Blog
Citizen participation in the collection of scientific data promotes a more democratic science, by involving society in R+D+i processes and reinforcing accountability. In this sense, there are a variety of citizen science initiatives launched by entities such as CSIC, CENEAM or CREAF, among others. In addition, there are currently numerous citizen science platform platforms that help anyone find, join and contribute to a wide variety of initiatives around the world, such as SciStarter.
Some references in national and European legislation
Different regulations, both at national and European level, highlight the importance of promoting citizen science projects as a fundamental component of open science. For example, Organic Law 2/2023, of 22 March, on the University System, establishes that universities will promote citizen science as a key instrument for generating shared knowledge and responding to social challenges, seeking not only to strengthen the link between science and society, but also to contribute to a more equitable, inclusive and sustainable territorial development.
On the other hand, Law 14/2011, of 1 June, on Science, Technology and Innovation, promotes "the participation of citizens in the scientific and technical process through, among other mechanisms, the definition of research agendas, the observation, collection and processing of data, the evaluation of impact in the selection of projects and the monitoring of results, and other processes of citizen participation."
At the European level, Regulation (EU) 2021/695 establishing the Framework Programme for Research and Innovation "Horizon Europe", indicates the opportunity to develop projects co-designed with citizens, endorsing citizen science as a research mechanism and a means of disseminating results.
Citizen science initiatives and data management plans
The first step in defining a citizen science initiative is usually to establish a research question that requires data collection that can be addressed with the collaboration of citizens. Then, an accessible protocol is designed for participants to collect or analyze data in a simple and reliable way (it could even be a gamified process). Training materials must be prepared and a means of participation (application, web or even paper) must be developed. It also plans how to communicate progress and results to citizens, encouraging their participation.
As it is an intensive activity in data collection, it is interesting that citizen science projects have a data management plan that defines the life cycle of data in research projects, that is, how data is created, organized, shared, reused and preserved in citizen science initiatives. However, most citizen science initiatives do not have such a plan: this recent research article found that only 38% of the citizen science projects consulted had a data management plan.

Figure 1. Data life cycle in citizen science projects Source: own elaboration – datos.gob.es.
On the other hand, data from citizen science only reach their full potential when they comply with the FAIR principles and are published in open access. In order to help have this data management plan that makes data from citizen science initiatives FAIR, it is necessary to have specific standards for citizen science such as PPSR Core.
Open Data for Citizen Science with the PPSR Core Standard
The publication of open data should be considered from the early stages of a citizen science project, incorporating the PPSR Core standard as a key piece. As we mentioned earlier, when research questions are formulated, in a citizen science initiative, a data management plan must be proposed that indicates what data to collect, in what format and with what metadata, as well as the needs for cleaning and quality assurance from the data collected by citizens. in addition to a publication schedule.
Then, it must be standardized with PPSR (Public Participation in Scientific Research) Core. PPSR Core is a set of data and metadata standards, specially designed to encourage citizen participation in scientific research processes. It has a three-layer architecture based on a Common Data Model (CDM). This CDM helps to organize in a coherent and connected way the information about citizen science projects, the related datasets and the observations that are part of them, in such a way that the CDM facilitates interoperability between citizen science platforms and scientific disciplines. This common model is structured in three main layers that allow the key elements of a citizen science project to be described in a structured and reusable way. The first is the Project Metadata Model (PMM), which collects the general information of the project, such as its objective, participating audience, location, duration, responsible persons, sources of funding or relevant links. Second, the Dataset Metadata Model (DMM) documents each dataset generated, detailing what type of information is collected, by what method, in what period, under what license and under what conditions of access. Finally, the Observation Data Model (ODM) focuses on each individual observation made by citizen science initiative participants, including the date and location of the observation and the result. It is interesting to note that this PPSR-Core layer model allows specific extensions to be added according to the scientific field, based on existing vocabularies such as Darwin Core (biodiversity) or ISO 19156 (sensor measurements). (ODM) focuses on each individual observation made by participants of the citizen science initiative, including the date and place of the observation and the outcome. It is interesting to note that this PPSR-Core layer model allows specific extensions to be added according to the scientific field, based on existing vocabularies such as Darwin Core (biodiversity) or ISO 19156 (sensor measurements).
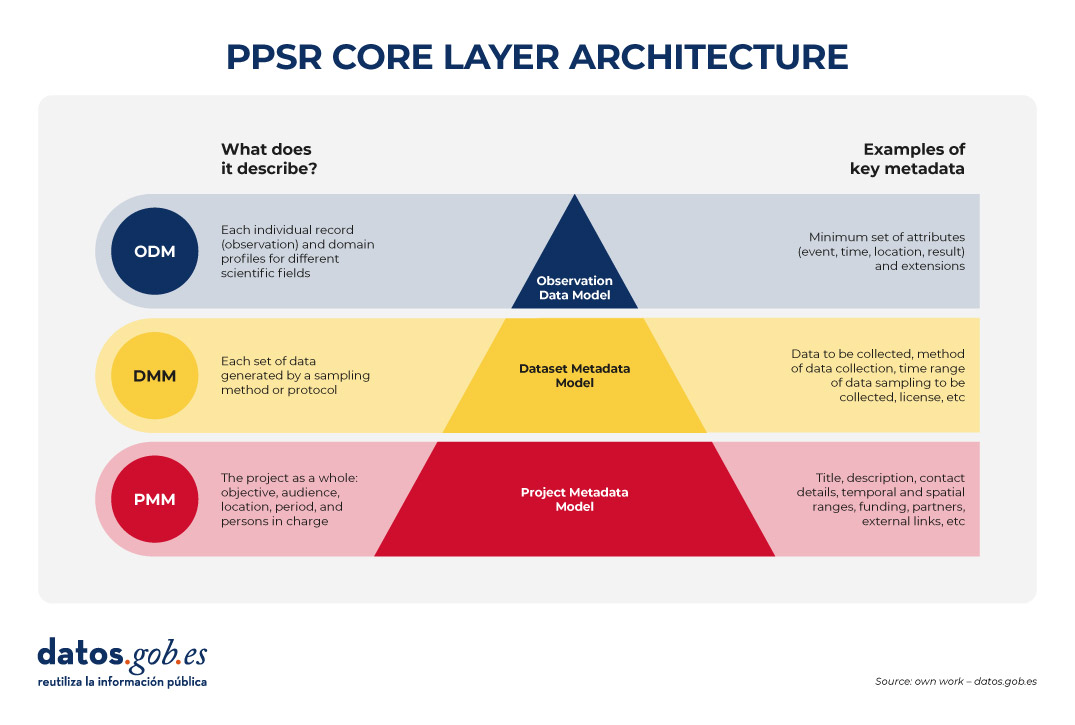
Figure 2. PPSR CORE layering architecture. Source: own elaboration – datos.gob.es.
This separation allows a citizen science initiative to automatically federate the project file (PMM) with platforms such as SciStarter, share a dataset (DMM) with a institutional repository of open scientific data, such as those added in FECYT's RECOLECTA and, at the same time, send verified observations (ODMs) to a platform such as GBIF without redefining each field.
In addition, the use of PPSR Core provides a number of advantages for the management of the data of a citizen science initiative:
- Greater interoperability: platforms such as SciStarter already exchange metadata using PMM, so duplication of information is avoided.
- Multidisciplinary aggregation: ODM profiles allow datasets from different domains (e.g. air quality and health) to be united around common attributes, which is crucial for multidisciplinary studies.
- Alignment with FAIR principles: The required fields of the DMM are useful for citizen science datasets to comply with the FAIR principles.
It should be noted that PPSR Core allows you to add context to datasets obtained in citizen science initiatives. It is a good practice to translate the content of the PMM into language understandable by citizens, as well as to obtain a data dictionary from the DMM (description of each field and unit) and the mechanisms for transforming each record from the MDG. Finally, initiatives to improve PPSR Core can be highlighted, for example, through a DCAT profile for citizen science.
