Documentación
La Agencia Española de Protección de Datos ha publicado recientemente la traducción al español de la Guía sobre generación de datos sintéticos, elaborada originalmente por la Autoridad de Protección de Datos de Singapur. Este documento ofrece orientación técnica y práctica para personas responsables, encargadas y delegadas de protección de datos sobre cómo implementar esta tecnología que permite simular datos reales manteniendo sus características estadísticas sin comprometer información personal.
La guía destaca cómo los datos sintéticos pueden impulsar la economía del dato, acelerar la innovación y mitigar riesgos en brechas de seguridad. Para ello, presenta casos prácticos, recomendaciones y buenas prácticas orientadas a reducir los riesgos de reidentificación. En este post, analizamos los aspectos clave de la Guía destacando casos de uso principales y ejemplos de aplicación práctica.
¿Qué son los datos sintéticos? Concepto y beneficios
Los datos sintéticos son datos artificiales generados mediante modelos matemáticos específicamente diseñados para sistemas de inteligencia artificial (IA) o aprendizaje automático (ML). Estos datos se crean entrenando un modelo con un conjunto de datos de origen para imitar sus características y estructura, pero sin replicar exactamente los registros originales.
Los datos sintéticos de alta calidad conservan las propiedades estadísticas y los patrones de los datos originales. Por lo tanto, permiten realizar análisis que produzcan resultados similares a los que se obtendrían con los datos reales. Sin embargo, al ser artificiales, reducen significativamente los riesgos asociados con la exposición de información sensible o personal.
Para profundizar en este tema, tienes disponible este Informe monográfico sobre datos sintéticos: ¿Qué son y para qué se usan? con información detallada sobre los fundamentos teóricos, metodologías y aplicaciones prácticas de esta tecnología.
La implementación de datos sintéticos ofrece múltiples ventajas para las organizaciones, por ejemplo:
- Protección de la privacidad: permiten realizar análisis de datos manteniendo la confidencialidad de la información personal o comercialmente sensible.
- Cumplimiento normativo: facilitan el seguimiento de regulaciones de protección de datos mientras se maximiza el valor de los activos de información.
- Reducción de riesgos: minimizan las posibilidades de brechas de datos y sus consecuencias.
- Impulso a la innovación: aceleran el desarrollo de soluciones basadas en datos sin comprometer la privacidad.
- Mejora en la colaboración: posibilitan compartir información valiosa entre organizaciones y departamentos de forma segura.
Pasos para generar datos sintéticos
Para implementar correctamente esta tecnología, la Guía sobre generación de datos sintéticos recomienda seguir un enfoque estructurado en cinco pasos:
- Conocer los datos: comprender claramente el propósito de los datos sintéticos y las características de los datos de origen que deben preservarse, estableciendo objetivos precisos respecto al umbral de riesgo aceptable y la utilidad esperada.
- Preparar los datos: identificar las ideas clave que deben conservarse, seleccionar los atributos relevantes, eliminar o seudonimizar identificadores directos, y estandarizar los formatos y estructuras en un diccionario de datos bien documentado.
- Generar datos sintéticos: seleccionar los métodos más adecuados según el caso de uso, evaluar la calidad mediante comprobaciones de integridad, fidelidad y utilidad, y ajustar iterativamente el proceso para lograr el equilibrio deseado.
- Evaluar riesgos de reidentificación: aplicar técnicas basadas en ataques para determinar la posibilidad de inferir información sobre individuos o su pertenencia al conjunto original, asegurando que los niveles de riesgo sean aceptables.
- Gestionar riesgos residuales: implementar controles técnicos, de gobernanza y contractuales para mitigar los riesgos identificados, documentando adecuadamente todo el proceso.
Aplicaciones prácticas y casos de éxito
Para obtener todas estas ventajas, los datos sintéticos pueden aplicarse en diversos escenarios que responden a necesidades específicas de las organizaciones. La Guía menciona, por ejemplo:
1. Generación de conjuntos de datos para entrenar modelos de IA/ML: los datos sintéticos resuelven el problema de la escasez de datos etiquetados (es decir, que se pueden utilizar) para entrenar modelos de IA. Cuando los datos reales son limitados, los datos sintéticos pueden ser una alternativa rentable. Además, permiten simular eventos extraordinarios o incrementar la representación de grupos minoritarios en los conjuntos de entrenamiento. Una aplicación interesante para mejorar el rendimiento y la representatividad de todos los grupos sociales en los modelos de IA.
2. Análisis de datos y colaboración: este tipo de datos facilitan el intercambio de información para análisis, especialmente en sectores como la salud, donde los datos originales son particularmente sensibles. Tanto en este sector como en otros, proporcionan a las partes interesadas una muestra representativa de los datos reales sin exponer información confidencial, permitiendo evaluar la calidad y potencial de los datos antes de establecer acuerdos formales.
3. Pruebas de software: son muy útiles para el desarrollo de sistemas y la realización de pruebas de software porque permiten utilizar datos realistas, pero no reales en entornos de desarrollo, evitando así posibles brechas de datos personales en caso de comprometerse el entorno de desarrollo.
La aplicación práctica de datos sintéticos ya está demostrando resultados positivos en diversos sectores:
I. Sector financiero: detección de fraudes. J.P. Morgan ha utilizado con éxito datos sintéticos para entrenar modelos de detección de fraude, creando conjuntos de datos con un mayor porcentaje de casos fraudulentos que permitieron mejorar significativamente la capacidad de los modelos para identificar comportamientos anómalos.
II. Sector tecnológico: investigación sobre sesgos en IA. Mastercard colaboró con investigadores para desarrollar métodos de prueba de sesgos en IA mediante datos sintéticos que mantenían las relaciones reales de los datos originales, pero eran lo suficientemente privados como para compartirse con investigadores externos, permitiendo avances que no habrían sido posibles sin esta tecnología.
III. Sector salud: salvaguarda de datos de pacientes. Johnson & Johnson implementó datos sintéticos generados por IA como alternativa a las técnicas tradicionales de anonimización para procesar datos sanitarios, logrando una mejora significativa en la calidad del análisis al representar eficazmente a la población objetivo mientras se protegía la privacidad de los pacientes.
El equilibrio entre utilidad y protección
Es importante destacar que los datos sintéticos no están inherentemente libres de riesgos. La semejanza con los datos originales podría, en determinadas circunstancias, permitir la filtración de información sobre individuos o datos confidenciales. Por ello, resulta crucial encontrar un equilibrio entre la utilidad de los datos y su protección.
Este equilibrio puede lograrse mediante la implementación de buenas prácticas durante el proceso de generación de datos sintéticos, incorporando medidas de protección como:
- Preparación adecuada de los datos: eliminación de valores atípicos, seudonimización de identificadores directos y generalización de datos granulares.
- Evaluación de riesgos de reidentificación: análisis de la posibilidad de que se puedan vincular los datos sintéticos con individuos reales.
- Implementación de controles técnicos: añadir ruido a los datos, reducir la granularidad o aplicar técnicas de privacidad diferencial.
Los datos sintéticos representan una oportunidad excepcional para impulsar la innovación basada en datos mientras se respeta la privacidad y se cumple con las normativas de protección de datos. Su capacidad para generar información estadísticamente representativa pero artificial los convierte en una herramienta versátil para múltiples aplicaciones, desde el entrenamiento de modelos de IA hasta la colaboración entre organizaciones y el desarrollo de software.
Al implementar adecuadamente las buenas prácticas y controles descritos en Guía sobre generación de datos sintéticos que ha traducido la AEPD, las organizaciones pueden aprovechar los beneficios de los datos sintéticos minimizando los riesgos asociados, posicionándose a la vanguardia de la transformación digital responsable. La adopción de tecnologías de mejora de la privacidad como los datos sintéticos no solo representa una medida defensiva, sino un paso proactivo hacia una cultura organizacional que valora tanto la innovación como la protección de datos, aspectos fundamentales para el éxito en la economía digital del futuro.
Blog
A medida que las organizaciones buscan aprovechar el potencial de los datos para tomar decisiones, innovar y mejorar sus servicios, surge un desafío fundamental: ¿cómo se puede equilibrar la recolección y el uso de datos con el respeto a la privacidad? Las tecnologías PET intentan dar solución a ese reto. En este post, exploraremos qué son y cómo funcionan.
¿Qué son las tecnologías PET?
Las tecnologías PET son un conjunto de medidas técnicas que utilizan diversos enfoques para la protección de la privacidad. El acrónimo PET viene de los términos en inglés “Privacy Enhancing Technologies” que se pueden traducir como “tecnologías de mejora de la privacidad”.
De acuerdo con la Agencia de la Unión Europea para la Ciberseguridad (ENISA) este tipo de sistemas protege la privacidad mediante:
- La eliminación o reducción de datos personales.
- Evitando el procesamiento innecesario y/o no deseado de datos personales.
