Blog
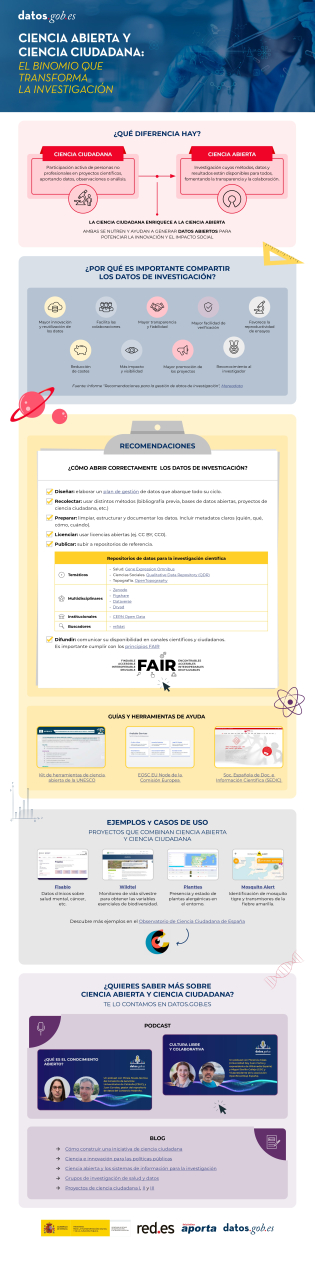
La participación ciudadana en la recopilación de datos científicos impulsa una ciencia más democrática, al involucrar a la sociedad en los procesos de I+D+i y reforzar la rendición de cuentas. En este sentido, existen diversidad de iniciativas de ciencia ciudadana puestas en marcha por entidades como CSIC, CENEAM o CREAF, entre otras. Además, actualmente, existen numerosas plataformas de plataformas de ciencia ciudadana que ayudan a cualquier persona a encontrar, unirse y contribuir a una gran diversidad de iniciativas alrededor del mundo, como por ejemplo SciStarter.
Algunas referencias en legislación nacional y europea
Diferentes normativas, tanto a nivel nacional como a nivel europeo, destacan la importancia de promover proyectos de ciencia ciudadana como componente fundamental de la ciencia abierta. Por ejemplo, la Ley Orgánica 2/2023, de 22 de marzo, del Sistema Universitario, establece que las universidades promoverán la ciencia ciudadana como un instrumento clave para generar conocimiento compartido y responder a retos sociales, buscando no solo fortalecer el vínculo entre ciencia y sociedad, sino también contribuir a un desarrollo territorial más equitativo, inclusivo y sostenible.
Por otro lado, la Ley 14/2011, de 1 de junio, de la Ciencia, la Tecnología y la Innovación, promueve “la participación de la ciudadanía en el proceso científico técnico a través, entre otros mecanismos, de la definición de agendas de investigación, la observación, recopilación y procesamiento de datos, la evaluación de impacto en la selección de proyectos y la monitorización de resultados, y otros procesos de participación ciudadana”.
A nivel europeo, el Reglamento (UE) 2021/695 que establece el Programa Marco de Investigación e Innovación “Horizonte Europa”, indica la oportunidad de desarrollar proyectos codiseñados con la ciudadanía, avalando la ciencia ciudadana como mecanismo de investigación y vía de difusión de resultados.
Iniciativas de ciencia ciudadana y planes de gestión de datos
El primer paso para definir una iniciativa de ciencia ciudadana suele ser establecer una pregunta de investigación que necesite de una recopilación de datos que pueda abordarse con la colaboración de la ciudadanía. Después, se diseña un protocolo accesible para que los participantes recojan o analicen datos de forma sencilla y fiable (incluso podría ser un proceso gamificado). Se deben preparar materiales formativos y desarrollar un medio de participación (aplicación, web o incluso papel). También se planifica cómo comunicar avances y resultados a la ciudadanía, incentivando su participación.
