply with the requirements of the new regulation, making some adjustments to the datasets it already offers through AEMET OpenData to align them with the new obligations. AEMET plans to include in this service the datasets required by the Regulation and which are currently not available, as it adapts its regulations on public prices, as well as the infrastructure and systems that make this possible. Additional datasets that will be available will be ten-minute observation data, hourly climatologies and some data parameters from regional radars and numerical wave and forecast models.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
The European open data portal (data.europa.eu) regularly organises virtual training sessions on topical issues in the open data sector, the regulations they affect and related technologies. In this post, we review the key takeaways from the latest webinar on High Value Datasets (HVD).
Among other issues, this seminar focused on transmitting best practices, as well as explaining the experiences of two countries, Finland and the Czech Republic, which were part of the report "High-value Datasets Best Practices in Europe", published by data.europa.eu, together with Denmark, Estonia, Italy, the Netherlands and Romania. The study was conducted immediately after the publication of the HVD implementation regulation in February 2023.
Best practices linked to the provision of high-value data
After an introduction explaining what high-value data are and what requirements they have to meet, the scope of the report was explained in detail during the webinar. In particular, challenges, good practices and recommendations from member states were identified, as detailed below.
Political and legal framework
- There is a need to foster a government culture that is primarily practical and focused on achievable goals, building on cultural values embedded in government systems, such as transparency.
- A strategic approach based on a broader regulatory perspective is recommended, building on previous efforts to implement far-reaching directives such as INSPIRE or DCAT as a standard for data publication. In this respect, it is appropriate to prioritise actions that overlap with these existing initiatives.
- The use of Creative Commons (CC) licences is recommended.
- On a cross-cutting level, another challenge is to combine compliance with the requirements of high-value datasets with the provisions of the General Data Protection Regulation (GDPR), when dealing with sensitive or personal data.
Governance and processes
- Engaging in strategic partnerships and fostering collaboration at national level is encouraged. Among other issues, it is recommended to coordinate efforts between ministries, agencies responsible for different categories of HVD and other related actors, especially in Member States with decentralised governance structures. To this end, it is important to set up interdisciplinary working groups to facilitate a comprehensive data inventory and to clarify which agency is responsible for which dataset. These groups will enable knowledge sharing and foster a sense of community and shared responsibility, which contributes to the overall success of data governance efforts.
- It is recommended to engage in regular exchanges with other Member States, to share ideas and solutions to common challenges.
- There is a need to promote sustainability through the individual accountability of agencies for their respective datasets. Ensuring the sustainability of national data portals means making sure that metadata is maintained with the resources available.
- It is advisable to develop a comprehensive data governance framework by first assessing available resources, including technical expertise, data management tools and key stakeholder input. This assessment process allows for a clear understanding of the rules, processes and responsibilities necessary for an effective implementation of data governance.
Technical aspects, metadata quality and new requirements
- It is proposed to develop a comprehensive understanding of the specific requirements for HVD. This involves identifying existing datasets to determine their compliance with the standards described in the implementing regulation for HVD. There is a need to build a systemic basis for identifying, improving the quality and availability of data by enhancing the overall value of high-value datasets.
- It is recommended to improve the quality of metadata directly at the data source before publishing them in portals, following the DCAT-AP guidelines for publishing high-value datasets and the controlled vocabularies for the six HVD categories. There is also a need to improve the implementation of APIs and bulk downloads from each data source. Its implementation presents significant challenges due to the scarcity of resources and expertise, making capacity building and resourcing essential.
- It is suggested to strengthen the availability of high-value datasets through external funding or strategic planning. The regulation requires all HVD to be accessible free of charge, so some Member States diversify funding sources by seeking financial support through external channels, e.g. by tapping into European projects. In this respect, it is recommended to adapt business models progressively to offer free data.
