Blog
IATE, which stands for Interactive Terminology for Europe, is a dynamic database designed to support the multilingual drafting of European Union texts. It aims to provide relevant, reliable and easily accessible data with a distinctive added value compared to other sources of lexical information such as electronic archives, translation memories or the Internet.
This tool is of interest to EU institutions that have been using it since 2004 and to anyone, such as language professionals or academics, public administrations, companies or the general public. This project, launched in 1999 by the Translation Center, is available to any organization or individual who needs to draft, translate or interpret a text on the EU.
Origin and usability of the platform
IATE was created in 2004 by merging different EU terminology databases.The original Eurodicautom, TIS, Euterpe, Euroterms and CDCTERM databases were imported into IATE. This process resulted in a large number of duplicate entries, with the consequence that many concepts are covered by several entries instead of just one. To solve this problem, a cleaning working group was formed and since 2015 has been responsible for organizing analyses and data cleaning initiatives to consolidate duplicate entries into a single entry. This explains why statistics on the number of entries and terms show a downward trend, as more content is deleted and updated than is created.
In addition to being able to perform queries, there is the possibility to download your datasets together with the IATExtract extraction tool that allows you to generate filtered exports.
This inter-institutional terminology base was initially designed to manage and standardize the terminology of EU agencies. Subsequently, however, it also began to be used as a support tool in the multilingual drafting of EU texts, and has now become a complex and dynamic terminology management system. Although its main purpose is to facilitate the work of translators working for the EU, it is also of great use to the general public.
IATE has been available to the public since 2007 and brings together the terminology resources of all EU translation services. The Translation Center manages the technical aspects of the project on behalf of the partners involved: European Parliament (EP), Council of the European Union (Consilium), European Commission (COM), Court of Justice (CJEU), European Central Bank (ECB), European Court of Auditors (ECA), European Economic and Social Committee (EESC/CoR), European Committee of the Regions (EESC/CoR), European Investment Bank (EIB) and the Translation Centre for the Bodies of the European Union (CoT).
The IATE data structure is based on a concept-oriented approach, which means that each entry corresponds to a concept (terms are grouped by their meaning), and each concept should ideally be covered by a single entry. Each IATE entry is divided into three levels:
-
Language Independent Level (LIL)
-
Language Level (LL)
-
Term Level (TL) For more information, see Section 3 ('Structure Overview') below.
Reference source for professionals and useful for the general public
IATE reflects the needs of translators in the European Union, so that any field that has appeared or may appear in the texts of the publications of the EU environment, its agencies and bodies can be covered. The financial crisis, the environment, fisheries and migration are areas that have been worked on intensively in recent years. To achieve the best result, IATE uses the EuroVoc thesaurus as a classification system for thematic fields.
As we have already pointed out, this database can be used by anyone who is looking for the right term about the European Union. IATE allows exploration in fields other than that of the term consulted and filtering of the domains in all EuroVoc fields and descriptors. The technologies used mean that the results obtained are highly accurate and are displayed as an enriched list that also includes a clear distinction between exact and fuzzy matches of the term.
The public version of IATE includes the official languages of the European Union, as defined in Regulation No. 1 of 1958. In addition, a systematic feed is carried out through proactive projects: if it is known that a certain topic is to be covered in EU texts, files relating to this topic are created or improved so that, when the texts arrive, the translators already have the required terminology in IATE.
How to use IATE
To search in IATE, simply type in a keyword or part of a collection name. You can define further filters for your search, such as institution, type or date of creation. Once the search has been performed, a collection and at least one display language are selected.
To download subsets of IATE data you need to be registered, a completely free option that allows you to store some user preferences in addition to downloading. Downloading is also a simple process and can be done in csv or tbx format.
The IATE download file, whose information can also be accessed in other ways, contains the following fields:
-
Language independent level:
-
Token number: the unique identifier of each concept.
-
Subject field: the concepts are linked to fields of knowledge in which they are used. The conceptual structure is organized around twenty-one thematic fields with various subfields. It should be noted that concepts can be linked to more than one thematic field.
-
Language level:
-
Language code: each language has its own ISO code.
-
Term level
-
Term: concept of the token.
-
Type of term. They can be: terms, abbreviation, phrase, formula or short formula.
-
Reliability code. IATE uses four codes to indicate the reliability of terms: untested, minimal, reliable or very reliable.
-
Evaluation. When several terms are stored in a language, specific evaluations can be assigned as follows: preferable, admissible, discarded, obsolete and proposed.
A continuously updated terminology database
The IATE database is a document in constant growth, open to public participation, so that anyone can contribute to its growth by proposing new terminologies to be added to existing files, or to create new files: you can send your proposal to iate@cdt.europa.eu, or use the 'Comments' link that appears at the bottom right of the file of the term you are looking for. You can provide as much relevant information as you wish to justify the reliability of the proposed term, or suggest a new term for inclusion. A terminologist of the language in question will study each citizen's proposal and evaluate its inclusion in the IATE.
In August 2023, IATE announced the availability of version 2.30.0 of this data system, adding new fields to its platform and improving functions, such as the export of enriched files to optimize data filtering. As we have seen, this EU inter-institutional terminology database will continue to evolve continuously to meet the needs of EU translators and IATE users in general.
