Blog
Hay una idea que se repite en casi cualquier iniciativa de datos: “si conectamos fuentes distintas, sacaremos más valor”. Y suele ser verdad. El matiz es que el valor aparece cuando podemos combinar datos sin fricción, sin malentendidos y sin sorpresas. El Decálogo del reutilizador de datos del sector público lo resume muy bien: la interoperabilidad es especialmente crítica justo cuando intentamos mezclar datos de diversas fuentes, que es donde los datos abiertos suelen aportar más.
En la práctica, la interoperabilidad no es solo “que haya una API” o “que el fichero sea descargable”. Es un concepto más amplio, con varias capas: si solo cuidamos una, las demás acaban rompiendo la reutilización. Conectamos… pero no entendemos qué significa cada campo. Entendemos… pero no hay estabilidad ni versionado. Hay estabilidad… pero no existe un proceso común para resolver incidencias. Y, aun teniendo todo lo anterior, pueden faltar reglas claras de uso. Por eso, también es un error pensar que la interoperabilidad es un problema puramente informático que se arregla “comprando el software adecuado”: la tecnología es solo la punta del iceberg. Si queremos que los datos fluyan de verdad entre administración pública, empresa y centros de investigación, necesitamos una visión holística.
Y aquí viene la buena noticia: se puede abordar de forma incremental, paso a paso. Para hacerlo bien, lo primero es aclarar qué tipo de interoperabilidad estamos buscando en cada caso, porque no todas las barreras son técnicas ni se resuelven del mismo modo.
En este post vamos a desglosar los distintos tipos de interoperabilidad que existen, para identificar qué aporta cada uno y qué falla cuando lo dejamos fuera.
Los distintos tipos de interoperabilidad
Siguiendo el Marco Europeo de Interoperabilidad (EIF), conviene pensar la interoperabilidad como un edificio con cuatro principales capas: técnica, semántica, organizativa y jurídica. Si una falla, el conjunto se resiente.
A continuación, unificamos las cuatro capas con un enfoque centrado en datos, incluyendo ejemplos aplicados a distintos sectores.
1. Interoperabilidad técnica: que los sistemas puedan intercambiar datos
Es la capa “visible”: infraestructuras, protocolos y mecanismos para enviar/recibir datos de forma fiable.
Pero, ¿qué implica en la práctica?
-
Formatos legibles por máquina: como CSV, JSON, XML, RDF, evitando los documentos solo para lectura humana (como PDF).
-
API y endpoints estables: con documentación, autenticación cuando aplique y versionado.
-
Requisitos no funcionales: disponibilidad, rendimiento, seguridad y trazabilidad técnica.
¿Cuáles son los errores o fallos típicos que generan problemas?
En el caso específico de la interoperabilidad técnica, estos vienen principalmente originados por cambios “silenciosos”, como, por ejemplo, que se alteren columnas y/o estructura y se rompan integraciones, o que haya URL no persistentes, API sin versionado o sin documentación.
Ejemplo: vamos a aterrizarlo a un caso concreto para el dominio de la movilidad
Imaginemos que un ayuntamiento publica en tiempo real la ocupación de aparcamientos. Si la API cambia el nombre de un campo o el endpoint sin avisar, las apps de navegación dejan de mostrar plazas disponibles, aunque “el dato exista”. El problema es técnico: falta estabilidad, versionado y contrato de interfaz.
2. Interoperabilidad semántica: que, además, se entiendan entre sí
Si la interoperabilidad técnica es “las tuberías”, la semántica es el idioma. Podemos tener sistemas perfectamente conectados y, aun así, obtener resultados desastrosos si cada parte interpreta los datos de forma distinta.
Pero, ¿qué implica en la práctica?
-
Glosarios de términos claros: definición de cada campo, unidad, formato, rango, reglas de negocio, granularidad y ejemplos.
-
Vocabularios controlados, taxonomías y ontologías para clasificar y codificar valores sin ambigüedad.
-
Identificadores unívocos y referencias normalizadas a través de datos de referencia con códigos oficiales, catálogos comunes, etc.
¿Cuáles son los errores o fallos típicos que generan problemas?
Normalmente aparecen cuando hay ambigüedad (por ejemplo, si solo pone fecha, no sabemos si es la fecha de registro, publicación o efecto), unidades distintas (por ejemplo, no se conoce la unidad de medida del dato: kWh vs MWh, euros vs miles de euros), códigos incompatibles (H/M vs 1/2 vs masculino/femenino) o incluso cambios de significado en series históricas sin explicarlo.
Ejemplo: vamos a aterrizarlo a un caso concreto en el sector energía
Una administración publica datos de consumo eléctrico por edificios. Un reutilizador cruza esos datos con otro dataset regional, pero uno está en kWh y el otro en MWh, o uno mide consumo “final” y el otro “bruto”. El cruce “cuadra” técnicamente, pero las conclusiones salen mal porque falta semántica: definiciones y unidades compartidas.
3. Interoperabilidad organizativa: que los procesos sostengan la coherencia
Aquí hablamos menos de sistemas y más de personas, responsabilidades y procesos. Los datos no se mantienen solos: se publican, se actualizan, se corrigen y se explican porque hay una organización detrás que lo hace posible.
Pero, ¿qué implica en la práctica?
-
Roles y responsabilidades claras: quién define, quién valida, quién publica, quién mantiene y quién responde ante incidencias.
-
Gestión de cambios: qué es un cambio mayor/menor, cómo se versiona, cómo se comunica y si se conserva el histórico.
-
Gestión de incidencias: canal único, tiempos de respuesta, priorización, trazabilidad y cierre.
-
Compromisos operativos (tipo acuerdos de nivel de servicio o SLA en sus siglas en inglés): frecuencia de actualización, ventanas de mantenimiento, criterios de calidad y revisiones periódicas.
Aquí pueden ayudarnos, por ejemplo, las especificaciones UNE sobre gobierno y gestión del dato donde se dan las claves para establecer modelos organizativos, roles, procesos de gestión y mejora continua. Por lo tanto, encajan precisamente en esta capa: ayudan a que publicar y compartir datos no dependa del “esfuerzo heroico” de un equipo, sino de un modo de trabajo estable en el que el equipo vaya madurando.
¿Cuáles son los errores o fallos típicos que generan problemas?
Los clásicos: “cada unidad publica a su manera”, no hay responsable claro, no existe un circuito para corregir errores, se actualiza sin avisar, no se conserva histórico o el feedback del reutilizador se pierde en un buzón genérico sin seguimiento.
Ejemplo: vamos a aterrizarlo a un caso concreto en medio ambiente
Una confederación publica datos de calidad del agua y varias unidades aportan mediciones. Si no hay un proceso común de validación, un calendario coordinado y un canal de incidencias, el dataset empieza a tener valores inconsistentes, lagunas y correcciones tardías. El problema no es la API ni el formato: es organizativo, porque el mantenimiento no está gobernado.
4. Interoperabilidad jurídica: que el intercambio sea viable y conforme
Esta es la capa que convierte el intercambio en algo seguro y escalable. Puedes tener datos perfectos a nivel técnico, semántico y organizativo… y aun así, no poder reutilizarlos si no hay claridad jurídica.
Pero, ¿qué implica en la práctica?
-
Licencia y condiciones de uso claras: atribución, redistribución, uso comercial, obligaciones, etc.
-
Compatibilidad entre licencias cuando se mezclan fuentes: evitando combinaciones inviables.
-
Cumplimiento de protección de datos: como el Reglamento General de Protección de Datos (RGPD), propiedad intelectual, secretos empresariales o límites sectoriales.
-
Reglas explícitas sobre qué se puede hacer y qué no: indicando también con qué requisitos.
¿Cuáles son los errores o fallos típicos que generan problemas?
La “jungla” clásica: licencias ausentes o ambiguas, condiciones contradictorias entre datasets, dudas sobre si hay datos personales o riesgo de reidentificación, o restricciones que se descubren cuando el proyecto ya está avanzado.
Ejemplo: vamos a aterrizarlo a un caso concreto en cultura y patrimonio
Un archivo público publica imágenes y metadatos de una colección. Técnicamente todo está bien, y los metadatos son ricos, pero la licencia es confusa o incompatible con otros datos que se quieren cruzar (por ejemplo, un repositorio privado con restricciones). Resultado: una empresa o una universidad decide no reutilizar por inseguridad jurídica. El bloqueo no es técnico: es jurídico.
En resumen, la interoperabilidad funciona como un “pack” de cuatro capas: conectar (técnica), entender lo mismo (semántica), mantenerlo de forma sostenida (organizativa) y poder reutilizar sin riesgo (jurídica).
Para verlo de un vistazo y con ejemplos reales, la siguiente infografía resume cómo se materializa cada capa en distintos sectores (estándares, modelos, prácticas y marcos normativos) y qué piezas suelen usarse como referencia en cada caso.
 Figura 1. Infografía: "Interoperabilidad: la clave para trabajar con datos de diversas fuentes". Versión accesible disponible aquí. Fuente: elaboración propia - datos.gob.es.
Figura 1. Infografía: "Interoperabilidad: la clave para trabajar con datos de diversas fuentes". Versión accesible disponible aquí. Fuente: elaboración propia - datos.gob.es.
La infografía anterior deja una idea clara: la interoperabilidad no depende de una sola decisión, sino de combinar estándares, acuerdos y reglas que cambian según el sector. A partir de aquí, tiene sentido bajar un nivel y ver qué referencias y herramientas se usan en España y en Europa para que esas cuatro capas (técnica, semántica, organizativa y jurídica) no se queden en teoría.
Una referencia práctica en España: NTI-RISP (y por qué tiene sentido citarla)
En el contexto español, la NTI-RISP es una guía muy útil porque pone negro sobre blanco qué hay que cuidar cuando publicamos información para que otros la puedan reutilizar: identificación, descripción (metadatos), formatos y términos de uso, entre otros aspectos.
Metadatos como pegamento: DCAT-AP y DCAT-AP-ES
En datos abiertos, donde más se nota la interoperabilidad “en el día a día” es en los catálogos: si los conjuntos de datos no se describen de forma coherente, cuesta encontrarlos, entenderlos y federarlos.
-
DCAT-AP aporta un modelo común de metadatos para catálogos de datos en Europa, apoyándose en vocabularios ampliamente reutilizados.
-
En España, DCAT-AP-ES se impulsa precisamente para reforzar esa interoperabilidad de catálogos con un perfil común que facilite intercambio y federación entre portales.
Cómo abordar la interoperabilidad sin morir de ambición
En lugar de “arreglarla de golpe”, suele funcionar mejor tratar la interoperabilidad como mejora continua porque se rompe con cambios en tecnología, organización o normativa. Un enfoque sencillo y realista:
-
Empieza por el “para qué”: ¿Quieres integrar en un servicio, cruzar para análisis, construir indicadores comparables, enriquecer entidades…? El objetivo determina el nivel de rigor necesario.
-
Asegura el mínimo técnico estable: acceso y formatos legibles por máquina, identificadores persistentes, documentación mínima, y algún versionado (aunque sea básico). Esto evita datasets “útiles hoy” que se rompen mañana.
-
Aplica semántica donde duele (principio de Pareto: 80/20 - establece que el 80% de los resultados provienen del 20% de las causas o acciones-): define muy bien los campos críticos (los que se cruzan/filtran), unidades, tablas de códigos y el significado exacto de fechas/estados. No hace falta “modelarlo todo” para reducir la mayoría de los errores.
-
Pon acuerdos operativos mínimos: quién mantiene, cuándo se actualiza, cómo se reportan incidencias, cómo se anuncian cambios y si se conserva el histórico. Aquí es donde un enfoque de gobierno del dato (y guías como NTI-RISP) marca la diferencia entre “dataset publicado” y “dataset sostenible”.
-
Pilota con un cruce real: un piloto pequeño detecta rápido si el problema era técnico, semántico, organizativo o jurídico, y te da una lista concreta de fricciones a eliminar.
Como conclusión, la interoperabilidad no es simplemente “tener una API”: es el resultado de alinear cuatro capas —técnica, semántica, organizativa y jurídica— para poder combinar datos sin fricción, sin malentendidos y con seguridad. Cada capa resuelve un problema distinto: la técnica evita roturas de integración, la semántica evita interpretaciones erróneas, la organizativa hace sostenible la publicación y el mantenimiento en el tiempo, y la jurídica elimina la inseguridad sobre qué se puede hacer con los datos.
