Documentación
Los datos poseen una naturaleza fluida y compleja: cambian, crecen y evolucionan constantemente, mostrando una volatilidad que los diferencia profundamente del código fuente. Para responder al desafío de gestionar esta evolución de manera fiable, hemos elaborado la nueva "Guía técnica: Control de versiones de datos".
Esta guía aborda una disciplina emergente que adapta los principios de la ingeniería de software al ecosistema de datos: el Control de Versiones de Datos (CVD). El documento no solo explora los fundamentos teóricos, sino que ofrece un enfoque práctico para resolver problemas críticos en la gestión de datos, como la reproducibilidad de modelos de Machine Learning, la trazabilidad en auditorías regulatorias y la colaboración eficiente en equipos distribuidos.
¿Por qué es necesaria una guía sobre versionado de datos?
Históricamente, la gestión de versiones de datos se ha realizado de forma manual (archivos con sufijos "_final_v2.csv"), un enfoque propenso a errores e insostenible en entornos profesionales. Aunque herramientas como Git han revolucionado el desarrollo de software, no están diseñadas para manejar eficientemente archivos de gran volumen o binarios, características intrínsecas de los conjuntos de datos.
Esta guía nace para cubrir esa brecha tecnológica y metodológica, explicando las diferencias fundamentales entre versionar código y versionar datos. El documento detalla cómo herramientas especializadas como DVC (Data Version Control) permiten gestionar el ciclo de vida de los datos con la misma rigurosidad que el código, garantizando que siempre se pueda responder a la pregunta: "¿Qué datos exactos se usaron para obtener este resultado?".
Estructura y contenidos
El documento sigue un enfoque progresivo, partiendo de los conceptos básicos hasta llegar a la implementación técnica, estructurándose en los siguientes bloques clave:
- Fundamentos del versionado: análisis de la problemática actual (el "modelo fantasma", auditorías imposibles) y definición de conceptos clave como snapshots, linaje de datos y checksums.
- Estrategias y metodologías: adaptación del versionado semántico (SemVer) a los conjuntos de datos, estrategias de almacenamiento (incremental vs. completo) y gestión de metadatos para garantizar la trazabilidad.
- Herramientas en la práctica: un análisis detallado de herramientas como DVC, Git LFS y soluciones nativas en la nube (AWS, Google Cloud, Azure), incluyendo una comparativa para elegir la más adecuada según el tamaño del equipo y los datos.
- Caso de estudio práctico: un tutorial paso a paso sobre cómo configurar un entorno local con DVC y Git, simulando un ciclo de vida real de datos: desde la generación y primer versionado, hasta la actualización, sincronización remota y recuperación de versiones anteriores (rollback).
- Gobernanza y mejores prácticas: recomendaciones sobre roles, políticas de retención y compliance para asegurar una implementación exitosa en la organización.

Figura 1: Ejemplo práctico de uso de commandos GIT y DVC incluido en la guía.
¿A quién va dirigida?
Esta guía está diseñada para un perfil técnico amplio dentro del sector público y privado: científicos de datos, ingenieros de datos, analistas y responsables de catálogos de datos.
Es especialmente útil para aquellos profesionales que buscan profesionalizar sus flujos de trabajo, garantizar la reproducibilidad científica de sus investigaciones o asegurar el cumplimiento normativo en sectores regulados. Aunque se recomienda tener conocimientos básicos de Git y línea de comandos, la guía incluye ejemplos prácticos y explicaciones detalladas que facilitan el aprendizaje.

Documentación
Se presenta a continuación una nueva guía de Análisis Exploratorio de Datos (AED) implementada en Python, que evoluciona y complementa la versión publicada en R en el año 2021. Esta actualización responde a las necesidades de una comunidad cada vez más diversa en el ámbito de la ciencia de datos.
El Análisis Exploratorio de Datos (AED o EDA, por sus siglas en inglés) representa un paso crítico previo a cualquier análisis estadístico, ya que permite:
- Comprender exhaustivamente los datos antes de analizarlos.
- Verificar el cumplimiento de los requisitos estadísticos que garantizarán la validez de los análisis posteriores.
Para ejemplificar su importancia, tomemos el caso de la detección y tratamiento de valores atípicos, una de las tareas a realizar en un AED. Esta fase tiene un impacto significativo en estadísticos fundamentales como la media, la desviación estándar o el coeficiente de variación.
Además de explicar las distintas fases de un AED, la guía las ilustra con un caso práctico. En este sentido, se mantiene como caso práctico el análisis de datos de calidad del aire de Castilla y León. A través de explicaciones que el usuario podrá replicar, se transforman los datos públicos en información valiosa mediante el uso de bibliotecas Python fundamentales como pandas, matplotlib y seaborn, junto con herramientas modernas de análisis automatizado como ydata-profiling.
¿Por qué una nueva guía en Python?
La elección de Python como lenguaje para esta nueva guía refleja su creciente relevancia en el ecosistema de la ciencia de datos. Su sintaxis intuitiva y su extenso catálogo de bibliotecas especializadas lo han convertido en una herramienta fundamental para el análisis de datos. Al mantener el mismo conjunto de datos y estructura analítica que la versión en R, se facilita la comprensión de las diferencias entre ambos lenguajes. Esto resulta especialmente valioso en entornos donde coexisten múltiples tecnologías. Este enfoque es particularmente relevante en el contexto actual, donde numerosas organizaciones están migrando sus análisis desde lenguajes/herramientas tradicionales como R, SAS o SPSS hacia Python. La guía busca facilitar estas transiciones y garantizar la continuidad en la calidad de los análisis durante el proceso de migración.
Novedades y mejoras
Se ha enriquecido el contenido con la introducción al AED automatizado y las herramientas de perfilado de datos, respondiendo así a una de las últimas tendencias en el campo. El documento profundiza en aspectos esenciales como la interpretación de datos medioambientales, ofrece un tratamiento más riguroso de los valores atípicos y presenta un análisis más detallado de las correlaciones entre variables. Además, incorpora buenas prácticas en la escritura de código.
La aplicación práctica de estos conceptos se ilustra a través del análisis de datos de calidad del aire, donde cada técnica cobra sentido en un contexto real. Por ejemplo, al analizar las correlaciones entre contaminantes, no solo se muestra cómo calcularlas, sino que se explica cómo estos patrones reflejan procesos atmosféricos reales y qué implicaciones tienen para la gestión de la calidad del aire.
Estructura y contenidos
La guía sigue un enfoque práctico y sistemático, cubriendo las cinco etapas fundamentales del AED:
- Análisis descriptivo para obtener una visión representativa de los datos
- Ajuste de los tipos de variables para garantizar la consistencia
- Detección y tratamiento de datos ausentes
- Identificación y gestión de datos atípicos
- Análisis de correlación entre variables
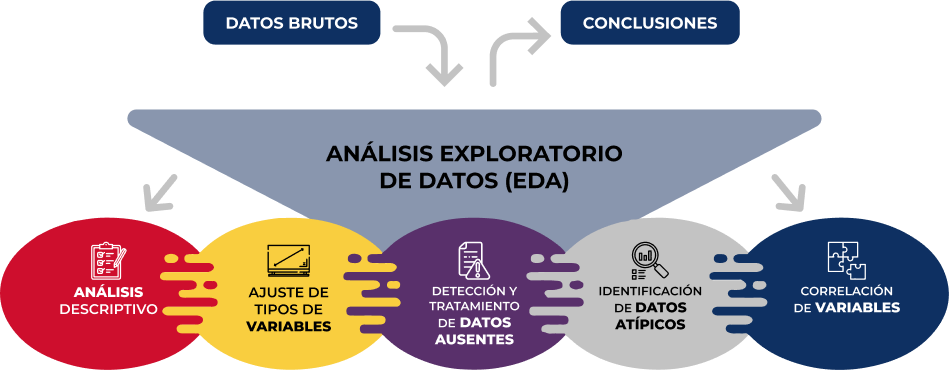
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
Como novedad en la estructura, se incluye una sección sobre análisis exploratorio automatizado, presentando herramientas modernas que facilitan la exploración sistemática de grandes conjuntos de datos.
¿A quién va dirigida?
Esta guía está diseñada para usuarios de datos abiertos que deseen realizar análisis exploratorios y reutilizar las valiosas fuentes de información pública que se encuentran en este y otros portales de datos a nivel mundial. Si bien es recomendable tener conocimientos básicos del lenguaje, la guía incluye recursos y referencias para mejorar las competencias en Python, así como ejemplos prácticos detallados que facilitan el aprendizaje autodidacta.
El material completo, que incluye tanto la documentación como el código fuente, se encuentra disponible en el repositorio de GitHub del portal. La implementación se ha realizado utilizando herramientas de código abierto como Jupyter Notebook en Google Colab, lo que permite reproducir los ejemplos y adaptar el código según las necesidades específicas de cada proyecto.
