Documentación
La pandemia originada el pasado año ha supuesto un cambio significativo en la forma que teníamos de ver el mundo y relacionarnos con este. En lo que al sector educativo se refiere, alumnos y docentes de todos los niveles se han visto obligados a tener que cambiar la metodología de enseñanza y aprendizaje presencial por un sistema telemático.
En este contexto, desde el marco de la Iniciativa Aporta se ha desarrollado el estudio “Tecnología educativa basada en datos para mejorar el aprendizaje en el aula y en el hogar”, realizado por José Luis Marín. Este informe ofrece diversas claves para reflexionar acerca de los nuevos retos y desafíos que plantea esta situación y que se pueden convertir en oportunidades si conseguimos introducir cambios que fomenten la mejora del proceso de enseñanza-aprendizaje más allá de solamente sustituir las clases presenciales por formación en línea.
La importancia de los datos para mejorar el sector educativo
A través de una tecnología educativa innovadora basada en datos e inteligencia artificial se pueden abordar algunos de los desafíos a los que se enfrenta el sistema educativo. Para este informe se han seleccionado 4 de estos retos:
- Supervisión no presencial de pruebas de evaluación: monitorización y vigilancia de pruebas evaluativas a través de recursos telemáticos.
- Identificación de problemas de comportamiento o atención: alerta a los docentes sobre actividades y conductas que indiquen problemas de atención, motivación o comportamiento.
- Programas formativos personalizados y más atractivos: adaptación de las rutas y el ritmo de aprendizaje de los alumnos.
- Mejora del rendimiento en exámenes estandarizados: uso de plataformas de aprendizaje en línea para mejorar resultados en pruebas estandarizadas, para reforzar el dominio de un tema en particular y para conseguir una evaluación más justa e igualitaria.
Para abordar cada uno de estos cuatro retos, se propone una sencilla estructura dividida en tres apartados:
- Descripción del problema, que nos permite poner el desafío en contexto.
- Análisis de algunos de los enfoques basados en el uso de datos e inteligencia artificial que se utilizan para ofrecer una solución tecnológica al reto en cuestión.
- Ejemplos de soluciones o experiencias relevantes o altamente innovadoras.
El informe también destaca la enorme complejidad que entraña este tipo de cuestiones, por lo que deben abordarse con cautela para evitar consecuencias negativas sobre los individuos, como pueden ser problemas de ciberseguridad, invasión de la privacidad o riesgo de exclusión de algunos colectivos, entre otros. Para ello, el documento finaliza con una serie de conclusiones que convergen en la idea de que el mejor camino para generar mejores resultados para todos los estudiantes, aliviando desigualdades, es combinar excelentes docentes y excelente tecnología que aumente sus capacidades. En este proceso los datos abiertos pueden jugar un papel aún más relevante para mejorar el estado del arte en tecnología educativa y asegurar un acceso más generalizado a determinadas innovaciones que en gran medida están basadas en tecnologías de aprendizaje automático o inteligencia artificial.
En este vídeo, su autor nos cuenta más sobre el informe:
Documentación
El dicho “una imagen vale más que mil palabras” es un claro ejemplo de sabiduría popular basada en la ciencia. El 90% de la información que procesamos es visual, gracias a un millón de fibras nerviosas que unen el ojo con el cerebro y a más de 20.000 millones de neuronas que realizan el procesamiento de los impulsos recibidos a gran velocidad. Por ello somos capaces de recordar el 80% de las imágenes que vemos, mientras que en el caso del texto y el sonido los porcentajes se reducen al 20% y al 10%, respectivamente.
Estos datos explican la importancia de la visualización de datos en cualquier sector de actividad. No es lo mismo contar cómo evoluciona un indicador, que verlo a través de elementos visuales, como gráficos o mapas. La visualización de datos nos ayuda a comprender conceptos complejos y supone una manera accesible para detectar y comprender tendencias y patrones en los datos.
Visualización de datos y Smart cities
En el caso de las Smart cities, donde se genera y captura tanta información, la visualización de datos es fundamental. A lo largo y ancho de una ciudad inteligente, hay un gran número de sensores y dispositivos inteligentes, con diferentes capacidades de detección, que generan una gran cantidad de datos en bruto. Por poner un ejemplo, solo la ciudad de Barcelona, dispone de más de 18.000 sensores repartidos por toda la ciudad que captan millones de datos. Esto datos permiten desde la vigilancia en tiempo real del entorno hasta la toma de decisiones informada o la rendición de cuentas. Visualizar estos datos a través de cuadros de mando visuales agiliza todos estos procesos.
Para ayudar a las Smart cities en esta tarea, desde el proyecto Ciudades abiertas, liderado por Red.es y cuatro ayuntamientos (A Coruña, Madrid, Santiago de Compostela y Zaragoza), se han seleccionado una serie de herramientas de visualización y se ha desarrollado una extensión para CKAN similar a la funcionalidad “Open With Apps”, inicialmente ideada para el portal Data.gov, que facilita la integración con este tipo de herramientas.
El método de integración inspirado en “Open with Apps”
La idea tras “Open With Apps” es permitir la integración con algunos servicios de terceros, para algunos formatos publicados en los portales de datos abiertos, como por ejemplo CSV o XLS, sin necesidad de descargar y cargar datos manualmente, a través de las APIs o URIs del servicio externo.