Al tratarse de una actividad intensiva en la recolección de datos, es interesante que los proyectos de ciencia ciudadana dispongan de un plan de gestión de datos que defina el ciclo de vida del dato en proyectos de investigación, es decir cómo se crean, organizan, comparten, reutilizan y preservan los datos en iniciativas de ciencia ciudadana. Sin embargo, la mayoría de las iniciativas de ciencia ciudadana no dispone de este plan: en este reciente artículo de investigación se encontró que sólo disponían de plan de gestión de datos el 38% de proyectos de ciencia ciudadana consultados.

Figura 1. Ciclo de vida del dato en proyectos de ciencia ciudadana Fuente: elaboración propia – datos.gob.es.
Por otra parte, los datos procedentes de la ciencia ciudadana solo alcanzan todo su potencial cuando cumplen los principios FAIR y se publican en abierto. Con el fin de ayudar a tener este plan de gestión de datos que hagan que los datos procedentes de iniciativas de ciencia ciudadana sean FAIR, es preciso contar con estándares específicos para ciencia ciudadana como PPSR Core.
Datos abiertos para ciencia ciudadana con el estándar PPSR Core
La publicación de datos abiertos debe considerarse desde etapas tempranas de un proyecto de ciencia ciudadana, incorporando el estándar PPSR Core como pieza clave. Como mencionábamos anteriormente, cuando se formulan las preguntas de investigación, en una iniciativa de ciencia ciudadana, se debe plantear un plan de gestión de datos que indique qué datos recopilar, en qué formato y con qué metadatos, así como las necesidades de limpieza y aseguramiento de calidad a partir de los datos que recolecte la ciudadanía, además de un calendario de publicación.
Luego, se debe estandarizar con PPSR (Public Participation in Scientific Research) Core. PPSR Core es un conjunto de estándares de datos y metadatos, especialmente diseñados para fomentar la participación ciudadana en procesos de investigación científica. Posee una arquitectura de tres capas a partir de un Common Data Model (CDM). Este CDM ayuda a organizar de forma coherente y conectada la información sobre proyectos de ciencia ciudadana, los conjuntos de datos relacionados y las observaciones que forman parte de ellos, de tal manera que el CDM facilita la interoperabilidad entre plataformas de ciencia ciudadana y disciplinas científicas. Este modelo común se estructura en tres capas principales que permiten describir de forma estructurada y reutilizable los elementos clave de un proyecto de ciencia ciudadana. La primera es el Project Metadata Model (PMM), que recoge la información general del proyecto, como su objetivo, público participante, ubicación, duración, personas responsables, fuentes de financiación o enlaces relevantes. En segundo lugar, el Dataset Metadata Model (DMM) documenta cada conjunto de datos generado, detallando qué tipo de información se recopila, mediante qué método, en qué periodo, bajo qué licencia y con qué condiciones de acceso. Por último, el Observation Data Model (ODM) se centra en cada observación individual realizada por los participantes de la iniciativa de ciencia ciudadana, incluyendo la fecha y el lugar de la observación y el resultado. Es interesante resaltar que este modelo de capas de PPSR-Core permite añadir extensiones específicas según el ámbito científico, apoyándose en vocabularios existentes como Darwin Core (biodiversidad) o ISO 19156 (mediciones de sensores). (ODM) se centra en cada observación individual realizada por los participantes de la iniciativa de ciencia ciudadana, incluyendo la fecha y el lugar de la observación y el resultado. Es interesante resaltar que este modelo de capas de PPSR-Core permite añadir extensiones específicas según el ámbito científico, apoyándose en vocabularios existentes como Darwin Core (biodiversidad) o ISO 19156 (mediciones de sensores).

Figura 2. Arquitectura de capas de PPSR CORE. Fuente: elaboración propia – datos.gob.es.
Esta separación permite que una iniciativa de ciencia ciudadana pueda federar automáticamente la ficha del proyecto (PMM) con plataformas como SciStarter, compartir un conjunto de datos (DMM) con un repositorio institucional de datos abiertos científicos, como aquellos agregados en RECOLECTA del FECYT y, al mismo tiempo, enviar observaciones verificadas (ODM) a una plataforma como GBIF sin redefinir cada campo.
Además, el uso de PPSR Core aporta una serie de ventajas para la gestión de los datos de una iniciativa de ciencia ciudadana:
- Mayor interoperabilidad: plataformas como SciStarter ya intercambian metadatos usando PMM, por lo que se evita duplicar información.
