Blog
In February 2024, the European geospatial community took a major step forward with the first major update of the INSPIRE implementation schemes in almost a decade. This update, which generates version 5.0 of the schemas, introduces changes that affect the way spatial data are harmonised, transformed and published in Europe. For implementers, policy makers and data users, these changes present both challenges and opportunities.
In this article, we will explain what these changes entail, how they impact on data validation and what steps need to be taken to adapt to this new scenario.
What is INSPIRE and why does it matter?
The INSPIRE Directive (Infrastructure for Spatial Information in Europe) determines the general rules for the establishment of an Infrastructure for Spatial Information in the European Community based on the Member States'' Infrastructures. Adopted by the European Parliament and the Council on March 14, 2007 (Directive 2007/2/EC), it is designed to achieve these objectives by ensuring that spatial information is consistent and accessible across EU member countries.
A key element of INSPIRE is the “application schemas”.These schemas define how data should be structured to comply with INSPIRE standards, ensuring that data from different countries are compatible with each other. In addition, the schemes make data validation easier with official tools, ensuring their quality and compliance with European standards.
What changes with the 5.0 upgrade?
The transition to version 5.0 brings significant modifications, some of which are not backwards compatible. Among the most notable changes are:
- Removal of mandatory properties: this simplifies data models, but requires implementers to review their previous configurations and adjust the data to comply with the new rules.
- Renaming of types and properties: with the update of the INSPIRE schemas to version 5.0, some element names and definitions have changed. This means that data that were harmonised following the 4.x schemas no longer exactly match the new specifications. In order to keep these data compliant with current standards, it is necessary to re-transform them using up-to-date tools. This re-transformation ensures that data continues to comply with INSPIRE standards and can be shared and used seamlessly across Europe. The complete table with these updates is as follows:
| Schema | Description of the change | Type of change | Latest version |
|---|---|---|---|
| ad | Changed the data type for the "building" association of the entity type Address. | Non-disruptive | v4.1 |
| au | Removed the enumeration from the schema and changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| BaseTypes.xsd | Removed VerticalPositionValue enumeration from BaseTypes schema. | Disruptive | v4.0 |
| ef | Added a new attribute "thematicId" to the AbstractMonitoringObject spatial object type | Non-disruptive | v4.1 |
| el-cov | Changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| ElevationBaseTypes.xsd | Deleted outline enumeration. | Disruptive | v5.0. |
| el-tin | Changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| el-vec | Removed the enumeration from the schema and changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| hh | Added new attributes to the EnvHealthDeterminantMeasure type, new entity types and removed some data types. | Disruptive | v5.0 |
| hy | Updated to version 5.0 as the schema imports the hy-p schema which was updated to version 5. | Disruptive y non-disruptive | v5.0 |
| hyp | Changed the data type of the geometry attribute of the DrainageBasin type. | Disruptive y non- disruptive | v5.0 |
| lcv | Added association role to the LandCoverUnit entity type. | Disruptive | v5.0 |
| mu | Changed the encoding of attributes referring to enumerations. | Disruptive | v4.0 |
| nz-core | Removed the enumeration from the schema and changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| ObservableProperties.xsd | Removed the enumeration from the schema and changed the encoding of attributes referring to enumerations. | Disruptive | v4.0 |
| pf | Changed the definition of the ProductionInstallation entity type. | Non-disruptive | v4.1 |
| plu | Fixed typo in the "backgroudMapURI" attribute of the BackgroundMapValue data type. | Disruptive | v4.0.1 |
| ps | Fixed typo in inspireId, added new attribute, and moved attributes to data type. | Disruptive | v5.0 |
| sr | Changed the stereotype of the ShoreSegment object from featureType to datatype. | Disruptive | v4.0.1 |
| su-vector | Added a new attribute StatisticalUnitType to entity type VectorStatisticalUnit | Non-disruptive | v4.1 |
| tn | Removed the enumeration from the schema and changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| tn-a | Changed the data type for the "controlTowers" association of the AerodromeNode entity type. | Non-disruptive | v4.1 |
| tn-ra | Removed enumerations from the schema and changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| tn-ro | Removed enumerations from the schema and changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| tn-w | Removed the abstract stereotype for the entity type TrafficSeparationScheme. Removed enumerations from the schema and changed the encoding of attributes referring to enumerations | Disruptive y non disruptive | v5.0 |
| us-govserv | Updated the version of the imported us-net-common schema (from 4.0 to 5.0). | Disruptive | v5.0 |
| us-net-common | Defined the data type for the authorityRole attribute. Changed the encoding of attributes referring to enumerations. | Disruptive | v5.0 |
| us-net-el | Updated the version of the imported us-net-common schema (from 4.0 to 5.0). | Disruptive | v5.0 |
| us-net-ogc | Updated the version of the imported us-net-common schema (from 4.0 to 5.0). | Disruptive | v5.0 |
| us-net-sw | Updated the version of the imported us-net-common schema (from 4.0 to 5.0). | Disruptive | v5.0 |
| us-net-th | Updated the version of the imported us-net-common schema (from 4.0 to 5.0). | Disruptive | v5.0 |
| us-net-wa | Updated the version of the imported us-net-common schema (from 4.0 to 5.0). | Disruptive | v5.0 |
Figure 1. Latest INSPIRE updates.
- Major changes in version 4.0: although normally a major change in a schema would lead to a new major version (e.g. from 4.0 to 5.0), some INSPIRE schemas in version 4.0 have received significant updates without changing version number. A notable example of this is the Planned Land Use (PLU) scheme. These updates imply that projects and services using the PLU scheme in version 4.0 must be reviewed and modified to adapt to the new specifications. This is particularly relevant for those working with XPlanung, a standard used in urban and land use planning in some European countries. The changes made to the PLU scheme oblige implementers to update their transformation projects and republish data to ensure that they comply with the new INSPIRE rules.
Impact on validation and monitoring
Updating affects not only how data is structured, but also how it is validated. The official INSPIRE tools, such as the Validador, have incorporated the new versions of the schemas, which generates different validation scenarios:
- Data conforming to previous versions: data harmonised to version 4.x can still pass basic validation tests, but may fail specific tests requiring the use of the updated schemas.
- Specific tests for updated themes: some themes, such as Protected Sites, require data to follow the most recent versions of the schemas to pass all compliance tests.
In addition, the Joint Research Center (JRC) has indicated that these updated versions will be used in official INSPIRE monitoring from 2025 onwards, underlining the importance of adapting as soon as possible.
What does this mean for consumers?
To ensure that data conforms to the latest versions of the schemas and can be used in European systems, it is essential to take concrete steps:
- If you are publishing new datasets: use the updated versions of the schemas from the beginning.
- If you are working with existing data: update the schemas of your datasets to reflect the changes you have made. This may involve adjusting types of features and making new transformations.
- Publishing services: If your data is already published, you will need to re-transform and republish it to ensure it conforms to the new specifications.
These actions are essential not only to comply with INSPIRE standards, but also to ensure long-term data interoperability.
Conclusion
The update to version 5.0 of the INSPIRE schemas represents a technical challenge, but also an opportunity to improve the interoperability and usability of spatial data in Europe. Adopting these modifications not only ensures regulatory compliance, but also positions implementers as leaders in the modernisation of spatial data infrastructure.
Although the updates may seem complex, they have a clear purpose: to strengthen the interoperability of spatial data in Europe. With better harmonised data and updated tools, it will be easier for governments, businesses and organisations to collaborate and make informed decisions on crucial issues such as sustainability, land management and climate change.
Furthermore, these improvements reinforce INSPIRE''s commitment to technological innovation, making European spatial data more accessible, useful and relevant in an increasingly interconnected world.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
One of the main requirements of the digital transformation of the public sector concerns the existence of optimal interoperability conditions for data sharing. This is an essential premise from a number of points of view, in particular as regards multi-entity actions and procedures. In particular, interoperability allows:
- The interconnection of the electronic registers powers and the filing of documents with public entities.
- The exchange of data, documents and files in the exercise of the respective competences, which is essential for administrative simplification and, in particular, to guarantee the right not to submit documents already in the possession of the public administrations;
- The development of advanced and personalised services based on the exchange of information, such as the citizen folder.
Interoperability also plays an important role in facilitating the integration of different open data sources for re-use, hence there is even a specific technical standard. It aims to establish common conditions to "facilitate and guarantee the process of re-use of public information from public administrations, ensuring the persistence of the information, the use of formats, as well as the appropriate terms and conditions of use".
Interoperability at European level
Interoperability is therefore a premise for facilitating relations between different entities, which is of particular importance in the European context if we take into account that legal relations will often be between different states. This is therefore a great challenge for the promotion of cross-border digital public services and, consequently, for the enforcement of essential rights and values in the European Union linked to the free movement of persons.
For this reason, the adoption of a regulatory framework to facilitate cross-border data exchange has been promoted to ensure the proper functioning of digital public services at European level. This is Regulation (EU) 2024/903 of the European Parliament and of the Council of 13 March 2024 laying down measures for a high level of public sector interoperability across the Union (known as the Interoperable Europe Act), which is directly applicable across the European Union from 12 July 2024.
