Noticia
La formación es uno de los pilares que sostienen el ecosistema de datos abiertos en Europa. Publicar datos es fundamental, pero igual de importante es que existan capacidades para comprenderlos, reutilizarlos y gestionarlos adecuadamente. En este contexto, el portal de datos abiertos europeo (data.europa.eu) pone a disposición un programa formativo online que permite familiarizarse con el ecosistema de datos abiertos desde distintos ángulos: conceptos básicos, marcos legales, tendencias emergentes, casos de éxito o buenas prácticas de publicación y reutilización.
Este programa ha incorporado en 2026 una novedad relevante: los learning paths o itinerarios de aprendizaje estructurados, que permiten avanzar paso a paso en el dominio del open data.
Desde datos.gob.es queremos dar a conocer esta actualización, que refuerza la oferta formativa europea y complementa iniciativas ya consolidadas. Te lo contamos en este post.
¿Qué cambia en 2026? Itinerarios paso a paso
La principal novedad es la incorporación de learning paths, concebidos como recorridos formativos estructurados que agrupan contenidos (lecturas, vídeos y cuestionarios) en un orden lógico y progresivo.
Hasta ahora, la academia permitía acceder libremente a cursos organizados por temática (Policy, Legal, Quality, Business, Impact, Communication y Portal) y nivel (principiante, intermedio o avanzado). Con los nuevos itinerarios, el aprendizaje se convierte en una experiencia más guiada:
- Se elige un itinerario según el nivel de experiencia.
- Se avanza de forma secuencial.
- Se realizan actividades y cuestionarios.
- Se obtiene una certificación al finaliza.
Esta estructura facilita especialmente el aprendizaje a quienes buscan una formación ordenada, con objetivos claros y una progresión definida.
Los nuevos itinerarios están orientados especialmente al sector público, aunque cualquier persona interesada puede realizarlos. Se organizan en tres niveles.
1. Nivel principiante: los fundamentos de los datos abiertos
Duración aproximada: 4 horas y 23 minutos.
Este itinerario ofrece una base sólida para comprender:
- Qué son los datos abiertos.
- Cuáles son sus principios fundamentales.
- Cómo se publican.
- Qué beneficios generan para la innovación, la transparencia y la reutilización.
Está pensado para personas que comienzan a trabajar con datos o desean entender el marco general del open data. También resulta útil para perfiles no técnicos que necesitan una visión estratégica. El objetivo es construir una base conceptual robusta antes de abordar aspectos más complejos.
2. Nivel intermedio: el marco jurídico y estratégico
Duración aproximada: 7 horas y 3 minutos.
El segundo itinerario profundiza en los aspectos legales y de política pública que sustentan la estrategia europea de datos. Entre los temas tratados se encuentran:
- El marco normativo europeo en materia de datos.
- Las implicaciones legales del intercambio de información.
- Las licencias de reutilización.
- El cumplimiento regulatorio.
Este nivel resulta especialmente relevante para responsables de transparencia, asesores jurídicos, gestores de portales y perfiles implicados en la gobernanza del dato.
Comprender el marco legal es un requisito para publicar datos con garantías y fomentar su reutilización de forma segura y conforme a la normativa europea.
3. Nivel avanzado: calidad e interoperabilidad
Duración aproximada: 4 horas y 39 minutos.
El tercer itinerario aborda dos cuestiones críticas para el éxito del open data: la calidad y la interoperabilidad.
Entre los contenidos se incluyen:
- Principios y métricas de calidad del dato.
- Metodologías de interoperabilidad.
- Directrices de estandarización.
- Gestión avanzada de metadatos.
- Aplicación de estándares europeos como DCAT-AP.
Este nivel está dirigido a perfiles técnicos o estratégicos que desean mejorar la coherencia, accesibilidad y reutilización de los datos publicados.
En un contexto europeo donde la interoperabilidad transfronteriza es esencial, adoptar estándares comunes es una condición para generar impacto real.
Certificados e insignias digitales
Uno de los elementos más atractivos de la actualización es la posibilidad de obtener certificados oficiales al completar cada itinerario formativo.
Para conseguirlos, el proceso es sencillo:
- Completar todos los módulos del itinerario.
- Superar el cuestionario final.
- Descargar el certificado correspondiente.
Además, la academia permite obtener insignias digitales (badges) a medida que se avanza en los contenidos. Estas credenciales pueden compartirse en perfiles profesionales y constituyen una forma tangible de acreditar competencias en materia de datos abiertos.
En un entorno laboral donde la alfabetización en datos es cada vez más demandada, contar con certificados europeas refuerza el perfil profesional y demuestra compromiso con la formación continua.
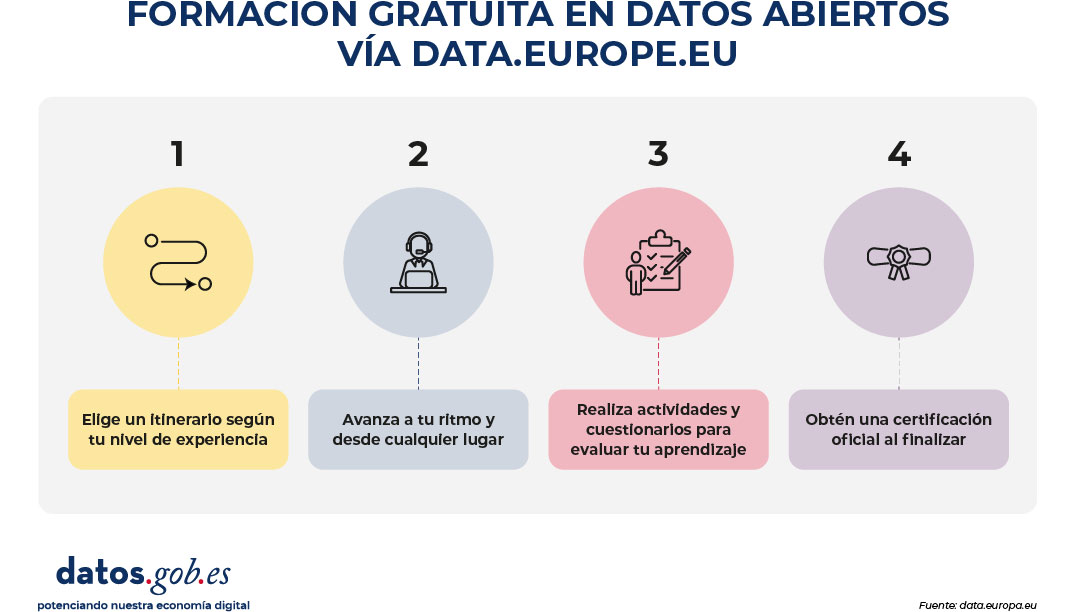
Figura 1. Proceso de formación gratuita en datos abiertos vía data.europe.eu
Formación continua como elemento estratégico
Una de las fortalezas de la academia es su enfoque aplicado. Los contenidos muestran cómo los datos abiertos se conectan con retos concretos como la mejora de servicios públicos, el impulso a la innovación y el desarrollo económico o la transparencia y la evaluación de políticas públicas.
Además, al tratarse de una plataforma gratuita y accesible en línea, elimina barreras económicas y facilita la participación desde cualquier territorio.
En este sentido, los learning paths representan un paso adelante hacia una formación más estructurada, coherente y reconocible. Porque, al integrar contenidos, evaluación y certificación en un único recorrido, la academia refuerza el valor del aprendizaje y facilita que cada persona avance a su propio ritmo.
El ecosistema europeo de datos está evolucionando rápidamente. La estrategia europea de datos, los espacios de datos sectoriales y los estándares comunes de interoperabilidad exigen profesionales formados y alineados con una visión compartida.
La incorporación de itinerarios estructurados en la academia de data.europa.eu es una apuesta por fortalecer las competencias necesarias para que los datos abiertos generen valor público. Porque estos nuevos itinerarios de formación definen un camino de aprendizaje más claro, progresivo y accesible para toda la comunidad. La actualización de la academia se desplegará a lo largo de 2026. Desde datos.gob.es continuaremos compartiendo información relevante para la comunidad española de datos abiertos.
Este visual resume algunos detalles importantes sobre la oferta formativa del portal europeo de datos abiertos
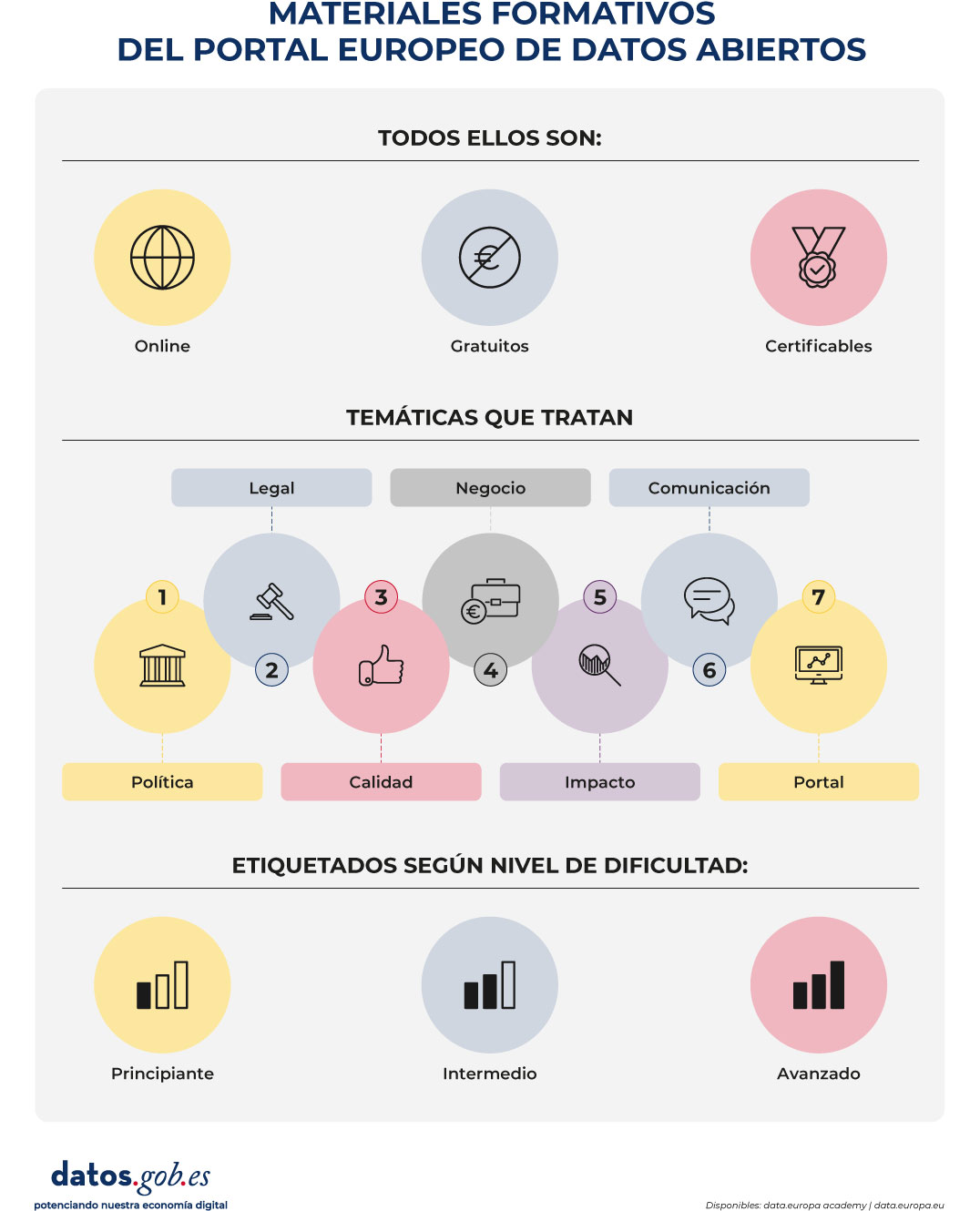
Figura 2. Materiales formativos del portal europeo de datos abiertos. Fuente: elaboración propia
Blog
En los últimos años, se ha puesto de manifiesto la necesidad de que la comunidad científica internacional disponga de mecanismos ágiles para compartir resultados de investigación con el fin de dar respuesta a desafíos como las pandemias, la crisis climática, la pérdida de biodiversidad o la transición energética. En este sentido, las tareas de I+D se han vuelto intensivas en el uso tanto de datos como de software especializado. Un ejemplo concreto se produjo durante la pandemia de COVID-19, cuando la compartición de datos habilitó la secuenciación rápida del genoma del SARS‑CoV‑2, resultando fundamental para el desarrollo de la vacuna de la COVID-19 en tiempo récord.
Es, por tanto, el momento de impulsar la ciencia abierta. Pero para que la ciencia abierta sea una realidad, es imprescindible evitar la fragmentación de los recursos de I+D. Más allá de las publicaciones científicas, es necesario conectar repositorios de datos distribuidos y promover herramientas software, que sean interoperables para facilitar la reutilización efectiva de los conjuntos de datos científicos.
En este contexto nace EOSC (European Open Science Cloud), una iniciativa europea que pretende conectar a la comunidad científica para hacer realidad la ciencia abierta y maximizar su impacto para la sociedad. EOSC ofrece al personal investigador en Europa un entorno multidisciplinar, abierto y de confianza donde poder publicar, descubrir y reutilizar datos, así como herramientas y servicios software en el ámbito científico.