Finally, the report highlights a suggested eight-step roadmap for compliance with the HVD implementation regulation:
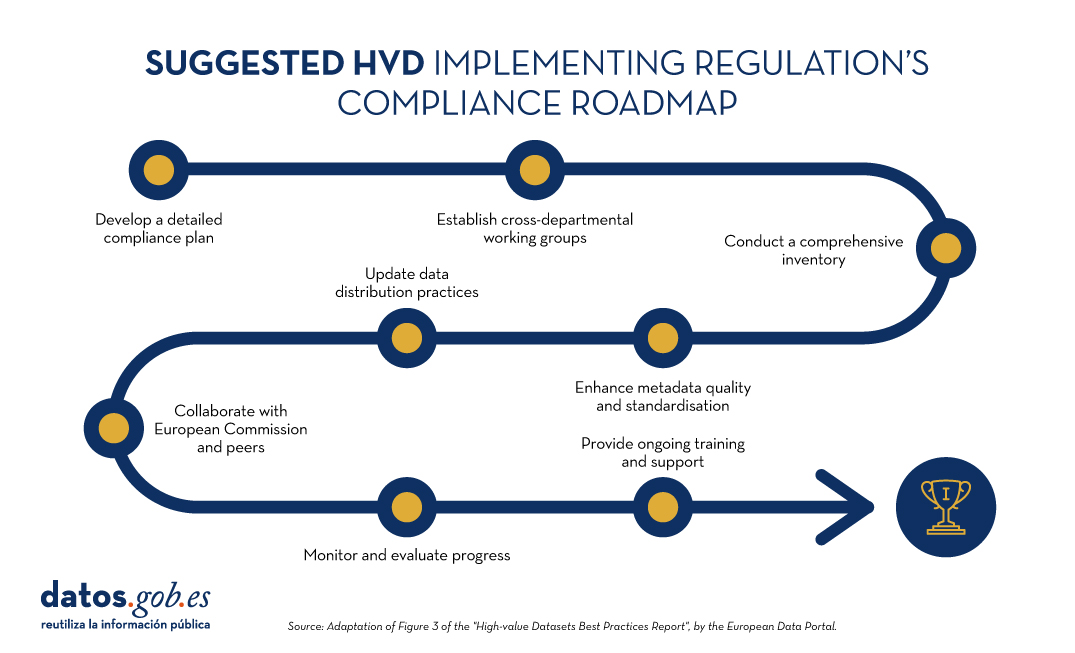
Figure 1: Suggested roadmap for HVD implementation. Adapted from Figure 3 of the European Data Portal's "High-value Datasets Best Practices Report".
The example of the Czech Republic
In a second part of the webinar, the Czech Republic presented their implementation case, which they are approaching from four main tasks: motivation, regulatory implementation, responsibility of public data provider agencies and technical requirements.
- Motivation among the different actors is being articulated through the constitution of working groups.
- Regulatory implementation focuses on dataset analysis and consistency or inconsistency with INSPIRE.
- To boost the accountability of public agencies, knowledge-sharing seminars are being held on linking INSPIRE and HVD using the DCAT-AP standard as a publication pathway.
- Regarding technical requirements, DCAT-AP and INSPIRE requirements are being integrated into metadata practices adapted to their national context. The Czech Republic has developed specifications for local open data catalogues to ensure compatibility with the National Open Data Catalogue. However, its biggest challenge is a strong dependency due to a lack of technical capacities.
The example of Finland
Finland then took the floor. Having pre-existing legislation (INSPIRE and other specific rules on open data and information management inpublic bodies), Finland required only minor adjustments to align with the national transposition of the HVD directive. The challenge is to understand and make INSPIRE and HVD coexist.
Its main strategy is based on the roadmap on information management in public bodies, which ensures harmonisation, interoperability, high quality management and security to implement the principles of open data. In addition, they have established two working groups to address the implementation of HVD:
- The first group, which is a coordinating group of data promoters, focused on practical and technical issues. As legal experts, they also provided guidance on understanding HVD regulation from a legal perspective.
- The second group is an inter-ministerial coordination group, a working group that ensures that there is no conflict or overlap between HVD regulation and national legislation. This group manages the inventory, in spreadsheet format, containing all the elements necessary for an HVD catalogue. By identifying areas where datasets do not meet these requirements, organisations can establish a roadmap to address the gaps and ensure full compliance over time.
The secretariat of the groups is provided by a geospatial data committee. Both have a wide network of stakeholders to articulate discussion and feedback on the measures taken.
Looking to the future, they highlight as a challenge the need to gain more technical and executive level experience.
End of the session
The webinar continued with the participation of Compass Gruppe (Germany), which markets, among other things, data from the Austrian commercial register. They have a portal that offers this data via APIs through a freemium business model.
In addition, it was recalled that Member States are obliged to report to Europe every two years on progress in HVD, an activity that is expected to boost the availability of harmonised federated metadata on the European data portal. The idea is that users will be able to find all HVD in the European Union, using the filtering available on the portal or through SPARQL queries.
The combination of the report's conclusions and the experiences of the rapporteur countries give us good clues to guide the implementation of HVD, in compliance with European regulations. In summary, the implementation of HVD poses the following challenges:
- Support the necessary funding to address the opening-up process.
- Overcoming technical challenges to develop efficient access APIs.
- Achieving a proper coexistence between INSPIRE and the HVD regulation
- Consolidate working groups that function as a robust mechanism for progress and convergence.
- Monitor progress and continuously follow up the process.
- Invest in technical training of staff.
- Create and maintain strong coordination in the face of the complex diversity of data holders.
- Potential quality assurance of high value datasets.
- Agree on a standardisation that is necessary from a business point of view.