Pero no todos los sistemas de visualización permiten esta funcionalidad. Por ello, desde el proyecto ciudades abiertas han analizado varias plataformas y herramientas online de creación de visualizaciones y análisis de datos, y han seleccionado 3 que cumplen con las características necesarias para el funcionamiento descrito:
-
La integración se realiza a través de enlaces a sitios web sin necesidad de descargar ningún software.
-
En la invocación sólo es necesario pasar como parámetro la URL de descarga del fichero de los datos.
El resultado de dicho análisis ha dado lugar al informe “Análisis y definición de especificaciones de integración con sistemas externos de visualización”, donde se destacan 3 herramientas que cumplen estas funcionalidades.
3 herramientas de visualización y análisis de datos sencillas
De acuerdo con el citado informe, las 3 plataformas que cumplen las características necesarias para lograr dicho funcionamiento son:
-
Plotly: facilita la creación de visualizaciones interactivas de datos y paneles de control para compartir en línea con la audiencia. Los usuarios más avanzados pueden procesar datos con cualquier función personalizada, así como crear simulaciones con scripts de Python. Los formatos que acepta son CSV, TSV, XLS y XLSX.
-
Carto: antes conocida como CartoDB, genera mapas interactivos a partir de datos geoespaciales. Los mapas se crean automáticamente y el usuario puede filtrar y refinar los datos para obtener más información. Acepta ficheros en formatos CSV, XLS, XLSX, KML (Google Earth), KMZ, GeoJSON y SHP.
-
Geojson.io: permite visualizar y editar datos geográficos en formato GeoJSON, así como exportar a un gran número de formatos.

Para cada una de estas herramientas el informe incluye una descripción de sus requisitos y limitaciones, su modo de uso, una llamada genérica y ejemplos concretos de llamadas junto con el resultado obtenido.
La extensión “Abrir con”
Como se mencionó anteriormente, dentro del proyecto también se ha desarrollado una extensión para CKAN denominada “Abrir con”. Esta extensión permite visualizar los ficheros de datos utilizando los sistemas externos de visualización antes descritos. Se puede acceder a ella a través de la cuenta de GitHub del proyecto.
El informe explica cómo llevar a cabo su instalación de manera sencilla, aunque si surge alguna duda acerca de su funcionamiento, los usuarios pueden ponerse en contacto con Ciudades abiertas a través del correo electrónico contacto@ciudadesabiertas.es.
Aquellos interesados en otras extensiones de CKAN relacionadas con la visualización de datos tienen a su disposición el informe Análisis de las Extensiones de Visualización para CKAN, realizado en el marco de la misma iniciativa. En la cuenta de Gighub, se espera que vayan publicando ejemplos de visualizaciones realizadas.
En definitiva, la visualización de datos es una pata fundamental de las Smart cities, y gracias al trabajo del equipo de Ciudades Abiertas ahora le resultará más fácil a cualquier iniciativa integrar soluciones sencillas de visualización de datos en sus plataformas de gestión de la información.
Documentación
En un portal de datos abiertos conviven una gran cantidad de fuentes de datos de distinta naturaleza, con diversos contenidos y formatos. Por ello es necesario proporcionar a cada archivo, recurso o contenido de la red, un contexto o definición que permita a las personas, y también a las máquinas, interpretar su significado. Es aquí donde entra el concepto de Linked data.
Linked Data o datos enlazados permite usar la web como una única gran base de datos global. Siguiendo este paradigma de publicación los datos quedan disponibles contextualizados e interconectados para su reutilización. Linked Data surgió a partir del proyecto de la Web Semántica inspirado por Tim Berners-Lee, padre de la Web, de la necesidad de introducir información de contexto en forma de metadatos en la Web.
El documento “LinkedData como modelo de datos abiertos” explica de forma breve los conceptos básicos para entender cómo funciona la web semántica y los datos enlazados, como es el caso de las URIs o identificadores únicos de recursos, las ontologías o los vocabularios que permiten describir relaciones entre ellos, para centrarse en cómo Aragón ha implementado estas tecnologías para desarrollar distintos servicios, como por ejemplo:
- La Estructura de Información Interoperable (EI2A), una ontología que homogeniza estructuras, vocabularios y características para dar respuesta a la diversidad y heterogeneidad de datos existentes dentro de la Administración, en el marco de Aragón Open Data. El documento explica algunas de las ontologías y vocabularios usados para el desarrollo.
- El Identificador Europeo de Legislación (ELI), que permite acceder online a la legislación en un formato formalizado que facilita su reutilización.
- La infraestructura semántica en Aragón Open Data, donde destaca el uso dela herramienta Virtuoso para el almacenamiento de los datos enlazados. El documento explica cuáles son las características de este servidor universal, cuya arquitectura permite la persistencia de datos en formatos RDF-XML, entre otros. Además, se explica cómo funciona el banco que almacena tripletas de forma nativa para la relación entre recursos y se muestran ejemplos de servicios de Aragón Open data que explotan dichas tripletas de datos como Aragopedia y Aragón Open Data Pool.
A continuación, puedes descargar el documento completo.