¿Qué es EOSC? Acceso federado a recursos científicos
European Open Science Cloud es la iniciativa europea para crear un entorno abierto y de confianza donde la comunidad investigadora pueda publicar, descubrir y reutilizar datos científicos, así como servicios software de investigación. Su enfoque es federar y escalar recursos científicos en Europa, promoviendo la interoperabilidad entre disciplinas. La ambición de EOSC es acelerar las prácticas de ciencia abierta, aumentando la productividad científica y reforzando la reproducibilidad de la investigación de tal manera que se maximice su impacto en la sociedad. Para ello, EOSC se concibe como un “sistema de sistemas”, es decir, en lugar de centralizar todos los datos y servicios en una única plataforma, EOSC interconecta plataformas ya existentes (es decir, realiza una federación en lugar de una integración) como repositorios de datos, infraestructuras de investigación, o proveedores de servicios software científicos.
La Comisión Europea sitúa EOSC como el espacio común europeo para datos de I+D y lo alinea con el objetivo europeo de conseguir alcanzar una economía y sociedad basadas en datos. En términos de impacto, esto favorece los siguientes aspectos:
- Investigación colaborativa, no sólo dentro de una misma disciplina científica sino también entre disciplinas diferentes y diversos territorios.
- Reutilización y combinación de recursos científicos digitales (como conjuntos de datos o servicios software), así como el impulso de la ciencia ciudadana.
- Impacto en la sociedad a través de políticas basadas en evidencia, al mejorar la trazabilidad, disponibilidad e interoperabilidad de datos que sustentan decisiones públicas.
Para hacer EOSC una realidad, se construye un modelo federado basado en nodos que actúan como puntos de entrada coordinados. Sobre ellos se establecen políticas comunes y capacidades compartidas (por ejemplo, autenticación federada, catálogos y guías de interoperabilidad) que permiten la reutilización de datos y servicios. Este enfoque se concreta en la Federación EOSC, que conecta infraestructuras y comunidades para ofrecer un acceso y reutilización de recursos científicos más homogénea.
¿Qué es la Federación EOSC?
Según el EOSC Federation Handbook (documento de referencia que describe su estructura operativa, marco legal y de gobernanza, y operativa técnica), la Federación EOSC (EOSC Federation) es una red distribuida de nodos. Estos nodos están interconectados y son capaces de colaborar para compartir y gestionar conocimiento y recursos científicos (como conjuntos de datos, software y servicios) entre comunidades temáticas y geográficas, cumpliendo los principios FAIR. Es decir, es una red distribuida que habilita capacidades para desarrollar una ciencia abierta interoperable, segura y fiable a escala europea, entre disciplinas y fronteras.
Como veíamos, el elemento básico de esta federación son los EOSC Nodes (nodos EOSC) que funcionan como puntos de entrada para la comunidad científica a la federación. Se trata de plataformas operadas por organizaciones o consorcios de alcance territorial o temático, que integran:
- Un conjunto de capacidades esenciales para operar, como, por ejemplo, servicios de autenticación y acceso o catálogo de recursos.
- Un conjunto de recursos, como, por ejemplo, productos de datos de investigación.
Una parte de esos recursos se selecciona como Node Exchange, representando lo que el nodo comparte con la federación. Al agregarse las contribuciones de varios nodos, se constituyen el EOSC Exchange, es decir, la oferta global de recursos de la federación.
Para que todo ello funcione, se definen las Federating Capabilities como capacidades comunes (técnicas y también organizativas, como soporte a usuarios) que permiten que los servicios funcionen entre nodos y no como silos aislados. Estas capacidades se habilitan mediante servicios federadores operados por uno o varios nodos y se apoyan en interfaces y guías de interoperabilidad recogidas en el EOSC Interoperability Framework. La siguiente imagen representa gráficamente este proceso:
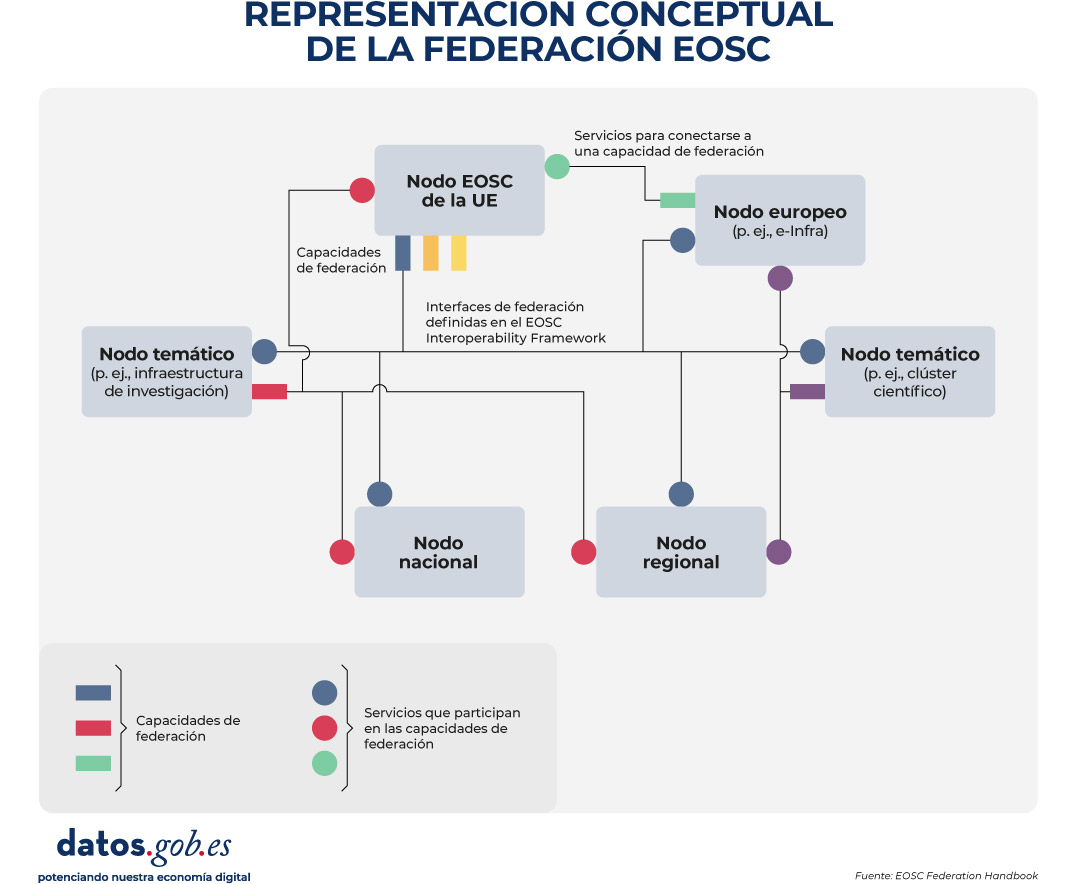
Figura 1. Representación conceptual de la Federación EOSC (fuente: EOSC Federation Handbook).
Existen dos capacidades federadas obligatorias: por una parte la infraestructura de autenticación y autorización (AAI) y, por otra, los catálogos de recursos que permiten a la comunidad científica descubrir y acceder a recursos ofrecidos por los nodos, no sólo manualmente sino por medio de servicios informáticos. Estas primeras capacidades se articulan en el EOSC EU Node.
EOSC EU Node: el primer nodo operativo
En este modelo federado, el EOSC EU Node (promovido por la Comisión Europea) es especialmente relevante como primer nodo de la Federación EOSC, proporcionando un conjunto inicial de datos, herramientas y servicios, y actuando como nodo de referencia para facilitar la interconexión de otros nodos.
Este nodo permite al personal investigador acceder con credenciales institucionales a capacidades como máquinas virtuales, recursos como GPUs, cuadernos interactivos, flujos científicos de trabajo en contenedores, almacenamiento, transferencia de datos y herramientas colaborativas, además de conectarse a un catálogo de recursos para descubrir resultados de investigación (conjuntos de datos científicos, publicaciones o servicios software especializados) procedentes de infraestructuras federadas.
Conclusiones
EOSC permite transformar recursos científicos dispersos en un ecosistema interoperable y reutilizable que permita a la comunidad científica desarrollar los objetivos de la ciencia abierta. La Federación EOSC, mediante nodos conectados y capacidades federadas (tales como AAI, catálogos o guías de interoperabilidad), facilita el acceso a datos FAIR, servicios y herramientas software, acelerando la colaboración científica y la reproducibilidad, además de permitir el impulso de propuestas de ciencia ciudadana e fomentar el impacto de los resultados científicos en la sociedad. Finalmente, cabe destacar que EOSC no sustituye lo que ya existe, sino que lo conecta, lo hace interoperable y lo proyecta a escala europea. En España avanza la definición de un nodo nacional para conectar capacidades existentes con la Federación EOSC. Por ello, la participación temprana de repositorios, infraestructuras, centros de investigación, universidades y proveedores de servicios será clave para construir una oferta representativa, definir prioridades y maximizar el impacto científico y social.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La construcción del ecosistema de uso secundario de los datos de salud electrónica en el Espacio Europeo de Datos de Salud (EEDS) plantea un escenario significativo de oportunidades para la investigación española, para la innovación y el emprendimiento. Para ello, la Unión Europea está impulsando multitud de proyectos estratégicos en los que participan hospitales, fundaciones de investigación sanitaria, universidades, centros de investigación y empresas españolas. La lista de proyectos es extensa y atiende a satisfacer al menos dos objetivos: potenciar la generación de infraestructuras capaces de generar conjuntos de datos de calidad y promover condiciones para su reutilización.
El papel de España. Fortalezas en el despliegue del Espacio Europeo de Salud
España ofrece condiciones significativamente favorables no sólo para participar sino también para contribuir significativamente a las tareas de creación del EEDS:
- En primer lugar, nuestro sistema público de salud se caracteriza por un alto nivel de integración y estructuración. A diferencia de los sistemas basados en mecanismos de reembolso, en los que puede existir una atomización en el ámbito de la provisión de servicios, en nuestro sistema disponemos de un marco de referencia clara en atención primaria, especialidades médicas y servicios hospitalarios.
- Por otra parte, la experiencia desplegada por nuestros entornos de salud a partir del Reglamento General de Protección de Datos (RGPD) y, particularmente, las lecciones aprendidas a partir de la disposición adicional decimoséptima sobre tratamientos de datos de salud de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD) constituyen una experiencia valiosa.
- La apertura del Espacio Nacional de Datos de Salud promovido por el Gobierno de España e impulsado por el Ministerio para la Transformación Digital y de la Función Pública, el Ministerio de Sanidad y las Comunidades Autónomas permite el despliegue de una infraestructura esencial para el EEDS.
El Espacio Nacional de Datos de Salud se presentó el pasado 29 de enero. En el evento se resaltó cómo este proyecto representa un cambio de paradigma que revoluciona la gestión del dato sanitario, impulsando un modelo federado, seguro y ético que preserva la soberanía y privacidad de la información mientras facilita su uso para investigación, innovación y políticas públicas. Su funcionamiento se basa en un catálogo federado de metadatos y un riguroso proceso de acceso y análisis en entornos seguros, que busca potenciar la ciencia abierta y los avances científicos y tecnológicos, beneficiando a pacientes, investigadores, gestores e industria.
Lecciones aprendidas desde los Proyectos Europeos
El camino que arranca el Reglamento (UE) 2025/327 del Parlamento Europeo y del Consejo, de 11 de febrero de 2025, relativo al Espacio Europeo de Datos de Salud, y por el que se modifican la Directiva 2011/24/UE y el Reglamento (UE) 2024/2847 (EEDSR) plantea retos significativos que se abordan en los proyectos de investigación financiados con fondos europeos y nacionales. Las lecciones aprendidas en algunos de ellos pueden ser de extraordinaria utilidad para la comunidad investigadora y de emprendimiento en nuestro país. No podemos olvidar que partimos de fortalezas significativas.
1.-Cumplimiento desde el diseño
La existencia de una nueva normativa obliga a desplegar un análisis riguroso del estado del arte en nuestras organizaciones, no sólo para implementar su despliegue sino también para asegurar las condiciones previas de confiabilidad legal de los conjuntos de datos y de la investigación que se proponga.
2.-Accountability: responsabilidad proactiva y solidez documental
En nuestro país venimos de una larga tradición de “accountability”. El EEDSR va a imponer al solicitante de datos un conjunto de requisitos documentales relevantes, como, por ejemplo, haber previsto las garantías para prevenir cualquier uso indebido de los datos de salud electrónicos. Esta cuestión tampoco podrá descuidarse desde el punto de vista de los tenedores de datos, quienes también tendrán que cumplir algunos requisitos. Por ejemplo, demostrar que los datos son legítimos y reutilizables es una cuestión ética y jurídicamente documentable; y el procedimiento simplificado para el acceso a los datos de salud electrónicos a través de un tenedor fiable de datos de salud obliga a este a documentar la seguridad de su espacio de datos o las capacidades para evaluar las solicitudes de acceso a datos de salud.
Uno de los principales escollos a los que nos enfrentamos en este periodo intermedio de implantación del EEDS reside precisamente en la cultura organizativa para la generación de evidencias verificables. A medida que la estandarización y el conjunto de reglas comunes del EEDS escalen será necesario profundizar en la dinámica de la responsabilidad proactiva entendida como responsabilidad demostrada.
3. Entornos seguros de procesamiento
En nuestro país, los entornos de salud por su propia definición deben ser entornos seguros. El despliegue del Esquema Nacional de Seguridad (ENS) y el del RGPD, han permitido que la totalidad del sistema de salud, público o privado, haya adoptado modelos de madurez perfectamente coherentes con las condiciones de los entornos de procesamiento seguro que define el EEDSR.
Retos del sistema español
Junto a las fortalezas inherentes a nuestro sistema, es necesario considerar aquellos aspectos que se presentan como retos.