Se invita a la comunidad a explorar esta nueva guía, experimentar con los ejemplos proporcionados y aprovechar estos recursos para desarrollar sus propios análisis de datos abiertos.
Haz click para ver la infografía completa, en versión accesible

Figura 2. Captura de la infografía. Fuente: elaboración propia.
Documentación
Antes de realizar un análisis de datos, con fines estadístico o predictivos por ejemplo a través de técnicas de machine learning, es necesario comprender la materia prima con la que vamos a trabajar. Hay que entender y evaluar la calidad de los datos para así, entre otros aspectos, detectar y tratar los datos atípicos o incorrectos, evitando posibles errores que pudieran repercutir en los resultados del análisis.
Una forma de llevar a cabo este pre-procesamiento es mediante un análisis exploratorio de datos (AED) o exploratory data analysis (EDA).
¿Qué es el análisis exploratorio de los datos?
El AED consiste en aplicar un conjunto de técnicas estadísticas dirigidas a explorar, describir y resumir la naturaleza de los datos, de tal forma que podamos garantizar su objetividad e interoperabilidad.
Gracias a ello se pueden identificar posibles errores, revelar la presencia de valores atípicos, comprobar la relación entre variables (correlaciones) y su posible redundancia, así como realizar un análisis descriptivo de los datos mediante representaciones gráficas y resúmenes de los aspectos más significativos.
En muchas ocasiones, esta exploración de los datos se descuida y no se lleva a cabo de manera correcta. Por este motivo, desde datos.gob.es hemos elaborado una guía introductoria que recoge una serie de tareas mínimas para realizar un correcto análisis exploratorios de datos, paso previo y necesario antes de llevar a cabo cualquier tipo de análisis estadístico o predictivo ligado a las técnicas de machine learning.
¿Qué incluye la guía?
La guía explica de forma sencilla cuáles son los pasos a seguir para garantizar unos datos consistentes y veraces. Para su elaboración se ha tomado como referencia el análisis exploratorio de datos descrito en el libro R for Data Science de Wickman y Grolemund (2017) disponible de forma gratuita. Estos pasos son:
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
En la guía se explica cada uno de estos pasos y por qué son necesarios. Asimismo, se ilustran de manera práctica a través de un ejemplo. Para dicho caso práctico, se ha utilizado el dataset relativo al registro de la calidad del aire en la Comunidad Autónoma de Castilla y León incluido en nuestro catálogo de datos abiertos. El tratamiento se ha llevado a cabo con herramientas tecnológicas open source y gratuitas. En la guía se recoge el código para que los usuarios pueden replicarlo de forma autodidacta siguiendo los pasos indicados.
La guía finaliza con un apartado de recursos adicionales para aquellos que quieran seguir profundizando en la materia.
¿A quién va dirigida?
El público objetivo de la guía es el usuario reutilizador de datos abiertos. Es decir, desarrolladores, emprendedores o incluso periodistas de datos que quieran extraer todo el valor posible de la información con la que trabajan para obtener unos resultados fiables.
Es aconsejable que el usuario tenga nociones básicas del lenguaje de programación R, elegido para ilustrar los ejemplos. No obstante, en el apartado de bibliografía se incluyen recursos para adquirir mayores habilidades en este campo.
A continuación, en el apartado documentación, puedes descargarte la guía, así como una infografía-resumen que ilustra los principales pasos del análisis exploratorios de datos. También tienes disponible el código fuente del ejemplo práctico en nuestro Github.
Haz click para ver la infografía completa, en versión accesible
Figura 2. Captura de la infografía. Fuente: elaboración propia.
Infografía - Análisis de datos abiertos con herramientas open source PARTE I

Infografía - Visualización de datos abiertos con herramientas open source PARTE II

Ver infografía completa
Blog
La Infraestructura de Pruebas para el Análisis de Datos (BDTI, por sus siglas en inglés, Big Data Test Infrastructure) es una herramienta financiada por el Programa Digital Europeo, que permite a las administraciones públicas realizar análisis con datos abiertos y herramientas de código abierto con el fin de impulsar la innovación.
Esta herramienta, alojada en la nube y de uso gratuito, se creó en 2019 para acelerar la transformación digital y social. Con este planteamiento y siguiendo también la Directiva Europea de Datos Abiertos, la Comisión Europea llegó a la conclusión de que, para lograr un impulso digital y económico, debía aprovecharse el poder de los datos de las administraciones públicas; es decir, aumentar su disponibilidad, calidad y usabilidad. Es así como nace BDTI, con el propósito de fomentar la reutilización de esta información proporcionando un entorno de prueba de análisis gratuito que permite a las administraciones públicas crear prototipos de soluciones en la nube antes de implementarlas en el entorno de producción de sus propias instalaciones.
¿Qué herramientas ofrece BDTI?
Big Data Test Infrastructure ofrece a las administraciones públicas europeas un conjunto de herramientas estándar de código abierto para el almacenamiento, procesamiento y análisis de sus datos. La plataforma consta de máquinas virtuales, clústeres de análisis e instalaciones de almacenamiento y de red. Las herramientas que ofrece son:
- Bases de datos: para almacenar datos y realizar consultas sobre los datos almacenados. El BDTI incluye actualmente una base de datos relacional (PostgreSQL), una base de datos orientada a documentos (MongoDB) y una base de datos gráfica (Virtuoso).
- Lago de datos: para almacenar grandes cantidades de datos estructurados y sin estructurar (MinIO). Los datos en bruto no estructurados se pueden procesar con configuraciones desplegadas de otros bloques de construcción (componentes BDTI) y almacenarse en un formato más estructurado dentro de la solución de lago de datos.
- Entornos de desarrollo: proporcionan las capacidades informáticas y las herramientas necesarias para realizar actividades estándar de análisis de datos sobre datos que provienen de fuentes externas, como lagos de datos y bases de datos.
- JupyterLab, un entorno de desarrollo interactivo y online para crear cuadernos Jupyter, código y datos.
- Rstudio, un entorno de desarrollo integrado para R, un lenguaje de programación para computación estadística y gráficos.
- KNIME, una plataforma de análisis, informes e integración de datos de código abierto que cuenta con componentes para el aprendizaje automático y la minería de datos, que se puede utilizar para todo el ciclo de vida de la ciencia de datos.
- H2O.ai, una plataforma de aprendizaje automático (machine learning o ML) e inteligencia artificial (IA) de código abierto diseñada para simplificar y acelerar la creación, el funcionamiento y la innovación con ML e IA en cualquier entorno.
- Procesamiento avanzado: también se pueden crear clústeres y herramientas para procesar grandes volúmenes de datos y realizar operaciones de búsqueda en tiempo real (Apache Spark, Elasticsearch y Kibana
- Visualización: BDTI también ofrece aplicaciones para visualizar datos como Apache Superset, capaz de manejar datos a escala de petabytes o Metabase.
- Orquestación: para la automatización de los procesos basados en datos durante todo su ciclo de vida, desde la preparación de datos hasta la toma de decisiones basadas en ellos y la realización de acciones basadas en esas decisiones, se ofrece:
- Apache Airflow, una plataforma de gestión de flujos de trabajo de código abierto que permite programar y ejecutar fácilmente canalizaciones de datos complejas.
A través de estas herramientas que se encuentran en entorno nube, los trabajadores públicos de países de los países de la UE pueden crear sus propios proyectos piloto para demostrar el valor que los datos pueden aportar a la innovación. Una vez finalizado el proyecto, los usuarios tienen la posibilidad descargar el código fuente y los datos para continuar el trabajo por sí mismos, utilizando entornos de su elección. Además, la sociedad civil, la academia y el sector privado pueden participar en estos proyectos piloto, siempre y cuando haya una entidad pública involucrada en el caso de uso.
Casos de éxito
Estos recursos han posibilitado la creación de proyectos diversos en diferentes países de la UE. En la web de BDTI, se recogen algunos ejemplos de casos de uso. Por ejemplo, Eurostat llevó a cabo un proyecto piloto en el que se utilizaron datos abiertos de anuncios de empleo en internet para mapear la situación de los mercados laborales europeos. Otros casos de éxito fue la optimización de la contratación pública por parte de la Agencia Noruega de Digitalización, los esfuerzos de intercambio de datos por parte de la European Blood Alliance y el trabajo para facilitar la comprensión del impacto de COVID-19. sobre la ciudad de Florencia .
En España, BDTI hizo posible un proyecto de minería de datos en la Conselleria de Sanitat de la Comunidad Valenciana. Gracias a BDTI se pudieron extraer conocimientos de la enorme cantidad de artículos clínicos científicos; una tarea que apoyó a clínicos y gestores en sus prácticas clínicas y en su trabajo diario.