Este documento forma parte de la serie de materiales didácticos y artículos tecnológicos que está realizando Aragón open Data con el fin de explicar cómo han desplegado distintas soluciones para dar respuesta a las necesidades de localización, acceso y reutilización de los distintos conjuntos de datos. Puedes completar su lectura con otro volumen de la serie: “Cómo implementar CKAN: caso real del portal Aragón Open Data”.
Documentación
Aragón Open Data es una de las iniciativas de datos abiertos más activas del panorama español. Además de la puesta en marcha, gestión y mantenimiento de un catálogo de datos interoperable, desde su inicio han llevado a cabo acciones para acercar la cultura de los datos abiertos a ciudadanos, empresas y todo tipo de organizaciones. Estas iniciativas abarcan el desarrollo de servicios para ofrecer los datos y facilitar su reutilización de forma sencilla como Aragopedia, Open Social Data o la reciente Aragón Open Data Focus (más información disponible en esta entrevista). Aragón Open Data es la iniciativa de datos abiertos del Gobierno de Aragón, Departamento de Ciencia, Universidad y Sociedad del Conocimiento, Dirección General de Administración Electrónica y Sociedad de la Información cofinanciado por el Fondo Europeo de Desarrollo Regional (FEDER) “Construyendo Europa desde Aragón”.
Dado el conocimiento que atesoran, no es de extrañar que hayan comenzado a desarrollar materiales didácticos y artículos tecnológicos con el fin de explicar cómo han desplegado distintas soluciones para dar respuesta a las necesidades de localización, acceso y reutilización de los distintos conjuntos de datos.
A continuación, se recoge uno de estos materiales, centrado en explicar cómo han implementado la solución de software CKAN para mejorar la disponibilidad de datos en el portal.
CKAN como solución software de gestión de datos abiertos en un caso real para el portal Aragón Open Data
CKAN es una plataforma de código abierto, gratuito y libre, desarrollada por la Open Knowledge Foundation, que sirve para publicar y catalogar colecciones de datos. Debido a sus carácter libre y gratuito, así como a su rápida implementación, se ha convertido en un referente a nivel mundial para la apertura de datos.
Desde su nacimiento en 2012, Aragón Open Data ha apostado por tecnología CKAN para la gestión de su sistema de datos abiertos. El documento “CKAN, piedra angular para la gestión de un sistema de datos abiertos” nos muestra cómo funciona su arquitectura y sirve de ejemplo a otras iniciativas que quieran poner en marcha una plataforma de este tipo.
En el documento se relatan los retos que se encontraron a la hora de migrar la plataforma original a una versión superior y cómo lo solucionaron con la construcción de una aplicación cliente. Este proceso generó como resultado la arquitectura actual del portal que se recoge en la siguiente figura:
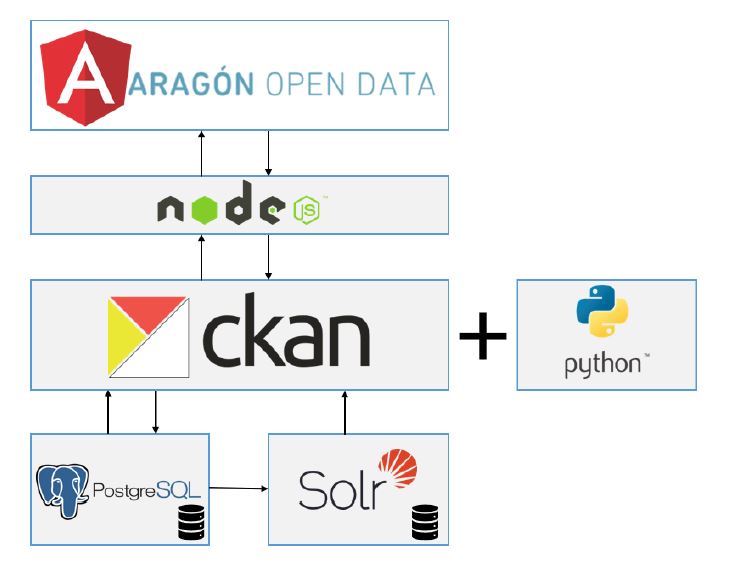
El backend de CKAN está desarrollado íntegramente en Python, con un frontal propio en Javascript, y permite desplegar una capa de servicios gestionable desde una API, y utilizar plugins base o extensiones que aportan funcionalidades adicionales a la plataforma. CKAN se apoya en una base de datos PostgreSQL, donde se almacenan los conjuntos de datos que alberga, sus recursos y demás metadatos necesarios para el funcionamiento de la plataforma, y hace uso de Solr, un motor de búsqueda que ayuda a agilizar la localización y disponibilidad de los conjuntos de datos.
Además de explicar esta arquitectura, el documento aborda las funcionalidades y extensiones utilizados en la instancia de CKAN personalizada, y cómo el conjunto de componentes integrados en la plataforma: Angular, NodeJS, PostgreSQL y Solr conviven para disponer conjuntos de datos que son la base para el desarrollo de servicios y soluciones de datos abiertos como Presupuestos de Aragón o el ya mencionado Aragón Open Data Focus.