1. Anonimización y seudonimización
En el contexto nacional la citada disposición adicional decimoséptima de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales, define condiciones específicas para la seudonimización. Estas consisten en la separación funcional entre los equipos que seudonimizan y los que reutilizan los datos, y en la definición de un entorno seguro que prevenga cualquier intento de reidentificación. A ello se suman garantías jurídicas en términos de compromisos individuales de no reidentificación, despliegue de la herramienta de la evaluación de impacto relativa a la protección de datos y supervisión por comités de ética. El reto de la anonimización se muestra más exigente, ya que implica la imposibilidad de vincular bajo ninguna condición los datos de salud con los del paciente original.
2. Reeskilling de los equipos
El Espacio Europeo de Datos de Salud (EEDS) planteará un desafío formativo sin precedentes que atravesará todos los sectores implicados en el ecosistema de datos sanitarios. Los comités de ética de investigación deberán familiarizarse no solo con los usos secundarios admisibles de los datos de salud, sino también con la integración del Reglamento de Inteligencia Artificial y con los principios éticos del marco ALTAI (Assessment List for Trustworthy Artificial Intelligence). Esta necesidad de reeskilling se extenderá igualmente a los sistemas de salud y la administración sanitaria, donde los organismos de acceso a datos (Health Data Access Bodies) requerirán personal altamente cualificado en estos nuevos marcos éticos y regulatorios, al igual que los tenedores fiables de datos que custodiarán la información sensible. El personal de desarrollo y los equipos de tecnologías de la información también deberán adquirir nuevas competencias en ámbitos técnicos críticos, como la catalogación, validación y curación de datos, así como en los estándares de interoperabilidad que permitan la comunicación efectiva entre sistemas. Quizás el reto de capacitación más delicado recaerá sobre los nuevos operadores, que podrán aprovechar las oportunidades de acceso a conjuntos de datos para usos secundarios innovadores. Esto concierne especialmente a las startups tecnológicas del sector salud. Para enfrentar un marco normativo muy exigente, (RGPD, Regalmento de IA, EEDSR), los recursos y capacidades para el cumplimiento legal (compliance) en las pymes españolas es notablemente limitado. Por ello será necesario construir desde el inicio una cultura sólida de protección de datos y desarrollo ético de sistemas de inteligencia artificial confiables.
3. Catalogación de datos: el desafío de la calidad y la estandarización
En el contexto del Espacio Europeo de Datos de Salud, profundizar en la estandarización de los datos mediante las metodologías más funcionales —como OMOP CDM para datos clínicos observacionales, HL7 FHIR para el intercambio dinámico de información, DICOM para imágenes médicas, o terminologías de referencia como SNOMED CT, LOINC y RxNorm— se presenta como un elemento estratégico fundamental para la creación y reutilización de conjuntos de datos de alta calidad. Sin embargo, la adopción de estos estándares no es suficiente por sí sola: los procesos de validación, anotación semántica y enriquecimiento de datos requieren de recursos humanos altamente cualificados capaces de garantizar la coherencia, completitud y precisión de la información, convirtiéndose esta capacitación en una auténtica precondición para la participación efectiva en el ecosistema europeo de datos de salud. El alineamiento con la catalogación estandarizada de conjuntos de datos siguiendo el estándar HealthDCAT-AP (Health Data Catalog Application Profile), que permite describir de manera homogénea los metadatos descriptivos de los recursos de datos sanitarios, se presenta como uno de los retos inmediatos, junto con la implementación de los trabajos que se vienen desplegando en relación con el data utility quality label, una etiqueta de calidad que evalúa la utilidad real de los datos para usos secundarios y que se está convirtiendo en un sello de confianza para usuarios e investigadores.
Si anteriormente en este artículo se subrayaron las altísimas capacidades del sistema sanitario español para generar datos de salud de manera sistemática y en volúmenes significativos, estos aspectos de catalogación, estandarización y certificación de calidad ocuparán un lugar absolutamente central para diseñar condiciones óptimas de competitividad europea en su reutilización, transformando la abundancia de datos en una verdadera ventaja estratégica que permita a España posicionarse como un actor relevante en el panorama de la investigación y la innovación con datos de salud electrónicos.
La experiencia del proyecto EUCAIM (Cancer Image EU)
El Reglamento del Espacio Europeo de Datos de Salud tiene por objeto permitir el uso secundario de los datos sanitarios electrónicos en toda Europa mediante normas armonizadas en un ecosistema federado. En el ámbito del cáncer, el acceso fragmentado a conjuntos de datos de alta calidad ralentiza la investigación, limita la reproducibilidad y socava la capacidad de Europa para desarrollar y validar herramientas de IA fiables para la oncología.
EUCAIM demuestra la viabilidad de un ecosistema para el uso secundario del cáncer a través de un modelo federado que permite el acceso transfronterizo bajo normas armonizadas garantizando un control adecuado de los recursos a nivel local. Y ello se despliega mediante un conjunto de componentes habilitadores:
1) Un entorno de procesamiento seguro (SPE) federado a nivel europeo
EUCAIM está creando un SPE federado para hacer cumplir las condiciones de acceso a los datos, controlar el procesamiento y apoyar el análisis transfronterizo seguro bajo las restricciones del EEDS. Este SPE se ajusta plenamente a los requisitos y medidas que establece el artículo 73 EEDSR en materia de entornos seguros.
2) Superación de la «barrera de la anonimización»
EUCAIM promueve una estrategia de anonimización por capas que combina procesos de anonimización local autónoma por el tenedor de datos con controles de la plataforma para permitir que los conjuntos de datos sigan siendo útiles para la investigación y el desarrollo de la IA. La importancia de este enfoque radica en que pretende conciliar la protección de la privacidad con la necesidad práctica de disponer de conjuntos con grandes volúmenes de datos caracterizados por su diversidad.
3) Catalogación y estandarización de datos
EUCAIM alinea la catalogación con los principios HealthDCAT-AP cuyo objetivo principal es aplicar los principios FAIR, esto es asegurar que los datos sean encontrables, accesibles, interoperables y reutilizables.
4) Reducción de costes legales
EUCAIM ha desplegado un marco de cumplimiento propio orientado al Reglamento General de Protección de Datos y el Reglamento de Inteligencia Artificial. Para ello, se dispone de un marco sólido de cumplimiento a nivel de una plataforma que se despliega en ecosistemas complejos de datos. Este se basa en evaluaciones de impacto en la protección de datos (incluidas en el RGPD) con especial atención a los derechos fundamentales. También incorpora la formación y el reciclaje profesional de los usuarios como requisito funcional, de modo que la capacidad de cumplimiento se convierta en una característica esencial.
5) Apoyo a los usuarios de datos
EUCAIM ofrece ventajas significativas a los usuarios de datos, incluidos los investigadores y los desarrolladores de IA, al establecer un entorno transparente y bien gobernado para el acceso a los datos. La adopción de criterios de gobernanza transparentes, obligaciones claramente definidas y su aplicación técnica por la plataforma, proporcionan a los usuarios de datos la garantía de que su acceso es adecuado y lícito, totalmente auditable y se mantiene estable a lo largo del tiempo. El diseño de la plataforma garantiza que los usuarios puedan aprovechar datos de gran utilidad para análisis avanzados, incluido el procesamiento federado en un entorno seguro. A través de la formación obligatoria y la implementación de procedimientos estandarizados, los equipos se benefician de una menor incertidumbre y están mejor equipados para alinearse con los requisitos de cumplimiento establecidos por el EEDSR, el RGPD y los marcos de gobernanza de la IA.
6) Garantía de los derechos de los pacientes
El enfoque de EUCAIM se basa en la protección de datos desde el diseño y por defecto que une las salvaguardias organizativas con controles técnicos sólidos. Este marco se ha construido expresamente para minimizar el riesgo de uso indebido de los datos, al tiempo que apoya la investigación y la innovación transfronterizas seguras y eficaces en materia de cáncer. El resultado es un sistema en el que la protección de la privacidad no es un obstáculo sino un elemento fundamental que permite el uso responsable de los datos en beneficio de la sociedad y la ciencia. El modelo refuerza la responsabilidad por el uso secundario de los datos sanitarios mediante la combinación de una sólida supervisión de la gobernanza, un registro exhaustivo de las acciones y obligaciones estrictas y exigibles para todas las entidades participantes. Todas las acciones realizadas con los datos de los pacientes se registran y se someten a revisión, lo que garantiza que todos los usos sean totalmente auditables. Esta trazabilidad garantiza que el tratamiento de los datos se mantenga dentro de los límites del uso permitido y que cualquier desviación pueda identificarse y abordarse rápidamente.
Gobernanza multinivel: la clave del éxito sostenible
La lección aprendida más relevante en EUCAIM se refiere a la necesidad imperiosa de una gobernanza multinivel articulada, coherente y operativa. En sentido amplio, resulta indispensable proporcionar herramientas y marcos de gobierno efectivos sobre tres dimensiones fundamentales:
- En primer lugar, sobre los procesos de generación de conjuntos de datos y sus condiciones de compartición, estableciendo criterios claros sobre qué datos se generan, cómo se estandarizan, quién ostenta derechos sobre ellos y bajo qué licencias y restricciones pueden ser compartidos con terceros.
- En segundo lugar, sobre los procesos de solicitud de acceso a datos, definiendo procedimientos transparentes y eficientes para que investigadores, innovadores y responsables de políticas públicas puedan identificar, solicitar y obtener acceso a los datos necesarios para sus proyectos, minimizando las cargas administrativas sin comprometer las garantías éticas y legales.
- En tercer lugar, sobre los procesos de validación de la corrección de los conjuntos de datos y de adhesión al sistema, así como los procedimientos de autorización de acceso a datos, asegurando que solo datos de calidad certificada alimenten la infraestructura y que únicamente usuarios autorizados y con propósitos legítimos accedan a información sensible.
Esta gobernanza procedimental no puede funcionar sin decisiones estratégicas y operativas en relación con la definición de roles y funciones en materia de recursos humanos. Para ello, es necesario contar con perfiles profesionales necesarios como gestores de datos, expertos en ética de la investigación, especialistas en ciberseguridad, curadores de datos y responsables de calidad. En segundo lugar, será fundamental la definición de los entornos seguros de procesamiento donde se ejecutan análisis sobre datos sensibles, garantizando que estos espacios cumplan con los más altos estándares técnicos de seguridad, trazabilidad, auditoría y preservación de la privacidad, y que estén diseñados para operar bajo el principio de confianza cero (zero trust) adaptado al contexto sanitario. Solo mediante esta arquitectura de gobernanza multinivel, que integre dimensiones técnicas, organizativas, éticas y legales en todos los niveles de decisión —desde el diseño de políticas nacionales hasta la gestión operativa diaria de las plataformas—, será posible construir infraestructuras de datos de salud verdaderamente sostenibles, confiables y capaces de generar valor social, científico y económico a largo plazo, posicionando al sistema sanitario español como un actor estratégico en el ecosistema europeo de innovación en salud.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El Open Data Maturity Report (Informe de madurez de datos abiertos) es una evaluación anual que desde 2015 analiza el desarrollo y la evolución de las iniciativas de datos abiertos en la Unión Europea. Coordinado por el Portal Europeo de Datos (data.europa.eu) y realizado en colaboración con la Comisión Europea, este informe evalúa a 36 países participantes: los 27 Estados miembros de la UE, 3 países de la Asociación Europea de Libre Comercio (Islandia, Noruega y Suiza) y 6 países candidatos a la adhesión.
El informe evalúa cuatro dimensiones fundamentales:
- Política (estrategias y marcos normativos)
- Portal (funcionalidades y usabilidad)
- Calidad (estándares de metadatos y datos)
- Impacto (reutilización y beneficios generados)
En la edición de 2025 España destacó con una puntuación del 100% en el bloque de impacto respecto a la media europea del 82,1%. En términos generales, ocupa la quinta posición entre los países de la Unión Europea con una puntuación total de 95,6%, formando parte del grupo de los países prescriptores de tendencias.
Un aspecto diferencial de esta edición del informe es la incorporación de un enfoque descriptivo y contextual que complementa el modelo normativo tradicional, creando clústeres de países para permitir comparaciones más justas. Estos clústeres agrupan países con características económicas, sociales, políticas y digitales similares, y se basan en perfiles que explican cómo se implementan las políticas de datos abiertos, no solo qué resultados se obtienen. El objetivo es invitar a los países a mirarse en sus peers (sus semejantes), aprender de experiencias comparables y fomentar un aprendizaje entre iguales más efectivo que el basado únicamente en rankings generales.
Además de cuantificarlo, el informe recoge casos de uso y buenas prácticas que llevan a cabo los países para abrir y reutilizar datos del sector público. En este post, destacamos algunas de ellas que pueden servir de inspiración para continuar mejorando nuestro ecosistema de datos abiertos.
La gobernanza inclusiva y coordinada de Croacia
Uno de los aspectos más destacables del informe 2025 es cómo algunos países han logrado establecer estructuras de gobernanza sólidas que garantizan la coordinación entre diferentes niveles de la administración y la participación de múltiples actores.
Croacia destaca por haber creado en 2025 la Coordinación para la Implementación de la Política de Datos Abiertos, un órgano multisectorial que supervisa el cumplimiento normativo, mejora la accesibilidad de los datos y apoya a las autoridades. Este modelo asegura una participación amplia y garantiza que las iniciativas nacionales y locales estén alineadas. El portal nacional funciona como hub central, complementado por portales locales como el de la ciudad de Zagreb. Además, se fomentan intercambios de conocimiento mediante reuniones de coordinación, actualizaciones periódicas y colaboraciones con universidades, como la Facultad de Ingeniería Eléctrica e Informática de la Universidad de Zagreb.