En ese contexto, los marcos y estándares sectoriales actúan como atajos prácticos para acelerar acuerdos y reducir ambigüedad, y por eso es útil ver ejemplos por sectores. Además, los metadatos y los catálogos interoperables son un auténtico multiplicador: cuando un conjunto de datos está bien descrito, se encuentra antes, se entiende mejor y se puede federar con menos coste. Por último, lo más efectivo suele ser un enfoque incremental y medible: empezar por el “para qué”, asegurar estabilidad técnica, reforzar la semántica crítica (80/20), formalizar acuerdos operativos mínimos y validar con un cruce real, en lugar de intentar “solucionar la interoperabilidad” como un único proyecto cerrado.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
Las ciudades, las infraestructuras y el medio ambiente generan hoy un flujo constante de datos procedentes de sensores, redes de transporte, estaciones meteorológicas y plataformas de Internet of Things (IoT), entendidas como redes de dispositivos físicos (semáforos digitales, sensores de calidad de aire, etc.) capaces de medir y transmitir información a través de sistemas digitales. Este volumen creciente de información permite mejorar la prestación de servicios públicos, anticipar emergencias, planificar el territorio y responder a retos asociados al clima, la movilidad o la gestión de recursos.
El incremento de fuentes conectadas ha transformado la naturaleza del dato geoespacial. Frente a los conjuntos tradicionales —actualizados de forma periódica y orientados a cartografía de referencia o inventarios administrativos— los datos dinámicos incorporan la dimensión temporal como componente estructural. Una observación de calidad del aire, un nivel de ocupación de tráfico o una medición hidrológica no solo describen un fenómeno, sino que lo sitúan en un momento concreto. La combinación espacio-tiempo convierte a estas observaciones en elementos fundamentales para sistemas operativos, modelos predictivos y análisis basados en series temporales.
En el ámbito de los datos abiertos, este tipo de información plantea tanto oportunidades como requerimientos específicos. Entre las oportunidades se encuentran la posibilidad de construir servicios digitales reutilizables, de facilitar la supervisión en tiempo casi real de fenómenos urbanos y ambientales, y de fomentar un ecosistema de reutilización basado en flujos continuos de datos interoperables. La disponibilidad de datos actualizados incrementa además la capacidad de evaluación y auditoría de políticas públicas, al permitir contrastar decisiones con observaciones recientes.
No obstante, la apertura de datos geoespaciales en tiempo real exige resolver problemas derivados de la heterogeneidad tecnológica. Las redes de sensores utilizan protocolos, modelos de datos y formatos diferentes; las fuentes generan volúmenes elevados de observaciones con alta frecuencia; y la ausencia de estructuras semánticas comunes dificulta el cruce de datos entre dominios como movilidad, medio ambiente, energía o hidrología. Para que estos datos puedan publicarse y reutilizarse de manera consistente, es necesario un marco de interoperabilidad que normalice la descripción de los fenómenos observados, la estructura de las series temporales y las interfaces de acceso.
Los estándares abiertos del Open Geospatial Consortium (OGC) proporcionan ese marco. Definen cómo representar observaciones, entidades dinámicas, coberturas multitemporales o sistemas de sensores; establecen API basadas en principios web que facilitan la consulta de datos abiertos; y permiten que plataformas distintas intercambien información sin necesidad de integraciones específicas. Su adopción reduce la fragmentación tecnológica, mejora la coherencia entre fuentes y favorece la creación de servicios públicos basados en datos actualizados.
Interoperabilidad: el requisito básico para abrir datos dinámicos
Las administraciones públicas gestionan hoy datos generados por sensores de distinto tipo, plataformas heterogéneas, proveedores diferentes y sistemas que evolucionan de forma independiente. La publicación de datos geoespaciales en tiempo real exige una interoperabilidad que permita integrar, procesar y reutilizar información procedente de múltiples fuentes. Esta diversidad provoca inconsistencias en formatos, estructuras, vocabularios y protocolos, lo que dificulta la apertura del dato y su reutilización por terceros. Veamos qué aspectos de la interoperabilidad están afectados:
- La interoperabilidad técnica: se refiere a la capacidad de los sistemas para intercambiar datos mediante interfaces, formatos y modelos compatibles. En los datos en tiempo real, este intercambio requiere mecanismos que permitan consultas rápidas, actualizaciones frecuentes y estructuras de datos estables. Sin estos elementos, cada flujo dependería de integraciones ad hoc, aumentando la complejidad y reduciendo la capacidad de reutilización.
- La interoperabilidad semántica: los datos dinámicos describen fenómenos que cambian en periodos cortos —niveles de tráfico, parámetros meteorológicos, caudales, emisiones atmosféricas— y deben interpretarse de forma coherente. Esto implica contar con modelos de observación, vocabularios y definiciones comunes que permitan a aplicaciones distintas entender el significado de cada medición y sus unidades, condiciones de captura o restricciones. Sin esta capa semántica, la apertura de datos en tiempo real genera ambigüedad y limita su integración con datos procedentes de otros dominios.
- La interoperabilidad estructural: los flujos de datos en tiempo real tienden a ser continuos y voluminosos, lo que hace necesario representarlos como series temporales o conjuntos de observaciones con atributos consistentes. La ausencia de estructuras normalizadas complica la publicación de datos completos, fragmenta la información e impide consultas eficientes. Para proporcionar acceso abierto a estos datos, es necesario adoptar modelos que representen adecuadamente la relación entre fenómeno observado, momento de la observación, geometría asociada y condiciones de medición.
- La interoperabilidad en el acceso vía API: constituye una condición esencial para los datos abiertos. Las API deben ser estables, documentadas y basadas en especificaciones públicas que permitan consultas reproducibles. En el caso de datos dinámicos, esta capa garantiza que los flujos puedan ser consumidos por aplicaciones externas, plataformas de análisis, herramientas cartográficas o sistemas de monitorización que operan en contextos distintos al que genera el dato. Sin API interoperables, el dato en tiempo real queda limitado a usos internos.
En conjunto, estos niveles de interoperabilidad determinan si los datos geoespaciales dinámicos pueden publicarse como datos abiertos sin generar barreras técnicas.
Estándares OGC para publicar datos geoespaciales en tiempo real
La publicación de datos georreferenciados en tiempo real requiere mecanismos que permitan que cualquier usuario —administración, empresa, ciudadanía o comunidad investigadora— pueda acceder a ellos de forma sencilla, con formatos abiertos y a través de interfaces estables. El Open Geospatial Consortium (OGC) desarrolla un conjunto de estándares que permiten exactamente esto: describir, organizar y exponer datos espaciales de forma interoperable y accesible, que contribuyan a la apertura de datos dinámicos.
Qué es OGC y por qué sus estándares son relevantes
El OGC es una organización internacional que define reglas comunes para que distintos sistemas puedan entender, intercambiar y usar datos geoespaciales sin depender de tecnologías concretas. Estas reglas se publican como estándares abiertos, lo que significa que cualquier persona o institución puede utilizarlos. En el ámbito de los datos en tiempo real, estos estándares permiten:
- Representar lo que un sensor mide (por ejemplo, temperatura o tráfico).
- Indicar dónde y cuándo se hizo la observación.
- Estructurar series temporales.
- Exponer datos a través de API abiertas.
- Conectar dispositivos y redes IoT con plataformas públicas.
En conjunto, este ecosistema de estándares permite que los datos geoespaciales —incluyendo los generados en tiempo real— puedan publicarse y reutilizarse siguiendo un marco coherente. Cada estándar cubre una parte específica del ciclo del dato: desde la definición de las observaciones y los sensores, hasta la forma en la que se exponen los datos mediante API abiertas o servicios web. Esta organización modular facilita que administraciones y organizaciones seleccionen los componentes que necesitan, evitando dependencias tecnológicas y garantizando que los datos puedan integrarse entre plataformas distintas.
La familia OGC API: API modernas para acceder a datos abiertos
Dentro de OGC, la línea más reciente es la familia OGC API, un conjunto de interfaces web modernas diseñadas para facilitar el acceso a datos geoespaciales mediante URL y formatos como JSON o GeoJSON, habituales en el ecosistema de datos abiertos.
Estas API permiten:
- Obtener solo la parte del dato que interesa.
- Realizar búsquedas espaciales (“dame solo lo que está en esta zona”).
- Acceder a datos actualizados sin necesidad de software especializado.
- Integrarlos fácilmente en aplicaciones web o móviles.
En este informe: “Cómo utilizar las OGC API para potenciar la interoperabilidad de los datos geoespaciales”, ya te hablamos de algunas las API más populares del OGP. Mientras que el informe se centra en cómo utilizar las OGC API para la interoperabilidad práctica, este post amplía el foco explicando los modelos de datos subyacentes del OGC —como O&M, SensorML o Moving Features— que sustentan esa interoperabilidad.
A partir de esta base, este post pone el foco en los estándares que hacen posible ese intercambio fluido de información, especialmente en contextos de datos abiertos y en tiempo real. Los estándares más importantes en el contexto de datos abiertos en tiempo real son:
|
Estándar OGC |
Qué permite hacer |
Uso principal en datos abiertos |
|---|---|---|
|
Es una interfaz web abierta que permite acceder a conjuntos de datos formados por “entidades” con geometría, como sensores, vehículos, estaciones o incidentes. Utiliza formatos simples como JSON y GeoJSON y permite realizar consultas espaciales y temporales. Es útil para publicar datos que se actualizan con frecuencia, como movilidad urbana o inventarios dinámicos. |
Consultar entidades con geometría; filtrar por tiempo o espacio; obtener datos en JSON/GeoJSON. |
Publicación abierta de datos dinámicos de movilidad, inventarios urbanos, sensores estáticos. |
|
OGC API – Environmental Data Retrieval (EDR) Proporciona un método sencillo para recuperar observaciones ambientales y meteorológicas. Permite solicitar datos en un punto, una zona o un intervalo temporal, y es especialmente adecuado para estaciones meteorológicas, calidad del aire o modelos climáticos. Facilita el acceso abierto a series temporales y predicciones. |
Solicitar observaciones ambientales en un punto, zona o intervalo temporal. |
Datos abiertos de meteorología, clima, calidad del aire o hidrología. |
|
Es el estándar más utilizado para datos IoT abiertos. Define un modelo uniforme para sensores, lo que miden y las observaciones que producen. Está diseñado para manejar grandes volúmenes de datos en tiempo real y ofrece un modo claro para publicar series temporales, datos de contaminación, ruido, hidrología, energía o alumbrado. |
Gestionar sensores y sus series temporales; transmitir grandes volúmenes de datos IoT. |
Publicación de sensores urbanos (aire, ruido, agua, energía) en tiempo real. |
|
OGC API – Connected Systems |
Describir redes de sensores, dispositivos e infraestructuras asociadas. |
Documentar como dato abierto la estructura de sistemas IoT municipales. |
|
OGC Moving Features |
Representar objetos móviles mediante trayectorias espacio-tiempo. |
Datos abiertos de movilidad (vehículos, transporte, embarcaciones). |
|
WMS-T |
Visualizar mapas que cambian en el tiempo |
Publicación de mapas meteorológicos o ambientales multitemporales |
Tabla 1. Estándares OGC relevantes para datos geoespaciales en tiempo real
Modelos que estructuran observaciones y datos dinámicos
Además de las API, OGC define varios modelos conceptuales de datos que permiten describir de forma coherente observaciones, sensores y fenómenos que cambian en el tiempo:
- O&M (Observations & Measurements): modelo que define los elementos esenciales de una observación —fenómeno medido, instante, unidad y resultado— y que sirve como base semántica para datos de sensores y series temporales.
- SensorML: lenguaje que describe las características técnicas y operativas de un sensor, incluyendo su ubicación, calibración y proceso de observación.
- Moving Features: modelo que permite representar objetos móviles mediante trayectorias espacio-temporales (como vehículos, embarcaciones o fauna).
Estos modelos facilitan que diferentes fuentes de datos puedan interpretarse de forma uniforme y combinarse en análisis y aplicaciones.
El valor de estos estándares para los datos abiertos
El uso de los estándares OGC facilita la apertura de datos dinámicos porque:
- Proporciona modelos comunes que reducen la heterogeneidad entre fuentes.
- Facilita la integración entre dominios (movilidad, clima, hidrología).