This regulation aims to provide the right conditions to facilitate cross-border interoperability, which requires an advanced approach to the establishment and management of legal, organisational, semantic and technical requirements. In particular, trans-European digital public services, i.e. those requiring interaction across Member States' borders through their network and information systems, will be affected. This would be the case, for example, for the change of residence to work or study in another Member State, the recognition of academic diplomas or professional qualifications, access to health and social security data or, as regards legal persons, the exchange of tax data or information necessary to participate in a tendering procedure in the field of public procurement. In short, "all those services that apply the "once-only" principle for accessing and exchanging cross-border data".
What are the main measures it envisages?
- Interoperability assessment: prior to decisions on conditions for trans-European digital public services by EU entities or public sector bodies of States, the Regulation requires them to carry out an interoperability assessment, although this will only be mandatory from January 2025. The result of this evaluation shall be published on an official website in a machine-readable format that allows for automatic translation.
- Sharing of interoperability solutions: the above mentioned entities shall be obliged to share interoperability solutions supporting a trans-European digital public service, including technical documentation and source code, as well as references to open standards or technical specifications used. However, there are some limits to this obligation, such as in cases where there are intellectual property rights in favour of third parties. In addition, these solutions will be published on the Interoperable Europe Portal, which will replace the current Joinup portal.
- Enabling of sandboxes: one of the main novelties consists of enabling public bodies to proceed with the creation of sandboxes or controlled interoperability test areas which, in the case of processing personal data, will be managed under the supervision of the corresponding supervisory authority competent to do so. The aim of this figure is to encourage innovation and facilitate cooperation based on the requirements of legal certainty, thereby promoting the development of interoperability solutions based on a better understanding of the opportunities and obstacles that may arise.
- Creation of a governance committee: as regards governance, it is envisaged that a committee will be set up comprising representatives of each of the States and of the Commission, which will be responsible for chairing it. Its main functions include establishing the criteria for interoperability assessment, facilitating the sharing of interoperability solutions, supervising their consistency and developing the European Interoperability Framework, among others. For their part, Member States will have to designate at least one competent authority for the implementation of the Regulation by 12 January 2025, which will act as a single point of contact in case there are several. Its main tasks will be to coordinate the implementation of the Act, to support public bodies in carrying out the assessment and, inter alia, to promote the re-use of interoperability solutions.
The exchange of data between public bodies throughout the European Union and its Member States with full legal guarantees is an essential priority for the effective exercise of their competences and, therefore, for ensuring efficiency in carrying out formalities from the point of view of good administration. The new Interoperable European Regulation is an important step forward in the regulatory framework to further this objective, but the regulation needs to be complemented by a paradigm shift in administrative practice. In this respect, it is essential to make a firm commitment to a document management model based mainly on data, which also makes it easier to deal with regulatory compliance with the regulation on personal data protection, and is also fully coherent with the approach and solutions promoted by the Data Governance Regulation when promoting the re-use of the information generated by public entities in the exercise of their functions.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec). The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Today's climate crisis and environmental challenges demand innovative and effective responses. In this context, the European Commission's Destination Earth (DestinE) initiative is a pioneering project that aims to develop a highly accurate digital model of our planet.
Through this digital twin of the Earth it will be possible to monitor and prevent potential natural disasters, adapt sustainability strategies and coordinate humanitarian efforts, among other functions. In this post, we analyse what the project consists of and the state of development of the project.
Features and components of Destination Earth
Aligned with the European Green Pact and the Digital Europe Strategy, Destination Earth integrates digital modeling and climate science to provide a tool that is useful in addressing environmental challenges. To this end, it has a focus on accuracy, local detail and speed of access to information.
In general, the tool allows:
- Monitor and simulate Earth system developments, including land, sea, atmosphere and biosphere, as well as human interventions.
- To anticipate environmental disasters and socio-economic crises, thus enabling the safeguarding of lives and the prevention of significant economic downturns.
- Generate and test scenarios that promote more sustainable development in the future.
To do this, DestinE is subdivided into three main components :
- Data lake:
- What is it? A centralised repository to store data from a variety of sources, such as the European Space Agency (ESA), EUMETSAT and Copernicus, as well as from the new digital twins.
- What does it provide? This infrastructure enables the discovery and access to data, as well as the processing of large volumes of information in the cloud.
·The DestinE Platform:.
- What is it? A digital ecosystem that integrates services, data-driven decision-making tools and an open, flexible and secure cloud computing infrastructure.
- What does it provide? Users have access to thematic information, models, simulations, forecasts and visualisations that will facilitate a deeper understanding of the Earth system.
- Digital cufflinks and engineering:
- What are they? There are several digital replicas covering different aspects of the Earth system. The first two are already developed, one on climate change adaptation and the other on extreme weather events.
- WHAT DOES IT PROVIDE? These twins offer multi-decadal simulations (temperature variation) and high-resolution forecasts.
Discover the services and contribute to improve DestinE
The DestinE platform offers a collection of applications and use cases developed within the framework of the initiative, for example:
- Digital twin of tourism (Beta): it allows to review and anticipate the viability of tourism activities according to the environmental and meteorological conditions of its territory.
- VizLab: offers an intuitive graphical user interface and advanced 3D rendering technologies to provide a storytelling experience by making complex datasets accessible and understandable to a wide audience..
- miniDEA: is an interactive and easy-to-use DEA-based web visualisation app for previewing DestinE data.
- GeoAI: is a geospatial AI platform for Earth observation use cases.
- Global Fish Tracking System (GFTS): is a project to help obtain accurate information on fish stocks in order to develop evidence-based conservation policies.
- More resilient urban planning: is a solution that provides a heat stress index that allows urban planners to understand best practices for adapting to extreme temperatures in urban environments..
- Danube Delta Water Reserve Monitoring: is a comprehensive and accurate analysis based on the DestinE data lake to inform conservation efforts in the Danube Delta, one of the most biodiverse regions in Europe.
Since October this year, the DestinE platform has been accepting registrations, a possibility that allows you to explore the full potential of the tool and access exclusive resources. This option serves to record feedback and improve the project system.
To become a user and be able to generate services, you must follow these steps..
Project roadmap:
The European Union sets out a series of time-bound milestones that will mark the development of the initiative:
- 2022 - Official launch of the project.
- 2023 - Start of development of the main components.
- 2024 - Development of all system components. Implementation of the DestinE platform and data lake. Demonstration.
- 2026 - Enhancement of the DestinE system, integration of additional digital twins and related services.
- 2030 - Full digital replica of the Earth.
Destination Earth not only represents a technological breakthrough, but is also a powerful tool for sustainability and resilience in the face of climate challenges. By providing accurate and accessible data, DestinE enables data-driven decision-making and the creation of effective adaptation and mitigation strategies.
Noticia
The 2024 Best Cases Awards of the Public Sector Tech Watch observatory now have finalists. These awards seek to highlight solutions that use emerging technologies, such as artificial intelligence or blockchain, in public administrations, through two categories:
- Solutions to improve the public services offered to citizens (Government-to-Citizen or G2C).
- Solutions to improve the internal processes of the administrations themselves (Government-to-Government or G2G).
The awards are intended to create a mechanism for sharing the best experiences on the use of emerging technologies in the public sector and thus give visibility to the most innovative administrations in Europe.
Almost 60% of the finalist solutions are Spanish.
In total, 32 proposals have been received, 14 of which have been pre-selected in a preliminary evaluation. Of these, more than half are solutions from Spanish organisations. Specifically, nine finalists have been shortlisted for the G2G category -five of them Spanish- and five for G2C -three of them linked to our country-.The following is a summary of what these Spanish solutions consist of.
Solutions to improve the internal processes of the administrations themselves.
- Innovation in local government: digital transformation and GeoAI for data management (Alicante Provincial Council).
Suma Gestión Tributaria, of the Diputación de Alicante, is the agency in charge of managing and collecting the municipal taxes of the city councils of its province. To optimise this task, they have developed a solution that combines geographic information systems and artificial intelligence (machine learning and deep learning) to improve training in detection of properties that do not pay taxes. This solution collects data from multiple administrations and entities in order to avoid delays in the collection of municipalities.
- Regional inspector of public infrastructures: monitoring of construction sites (Provincial Council of Bizkaia and Interbiak).
The autonomous road inspector and autonomous urban inspector help public administrations to automatically monitor roads. These solutions, which can be installed in any vehicle, use artificial or computer vision techniques along with information from sensors to automatically check the condition of traffic signs, road markings, protective barriers, etc. They also perform early forecasting of pavement degradation, monitor construction sites and generate alerts for hazards such as possible landslides.
- Application of drones for the transport of biological samples (Centre for Telecommunications and Information Technologies -CTTI-, Generalitat de Catalunya).
This pilot project implements and evaluates a health transport route in the Girona health region. Its aim is to transport biological samples (blood and urine) between a primary health centre and a hospital using drones. As a result, the journey time has been reduced from 20 minutes with ground transport to seven minutes with the use of drones. This has improved the quality of the samples transported, increased flexibility in scheduling transport times and reduced environmental impact.