Another important aspect is that this database is used for the development of computer-assisted translation (CAT) tools, which helps to ensure the quality of the translation work of the EU translation services. The results of translators' terminology work are stored in IATE and translators, in turn, use this database for interactive searches and to feed domain- or document-specific terminology databases for use in their CAT tools.
IATE, with more than 7 million terms in over 700,000 entries, is a reference in the field of terminology and is considered the largest multilingual terminology database in the world. More than 55 million queries are made to IATE each year from more than 200 countries, which is a testament to its usefulness.
Blog
Behind a voice-enabled virtual assistant, a movie recommendation on a streaming platform, or the development of some COVID-19 vaccines, there are machine learning models. This branch of artificial intelligence enables systems to learn and improve their performance.
Machine learning (ML) is one of the fields driving technological progress today, and its applications are growing every day. Examples of solutions developed with machine learning include DALL-E, the set of language models in Spanish known as MarIA, and even Chat GPT-3, a generative AI tool capable of creating content of all types, such as code for programming data visualizations from the datos.gob.es catalog.
All of these solutions work thanks to large data repositories that make system learning possible. Among these, open data plays a fundamental role in the development of artificial intelligence as it can be used to train machine learning models.
Based on this premise, along with the ongoing effort of governments to open up data, there are non-governmental organizations and associations that contribute by developing applications that use machine learning techniques aimed at improving the lives of citizens. We highlight three of them:
ML Commons is driving a better machine learning system for everyone
This initiative aims to improve the positive impact of machine learning on society and accelerate innovation by offering tools such as open datasets, best practices, and algorithms. Its founding members include companies such as Google, Microsoft, DELL, Intel AI, Facebook AI, among others.
According to ML Commons, around 80% of research in the field of machine learning is based on open data. Therefore, open data is vital to accelerate innovation in this field. However, nowadays, "most public data files available are small, static, legally restricted, and not redistributable," as David Kanter, director of ML Commons, assures.
In this regard, innovative ML technologies require large datasets with licenses that allow their reuse, that can be redistributed, and that are continually improving. Therefore, ML Commons' mission is to help mitigate that gap and thus promote innovation in machine learning.
The main goal of this organization is to create a community of open data for the development of machine learning applications. Its strategy is based on three pillars:
Firstly, creating and maintaining comprehensive open datasets, including The People's Speech, with over 30,000 hours of speech in English to train natural language processing (NLP) models, Multilingual Spoken Words, with over 23 million expressions in 50 different languages, or Dollar Street, with over 38,000 images of homes from around the world in various socio-economic situations. The second pillar involves promoting best practices that facilitate standardization, such as the MLCube project, which proposes standardizing the container process for ML models to facilitate shared use. Lastly, benchmarking in study groups to define benchmarks for the developer and research community.
Taking advantage of the benefits and being part of the ML Commons community is free for academic institutions and small companies (less than ten workers).
Datacommons synthesizes different sources of open data into a single portal
Datacommons aims to enhance democratic data flows within the cooperative and solidarity economy and its main objective is to offer purified, normalized, and interoperable data.
The variety of formats and information offered by public portals of open data can be a hindrance to research. The goal of Datacommons is to compile open data into an encyclopedic website that organizes all datasets through nodes. This way, users can access the source that interests them the most.
This platform, designed for educational and journalistic research purposes, functions as a reference tool for navigating through different sources of data. The team of collaborators works to keep the information up-to-date and interacts with the community through its email (support@datacommons.org) or GitHub forum.
Papers with Code: the open repository of materials to feed machine learning models
This is a portal that offers code, reports, data, methods, and evaluation tables in open and free format. All content on the website is licensed under CC-BY-SA, meaning it allows copying, distributing, displaying, and modifying the work, even for commercial purposes, by sharing the contributions made with the same original license.
Any user can contribute by providing content and even participate in the community's Slack channel, which is moderated by responsible individuals who protect the platform's defined inclusion policy.
As of today, Papers with Code hosts 7806 datasets that can be filtered by format (graph, text, image, tabular, etc.), task (object detection, queries, image classification, etc.), or language. The team maintaining Papers with Code belongs to the Meta Research Institute.
The goal of ML Commons, Data Commons, and Papers with Code is to maintain and grow open data communities that contribute to the development of innovative technologies, including artificial intelligence (machine learning, deep learning, etc.) with all the possibilities its development can offer to society.
As part of this process, the three organizations play a fundamental role: they offer standard and redistributable data repositories to train machine learning models. These are useful resources for academic exercises, promoting research, and ultimately facilitating the innovation of technologies that are increasingly present in our society.
Empresa reutilizadora
KSNET (Knowledge Sharing Network S.L) is a company dedicated to the transfer of knowledge that aims to improve programmes and policies with both a social and economic impact. That is why they accompany their clients throughout the process of creating these programmes, from the diagnosis, design and implementation phase to the evaluation of the results and impact achieved, also providing a vision of the future based on proposals for improvement.
Blog
Programming libraries refer to the sets of code files that have been created to develop software in a simple way . Thanks to them, developers can avoid code duplication and minimize errors with greater agility and lower cost. There are many bookstores, focused on different activities. A few weeks ago we saw some examples of libraries for creating visualizations , and this time we are going to focus on useful libraries for machine learning tasks .
