Word Embeddings - Practical Exercise on Tag Processing


Fecha del documento: 27-11-2024

Open data portals play a fundamental role in accessing and reusing public information. A key aspect in these environments is the tagging of datasets, which facilitates their organization and retrieval.
Word embeddings represent a transformative technology in the field of natural language processing, allowing words to be represented as vectors in a multidimensional space where semantic relationships are mathematically preserved. This exercise explores their practical application in a tag recommendation system, using the datos.gob.es open data portal as a case study.
The exercise is developed in a notebook that integrates the environment configuration, data acquisition, and recommendation system processing, all implemented in Python. The complete project is available in the Github repository.
Access the data lab repository on GitHub.
Run the data preprocessing code on Google Colab.
In this video, the author explains what you will find both on Github and Google Colab (English subtitles available).
Understanding word embeddings
Word embeddings are numerical representations of words that revolutionize natural language processing by transforming text into a mathematically processable format. This technique encodes each word as a numerical vector in a multidimensional space, where the relative position between vectors reflects semantic and syntactic relationships between words. The true power of embeddings lies in three fundamental aspects:
- Context capture: unlike traditional techniques such as one-hot encoding, embeddings learn from the context in which words appear, allowing them to capture meaning nuances.
- Semantic algebra: the resulting vectors allow mathematical operations that preserve semantic relationships. For example, vector('Madrid') - vector('Spain') + vector('France') ≈ vector('Paris'), demonstrating the capture of capital-country relationships.
- Quantifiable similarity: similarity between words can be measured through metrics, allowing identification of not only exact synonyms but also terms related in different degrees and generalizing these relationships to new word combinations.
In this exercise, pre-trained GloVe (Global Vectors for Word Representation) embeddings were used, a model developed by Stanford that stands out for its ability to capture global semantic relationships in text. In our case, we use 50-dimensional vectors, a balance between computational complexity and semantic richness. To comprehensively evaluate its ability to represent Spanish language, multiple tests were conducted:
- Word similarity was analyzed using cosine similarity, a metric that evaluates the angle between two word vectors. This measure results in values between -1 and 1, where values close to 1 indicate high semantic similarity, while values close to 0 indicate little or no relationship. Terms like "amor" (love), "trabajo" (work), and "familia" (family) were evaluated to verify that the model correctly identified semantically related words.
