Documentación
In a platform such as datos.gob.es, where the frequency of dataset updates is constant, it is necessary to have mechanisms that facilitate massive and automatic queries.
In datos.gob.es we have an API and a SPARQL point to facilitate this task. Both tools allow querying the metadata associated with the datasets of the National Open Data Catalog based on the definitions included in the Technical Interoperability Standard for the Reuse of Information Resources (NTI-RISP). Specifically, the semantic database of datos.gob.es contains two graphs, one containing the entire Catálogo de datos de datos.gob.es and another with the URIs corresponding to the taxonomy of primary sectors and the identification of geographic coverage based on the NTI.
In order to help reusers to perform their searches through these functionalities, we provide users with two videos that show in a simple way the steps to follow to get the most out of both tools.
Video 1: How to make queries to the datos.gob.es catalog through an API?
An application programming interface or API is a mechanism that allows communication and information exchange between systems. Thanks to the API of datos.gob.es you can automatically query the datasets of a publisher, the datasets that belong to a specific subject or those that are available in a specific format, among many other queries.
The video shows:
- How to use the datos.gob.es API.
- What types of queries can be made using this API
- An example to learn how to list the datasets in the catalog.
- What other Open Data Initiatives are publishing APIs
- How to consult other available APIs
You also have at your disposal an infographic with examples of APIs for open data access.
Video 2: How to perform queries to the .gob.es data catalog through the SPARQL point?
A SPARQL point is an alternative way to query the metadata of the datos.gob.es catalog using a service that allows queries over RDF graphs using the SPARQL language.
With this video, you will see:
- How to use the SPARQL point of datos.gob.es.
- What queries can be performed using the SPARQL point
- What methods exist for querying the SPARQL point
- Examples on how to perform a query to find out which datasets are available in the catalog or how to obtain the list of all the organizations that publish data in the catalog.
- It also includes examples of SPARQL points in different national initiatives.
These videos are mainly aimed at data reusers. From datos.gob.es we have also prepared a series of videos for publishers explaining the various features available to them on the platform.
Documentación
Open data publishers in the National Catalog hosted in datos.gob.es have at their disposal several internal functionalities to easily manage their datasets and everything related to them.
To bring these possibilities closer to the registered users, from datos.gob.es we have prepared a series of videos detailing the steps to follow in order to develop different actions on the platform.
It should be noted that these videos are aimed at data publishers. Soon we will also publish videos focused on the tools available for data reuse, which will be very useful for developers, companies, organizations or individuals who want to extract the maximum possible value from the datasets accessible from this platform.
Video 1: Backoffice functionalities for registered users
The first video explains the functionalities that registered users can use to interact with the platform. Specifically, it addresses the following topics:
- How to access the organization's data catalog and create, manage, locate or filter existing datasets.
- How to use the broken links feature to find out if any datasets are inaccessible.
- What interactive statistics the dashboard provides and how to download them in various formats, such as CSV or JSON.
- How to disseminate data-driven initiatives, applications or success stories through the platform.
- How to handle requests for data or comments.
- How to adjust the user profile.
Video 2: How to manually upload datasets to datos.gob.es?
The publishers of datos.gob.es can upload their datasets in two different ways:
- Manual: The user must complete for each dataset, individually, a form detailing its metadata.
- Automatic (federated): Registration and updating is done periodically from an RDF file with the metadata available through a URL on the publisher's website. This is a batch process that allows managing the upload of several sets at once.
This video focuses on the first way, including information on:
- What steps to follow to create new datasets manually.
- Which metadata are mandatory to include and which are recommended, so that users can more easily locate the information they are interested in.
- How to modify the metadata.
- How to add distributions - that is, downloadable files in a particular format or level of disaggregation - to the new dataset. It also indicates what the mandatory metadata of the distributions are and how they can be modified.
- How the organization's datasets and their distributions are removed.
Video 3: How to perform an automatic dataset upload to datos.gob.es?
This video focuses on the second way to publish datasets in datos.gob.es, through data federation sources. Thanks to the video you will learn:
- What is a federation source
- How to create, query, filter and sort the data sources of an organization.
- How to consult through a dashboard, the details of the last execution or the history of tasks of a federation source.
- How to edit and update a federation source.
- How to execute a federation manually from the dashboard.
- How to delete or clean up federation tasks already performed.
- How to view the status of the last federation.
- How to delete a data source from an organization, both keeping and deleting the previously imported datasets too.