- Robotic automation of processes in the administration of justice (Ministry of the Presidency, Justice and Relations with the Courts).
Ministry of the Presidency, Justice and Relations with the Courts has implemented a solution for the robotisation of administrative processes in order to streamline routine, repetitive and low-risk work. To date, more than 25 process automation lines have been implemented, including the automatic cancellation of criminal records, nationality applications, automatic issuance of life insurance certificates, etc. As a result, it is estimated that more than 500,000 working hourshave been saved.
- Artificial intelligence in the processing of official publications (Official Gazette of the Province of Barcelona and Official Documentation and Publications Service, Barcelona Provincial Council).
CIDO (Official Information and Documentation Search Engine) has implemented an AI system that automatically generates summaries of official publications of the public administrations of Barcelona. Using supervised machine learning and neural networkstechniques, the system generates summaries of up to 100 words for publications in Catalan or Spanish. The tool allows the recording of manual modifications to improve accuracy.
Solutions to improve the public services offered to citizens
- Virtual Desk of Digital Immediacy: bringing Justice closer to citizens through digitalisation (Ministry of the Presidency, Justice and Relations with the Courts).
The Virtual Digital Immediacy Desktop (EVID) allows remote hearings with full guarantees of legal certainty using blockchain technologies. The solution integrates the convening of the hearing, the provision of documentation, the identification of the participants, the acceptance of consents, the generation of the document justifying the action carried out, the signing of the document and the recording of the session. In this way, legal acts can be carried out from anywhere, without the need to travel and in a simple way, making justice more inclusive, accessible and environmentally friendly. By the end of June 2024, more than 370,000 virtual sessions had been held through EVID.
- Application of Generative AI to make it easier for citizens to understand legal texts (Entitat Autònoma del Diari Oficial i Publicacions -EADOP-, Generalitat de Catalunya).
Legal language is often a barrier that prevents citizens from easily understanding legal texts. To remove this obstacle, the Government is making available to users of the Legal Portal of Catalonia and to the general public the summaries of Catalan law in simple language obtained from generative artificial intelligence. The aim is to have summaries of the more than 14,000 14,000 existing regulatory provisions adapted to clear communication available by the end of the year. The abstracts will be published in Catalan and Spanish, with the prospect of also offering a version in Aranesein the future.
- Emi - Intelligent Employment (Consellería de Emprego, Comercio e Emigración de la Xunta de Galicia).
Emi, Intelligent Employment is an artificial intelligence and big data tool that helps the offices of the Public Employment Service of Galicia to orient unemployed people towards the skills required by the labour market, according to their abilities. AI models make six-month projections of contracts for a particular occupation for a chosen geographical area. In addition, they allow estimating the probability of finding employment for individuals in the coming months.
You can see all the solutions presented here. The winners will be announced at the final event on 28 November. The ceremony takes place in Brussels, but can also be followed online. To do so, you need to register here.
Public Sector Tech Watch: an observatory to inspire new projects
Public Sector Tech Watch (PSTW), managed by the European Commission, is positioned as a "one-stop shop" for all those interested - public sector, policy makers, private companies, academia, etc. - in the latest technological developments to improve public sector performance and service delivery. For this purpose, it has several sections where the following information of interest is displayed:
- Cases: contains examples of how innovative technologies and their associated data are used by public sector organisations in Europe.
- Stories: presents testimonials to show the challenges faced by European administrations in implementing technological solutions.
If you know of a case of interest that is not currently monitored by PSTW, you can register it here. Successful cases are reviewed and evaluated before being included in the database.
Noticia
As part of the European Cybersecurity Awareness Month, the European data portal, data.europa.eu, has organized a webinar focused on the protection of open data.This event comes at a critical time when organisations, especially in the public sector, face the challenge of balancing data transparency and accessibility with the need to protect against cyber threats.
The online seminar was attended by experts in the field of cybersecurity and data protection, both from the private and public sector.
The expert panel addressed the importance of open data for government transparency and innovation, as well as emerging risks related to data breaches, privacy issues and other cybersecurity threats. Data providers, particularly in the public sector, must manage this paradox of making data accessible while ensuring its protection against malicious use.
During the event, a number of malicious tactics used by some actors to compromise the security of open data were identified. These tactics can occur both before and after publication. Knowing about them is the first step in preventing and counteracting them.
Pre-publication threats
Before data is made publicly available, it may be subject to the following threats:
-
Supply chain attacks: attackers can sneak malicious code into open data projects, such as commonly used libraries (Pandas, Numpy or visualisation modules), by exploiting the trust placed in these resources. This technique allows attackers to compromise larger systems and collect sensitive information in a gradual and difficult to detect manner.
- Manipulation of information: data may be deliberately altered to present a false or misleading picture. This may include altering numerical values, distorting trends or creating false narratives. These actions undermine the credibility of open data sources and can have significant consequences, especially in contexts where data is used to make important decisions.
- Envenenamiento de datos (data poisoning): attackers can inject misleading or incorrect data into datasets, especially those used for training AI models. This can result in models that produce inaccurate or biased results, leading to operational failures or poor business decisions.
Post-publication threats
Once data has been published, it remains vulnerable to a variety of attacks:
-
Compromise data integrity: attackers can modify published data, altering files, databases or even data transmission. These actions can lead to erroneous conclusions and decisions based on false information.
- Re-identification and breach of privacy: data sets, even if anonymised, can be combined with other sources of information to reveal the identity of individuals. This practice, known as 're-identification', allows attackers to reconstruct detailed profiles of individuals from seemingly anonymous data. This represents a serious violation of privacy and may expose individuals to risks such as fraud or discrimination.
- Sensitive data leakage: open data initiatives may accidentally expose sensitive information such as medical records, personally identifiable information (emails, names, locations) or employment data. This information can be sold on illicit markets such as the dark web, or used to commit identity fraud or discrimination.
Following on from these threats, the webinar presented a case study on how cyber disinformation exploited open data during the energy and political crisis associated with the Ukraine war in 2022. Attackers manipulated data, generated false content with artificial intelligence and amplified misinformation on social media to create confusion and destabilise markets.
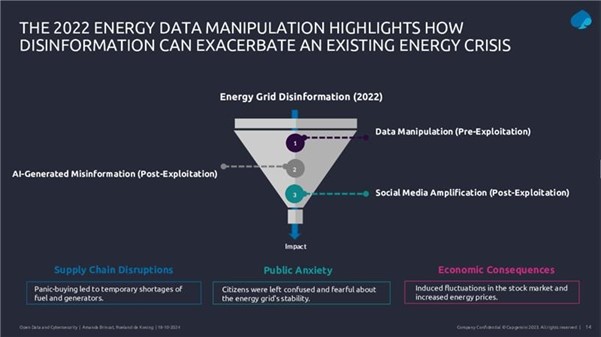
Figure 1. Slide from the webinar presentation "Safeguarding open data: cybersecurity essentials and skills for data providers".
Data protection and data governance strategies
In this context, the implementation of a robust governance structure emerges as a fundamental element for the protection of open data. This framework should incorporate rigorous quality management to ensure accuracy and consistency of data, together with effective updating and correction procedures. Security controls should be comprehensive, including:
- Technical protection measures.
- Integrity check procedures.
- Access and modification monitoring systems.
Risk assessment and risk management requires a systematic approach starting with a thorough identification of sensitive and critical data. This involves not only the cataloguing of critical information, but also a detailed assessment of its sensitivity and strategic value. A crucial aspect is the identification and exclusion of personal data that could allow the identification of individuals, implementing robust anonymisation techniques where necessary.
For effective protection, organisations must conduct comprehensive risk analyses to identify potential vulnerabilities in their data management systems and processes. These analyses should lead to the implementation of robust security controls tailored to the specific needs of each dataset. In this regard, the implementation of data sharing agreements establishes clear and specific terms for the exchange of information with other organisations, ensuring that all parties understand their data protection responsibilities.
Experts stressed that data governance must be structured through well-defined policies and procedures that ensure effective and secure information management. This includes the establishment of clear roles and responsibilities, transparent decision-making processes and monitoring and control mechanisms. Mitigation procedures must be equally robust, including well-defined response protocols, effective preventive measures and continuous updating of protection strategies.
In addition, it is essential to maintain a proactive approach to security management. A strategy that anticipates potential threats and adapts protection measures as the risk landscape evolves. Ongoing staff training and regular updating of policies and procedures are key elements in maintaining the effectiveness of these protection strategies. All this must be done while maintaining a balance between the need for protection and the fundamental purpose of open data: its accessibility and usefulness to the public.
Legal aspects and compliance
In addition, the webinar explained the legal and regulatory framework surrounding open data. A crucial point was the distinction between anonymization and pseudo-anonymization in the context of the GDPR (General Data Protection Regulation).
On the one hand, anonymised data are not considered personal data under the GDPR, because it is impossible to identify individuals. However, pseudo-anonymisation retains the possibility of re-identification if combined with additional information. This distinction is crucial for organisations handling open data, as it determines which data can be freely published and which require additional protections.