By addressing these challenges, we will successfully open up high-value data, driving its re-use for the benefit of society as a whole.
You can re-watch the recording of the session here
Blog
Spain, as part of the European Union, is committed to the implementation of the European directives on open data and re-use of public sector information. This includes the adoption of initiatives such as the Implementing Regulation (EU) 2023/138 issued by the European Commission, which defines specific guidelines for government entities with regard to the availability of High value datasets (HVD). These data are categorised into themes previously detailed in earlier discussions: Geospatial, Earth Observation and Environment, Meteorology, Statistics, Societies and Societal Properties, and Mobility. In this article we will focus on the last group mentioned.
The Mobility category encompasses data collections falling under the domain of "Transport Networks", as demarcated in Annex I of the Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE). In particular, this Directive refers to the requirement to make available to users datasets relating to road, rail, air and inland waterway networks, with their associated infrastructure, connections between different networks and the trans-European transport network, as defined by Decision No 1692/96/EC of the European Parliament and of the Council of 23 July 1996 on Community guidelines for the development of the trans-European transport network.
In addition, it includes the datasets as described in the Directive 2005/44/EC of the European Parliament and of the Council of 7 September 2005 on harmonised River Information Services (RIS) on inland waterways in the Community. The main objective of the Directive is to improve inland waterway traffic and transport, and it applies to canals, rivers, lakes and ports capable of accommodating vessels of between 1,000 and 1,500 tonnes. These datasets include:
| Data type | Inland waterways datasets |
|---|---|
| Static data |
|
| Dynamic data |
|
| Inland electronic and navigational charts (Inland ENC according to the Inland ECDIS Standard) |
|
Figure 1: Table with the high value datasets related to Directive 2005/44/EC for the creation of a trans-European river information network.
In order for all of us to make the most of the information available, the Regulation defines some basic rules on how this data is shared:
- Free and easy to use. The data must be ready to be used and shared with everyone for any purpose by acknowledging and citing the source of the data, as prescribed by the Creative Commons BY 4.0 licence.
- Easy to read and use. Data will be presented in a way that both people and computers can easily understand them and everything will be explained in public.
- Direct and easy access. There will be special ways (called APIs) that allow programs to access data automatically. In addition, the user can alternatively download a lot of information at once.
- Always up to date. It is important that data is up to date, so there will be access to the most recent version. But if the user needs to access previous data, it will also be possible to view previous versions.
- Detailed and precise. Data will be shared in as much detail as possible, to a very fine level of accuracy, so that the whole territory is covered when combined.
- Information on information. There will be "information about the information" (metadata) that will tell everything about the data. The metadata shall contain at least the elements listed in the Annex to Commission Regulation (EC) No 1205/2008 of 3 December 2008.
- Understandable and orderly: It will explain well how the data are organised and what all means, in a way that is easy for everyone to understand (structure and semantics).
- Common language. Data shall use vocabularies, code lists and categories that are recognised and accepted at European or global level.
in Spain, who is responsible for the creation and maintenance of mobility data?
In Spain, the responsibility for the creation and maintenance of mobility data generally lies with different governmental entities, depending on the type of mobility and the territorial scope:
- Level national level. The Ministry of Transport and Sustainable Mobility is the main body in charge of mobility in terms of infrastructure and transport at national level. This would include data on roads, railways, air and maritime transport.
- Regional and local level. Autonomous communities and municipalities also play an important role in urban and regional mobility. They are responsible for urban mobility, public transport and public roads, within their respective jurisdictions.
- Public business entities. There are entities such as ADIF (acronym for Administrador de Infraestructuras Ferroviarias, that is Railway Infrastructure Administrator), AENA (acronym for Aeropuertos Españoles y Navegación Aérea, that is Spanish Airports and Air Navigation), Puertos del Estado (State Ports) and others tentities hat manage specific data related to their field of action in rail, air and maritime transport, respectively.
In Spain, the Ministry of Transport and Sustainable Mobility, in collaboration with the autonomous communities, plays a key role in providing access to a wide range of mobility data. In compliance with INSPIRE and LISIGE (Law 14/2010 of 5 July 2010 on geographic information infrastructures and services in Spain, which transposes the INSPIRE Directive), it offers resources such as the Geoportal of the Spatial Data Infrastructure of Spain (IDEE in Spanish acronyms) where citizens and professionals can access geographic data and services, especially with regard to mobility.
Does Spain comply with the HVD Mobility Regulation?
To solve this question we have to go to the INSPIRE Geoportal where official information classified as high value datasets in Europe is available. Specifically in the mobility category.

Figure 2: Screenshot of the Inspire Geoportal.
As of April 2024 Spain has published the following information in the INSPIRE Geoportal:
- Port service areas in Spain. The port service areas include the cartographic and alphanumeric information of the land service area and water areas I and II. The Spanish State-owned Port System is made up of 46 ports of general interest, managed by 28 Port Authorities.