Video 4: What is the purpose of the widget of the datos.gob.es catalog?
A Widget is a piece of code in HTML language that contains functionalities that can be embedded and executed in web pages in a simple way. Thanks to the Widget that we provide you with, you will be able to include in any website, a catalog with the reference to all the datasets that you have registered in datos.gob.es.
This video explains:
- What is the widget, showing examples of use.
- How to generate the HTML code associated with the widget
- How to embed the data catalog view in any publisher's portal.
To learn more about these and other aspects, you also have at your disposal several user guides in this link.
Documentación
Discover which are the strategic frameworks that mark the publication and use of open data, as well as the most outstanding datasets at local, regional, national and international level through the various infographics that we will publish periodically.
European Health Data Space: objectives and approach
 |
Published: February 2025 In this infographic we tell you the keys to the EU''s first common European data space in a specific sector and the only one that regulates primary, as well as secondary data use. Discover the areas of action, related projects and next steps. |
Data and its governance in the European Artificial Intelligence Regulation
 |
Published: October 2024 The European Regulation on Artificial Intelligence seeks to constitute a reference framework for the development of any system and to inspire codes of good practice, technical standards and certification schemes. In this infographic we tell you about its keys. |
Examples of open datasets published by local entities
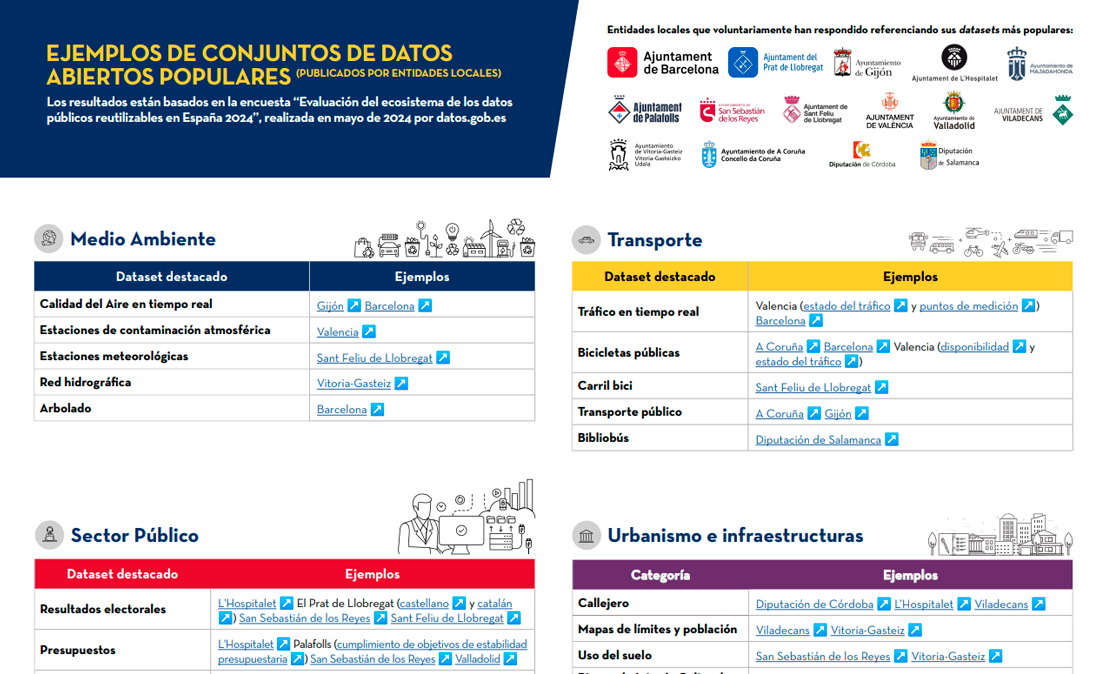 |
Published: September 2024 In order to learn about their open data activities, a survey was conducted last May in which representatives of local entities participated. This infographic collects examples of the most popular datasets from their portals. |
European Declaration on Digital Rights and Principles
 |
Published: August 2024 The Declaration is based on the EU Charter of Fundamental Rights, which promotes a digital transition shaped by European values. In this infographic, the principles that shape it and the opinion of European citizenship for each of them are presented. |
Artificial intelligence strategy 2024
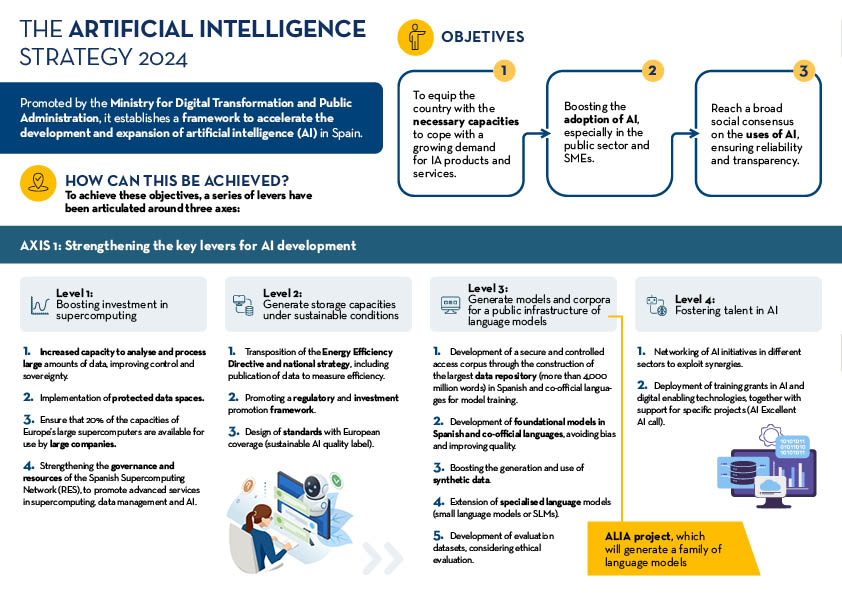 |
Published: July 2024 The new artificial intelligence strategy 2024 establishes a framework to accelerate the development and expansion of AI in Spain. It is articulated around three main axes developed through eight lines of action, which are detailed in this infographic. |
High value datasets
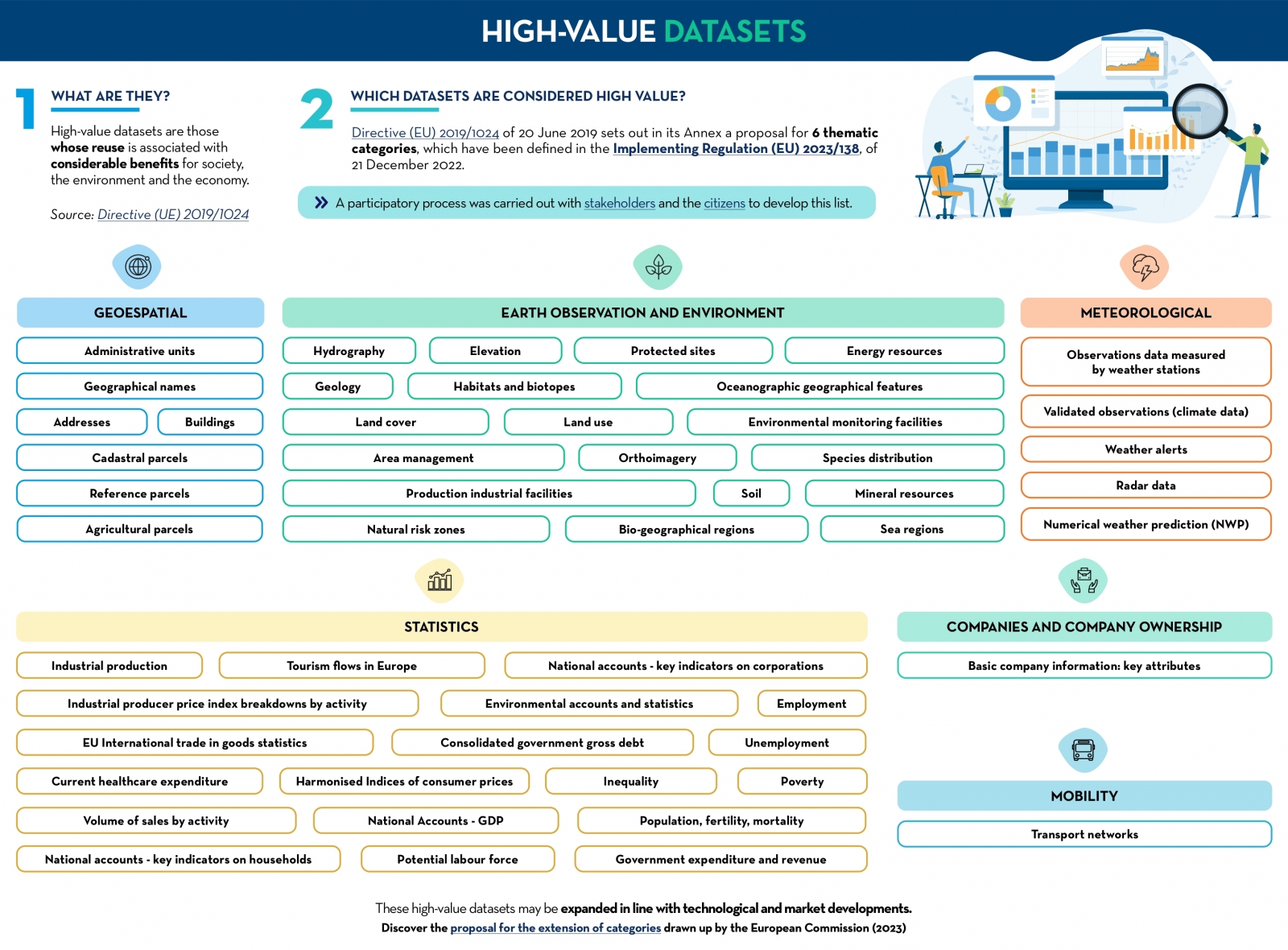 |
Published: March 2024 This infographic shows the high-value data categories defined in Implementing Regulation (EU) 2023/138 of 21 December 2022. Find out what these categories are and how the datasets linked to them should be published. A one-page version has also been created to facilitate printing: click here. |
Gaia-X and European data spaces
 |
Published: April 2022 This infographic shows the context driving the development of data spaces, focusing on some related European initiatives such as Gaia-X and ISDA. |
Trends in open data around the world
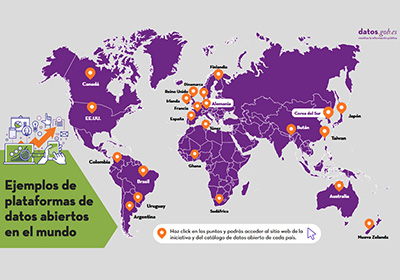 |
Published: November 2021 Through this interactive infographic you can easily access the open data platforms and datasets of several leading countries. The infographic is accompanied by a post which briefly analyzes the strategies and next steps to be taken by these initiatives, showing what are the main trends worldwide. |
The most demanded datasets published by local entities
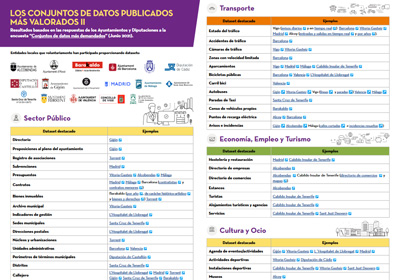 |
Published: July 2021 17 local entities, including city councils, provincial councils and an island council, share with the users of datos.gob.es which are their most demanded datasets, among all those published under standards that favour their reuse. The datasets are segmented by thematic categories, highlighting transport, environment and public sector data. |
The Open Government and Public Data Strategies of the Autonomous Communities
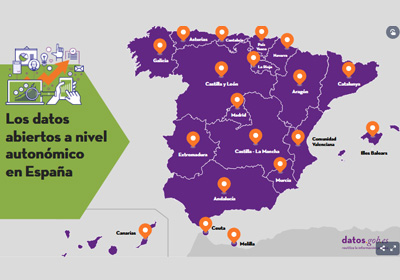 |
Published: June 2021 An interactive map shows the open data initiatives at regional level in Spain, including in each case the url to its portal and the main documents detailing its strategic framework. The infographic is accompanied by an article which addresses the commitments made by each Autonomous Region in the IV Open Government Plan of Spain. |
What are the most demanded datasets?
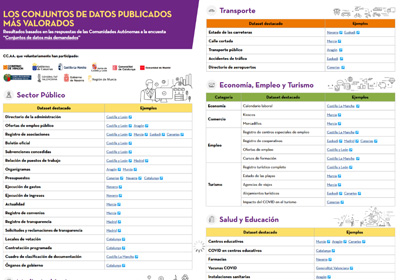 |
Published: May 2021 This infographic compiles some 100 datasets published by regional organizations, which are offered in open format according to standards that facilitate their reuse. The datasets are shown divided by thematic categories, highlighting those related to the public sector, the economy, employment and tourism, and the environment. |
The data-related strategies that will mark 2021
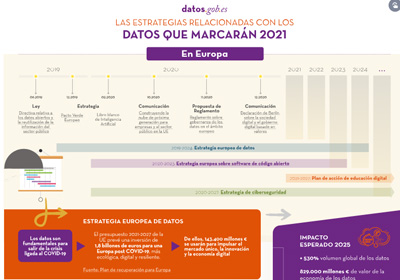 |
Published: January 2021 This interactive infographic shows the strategic, regulatory and political situation affecting the world of open data in Spain and Europe. It includes the main points of the European Data Strategy, the Regulation on Data Governance in Europe or the Spain Digital 2025 plan, among others. |
Documentación
Open data can be the basis for various disruptive technologies, such as Artificial Intelligence, which can lead to improvements in society and the economy. These infographics address both tools for working with data and examples of the use of open data in these new technologies. New content will be published periodically.