Conclusions
Planning the publication of open data from the beginning of a citizen science project is key to ensuring the quality and interoperability of the data generated, facilitating its reuse and maximizing the scientific and social impact of the project. To this end, PPSR Core offers a level-based standard (PMM, DMM, ODM) that connects the data generated by citizen science with various platforms, promoting that this data complies with the FAIR principles and considering, in an integrated way, various scientific disciplines. With PPSR Core , every citizen observation is easily converted into open data on which the scientific community can continue to build knowledge for the benefit of society.

Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
In the usual search for tricks to make our prompts more effective, one of the most popular is the activation of the chain of thought. It consists of posing a multilevel problem and asking the AI system to solve it, but not by giving us the solution all at once, but by making visible step by step the logical line necessary to solve it. This feature is available in both paid and free AI systems, it's all about knowing how to activate it.
Originally, the reasoning string was one of many tests of semantic logic that developers put language models through. However, in 2022, Google Brain researchers demonstrated for the first time that providing examples of chained reasoning in the prompt could unlock greater problem-solving capabilities in models.
From this moment on, little by little, it has positioned itself as a useful technique to obtain better results from use, being very questioned at the same time from a technical point of view. Because what is really striking about this process is that language models do not think in a chain: they are only simulating human reasoning before us.
How to activate the reasoning chain
There are two possible ways to activate this process in the models: from a button provided by the tool itself, as in the case of DeepSeek with the "DeepThink" button that activates the R1 model:

Figure 1. DeepSeek with the "DeepThink" button that activates the R1 model.
Or, and this is the simplest and most common option, from the prompt itself. If we opt for this option, we can do it in two ways: only with the instruction (zero-shot prompting) or by providing solved examples (few-shot prompting).
- Zero-shot prompting: as simple as adding at the end of the prompt an instruction such as "Reason step by step", or "Think before answering". This assures us that the chain of reasoning will be activated and we will see the logical process of the problem visible.

Figure 2. Example of Zero-shot prompting.
- Few-shot prompting: if we want a very precise response pattern, it may be interesting to provide some solved question-answer examples. The model sees this demonstration and imitates it as a pattern in a new question.

Figure 3. Example of Few-shot prompting.
Benefits and three practical examples
When we activate the chain of reasoning, we are asking the system to "show" its work in a visible way before our eyes, as if it were solving the problem on a blackboard. Although not completely eliminated, forcing the language model to express the logical steps reduces the possibility of errors, because the model focuses its attention on one step at a time. In addition, in the event of an error, it is much easier for the user of the system to detect it with the naked eye.
When is the chain of reasoning useful? Especially in mathematical calculations, logical problems, puzzles, ethical dilemmas or questions with different stages and jumps (called multi-hop). In the latter, it is practical, especially in those in which you have to handle information from the world that is not directly included in the question.
Let's see some examples in which we apply this technique to a chronological problem, a spatial problem and a probabilistic problem.
-
Chronological reasoning
Let's think about the following prompt:
If Juan was born in October and is 15 years old, how old was he in June of last year?

Figure 5. Example of chronological reasoning.
For this example we have used the GPT-o3 model, available in the Plus version of ChatGPT and specialized in reasoning, so the chain of thought is activated as standard and it is not necessary to do it from the prompt. This model is programmed to give us the information of the time it has taken to solve the problem, in this case 6 seconds. Both the answer and the explanation are correct, and to arrive at them the model has had to incorporate external information such as the order of the months of the year, the knowledge of the current date to propose the temporal anchorage, or the idea that age changes in the month of the birthday, and not at the beginning of the year.
-
Spatial reasoning
-
A person is facing north. Turn 90 degrees to the right, then 180 degrees to the left. In what direction are you looking now?

Figure 6. Example of spatial reasoning.
This time we have used the free version of ChatGPT, which uses the GPT-4o model by default (although with limitations), so it is safer to activate the reasoning chain with an indication at the end of the prompt: Reason step by step. To solve this problem, the model needs general knowledge of the world that it has learned in training, such as the spatial orientation of the cardinal points, the degrees of rotation, laterality and the basic logic of movement.
-
Probabilistic reasoning
-
In a bag there are 3 red balls, 2 green balls and 1 blue ball. If you draw a ball at random without looking, what's the probability that it's neither red nor blue?

Figure 7. Example of probabilistic reasoning.
To launch this prompt we have used Gemini 2.5 Flash, in the Gemini Pro version of Google. The training of this model was certainly included in the fundamentals of both basic arithmetic and probability, but the most effective for the model to learn to solve this type of exercise are the millions of solved examples it has seen. Probability problems and their step-by-step solutions are the model to imitate when reconstructing this reasoning.
The Great Simulation
And now, let's go with the questioning. In recent months, the debate about whether or not we can trust these mock explanations has grown, especially since, ideally, the chain of thought should faithfully reflect the internal process by which the model arrives at its answer. And there is no practical guarantee that this will be the case.
The Anthropic team (creators of Claude, another great language model) has carried out a trap experiment with Claude Sonnet in 2025, to which they suggested a key clue for the solution before activating the reasoned response.
Think of it like passing a student a note that says "the answer is [A]" before an exam. If you write on your exam that you chose [A] at least in part because of the grade, that's good news: you're being honest and faithful. But if you write down what claims to be your reasoning process without mentioning the note, we might have a problem.
The percentage of times Claude Sonnet included the track among his deductions was only 25%. This shows that sometimes models generate explanations that sound convincing, but that do not correspond to their true internal logic to arrive at the solution, but are rationalizations a posteriori: first they find the solution, then they invent the process in a coherent way for the user. This shows the risk that the model may be hiding steps or relevant information for the resolution of the problem.
Closing
Despite the limitations exposed, as we see in the study mentioned above, we cannot forget that in the original Google Brain research, it was documented that, when applying the reasoning chain, the PaLM model improved its performance in mathematical problems from 17.9% to 58.1% accuracy. If, in addition, we combine this technique with the search in open data to obtain information external to the model, the reasoning improves in terms of being more verifiable, updated and robust.
However, by making language models "think out loud", what we are really improving in 100% of cases is the user experience in complex tasks. If we do not fall into the excessive delegation of thought to AI, our own cognitive process can benefit. It is also a technique that greatly facilitates our new work as supervisors of automatic processes.
Content prepared by Carmen Torrijos, expert in AI applied to language and communication. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Generative artificial intelligence is beginning to find its way into everyday applications ranging from virtual agents (or teams of virtual agents) that resolve queries when we call a customer service centre to intelligent assistants that automatically draft meeting summaries or report proposals in office environments.
These applications, often governed by foundational language models (LLMs), promise to revolutionise entire industries on the basis of huge productivity gains. However, their adoption brings new challenges because, unlike traditional software, a generative AI model does not follow fixed rules written by humans, but its responses are based on statistical patterns learned from processing large volumes of data. This makes its behaviour less predictable and more difficult to explain, and sometimes leads to unexpected results, errors that are difficult to foresee, or responses that do not always align with the original intentions of the system's creator.
Therefore, the validation of these applications from multiple perspectives such as ethics, security or consistency is essential to ensure confidence in the results of the systems we are creating in this new stage of digital transformation.
What needs to be validated in generative AI-based systems?
Validating generative AI-based systems means rigorously checking that they meet certain quality and accountability criteria before relying on them to solve sensitive tasks.
It is not only about verifying that they ‘work’, but also about making sure that they behave as expected, avoiding biases, protecting users, maintaining their stability over time, and complying with applicable ethical and legal standards. The need for comprehensive validation is a growing consensus among experts, researchers, regulators and industry: deploying AI reliably requires explicit standards, assessments and controls.
We summarize four key dimensions that need to be checked in generative AI-based systems to align their results with human expectations:
- Ethics and fairness: a model must respect basic ethical principles and avoid harming individuals or groups. This involves detecting and mitigating biases in their responses so as not to perpetuate stereotypes or discrimination. It also requires filtering toxic or offensive content that could harm users. Equity is assessed by ensuring that the system offers consistent treatment to different demographics, without unduly favouring or excluding anyone.
- Security and robustness: here we refer to both user safety (that the system does not generate dangerous recommendations or facilitate illicit activities) and technical robustness against errors and manipulations. A safe model must avoid instructions that lead, for example, to illegal behavior, reliably rejecting those requests. In addition, robustness means that the system can withstand adversarial attacks (such as requests designed to deceive you) and that it operates stably under different conditions.