- Evita dependencias de tecnología propietaria.
- Permite que el dato sea reutilizado en análisis, aplicaciones o servicios públicos.
- Mejora la transparencia, al documentar sensores, métodos y frecuencias.
- Asegura que los datos pueden ser consumidos directamente por herramientas comunes.
En conjunto, forman una infraestructura conceptual y técnica que permite publicar datos geoespaciales en tiempo real como datos abiertos, sin necesidad de desarrollar soluciones específicas para cada sistema.
Casos de uso de datos geoespaciales abiertos en tiempo real
Los datos georreferenciados en tiempo real ya se publican como datos abiertos en distintos ámbitos sectoriales. Estos ejemplos muestran cómo diferentes administraciones y organismos aplican estándares abiertos y API para poner a disposición del público datos dinámicos relacionados con movilidad, medio ambiente, hidrología y meteorología.
A continuación, se presentan varios dominios donde las Administraciones Públicas ya publican datos geoespaciales dinámicos utilizando estándares OGC.
Movilidad y transporte
Los sistemas de movilidad generan datos de forma continua: disponibilidad de vehículos compartidos, posiciones en tiempo casi real, sensores de paso en carriles bici, aforos de tráfico o estados de intersecciones semaforizadas. Estas observaciones dependen de sensores distribuidos y requieren modelos de datos capaces de representar variaciones rápidas en el espacio y en el tiempo.
Los estándares OGC desempeñan un papel central en este ámbito. En particular, OGC SensorThings API permite estructurar y publicar observaciones procedentes de sensores urbanos mediante un modelo uniforme –incluyendo dispositivos, mediciones, series temporales y relaciones entre ellos– accesible a través de una API abierta. Esto facilita que diferentes operadores y municipios publiquen datos de movilidad de forma interoperable, reduciendo la fragmentación entre plataformas.
El uso de estándares OGC en movilidad no solo garantiza compatibilidad técnica, sino que posibilita que estos datos se puedan reutilizar junto con información ambiental, cartográfica o climática, generando análisis multitemáticos para planificación urbana, sostenibilidad o gestión operativa del transporte.
Ejemplo:
El servicio abierto de Toronto Bike Share, que publica en formato SensorThings API el estado de sus estaciones de bicicletas y la disponibilidad de vehículos.
Aquí cada estación es un sensor y cada observación indica el número de bicicletas disponibles en un momento concreto. Este enfoque permite que analistas, desarrolladores o investigadores integren estos datos directamente en modelos de movilidad urbana, sistemas de predicción de demanda o paneles de control ciudadano sin necesidad de adaptaciones específicas.
Calidad del aire, ruido y sensores urbanos
Las redes de monitorización de calidad del aire, ruido o condiciones ambientales urbanas dependen de sensores automáticos que registran mediciones cada pocos minutos. Para que estos datos puedan integrarse en sistemas de análisis y publicarse como datos abiertos, es necesario disponer de modelos y API coherentes.
En este contexto, los servicios basados en estándares OGC permiten publicar datos procedentes de estaciones fijas o sensores distribuidos de forma interoperable. Aunque muchas administraciones utilizan interfaces tradicionales como OGC WMS para servir estos datos, la estructura subyacente suele apoyarse en modelos de observaciones derivados de la familia Observations & Measurements (O&M), que define cómo representar un fenómeno medido, su unidad y el instante de observación.
Ejemplo:
El servicio Defra UK-AIR Sensor Observation Service proporciona acceso a datos de mediciones de calidad del aire en tiempo casi real desde estaciones in situ en Reino Unido.
La combinación de O&M para la estructura del dato y API abiertas para su publicación facilita que estos sensores urbanos formen parte de ecosistemas más amplios que integran movilidad, meteorología o energía, permitiendo análisis urbanos avanzados o paneles ambientales en tiempo casi real.
Ciclo del agua, hidrología y gestión del riesgo
Los sistemas hidrológicos generan datos cruciales para la gestión del riesgo: niveles y caudales en ríos, precipitaciones, humedad del suelo o información de estaciones hidrometeorológicas. La interoperabilidad es especialmente importante en este dominio, ya que estos datos se combinan con modelos hidráulicos, predicción meteorológica y cartografía de zonas inundables.
Para facilitar el acceso abierto a series temporales y observaciones hidrológicas, varios organismos utilizan OGC API – Environmental Data Retrieval (EDR), una API diseñada para recuperar datos ambientales mediante consultas sencillas en puntos, áreas o intervalos temporales.
Ejemplo:
El USGS (United States Geological Survey), que documenta el uso de OGC API – EDR para acceder a series de precipitación, temperatura o variables hidrológicas.
Este caso muestra cómo EDR permite solicitar observaciones específicas por ubicación o fecha, devolviendo únicamente los valores necesarios para el análisis. Aunque los datos concretos de hidrología del USGS se sirven mediante su API propia, este caso demuestra cómo EDR encaja con la estructura de datos hidrometeorológicos y cómo se aplica en flujos operativos reales.
El empleo de estándares OGC en este ámbito permite que los datos hidrológicos dinámicos se integren con zonas inundables, ortoimágenes o modelos climáticos, creando una base sólida para sistemas de alerta temprana, planificación hidráulica y evaluación del riesgo.
Observación y predicción meteorológica
La meteorología es uno de los dominios con mayor producción de datos dinámicos: estaciones automáticas, radares, modelos numéricos de predicción, observaciones satelitales y productos atmosféricos de alta frecuencia. Para publicar esta información como datos abiertos, la familia de OGC API se está convirtiendo en un elemento clave, especialmente mediante OGC API – EDR, que permite recuperar observaciones o predicciones en ubicaciones concretas y en distintos niveles temporales.
Ejemplo:
El servicio NOAA OGC API – EDR, que proporciona acceso a datos meteorológicos y variables atmosféricas del National Weather Service (Estados Unidos).
Esta API permite consultar datos en puntos, áreas o trayectorias, facilitando la integración de observaciones meteorológicas en aplicaciones externas, modelos o servicios basados en datos abiertos.
El uso de OGC API en meteorología permite que datos procedentes de sensores, modelos y satélites puedan consumirse mediante una interfaz unificada, facilitando su reutilización para pronósticos, análisis atmosféricos, sistemas de soporte a la decisión y aplicaciones climáticas.
Buenas prácticas para publicar datos geoespaciales abiertos en tiempo real
La publicación de datos geoespaciales dinámicos requiere adoptar prácticas que garanticen su accesibilidad, interoperabilidad y sostenibilidad. A diferencia de los datos estáticos, los flujos en tiempo real presentan requisitos adicionales relacionados con la calidad de las observaciones, la estabilidad de las API y la documentación del proceso de actualización. A continuación, se presentan algunas prácticas recomendadas para administraciones y organizaciones que gestionan este tipo de datos.
- Formatos y API abiertas estables: el uso de estándares OGC —como OGC API, SensorThings API o EDR— facilita que los datos puedan consumirse desde múltiples herramientas sin necesidad de adaptaciones específicas. Las API deben ser estables en el tiempo, ofrecer versiones bien definidas y evitar dependencias de tecnologías propietarias. Para datos ráster o modelos dinámicos, los servicios OGC como WMS, WMTS o WCS siguen siendo adecuados para visualización y acceso programático.
- Metadatos compatibles con DCAT-AP y modelos OGC: la interoperabilidad de catálogos requiere describir los conjuntos de datos utilizando perfiles como DCAT-AP, complementado con metadatos geoespaciales y de observación basados en O&M (Observations & Measurements) o SensorML. Estos metadatos deben documentar la naturaleza del sensor, la unidad de medida, la frecuencia de muestreo y posibles limitaciones del dato.
- Políticas de calidad, frecuencia de actualización y trazabilidad: los datasets dinámicos deben indicar explícitamente su frecuencia de actualización, la procedencia de las observaciones, los mecanismos de validación aplicados y las condiciones bajo las cuales se generaron. La trazabilidad es esencial para que terceros puedan interpretar correctamente los datos, reproducir análisis e integrar observaciones procedentes de fuentes distintas.
- Documentación, límites de uso y sostenibilidad del servicio: la documentación debe incluir ejemplos de uso, parámetros de consulta, estructura de respuesta y recomendaciones para gestionar el volumen de datos. Es importante establecer límites razonables de consulta para garantizar la estabilidad del servicio y asegurar que la administración puede mantener la API a largo plazo.
- Aspectos de licencias para datos dinámicos: la licencia debe ser explícita y compatible con la reutilización, como CC BY 4.0 o CC0. Esto permite integrar datos dinámicos en servicios de terceros, aplicaciones móviles, modelos predictivos o servicios de interés público sin restricciones innecesarias. La consistencia en la licencia facilita también el cruce de datos procedentes de distintas fuentes.
Estas prácticas permiten que los datos dinámicos se publiquen de forma fiable, accesible y útil para toda la comunidad reutilizadora.
Los datos geoespaciales dinámicos se han convertido en una pieza estructural para comprender fenómenos urbanos, ambientales y climáticos. Su publicación mediante estándares abiertos permite que esta información pueda integrarse en servicios públicos, análisis técnicos y aplicaciones reutilizables sin necesidad de desarrollos adicionales. La convergencia entre modelos de observación, API OGC y buenas prácticas en metadatos y licencias ofrece un marco estable para que administraciones y reutilizadores trabajen con datos procedentes de sensores de forma fiable. Consolidar este enfoque permitirá avanzar hacia un ecosistema de datos públicos más coherente, conectado y preparado para usos cada vez más demandantes en movilidad, energía, gestión del riesgo y planificación territorial.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
Los datos son el motor de la innovación, y su potencial transformador se refleja en todos los ámbitos, destacando especialmente en el de la salud. Desde diagnósticos más rápidos hasta tratamientos personalizados y políticas públicas más eficaces, el uso inteligente de la información sanitaria tiene el poder de cambiar vidas de forma profunda y significativa.
Pero, para que estos datos desplieguen todo su valor y se conviertan en una fuerza real para el progreso, es fundamental que "hablen el mismo idioma". Es decir, que estén bien organizados, sean fáciles de encontrar y puedan compartirse de forma segura y coherente entre distintos sistemas, países y profesionales.
Aquí es donde entra en juego HealthDCAT-AP, una nueva especificación europea que, aunque suene técnico, tiene mucho que ver con nuestro bienestar como ciudadanos. HealthDCAT-AP está diseñado para describir los datos de salud —desde estadísticas agregadas hasta registros clínicos anonimizados— de manera homogénea, clara y reutilizable, a través de metadatos. En definitiva, no actúa sobre los datos clínicos en sí, sino que facilita que puedan localizarse y comprenderse mejor gracias a una descripción estandarizada.
HealthDCAT-AP se ocupa exclusivamente de los metadatos, es decir, de cómo se describen y organizan los conjuntos de datos en los catálogos, diferenciándose de HL7, FHIR y DICOM que estructuran el intercambio de información clínica e imágenes; CDA que describe la arquitectura de los documentos; y SNOMED CT, LOINC y CIE-10 que estandarizan la semántica de diagnósticos, procedimientos y observaciones para garantizar que los datos tengan el mismo significado en cualquier contexto
Este artículo explora cómo HealthDCAT-AP, en el contexto del Espacio Europeo de Datos Sanitarios (EHDS) y del Espacio Nacional de Datos Sanitarios (ENDS), aporta valor principalmente a quienes reutilizan los datos —como investigadores, innovadores o responsables de políticas públicas— y, en última instancia, beneficia también a la ciudadanía a través de los avances que estos generan.
¿Qué es HealthDCAT-AP y cuál es su relación con DCAT-AP?
Imagina una biblioteca enorme llena de libros sobre salud, pero sin ningún sistema para organizarlos. Buscar una información concreta sería una tarea caótica. Con los datos de salud ocurre algo similar: si no están bien descritos, localizarlos y reutilizarlos es prácticamente imposible.
HealthDCAT-AP nace para resolver este reto. Es una especificación técnica europea que permite describir de forma clara y uniforme los conjuntos de datos sanitarios dentro de catálogos de datos a, facilitando su búsqueda, acceso, comprensión y reutilización. En otras palabras, hace que la descripción de los datos sanitarios hable el mismo idioma en toda Europa, lo que resulta clave para mejorar la atención, la investigación y las políticas de salud.