Data Scientist's decalogue
 |
Published: octubre 2025 From understanding the problem before looking at the data, to visualizing to communicate and staying up to date, this decalogue offers a comprehensive overview of the life cycle of a responsible and well-structured data project. |
Open data visualization with open source tools
 |
Published: june 2025 This infographic compiles data visualisation tools, the last step of exploratory data analysis. It is the second part of the infographic on open data analysis with open source tools. |
Open data analysis with open source tools
 |
Published: March 2025 EDA is the application of a set of statistical techniques aimed at exploring, describing and summarising the nature of data in a way that ensures its objectivity and interoperability. In this infographic, we compile free tools to perform the first three steps of data analysis. |
New geospatial data capture techniques
 |
Published: January 2025 Geospatial data capture is essential for understanding the environment, making decisions and designing effective policies. In this infographic, we will explore new methods of data capture. |
Exploratory Data Analysis (EDA)
 |
Published: November 2024 Based on the report “Guía Práctica de Introducción al Análisis Exploratorio de Datos”, an infographic has been prepared that summarises in a simple way what this technique consists of, its benefits and the steps to follow in order to carry it out correctly. |
Glossary of terms related to new technologies and data
 |
Published: May 2024 This infographic focuses on terms related to new technologies related to data. |
Glossary of terms related to open data
 |
Published: April 2024 This infographic includes the definition of various terms related to open data. |
Synthetic Data (EDA)
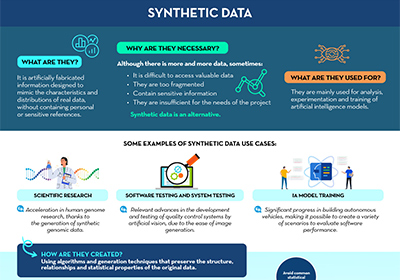 |
Published: October 2023 Based on the report ''Synthetic Data: What are they and what are they used for?'', an infographic has been prepared that summarizes in a simple way the main keys of synthetic data and how they overcome the limitations of real data. |
The role of open data in artificial intelligence
 |
Published: January 2023 This infographic details what artificial intelligence is and the role that open data plays within it. It also provides various examples of AI use cases. |
Emerging Technologies and Open Data: Predictive Analytics
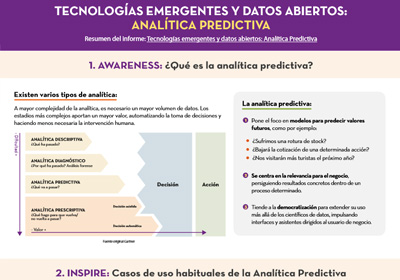 |
Published: April 2021 This infographic is a summary of the report "Emerging Technologies and Open Data: Predictive Analytics", from the "Awareness, Inspire, Action" series. It explains what predictive analytics is and its most common use cases. It also shows a practical example, using the dataset related to traffic accident in the city of Madrid. |
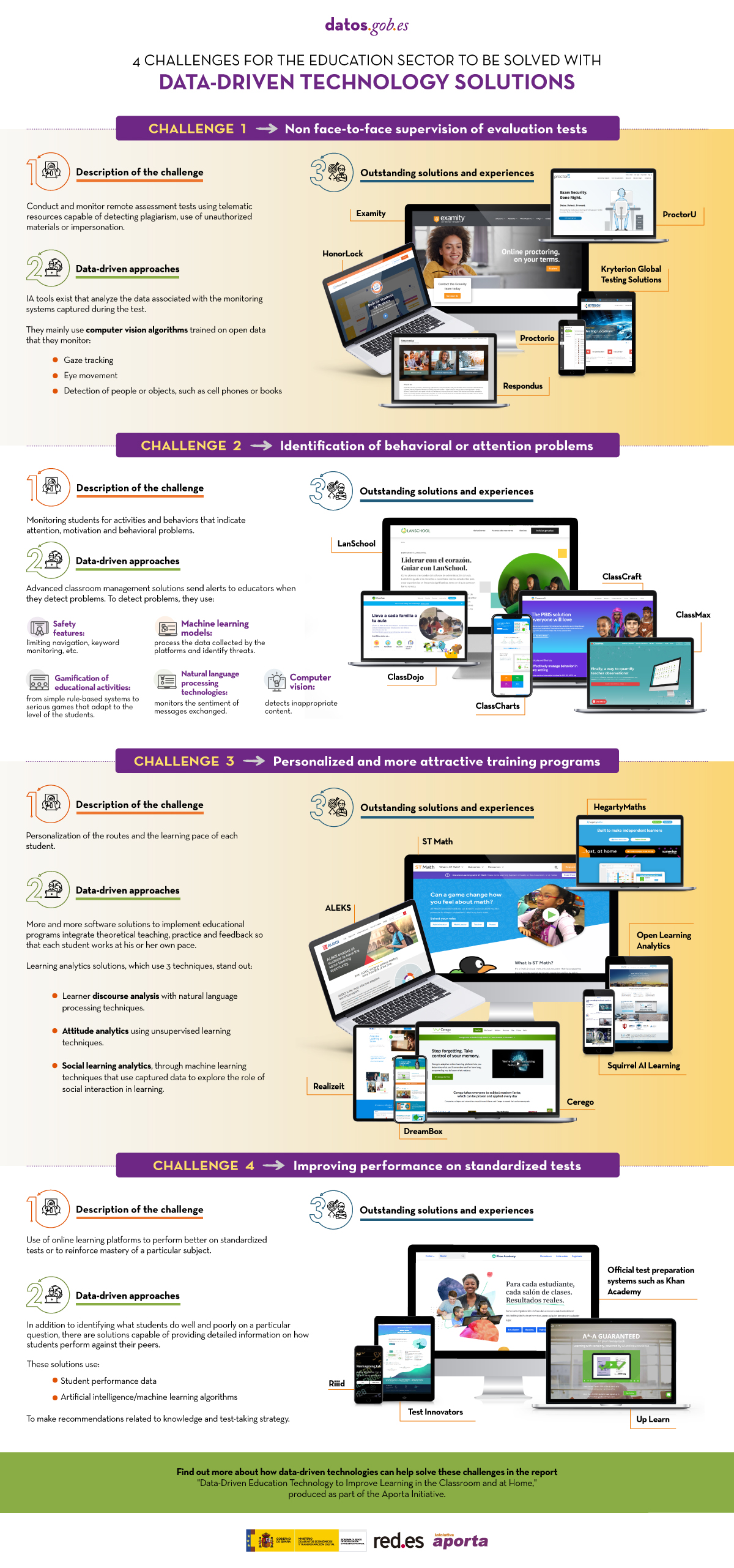
Data-driven education technology to improve learning in the classroom and at home
 |
Published: August 2020 Innovative educational technology based on data and artificial intelligence can address some of the challenges facing the education system, such as monitoring online assessment tests, identifying behavioral problems, personalized training or improving performance on standardized tests. This infographic, a summary of the report "Data-driven educational technology to improve learning in the classroom and at home", shows some examples. |
{kind=link}
Documentación
"Information and data are more valuable when they are shared and the opening of government data could allow [...] to examine and use public information in a more transparent, collaborative, efficient and productive way". This was, in general terms, the idea that revolutionized more than ten years ago a society for which the opening of government data was a totally unknown action. It is from this moment that different trends began to emerge that will mark the evolution of the open data movement around the world.
This report, written by Carlos Iglesias, analyzes the main trends in the still incipient history of global open data, paying special attention to open data within public administrations. To this end, this analysis reflects the main problems and opportunities that have arisen over the years, as well as the trends that will help to continue driving the movement forward:
For the preparation of this report, we have used as a reference the report "“The Emergence of a Third Wave of Open Data”, which analyses the new stage that is opening up in the world of open data, published by the Open Data Policy Lab. This analysis serves as a reference to present both the current trends and the most important challenges associated with open data.
The final part of this report presents some of the actions that will play a key role in strengthening and consolidating the future of open data over the next ten years. These actions have been adapted to the European Union environment, and specifically to Spain (including its regulatory framework).
Below, you can download the full report, as well as its executive summary and a summary presentation in power point format.
Documentación
1. Introduction
Data visualization is a task linked to data analysis that aims to graphically represent underlying data information. Visualizations play a fundamental role in the communication function that data possess, since they allow to drawn conclusions in a visual and understandable way, allowing also to detect patterns, trends, anomalous data or to project predictions, alongside with other functions. This makes its application transversal to any process in which data intervenes. The visualization possibilities are very numerous, from basic representations, such as a line graphs, graph bars or sectors, to complex visualizations configured from interactive dashboards.
Before we start to build an effective visualization, we must carry out a pre-treatment of the data, paying attention to how to obtain them and validating the content, ensuring that they do not contain errors and are in an adequate and consistent format for processing. Pre-processing of data is essential to start any data analysis task that results in effective visualizations.
A series of practical data visualization exercises based on open data available on the datos.gob.es portal or other similar catalogues will be presented periodically. They will address and describe, in a simple way; the stages necessary to obtain the data, perform the transformations and analysis that are relevant for the creation of interactive visualizations, from which we will be able summarize on in its final conclusions the maximum mount of information. In each of the exercises, simple code developments will be used (that will be adequately documented) as well as free and open use tools. All generated material will be available for reuse in the Data Lab repository on Github.
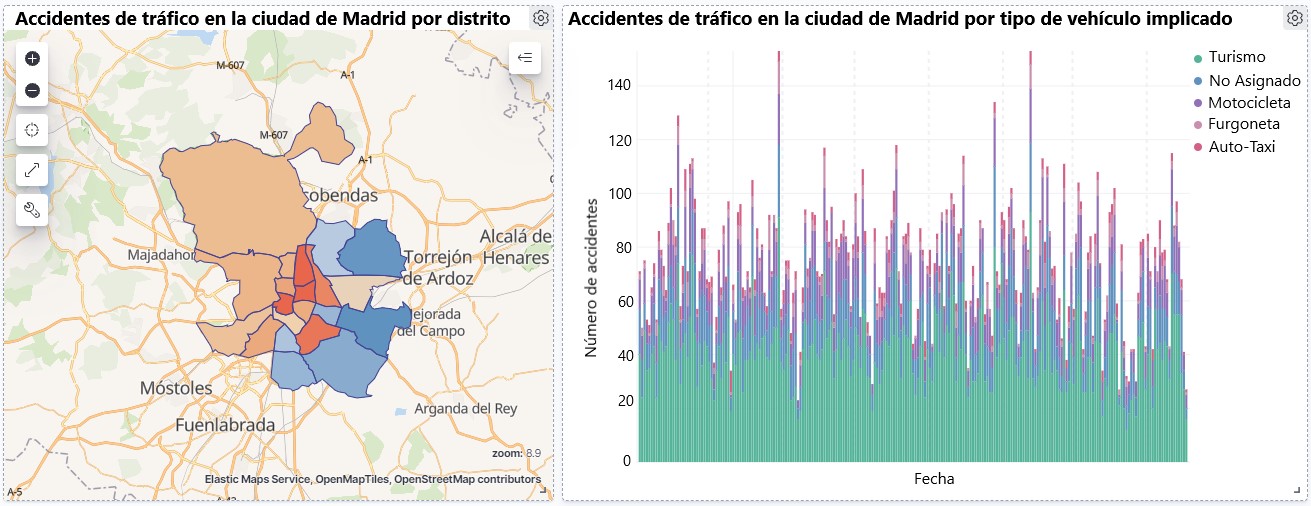
Visualization of traffic accidents occurring in the city of Madrid, by district and type of vehicle
2. Objetives
The main objective of this post is to learn how to make an interactive visualization based on open data available on this portal. For this exercise, we have chosen a dataset that covers a wide period and contains relevant information on the registration of traffic accidents that occur in the city of Madrid. From these data we will observe what is the most common type of accidents in Madrid and the incidence that some variables such as age, type of vehicle or the harm produced by the accident have on them.