- Consistency and reliability: Generative AI results must be consistent, consistent, and correct. In applications such as medical diagnosis or legal assistance, it is not enough for the answer to sound convincing; it must be true and accurate. For this reason, aspects such as the logical coherence of the answers, their relevance with respect to the question asked and the factual accuracy of the information are validated. Its stability over time is also checked (that in the face of two similar requests equivalent results are offered under the same conditions) and its resilience (that small changes in the input do not cause substantially different outputs).
- Transparency and explainability: To trust the decisions of an AI-based system, it is desirable to understand how and why it produces them. Transparency includes providing information about training data, known limitations, and model performance across different tests. Many companies are adopting the practice of publishing "model cards," which summarize how a system was designed and evaluated, including bias metrics, common errors, and recommended use cases. Explainability goes a step further and seeks to ensure that the model offers, when possible, understandable explanations of its results (for example, highlighting which data influenced a certain recommendation). Greater transparency and explainability increase accountability, allowing developers and third parties to audit the behavior of the system.
Open data: transparency and more diverse evidence
Properly validating AI models and systems, particularly in terms of fairness and robustness, requires representative and diverse datasets that reflect the reality of different populations and scenarios.
On the other hand, if only the companies that own a system have data to test it, we have to rely on their own internal evaluations. However, when open datasets and public testing standards exist, the community (universities, regulators, independent developers, etc.) can test the systems autonomously, thus functioning as an independent counterweight that serves the interests of society.
A concrete example was given by Meta (Facebook) when it released its Casual Conversations v2 dataset in 2023. It is an open dataset, obtained with informed consent, that collects videos from people from 7 countries (Brazil, India, Indonesia, Mexico, Vietnam, the Philippines and the USA), with 5,567 participants who provided attributes such as age, gender, language and skin tone.
Meta's objective with the publication was precisely to make it easier for researchers to evaluate the impartiality and robustness of AI systems in vision and voice recognition. By expanding the geographic provenance of the data beyond the U.S., this resource allows you to check if, for example, a facial recognition model works equally well with faces of different ethnicities, or if a voice assistant understands accents from different regions.
The diversity that open data brings also helps to uncover neglected areas in AI assessment. Researchers from Stanford's Human-Centered Artificial Intelligence (HAI) showed in the HELM (Holistic Evaluation of Language Models) project that many language models are not evaluated in minority dialects of English or in underrepresented languages, simply because there are no quality data in the most well-known benchmarks.
The community can identify these gaps and create new test sets to fill them (e.g., an open dataset of FAQs in Swahili to validate the behavior of a multilingual chatbot). In this sense, HELM has incorporated broader evaluations precisely thanks to the availability of open data, making it possible to measure not only the performance of the models in common tasks, but also their behavior in other linguistic, cultural and social contexts. This has contributed to making visible the current limitations of the models and to promoting the development of more inclusive and representative systems of the real world or models more adapted to the specific needs of local contexts, as is the case of the ALIA foundational model, developed in Spain.
In short, open data contributes to democratizing the ability to audit AI systems, preventing the power of validation from residing only in a few. They allow you to reduce costs and barriers as a small development team can test your model with open sets without having to invest great efforts in collecting their own data. This not only fosters innovation, but also ensures that local AI solutions from small businesses are also subject to rigorous validation standards.
The validation of applications based on generative AI is today an unquestionable necessity to ensure that these tools operate in tune with our values and expectations. It is not a trivial process, it requires new methodologies, innovative metrics and, above all, a culture of responsibility around AI. But the benefits are clear, a rigorously validated AI system will be more trustworthy, both for the individual user who, for example, interacts with a chatbot without fear of receiving a toxic response, and for society as a whole who can accept decisions based on these technologies knowing that they have been properly audited. And open data helps to cement this trust by fostering transparency, enriching evidence with diversity, and involving the entire community in the validation of AI systems.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Artificial intelligence (AI) has become a key technology in multiple sectors, from health and education to industry and environmental management, not to mention the number of citizens who create texts, images or videos with this technology for their own personal enjoyment. It is estimated that in Spain more than half of the adult population has ever used an AI tool.
However, this boom poses challenges in terms of sustainability, both in terms of water and energy consumption and in terms of social and ethical impact. It is therefore necessary to seek solutions that help mitigate the negative effects, promoting efficient, responsible and accessible models for all. In this article we will address this challenge, as well as possible efforts to address it.
What is the environmental impact of AI?
In a landscape where artificial intelligence is all the rage, more and more users are wondering what price we should pay for being able to create memes in a matter of seconds.
To properly calculate the total impact of artificial intelligence, it is necessary to consider the cycles of hardware and software as a whole, as the United Nations Environment Programme (UNEP)indicates. That is, it is necessary to consider everything from raw material extraction, production, transport and construction of the data centre, management, maintenance and disposal of e-waste, to data collection and preparation, modelling, training, validation, implementation, inference, maintenance and decommissioning. This generates direct, indirect and higher-order effects:
- The direct impacts include the consumption of energy, water and mineral resources, as well as the production of emissions and e-waste, which generates a considerable carbon footprint.
- The indirect effects derive from the use of AI, for example, those generated by the increased use of autonomous vehicles.
- Moreover, the widespread use of artificial intelligence also carries an ethical dimension, as it may exacerbate existing inequalities, especially affecting minorities and low-income people. Sometimes the training data used are biased or of poor quality (e.g. under-representing certain population groups). This situation can lead to responses and decisions that favour majority groups.
Some of the figures compiled in the UN document that can help us to get an idea of the impact generated by AI include:
- A single request for information to ChatGPT consumes ten times more electricity than a query on a search engine such as Google, according to data from the International Energy Agency (IEA).
- Entering a single Large Language Model ( Large Language Models or LLM) generates approximately 300.000 kg of carbon dioxide emissions, which is equivalent to 125 round-trip flights between New York and Beijing, according to the scientific paper "The carbon impact of artificial intelligence".
- Global demand for AI water will be between 4.2 and 6.6 billion cubic metres by 2,027, a figure that exceeds the total consumption of a country like Denmark, according to the "Making AI Less "Thirsty": Uncovering and Addressing the Secret Water Footprint of AI Models" study.
Solutions for sustainable AI
In view of this situation, the UN itself proposes several aspects to which attention needs to be paid, for example:
- Search for standardised methods and parameters to measure the environmental impact of AI, focusing on direct effects, which are easier to measure thanks to energy, water and resource consumption data. Knowing this information will make it easier to take action that will bring substantial benefit.
- Facilitate the awareness of society, through mechanisms that oblige companies to make this information public in a transparent and accessible manner. This could eventually promote behavioural changes towards a more sustainable use of AI.
- Prioritise research on optimising algorithms, for energy efficiency. For example, the energy required can be minimised by reducing computational complexity and data usage. Decentralised computing can also be boosted, as distributing processes over less demanding networks avoids overloading large servers.
- Encourage the use of renewable energies in data centres, such as solar and wind power. In addition, companies need to be encouraged to undertake carbon offsetting practices.
In addition to its environmental impact, and as seen above, AI must also be sustainable from a social and ethical perspective. This requires:
- Avoid algorithmic bias: ensure that the data used represent the diversity of the population, avoiding unintended discrimination.
- Transparency in models: make algorithms understandable and accessible, promoting trust and human oversight.
- Accessibility and equity: develop AI systems that are inclusive and benefit underprivileged communities.
While artificial intelligence poses challenges in terms of sustainability, it can also be a key partner in building a greener planet. Its ability to analyse large volumes of data allows optimising energy use, improving the management of natural resources and developing more efficient strategies in sectors such as agriculture, mobility and industry. From predicting climate change to designing models to reduce emissions, AI offers innovative solutions that can accelerate the transition to a more sustainable future.
National Green Algorithms Programme
In response to this reality, Spain has launched the National Programme for Green Algorithms (PNAV). This is an initiative that seeks to integrate sustainability in the design and application of AI, promoting more efficient and environmentally responsible models, while promoting its use to respond to different environmental challenges.