Todo ello, sin perder la funcionalidad del sistema de información. Es decir, gracias a ellas se puede utilizar datos que de otra manera permanecerían sin explotar, ya que limita los riesgos de revelación de datos personales o protegidos, cumpliendo con la legislación vigente.
Relación entre utilidad y privacidad en datos protegidos
Para comprender la importancia de las tecnologías PET, es necesario abordar la relación que existe entre utilidad y privacidad del dato. La protección de datos de carácter personal siempre supone pérdida de utilidad, bien porque limita el uso de los datos o porque implica someterles a tantas transformaciones para evitar identificaciones que pervierte los resultados. La siguiente gráfica muestra cómo a mayor privacidad, menor es la utilidad de los datos.
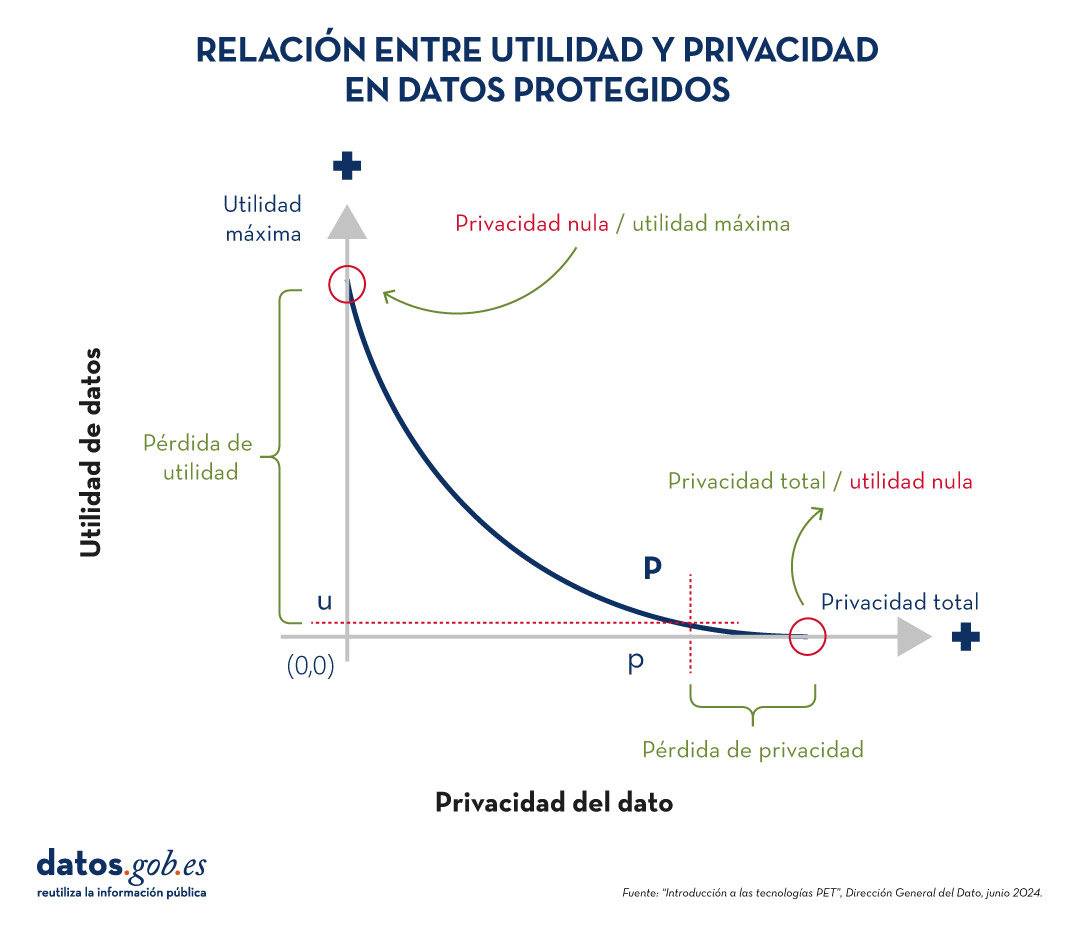
Figura 1. Relación entre utilidad y privacidad en datos protegido. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Las técnicas PET permiten alcanzar un compromiso entre privacidad y utilidad más favorable. No obstante, hay que tener en cuenta que siempre existirá cierta limitación de la utilidad cuando explotamos datos protegidos.
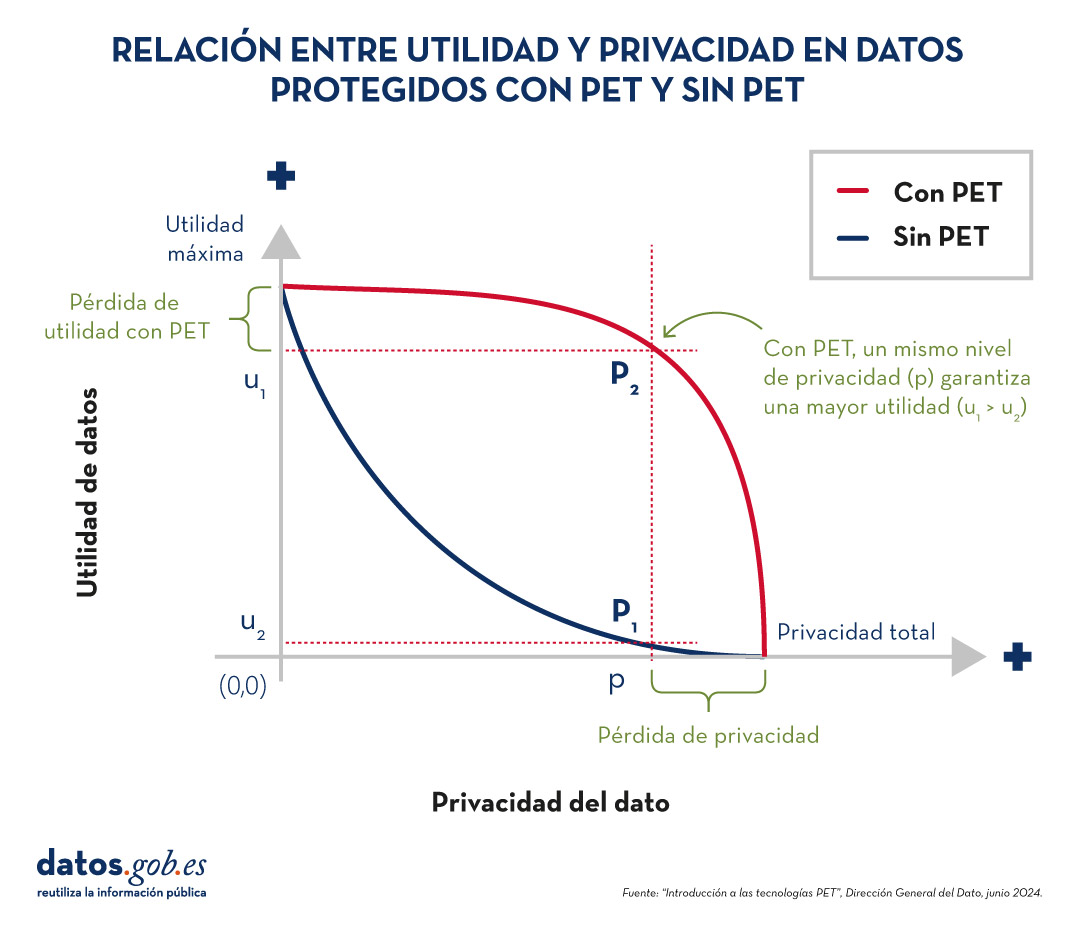
Figura 2. Relación entre utilidad y privacidad en datos protegidos con PET y sin PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Técnicas PET más populares
Para aumentar la utilidad y poder explotar datos protegidos limitando los riesgos, es necesario aplicar una serie de técnicas PET. El siguiente esquema, recoge algunas de las principales:
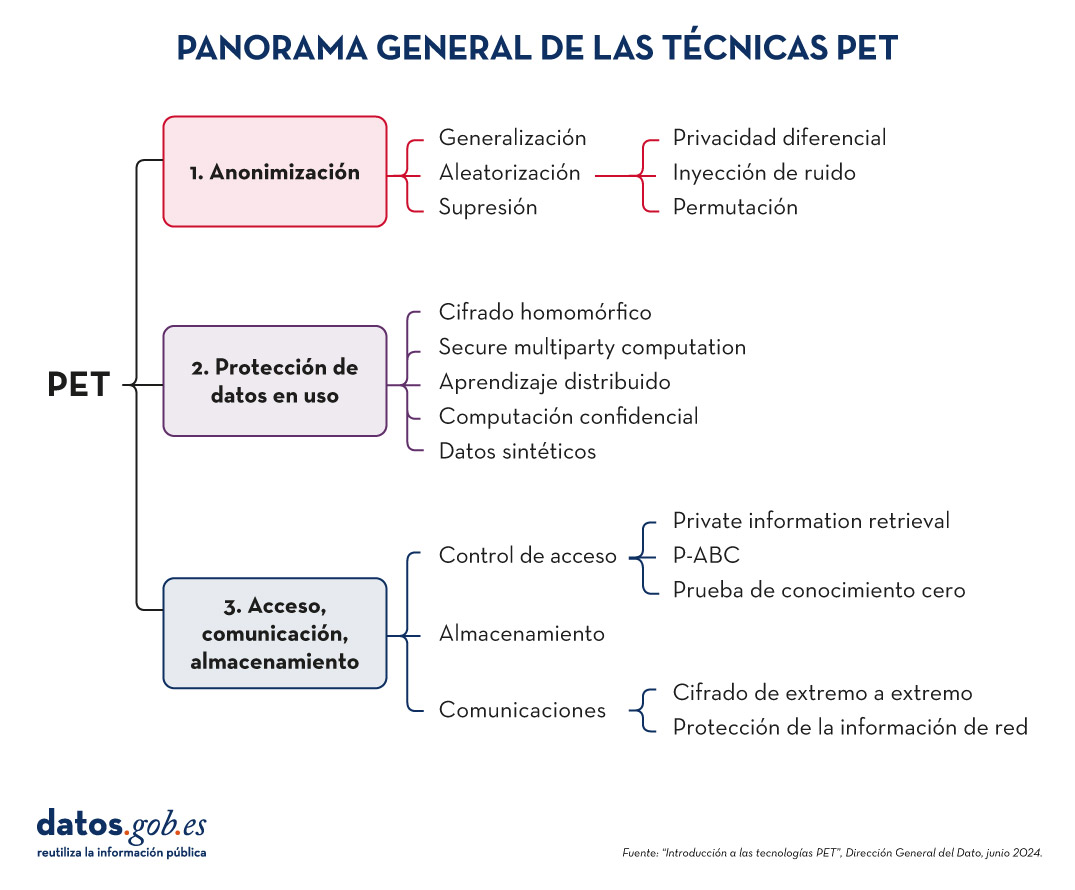
Figura 3. Panorama general de las técnicas PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Como veremos a continuación, estas técnicas abordan distintas fases del ciclo de vida de los datos.