La estructura completa de gobernanza de datos de Francia
Este país lidera el ranking del Open Data Maturity Report gracias, entre otros, a su modelo de gobernanza integral que integra roles de datos abiertos en todos los niveles administrativos. A nivel nacional, el Administrador General de Datos coordina la política de datos públicos y supervisa una red de chief data officers (responsables de datos) en cada ministerio. Etalab, la unidad nacional de datos abiertos e innovación digital, gestiona esta red y proporciona apoyo técnico.
A nivel ministerial, cada responsable de datos gestiona la política de datos (apertura, calidad y reutilización), apoyado por Etalab. Algunos ministerios designan además oficiales de datos abiertos específicos y data stewards (gestor o administrador de datos) que manejan aspectos técnicos y organizativos de la publicación. A nivel local, cada representante regional (préfet) designa un referente para datos, algoritmos y códigos fuente. La Dirección Interministerial Digital coordina además una red de gestores de API para permitir el acceso dinámico a los datos. También garantizan el cumplimiento de DCAT-AP en sus metadatos, como hacemos en España.
Puedes consultar aquí cómo funciona DCAT-AP y para qué sirve
Implementación efectiva: de la estrategia a la acción en Italia
Las administraciones públicas italianas están obligadas a adoptar planes de publicación de datos, siguiendo las directrices nacionales, que priorizan conjuntos de datos de alto valor, datos dinámicos e información solicitada por usuarios. La implementación se apoya en un robusto sistema de monitorización. La Agencia para la Italia Digital (AgID) realiza seguimiento del progreso mediante su panel de transformación digital, que reporta el crecimiento de conjuntos de datos en dati.gov.it.
Las políticas se actualizan regularmente: el último plan trienal (2024-2026) fue adoptado en diciembre de 2024. Para asistir a los titulares de datos y funcionarios, AgID proporciona orientación, realiza webinarios y lanzó la AgID Academy para fortalecer competencias digitales.
Cultura de reutilización en Polonia y Ucrania
Un aspecto crucial para fomentar la apertura de datos es proporcionar recursos prácticos que guíen a las organizaciones públicas en todo el proceso. Polonia destaca por su manual de datos abiertos, cuya segunda edición fue publicada por el Ministerio de Asuntos Digitales.
Este manual actualizado introduce nuevas categorías de datos, explica cómo las regulaciones moldean las políticas de datos abiertos y presenta el Portal de Datos de Polonia.
El manual funciona como una lista de verificación para las oficinas, guiándolas a través de sus responsabilidades para abrir datos y fomentar una cultura de reutilización e incluyen herramientas como una checklist de apertura para el cumplimiento.
En relación, Ucrania también ha adoptado un enfoque hacia la reutilización y la generación de recursos que incentivan esta reutilización de datos. El Ministerio de Transformación Digital ha desarrollado un conjunto completo de recursos y herramientas que incluyen documentación técnica detallada y plantillas para ayudar a preparar y publicar conjuntos de datos alineados con estándares nacionales, cubriendo estructuración de metadatos, licenciamiento y cumplimiento con el estándar DCAT-AP.
El portal nacional incluye funcionalidades de seguimiento de publicación y reutilización de conjuntos de datos. Los proveedores reciben retroalimentación sobre calidad y completitud de sus metadatos, ayudándoles a identificar áreas de mejora. Además, se organizan sesiones de capacitación y talleres regulares para desarrollar las habilidades de los publicadores, promoviendo un entendimiento compartido de los principios de datos abiertos y requisitos técnicos.
Albania: rediseño integral del portal
Este país ejemplifica las mejoras de madurez que pueden lograrse mediante una actualización integral del portal nacional de datos abiertos. La renovación a gran escala del portal mejoró la usabilidad, la transparencia y el compromiso del usuario.
El portal actualizado presenta ahora un sistema de calificación de conjuntos de datos (1-5 estrellas), una sección dedicada de noticias sobre temas de datos abiertos y múltiples opciones de notificación, incluyendo feeds RSS y Atom, y correo electrónico. Los usuarios pueden seguir el progreso de sus solicitudes de datos, que se monitorizan activamente y se resumen las respuestas en informes públicamente disponibles.
Para mejor entender y responder a las necesidades de los usuarios, el equipo del portal rastrea palabras clave de búsqueda, analiza tráfico y realiza encuestas y talleres con usuarios.
Lituania: metodología oficial de monitorización
Una de las prácticas clave destacadas en el informe es la adopción de marcos formales y metodologías estructuradas que proporcionan una forma sistemática de evaluar el impacto de los datos abiertos. Lituania sobresale con un enfoque integral porque define cómo las instituciones deben reportar sobre actividades de datos abiertos, garantizando consistencia, responsabilidad y cumplimiento en todo el sector público.
Además, el Ministerio de Economía e Innovación realizó cálculos para estimar el impacto económico de los datos abiertos. Este análisis proporciona evidencia cuantificable de la contribución de los datos abiertos a la innovación, productividad y creación de empleo. Los resultados muestran que los datos abiertos en Lituania crean un valor de mercado de aproximadamente 566 millones de euros (alrededor del 1,2% del PIB) y respaldan cerca de 8.000 empleos de valor agregado.
Alemania: financiación sistemática para colaboración
La iniciativa mFund de Alemania proporciona apoyo financiero estructurado para proyectos de datos relacionados con movilidad, fomentando asociaciones más allá del gobierno.
Un ejemplo es el proyecto miki (mobil im Kiez), que desarrolla soluciones de navegación y orientación para personas con movilidad limitada mediante el compromiso activo de la sociedad civil. El equipo creó un prototipo nacional con visualizaciones para ciudades como Colonia, Kassel, Múnich, Potsdam y Saarbrücken, mostrando barreras de edificios y superficies de caminos. Estas visualizaciones se integrarán en Wheelmap.org, ayudando a individuos con discapacidades de movilidad.
Conclusión
En conclusión, el Open Data Maturity Report 2025 demuestra que los países europeos más maduros en datos abiertos comparten características comunes: gobernanza inclusiva y bien estructurada, implementación efectiva respaldada por planificación y monitorización, apoyo práctico a publicadores de datos, innovación técnica continua en portales y, crucialmente, medición sistemática del impacto.
Las buenas prácticas aquí destacadas son transferibles y adaptables. Invitamos a las administraciones públicas españolas a explorar estas experiencias, adaptarlas a sus contextos locales y compartir sus propias innovaciones, contribuyendo así a un ecosistema europeo de datos abiertos cada vez más robusto y orientado al impacto.
Blog
En la era de la Inteligencia Artificial (IA), los datos han dejado de ser simples registros para convertirse en el combustible esencial de la innovación. Sin embargo, para que ese combustible impulse realmente nuevos servicios, políticas públicas más eficaces o modelos de IA avanzados, no basta con disponer de grandes volúmenes de información: los datos deben ser variados, de calidad y, sobre todo, accesibles.
En este contexto cobra protagonismo el data pooling o agrupación de datos, una práctica que consiste en poner datos en común para generar mayor valor a partir de su uso conjunto. Lejos de ser una idea abstracta, el data pooling se perfila como uno de los mecanismos clave para transformar la economía del dato en Europa y acaba de recibir un nuevo impulso con la propuesta del Digital Omnibus, orientada a simplificar y reforzar el marco europeo de compartición de datos.
Como ya analizamos en nuestro reciente post sobre la Estrategia de la Unión de Datos, la Unión Europea aspira a construir un mercado único de datos en el que la información pueda fluir de forma segura y con garantías. El data pooling es, precisamente, la herramienta operativa que permite hacer tangible esa visión, conectando datos hoy dispersos entre administraciones, empresas y sectores.
Pero ¿qué significa exactamente “data pooling”? ¿Por qué se habla cada vez más de este concepto en el contexto de la estrategia europea de datos y del nuevo Digital Omnibus? Y, sobre todo, ¿qué oportunidades abre para las administraciones públicas, las empresas y los reutilizadores de datos? en este artículo tratamos de responder estas preguntas.
¿Qué es el data pooling, cómo funciona y para qué sirve?
Para entender qué es el data pooling, puede resultar útil pensar en una cooperativa agrícola tradicional. En ella, pequeños productores que, de forma individual, tienen recursos limitados deciden poner en común su producción y sus medios. Al hacerlo, ganan escala, acceden a mejores herramientas y pueden competir en mercados a los que no llegarían por separado.
En el ámbito digital, el data pooling funciona de manera muy similar. Consiste en combinar o agrupar conjuntos de datos procedentes de distintas organizaciones o fuentes para analizarlos o reutilizarlos con un objetivo compartido. Al crear este “depósito común” de información —físico o lógico— se habilitan análisis más complejos y valiosos que difícilmente podrían realizarse desde una única fuente aislada.
Este “poner datos en común” puede adoptar distintas formas, en función de las necesidades técnicas y organizativas de cada iniciativa:
- Repositorios compartidos, en los que varias organizaciones aportan datos a una misma plataforma.
- Accesos conjuntos o federados, donde los datos permanecen en sus sistemas de origen, pero pueden analizarse de forma coordinada.
- Acuerdos de gobernanza, que establecen reglas claras sobre quién puede acceder a los datos, con qué finalidad y bajo qué condiciones.
En todos los casos, la idea central es la misma: cada participante contribuye con sus datos y, a cambio, todos se benefician de un mayor volumen, diversidad y riqueza de información, siempre bajo normas previamente acordadas.
¿Para qué sirve poner los datos en común?
El creciente interés por el data pooling no es casual. Compartir datos de forma estructurada permite, entre otras cosas:
- Detectar patrones que no son visibles con datos aislados, especialmente en ámbitos complejos como la movilidad, la salud, la energía o el medio ambiente.
- Mejorar el desarrollo de la inteligencia artificial, que necesita datos diversos, de calidad y a escala para generar resultados fiables.
- Evitar duplicidades, reduciendo costes y esfuerzos tanto en el sector público como en el privado.
- Impulsar la innovación, facilitando nuevos servicios, estudios comparativos o análisis predictivos.
- Reforzar la toma de decisiones basada en evidencias, un aspecto especialmente relevante en el diseño de políticas públicas.
En otras palabras, el data pooling multiplica el valor de los datos existentes sin necesidad de generar siempre nuevos conjuntos de información.
Distintos tipos de data pooling y su valor
No todos los data pools son iguales. Dependiendo del contexto y del objetivo perseguido, pueden identificarse distintos modelos de agrupación de datos:
- Data pooling M2M (Machine-to-Machine), muy habitual en el Internet de las Cosas (IoT). Por ejemplo, cuando fabricantes de sensores industriales agrupan datos de miles de máquinas para anticipar fallos o mejorar el mantenimiento.
- Data pooling transversal o intersectorial, que combina datos de sectores distintos —como transporte y energía— para optimizar servicios, por ejemplo, la gestión de la recarga de vehículos eléctricos en ciudades inteligentes.
- Data pooling para investigación, especialmente relevante en el ámbito de la salud, donde hospitales o centros de investigación comparten datos anonimizados para entrenar algoritmos capaces de detectar enfermedades poco frecuentes o mejorar diagnósticos.
Estos ejemplos muestran que el data pooling no es una solución única, sino un conjunto de prácticas adaptables, capaces de generar valor económico, social y científico cuando se aplican con las garantías adecuadas.
Del potencial a la práctica: garantías, reglas claras y nuevas oportunidades para el data pooling
Hablar de poner datos en común no significa hacerlo sin límites. Para que el data pooling genere confianza y valor sostenible, es imprescindible abordar cómo compartir datos de forma responsable. Este ha sido, de hecho, uno de los grandes retos que han condicionado su adopción en los últimos años.
Entre las principales preocupaciones destacan la protección de los datos personales, garantizando el cumplimiento del Reglamento General de Protección de Datos (RGPD) y minimizando riesgos de reidentificación; la confidencialidad y la protección de los secretos comerciales, especialmente cuando participan empresas; así como la calidad e interoperabilidad de los datos, ya que combinar información inconsistente puede conducir a conclusiones erróneas. A todo ello se suma un elemento transversal: la confianza entre las partes, sin la cual ningún mecanismo de compartición puede funcionar.
Por este motivo, el data pooling no es solo una cuestión técnica. Requiere marcos legales claros, modelos de gobernanza sólidos y mecanismos de confianza, que den seguridad tanto a quienes comparten los datos como a quienes los reutilizan.
El papel de Europa: de compartir datos a crear ecosistemas
Consciente de estos retos, la Unión Europea lleva años trabajando para construir un mercado único de datos, en el que compartir información sea más sencillo, seguro y beneficioso para todos los actores implicados. En este contexto han surgido iniciativas clave como los espacios europeos de datos, organizados por sectores estratégicos (salud, movilidad, industria, energía, agricultura), el impulso a estándares e interoperabilidad, y la aparición de intermediarios de datos como terceros de confianza que facilitan la compartición.
El data pooling encaja plenamente en esta visión: es uno de los mecanismos prácticos que permiten que estos espacios de datos funcionen y generen valor real. Al facilitar la agregación y el uso conjunto de datos, el pooling actúa como el “motor” que hace operativos muchos de estos ecosistemas.
Todo ello se enmarca en la Estrategia de la Unión de Datos, que busca conectar políticas, infraestructuras y normas para que los datos puedan circular de forma segura y eficiente en toda Europa.