- The model's ability to solve linguistic analogies was tested, for example, "hombre es a mujer lo que rey es a reina" (Man is to woman what king is to queen), confirming its ability to capture complex semantic relationships.
- Vector operations were performed (such as "rey - hombre + mujer") to check if the results maintained semantic coherence.
- Finally, dimensionality reduction techniques were applied to a representative sample of 40 Spanish words, allowing visualization of semantic relationships in a two-dimensional space. The results revealed natural grouping patterns among semantically related terms, as observed in the figure:
- Emotions: alegría (joy), felicidad (happiness) or pasión (passion) appear grouped in the upper right.
- Family-related terms: padre (father), hermano (brother) or abuelo (grandfather) concentrate at the bottom.
- Transport: coche (car), autobús (bus), or camión (truck) form a distinctive group.
- Colors: azul (blue), verde (green) or rojo (red) appear close to each other.
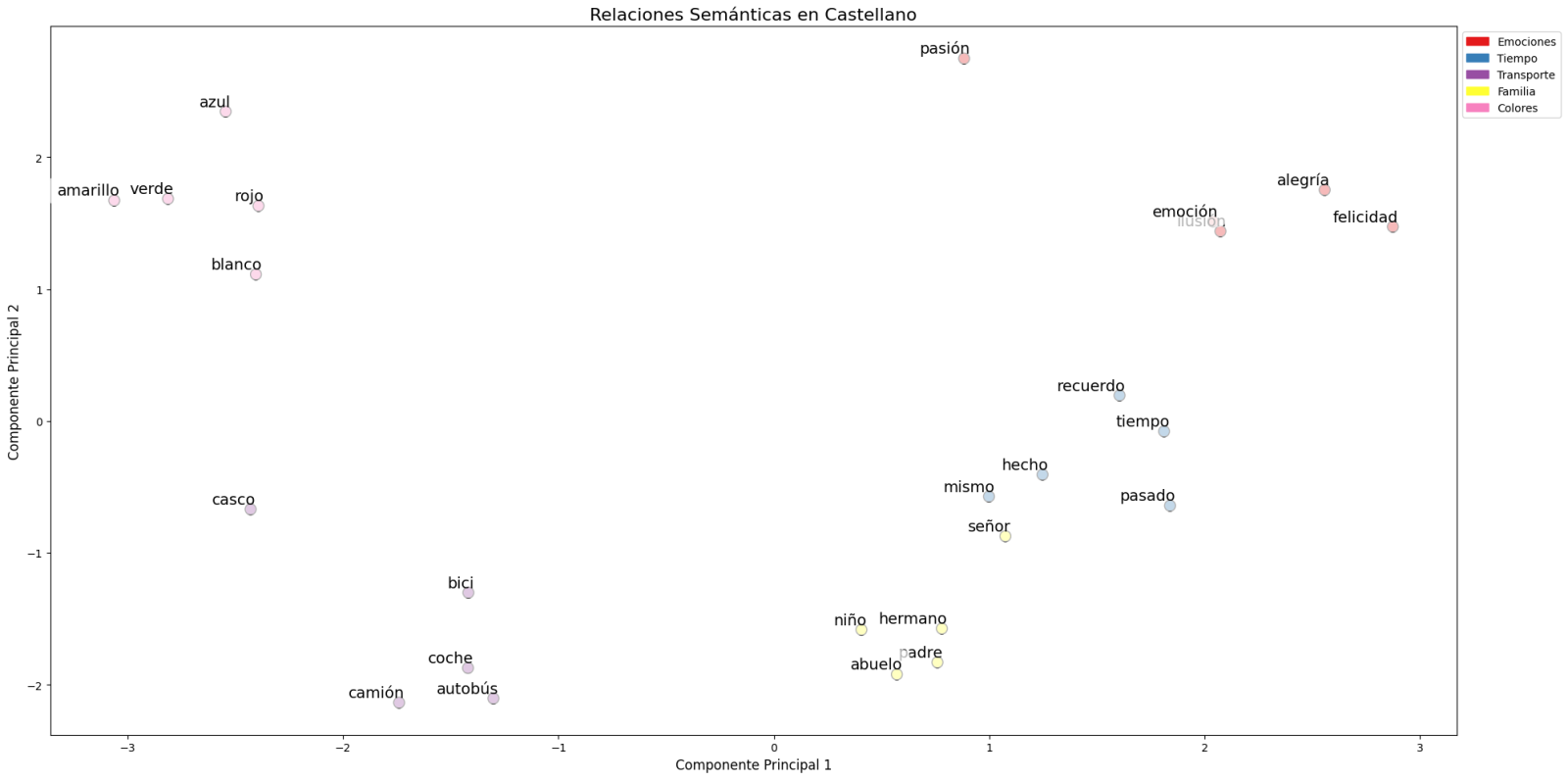
Figure 1. Principal Components Analysis on 50 dimensions (embeddings) with an explained variability percentage by the two components of 0.46
To systematize this evaluation process, a unified function has been developed that encapsulates all the tests described above. This modular architecture allows automatic and reproducible evaluation of different pre-trained embedding models, thus facilitating objective comparison of their performance in Spanish language processing. The standardization of these tests not only optimizes the evaluation process but also establishes a consistent framework for future comparisons and validations of new models by the public.
The good capacity to capture semantic relationships in Spanish language is what we leverage in our tag recommendation system.
Embedding-based Recommendation System
Leveraging the properties of embeddings, we developed a tag recommendation system that follows a three-phase process:
- Embedding generation: for each dataset in the portal, we generate a vector representation combining the title and description. This allows us to compare datasets by their semantic similarity.
- Similar dataset identification: using cosine similarity between vectors, we identify the most semantically similar datasets.
- Tag extraction and standardization: from similar sets, we extract their associated tags and map them with Eurovoc thesaurus terms. This thesaurus, developed by the European Union, is a multilingual controlled vocabulary that provides standardized terminology for cataloging documents and data in the field of European policies. Again, leveraging the power of embeddings, we identify the semantically closest Eurovoc terms to our tags, thus ensuring coherent standardization and better interoperability between European information systems.
