Documentación
En una plataforma como datos.gob.es, donde la frecuencia de actualización de los conjuntos de datos es constante, es necesario contar con mecanismos que faciliten la realización de consultas de forma masiva y automática.
En datos.gob.es contamos con una API y un punto SPARQL para facilitar esta tarea. Ambas herramientas permiten consultar los metadatos asociados a los conjuntos de datos del Catálogo Nacional de datos abiertos en base a las definiciones incluidas en la Norma Técnica de Interoperabilidad de Reutilización de recursos de información (NTI-RISP). En concreto, la base de datos semántica de datos.gob.es contiene dos grafos, uno que contiene todo el Catálogo de datos y otro con las URIs correspondientes a la taxonomía de sectores primarios y a la identificación de cobertura geográfica en base a la NTI.
Para ayudar a los reutilizadores a realizar sus búsquedas a través de estas funcionalidades, ponemos a disposición de los usuarios dos vídeos que muestran de manera sencilla los pasos a seguir para sacar el máximo partido a ambas herramientas.
Vídeo 1: ¿Cómo realizar consultas al catálogo de datos.gob.es a través de una API?
Una interfaz de programación de aplicaciones o API es un mecanismo que permite la comunicación e intercambio de información entre sistemas. Gracias a la API de datos.gob.es puedes consultar de forma automática los conjuntos de datos de un publicador, los datasets que pertenecen a una temática determinada o los que están disponibles en un formato concreto, entre otras muchas consultas.
El vídeo muestra:
- Cómo usar la API de datos.gob.es
- Qué tipos de consultas se pueden realizar utilizando dicha API
- Un ejemplo para aprender a listar los datasets que hay en el catálogo
- Qué otras Iniciativas de Datos Abiertos están publicando APIs
- Cómo se pueden consultar otras API disponibles
También tienes a tu disposición con una infografía con ejemplos de APIs para el acceso a datos abiertos.
Vídeo 2: ¿Cómo realizar consultas al catálogo de datos.gob.es a través del punto SPARQL?
Un punto SPARQL es una forma alternativa de consultar los metadatos del catálogo de datos.gob.es utilizando un servicio que permite realizar consultas sobre grafos RDF utilizando el lenguaje SPARQL.
Con este vídeo, podrás ver:
- Cómo usar el punto SPARQL de datos.gob.es
- Qué consultas se pueden realizar utilizando el punto SPARQL
- Qué métodos existen para consultar el punto SPARQL
- Ejemplos sobre cómo realizar una consulta para conocer qué conjuntos de datos están disponibles en el catálogo o cómo obtener la lista de todos los organismos que publican datos en el catálogo
- Incluye además ejemplos de puntos SPARQL en diferentes iniciativas del ámbito nacional
Estos vídeos están dirigidos principalmente a reutilizadores de datos. Desde datos.gob.es también hemos preparado una serie de vídeo para publicadores donde se explican las diversas funcionalidades que tienen a su disposición en la plataforma.
Documentación
Los publicadores de datos abiertos en el Catálogo Nacional albergado en datos.gob.es tienen a su disposición diversas funcionalidades internas para gestionar de manera sencilla sus datasets y todo lo relacionado con ellos.
Para acercar estas posibilidades a los usuarios registrados, desde datos.gob.es hemos preparado una serie de vídeos donde se detallan los pasos a seguir para poder desarrollar diversas acciones en la plataforma.
Cabe incidir en que estos vídeos están dirigidos a publicadores de datos, próximamente se publicarán también vídeos enfocados en las herramientas disponibles para la reutilización de los datos, de gran utilidad para desarrolladores, empresas, organismos o particulares que quieran extraer el máximo valor posible a los datasets accesibles desde esta plataforma.
Vídeo 1: Funcionalidades de backoffice para usuarios registrados
El primer vídeo explica las funcionalidades que los usuarios registrados pueden utilizar para interactuar con la plataforma. En concreto, aborda los siguientes temas:
- Cómo acceder al catálogo de datos de la organización y crear, gestionar, localizar o filtrar datasets existentes.
- Cómo utilizar la función de enlaces rotos para saber si hay algún conjunto de datos inaccesible.
- Qué estadísticas interactivas proporciona el cuadro de mando y cómo descargarlas en diversos formatos, como CSV o JSON.
- Cómo difundir iniciativas, aplicaciones o casos de éxito basados en datos a través de la plataforma.
- Cómo atender peticiones de datos o comentarios.
- Cómo ajustar el perfil de usuario.
Vídeo 2: ¿Cómo realizar una carga manual de conjuntos de datos en datos.gob.es?
Los publicadores de datos.gob.es pueden dar de alta sus conjuntos de datos se dos maneras distintas:
- Manual: El usuario debe completar para cada conjunto de datos, de manera individual, un formulario donde se detallan sus metadatos.
- Automática (federada): El alta y actualización se hace de forma periódica a partir de un fichero RDF con los metadatos disponibles a través de una URL en el sitio web del publicador. Se trata de un proceso por lotes que permite gestionar la carga de varios conjuntos a la vez.
Este vídeo se centra en la primera manera, incluyendo información sobre:
- Qué pasos hay que seguir para crear nuevos conjuntos de datos de manera manual.
- Qué metadatos es obligatorio incluir y cuáles recomendables, para que los usuarios puedan localizar más fácilmente aquella información que les interesa.
- Cómo modificar los metadatos.
- Cómo se añaden distribuciones -es decir, archivos descargables en un formato o nivel de desagregación determinado- al nuevo conjunto de datos. También se indica cuáles son lo metadatos obligatorios de las distribuciones y cómo se pueden modificar.
- Cómo se eliminan los conjuntos de datos de la organización y sus distribuciones.
Vídeo 3: ¿Cómo realizar una carga automática de conjuntos de datos en datos.gob.es?
Este vídeo se centra en la segunda forma de publicar datasets en datos.gob.es, a través de fuentes de federación de datos. Gracias al vídeo aprenderás:
- Qué es una fuente de federación
- Cómo crear, consultar, filtrar y ordenar las fuentes de datos de una organización.
- Cómo consultar mediante un cuadro de mando, los detalles de la última ejecución o el histórico de tareas de una fuente de federación.
- Cómo editar y actualizar una fuente de federación.
- Cómo ejecutar una federación de forma manual desde el cuadro de mando.
- Cómo eliminar o limpiar las tareas de federación ya realizadas.
- Cómo ver el estado de la última federación.
- Cómo eliminar una fuente de datos de una organización, tanto manteniendo como eliminado también los conjuntos de datos previamente importados.
Video 4: ¿Para qué sirve el widget del catálogo de datos.gob.es?
Un Widget es una porción de código en lenguaje HTML que contiene funcionalidades que se pueden incrustar y ejecutar en páginas web de forma sencilla. Gracias al Widget que te proporcionamos podrás incluir en cualquier sitio web, un catálogo con la referencia a todos los conjuntos de datos que hayas dado de alta en datos.gob.es.
Este vídeo explica:
- Qué es el widget, mostrando ejemplos de uso
- Cómo se genera el código HTML asociado al widget
- Cómo se puede embeber la vista del catálogo de datos en cualquier portal del publicador.
Para profundizar en estos y otros aspectos, también tienes a tu disposición varias guías de usuario en este enlace.
Documentación
Descubre cuáles son los marcos estratégicos que marcan la publicación y utilización de datos abiertos, así como los conjuntos de datos más destacados a nivel local, regional, nacional e internacional a través de las diversas infografías que iremos publicando periódicamente.