El gran freno: la fragmentación normativa
Hasta hace poco, este potencial se encontraba con un obstáculo importante: la complejidad del marco legal europeo en materia de datos. Una organización que quisiera participar en un data pool transfronterizo debía navegar entre múltiples normas —RGPD, Data Governance Act, Data Act, Directiva de Datos Abiertos y regulaciones sectoriales o nacionales— con definiciones, obligaciones y autoridades competentes no siempre alineadas. Esta fragmentación generaba inseguridad jurídica: dudas sobre responsabilidades, miedo a sanciones, o incertidumbre sobre la protección real de los secretos comerciales. En la práctica, este “laberinto normativo” ha frenado durante años el desarrollo de muchos espacios comunes de datos y ha limitado la adopción del data pooling, especialmente entre pymes y empresas medianas con menos capacidad jurídica y técnica.
El Digital Omnibus: simplificar para que el data pooling escale
Es en este punto donde entra en juego el Digital Omnibus, la propuesta de la Comisión Europea para simplificar y armonizar el marco jurídico digital. Lejos de añadir nuevas capas regulatorias, el objetivo del Omnibus es ordenar, consolidar y reducir cargas administrativas, facilitando que compartir datos sea viable en la práctica.
Desde la perspectiva del data pooling, el mensaje es claro: menos fragmentación, más claridad y mayor confianza. El Omnibus busca concentrar las reglas en un marco más coherente, evitar duplicidades y eliminar barreras innecesarias que hasta ahora desincentivaban la colaboración basada en datos, especialmente en proyectos transfronterizos.
Además, se refuerza el papel de los servicios de intermediación de datos, actores clave para organizar el pooling de forma neutral y confiable. Al clarificar su rol y reducir determinadas cargas, se favorece la aparición de nuevos modelos —incluidas startups tecnológicas— capaces de actuar como “árbitros” del intercambio de datos entre múltiples participantes.
Otro elemento especialmente relevante es el refuerzo de la protección de los secretos comerciales, permitiendo a los poseedores de datos limitar o denegar el acceso cuando exista un riesgo real de uso indebido o transferencia a entornos sin garantías adecuadas. Este punto resulta clave para sectores industriales y estratégicos, donde la confianza es condición indispensable para compartir datos.
Nuevas oportunidades del data pooling: sector público, empresas y reutilización de datos
La simplificación normativa y el refuerzo de la confianza que introduce el Digital Omnibus no son un fin en sí mismos. Su verdadero valor reside en las oportunidades concretas que abre el data pooling para distintos actores del ecosistema del dato, especialmente para el sector público, las empresas y los reutilizadores de información.
En el caso de las administraciones públicas, el data pooling ofrece un potencial especialmente relevante. Permite combinar datos procedentes de distintas fuentes y niveles administrativos para mejorar el diseño y la evaluación de las políticas públicas, avanzar hacia una toma de decisiones basada en evidencias y ofrecer servicios más eficaces y personalizados a la ciudadanía. Al mismo tiempo, facilita la ruptura de silos de información, la reutilización de datos ya disponibles y la reducción de duplicidades, con el consiguiente ahorro de costes y esfuerzos.
Además, el data pooling refuerza la colaboración entre el sector público, el ámbito investigador y el sector privado, siempre bajo marcos seguros y transparentes. En este contexto, no compite con los datos abiertos, sino que los complementa, permitiendo conectar conjuntos de datos que hoy se publican de forma fragmentada y habilitando análisis más avanzados que amplían su valor social y económico.
Desde el punto de vista empresarial, el Digital Omnibus introduce una novedad significativa al ampliar el foco más allá de las pymes tradicionales. Las denominadas small mid-caps, empresas de mediana capitalización que también sufren el impacto de la burocracia, pasan a beneficiarse de la simplificación normativa. Esto incrementa de forma notable la base de organizaciones capaces de participar en esquemas de data pooling y amplía el volumen y la diversidad de datos disponibles en sectores estratégicos como la industria, la automoción o la química.
El impacto económico de este nuevo escenario es también relevante. La Comisión Europea estima importantes ahorros de costes administrativos y operativos, tanto para empresas como para administraciones públicas. Pero más allá de las cifras, estos ahorros representan capacidad liberada para innovar, invertir en nuevos servicios digitales y desarrollar modelos de inteligencia artificial más avanzados, alimentados por datos que ahora pueden compartirse con mayor seguridad.
En definitiva, el data pooling se consolida como una palanca clave para pasar de la compartición puntual de datos a la generación sistemática de valor, sentando las bases de una economía del dato más colaborativa, eficiente y competitiva en Europa.
Conclusión: cooperar para competir
La propuesta del data pooling en el Digital Omnibus marca un antes y un después en la forma en que entendemos la propiedad de la información. Europa ha entendido que, en la economía global del dato, la soberanía no se defiende cerrando fronteras, sino creando entornos seguros donde la colaboración sea la opción más sencilla y rentable.
El data pooling es el corazón de esta transformación. Al reducir la burocracia, simplificar las notificaciones y proteger los secretos comerciales, el Omnibus está quitando las piedras del camino para que empresas y ciudadanos puedan disfrutar de los beneficios de una verdadera Unión de Datos.
En definitiva, se trata de pasar de una economía de silos aislados a una de redes conectadas. Porque, en el mundo de los datos, compartir no es perder el control, es ganar escala.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
Hablar de dominio público es hablar de acceso libre al conocimiento, de cultura compartida y de innovación abierta. El concepto se ha convertido en una pieza clave para comprender cómo circula la información y cómo se construye el patrimonio común de la humanidad.
En este post exploraremos qué significa el dominio público y te mostraremos ejemplos de repositorios donde puedes descubrir y disfrutar de obras que ya forman parte de todos.
¿Qué es el dominio público?
Seguro que en algún momento de tu vida has visto la imagen de Mickey Mouse manejando el timón en un barco de vapor. Una imagen característica de la compañía Disney que ya puedes utilizar libremente en tus propias obras. Esto se debe a que esta primera versión de Mickey (Steamboat Willie, 1928) pasó a ser de dominio público en enero de 2024 -ojo, solo es “libre” la versión de esa fecha, adaptaciones posteriores sí continúan protegidas, como explicaremos después-.
Cuando hablamos de dominio público, hacemos referencia al conjunto de conocimiento, información, obras y creaciones (libros, música, películas, fotos, software, etc.) que no están protegidas por derechos de autor. Debido a ello, cualquier persona puede reproducirlas, copiarlas, adaptarlas y distribuirlas sin necesidad de pedir permiso ni pagar licencias. No obstante, sí se deben respetar siempre los derechos morales del autor, que son irrenunciables y no caducan. Estos derechos incluyen respetar siempre la autoría y la integridad de la obra*.
El dominio público, por tanto, da forma al espacio cultural donde las obras pasan a ser patrimonio común de la sociedad, lo cual supone múltiples beneficios:
- Acceso gratuito a la cultura y al conocimiento: cualquier ciudadano puede leer, ver, escuchar o descargar esas obras sin pagar licencias ni suscripciones. Esto favorece la educación, la investigación y el acceso universal a la cultura.
- Conservación de la memoria y el patrimonio: el dominio público garantiza que parte importante de nuestra historia, ciencia y arte se mantenga accesible para las generaciones presentes y futuras, sin quedar limitada por restricciones legales.
- Fomenta la creatividad y la innovación: artistas, desarrolladores, empresas, etc. pueden reutilizar y mezclar obras del dominio público para crear nuevos productos (como adaptaciones, nuevas ediciones, videojuegos, cómics, etc.) sin miedo a infringir derechos.
- Impulso tecnológico: archivos, museos y bibliotecas pueden digitalizar y difundir libremente sus fondos en dominio público, lo que genera oportunidades para proyectos digitales y desarrollo de nuevas herramientas. Por ejemplo, estas obras pueden utilizarse para entrenar modelos de inteligencia artificial y herramientas de procesamiento del lenguaje natural.
¿Qué obras y elementos pertenecen al dominio público, según la legislación española?
En el dominio público encontramos tanto contenidos cuyos derechos de autor han expirado como contenidos que nunca han estado protegidos. Veamos que dice la legislación española al respecto:
Obras cuya protección por derechos de autor ha expirado.
Para saber si una obra pertenece al dominio público, debemos fijarnos en la fecha de la muerte de su autor. En este sentido, en España, hay una fecha de inflexión: 1987. A partir de ese año, y según la ley de propiedad intelectual, las obras artísticas pasan a dominio público una vez transcurridos 70 años de la muerte de su autor. No obstante, los autores fallecidos antes de dicho año están sujetos a la Ley de 1879, donde el plazo en general era de 80 años – con excepciones-.
Solo las creaciones “originales literarias, artísticas o científicas” que impliquen un nivel suficiente de creatividad están protegidas, independientemente de su soporte (papel, digital, audiovisual, etc.). Esto incluye desde libros, composiciones musicales, obras teatrales, audiovisuales o pictóricas y esculturas hasta gráficos, mapas y diseños relativos a la topografía, la geografía y la ciencia o programas de ordenador, entre otros.
Cabe destacar que también son objeto de propiedad intelectual las traducciones y adaptaciones, las revisiones, actualizaciones y anotaciones; los compendios, resúmenes y extractos; los arreglos musicales, las colecciones de obras ajenas, como las antologías o cualesquiera transformaciones de una obra literaria, artística o científica. Por tanto, una adaptación reciente de El Quijote contará con su propia protección.
Obras que no pueden acogerse a la protección de los derechos de autor.
Como veíamos, no todo lo que se produce puede acogerse a derechos de autor, algunos ejemplos son:
- Documentos oficiales: las leyes, decretos, sentencias y otros textos oficiales no están sujetos a derechos de autor. Se consideran demasiado relevantes para la vida pública como para imponerles restricciones, y por ello forman parte del dominio público desde el momento de su publicación.
- Obras cedidas voluntariamente: los propios titulares de derechos pueden decidir liberar sus obras antes de que expire el plazo legal. Para ello existen herramientas como la licencia Creative Commons CC0 , que permite renunciar a la protección y poner la obra directamente a disposición de todos.
- Hechos e información: el derecho de autor no cubre hechos ni datos. La información y los acontecimientos son patrimonio común y pueden ser usados libremente por cualquiera.
Europeana y su defensa del dominio público
Europeana es la gran biblioteca digital de Europa, un proyecto impulsado por la Unión Europea que reúne millones de recursos culturales procedentes de archivos, museos y bibliotecas de todo el territorio. Su misión es facilitar el acceso libre y abierto al patrimonio cultural europeo, y en ese sentido el dominio público ocupa un lugar central. Europeana defiende que las obras que han perdido su protección por derechos de autor deben permanecer libres de restricciones, incluso cuando se digitalizan, porque forman parte del patrimonio común de la humanidad.
Fruto de su compromiso, recientemente ha actualizado su Carta del Dominio Público, donde recoge una serie de principios y guías esenciales para un dominio público robusto y vibrante en el entorno digital. Entre otras cuestiones, menciona cómo los avances tecnológicos y los cambios normativos han ampliado las posibilidades de acceso al patrimonio cultural, pero también han generado riesgos para la disponibilidad y reutilización de los materiales en dominio público. Por ello, propone ocho medidas para proteger y fortalecer el dominio público:
- Abogar contra la ampliación de los plazos o el alcance del copyright, que limita el acceso ciudadano a la cultura compartida.
- Oponerse a intentos de control indebido sobre materiales libres, evitando licencias, tarifas o restricciones contractuales que reconstituyan derechos.
- Garantizar que las reproducciones digitales no generen nuevas capas de protección, incluyendo fotos o modelos 3D, salvo que sean creaciones originales.
- Evitar contratos que restrinjan la reutilización: la financiación de la digitalización no debe traducirse en barreras legales.
- Etiquetar de forma clara y precisa las obras en dominio público, proporcionando datos como autor y fecha para facilitar su identificación.
- Equilibrar el acceso con otros intereses legítimos, respetando leyes, valores culturales y la protección de grupos vulnerables.
- Salvaguardar la disponibilidad del patrimonio, frente a amenazas como conflictos, cambio climático o la fragilidad de plataformas digitales, promoviendo una preservación sostenible.
- Ofrecer reproducciones y metadatos de alta calidad y reutilizables, en formatos abiertos y legibles por máquina, para potenciar su uso creativo y educativo.
Otras plataformas para acceder a obras de dominio público
Además de Europeana, en España contamos con un ecosistema de proyectos que ponen al alcance de todos el patrimonio cultural en dominio público:
- La Biblioteca Nacional de España (BNE) desempeña un papel clave: cada año publica la lista de autores españoles que entran en dominio público y ofrece acceso a sus obras digitalizadas a través de BNE Digital, un portal que permite consultar manuscritos, libros, grabados y otros materiales históricos. Así, podemos encontrar obras de autores de la talla de Antonio Machado o Federico García Lorca. Además, la BNE publica en abierto el conjunto de datos con información sobre los autores en dominio público.
- La Biblioteca Virtual del Patrimonio Bibliográfico (BVPB), impulsada por el Ministerio de Cultura, reúne miles de obras antiguas digitalizadas, garantizando que textos y materiales fundamentales de nuestra historia literaria y científica puedan ser preservados y reutilizados sin restricciones. Incluye reproducciones facsímiles digitales de manuscritos, libros impresos, fotografías históricas, materiales cartográficos, partituras, mapas, etc.
- Hispana actúa como un gran agregador nacional al conectar colecciones digitales de archivos, bibliotecas y museos españoles, ofreciendo un acceso unificado a materiales que forman parte del dominio público. Para ello, recolecta y hace accesibles los metadatos de los objetos digitales, permitiendo visualizar dichos objetos a través de enlaces que dirijan a las páginas de las instituciones propietarias.
En conjunto, todas estas iniciativas refuerzan la idea de que el dominio público no es un concepto abstracto, sino un recurso vivo y accesible que se expande cada año y que permite que nuestra cultura siga circulando, inspirando y generando nuevas formas de conocimiento.