To illustrate the risks of inadequate anonymisation, the webinar presented the Netflix case in 2006, when the company published a supposedly anonymised dataset to improve its recommendation algorithm. However, researchers were able to "re-identify" specific users by combining this data with publicly available information on IMDb. This case demonstrates how the combination of different datasets can compromise privacy even when anonymisation measures have been taken.
In general terms, the role of the Data Governance Act in providing a horizontal governance framework for data spaces was highlighted, establishing the need to share information in a controlled manner and in accordance with applicable policies and laws. The Data Governance Regulation is particularly relevant to ensure that data protection, cybersecurity and intellectual property rights are respected in the context of open data.
The role of AI and cybersecurity in data security
The conclusions of the webinar focused on several key issues for the future of open data. A key element was the discussion on the role of artificial intelligence and its impact on data security. It highlighted how AI can act as a cyber threat multiplier, facilitating the creation of misinformation and the misuse of open data.
On the other hand, the importance of implementing Privacy Enhancing Technologies (PETs ) as fundamental tools to protect data was emphasized. These include anonymisation and pseudo-anonymisation techniques, data masking, privacy-preserving computing and various encryption mechanisms. However, it was stressed that it is not enough to implement these technologies in isolation, but that they require a comprehensive engineering approach that considers their correct implementation, configuration and maintenance.
The importance of training
The webinar also emphasised the critical importance of developing specific cybersecurity skills. ENISA's cyber skills framework, presented during the session, identifies twelve key professional profiles, including the Cybersecurity Policy and Legal Compliance Officer, the Cybersecurity Implementer and the Cybersecurity Risk Manager. These profiles are essential to address today's challenges in open data protection.
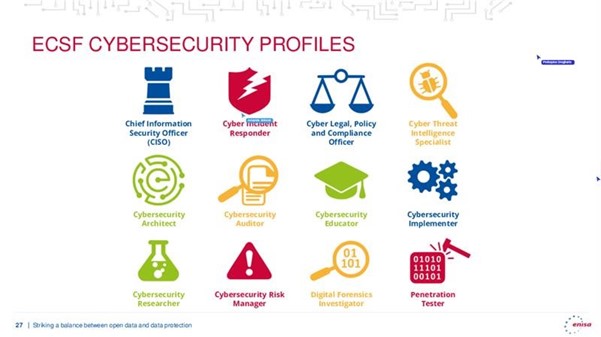
Figure 2. Slide presentation of the webinar " Safeguarding open data: cybersecurity essentials and skills for data providers".
In summary, a key recommendation that emerged from the webinar was the need for organisations to take a more proactive approach to open data management. This includes the implementation of regular impact assessments, the development of specific technical competencies and the continuous updating of security protocols. The importance of maintaining transparency and public confidence while implementing these security measures was also emphasised.
Blog
Today, digital technologies are revolutionising various sectors, including the construction sector, driven by the European Digital Strategy which not only promotes innovation and the adoption of digital technologies, but also the use and generation of potentially open data. The incorporation of advanced technologies has fostered a significant transformation in construction project management, making information more accessible and transparent to all stakeholders.
One of the key elements in this transformation are Digital Building Permits and Digital Building Logs, concepts that are improving the efficiency of administrative processes and the execution of construction projects, and which can have a significant impact on the generation and management of data in the municipalities that adopt them.
Digital Building Permits (DBP) and Digital Building Logs (DBL) not only generate key information on infrastructure planning, execution and maintenance, but also make this data accessible to the public and other stakeholders. The availability of this open data enables advanced analysis, academic research, and the development of innovative solutions for building more sustainable and safer infrastructure.
What is the Digital Building Permit?
The Digital Building Permit is the digitalisation of traditional building permit processes. Traditionally, this process was manual, involving extensive exchange of physical documents and coordination between multiple stakeholders. With digitisation, this procedure is simplified and made more efficient, allowing for a faster, more transparent and less error-prone review. Furthermore, thanks to this digitisation, large amounts of valuable data are proactively generated that not only optimise the process, but can also be used to improve transparency and carry out research in the sector. This data can be harnessed for advanced analytics, contributing to the development of smarter and more sustainable infrastructures. It also facilitates the integration of technologies such as Building Information Modelling (BIM) and digital twins, which are essential for the development of smart infrastructures.
- BIM allows the creation of detailed digital representations of infrastructure, incorporating precise information about each building component. This digital model facilitates not only the design, but also the management and maintenance of the building throughout its life cycle. In Spain, the legislation related to the use of Building Information Modeling (BIM) is mainly governed by the Law 9/2017 on Public Sector Contracts. This law establishes the possibility to require the use of BIM in public works projects. This regulation aims to improve efficiency, transparency and sustainability in the procurement and execution of public works and services in Spain.
- Digital twins are virtual replicas of physical infrastructures that allow the behaviour of a building to be simulated and analysed in real time thanks to the data generated. This data is not only crucial for the functioning of the digital twin, but can also be used as open data for research, public policy improvement and transparency in the management of infrastructures. These digital twins are essential to anticipate problems before they occur, optimise energy efficiency and proactively manage maintenance.
Together, these technologies can not only streamline the permitting process, but also ensure that buildings are safer, more sustainable and aligned with current regulations, promoting the development of smart infrastructure in an increasingly digitised environment.
What is a Digital Building Log?
The Digital Building Log is a tool for keeping a detailed and digitised record of all activities, decisions and modifications made during the life of a construction project. This register includes data on permits issued, inspections carried out, design changes, and any other relevant interventions. It functions as a digital logbook that provides a transparent and traceable overview of the entire construction process.
This approach not only improves transparency and traceability, but also facilitates monitoring and compliance by keeping an up-to-date register accessible to all stakeholders.
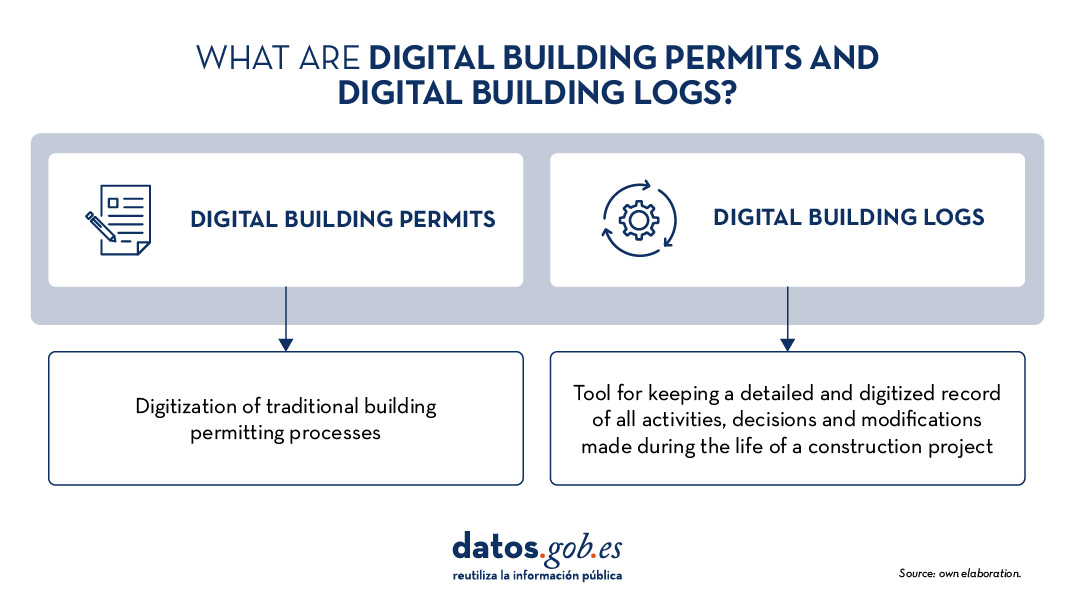
Figure 1. What are Digital Building Permits and Digital Building Logs? Own elaboration.
Key Projects and Objectives in the Sector
Several European projects are incorporating Digital Building Permits and Digital Building Logs as part of their strategy to modernise the construction sector. Some of the most innovative projects in this field are highlighted below:
ACCORD
The ACCORD Project (2022-2025) is an European initiative that aims to transform the process of obtaining and managing construction permits through digitisation. ACCORD, which stands for"Automated Compliance Checking and Orchestration of Building Projects", aims to develop a semantic framework to automatically check compliance, improve efficiency and ensure transparency in the building sector. In addition, ACCORD will develop:
- A rule formalisation tool based on semantic web technologies.
- A semantic rules database.
- Microservices for compliance verification in construction.
- A set of open and standardised APIs to enable integrated data flow between building permit, compliance and other information services.
