Study on nutrition in spanish homes


Fecha del documento: 20-06-2023
1. Introduction
Visualizations are graphical representations of data that allow the information linked to them to be communicated in a simple and effective way. The visualization possibilities are very wide, from basic representations, such as line, bar or sector graphs, to visualizations configured on interactive dashboards.
In this "Step-by-Step Visualizations" section we are regularly presenting practical exercises of open data visualizations available in datos.gob.es or other similar catalogs. They address and describe in a simple way the stages necessary to obtain the data, perform the transformations and analyses that are relevant to, finally, enable the creation of interactive visualizations that allow us to obtain final conclusions as a summary of said information. In each of these practical exercises, simple and well-documented code developments are used, as well as tools that are free to use. All generated material is available for reuse in the GitHub Data Lab repository.
Then, as a complement to the explanation that you will find below, you can access the code that we will use in the exercise and that we will explain and develop in the following sections of this post.
Access the data lab repository on Github.
Run the data pre-processing code on top of Google Colab.
2. Objetive
The main objective of this exercise is to show how to generate an interactive dashboard that, based on open data, shows us relevant information on the food consumption of Spanish households based on open data. To do this, we will pre-process the open data to obtain the tables that we will use in the visualization generating tool to create the interactive dashboard.
Dashboards are tools that allow you to present information in a visual and easily understandable way. Also known by the term "dashboards", they are used to monitor, analyze and communicate data and indicators. Your content typically includes charts, tables, indicators, maps, and other visuals that represent relevant data and metrics. These visualizations help users quickly understand a situation, identify trends, spot patterns, and make informed decisions.
Once the data has been analyzed, through this visualization we will be able to answer questions such as those posed below:
- What is the trend in recent years regarding spending and per capita consumption in the different foods that make up the basic basket?
- What foods are the most and least consumed in recent years?
- In which Autonomous Communities is there a greater expenditure and consumption in food?
- Has the increase in the cost of certain foods in recent years meant a reduction in their consumption?
These, and many other questions can be solved through the dashboard that will show information in an orderly and easy to interpret way.
3. Resources
3.1. Datasets
The open datasets used in this exercise contain different information on per capita consumption and per capita expenditure of the main food groups broken down by Autonomous Community. The open datasets used, belonging to the Ministry of Agriculture, Fisheries and Food (MAPA), are provided in annual series (we will use the annual series from 2010 to 2021)
Annual series data on household food consumption
These datasets are also available for download from the following Github repository.
These datasets are also available for download from the following Github repository.
3.2. Tools
To carry out the data preprocessing tasks, the Python programming language written on a Jupyter Notebook hosted in the Google Colab cloud service has been used.
"Google Colab" or, also called Google Colaboratory, is a cloud service from Google Research that allows you to program, execute and share code written in Python or R on a Jupyter Notebook from your browser, so it does not require configuration. This service is free of charge.
For the creation of the dashboard, the Looker Studio tool has been used.
"Looker Studio" formerly known as Google Data Studio, is an online tool that allows you to create interactive dashboards that can be inserted into websites or exported as files. This tool is simple to use and allows multiple customization options.
If you want to know more about tools that can help you in the treatment and visualization of data, you can use the report "Data processing and visualization tools".
4. Processing or preparation of data
The processes that we describe below you will find commented in the following Notebook that you can run from Google Colab.
Before embarking on building an effective visualization, we must carry out a prior treatment of the data, paying special attention to its obtaining and the validation of its content, making sure that it is in the appropriate and consistent format for processing and that it does not contain errors.
As a first step of the process, once the initial data sets are loaded, it is necessary to perform an exploratory data analysis (EDA) to properly interpret the starting data, detect anomalies, missing data or errors that could affect the quality of subsequent processes and results. If you want to know more about this process, you can resort to the Practical Guide of Introduction to Exploratory Data Analysis.
The next step is to generate the pre-processed data table that we will use to feed the visualization tool (Looker Studio). To do this, we will modify, filter and join the data according to our needs.
The steps followed in this data preprocessing, explained in the following Google Colab Notebook, are as follows:
- Installation of libraries and loading of datasets
- Exploratory Data Analysis (EDA)
- Generating preprocessed tables
You will be able to reproduce this analysis with the source code that is available in our GitHub account. The way to provide the code is through a document made on a Jupyter Notebook that once loaded into the development environment you can run or modify easily. Due to the informative nature of this post and to favor the understanding of non-specialized readers, the code is not intended to be the most efficient, but to facilitate its understanding so you will possibly come up with many ways to optimize the proposed code to achieve similar purposes. We encourage you to do so!