Esta especificación técnica se basa en DCAT-AP, la especificación general utilizada para describir catálogos de conjuntos de datos del sector público en Europa. Mientras que DCAT-AP proporciona una estructura común para todo tipo de datos, HealthDCAT-AP es su extensión especializada en salud, que adapta y amplía ese modelo para cubrir las particularidades de los datos clínicos, epidemiológicos o biomédicos.
HealthDCAT-AP fue desarrollado en el marco del proyecto piloto europeo EHDS2 (European Health Data Space 2) y continúa evolucionando gracias al apoyo de proyectos como HealthData@EU Pilot, que trabajan en el despliegue de la futura infraestructura europea de datos sanitarios. La especificación está en desarrollo activo y su versión más reciente, junto con documentación y ejemplos, puede consultarse públicamente en su repositorio oficial de GitHub.
Así mismo, HealthDCAT-AP está diseñado para aplicar los principios FAIR que los datos sean Encontrables, Accesibles, Interoperables y Reutilizables. Esto significa que, aunque los datos sanitarios puedan ser complejos o sensibles, su descripción (metadatos) es clara, estandarizada y útil. Cualquier profesional o institución —ya sea en España o en otro país europeo— puede saber qué datos existen, cómo acceder a ellos y con qué condiciones. Esto fomenta la confianza, la transparencia y el uso responsable de los datos sanitarios. HealthDCAT-AP es además una piedra angular del EHDS y por ende del ENDS. Su adopción permitirá que hospitales, centros de investigación o administraciones compartan información de forma coherente y segura a lo largo de toda Europa. Así, se impulsa la colaboración entre países y se maximiza el valor de los datos para beneficio de toda la ciudadanía.
Para facilitar su uso y adopción, desde Europa, bajo las iniciativas mencionadas anteriormente, se han creado herramientas como el editor y el validador HealthDCAT-AP, que permiten a cualquier organización generar descripciones de conjuntos de datos a través de los metadatos que sean compatibles sin necesidad de conocimientos técnicos avanzados. Esto elimina barreras y anima a más entidades a participar en este ecosistema de datos de salud en red.
¿Cómo contribuye HealthDCAT-AP al valor público de los datos de salud?
Aunque HealthDCAT-AP es una especificación técnica centrada en la descripción de conjuntos de datos de salud, su adopción tiene implicaciones prácticas que van más allá del ámbito tecnológico. Al ofrecer una forma común y estructurada de documentar qué datos existen, cómo pueden utilizarse y en qué condiciones, contribuye a que distintos actores —desde hospitales y administraciones hasta centros de investigación o startups— puedan acceder, combinar y reutilizar mejor la información disponible, habilitando el denominado uso secundario de la misma, más allá del uso primario asistencial.
A continuación, se detallan algunos de los ámbitos donde su contribución técnica se traduce en beneficios concretos para el conjunto de la sociedad.
- Diagnósticos más rápidos y tratamientos personalizados: cuando los datos están bien organizados y son accesibles para quienes los necesitan, los avances en investigación médica se aceleran. Esto permite desarrollar herramientas de inteligencia artificial que detectan enfermedades antes, identificar patrones en grandes poblaciones y adaptar tratamientos al perfil de cada paciente. Es la base de la medicina personalizada, que mejora resultados y reduce riesgos.
- Mejor acceso al conocimiento sobre qué datos existen: HealthDCAT-AP permite a investigadores, gestores sanitarios o autoridades localizar más fácilmente conjuntos de datos útiles, gracias a su descripción estandarizada. Esto puede facilitar, por ejemplo, el análisis de desigualdades en salud o la planificación de recursos en situaciones de crisis.
- Mayor transparencia y trazabilidad: El uso de metadatos permite saber quién es responsable de cada conjunto de datos, con qué finalidad se puede usar y en qué condiciones. Esto fortalece la confianza en el ecosistema de reutilización de datos.
- Servicios sanitarios más eficientes: la estandarización de los metadatos mejora los flujos de información entre centros, regiones y sistemas. Esto reduce la burocracia, evita duplicidades, optimiza el uso de recursos y libera tiempo y dinero que pueden reinvertirse en mejorar la atención directa a los pacientes.
- Más innovación y nuevas soluciones para el ciudadano: al facilitar el acceso a mayores conjuntos de datos, HealthDCAT-AP impulsa el desarrollo de nuevas herramientas digitales centradas en el paciente: apps de autocuidado, sistemas de seguimiento remoto, comparadores de servicios, etc. Muchas de estas soluciones nacen fuera del sistema sanitario —en universidades, startups o asociaciones— pero benefician directamente a la ciudadanía.
- Una Europa conectada en torno a la salud: al compartir una forma común de describir los datos, HealthDCAT-AP hace posible que un conjunto de datos creado en España pueda ser comprendido y utilizado en Alemania o Finlandia, y viceversa. Esto favorece la colaboración internacional, refuerza la cohesión europea y garantiza que los ciudadanos se beneficien de avances científicos independientemente de su país.
¿Y qué papel juega España en todo esto?
España no solo está alineada con el futuro del dato sanitario en Europa: está participando activamente en su construcción. Gracias a una sólida base legal, un sistema sanitario ampliamente digitalizado, la experiencia acumulada en la compartición segura de información de salud dentro del SNS, y una larga trayectoria en datos abiertos —a través de iniciativas como datos.gob.es—, nuestro país se encuentra en una posición privilegiada para contribuir y beneficiarse del Espacio Europeo de Datos Sanitarios (EHDS).
Desde hace años, España ha desarrollado marcos legales y capacidades técnicas que anticipan muchos de los requisitos del Reglamento EHDS. La digitalización generalizada de la atención sanitaria y la experiencia en el uso de datos de forma segura y responsable permiten avanzar hacia un modelo interoperable, ético y orientado al bien común.
En este contexto, el proyecto del Espacio Nacional de Datos de Salud supone un paso decisivo. Esta iniciativa tiene como objetivo, convertirse en la plataforma nacional de referencia para el análisis y explotación de datos sanitarios para uso secundario., concibiéndose como catalizador de la investigación e innovación en salud, referente en la aplicación de soluciones disruptivas y puerta de acceso a diferentes orígenes de datos. Todo ello se realiza bajo condiciones estrictas de anonimización, seguridad, transparencia y protección de derechos, garantizando que los datos solo se utilicen con fines legítimos y con pleno respeto a la normativa vigente.
La familiaridad de España con estándares como DCAT-AP facilita el despliegue de HealthDCAT-AP. Plataformas como datos.gob.es, que ya actúan como punto de referencia en la publicación de datos abiertos, serán clave en su despliegue y difusión.
Conclusiones
HealthDCAT-AP puede sonar a algo técnico, pero en realidad es una especificación que puede llegar a repercutir en nuestra vida diaria. Al ayudar a describir mejor los datos de salud, facilita que esa información se utilice de forma útil, segura y responsable.
Esta especificación permite que la descripción de conjuntos de datos hable el mismo idioma en toda Europa. Así, se pueden encontrar más fácilmente, compartir con quien corresponde y reutilizar para fines que nos benefician a todos: diagnósticos más rápidos, tratamientos más personalizados, decisiones de salud pública más acertadas o nuevas herramientas digitales que mejoran nuestra calidad de vida.
España, gracias a su experiencia en datos abiertos y a su sistema sanitario digitalizado, está participando activamente en esta transformación realizando un esfuerzo conjunto entre profesionales, instituciones, empresas, investigadores, etc. y también ciudadanos. Porque cuando los datos se entienden y se gestionan bien, pueden marcar la diferencia. Pueden salvar tiempo, recursos, e incluso vidas.
HealthDCAT-AP no es solo una especificación técnica: es un paso adelante hacia una salud más conectada, transparente y centrada en las personas. Una especificación pensada para maximizar el uso secundario de la información de salud, y para que, con ello, todos como ciudadanos podamos salir beneficiados.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
Una de las principales exigencias que plantea la transformación digital del sector público se refiere a la existencia de unas condiciones óptimas de interoperabilidad a la hora de compartir datos. Se trata de una premisa esencial desde diversos puntos de vista, en particular por lo que se refiere a las actuaciones y trámites en los que participan varias entidades. En concreto, la interoperabilidad permite:
- La interconexión de los registros electrónicos de apoderamientos y de presentación de escritos ante las entidades públicas.
- El intercambio de datos, documentos y expedientes en el ejercicio de las respectivas competencias, lo que resulta esencial para la simplificación administrativa y, en especial, a la hora de garantizar el derecho a no presentar documentos que ya obren en poder de las Administraciones públicas;
- El desarrollo de servicios avanzados y personalizados basados en el intercambio de información, como puede ser el caso de la carpeta ciudadana.
La interoperabilidad también juega un papel destacado a la hora de facilitar la integración de diversas fuentes de datos abiertos de cara a su reutilización, de ahí que exista incluso una norma técnica específica a este respecto. Con ella se pretende fijar unas condiciones comunes que permitan “facilitar y garantizar el proceso de reutilización de la información de carácter público procedente de las Administraciones públicas, asegurando la persistencia de la información, el uso de formatos, así como los términos y condiciones de uso adecuados”.
La interoperabilidad en el ámbito europeo
La interoperabilidad es, por tanto, una premisa para facilitar las relaciones entre diversas entidades, lo que resulta de especial trascendencia en el contexto europeo si tenemos en cuenta que las relaciones jurídicas se darán con frecuencia entre Estados distintos. Se trata, por tanto, de un gran desafío para el impulso de servicios públicos digitales transfronterizos y, en consecuencia, para hacer efectivos derechos y valores esenciales en la Unión Europea vinculados a la libre circulación de personas.
Por esta razón se ha impulsado la aprobación de un marco normativo que facilite el intercambio de datos transfronterizo para garantizar el correcto funcionamiento de los servicios públicos digitales a nivel europeo. Se trata del Reglamento (UE) 2024/903 del Parlamento Europeo y del Consejo, de 13 de marzo de 2024, por el que se establecen medidas a fin de garantizar un alto nivel de interoperabilidad del sector público en toda la Unión (denominado Reglamento sobre la Europa Interoperable), normativa directamente aplicable con carácter general en toda la Unión Europea desde el día 12 de julio de 2024.
Con esta regulación se pretende ofrecer las condiciones adecuadas para facilitar la interoperabilidad transfronteriza, lo que requiere un planteamiento avanzado en el establecimiento y la gestión de los requisitos jurídicos, organizativos, semánticos y técnicos. En concreto, estarán afectados los servicios públicos digitales transeuropeos, esto es, aquellos que requieran interacción a través de las fronteras de los Estados miembros mediante sus sistemas de redes y de información. Este sería el caso, por ejemplo, del cambio de residencia para trabajar o estudiar en otro Estado miembro, el reconocimiento de títulos académicos o cualificaciones profesionales, el acceso a los datos de salud y Seguridad Social o, por lo que se refiere a las personas jurídicas, el intercambio de datos fiscales o de información necesaria para participar en un procedimiento de licitación en el ámbito de la contratación pública. En definitiva, “todos aquellos servicios que aplican el principio de «solo una vez» para acceder a datos transfronterizos e intercambiarlos”.
¿Cuáles son las principales medidas que contempla?
- Evaluación de interoperabilidad: con carácter previo a la adopción de decisiones sobre condiciones relativas a servicios públicos digitales transeuropeos por parte de las entidades de la Unión Europea o de los organismos del sector público de los Estados, el Reglamento les obliga a que lleven a cabo una evaluación de la interoperabilidad, si bien se trata de una medida que sólo será preceptiva a partir de enero de 2025. El resultado de dicha evaluación deberá ser publicado en un sitio web oficial en un formato legible por máquina que permita su traducción automática.
- Compartición de soluciones de interoperabilidad: las entidades antes referidas estarán obligadas a compartir las soluciones de interoperabilidad que den soporte a un servicio público digital transeuropeo, lo que incluye la documentación técnica y el código fuente, así como las referencias a las normas abiertas o especificaciones técnicas que se hubieren utilizado. No obstante, esta obligación tiene algunos límites, como sucede en aquellos supuestos en que existan derechos de propiedad intelectual a favor de terceros. Además, dichas soluciones serán objeto de publicación en el Portal de la Europa Interoperable, que habrá de sustituir al actual portal Joinup.