Cursos, boletín y otros recursos
Además de publicar casos de uso, la web Big Data Test Infrastructure ofrece un curso online y gratuito para aprender a sacar el máximo partido a BDTI. Este curso se centra en un caso de uso altamente práctico: analizar la financiación de proyectos verdes e iniciativas en regiones contaminadas de la UE, utilizando datos abiertos de data.europa.eu y otras fuentes abiertas.
Por otro lado, recientemente se ha lanzado una newsletter de envío mensual sobre las últimas noticias de BDTI, buenas prácticas y oportunidades de análisis de datos para el sector público.
En definitiva, la reutilización de los datos del sector público (RISP) es una prioridad para la Comisión Europea y BDTI (Big Data Test Infrastructure) una de las herramientas que contribuyen a su desarrollo. Si trabajas en la administración pública y te interesa utilizar BDTI regístrate aquí.
Evento
Nunca se acaban las oportunidades para debatir, aprender y compartir experiencias sobre datos abiertos y tecnologías relacionadas. En este post, seleccionamos algunas de las que tendrán lugar próximamente, y te contamos todo lo que tienes que saber: de qué va, cuándo y dónde se celebra y cómo puedes inscribirte.
No te pierdas esta selección de eventos sobre temáticas de vanguardia como los datos geoespaciales, las estrategias de reutilización de datos accesibles e incluso las tendencias innovadoras de periodismo de datos. ¿Lo mejor? Todos son gratuitos.
Hablemos del dato en Alicante
La Asociación Nacional de Big Data y Analytics (ANBAN) organiza un evento abierto y gratuito en Alicante para debatir e intercambiar opiniones sobre datos e inteligencia artificial. Durante el encuentro no solo se presentarán casos de uso que relacionen datos con IA, sino que también se dedicará una parte a incentivar el networking entre los asistentes.
- ¿De qué trata?: 'Hablemos del dato’ empezará con dos charlas sobre proyectos de inteligencia artificial que ya estén creando impacto. Posteriormente, se explicará en qué va a consistir el curso sobre IA que ha organizado la Universidad de Alicante junto a ANBAN. La parte final del evento será más distendida para animar a los asistentes a establecer conexiones de valor.
- ¿Cuándo y dónde?: El jueves 29 de febrero a las 20.30h en ULAB (Pza. San Cristóbal, 14) en Alicante.
- ¿Cómo me inscribo?: Reserva tu lugar apuntándote aquí: https://www.eventbrite.es/e/entradas-hablemos-del-dato-beers-alicante-823931670807?aff=oddtdtcreator&utm_source=rrss&utm_medium=colaborador&utm_campaign=HDD-ALC-2902
Open Data Day en Barcelona: Reutilización de datos para mejorar la ciudad
El Open Data Day es un evento internacional que agrupa actividades sobre los datos abiertos alrededor del mundo. En este marco, la iniciativa Barcelona Open Data ha organizado un acto para dialogar sobre proyectos y estrategias de publicación y reutilización de datos abiertos para hacer posible una ciudad limpia, segura, amigable y accesible.
- ¿De qué trata?: A través de proyectos con datos abiertos y estrategias basadas en ellos, se abordará el reto de la seguridad, la coexistencia de usos y el mantenimiento de espacios compartidos en los municipios. El objetivo es generar diálogo entre las organizaciones que publican datos y los reutilizan para aportar valor y desarrollar estrategias de manera conjunta.
- ¿Cuándo y dónde?: El día 6 de marzo de 17h a 19.30h en Ca l’Alier (C/ de Pere IV, 362).
- ¿Cómo me inscribo?: A través de este enlace: https://www.eventbrite.es/e/entradas-open-data-day-2024-819879711287?aff=oddtdtcreator
Presentación de la “Guía de Buenas Prácticas para Periodistas de Datos”
El Observatori Valencià de Dades Obertes i Transparència de la Universitat Politècnica de València ha creado una guía dirigida a periodistas y profesionales del dato con consejos prácticos para convertir los datos en historias periodísticas atractivas y relevantes para la sociedad. La autora de este material de referencia dialogará con un periodista de datos sobre los retos y oportunidades que los datos ofrecen en el ámbito periodístico.
- ¿De qué trata?: Es un evento que abordará conceptos clave de la Guía de Buenas Prácticas para Periodistas de Datos mediante ejemplos prácticos y casos para analizar y visualizar datos correctamente. La ética también será un tema que se abordará durante la presentación.
- ¿Cuándo y dónde?: El viernes 8 de marzo de 12h a 13h en el Salón de Actos de la Facultad de ADE de la UPV (Avda. Tarongers s/n) en Valencia.
- ¿Cómo me inscribo?: Más información e inscripción aquí: https://www.eventbrite.es/e/entradas-presentacion-de-la-guia-de-buenas-practicas-para-periodistas-de-datos-835947741197
Jornadas de Geodatos del Geoportal del Ayuntamiento de Madrid
Madrid acoge la sexta edición de este evento que reúne responsables de instituciones y empresas de referencia en cartografía, sistemas de información geográfica, gemelo digital, BIM, Big Data e inteligencia artificial. También se aprovechará el evento para hacer entrega de los premios del Estand del Geodato.
- ¿De qué trata?: Siguiendo la estela de otros años, las Jornadas de Geodatos de Madrid presentan casos prácticos y novedades sobre cartografía, gemelo digital, reutilización de datos georreferenciados, así como los mejores trabajos presentados al Estand del Geodato.
- ¿Cuándo y dónde?: El evento empieza el día 12 de marzo a las 9h en Auditorio de La Nave en Madrid y durará hasta las 14h. El día siguiente, 13 de marzo la sesión será virtual y se presentarán los proyectos y las novedades de la producción de geo información y de la distribución a través del Geoportal de Madrid.
- ¿Cómo me inscribo?: A través del portal del evento. Las plazas son limitadas https://geojornadas.madrid.es/
III Jornadas de Cultura Libre de la URJC
Las Jornadas de Cultura Libre de la Universidad Rey Juan Carlos son un punto de encuentro, aprendizaje e intercambio de experiencias en torno a la cultura libre en la universidad. Se abordarán temas como la publicación abierta de materiales docentes e investigativos, la ciencia abierta, los datos abiertos, y el software libre.
- ¿De qué trata?: Son dos días durante los que se ofrecerán presentaciones a cargo de expertos, talleres sobre temas específicos y se dará la oportunidad a la comunidad universitaria de presentar ponencias. Además, habrá un espacio ferial donde se compartirán herramientas y novedades relacionadas con la cultura y el software libre, así como un área de exposición de poster
- ¿Cuándo y dónde?: El 20 y 21 de marzo en el Campus de Fuenlabrada de la URJC
- ¿Cómo me inscribo?: La inscripción es gratuita mediante este enlace: https://eventos.urjc.es/109643/tickets/iii-jornadas-de-cultura-libre-de-la-urjc.html
Estos son algunos de los eventos que sucederán próximamente. De todas formas, no olvides seguirnos en redes sociales para no perderte ninguna novedad sobre innovación y datos abiertos. Estamos en Twitter y LinkedIn, también nos puedes escribir a dinamizacion@datos.gob.es si quieres que incluyamos algún otro evento a la lista o si necesitas información extra.
Blog
La segmentación de imágenes es un método que divide una imagen digital en subgrupos (segmentos) para reducir la complejidad de esta y, así, poder facilitar su procesamiento o análisis. La finalidad de la segmentación es asignar etiquetas a píxeles para identificar objetos, personas u otros elementos en la imagen.
La segmentación de las imágenes es clave para las tecnologías y algoritmos de visión artificial, pero también se utiliza hoy en día para muchas aplicaciones como, por ejemplo, el análisis de imágenes médicas, la visión de los vehículos autónomos, el reconocimiento y la detección de rostros o el análisis de imágenes satelitales, entre otras.
Segmentar una imagen es un proceso lento y costoso, por eso en lugar de procesar la imagen completa, una práctica común es la segmentación de imágenes mediante el enfoque de desplazamiento medio. Este procedimiento emplea una ventana desplazable que atraviesa progresivamente la imagen, calculando el promedio de los valores de píxeles contenidos en dicha región.
Este cálculo se efectúa con el propósito de establecer los píxeles que han de ser incorporados a cada uno de los segmentos delineados. Conforme la ventana avanza a lo largo de la imagen, lleva a cabo de manera iterativa una recalibración del cálculo para garantizar la idoneidad de cada uno de los segmentos resultantes.
A la hora de segmentar una imagen los factores o características que se tienen en cuenta son principalmente:
- El color: Los diseñadores gráficos tienen la posibilidad de emplear una pantalla de tonalidad verdosa con el fin de asegurar una uniformidad cromática en el fondo de la imagen. Esta práctica posibilita la automatización de la detección y sustitución del fondo durante la etapa de postprocesamiento.
- Bordes: La segmentación basada en bordes es una técnica que identifica los bordes de varios objetos en una imagen determinada. Estos se identifican en función de las variaciones de contraste, textura, color y saturación.