Gracias a Europeana, BNE Digital, la BVPB, Hispana y otros muchos proyectos de este tipo, hoy tenemos la posibilidad de acceder a un patrimonio cultural inmenso que nos conecta con nuestro pasado y nos impulsa hacia el futuro. Cada obra que entra en el dominio público amplía las oportunidades de aprendizaje, innovación y disfrute colectivo, recordándonos que la cultura, cuando se comparte, se multiplica.
*De acuerdo con la Ley de Propiedad intelectual, la integridad de la obra hace referencia a impedir cualquier deformación, modificación, alteración o atentado contra ella que suponga perjuicio a sus legítimos intereses o menoscabo a su reputación.
Noticia
España vuelve a destacar en el panorama europeo de datos abiertos. El informe Open Data Maturity 2025 sitúa a nuestro país entre los líderes en la apertura y reutilización de información del sector público, consolidando una trayectoria ascendente en innovación digital.
El informe, elaborado anualmente por el portal europeo de datos, data.europa.eu, evalúa el grado de madurez de los datos abiertos en Europa. Para ello analiza varios indicadores, agrupados en cuatro dimensiones: política, portal, calidad e impacto. En la edición de este año han participado 36 países, incluidos los 27 Estados miembros de la Unión Europea (EU), tres países de la Asociación Europea de Libre Comercio (Islandia, Noruega y Suiza) y seis países candidatos (Albania, Bosnia y Herzegovina, Montenegro, Macedonia del Norte, Serbia y Ucrania).
Este año, España se sitúa en quinta posición entre los países de la Unión Europea y sexta del total de países analizados, empatada con Italia. En concreto se ha obtenido una puntuación total de 95,6%, muy por encima de la media de los países analizados (81,1%). Con este dato, España mejora su puntuación con respecto a 2024, cuando obtuvo un 94,8%.
España, entre los líderes europeos
Con esta posición, España se sitúa un año más entre los países prescriptores en materia de datos abiertos (trendsetters), es decir, aquellos que marcan tendencia y sirven de ejemplo de buenas prácticas a otros Estados. España comparte grupo con Francia, Lituania, Polonia, Ucrania, Irlanda, la ya mencionada Italia, Eslovaquia, Chipre, Portugal, Estonia y República Checa.
Los países de este grupo cuentan con políticas avanzadas de datos abiertos, alineadas con los progresos técnicos y políticos de la Unión Europea, incluyendo la publicación de conjuntos de datos de alto valor. Además, existe una coordinación sólida de las iniciativas relacionadas con los datos abiertos en todos los niveles de la administración. Sus portales nacionales ofrecen funciones completas y metadatos de calidad, con escasas limitaciones en publicación o uso. Esto lleva a que los datos publicados se puedan reutilizar más fácilmente para múltiples fines, contribuyendo a generar un impacto positivo en distintos ámbitos.
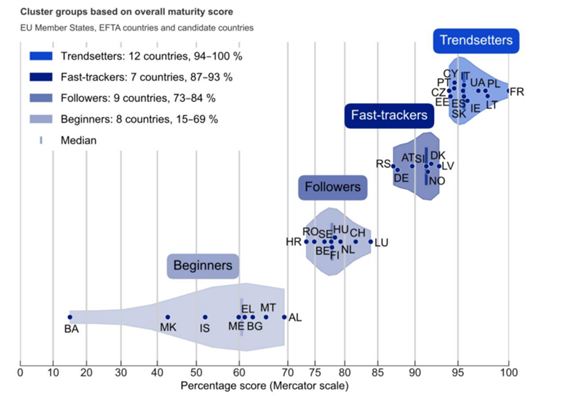
Figura 1. Países integrantes de los distintos clusters.
Las claves del avance de España
De acuerdo con el informe, España reforzó su liderazgo en materia de datos abiertos mediante el desarrollo de políticas estratégicas, la modernización técnica y la innovación impulsada por la reutilización. En concreto, las mejoras en el ámbito político son las que han impulsado el crecimiento de España:
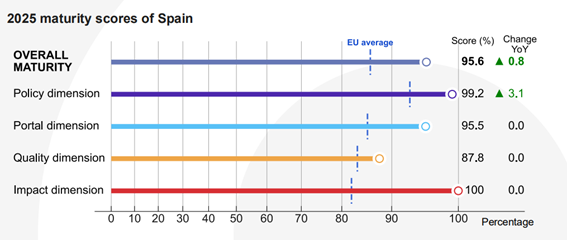
Figura 2. Puntuación de España en las distintas dimensiones junto con el crecimiento sobre el año anterior.
Tal y como se muestra en la imagen, la dimensión política ha alcanzado una puntuación de 99,2% frente al 96% del año pasado, destacando sobre la media europea que es del 93,1%. El motivo de este crecimiento es el avance en el marco normativo. En este sentido, el informe destaca la configuración del V Plan de Gobierno Abierto, desarrollado a través de un proceso de cocreación en el que participaron todos los grupos de interés. Este plan ha introducido nuevas iniciativas relacionadas con la gobernanza y la reutilización de datos abiertos. Otra cuestión destacada es que España impulsó la publicación de conjuntos de datos de alto valor, en consonancia con el Reglamento de Ejecución (UE) 2023/138.
El resto de dimensiones se mantienen estables, todas ellas con puntuaciones por encima de la media europea: en la dimensión portal se ha obtenido un 95,5% en comparación con el 85,45% europeo, mientras que la de calidad ha sido valorada con un 87,8% versus el 83.4% del resto de países analizados. El bloque de Impacto continúa siendo nuestra gran baza, con un 100% frente al 82.1% europeo. En esta dimensión continuamos posicionándonos como grandes líderes, gracias a una definición clara de reutilización, la medición sistemática del uso de datos y la existencia de ejemplos de impacto en los ámbitos gubernamental, social, ambiental y económico.
Aunque no se hayan producido grandes movimientos en la puntuación de estas dimensiones, el informe sí destaca hitos de España en todos los ámbitos. Por ejemplo, la plataforma datos.gob.es se sometió a un importante rediseño, que incluyó ajustes al perfil de metadatos DCAT-AP-ES, con el fin de mejorar la calidad e interoperabilidad. En este sentido, se publicó una guía de implementación específica y se consolidó una comunidad de aprendizaje y desarrollo a través de GitHub. Además, se mejoraron el motor de búsqueda y las herramientas de supervisión del portal, incluyendo el seguimiento de la reutilización externa a través de referencias de GitHub y análisis enriquecidos a través de cuadros de mando interactivos.
La implicación del sector infomediario ha sido clave a la hora de reforzar el liderazgo de España en datos abiertos. El informe destaca la importancia de actividades como el Encuentro Nacional de Datos Abiertos, con retos que se trabajan conjuntamente por parte de un equipo multidisciplinar con representantes de instituciones públicas, privadas y académicas, edición tras edición. A ello hay que sumar que la Federación Española de Municipios y Provincias identificó 80 conjuntos de datos esenciales en los que los gobiernos locales deben poner el foco a la hora de avanzar en la apertura de información, fomentando la coherencia y reutilización a nivel municipal.
La siguiente imagen muestra la puntuación específica de cada una de las subdimensiones analizadas:
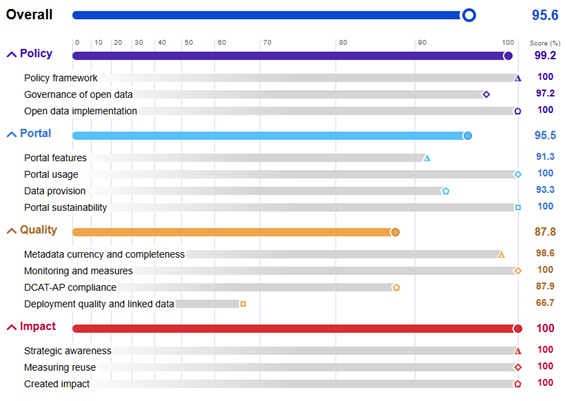
Figura 3. Puntuación de España en las distintas dimensiones y subcategorías.
Puedes ver el detalle del informe de España en la web del portal europeo.
Próximos pasos y retos comunes
El informe finaliza con una serie de recomendaciones concretas para cada grupo de países. Para el grupo de trendsetters, en el que se encuentra España, las recomendaciones no se centran tanto en alcanzar la madurez —ya lograda—, sino en profundizar y expandir su papel como referentes europeos. Algunas de las recomendaciones son:
- Consolidar ecosistemas temáticos (comunidades de proveedores y reutilizadores) y priorizar los datos de alto valor de forma sistemática.
- Alinear la acción local con la estrategia nacional, habilitando políticas “data-driven”.
- Cooperar con data.europa.eu y otros países para implementar y adaptar un marco de evaluación de impacto con métricas por dominios.
- Desarrollar perfiles de usuario y permitir sus contribuciones al portal nacional.
- Mejorar la calidad de datos y metadatos, y su localización, mediante herramientas de validación, inteligencia artificial y flujos centrados en el usuario.
- Aplicar estándares específicos de dominio para armonizar datasets y maximizar la interoperabilidad, calidad y reutilización.
- Ofrecer formación avanzada y certificada en normativa y alfabetización de datos.
- Colaborar internacionalmente en soluciones reutilizables, como software compartido u open source.
España ya trabaja en muchos de estos puntos para continuar mejorando su oferta de datos abiertos. El objetivo es que cada vez más reutilizadores puedan aprovechar de forma sencilla el potencial de la información pública para generar servicios y soluciones que generen un impacto positivo en toda la sociedad.
La posición alcanzada por España en este ranking europeo es fruto del trabajo de todas las iniciativas públicas, empresas, comunidades de usuarios y reutilizadores ligados a los datos abiertos, que impulsan un ecosistema que no deja de crecer. ¡Gracias por el esfuerzo!
Noticia
El pasado 19 de noviembre, la Comisión Europea presentó la Estrategia Unión de Datos (Data Union Strategy), una hoja de ruta que busca consolidar un ecosistema europeo de datos robusto, seguro y competitivo. Esta estrategia se articula en torno a tres pilares fundamentales: ampliar el acceso a datos de calidad para la inteligencia artificial y la innovación, simplificar el marco normativo existente, y proteger la soberanía digital europea. En este post, explicaremos en detalle cada uno de estos pilares, así como el calendario de implementación del plan previsto para los próximos dos años.
Pilar 1: ampliar el acceso a datos de calidad para la IA y la innovación
El primer pilar de la estrategia se centra en garantizar que empresas, investigadores y administraciones públicas tengan acceso a datos de alta calidad que permitan desarrollar aplicaciones innovadoras, especialmente en el ámbito de la inteligencia artificial. Para ello, la Comisión propone una serie de iniciativas interconectadas que abarcan desde la creación de infraestructuras hasta el desarrollo de estándares y facilitadores técnicos. Como parte de este pilar se establecen una serie de acciones: la ampliación de espacios comunes europeos de datos, el desarrollo de los data labs, el impulso del Cloud and AI Development Act, la ampliación de activos de datos estratégicos y la elaboración de facilitadores para implementar estas medidas.
1.1 Ampliación de los Espacios Comunes Europeos de Datos (CEDS)
Los Espacios Comunes Europeos de Datos constituyen uno de los elementos centrales de esta estrategia:
-
Inversión prevista: 100 millones de euros para su despliegue.
-
Sectores prioritarios: salud, movilidad, energía, administración pública (legal) y medio ambiente.
-
Interoperabilidad: se apuesta por SIMPL para la interoperabilidad entre espacios de datos con el apoyo del Centro Europeo de Competencia en Datos (DSSC, por sus siglas en inglés Data Spaces Support Center).
-
Aplicaciones clave:
-
Espacio Europeo de Datos de Salud (EHDS): mención especial por su función como puente entre los sistemas de datos de salud y el desarrollo de la IA.
-
Nuevo Espacio de Datos de Defensa: para el desarrollo de sistemas de última generación, coordinado por la Agencia Europea de Defensa.
-
1.2 Laboratorios de datos (Data Labs): el nuevo ecosistema para conectar datos y desarrollo de IA
La estrategia plantea utiliza Data Labs como puntos de conexión entre el desarrollo de inteligencia artificial y los datos europeos.
Estos laboratorios emplean el data pooling, un proceso de combinación y compartición de datos públicos y restringidos provenientes de múltiples fuentes en un repositorio centralizado o entorno compartido. Todo esto facilita el acceso y uso de información. En concreto, los servicios que ofrecen los Data Labs son:
-
Facilita el acceso a los datos.
-
Infraestructura técnica y herramientas.
-
Data pooling.
-
Filtrado de datos y etiquetado
-
Guía regulatoria y formación.
-
Reducción de la brecha entre los espacios de datos y los ecosistemas de IA.
Plan de implementación:
-
Primera fase: los primeros Data Labs se establecerán en el marco de las AI Factories (gigafactorías de IA), ofreciendo servicios de datos para conectar el desarrollo de IA con los espacios de datos europeos.
-
Data Labs sectoriales: se establecerán de forma independiente en otros ámbitos para cubrir necesidades específicas, por ejemplo, en el sector energético.
-
Modelo autosostenible: se prevé que el modelo de Data Labs pueda desplegarse comercialmente, convirtiéndolo en un ecosistema autosostenible que conecta datos e IA.
1.3 Cloud and AI Development Act: impulso a la nube soberana
Para el impulso de la tecnología de nube, la Comisión propondrá en el primer trimestre de 2026 este nuevo reglamento. Actualmente hay una consulta pública abierta en la que se puede participar aquí.