- Spanish Transport Networks. The Transport Network of the Geographic Reference Information of the National Cartographic System of Spain is a three-dimensional network of national coverage, defined and published in accordance with the INSPIRE Directive, which contemplates five modes of transport: road, rail, inland waterways, air and cable, together with their respective intermodal connections and the infrastructures associated with each mode. This information has the linear geometry of the roads and the punctual geometry of the portals and kilometre points.
- ADIF''s Spanish Rail Transport Network. Public geographic dataset on the adaptation of the Spanish ADIF Common Traamification to the INSPIRE regulations (Transport Networks Annex I).
The publication of these high-value datasets responds positively to the question of Spain''s compliance with the HVD regulation, and is an achievement that reflects Spain''s continued commitment to transparency and access to mobility data.
The joint effort between the Ministry of Transport, Mobility and Urban Agenda, the National Cartographic System and the Autonomous Communities and Public Business Entities underlines the importance of a collaborative approach to mobility information management.
The availability of this data highlights Spain''s commitment to publishing high-value datasets and underlines the importance of continuously improving access to information to optimise inland navigation and mobility data.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of its author.
Noticia
The Use Case Observatory is an initiative led by data.europa.eu, the European Open Data Portal. This is a research project on the economic, governmental, social and environmental impact of open data. The project will run for three years, from 2022 to 2025, during which the European Data Portal will monitor 30 cases of open data re-use and publish findings in regular deliverables.
In 2022 it made a first report and now, in April 2024, it has presented volume 2 of the exploratory analysis on the use of open data. In this second instalment, he analyses thirteen of the initial use cases that remain under study, three of them Spanish, and draws the following conclusions:
- The paper first of all underlines the high potential of open data re-use.
- It stresses that many organisations and applications owe their very existence to open data.
- It also points to the need to unlock more broadly the potential impact of open data on the economy, society and the environment.
- To achieve the above point, it points to continued support for the reuse community as crucial to identifying opportunities for financial growth.
The three Spanish cases: UniversiDATA-Lab, Tangible Data and Planttes
To select the use cases, the Use Case Observatory conducted an inventory based on three sources: the examples collected in the European portal's annual maturity studies , the solutions participating in the EU Datathon and the reuse examples available in the data.europa.eu use case repository. Only projects developed in Europe were taken into account, trying to maintain a balance between the different countries.
In addition, projects that had won an award or were aligned with the European Commission's priorities for 2019 to 2024 were highlighted. To finalise the selection, data.europa.eu conducted interviews with representatives of eligible use cases interested in participating in the project.
On this second occasion, the new report reviews one project in the economic impact area, three in the governmental area, six in the social area and four in the environmental area.
In both the first volume and this one, he highlights three Spanish cases: UniversiDATA-Lab and Tangible Data in the social field and Planttes in the environmental category.
UniversiDATA-Lab, the union of six universities around open data
In the case of UniversiDATA-Lab it is focused on higher education. It is a public portal for the advanced and automatic analysis of datasets published by the six Spanish universities that are part of the UniversiDATAportal: the Autonomous University of Madrid (UAM), the Carlos III University of Madrid, the Complutense University of Madrid (UCM), the University of Huelva, the University of Valladolid (UVa) and the Juan Carlos I University.
The aim of UniversiDATA-Lab is to transform the static analyses of the portal section into dynamic results. The Observatory's report notes that this project "encourages the use of shared resources" between the different university centres. Another notable impact is the implementation of dynamic web applications that read the UniversiDATA catalogue in real time, retrieve all available data and perform online data analysis.
Regarding the previous report, it praises its "considerable effort to convert intricate data into user-friendly information", and notes that this project provides detailed documentation to help users understand the nature of the data analysed.
Tangible Data, making spatial data understandable
Tangible Data is a project that transforms data from its digital context into a physical context by creating data sculptures in public space. These data sculptures help people who lack certain digital skills to understand them. It uses data from international agencies (e.g. NASA, World Bank) and other similar platforms as data sources.
In this second volume, they highlight its "significant" evolution, as since last year the project has moved from minimum viable product testing to the delivery of integral projects. This has allowed them to "explore commercial and educational opportunities, such as exhibitions, workshops, etc.", as extrapolated from the interviews conducted. In addition, the four key processes (design, creation, delivery and measurement) have been standardised and have made the project globally accessible and rapidly deployable.
Planttes, an environmental initiative that is making its way into the Observatory
The third Spanish example, Planttes, is a citizen science app that informs users about which plants are in flower and whether this can affect people allergic to pollen. It uses open data from the Aerobiology Information Point (PIA-UAB), among others, which it complements with data provided by users to create personalised maps.