CKAN incorpora una extensión que permite soportar serializaciones de datos en RFD que, además de permitir la exposición de datos enlazados en formatos como RDF-XML o Turtle, se utiliza para federar conjuntos de datos que siguen la especificación DCAT de metadatos, lo que hace de CKAN una plataforma más versátil y apropiada para la publicación de Linked Data, algo que también ha hecho Aragón Open Data como podemos ver en este otro documento.
Puedes descargar el documento “CKAN como solución software de gestión de datos abiertos en un caso real para el portal Aragón Open Data” a continuación. Además, puedes complementar su lectura con estos dos artículos adicionales:
- Recolección automática de datos abiertos: Explica cómo Aragón Open Data federa datos abiertos utilizando un plugin de CKAN.
- Arquitectura ELK como herramienta de datos abiertos: Explica cómo Aragón Open Data utiliza una arquitectura basada en el stack tecnológico ELK (Elasticsearch, Logstash y Kibana).
Documentación
En España conviven numerosas iniciativas de datos abiertos impulsadas desde distintos niveles de la administración: ayuntamientos, comunidades autónomas y organismos estatales. Este ecosistema, tan rico como diverso, genera un gran volumen de información de valor, pero también plantea un reto evidente: ¿cómo facilitar que cualquier persona o entidad pueda localizar de forma sencilla los datos que necesita, sin tener que recorrer decenas de catálogos distintos?
Para dar respuesta a esta necesidad, el Catálogo Nacional de Datos Abiertos, alojado en datos.gob.es, actúa como un punto de acceso único al conjunto de datos puestos a disposición de la ciudadanía por parte del sector público español. Su función armonizadora permite centralizar la información procedente de múltiples iniciativas, ofreciendo a los reutilizadores un espacio común donde buscar datos de forma más eficiente. Además, gracias a su federación con portal de datos europeos (data.europa.eu), los conjuntos de datos publicados por las administraciones españolas ganan visibilidad en el ámbito internacional.
Pasos a seguir
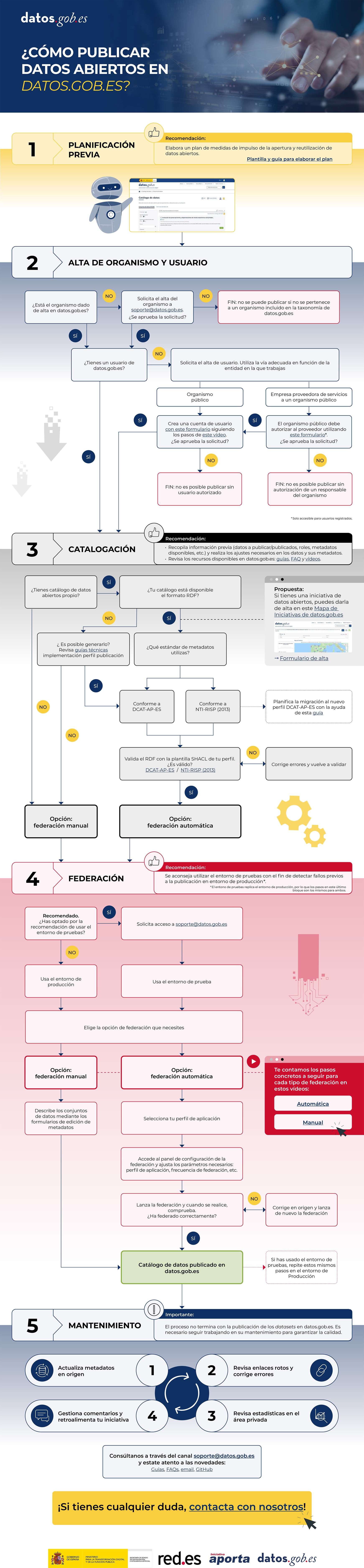
Publicar datos abiertos en el Catálogo Nacional es un proceso más sencillo de lo que parece si se conocen las fases clave.
1. Planificación previa
Antes de empezar, conviene preparar el terreno. Para ello, se recomienda realizar un plan de medidas de impulso de la apertura y reutilización de datos abiertos, en el que el organismo defina, entre otras cuestiones, qué datos va a abrir, con qué propósito y bajo qué criterios de calidad, actualización y formato. Una buena planificación permite anticipar necesidades técnicas, coordinar a los equipos implicados y garantizar que los datos publicados serán realmente útiles para los reutilizadores.
En datos.gob.es se pueden encontrar múltiples recursos para ayudar en esta tarea, como esta plantilla, o diversas guías, como la Guía para el despliegue de portales de datos. Buenas prácticas y recomendaciones.
2. Alta del organismo y del usuario
La segunda fase se centra en gestionar el alta del organismo y de los usuarios que se encargarán de la publicación. Las cuentas de usuario están reservadas solo para los organismos o entidades publicadoras de datos abiertos (no son necesarias para poder acceder o descargar conjuntos de datos del catálogo).
Para poder federar datos en el catálogo nacional, el organismo debe estar registrado en la taxonomía oficial y validado por el equipo de datos.gob.es. A su vez, los usuarios responsables necesitan disponer de una cuenta autorizada, ya sea como personal del propio organismo o como proveedores externos acreditados (previamente autorizados). Sin este paso administrativo, no es posible acceder a las herramientas necesarias para catalogar y publicar datos. Este vídeo te explica cómo solicitar la cuenta de usuario:
3. Catalogación
En esta fase el organismo prepara los metadatos de sus conjuntos de datos siguiendo los perfiles de aplicación establecidos, preferentemente DCAT-AP-ES. En este punto se determina si se cuenta con un catálogo propio capaz de generar metadatos en RDF o si será necesario recurrir a otras alternativas. La validación mediante plantillas SHACL es fundamental para garantizar que los metadatos cumplen los requisitos técnicos y semánticos, evitando errores que puedan impedir la federación.