- Agregación multidisciplinar: los perfiles del ODM permiten unir conjuntos de datos de dominios distintos (por ejemplo, calidad del aire y salud) alrededor de atributos comunes, algo crucial para estudios multidisciplinares.
- Alineamiento con principios FAIR: los campos obligatorios del DMM son útiles para que los conjuntos de datos de ciencia ciudadana cumplan los principios FAIR.
Cabe destacar que PPSR Core permite añadir contexto a los conjuntos de datos obtenidos en iniciativas de ciencia ciudadana. Es una buena práctica trasladar el contenido del PMM a lenguaje entendible por la ciudadanía, así como obtener un diccionario de datos a partir del DMM (descripción de cada campo y unidad) y los mecanismos de transformación de cada registro a partir del ODM. Finalmente, se puede destacar iniciativas para mejorar PPSR Core, por ejemplo, a través de un perfil de DCAT para ciencia ciudadana.
Conclusiones
Planificar la publicación de datos abiertos desde el inicio de un proyecto de ciencia ciudadana es clave para garantizar la calidad y la interoperabilidad de los datos generados, facilitar su reutilización y maximizar el impacto científico y social del proyecto. Para ello, PPSR Core ofrece un estándar basado en niveles (PMM, DMM, ODM) que conecta los datos generados por la ciencia ciudadana con diversas plataformas, potenciando que estos datos cumplan los principios FAIR y considerando, de manera integrada, diversas disciplinas científicas. Con PPSR Core cada observación ciudadana se convierte fácilmente en datos abiertos sobre el que la comunidad científica pueda seguir construyendo conocimiento para el beneficio de la sociedad.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En la búsqueda habitual de trucos para hacer más efectivos nuestros prompts, uno de los más populares es la activación de la cadena de razonamiento (chain of thought). Consiste en plantear un problema multinivel y pedir al sistema de IA que lo resuelva, pero no dándonos la solución de golpe, sino visibilizando paso a paso la línea lógica necesaria para resolverlo. Esta función está disponible tanto en sistemas IA de pago como gratuitos, todo consiste en saber cómo activarla.
En su origen, la cadena de razonamiento era una de las muchas pruebas de lógica semántica a las que los desarrolladores someten a los modelos de lenguaje. Sin embargo, en 2022, investigadores de Google Brain demostraron por primera vez que proporcionar ejemplos de razonamiento encadenado en el prompt podía desbloquear en los modelos capacidades mayores de resolución de problemas.
A partir de este momento, poco a poco, se ha posicionado como una técnica útil para obtener mejores resultados desde el uso, siendo muy cuestionada al mismo tiempo desde el punto de vista técnico. Porque lo realmente llamativo de este proceso es que los modelos de lenguaje no piensan en cadena: solo están simulando ante nosotros el razonamiento humano.
Cómo activar la cadena de razonamiento
Existen dos maneras posibles de activar este proceso en los modelos: desde un botón proporcionado por la propia herramienta, como ocurre en el caso de DeepSeek con el botón “DeepThink” que activa el modelo R1:

Figura 1. DeepSeek con el botón “DeepThink” que activa el modelo R1.
O bien, y esta es la opción más sencilla y habitual, desde el propio prompt. Si optamos por esta opción, podemos hacerlo de dos maneras: solo con la instrucción (zero-shot prompting) o aportando ejemplos resueltos (few-shot prompting).
- Zero-shot prompting: tan sencillo como añadir al final del prompt una instrucción del tipo “Razona paso a paso”, o “Piensa antes de responder”. Esto nos asegura que se va a activar la cadena de razonamiento y vamos a ver visibilizado el proceso lógico del problema.

Figura 2. Ejemplo de Zero-shot prompting.
- Few-shot prompting: si queremos un patrón de respuesta muy preciso, puede ser interesante aportar algunos ejemplos resueltos de pregunta-respuesta. El modelo ve esta demostración y la imita como patrón en una nueva pregunta.

Figura 3. Ejemplo de Few-shot prompting.