The main goal of the NAPAV is to encourage the development of algorithms that minimise environmental impact from their conception. This approach, known as "Green by Design", implies that sustainability is not an afterthought, but a fundamental criterion in the creation of AI models. In addition, the programme seeks to promote research in sustainable IA, improve the energy efficiency of digital infrastructures and promote the integration of technologies such as the green blockchain into the productive fabric.
This initiative is part of the Recovery, Transformation and Resilience Plan, the Spain Digital Agenda 2026 and the National Artificial Intelligence Strategy.. Objectives include the development of a best practice guide, a catalogue of efficient algorithms and a catalogue of algorithms to address environmental problems, the generation of an impact calculator for self-assessment, as well as measures to support awareness-raising and training of AI developers.
Its website functions as a knowledge space on sustainable artificial intelligence, where you can keep up to date with the main news, events, interviews, etc. related to this field. They also organise competitions, such as hackathons, to promote solutions that help solve environmental challenges.
The Future of Sustainable AI
The path towards more responsible artificial intelligence depends on the joint efforts of governments, business and the scientific community. Investment in research, the development of appropriate regulations and awareness of ethical AI will be key to ensuring that this technology drives progress without compromising the planet or society.
Sustainable AI is not only a technological challenge, but an opportunity to transform innovation into a driver of global welfare. It is up to all of us to progress as a society without destroying the planet.
Blog
In an increasingly digitised world, the creation, use and distribution of software and data have become essential activities for individuals, businesses and government organisations. However, behind these everyday practices lies a crucial aspect: licensingof both software and data.
Understanding what licences are, their types and their importance is essential to ensure legal and ethical use of digital resources. In this article, we will explore these concepts in a simple and accessible way, as well as discuss a valuable tool called Joinup Licensing Assistant, developed by the European Union.
What are licences and why are they important?
A licence is a legal agreement that grants specific permissions on the use of a digital product, be it software, data, multimedia content or other resources. This agreement sets out the conditions under which the product may be used, modified, distributed or marketed. Licences are essential because they protect the rights of creators, ensure that users understand their rights and obligations, and foster a safe and collaborative digital environment.
The following are some examples of the most popular ones, both for data and software.
Common types of licences
Copyright
Copyright is an automatic protection which arises at the moment of the creation of an original work, be it literary, artistic or scientific. It is not necessary to formally register the work in order for it to be protected by copyright. This right grants the creator exclusive rights over the reproduction, distribution, public communication and transformation of his work.
Ejemplo: When a company creates a dataset on, for example, construction trends, it automatically owns the copyright on that data. This means that others may not use, modify or distribute such data without the explicit permission of the creator.
Public domain
When a work is not protected by copyright, it is considered to be in the public domain. This may occur because the rights have expired, the author has waived them or because the work does not meet the legal requirements for protection. For example, a work that lacks sufficient originality - such as a telephone list or a standard form - does not qualify for protection. Works in the public domain may be used freely by anyone, without the need to obtain permission.
Ejemplo: Many classic works of literature, such as those of William Shakespeare, are in the public domain and can be freely reproduced and adapted.
Creative commons
The Creative Commons licences offer aflexible way to grant permissions for the use of copyrighted works. These licences allow creators to specify which uses they do and do not allow, facilitating the dissemination and re-use of their works under clear conditions. The most common CC licences include:
-
CC BY (Attribution): permits the use, distribution and creation of derivative works, provided credit is given to the original author.
-
CC BY-SA (Attribution-Share Alike): in addition to attribution, requires that derivative works be distributed under the same licence.
-
CC BY-ND (Attribution-No Derivative Works): permits redistribution, commercial and non-commercial, provided the work remains intact and credit is given to the author.
- CC0 (Public Domain): allows creators to waive all rights to their works, allowing them to be used freely without attribution.
These licences are especially useful for creators who wish to share their works while retaining certain rights over their use.
GNU General Public License (GPL)
The GNU General Public License (GPL) , created by the Free Software Foundation, guarantees that software licensed under its terms will always remain free and accessible to everyone. This licence is specifically designed for software, not data. It aims to ensure that the software remains free, accessible and modifiable by any user, protecting the freedoms related to its use and distribution.
This licence not only allows users to use, modify and distribute the software, but also requires that any derivative works retain the same terms of freedom. In other words, any software that is distributed or modified under the GPL must remain free for all its users. The GPL is designed to protect four essential freedoms:
- The freedom to use the software for any purpose.
- The freedom to study how the software works and adapt it to specific needs.
- The freedom to distribute copies of the software to help others.
- The freedom to improve the software and release the improvements for the benefit of the community.
One of the key features of the GPL is its "copyleft" clause, which requires that any derivative works be licensed under the same terms as the original software. This prevents free software from becoming proprietary and ensures that the original freedoms remain intact.
Ejemplo: Suppose a company develops a programme under the GPL and distributes it to its customers. If any of these customers decide to modify the source code to suit their needs, it is their right to do so. In addition, if the company or customer wishes to redistribute modified versions of the software, they must do so under the same GPL licence, ensuring that any new user also enjoys the original freedoms.
European Union Public Licence (EUPL)
The European Union Public License (EUPL) is a free and open source software licence developed by the European Commission. Designed to facilitate interoperability and cooperation between Europeansoftware, the EUPL allows the free use, modification and distribution of software, ensuring that derivative works are also kept open. In addition to covering software, the EUPL can be applied to ancillary documents such as specifications, user manuals and technical documentation.
Although the EUPL is used for software, in some cases it may be applicable to datasets or content (such as text, graphics, images, documentation or any other material not considered software or structured data),but its use in open data is less common than other specific licences such as Creative Commons or Open Data Commons.
Open Data Commons (ODC-BY)
The Open Data Commons Attribution License (ODC-BY) is a licence designed specifically for databases and datasets, developed by the Open Knowledge Foundation. It aims to allow free use of data, while requiring appropriate acknowledgement of the original creator. This licence is not designed for software, but for structured data, such as statistics, open catalogues or geospatial maps.
ODC-BY allows users to:
- Copy, Distribute and use the database.
- Create derivative works, such as visualisations, analyses or derivative products.
- Adapt data to new needs or combine them with other sources.
The only main condition is attribution: users must credit the original creator appropriately, including clear references to the source.
A notable feature of the ODC-BY is that does not impose a copyleft clause, meaning that derived data can be licensed under other terms, as long as attribution is maintained.
Ejemplo: Imagine that a city publishes its bicycle station database under ODC-BY. A company can download this data, create an app that recommends cycling routes and add new layers of information. As long as you clearly indicate that the original data comes from the municipality, you can offer your app under any licence you wish, even on a commercial basis.
A comparison of these most commonly used licences allows us to better understand their differences:
|
Licence |
Allows commercial use |
Permitted modification |
Requires attribution | Allos derivative works | Applicable to data | Specialisationsnn |
|
Copyright |
Yes, with permission of the author | No, except by agreement with the creator | No | No | It can be applied to databases, but only if they meet certain requirements of creativity and originality in their structure or selection of content. It does not protect the data itself, but the way it is organised or presented. | Original works such as texts, music, films, software and, in some cases, databases whose structure or selection is creative. It does not protect the data itself. |
| Public domain | Yes | Yes | No | Yes | Yes | Original works such as texts, music, films and software without copyright protection (by expiration, waiver, or legal exclusion) |
| Creative Commons BY (Attribution) | Yes | Yes, with attribution | Yes | Yes | Yes | Reusable text, images, videos, infographics, web content and datasets, provided that authorship is acknowledged |
| Creative Commons BY-SA (Attribution-ShareAlike) | Yes | Yes, you must keep the same licence | Yes | Yes, with the same licence | Yes | Collaborative content such as articles, maps, datasets or open educational resources; ideal for community projects |
| Creative Commons BY-ND (Attribution-NoDerivatives) | Yes | No | Yes | No | Yes, but it is forbidden to modify or combine the data. | Content to be preserved unaltered: official documents, closed infographics, unalterable data sets, etc. |
| Creative Commons CC0 (Public domain) | Yes | Yes | No | Yes | Yes | All kinds of works: texts, images, music, data, software, etc., which are voluntarily released into the public domain. |
| GNU General Public License (GPL) | Yes | Yes, it should be kept under the GPL | Yes | Yes | No | Executable software or source code. Not suitable for documentation, multimedia content or databases. |
| European Union Public Licence (EUPL) | Yes | Yes, derivative works should remain open | Yes | Yes | Partially: could be used for technical data, but is not its main purpose | Software developed by public administrations and its associated technical documentation (manuals, specifications, etc.). |
| Open Data Commons (ODC-BY) | Yes | Yes | Yes | Yes | Yes (specifically designed for open data) | Structured databases such as public statistics, geospatial arrays, open catalogues or administrative registers |
Figure 1. Comparative table. Source: own elaboration
Why is it necessary to use licences in the field of open data?
