





Open Data for the World: Common Crawl Frees Petabytes of Web Data


Fecha de la noticia: 22-05-2024

Common Crawl plays a crucial role in the open data universe, providing free access to a vast collection of web data. This ever-growing archive allows researchers and developers to explore and analyse global trends, train artificial intelligence models and advance understanding of the broad digital landscape.
What is Common Crawl?
Common Crawl can be considered a technology and data platform that offers a large-scale web data archiving and crawling service. The type of data stored is particular, since these are complete web pages including their code, images and the rest of the resources that compose them. It works through the use of crawling robots (software robots) that continuously browse the Internet to capture entire web pages, which are stored and made publicly accessible in standardised formats. In the same way that there are websites that store the content of the historical series of the quotations of the main stock exchanges of the planet or websites that historicise the environmental variables of the different regions of the world, Common Crawl captures and saves the web pages that circulate on the Internet over time.
Common Crawl is a non-profit organisation founded in 2011 by Gil Elbaz. Headquartered in San Francisco in the United States, its mission is to enable researchers, entrepreneurs and developersaround the world to gain unlimited access to a wealth of information, enabling them to explore, analyse and create innovative applications and services. In the organisation's own words:
Open data derived from web scans can contribute to informed decision making at both the individual and governmental level. Open data fosters interdisciplinary collaborations that can drive greater efficiency and effectiveness in solving complex challenges, from environmental problems to public health crises. Overall, embracing open data from web explorations enriches society with innovation, empowerment and collaboration
By embracing Open Data, we foster an inclusive and thriving knowledge ecosystem, where the collective intelligence of the global community can lead to transformative discoveries and have a positive impact on society
Adapted from https://commoncrawl.org
Potential uses of Common Crawl
The ubiquity of the web makes the practical applications of accessing much of the information available on Internet websites virtually limitless. However, three examples can be highlighted:
- Research in Artificial Intelligence and Machine Learning: This is perhaps the most straight forward application case. In particular, we know that GPT-3 was trained with much of the data generated by Common Crawl. Researchers and developers use Common Crawl's vast text datasets to train natural language processing (NLP) models, which helps improve machine understanding of human language in applications such as machine translation, text summarisation, and content generation. A derivative of the same use case is sentiment analysis: Common Crawl data allows for large-scale sentiment analysis, which is useful for understanding public opinions on a variety of topics, from products to policies.
- Development of Web Tools and Services: Every type of software product, from search engines to educational tools, benefits from the data made available by the Common Crawl Foundation. This data is an invaluable source for developers working on improving search and information processing algorithms.
- Market and Competition Studies: Companies from different sectors use Common Crawl data to monitor trends in real time, analysing the frequency and context in which certain terms are mentioned on the web. In this way, they generate competitive analyses of their market position vis-à-vis their competitors. By having access to up-to-date information on how companies are presenting their products and services on the web, companies can routinely and massively perform competitive analysis.
Let us take a closer look at this last example. Let's say we have an idea for a new company, a start-up, based on a mobile application business model, be it for the sale of second-hand clothes, food delivery or home delivery. In any case, any entrepreneur should analyse the market before embarking on the adventure of building a new company, in order to detect potential opportunities.