-
Antes de la explotación de los datos: anonimización
La anonimización consiste en transformar conjuntos de datos de carácter privado para que no se pueda identificar a ninguna persona. De esta forma, ya no les aplica el Reglamento General de Protección de Datos (RGPD).
Es importante garantizar que la anonimización se ha realizado de forma efectiva, evitando riesgos que permitan la reidentificación a través de técnicas como la vinculación (identificación de un individuo mediante el cruzado de datos), la inferencia (deducción de atributos adicionales en un dataset), la singularización (identificación de individuos a partir de los valores de un registro) o la composición (pérdida de privacidad acumulada debida a la aplicación reiterada de tratamientos). Para ello, es recomendable combinar varias técnicas, las cuales se pueden agrupar en tres grandes familias:
- Aleatorización: supone modificar los datos originales al introducir un elemento de azar. Esto se logra añadiendo ruido o variaciones aleatorias a los datos, de manera que se preserven patrones generales y tendencias, pero se haga más difícil la identificación de individuos.
- Generalización: consiste en reemplazar u ocultar valores específicos de un conjunto de datos por valores más amplios o menos precisos. Por ejemplo, en lugar de registrar la edad exacta de una persona, se podría utilizar un rango de edades (como 35-44 años).
- Supresión: implica eliminar completamente ciertos datos del conjunto, especialmente aquellos que pueden identificar a una persona de manera directa. Es el caso de los nombres, direcciones, números de identificación, etc.
Puedes profundizar sobre estos tres enfoques generales y las diversas técnicas que los integran en la guía práctica “Introducción a la anonimización de datos: técnicas y casos prácticos”. También recomendamos la lectura del artículo malentendidos comunes en la anonimización de datos.
2. Protección de datos en uso
En este apartado se abordan técnicas que salvaguardan la privacidad de los datos durante la aplicación de tratamientos de explotación.
-
Cifrado homomórfico: es una técnica de criptografía que permite realizar operaciones matemáticas sobre datos cifrados sin necesidad de descifrarlos primero. Por ejemplo, un cifrado será homomórfico si se cumple que, si se cifran dos números y se realiza una suma en su forma cifrada, el resultado cifrado, al ser descifrado, será igual a la suma de los números originales.
- Computación Segura Multipartita (Secure Multiparty Computation o SMPC): es un enfoque que permite que múltiples partes colaboren para realizar cálculos sobre datos privados sin revelar su información a los demás participantes. Es decir, permite que diferentes entidades realicen operaciones conjuntas y obtengan un resultado común, mientras mantienen la confidencialidad de sus datos individuales.
- Aprendizaje distribuido: tradicionalmente, los modelos de machine learning aprenden de forma centralizada, es decir, requieren reunir todos los datos de entrenamiento procedentes de múltiples fuentes en un único conjunto de datos a partir del cual un servidor central elabora el modelo que se desea. En el caso del aprendizaje distribuido, los datos no se concentran en un solo lugar, sino que permanecen en diferentes ubicaciones, dispositivos o servidores. En lugar de trasladar grandes cantidades de datos a un servidor central para su procesamiento, el aprendizaje distribuido permite que los modelos de machine learning se entrenen en cada una de estas ubicaciones, integrando y combinando los resultados parciales para obtener un modelo final.
- Computación confidencial y entornos de computación de confianza (Trusted Execution Environments o TEE): la computación confidencial se refiere a un conjunto de técnicas y tecnologías que permiten procesar datos de manera segura dentro de entornos de hardware protegidos y certificados, conocidos como entornos de computación de confianza.
- Datos sintéticos: son datos generados artificialmente que imitan las características y patrones estadísticos de datos reales sin representar a personas o situaciones específicas. Reproducen las propiedades relevantes de los datos reales, como distribución, correlaciones y tendencias, pero sin información que permita identificar a individuos o casos específicos. Puedes aprender más sobre este tipo de datos en el informe Datos sintéticos: ¿Qué son y para qué se usan?.
3. Acceso, comunicación y almacenamiento
Las técnicas PET no solo abarcan la explotación de los datos. Entre ellas también encontramos procedimientos dirigidos a asegurar el acceso a recursos, la comunicación entre entidades y el almacenamiento de datos, garantizando siempre la confidencialidad de los participantes. Algunos ejemplos son:
Técnicas de control de acceso
- Recuperación Privada de Información (Private information retrieval o PIR): es una técnica criptográfica que permite a un usuario consultar una base de datos o servidor sin que este último pueda saber qué información está buscando el usuario. Es decir, asegura que el servidor no conozca el contenido de la consulta, preservando así la privacidad del usuario.
- Credenciales Basadas en Atributos con Privacidad (Privacy-Attribute Based Credentials o P-ABC): es una tecnología de autenticación que permite a los usuarios demostrar ciertos atributos o características personales (como la mayoría de edad o la ciudadanía) sin revelar su identidad. En lugar de mostrar todos sus datos personales, el usuario presenta solo aquellos atributos necesarios para cumplir con los requisitos de la autenticación o autorización, manteniendo así su privacidad.
- Prueba de conocimiento cero (Zero-Knowledge Proof o ZKP): es un método criptográfico que permite a una parte demostrar a otra que posee cierta información o conocimiento (como una contraseña) sin revelar el propio contenido de ese conocimiento. Este concepto es fundamental en el ámbito de la criptografía y la seguridad de la información, ya que permite la verificación de información sin la necesidad de exponer datos sensibles.
Técnicas de comunicaciones
- Cifrado extremo a extremo (End to End Encryption o E2EE): esta técnica protege los datos mientras se transmiten entre dos o más dispositivos, de forma que solo los participantes autorizados en la comunicación pueden acceder a la información. Los datos se cifran en el origen y permanecen cifrados durante todo el trayecto hasta que llegan al destinatario. Esto significa que, durante el proceso, ningún individuo u organización intermediaria (como proveedores de internet, servidores de aplicaciones o proveedores de servicios en la nube) puede acceder o descifrar la información. Una vez que llegan a destino, el destinatario es capaz de descifrarlos de nuevo.
- Protección de información de Red (Proxy & Onion Routing): un proxy es un servidor intermediario entre el dispositivo de un usuario y el destino de la conexión en internet. Cuando alguien utiliza un proxy, su tráfico se dirige primero al servidor proxy, que luego reenvía las solicitudes al destino final, permitiendo el filtrado de contenidos o el cambio de direcciones IP. Por su parte, el método Onion Routing protege el tráfico en internet a través de una red distribuida de nodos. Cuando un usuario envía información usando Onion Routing, su tráfico se cifra varias veces y se envía a través de múltiples nodos, o "capas" (de ahí el nombre "onion", que significa "cebolla" en inglés).
Técnicas de almacenamiento
- Almacenamiento garante de la confidencialidad (Privacy Preserving Storage o PPS): su objetivo es proteger la confidencialidad de los datos en reposo e informar a los custodios de los datos de una posible brecha de seguridad, utilizando técnicas de cifrado, acceso controlado, auditoría y monitoreo, etc.