Of this project, the Observatory notes that, by harnessing community involvement and technology, "the initiative has made significant progress in understanding and mitigating the impact of pollen allergies with a commitment to furthering awareness and education in the years to come".
Regarding the work developed, he points out that Planttes has evolved from a mobile application to a web application in order to improve accessibility. The aim of this transition is to make it easier for users to use the platform without the limitations of mobile applications.
The Use Case Observatory will deliver its third volume in 2025. Its raison d'être goes beyond analysing and outlining achievements and challenges. As this is an ongoing project over three years, it will allow for the extrapolation of concrete ideas for improving open data impact assessment methodologies.
Blog
The Implementing Regulation (EU) 2023/138 of the European Commission sets clear guidelines for public bodies on the availability of high-value datasets within 16 months. These high-value datasets are grouped into the following themes, which were already described in this post post:

This article focuses on the geospatial category, called High-Value Geospatial Datasets (HVDG).
For all HVDGs, the following shall apply Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an infrastructure for spatial information in the European Community (INSPIRE) with the exception of agricultural and reference parcels, for which Regulation (EU) 2021/211/EEC applies Regulation (EU) No 2021/2116 of the European Parliament and of the Council of 2 December 2021.
As reflected in the table below, the regulation provides detailed information on the requirements to be considered for these HVDGs, such as scales or granularity and attributes of each dataset. These are complementary to the attributes defined in the European Regulation (No 1089/2010), which establishes the interoperability of spatial data sets and services.
| Datasets | Scales | Attributes |
|---|---|---|
| Administrative units |
Levels of generalisation available with a granularity down to the scale of 1:5 000. From municipalities to countries; maritime units. |
|
| Geographical names |
Not applicable. |
|
| Directorates | Not applicable. |
|
| Buildings | Levels of generalisation available with a granularity up to the scale of 1:5 000 |
|
| Cadastral parcels | Levels of generalisation available with a granularity up to the scale of 1:5 000 |
|
| Reference areas | Levels of generalisation available with a granularity up to the scale of 1:5 000 |
|
| Agricultural areas | Level of accuracy equivalent to 1:10 000 scale and from 2016, 1:5 000 scale |
|
To ensure the accessibility and re-use of all these valuable datasets, it is imperative to follow certain provisions to facilitate their publication. Here are the key requirements:
- Open Licence: All datasets must be made available for re-use under a licence Creative Commons BY 4.0 or any equivalent less restrictive open licence. This encourages the freedom to share and adapt information.
- Open and Machine Readable Format: Data should be presented in an open, machine-readable format and be publicly documented. This ensures that the information is easily understandable and accessible to any person or automated system.
- Application Programming Interfaces (APIs) and Mass Download: Application programming interfaces (APIs) should be provided to facilitate programmatic access to data. In addition, direct bulk downloading of datasets should be possible, allowing flexible options for users according to their needs.
- Updated version: The availability of datasets in their most up-to-date version is essential. This ensures that users have access to the latest information, promoting the relevance and accuracy of data.
- Metadata: The description of the data will also be carefully taken care of through the use of metadata. This metadata shall, as a minimum, include the elements as defined in Commission Regulation (EC) No 1205/2008 of 3 December 2008. This regulation implements Directive 2007/2/EC of the European Parliament and of the Council and sets standards for metadata associated with datasets. The use of standardised metadata provides additional information essential for understanding, interpreting and using datasets effectively. By following these standards, interoperability and consistency in reporting is facilitated, thus promoting a more complete and accurate understanding of the available data.
These provisions not only promote transparency and openness, but also facilitate collaboration and the effective use of information in a variety of contexts.
Does Spain comply with the Geospatial HVD Regulation?
The INSPIRE (Infrastructure for Spatial Information in Europe) Directive determines the general rules for the establishment of an Infrastructure for Spatial Information in the European Community based on the Infrastructures of the Member States. Adopted by the European Parliament and Council on 14 March 2007 (Directive 2007/2/EC), entered into force on 25 April 2007.
INSPIRE makes it easier to find, share and use spatial data from different countries and in each of the regions, with HVDs available in the the Commission's new catalogue of HVDs and in each of the catalogues of the Spatial Data Infrastructures of the Autonomous Communities, as well as in the Official INSPIRE Data and Services Catalogue of Spain. The information is available through an online platform whit data from different countries.

WARNING!: They are currently working on this Geoportal carrying out the tasks of data dump, therefore, there may be some temporal inconsistency with the data provided, which correspond to the Official Catalogue of INSPIRE Data and Services (CODSI).