Espacio Europeo de Datos de Salud: objetivos y planteamiento
 |
Publicada: febrero 2025 En esta infografía te contamos las claves del primer espacio común europeo de datos de la UE en un sector específico y el único que regula el uso primario de los datos, además del secundario. Descubre las áreas de acción, proyectos relacionados y próximos pasos. |
Los datos y su gobernanza en el Reglamento Europeo de Inteligencia Artificial
 |
Publicada: octubre 2024 El Reglamento Europeo de Inteligencia Artificial busca constituir un marco de referencia para el desarrollo de cualquier sistema e inspirar los códigos de buenas prácticas, normas técnicas y esquemas de certificación. En esta infografía te contamos sus claves. |
Ejemplos de conjuntos de datos abiertos publicados por entidades locales
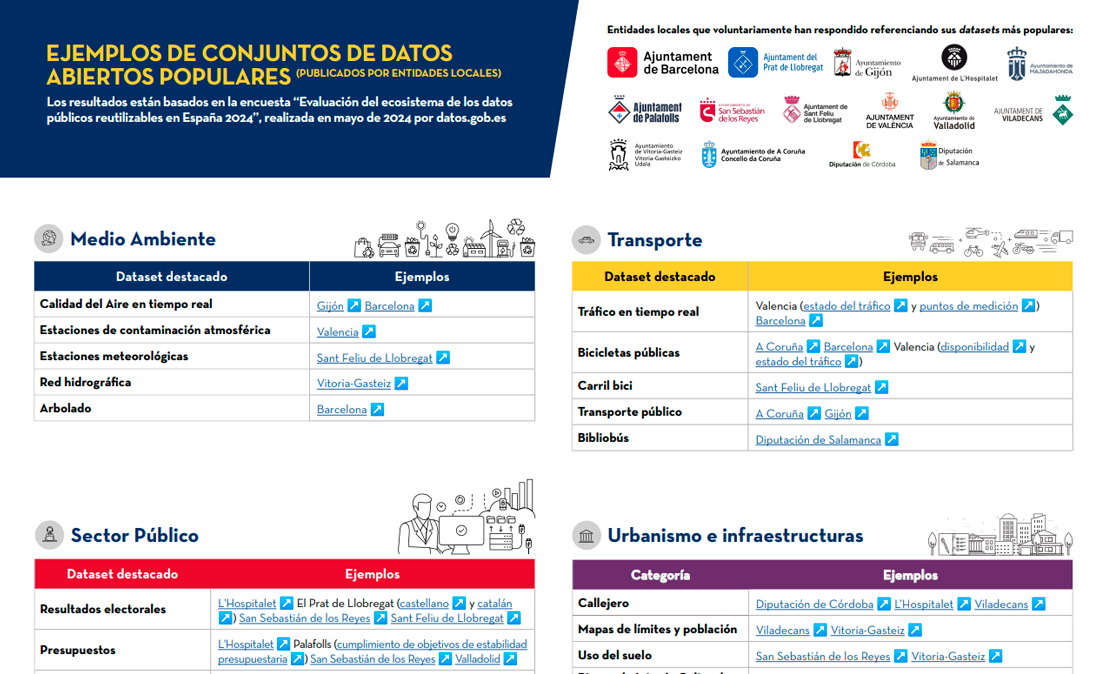 |
Publicada: septiembre 2024 Para conocer las actividades que llevan a cabo en materia de datos abiertos, el pasado mes de mayo se realizó una encuesta en la que participaron representantes de entidades locales. Esta infografía recoge ejemplos de los conjuntos de datos más populares de sus portales. |
Declaración Europea sobre Derechos y Principios Digitales
 |
Publicada: agosto 2024 La Declaración se basa en la Carta de Derechos Fundamentales de la UE, que promueve una transición digital configurada por los valores europeos. En esta infografía, se presentan los principios que la configuran y la opinión de la ciudadanía europea para cada uno de ellos. |
Estrategia de inteligencia artificial 2024
 |
Publicada: julio 2024 La nueva estrategia de inteligencia artificial 2024 establece un marco para acelerar el desarrollo y expansión de la IA en España. Se articula en torno a tres ejes principales desarrollados a través de ocho líneas de acción, los cuales se detallan en esta infografía. |
Conjuntos de datos de alto valor
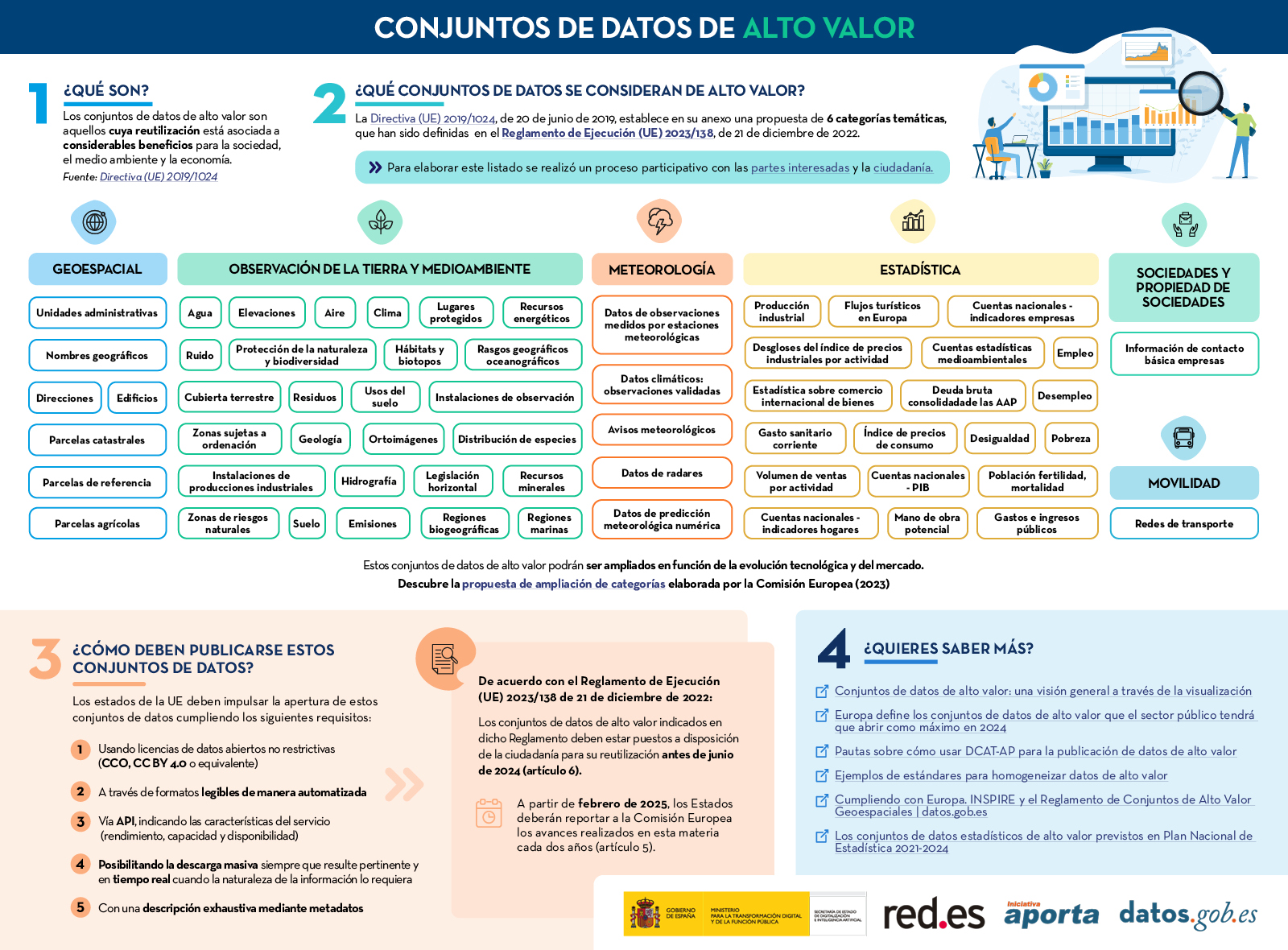 |
Publicada: marzo 2024 Esta infografía muestra las categorías de datos de alto valor definidas en el Reglamento de Ejecución (UE) 2023/138, de 21 de diciembre de 2022. Descubre cuáles son estas categorías y cómo deben publicarse los conjuntos de datos ligados a ellas. También se ha creado una versión a una página para facilitar su impresión: accede aquí |
Gaia-X y los espacios de datos europeos
 |
Publicada: abril 2022 Esta infografía muestra el contexto que impulsa el desarrollo de los espacios de datos, haciendo foco en algunas iniciativas europeas relacionadas como Gaia-X y ISDA. |
Tendencias en datos abiertos a lo largo del mundo
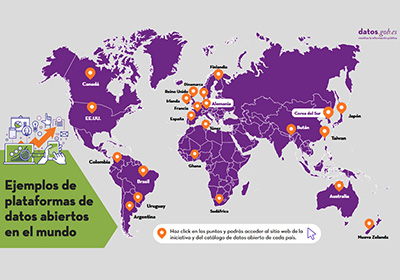 |
Publicada: noviembre 2021 A través de esta infografía interactiva puedas acceder fácilmente a las plataformas y conjuntos de datos abiertos de varios países destacados. La infografía se acompaña de un post donde se analizan brevemente las estrategias y próximos pasos a seguir por dichas iniciativas, mostrando cuáles son las principales tendencias a nivel mundial. |
Los conjuntos de datos más demandados publicados por entidades locales
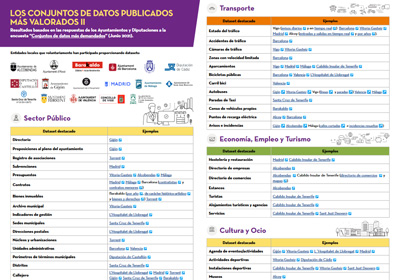 |
Publicada: julio 2021 17 entidades locales, incluyendo ayuntamientos, diputaciones y un cabildo insular, comparten con los usuarios de datos.gob.es cuáles son sus conjuntos de datos más demandados, entre todos aquellos publicados bajo unos estándares que favorecen su reutilización. Los conjuntos de datos se muestran segmentados por categorías temáticas, destacando los datos de transporte, medio ambiente y sector público. |
Las estrategias de gobierno abierto y datos públicos de las Comunidades Autónomas
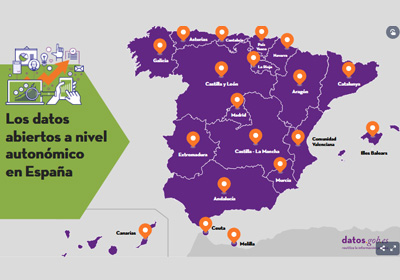 |
Publicada: junio 2021 A través de un mapa interactivo se recogen las iniciativas de datos abiertos a nivel autonómico de España, incluyendo en cada caso la url a su portal y a los principales documentos donde se detalla su marco estratégico. La infografía va acompañada de un artículo donde se abordan los compromisos adquiridos por cada CC.AA. en el IV Plan de Gobierno Abierto de España. |
¿Cuáles son los conjuntos de datos más demandados de las Comunidades Autónomas?
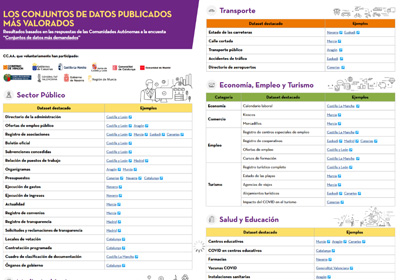 |
Publicada: mayo 2021 En esta infografía se recopilan unos 100 conjuntos de datos publicados por organismos autonómicos, que se ofrecen en abierto de acuerdo a unos estándares que facilitan su reutilización. Los datasets se muestran divididos por categorías temáticas, destacando los relacionados con el sector público, la economía, el empleo y el turismo, y el medio ambiente. |
Las estrategias relacionadas con los datos que marcarán 2021
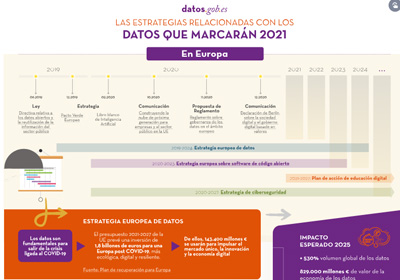 |
Publicada: enero 2021 Esta infografía interactiva muestra la situación estratégica, normativa y política que afecta al mundo de los datos abiertos en España y Europa. En ella se recogen los principales puntos de la Estrategia Europea de Datos, el Reglamento sobre Gobernanza de los datos en Europa o el plan España Digital 2025, entre otros. |
Documentación
Los datos abiertos pueden ser la base de diversas tecnologías disruptivas, como la Inteligencia Artificial, que impliquen mejoras para la sociedad y la economía. En estas infografías se abordan tanto herramientas para trabajar con los datos, como ejemplos del uso de datos abiertos en estas nuevas tecnologías. Se irán publicando nuevos contenidos de manera periódica.