3. Resources
3.1. Datasets
For this analysis, a dataset available in datos.gob.es on traffic accidents in the city of Madrid published by the City Council has been selected. This dataset contains a time series covering the period 2010 to 2021 with different subcategories that facilitate the analysis of the characteristics of traffic accidents that occurred. For example, the environmental conditions in which each accident occurred or the type of accident. Information on the structure of each data file is available in documents covering the period 2010-2018 and 2019 onwards. It should be noted that there are inconsistencies in the data before and after the year 2019, due to data structure variations. This is a common situation that data analysts must face when approaching the preprocessing tasks of the data that will be used, this is derived from the lack of a homogeneous structure of the data over time. For example, alterations on the number of variables, modification of the type of variables or changes to different measurement units. This is a compelling reason that justifies the need to accompany each open data set with complete documentation explaining its structure.
3.2. Tools
R (versión 4.0.3) and RStudio with the RMarkdown complement have been used to carry out the pre-treatment of the data (work environment setup, programming and writing).
R is an object-oriented and interpreted open-source programming language, initially created for statistical computing and the creation of graphical representations. Nowadays, it is a very powerful tool for all types of data processing and manipulation permanently updated. It contains a programming environment, RStudio, also open source.
The Kibana tool has been used for the creation of the interactive visualization.
Kibana is an open source tool that belongs to the Elastic Stack product suite (Elasticsearch, Beats, Logstash and Kibana) that enables visualization creation and exploration of indexed data on top of the Elasticsearch analytics engine.
If you want to know more about these tools or anyother that can help you in data processing and creating interactive visualizations, you can consult the report \"Data processing and visualization tools\".
4. Data processing
For the realization of the subsequent analysis and visualizations, it is necessary to prepare the data adequately, so that the results obtained are consistent and effective. We must perform an exploratory data analysis (EDA), in order to know and understand the data with which we want to work. The main objective of this data pre-processing is to detect possible anomalies or errors that could affect the quality of subsequent results and identify patterns of information contained in the data.
To facilitate the understanding of readers not specialized in programming, the R code included below, which you can access by clicking on the \"Code\" button in each section, is not designed to maximize its efficiency, but to facilitate its understanding, so it is possible that more advanced readers in this language might consider alternatives more efficient to encode some functionalities. The reader will be able to reproduce this analysis if desired, as the source code is available on datos.gob.es's Github account. In order to provide the code a plain text document will be used, which once loaded into the development environment can be easily executed or modified if desired.
4.1. Installation and loading of libraries
For the development of this analysis, we need to install a series of additional R packages to the base distribution, incorporating the functions and objects defined by them into the work environment. There are many packages available in R but the most suitable to work with this dataset are: tidyverse, lubridate and data.table.Tidyverse is a collection of R packages (it contains other packages such as dplyr, ggplot2, readr, etc.) specifically designed to work in Data Science, facilitating the loading and processing of data, and graphical representations and other essential functionalities for data analysis. It requires a progressive knowledge to get the most out of the packages that integrates. On the other hand, the lubridate package will be used for the management of date variables. Finally the data.table package allows a more efficient management of large data sets. These packages will need to be downloaded and installed in the development environment.
#Lista de librerías que queremos instalar y cargar en nuestro entorno de desarrollo librerias <- c(\"tidyverse\", \"lubridate\", \"data.table\")#Descargamos e instalamos las librerías en nuestros entorno de desarrollo package.check <- lapplay (librerias, FUN = function(x) { if (!require (x, character.only = TRUE)) { install.packages(x, dependencies = TRUE) library (x, character.only = TRUE } }4.2. Uploading and cleaning data
a. Loading datasets
The data that we are going to use in the visualization are divided by annuities in CSV files. As we want to perform an analysis of several years we must download and upload in our development environment all the datasets that interest us.
To do this, we generate the working directory \"datasets\", where we will download all the datasets. We use two lists, one with all the URLs where the datasets are located and another with the names that we assign to each file saved on our machine, with this we facilitate subsequent references to these files.
#Generamos una carpeta en nuestro directorio de trabajo para guardar los datasets descargadosif (dir.exists(\".datasets\") == FALSE)#Nos colocamos dentro de la carpetasetwd(\".datasets\")#Listado de los datasets que nos interese descargardatasets <- c(\"https://datos.madrid.es/egob/catalogo/300228-10-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-11-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-12-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-13-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-14-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-15-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-16-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-17-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-18-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-19-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-21-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-22-accidentes-trafico-detalle.csv\")#Descargamos los datasets de interésdt <- list()for (i in 1: length (datasets)){ files <- c(\"Accidentalidad2010\", \"Accidentalidad2011\", \"Accidentalidad2012\", \"Accidentalidad2013\", \"Accidentalidad2014\", \"Accidentalidad2015\", \"Accidentalidad2016\", \"Accidentalidad2017\", \"Accidentalidad2018\", \"Accidentalidad2019\", \"Accidentalidad2020\", \"Accidentalidad2021\") download.file(datasets[i], files[i]) filelist <- list.files(\".\") print(i) dt[i] <- lapply (filelist[i], read_delim, sep = \";\", escape_double = FALSE, locale = locale(encoding = \"WINDOWS-1252\", trim_ws = \"TRUE\") }b. Creating the worktable
Once we have all the datasets loaded into our development environment, we create a single worktable that integrates all the years of the time series.
Accidentalidad <- rbindlist(dt, use.names = TRUE, fill = TRUE)Once the worktable is generated, we must solve one of the most common problems in all data preprocessing: the inconsistency in the naming of the variables in the different files that make up the time series. This anomaly produces variables with different names, but we know that they represent the same information. In this case it is explained in the data dictionary described in the documentation of the files, if this was not the case, it is necessary to resort to the observation and descriptive exploration of the files. In this case, the variable \"\"RANGO EDAD\"\" that presents data from 2010 to 2018 and the variable \"\"RANGO EDAD\"\" that presents the same data but from 2019 to 2021 are different. To solve this problem, we must unite/merge the variables that present this anomaly in a single variable.
#Con la función unite() unimos ambas variables. Debemos indicarle el nombre de la tabla, el nombre que queremos asignarle a la variable y la posición de las variables que queremos unificar. Accidentalidad <- unite(Accidentalidad, LESIVIDAD, c(25, 44), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, NUMERO_VICTIMAS, c(20, 27), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, RANGO_EDAD, c(26, 35, 42), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, TIPO_VEHICULO, c(20, 27), remove = TRUE, na.rm = TRUE)Once we have the table with the complete time series, we create a new table counting only the variables that are relevant to us to make the interactive visualization that we want to develop.
Accidentalidad <- Accidentalidad %>% select (c(\"FECHA\", \"DISTRITO\", \"LUGAR ACCIDENTE\", \"TIPO_VEHICULO\", \"TIPO_PERSONA\", \"TIPO ACCIDENTE\", \"SEXO\", \"LESIVIDAD\", \"RANGO_EDAD\", \"NUMERO_VICTIMAS\") c. Variable transformation
Next, we examine the type of variables and values to transform the necessary variables to be able to perform future aggregations, graphs or different statistical analyses.
#Re-ajustar la variable tipo fechaAccidentalidad$FECHA <- dmy (Accidentalidad$FECHA #Re-ajustar el resto de variables a tipo factor Accidentalidad$'TIPO ACCIDENTE' <- as.factor(Accidentalidad$'TIPO.ACCIDENTE')Accidentalidad$'Tipo Vehiculo' <- as.factor(Accidentalidad$'Tipo Vehiculo')Accidentalidad$'TIPO PERSONA' <- as.factor(Accidentalidad$'TIPO PERSONA')Accidentalidad$'Tramo Edad' <- as.factor(Accidentalidad$'Tramo Edad')Accidentalidad$SEXO <- as.factor(Accidentalidad$SEXO)Accidentalidad$LESIVIDAD <- as.factor(Accidentalidad$LESIVIDAD)Accidentalidad$DISTRITO <- as.factor (Accidentalidad$DISTRITO)d. Creation of new variables
Let's divide the variable \"\"FECHA\"\" into a hierarchy of variables of date types, \"\"Año\", \"\"Mes\"\" and \"\"Día\"\". This action is very common in data analytics, since it is interesting to analyze other time ranges, for example; years, months, weeks (and any other unit of time), or we need to generate aggregations from the day of the week.
#Generación de la variable AñoAccidentalidad$Año <- year(Accidentalidad$FECHA)Accidentalidad$Año <- as.factor(Accidentalidad$Año) #Generación de la variable MesAccidentalidad$Mes <- month(Accidentalidad$FECHA)Accidentalidad$Mes <- as.factor(Accidentalidad$Mes)levels (Accidentalidad$Mes) <- c(\"Enero\", \"Febrero\", \"Marzo\", \"Abril\", \"Mayo\", \"Junio\", \"Julio\", \"Agosto\", \"Septiembre\", \"Octubre\", \"Noviembre\", \"Diciembre\") #Generación de la variable DiaAccidentalidad$Dia <- month(Accidentalidad$FECHA)Accidentalidad$Dia <- as.factor(Accidentalidad$Dia)levels(Accidentalidad$Dia)<- c(\"Domingo\", \"Lunes\", \"Martes\", \"Miercoles\", \"Jueves\", \"Viernes\", \"Sabado\")e. Detection and processing of lost data
The detection and processing of lost data (NAs) is an essential task in order to be able to process the variables contained in the table, since the lack of data can cause problems when performing aggregations, graphs or statistical analysis.