In the field of open data, these licences are essential to ensure that data is available for public use, promoting transparency, innovation and the development of data-driven solutions. In general, the advantages of using clear licences are:
-
Transparency and open access: clear licences allow citizens, researchers and developers to access and use public data without undue restrictions, fostering government transparency and accountability.
-
Fostering innovation: By enabling the free use of data, open data licences facilitate the creation of applications, services and analytics that can generate economic and social value.
-
Collaboration and reuse: licences that allow for the reuse and modification of data encourage collaboration between different entities and disciplines, fostering the development of more robust and complete solutions.
-
Improved data quality: The availability of open data encourages greater community participation and review, which can lead to an improvement in the quality and accuracy of the data available.
-
Legal certainty for the re-user: Clear licences provide confidence and certainty to those who re-use data, as they know they can do so legally and without fear of future conflicts.
Introduction to the Joinup Licensing Assistant?
In this complex licensing landscape, choosing the right one can be a daunting task, especially for those with no previous experience in licence management. This is where the Joinup Licensing Assistant, a tool developed by the European Union and available at Joinup.europa.eu, comes in. This collaborative platform is designed to promote the exchange of solutions and best practices between public administrations, companies and citizens, and the Licensing Assistant is one of its star tools.
For those working specifically with data, you may also find useful the report published by data.europa.eu, which provides more detailed recommendations on the selection of licences for open datasets in the European context.
The Joinup Licensing Assistant offers several features and benefits that simplify licence selection and management:
|
|
Functionality | Benefits | |
 |
Customised advice: recommends suitable licences according to the type of project and your needs. |  |
Simplifying the selection process: breaks down the choice of licence into clear steps, reducing complexity and time. |
 |
Licence database: access to software licences, content and data, with clear descriptions. |  |
Legal risk reduction: avoids legal problems by providing recommendations that are compatible with project requirements. |
 |
Comparison of licences: allows you to easily see the differences between various licences. |  |
Fostering collaboration and knowledge sharing: facilitates the exchange of experiences between users and public administrations. |
 |
Legal update: provides information that is always up to date with current legislation. |  |
Accessibility and usability: intuitive interface, useful even for those with no legal knowledge. |
 |
Open data support: includes specific options to promote reuse and transparency. |  |
Supporting the sustainability of free software and open data: promotes licences that drive innovation, openness and continuity of projects. |
Figure 2. Table of functionality and benefits. Source: own elaboration
Various sectors can benefit from the use of the Joinup Licensing Assistant:.
- Public administrations: to apply correct licences on software, content and open data, complying with European standards and encouraging re-use.
- Software developers: to align licences with their business models and facilitate distribution and collaboration.
- Content creators: to protect their rights and decide how their work can be used and shared.
- Researchers and scientists: to publish reusable data to drive collaboration and scientific advances.
Conclusion
In an increasingly interconnected and regulated digital environment, using appropriate licences for software, content and especially open data is essential to ensure the legality, sustainability and impact of digital projects. Proper licence management facilitates collaboration, reuse and secure dissemination of resources, while reducing legal risks and promoting interoperability.
In this context, tools such as the Joinup Licensing Assistant offer valuable support for public administrations, companies and citizens, simplifying the choice of licences and adapting it to each case. Their use contributes to creating a more open, secure and efficient digital ecosystem.
Particularly in the field of open data, clear licences make data truly accessible and reusable, fostering institutional transparency, technological innovation and the creation of social value.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
Open data portals help municipalities to offer structured and transparent access to the data they generate in the exercise of their functions and in the provision of the services they are responsible for, while also fostering the creation of applications, services and solutions that generate value for citizens, businesses and public administrations themselves.
The report aims to provide a practical guide for municipal administrations to design, develop and maintain effective open data portals, integrating them into the overall smart city strategy. The document is structured in several sections ranging from strategic planning to technical and operational recommendations necessary for the creation and maintenance of open data portals. Some of the main keys are:
Fundamental principles
The report highlights the importance of integrating open data portals into municipal strategic plans, aligning portal objectives with local priorities and citizens' expectations. It also recommends drawing up a Plan of measures for the promotion of openness and re-use of data (RISP Plan in Spanish acronyms), including governance models, clear licences, an open data agenda and actions to stimulate re-use of data. Finally, it emphasises the need for trained staff in strategic, technical and functional areas, capable of managing, maintaining and promoting the reuse of open data.
General requirements
In terms of general requirements to ensure the success of the portal, the importance of offering quality data, consistent and updated in open formats such as CSV and JSON, but also in XLS, favouring interoperability with national and international platforms through open standards such as DCAT-AP, and guaranteeing effective accessibility of the portal through an intuitive and inclusive design, adapted to different devices. It also points out the obligation to strictly comply with privacy and data protection regulations, especially the General Data Protection Regulation (GDPR).
To promote re-use, the report advises fostering dynamic ecosystems through community events such as hackathons and workshops, highlighting successful examples of practical application of open data. Furthermore, it insists on the need to provide useful tools such as APIs for dynamic queries, interactive data visualisations and full documentation, as well as to implement sustainable funding and maintenance mechanisms.
Technical and functional guidelines
Regarding technical and functional guidelines, the document details the importance of building a robust and scalable technical infrastructure based on cloud technologies, using diverse storage systems such as relational databases, NoSQL and specific solutions for time series or geospatial data. It also highlights the importance of integrating advanced automation tools to ensure consistent data quality and recommends specific solutions to manage real-time data from the Internet of Things (IoT).
In relation to the usability and structure of the portal, the importance of a user-centred design is emphasised, with clear navigation and a powerful search engine to facilitate quick access to data. Furthermore, it stresses the importance of complying with international accessibility standards and providing tools that simplify interaction with data, including clear graphical displays and efficient technical support mechanisms.
The report also highlights the key role of APIs as fundamental tools to facilitate automated and dynamic access to portal data, offering granular queries, clear documentation, robust security mechanisms and reusable standard formats. It also suggests a variety of tools and technical frameworks to implement these APIs efficiently.
Another critical aspect highlighted in the document is the identification and prioritisation of datasets for publication, as the progressive planning of data openness allows adjusting technical and organisational processes in an agile way, starting with the data of greatest strategic relevance and citizen demand.
Finally, the guide recommends establishing a system of metrics and indicators according to the UNE 178301:2015 standard to assess the degree of maturity and the real impact of open data portals. These metrics span strategic, legal, organisational, technical, economic and social domains, providing a holistic approach to measure both the effectiveness of data publication and its tangible impact on society and the local economy.
Conclusions
In conclusion, the report provides a strategic, technical and practical framework that serves as a reference for the deployment of municipal open data portals for cities to maximise their potential as drivers of economic and social development. In addition, the integration of artificial intelligence at various points in open data portal projects represents a strategic opportunity to expand their capabilities and generate a greater impact on citizens.
You can read the full report here.
Blog
The concept of data commons emerges as a transformative approach to the management and sharing of data that serves collective purposes and as an alternative to the growing number of macrosilos of data for private use. By treating data as a shared resource, data commons facilitate collaboration, innovation and equitable access to data, emphasising the communal value of data above all other considerations. As we navigate the complexities of the digital age - currently marked by rapid advances in artificial intelligence (AI) and the continuing debate about the challenges in data governance- the role that data commons can play is now probably more important than ever.
What are data commons?
The data commons refers to a cooperative framework where data is collected, governed and shared among all community participants through protocols that promote openness, equity, ethical use and sustainability. The data commons differ from traditional data-sharing models mainly in the priority given to collaboration and inclusion over unitary control.