Decálogo del científico de datos
 |
Publicada: octubre 2025 Desde comprender el problema antes de mirar los datos, hasta visualizar para comunicar y mantenerse actualizado, este decálogo ofrece una visión completa del ciclo de vida de un proyecto de datos responsable y bien estructurado. |
Visualización de datos abiertos con herramientas open source
 |
Publicada: junio 2025 Esta infografía recopila herramientas de visualización de datos, el último paso del análisis exploratorio de datos. Es la segunda parte de la infografía sobre análisis de datos abiertos con herramientas open source. |
Análisis de datos abiertos con herramientas open source
 |
Publicada: marzo 2025 El AED consiste en aplicar un conjunto de técnicas estadísticas dirigidas a explorar, describir y resumir la naturaleza de los datos, de tal forma que podamos garantizar su objetividad e interoperabilidad. En esta infografía, recopilamos herramientas gratuitas para realizar los tres primeros pasos de un análisis de datos. |
Nuevas técnicas de captura de datos geoespaciales
 |
Publicada: enero 2025 La captura de datos geoespaciales es esencial para entender el entorno, tomar decisiones y diseñar políticas efectivas. En esta infografía, exploraremos nuevos métodos de captura de datos. |
Análisis Exploratorio de Datos (EDA)
 |
Publicada: noviembre 2024 En base a lo recogido en el informe “Guía Práctica de Introducción al Análisis Exploratorio de Datos”, se ha elaborado una infografía que resume de manera sencilla en qué consiste esta técnica, sus beneficios y cuáles son los pasos a seguir para realizarlo correctamente. |
Glosario de datos abiertos y nuevas tecnologías relacionadas
 |
Publicada: abril 2024 y mayo 2024 En esta página se recogen dos infografías. La primera infografía recoge la definición de diversos términos relacionados con los datos abiertos, mientras que la segunda se centra en nuevas tecnologías relacionadas con los datos. |
7. Datos sintéticos
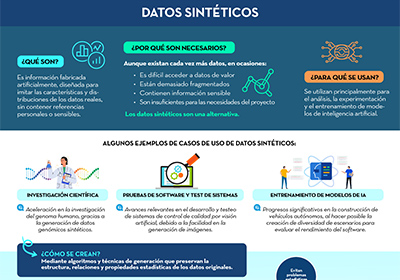 |
Publicada: octubre 2023 En base a lo recogido en el informe ''Datos sintéticos: ¿Qué son y para qué se usan?'', se ha elaborado una infografía que resume de manera sencilla las principales claves de los datos sintéticos y cómo permiten superar las limitaciones de los datos reales. |
Inteligencia artificial y datos abiertos
 |
Publicada: enero 2023 En esta infografía se detalla qué es la inteligencia artificial y cuál es el papel que juegan los datos abiertos dentro de la misma. Además, se ofrecen diferentes ejemplos de casos de uso de la inteligencia artificial. |
Tecnologías emergentes y datos abiertos: Analítica Predictiva
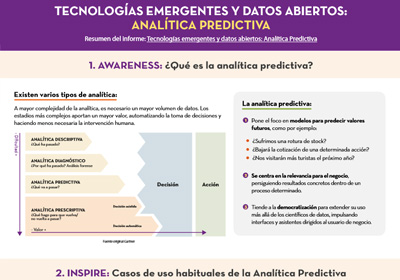 |
Publicada: abril 2021 Esta infografía es un resumen del informe Tecnologías emergentes y datos abiertos: Analítica Predictiva, de la serie “Awareness, Inspire, Action”. En ella se explica en qué consiste la analítica predictiva y sus casos de uso más habituales. También se muestra un ejemplo práctico, utilizando el conjunto de datos accidentes de tráfico en la ciudad de Madrid. |
4 retos del sector educativo a resolver con soluciones tecnológicas basadas en datos
 |
Publicada: agosto 2020 A través de una tecnología educativa innovadora basada en datos e inteligencia artificial se pueden abordar algunos de los desafíos a los que se enfrenta el sistema educativo, como la supervisión de pruebas de evaluación online, la identificación de problemas de comportamiento, la formación personalizada o la mejora del rendimiento en exámenes estandarizados. En esta infografía, resumen del informe “Tecnología educativa basada en datos para mejorar el aprendizaje en el aula y en el hogar”, se muestran algunos ejemplos. |
{kind=link}
Documentación
“La información y los datos son más valiosos cuando se comparten y la apertura de los datos de la administración podría permitir […] examinar y utilizar la información pública de forma más transparente, colaborativa, eficaz y productiva”. Esta fue, en términos generales, la idea que revolucionó hace ya más de diez años a una sociedad para la que la apertura de los datos gubernamentales era una acción totalmente desconocida. Es a partir de este momento cuando comienzan a presentarse diferentes tendencias que irán marcando la evolución del movimiento de los datos abiertos en todo el mundo.
A lo largo de este informe, elaborado por Carlos Iglesias, se analizan las principales tendencias de la aún incipiente historia del open data mundial, prestando especial atención a los datos abiertos dentro de las administraciones públicas. Para ello, este análisis refleja los principales problemas y oportunidades que se han ido presentando a lo largo de estos años, así como las tendencias que ayudarán a seguir impulsando el movimiento:
Para la elaboración de este informe se ha tomado como referencia el informe “The Emergence of a Third Wave of Open Data”, que analiza la nueva etapa que se abre en el mundo de los datos abiertos, publicado por el Open Data Policy Lab. Este análisis sirve como referencia para presentar tanto las tendencias actuales, como los desafíos asociados más destacados de los datos abiertos.
En la parte final de este informe, se presentan algunas labores que jugarán un papel fundamental a la hora de reforzar y consolidar el futuro de los datos abiertos a lo largo de los próximos diez años. Estas acciones se han adaptado al entorno de la Unión Europea, y específicamente al de España (incluyendo su marco normativo).
A continuación, puedes descargar el informe completo, así como su resumen ejecutivo y una presentación resumen en formato power point.
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
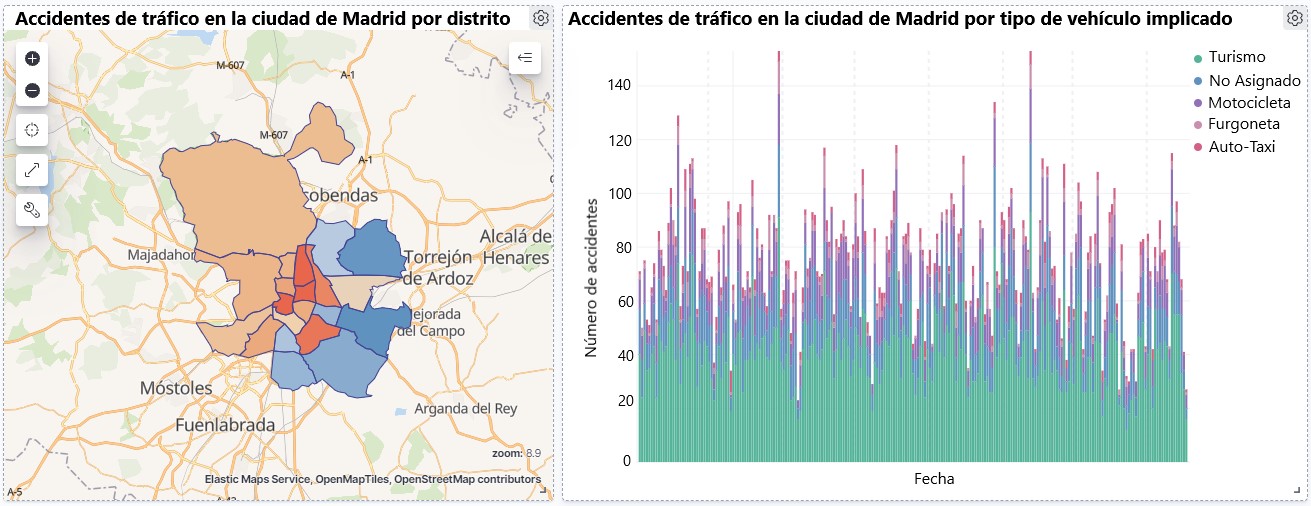
Visualización sobre la accidentalidad de tráfico ocurrida en la ciudad de Madrid, por distrito y tipo de vehículo
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos disponibles en este portal. Para este ejercicio práctico hemos escogido un conjunto de datos que abarca una amplio periodo temporal y que contiene información relevante sobre el registro de accidentes de tráfico que ocurren en la ciudad de Madrid. A partir de estos datos observaremos cuál es el tipo de accidentes más comunes en Madrid y la incidencia que en ellos tiene algunas variables como la edad, el tipo de vehículo o la lesividad que produce el accidente.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se ha seleccionado un conjuntos de datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid publicados por el Ayuntamiento de Madrid y que se encuentra disponible en datos.gob.es. Este conjunto de datos contiene una serie temporal que abarca el periodo 2010 hasta 2021 con diferentes desagregaciones que facilitan el análisis de las características que presentan los accidentes de tráfico ocurridos, entre otras, las condiciones ambientales en las que se produjo cada siniestro o el tipo de accidente. La información de la estructura de cada archivo de datos está disponible en documentos que abarcan el periodo 2010-2018 y 2019 en adelante. Cabe destacar que existen inconsistencias en los datos antes y después del año 2019, ya que la estructura de datos varía. Esta es una situación bastante habitual a la que deben enfrentarse los analistas de datos a la hora de abordar las tareas de preprocesamiento de los datos con los que se trabajará posteriormente, derivada de la carencia de una estructura homogénea de los datos a lo largo del tiempo. Por ejemplo, alteración del número de variables, modificación del tipo de variables o cambios a diferentes unidades de medida. Esta es una razón de peso que justifica la necesidad de acompañar cada conjunto de datos abiertos de un completo documento que explique su estructura.