Next, we will analyze the absence of data (detection of NAs) in the table:
#Suma de todos los NAs que presenta el datasetsum(is.na(Accidentalidad))#Porcentaje de NAs en cada una de las variablescolMeans(is.na(Accidentalidad))Once the NAs presented by the dataset have been detected, we must treat them somehow. In this case, as all the interesting variables are categorical, we will complete the missing values with the new value \"Unassigned\", this way we do not lose sample size and relevant information.
#Sustituimos los NAs de la tabla por el valor \"No asignado\"Accidentalidad [is.na(Accidentalidad)] <- \"No asignado\"f. Level assignments in variables
Once we have the variables of interest in the table, we can perform a more exhaustive analysis of the data and categories presented by each of the variables. If we analyze each one independently, we can see that some of them have repeated categories, simply by use of accents, special characters or capital letters. We will reassign the levels to the variables that require so that future visualizations or statistical analysis are built efficiently and without errors.
For space reasons, in this post we will only show an example with the variable \"HARMFULNESS\". This variable was typified until 2018 with a series of categories (IL, HL, HG, MT), while from 2019 other categories were used (values from 0 to 14). Fortunately, this task is easily approachable since it is documented in the information about the structure that accompanies each dataset. This issue (as we have said before), that does not always happen, greatly hinders this type of data transformations.
#Comprobamos las categorías que presenta la variable \"LESIVIDAD\"levels(Accidentalidad$LESIVIDAD)#Asignamos las nuevas categoríaslevels(Accidentalidad$LESIVIDAD)<- c(\"Sin asistencia sanitaria\", \"Herido leve\", \"Herido leve\", \"Herido grave\", \"Fallecido\", \"Herido leve\", \"Herido leve\", \"Herido leve\", \"Ileso\", \"Herido grave\", \"Herido leve\", \"Ileso\", \"Fallecido\", \"No asignado\")#Comprobamos de nuevo las catergorías que presenta la variablelevels(Accidentalidad$LESIVIDAD)4.3. Dataset Summary
Let's see what variables and structure the new dataset presents after the transformations made:
str(Accidentalidad)summary(Accidentalidad)The output of these commands will be omitted for reading simplicity. The main characteristics of the dataset are:
- It is composed of 14 variables: 1 date variable and 13 categorical variables.
- The time range covers from 01-01-2010 to 31-06-2021 (the end date may vary, since the dataset of the year 2021 is being updated periodically).
- For space reasons in this post, not all available variables have been considered for analysis and visualization.
4.4. Save the generated dataset
Once we have the dataset with the structure and variables ready for us to perform the visualization of the data, we will save it as a data file in CSV format to later perform other statistical analysis. Or use it in other data processing or visualization tools such as the one we address below. It is important to save it with a UTF-8 (Unicode Transformation Format) encoding so that special characters are correctly identified by any software.
write.csv(Accidentalidad, file = Accidentalidad.csv\", fileEncoding=\"UTF-8\")5. Creation of the visualization on traffic accidents that occur in the city of Madrid using Kibana
To create this interactive visualization the Kibana tool (in its free version) has been used on our local environment. Before being able to perform the visualization it is necessary to have the software installed since we have followed the steps of the download and installation tutorial provided by the company Elastic.
Once the Kibana software is installed, we proceed to develop the interactive visualization. Below there are two video tutorials, which show the process of creating the visualization and interacting with it.
This first video tutorial shows the visualization development process by performing the following steps:
- Loading data into Elasticsearch, generating an index in Kibana that allows us to interact with the data practically in real time and interaction with the variables presented by the dataset.
- Generation of the following graphical representations:
- Line graph to represent the time series on traffic accidents that occurred in the city of Madrid.
- Horizontal bar chart showing the most common accident type
- Thematic map, we will show the number of accidents that occur in each of the districts of the city of Madrid. For the creation of this visual it is necessary to download the \"dataset containing the georeferenced districts in GeoJSON format\".
- Construction of the dashboard integrating the visuals generated in the previous step.
In this second video tutorial we will show the interaction with the visualization that we have just created:
6. Conclusions
Observing the visualization of the data on traffic accidents that occurred in the city of Madrid from 2010 to June 2021, the following conclusions can be drawn:
- The number of accidents that occur in the city of Madrid is stable over the years, except for 2019 where a strong increase is observed and during the second quarter of 2020 where a significant decrease is observed, which coincides with the period of the first state of alarm due to the COVID-19 pandemic.
- Every year there is a decrease in the number of accidents during the month of August.
- Men tend to have a significantly higher number of accidents than women.
- The most common type of accident is the double collision, followed by the collision of an animal and the multiple collision.
- About 50% of accidents do not cause harm to the people involved.
- The districts with the highest concentration of accidents are: the district of Salamanca, the district of Chamartín and the Centro district.
Data visualization is one of the most powerful mechanisms for autonomously exploiting and analyzing the implicit meaning of data, regardless of the degree of the user's technological knowledge. Visualizations allow us to build meaning on top of data and create narratives based on graphical representation.
If you want to learn how to make a prediction about the future accident rate of traffic accidents using Artificial Intelligence techniques from this data, consult the post on \"Emerging technologies and open data: Predictive Analytics\".
We hope you liked this post and we will return to show you new data reuses. See you soon!
Documentación
1. Introduction
Data visualization is a task linked to data analysis that aims to graphically represent underlying data information. Visualizations play a fundamental role in the communication function that data possess, since they allow to drawn conclusions in a visual and understandable way, allowing also to detect patterns, trends, anomalous data or to project predictions, alongside with other functions. This makes its application transversal to any process in which data intervenes. The visualization possibilities are very numerous, from basic representations, such as a line graphs, graph bars or sectors, to complex visualizations configured from interactive dashboards.
Before we start to build an effective visualization, we must carry out a pre-treatment of the data, paying attention to how to obtain them and validating the content, ensuring that they do not contain errors and are in an adequate and consistent format for processing. Pre-processing of data is essential to start any data analysis task that results in effective visualizations.
A series of practical data visualization exercises based on open data available on the datos.gob.es portal or other similar catalogues will be presented periodically. They will address and describe, in a simple way; the stages necessary to obtain the data, perform the transformations and analysis that are relevant for the creation of interactive visualizations, from which we will be able summarize on in its final conclusions the maximum mount of information. In each of the exercises, simple code developments will be used (that will be adequately documented) as well as free and open use tools. All generated material will be available for reuse in the Data Lab repository on Github.
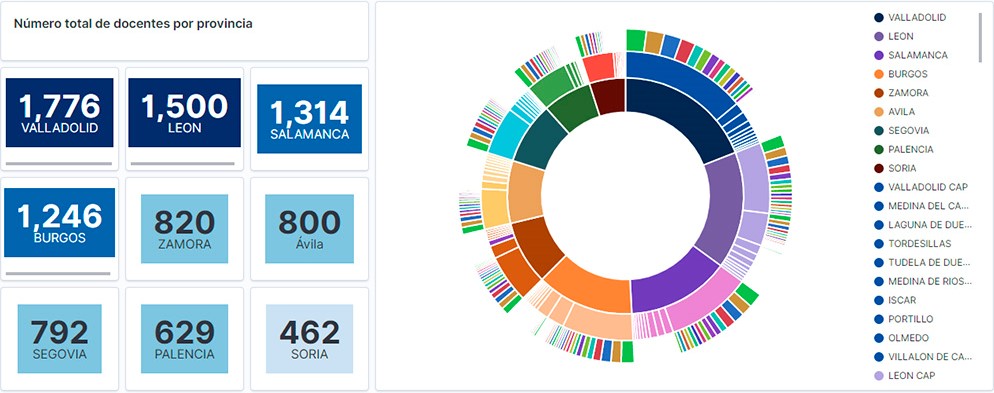
Visualization of the teaching staff of Castilla y León classified by Province, Locality and Teaching Specialty
2. Objetives
The main objective of this post is to learn how to treat a dataset from its download to the creation of one or more interactive graphs. For this, datasets containing relevant information on teachers and students enrolled in public schools in Castilla y León during the 2019-2020 academic year have been used. Based on these data, analyses of several indicators that relate teachers, specialties and students enrolled in the centers of each province or locality of the autonomous community.
3. Resources
3.1. Datasets
For this study, datasets on Education published by the Junta de Castilla y León have been selected, available on the open data portal datos.gob.es. Specifically:
- Dataset of the legal figures of the public centers of Castilla y León of all the teaching positions, except for the schoolteachers, during the academic year 2019-2020. This dataset is disaggregated by specialty of the teacher, educational center, town and province.
- Dataset of student enrolments in schools during the 2019-2020 academic year. This dataset is obtained through a query that supports different configuration parameters. Instructions for doing this are available at the dataset download point. The dataset is disaggregated by educational center, town and province.
3.2. Tools
To carry out this analysis (work environment set up, programming and writing) Python (versión 3.7) programming language and JupyterLab (versión 2.2) have been used. This tools will be found integrated in Anaconda, one of the most popular platforms to install, update or manage software to work with Data Science. All these tools are open and available for free.
JupyterLab is a web-based user interface that provides an interactive development environment where the user can work with so-called Jupyter notebooks on which you can easily integrate and share text, source code and data.
To create the interactive visualization, the Kibana tool (versión 7.10) has been used.
Kibana is an open source application that is part of the Elastic Stack product suite (Elasticsearch, Logstash, Beats and Kibana) that provides visualization and exploration capabilities of indexed data on top of the Elasticsearch analytics engine..
If you want to know more about these tools or others that can help you in the treatment and visualization of data, you can see the recently updated \"Data Processing and Visualization Tools\" report.
4. Data processing
As a first step of the process, it is necessary to perform an exploratory data analysis (EDA) to properly interpret the starting data, detect anomalies, missing data or errors that could affect the quality of subsequent processes and results. Pre-processing of data is essential to ensure that analyses or visualizations subsequently created from it are consistent and reliable.