4. Federación
La federación es el proceso mediante el cual los metadatos del organismo se incorporan al catálogo nacional. Esta federación puede realizarse de dos formas:
- Manual: implica dar de alta cada dataset de manera individual, completando para cada conjunto de datos un formulario donde se detallan sus metadatos.
- Automática: el alta y actualización se hace de forma periódica a partir de un fichero RDF donde se incluyen los metadatos disponibles a través de una url en el sitio web del publicador. Ya no es necesario trabajar individualmente con cada dataset, sino que el proceso puede abarcar automáticamente a varios conjuntos de datos.
En ambas modalidades, antes de federar en producción, se recomienda utilizar el entorno de pruebas para verificar que los conjuntos de datos se integran correctamente y que los metadatos se visualizan como se espera.
5. Mantenimiento
Para que los datos publicados sigan siendo útiles, actualizados y accesibles, es necesario realizar un mantenimiento continuo. Esto implica revisar y actualizar los metadatos y los recursos cuando sea necesario o corregir enlaces rotos, entre otros. Estas actividades son esenciales para asegurar la calidad del catálogo y para que los datos abiertos sigan generando valor a lo largo del tiempo.
Infografía resumen del flujo a seguir
Para facilitar la comprensión de los pasos a seguir, ponemos a disposición de los usuarios la siguiente infografía-resumen. No obstante, el equipo de soporte de datos.gob.es estará encantado de atender cualquier duda o comentario.
Documentación
El procesamiento del lenguaje natural es hacer que las máquinas (los ordenadores) entiendan el lenguaje humano: hablado o en forma de texto. De manera más formal, el procesamiento del lenguaje natural es un campo híbrido entre la informática y la lingüística, que utiliza diferentes técnicas, algunas de ellas basadas en inteligencia artificial, para interpretar el lenguaje humano.
En este informe, elaborado por el experto en transformación digital Alejandro Alija, veremos cómo el procesamiento del lenguaje natural está mucho más cerca de nuestro día a día de lo que podemos pensar inicialmente. Aplicaciones como la traducción automática de textos; el análisis de sentimiento en redes sociales; las búsquedas que realizamos en internet; la generación de resúmenes meteorológicos o las sencillas peticiones que hacemos a nuestro altavoz inteligente, tienen una fuerte componente tecnológica de procesamiento del lenguaje natural.
El peso específico que el procesamiento del lenguaje natural tiene (y va a tener) en la industria y en la economía es cada vez mayor, puesto que la mayoría de los datos que se producen en el mundo (fundamentalmente a través de Internet) son datos en forma de textos y voz (datos desestructurados). Los datos abiertos juegan un papel crucial para esta tecnología. Los algoritmos de inteligencia artificial que se usan para analizar y entender el lenguaje natural, requieren de una ingente cantidad de datos de calidad para ser entrenados. Multitud de estos datos proceden de los repositorios de datos abiertos de instituciones tanto públicas como privadas.
A lo largo de este informe, se repasa la historia del procesamiento del lenguaje natural, desde sus inicios hasta nuestros días. Además, en la sección Inspire, se describen algunos de los casos de uso más representativos que aprovechan el potencial del procesamiento del lenguaje natural. La predicción de texto al escribir un nuevo email, la clasificación de textos en categorías o la generación de noticias falsas, son solo algunos de los casos que se repasan en este informe.
Finalmente, para aquellos lectores más entusiastas, en la sección Action, se desarrolla un caso de uso completo (utilizando herramientas de programación) sobre el análisis de sentimiento en conversaciones sobre debates públicos ciudadanos.
El informe finaliza con un listado de recursos y lecturas para que aquellos usuarios que deseen continuar ampliando sus conocimientos sobre Inteligencia Artificial.
A continuación, puedes acceder a cada una de las secciones del informe:
También puedes descargarte el informe completo y el resto de materiales adicionales en los siguientes enlaces:
Nota: El código publicado pretende ser una guía para el lector, pero puede requerir de dependencias externas o configuraciones específicas para cada usuario que desee ejecutarlo.
Documentación
Estrenamos una nueva serie de informes en datos.gob.es, que bajo la metodología “Awareness, Inspire, Action” trata de explicar cómo funcionan distintas tecnologías emergentes y su relación con los datos abiertos. El objetivo es introducir en la materia al lector mediante el empleo de casos de uso prácticos, sencillos y reconocibles.
El primer informe de la serie está dedicado a la Inteligencia Artificial. Podemos definir la Inteligencia Artificial (IA) como la capacidad de una máquina para imitar la inteligencia humana. Esta tecnología tendrá un gran impacto en nuestras vidas, mediante dos vías: la automatización de tareas cotidianas, rutinarias y peligrosas y el aumento de las capacidades humanas, ayudando a potenciar la fuerza del trabajo del futuro.