The results show that the system can generate coherent and standardized tag recommendations. To illustrate the system's operation, let's take the case of the dataset "Tarragona City Activities Agenda":
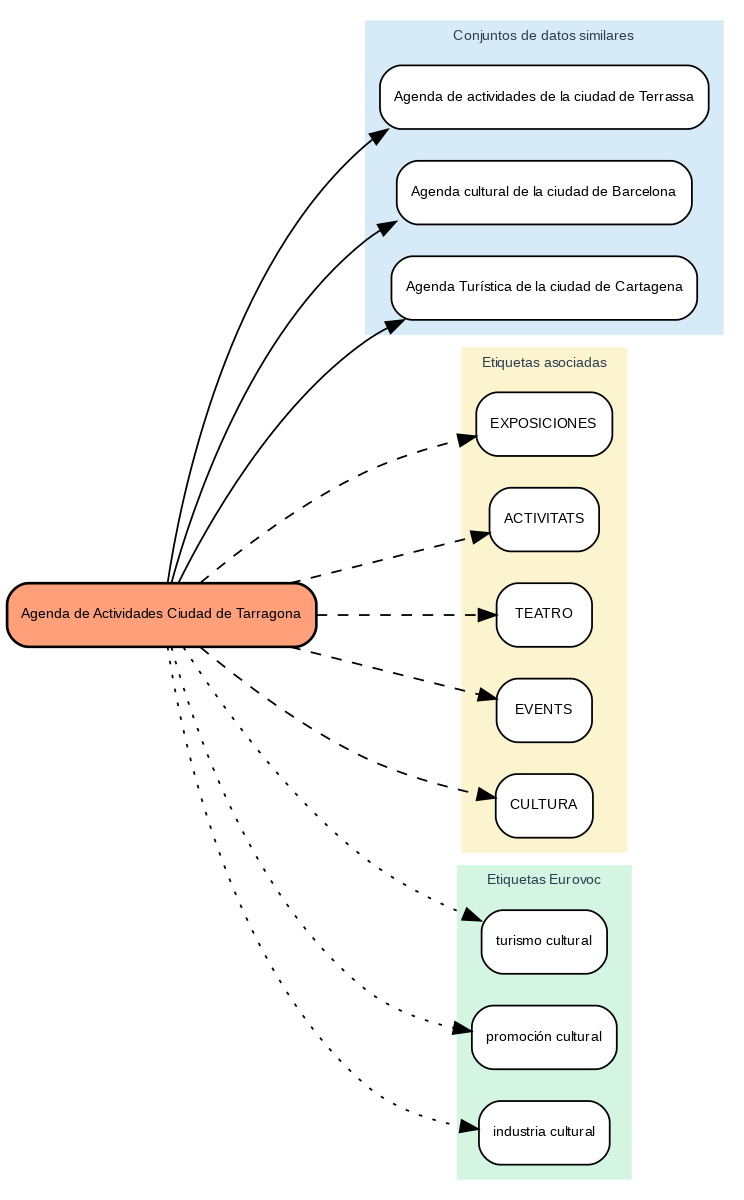
Figure 2. Tarragona City Events Guide
The system:
- Finds similar datasets like "Terrassa Activities Agenda" and "Barcelona Cultural Agenda".
- Identifies common tags from these datasets, such as "EXHIBITIONS", "THEATER", and "CULTURE".
- Suggests related Eurovoc terms: "cultural tourism", "cultural promotion", and "cultural industry".
Advantages of the Approach
This approach offers significant advantages:
- Contextual Recommendations: the system suggests tags based on the real meaning of the content, not just textual matches.
- Automatic Standardization: integration with Eurovoc ensures a controlled and coherent vocabulary.
- Continuous Improvement: the system learns and improves its recommendations as new datasets are added.
- Interoperability: the use of Eurovoc facilitates integration with other European systems.
Conclusions
This exercise demonstrates the great potential of embeddings as a tool for associating texts based on their semantic nature. Through the analyzed practical case, it has been possible to observe how, by identifying similar titles and descriptions between datasets, precise recommendations of tags or keywords can be generated. These tags, in turn, can be linked with keywords from a standardized thesaurus like Eurovoc, applying the same principle.
Despite the challenges that may arise, implementing these types of systems in production environments presents a valuable opportunity to improve information organization and retrieval. The accuracy in tag assignment can be influenced by various interrelated factors in the process:
- The specificity of dataset titles and descriptions is fundamental, as correct identification of similar content and, therefore, adequate tag recommendation depends on it.
- The quality and representativeness of existing tags in similar datasets directly determines the relevance of generated recommendations.
- The thematic coverage of the Eurovoc thesaurus, which, although extensive, may not cover specific terms needed to describe certain datasets precisely.
- The vectors' capacity to faithfully capture semantic relationships between content, which directly impacts the precision of assigned tags.
For those who wish to delve deeper into the topic, there are other interesting approaches to using embeddings that complement what we've seen in this exercise, such as:
- Using more complex and computationally expensive embedding models (like BERT, GPT, etc.)
- Training models on a custom domain-adapted corpus.
- Applying deeper data cleaning techniques.
In summary, this exercise not only demonstrates the effectiveness of embeddings for tag recommendation but also unlocks new possibilities for readers to explore all the possibilities this powerful tool offers.