1.4 Activos de datos estratégicos: sector público, recursos científicos, culturales y lingüísticos
Por un lado, en 2026 se propondrá ampliar la lista de los datos de alto valor High value datasets en inglés o HVDS para incluir datos legales, judiciales y administrativos, entre otros. Y, por otro lado, la Comisión mapeará bases existentes y financiará nuevas infraestructuras digitales.
1.5 Facilitadores horizontales: datos sintéticos, data pooling y estándares
La Comisión Europea elaborará guías y estándares sobre datos sintéticos y se financiará I+D avanzada en técnicas para su generación de a través de Horizon Europe.
Otro tema que la UE quiere impulsar es el data pooling, como explicamos anteriormente. Compartir datos de etapas tempranas del ciclo productivo puede generar beneficios colectivos, pero persisten barreras por incertidumbre legal y temor a infringir normas de competencia. ¿Su propósito? Convertir el data pooling en una opción confiable y legalmente segura para acelerar avances en sectores críticos.
Finalmente, en materia de estandarización, se solicitará a las organizaciones europeas de normalización (CEN/CENELEC) el desarrollo de nuevos estándares técnicos en dos ámbitos clave: la calidad del dato y el etiquetado. Estos estándares permitirán establecer criterios comunes sobre cómo deben ser los datos para garantizar su fiabilidad y cómo deben etiquetarse para facilitar su identificación y uso en diferentes contextos.
Pilar 2: Simplificación Normativa
El segundo pilar aborda uno de los desafíos más señalados por empresas y organizaciones: la complejidad del marco regulatorio europeo en materia de datos. La estrategia propone una serie de medidas destinadas a simplificar y consolidar la legislación existente.
2.1 Derogaciones y consolidación normativa: hacia un marco más coherente
Se quieren eliminar normativas cuyas funciones ya están cubiertas por legislación más reciente, evitando así duplicidades y contradicciones. En primer lugar, se derogará el Reglamento de Libre Flujo de Datos no Personales (FFoNPD), ya que sus funciones están ahora cubiertas por la Data Act (Ley de Datos). No obstante, se preservará explícitamente la prohibición de localización injustificada de datos, un principio fundamental para el mercado único digital.
Del mismo modo, la Data Governance Act (Reglamento europeo de gobernanza de datos o DGA) será eliminada como norma independiente, migrando sus provisiones esenciales a la Data Act. Este movimiento simplifica el marco regulatorio y, además, alivia la carga administrativa: las obligaciones para los intermediarios de datos pasarán a ser más ligeras y de carácter voluntario.
En cuanto al sector público, la estrategia plantea una consolidación importante. Las normas sobre intercambio de datos públicos, actualmente dispersas entre la DGA y la Directiva de Datos Abiertos (Open Data Directive), se fusionarán en un único capítulo dentro de la Data Act. Esta unificación facilitará tanto la aplicación como la comprensión del marco legal por parte de las administraciones públicas.
2.2 Reforma de cookies: equilibrio entre protección y usabilidad
Otro detalle relevante es la regulación de cookies que experimentará una modernización significativa, integrándose en el marco del Reglamento General de Protección de Datos (RGPD). La reforma busca un equilibrio: por un lado, se legalizarán usos de bajo riesgo que actualmente generan incertidumbre legal; por otro, se simplificarán los banners de consentimiento mediante sistemas de "un solo clic" (one-click). El objetivo es claro: reducir la denominada "fatiga del usuario" ante las solicitudes repetitivas de consentimiento que todos conocemos al navegar por Internet.
2.3 Ajustes al RGPD para facilitar el desarrollo de IA
El Reglamento General de Protección de Datos también será objeto de una reforma focalizada, diseñada específicamente para liberar datos de forma responsable en beneficio del desarrollo de la inteligencia artificial. Esta intervención quirúrgica aborda tres aspectos concretos:
-
Aclara cuándo puede aplicarse el interés legítimo para el entrenamiento de modelos de IA.
-
Define con mayor precisión la distinción entre datos anónimos y seudonimizados, especialmente en relación con el riesgo de reidentificación.
-
Armoniza las evaluaciones de impacto en protección de datos, facilitando su aplicación coherente en toda la Unión.
2. 4 Implementación y Apoyo a la Data Act
La Data Act, recientemente aprobada, será objeto de ajustes para mejorar su aplicación. Por un lado, se refina el alcance del intercambio de datos de empresas a gobiernos (B2G), limitándolo estrictamente a situaciones de emergencia. Por otro lado, se amplía el paraguas de protección: las condiciones favorables que actualmente disfrutan las pequeñas y medianas empresas (PYMES) se extenderán también a las empresas medianas o small mid-caps, aquellas que tienen entre 250 y 749 empleados.
Para facilitar la implementación práctica de la norma, ya se ha publicado un modelo de cláusulas contractuales tipo para el intercambio de datos, proporcionando así una plantilla que las organizaciones pueden utilizar directamente. Además, durante el primer trimestre de 2026 se publicarán dos guías adicionales: una sobre el concepto de "compensación razonable" en los intercambios de datos, y otra destinada a clarificar las definiciones clave de la Data Act que puedan generar dudas interpretativas.
Consciente de que las PYMES pueden tener dificultades para navegar este nuevo marco legal, se creará un Helpdesk Legal en el cuarto trimestre de 2025. Este servicio de asistencia ofrecerá asesoramiento directo sobre la aplicación de la Data Act, dando prioridad precisamente a las pequeñas y medianas empresas que carecen de departamentos jurídicos especializados.
2.5 Evolución de la gobernanza: hacia un ecosistema más coordinado
La arquitectura de gobernanza del ecosistema europeo de datos también experimenta cambios significativos. El European Data Innovation Board (EDIB) evoluciona desde un órgano principalmente consultivo hacia un foro de debates más técnicos y estratégicos, incorporando tanto a los Estados miembros como a representantes de la industria. Para ello, se modificará su articulado con dos objetivos: permitir la inclusión en los debates de las autoridades competentes en materia de Data Act, y dotar de mayor flexibilidad a la Comisión Europea en la composición y funcionamiento del organismo.
Complementariamente, se articulan dos mecanismos adicionales de retroalimentación y anticipación. La Apply AI Alliance canalizará el feedback sectorial, recogiendo las experiencias y necesidades específicas de cada industria. Por su parte, el AI Observatory actuará como radar de tendencias, identificando desarrollos emergentes en el ámbito de la inteligencia artificial y traduciéndolos en recomendaciones de políticas públicas. De este modo, se cierra un círculo virtuoso donde la política se nutre constantemente de la realidad del terreno.
Pilar 3: Protección de la soberanía del dato europeo
El tercer pilar se centra en garantizar que los datos europeos reciban un trato justo y seguro, tanto dentro como fuera de las fronteras de la Unión. La intención es que solo se compartan datos con países de la misma visión regulatoria.
3.1 Medidas específicas para proteger los datos europeos
-
Publicación de guías para evaluar el trato justo de datos de la UE en el extranjero (segundo trimestre 2026):
-
Publicación de toolbox contra prácticas injustas (segundo trimestre 2026):
-
La localización injustificada.
-
La exclusión.
-
Las salvaguardas débiles.
-
La fuga de datos.
-
-
Adopción de medidas para proteger los datos no personales sensibles.
Todas estas medidas se plantean implementar desde el último cuatrimestre de 2025 y durante todo 2026 en un despliegue progresivo que permitirá una adopción gradual y coordinada de las diferentes medidas, tal y como establece la Data Union Strategy.
En resumen, la Estrategia Unión de Datos representa un esfuerzo integral por consolidar el liderazgo europeo en la economía del dato. Para ello se impulsará el data pooling y los espacios de datos de los Estados miembro, se apostará por los Data Labs y las gigafactorías de IA y se incentivará la simplificación normativa.
Noticia
El portal europeo de datos abiertos ha publicado el tercer volumen de su Observatorio de Casos de Uso (Use Case Observatory, en inglés), un informe que recopila la evolución de proyectos de reutilización de datos en toda Europa. Esta iniciativa pone de relieve los avances logrados en cuatro áreas: impacto económico, gubernamental, social y medioambiental.
El cierre de una investigación de tres años
Entre 2022 y 2025, el portal europeo de datos abiertos ha llevado a cabo un seguimiento sistemático de la evolución de diversos proyectos europeos. La investigación comenzó con una selección inicial de 30 iniciativas representativas, que fueron analizadas en profundidad para identificar su potencial de impacto.
Tras dos años, 13 proyectos continuaron en el estudio, entre los que se encontraban tres españoles: Planttes, Tangible Data y UniversiDATA-Lab. Se estudió su desarrollo a lo largo del tiempo para comprender cómo la reutilización de datos abiertos puede generar beneficios reales y sostenibles.
La publicación del volumen III en octubre de 2025 marca el cierre de esta serie de informes, tras el volumen I (2022) y el volumen II (2024). Este último documento ofrece una visión longitudinal, mostrando cómo los proyectos han madurado en tres años de observación y qué impactos concretos han generado en sus respectivos contextos.
Conclusiones comunes
Este tercer y último informe recopila una serie de conclusiones clave:
Impacto económico
Los datos abiertos impulsan el crecimiento y la eficiencia en todos los sectores. Contribuyen a la creación de empleo, tanto de forma directa como indirecta, facilitan procesos de contratación más inteligentes y estimulan la innovación en ámbitos como la planificación urbana y los servicios digitales.
El informe muestra el ejemplo de:
- Naar Jobs (Bélgica): una aplicación para la búsqueda de empleo cerca del domicilio de los usuarios y focalizada en las opciones de transporte disponible.
Esta aplicación demuestra cómo los datos abiertos pueden convertirse en un motor para el empleo regional y el desarrollo empresarial.
Impacto gubernamental
La apertura de datos fortalece la transparencia, la rendición de cuentas y la participación ciudadana.
A este campo pertenecen dos casos de uso analizados:
- Waar is mijn stemlokaal? (Holanda): plataforma para la búsqueda de colegios electorales.
- Statsregnskapet.no (Noruega): web para visualizar los ingresos y gastos del gobierno.
Ambos ejemplos evidencian cómo el acceso a la información pública empodera a los ciudadanos, enriquece el trabajo de los medios de comunicación y respalda la elaboración de políticas basadas en evidencia. Todo ello ayuda a reforzar los procesos democráticos y la confianza en las instituciones.
Impacto social
Los datos abiertos promueven la inclusión, la colaboración y el bienestar.
A este campo pertenecen las siguientes iniciativas analizadas:
- UniversiDATA-Lab (España): repositorio de datos universitarios que facilita aplicaciones analíticas.
- VisImE-360 (Italia): herramienta para mapear la discapacidad visual y orientar recursos sanitarios.
- Tangible Data (España): empresa centrada en realizar esculturas físicas que convierten datos en experiencias accesibles.
- EU Twinnings (Países Bajos): plataforma que compara regiones europeas para encontrar “ciudades gemelas”
- Open Food Facts (Francia): base de datos colaborativa sobre productos alimenticios.
- Integreat (Alemania): aplicación que centraliza información pública para apoyar la integración de migrantes.
Todos ellos muestran cómo las soluciones basadas en datos pueden amplificar la voz de los colectivos vulnerables, mejorar los resultados en salud y abrir nuevas oportunidades educativas. Incluso los efectos más pequeños, como la mejora en la vida de una sola persona, pueden resultar significativos y duraderos.
Impacto medioambiental
Los datos abiertos actúan como un poderoso facilitador de la sostenibilidad.
Al igual que pasaba con el impacto ambiental, en esta área encontramos un gran número de casos de uso:
- Digital Forest Dryads (Estonia): proyecto que emplea datos para monitorizar los bosques y fomentar su conservación.
- Air Quality in Cyprus (Chipre): plataforma que informa sobre la calidad del aire y apoya políticas ambientales.
- Planttes (España): aplicación de ciencia ciudadana que ayuda a personas con alergias al polen mediante el seguimiento de la fenología de plantas.
- Environ-Mate (Irlanda): herramienta que promueve hábitos sostenibles y conciencia ecológica.
Estas iniciativas ponen de relieve cómo la reutilización de datos contribuye a sensibilizar, impulsar cambios de comportamiento y permitir intervenciones específicas para proteger los ecosistemas y fortalecer la resiliencia climática.
El volumen III también señala retos comunes: la necesidad de financiación sostenible, la importancia de combinar datos institucionales con datos generados por la ciudadanía y la conveniencia de involucrar a los usuarios finales en todo el ciclo de vida de los proyectos. Además, subraya la importancia de la colaboración europea y la interoperabilidad transnacional para escalar el impacto.
En conjunto, el informe refuerza la relevancia de seguir invirtiendo en ecosistemas de datos abiertos como herramienta clave para afrontar desafíos sociales y promover una transformación inclusiva.
El impacto de los proyectos españoles en la reutilización de datos abiertos
Como hemos mencionado, tres de los casos de uso analizados en el Use Case Observatory tienen sello español. Estas iniciativas destacan por su capacidad de combinar innovación tecnológica con impacto social y medioambiental, y ponen de manifiesto la relevancia de España dentro del ecosistema europeo de datos abiertos. Su trayectoria demuestra cómo nuestro país contribuye activamente a transformar los datos en soluciones que mejoran la vida de las personas y refuerzan la sostenibilidad y la inclusión. A continuación, hacemos un zoom en lo que el informe dice sobre ellas.
Esta iniciativa de ciencia ciudadana ayuda a personas con alergias al polen mediante información en tiempo real sobre plantas alergénicas en floración. Desde su aparición en el Volumen I del Use Case Observatory, ha evolucionado como plataforma participativa en la que los usuarios aportan fotos y datos fenológicos para crear un mapa de riesgo personalizado. Este modelo participativo ha permitido mantener un flujo constante de información validada por investigadores y ofrecer mapas cada vez más completos. Con más de 1.000 descargas iniciales y unos 65.000 visitantes anuales en su web, es una herramienta útil para personas con alergias, educadores e investigadores.