5. Displaying the interactive dashboard
Once we have done the preprocessing of the data, we go with the generation of the dashboard. A scorecard is a visual tool that provides a summary view of key data and metrics. It is useful for monitoring, decision-making and effective communication, by providing a clear and concise view of relevant information.
For the realization of the interactive visualizations that make up the dashboard, the Looker Studio tool has been used. Being an online tool, it is not necessary to have software installed to interact or generate any visualization, but it is necessary that the data table that we provide is properly structured, which is why we have carried out the previous steps related to the preprocessing of the data. If you want to know more about how to use Looker Studio, in the following link you can access training on the use of the tool.
Below is the dashboard, which can be opened in a new tab in the following link. In the following sections we will break down each of the components that make it up.
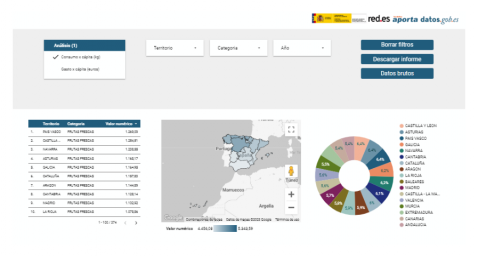
5.1. Filters
Filters in a dashboard are selection options that allow you to visualize and analyze specific data by applying various filtering criteria to the datasets presented in the dashboard. They help you focus on relevant information and get a more accurate view of your data.

The filters included in the generated dashboard allow you to choose the type of analysis to be displayed, the territory or Autonomous Community, the category of food and the years of the sample.
It also incorporates various buttons to facilitate the deletion of the chosen filters, download the dashboard as a report in PDF format and access the raw data with which this dashboard has been prepared.
5.2. Interactive visualizations
The dashboard is composed of various types of interactive visualizations, which are graphical representations of data that allow users to actively explore and manipulate information.
Unlike static visualizations, interactive visualizations provide the ability to interact with data, allowing users to perform different and interesting actions such as clicking on elements, dragging them, zooming or reducing focus, filtering data, changing parameters and viewing results in real time.
This interaction is especially useful when working with large and complex data sets, as it makes it easier for users to examine different aspects of the data as well as discover patterns, trends and relationships in a more intuitive way.
To define each type of visualization, we have based ourselves on the data visualization guide for local entities presented by the NETWORK of Local Entities for Transparency and Citizen Participation of the FEMP.
5.2.1 Data tables
Data tables allow the presentation of a large amount of data in an organized and clear way, with a high space/information performance.
However, they can make it difficult to present patterns or interpretations with respect to other visual objects of a more graphic nature.
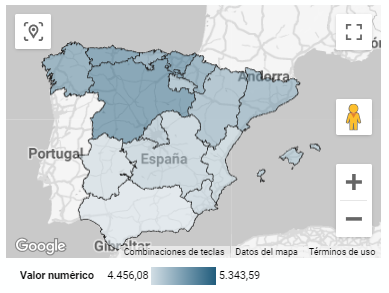
5.2.2 Map of chloropetas
t is a map in which numerical data are shown by territories marking with intensity of different colours the different areas. For its elaboration it requires a measure or numerical data, a categorical data for the territory and a geographical data to delimit the area of each territory.
5.2.3 Pie chart
It is a graph that shows the data from polar axes in which the angle of each sector marks the proportion of a category with respect to the total. Its functionality is to show the different proportions of each category with respect to a total using pie charts.
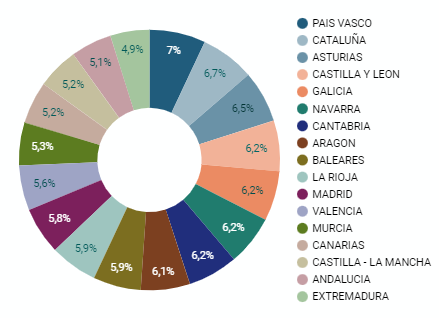
Figure 4. Dashboard pie chart
5.2.4 Line chart
It is a graph that shows the relationship between two or more measurements of a series of values on two Cartesian axes, reflecting on the X axis a temporal dimension, and a numerical measure on the Y axis. These charts are ideal for representing time data series with a large number of data points or observations.