Today, the Internet is the world's largest source of information, but at this point, the Common Crawl savvy entrepreneur can leverage this open data platform to gain an advantage over others. How? Quite simply, a person who is not familiar with this platform will start a manual browsing process looking for information about the sector and the market on the websites of their potential competitors. You will go to these websites and see how your competitors advertise their products or services, what kind of keywords they use and what web resources they exploit most frequently (videos, social media ads, promotions, cross-services, etc.). This manual process is slow and expensive, in terms of time consumed, as it depends on the expertise of the entrepreneur and the method he/she uses to extract the business information of interest. On the other hand, a person who knows about Common Crawl and has some technical knowledge could use Common Crawl data to analyse competitors' websites, extracting key information such as prices, product descriptions and marketing strategies in a massive and automatic way. With this information, the tool would offer its users a comparative view of the market, identifying which products are popular, how competitors are positioned in terms of pricing and what promotional tactics they use, without the need for costly manual data collection, as in the case of the first entrepreneur.
Going deep into Common Crawl
Common Crawl can be seen as a technology product that offers a large-scale web data archiving and crawling service. Its very name includes the word Crawl which refers to the word crawler . In this context, crawlers are software robots - sometimes known as web crawlers - whose mission is to navigate the web by simulating human behaviour and then capture certain data from target websites. A typical use case for these bots is to browse websites to find navigation faults such as broken links that do not return the right page when clicked on.
In this sense, there are two key elements of Common Crawl as a technology platform:
- Webcrawlers: It uses automated trackers that scan the web to collect information. These crawlers follow links from page to page, capturing HTML content, links, and other relevant elements. Although it is not easy to find technical information on the details of how Common Crawl works, we know that its main crawler is called CCBot and is based on the Apache Nut project.
- Data Storage: The collected data are stored in WARC, WAT and WET files. These files are hosted on Amazon S3, facilitating global access through a cloud storage platform.
- WARC (Web ARChive): Contains the complete web content, including HTML, images and other multimedia resources.
- WAT (Web ARChive-Terse): Provides metadata about the content of the WARC file, such as external and internal links and HTTP headers.
- WET (Web ARChive Extracted Text): Contains text extracted from the pages, removing all HTML and other non-text formatting.
For more information on how to access the datasets, please consult this website.
Technical characteristics of Common Crawl
Some of the main features of Common Crawl are:
- Data Volume
Common Crawl captures more than 2 billion web pages in each of its monthly crawls, generating around 250 terabytes of data. These crawls accumulate petabytes of data stored over time, representing one of the largest collections of publicly accessible web data.
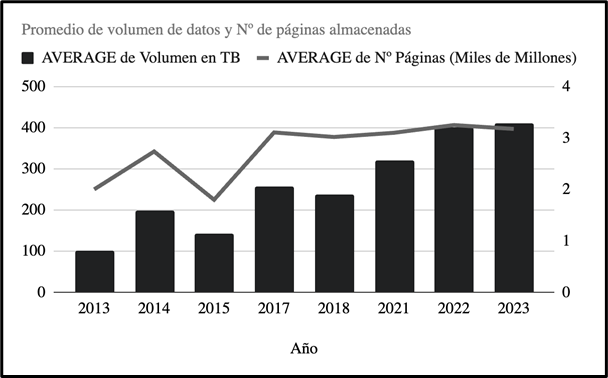
Evolution of the volume of data stored by Common Crawl over time. Adapted from the original source: https://en.wikipedia.org/wiki/Common_Crawl.
- Accessibility
The Common Crawl collection includes pages from more than 40 languages, covering a wide variety of topics and categories. This makes the data exceptionally useful for research that requires a global perspective or for projects that need data in multiple languages.
- Update Frequency
The Common Crawl database is updated monthly. Each monthly crawl is planned and executed to capture a broad and representative snapshot of the web.
- Diversity
The Common Crawl collection includes pages from more than 40 languages, covering a wide variety of topics and categories. This makes the data exceptionally useful for research that requires a global perspective or for projects that need data in multiple languages.
Conclusion
Common Crawl stands out as an invaluable tool for open data access. Its ability to offer petabytes of web data for free not only facilitates artificial intelligence research and market analysis, but also democratises access to information, enabling entrepreneurs and developers around the world to innovate and create effective solutions to complex problems. This open data model not only enriches scientific and technological knowledge, but also drives collaboration between very different sectors and societal domains and efficiency in solving global challenges. The applications of the data provided by Common Crawls are therefore inexhaustible and from a technical perspective, the software tools involved in the technology platform are exciting.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.