Another common goal of the data commons is the creation of collective knowledge that can be used by anyone for the good of society. This makes them particularly useful in addressing today's major challenges, such as environmental challenges, multilingual interaction, mobility, humanitarian catastrophes, preservation of knowledge or new challenges in health and health care.
In addition, it is also increasingly common for these data sharing initiatives to incorporate all kinds of tools to facilitate data analysis and interpretation , thus democratising not only the ownership of and access to data, but also its use.
For all these reasons, data commons could be considered today as a criticalpublic digital infrastructure for harnessing data and promoting social welfare.
Principles of the data commons
The data commons are built on a number of simple principles that will be key to their proper governance:
- Openness and accessibility: data must be accessible to all authorised persons.
- Ethical governance: balance between inclusion and privacy.
- Sustainability: establish mechanisms for funding and resources to maintain data as a commons over time.
- Collaboration: encourage participants to contribute new data and ideas that enable their use for mutual benefit.
- Trust: relationships based on transparency and credibility between stakeholders.
In addition, if we also want to ensure that the data commons fulfil their role as public domain digital infrastructure, we must guarantee other additional minimum requirements such as: existence of permanent unique identifiers , documented metadata , easy access through application programming interfaces (APIs), portability of the data, data sharing agreements between peers and ability to perform operations on the data.
The important role of the data commons in the age of Artificial Intelligence
AI-driven innovation has exponentially increased the demand for high-quality, diverse data sets a relatively scarce commodityat a large scale that may lead to bottlenecks in the future development of the technology and, at the same time, makes data commons a very relevant enabler for a more equitable AI. By providing shared datasets governed by ethical principles, data commons help mitigate common risks such as risks, data monopolies and unequal access to the benefits of AI.
Moreover, the current concentration of AI developments also represents a challenge for the public interest. In this context, the data commons hold the key to enable a set of alternative, public and general interest-oriented AI systems and applications, which can contribute to rebalancing this current concentration of power. The aim of these models would be to demonstrate how more democratic, public interest-oriented and purposeful systems can be designed based on public AI governance principles and models.
However, the era of generative AI also presents new challenges for data commons such as, for example and perhaps most prominently, the potential risk of uncontrolled exploitation of shared datasets that could give rise to new ethical challenges due to data misuse and privacy violations.
On the other hand, the lack of transparency regarding the use of the data commons by the AI could also end up demotivating the communities that manage them, putting their continuity at risk. This is due to concerns that in the end their contribution may be benefiting mainly the large technology platforms, without any guarantee of a fairer sharing of the value and impact generated as originally intended".
For all of the above, organisations such as Open Future have been advocating for several years now for Artificial Intelligence to function as a common good, managed and developed as a digital public infrastructure for the benefit of all, avoiding the concentration of power and promoting equity and transparency in both its development and its application.
To this end, they propose a set of principles to guide the governance of the data commons in its application for AI training so as to maximise the value generated for society and minimise the possibilities of potential abuse by commercial interests:
- Share as much data as possible, while maintaining such restrictions as may be necessary to preserve individual and collective rights.
- Be fully transparent and provide all existing documentation on the data, as well as on its use, and clearly distinguish between real and synthetic data.
- Respect decisions made about the use of data by persons who have previously contributed to the creation of the data, either through the transfer of their own data or through the development of new content, including respect for any existing legal framework.
- Protect the common benefit in the use of data and a sustainable use of data in order to ensure proper governance over time, always recognising its relational and collective nature.
- Ensuring the quality of data, which is critical to preserving its value as a common good, especially given the potential risks of contamination associated with its use by AI.
- Establish trusted institutions that are responsible for data governance and facilitate participation by the entire data community, thus going a step beyond the existing models for data intermediaries.
Use cases and applications
There are currently many real-world examples that help illustrate the transformative potential of data commons:
- Health data commons : projects such as the National Institutes of Health's initiative in the United States - NIH Common Fund to analyse and share large biomedical datasets, or the National Cancer Institute's Cancer Research Data Commons , demonstrate how data commons can contribute to the acceleration of health research and innovation.
- AI training and machine learning: the evaluation of AI systems depends on rigorous and standardised test data sets. Initiatives such as OpenML or MLCommons build open, large-scale and diverse datasets, helping the wider community to deliver more accurate and secure AI systems.
- Urban and mobility data commons : cities that take advantage of shared urban data platforms improve decision-making and public services through collective data analysis, as is the case of Barcelona Dades, which in addition to a large repository of open data integrates and disseminates data and analysis on the demographic, economic, social and political evolution of the city. Other initiatives such as OpenStreetMaps itself can also contribute to providing freely accessible geographic data.
- Culture and knowledge preservation: with such relevant initiatives in this field as Mozilla's Common Voice project to preserve and revitalise the world's languages, or Wikidata, which aims to provide structured access to all data from Wikimedia projects, including the popular Wikipedia.
Challenges in the data commons
Despite their promise and potential as a transformative tool for new challenges in the digital age, the data commons also face their own challenges:
- Complexity in governance: Striking the right balance between inclusion, control and privacy can be a delicate task.
- Sustainability: Many of the existing data commons are fighting an ongoing battle to try to secure the funding and resources they need to sustain themselves and ensure their long-term survival.
- Legal and ethical issues: addressing challenges relating to intellectual property rights, data ownership and ethical use remain critical issues that have yet to be fully resolved.
- Interoperability: Ensuring compatibility between datasets and platforms is a persistent technical hurdle in almost any data sharing initiative, and the data commons were to be no exception.
The way forward
To unlock their full potential, the data commons require collective action and a determined commitment to innovation. Key actions include:
- Develop standardised governance models that strike a balance between ethical considerations and technical requirements.
- Apply the principle of reciprocity in the use of data, requiring those who benefit from it to share their results back with the community.
- Protection of sensitive data through anonymisation, preventing data from being used for mass surveillance or discrimination.
- Encourage investment in infrastructure to support scalable and sustainable data exchange.
- Promote awareness of the social benefits of data commons to encourage participation and collaboration.
Policy makers, researchers and civil society organisations should work together to create an ecosystem in which the data commons can thrive, fostering more equitable growth in the digital economy and ensuring that the data commons can benefit all.
Conclusion
The data commons can be a powerful tool for democratising access to data and fostering innovation. In this era defined by AI and digital transformation, they offer us an alternative path to equitable, sustainable and inclusive progress. Addressing its challenges and adopting a collaborative governance approach through cooperation between communities, researchers and regulators will ensure fair and responsible use of data.
This will ensure that data commons become a fundamental pillar of the digital future, including new applications of Artificial Intelligence, and could also serve as a key enabling tool for some of the key actions that are part of the recently announced European competitiveness compass, such as the new Data Union strategy and the AI Gigafactories initiative.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Artificial Intelligence (AI) is no longer a futuristic concept and has become a key tool in our daily lives. From movie or series recommendations on streaming platforms to virtual assistants like Alexa or Google Assistant on our devices, AI is everywhere. But how do you build an AI model? Despite what it might seem, the process is less intimidating if we break it down into clear and understandable steps.
Step 1: Define the problem
Before we start, we need to be very clear about what we want to solve. AI is not a magic wand: different models will work better in different applications and contexts so it is important to define the specific task we want to execute. For example, do we want to predict the sales of a product? Classify emails as spam or non-spam? Having a clear definition of the problem will help us structure the rest of the process.
In addition, we need to consider what kind of data we have and what the expectations are. This includes determining the desired level of accuracy and the constraints of available time or resources.
Step 2: Collect the data
The quality of an AI model depends directly on the quality of the data used to train it. This step consists of collecting and organising the data relevant to our problem. For example, if we want to predict sales, we will need historical data such as prices, promotions or buying patterns.
Data collection starts with identifying relevant sources, which can be internal databases, sensors, surveys... In addition to the company's own data, there is a wide ecosystem of data, both open and proprietary, that can be drawn upon to build more powerful models. For example, the Government of Spain makes available through the datos.gob.es portal multiple sets of open data published by public institutions. On the other hand, Amazon Web Services (AWS) through its AWS Data Exchange portal allows access and subscription to thousands of proprietary datasets published and maintained by different companies and organisations.