3.2. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
R es un lenguaje de programación open source orientado a objetos e interpretado, creado inicialmente para la computación estadística y la creación de representaciones gráficas. En la actualidad, es una herramienta muy poderosa para todo tipo de procesamiento y manipulación de datos que está permanentemente actualizada. Además dispone de un entorno de programación, RStudio, también open source.
Para la creación de la visualización interactiva se ha utilizado la herramienta Kibana.
Kibana es una herramienta open source que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstash y Kibana) que permite la creación de visualización y la exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres saber más sobre estas herramientas u otras que puedan ayudarte en el procesado de datos y la creación de visualizaciones interactivas, puedes consultar el informe \"Herramientas de procesado y visualización de datos\".
4. Tratamiento de datos
Para la realización de los análisis y visualizaciones posteriores, es necesario preparar los datos de una forma adecuada, para que los resultados obtenidos sean consistentes y efectivos. Debemos realizar un análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer y comprender los datos con los cuales queremos trabajar. El objetivo principal de este pre-procesamiento de los datos es detectar posibles anomalías o errores que pudieran afectar a la calidad de los resultados posteriores e identificar patrones de información contenidos en los datos.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo click en el botón de \"Código\" de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren forma alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de texto plano, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
Para el desarrollo de este análisis necesitamos instalar una serie de paquetes de R adicionales a la distribución base, incorporando al entorno de trabajo las funciones y objetos definidos por ellas. Hay muchos paquetes disponibles en R pero las más adecuadas para trabajar con este conjunto de datos son: tidyverse, lubridate y data.table. tidyverse es una colección de paquetes de R (contiene a su vez otros paquetes como dplyr, ggplot2, readr, etc) diseñados específicamente para trabajar en Data Science, que facilitar la carga y tratamiento de datos, y las representaciones gráficas, entre otras funcionalidades esenciales para el análisis de datos, pero que requiere un conocimiento progresivo para obtener el máximo partido de los paquetes que integra. Por otro lado, el paquete lubridate lo usaremos para el manejo de variables tipo fecha y por último el paquete data.table permite realizar una gestión más eficiente de conjuntos de datos grandes. Estos paquetes será preciso descargarlos e instalarlos en el entorno de desarrollo.
#Lista de librerías que queremos instalar y cargar en nuestro entorno de desarrollo librerias <- c(\"tidyverse\", \"lubridate\", \"data.table\")#Descargamos e instalamos las librerías en nuestros entorno de desarrollo package.check <- lapplay (librerias, FUN = function(x) { if (!require (x, character.only = TRUE)) { install.packages(x, dependencies = TRUE) library (x, character.only = TRUE } }4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros CSV. Como queremos realizar un análisis de varios años debemos descargar y cargar en nuestro entorno de desarrollo todos los conjuntos de datos que nos interesen.
Para ello, generamos el directorio de trabajo \"datasets\", donde descargaremos todos los conjuntos de datos. Usamos dos listas, una con todas las URLs donde se encuentran localizados los datasets y otra con los nombres que asignamos a cada fichero guardado en nuestra maquina, con ello facilitamos posteriores referencias a estos ficheros.
#Generamos una carpeta en nuestro directorio de trabajo para guardar los datasets descargadosif (dir.exists(\".datasets\") == FALSE)#Nos colocamos dentro de la carpetasetwd(\".datasets\")#Listado de los datasets que nos interese descargardatasets <- c(\"https://datos.madrid.es/egob/catalogo/300228-10-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-11-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-12-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-13-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-14-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-15-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-16-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-17-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-18-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-19-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-21-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-22-accidentes-trafico-detalle.csv\")#Descargamos los datasets de interésdt <- list()for (i in 1: length (datasets)){ files <- c(\"Accidentalidad2010\", \"Accidentalidad2011\", \"Accidentalidad2012\", \"Accidentalidad2013\", \"Accidentalidad2014\", \"Accidentalidad2015\", \"Accidentalidad2016\", \"Accidentalidad2017\", \"Accidentalidad2018\", \"Accidentalidad2019\", \"Accidentalidad2020\", \"Accidentalidad2021\") download.file(datasets[i], files[i]) filelist <- list.files(\".\") print(i) dt[i] <- lapply (filelist[i], read_delim, sep = \";\", escape_double = FALSE, locale = locale(encoding = \"WINDOWS-1252\", trim_ws = \"TRUE\") }b. Creación de la tabla de trabajo
Una vez que tenemos todos los conjuntos de datos cargados en nuestro entorno de desarrollo, creamos una única tabla de trabajo que integra todos los años de la serie temporal.
Accidentalidad <- rbindlist(dt, use.names = TRUE, fill = TRUE)Una vez generada la tabla de trabajo, debemos solucionar uno de los problemas más comunes en todo preprocesamiento de datos: la inconsistencia en el nombre de las variables en los diferentes ficheros que componen la serie temporal. Esta anomalía produce variables con nombres diferentes, pero sabemos que representan la misma información. En este caso porque está explicado en el diccionario de datos descrito en la documentación de los archivos, si no fuese así, es necesario recurrir a la observación y exploración descriptiva de los archivos. En este caso, la variable \"RANGO EDAD\" que presenta datos desde 2010 hasta 2018 y la variable \"RANGO DE EDAD\" que presenta los mismos datos pero desde el año 2019 hasta 2021 son diferentes. Para solucionar esta problemática debemos unificar las variables que presentan esta anomalía en una única variable.
#Con la función unite() unimos ambas variables. Debemos indicarle el nombre de la tabla, el nombre que queremos asignarle a la variable y la posición de las variables que queremos unificar. Accidentalidad <- unite(Accidentalidad, LESIVIDAD, c(25, 44), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, NUMERO_VICTIMAS, c(20, 27), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, RANGO_EDAD, c(26, 35, 42), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, TIPO_VEHICULO, c(20, 27), remove = TRUE, na.rm = TRUE)Una vez que tenemos la tabla con la serie temporal completa, generamos una nueva tabla contiendo únicamente las variables que nos interesan para realizar la visualización interactiva que queremos desarrollar.
Accidentalidad <- Accidentalidad %>% select (c(\"FECHA\", \"DISTRITO\", \"LUGAR ACCIDENTE\", \"TIPO_VEHICULO\", \"TIPO_PERSONA\", \"TIPO ACCIDENTE\", \"SEXO\", \"LESIVIDAD\", \"RANGO_EDAD\", \"NUMERO_VICTIMAS\") c. Transformación de variables
A continuación, examinamos el tipo de variables y valores para transformar los tipos que sea necesario para poder realizar futuras agregaciones, gráficos o diferentes análisis estadísticos.
#Re-ajustar la variable tipo fechaAccidentalidad$FECHA <- dmy (Accidentalidad$FECHA #Re-ajustar el resto de variables a tipo factor Accidentalidad$'TIPO ACCIDENTE' <- as.factor(Accidentalidad$'TIPO.ACCIDENTE')Accidentalidad$'Tipo Vehiculo' <- as.factor(Accidentalidad$'Tipo Vehiculo')Accidentalidad$'TIPO PERSONA' <- as.factor(Accidentalidad$'TIPO PERSONA')Accidentalidad$'Tramo Edad' <- as.factor(Accidentalidad$'Tramo Edad')Accidentalidad$SEXO <- as.factor(Accidentalidad$SEXO)Accidentalidad$LESIVIDAD <- as.factor(Accidentalidad$LESIVIDAD)Accidentalidad$DISTRITO <- as.factor (Accidentalidad$DISTRITO)d. Generación de nuevas variables
Vamos a dividir la variable \"FECHA\" en una jerarquía de variables de tipo fecha, \"Año\", \"Mes\" y \"Día\". Esta acción es muy común en la analítica de datos, ya que en muchas ocasiones interesa analizar otros rangos de tiempo, por ejemplo, años, meses, semanas y cualquier otra unidad de tiempo, o necesitamos generar agregaciones a partir del día de la semana.
#Generación de la variable AñoAccidentalidad$Año <- year(Accidentalidad$FECHA)Accidentalidad$Año <- as.factor(Accidentalidad$Año) #Generación de la variable MesAccidentalidad$Mes <- month(Accidentalidad$FECHA)Accidentalidad$Mes <- as.factor(Accidentalidad$Mes)levels (Accidentalidad$Mes) <- c(\"Enero\", \"Febrero\", \"Marzo\", \"Abril\", \"Mayo\", \"Junio\", \"Julio\", \"Agosto\", \"Septiembre\", \"Octubre\", \"Noviembre\", \"Diciembre\") #Generación de la variable DiaAccidentalidad$Dia <- month(Accidentalidad$FECHA)Accidentalidad$Dia <- as.factor(Accidentalidad$Dia)levels(Accidentalidad$Dia)<- c(\"Domingo\", \"Lunes\", \"Martes\", \"Miercoles\", \"Jueves\", \"Viernes\", \"Sabado\")e. Detección y tratamiento de datos perdidos
La detección y tratamiento de datos perdidos (NAs) es esencial para poder procesar de manera adecuada las variables que contiene la tabla, ya que la ausencia de datos puede ocasionar problemas a la hora de realizar agregaciones, gráficos o análisis estadísticos.
A continuación analizaremos la ausencia de datos (detección de NAs) en la tabla:
#Suma de todos los NAs que presenta el datasetsum(is.na(Accidentalidad))#Porcentaje de NAs en cada una de las variablescolMeans(is.na(Accidentalidad))Una vez detectados los NAs que presenta el dataset, debemos tratarlos de alguna forma. En este caso, como todas las variables de interés, son categóricas, vamos a completar los valores ausentes por un valor de \"No asignado\", para no perder tamaño muestral e información relevante.
#Sustituimos los NAs de la tabla por el valor \"No asignado\"Accidentalidad [is.na(Accidentalidad)] <- \"No asignado\"f. Asignaciones de niveles en las variables
Una vez que tenemos en la tabla las variables de interés, podemos realizar un examen más exhaustivo de los datos y categorías que presenta cada una de las variable. Si analizamos cada una de manera independiente, podemos observar que algunas de ellas presentan categorías repetidas, simplemente por uso de tildes, caracteres especiales o mayúsculas. Para que las futuras visualizaciones o análisis estadísticos se construyan de manera eficiente y sin errores, vamos a reasignar los niveles a las variables que lo requieran.