In Spain, we can find the Law 14/2010 of 5 July 2010 on geographic information infrastructures and services in Spain (LISIGE), which transposes Directive 2007/2/EC INSPIRE. This law frames the work to make all national spatial data available and obliges the adaptation of national spatial data to the Technical Guides or Guidelines collected by the INSPIRE Directive, thus ensuring that these data are compatible and interoperable in a Community and cross-border context.
LISIGE applies to geographic data that meet these conditions:
- Refering to a geographical area of the national territory, the territorial sea, the contiguous zone, the continental shelf and the exclusive economic zone.
- Having been generated by or under the responsibility of public administrations.
- Being in electronic format.
- Their production and maintenance is the responsibility of a public sector administration or body.
- Being within the themes of Annexes I (Geographic Reference Information), II (Fundamental Thematic Data) or III (General Thematic Data) referred to in the aforementioned law
Furthermore, it is clarified that the geographic data and services regulated by the LISIGE will be available on the NSDI Geoportal and on the CODSI as well as in the rest of the catalogues of the Autonomous Communities. The National Geographic Institute (IGN) is responsible for its maintenance.
Thanks to the tireless efforts of the entire Spanish administration since the publication of LISIGE, Spain has achieved a remarkable milestone. It is currently available on the INSPIRE Geoportal a wide range of information classified as High Value Geospatial Data Set (HVDG) is now available on the INSPIRE Geoportal. This achievement reflects our country's continued commitment to transparency and access to high quality geospatial data.
As of January 2024 Spain has published in the INSPIRE Geoportal and in CODSI the following information related to the High Geospatial Value Datasets (HVD)
- 31 datasets associated with their metadata
- 34 download services (WFS, ATOM Feed, OGC Api Feature)
- 28 visualisation services (WMS, WMTS)
Analysing the sets of high geospatial value we see that, according to the thematics, they have already been published:
| HVDG Spain | Datasets | Download services | Visualisation services | Covers Spanish territory |
|---|---|---|---|---|
| Administrative units |
5 | 7 | 7 | Sí |
| Geographical names |
7 | 8 | 8 | Sí |
| Directorates | 6 | 5 | 7 | Sí |
| Buildings | 5 | 3 | 4 | Sí |
| Cadastral parcels | 3 | 3 | 3 | Sí |
| Reference areas | 3 | 0 | 3 | Sí |
| Agricultural areas | 2 | 2 | 2 | Sí |
Spain currently complies with the HVDG Regulation in all categories. Specifically, it complies with the established legislation at the level of scale or granularity, attributes, license, format, availability of the data in API or maximum download, with being the most updated version and with the metadata.
A detailed analysis of the datasets published under the HVD framework highlights several key issues:
- Comprehensive Geographic Coverage: At least one dataset covering the whole of Spain has been made available.
- Comprehensive Metadata: Metadata has been generated for all High Geospatial Value Datasets (HVDGs). These metadata are published in the Official INSPIRE Catalogue of INSPIRE Data and Services (CODSI), validated to comply with the standards of the Commission Regulation (EC) No 1205/2008.
- Viewing and Downloading Services: All HVDGs have viewing and download services. Download services can be bulk download or download APIs. Currently, they are WFS and ATOM. In the future may be OGC API Feature or API Coverage.
- Open Licences and Open Formats: All published services are licensed under Creative Commons BY 4.0, and download services use standard and open formats such as the GML format documented by the international standard ISO 19136.
- Compliance with INSPIRE Data Models: Almost all datasets comply with the INSPIRE data models, thus ensuring the consistency and quality of the attributes set out in the HVDG regulation.
- Data Updated and Maintained: Download services guarantee the availability of data in the most up-to-date version. Each public administration responsible for the data is responsible for maintaining and updating the information.
This analysis highlights the commitment and efficiency in the management of geospatial data in Spain, contributing to the transparency, accessibility and quality of the information provided to the community.
It should be noted that, in Spain, all HVDG requirements are met. Organisations such as the CNIG and the ICGC or the Government of Navarre, in addition to publishing through WFS or ATOM services, are already working on publishing these datasets with the APIs of OGC.
The INSPIRE Geoportal has become a valuable source of information, thanks to the dedication and collaboration of various governmental entities, including Spanish ones. This breakthrough not only highlights progress in the implementation of geospatial standards, but also strengthens the basis for sustainable development and informed decision-making in Spain. A significant achievement for the country in the geospatial field!
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
The energy transition is also a transition of raw materials. When we imagine a sustainable future, we conceive it based on a series of strategic sectors such as renewable energies or electric mobility. Similarly, we imagine a connected and digital future, where new innovations and business models related to the fourth industrial revolution allow us to solve global challenges such as food shortages or access to education. In short, we focus on technologies that help us improve our quality of life.
Why are critical minerals important?