El informe ha sido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación, y aborda los siguientes contenidos:
-
El informe comienza con la sección de Awareness donde se explica el concepto de IA de manera sencilla, esbozando brevemente dos de sus sub-campos: el Machine Learning y el Deep Learning. Esta sección también incluye una breve reseña histórica, donde se repasa la evolución de la IA, y se recopilan y explican los factores que la hacen posible.
-
A continuación, en la sección de Inspire se profundiza en los casos de uso de la IA. Para ello el autor ha tomado como referencia sus dos áreas de impacto: la IA como amplificador del lenguaje humano, con tareas como la traducción de informes o la conversión del lenguaje escrito al hablado (y viceversa), y la IA como extensión de la visión humana, ilustrada a través de ejemplos de uso del reconocimiento y clasificación de imágenes.
-
Por último, en la sección Action se desarrolla uno de los casos prácticos mencionados en el apartado de Inspire: el reconocimiento y clasificación de imágenes. Para ellos se ha seleccionado un conjunto de imágenes disponible en el catálogo de datos de datos.gob.es (el Archivo fotográfico del Gobierno Vasco: imágenes sobre Euskadi y la actividad de Gobierno). Utilizando herramientas de IA, se ha procedido a clasificar las imágenes y anotar su descripción. Este ejemplo puede ser replicado por el lector ya que se ha puesto a su disposición el código necesario para su desarrollo.
El informe finaliza con un listado de recursos y lecturas para que aquellos usuarios que deseen continuar ampliando sus conocimientos sobre Inteligencia Artificial.
A continuación, puedes acceder a cada una de las secciones del informe:
También puedes descargarte el informe completo y el resto de materiales adicionales en los siguientes enlaces:
Nota: El código publicado pretende ser una guía para el lector, pero puede requerir de dependencias externas o configuraciones específicas para cada usuario que desee ejecutarlo.
Documentación
Los datos abiertos son uno de los elementos clave de las ciudades inteligentes (también llamadas Smart cities). La recopilación de información, su análisis y su uso permiten hacer frente a muchos de los desafíos a los que se enfrentan las ciudades actualmente, como la creación de servicios públicos que den respuesta a una población cada vez mayor.
De todos los conjuntos de datos abiertos que se publican en las ciudades, los datos en tiempo real aportan múltiples ventajas. Conocer la situación de nuestras ciudades en tiempo real puede servir para tomar decisiones y mejorar la eficiencia en la movilidad urbana, la gestión energética o las condiciones ambientales, entre otros aspectos.
En este contexto, el informe “Datos abiertos en tiempo real: casos de uso para ciudades inteligentes” busca impulsar la apertura de este tipo de datos mostrando las ventajas de su uso. El informe analiza la relación entre datos abiertos y ciudades inteligentes, y muestra una serie de conjuntos de datos que las entidades locales deberían publicar en tiempo real, de acuerdo con el informe “Datos Abiertos 2019 - 40 conjuntos de datos a publicar por las Entidades Locales”, de la FEMP (Federación Española de Municipios y Provincias). Estos conjuntos de datos pertenecen a los ámbitos del transporte y la movilidad - aparcamientos públicos, bicicletas públicas, tráfico, transporte público - , y el medio ambiente – calidad del aire y contaminación acústica-.
Cada conjunto de datos se ha analizado destacando algunos casos de uso y ejemplos de reutilización, prestando especial atención al impacto positivo que tienen para la ciudadanía. También se han abordado las tecnologías implicadas en su despliegue, los stakeholders afectados o los desafíos futuros, entre otros factores.
Las conclusiones del análisis quedan recogidas en cada una de las fichas que puedes ver a continuación:
Conjuntos de datos
También puedes descargarte el informe completo y el resto de materiales adicionales en los siguientes enlaces.
Evento
El próximo 25 de septiembre, la Secretaría de Estado para el Avance Digital organiza la jornada Infoday sobre tecnologías del lenguaje. El evento se enmarca dentro de la XXXV Conferencia Internacional de la SEPLN (Sociedad Española para el Procesamiento del Lenguaje Natural) y de las actividades de difusión del Plan de Impulso de las tecnologías del Lenguaje, cuyo objetivo es fomentar el desarrollo del procesamiento del lenguaje natural y la traducción automática en lengua española y lenguas cooficiales.
Con este evento se quiere mostrar y resaltar la importancia de las campañas de procesamiento del lenguaje natural en todos los ámbitos, pero especialmente el campo de la sanidad y la biomedicina, así como concienciar sobre los distintos elementos necesarios para que los proyectos de tecnologías del lenguaje lleguen a buen fin, como pueden ser los datos abiertos.
La jornada se desarrollará en horario de mañana de 9:00 a 14:00 en la sede de la Universidad del País Vasco, en Bilbao (Avenida Abandoibarra, 3), y se estructura en dos partes:
-
Parte I: Avances del Plan de Impulso a las tecnologías del lenguaje (Plan TL). En la primera parte del evento se abordarán las principales iniciativas que se están llevando a cabo dentro del Plan TL. Se pondrá el foco en algunos aspectos destacados, como las infraestructuras lingüísticas y los proyectos europeos de traducción automática. Además, se mostrarán los resultados de algunos de los últimos estudios realizados. Uno de estos trabajos es “Datos reutilizables como recursos lingüísticos”, cuya ponencia defenderá Leonardo Campillos, de la Universidad Autónoma de Madrid (UAM), y que ha sido realizado con financiación de la Secretaría de Estado para el Avance Digital y Red.es dentro del ámbito del Plan TL.