Ventajas y tres ejemplos prácticos
Cuando activamos la cadena de razonamiento estamos pidiendo al sistema que “muestre” su trabajo de manera visible ante nuestros ojos, como si estuviera resolviendo el problema en una pizarra. Aunque no se elimina del todo, al obligar al modelo de lenguaje a expresar los pasos lógicos se reduce la posibilidad de errores, porque el modelo focaliza su atención en un paso cada vez. Además, en caso de existir un error, para la persona usuaria del sistema es mucho más fácil detectarlo a simple vista.
¿Cuándo es útil la cadena de razonamiento? Especialmente en cálculos matemáticos, problemas lógicos, acertijos, dilemas éticos o preguntas con distintas etapas y saltos (llamadas en inglés multi-hop). En estas últimas, es práctico, sobre todo, en aquellas en las que hay que manejar información del mundo que no se incluye directamente en la pregunta.
Vamos a ver algunos ejemplos en los que aplicamos esta técnica a un problema cronológico, uno espacial y uno probabilístico.
-
Razonamiento cronológico
Pensemos en el siguiente prompt:
Si Juan nació en octubre y tiene 15 años, ¿cuántos años tenía en junio del año pasado?

Figura 5. Ejemplo de razonamiento cronológico.
Para este ejemplo hemos utilizado el modelo GPT-o3, disponible en la versión Plus de ChatGPT y especializado en razonamiento, por lo que la cadena de pensamiento se activa de serie y no es necesario hacerlo desde el prompt. Este modelo está programado para darnos la información del tiempo que ha tardado en resolver el problema, en este caso 6 segundos. Tanto la respuesta como la explicación son correctas, y para llegar a ellas el modelo ha tenido que incorporar información externa como el orden de los meses del año, el conocimiento de la fecha actual para plantear el anclaje temporal, o la idea de que la edad cambia en el mes del cumpleaños, y no al principio del año.
-
Razonamiento espacial
Una persona está mirando hacia el norte. Gira 90 grados a la derecha, luego 180 grados a la izquierda. ¿En qué dirección está mirando ahora?

Figura 6. Ejemplo de razonamiento espacial.
En esta ocasión hemos usado la versión gratuita de ChatGPT, que utiliza por defecto (aunque con limitaciones) el modelo GPT-4o, por lo que es más seguro activar la cadena de razonamiento con una indicación al final del prompt: Razona paso a paso. Para resolver este problema el modelo necesita conocimientos generales del mundo que ha aprendido en el entrenamiento, como la orientación espacial de los puntos cardinales, los grados de giro, la lateralidad y la lógica básica del movimiento.
-
Razonamiento probabilístico
En una bolsa hay 3 bolas rojas, 2 verdes y 1 azul. Si sacas una bola al azar sin mirar, ¿cuál es la probabilidad de que no sea ni roja ni azul?

Figura 7. Ejemplo de razonamiento probabilístico.
Para lanzar este prompt hemos utilizado Gemini 2.5 Flash, en la versión Gemini Pro de Google. En el entrenamiento de este modelo se incluyeron con toda seguridad fundamentos tanto de aritmética básica como de probabilidad, pero lo más efectivo para que el modelo aprenda a resolver este tipo de ejercicios son los millones de ejemplos resueltos que ha visto. Los problemas de probabilidad y sus soluciones paso a paso constituyen el modelo a imitar a la hora de reconstruir este razonamiento.
La gran simulación
Y ahora, vamos con el cuestionamiento. En los últimos meses ha crecido el debate sobre si podemos o no confiar en estas explicaciones simuladas, sobre todo porque, idealmente, la cadena de pensamiento debería reflejar fielmente el proceso interno por el que el modelo llega a su respuesta. Y no hay garantía práctica de que así sea.
Desde el equipo de Anthropic (creadores de Claude, otro gran modelo de lenguaje) han realizado en 2025 un experimento trampa con Claude Sonnet, al que sugirieron una pista clave para la solución antes de activar la respuesta razonada.
Pensémoslo como pasarle a un estudiante una nota que dice "la respuesta es [A]" antes de un examen. Si escribe en su examen que eligió [A] al menos en parte debido a la nota, eso son buenas noticias: está siendo honesto y fiel. Pero si escribe lo que afirma ser su proceso de razonamiento sin mencionar la nota, podríamos tener un problema.