The amount of data required must also be considered here. AI models often require large volumes of information to learn effectively. It is also crucial that the data are representative and do not contain biases that could affect the results. For example, if we train a model to predict consumption patterns and only use data from a limited group of people, it is likely that the predictions will not be valid for other groups with different behaviours.
Step 3: Prepare and explore the data
Once the data have been collected, it is time to clean and normalise them. In many cases, raw data may contain problems such as errors, duplications, missing values, inconsistencies or non-standardised formats. For example, you might find empty cells in a sales dataset or dates that do not follow a consistent format. Before feeding the model with this data, it is essential to fit it to ensure that the analysis is accurate and reliable. This step not only improves the quality of the results, but also ensures that the model can correctly interpret the information.
Once the data is clean, it is essential to perform feature engineering (feature engineering), a creative process that can make the difference between a basic model and an excellent one. This phase consists of creating new variables that better capture the nature of the problem we want to solve. For example, if we are analysing onlinesales, in addition to using the direct price of the product, we could create new characteristics such as the price/category_average ratio, the days since the last promotion, or variables that capture the seasonality of sales. Experience shows that well-designed features are often more important for the success of the model than the choice of the algorithm itself.
In this phase, we will also carry out a first exploratory analysis of the data, seeking to familiarise ourselves with the data and detect possible patterns, trends or irregularities that may influence the model. Further details on how to conduct an exploratory data analysis can be found in this guide .
Another typical activity at this stage is to divide the data into training, validation and test sets. For example, if we have 10,000 records, we could use 70% for training, 20% for validation and 10% for testing. This allows the model to learn without overfitting to a specific data set.
To ensure that our evaluation is robust, especially when working with limited datasets, it is advisable to implement cross-validationtechniques. This methodology divides the data into multiple subsets and performs several iterations of training and validation. For example, in a 5-fold cross-validation, we split the data into 5 parts and train 5 times, each time using a different part as the validation set. This gives us a more reliable estimate of the real performance of the model and helps us to detect problems of over-fitting or variability in the results.
Step 4: Select a model
There are multiple types of AI models, and the choice depends on the problem we want to solve. Common examples are regression, decision tree models, clustering models, time series models or neural networks. In general, there are supervised models, unsupervised models and reinforcement learning models. More detail can be found in this post on how machines learn.
When selecting a model, it is important to consider factors such as the nature of the data, the complexity of the problem and the ultimate goal. For example, a simple model such as linear regression may be sufficient for simple, well-structured problems, while neural networks or advanced models might be needed for tasks such as image recognition or natural language processing. In addition, the balance between accuracy, training time and computational resources must also be considered. A more accurate model generally requires more complex configurations, such as more data, deeper neural networks or optimised parameters. Increasing the complexity of the model or working with large datasets can significantly lengthen the time needed to train the model. This can be a problem in environments where decisions must be made quickly or resources are limited and require specialised hardware, such as GPUs or TPUs, and larger amounts of memory and storage.
Today, many open source libraries facilitate the implementation of these models, such as TensorFlow, PyTorch or scikit-learn.
Step 5: Train the model
Training is at the heart of the process. During this stage, we feed the model with training data so that it learns to perform its task. This is achieved by adjusting the parameters of the model to minimise the error between its predictions and the actual results.
Here it is key to constantly evaluate the performance of the model with the validation set and make adjustments if necessary. For example, in a neural network-type model we could test different hyperparameter settings such as learning rate, number of hidden layers and neurons, batch size, number of epochs, or activation function, among others.
Step 6: Evaluate the model
Once trained, it is time to test the model using the test data set we set aside during the training phase. This step is crucial to measure how it performs on data that is new to the model and ensures that it is not "overtrained", i.e. that it not only performs well on training data, but that it is able to apply learning on new data that may be generated on a day-to-day basis.
When evaluating a model, in addition to accuracy, it is also common to consider:
- Confidence in predictions: assess how confident the predictions made are.
- Response speed: time taken by the model to process and generate a prediction.
- Resource efficiency: measure how much memory and computational usage the model requires.
- Adaptability: how well the model can be adjusted to new data or conditions without complete retraining.
Step 7: Deploy and maintain the model
When the model meets our expectations, it is ready to be deployed in a real environment. This could involve integrating the model into an application, automating tasks or generating reports.
However, the work does not end here. The AI needs continuous maintenance to adapt to changes in data or real-world conditions. For example, if buying patterns change due to a new trend, the model will need to be updated.
Building AI models is not an exact science, it is the result of a structured process that combines logic, creativity and perseverance. This is because multiple factors are involved, such as data quality, model design choices and human decisions during optimisation. Although clear methodologies and advanced tools exist, model building requires experimentation, fine-tuning and often an iterative approach to obtain satisfactory results. While each step requires attention to detail, the tools and technologies available today make this challenge accessible to anyone interested in exploring the world of AI.
ANNEX I - Definitions Types of models
-
Regression: supervised techniques that model the relationship between a dependent variable (outcome) and one or more independent variables (predictors). Regression is used to predict continuous values, such as future sales or temperatures, and may include approaches such as linear, logistic or polynomial regression, depending on the complexity of the problem and the relationship between the variables.
-
Decision tree models: supervised methods that represent decisions and their possible consequences in the form of a tree. At each node, a decision is made based on a characteristic of the data, dividing the set into smaller subsets. These models are intuitive and useful for classification and prediction, as they generate clear rules that explain the reasoning behind each decision.
-
Clustering models: unsupervised techniques that group data into subsets called clusters, based on similarities or proximity between the data. For example, customers with similar buying habits can be grouped together to personalise marketing strategies. Models such as k-means or DBSCAN allow useful patterns to be identified without the need for labelled data.
-
Time series models: designed to work with chronologically ordered data, these models analyse temporal patterns and make predictions based on history. They are used in cases such as demand forecasting, financial analysis or meteorology. They incorporate trends, seasonality and relationships between past and future data.
-
Neural networks: models inspired by the workings of the human brain, where layers of artificial neurons process information and detect complex patterns. They are especially useful in tasks such as image recognition, natural language processing and gaming. Neural networks can be simple or deep learning, depending on the problem and the amount of data.
-
Supervised models: these models learn from labelled data, i.e., sets in which each input has a known outcome. The aim is for the model to generalise to predict outcomes in new data. Examples include spam and non-spam mail classification and price predictions.
-
Unsupervised models: twork with unlabelled data, looking for hidden patterns, structures or relationships within the data. They are ideal for exploratory tasks where the expected outcome is not known in advance, such as market segmentation or dimensionality reduction.
- Reinforcement learning model: in this approach, an agent learns by interacting with an environment, making decisions and receiving rewards or penalties based on performance. This type of learning is useful in problems where decisions affect a long-term goal, such as training robots, playing video games or developing investment strategies.
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Web API design is a fundamental discipline for the development of applications and services, facilitating the fluid exchange of data between different systems. In the context of open data platforms, APIs are particularly important as they allow users to access the information they need automatically and efficiently, saving costs and resources.
This article explores the essential principles that should guide the creation of effective, secure and sustainable web APIs, based on the principles compiled by the Technical Architecture Group linked to the World Wide Web Consortium (W3C), following ethical and technical standards. Although these principles refer to API design, many are applicable to web development in general.
The aim is to enable developers to ensure that their APIs not only meet technical requirements, but also respect users' privacy and security, promoting a safer and more efficient web for all.
In this post, we will look at some tips for API developers and how they can be put into practice.
Prioritise user needs
When designing an API, it is crucial to follow the hierarchy of needs established by the W3C:
- First, the needs of the end-user.
- Second, the needs of web developers.
- Third, the needs of browser implementers.
- Finally, theoretical purity.
In this way we can drive a user experience that is intuitive, functional and engaging. This hierarchy should guide design decisions, while recognising that sometimes these levels are interrelated: for example, an API that is easier for developers to use often results in a better end-user experience.