Estos son solo algunos ejemplos de tecnologías PET, pero hay más familias y subfamilias. Gracias a ellas, contamos con herramientas que nos permiten extraer valor de los datos de forma segura, garantizando la privacidad de los usuarios. Datos que pueden ser de gran utilidad en múltiples sectores, como la salud, el cuidado del medio ambiente o la economía.
Documentación
En la era de los datos, nos enfrentamos al desafío de la escasez de datos de valor para la construcción de nuevos productos y servicios digitales. Aunque vivimos en una época en la que los datos están por todas partes, a menudo nos encontramos con dificultades para acceder a datos de calidad que nos permitan comprender procesos o sistemas desde una perspectiva basada en datos. La falta de disponibilidad, la fragmentación, la seguridad y la privacidad son solo algunas de las razones que dificultan el acceso a datos reales.
Sin embargo, los datos sintéticos han surgido como una solución prometedora a este problema. Los datos sintéticos son información fabricada artificialmente que imita las características y distribuciones de los datos reales, sin contener información personal o sensible. Estos datos se generan mediante algoritmos y técnicas que preservan la estructura y las propiedades estadísticas de los datos originales.
Los datos sintéticos son útiles en diversas situaciones donde la disponibilidad de datos reales es limitada o se requiere proteger la privacidad de las personas involucradas. Tienen aplicaciones en la investigación científica, pruebas de software y sistemas, y entrenamiento de modelos de inteligencia artificial. Permiten a los investigadores explorar nuevos enfoques sin acceder a datos sensibles, a los desarrolladores probar aplicaciones sin exponer datos reales y a los expertos en IA entrenar modelos sin la necesidad de recopilar todos los datos del mundo real que en ocasiones son, simplemente, imposibles de capturar en tiempos y costes asumibles.
Existen diferentes métodos para generar datos sintéticos, como el remuestreo, el modelado probabilístico y generativo, y los métodos de perturbación y enmascaramiento. Cada método tiene sus ventajas y desafíos, pero en general, los datos sintéticos ofrecen una alternativa segura y confiable para el análisis, la experimentación y el entrenamiento de modelos de inteligencia artificial.
Es importante destacar que el uso de datos sintéticos ofrece una solución viable para superar las limitaciones de acceso a datos reales y abordar preocupaciones de privacidad y seguridad. Los datos sintéticos permiten realizar pruebas, entrenar algoritmos y desarrollar aplicaciones sin exponer información confidencial. Sin embargo, es fundamental garantizar la calidad y la fidelidad de los datos sintéticos mediante evaluaciones rigurosas y comparaciones con los datos reales.
En este informe, abordamos de forma introductoria la disciplina de los datos sintéticos, ilustrando algunos casos de uso de valor para los diferentes tipos de datos sintéticos que se pueden generar. Los vehículos autónomos, la secuenciación de ADN o los controles de calidad en las cadenas de producción son solo algunos de los casos que detallamos en este informe. Además, hemos destacado el uso del software open-source SDV (Synthetic Data Vault), desarrollado en el entorno académico del MIT, que utiliza algoritmos de aprendizaje automático para crear datos sintéticos tabulares que imitan las propiedades y distribuciones de los datos reales. Desarrollamos un ejemplo práctico, en un entorno de Google Colab para generar datos sintéticos sobre clientes ficticios alojados en un hotel ficticio. Hemos seguido un flujo de trabajo que involucra la preparación de datos reales y metadatos, el entrenamiento del sintetizador y la generación de datos sintéticos basados en los patrones aprendidos. Además, hemos aplicado técnicas de anonimización para proteger los datos sensibles y hemos evaluado la calidad de los datos sintéticos generados.
En resumen, los datos sintéticos son una herramienta poderosa en la era de los datos, ya que nos permiten superar la escasez y la falta de disponibilidad de datos de valor. Con su capacidad para imitar los datos reales sin comprometer la privacidad, los datos sintéticos tienen el potencial de transformar la forma en que desarrollamos proyectos de inteligencia artificial y análisis. A medida que avanzamos en esta nueva era, es probable que los datos sintéticos desempeñen un papel cada vez más importante en la generación de nuevos productos y servicios digitales.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
En esta infografía se resume el concepto y sus principales aplicaciones:

Puedes descargarla en PDF aquí
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.
Blog
En la etapa protagonizada por la inteligencia artificial que estamos comenzando, los datos abiertos se han convertido por derecho propio en un activo cada vez más valioso no sólo como soporte a la transparencia, sino también para el progreso de la innovación y el desarrollo tecnológico en general.
La apertura de datos ha traído enormes beneficios al brindar acceso público a conjuntos de datos que habilitan el impulso de iniciativas de transparencia gubernamental, que estimulan investigaciones científicas y que promueven la innovación en sectores tan variados como la salud, la educación, la agricultura, o la lucha contra el cambio climático.
Sin embargo, a medida que aumenta la disponibilidad de datos, también lo hace la preocupación por la privacidad ya que la exposición y tratamiento indebido de datos personales puede poner en peligro la privacidad de las personas. ¿Qué herramientas tenemos para mantener el equilibrio entre el acceso abierto a la información y la protección de los datos personales para garantizar la privacidad de las personas en un futuro que ya es digital?
Anonimización y pseudonimización
Para abordar estas preocupaciones, se han desarrollado técnicas como la anonimización y pseudonimización que con frecuencia se confunden. La anonimización se refiere al proceso por el que se modifica un conjunto de datos para que no exista una probabilidad razonable de que pueda identificarse a una persona física en el mismo. Es importante destacar que, en este caso, después del tratamiento, el conjunto de datos anonimizado ya no estaría bajo el ámbito de aplicación del Reglamento General de Protección de Datos (RGPD). En este informe de datos.gob.es se analizan tres enfoques generales para la anonimización de datos: aleatorización, generalización y seudonimización.
Por su parte, la pseudonimización es el proceso de reemplazar atributos identificables con pseudónimos o identificadores ficticios de forma que los datos no puedan atribuirse a la persona física sin utilizar información adicional. El tratamiento de pseudonimización genera dos nuevos conjuntos de datos: el que contiene la información pseudonimizada y el que contiene la información adicional que permite revertir la anonimización. El conjunto de datos pseudonimizados y la información adicional vinculada con dicho conjunto de datos sí están bajo el ámbito de aplicación del Reglamento General de Protección de Datos (RGPD). Además, se requiere que dicha información adicional esté independizada y sujeta a medidas técnicas y organizativas destinadas a garantizar que los datos personales no se atribuyan a una persona física.
Consentimiento
Otro aspecto clave para garantizar la privacidad es el cada vez más presente consentimiento “inequívoco” de los interesados por el que las personas manifiestan ser conscientes y estar de acuerdo con cómo se tratarán sus datos antes de que estos se compartan o utilicen. Es necesario que las organizaciones y las entidades que recopilan datos proporcionen políticas de privacidad claras y comprensibles pero cada vez más se pone de manifiesto la necesidad de una mayor educación en materia de tratamiento de datos que ayude a las personas a comprender mejor sus derechos y que garantice decisiones más informadas.
En respuesta a la creciente necesidad de gestionar adecuadamente estos consentimientos, han surgido soluciones tecnológicas que buscan simplificar y mejorar el proceso para los usuarios. Estas soluciones conocidas como plataformas de gestión de los consentimientos (CMP, por sus siglas en inglés), nacieron originalmente en el ámbito del sector salud y permiten a las organizaciones recopilar, almacenar y rastrear los consentimientos de los usuarios de una manera más eficiente y transparente. Estas herramientas ofrecen interfaces amigables y visualmente atractivas que facilitan la comprensión de qué datos se están recopilando y con qué propósito. Pero, sobre todo, estas plataformas proporcionan a los usuarios la posibilidad de modificar o retirar su consentimiento en cualquier momento, otorgándoles un mayor control sobre sus datos personales.
Entrenamientos de inteligencia artificial
El entrenamiento de modelos de inteligencia artificial (IA) se perfila como uno de los campos más desafiantes en materia de gestión de la privacidad por la multitud de dimensiones que es necesario tener en cuenta. A medida que la IA continúa evolucionando y se integra más profundamente en nuestra vida cotidiana, la necesidad de entrenar modelos con grandes cantidades de datos aumenta, como han puesto de manifiesto los vertiginosos avances en materia de IA generativa del último año. Sin embargo, esta práctica a menudo se enfrenta a profundos dilemas éticos y de privacidad ya que los datos de mayor valor en algunos escenarios no son en absoluto abiertos.
Los avances en tecnologías como el aprendizaje federado, que permite entrenar algoritmos de IA a través de una arquitectura descentralizada formada por múltiples dispositivos los cuales contienen sus propios datos locales y privados, son parte de la solución a este desafío. De este modo, no se intercambian datos de forma explícita, algo que es clave en aplicaciones de salud, defensa o farmacia.