Due to the informative nature of this post and to favor the understanding of non-specialized readers, the code does not intend to be the most efficient, but to facilitate its understanding. So you will probably come up with many ways to optimize the proposed code to get similar results. We encourage you to do so! You will be able to reproduce this analysis since the source code is available in our Github account. The way to provide the code is through a document made on JupyterLab that once loaded into the development environment you can execute or modify easily.
4.1. Installation and loading of libraries
The first thing we must do is import the libraries for the pre-processing of the data. There are many libraries available in Python but one of the most popular and suitable for working with these datasets is Pandas. The Pandas library is a very popular library for manipulating and analyzing datasets.
import pandas as pd 4.2. Loading datasets
First, we download the datasets from the open data catalog datos.gob.es and upload them into our development environment as tables to explore them and perform some basic data cleaning and processing tasks. For the loading of the data we will resort to the function read_csv(), where we will indicate the download url of the dataset, the delimiter (\"\";\"\" in this case) and, we add the parameter \"encoding\"\" that we adjust to the value \"\"latin-1\"\", so that it correctly interprets the special characters such as the letters with accents or \"\"ñ\"\" present in the text strings of the dataset.
#Cargamos el dataset de las plantillas jurídicas de los centros públicos de Castilla y León de todos los cuerpos de profesorado, a excepción de los maestros url = \"https://datosabiertos.jcyl.es/web/jcyl/risp/es/educacion/plantillas-centros-educativos/1284922684978.csv\"docentes = pd.read_csv(url, delimiter=\";\", header=0, encoding=\"latin-1\")docentes.head(3)#Cargamos el dataset de los alumnos matriculados en los centros educativos públicos de Castilla y León alumnos = pd.read_csv(\"matriculaciones.csv\", delimiter=\",\", names=[\"Municipio\", \"Matriculaciones\"], encoding=\"latin-1\") alumnos.head(3)The column \"\"Localidad\"\" of the table \"\"alumnos\"\" is composed of the code of the municipality and the name of the same. We must divide this column in two, so that its treatment is more efficient.
columnas_Municipios = alumnos[\"Municipio\"].str.split(\" \", n=1, expand = TRUE)alumnos[\"Codigo_Municipio\"] = columnas_Municipios[0]alumnos[\"Nombre_Munipicio\"] = columnas_Munipicio[1]alumnos.head(3)4.3. Creating a new table
Once we have both tables with the variables of interest, we create a new table resulting from their union. The union variables will be: \"\"Localidad\"\" in the table of \"\"docentes\"\" and \"\"Nombre_Municipio” in the table of \"\"alumnos\".
docentes_alumnos = pd.merge(docentes, alumnos, left_on = \"Localidad\", right_on = \"Nombre_Municipio\")docentes_alumnos.head(3)4.4. Exploring the dataset
Once we have the table that interests us, we must spend some time exploring the data and interpreting each variable. In these cases, it is very useful to have the data dictionary that always accompanies each downloaded dataset to know all its details, but this time we do not have this essential tool. Observing the table, in addition to interpreting the variables that make it up (data types, units, ranges of values), we can detect possible errors such as mistyped variables or the presence of missing values (NAs) that can reduce analysis capacity.
docentes_alumnos.info()In the output of this section of code, we can see the main characteristics of the table:
- Contains a total of 4,512 records
- It is composed of 13 variables, 5 numerical variables (integer type) and 8 categorical variables (\"object\" type)
- There is no missing of values.
Once we know the structure and content of the table, we must rectify errors, as is the case of the transformation of some of the variables that are not properly typified, for example, the variable that houses the center code (\"Código.centro\").
docentes_alumnos.Codigo_centro = data.Codigo_centro.astype(\"object\")docentes_alumnos.Codigo_cuerpo = data.Codigo_cuerpo.astype(\"object\")docentes_alumnos.Codigo_especialidad = data.Codigo_especialidad.astype(\"object\")Once we have the table free of errors, we obtain a description of the numerical variables, \"\"Plantilla\" and \"\"Matriculaciones\", which will help us to know important details. In the output of the code that we present below we observe the mean, the standard deviation, the maximum and minimum number, among other statistical descriptors.
docentes_alumnos.describe()4.5. Save the dataset
Once we have the table free of errors and with the variables that we are interested in graphing, we will save it in a folder of our choice to use it later in other analysis or visualization tools. We will save it in CSV format encoded as UTF-8 (Unicode Transformation Format) so that special characters are correctly identified by any tool we might use later.
df = pd.DataFrame(docentes_alumnos)filname = \"docentes_alumnos.csv\"df.to_csv(filename, index = FALSE, encoding = \"utf-8\")5. Creation of the visualization on the teachers of the public educational centers of Castilla y León using the Kibana tool
For the realization of this visualization, we have used the Kibana tool in our local environment. To do this it is necessary to have Elasticsearch and Kibana installed and running. The company Elastic makes all the information about the download and installation available in this tutorial.
Attached below are two video tutorials, which shows the process of creating the visualization and the interaction with the generated dashboard.
In this first video, you can see the creation of the dashboard by generating different graphic representations, following these steps:
- We load the table of previously processed data into Elasticsearch and generate an index that allows us to interact with the data from Kibana. This index allows search and management of data, practically in real time.
- Generation of the following graphical representations:
- Graph of sectors where to show the teaching staff by province, locality and specialty.
- Metrics of the number of teachers by province.
- Bar chart, where we will show the number of registrations by province.
- Filter by province, locality and teaching specialty.
- Construction of the dashboard.
In this second video, you will be able to observe the interaction with the dashboard generated previously.
6. Conclusions
Observing the visualization of the data on the number of teachers in public schools in Castilla y León, in the academic year 2019-2020, the following conclusions can be obtained, among others:
- The province of Valladolid is the one with both the largest number of teachers and the largest number of students enrolled. While Soria is the province with the lowest number of teachers and the lowest number of students enrolled.
- As expected, the localities with the highest number of teachers are the provincial capitals.
- In all provinces, the specialty with the highest number of students is English, followed by Spanish Language and Literature and Mathematics.
- It is striking that the province of Zamora, although it has a low number of enrolled students, is in fifth position in the number of teachers.
This simple visualization has helped us to synthesize a large amount of information and to obtain a series of conclusions at a glance, and if necessary, make decisions based on the results obtained. We hope you have found this new post useful and we will return to show you new reuses of open data. See you soon!
Documentación
1. Introduction
Data visualization is a task linked to data analysis that aims to represent graphically the underlying information. Visualizations play a fundamental role in data communication, since they allow to draw conclusions in a visual and understandable way, also allowing detection of patterns, trends, anomalous data or projection of predictions, among many other functions. This makes its application transversal to any process that involves data. The visualization possibilities are very broad, from basic representations such as line, bar or sector graph, to complex visualizations configured on interactive dashboards.
Before starting to build an effective visualization, a prior data treatment must be performed, paying attention to their collection and validation of their content, ensuring that they are free of errors and in an adequate and consistent format for processing. The previous data treatment is essential to carry out any task related to data analysis and realization of effective visualizations.
We will periodically present a series of practical exercises on open data visualizations that are available on the portal datos.gob.es and in other similar catalogues. In there, we approach and describe in a simple way the necessary steps to obtain data, perform transformations and analysis that are relevant to creation of interactive visualizations from which we may extract all the possible information summarised in final conclusions. In each of these practical exercises we will use simple code developments which will be conveniently documented, relying on free tools. Created material will be available to reuse in Data Lab on Github.
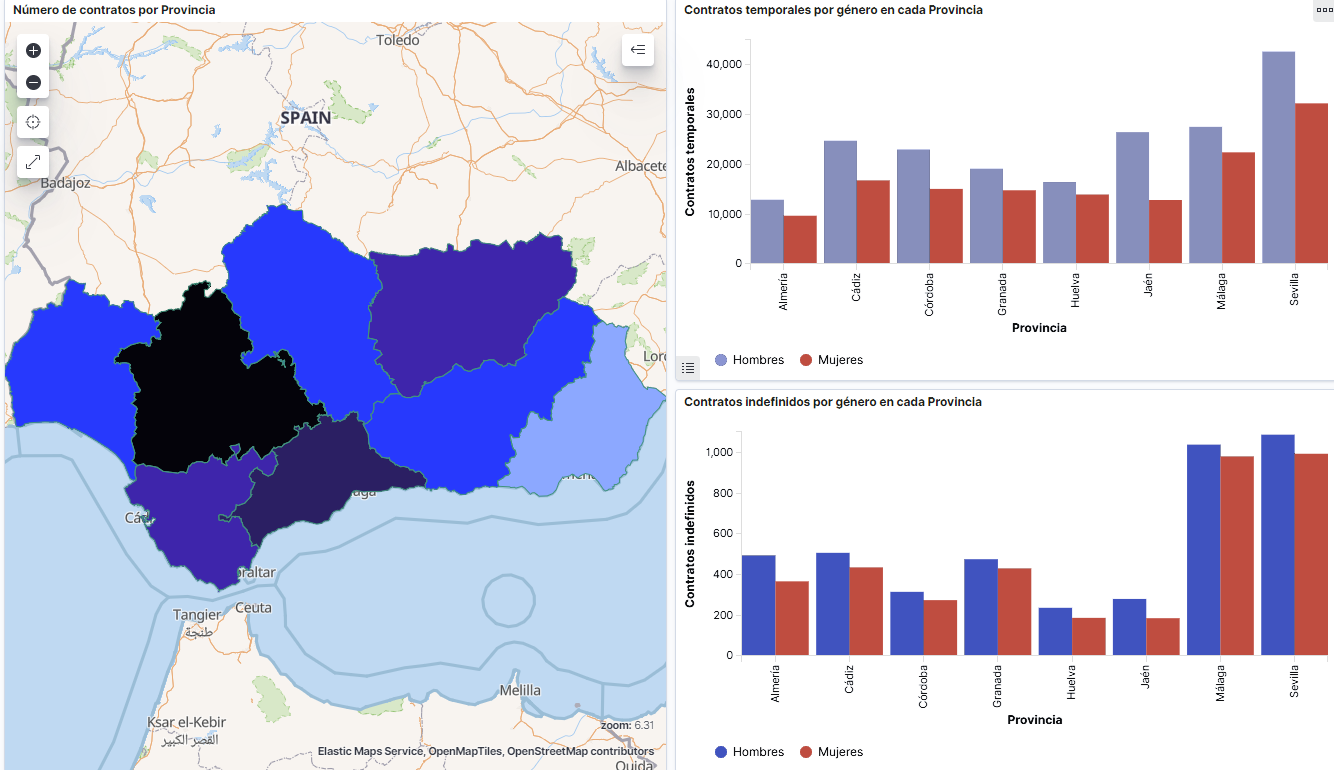
Captura del vídeo que muestra la interacción con el dashboard de la caracterización de la demanda de empleo y la contratación registrada en España disponible al final de este artículo
2. Objetives
The main objective of this post is to create an interactive visualization using open data. For this purpose, we have used datasets containing relevant information on evolution of employment demand in Spain over the last years. Based on these data, we have determined a profile that represents employment demand in our country, specifically investigating how does gender gap affects a group and impact of variables such as age, unemployment benefits or region.