Por razones de espacio, en este post solo mostraremos un ejemplo con la variable \"LESIVIDAD\". Esta variable estaba tipificada hasta 2018 con una serie de categorías (IL, HL, HG, MT), mientras que a partir de 2019 se usaron otras categorías (valores del 0 al 14). Afortunadamente esta tarea resulta fácilmente abordable dado que está documentada en la información sobre la estructura que acompaña cada dataset, cuestión, como hemos comentado con anterioridad que no siempre ocurre, lo que dificulta enormemente este tipo de transformaciones de datos.
#Comprobamos las categorías que presenta la variable \"LESIVIDAD\"levels(Accidentalidad$LESIVIDAD)#Asignamos las nuevas categoríaslevels(Accidentalidad$LESIVIDAD)<- c(\"Sin asistencia sanitaria\", \"Herido leve\", \"Herido leve\", \"Herido grave\", \"Fallecido\", \"Herido leve\", \"Herido leve\", \"Herido leve\", \"Ileso\", \"Herido grave\", \"Herido leve\", \"Ileso\", \"Fallecido\", \"No asignado\")#Comprobamos de nuevo las catergorías que presenta la variablelevels(Accidentalidad$LESIVIDAD)4.3. Resumen del dataset
Veamos que variables y estructura presenta el nuevo conjunto de datos tras las transformaciones realizadas:
str(Accidentalidad)summary(Accidentalidad)La salida de estos comandos la omitiremos para simplificar lectura. Las principales características que presenta el conjunto de datos son:
- Está compuesto por 14 variables: 1 variable tipo fecha y 13 variables de tipo categórico.
- El rango temporal abarca desde 01-01-2010 hasta el 31-06-2021 (la fecha final puede variar, ya que el dataset del año 2021 se esta actualizando periódicamente).
- Por cuestiones de espacio en este post, no todas las variables disponibles se han tenido en cuenta para el análisis y la visualización.
4.4. Guardar el dataset generado
Una vez que tenemos el conjunto de datos con la estructura y variables que nos interesan para realizar la visualización de los datos, lo guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos como la que abordamos a continuación. Es importante guardarlo con una codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier software.
write.csv(Accidentalidad, file = Accidentalidad.csv\", fileEncoding=\"UTF-8\")5. Creación de la visualización sobre los accidentes de tráfico que ocurren en la ciudad de Madrid usando Kibana
Para la realización de esta visualización interactiva se ha usado la herramienta Kibana en su versión gratuita sobre nuestro entorno local. Antes de poder realizar la visualización es necesario tener instalado el software y para ello hemos seguido los pasos del tutorial de descarga e instalación proporcionado por la compañía Elastic.
Una vez instalado el software de Kibana, procedemos a desarrollar la visualización interactiva. A continuación se incluyen dos vídeo tutoriales, en los cuales se muestra el proceso de realización de la visualización interactiva y la interacción con la misma.
En este primer vídeo tutorial, se muestra el proceso de desarrollo de la visualización realizando los pasos que se indican a continuación:
- Carga de datos en Elasticsearch, generación de un índice en Kibana que nos permita interactuar con los datos prácticamente en tiempo real e interacción con las variables que presenta el conjunto de datos.
- Generación de las siguientes representaciones gráficas:
- Gráfico de líneas para representar la serie temporal sobre los accidentes de tráfico ocurridos en la ciudad de Madrid.
- Gráfico de barras horizontales mostrando el tipo de accidente más común.
- Mapa temático, mostraremos el número de accidentes que ocurren en cada una de los distritos de la ciudad de Madrid. Para la creación de este visual es necesario la descarga del \"conjunto de datos que contiene los distritos georreferenciados en formato GeoJSON\".
- Construcción del dashboard integrando los visuales generados en el paso anterior.
En este segundo vídeo tutorial mostraremos la interacción con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid desde 2010 hasta junio de 2021, se pueden obtener, entre otras, las siguientes conclusiones:
- El número de accidentes que ocurren en la ciudad de Madrid es estable a lo largo de los años, a excepción del año 2019 donde se observa un fuerte incremento y durante el segundo trimestre de 2020 donde se observa una significativa disminución, que coincide con el período del primer estado de alarma a causa de la pandemia del COVID-19.
- Todos los años se observa una disminución del número de accidentes durante el mes de agosto.
- Los hombres suelen tener un número significativamente mayor de accidentes que las mujeres.
- El tipo de accidente más común es la colisión doble, seguido del atropello a un animal y la colisión múltiple.
- Alrededor del 50% de los accidentes no ocasionan daños a las personas implicadas.
- Los distritos con mayor concentración de accidentes son: el distrito de Salamanca, el distrito de Chamartín y el distrito Centro.
La visualización de datos es una de los mecanismos más potentes para explotar y analizar de manera autónoma el significado implícito de los datos, independientemente del grado del conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Si quieres aprender cómo realizar una predicción sobre la siniestralidad futura de accidentes de tráfico utilizando técnicas de Inteligencia Artificial a partir de estos datos, consulta el post sobre \"Tecnologías emergentes y datos abiertos: Analítica Predictiva\".
Esperamos que os haya gustado este post y volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
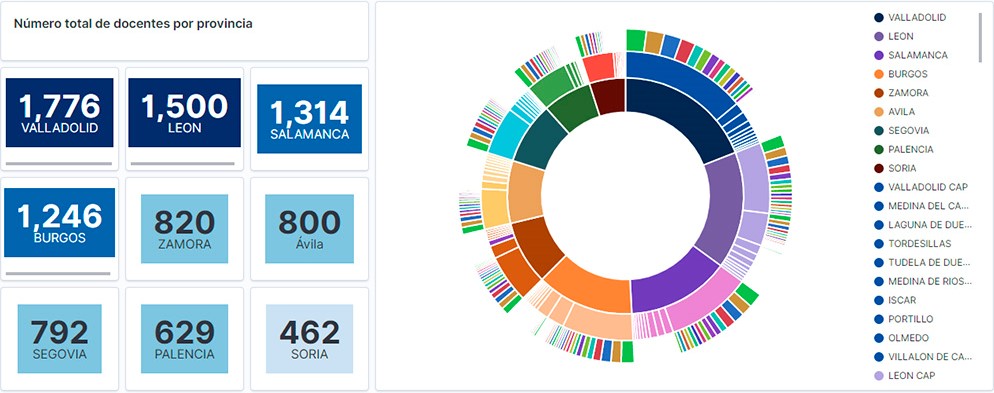
Visualización del personal docente de Castilla y León clasificados por Provincia, Localidad y Especialidad docente
2. Objetivos
El objetivo principal de este post es aprender a tratar un conjunto de datos desde su descarga hasta la creación de uno o varios gráficos interactivos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre los docentes y alumnos matriculados en los centros públicos de Castilla y León durante el año académico 2019-2020. A partir de estos datos se realizan análisis de varios indicadores que relacionan docentes, especialidades y alumnado matriculado en los centros de cada provincia o localidad de la comunidad autónoma.
3. Recursos
3.1. Conjuntos de datos
Para este estudio se han seleccionado conjuntos de datos de la temática Educación publicados por la Junta de Castilla y León, disponibles en el portal de datos abiertos datos.gob.es. Concretamente:
- Dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros, durante el curso académico 2019-2020. Este dataset se encuentra desagregado por especialidad del docente, centro educativo, localidad y provincia.
- Dataset de las matriculaciones de alumnos en centros educativos durante el curso académico 2019-2020. Este conjunto de datos se obtiene a través de una consulta que admite diferentes parámetros de configuración. Las instrucciones para realizarla se encuentran disponibles en el mismo punto de descarga del dataset. El conjunto de datos se encuentra desagregado por centro educativo, localidad y provincia.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado el lenguaje de programación Python (versión 3.7) y JupyterLab (versión 2.2), herramientas que encontrarás integradas en Anaconda, una de las plataformas más populares para instalar, actualizar o administrar software para trabajar con Data Science. Todas estas herramientas son abiertas y están disponibles de forma gratuita.
JupyterLab es una interfaz de usuario basada en web que proporciona un entorno de desarrollo interactivo donde el usuario puede trabajar con los denominados cuadernos Jupyter sobre los que podrás integrar y compartir fácilmente texto, código fuente y datos.
Para la creación de la visualización interactiva se ha usado la herramienta de Kibana (versión 7.10).
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Logstash, Beats y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres conocer más sobre estas herramientas u otras que pueden ayudarte en el tratamiento y la visualización de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son consistentes y confiables.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas! Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de Github. La forma de proporcionar el código es a través de un documento realizado sobre JupyterLab que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla.
4.1. Instalación y carga de librerías
Lo primero que debemos hacer es importar las librerías para el pre-procesamiento de los datos. Hay muchas librerías disponibles en Python pero una de las más populares y adecuada para trabajar con estos conjuntos de datos es Pandas. La librería Pandas es una librería muy popular para manipular y analizar conjuntos de datos.
import pandas as pd 4.2. Carga de datasets
En primer lugar descargamos los conjuntos de datos del catálogo de datos abiertos datos.gob.es y los cargamos en nuestro entorno de desarrollo como tablas para explorarlos y realizar algunas tareas básicas de limpieza y procesado de datos. Para la carga de los datos recurriremos a la función read_csv(), donde le indicaremos la url de descarga del dataset, el delimitador (\";\" en este caso) y, para que interprete correctamente los caracteres especiales como las letras con tildes o \"ñ\" presentes en las cadenas de texto del conjunto de datos, le añadimos el parámetro \"encoding\" que ajustamos al valor \"latin-1\".