These libraries are highly practical when implementing Machine Learning flows . This discipline, belonging to the field of Artificial Intelligence, uses algorithms that offer, for example, the ability to identify patterns in massive data or the ability to help develop predictive analysis.
Below, we show you some of the most popular data analysis and Machine Learning libraries that currently exist for the main programming languages, such as Python or R:
Libraries for Python
NumPy
- Description:
This Python library is specialized in mathematical computation and big data analysis . It allows working with arrays that allow representing collections of data of the same type in various dimensions, as well as very efficient functions for their manipulation.
- Support materials:
Here we find the Beginner's Guide , with basic concepts and tutorials, the User's Guide , with information on general features, or the Contributor's Guide , to help maintain and develop the code or write technical documentation. NumPy also has a Reference Guide that details functions, modules and objects included in this library, as well as a series of tutorials to learn how to use it easily.
Pandas
- Description :
It is one of the most used libraries for data processing in Python . This data analysis and manipulation tool is characterized, among other aspects, by defining new data functionalities based on the arrays of the NumPy library . It allows you to easily read and write files in CSV, Excel format and specify queries to SQL databases .
- Support materials:
Its website has different documents such as the User's Guide , with detailed basic information and useful explanations, the Developer's Guide , which details the steps to follow when identifying errors or suggestions for improvements in functionalities, as well as the Reference Guide , with a detailed description of its API. In addition, it offers a series of tutorials contributed by the community and references on equivalent operations in other software and languages such as SAS, SQL or R.
Scikit-learn
- Description:
Scikit-Learn is a library that implements a large number of Machine Learning algorithms for classification, regression, clustering , and dimensionality reduction tasks . In addition, it is compatible with other Python libraries such as NumPy, SciPy and Matplotlib (Matpotlib is a data visualization library and as such is included in the previous article ).
- Support materials:
This library has different help documents such as an Installation Manual , a User's Guide or a Glossary of common terms and elements of its API . In addition, it offers a section with different examples that illustrate the features of the library, as well as other sections of interest with tutorials , frequently asked questions or access to its GitHub .
Scipy
- Description:
This library features a collection of mathematical algorithms and functions built on top of the NumPy extension . It includes extension modules for Python on statistics, optimization, integration, linear algebra or image processing, among others.
- Support materials:
Like the previous examples, this library also has materials such as Installation Guides , User Guides , Developer Guides or a document with detailed descriptions of its API . It also provides information on act , a tool for running GitHub actions locally.
Libraries for R
mlr
- Description:
This library offers essential components to develop machine learning tasks, among others, preprocessing, pipelining , feature selection, visualization and implementation of supervised and unsupervised techniques using a wide range of algorithms.
- Support materials:
On its website, it has multiple resources for users and developers, among which a reference tutorial stands out that presents an extensive tour that covers the basic aspects of tasks, predictions or data preprocessing to the implementation of complex projects using advanced functions.
In addition, it has a section that redirects to GitHub in which it offers talks, videos and workshops of interest on the operation and uses of this library.
Tidyverse
- Description:
This library offers a collection of R packages designed for data science that provide very useful functionality to import, transform, visualize, model and communicate information from data. They all share the same design philosophy, grammar, and underlying data structures. The main packages that make it up are: dplyr, ggplot2, forcats, tibble, readr, stringr, tidyr and purrr.
- Support materials:
Tidyverse has a blog where you can find posts about programming, packages or tricks and techniques to work with this library. In addition, it has a section that recommends books and workshops to learn how to use this library in a simpler and more enjoyable way.
Caret
- Description:
This popular library contains an interface that unifies hundreds of functions for training classifiers and regressors under a single framework , greatly facilitating all stages of preprocessing, training, optimization and validation of predictive models.
- Support materials:
The project website contains exhaustive information that makes it easier for the user to tackle the aforementioned tasks. References can also be found on CRAN and the project is hosted on GitHub . Some resources of interest for managing this library can be found through books such as Applied Predictive Modeling , articles , seminars or tutorials , among others.
Libraries to tackle Big Data tasks
TensorFlow
- Description:
In addition to Python and R, this library is also compatible with other languages such as JavaScript, C++ or Julia. TensorFlow offers the ability to build and train ML models using APIs . The most prominent API is Keras , which allows building and training deep learning models (Deep Learning).
- Support materials:
On its website you can find resources such as previously established and developed models and data sets, tools , libraries and extensions , certification programs , knowledge about machine learning or resources and tools to integrate responsible AI practices . You can access their GitHub page here .
Dmlc XGBoost
- Description:
Scalable, portable and distributed "Gradient Boosting" (GBM, GBRT, GBDT) library supports C ++, Python, R, Java, Scala, Perl and Julia programming languages . This library allows you to solve many data science problems quickly and accurately and can be integrated with Flink, Spark and other cloud data flow systems to tackle Big Data tasks.
- Support materials:
On its website it has a blog with related topics such as algorithm updates or integrations, as well as a documentation section that has installation guides, tutorials, frequently asked questions, a user forum or packages for the different programming languages. You can access their GitHub page via this link .