Asimismo, están ganando tracción técnicas como la privacidad diferencial que permite garantizar, mediante la incorporación de ruido aleatorio, aplicando funciones matemáticas a la información original, que en el resultado del proceso de análisis de los datos a los que se ha aplicado esta técnica no hay pérdida en la utilidad de los resultados obtenidos.
Web3
Pero si algún avance promete revolucionar nuestra interacción en internet, otorgando mayor control y propiedad a los usuarios sobre sus datos, este sería la web3 ya que, en este nuevo paradigma, la gestión de la privacidad es inherente a su propio diseño. Con la integración de tecnologías como la cadena de bloques (blockchain), los contratos inteligentes (smart contracts) y las organizaciones autónomas descentralizadas, la web3 busca proporcionar a los individuos un control total sobre su identidad y todos sus datos, eliminando intermediarios y potencialmente reduciendo puntos de vulnerabilidad a la privacidad.
A diferencia de las plataformas centralizadas actuales, donde los datos de los usuarios a menudo son “propiedad” o están controlados por empresas privadas, la web 3.0 aspira a que cada persona sea dueña y gestora de su propia información. No obstante, esta descentralización también plantea desafíos por lo que es esencial que, mientras se despliega esta nueva era de la web, se desarrollen herramientas y protocolos robustos que garanticen tanto la libertad como la privacidad de los usuarios en el entorno digital.
La privacidad en la era de los datos abiertos, la inteligencia artificial y la web3 obliga, sin duda, a trabajar con equilibrios delicados que a menudo son inestables. Por ello, un nuevo conjunto de soluciones tecnológicas, fruto de la colaboración entre gobiernos, empresas y ciudadanos, será esencial para mantener este equilibrio y garantizar que, mientras disfrutamos de los beneficios de un mundo cada vez más digital, también seamos capaces de proteger los derechos fundamentales de las personas.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La anonimización de datos es un proceso complejo y habitualmente propenso a malentendidos. En el peor de los casos, estos errores de concepto conllevan la fuga de datos personales (data leakage), afectando directamente a las garantías que deberían ofrecerse a los usuarios con respecto a su privacidad.
La anonimización tiene por objetivo convertir los datos en anónimos, evitando la reidentificación de los individuos. Sin embargo, la mera aplicación de técnicas de anonimización no garantiza el anonimato de los datos. El riesgo principal se mide precisamente por la probabilidad de reidentificación, es decir, la probabilidad de que se identifique a un individuo dentro de un conjunto de datos.
La mayoría de los ataques realizados sobre conjuntos de datos anonimizados tratan de explotar debilidades comunes en el proceso, normalmente mediante el uso de datos complementarios. Un ejemplo muy conocido es el caso del conjunto de datos publicado por Netflix en 2007, donde a partir de los datos obtenidos de Internet Movie Database (IMDb), dos investigadores de la Universidad de Texas fueron capaces de identificar a los usuarios y vincularlos con sus posibles preferencias políticas y otros datos sensibles.
Pero estos fallos no sólo afectan a empresas privadas, a mediados de los 90, el Dr. Sweeney fue capaz de re-identificar registros médicos del Gobernador de Massachusetts, quién había asegurado que el conjunto de datos publicados era seguro. Más adelante, en el año 2000, el mismo investigador demostró que era posible re-identificar al 87% de los habitantes de Estados unidos con sólo conocer su código postal, fecha de nacimiento el sexo.
A continuación, veremos algunos ejemplos habituales de malentendidos que es importante evitar si queremos abordar un proceso de anonimización de forma adecuada.
No siempre es posible anonimizar un conjunto de datos
La anonimización de datos es un proceso diseñado a medida, para cada fuente de datos y para cada estudio o caso de uso a desarrollar. En ocasiones, el riesgo de reidentificación puede ser inasumible o el conjunto de datos resultante podría no tener la utilidad suficiente. Dependiendo del contexto concreto y los requisitos establecidos, la anonimización podría no ser viable.
Sin embargo, un error común es pensar que siempre es factible anonimizar un conjunto de datos, cuando realmente depende del nivel de garantías requerido o la utilidad necesaria para el caso de estudio.
La automatización y reutilización de procesos de anonimización es limitada
Aunque es posible automatizar algunas partes del proceso, otras fases requieren la intervención manual de un experto. Es especial, no existen herramientas que permitan evaluar de forma fiable la utilidad del conjunto de datos resultante para un escenario concreto, o la detección de posibles identificadores indirectos a partir de fuentes externas de datos.
De igual modo, no es recomendable reutilizar procesos de anonimización aplicados sobre fuentes de datos diferentes. Los condicionantes varían en cada caso concreto, siendo crítico evaluar el volumen de datos disponible, la existencia de fuentes de datos complementarias y el público objetivo.
La anonimización no es ni permanente ni absoluta
Debido a la posible aparición de nuevos datos o el desarrollo de nuevas técnicas, el riesgo de reidentificación aumenta con el paso del tiempo. El nivel de anonimización se debe medir en una escala, no es un concepto binario, donde normalmente la anonimización no puede considerarse absoluta, porque no es posible asumir un nivel de riesgo nulo.
La seudonimización no es lo mismo que la anonimización
En concreto, esta técnica consiste en modificar los valores de atributos clave (como identificadores) por otros valores que no estén vinculados al registro original.
El problema principal es que sigue existiendo la posibilidad de vincular a la persona física de manera indirecta a partir de datos adicionales, haciendo que sea un proceso reversible. De hecho, normalmente el responsable del tratamiento de datos preserva la capacidad de deshacer dicho proceso.
El cifrado no es una técnica de anonimización, sino de seudonimización
El cifrado de datos se enmarca en la seudonimización, en este caso reemplazando los atributos clave por versiones cifradas. La información adicional sería la clave de cifrado, custodiada por el responsable del tratamiento de los datos.
El ejemplo más conocido es el conjunto de datos publicado en 2013 por la Comisión de Taxis y Limusinas de la ciudad de Nueva York. Entre otros datos, contenía ubicaciones de recogida y destino, horarios y en especial el número de licencia cifrado. Posteriormente se descubrió que era relativamente sencillo deshacer el cifrado e identificar a los conductores.
Conclusiones
Existen otros lugares comunes que dan lugar a malentendidos respecto a la anonimización, como el equívoco generalizado sobre la pérdida total de la utilidad de un conjunto de datos anonimizado, o la falta de interés por la reidentificación de datos personales.
La anonimización es un proceso técnicamente complejo, que requiere de la participación de perfiles especializados y técnicas avanzadas de análisis de datos. Un proceso sólido de anonimización, evalúa el riesgo de reidentificación y define las pautas para gestionarlo a lo largo del tiempo.
A cambio, la anonimización permite compartir más fuentes de datos, de forma más segura y preservando su utilidad en multitud de escenarios, con especial hincapié en el análisis de datos de salud y estudios de investigación que habilitan el avance de la ciencia a nuevos niveles.
Si quieres profundizar en esta materia te invitamos a leer la guia de Introducción a la anonimización de datos: Técnicas y casos prácticos, la cual incluye un conjunto de ejemplos prácticos. El código y los datos utilizados en el ejercicio, están disponibles en Github.
Contenido elaborado por José Barranquero, experto en Ciencia de Datos y Computación Cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La anonimización de datos define la metodología y el conjunto de buenas prácticas y técnicas que reducen el riesgo de identificación de personas, la irreversibilidad del proceso de anonimización y la auditoría de la explotación de los datos anonimizados, monitorizando quién, cuándo y para qué se usan.
Este proceso es fundamental, tanto cuando hablamos de datos abiertos como de datos en general, para proteger la privacidad de las personas, garantizando el cumplimiento normativo y de los derechos fundamentales.
El informe “Introducción a la anonimización de datos: Técnicas y casos prácticos”, elaborado por Jose Barranquero, define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
El objetivo del informe es ofrecer una introducción suficiente y concisa, principalmente orientada a publicadores de datos que necesitan garantizar la privacidad de estos. No se trata de una guía exhaustiva, sino una primera toma de contacto para entender los riesgos y técnicas disponibles, así como la complejidad inherente a cualquier proceso de anonimización de datos.
¿Qué técnicas se incluyen en el informe?
Tras una introducción donde se definen los términos más relevantes y los principios básicos de anonimización, el informe se centra en comentar tres enfoques generales para la anonimización de datos, cada uno de los cuales está integrado a su vez por diversas técnicas:
- Aleatorización: tratamiento de datos, eliminando la correlación con el individuo, mediante la adición de ruido, la permutación, o la Privacidad Diferencial.
- Generalización: alteración de escalas u órdenes de magnitud a través de técnicas basadas en agregación como Anonimato-K, Diversidad-L, o Proximidad-T.
- Seudonimización: reemplazo de valores por versiones cifradas o tokens, habitualmente a través de algoritmos de HASH, que impiden la identificación directa del individuo, a menos que se combine con otros datos adicionales, que deben estar custodiados de forma adecuada.