- Contraste: Se procesa la imagen distinguiendo entre una figura oscura y un fondo claro basándose en valores de alto contraste.
Estos factores se aplican en distintas técnicas de segmentación:
- Umbrales: Divide los píxeles en función de su intensidad en relación con un valor o umbral determinado. Este método es el más adecuado para segmentar objetos con mayor intensidad que otros objetos o fondos.
- Regiones: Consiste en dividir una imagen en regiones con características semejantes agregando los píxeles con características similares.
- Clústeres: Los algoritmos de agrupamiento son algoritmos de clasificación no supervisados que ayudan a identificar información oculta en las imágenes. El algoritmo divide las imágenes en grupos de píxeles con características similares, separando los elementos en grupos y agrupando elementos similares en estos grupos.
- Cuencas hidrográficas: Se trata de un proceso que transforma las imágenes a escala de grises, tratándolas como mapas topográficos, donde el brillo de los píxeles determina la altura. Esta técnica sirve para detectar líneas que forman crestas y cuencas. marcando las áreas entre las líneas divisorias de aguas.
El aprendizaje automático y el aprendizaje profundo (Deep learning) han mejorado estas técnicas, como la segmentación de clústeres, pero también han generado nuevos enfoques de segmentación que utilizan el entrenamiento de modelos para mejorar la capacidad de los programas a la hora de identificar características importantes. La tecnología de redes neuronales profundas es especialmente efectiva para las tareas de segmentación de imágenes.
En la actualidad encontramos distintos tipos de segmentación de imágenes, siendo las principales:
- Segmentación Semántica: La segmentación semántica de imágenes es un proceso que permite crear regiones dentro de una imagen y atribuir significado semántico a cada una de ellas. Estos objetos o también conocidas como clases semánticas, por ejemplo: coche, autobús, persona, árbol, etc., han sido previamente definidas mediante el entrenamiento de modelos en los que se clasifican y etiquetan estos objetos. El resultado es una imagen en lo que se han clasificado los pixeles en cada objeto o clase localizado.
- Segmentación de instancias: La segmentación de instancias combina el método de segmentación semántica (interpretando los objetos de una imagen) y la detección de objetos (al localizarlos dentro de la imagen). Como resultado de esta segmentación, se localizan los objetos, para que cada uno de ellos sea singularizado por medio de una ventana delimitadora (bounding box) y una máscara binaria, las cuales determinan qué píxeles de dicha ventana pertenecen al objeto localizado.
- Segmentación panóptica: Es el tipo más actual de segmentación. Se trata de una combinación de segmentación semántica y de instancias. Este método sí puede determinar la identidad de cada objeto porque esta técnica de segmentación localiza y distingue los diferentes objetos o instancias y asigna dos etiquetas a cada píxel de la imagen: una etiqueta semántica y una ID de instancia. De esta forma cada objeto es único.

En la imagen se pueden observar los resultados de aplicar las distintas segmentaciones a una imagen satelital. La segmentación semántica devuelve una categoría por cada tipo de objeto identificado. La segmentación por instancia devuelve los objetos individualizados y la caja delimitadora y, en la segmentación panóptica, obtenemos los objetos individualizados y el contexto también diferenciado, pudiendo detectar el suelo y la región de calles.
El nuevo modelo de Meta: SAM
En abril del 2023, el departamento de investigación de Meta presentó un nuevo modelo de Inteligencia Artificial (IA) al que llamaron SAM (Segment Anything Model). Con SAM se puede realizar la segmentación de una imagen mediante tres formas:
- Seleccionando un punto en la imagen, se buscará y distinguirá el objeto que intersecta con ese punto y se buscará todos los objetos iguales encontrados en la imagen.
- Por ventana delimitadora o bounding box, sobre la imagen se dibuja un rectángulo y se identifican todos los objetos encontrados en esa área.
- Por palabras, mediante una consola se escribe una palabra y SAM puede identificar los objetos que coincidan con esa palabra u orden explícita tanto en imágenes o videos, incluso si ese dato no fue incluido en su entrenamiento.
SAM es un modelo flexible que fue entrenado con el conjunto de datos más grande hasta la fecha, llamado SA-1B y que cuenta con 11 millones de imágenes y 1.1 mil millones de máscaras en segmentación. Gracias a estos datos, SAM es capaz de detectar todo tipo de objetos sin necesidad de un entrenamiento adicional.
Por ahora, el modelo SAM y el conjunto de datos SA-1B está disponible para su uso no comercial y con fines de investigación. De este modo, los usuarios que suban sus imágenes tendrán que comprometerse a utilizarlo únicamente con fines de académicos. Para probarla, ingresa a este enlace de GitHub.
En agosto del 2023, el Grupo de Análisis de Imagen y Vídeo de la Academia China de las Ciencias, lanza una actualización de su modelo llamado FastSAM que reduce considerablemente el tiempo de procesado, se consigue una velocidad de ejecución 50 veces mayor, haciendo que el modelo sea más práctico de ejecutar que el modelo SAM original. Esta aceleración la consiguen habiendo entrenado el modelo con el 2% de los datos utilizados para entrenar SAM. FastSAM tiene menos requisitos computacionales que SAM, sin dejar de alcanzar una gran precisión.
SAMGEO: la versión que permite analizar datos geoespaciales
El paquete segment-geospatial desarrollado por Qiusheng Wu tiene como finalidad facilitar el uso de Segment Anything Model (SAM) para datos geoespaciales, para ello se he desarrollado los paquetes de Python segment-anything-py y segment-geospatial , que están disponibles en PyPI y conda-forge.
El objetivo es simplificar el proceso de aprovechamiento de SAM para el análisis de datos geoespaciales al permitir que los usuarios lo logren con un mínimo esfuerzo de codificación. A partir de estas librerías, se desarrolla el plugin de QGIS Geo-SAM y se desarrolla el uso del modelo en ArcGIS Pro.

Conclusiones
En definitiva, SAM supone una gran revolución no sólo por las posibilidades que abre a la hora de editar fotografías o extraer elementos de imágenes para collages o edición de video, sino también por las oportunidades de mejora que permiten aumentar la visión por computadora, a la hora de usar lentes de realidad aumentada o cascos de realidad virtual.
También SAM supone una revolución para la obtención de información espacial, mejorando la detención de objetos mediante imágenes satelitales y facilitando la detección de cambios en el territorio de forma rápida.
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La serie “Stories of use cases”, organizada por el portal de datos abiertos europeo (data.europe.eu), es un conjunto de eventos online sobre el uso de los datos abiertos para contribuir a la consecución de objetivos comunes de la Unión Europea como la consolidación de la democracia, el impulso de la economía, la lucha contra el cambio climático o la transformación digital. La serie consta de cuatro eventos y todas las grabaciones están disponibles en el canal de Youtube del portal europeo de datos abiertos. También están publicadas las presentaciones que se utilizaron para exponer cada caso.
En un post anterior de datos.gob.es, explicamos las aplicaciones que se presentaron en dos de los eventos de la serie, en concreto, sobre economía y democracia. Ahora, nos centramos en los casos de uso relacionados con clima y tecnología, así como los conjuntos de datos abiertos que se emplearon para su desarrollo.
Los datos abiertos han permitido el desarrollo de aplicaciones que ofrecen información y servicios variados. En materia de clima, algunos ejemplos logran identificar la trazabilidad del proceso de gestión de residuos o visualizar datos relevantes sobre agricultura ecológica. Mientras que la aplicación de los datos abiertos en el ámbito tecnológico facilita la gestión de procesos. ¡Descubre los ejemplos destacados por el portal de datos abiertos europeo!
Datos abiertos para cumplir con el European Green Deal
El European Green Deal es una estrategia de la Comisión Europea que tiene como objetivo lograr la neutralidad climática en Europa para el año 2050 y fomentar el crecimiento económico sostenible. Para alcanzar este objetivo, la Comisión Europea está trabajando en varias líneas de acción, como la reducción de emisiones de gases de efecto invernadero, la transición hacia una economía circular y la mejora de la eficiencia energética. Bajo esta meta común y empleando conjuntos de datos abiertos, se han desarrollado las tres aplicaciones que se presentan en uno de los webinars de la serie sobre casos de uso de datos.europe.eu: Eviron mate, Geofluxus y MyBioEuBuddy.
-
Eviron mate: Es un proyecto educativo que tiene como objetivo concienciar a los jóvenes sobre el cambio climático y los datos relacionados con él. Para lograr este objetivo, Eviron mate utiliza datos abiertos de Eurostat, el programa Copernicus y data.europa.eu.
- Geofluxus: Es una iniciativa que realiza un seguimiento de los residuos desde su punto de origen hasta su destino final, para fomentar la reutilización de materiales y reducir la cantidad de residuos. Su principal objetivo es extender la vida útil de los materiales y ofrecer herramientas a las empresas para tomar mejores decisiones con sus desechos. Para ello, Geofluxus utiliza datos abiertos de Eurostat y de diferentes portales de datos abiertos nacionales.