H20
- Description:
This library combines the main algorithms of Machine Learning and statistical learning with Big Data , as well as being able to work with millions of records. H20 is written in Java , and follows the Key/Value paradigm to store data and Map/Reduce to implement algorithms. Thanks to its API , it can be accessed from R, Python or Scala.
- Support materials:
It has a series of videos in the form of a tutorial to teach and facilitate its use for users. On its GitHub page you can find additional resources such as blogs , projects, resources, research papers, courses or books about H20 .
In this article we have offered a sample of some of the most popular libraries that offer versatile functionality to tackle typical data science and machine learning tasks, although there are many others . This type of library is constantly evolving thanks to the possibility it offers its users to participate in its improvement through actions such as contributing to code writing, generating new documentation or reporting errors. All this allows you to continuously enrich and refine your results.
If you know of any other bookstore of interest that you want to recommend, you can leave us a message in comments or send us an email to dinamizacion@datos.gob.es
Content prepared by the datos.gob.es team.
Entrevista
The AMETIC association represents companies of all sizes linked to the Spanish digital technology industry, a key sector for the national GDP. Among other issues, AMETIC seeks to promote a favorable environment for the growth of companies in the sector, promoting digital talent and the creation and consolidation of new companies.
At datos.gob.es we spoke with Antonio Cimorra, Director of Digital Transformation and Enabling Technologies at AMETIC, to reflect on the role of open data in innovation and as the basis for new products, services and even business models.
Full interview:
1. How does open data help drive digital transformation? What disruptive technologies are the most benefited by the opening of data?
Open data is one of the pillars of the data economy , which is called to be the basis of our present and future development and the digital transformation of our society. All industries, public administrations and citizens themselves have only just begun to discover and use the enormous potential and usefulness that the use of data brings to improving the competitiveness of companies, to the efficiency and improvement of services. of Public Administrations and to social relations and people's quality of life.
2. One of the areas in which they work from AMETIC is Artificial Intelligence and Big Data, among whose objectives is to promote the creation of public platforms for sharing open data. Could you explain to us what actions you are carrying out or have carried out for this?
At AMETIC we have an Artificial Intelligence and Big Data Commission in which the main companies that provide this technology participate . From this area, we work on the definition of initiatives and proposals that contribute to disseminating their knowledge among potential users, with the consequent advantages that their incorporation in the public and private sectors entails. Outstanding examples of actions in this area are the recent presentation of the AMETIC Artificial Intelligence Observatory, as well as the AMETIC Artificial Intelligence Summit. which in 2022 will celebrate its fifth edition that will focus on showing how Artificial Intelligence can contribute to meeting the Sustainable Development Goals and the Transformation Plans to be executed with European Funds
3. Open data can serve as a basis for developing services and solutions that give rise to new companies . Could you tell us an example of a use case carried out by your partners?
Open data, and very particularly the reuse of public sector information, are the basis for the development of countless applications and entrepreneurial initiatives both in consolidated companies in our technology sector and in many other cases of small companies or startups found in this source of information the motor of development of new businesses and approach to the market.
4. What types of data are most in demand by the companies you represent?
At present, all industrial and social activity data are in great demand by companies , due to their great value in the development of projects and solutions that have been demonstrating their interest and extension in all areas and types of organizations and users. usually.
5. It is also essential to have data sharing initiatives such as GAIA-X , built on the values of digital sovereignty and data availability. How have companies received the creation of a national hub ?
The technology sector has received the creation of the GAIA-X national hub very positively, understanding that our contribution from Spain to this European project will be of enormous value to our companies from very different fields of activity. Data sharing spaces in sectors such as tourism, health, mobility, industry, to give a few examples, have Spanish companies and experiences that are an example and a reference at European and global level .
6. Right now there is a great demand for professionals related to data collection, analysis and visualization. However, the supply of professionals, although it is growing, continues to be limited . What should be done to boost training in skills related to data and digitization?
The supply of technology professionals is one of the biggest problems for the development of our local industry and for the digital transformation of society. It is a difficulty that we can describe as historical, and that far from going less, every day there is a greater number of positions and profiles to cover. It is a worldwide problem that shows that there is no single or simple formula to solve it, but we can mention the importance of all social and professional agents developing joint and collaborative actions that allow the digital training of our population from an early age. and cycles and specialized training and degree programs that are characterized by their proximity to what will be the professional careers for which it is necessary to have the participation of the business sector
7. During the last years, you have been part of the jury of the different editions of the Aporta Challenge. How do you think these types of actions contribute to boosting data-driven businesses?
The Aporta Challenge has been an example of support and encouragement for the definition of many projects around open data and for the development of its own industry that in recent years has been growing very significantly with the availability of data of very different groups, in many cases by the Public Administrations, and their subsequent reuse and incorporation into applications and solutions of interest to very different users.
Open data constitutes one of the pillars of the data economy, which is called to be the basis of our present and future development and of the digital transformation of our society.
8. What are the next actions that are going to be carried out in AMETIC linked to the data economy?
Among the most outstanding actions of AMETIC in relation to the data economy, it is worth mentioning our recent incorporation into the national hub of GAIA-X for which we have been elected members of its board of directors, and where we will represent and incorporate the vision and contributions of the digital technology industry in all the data spaces that are constituted , serving as a channel for the participation of the technology companies that carry out their activity in our country and that have to form the basis of the projects and use cases that integrate into the European network GAIA-X in collaboration with other national hubs.