3. Resources
3.1. Datasets
For this analysis we have selected datasets published by the Public State Employment Service (SEPE), coordinated by the Ministry of Labour and Social Economy, which collects time series data with distinct breakdowns that facilitate the analysis of the qualities of job seekers. These data are available on datos.gob.es, with the following characteristics:
- Demandantes de empleo por municipio: contains the number of job seekers broken down by municipality, age and gender, between the years 2006-2020.
- Gasto de prestaciones por desempleo por Provincia: time series between the years 2010-2020 related to unemployment benefits expenditure, broken down by province and type of benefit.
- Contratos registrados por el Servicio Público de Empleo Estatal (SEPE) por municipio: these datasets contain the number of registered contracts to both, job seekers and non-job seekers, broken down by municipality, gender and contract type, between the years 2006-2020.
3.2. Tools.
R (versión 4.0.3) and RStudio with RMarkdown add-on have been used to carry out this analysis (working environment, programming and drafting).
RStudio is an integrated open source development environment for R programming language, dedicated to statistical analysis and graphs creation.
RMarkdown allows creation of reports integrating text, code and dynamic results into a single document.
To create interactive graphs, we have used Kibana tool.
Kibana is an open code application that forms a part of Elastic Stack (Elasticsearch, Beats, Logstasg y Kibana) qwhich provides visualization and exploration capacities of the data indexed on the analytics engine Elasticsearch. The main advantages of this tool are:
- Presents visual information through interactive and customisable dashboards using time intervals, filters faceted by range, geospatial coverage, among others
- Contains development tools catalogue (Dev Tools) to interact with data stored in Elasticsearch.
- It has a free version ready to use on your own computer and enterprise version that is developed in the Elastic cloud and other cloud infrastructures, such as Amazon Web Service (AWS).
On Elastic website you may find user manuals for the download and installation of the tool, but also how to create graphs, dashboards, etc. Furthermore, it offers short videos on the youtube channel and organizes webinars dedicated to explanation of diverse aspects related to Elastic Stack.
If you want to learn more about these and other tools which may help you with data processing, see the report “Data processing and visualization tools” that has been recently updated.
4. Data processing
To create a visualization, it´s necessary to prepare the data properly by performing a series of tasks that include pre-processing and exploratory data analysis (EDA), to understand better the data that we are dealing with. The objective is to identify data characteristics and detect possible anomalies or errors that could affect the quality of results. Data pre-processing is essential to ensure the consistency and effectiveness of analysis or visualizations that are created afterwards.
In order to support learning of readers who are not specialised in programming, the R code included below, which can be accessed by clicking on “Code” button, is not designed to be efficient but rather to be easy to understand. Therefore, it´s probable that the readers more advanced in this programming language may consider to code some of the functionalities in an alternative way. A reader will be able to reproduce this analysis if desired, as the source code is available on the datos.gob.es Github account. The way to provide the code is through a RMarkdown document. Once it´s loaded to the development environment, it may be easily run or modified.
4.1. Installation and import of libraries
R base package, which is always available when RStudio console is open, includes a wide set of functionalities to import data from external sources, carry out statistical analysis and obtain graphic representations. However, there are many tasks for which it´s required to resort to additional packages, incorporating functions and objects defined in them into the working environment. Some of them are already available in the system, but others should be downloaded and installed.
#Instalación de paquetes \r\n #El paquete dplyr presenta una colección de funciones para realizar de manera sencilla operaciones de manipulación de datos \r\n if (!requireNamespace(\"dplyr\", quietly = TRUE)) {install.packages(\"dplyr\")}\r\n #El paquete lubridate para el manejo de variables tipo fecha \r\n if (!requireNamespace(\"lubridate\", quietly = TRUE)) {install.packages(\"lubridate\")}\r\n#Carga de paquetes en el entorno de desarrollo \r\nlibrary (dplyr)\r\nlibrary (lubridate)\r\n4.2. Data import and cleansing
a. Import of datasets
Data which will be used for visualization are divided by annualities in the .CSV and .XLS files. All the files of interest should be imported to the development environment. To make this post easier to understand, the following code shows the upload of a single .CSV file into a data table.
To speed up the loading process in the development environment, it´s necessary to download the datasets required for this visualization to the working directory. The datasets are available on the datos.gob.es Github account.
#Carga del datasets de demandantes de empleo por municipio de 2020. \r\n Demandantes_empleo_2020 <- \r\n read.csv(\"Conjuntos de datos/Demandantes de empleo por Municipio/Dtes_empleo_por_municipios_2020_csv.csv\",\r\n sep=\";\", skip = 1, header = T)\r\nOnce all the datasets are uploaded as data tables in the development environment, they need to be merged in order to obtain a single dataset that includes all the years of the time series, for each of the characteristics related to job seekers that will be analysed: number of job seekers, unemployment expenditure and new contracts registered by SEPE.
#Dataset de demandantes de empleo\r\nDatos_desempleo <- rbind(Demandantes_empleo_2006, Demandantes_empleo_2007, Demandantes_empleo_2008, Demandantes_empleo_2009, \r\n Demandantes_empleo_2010, Demandantes_empleo_2011,Demandantes_empleo_2012, Demandantes_empleo_2013,\r\n Demandantes_empleo_2014, Demandantes_empleo_2015, Demandantes_empleo_2016, Demandantes_empleo_2017, \r\n Demandantes_empleo_2018, Demandantes_empleo_2019, Demandantes_empleo_2020) \r\n#Dataset de gasto en prestaciones por desempleo\r\ngasto_desempleo <- rbind(gasto_2010, gasto_2011, gasto_2012, gasto_2013, gasto_2014, gasto_2015, gasto_2016, gasto_2017, gasto_2018, gasto_2019, gasto_2020)\r\n#Dataset de nuevos contratos a demandantes de empleo\r\nContratos <- rbind(Contratos_2006, Contratos_2007, Contratos_2008, Contratos_2009,Contratos_2010, Contratos_2011, Contratos_2012, Contratos_2013, \r\n Contratos_2014, Contratos_2015, Contratos_2016, Contratos_2017, Contratos_2018, Contratos_2019, Contratos_2020)b. Selection of variables
Once the tables with three time series are obtained (number of job seekers, unemployment expenditure and new registered contracts), the variables of interest will be extracted and included in a new table.
First, the tables with job seekers (“unemployment_data”) and new registered contracts (“contracts”) should be added by province, to facilitate the visualization. They should match the breakdown by province of the unemployment benefits expenditure table (“unemployment_expentidure”). In this step, only the variables of interest will be selected from the three datasets.
#Realizamos un group by al dataset de \"datos_desempleo\", agruparemos las variables numéricas que nos interesen, en función de varias variables categóricas\r\nDtes_empleo_provincia <- Datos_desempleo %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(total.Dtes.Empleo = (sum(total.Dtes.Empleo)), Dtes.hombre.25 = (sum(Dtes.Empleo.hombre.edad...25)), \r\n Dtes.hombre.25.45 = (sum(Dtes.Empleo.hombre.edad.25..45)), Dtes.hombre.45 = (sum(Dtes.Empleo.hombre.edad...45)),\r\n Dtes.mujer.25 = (sum(Dtes.Empleo.mujer.edad...25)), Dtes.mujer.25.45 = (sum(Dtes.Empleo.mujer.edad.25..45)),\r\n Dtes.mujer.45 = (sum(Dtes.Empleo.mujer.edad...45)))\r\n#Realizamos un group by al dataset de \"contratos\", agruparemos las variables numericas que nos interesen en función de las varibles categóricas.\r\nContratos_provincia <- Contratos %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(Total.Contratos = (sum(Total.Contratos)),\r\n Contratos.iniciales.indefinidos.hombres = (sum(Contratos.iniciales.indefinidos.hombres)), \r\n Contratos.iniciales.temporales.hombres = (sum(Contratos.iniciales.temporales.hombres)), \r\n Contratos.iniciales.indefinidos.mujeres = (sum(Contratos.iniciales.indefinidos.mujeres)), \r\n Contratos.iniciales.temporales.mujeres = (sum(Contratos.iniciales.temporales.mujeres)))\r\n#Seleccionamos las variables que nos interesen del dataset de \"gasto_desempleo\"\r\ngasto_desempleo_nuevo <- gasto_desempleo %>% select(Código.mes, Comunidad.Autónoma, Provincia, Gasto.Total.Prestación, Gasto.Prestación.Contributiva)Secondly, the three tables should be merged into one that we will work with from this point onwards..