- Habilitación de sandboxes: una de las principales novedades consiste en la habilitación a los organismos públicos para que procedan a la creación de sandboxes o espacios controlados de pruebas de interoperabilidad que, en el caso de tratar datos de carácter personal, serán gestionados bajo la supervisión de la correspondiente autoridad de control competente para ello. Con esta figura se pretende fomentar la innovación y facilitar la cooperación desde las exigencias de la seguridad jurídica, impulsando a tal efecto el desarrollo de soluciones de interoperabilidad a partir de la mejor comprensión de las oportunidades y los obstáculos que puedan plantearse.
- Creación de un comité para la gobernanza: por lo que se refiere a la gobernanza, se contempla la creación de un comité compuesto por representantes de cada uno de los Estados y de la Comisión, a quien corresponderá su presidencia. Entre sus principales funciones se encuentran establecer los criterios para la evaluación de la interoperabilidad, facilitar la puesta en común de las soluciones de interoperabilidad, supervisar la coherencia de las mismas o desarrollar el Marco Europeo de Interoperabilidad, entre otras. Por su parte, los Estados miembros tendrán que designar al menos una autoridad competente para la aplicación del Reglamento antes del 12 de enero de 2025, que hará las funciones de punto de contacto único en caso de que existan varias. Sus principales funciones consistirán en coordinar la aplicación de la normativa, apoyar a los organismos públicos en la realización de la evaluación y, entre otras, fomentar la reutilización de soluciones de interoperabilidad.
El intercambio de datos entre los organismos públicos del conjunto de la Unión Europea y sus Estados miembros con plenas garantías jurídicas constituye una prioridad esencial para el eficaz ejercicio de sus competencias y, por tanto, para garantizar la eficacia en la realización de los trámites desde la perspectiva de la buena administración. El nuevo Reglamento sobre la Europea Interoperable supone un importante avance en el marco normativo a la hora de impulsar este objetivo, pero es necesario complementar la regulación con un cambio de paradigma en la práctica administrativa. A este respecto es imprescindible apostar decididamente por un modelo de gestión documental basada principalmente en datos, lo que además permite abordar de manera más sencilla el cumplimiento normativo de la regulación sobre protección de datos de carácter personal, resultando plenamente coherente con el planteamiento y las soluciones impulsadas por el Reglamento de Gobernanza de Datos a la hora de promover la reutilización de la información generada por las entidades públicas en el ejercicio de sus funciones.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Uno de los principales objetivos de Reglamento (UE), del Parlamento Europeo y del Consejo de 13 de diciembre de 2023 sobre normas armonizadas para un acceso justo a los datos y su utilización (Reglamento de Datos) consiste en promover el desarrollo de criterios de interoperabilidad en los espacios de datos, los servicios de tratamiento de datos y los contratos inteligentes. A este respecto, el Reglamento entiende la interoperabilidad como:
La capacidad de dos o más espacios de datos o redes de comunicación, sistemas, productos conectados, aplicaciones, servicios de tratamiento de datos o componentes para intercambiar y utilizar datos con el fin de desempeñar sus funciones.
Según afirma expresamente dicha norma “los datos interoperables y de alta calidad de diferentes ámbitos incrementan la competitividad y la innovación, y garantizan un crecimiento económico sostenible”, para lo cual resulta necesario que “los mismos datos pueden utilizarse y reutilizarse para diversos fines y de modo ilimitado, sin pérdida de calidad o cantidad”. Así pues, considera que resulta imprescindible “un enfoque regulador para la interoperabilidad que sea ambicioso y que inspire la innovación para superar la dependencia de un solo proveedor, que obstaculiza la competencia y el desarrollo de nuevos servicios”.
Interoperabilidad y espacios de datos
Esta preocupación ya existía en la Estrategia Europea de Datos, donde la interoperabilidad se consideraba un elemento clave para poner en valor los datos y, de manera singular, para el despliegue de la Inteligencia Artificial. De hecho, la interoperabilidad es una premisa inexcusable para los espacios de datos, de modo que el establecimiento de protocolos adecuados se convierte en esencial para garantizar su potencial, tanto por lo que se refiere a cada uno de los espacios de datos a nivel interno como, asimismo, a la hora de facilitar una integración transversal de varios de ellos.
En este sentido, son frecuentes las iniciativas de estandarización y los encuentros para tratar de establecer unas condiciones específicas de interoperabilidad en este tipo de escenarios, caracterizados por la diversidad de las fuentes de datos. Aunque supone una dificultad añadida, lo cierto es que un enfoque transversal, que integre varios espacios de datos, proporciona un mayor impacto en la generación de servicios de valor añadido y permite crear las condiciones jurídicas adecuadas para la innovación.
Según establece el Reglamento de Datos quienes participen en los espacios de datos y ofrezcan datos o servicios de datos a otros actores que intervengan en los mismos habrán de cumplir una serie de requisitos encaminados, precisamente, a garantizar unas condiciones adecuadas de interoperabilidad y que, de este modo, los datos puedan tratarse conjuntamente. Para ello, se proporcionará una descripción del contenido, la estructura, el formato y otras condiciones de uso de los datos, de manera que se facilite el acceso a los mismos y su compartición de manera automatizada, incluso en tiempo real o permitiendo la descarga masiva cuando proceda.
Conviene tener en cuenta que para los espacios de datos es esencial cumplir con los estándares técnicos y semánticos de interoperabilidad, puesto que una mínima normalización de las condiciones jurídicas facilita enormemente su funcionamiento. En concreto, es de gran importancia asegurar que quien aporte los datos es titular de los derechos necesarios para compartirlos en dicho entorno y, asimismo, poder acreditarlo de manera automatizada.
Interoperabilidad en los servicios de tratamiento de datos
El Reglamento de Datos presta una especial atención a la necesidad de mejorar la interoperabilidad entre los distintos proveedores de servicios de tratamiento de datos, de manera que los clientes puedan beneficiarse de la interacción entre cada uno de ellos, reduciendo así la dependencia de proveedores concretos.
Para ello, en primer lugar, refuerza la obligación de informar que tienen los proveedores que prestan este tipo de servicios, a las que deberán añadirse aquellas derivadas de la regulación general en materia de suministro de contenidos y servicios digitales. En particular, deberán constar por escrito:
- Las condiciones contractuales relativas a los derechos del cliente, sobre todo en situaciones relacionadas con un posible cambio a otro proveedor o infraestructura.
- Una indicación completa de los datos que podrán exportarse durante el proceso de cambio de proveedor, de manera que el alcance de la obligación de interoperabilidad habrá de estar previamente fijado. Además, dicha información tiene que ofrecerse a través de un registro en línea actualizado que ofrecerá el proveedor de servicios.
El Reglamento pretende garantizar que el derecho de los clientes a la libre elección del proveedor de los servicios de datos no se vea afectado por barreras y dificultades derivados de la falta de interoperabilidad. Incluso, la regulación contempla una obligación de proactividad para que el cambio de proveedor tenga lugar sin incidencias en la prestación del servicio al cliente, por lo que les obliga a adoptar aquellas medidas que sean razonables para asegurar una “equivalencia funcional” e, incluso, a ofrecer de manera gratuita interfaces abiertas que faciliten dicho proceso. No obstante, en algún caso –en concreto, cuando se pretenda utilizar en paralelo dos servicios–, se permite al antiguo proveedor repercutir ciertos costes que se le puedan haber generado.
En última instancia, la interoperabilidad de los servicios de tratamiento de datos va más allá de simples aspectos técnicos o semánticos, de manera que se convierte en una premisa inexcusable para asegurar la portabilidad de los activos digitales, garantizar las condiciones de seguridad e integridad de los servicios y, entre otros objetivos, no interferir en la incorporación de las innovaciones tecnológicas, todo ello con un marcado protagonismo de los servicios en la nube.
Contratos inteligentes e interoperabilidad
El Reglamento de Datos también presta una especial atención a las condiciones de interoperabilidad que permitan la ejecución automatizada de los intercambios de datos, para lo cual resulta esencial fijarlas de manera predeterminada. De lo contrario, se verían afectadas las condiciones óptimas de funcionamiento que requiere el entorno digital, especialmente desde el punto de vista de la eficiencia.
La nueva regulación contempla obligaciones específicas para los proveedores de contratos inteligentes y, asimismo, para quienes desplieguen este tipo de herramientas al llevar a cabo su actividad comercial, empresarial o profesional. A tal efecto, se entiende por contrato inteligente aquel
programa informático utilizado para la ejecución automatizada de un acuerdo o de parte de este, que utiliza una secuencia de registros electrónicos de datos y garantiza su integridad y la exactitud de su orden cronológico.
Dichos sujetos han de garantizar que los contratos inteligentes cumplen con las obligaciones que contempla el Reglamento por lo que se refiere a la puesta a disposición de datos y, entre otros aspectos, será imprescindible garantizar “la coherencia con las condiciones del acuerdo de intercambio de datos que ejecuta el contrato inteligente”. En consecuencia, serán responsables del efectivo cumplimiento de tales exigencias, para lo cual deberán llevar a cabo una evaluación de conformidad y expedir una declaración relativa a la observancia de tales requisitos.
Para facilitar el cumplimiento de estas garantías, el Reglamento contempla una presunción de cumplimiento cuando se respeten las normas armonizadas publicadas en el Diario Oficial de la Unión Europea, para lo cual se autoriza a la Comisión a fin de que solicite a organizaciones europeas de normalización la elaboración de disposiciones específicas.
En los últimos cinco años y, en particular desde la Estrategia de 2020, se ha producido un importante avance en la regulación europea que permite afirmar que existen unas condiciones jurídicas adecuadas para garantizar la disponibilidad de los datos de calidad para impulsar la innovación tecnológica. Por lo que se refiere a la interoperabilidad, ya se han dado pasos muy relevantes, especialmente en el sector público, donde podemos encontrar tecnologías disruptivas que pueden resultar de enorme utilidad. Sin embargo, todavía está pendiente el desafío de concretar de manera precisa el alcance de las obligaciones establecidas legalmente.
Por ello el propio Reglamento de Datos habilita a la Comisión para que pueda adoptar especificaciones comunes que garanticen el efectivo cumplimiento de las medidas que contempla si fuera necesario. No obstante, se trata de una medida de carácter subsidiario, ya que previamente se han de intentar otras vías para conseguir la interoperabilidad, como es el caso de la elaboración de normas armonizadas a través de organizaciones de normalización.
En definitiva, a la hora de regular la interoperabilidad se requiere un planteamiento ambicioso, tal y como reconoce el propio Reglamento de Datos, si bien se trata de un proceso complejo que precisa de medidas de ejecución en diferentes niveles que van más allá de la simple aprobación de normas jurídicas, aun cuando dicha legislación suponga un importante avance para dinamizar la innovación en condiciones adecuadas, esto es, más allá de las simples premisas tecnológicas.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El proceso de modernización tecnológica en la Administración de Justicia en España se inició, en gran medida, en el año 2011. Ese año se aprobó la primera regulación que específicamente se destinaba a impulsar el uso de las tecnologías de la información y la comunicación. El objetivo de dicha regulación consistía, sustancialmente, en establecer las condiciones para reconocer la validez del uso de medios electrónicos en las actuaciones judiciales y, sobre todo, en dotar de seguridad jurídica a la tramitación procesal y a los actos de comunicación, incluyendo la presentación de escritos y la recepción de notificaciones de resoluciones. En este sentido, la legislación estableció un estatuto jurídico básico para quienes se relacionaran con la Administración de Justicia, especialmente para el caso de los profesionales. Asimismo, se dio carta de naturaleza legal a la presencia en Internet de la Administración de Justicia, fundamentalmente con la aparición de las sedes electrónicas y los puntos de acceso, admitiendo expresamente la posibilidad de que las actuaciones de realizaran de manera automatizada.
Sin embargo, al igual que sucede con la regulación legal del procedimiento administrativo común y el régimen jurídico del sector público de 2015, el modelo de gestión en que se inspiró estaba sustancialmente orientado a la generación, conservación y archivo de los documentos y los expedientes. Aunque ya se advertía una tímida consideración de los datos, lo cierto es que en gran medida adolecía de una excesiva generalidad en el alcance de la regulación, ya que se limitaba a reconocer y garantizar la seguridad, la interoperabilidad y la confidencialidad.