- MyBioEuBuddy es un proyecto que ofrece información y visualizaciones sobre la agricultura sostenible en Europa, utilizando datos abiertos de Eurostat y de diferentes portales de datos abiertos regionales.
El papel de los datos abiertos en la transformación digital
Además de contribuir a la lucha contra el cambio climático permitiendo monitorizar procesos relacionados con el medio ambiente, los datos abiertos pueden ofrecer resultados interesantes en otros ámbitos que también operan en la era digital. La combinación del uso de datos abiertos con tecnologías innovadoras ofrece un resultado muy valioso, por ejemplo, en procesamiento de lenguaje natural, inteligencia artificial o realidad aumentada, entre otras.
Otro de los seminarios online de la serie sobre casos de uso presentado por el European Data Portal se adentró en este tema: el impulso de la transformación digital en Europa mediante datos abiertos. Durante el evento, se presentaron tres aplicaciones que combinan tecnología puntera y datos abiertos: Big Data Test Infrastructure, Lobium y 100 europeans.
- "Big Data Test Infrastructure (BDTI)": Es una herramienta de la Comisión Europea que cuenta con una plataforma en la nube para facilitar el análisis de datos abiertos para las administraciones del sector público, brindando una solución gratuita y lista para usar. BDTI ofrece herramientas de código abierto que fomentan la reutilización de datos del sector público. Desde cualquier administración pública, se puede solicitar el servicio de asesoramiento gratuito rellenando este formulario. El BDTI ya ha ayudado a algunas entidades del sector público a optimizar procesos de contratación, obtener información sobre movilidad para rediseñar servicios o apoyar a los médicos extrayendo conocimiento de artículos.
- Lobium: Web que ayuda a los gerentes de asuntos públicos a abordar las complejidades de sus tareas. Su objetivo es proporcionar herramientas para la administración de campañas, informes internos, medición de KPI y paneles de control de asuntos gubernamentales. En definitiva, su solución permite aprovechar las ventajas de las herramientas digitales para mejorar y optimizar las gestiones públicas.
- 100 europeans: Es una aplicación que visualiza estadísticas europeas de manera sencilla, dividiendo la población europea en 100 personas. Mediante una navegación de scrolling presenta visualizaciones de datos con cifras sobre los hábitos saludables y de consumo en Europa.
Las seis aplicaciones son ejemplos de cómo los datos abiertos pueden servir para desarrollar soluciones de interés para la sociedad. Descubre más casos de uso creados con datos abiertos en este artículo que hemos publicado en datos.gob.es.

Conoce más sobre estas aplicaciones en sus seminarios -> Grabaciones aquí
Documentación
Este informe, que publica el Portal de Datos Europeo, analiza el potencial de reutilización de los datos en tiempo real. Los datos en tiempo real ofrecen información con alta frecuencia de actualización sobre el entorno que nos rodea (por ejemplo, información sobre el tráfico, datos meteorológicos, mediciones de la contaminación ambiental, información sobre riesgos naturales, etc.).
El documento resume los resultados y conclusiones de un seminario web organizado por el equipo del Portal de Datos Europeo celebrado el pasado 5 de abril de 2022, donde se explicaron diferentes formas de compartir datos en tiempo real desde plataformas de datos abiertos.
En primer lugar, el informe hace un repaso sobre el fundamento de los datos en tiempo real e incluye ejemplos que justifican el valor que aporta este tipo de datos para, a continuación, describir dos enfoques tecnológicos sobre cómo compartir datos en tiempo real del ámbito de IoT y el transporte. Incluye, además, un bloque que resume las principales conclusiones de las preguntas y comentarios de los participantes que giran, principalmente, en torno a difentes necesidades de fuentes de datos y funcionalidades requeridas para su reutilización.
Para terminar, basándose en el feedback y la discusión generada, se proporciona un conjunto de recomendaciones y acciones a corto y medio plazo sobre cómo mejorar la capacidad para localizar fuentes de datos en tiempo real a través del Portal de Datos Europeo.
Este informe se encuentra disponible en el siguiente enlace: "Datos en tiempo real: Enfoques para integrar fuentes de datos en tiempo real en data.europa.eu"
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información que finalmente se resume en unas conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre el alumnado de la universidad española a lo largo de los últimos años. A partir de estos datos observaremos las características que presenta el alumnado de la universidad española y cuáles son los estudios más demandados.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio de Universidades, que recoge series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presenta el alumnado de la universidad española. Estos datos se encuentran disponibles en el catálogo de datos.gob.es y en el propio catálogo de datos del Ministerio de Universidades. Concretamente los datasets que usaremos son:
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de doctorado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de máster por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de grado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculaciones por cada una de las titulaciones impartidas por las universidades españolas que se encuentra publicado en la sección de Estadísticas de la página oficial del Ministerio de Universidades. El contenido de esta dataset abarca desde el curso 2015-2016 al 2020-2021, aunque para este último curso los datos con provisionales.
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación R desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Datawrapper.
Datawrapper es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en línea o exportarse como PNG, PDF o SVG. Esta herramienta es muy sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Preprocesamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Creación de tablas de trabajo
- Ajuste del nombre de algunas variables
- Agrupación de varias variables en una única con diferentes factores
- Transformación de variables
- Detección y tratamiento de datos ausentes (NAs)
- Creación de nuevas variables calculadas
- Resumen de las tablas transformadas
- Preparación de datos para su representación visual
- Almacenamiento de archivos con las tablas de datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
5. Visualización de datos
Una vez realizado el preprocesamiento de los datos, vamos con la visualización. Para la realización de esta visualización interactiva usamos la herramienta Datawrapper en su versión gratuita. Se trata de una herramienta muy sencilla con especial aplicación en el periodismo de datos que te animamos a utilizar. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que la tabla de datos que le proporcionemos este estructurada adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos la siguientes:
- ¿Cómo se está distribuyendo el número de hombres y mujeres entre los alumnos matriculados de grado, máster y doctorado a lo largo de los últimos cursos?
Si nos centramos en el último curso 2020-2021:
- ¿Cuáles son las ramas de enseñanza más demandadas en las universidades españolas? ¿Y las titulaciones?
- ¿Cuáles son las universidades con mayor número de matriculaciones y dónde se ubican?
- ¿En qué rangos de edad se encuentra el alumnado universitario de grado?
- ¿Cuál es la nacionalidad de los estudiantes de grado de las universidades españolas?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Distribución de las matriculaciones en las universidades españolas desde el curso 2015-2016 hasta 2020-2021, desagregado por sexo y nivel académico
Esta representación visual la hemos realizado teniendo en cuenta las matriculaciones de grado, master y Doctorado. Una vez que hemos subido la tabla de datos a Datawrapper (conjunto de datos \"Matriculaciones_NivelAcademico\"), hemos seleccionado el tipo de gráfico a realizar, en este caso un diagrama de barras apiladas (stacked bars) para poder reflejar por cada curso y sexo, las personas matriculadas en cada nivel académico. De esta forma podemos ver, además, el global de estudiantes matriculados por curso. A continuación, hemos seleccionado el tipo de variable a representar (Matriculaciones) y las variables de desagregación (Sexo y Curso). Una vez obtenido el gráfico, podemos modificar de forma muy sencilla la apariencia, modificando los colores, la descripción y la información que muestra cada eje, entre otras características.
Para responder a las siguientes preguntas, nos centraremos en el alumnado de grado y en el curso 2020-2021, no obstante, las siguientes representaciones visuales pueden ser replicadas para el alumnado de máster y doctorado, y para los diferentes cursos.
5.2. Mapa de las universidades españolas georreferenciadas, donde se muestra el número de matriculados que presentan cada una de ellas
Para la realización del mapa hemos utilizado un listado de las universidades españolas georreferenciadas publicado por el Portal de Datos Abiertos de Esri España. Una vez descargados los datos de las distintas áreas geográficas en formato GeoJSON, los transformamos en Excel, para poder realizar una unión entre el datasets de las universidades georreferenciadas y el dataset que presenta el número de matriculados por cada universidad que previamente hemos preprocesado. Para ello hemos utilizado la función BUSCARV() de Excel que nos permitirá localizar determinados elementos en un rango de celdas de una tabla.
Antes de subir el conjunto de datos a Datawrapper, debemos seleccionar la capa que muestra el mapa de España dividido en provincias que nos proporciona la propia herramienta. Concretamente, hemos seleccionado la opción \"Spain>>Provinces(2018)\". Seguidamente procedemos a incorporar el conjunto de datos \"Universidades\", antes generado, (este conjunto de datos se adjunta en la carpeta de conjuntos de datos de GitHub para esta visualización paso a paso), indicando que columnas contienen los valores de las variables Latitud y Longitud.