El documento describe cada una de estas técnicas, así como los riesgos que suponen, aportando recomendaciones para evitarlos. Si bien, la decisión final sobre qué técnica o conjunto de técnicas es más adecuada depende de cada caso particular.
El informe finaliza con un conjunto de ejemplos prácticos sencillos que muestran la aplicación de las técnicas Anonimato-K y seudonimización mediante cifrado con borrado de clave. Para simplificar la ejecución del caso, se pone a disposición de los usuarios el código y los datos utilizados en el ejercicio, disponibles en Github. Para seguir el ejercicio, es recomendable tener unos conocimientos mínimos del lenguaje pyhton.
A continuación, puedes descargar el informe completo, así como el resumen ejecutivo y una presentación-resumen.
Entrevista
Hace unos meses, la compañía Facebook nos sorprendió a todos con un cambio de nombre: se convirtió en Meta. Este cambio alude al concepto de "metaverso" que la marca quiere desarrollar, uniendo el mundo real y el virtual, conectando personas y comunidades.
Dentro de las iniciativas enmarcadas en Meta, se encuentra Data for Good, centrada en la compartición de datos preservando la privacidad de las persona. Helene Verbrugghe, Public Policy Manager para España y Portugal de Meta ha hablado con datos.gob.es para contarnos más sobre los datos que compartir y su utilidad para el avance de la economía y la sociedad.
Entrevista completa:
1. ¿Qué tipos de datos se ofrecen a través de la Iniciativa Data for Good?
El equipo de Data For Good de Meta ofrece diferentes herramientas que incluyen mapas, encuestas y datos para ayudar a nuestros cerca de 600 partners en todo el mundo, que son desde grandes instituciones de la ONU como UNICEF y la Organización Mundial de la Salud, hasta universidades locales en España como la Universitat Poliècnica de Catalunya y la Universidad de Valencia.
Para apoyar la respuesta internacional a la COVID-19, se han utilizado en gran medida datos como los incluidos en nuestros Mapas de Rango de Movimiento para medir la eficacia de las medidas de permanencia en casa, y en nuestra Encuesta de Tendencias e Impacto de la COVID-19 para comprender cuestiones como la reticencia a la vacunación e informar sobre las campañas de divulgación. Otras herramientas, como nuestros mapas de densidad de población de alta resolución, han servido para elaborar planes de electrificación rural e inversiones quinquenales en agua y saneamiento en lugares como Ruanda y Zambia. También contamos con mapas de pobreza basados en IA que han ayudado a ampliar la protección social en Togo y un índice de conectividad social internacional que ha sido útil para comprender el comercio transfronterizo y los flujos financieros. Por último, recientemente hemos trabajado para apoyar a grupos como la Federación Internacional de la Cruz Roja y la Organización Internacional para las Migraciones en su respuesta a la crisis de Ucrania, proporcionando información agregada sobre los volúmenes de personas que salen del país y llegan a lugares como Polonia, Alemania y Chequia.
La privacidad está integrada en todos nuestros productos por defecto; agregamos y desidentificamos la información de las plataformas de Meta, y no compartimos la información personal de nadie.
2. ¿Cuál es el valor para la ciudadanía y las empresas? ¿Por qué es importante que las compañías privadas compartan sus datos?
La toma de decisiones, sobre todo en política pública, requiere de información lo más exacta posible. A medida que más personas se conectan y comparten contenido online, Meta proporciona una ventana única al mundo. El alcance de la plataforma de Facebook a través de miles de millones de personas en todo el mundo nos permite ayudar a llenar los vacíos de datos clave. Por ejemplo, Meta se encuentra en una posición única para comprender lo que la gente necesita en las primeras horas de una catástrofe o en la conversación pública en torno a una crisis sanitaria, información que es crucial para la toma de decisiones pero que antes no estaba disponible o era demasiado cara para recopilarla a tiempo.
Por ejemplo, para apoyar la respuesta a la crisis en Ucrania, podemos proporcionar información actualizada sobre los cambios de población en los países vecinos casi en tiempo real, de forma más rápida que otras estimaciones. También podemos recopilar datos a escala promoviendo encuestas en Facebook como nuestra Encuesta de Tendencias e Impacto de COVID-19, que se ha utilizado para comprender mejor cómo afectará a la transmisión el comportamiento de uso de mascarillas en 200 países y territorios de todo el mundo.
3. La información que se comparte a través de Data for Good está anonimizada, pero ¿cómo es el proceso? ¿Cómo se garantiza la seguridad y privacidad de los datos de los usuarios?
Data For Good respeta las decisiones de los usuarios de Facebook. Por ejemplo, todas las encuestas de Data For Good son completamente voluntarias. En cuanto a los datos de ubicación que se utilizan para los mapas de Data For Good, los usuarios pueden elegir si quieren compartir esa información desde la configuración del historial de ubicaciones.
También nos esforzamos en compartir cómo protegemos la privacidad publicando blogs sobre nuestros métodos y enfoques. Por ejemplo, puede leer sobre nuestro enfoque de privacidad diferencial para proteger los datos de movilidad utilizados en la respuesta a la COVID-19 aquí.
4. ¿Qué otros retos os habéis encontrado a la hora de poner en marcha una iniciativa de este tipo y cómo los habéis solucionado?
Cuando iniciamos Data For Good, la gran mayoría de nuestros conjuntos de datos sólo estaban disponibles a través de un acuerdo de licencia, lo que suponía un proceso engorroso para algunos socios e inviable para muchos gobiernos. Sin embargo, al comienzo de la pandemia de COVID-19, nos dimos cuenta de que, para poder operar a escala, tendríamos que hacer que una mayor parte de nuestro trabajo fuera de dominio público, incorporando al mismo tiempo medidas estrictas, como la privacidad diferencial, que garantizaran la seguridad. En los últimos años, la mayoría de nuestros conjuntos de datos se han hecho públicos en plataformas como Humanitarian Data Exchange, y a través de esta herramienta y otras API, nuestras herramientas públicas se han consultado más de 55 millones de veces el año pasado. Nos sentimos orgullosos de la evolución hacia el uso compartido del código abierto, que nos ha ayudado a superar las dificultades que teníamos al principio para ampliar y satisfacer la demanda de nuestros datos por parte de los partners en todo el mundo.
5. ¿Cuáles son los planes de futuro de Meta en relación con Data for Good?
Nuestro objetivo es seguir ayudando a nuestros socios a sacar el máximo provecho de nuestras herramientas, al mismo tiempo que seguimos evolucionando y creando nuevas formas de ayudar a resolver problemas del mundo real. En el último año, nos hemos centrado en aumentar nuestro conjunto de herramientas para responder a problemas como el cambio climático mediante iniciativas como nuestra Encuesta de Opinión sobre el Cambio Climático, que se ampliará este año; así como en la evolución de nuestros conocimientos sobre los flujos de población transfronterizos, que están demostrando ser fundamentales para apoyar la respuesta a la crisis en Ucrania.
Blog
Nos encontramos es un momento histórico, donde los datos se han convertido en un activo clave para casi cualquier proceso de nuestra vida cotidiana. Cada vez hay más formas de recoger datos y más capacidad para procesarlos y compartirlos, donde juegan un papel crucial nuevas tecnologías como IoT, Blockchain, Inteligencia Artificial, Big Data y Linked Data.
Tanto cuando hablamos de datos abiertos, como de datos en general, es crítico poder garantizar la privacidad de los usuarios y la protección de sus datos personales, entendidos como derechos fundamentales. Un aspecto que en ocasiones no recibe especial atención a pesar de las rigurosas normativas existentes, como el RGPD.
¿Qué es la anonimización y qué técnicas existen?
La anonimización de datos define la metodología y el conjunto de buenas prácticas y técnicas que reducen el riesgo de identificación de personas, la irreversibilidad del proceso de anonimización y la auditoría de la explotación de los datos anonimizados, monitorizando quién, cuándo y para qué se usan. Es decir, cubre tanto el objetivo de anonimización, como el de mitigación del riesgo de reidentificación, siendo este último un aspecto clave.
Para comprenderlo bien, es necesario hablar de cadena de confidencialidad, un término que incluye el análisis de riesgos específicos para la finalidad del tratamiento a realizar. La rotura de esta cadena implica la posibilidad de reidentificación, es decir de identificar a las personas específicas a las que pertenecen los datos a partir de ellos. Para evitarlo, existen múltiples técnicas de anonimización de datos, que buscan principalmente garantizar el avance de la sociedad de la información sin menoscabar el respeto a la protección de los datos.
Las técnicas de anonimización están enfocadas a identificar y ofuscar microdatos, identificadores indirectos y otros datos sensibles. Cuando hablamos de ofuscar, nos referimos a cambiar o alterar datos sensitivos o que identifican a una persona (personally identifiable information o PII, en inglés), con el objetivo de proteger la información confidencial. En este caso, los microdatos son datos únicos para cada individuo, que pueden permitir su identificación directa (DNI, código de historia clínica, nombre completo, etc). Los datos de identificación indirecta pueden ser cruzados con la misma o diferentes fuentes para identificar a un individuo (sociodemográficos, configuración del navegador, etc). Cabe destacar que son datos sensibles los referidos en el artículo 9 del RGPD (en especial, los datos financieros y médicos).