En este contexto, la aprobación del Real Decreto-ley 6/2023, de 19 de diciembre ha supuesto un hito muy relevante en este proceso, por cuanto incorpora importantes medidas que pretenden ir más allá de la mera modernización tecnológica. Entre otras cuestiones, intenta sentar las bases para abordar una efectiva transformación digital en este ámbito.
Hacia una orientación de la gestión basada en los datos
Aun cuando este nuevo marco normativo en gran medida consolida y actualiza la regulación anterior, supone un importante paso adelante a la hora de facilitar la transformación digital por cuanto establece algunas premisas esenciales sin las que sería imposible plantear este objetivo. En concreto, según se afirma con rotundidad en su Exposición de Motivos:
Desde la comprensión de la importancia capital de los datos en una sociedad contemporánea digital, se realiza una apuesta clara y decisiva por su empleo racional para lograr evidencia y certidumbre al servicio de la planificación y elaboración de estrategias que coadyuven a una mejor y más eficaz política pública de Justicia. […] De estos datos no se beneficiará únicamente la propia Administración, sino toda la ciudadanía mediante la incorporación en la Administración de Justicia del concepto de «dato abierto». Esta misma orientación al dato facilitará las denominadas actuaciones automatizadas, asistidas y proactivas.
En este sentido, se reconoce expresamente un principio general de orientación al dato, superando de este modo las restricciones de un modelo de gestión electrónica basada en los documentos y los expedientes como el que ha existido hasta ahora. Con ello se pretende no sólo alcanzar objetivos de mejora en la tramitación procesal sino, asimismo, facilitar su utilización para otras finalidades como la elaboración de cuadros de mando, la generación de actuaciones automatizadas, asistidas y proactivas, la utilización de sistemas de inteligencia artificial y su publicación en portales de datos abiertos.
¿Cómo se ha concretado este principio?
Las principales novedades de este marco regulatorio desde la perspectiva del principio de orientación al dato son las siguientes:
-
Con carácter general, los sistemas informáticos y de comunicación habrán de permitir el intercambio de información en formato de datos estructurados, debiendo facilitar su automatización y la integración en el expediente judicial. A tal efecto, se contempla la puesta en marcha de una plataforma de interoperabilidad de datos, que habrá de ser compatible con la Plataforma de Intermediación de Datos de la Administración General del Estado.
-
La interoperabilidad de datos entre los órganos judiciales y fiscales y, asimismo, los portales de datos se configuran como servicios electrónicos de la Administración de Justicia. Las concretas condiciones técnicas de prestación de tales servicios habrán de ser definidas a través del Comité técnico estatal de la Administración judicial electrónica (CTEAJE).
-
Con el fin, entre otros objetivos, de facilitar el impulso de la inteligencia artificial, la realización de actividades automatizadas, asistidas y proactivas, así como la publicación de información en portales de datos abiertos, se establece la exigencia de que todos los sistemas de información y comunicación aseguren que la gestión de la información incorpore metadatos y se basen en modelos de datos comunes e interoperables. Por lo que se refiere, en concreto, a las comunicaciones, la orientación al dato se proyecta asimismo en los canales electrónicos utilizados para su realización.
-
En la definición legal de expediente judicial, a diferencia de lo que sucede en el ámbito del procedimiento administrativo común, se incorpora una referencia explícita a los datos como una de las unidades básicas que lo integran.
-
Se incluye una regulación específica para el denominado Portal de datos de la Administración de Justicia, de manera que se consagra legalmente, por primera, vez la actual herramienta de acceso a datos en este ámbito. En concreto, además de establecer ciertos contenidos mínimos y asignar competencias a diversos órganos, se contempla la creación de un apartado específico sobre datos abiertos, así como un mandato a las Administraciones competentes para que sean automáticamente procesables e interoperables con el portal de datos abiertos del Estado. A este respecto, se declara de aplicación la normativa general ya existente para el resto del sector público, sin perjuicio de las singularidades que puedan contemplarse específicamente en la regulación procesal.

En definitiva, la nueva regulación supone un paso importante a la hora de articular el proceso de transformación digital de la Administración de Justicia a partir de un modelo de gestión basado en los datos. Sin embargo, las singularidades competenciales y organizativas propias de este ámbito requieren de un modelo de gobernanza singular. Por esta razón se ha contemplado un marco institucional de cooperación especifico cuyo eficaz funcionamiento resulta esencial para la puesta en marcha de las previsiones legales y, en definitiva, para abordar los retos, dificultades y oportunidades que plantean los datos abiertos y la reutilización de la información del sector público en el ámbito judicial. Unos retos que es necesario afrontar decididamente para que la modernización tecnológica de la Administración de Justicia facilite su efectiva transformación digital.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Unión Europea ha situado la transformación digital del sector público en el centro de su agenda política. A través de diversas iniciativas, encuadradas dentro del programa político la Década Digital, la UE busca impulsar la eficiencia de los servicios públicos y ofrecer una mejor experiencia a los ciudadanos. Un objetivo para el que es fundamental el intercambio de datos e información de manera ágil entre instituciones y países.
Es aquí donde cobra importancia la interoperabilidad y la busca de nuevas soluciones para impulsarla. Las tecnologías emergentes como la inteligencia artificial (IA), suponen grandes oportunidades en este campo, gracias a su capacidad para analizar y procesar enormes cantidades de datos.
Un informe para analizar el estado de la cuestión
Ante este contexto, la Comisión Europea ha publicado un extenso y exhaustivo informe titulado “Artificial Intelligence for Interoperability in the European Public Sector”, donde ofrece un análisis sobre cómo la IA ya están mejorando la interoperabilidad en el sector público europeo. El informe se divide en tres partes:
- Una revisión bibliográfica y política sobre las sinergias entre AI y la interoperabilidad. En ella se destaca el trabajo legislativo llevado a cabo por la UE. Se resalta la Ley sobre la Europa Interoperable que busca establecer una estructura de gobernanza e impulsar un ecosistema de soluciones reutilizables e interoperables para la administración pública. También se menciona la Ley de Inteligencia Artificial, diseñada para garantizar que los sistemas de IA utilizados en la UE sean seguros, transparentes, trazables, no discriminatorios y respetuosos con el medio ambiente.
- El informe continúa con un análisis cuantitativo de 189 casos de uso. Para seleccionar estos casos, se ha tenido en cuenta el inventario realizado en el informe “AI Watch. Panorama europeo del uso de la Inteligencia Artificial por el sector público” que incluye 686 ejemplos, actualizado a 720 recientemente.
- Un estudio cualitativo que profundiza en algunos de los casos anteriores. En concreto, se han caracterizado siete casos de uso (dos de e
sllos españoles), con un objetivo exploratorio. Es decir, se busca extraer conocimiento sobre los retos a afrontar de la interoperabilidad y cómo pueden ayudar las soluciones basadas en la IA a ello.
Conclusiones del estudio
La IA se está convirtiendo en una herramienta esencial para estructurar, conservar, normalizar y procesar los datos de la administración pública, mejorando la interoperabilidad dentro y fuera de la misma. Una tarea que ya realizan muchas organizaciones.
De entre todos los casos de uso de IA en el sector público analizados en el estudio, el 26% estaban relacionados con la interoperabilidad. Estas herramientas se utilizan para mejorar la interoperabilidad operando en diferentes niveles: técnico, semántico, jurídico y organizativo. Un mismo sistema de IA puede operar en distintas capas.
- La capa semántica de la interoperabilidad es la más relevante (91% de los casos). El uso de ontologías y taxonomías para crear un lenguaje común, combinado con la IA, puede ayudar a establecer la interoperabilidad semántica entre diferentes sistemas. Un ejemplo es el proyecto EPISA60, que se basa en procesamiento del lenguaje natural, utilizando reconocimiento de entidades y aprendizaje automático para explorar documentos digitales.
- En segundo lugar, se encuentra la capa organizativa, con un 35% de casos. Se destaca el uso de IA para la armonización de políticas, modelos de gobernanza y reconocimiento mutuo de datos, entre otros. En este sentido, el Ministerio de Justicia de Austria lanzó el proyecto JustizOnline que integra varios sistemas y procesos relacionados con la impartición de justicia.
- El 33% de los casos se centraba en la capa jurídica. En este caso se busca que el intercambio de datos se realice cumpliendo con los requisitos legales sobre protección de datos y privacidad. La Comisión Europea está elaborando un estudio para explorar cómo puede utilizarse la IA para verificar la transposición de la legislación de la UE por parte de los Estados miembros. Para ello se comparan distintos artículos de las leyes con ayuda de una IA.
- Por último, está la capa técnica, con un 21% de casos. En este campo, la IA puede ayudar al intercambio de datos de forma fluida y segura. Un ejemplo es el trabajo realizado en el centro de investigación belga VITO, basado en técnicas de codificación/decodificación y transporte de datos con IA.
En concreto, las tres acciones más comunes que los sistemas basados en IA realizan para impulsar la interoperabilidad de los datos son: detectar información (42%), estructurarla (22%) y clasificarla (16%). En la siguiente tabla, extraída del informe, se pueden ver todas las actividades detalladas:
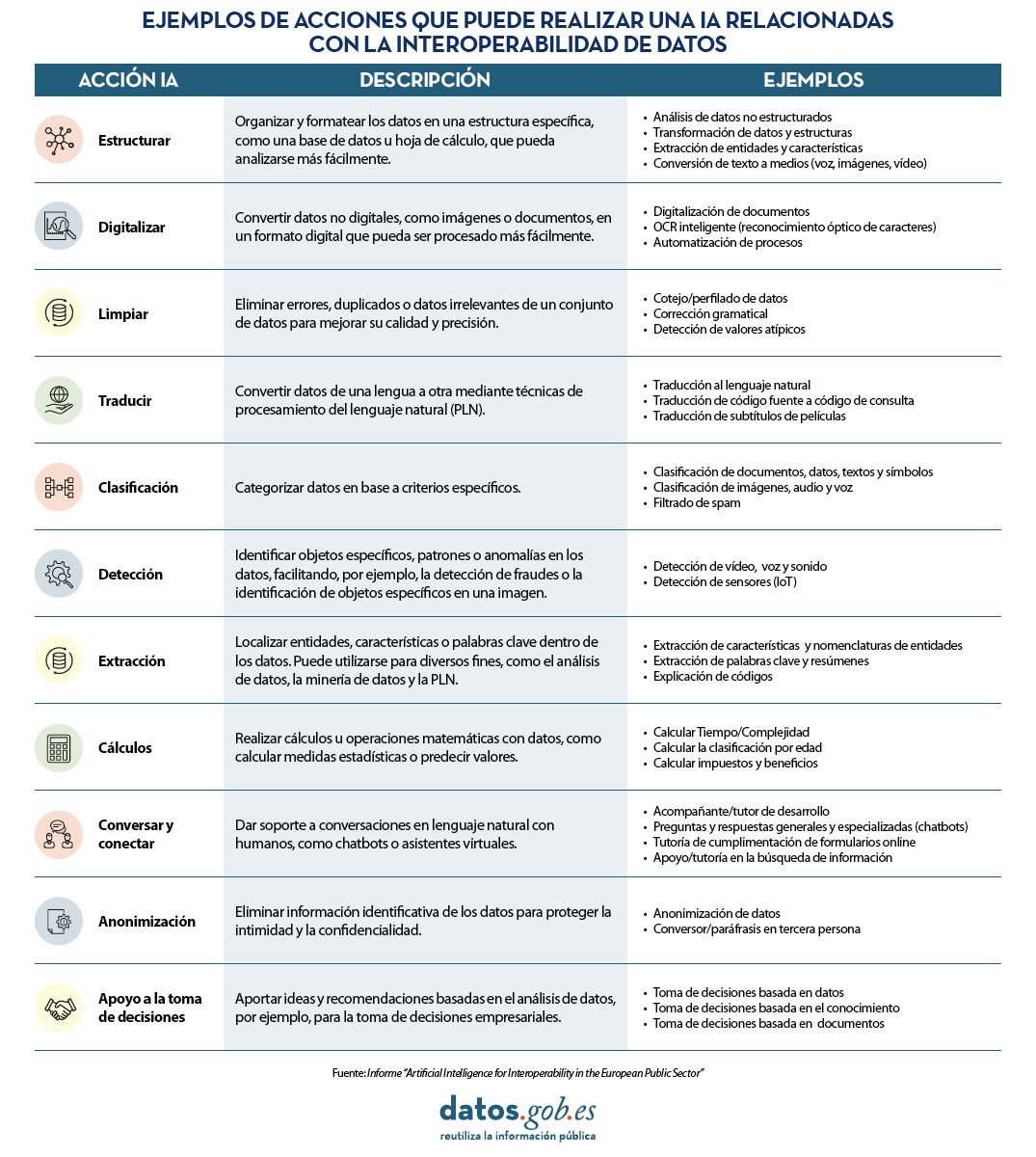
Descarga aquí la versión accesible de la tabla
El informe también analiza el uso de IA en áreas concretas. Destaca su uso en “servicios públicos generales” (41%), seguido de “orden público y seguridad” (17%) y “asuntos económicos” (16%). Con respecto a sus beneficios, destaca la simplificación administrativa (59%), seguido de la evaluación de la eficacia y la eficiencia (35%) y la preservación de la información (27%).