El proyecto ha reforzado su presencia digital, con una creciente visibilidad gracias al apoyo de instituciones como la Universidad Autónoma de Barcelona y la Universidad de Granada, además de la promoción realizada por la empresa Thigis.
Entre sus retos figuran ampliar la cobertura geográfica más allá de Cataluña y Granada y sostener la participación y validación de datos. Por ello, de cara al futuro, busca extender su alcance territorial, fortalecer la colaboración con escuelas y comunidades, integrar más datos en tiempo real y mejorar sus capacidades predictivas.
A lo largo de este tiempo, Planttes se ha consolidado como un ejemplo de cómo la ciencia impulsada por la ciudadanía puede mejorar la salud pública y la conciencia ambiental, demostrando el valor de la ciencia ciudadana en la educación ambiental, la gestión de alergias y el seguimiento del cambio climático.
El proyecto transforma conjuntos de datos en esculturas físicas que representan retos globales como el cambio climático o la pobreza, integrando códigos QR y NFC para contextualizar la información. Reconocido en los EU Open Data Days 2025, Tangible Data ha inaugurado su instalación Tangible climate en el Museo Nacional de Ciencias Naturales de Madrid.
Tangible Data ha evolucionado en tres años desde un proyecto prototipo basado en esculturas 3D para visualizar datos de sostenibilidad hasta convertirse en una plataforma educativa y cultural que conecta los datos abiertos con la sociedad. El Volumen III del Use Case Observatory refleja su expansión en escuelas y museos, la creación de un programa educativo para estudiantes de 15 años y el desarrollo de experiencias interactivas con inteligencia artificial, consolidando su compromiso con la accesibilidad y el impacto social.
Entre sus retos destacan la financiación y la ampliación del programa educativo, mientras que sus objetivos futuros incluyen escalar las actividades escolares, exhibir esculturas de gran formato en espacios públicos y reforzar la colaboración con artistas y museos. En conjunto, sigue fiel a su misión de hacer los datos tangibles, inclusivos y accionables.
UniversiDATA-Lab es un repositorio dinámico de aplicaciones analíticas basadas en datos abiertos de universidades españolas, creado en 2020 como colaboración público-privada y actualmente integrado por seis instituciones. Su infraestructura unificada facilita la publicación y reutilización de datos en formatos estandarizados, reduciendo barreras y permitiendo que estudiantes, investigadores, empresas y ciudadanos accedan a información útil para la educación, la investigación y la toma de decisiones.
En los últimos tres años, el proyecto ha pasado de ser un prototipo a una plataforma consolidada, con aplicaciones activas como el visor de presupuestos y de jubilaciones, y un visor de contratación en fase beta. Además, organiza un datathon periódico que impulsa la innovación y proyectos con impacto social.
Entre sus retos destacan la resistencia interna en algunas universidades y la compleja anonimización de datos sensibles, aunque ha respondido con protocolos sólidos y un enfoque en la transparencia. De cara al futuro, busca ampliar su catálogo, sumar nuevas universidades y lanzar aplicaciones sobre cuestiones emergentes como abandono escolar, diversidad del profesorado o sostenibilidad, aspirando a convertirse en referente europeo en reutilización de datos abiertos en educación superior.
Conclusión
Como conclusión, el tercer volumen del Use Case Observatory confirma que los datos abiertos se han consolidado como una herramienta clave para impulsar la innovación, la transparencia y la sostenibilidad en Europa. Los proyectos analizados —y en particular las iniciativas españolas Planttes, Tangible Data y UniversiDATA-Lab— demuestran que la reutilización de la información pública puede traducirse en beneficios concretos para la ciudadanía, la educación, la investigación y el medio ambiente.
Noticia
¿Sabías que menos de dos de cada diez empresas europeas utilizan inteligencia artificial (IA) en sus operaciones? Este dato, correspondiente a 2024, revela el margen de mejora que existe en la adopción de esta tecnología. Para revertir esta situación y aprovechar el potencial transformador de la IA, la Unión Europea ha diseñado un marco estratégico integral que combina inversión en infraestructuras de computación, acceso a datos de calidad y medidas específicas para sectores clave como la sanidad, la movilidad o la energía.
En este artículo te explicamos las principales estrategias europeas en esta materia, con especial atención a la Apply AI Strategy (Estrategia Aplicar IA) o el AI Continent Action Plan (Plan de Acción del Continente de IA) adoptadas este año en octubre y abril respectivamente. Además, te contaremos cómo estas iniciativas se complementan con otras estrategias europeas para crear un ecosistema integral de innovación.
Contexto: plan de acción y sectores estratégicos
Por un lado, el AI Continent Action Plan establece cinco pilares estratégicos:
- Infraestructuras de computación: escalar la capacidad de computación mediante AI Factories, AI Gigafactories y el Cloud and AI Act, en concreto:
- AI factories: se impulsarán las infraestructuras para entrenar y mejorar modelos de inteligencia artificial. Este eje estratégico cuenta con un presupuesto de 10.000 millones de euros y se espera que dé lugar a, al menos, 13 fábricas de IA para 2026.
- AI gigafactories: también se tendrán en cuenta las infraestructuras necesarias para entrenar y desarrollar modelos complejos de IA, cuatriplicando la capacidad de las AI factories. En este caso se invierten 20.000 millones de euros para el desarrollo de 5 giga fábricas.
- Cloud and AI Act: se trabaja en un marco regulatorio para impulsar la investigación en infraestructuras altamente sostenibles, fomentar inversiones y triplicar la capacidad de los centros de datos de la UE en los próximos cinco a siete años.
- Acceso a datos de calidad: facilitar el acceso a conjuntos de datos robustos y bien organizados a través de los conocidos como Data Labs en las AI Factories.
- Talento y competencias: reforzar las habilidades en IA en toda la población, en concreto:
- Crear acuerdos de colaboración internacional.
- Ofrecer becas en IA para los mejores estudiantes, investigadores y profesionales del sector.
- Promover las habilidades en estas tecnologías a través de una academia específica.
- Testear un grado específico en IA generativa.
- Apoyar la actualización formativa a través del hub de innovación digital europeo.
- Desarrollo y adopción de algoritmos: impulsar el uso de inteligencia artificial en sectores estratégicos.
- Marco regulatorio: facilitar el cumplimiento del Reglamento de IA de manera sencilla e innovadora y proporcionar herramientas gratuitas y adaptables para las empresas.
Por otro lado, la recientemente presentada, en octubre de 2025, Apply AI Strategy busca potenciar la competitividad de los sectores estratégicos y fortalecer la soberanía tecnológica de la UE, impulsando la adopción y la innovación en IA en toda Europa, particularmente entre las pequeñas y medianas empresas. ¿De qué manera? La estrategia promueve una política de "IA primero" (AI first), que anima a las organizaciones a considerar la inteligencia artificial como solución potencial cada vez que tomen decisiones estratégicas o políticas, evaluando cuidadosamente tanto los beneficios como los riesgos de la tecnología. Además, fomenta un enfoque de compra europeo, es decir, que las organizaciones, particularmente las administraciones públicas, prioricen soluciones desarrolladas en Europa. Es más, se les da especial importancia a las soluciones de IA de código abierto (open source), porque ofrecen mayor transparencia y posibilidad de adaptación, menor dependencia de proveedores externos y se alinean con los valores europeos de apertura e innovación compartida.
La Apply AI Strategy se estructura en tres secciones principales:
1. Iniciativas sectoriales emblemáticas
La estrategia identifica 11 ámbitos prioritarios donde la IA puede generar mayor impacto y donde Europa tiene fortalezas competitivas:
- Sanidad y sector farmacéutico: se establecerán centros europeos avanzados de detección impulsados por IA para acelerar la introducción de herramientas innovadoras de prevención y diagnóstico, con especial atención a enfermedades cardiovasculares y cáncer.
- Robótica: se impulsará la adopción para la adopción de robótica europea que conecte desarrolladores e industrias usuarias, impulsando soluciones de robótica potenciada por IA.
- Fabricación, ingeniería y construcción: se apoyará el desarrollo de modelos de IA de vanguardia adaptados a la industria, facilitando la creación de gemelos digitales y optimización de procesos productivos.
- Defensa, seguridad y espacio: se acelerará el desarrollo de capacidades europeas de conocimiento situacional y control habilitadas por IA, además de infraestructura de computación altamente segura para modelos de IA de defensa y espacio.
- Movilidad, transporte y automoción: se lanzará la iniciativa "Autonomous Drive Ambition Cities" para acelerar el despliegue de vehículos autónomos en ciudades europeas.
- Comunicaciones electrónicas: se creará una plataforma europea de IA para telecomunicaciones que permitirá a operadores, proveedores e industrias usuarias colaborar en el desarrollo de elementos tecnológicos de código abierto.
- Energía: se apoyará el desarrollo de modelos de IA para mejorar la previsión, optimización y equilibrio del sistema energético.
- Clima y medio ambiente: se desplegará un modelo de IA de código abierto del sistema terrestre y aplicaciones relacionadas que permitan mejores previsiones meteorológicas, monitoreo de la Tierra y escenarios hipotéticos.
- Agroalimentario: se fomentará la creación de una plataforma de IA agroalimentaria que facilite la adopción de herramientas agrícolas habilitadas por esta tecnología.
- Sectores culturales y creativos, y medios: se incentivará el desarrollo de microestudios especializados en producción virtual mejorada con IA y plataformas paneuropeas que utilicen tecnologías de IA multilingüe.
- Sector público: se construirá una guía de herramientas de IA dedicada a las administraciones públicas con un repositorio compartido de buenas prácticas, de código abierto y reutilizables, y se acelerará la adopción de soluciones de IA generativa escalables.
2. Medidas transversales de apoyo
Para que la adopción de la inteligencia artificial sea efectiva, la estrategia aborda desafíos comunes a todos los sectores, en concreto:
- Oportunidades para las pymes europeas: los más de 250 European Digital Innovation Hubs (centros europeos de innovación digital) han sido transformados en Centros de Experiencia en IA. Estos centros actúan como puntos de acceso privilegiados al ecosistema europeo de innovación en inteligencia artificial, conectando a las empresas con las AI Factories, los laboratorios de datos y las instalaciones de prueba.
- Fuerza laboral preparada para la IA: se proporcionará acceso a formaciones prácticas en alfabetización en esta materia, adaptadas a sectores y perfiles profesionales a través de la Academia de Competencias en IA.
- Apoyo al desarrollo de IA avanzada: la iniciativa Frontier AI Iniciative busca acelerar el progreso en capacidades de IA de vanguardia en Europa. A través de este proyecto se crearán concursos para desarrollar modelos de inteligencia artificial avanzados de código abierto, que estarán disponibles para administraciones públicas, la comunidad científica y el sector empresarial europeo.
- Confianza en el mercado europeo: se reforzará la divulgación para garantizar el cumplimiento del Reglamento de IA de la Unión Europea, proporcionando directrices sobre la clasificación de sistemas de alto riesgo y sobre la interacción del Reglamento con otra legislación sectorial.
3. Nuevo sistema de gobernanza
En este contexto, es especialmente importante asegurar una correcta coordinación de la estrategia. Por lo tanto, se plantea lo siguiente:
- Apply AI Alliance: la Alianza de IA, que ya existía, se transforma en el foro principal de coordinación que reúne a proveedores de IA, líderes industriales, el mundo académico y el sector público. Los grupos sectoriales específicos permitirán discutir y monitorear la implementación de la estrategia.
- AI Observatory: se establecerá un Observatorio de IA para proporcionar indicadores robustos que evalúen su impacto en los sectores actualmente listados y futuros, monitorear desarrollos y tendencias.
Estrategias complementarias: ciencia y datos como ejes principales
La Apply AI Strategy no actúa de forma aislada, sino que se complementa con otras dos estrategias fundamentales: la estrategia de IA en ciencia (AI in Science Strategy) y la estrategia de unión de los datos (Data Union Strategy).
AI in Science Strategy
Presentada junto con la Apply AI Strategy, esta estrategia apoya e incentiva el desarrollo y uso de la inteligencia artificial por parte de la comunidad científica europea. Su elemento central es RAISE (Resource for AI Science in Europe), que se ha presentado en noviembre el AI in Science Summit y agrupará recursos estratégicos: financiación, capacidad de computación, datos y talento. RAISE operará en dos pilares: Ciencia para la IA (investigación básica para avanzar en capacidades fundamentales) y IA en la Ciencia (uso de inteligencia artificial para el progreso en diferentes disciplinas científicas).
Data Union Strategy
Esta estrategia se centrará en garantizar la disponibilidad de conjuntos de datos de alta calidad y a gran escala, esenciales para entrenar modelos de IA. Un elemento clave serán los Data Labs asociados a las AI Factories, que reunirán y federarán datos de diferentes sectores, vinculándose con los Espacios Europeos Comunes de Datos correspondientes, poniéndolos a disposición de desarrolladores bajo las condiciones apropiadas.
En resumen, a través de inversiones significativas en infraestructura, acceso a datos de calidad, desarrollo de talento y un marco regulatorio que promueve la innovación responsable, la Unión Europea está creando las condiciones necesarias para que empresas, administraciones públicas y ciudadanos aprovechen todo el potencial transformador de la inteligencia artificial. El éxito de estas estrategias dependerá de la colaboración entre instituciones europeas, gobiernos nacionales, empresas, investigadores y desarrolladores.