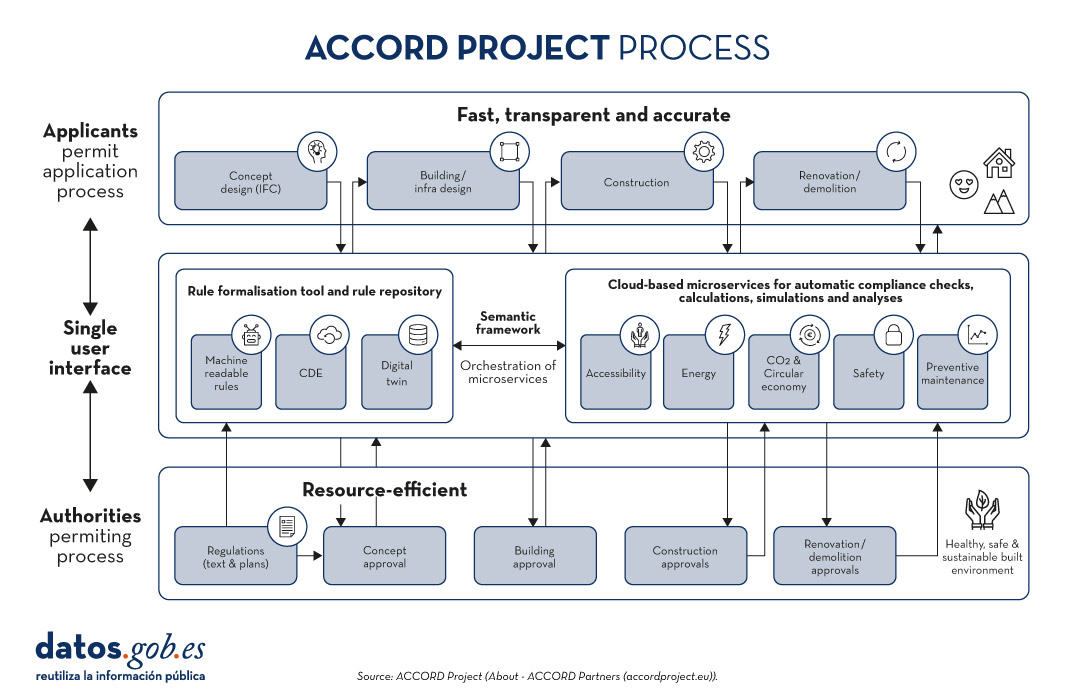
Figure 2. ACCORD project process.Source: Proyecto ACCORD.
The ACCORD Project focuses on several demonstrations in various European countries, each with a specific focus facilitated by the analysis and use of the data:
- In Estonia and Finland, ACCORD focuses on improving accessibility and safety in urban spaces through the automation of building permits. In Estonia, work is being done on automatic verification of compliance with planning and zoning regulations, while in Finland, the focus is on developing healthy and safe urban spaces by digitising the permitting process and integrating urban data.
- In Germany, ACCORD focuses on automated verification for land use permits and green building certification. The project aims to automate the verification of regulatory compliance in these areas by integrating micro-services that automatically verify whether construction projects comply with sustainability and land use regulations before permits are issued.
- In the UK, ACCORD focuses on ensuring the design integrity of structural components of steel modular homes by using BIM modelling and finite element analysis (FEA). This approach allows automatic verification of the compliance of structural components with safety and design standards prior to their implementation in construction. The project facilitates the early detection of potential structural failures, thus improving safety and efficiency in the construction process.
- In Spain, ACCORD focuses on automating urban planning compliance in Malgrat de Martown council using BIM and open cadastral data. The aim is to improve efficiency in the design and construction phase, ensuring that projects comply with local regulations before they start. This includes automatic verification of urban regulations to facilitate faster and more accurate building permits.
CHEK
The CHEK Project (2022-2025) which stands for"Change Toolkit for Digital Building Permit" is a European initiative that aims to remove the barriers municipalities face in adopting the digitisation of building permit management processes.
CHEK will develop scalable solutions including open standards and interoperability (geospatial and BIM), educational tools to bridge knowledge gaps and new technologies for permit digitisation and automatic compliance verification. The objective is to align digital technologies with municipal-level administrative processing, improve accuracy and efficiency, and demonstrate scalability in European urban areas, achieving a tRL 7E technology maturity level.
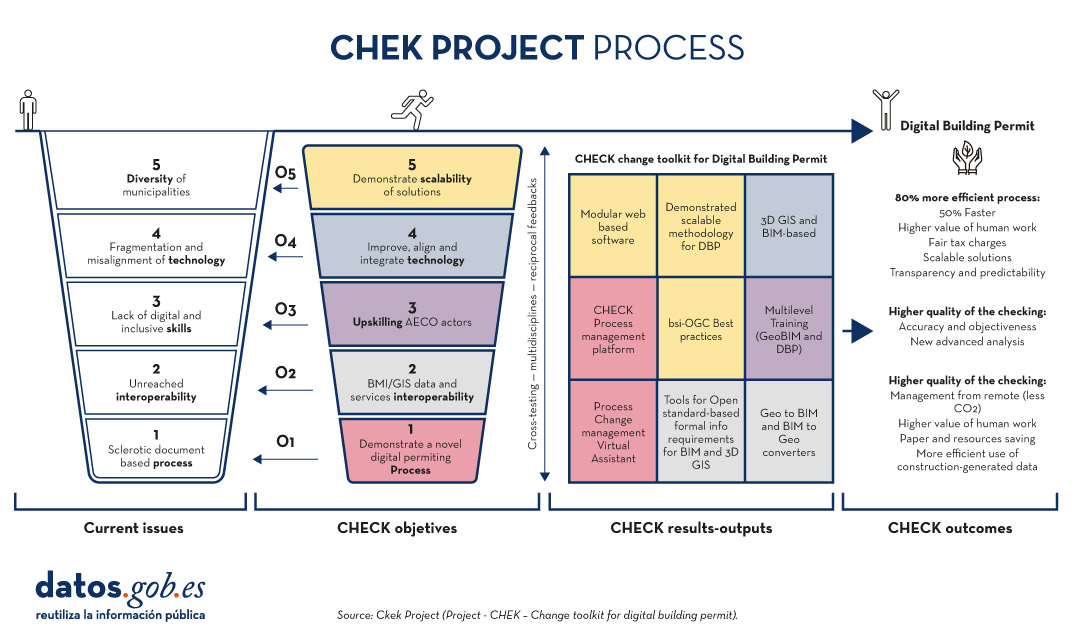
Figure 3. CHEK Project Process. Source: Proyecto CHEK.
This requires:
- Adapt available digital technologies to municipal processes, enabling new methods and business models.
- Develop open data standards, including building information modelling (BIM), 3D urban modelling and reciprocal integration (GeoBIM).
- Improve training for public employees and users.
- Improving, adapting and integrating technology.
- Realise and demonstrate scalability.
CHEK will provide a set of methodological and technological tools to fully digitise building permits and partially automate building design compliance checks, leading to a 60% efficiency improvement and the adoption of DBP by 85% of European municipalities.
The future of construction and the contribution to open data
The implementation of Digital Building Permits and Digital Building Logs is transforming the building landscape. As these tools are integrated into construction processes, future scenarios on the horizon include:
- Digitised construction: In the not too distant future, construction projects could be managed entirely digitally, from permit applications to ongoing project monitoring. This will eliminate the need for physical documents and significantly reduce errors and delays.
- Real-time digital cufflinks: Digital Building Logs will feed digital twins in real time, enabling continuous and predictive monitoring of projects. This will allow developers and regulators to anticipate problems before they occur and make informed decisions quickly.
- Global data interoperability: With the advancement of data spaces, building systems are expected to become globally interoperable. This will facilitate international collaboration and allow standards and best practices to be widely shared and adopted.
Digital Building Permits and Digital Building Logs are not only tools for process optimisation in the building sector, but also vehicles for the creation of open data that can be used by a wide range of actors. The implementation of these systems not only generates technical data on the progress of works, but also provides data that can be reused by authorities, developers and citizens, thus fostering an open collaborative environment. This data can be used to improve urban analysis, assist in public infrastructure planning and optimise monitoring and transparency in project implementation.
The use of open data through these platforms also facilitates the development of innovative applications and technological services that improve efficiency, promote sustainability and contribute to more efficient resource management in cities. Such open data can, for example, allow citizens to access information on building conditions in their area, while giving governments a clearer, real-time view of how projects are developing, enabling data-driven decision-making.
Projects such as ACCORD and CHECK demonstrate how these technologies can integrate digitalisation, automation and open data to transform the European construction sector.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of its author.
Evento
In an increasingly information-driven world, open data is transforming the way we understand and shape our societies. This data are a valuable source of knowledge that also helps to drive research, promote technological advances and improve policy decision-making.
In this context, the Publications Office of the European Union organises the annual EU Open Data Days to highlight the role of open data in European society and all the new developments. The next edition will take place on 19-20 March 2025 at the European Conference Centre Luxembourg (ECCL) and online.
This event, organised by the data.europa.eu, europe's open data portal, will bring together data providers, enthusiasts and users from all over the world, and will be a unique opportunity to explore the potential of open data in various sectors. From success stories to new initiatives, this event is a must for anyone interested in the future of open data.
What are EU Open Data Days?