Casos de uso de IA en España
En la tercera parte del informe se analizan en detalle casos de uso concretos de soluciones basadas en IA que han ayudado a mejorar la interoperabilidad del sector público. De las siete soluciones caracterizadas, dos son de España:
- Vulnerabilidad energética - evaluación automatizada del informe sobre pobreza energética. Cuando las empresas proveedoras de servicios de energía detectan impagos, antes de cortar el servicio deben consultar con el ayuntamiento para determinar si el usuario se encuentra en situación de vulnerabilidad social, en cuyo caso no se le pueden cortar los suministros. Los ayuntamientos reciben mensualmente listados de las compañías en diferentes formatos y tienen que pasar por un costoso proceso burocrático manual para validar si un ciudadano está en riesgo social o económico. Para solucionar este reto, la Administració Oberta de Catalunya (AOC) ha desarrollado una herramienta que automatiza el proceso de verificación de datos mejorando la interoperabilidad entre las empresas, los municipios y otras administraciones.
- Transcripciones automatizadas para agilizar los procedimientos judiciales. En el País Vasco, las transcripciones de juicios por parte de la administración se realizan revisando manualmente los vídeos de todas las sesiones. Por lo tanto, no es posible buscar fácilmente palabras, frases, etc. Esta solución convierte los datos de voz en texto automáticamente, lo que permite realizar búsquedas y ahorrar tiempo.
Recomendaciones
El informe finaliza con una serie de recomendaciones sobre lo que deberían hacer las administraciones públicas:
- Aumentar la concienciación interna sobre las posibilidades de la IA para mejorar la interoperabilidad. A través de la experimentación, podrán descubrir los beneficios y el potencial de esta tecnología.
- Enfocar la adopción de una solución IA como un proyecto complejo con implicaciones no solo técnicas, sino también organizativas, legales, éticas, etc.
- Crear las condiciones óptimas para una colaboración efectiva entre agencias públicas. Para ello es necesaria una comprensión común de los retos a afrontar, con el fin de facilitar el intercambio de datos y la integración de los diferentes sistemas y servicios.
- Promover el uso de ontologías y taxonomías uniformes y estandarizadas para crear un lenguaje común y una comprensión compartida de los datos que ayuden a establecer la interoperabilidad semántica entre sistemas.
- Evaluar las legislaciones actuales, tanto en las primeras etapas de experimentación como durante la implementación de una solución de IA, de manera regular. También se debe considerar la posibilidad de colaborar con actores externos para evaluar la adecuación del marco jurídico. En este sentido, el informe también incluye recomendaciones para las próximas actualizaciones políticas de la UE.
- Apoyar la mejora de las competencias de los especialistas en IA e interoperabilidad dentro de la administración pública. Se busca que las tareas críticas de supervisión de los sistemas de IA queden dentro de la organización.
La interoperabilidad es uno de los motores clave del gobierno digital, ya que permite el intercambio fluido de datos y procesos, fomentando la colaboración eficaz. La IA puede ayudar a automatizar tareas y procesos, reducir costes y mejorar la eficiencia. Por eso es recomendable impulsar su adopción por los organismos públicos de todos los niveles.
Blog
¿Qué retos afrontan los publicadores de datos?
En la era digital actual, la información es un activo estratégico que impulsa la innovación, la transparencia y la colaboración en todos los sectores de la sociedad. Es por ello por lo que las iniciativas de publicación de datos han experimentado un enorme desarrollo como mecanismo fundamental para desbloquear el potencial de estos datos, permitiendo que gobiernos, organizaciones y ciudadanos accedan, utilicen y compartan.
No obstante, existen aún muchos retos tanto para publicadores de datos como para consumidores de los mismos. Aspectos como el mantenimiento de las APIs (Application Programming Interfaces) que nos permiten acceder y consumir los conjuntos de datos publicados o la correcta replicación y sincronización de conjuntos de datos cambiantes siguen siendo desafíos muy relevantes para estos actores.
En este post, exploraremos cómo los Linked Data Event Streams (LDES), un nuevo mecanismo de publicación de datos, pueden ayudarnos a solventar estos retos. ¿Qué es exactamente LDES? ¿Cómo difiere de las prácticas tradicionales de publicación de datos? Y, lo más importante, ¿cómo puede ayudar a publicadores y consumidores de datos a facilitar el uso de los conjuntos de datos disponibles?
Destilando los aspectos claves de LDES
Cuando desde la Universidad de Gante se comenzó a trabajar en un nuevo mecanismo para la publicación de datos abiertos, la pregunta a la que pretendían dar respuesta era: ¿Cuál es la mejor API posible que podemos diseñar para exponer conjuntos de datos abiertos?
En la actualidad, los organismos publicadores de datos recurren a múltiples mecanismos para publicar sus diferentes conjuntos de datos. Por un lado, es fácil encontrarnos APIs. Destacan las de tipo SPARQL, estándar para consulta de datos enlazados (Link Data), pero también de tipo REST o de tipo WFS, para el acceso a conjuntos de datos con componente geoespacial. Por otro lado, es muy común que encontremos la posibilidad de acceder a volcados de datos en diferentes formatos (i.e. CSV, JSON, XLS, etc.) que podamos descargar para su utilización.
En el caso de los volcados de datos, es muy fácil encontrarnos con problemas de sincronización. Esto ocurre cuando, tras un primer volcado, se produce un cambio que requiere la modificación del conjunto de datos original como, por ejemplo, el cambio del nombre de una calle en un callejero previamente descargado. Ante este cambio, si el tercero opta por modificar el nombre de la calle sobre el volcado inicial en lugar de esperar a que el publicador actualice sus datos en el repositorio maestro para realizar un nuevo volcado, los datos manejados por el tercero quedarán desincronizados frente a los manejados por el publicador. De igual forma, si es el publicador el que actualiza su repositorio maestro pero estos cambios no son descargados por el tercero, ambos manejarán diferentes versiones del conjunto de datos.
Por otra parte, si el publicador ofrece el acceso a los datos a través de APIs de consulta, en lugar de mediante volcados de los datos a los terceros, se solucionan los problemas de sincronización, pero la construcción y mantenimiento de un alto y variado volumen de las mismas supone un elevado esfuerzo a los publicadores de datos.
LDES busca solventar estas diferentes problemáticas aplicando el concepto de Linked Data a un event stream o flujo de datos. Según la definición que aparece en su propia especificación, un Linked Data Event Stream (LDES) es una colección de objetos inmutables donde cada objeto está descrito en ternas RDF.
En primer lugar, el hecho de que los LDES apuesten por Linked Data aporta principios de diseño que permiten combinar datos diversos y/o pertenecientes a diferentes fuentes, así como su consulta a través de mecanismos semánticos que permiten legibilidad tanto por humanos como por máquinas. En resumen, aporta interoperabilidad y consistencia entre conjuntos de datos, y facilita por tanto su búsqueda y descubrimiento.
Por otro lado, los event streams o flujos de datos, permiten a los consumidores replicar la historia de los conjuntos de datos, así como sincronizar los cambios recientes. Cualquier nuevo registro añadido a un conjunto de datos o cualquier modificación de los registros existentes (en definitiva, cualquier cambio), se registra como un nuevo evento incremental en el LDES que no alterará los eventos anteriores. Por tanto, pueden publicarse y consumirse datos como una secuencia de eventos, lo cual es útil para datos que cambian con frecuencia, como información en tiempo real o información que sufre actualizaciones constantes, ya que permite la sincronización de las últimas actualizaciones sin necesidad de hacer una nueva descarga completa de todo el repositorio maestro tras cada modificación.
En un modelo de este tipo, el editor solo necesitará desarrollar y mantener una API, el LDES, en lugar de múltiples APIs como WFS, REST o SPARQL. Los diferentes terceros que deseen utilizar los datos publicados se conectarán (cada tercero implementará su cliente LDES) y recibirán los eventos de los streams a los que se hayan suscrito. Cada tercero creará a partir de la información recabada las APIs específicas que considere oportunas en base al tipo de aplicaciones que quieran desarrollar o fomentar. En definitiva, el publicador no tendrá que resolver todas las potenciales necesidades que tenga cada tercero en la publicación de datos, sino que dando un interfaz LDES (API base mínima) cada tercero se centrará en su problemática.
Además, para facilitar el acceso en grandes volúmenes de datos o a datos que pueden estar distribuidos en diferentes fuentes, como un inventario de puntos de recarga eléctrica en Europa, LDES aporta la capacidad de fragmentación de los conjuntos de datos. A través de la especificación TREE (en inglés, árbol), LDES permite establecer diferentes tipos de relaciones entre fragmentos de datos. Esta especificación permite publicar colecciones de entidades, llamados miembros, y ofrece la capacidad de generar una o más representaciones de estas colecciones. Estas representaciones se organizan como vistas, distribuyendo los miembros a través de páginas o nodos interconectados mediante relaciones. Así, si deseamos que los datos se puedan consultar a través de índices temporales, se podrá establecer una fragmentación temporal y acceder solo a las páginas de un intervalo temporal. De igual forma, se podrán plantear índices alfabéticos o geoespaciales y así un consumidor podrá acceder sólo a aquellos datos necesarios sin la necesidad de realizar el “volcado” del conjunto de datos completo.
¿Qué conclusiones podemos extraer de LDES?
En este post hemos observado el potencial de LDES como mecanismo para la publicación de datos. Algunos de los aprendizajes más relevantes son:
- LDES persigue facilitar la publicación de datos a través de APIs base mínimas que sirvan como punto de conexión para cualquier tercero que desee consultar o construir aplicaciones y servicios sobre conjuntos de datos.
- La construcción de un servidor LDES, no obstante, tiene cierto nivel de complejidad técnica a la hora de establecer la arquitectura necesaria para el manejo de los flujos de datos publicados y su adecuada consulta por parte de consumidores de datos.
- El diseño de LDES permite la gestión tanto de datos con una elevada tasa de cambios (i.e. datos provenientes de sensores), como datos con una baja tasa de cambios (i.e. datos provenientes de un callejero). Ambos escenarios pueden manejar cualquier modificación del conjunto de datos como un flujo de datos.
- LDES soluciona de forma eficiente la gestión de registros históricos, versiones y fragmentos de conjuntos de datos. Para ello se apoya en la especificación TREE pudiendo establecer diferentes tipos de fragmentación sobre el mismo conjunto de datos.
¿Te gustaría saber más?
Dejamos a continuación algunas referencias que han servido para redactar este post y pueden servir al lector que desee profundizar en el mundo de LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Unión Europea tiene como objetivo potenciar la Economía del Dato, impulsando el flujo libre de datos entre los estados miembros y entre sectores estratégicos, en beneficio de empresas, investigadores, administraciones públicas y ciudadanos. Sin duda, los datos son un factor crítico en la revolución industrial y tecnológica que estamos viviendo, y por ello una de las prioridades digitales de la UE pasa por capitalizar su valor latente, apoyándose para ello en un mercado único donde estos puedan compartirse bajo condiciones de seguridad, y sobre todo de soberanía, pues sólo así se garantizarán los indiscutibles valores y derechos europeos.