Noticia
Summer is just around the corner and with it the well-deserved holidays. Undoubtedly, this time of year gives us time to rest, reconnect with the family and spend pleasant moments with our friends.
However, it is also a great opportunity to take advantage of and improve our knowledge of data and technology through the courses that different universities make available to us during these dates. Whether you are a student or a working professional, these types of courses can contribute to increase your training and help you gain competitive advantages in the labour market.
Below, we show you some examples of summer courses from Spanish universities on these topics. We have also included some online training, available all year round, which can be an excellent product to learn during the summer season.
Courses related to open data
We begin our compilation with the course 'Big & Open Data. Analysis and programming with R and Python' given by the Complutense University of Madrid. It will be held at the Fundación General UCM from 5 to 23 July, Monday to Friday from 9 am to 2 pm. This course is aimed at university students, teachers, researchers and professionals who wish to broaden and perfect their knowledge of this subject.
Data analysis and visualisation
If you are interested in learning the R language, the University of Santiago de Compostela organises two courses related to this subject, within the framework of its 'Universidade de Verán' The first one is 'Introduction to geographic and cartographic information systems with the R environment', which will be held from 6 to 9 July at the Faculty of Geography and History of Santiago de Compostela. You can consult all the information and the syllabus through this link.
The second is 'Visualisation and analysis of data with R', which will take place from 13 to 23 July at the Faculty of Mathematics of the USC. In this case, the university offers students the possibility of attending in two shifts (morning and afternoon). As you can see in the programme, statistics is one of the key aspects of this training.
If your field is social sciences and you want to learn how to handle data correctly, the course of the International University of Andalusia (UNIA) 'Techniques of data analysis in Humanities and Social Sciences' seeks to approach the use of new statistical and spatial techniques in research in these fields. It will be held from 23 to 26 August in classroom mode.
Big Data
Big Data is increasingly becoming one of the elements that contribute most to the acceleration of digital transformation. If you are interested in this field, you can opt for the course 'Big Data Geolocated: Tools for capture, analysis and visualisation' which will be given by the Complutense University of Madrid from 5 to 23 July from 9 am to 2 pm, in person at the Fundación General UCM.
Another option is the course 'Big Data: technological foundations and practical applications' organised by the University of Alicante, which will be held online from 19 to 23 July.
Artificial intelligence
The Government has recently launched the online course 'Elements of AI' in Spanish with the aim of promoting and improving the training of citizens in artificial intelligence. The Secretary of State for Digitalisation and Artificial Intelligence will implement this project in collaboration with the UNED, which will provide the technical and academic support for this training. Elements of AI is a massive open educational project (MOOC) that aims to bring citizens knowledge and skills on Artificial Intelligence and its various applications. You can find out all the information about this course here. And if you want to start the training now, you can register through this link. The course is free of charge.
Another interesting training related to this field is the course 'Practical introduction to artificial intelligence and deep learning' organised by the International University of Andalusia (UNIA). It will be taught in person at the Antonio Machado headquarters in Baeza between 17 and 20 August 2021. Among its objectives, it offers students an overview of data processing models based on artificial intelligence and deep learning techniques, among others.
These are just a few examples of courses that are currently open for enrolment, although there are many more, as the offer is wide and varied. In addition, it should be remembered that summer has not yet begun and that new data-related courses could appear in the coming weeks. If you know of any other course that might be of interest, do not hesitate to leave us a comment below or write to us at contacto@datos.gob.es.
Evento
The current healthcare situation has changed the way in which major events are held, with most of them moving from being held in person to online. However, little by little, the face-to-face format is being taken up again, returning to the offline format and even combining both experiences.
In this article we are going to discover some events related to the world of technology and data, both private and public, that will be held in the coming weeks and that you should not miss. Join us to discover them!
OpenExpo Virtual Experience 2021
8 to 10 June 2021 – Online
OpenExpo Europe has positioned itself in recent years as one of the main windows for dissemination in technological innovation, digital transformation and open source in Europe. Its main objective is to disseminate the latest trends, tools and services in innovation and technology among professionals in the technology sector, as well as helping them to increase their network of contacts.
The OpenExpo Virtual Experience initiative was launched last year, following the success achieved with the dissemination of online content on cybersecurity, blockchain, AI, virtual reality, IoT and big data, among other topics.
At this event, attendees will be able to enjoy more than 50 activities led by professional experts in technology and innovation: presentations, case studies, interviews, debates, workshops, Q&A sessions, 1to1 meetings, etc. Some of the topics to be addressed are Govtech and the public administration's commitment to innovation, free educational software and Gaia-X, one of the European Commission's major projects in the field of data.
Advanced Factories
8 to 10 June 2021 – Barcelona
Barcelona will host the annual Advanced Factories summit, which brings together the most cutting-edge companies in Industry 4.0. Some of the focal points of this world-class meeting will be: industrial automation, sensors, energy efficiency, artificial intelligence, blockchain, machine learning and big data.