#Cargamos el dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros url = \"https://datosabiertos.jcyl.es/web/jcyl/risp/es/educacion/plantillas-centros-educativos/1284922684978.csv\"docentes = pd.read_csv(url, delimiter=\";\", header=0, encoding=\"latin-1\")docentes.head(3)#Cargamos el dataset de los alumnos matriculados en los centros educativos públicos de Castilla y León alumnos = pd.read_csv(\"matriculaciones.csv\", delimiter=\",\", names=[\"Municipio\", \"Matriculaciones\"], encoding=\"latin-1\") alumnos.head(3)La columna \"Municipio\" de la tabla \"alumnos\" está compuesta por el código del municipio y el nombre del mismo. Debemos dividir esta columna en dos, para que su tratamiento sea más eficiente.
columnas_Municipios = alumnos[\"Municipio\"].str.split(\" \", n=1, expand = TRUE)alumnos[\"Codigo_Municipio\"] = columnas_Municipios[0]alumnos[\"Nombre_Munipicio\"] = columnas_Munipicio[1]alumnos.head(3)4.3. Creación de una nueva tabla
Una vez que tenemos ambas tablas con las variables de interés, creamos una nueva tabla resultado de su unión. La variables de unión serán: \"Localidad\" en la tabla de \"docentes\" y \"Nombre_Municipio\" en la de \"alumnos\".
docentes_alumnos = pd.merge(docentes, alumnos, left_on = \"Localidad\", right_on = \"Nombre_Municipio\")docentes_alumnos.head(3)4.4. Exploración del conjunto de datos
Una vez que disponemos de la tabla que nos interesa, debemos dedicar un tiempo a explorar los datos e interpretar cada variable. En estos casos es de enorme utilidad disponer del diccionario de datos que siempre debe acompañar a cada dataset descargado para conocer todos sus detalles, pero en esta ocasión no disponemos de esta esencial herramienta. Observando la tabla, además de interpretar las variables que lo integran (tipos de datos, unidades, rangos de valores), podemos detectar posibles errores como variables mal tipificadas o la presencia de valores perdidos (NAs) que pueden restar capacidad de análisis.
docentes_alumnos.info()En la salida de esta sección de código, podemos observar las principales características que presenta la tabla:
- Contiene un total de 4.512 registros
- Está compuesto de 13 variables, 5 variables numéricas (de tipo entero) y 8 variables de tipo categórico (tipo \"object\")
- No hay ausencia de valores.
Una vez que conocemos la estructura y contenido de la tabla, debemos rectificar errores, como es el caso de la transformación de algunas de las variables que no están tipificadas de manera adecuada, por ejemplo, la variable que alberga el código del centro (\"Código.centro\").
docentes_alumnos.Codigo_centro = data.Codigo_centro.astype(\"object\")docentes_alumnos.Codigo_cuerpo = data.Codigo_cuerpo.astype(\"object\")docentes_alumnos.Codigo_especialidad = data.Codigo_especialidad.astype(\"object\")Una vez que tenemos la tabla libre de errores, obtenemos una descripción de las variables numéricas, \"Plantilla\" y \"Matriculaciones\", que nos ayudará a conocer detalles importantes. En la salida del código que presentamos a continuación observamos la media, la desviación estándar, el número máximo y mínimo, entre otros descriptores estadísticos.
docentes_alumnos.describe()4.5. Guardar el dataset
Una vez que tenemos la tabla libre de errores y con las variables que nos interesa graficar, lo guardaremos en una carpeta de nuestra elección para usarla posteriormente en otras herramientas de análisis o visualización. Lo guardaremos en formato CSV codificada como UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta que usemos posteriormente.
df = pd.DataFrame(docentes_alumnos)filname = \"docentes_alumnos.csv\"df.to_csv(filename, index = FALSE, encoding = \"utf-8\")5. Creación de la visualización sobre los docentes de los centro educativos públicos de Castilla y León usando la herramienta Kibana
Para la realización de esta visualización hemos usado la herramienta Kibana en nuestro entorno local. Para realizarla es necesario tener instalado y en funcionamiento Elasticsearch y Kibana. La compañía Elastic nos pone a disposición toda la información sobre la descarga e instalación en este tutorial.
A continuación se adjuntan dos vídeo tutoriales, donde se muestra el proceso de realización de la visualización y la interacción con el dashboad generado.
En este primer vídeo, podrás ver la creación del cuadro de mando (dashboard) mediante la generación de diferentes representaciones gráficas, siguiendo los siguientes pasos:
- Cargamos la tabla de datos previamente procesados en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
- Gráfico de sectores donde mostrar la plantilla docente por provincia, localidad y especialidad.
- Métricas del número de docentes por provincia.
- Gráfico de barras, donde mostraremos el número de matriculaciones por provincia.
- Filtro por provincia, localidad y especialidad docente.
- Construcción del dashboard.
En este segundo vídeo, podrás observa la interacción con el cuadro de mando (dashboard) generado anteriormente.
6. Conclusiones
Observando la visualización de los datos sobre el número de docentes de los centros educativos públicos de Castilla y León, en el curso académico 2019-2020, se pueden obtener, entre otras, las siguientes conclusiones:
- La provincia de Valladolid es la que posee el mayor número de docentes e igualmente, el mayor número de alumnos matriculados. Mientras que Soria es la provincia con menor número de docentes y menor número de alumnos matriculados.
- Como era de esperar, las localidades que presentan mayor número de docentes son las capitales de provincia.
- En todas las provincias, la especialidad con mayor número de alumnos es Inglés, seguida de Lengua Castellana y Literatura y Matemáticas.
- Llama la atención, que la provincia de Zamora, aunque posee un número bajo de alumnos matriculados, está en quinta posición en el número de docentes.
Esta sencilla visualización nos ha ayudado a sintetizar una gran cantidad de información y a obtener una serie de conclusiones a golpe de vista, y si fuera necesario tomar decisiones en función de los resultados obtenidos. Esperamos que os haya resultado útil este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
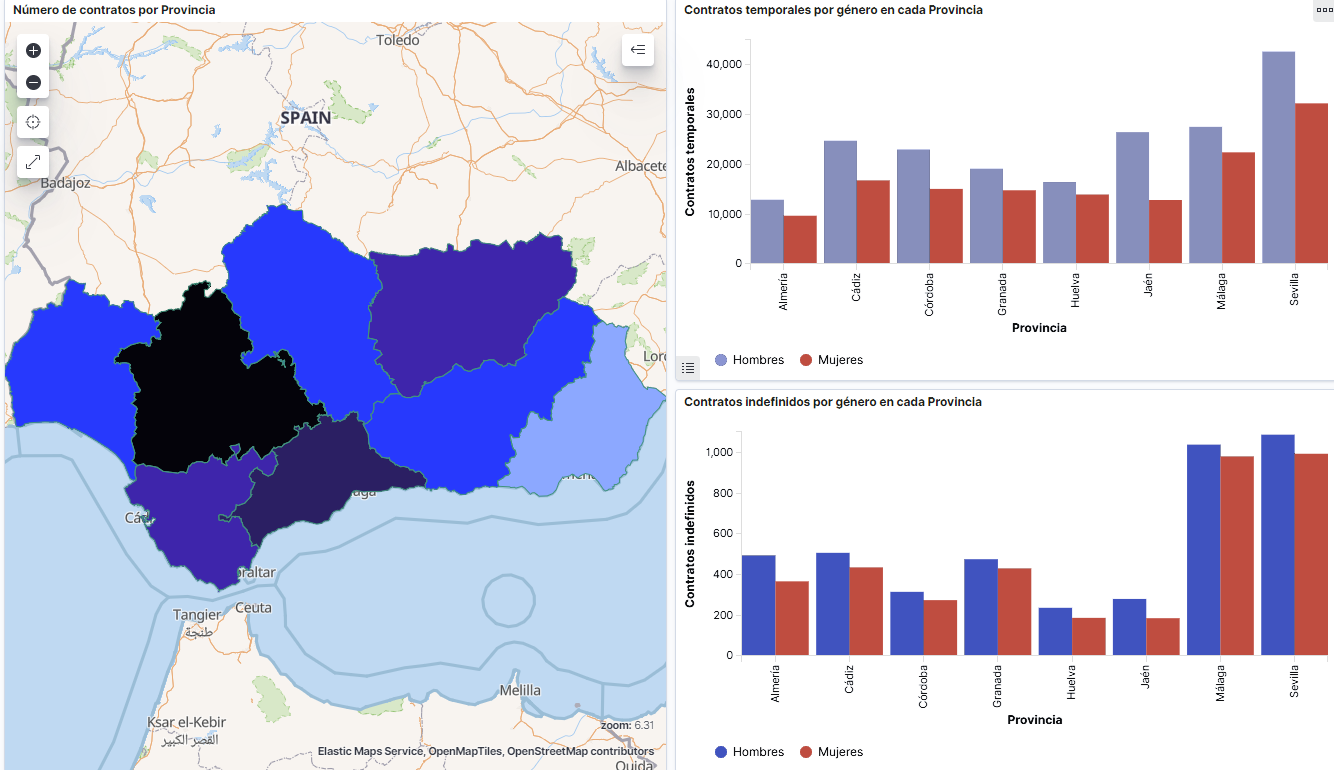
Captura del vídeo que muestra la interacción con el dashboard de la caracterización de la demanda de empleo y la contratación registrada en España disponible al final de este artículo
2. Objetivos
El objetivo principal de este post es realizar una visualización interactiva partiendo de datos abiertos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre la evolución de la demanda de empleo en España a lo largo de los últimos años. A partir de estos datos se determina el perfil que representa la demanda de empleo en nuestro país, estudiando específicamente cómo afecta la brecha de género al colectivo y la incidencia de variables como la edad, la prestación por desempleo o la región.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se han seleccionado conjuntos de datos publicados por el Servicio Público de Empleo Estatal (SEPE), coordinado por el Ministerio de Trabajo y Economía Social, que recogen series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presentan los demandantes de empleo. Estos datasets se encuentran disponibles en datos.gob.es con las siguientes características:
- Demandantes de empleo por municipio: contiene el número de demandantes de empleo desagregado por municipio, edad y sexo, desde 2006 hasta 2020.
- Gasto de prestaciones por desempleo por Provincia: serie temporal desde 2010 hasta 2020 sobre el gasto en prestaciones por desempleo, desagregado por provincia y el tipo de prestación.