A partir de este punto, Datawrapper ha generado un mapa en el que se muestran las ubicaciones de cada una de las universidades. Ahora podemos modificar el mapa según nuestras preferencias y ajustes. En este caso, haremos que el tamaño de los puntos y el color dependa del número de matriculaciones que presente cada universidad. Además, para que estos datos se muestren, en la pestaña “Annotate”, en la sección “Tooltips”, debemos indicarle las variables o el texto que deseemos que aparezca.
5.3. Ranking de matriculaciones por titulación
Para esta representación gráfica utilizamos el objeto visual de Datawrapper tabla (Table) y el conjunto de datos \"Titulaciones_totales\" para mostrar el número de matriculaciones que presenta cada una de las titulaciones impartidas durante el curso 2020-2021. Dado que el número de titulaciones es muy extenso, la herramienta nos ofrece la posibilidad de incluir un buscador que permite filtrar los resultados.
5.4. Distribución de matriculaciones por rama de enseñanza
Para esta representación visual, hemos utilizado el conjunto de datos \"Matriculaciones_Rama_Grado\" y seleccionado gráficos de sectores (Pie Chart), donde hemos representado el número de matriculaciones según sexo en cada una de las ramas de enseñanza en las cuales se dividen las titulaciones impartidas por las universidades (Ciencias Sociales y Jurídicas, Ciencias de la Salud, Artes y Humanidades, Ingeniería y Arquitectura y Ciencias). Al igual que en el resto de gráficos, podemos modificar el color del gráfico, en este caso en función de la rama de enseñanza.
5.5. Matriculaciones de Grado por edad y nacionalidad
Para la realización de estas dos representaciones de datos visuales utilizamos diagramas de barras (Bar Chart), donde mostramos la distribución de matriculaciones en el primero, desagregada por sexo y nacionalidad, utilizaremos el conjunto de datos \"Matriculaciones_Grado_nacionalidad\" y en el segundo, desagregada por sexo y edad, utilizando el conjunto de datos \"Matriculaciones_Grado_edad\". Al igual que los visuales anteriores, la herramienta facilita de forma sencilla la modificación de las características que presentan los gráficos.
6. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implamentar se puede observar lo siguiente:
- El número de matriculaciones aumenta a lo largo de los cursos académicos independientemente del nivel académico (grado, máster o doctorado).
- El número de mujeres matriculadas es mayor que el de hombres en grado y máster, sin embargo es menor en el caso de las matriculaciones de doctorado, excepto en el curso 2019-2020.
- La mayor concentración de universidades la encontramos en la Comunidad de Madrid, seguido de la comunidad autónoma de Cataluña.
- La universidad que concentra mayor número de matriculaciones durante el curso 2020-2021 es la UNED (Universidad Nacional de Educación a Distancia) con 146.208 matriculaciones, seguida de la Universidad Complutense de Madrid con 57.308 matriculaciones y la Universidad de Sevilla con 52.156.
- La titulación más demandada el curso 2020-2021 es el Grado en Derecho con 82.552 alumnos a nivel nacional, seguido del Grado de Psicología con 75.738 alumnos y sin apenas diferencia, el Grado en Administración y Dirección de Empresas con 74.284 alumnos.
- La rama de enseñanza con mayor concentración de alumnos es Ciencias Sociales y Jurídicas, mientras que la menos demandada es la rama de Ciencias.
- Las nacionalidades que más representación tienen en la universidad española son de la región de la unión europea, seguido de los países de América Latina y Caribe, a expensas de la española.
- El rango de edad entre los 18 y 21 años es el más representado en el alumnado de las universidades españolas.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
Las visualizaciones son una representación gráfica que nos permite comunicar de una manera sencilla la información ligada a los datos. Mediante elementos visuales, como gráficos, mapas o nubes de palabras, las visualizaciones, también nos ayudan a comprender tendencias, patrones o valores atípicos que pueden presentar los datos.
Las visualizaciones se pueden generar a partir de datos de diferente naturaleza, como pueden ser las palabras que conforman una noticia, un libro o una canción. Para realizar visualizaciones a partir de este tipo de datos, es necesario que las maquinas, mediante programas de software, sean capaces de entender, interpretar y reconocer las palabras que configuran el lenguaje humano (escrito o hablado) en múltiples idiomas. El campo de estudio enfocado en el tratamiento de estos datos se denomina Procesamiento del Lenguaje Natural (PLN). Es un campo interdisciplinar que combina el poder de la inteligencia artificial, la lingüística computacional y la informática. Los sistemas basados en PLN han permitido grandes innovaciones como el buscador de Google, el asistente de voz de Amazon, los traductores automáticos, el análisis de sentimientos de diferentes redes sociales o incluso detección de spam en una cuenta de correo electrónico.
En este ejercicio práctico, vamos a implementar una visualización gráfica de un resumen de palabras clave representativas de varios textos extraídas mediante la aplicación de técnicas de PLN. En concreto, vamos a crear una nube de palabras que resuma cuál son los términos que más se repiten en varios posts del portal.
Esta visualización se engloba dentro de la serie de ejercicios prácticos, en los cuales se utilizan datos abiertos disponibles en el portal datos.gob.es. En estos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar transformaciones y análisis que resulten pertinentes para la creación de la visualización, extrayendo la máxima información. En cada uno de los ejercicios prácticos se usan sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en GitHub.
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización que incluya imágenes, generadas a partir de conjuntos de palabras representativas de diversos textos, conocidas popularmente como “nubes de palabras”. Para este ejercicio práctico hemos escogido 6 post publicados en la sección de blog del portal de datos.gob.es. A partir de estos textos y utilizando técnicas de PLN generaremos una nube de palabras para cada texto que nos permitirá detectar de manera sencilla y visual la frecuencia e importancia de cada palabra, facilitando la identificación de las palabras clave y la temática principal de cada uno de los posts.

A partir de un texto construimos una nube de palabras aplicando técnicas de Procesamiento de Lenguaje Natural (PLN)
3. Recursos
3.1. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo), como la visualización propiamente dicha, se utiliza Python (versión 3.7) y Jupyter Notebook (versión 6.1), herramientas que encontraras integradas en, junto con muchas otras, en Anaconda, una de las plataformas más populares para instalar, actualizar y administrar software para trabajar en ciencia de datos. Para abordar las tareas relacionadas con el Procesamiento del Lenguaje Natural, utilizamos dos librerías, Scikit-Learn (sklearn) y wordcloud. Todas estas herramientas son Open Source y están disponibles de manera gratuita.
Scikit-Learn es una amplia librería muy popular, diseñada principalmente para llevar a cabo tareas de aprendizaje automático sobre datos en forma de texto. Entre otros, cuenta con algoritmos para realizar tareas de clasificación, regresión, clustering y reducción de dimensionalidades. Además, está diseñada para el aprendizaje profundo sobre datos textuales, siendo útil para el manejo de conjuntos de características textuales en forma de matrices, la realización de tareas como el cálculo de similitudes, la clasificación de texto y la agrupación de clústeres. En Python, para realizar este tipo de tareas, también es posible trabajar con otras librerías igualmente populares como NLTK o spacy, entre otras.
wordcloud es una librería especializada en la creación de nubes de palabras utilizando un algoritmo simple y que puede ser modificado fácilmente.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en Python que se incluye a continuación, al que puedes acceder haciendo click en el botón “Código” de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren formas alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de GitHub de datos.gob.es. La forma de proporcionar el código es a través de un Jupyter Notebook, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
3.2. Conjuntos de datos
Para este análisis se han seleccionado 6 posts publicados recientemente en el portal de datos abiertos datos.gob.es, en su sección de blog. Estos posts están relacionado con diferentes temáticas relativas a los datos abiertos:
- Lo último en el procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cientos de palabras.
- La importancia de la anonimización y la privacidad de datos.
- El valor de los datos en tiempo real a través de un ejemplo práctico.
- Nuevas iniciativas para abrir y aprovechar datos para investigación en salud.
- Kaggle y otras plataformas alternativas para aprender ciencia de datos.
- La infraestructura de Datos Espaciales de España (IDEE), un referente de la información geoespacial.
4. Tratamiento de datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos o preprocesamiento de los datos, prestando atención a la obtención de los mismos, asegurando que no contienen errores y se encuentran en un formato adecuado para su procesamiento. Un tratamiento previo de los datos es esencial para construir cualquier representación visual efectiva y consistente.