For the fourth consecutive year, this summit will host the Industry 4.0 Congress under the slogan "We are the future of automation", which will begin with a presentation on the role of data in the transformation of this sector.
Mobile World Congress (MWC) 2021
28 June to 01 July 2021 – Barcelona
This great technological event was suspended in 2020, but in 2021 it will re-emerge as a new event with great guarantees of health safety. As a novelty, this year's MWC will feature several virtual activities that will complement the on-site edition of the event. "Connected Impact" is the chosen theme, which places the COVID-19 pandemic as the main element influencing this year's technological trends.
As usual, leading professionals from the sector and prominent speakers will be taking part. Among them is Carme Artigas, Secretary of State for Digitalisation and Artificial Intelligence, who will participate with a presentation on data in the age of intelligence.
As in previous years, the in-house event for startups 4YFN (4 Years From Now) will be held as part of the MWC. Its aim is to support contact between startups and investors, providing access to an international network of contacts and different business opportunities. Among the participating companies we can find many focused on the world of data and its reuse. Red.es selects Spanish companies and startups to participate in the different representation spaces that are organised.
South Summit
5 to 7 October 2021 – Online
The autumn will see the arrival of South Summit, a showcase in the form of a competition to give more visibility to disruptive projects seeking new customers, funding or strategic partnerships. It will feature investors and leading innovation companies from Spain, southern Europe and Latin America, regardless of the industry, country of origin or stage of development of the project.
This year the organisation has decided not to hold the event in person, so the project presentations will take place virtually.
IoT Solutions World Congress
5 to 7 October 2021 – Barcelona
This is undoubtedly one of the most high-profile IoT events in the world. Due to the growing demand from the sector, more than 8,000 visitors are expected to attend an event that will bring together industry experts to analyse how the Internet of Things is transforming production, transport, logistics, public services and sectors such as healthcare and energy.
Some of the papers to be presented include "Leveraging EdgeX Foundry as an Open, Trusted Data Framework for Smart Meter Monitoring", "Using Mobile, IoT and Data Analytics to Take a Localized Approach to the Global Waste Problem" and "Making Cities, Infrastructures & Construction Sites Smarter with Time Series Data".
Semantic Web for E-Government
24 October - online
This online event will focus on a review of the semantic web and its importance in achieving interoperability and integration between the different organisational levels of public administrations. Two current e-government and open data initiatives will be presented:
- The European Data Portal, a platform for integrating and assessing Europe's Linked Open Government Data. It will address the multiple applications of semantic web standards in the European Data Portal, such as DCAT, SKOS, SHACL and DQV. Special attention will also be given to the measurement and publication of quality information.
- Ciudades Abiertas: good practices for data harmonisation with local public administrations. It will be explained how a set of vocabularies is being developed to support a homogeneous provision of open data in the framework of Ciudades Abiertas, a collaborative project with four Spanish cities (Zaragoza, A Coruña, Madrid and Santiago de Compostela).
Smart City Expo World Congress
16 to 18 November 2021 – Barcelona
For several years now, Smart City Expo World Congress (SCEWC) has become a benchmark event that combines technological innovation with the field of Smart Cities. It brings together experts, companies and entrepreneurs with the aim of creating synergies and promoting new projects.
In 2021, the congress celebrates its tenth anniversary and its organisers will once again opt to hold the event in person, combined with a digital platform that will offer a multitude of opportunities to its attendees.
This event is usually the framework chosen by Open Data Barcelona to showcase the finalists of its World Data Viz Challenge, although the 2021 edition has not yet been announced.
EU Open Data Days
23 to 25 November 2021 - Online
This year we will also attend the first edition of the EU Open Data Days, organised by the Publications Office of the European Union in collaboration with the Aporta Initiative. The event will be virtual and will be divided into two activities:
- EU Dataviz 2021 (23-24 November). A programme of conferences focusing on open data and visualisations. They are currently defining the agenda which we will share with you soon.
- EU Datathon 2021 (25 November). In the months leading up to this event, a competition will be held to encourage the creation of products based on open data, such as mobile or web applications, that offer a response to different challenges related to EU priorities. The deadline for submissions is 11 June. The final will be held on 25 November as part of the Open Days.
This is just a selection of some of the major technology events coming up - do you know of any more you would like to highlight? Then don't hesitate to write us a comment or send us your proposal by email to contacto@datos.gob.es.
Blog
The promotion of digitalisation in industrial activity is one of the main axes for tackling the transformation that the Spain's Digital Agenda 2025 aims to promote. In this respect, several initiatives have already been launched by public institutions, including the Connected Industry 4.0 programme, through which the aim is to promote a framework for joint and coordinated action by the public and private sectors in this field.
Apart from the debates on what Industry 4.0 means and the challenges it poses, one of the main requirements identified to assess the maturity and viability of this type of project is the existence of "a strategy for collecting, analysing and using relevant data, promoting the implementation of technologies that facilitate this, aimed at decision-making and customer satisfaction", as well as the use of technologies that "allow predictive and prescriptive models, for example, Big Data and Artificial Intelligence". Precisely, the Spanish Artificial R+D+I Strategy gives a singular relevance to the massive use of data that, in short, requires its availability in adequate conditions, both from a quantitative and qualitative perspective. In the case of Industry 4.0 this requirement becomes strategic, particularly if we consider that almost a half of companies' technological expenditure is linked to data management.