EU Open Data Days are an opportunity to exchange ideas and network with others interested in the world of open data and related technologies. This event is particularly aimed at professionals involved in data publishing and reuse, analysis, policy making or academic research.However, it is also open to the general public. After all, these are two days of sharing, learning and contributing to the future of open data in Europe.
What can you expect from EU Open Data Days 2025?
The event programme is designed to cover a wide range of topics that are key to the open data ecosystem, such as:
- Success stories and best practices: real experiences from those at the forefront of data policy in Europe, to learn how open data is being used in different business models and to address the emerging frontiers of artificial intelligence.
- Challenges and solutions: an overview of the challenges of using open data, from the perspective of publishers and users, addressing technical, ethical and legal issues.
- Visualising impact: analysis of how data visualisation is changing the way we communicate complex information and how it can facilitate better decision-making and encourage citizen participation.
- Data literacy: training to acquire new skills to maximise the potential of open data in each area of work or interest of the attendees.
An event open to all sectors
The EU Open Data Days are aimed at a wide audience: the public, the media, the general public and the general public.
- Private sector: data analytics specialists, developers and technology solution providers will be able to learn new techniques and trends, and connect with other professionals in the sector.
- Public sector: policy makers and government officials will discover how open data can be used to improve decision-making, increase transparency and foster innovation in policy design.
- Academia and education: researchers, teachers and students will be able to engage in discussions on how open data is fuelling new research and advances in areas as diverse as social sciences, emerging technologies and economics.
- Journalism and media: Data journalists and communicators will learn how to use data visualisation to tell more powerful and accurate stories, fostering better public understanding of complex issues.
Submit your proposal before 22 October
Would you like to present a paper at the EU Open Data Days 2025? You have until Tuesday 22 October to send your proposal on one of the above-mentioned themes. Papers that address open data or related areas are sought, such as data visualisation or the use of artificial intelligence in conjunction with open data.
The European data portal is looking for inspiring cases that demonstrate the impact of open data use in Europe and beyond. The call is open to participants from all over the world and from all sectors: from international, national and EU public organisations, to academics, journalists and data visualisation experts. Selected projects will be part of the conference programme, and presentations must be made in English.
Proposals should be between 20 and 35 minutes in length, including time for questions and answers. If your proposal is selected, travel and accommodation expenses (one night) will be reimbursed for participants from the academic sector, the public sector and NGOs.
For further details and clarifications, please contact the organising team by email: EU-Open-Data-Days@ec.europa.eu.
- Deadline for submission of proposals: 22 October 2024.
- Notification to selected participants: November 2024.
- Delivery of the draft presentation: 15 January 2025.
- Delivery of the final presentation: 18 February 2025.
- Conference dates: 19-20 March 2025.
The future of open data is now. The EU Open Data Days 2025 will not only be an opportunity to learn about the latest trends and practices in data use, but also to build a stronger and more collaborative community around open data. Registration for the event will open in late autumn 2024, we will announce it through our social media channels on TwitterlinkedIn and Instagram.
Blog
Data literacy has become a crucial issue in the digital age. This concept refers to the ability of people to understand how data is used, how it is accessed, created, analysed, used or reused, and communicated.
We live in a world where data and algorithms influence everyday decisions and the opportunities people have to live well. Its effect can be felt in areas ranging from advertising and employment provision to criminal justice and social welfare. It is therefore essential to understand how data is generated and used.
Data literacy can involve many areas, but we will focus on its relationship with digital rights on the one hand and Artificial Intelligence (AI) on the other. This article proposes to explore the importance of data literacy for citizenship, addressing its implications for the protection of individual and collective rights and the promotion of a more informed and critical society in a technological context where artificial intelligence is becoming increasingly important.
The context of digital rights
More and more studies studies increasingly indicate that effective participation in today's data-driven, algorithm-driven society requires data literacy indicating that effective participation in today's data-driven, algorithm-driven society requires data literacy. Civil rights are increasingly translating into digital rights as our society becomes more dependent on digital technologies and environments digital rights as our society becomes more dependent on digital technologies and environments. This transformation manifests itself in various ways:
- On the one hand, rights recognised in constitutions and human rights declarations are being explicitly adapted to the digital context. For example, freedom of expression now includes freedom of expression online, and the right to privacy extends to the protection of personal data in digital environments. Moreover, some traditional civil rights are being reinterpreted in the digital context. One example of this is the right to equality and non-discrimination, which now includes protection against algorithmic discrimination and against bias in artificial intelligence systems. Another example is the right to education, which now also extends to the right to digital education. The importance of digital skills in society is recognised in several legal frameworks and documents, both at national and international level, such as the Organic Law 3/2018 on Personal Data Protection and Guarantee of Digital Rights (LOPDGDD) in Spain. Finally, the right of access to the internet is increasingly seen as a fundamental right, similar to access to other basic services.
- On the other hand, rights are emerging that address challenges unique to the digital world, such as the right to be forgotten (in force in the European Union and some other countries that have adopted similar legislation1), which allows individuals to request the removal of personal information available online, under certain conditions. Another example is the right to digital disconnection (in force in several countries, mainly in Europe2), which ensures that workers can disconnect from work devices and communications outside working hours. Similarly, there is a right to net neutrality to ensure equal access to online content without discrimination by service providers, a right that is also established in several countries and regions, although its implementation and scope may vary. The EU has regulations that protect net neutrality, including Regulation 2015/2120, which establishes rules to safeguard open internet access. The Spanish Data Protection Act provides for the obligation of Internet providers to provide a transparent offer of services without discrimination on technical or economic grounds. Furthermore, the right of access to the internet - related to net neutrality - is recognised as a human right by the United Nations (UN).
This transformation of rights reflects the growing importance of digital technologies in all aspects of our lives.
The context of artificial intelligence
The relationship between AI development and data is fundamental and symbiotic, as data serves as the basis for AI development in a number of ways:
- Data is used to train AI algorithms, enabling them to learn, detect patterns, make predictions and improve their performance over time.
- The quality and quantity of data directly affect the accuracy and reliability of AI systems. In general, more diverse and complete datasets lead to better performing AI models.
- The availability of data in various domains can enable the development of AI systems for different use cases.
Data literacy has therefore become increasingly crucial in the AI era, as it forms the basis for effectively harnessing and understanding AI technologies.
In addition, the rise of big data and algorithms has transformed the mechanisms of participation, presenting both challenges and opportunities. Algorithms, while they may be designed to be fair, often reflect the biases of their creators or the data they are trained on. This can lead to decisions that negatively affect vulnerable groups.
In this regard, legislative and academic efforts are being made to prevent this from happening. For example, the EuropeanArtificial Intelligence Act (AI Act) includes safeguards to avoid harmful biases in algorithmic decision-making. For example, it classifies AI systems according to their level of potential risk and imposes stricter requirements on high-risk systems. In addition, it requires the use of high quality data to train the algorithms, minimising bias, and provides for detailed documentation of the development and operation of the systems, allowing for audits and evaluations with human oversight. It also strengthens the rights of persons affected by AI decisions, including the right to challenge decisions made and their explainability, allowing affected persons to understand how a decision was reached.
The importance of digital literacy in both contexts
Data literacy helps citizens make informed decisions and understand the full implications of their digital rights, which are also considered, in many respects, as mentioned above, to be universal civil rights. In this context, data literacy serves as a critical filter for full civic participation that enables citizens to influence political and social decisions full civic participation that enables citizens to influence political and social decisions. That is,those who have access to data and the skills and tools to navigate the data infrastructure effectively can intervene and influencepolitical and social processes in a meaningful way , something which promotes the Open Government Partnership.
On the other hand, data literacy enables citizens to question and understand these processes, fostering a culture of accountability and transparency in the use of AI. There arealso barriers to participation in data-driven environments. One of these barriers is the digital divide (i.e. deprivation of access to infrastructure, connectivity and training, among others) and, indeed, lack of data literacy. The latter is therefore a crucial concept for overcoming the challenges posed by datification datification of human relations and the platformisation of content and services.
Recommendations for implementing a preparedness partnership
Part of the solution to addressing the challenges posed by the development of digital technology is to include data literacy in educational curricula from an early age.
This should cover:
- Data basics: understanding what data is, how it is collected and used.
- Critical analysis: acquisition of the skills to evaluate the quality and source of data and to identify biases in the information presented. It seeks to recognise the potential biases that data may contain and that may occur in the processing of such data, and to build capacity to act in favour of open data and its use for the common good.
- Rights and regulations: information on data protection rights and how European laws affect the use of AI. This area would cover all current and future regulation affecting the use of data and its implication for technology such as AI.
- Practical applications: the possibility of creating, using and reusing open data available on portals provided by governments and public administrations, thus generating projects and opportunities that allow people to work with real data, promoting active, contextualised and continuous learning.
By educating about the use and interpretation of data, it fosters a more critical society that is able to demand accountability in the use of AI. New data protection laws in Europe provide a framework that, together with education, can help mitigate the risks associated with algorithmic abuse and promote ethical use of technology. In a data-driven society, where data plays a central role, there is a need to foster data literacy in citizens from an early age.