-
Parte II: Campañas de evaluación en sanidad. En la segunda parte, se analizará la situación de las distintas campañas realizadas en el campo de la sanidad y la biomedicina, prestando especial atención a las tareas de anonimización. Para ello se realizarán dos mesas redondas, que llevan por título “Campañas de evaluación, experiencias, necesidades, impacto y visión de participantes” y “Protección de datos de salud, aspectos legales, transferencia de conocimiento, soluciones PLN clínicos y oportunidades para la academia e industria de TL”.
A través de esta agenda se busca generar un espacio para intercambiar experiencias, que permitan evitar duplicidades y aprovechar sinergias entre los distintos actores involucrados en el universo de las tecnologías del lenguaje: entidades públicas, empresas privadas, sector académico, investigadores, etc.
La asistencia al evento es gratuita, pero para poder asistir es necesario registrarse previamente a través de este enlace.
Documentación
La academia del portal de datos abiertos europeo (data.europa.eu) pone a disposición de la ciudadanía un programa formativo online para aquellos interesados en desarrollar sus habilidades en materia de datos abiertos. Estos materiales de acceso gratuito permiten familiarizarse con el ecosistema desde distintos ángulos: conceptos básicos, marcos legales, tendencias emergentes, casos de éxito o buenas prácticas de publicación y reutilización. Estos materiales de acceso gratuito permiten familiarizarse con el ecosistema de datos abiertos desde distintos ángulos: conceptos básicos, marcos legales, tendencias emergentes, casos de éxito o buenas prácticas de publicación y reutilización.
¿A quién van dirigidos?
Los cursos de la data.europa academy están dirigidos a profesionales y organizaciones que trabajan con datos públicos en Europa —especialmente administraciones, instituciones académicas y entidades que publican, gestionan o reutilizan datos abiertos—, pero también a cualquier persona interesada en comprender cómo los datos pueden impulsar la transparencia, la innovación y la toma de decisiones.
Además, están diseñados para distintos niveles de experiencia, desde quienes se inician en los conceptos básicos hasta especialistas que buscan profundizar en aspectos legales, técnicos o de calidad, lo que permite que perfiles muy diversos encuentren un recorrido formativo adaptado a sus necesidades.