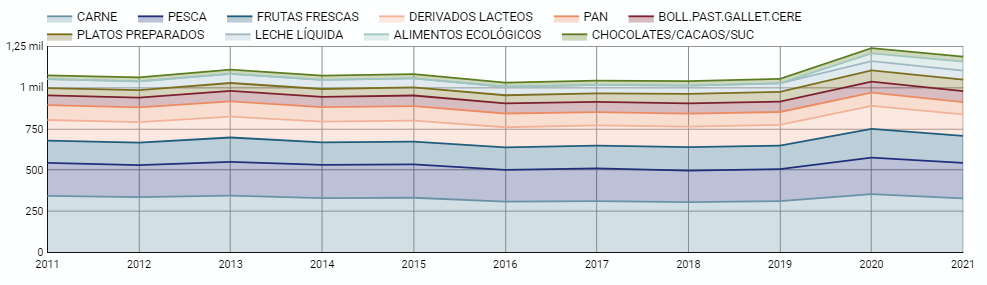
Figure 5. Dashboard line chart
5.2.5 Bar chart
It is a graph of the most used for the clarity and simplicity of preparation. It makes it easier to read values from the ratio of the length of the bars. The chart displays the data using an axis that represents the quantitative values and another that includes the qualitative data of the categories or time.
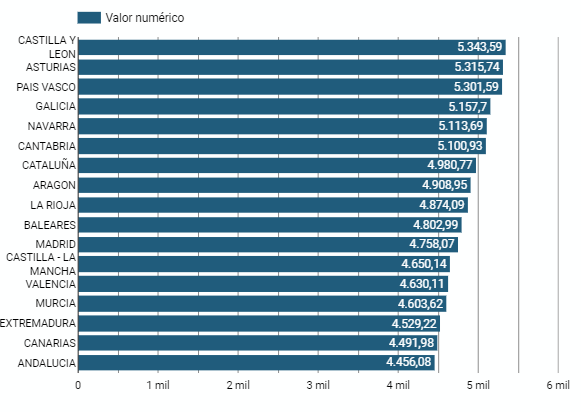
Figure 6. Dashboard bar chart
5.2.6 Hierarchy chart
It is a graph formed by different rectangles that represent categories, and that allows hierarchical groupings of the sectors of each category. The dimension of each rectangle and its placement varies depending on the value of the measurement of each of the categories shown with respect to the total value of the sample.
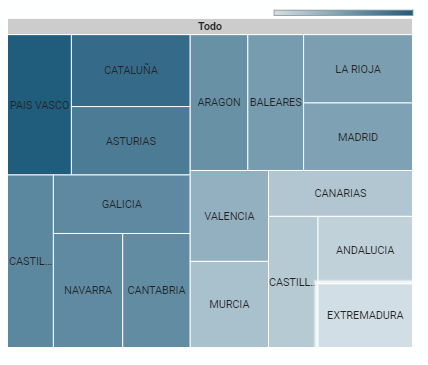
Figure 7. Dashboard Hierarchy chart
6. Conclusions
Dashboards are one of the most powerful mechanisms for exploiting and analyzing the meaning of data. It should be noted the importance they offer us when it comes to monitoring, analyzing and communicating data and indicators in a clear, simple and effective way.
As a result, we have been able to answer the questions originally posed:
- The trend in per capita consumption has been declining since 2013, when it peaked, with a small rebound in 2020 and 2021.
- The trend of per capita expenditure has remained stable since 2011 until in 2020 it has suffered a rise of 17.7%, going from being the average annual expenditure of 1052 euros to 1239 euros, producing a slight decrease of 4.4% from the data of 2020 to those of 2021.
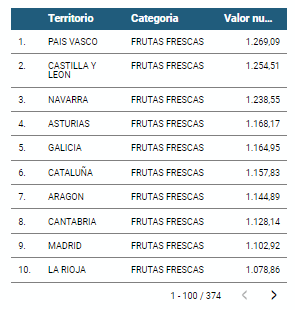
- The three most consumed foods during all the years analyzed are: fresh fruits, liquid milk and meat (values in kgs)
- The Autonomous Communities where per capita spending is highest are the Basque Country, Catalonia and Asturias, while Castilla la Mancha, Andalusia and Extremadura have the lowest spending.
- The Autonomous Communities where a higher per capita consumption occurs are Castilla y León, Asturias and the Basque Country, while in those with the lowest are Extremadura, the Canary Islands and Andalusia.
We have also been able to observe certain interesting patterns, such as a 17.33% increase in alcohol consumption (beers, wine and spirits) in the years 2019 and 2020.
You can use the different filters to find out and look for more trends or patterns in the data based on your interests and concerns.
We hope that this step-by-step visualization has been useful for learning some very common techniques in the treatment and representation of open data. We will be back to show you new reuses. See you soon!