1The right to be forgotten was first established in May 2014 following a ruling by the Court of Justice of the European Union. Subsequently, in 2018, it was reinforced with the General Data Protection Regulation (GDPR)which explicitly includes it in its Article 17 as a "right of erasure". In July 2015, Russia passed a law allowing citizens to request the removal of links on Russian search engines if the information"violates Russian law or if it is false or outdated". Turkey has established its own version of the right to be forgotten, following a similar model to that of the EU. Serbia has also implemented a version of the right to be forgotten in its legislation. In Spain, the Ley Orgánica de Protección de Datos Personales (LOPD) regulates the right to be forgotten, especially with regard to debt collection files. In the United Statesthe right to be forgotten is considered incompatible with the Constitution, mainly because of the strong protection of freedom of expression. However, there are some related regulations, such as the Fair Credit Reporting Act of 1970, which allows in certain situations the deletion of old or outdated information in credit reports.
2Some countries where this right has been established include Spain, regulated by Article 88 of Organic Law 3/2018 on Personal Data Protection; France, which, in 2017, became the first country to pass a law on the right to digital disconnection; Germany, included in the Working Hours and Rest Time Act(Arbeitszeitgesetz); Italy, under Law 81/201; and Belgium. Outside Europe, it is, for example, in Chile.
Content prepared by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy and gender disinformation. The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
Digital transformation has become a fundamental pillar for the economic and social development of countries in the 21st century. In Spain, this process has become particularly relevant in recent years, driven by the need to adapt to an increasingly digitalised and competitive global environment. The COVID-19 pandemic acted as a catalyst, accelerating the adoption of digital technologies in all sectors of the economy and society.
However, digital transformation involves not only the incorporation of new technologies, but also a profound change in the way organisations operate and relate to their customers, employees and partners. In this context, Spain has made significant progress, positioning itself as one of the leading countries in Europe in several aspects of digitisation.
The following are some of the most prominent reports analysing this phenomenon and its implications.
State of the Digital Decade 2024 report
The State of the Digital Decade 2024 report examines the evolution of European policies aimed at achieving the agreed objectives and targets for successful digital transformation. It assesses the degree of compliance on the basis of various indicators, which fall into four groups: digital infrastructure, digital business transformation, digital skills and digital public services.

Figure 1. Taking stock of progress towards the Digital Decade goals set for 2030, “State of the Digital Decade 2024 Report”, European Commission.
In recent years, the European Union (EU) has significantly improved its performance by adopting regulatory measures - with 23 new legislative developments, including, among others, the Data Governance Regulation and the Data Regulation- to provide itself with a comprehensive governance framework: the Digital Decade Policy Agenda 2030.
The document includes an assessment of the strategic roadmaps of the various EU countries. In the case of Spain, two main strengths stand out:
- Progress in the use of artificial intelligence by companies (9.2% compared to 8.0% in Europe), where Spain's annual growth rate (9.3%) is four times higher than the EU (2.6%).
- The large number of citizens with basic digital skills (66.2%), compared to the European average (55.6%).
On the other hand, the main challenges to overcome are the adoption of cloud services ( 27.2% versus 38.9% in the EU) and the number of ICT specialists ( 4.4% versus 4.8% in Europe).
The following image shows the forecast evolution in Spain of the key indicators analysed for 2024, compared to the targets set by the EU for 2030.

Figure 2. Key performance indicators for Spain, “Report on the State of the Digital Decade 2024”, European Commission.
Spain is expected to reach 100% on virtually all indicators by 2030. 26.7 billion (1.8 % of GDP), without taking into account private investments. This roadmap demonstrates the commitment to achieving the goals and targets of the Digital Decade.
In addition to investment, to achieve the objective, the report recommends focusing efforts in three areas: the adoption of advanced technologies (AI, data analytics, cloud) by SMEs; the digitisation and promotion of the use of public services; and the attraction and retention of ICT specialists through the design of incentive schemes.
European Innovation Scoreboard 2024
The European Innovation Scoreboard carries out an annual benchmarking of research and innovation developments in a number of countries, not only in Europe. The report classifies regions into four innovation groups, ranging from the most innovative to the least innovative: Innovation Leaders, Strong Innovators, Moderate Innovators and Emerging Innovators.
Spain is leading the group of moderate innovators, with a performance of 89.9% of the EU average. This represents an improvement compared to previous years and exceeds the average of other countries in the same category, which is 84.8%. Our country is above the EU average in three indicators: digitisation, human capital and financing and support. On the other hand, the areas in which it needs to improve the most are employment in innovation, business investment and innovation in SMEs. All this is shown in the following graph:
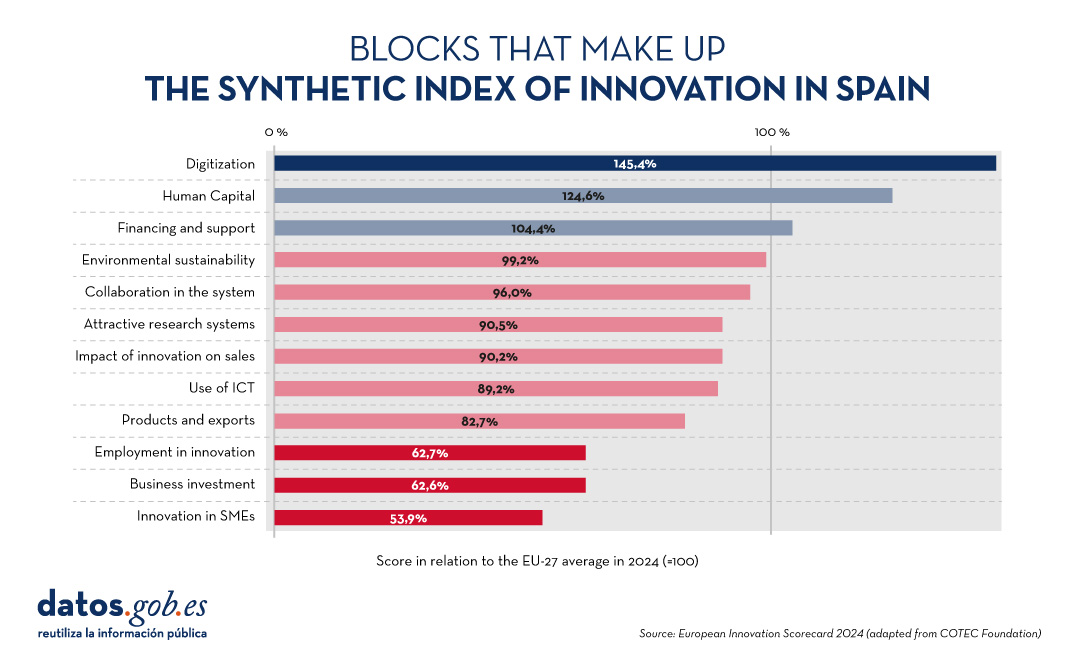
Figure 3. Blocks that make up the synthetic index of innovation in Spain, European Innovation Scorecard 2024 (adapted from the COTEC Foundation).
Spain's Digital Society Report 2023
The Telefónica Foundation also periodically publishes a report which analyses the main changes and trends that our country is experiencing as a result of the technological revolution.
The edition currently available is the 2023 edition. It highlights that "Spain continues to deepen its digital transformation process at a good pace and occupies a prominent position in this aspect among European countries", highlighting above all the area of connectivity. However, digital divides remain, mainly due to age.
Progress is also being made in the relationship between citizens and digital administrations: 79.7% of people aged 16-74 used websites or mobile applications of an administration in 2022. On the other hand, the Spanish business fabric is advancing in its digitalisation, incorporating digital tools, especially in the field of marketing. However, there is still room for improvement in aspects of big data analysis and the application of artificial intelligence, activities that are currently implemented, in general, only by large companies.
Artificial Intelligence and Data Talent Report
IndesIA, an association that promotes the use of artificial intelligence and Big Data in Spain, has carried out a quantitative and qualitative analysis of the data and artificial intelligence talent market in 2024 in our country.
According to the report, the data and artificial intelligence talent market represents almost 19% of the total number of ICT professionals in our country. In total, there are 145,000 professionals (+2.8% from 2023), of which only 32% are women. Even so, there is a gap between supply and demand, especially for natural language processing engineers. To address this situation, the report analyses six areas for improvement: workforce strategy and planning, talent identification, talent activation, engagement, training and development, and data-driven culture .
Other reports of interest
The COTEC Foundation also regularly produces various reports on the subject. On its website we can find documents on the budget execution of R&D in the public sector, the social perception of innovation or the regional talent map.
For their part, the Orange Foundation in Spain and the consultancy firm Nae have produced a report to analyse digital evolution over the last 25 years, the same period that the Foundation has been operating in Spain. The report highlights that, between 2013 and 2018, the digital sector has contributed around €7.5 billion annually to the country's GDP.
In short, all of them highlight Spain's position among the European leaders in terms of digital transformation, but with the need to make progress in innovation. This requires not only boosting economic investment, but also promoting a cultural change that fosters creativity. A more open and collaborative mindset will allow companies, administrations and society in general to adapt quickly to technological changes and take advantage of the opportunities they bring to ensure a prosperous future for Spain.