- Contratos registrados por el Servicio Público de Empleo Estatal (SEPE) por municipio: estos conjuntos de datos contienen el número de contratos registrados tanto a demandantes como a no demandantes de empleo, desagregados por municipio, sexo y tipo de contrato, desde 2006 hasta 2020.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
RStudio es un entorno de desarrollo open source integrado para el lenguaje de programación R, dedicado al análisis estadístico y la creación de gráficos.
RMarkdown permite la realización de informes integrando texto, código y resultados dinámicos en un único documento.
Para la creación de los gráficos interactivos se ha utilizado la herramienta Kibana.
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstasg y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch. Las principales ventajas de esta herramienta son:
- Presenta la información de manera visual a través de dashboards interactivos y personalizables mediante intervalos temporales, filtros facetados por rango, cobertura geoespacial, entre otros.
- Dispone de un catálogo de herramientas de desarrollo (Dev Tools) para interactuar con los datos almacenados en Elasticsearch.
- Cuenta con una versión gratuita para utilizar en tu propio ordenador y una versión enterprise que se desarrolla en un cloud propio de Elastic u otras infraestructuras en cloud como Amazon Web Service (AWS).
En la propia web de Elastic encontramos manuales de usuario para la descarga e instalación de la herramienta, o cómo crear gráficos o dashboards, entre otros. Además ofrece vídeos cortos en su canal de youtube y organiza webinars donde explican diversos aspectos relacionados con Elastic Stack.
Si quieres saber más sobre estas herramientas u otras que pueden ayudarte en el procesado de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Para la realización una visualización, es necesario preparar los datos de la forma adecuada realizando una serie de tareas que incluyen el preprocesado y el análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer la realidad de los datos a los que nos enfrentamos. El objetivo es identificar características de los datos y detectar las posibles anomalías o errores que pudieran afectar a la calidad de los resultados. Un tratamiento previo de los datos es esencial para que los análisis o las visualizaciones que se realicen posteriormente sean consistentes y efectivas.
Para favorecer el entendimiento de los lectores no especialistas en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo clik en \"Código\", no está diseñado para su eficiencia sino para su fácil comprensión, por lo que es posible que lectores más avanzados en este lenguaje de programación consideren una forma de codificar algunas funcionalidades de forma alternativa. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en cuenta en Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de RMarkdown. Una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
El paquete base de R, siempre disponible desde que abrimos la consola en RStudio, incorpora un amplio conjunto de funcionalidades para cargar datos de fuentes externas, llevar a cabo análisis estadísticos y obtener representaciones gráficas. No obstante, hay multitud de tareas para las que necesitamos recurrir a paquetes adicionales incorporando al entorno de trabajo las funciones y objetos definidos en ellas. Algunos de ellos ya están instalados en el sistema, pero otros será preciso descargarlos e instalarlos.
#Instalación de paquetes \r\n #El paquete dplyr presenta una colección de funciones para realizar de manera sencilla operaciones de manipulación de datos \r\n if (!requireNamespace(\"dplyr\", quietly = TRUE)) {install.packages(\"dplyr\")}\r\n #El paquete lubridate para el manejo de variables tipo fecha \r\n if (!requireNamespace(\"lubridate\", quietly = TRUE)) {install.packages(\"lubridate\")}\r\n#Carga de paquetes en el entorno de desarrollo \r\nlibrary (dplyr)\r\nlibrary (lubridate)\r\n4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros .CSV y .XLS. Debemos cargar en nuestro entorno de desarrollo todos los ficheros que nos interesan. El siguiente código muestra como ejemplo la carga de un único fichero .CSV en una tabla de datos para que la lectura de este post sea más comprensible.
Para agilizar el proceso de carga en el entorno de desarrollo, es necesario descargar en el directorio de trabajo los conjuntos de datos necesarios para esta visualización, que se encuentran disponibles en la cuenta de Github de datos.gob.es.
#Carga del datasets de demandantes de empleo por municipio de 2020. \r\n Demandantes_empleo_2020 <- \r\n read.csv(\"Conjuntos de datos/Demandantes de empleo por Municipio/Dtes_empleo_por_municipios_2020_csv.csv\",\r\n sep=\";\", skip = 1, header = T)\r\nUna vez que tenemos todos los conjuntos de datos cargados como tablas en el entorno de desarrollo, debemos unificarlos para así tener un único dataset que integre todos los años de la serie temporal, por cada una de las características relacionadas con los demandantes de empleo que se quiere analizar: número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados por el SEPE.
#Dataset de demandantes de empleo\r\nDatos_desempleo <- rbind(Demandantes_empleo_2006, Demandantes_empleo_2007, Demandantes_empleo_2008, Demandantes_empleo_2009, \r\n Demandantes_empleo_2010, Demandantes_empleo_2011,Demandantes_empleo_2012, Demandantes_empleo_2013,\r\n Demandantes_empleo_2014, Demandantes_empleo_2015, Demandantes_empleo_2016, Demandantes_empleo_2017, \r\n Demandantes_empleo_2018, Demandantes_empleo_2019, Demandantes_empleo_2020) \r\n#Dataset de gasto en prestaciones por desempleo\r\ngasto_desempleo <- rbind(gasto_2010, gasto_2011, gasto_2012, gasto_2013, gasto_2014, gasto_2015, gasto_2016, gasto_2017, gasto_2018, gasto_2019, gasto_2020)\r\n#Dataset de nuevos contratos a demandantes de empleo\r\nContratos <- rbind(Contratos_2006, Contratos_2007, Contratos_2008, Contratos_2009,Contratos_2010, Contratos_2011, Contratos_2012, Contratos_2013, \r\n Contratos_2014, Contratos_2015, Contratos_2016, Contratos_2017, Contratos_2018, Contratos_2019, Contratos_2020)b. Selección de variables
Una vez que tenemos las tablas con las tres series temporales (número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados), crearemos una nueva tabla que incluirá las variables que interesan de cada una de ellas.
En primer lugar, agregaremos por provincia las tablas de demandantes de empleo (“datos_desempleo”) y contratos nuevos contratos registrados (“contratos”) para facilitar la visualización y que coincidan con la desagregación por provincia de la tabla de gasto en prestaciones por desempleo (“gasto_desempleo”). En este paso, seleccionamos únicamente las variables que interesen de los tres conjuntos de datos.
#Realizamos un group by al dataset de \"datos_desempleo\", agruparemos las variables numéricas que nos interesen, en función de varias variables categóricas\r\nDtes_empleo_provincia <- Datos_desempleo %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(total.Dtes.Empleo = (sum(total.Dtes.Empleo)), Dtes.hombre.25 = (sum(Dtes.Empleo.hombre.edad...25)), \r\n Dtes.hombre.25.45 = (sum(Dtes.Empleo.hombre.edad.25..45)), Dtes.hombre.45 = (sum(Dtes.Empleo.hombre.edad...45)),\r\n Dtes.mujer.25 = (sum(Dtes.Empleo.mujer.edad...25)), Dtes.mujer.25.45 = (sum(Dtes.Empleo.mujer.edad.25..45)),\r\n Dtes.mujer.45 = (sum(Dtes.Empleo.mujer.edad...45)))\r\n#Realizamos un group by al dataset de \"contratos\", agruparemos las variables numericas que nos interesen en función de las varibles categóricas.\r\nContratos_provincia <- Contratos %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(Total.Contratos = (sum(Total.Contratos)),\r\n Contratos.iniciales.indefinidos.hombres = (sum(Contratos.iniciales.indefinidos.hombres)), \r\n Contratos.iniciales.temporales.hombres = (sum(Contratos.iniciales.temporales.hombres)), \r\n Contratos.iniciales.indefinidos.mujeres = (sum(Contratos.iniciales.indefinidos.mujeres)), \r\n Contratos.iniciales.temporales.mujeres = (sum(Contratos.iniciales.temporales.mujeres)))\r\n#Seleccionamos las variables que nos interesen del dataset de \"gasto_desempleo\"\r\ngasto_desempleo_nuevo <- gasto_desempleo %>% select(Código.mes, Comunidad.Autónoma, Provincia, Gasto.Total.Prestación, Gasto.Prestación.Contributiva)En segundo lugar, procedemos a unir las tres tablas en una que será con la que trabajemos a partir de este punto.
Caract_Dtes_empleo <- Reduce(merge, list(Dtes_empleo_provincia, gasto_desempleo_nuevo, Contratos_provincia))
c. Transformación de variables
Una vez tengamos la tabla con las variables de interés para el análisis y la visualización, debemos transformar algunas de ellas a otros tipos más adecuados para futuras agregaciones.
#Transformación de una variable fecha\r\nCaract_Dtes_empleo$Código.mes <- as.factor(Caract_Dtes_empleo$Código.mes)\r\nCaract_Dtes_empleo$Código.mes <- parse_date_time(Caract_Dtes_empleo$Código.mes(c(\"200601\", \"ym\")), truncated = 3)\r\n#Transformamos a variable numérica\r\nCaract_Dtes_empleo$Gasto.Total.Prestación <- as.numeric(Caract_Dtes_empleo$Gasto.Total.Prestación)\r\nCaract_Dtes_empleo$Gasto.Prestación.Contributiva <- as.numeric(Caract_Dtes_empleo$Gasto.Prestación.Contributiva)\r\n#Transformación a variable factor\r\nCaract_Dtes_empleo$Provincia <- as.factor(Caract_Dtes_empleo$Provincia)\r\nCaract_Dtes_empleo$Comunidad.Autónoma <- as.factor(Caract_Dtes_empleo$Comunidad.Autónoma)d. Análisis exploratorio
Veamos qué variables y estructura presenta el nuevo conjunto de datos.
str(Caract_Dtes_empleo)\r\nsummary(Caract_Dtes_empleo)La salida de esta porción de código se omite para facilitar la lectura. Las características principales que presenta el conjunto de datos son:
- El rango temporal abarca desde enero de 2010 hasta diciembre de 2020.
- El número de columnas (variables) es de 17.