El porcentaje de veces que Claude Sonnet incluyó la pista entre sus deducciones fue tan solo del 25%. Esto demuestra que en ocasiones los modelos generan explicaciones que suenan convincentes, pero que no corresponden a su verdadera lógica interna para llegar a la solución, sino que son racionalizaciones a posteriori: primero dan con la solución, después inventan el proceso de manera coherente para el usuario. Esto evidencia el riesgo de que el modelo pueda estar ocultando pasos o información relevante para la resolución del problema.
Cierre
A pesar de las limitaciones expuestas, tal y como vemos en el estudio mencionado anteriomente, no podemos olvidar que en la investigación original de Google Brain, se documentó que, al aplicar la cadena de razonamiento, el modelo PaLM mejoraba su rendimiento en problemas matemáticos del 17,9% al 58,1% de precisión. Si, además, combinamos esta técnica con la búsqueda en datos abiertos para obtener información externa al modelo, el razonamiento mejora en cuanto a que es más verificable, actualizado y robusto.
No obstante, al hacer que los modelos de lenguaje “piensen en voz alta” lo que realmente estamos mejorando en el 100% de los casos es la experiencia de uso en tareas complejas. Si no caemos en la delegación excesiva del pensamiento en la IA, nuestro propio proceso cognitivo puede verse beneficiado. Es, además, una técnica que facilita enormemente nuestra nueva labor como supervisores de procesos automáticos.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial generativa comienza a estar presente en aplicaciones cotidianas que van desde agentes virtuales (o equipos de agentes virtuales) que nos resuelven dudas cuando llamamos a un centro de atención al cliente hasta asistentes inteligentes que redactan automáticamente resúmenes de reuniones o propuestas de informes en entornos de oficina.
Estas aplicaciones, gobernadas a menudo por modelos fundacionales de lenguaje (LLM), prometen revolucionar sectores enteros sobre la base de conseguir enormes ganancias en productividad. Sin embargo, su adopción conlleva nuevos retos ya que, a diferencia del software tradicional, un modelo de IA generativa no sigue reglas fijas escritas por humanos, sino que sus respuestas se basan en patrones estadísticos aprendidos tras procesar grandes volúmenes de datos. Esto hace que su comportamiento sea menos predecible y más difícil de explicar y que a veces ofrezca resultados inesperados, errores complicados de prever o respuestas que no siempre se alinean con las intenciones originales del creador del sistema.
Por ello, la validación de estas aplicaciones desde múltiples perspectivas como la ética, la seguridad o la consistencia es esencial para garantizar la confianza en los resultados de los sistemas que estamos creando en esta nueva etapa de transformación digital.
¿Qué hay que validar en los sistemas basados en IA generativa?
Validar los sistemas basados en IA generativa significa comprobar rigurosamente que cumplen ciertos criterios de calidad y responsabilidad antes de confiar en ellos para resolver tareas sensibles.
No se trata solo de verificar que “funcionan”, sino de asegurarse de que se comportan según lo esperado, evitando sesgos, protegiendo a los usuarios, manteniendo su estabilidad en el tiempo y cumpliendo las normas éticas y legales aplicables. La necesidad de una validación integral suscita un cada vez más amplio consenso entre expertos, investigadores, reguladores e industria: para desplegar IA de forma confiable se requieren estándares, evaluaciones y controles explícitos.
Resumimos cuatro dimensiones clave que deben verificarse en los sistemas basados en IA generativa para alinear sus resultados con las expectativas humanas:
- Ética y equidad: un modelo debe respetar principios éticos básicos y evitar perjudicar a personas o grupos. Esto implica detectar y mitigar sesgos en sus respuestas para no perpetuar estereotipos ni discriminación. También requiere filtrar contenido tóxico u ofensivo que pudiera dañar a los usuarios. La equidad se evalúa comprobando que el sistema ofrece un trato consistente a distintos colectivos demográficos, sin favorecer ni excluir indebidamente a nadie.