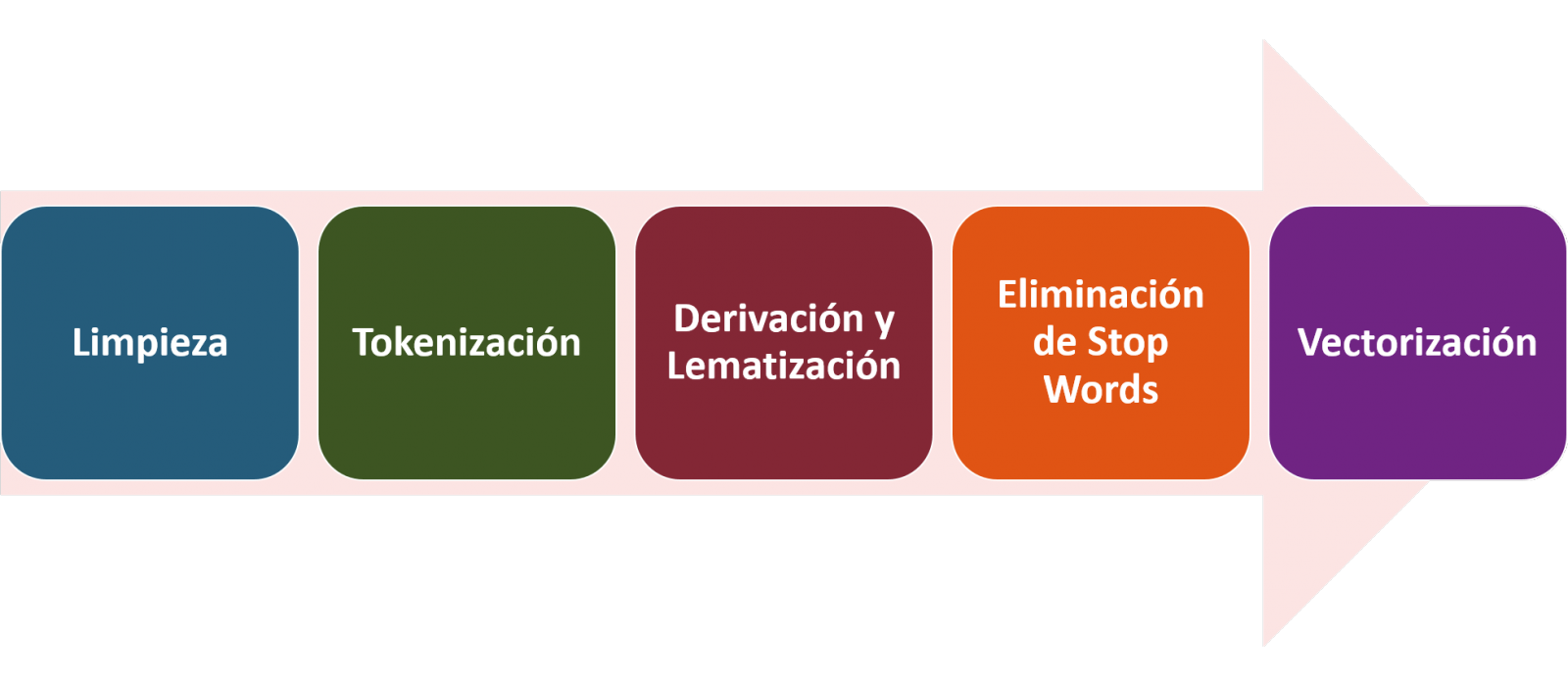
En PLN, el preprocesamiento de los datos consiste fundamentalmente en una serie de transformaciones que se realizan sobre los datos de entrada, en nuestro caso varios posts en formato TXT, con el objetivo de obtener datos uniformes y sin elementos que puedan afectar a la calidad de los resultados, con el fin de facilitar su posterior procesamiento para realizar tareas como, generar una nube de palabras, realizar minería de opiniones/sentimientos o generar resúmenes automatizados a partir de textos de entrada. De forma general, el flujograma que se sigue para realizar un preprocesamiento de texto incluye las siguientes etapas:
- Limpieza: eliminación de los caracteres y símbolos especiales que contribuyen a distorsionar los resultados, por ejemplo, los signos de puntuación.
- Tokenizar: la tokenización es el proceso de separar un texto en unidades más pequeñas, tokens. Los tokens pueden ser oraciones, palabras o incluso caracteres.
- Derivación y Lematización: este proceso consiste en transformar las palabras a su forma básica, es decir a su forma canónica o lema, eliminando plurales, tiempos verbales o géneros. Esta acción en ocasiones no es necesaria ya que no siempre se requiere para el procesamiento posterior saber la similitud semántica entre las diferentes palabras del texto.
- Eliminación de stop words: las stop words o palabras vacías son aquellas palabras de uso común pero que no contribuyen de una manera significativa en el texto. Estas palabras deben eliminarse antes del procesamiento del texto ya que no aportan ninguna información única que pueda ser usada para la clasificación o agrupación del texto, por ejemplo, los artículos determinantes como ‘los’, ‘las’, ‘una’ ‘unos’, etc.
- Vectorización: en este paso transformamos cada uno de los tokens obtenidos en el paso anterior a un vector de números reales que se genera en base a la frecuencia de la aparición de cada palabra en el texto. La vectorización permite que las maquinas sean capaces de procesar texto y aplicar, entre otras, técnicas de aprendizaje automático.
4.1. Instalación y carga de librerías
Antes de empezar con el preprocesamiento de datos, debemos importar las librerías con las cuales vamos a trabajar. Python dispone de una gran cantidad de librerías que permiten implementar funcionalidades para muchas tareas, como visualización de datos, Machine Learning, Deep Learning o Procesamiento del Lenguaje Natural, entre muchas otras. Las librerías que utilizaremos para este análisis y visualización son:
- os, que permite acceder a funcionalidades dependientes del sistema operativo, como manipular la estructura de directorios.
- re, proporciona funciones para procesar expresiones regulares.
- pandas, es una librería muy popular y esencial para procesar tablas de datos.
- string, proporciona una serie de funciones muy útiles para el manejo de cadenas de caracteres.
- matplotlib.pyplot, contiene una colección de funciones que nos permitirán generar las representaciones gráficas de las nubes de palabras.
- sklearn.feature_extraction.text (librería Scikit-Learn), convierte una colección de documentos de texto en una matriz de vectores. De esta librería usaremos algunos comandos que comentaremos más adelante.
- wordcloud, librería con la cual podremos generar la nube de palabras.
# Importaremos las librerías necesarias para realizar este análisis y la visualización. import os import re import pandas as pd import string import matplotlib.pyplot as plt from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from wordcloud import WordCloud4.2. Carga de datos
Una vez cargadas las librerías, preparamos los datos con los cuales vamos a trabajar. Antes de comenzar a cargar los datos, en el directorio de trabajo debemos tener: (a) una carpeta denominada “post” que contendrá todos los archivos en formato TXT con los cuales vamos a trabajar y que están disponibles en el repositorio de este proyecto del GitHub de datos.gob.es; (b) un archivo denominado “stop_words_spanish.txt” que contiene el listado de las stop words en español, que también está disponible en dicho repositorio y (c) una carpeta llamada “imagenes” donde guardaremos las imágenes de las nubes de palabras en formato PNG, que crearemos a continuación.
# Generamos la carpeta \"imagenes\".nueva_carpeta = \"imagenes/\" try: os.mkdir(nueva_carpeta)except OSError: print (\"Ya existe una carpeta llamada %s\" % nueva_carpeta)else: print (\"Se ha creado la carpeta: %s\" % nueva_carpeta)Seguidamente, procederemos a cargar los datos. Los datos de entrada, como ya hemos comentado anteriormente, se encuentran en ficheros TXT y cada fichero contiene un post. Como queremos realizar el análisis y la visualización de varios posts al mismo tiempo, cargaremos en nuestro entorno de desarrollo todos los textos que nos interesen, para posteriormente insertarlos en una única tabla o dataframe.
# Generamos una lista donde incluiremos todos los archivos que debe leer, indicándole la carpeta donde se encuentran.filePath = []for file in os.listdir(\"./post/\"): filePath.append(os.path.join(\"./post/\", file))# Generamos un dataframe en el cual incluiremos una fila por cada post.post_df = pd.DataFrame()for file in filePath: with open (file, \"rb\") as readFile: post_df = pd.DataFrame([readFile.read().decode(\"utf8\")], append(post_df)# Nombramos la columna que contiene los textos en el dataframe.post_df.columns = [\"texto\"]4.3. Preprocesamiento de datos
Para el objetivo que nos hemos planteado, generar nubes de palabras para cada post, vamos a realizar las siguientes tareas de preprocesamiento.
a) Limpieza de datos
Una vez generada la tabla que contiene los textos con los cuales vamos a trabajar, debemos eliminar el ruido ajeno al texto que nos interesa: caracteres especiales, signos de puntuación y retornos de carro.
En primer lugar, ponemos en minúscula todos los caracteres para evitar cualquier error en los procesos que distinguen entre mayúsculas y minúsculas, mediante el uso del comando lower().