- Presenta dos variables categóricas (“Provincia” y “Comunidad.Autónoma”), una variable tipo fecha (“Código.mes”) y el resto son variables numéricas.
e. Detección y tratamiento de datos perdidos
Seguidamente analizaremos si el dataset presenta valores perdidos (NAs). El tratamiento o la eliminación de los NAs es esencial, ya que si no es así no será posible procesar adecuadamente las variables numéricas.
any(is.na(Caract_Dtes_empleo)) \r\n#Como el resultado es \"TRUE\", eliminamos los datos perdidos del dataset, ya que no sabemos cual es la razón por la cual no se encuentran esos datos\r\nCaract_Dtes_empleo <- na.omit(Caract_Dtes_empleo)\r\nany(is.na(Caract_Dtes_empleo))4.3. Creación de nuevas variables
Para realizar la visualización, vamos a crear una nueva variable a partir de dos variables que se encuentran en la tabla de datos. Esta acción es muy común en el análisis de datos ya que en ocasiones interesa trabajar con datos calculados (por ejemplo, la suma o la media de diferentes variables) en lugar de los datos de origen. En este caso vamos a calcular el gasto medio en prestaciones por desempleo para cada demandante de empleo. Para ello utilizaremos las variables de gasto total por prestación (“Gasto.Total.Prestación”) y el total de demandantes de empleo (“total.Dtes.Empleo”).
Caract_Dtes_empleo$gasto_desempleado <-\r\n (1000 * (Caract_Dtes_empleo$Gasto.Total.Prestación/\r\n Caract_Dtes_empleo$total.Dtes.Empleo))4.4. Guardar el dataset
Una vez que tenemos la tabla con las variables que nos interesan para los análisis y las visualizaciones, la guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos. Es importante utilizar la codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta.
write.csv(Caract_Dtes_empleo,\r\n file=\"Caract_Dtes_empleo_UTF8.csv\",\r\n fileEncoding= \"UTF-8\")5. Creación de la visualización sobre la caracterización de la demanda de empleo en España usando Kibana
El desarrollo de esta visualización interactiva se ha realizado usando Kibana en nuestro entorno local. Tanto para la descarga del software, como para la instalación del mismo, hemos recurrido al tutorial realizado por la propia compañía, Elastic.
A continuación se adjunta un vídeo tutorial donde se muestra todo el proceso de realización de la visualización. En el vídeo podrás ver la creación de un cuadro de mando (dashboard) con diferentes indicadores interactivos mediante la generación de representaciones gráficas de diferentes tipos. Los pasos para obtener el dashboard son los siguientes:
- Cargamos los datos en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos en los archivos cargados, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
- Gráfico de líneas para representar la serie temporal sobre los demandantes de empleo en España desde 2006 hasta 2020.
- Gráfico de sectores de los demandantes de empleo desagregados por Provincia y Comunidad Autónoma.
- Mapa temático, mostrando el número de contratos nuevos registrados en cada Provincia del territorio. Para la creación de este visual es necesaria la descarga de un dataset de la georeferenciación de las Provincias publicado en el portal de datos abiertos Open Data Soft.
- Construcción del dashboard.
Seguidamente mostraremos un vídeo tutorial interactuando con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre el perfil de los demandantes de empleo en España en el periodo 2010 hasta 2020, se pueden obtener, entre otras, las siguientes conclusiones:
- Existen dos incrementos significativos en el número de demandantes de empleo. El primero aproximadamente en 2010, que coincide con la crisis económica. El segundo, mucho más pronunciado en 2020, que coincide con la crisis derivada de la pandemia.
- Se observa que existe una brecha de género en el colectivo de demandantes de empleo: el número de mujeres demandantes de empleo es mayor a lo largo de toda la serie temporal, principalmente en los grupos de edad de mayores de 25.
- A nivel regional, Andalucía, seguida de Cataluña y Comunidad Valenciana, son las Comunidades Autónomas con mayor número de demandantes de empleo. En contraste, Andalucía, es la Comunidad Autónoma con menor gasto por desempleo, mientras que Cataluña, es la que presenta mayor gasto por desempleo.
- Los contratos de tipo temporal son los prioritarios y las provincias que generan mayor número de contratos son Madrid y Barcelona, que coinciden con las provincias con mayor número de habitantes, mientras que en el lado opuesto, las provincias que menos número de contratos realizan son Soria, Ávila, Teruel o Cuenca, que coincide con las zonas más despobladas de España.
Esta visualización nos ha ayudado a sintetizar gran cantidad de información y darle sentido pudiendo obtener unas conclusiones y si fuera necesario tomar decisiones en función de los resultados. Esperemos que os haya gustado este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!
Documentación
La visualización es crítica para el análisis de datos. Aporta una primera línea de ataque, revelando estructuras intrincadas en datos que no pueden ser absorbidas de otro modo. Descubrimos efectos inimaginables y cuestionamos aquellos que han sido imaginados.”
William S. Cleveland (de Visualizing Data, Hobart Press)
A lo largo de los años se ha generado y almacenado una enorme cantidad de información pública. Esta información, si se observa de forma lineal, consta de una gran cantidad de números y hechos inconexos que, fuera de contexto, carecen de cualquier significado. Por ello, la visualización se presenta como una fácil solución hacia la comprensión e interpretación de la información.
Para obtener buenas visualizaciones es preciso trabajar con datos que cumplan dos características:
- Tienen que ser datos de calidad. Es necesario que sean precisos, completos, fiables, actuales y relevantes.
- Tienen que estar bien tratados. Es decir, convenientemente identificados, correctamente extraídos, de forma estructurada, etc.
Por tanto, es importante procesar adecuadamente la información antes de su tratamiento gráfico. El tratamiento de los datos y su visualización forman un tándem atractivo para el usuario que demanda, cada vez más, poder interpretar datos de forma ágil y rápida.
Existen un gran número de herramientas destinado a este fin. El informe “Herramientas de procesado y visualización de datos” nos ofrece un listado de diferentes herramientas que nos ayudan en el procesamiento de los datos, desde la obtención de los mismos hasta la creación de una visualización que nos permita interpretarlos de manera sencilla.
¿Qué puedes encontrar en el informe?
La guía incluye una recopilación de herramientas de:
- Web scraping
- Depuración de datos
- Conversión de datos
- Análisis de datos para programadores y no programadores
- Servicios de visualización genéricos, geoespaciales y librerías y APIs.
- Análisis de redes
Todas las herramientas presentes en la guía tienen una versión de libre disposición para que cualquier usuario pueda acceder a ellas.
Nueva edición 2021: incorporación de nuevas herramientas
La primera versión de este informe vio la luz en 2016. Cinco años después se ha procedido a su actualización. Las novedades y cambios efectuados son:
- Se han incorporado nuevas herramientas de procesado y visualización de datos actualmente populares como Talend Open Studio, Python, Kibana o Knime.
- Se han eliminado algunas herramientas desfasadas.
- Se ha actualizado la maquetación.
Si conoces alguna herramienta adicional, no incluida actualmente en la guía, te invitamos a compartir la información en los comentarios.
Además, hemos preparado una serie de post donde se explican los distintos tipos de herramientas que pueden encontrar en el informe:
Documentación
Para poder extraer todo el valor de los datos, es necesario clasificarlos, filtrarlos y cruzarlos mediante procesos de analítica que nos ayuden a sacar conclusiones, convirtiendo los datos en información y conocimiento. Tradicionalmente la analítica de datos se divide en 3 categorías:
-
Analítica descriptiva, que nos ayuda a entender la situación actual, qué ha pasado para llegar hasta ella y por qué se ha producido.
-
Analítica predictiva, cuyo objetivo es anticipar hechos relevantes. Es decir, nos cuenta qué va a pasar para que un ser humano pueda tomar una decisión.
-
Analítica prescriptiva, donde se proporciona información sobre las decisiones más acertadas en base a una serie de escenarios futuros. Es decir, nos indica qué hacer.
El tercer informe de la serie “Awareness, Inspire, Action” se centra en el segundo estadio, el de la Analítica predictiva. Para ello sigue la misma metodología que los dos informes anteriores, dedicados a la Inteligencia Artificial y el Procesamiento del Lenguaje Natural.
La analítica predictiva nos permite responder preguntas de negocio como ¿sufriremos una rotura de stock? ¿Bajará la cotización de una determinada acción? O ¿Nos visitarán más turistas el próximo puente? En base a esta información las empresas pueden definir su estrategia de negocio, y los organismos públicos elaborar políticas que respondan a las necesidades de los ciudadanos.
Tras una breve introducción que contextualiza la materia a tratar y explica la metodología, el informe, elaborado por Alejandro Alija, se desarrolla de la siguiente manera:
-
Awareness. En la sección Awareness se explican los conceptos clave, destacando los tres atributos de la analítica predictiva: el énfasis en la predicción, la relevancia para el negocio de los conocimientos resultantes y su tendencia a la democratización para extender su uso más allá de los usuarios especialistas y científicos de datos. En este apartado también se mencionan los modelos matemáticos de los que hace uso y se detallan algunos de sus hitos más importantes a lo largo de la historia, como el protocolo de Kyoto o su utilidad para detectar la fuga de clientes.
-
Inspire. La sección Inspire analiza algunos de los casos de uso de la analítica predictiva con más relevancia en la actualidad en tres sectores muy diferentes. Empieza con el sector industrial, donde se explica cómo funciona el mantenimiento predictivo y la detección de anomalías. Continua con ejemplos relativos a la predicción de precios y demanda, en la cadena de distribución de un supermercado y en el sector energía. Y finaliza con el sector salud y el diagnóstico aumentado de imagen médica.
-
Action: En la sección Action se desarrolla de forma práctica un caso de uso concreto, utilizando para ello datos y herramientas tecnológicas reales. En este caso el conjunto de datos seleccionado es accidentes de tráfico en la ciudad de Madrid, publicado por el Ayuntamiento de Madrid. A través de la metodología recogida en la siguiente figura, se explica de manera sencilla cómo utilizar técnicas de análisis de series temporales para modelar y predecir el número de accidentes en los meses futuros.
El informe finaliza con la sección Última parada, donde se recopilan cursos, libros y artículos de interés para aquellos usuarios que quieran seguir avanzando en la materia.
En este vídeo, su autor te cuanta más sobre el informe y la analítica predictiva.
A continuación, puedes descargarte el informe completo en pdf y word (versión reutilizable), así como acceder al código utilizado en el ejemplo de Action en este enlace.