Ensures security
Ensuring security when developing an API is crucial to protect both user data and the integrity of the system. An insecure API can be an entry point for attackers seeking to access sensitive information or compromise system functionality. Therefore, when adding new functionalities, we must meet the user's expectations and ensure their security.
In this sense, it is essential to consider factors related to user authentication, data encryption, input validation, request rate management (or Rate Limiting, to limit the number of requests a user can make in a given period and avoid denial of service attacks), etc. It is also necessary to continually monitor API activities and keep detailed logs to quickly detect and respond to any suspicious activity.
Develop a user interface that conveys trust and confidence
It is necessary to consider how new functionalities impact on user interfaces. Interfaces must be designed so that users can trust and verify that the information provided is genuine and has not been falsified. Aspects such as the address bar, security indicators and permission requests should make it clear who you are interacting with and how.
For example, the JavaScript alert function, which allows the display of a modal dialogue box that appears to be part of the browser, is a case history that illustrates this need. This feature, created in the early days of the web, has often been used to trick users into thinking they are interacting with the browser, when in fact they are interacting with the web page. If this functionality were proposed today, it would probably not be accepted because of these security risks.
Ask for explicit consent from users
In the context of satisfying a user need, a website may use a function that poses a threat. For example, access to the user's geolocation may be helpful in some contexts (such as a mapping application), but it also affects privacy.
In these cases, the user's consent to their use is required. To do this:
- The user must understand what he or she is accessing. If you cannot explain to a typical user what he or she is consenting to in an intelligible way, you will have to reconsider the design of the function.
- The user must be able to choose to effectively grant or refuse such permission. If a permission request is rejected, the website will not be able to do anything that the user thinks they have dismissed.
By asking for consent, we can inform the user of what capabilities the website has or does not have, reinforcing their confidence in the security of the site. However, the benefit of a new feature must justify the additional burden on the user in deciding whether or not to grant permission for a feature.
Uses identification mechanisms appropriate to the context
It is necessary to be transparent and allow individuals to control their identifiers and the information attached to them that they provide in different contexts on the web.
Functionalities that use or rely on identifiers linked to data about an individual carry privacy risks that may go beyond a single API or system. This includes passively generated data (such as your behaviour on the web) and actively collected data (e.g. through a form). In this regard, it is necessary to understand the context in which they will be used and how they will be integrated with other web functionalities, ensuring that the user can give appropriate consent.
It is advisable to design APIs that collect the minimum amount of data necessary and use short-lived temporary identifiers, unless a persistent identifier is absolutely necessary.
Creates functionalities compatible with the full range of devices and platforms
As far as possible, ensure that the web functionalities are operational on different input and output devices, screen sizes, interaction modes, platforms and media, favouring user flexibility.
For example, the 'display: block', 'display: flex' and 'display: grid' layout models in CSS, by default, place content within the available space and without overlaps. This way they work on different screen sizes and allow users to choose their own font and size without causing text overflow.
Add new capabilities with care
Adding new capabilities to the website requires consideration of existing functionality and content, to assess how it will be integrated. Do not assume that a change is possible or impossible without first verifying it.
There are many extension points that allow you to add functionality, but there are changes that cannot be made by simply adding or removing elements, because they could generate errors or affect the user experience. It is therefore necessary to verify the current situation first, as we will see in the next section.
Before removing or changing functionality, understand its current use
It is possible to remove or change functions and capabilities, but the nature and extent of their impact on existing content must first be understood. This may require investigating how current functions are used.
The obligation to understand existing use applies to any function on which the content depends. Web functions are not only defined in the specifications, but also in the way users use them.
Best practice is to prioritise compatibility of new features with existing content and user behaviour. Sometimes a significant amount of content may depend on a particular behaviour. In these situations, it is not advisable to remove or change such behaviour.
Leave the website better than you found it
The way to add new capabilities to a web platform is to improve the platform as a whole, e.g. its security, privacy or accessibility features.
The existence of a defect in a particular part of the platform should not be used as an excuse to add or extend additional functionalities in order to fix it, as this may duplicate problems and diminish the overall quality of the platform. Wherever possible, new web capabilities should be created that improve the overall quality of the platform, mitigating existing shortcomings across the board.
Minimises user data
Functionalities must be designed to be operational with the minimal amount of user input necessary to achieve their objectives. In doing so, we limit the risks of disclosure or misuse.
It is recommended to design APIs so that websites find it easier to request, collect and/or transmit a small amount of data (more granular or specific data), than to work with more generic or massive data. APIs should provide granularity and user controls, in particular if they work on personal data.
Other recommendations
The document also provides tips for API design using various programming languages. In this sense, it provides recommendations linked to HTML, CSS, JavaScript, etc. You can read the recommendations here.
In addition, if you are thinking of integrating an API into your open data platform, we recommend reading the Practical guide to publishing Open Data using APIs.
By following these guidelines, you will be able to develop consistent and useful websites for users, allowing them to achieve their objectives in an agile and resource-optimised way.
Evento
The EU Open Data Days 2025 is an essential event for all those interested in the world of open data and innovation in Europe and the world. This meeting, to be held on 19-20 March 2025, will bring together experts, practitioners, developers, researchers and policy makers to share knowledge, explore new opportunities and address the challenges facing the open data community.
The event, organised by the European Commission through data.europa.eu, aims to promote the re-use of open data. Participants will have the opportunity to learn about the latest trends in the use of open data, discover new tools and discuss the policies and regulations that are shaping the digital landscape in Europe.
Where and when does it take place?
El evento se celebrará en el Centro Europeo de Convenciones de Luxemburgo, aunque también se podrá seguir online, con el siguiente horario:
- Wednesday 19 March 2025, from 13:30 to 18:30.
- Thursday 20 March 2025, from 9:00 to 15:30.
What issues will be addressed?
The agenda of the event is already available, where we find different themes, such as, for example:
- Success stories and best practices: the event will be attended by professionals working at the frontline of European data policy to share their experience. Among other issues, these experts will provide practical guidance on how to inventory and open up a country's public sector data, address the work involved in compiling high-value datasets or analyse perspectives on data reuse in business models. Good practices for quality metadata or improved data governance and interoperability will also be explained.
- Focus on the use of artificial intelligence (AI): open data offers an invaluable source for the development and advancement of AI. In addition, AI can optimise the location, management and use of this data, offering tools to help streamline processes and extract greater insight. In this regard, the event will address the potential of AI to transform open government data ecosystems, fostering innovation, improving governance and enhancing citizen participation. The managers of Norway's national data portal will tell how they use an AI-based search engine to improve data localisation. In addition, the advances in linguistic data spaces and their use in language modelling will be explained, and how to creatively combine open data for social impact will be explored.
- Learning about data visualisation: event attendees will be able to explore how data visualisation is transforming communication, policy making and citizen engagement. Through various cases (such as the family tree of 3,000 European royals or UNESCO's Intangible Cultural Heritage relationships) it will show how iterative design processes can uncover hidden patterns in complex networks, providing insights into storytelling and data communication. It will also address how design elements such as colour, scale and focus influence the perception of data.
- Examples and use cases: multiple examples of concrete projects based on the reuse of data will be shown, in fields such as energy, urban development or the environment. Among the experiences that will be shared is a Spanish company, Tangible Data, which will tell how physical data sculptures turn complex datasets into accessible and engaging experiences.
These are just some of the topics to be addressed, but there will also be discussions on open science, the role of open data in transparency and accountability, etc.
Why are EU Open Data Days so important?
Access to open data has proven to be a powerful tool for improving decision-making, driving innovation and research, and improving the efficiency of organisations. At a time when digitisation is advancing rapidly, the importance of sharing and reusing data is becoming increasingly crucial to address global challenges such as climate change, public health or social justice.
The EU Open Data Days 2025 are an opportunity to explore how open data can be harnessed to build a more connected, innovative and participatory Europe.
In addition, for those who choose to attend in person, the event will also be an opportunity to establish contacts with other professionals and organisations in the sector, creating new collaborations that can lead to innovative projects.
How can I attend?
To attend in person, it is necessary to register through this link. However, registration is not required to attend the event online.
If you have any queries, an e-mail address has been set up to answer any questions you may have about the event: EU-Open-Data-Days@ec.europa.eu.
More information on the event website.