Although a relevant part of the data will be those generated in the development of their own activity by the companies, it cannot be ignored that the re-use of data from third parties acquires a singular importance due to the added value it provides, especially with regard to the information provided by public sector entities. In any case, the specific sectors in which industrial activity takes place will determine which type of data is particularly useful. In this sense, the food industry may have a greater interest in knowing as accurately as possible not only weather forecasts but also historical data related to climate and, in this way, adequately planning both its production and also the management of its personnel, logistics activities and even future investments. Or, to continue with another example, the pharmaceutical industry and the industry linked to the supply of health material could make more effective and efficient decisions if they could access updated information from the autonomous health systems under suitable conditions, which would ultimately not only benefit them but also better satisfy their own public interests.
Beyond the particularities of each of the sectors on which the specific business activity is projected, in general, public sector entities have relevant data banks whose effective opening in order to allow their reuse in an automated manner would be of great interest to facilitate the digital transformation of industrial activity. Specifically, the availability of socio-economic information can provide undeniable added value, so that the adoption of decisions on the activity of companies can be based on data generated by public statistics services, on parameters which are relevant from the perspective of economic activity - for example, taxes or income levels - or even on the planning of the activity of public bodies with implications for assets, as occurs in the field of subsidies or contracting. On the other hand, there are many public registers with structured information whose opening would provide an important added value from an industrial perspective, such as those which provide relevant information on the population or the opening of establishments which carry out economic activities which directly or indirectly affect the conditions in which industrial activity is carried out, either in terms of production conditions or the market in which their products are distributed. In addition, the accessibility of environmental, town planning and, in general, territorial planning information would be an undeniable asset in the context of the digital transformation of industrial activity, as it would allow the integration of essential variables for the data processing required by this type of company.
However, the availability of data from third parties in projects linked to Industry 4.0 cannot be limited to the public sector alone, as it is particularly important to be able to rely on data provided by private subjects. In particular, there are certain sectors of activity in which their accessibility for the purposes of reuse by industrial companies would be of particular relevance, such as telecommunications, energy or, among others, financial institutions. However, unlike what happens with data generated in the public sector, there is no regulation that obliges private subjects to offer information generated in the development of their own activity to third parties in open and reusable formats.
Moreover, there may sometimes be a legitimate interest on the part of such entities to prevent other parties from accessing the data they hold, for example, if possible intellectual or industrial property rights are affected, if there are contractual obligations to be fulfilled or if, simply for commercial reasons, it is advisable to prevent relevant information from being made available to competing companies. However, apart from the timid European regulation aimed at facilitating the free circulation of not personal data, there is no specific regulatory framework that is applicable to the private sector and therefore, in the end, the possibility of re-using relevant information for projects related to Industry 4.0 would be limited to agreements that can be reached on a voluntary basis.
Therefore, the decisive promotion of Industry 4.0 requires the existence of an adequate ecosystem with regard to the accessibility of data generated by other entities which, in short, cannot be limited solely and exclusively to the public sector. It is not simply a question of adopting a perspective of increasing efficiency from a cost perspective but, rather, of optimising all processes; this also affects certain social aspects of growing importance such as energy efficiency, respect for the environment or improvement in working conditions. And it is precisely in relation to these challenges that the role to be played by the Public Administration is crucial, not only offering relevant data for reuse by industrial companies but, above all, promoting the consolidation of a technological and socially advanced production model based on the parameters of Industry 4.0, which also requires the dynamisation of adequate legal conditions to guarantee the accessibility of information generated by private entities in certain strategic sectors.
Content prepared by Julián Valero, professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec).
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Evento
We live in an era in which training has become an essential element, both to enter and to progress in an increasingly competitive labour market, as well as to be part of research projects that can lead to great improvements in our lifetime.
Summer is coming and with it, a renewed training offer that does not rest at all in the summer season, but quite the opposite. Every year, the number of courses related to data science, analytics or open data increases. The current labour market demands and requires professionals specialized in these technological fields, as reflected by the EC in its European Data Strategy, where it is highlighted that the EU will provide financing "to expand the digital talent pool with in the order of 250000 people who will be able to deploy the latest technologies in businesses throughout the EU”.
In this sense, the possibilities offered by new technologies to carry out any type of online training, from your own home with the maximum guarantees, help more professionals to use this type of course each year.
From datos.gob.es we have selected a series of online courses, both free and paid, related to data that may be of interest to you:
- We started with the Machine Learning and Data Science Course taught by the Polytechnic University of Valencia, which stands out for offering its future students the learning necessary to extract technical knowledge from the data. With a 5-week program, this course introduce R language and, among other things, different preprocessing techniques and data visualization.
- The Modern Methods in Data Analytics course is another option if you are looking to expand your data training and learn English at the same time. The University of Utrecht will begin to teach this course completely online from August 31, totally focused on the study of linear models and longitudinal data analysis, among other fields.
- Another of the English courses that will begin on June 16 is a 9-week training programme focused on Data Analytics and which is taught by the Ironhack International School. This is a recommended course for those who want to learn how to load, clean, explore and extract information from a wide range of datasets, as well as how to use Python, SQL and Tableau, among other aspects.