En general, pueden considerarse varias técnicas de anonimización, sin que la legislación europea contenga ninguna norma prescriptiva, existiendo 4 enfoques generales:
- Aleatorización: alteración de los datos, eliminando la correlación con el individuo, mediante la adición de ruido, la permutación, o la privacidad diferencial (es decir, recoger datos del global de usuarios sin saber a quién corresponde cada dato).
- Generalización: alteración de escalas u órdenes de magnitud a través de técnicas como Agregación/Anonimato-K o Diversidad-l/Proximidad-t.
- Cifrado: ofuscación a través de algoritmos de HASH, con borrado de clave, o procesado directo de datos cifrados a través de técnicas homomórficas. Ambas técnicas pueden ser complementadas con sellos de tiempo o firma electrónica.
- Seudonimización: reemplazo de atributos por versiones cifradas o tokens que impide la identificación directa del individuo. El conjunto sigue considerándose como datos de carácter personal, porque es factible la reidentificación a través de claves custodiadas. impide la identificación directa del individuo. El conjunto sigue considerándose como datos de carácter personal, porque es factible la reidentificación a través de claves custodiadas.
Principios básicos de la anonimización
Al igual que otros procesos de protección de datos, la anonimización debe regirse por el concepto de privacidad desde el diseño y por defecto (Art. 25 del RGPD), teniendo en cuenta 7 principios:
- Proactivo: el diseño debe plantearse desde las etapas iniciales de conceptualización, identificando microdatos, datos de identificación indirecta y datos sensibles, estableciendo escalas de sensibilidad que sean informadas a todos los implicados en el proceso de anonimización.
- Privacidad por defecto: es necesario establecer el grado de detalle o granularidad de los datos anonimizados con el objetivo de preservar la confidencialidad, eliminando variables no esenciales para el estudio a realizar, teniendo en cuenta factores de riesgo y beneficio.
- Objetivo: dada la imposibilidad de una anonimización absoluta, es crítico evaluar el nivel de riesgo de re-identificación asumido y establecer las políticas adecuadas de contingencia.
- Funcional: para garantizar la utilidad del conjunto de datos anonimizado, es necesario definir claramente la finalidad del estudio e informar a los usuarios de los procesos de distorsión empleados para que sean tenidos en cuenta durante su explotación.
- Integral: el proceso de anonimización va más allá de la generación del conjunto de datos, siendo aplicable también durante el estudio de estos, a través de contratos de confidencialidad y uso limitado, validados mediante las auditorías pertinentes durante todo el ciclo de vida.
- Informativo: este es un principio clave, siendo necesario que todos los participantes en el ciclo de vida sean debidamente capacitados e informados respecto a su responsabilidad y los riegos asociados.
- Atómico es recomendable, en la medida de lo posible, que el equipo de trabajo se defina con personas independientes para cada función dentro del proceso.
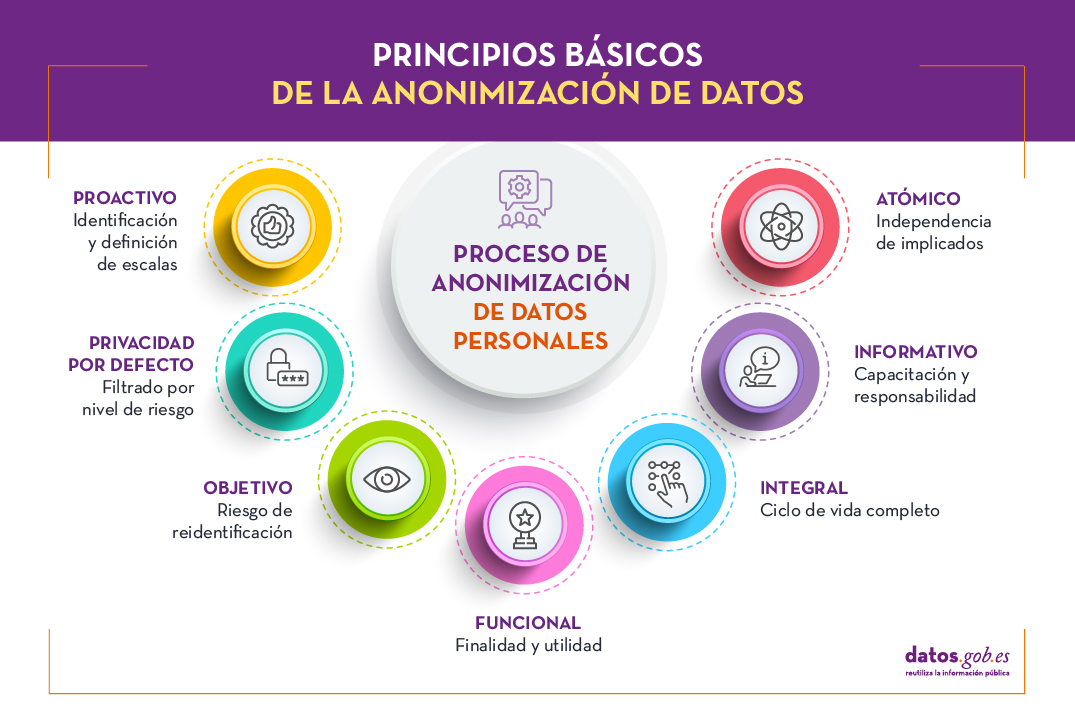
En un proceso de anonimización, una tarea esencial es definir un esquema basado en los tres niveles de identificación de personas: microdatos, identificadores indirectos y datos sensibles (principio de proactividad), donde se asigne un valor cuantitativo a cada una de las variables. Esta escala debe ser conocida por todo el personal implicado (principio de información) y es crítico para la Evaluación de Impacto en la Protección de los Datos Personales (EIPD).
¿Cuáles son los principales riesgos y retos asociados a la anonimización?
Dado el avance de la tecnología, es especialmente complejo poder garantizar la anonimización absoluta, por lo que el riesgo de reidentificación se aborda como un riesgo residual, asumido y gestionado, y no como un incumplimiento de la normativa. Es decir, se rige por el principio de objetividad, siendo necesario establecer políticas de contingencia. Estas políticas deben plantearse en términos de coste frente a beneficio, haciendo que el esfuerzo necesario para la reidentificación no sea asumible o sea razonablemente imposible.
Cabe señalar que el riesgo de reidentificación aumenta con el paso del tiempo, debido a la posible aparición de nuevos datos o el desarrollo de nuevas técnicas, como los futuros avances en computación cuántica, que podrían conllevar la ruptura de claves de cifrado.
En concreto se establecen tres vectores de riesgo concretos asociados a la reidentificación, definidos en el Dictamen 05/2014 sobre técnicas de anonimización:
- Singularización (singling out): riesgo de extraer atributos que permitan identificar a un individuo.
- Vinculabilidad (linkability): riesgo de vincular al menos dos atributos al mismo individuo o grupo, en uno o varios conjuntos de datos.
- Inferencia (inference): riesgo de deducir el valor de un atributo crítico a partir de otros atributos.
La siguiente tabla, propuesta en el mismo dictamen, muestra el nivel de garantías que podría ofrecer cada técnica:
| ¿Existe riesgo de singularización? | ¿Existe riesgo de vinculabilidad? | ¿Existe riesgo de inferencia? | |
|---|---|---|---|
| Seudonimización | Sí | Sí | Sí |
| Adición de ruido | Sí | Puede que no | Puede que no |
| Sustitución | Sí | Sí | Puede que no |
| Agregación y anonimato K | No | Sí | Sí |
| Diversidad l | No | Sí | Puede que no |
| Privacidad diferencial | Puede que no | Puede que no | Puede que no |
| Hash/Tokens | Sí | Sí | Puede que no |
Otro factor importante es la calidad de los datos resultantes para un fin determinado, también denominado utilidad, dado que en ocasiones es necesario sacrificar parte de la información (principio de privacidad por defecto). Esto conlleva un riesgo inherente para el que es necesario identificar y plantear medidas de mitigación para evitar la pérdida de potencial informativo del conjunto de datos anonimizado, enfocado a un caso de uso concreto (principio de funcionalidad).
En definitiva, el reto reside en conseguir que el análisis de los datos anonimizados no difiera significativamente con respecto al mismo análisis realizado sobre el conjunto de datos original, consiguiendo minimizar el riesgo de reidentificación mediante la combinación de varias técnicas de anonimización y la monitorización de todo el proceso; desde la anonimización a la explotación con una finalidad concreta.