These sectors depend on a series of key technologies, such as energy storage batteries, wind turbines, solar panels, electrolyzers, drones, robots, data transmission networks, electronic devices and space satellites. These are technologies that in recent years have undergone a great technological evolution and an enormous growth in demand worldwide. If we analyze the development forecasts to 2030, we can expect annual growth of at least double digits for many of them, as shown in Figure 1.

Figure 1: Expected growth up to 2030 of some of the key technologies for strategic sectors. Source: McKinsey (image 1, image 2, image 3)
However, as can be seen in Figure 2, many of these future technologies are highly dependent on a set of critical raw materials necessary for their development. Indium and gallium are key to the manufacture of energy-efficient LED lighting, silicon is indispensable for the manufacture of microchips and semiconductors, and the platinum group of metals (such as iridium, palladium, platinum rhodium or ruthenium) are used in catalysts for hydrogen electrolyzers.

Figure 2: Semi-quantitative representation of raw material flows to the fifteen key technologies and five strategic sectors. Source: JRC Study
So, when does a material become critical? There are several factors that allow us to determine whether a raw material is considered critical:
- Its world reserves are scarce
- There are no alternative materials that can perform their function (their properties are unique or very unique).
- They are indispensable materials for key economic sectors of the future, and/or their supply chain is high-risk.
In the words of Margrethe Vestager, Executive Vice-President of the European Commission, "without a secure and sustainable supply of critical raw materials, there will be no green (sustainable) and industrial transition".
Research into sources of critical minerals data
In order to know in detail the situation of public minerals in Europe, we need to locate quality data. A task for which we will have to look into several sources.
First of all, we go to the European open data portal. From its search engine, in a first iteration, we see that there are more than 46,000 datasets for the query "critical raw materials" (Figure 3).
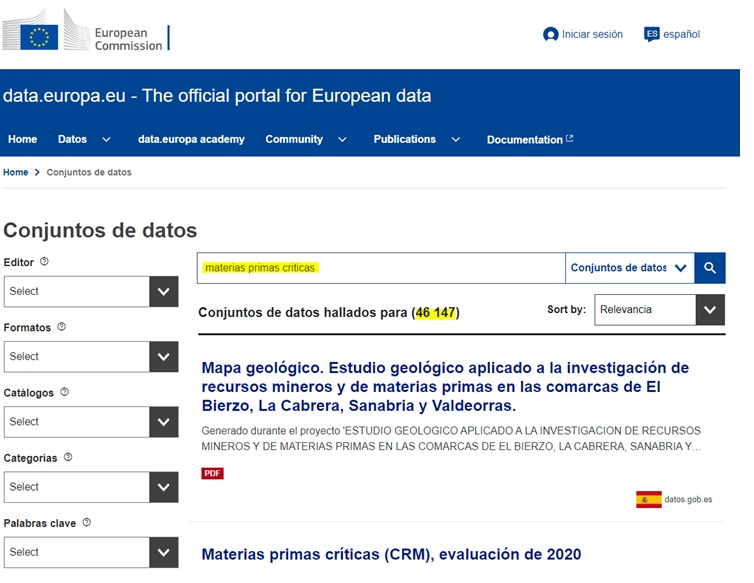
After a first analysis of the available data categories, we adjusted the filters until we narrowed down the datasets of interest to 190 (Figure 4). Particular attention is drawn to the data published by the JRC (European Commission Joint Research Center) and, in particular, to the dataset entitled Critical Raw Materials (CRM), 2020 assessment.
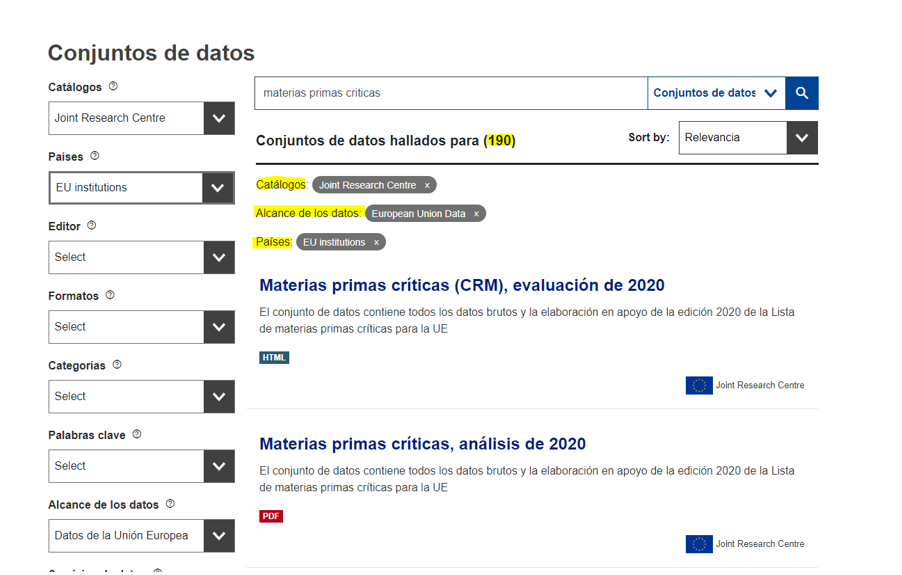
Figure 4: Second search for critical raw materials in the European data portal.