Caract_Dtes_empleo <- Reduce(merge, list(Dtes_empleo_provincia, gasto_desempleo_nuevo, Contratos_provincia))
c. Transformation of variables
When the table with variables of interest is created for further analysis and visualization, some of them should be transformed to other types, more adequate for future aggregations.
#Transformación de una variable fecha\r\nCaract_Dtes_empleo$Código.mes <- as.factor(Caract_Dtes_empleo$Código.mes)\r\nCaract_Dtes_empleo$Código.mes <- parse_date_time(Caract_Dtes_empleo$Código.mes(c(\"200601\", \"ym\")), truncated = 3)\r\n#Transformamos a variable numérica\r\nCaract_Dtes_empleo$Gasto.Total.Prestación <- as.numeric(Caract_Dtes_empleo$Gasto.Total.Prestación)\r\nCaract_Dtes_empleo$Gasto.Prestación.Contributiva <- as.numeric(Caract_Dtes_empleo$Gasto.Prestación.Contributiva)\r\n#Transformación a variable factor\r\nCaract_Dtes_empleo$Provincia <- as.factor(Caract_Dtes_empleo$Provincia)\r\nCaract_Dtes_empleo$Comunidad.Autónoma <- as.factor(Caract_Dtes_empleo$Comunidad.Autónoma)d. Exploratory analysis
Let´s see what variables and structure the new dataset presents.
str(Caract_Dtes_empleo)\r\nsummary(Caract_Dtes_empleo)The output of this portion of the code is omitted to facilitate reading. Main characteristics presented in the dataset are as follows:
- Time range covers a period from January to December 2020.
- Number of columns (variables) is 17. .
- It presents two categorical variables (“Province”, “Autonomous.Community”), one date variable (“Code.month”) and the rest are numerical variables.
e. Detection and processing of missing data
Next, we will analyse whether the dataset has missing values (NAs). A treatment or elimination of NAs is essential, otherwise it will not be possible to process properly the numerical variables.
any(is.na(Caract_Dtes_empleo)) \r\n#Como el resultado es \"TRUE\", eliminamos los datos perdidos del dataset, ya que no sabemos cual es la razón por la cual no se encuentran esos datos\r\nCaract_Dtes_empleo <- na.omit(Caract_Dtes_empleo)\r\nany(is.na(Caract_Dtes_empleo))4.3. Creation of new variables
In order to create a visualization, we are going to make a new variable from the two variables present in the data table. This operation is very common in the data analysis, as sometimes it´s interesting to work with calculated data (e.g., the sum or the average of different variables) instead of source data. In this case, we will calculate the average unemployment expenditure for each job seeker. For this purpose, variables of total expenditure per benefit (“Expenditure.Total.Benefit”) and the total number of job seekers (“total.JobSeekers.Employment”) will be used.
Caract_Dtes_empleo$gasto_desempleado <-\r\n (1000 * (Caract_Dtes_empleo$Gasto.Total.Prestación/\r\n Caract_Dtes_empleo$total.Dtes.Empleo))4.4. Save the dataset
Once the table containing variables of interest for analysis and visualizations is obtained, we will save it as a data file in CSV format to perform later other statistical analysis or use it within other processing or data visualization tools. It´s important to use the UTF-8 encoding (Unicode Transformation Format), so the special characters may be identified correctly by any other tool.
write.csv(Caract_Dtes_empleo,\r\n file=\"Caract_Dtes_empleo_UTF8.csv\",\r\n fileEncoding= \"UTF-8\")5. Creation of a visualization on the characteristics of employment demand in Spain using Kibana
The development of this interactive visualization has been performed with usage of Kibana in the local environment. We have followed Elastic company tutorial for both, download and installation of the software.
Below you may find a tutorial video related to the whole process of creating a visualization. In the video you may see the creation of dashboard with different interactive indicators by generating graphic representations of different types. The steps to build a dashboard are as follows:
A continuación se adjunta un vídeo tutorial donde se muestra todo el proceso de realización de la visualización. En el vídeo podrás ver la creación de un cuadro de mando (dashboard) con diferentes indicadores interactivos mediante la generación de representaciones gráficas de diferentes tipos. Los pasos para obtener el dashboard son los siguientes:
- Load the data into Elasticsearch and generate an index that allows to interact with the data from Kibana. This index permits a search and management of the data in the loaded files, practically in real time.
- Generate the following graphic representations:
- Line graph to represent a time series on the job seekers in Spain between 2006 and 2020.
- Sector graph with job seekers broken down by province and Autonomous Community
- Thematic map showing the number of new contracts registered in each province on the territory. For creation of this visual it´s necessary to download a dataset with province georeferencing published in the open data portal Open Data Soft.
- Build a dashboard.
Below you may find a tutorial video interacting with the visualization that we have just created:
6. Conclusions
Looking at the visualization of the data related to the profile of job seekers in Spain during the years 2010-2020, the following conclusions may be drawn, among others:
- There are two significant increases of the job seekers number. The first, approximately in 2010, coincides with the economic crisis. The second, much more pronounced in 2020, coincides with the pandemic crisis.
- A gender gap may be observed in the group of job seekers: the number of female job seekers is higher throughout the time series, mainly in the age groups above 25.
- At the regional level, Andalusia, followed by Catalonia and Valencia, are the Autonomous Communities with the highest number of job seekers. In contrast to Andalusia, which is an Autonomous Community with the lowest unemployment expenditure, Catalonia presents the highest value.
- Temporal contracts are leading and the provinces which generate the highest number of contracts are Madrid and Barcelona, what coincides with the highest number of habitants, while on the other side, provinces with the lowest number of contracts are Soria, Ávila, Teruel and Cuenca, what coincides with the most depopulated areas of Spain.
This visualization has helped us to synthetise a large amount of information and give it a meaning, allowing to draw conclusions and, if necessary, make decisions based on results. We hope that you like this new post, we will be back to present you new reuses of open data. See you soon!
Documentación
Visualization is critical for data analysis. It provides a first line of attack, revealing intricate structures in data that cannot be absorbed otherwise. We discover unimaginable effects and question those that have been imagined."
William S. Cleveland (de Visualizing Data, Hobart Press)
Over the years an enormous amount of public information has been generated and stored. This information, if viewed in a linear fashion, consists of a large number of disjointed numbers and facts that, out of context, lack any meaning. For this reason, visualization is presented as an easy solution towards understanding and interpreting information.
To obtain good visualizations, it is necessary to work with data that meets two characteristics:
- It has to be quality data. They need to be accurate, complete, reliable, current and relevant.
- They have to be well treated. That is, conveniently identified, correctly extracted, in a structured way, etc.
Therefore, it is important to properly process the information before its graphic treatment. The treatment of the data and its visualization form an attractive tandem for the user who demands, more and more, to be able to interpret data in an agile and fast way.
There are a large number of tools for this purpose. The report "Data processing and visualization tools" offers us a list of different tools that help us in data processing, from obtaining them to creating a visualization that allows us to interpret them in a simple way.
What can you find in the report?
The guide includes a collection of tools for:
- Web scraping
- Data debugging
- Data conversion
- Data analysis for programmers and non-programmers
- Generic visualization services, geospatial and libraries and APIs.
- Network analysis
All the tools present in the guide have a freely available version so that any user can access them.
New edition 2021: incorporation of new tools
The first version of this report was published in 2016. Five years later it has been updated. The news and changes made are:
- New currently popular data visualization and processing tools such as Talend Open Studio, Python, Kibana or Knime have been incorporated.
- Some outdated tools have been removed.
- The layout has been updated.
If you know of any additional tools, not currently included in the guide, we invite you to share the information in the comments.
In addition, we have prepared a series of posts where the different types of tools that can be found in the report are explained:
Documentación
In order to extract the full value of data, it is necessary to classify, filter and cross-reference it through analytics processes that help us draw conclusions, turning data into information and knowledge. Traditionally, data analytics is divided into 3 categories:
- Descriptive analytics, which helps us to understand the current situation, what has happened to get there and why it has happened.
- Predictive analytics, which aims to anticipate relevant events. In other words, it tells us what is going to happen so that a human being can make a decision.
- Prescriptive analytics, which provides information on the best decisions based on a series of future scenarios. In other words, it tells us what to do.
The third report in the "Awareness, Inspire, Action" series focuses on the second stage, Predictive Analytics. It follows the same methodology as the two previous reports on Artificial Intelligence and Natural Language Processing.
Predictive analytics allows us to answer business questions such as: Will we suffer a stockout, will the price of a certain share fall, or will more tourists visit us in the future? Based on this information, companies can define their business strategy, and public bodies can develop policies that respond to the needs of citizens.
After a brief introduction that contextualises the subject matter and explains the methodology, the report, written by Alejandro Alija, is developed as follows:
- Awareness. The Awareness section explains the key concepts, highlighting the three attributes of predictive analytics: the emphasis on prediction, the business relevance of the resulting knowledge and its trend towards democratisation to extend its use beyond specialist users and data scientists. This section also mentions the mathematical models it makes use of and details some of its most important milestones throughout history, such as the Kyoto protocol or its usefulness in detecting customer leakage.
- Inspire. The Inspire section analyses some of the most relevant use cases of predictive analytics today in three very different sectors. It starts with the industrial sector, explaining how predictive maintenance and anomaly detection works. It continues with examples relating to price and demand prediction, in the distribution chain of a supermarket and in the energy sector. Finally, it ends with the health sector and augmented medical imaging diagnostics.
- Action. In the Action section, a concrete use case is developed in a practical way, using real data and technological tools. In this case, the selected dataset is traffic accidents in the city of Madrid, published by the Madrid City Council. Through the methodology shown in the following figure, it is explained in a simple way how to use time series analysis techniques to model and predict the number of accidents in future months.

The report ends with the Last stop section, where courses, books and articles of interest are compiled for those users who want to continue advancing in the subject.
In this video, the author tells you more about the report and predictive analytics (only available in Spanish).
Below, you can download the full report in pdf and word (reusable version), as well as access the code used in the Action example at this link.