Referencias y normativas
- REGLAMENTO (UE) 2016/679 DEL PARLAMENTO EUROPEO Y DEL CONSEJO de 27 de abril de 2016
- DIRECTIVA (UE) 2019/1024 DEL PARLAMENTO EUROPEO Y DEL CONSEJO de 20 de junio de 2019
- Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales
- Guidelines 03/2020 on the processing of data concerning health for the purpose of scientific research in the context of the COVID-19 outbreak – European Data Protection Board
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los jóvenes se han consolidado en los últimos años como el grupo demográfico más conectado en el mundo y son también en la actualidad los actores más relevantes dentro de la nueva economía digital. Uno de cada tres usuarios de internet a lo largo del planeta es un niño. Además esta tendencia se ha venido acelerando todavía más en el contexto actual de emergencia sanitaria, en el que los jóvenes han incrementado exponencialmente el tiempo que pasan online a la vez que son mucho más activos y comparten mucha más información en las redes sociales. Un ejemplo claro de las consecuencias de este uso incremental lo tenemos en las necesidades en torno a la enseñanza online, donde se plantean nuevos retos en torno a la privacidad de los estudiantes, mientras conocemos ya algunos primeros casos relacionados con problemas en la gestión de los datos bastante preocupantes.
Por otro lado, los jóvenes se preocupan por su privacidad más de lo que inicialmente podemos pensar. No obstante, reconocen tener bastantes problemas a la hora de entender cómo los distintos servicios y herramientas online recopilan y reutilizan su información personal y con qué finalidad lo hacen.
Es por todo lo anterior que, aunque en general la legislación relacionada con la privacidad online todavía sigue desarrollándose a lo largo del mundo, son ya varios los gobiernos que en la actualidad reconocen que los niños —y los menores de edad en general— requieren de un tratamiento especial en cuanto a la privacidad de sus datos como grupo particularmente vulnerable en el contexto digital.
Así pues, los menores cuentan ya con un grado de protección especial en algunos de los marcos legislativos de referencia en cuanto a privacidad a nivel global, como es el caso de la regulación Europea (GDPR) o la Estadounidense (COPPA). Por ejemplo, ambas establecen límites a la edad general de consentimiento legal para el tratamiento de los datos personales (16 años en la GDPR y 13 años en la COPPA), además de disponer otras medidas de protección adicionales como requerir el consentimiento de los padres, limitar el ámbito de uso de esos datos o utilizar un lenguaje más sencillo en la información proporcionada sobre la privacidad.
Sin embargo, el grado de protección que ofrecemos a los niños y jóvenes en el mundo online no es todavía comparable con la protección con la que cuentan en el mundo offline, y por ello debemos seguir avanzando en la creación de espacios online seguros que cuenten con fuertes medidas de respeto de la privacidad y características específicas para que los menores puedan sentirse seguros y estar realmente protegidos —además de continuar educando tanto a los jóvenes como a sus tutores en las buenas prácticas en cuanto a la gestión de los datos personales.
Con ese objetivo ha nacido la iniciativa de gestión responsable de los datos de relativos a la infancia (RD4C), promovida por UNICEF y The GovLab. El objetivo de esta iniciativa es concienciar acerca de la necesidad de prestar especial atención a las actividades relacionadas con los datos que afectan a los menores, ayudándonos a comprender mejor los posibles riesgos y a mejorar las prácticas en torno a la recopilación y análisis de datos para poder así mitigarlos. Para ello nos proponen una serie de principios que deberíamos seguir en el tratamiento de dichos datos:

- Procesos participativos: Involucrando e informando a las personas y grupos afectados por el uso de datos para y sobre los niños.
- Responsabilidad y rendición de cuentas: Estableciendo procesos, funciones y responsabilidades institucionales en cuanto al tratamiento de los datos.
- Centrado en las personas: Dando prioridad a las necesidades y expectativas de los niños y jóvenes, sus tutores y sus círculos sociales.
- Prevención de daños: Evaluando de forma anticipada los potenciales riesgos durante las etapas del ciclo de vida de los datos, incluyendo recopilación, almacenamiento, preparación, intercambio, análisis y uso.
- Proporcional: Ajustando la amplitud de la recopilación de datos y la duración de la retención de los mismos con el propósito inicialmente previsto.
- Protección de los derechos de los niños: Reconociendo los distintos derechos y requisitos necesarios para ayudar a los niños a desarrollar todo su potencial.
- Dirigido por un propósito: Especificando para qué se necesitan los datos y cómo su uso puede suponer un beneficio potencial para la mejora de la vida de los niños.
Algunos gobiernos han comenzado también a ir un paso más allá y favorecer un grado de protección más alto a los menores mediante el desarrollo de sus propias pautas destinadas a mejorar el diseño de los servicios online. Un buen ejemplo lo tenemos en el código de conducta elaborado por el Reino Unido que —de forma similar al R4DC— insta también a obrar siempre en interés de los propios menores, pero introduce además una serie de patrones de diseño de los servicios que incluye recomendaciones como la inclusión de controles parentales, la limitación en la recolección de datos personales o las restricciones en cuanto al uso de patrones de diseños engañosos que fomenten la compartición de datos. Otro buen ejemplo lo tenemos en la nota técnica publicada por la Agencia Española de Protección de Datos (AEPD) para la protección del menor en Internet, que nos ofrece recomendaciones detalladas para facilitar el control parental en el acceso a servicios y aplicaciones online.
Desde datos.gob.es queremos también contribuir al uso responsable de los datos que afectan a los jóvenes, y creemos también en los procesos participativos. Es por ello que hemos incluido los problemas de seguridad y/o privacidad de los datos en el ámbito de la enseñanza como uno de los retos a resolver en el próximo Desafío Aporta. Esperamos que os animéis a participar y nos enviéis todas vuestras ideas en este y otros ámbitos relacionados con la educación digital antes del 18 de Noviembre.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos tienen un gran potencial para mejorar la transparencia y la rendición de cuentas o para la mejora de los servicios públicos y la creación de nuevos servicios, pero al mismo tiempo muestran también una cara menos amigable al aumentar nuestra vulnerabilidad y exponer información cada vez más detallada que no siempre es utilizada en nuestro beneficio. Esta cada vez más abundante información personal convenientemente combinada puede a su vez llevar a la identificación personal final o incluso a sofisticadas herramientas de control masivo si no se toman las medidas necesarias para evitarlo. Prácticamente cada aspecto de nuestras vidas ofrece muestras ya de esa doble vertiente positiva y negativa:
-
Por un lado la medicina de precisión nos ofrece grandes avances en el diagnóstico y tratamiento de las enfermedades, pero para ello será necesario recopilar y analizar una gran cantidad de información sobre los pacientes.
-
Los datos han revolucionado también la forma en la que nos desplazamos por las ciudades gracias a la multitud de aplicaciones disponibles y esos mismos datos son de gran utilidad también en la planificación urbana, pero por lo general al coste de compartir prácticamente todos nuestros movimientos a lo largo del día.
-
En el entorno educativo los datos pueden ofrecer experiencias de aprendizaje más adaptadas a los distintos perfiles y necesidades, aunque para ello será nuevamente necesario exponer datos sensibles sobre los expedientes académicos.
En definitiva, los datos personales están en todas partes: cada vez que usamos las redes sociales, cuando hacemos nuestras compras ya sea online o en una gran superficie, cuando hacemos una búsqueda online, cada vez que enviamos un correo electrónico o un mensaje o simplemente navegando por la red… Hoy en día guardamos mucha más información íntima en nuestros móviles que la que solíamos guardar en nuestros diarios personales. Nuevos retos como la gran cantidad de datos que las ciudades digitales gestionan sobre sus ciudadanos necesitan también de nuevos enfoques prácticos para garantizar la seguridad y privacidad de esos datos.
A todo lo anterior hay que sumar que, al ritmo al que sigue avanzado la tecnología hoy en día, puede llegar a ser realmente difícil el garantizar que la privacidad futura de nuestros datos se seguirá manteniendo inalterada, debido a las múltiples posibilidades que ofrece la interconexión de todos estos datos. Parece pues que en este nuevo mundo dirigido por los datos en el que nos adentramos será necesario también empezar a replantearnos el futuro de una nueva economía basada en los datos personales, una nueva forma de gestionar nuestras identidades y datos digitales y los nuevos mercados de datos asociados.
El problema de la privacidad en la gestión de los datos personales no ha hecho más que empezar y está aquí para quedarse como parte de nuestras identidades digitales. No sólo necesitamos un nuevo marco legal y nuevos estándares que se adapten a los tiempos actuales y protejan nuestros datos, sino que también debemos esforzarnos en concienciar y educar a toda una nueva generación sobre la importancia de la privacidad online. Nuestros datos nos pertenecen y debemos ser capaces de retomar y mantener el pleno control sobre ellos y poder así garantizar que se usarán únicamente bajo nuestro consentimiento explícito. Algunas iniciativas pioneras están trabajando ya en áreas clave como la sanidad, la energía o las redes sociales para devolver el control de los datos a sus verdaderos dueños.