Seguidamente eliminamos los signos de puntuación, como puntos, comas, exclamaciones, interrogaciones, entre muchos otros. Para la eliminación de estos recurriremos a la cadena preinicializada string.punctuacion de la librería string, que devuelve un conjunto de símbolos considerados signos de puntuación. Además, debemos eliminar las tabulaciones, saltos de carro y espacios extra, que no aportan información en este análisis, mediante el uso de expresiones regulares.
Es fundamental aplicar todos estos pasos en una única función para que se procesen de forma secuencial, debido a que todos los procesos están altamente relacionados.
# Eliminamos los signos de puntuación, los saltos de carro/tabulaciones y espacios en blanco extra.# Para ello generamos una función en la cual indicamos todos los cambios que queremos aplicar al texto.def limpiar_texto(texto): texto = texto.lower() texto = re.sub(\"\\[.*?¿\\]\\%\", \" \", texto) texto = re.sub(\"[%s]\" % re.escape(string.punctuation), \" \", texto) texto re.sub(\"\\w*\\d\\w*\", \" \", texto) return texto# Aplicamos los cambios al texto.limpiar_texto = lambda x: limpiar_texto(x)post_clean = pd.DataFrame(post_clean.texto.apply/limpiar_texto)b) Tokenizar
Una vez que hemos eliminado el ruido en los textos con los cuales vamos a trabajar, “tokenizaremos” en palabras cada uno de los textos. Para ello utilizaremos la funció split(), usando como separador entre palabras, el espacio. Esto permitirá separar las palabras de manera independiente (tokens) para análisis futuros.
# Tokenizar los textos. Se crea una nueva columna en la tabla con los tokens con el texto \"tokenizado\".def tokenizar(text): text = texto.split(sep = \" \") return(text)post_df[\"texto_tokenizado\"] = post_df[\"texto\"].apply(lambda x: tokenizar(x))c) Eliminación de \"stop words\"
Después de eliminar los signos de puntuación y otros elementos que pueden distorsionar la visualización objetivo, eliminaremos las “stop words” o palabras vacías. Para la realización de este paso usamos una lista de stop words del castellano dado que cada idioma posee su propia lista. Esta lista consta de un total de 608 palabras, en las que se incluyen artículos, preposiciones, verbos copulativos, adverbios, entre otros y está actualizada recientemente. Esta lista puede descargarse desde la cuenta de GitHub de datos.gob.es en formato TXT y debe estar ubicada en el directorio de trabajo.
# Leemos el archivo que contiene las palabras vacías en castellano.with open \"stop_words_spanish.txt\", encoding = \"UTF8\") as f: lines = f.read().splitlines()En esta lista de palabras, incluiremos nuevas palabras que no aportan información relevante a nuestros textos o aparecen recurrentemente debido al contexto de los mismos. En este caso, existe una serie de palabras, que nos conviene eliminar ya que están presentes en todos los posts de manera repetitiva dado que todos tratan sobre el tema de datos abiertos y existe una alta probabilidad de que éstas sean las palabras más significativas. Algunas de estas palabras son, “datos”, “dato”, “abiertos”, “caso”, entre otras. Esto permitirá obtener una representación gráfica más representativa del contenido de cada post.
Por otro lado, una inspección visual de los resultados obtenidos permite detectar palabras o caracteres derivados de errores incluidos en los textos, que evidentemente no tienen significado y que no han sido eliminados en los pasos anteriores. Estos, deben ser retirados del análisis para que no distorsionen los resultados posteriores. Se trata de palabras como, “nen”, “nun” o “nla”.
# Actualizamos nuestra lista de stop words.stop_words.extend((\"caso\", \"forma\",\"unido\", \"abiertos\", \"post\", \"espera\", \"datos\", \"dato\", \"servicio\", \"nun\", \"día\", \"nen\", \"data\", \"conjuntos\", \"importantes\", \"unido\", \"unión\", \"nla\", \"r\", \"n\"))# Eliminamos las stop words de nuestra tabla.post_clean = post_clean [~(post_clean[\"texto_tokenizado\"].isin(stop_words))]d) Vectorización
Las maquinas no son capaces de comprender palabras y oraciones, por lo que estas deben convertirse en alguna estructura numérica. El método consiste en generar vectores a partir de cada token. En este post utilizamos una técnica sencilla conocida como bolsa de palabras (BoW). Consiste en asignar un peso a cada token proporcional a la frecuencia de aparición de dicho token en el texto. Para ello, trabajamos sobre una matriz en la que cada fila representa un texto y cada columna un token. Para realizar la vectorización recurriremos a los comandos CountVectorizer() y TfidTransformer() de la lirería Scikit-Learn.
La función CountVectorizer() permite transformar un texto en un vector de frecuencias o recuentos de palabras. En este caso obtendremos 6 vectores con tantas dimensiones como tokens hay en cada texto, uno por cada post, que integraremos en una única matriz, donde las columnas serán los tokens o palabras y las filas serán los posts.
# Calculamos la matriz de frecuencia de palabras del texto.vectorizador = CountVectorizer()post_vec = vectorizador.fit_transform(post_clean.texto_tokenizado)Una vez generada la matriz de frecuencia de palabras, es necesario convertirla en una forma vectorial normalizada con el objetivo de reducir el impacto de los tokens que ocurren con mucha frecuencia en el texto. Para ello utilizaremos la función TfidfTransformer().
# Convertimos una matriz de frecuencia de palabras en una forma vectorial regularizada.transformer = TfidfTransformer()post_trans = transformer.fit_transform(post_vec).toarray()Si quieres saber más sobre la importancia de aplicar está técnica, encontrarás numerosos artículos en Internet que hablan sobre ello y lo relevante que es, entre otras cuestiones, para la optimización de SEO.
5. Creación de la nube de palabras
Una vez que hemos realizado un preprocesamiento del texto, como indicábamos al inicio del post, es posible realizar tareas propias de PLN. En este ejercicio crearemos una nube de palabras o “WordCloud” para cada uno de los textos analizados.
Una nube de palabras, es una representación visual de las palabras con mayor número de ocurrencias en el texto. Permite detectar de manera sencilla la frecuencia e importancia de cada una de las palabras, facilitando la identificación de las palabras clave y descubriendo con un solo golpe de vista la temática principal tratada en el texto.
Para ello vamos a utilizar la librería “wordcloud” que incorpora las funciones necesarias para construir cada representación. En primer lugar, debemos indicar las características que presentará cada nube de palabras, como es el color de fondo (función background_color), el mapa de colores que tomaran las palabras (función colormap), el tamaño máximo de letra (función max_font_size) o fijar una semilla para que la nube de palabras generada siempre sea igual (función random_state) en futuras ejecuciones. Podemos aplicar estas y muchas otras funciones para personalizar cada nube de palabras.
# Indicamos las características que presentará cada nube de palabras.wc = WordCloud(stopwords = stop_words, background_color = \"black\", colormap = \"hsv\", max_font_size = 150, random_state = 123)Una vez que hemos indicado las características que queremos que presente cada nube de palabras, procedemos a crearla y guardarla como imagen en formato PNG. Para generar la nube de palabras, usaremos un bucle en el cual le indicaremos diferentes funciones de la librería matplotlib (representada por el prefijo plt) necesarias para generar gráficamente la nube de palabras según la especificación definida en el paso anterior. Debemos indicarle que debe realizar una nube de palabras por cada fila de la tabla, es decir por cada texto, con la función plt.subplot(). Con el comando plt.imshow() indicamos que el resultado es una imagen en 2D. Si queremos que no se muestren los ejes debemos indicárselo con la función plt.axis(). Por último, con la función plt.savefig() guardaremos la visualización generada.
# Generamos las nubes de palabras para cada uno de los posts.for index, i in enumerate(post.columns): wc.generate(post.texto_tokenizado[i]) plt.subplot(3, 2, index+1 plt.imshow(wc, interpolation = \"bilinear\") plt.axis(\"off\") plt.savefig(\"imagenes/.png\")# Mostramos las nubes de palabras resultantes.plt.show()La visualización obtenida es:

Visualización de las nubes de palabras obtenidas a partir de los textos de diferentes posts de la sección de blog de datos.gob.es
5. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Las nubes de palabras son una herramienta que permite agilizar el análisis de datos textuales, puesto que a través de ellas podemos identificar e interpretar de manera rápida y sencilla las palabras con mayor relevancia en el texto analizado, lo que nos da una idea de la temática.
Si quieres aprender más sobre el Procesamiento del Lenguaje Natural, puedes consultar la guía \"Tecnologías emergentes y datos abiertos: Procesamiento del lenguaje natural\" y los posts \"Procesamiento del lenguaje natural\" y \"Lo último en procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cuentos de palabras\".
Esperemos que esta visualización paso a paso te haya enseñado algunas cosas sobre los entresijos del Procesamiento del Lenguaje Natural y la creación de nubes de palabras. Volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!