This dataset contains a direct link to a web portal, the RMIS (Raw Material Information System), which is actually the European Commission's reference knowledge base on raw materials through which we can access very relevant data and analysis.

Figure 5: RMIS - European Commission's knowledge base for raw materials
Through the RMIS, we find a very interesting publication for any study on the subject. Although this publication is in PDF format, it allows us to access the list of strategic, critical and non-critical materials identified by the European Commission indicating their level of criticality and their use in different key technologies as shown in Figure 6.

Figure 6: Table of strategic, critical and non-critical raw materials used different key technologies contained in the PDF file. Source: Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU - A foresight study, JRC 2023.
Continuing our exploration, in this case in search of data on mineral reserves in the European continent, we found the European Gelological Data Infrastructure (EDGI) platform, which has an extensive catalog with more than 5,700 datasets and geological services. In our case, after performing a search in its data catalog, we selected three datasets containing interesting information in terms of findings of critical lithium, cobalt and graphite minerals (Figure 7).

Figure 7: Searching for datasets in the EDGI catalog
From the EDGI viewer, we can view the contents of these three datasets before downloading them in GeoJSON format (Figure 8). The three datasets have been originated from the FRAME project (Forecasting And Assessing Europe's Strategic Raw Materials Needs), in which multiple European entities participate, including the Geological and Mining Institute of Spain (IGME).
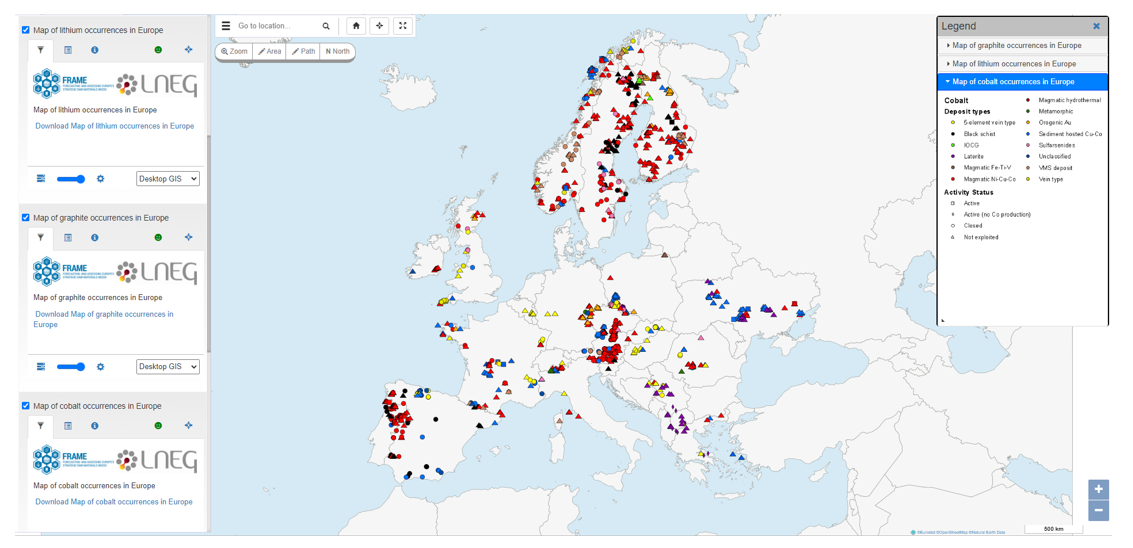
Figure 8: Querying selected datasets through EDGI visualization platform. Source: Map of cobalt occurrences in Europe, Map of graphite occurrences in Europe, Map of lithium occurrences in Europe, FRAME project.
Lastly, we went to the data portal of the International Energy Agency (IEA) (Figure 9). In this case, we found, among its more than 70 datasets, one directly related to our field of research, entitled Critical Minerals Demand Dataset, which we proceeded to download for further analysis in excel format.
Figure 9: Capture of the International Energy Agency (IEA) data portal.
After this search, we have located some interesting data that can help us to carry out different analyses.
Although this exercise has been carried out under the theme of critical minerals, European open data portals provide a large amount of information and diverse data sets on many areas of interest that can help us understand the challenges we face as a society, from the energy transition to the fight against poverty or food waste. Data that will allow us to carry out analyses aimed at making better decisions to move towards a more prosperous and sustainable future.
Content elaborated by Juan Benavente, industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.