- Next we discover the course on Business Digitization and Big Data: Data, Information and Knowledge in Highly Competitive Markets, taught by FGUMA (General Foundation of the University of Malaga). Its duration is 25 hours and its registration deadline is June 15. If you are a professional related to business management and / or entrepreneurship, this course will surely be of interest to you.
- R for Data Science is another course offered by the FGUMA. Its main objective is to show an introductory view to the R programming language for data analysis tasks, including advanced reports and visualizations, presenting techniques typical of computer learning as an extra value. As with the previous course, the deadline for registration for this training is June 15.
- For its part, Google Cloud offers a completely online and free learning path for data professionals seeking to perfect the design, complication, analysis and optimization of macrodata solutions. Surely this Specialized program: Data Engineering, Big Data, and Machine Learning on GCP fits into the training you had planned.
In addition to these specific courses, it is worth noting the existence of online training platforms that offer courses related to new technologies on an ongoing basis. These courses are known as MOOC and are an alternative to traditional training, in areas such as Machine Learning, Data Analytics, Business Intelligence or Deep Learning, knowledge that is increasingly demanded by companies.
This is just a selection of the many courses that exist as data related training offerings. However, we would love to count on your collaboration by sending us, through the comments, other courses of interest in the field of data to complete this list in the future.
Blog
People, governments, economy, infrastructure, environment ... all these elements come together in our cities and they have to make the most of the constant flow of data on their streets to be more efficient. Analysis of the efficiency of services, monitoring of investment, improvement of public transport, participation and collaboration with citizens, reduction of waste or prevention of natural disasters are just some of the multiple examples of innovation in cities driven by data that how local governments are getting better services and improving the quality of life of their citizens thanks to the openness and better exploitation of their data.
From finding a parking space to discover new leisure places or simply move around the city. The applications that facilitate us day by day are already part of the usual urban landscape. At the same time, the data is also transforming the cities little by little and offers us an alternative vision of them through the definition of new virtual neighborhoods based on the footprint we are leaving with our actions and our data.
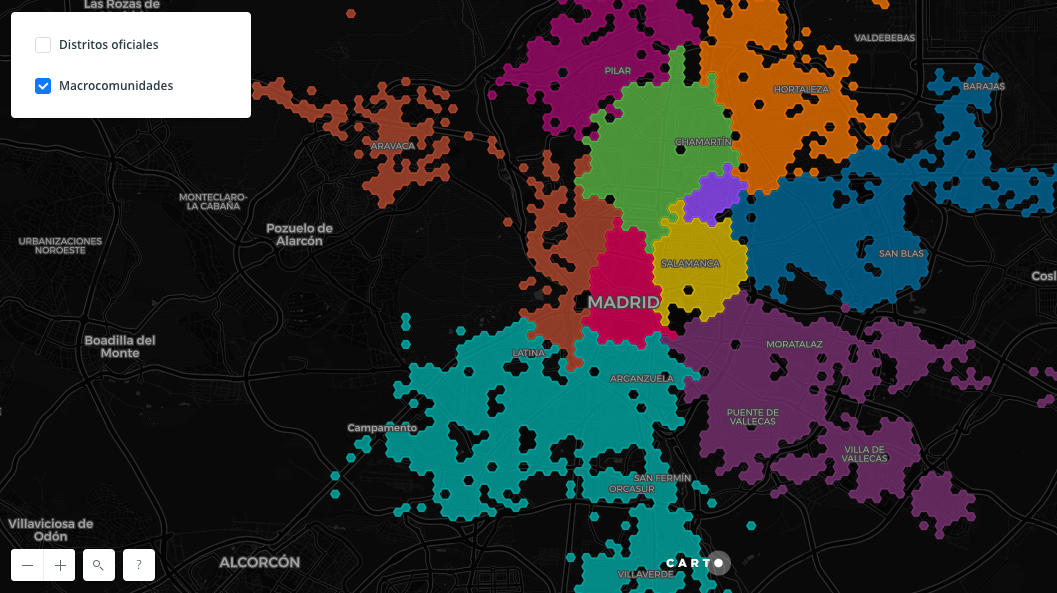
Hyperconnected cities, driven by data, managed by artificial intelligence and inhabited by a greater number of robots than humans will no longer be exclusive to science fiction movies and series, but real projects in the middle of the desert with already defined plans that have been launched in search of diversification and with the aim of transforming and renewing economies that are too dependent on the old oil ironically thanks to the supposed new oil of the data. Returning for a moment to the present, we also find examples of how this transformation through data is real and is happening in such tangible cases as the prevention of crimes and the reduction of violence in the favelas of Rio de Janeiro.
But not all expectations are so optimistic, since the transformative vision that some technology companies have for our neighborhoods also generates serious doubts, not only about how our most personal data will be managed and who will actually be the othe that have access and control over them, but also on the supposed transforming power of the data itself.
Right now the only thing that seems to be totally clear is that the role of data in the transformation of cities and citizens of the immediate future will be essential and we must find our own way halfway between the most optimistic and the most pessimistic visions to define what we understand as the new paradigm of Smart Cities, but always with a focus on the human element and not only on purely technological aspects and with participation and co-creation as key elements.