Do you know of any other reports on the subject? Leave us a comment or write to us at dinamizacion@datos.gos.es.
Blog
Digital transformation has reached almost every aspect and sector of our lives, and the world of products and services is no exception. In this context, the Digital Product Passport (DPP) concept is emerging as a revolutionary tool to foster sustainability and the circular economy. Accompanied by initiatives such as CIRPASS (Circular Product Information System for Sustainability), the DPP promises to change the way we interact with products throughout their life cycle. In this article, we will explore what DPP is, its origins, applications, risks and how it can affect our daily lives and the protection of our personal data.
What is the Digital Product Passport (DPP)? Origin and importance
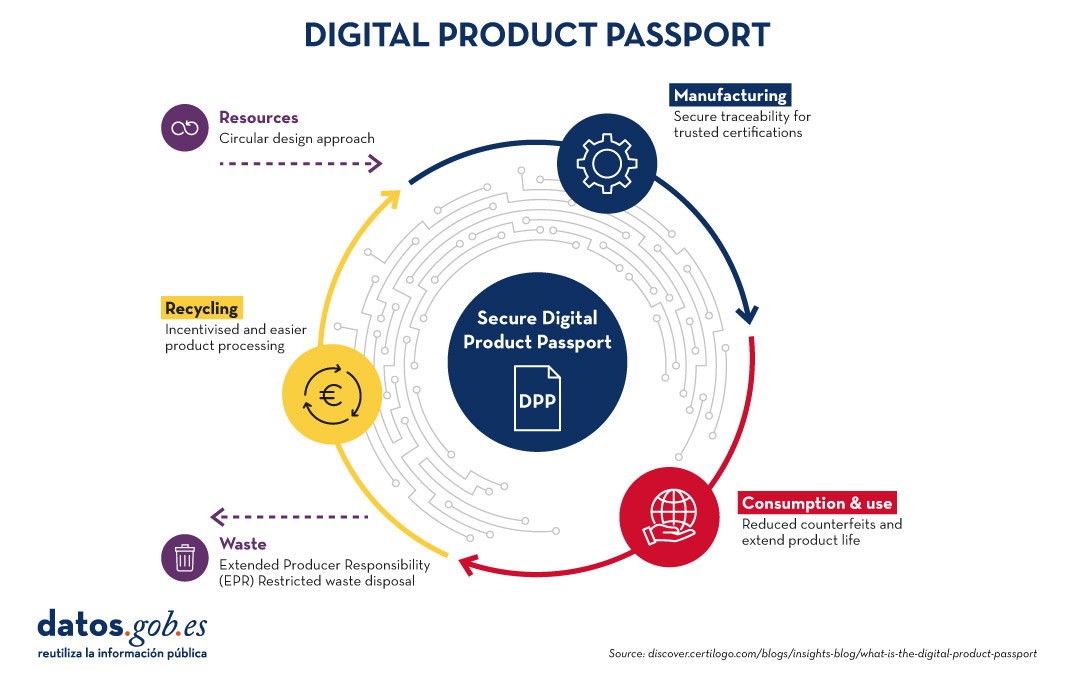
The Digital Product Passport is a digital collection of key information about a product, from manufacturing to recycling. This passport allows products to be tracked and managed more efficiently, improving transparency and facilitating sustainable practices. The information contained in a DPP may include details on the materials used, the manufacturing process, the supply chain, instructions for use and how to recycle the product at the end of its life.
The DPP has been developed in response to the growing need to promote the circular economy and reduce the environmental impact of products. The European Union (EU) has been a pioneer in promoting policies and regulations that support sustainability. Initiatives such as the EU's Circular Economy Action Plan have been instrumental in driving the DPP forward. The objectives of this plan are as follows:
- Greater Transparency: Consumers no longer have to guess about the origin of their products and how to dispose of them correctly. With a machine-readable DPP (e.g. QR code or NFC tag) attached to end products, consumers can make informed purchasing decisions and brands can eliminate greenwashing with confidence.
- Simplified Compliance: By creating an audit of events and transactions in a product's value chain, the DPP provides the brand and its suppliers with the necessary data to address compliance demands efficiently.
- Sustainable Production: By tracking and reporting the social and environmental impacts of a product from source to disposal, brands can make data-driven decisions to optimise sustainability in product development.
- Circular Economy: The DPP facilitates a circular economy by promoting eco-design and the responsible production of durable products that can be reused, remanufactured and disposed of correctly.
The following image summarises the main advantages of the digital passport at each stage of the digital product manufacturing process:
CIRPASS as a facilitator of DPP implementation
CIRPASS is a platform that supports the implementation of the DPP. This European initiative aims to standardise the collection and exchange of data on products, facilitating their traceability and management throughout their life cycle. CIRPASS plays a crucial role in creating an interoperable digital framework that connects manufacturers, consumers and recyclers.
DPP applications in various sectors
On 5 March 2024, CIRPASS, in collaboration with the European Commission, organised an event on the future development of the Digital Product Passport. The event brought together various stakeholders from different industries and organisations, who, with an eminently practical approach presented and discussed various aspects of the upcoming regulation and its requirements, possible solutions, examples of use cases, and the obstacles and opportunities for the affected industries and businesses.
The following are the applications of DPP in various sectors as explained at the event:
- Textile industry: It allows consumers to know the origin of the garments, the materials used and the working conditions in the factories.
- Electronics: Facilitates recycling and reuse of components, reducing electronic waste.
- Automotive: It assists in tracking parts and materials, promoting the repair and recycling of vehicles.
- Power supply: It provides information on food traceability, ensuring safety and sustainability in the supply chain.
The impact of the DPP on citizens' lives
But what impact will the use of this kind of novel paradigm have on our daily lives? And how does this impact on us as end users of multiple products and services such as those mentioned above? We will focus on four base cases: informed consumers in any field, ease of product repair, trust and transparency, and efficient recycling.
The DPP provides consumers with access to detailed information about the products they buy, such as their origin, materials and production practices. This allows consumers to make more informed choices and opt for products that are sustainable and ethical. For example, a consumer can choose a garment made from organic materials and produced under fair labour conditions, thus promoting responsible and conscious consumption.
Similarly, one of the great benefits of the DPP is the inclusion of repair guides within the digital passport. This means that consumers can easily access detailed instructions on how to repair a product instead of discarding it when it breaks down. For example, if an appliance stops working, the DPP can provide a step-by-step repair manual, allowing the user to fix it himself or take it to a technician with the necessary information. This not only extends the lifetime of products, but also reduces e-waste and promotes sustainability.
Also, access to detailed and transparent product information through the DPP can increase consumers' trust in brands. Companies that provide a complete and accurate DPP demonstrate their commitment to transparency and accountability, which can enhance their reputation and build customer loyalty. In addition, consumers who have access to this information are better able to make responsible purchasing decisions, thus encouraging more ethical and sustainable consumption habits.
Finally, the DPP facilitates effective recycling by providing clear information on how to break down and reuse the materials in a product. For example, a citizen who wishes to recycle an electronic device can consult the DPP to find out which parts can be recycled and how to separate them properly. This improves the efficiency of the recycling process and ensures that more materials are recovered and reused instead of ending up in landfill, contributing to a circular economy.
Risks and challenges of the DPP
Similarly, as a novel technology and as part of the digital transformation that is taking place in the product sectors, the DPP also presents certain challenges, risks and challenges such as:
- Data Protection: The collection and storage of large amounts of data can put consumers' privacy at risk if not properly managed.
- Security: Digital data is vulnerable to cyber-attacks, which requires robust security measures.
- Interoperability: Standardisation of data across different industries and countries can be complex, making it difficult to implement the DPP on a large scale.
- Costs: Creating and maintaining digital passports can be costly, especially for small and medium-sized enterprises.
Data protection implications
The implementation of the DPP and systems such as CIRPASS implies careful management of personal data. It is essential that companies and digital platforms comply with data protection regulations, such as the EU's General Data Protection Regulation (GDPR). Organisations must ensure that the data collected is used in a transparent manner and with the explicit consent of consumers. In addition, advanced security measures must be implemented to protect the integrity and confidentiality of the data.
Relationship with European Data Spaces
The European Data Spaces are an EU initiative to create a single market for data, promoting innovation and the digital economy. The DPP and CIRPASS are aligned with this vision, as they encourage the exchange of information between different actors in the economy. Data interoperability is essential for the success of the European Data Spaces, and the DPP can contribute significantly to this goal by providing structured and accessible product data.
Conclusion
In conclusion, the Digital Product Passport and the CIRPASS initiative represent a significant step towards a more circular and sustainable economy. Through the collection and exchange of detailed product data, these systems can improve transparency, encourage responsible consumption practices and reduce environmental impact. However, their implementation requires overcoming challenges related to data protection, security and interoperability. As we move towards a more digitised future, the DPP and CIRPASS have the potential to transform the way we interact with products and contribute to a more sustainable world.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant The content and the point of view reflected in this publication are the sole responsibility of its author.