Así, la Estrategia Europea de Datos busca potenciar su intercambio a gran escala, bajo entornos distribuidos y federados, pero que sin embargo garanticen la ciberseguridad y la transparencia. Para lograr escala, y liberar todo el potencial de los datos en la economía digital, un elemento fundamental es la generación de confianza. Esta, como elemento basal que condiciona la liquidez del ecosistema, debe desarrollarse coherentemente a lo largo de diferentes ámbitos y entre diferentes actores (proveedores de datos, usuarios, intermediarios, plataformas de servicios, desarrolladores, …). Por ende, su articulación afecta a diferentes perspectivas, incluida la de negocio y funcional, la legal y regulatoria, la operacional, e incluso la tecnológica. Por tanto, el éxito en estos proyectos de alta complejidad pasa por desarrollar estrategias que busquen minimizar las barreras de entrada a los participantes, y maximizar la eficacia y sostenibilidad de los servicios ofrecidos. Esto a su vez se traduce en el desarrollo de infraestructuras y modelos de gobernanza para los datos que sean fácilmente escalables, y que sirvan de base para un intercambio efectivo de datos con que generar valor para todos sus participantes.
Una metodología para impulsar los espacios de datos
España ha hecho suyo el cometido de llevar a la práctica esa estrategia europea, y desde hace años se trabaja en crear el entorno propicio para facilitar el despliegue y asentamiento de una Economía del Dato Soberana, apoyándose, entre otros instrumentos, en el Plan de Recuperación, Transformación y Resiliencia. En este sentido, y desde su papel coordinador y posibilista, la Oficina del Dato ha desplegado esfuerzos en el diseño de una metodología conceptual general, agnóstica a un sector concreto. Esta configura la creación de ecosistemas de datos alrededor de proyectos prácticos que aporten valor a los miembros de dicho ecosistema.
Por ello, la metodología consta de varios elementos, siendo la experimentación uno de ellos. Esto es así debido a que, por su naturaleza flexible, los datos pueden ser tratados, modelizados, y por ende interpretados, desde distintas perspectivas. Por este motivo, la experimentación resulta clave para calibrar adecuadamente aquellos procesos y tratamientos necesarios para llegar al mercado con pilotos o casos de negocio ya cercanos a las industrias, de modo que estén más cerca a generar un impacto positivo. En este sentido, se hace necesario demostrar el valor tangible y apuntalar su sostenibilidad, lo que implica contar, como mínimo, con:
- Marcos de referencia para una gobernanza efectiva de datos
- Actuaciones para mejorar la disponibilidad y la calidad de los datos, buscando también incrementar su interoperabilidad por diseño
- Herramientas y plataformas de intercambio y explotación de datos.
Así mismo, y dado que cada sector tiene su propia especificidad en lo que respecta a tipos y semánticas de datos, modelos de negocio, y necesidades de los participantes, la creación de comunidades de expertos, representando la voz del mercado, es otro elemento fundamental de cara a generar proyectos de utilidad. En base a esta escucha activa, que conduzca a la compresión de las dinámicas del dato en cada sector, se logra caracterizar las condiciones de mercado y de gobernanza necesarias para el despliegue de los espacios de datos en sectores estratégicos como el turismo, la movilidad, agroalimentación, comercio, salud o la industria.
En este proceso de generación de comunidad, las cooperativas de datos juegan un papel fundamental, así como la figura más general del intermediario de datos, que sirve para sensibilizar sobre la oportunidad existente y favorecer la creación y consolidación efectiva de estos nuevos modelos de negocio.
Todos estos elementos son distintas piezas de un puzle con que explorar nuevas oportunidades de desarrollo de negocio, así como para el diseño de proyectos tangibles con que demostrar el valor diferencial que la compartición de datos aportará a la realidad de las industrias. Así, y desde la perspectiva operativa, el último elemento de la metodología es el desarrollo de casos de uso concretos. Estos también permitirán desplegar iterativamente un catálogo de experiencias y recursos de datos reutilizables en cada sector, con que facilitar la construcción de nuevos proyectos. Este catálogo se convierte así en la pieza central de una plataforma común sectorial y federada, y cuya arquitectura distribuida facilita también la interconexión intersectorial.
Sobre hombros de gigantes
Hay que destacar que España no parte de cero, pues cuenta ya con un potente ecosistema de innovación y experimentación en datos, que ofrece servicios avanzados. Creemos por tanto interesante progresar en la armonización o complementariedad de sus objetivos, así como en la difusión de sus capacidades para ganar capilaridad. Además, la metodología planteada refuerza el alineamiento con los proyectos europeos del mismo ámbito, lo que servirá para conectar los aprendizajes y avances desde la escala nacional a los realizados a nivel UE, así como para poner en práctica las tareas de diseño de los "cianotipos" promulgados por la Comisión Europea a través del Data Spaces Support Centre.
Por último, el impulso de proyectos experimentales o piloto permite también el desarrollo de estándares para tecnologías innovadoras de datos, guardando una estrecha relación con el proyecto Gaia-X. Así, el Hub Gaia-X España cuenta con un nodo de interoperabilidad, que sirve para certificar el cumplimiento de las reglas prescritas por cada sector, y por ende para generar la citada confianza digital en base a sus necesidades específicas.
Desde la Oficina del Dato, creemos que la interconexión y la escalabilidad a futuro de los proyectos de datos se encuentran en el centro del esfuerzo de implementación de la Estrategia Europea de Datos, y resultan cruciales para alcanzar una Economía del Dato dinámica y rica, pero a su vez garante de los valores europeos y donde la trazabilidad y la transparencia ayuden a colectivizar el valor del dato, catalizando una economía más fuerte y cohesionadora.
Blog
El almacenamiento de datos en la nube es actualmente uno de los segmentos de software empresarial que experimenta un crecimiento más rápido, lo que está facilitando la incorporación de un gran número de nuevos usuarios al campo de la analítica.
Como ya presentamos en un post anterior, un nuevo formato, Parquet, tiene entre sus objetivos potenciar y avanzar en la analítica para esta comunidad en rápido crecimiento y facilitar la interoperabilidad entre diversos almacenes de datos en la nube y motores informáticos.
Parquet es descrito por su propio creador, Apache, como: “Un formato de archivo de datos de código abierto diseñado para el almacenamiento y la recuperación eficiente de datos. Proporciona un rendimiento mejorado para manejar datos complejos de forma masiva".
Parquet se define como un formato de datos orientado a columnas que se plantea como una alternativa moderna a los archivos CSV. A diferencia de los formatos basados en filas, como el CSV, Parquet almacena los datos en función de columnas, lo que implica que los valores de cada columna de la tabla se almacenan contiguamente, en lugar de los valores de cada registro, como se muestra a continuación:
Este método de almacenamiento presenta ventajas en términos de almacenamiento compacto y consultas rápidas en comparación con los formatos clásicos. Parquet funciona eficazmente en los conjuntos de datos desnormalizados que contienen muchas columnas y permite consultar estos datos de manera más rápida y eficiente.
En agosto de 2023 se lanzó un nuevo formato para datos espaciales: el GeoParquet 1.0.0. Durante ese mismo mes, el Open Geospatial Consortium (OGC) informó sobre la formación de un nuevo Grupo de Trabajo de Estándares GeoParquet, cuyo objetivo es promover la adopción de este formato como un estándar de codificación OGC para datos vectoriales nativos en la nube.
GeoParquet 1.0.0 corrige algunas carencias de Parquet, que no ofrecía un buen soporte de datos espaciales. Igualmente la interoperabilidad en los entornos de la nube era compleja para los datos geoespaciales, porque al no existir un estándar o directrices sobre cómo almacenar los datos geográficos, estoseran interpretados de diferente manera por cada sistema. Esto conllevaba dos resultados significativos:
- No era posible exportar datos espaciales de un sistema e importarlos a otro sin un procesamiento significativo entre ellos.
· Los proveedores de datos no podían compartir sus datos en un formato unificado. Si deseaban habilitar a los usuarios en diferentes sistemas, debían admitir las diversas variaciones de soporte espacial en los diferentes motores.
Estas deficiencias han sido solventadas con GeoParquet que, además agrega tipos geoespaciales al formato Parquet, al mismo tiempo que establece una serie de estándares para varios aspectos claves en la representación de datos espaciales:
· Columnas que contienen datos espaciales: se permite tener múltiples columnas que contengan datos espaciales (Punto, Línea y Polígono), con la designación de una columna como "principal".
· Codificación de geometría/geografía: define cómo se codifica la información de geometría o geografía. Inicialmente se utiliza una codificación en binario conocida y Well-known text (WKT) , pero se está trabajando para implementar GeoArrow como una nueva forma de codificación.
· Sistema de referencia espacial: especifica en qué sistema de referencia espacial se encuentran los datos. La especificación es compatible con varios sistemas de referencia de coordenadas alternativos.
· Tipo de coordenadas: define si las coordenadas son planas o esféricas, proporcionando información sobre la geometría y naturaleza de las coordenadas utilizadas.
A esto, hay que añadir que GeoParquet incluye metadatos en dos niveles:
- Metadatos de archivo que indican atributos como la versión de esta especificación utilizada.
- Metadatos de columna con características adicionales para cada geometría como son: sistema de referencia espacial, tipo de geometría, resolución de la geometría, etc.
Otra característica que hace que GeoParquet se esté convirtiendo en un formato muy recomendable, es que es más rápido y ligero que otros más extendidos. La siguiente comparativa muestra el tamaño en distintos formatos (GeoParquet, shaperfile y geopackage) de un mismo archivo con edificios en CSV de un tamaño de 498 megabytes. Se transforma este fichero a estos formatos y se muestra gráficamente el resultado:
Fuente: Comparación de un mismo conjunto de datos en distintos formatos. Elaboración propia.
La reducción de tamaño para los datos en Geoparquet es notoria. La principal razón detrás de esto es que Parquet se comprime de forma predeterminada. Si bien otros formatos también pueden comprimirse, no se pueden utilizar directamente hasta que se descompriman. Además, se ha optimizado significativamente su rendimiento, contribuyendo así a su eficiencia en el procesamiento de datos espaciales.
Es aquí donde cobra vital importancia GeoParquet, al establecer una forma común de codificar y describir datos espaciales. Esto facilita la creación y compartición de datos espaciales en la nube, reduciendo la complejidad y los costos asociados. Asimismo, permite el intercambio de datos entre sistemas sin necesidad de transformaciones intermedias, convirtiendo a GeoParquet en un potencial formato de distribución geoespacial nativo de la nube y un recurso invaluable para cualquier tarea geoespacial cotidiana.
Estos estándares son fundamentales para garantizar la consistencia, interoperabilidad y comprensión uniforme de los datos espaciales, lo que facilita su manejo y uso en una variedad de aplicaciones y un conjunto variado de herramientas modernas de ciencia de datos, como BigQuery, DuckDB, R, Python, GeoPandas, GDAL, entre otras, que utilizan Parquet de manera efectiva y que están incorporando cada vez más capacidades de soporte geoespacial. Dentro del ecosistema GIS, tanto ArcGIS, FME y QGIS (a partir de la versión 3.28) ya cuentan con el soporte para este formato, permitiendo su carga así como la transformación de los datos a GeoParquet.
GeoParquet, ha sido ampliamente celebrado por las empresas dedicadas al análisis espacial: Carto, Google BigQuery, Planet, entre otras. Porque les permiten ampliar y mejorar su integración en el campo de la analítica espacial.
El lanzamiento en agosto de 2023 fue de la versión 1.0.0, pero en la hoja de ruta del proyecto se anuncian nuevas mejoras para la versión 2.0.0:
- Objetos 3D: GeoParquet tiene como objetivo incluir el soporte de coordenadas 3D.
- Particiones de datos espaciales: GeoParquet tiene como requisitos futuros el crear particiones geoespaciales para cargar datos de manera eficiente desde el datalake.
· Mejorar la especificación de datos espaciales: Incluyendo GeoArrow como codificación de los datos espaciales. Esto supondría un gran avance porque los datos espaciales en la actualidad pueden ser sólo de una tipología: o son puntos, o son líneas o son polígonos. GeoArrow permitiría almacenar varios tipos en una misma geometría.
· Índices: para obtener el mejor rendimiento posible, los índices espaciales son esenciales para encontrar más rápido aquello que buscamos y para agilizar las consultas a los datos.
GeoParquet es, en definitiva, un interesante formato ya que establece una forma común de codificar y describir datos espaciales, facilitando la creación y compartición en la nube, de una manera más eficiente que otros formatos. Permaneceremos atentos a las novedades de este formato de datos espaciales.
Referencias
- Especificación GeoParquet: https://geoparquet.org/releases/v1.0.0-beta.1/
- Especificación GeoParquet OGC: https://github.com/opengeospatial/geoparquet/
_________________________________________________________
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.