¿Cómo se organizan los cursos?
Los materiales formativos están organizados por temática:
- Policy (política)
- Legal (legal)
- Quality (calidad)
- Business (negocio)
- Impact (impacto)
- Communication (comunicación)
- Portal (portal)
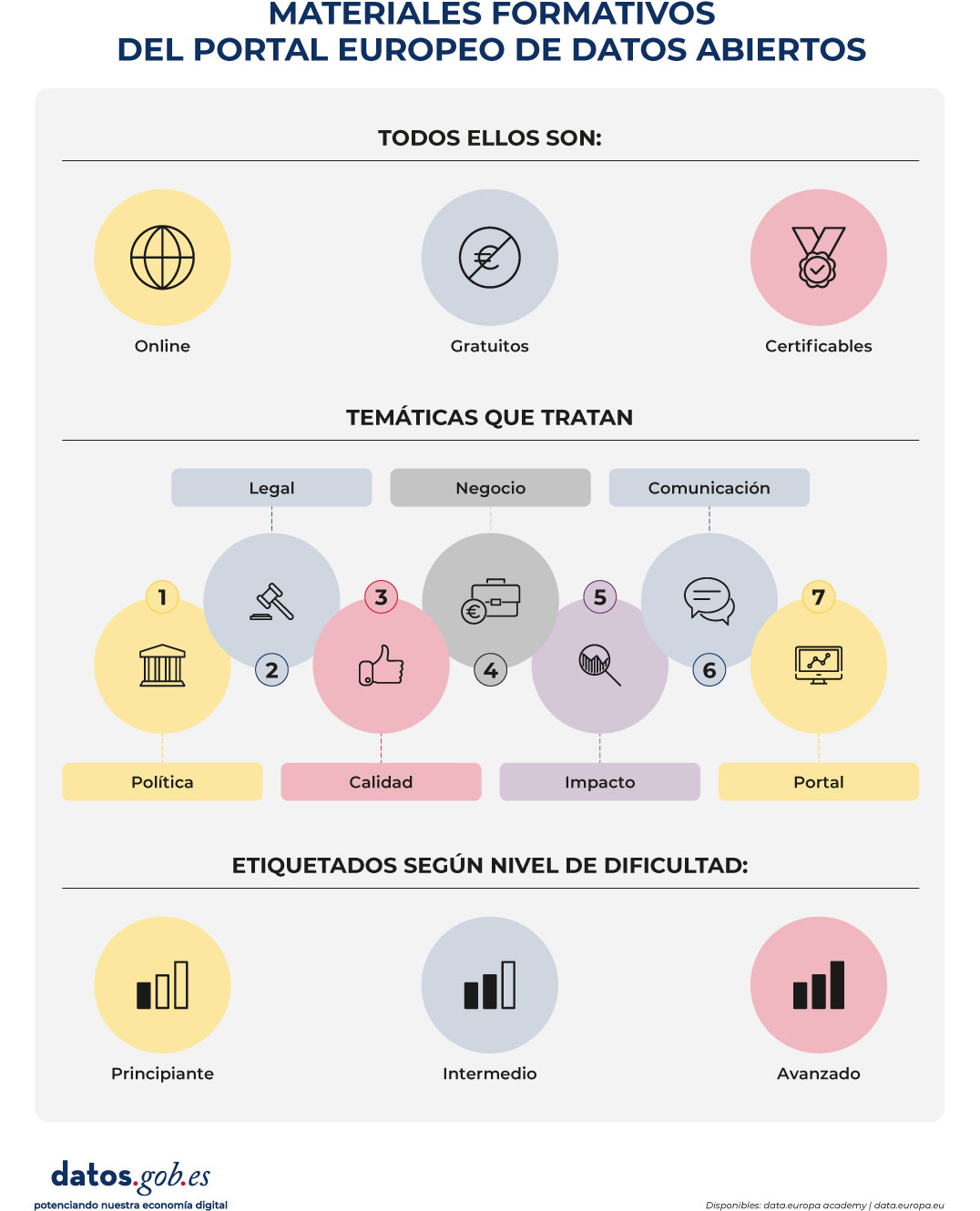
Figura 1. Materiales formativos del portal europeo de datos abiertos. Fuente: elaboración propia
Para cada materia, hay disponibles diversos materiales: lecturas, vídeos, herramientas, webinars, cuestionarios, etc. que buscan ayudar a comprender, utilizar y compartir datos abiertos de forma eficaz.
Como se mencionaba previamente, los cursos se dividen por nivel de experiencia (principiante, intermedio o avanzado). Los usuarios también pueden filtrar por la audiencia a la que se dirigen (proveedores de datos, desarrolladores, periodistas, etc.), además de temática o formato.
Los usuarios pueden optar por seguir una temática completa o seleccionar contenidos específicos según sus intereses. Esta flexibilidad permite adaptar la formación a diferentes necesidades profesionales.
Además, desde 2026 están disponible una serie de itinerarios (learning path) concebidos como recorridos formativos estructurados que agrupan contenidos de diversas áreas temáticas en un orden lógico y progresivo para distintos fines.
Certificados e insignias digitales
Uno de los aspectos más valorados de los itinerarios formativos es la posibilidad de obtener certificados oficiales que permiten acreditar de manera formal las competencias adquiridas. Estos certificados están disponibles para los distintos itinerarios. Para conseguirlos, basta con completar todos los módulos del recorrido, superar la evaluación final y descargar el certificado generado al finalizar.
Junto a estos reconocimientos, la plataforma también ofrece insignias digitales (badges) que se van desbloqueando a medida que se avanza en los contenidos. Estas badges pueden incorporarse a perfiles profesionales y sirven como una evidencia clara y verificable del dominio de distintas áreas relacionadas con los datos abiertos.
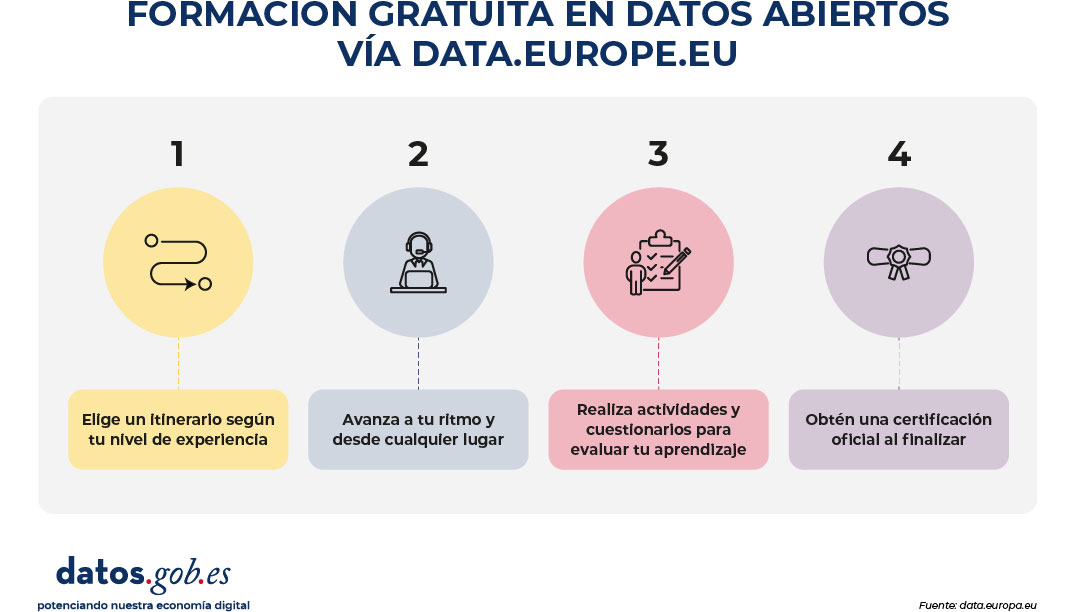
Figura 2. Proceso de formación gratuita en datos abiertos vía data.europe.eu