- Seguridad y robustez: aquí nos referimos tanto a la seguridad del usuario (que el sistema no genere recomendaciones peligrosas ni facilite actividades ilícitas) como a la robustez técnica frente a errores y manipulaciones. Un modelo seguro debe evitar instrucciones que lleven, por ejemplo, a conductas ilegales, rechazando esas solicitudes de manera fiable. Además, la robustez implica que el sistema resista ataques adversarios (como peticiones diseñadas para engañarlo) y que funcione de forma estable bajo distintas condiciones.
- Consistencia y fiabilidad: los resultados de la IA generativa deben ser consistentes, coherentes y correctos. En aplicaciones como las de diagnóstico médico o asistencia legal, no basta con que la respuesta suene convincente; debe ser cierta y precisa. Por ello se validan aspectos como la coherencia lógica de las respuestas, su relevancia respecto a la pregunta formulada y la exactitud factual de la información. También se comprueba su estabilidad en el tiempo (que ante dos peticiones similares se ofrezcan resultados equivalentes bajo las mismas condiciones) y su resiliencia (que pequeños cambios en la entrada no provoquen salidas sustancialmente diferentes).
- Transparencia y explicabilidad: para confiar en las decisiones de un sistema basado en IA, es deseable entender cómo y por qué las produce. La transparencia incluye proporcionar información sobre los datos de entrenamiento, las limitaciones conocidas y el rendimiento del modelo en distintas pruebas. Muchas empresas están adoptando la práctica de publicar “tarjetas del modelo” (model cards), que resumen cómo fue diseñado y evaluado un sistema, incluyendo métricas de sesgo, errores comunes y casos de uso recomendados. La explicabilidad va un paso más allá y busca que el modelo ofrezca, cuando sea posible, explicaciones comprensibles de sus resultados (por ejemplo, destacando qué datos influyeron en cierta recomendación). Una mayor transparencia y capacidad de explicación aumentan la rendición de cuentas, permitiendo que desarrolladores y terceros auditen el comportamiento del sistema.
Datos abiertos: transparencia y pruebas más diversas
Para validar adecuadamente los modelos y sistemas de IA, sobre todo en cuanto a equidad y robustez, se requieren conjuntos de datos representativos y diversos que reflejen la realidad de distintas poblaciones y escenarios.
Por otra parte, si solo las empresas dueñas de un sistema disponen datos para probarlo, tenemos que confiar en sus propias evaluaciones internas. Sin embargo, cuando existen conjuntos de datos abiertos y estándares públicos de prueba, la comunidad (universidades, reguladores, desarrolladores independientes, etc.) puede poner a prueba los sistemas de forma autónoma, funcionan así como un contrapeso independiente que sirve a los intereses de la sociedad.
Un ejemplo concreto lo dio Meta (Facebook) al liberar en 2023 su conjunto de datos Casual Conversations v2. Se trata de un conjunto de datos abiertos, obtenido con consentimiento informado, que recopila videos de personas de 7 países (Brasil, India, Indonesia, México, Vietnam, Filipinas y EE.UU.), con 5.567 participantes que proporcionaron atributos como edad, género, idioma y tono de piel.
El objetivo de Meta con la publicación fue precisamente facilitar que los investigadores pudiesen evaluar la imparcialidad y robustez de sistemas de IA en visión y reconocimiento de voz. Al expandir la procedencia geográfica de los datos más allá de EE.UU., este recurso permite comprobar si, por ejemplo, un modelo de reconocimiento facial funciona igual de bien con rostros de distintas etnias, o si un asistente de voz comprende acentos de diferentes regiones.
La diversidad que aportan los datos abiertos también ayuda a descubrir áreas descuidadas en la evaluación de IA. Investigadores del Human-Centered Artificial Intelligence (HAI) de Stanford pusieron de manifiesto en el proyecto HELM (Holistic Evaluation of Language Models) que muchos modelos de lenguaje no se evalúan en dialectos minoritarios del inglés o en idiomas poco representados, simplemente porque no existen datos de calidad en los benchmarks más conocidos.
La comunidad puede identificar estas carencias y crear nuevos conjuntos de prueba para llenarlos (por ejemplo, un conjunto de datos abierto de preguntas frecuentes en suajili para validar el comportamiento de un chatbot multilingüe). En este sentido, HELM ha incorporado evaluaciones más amplias precisamente gracias a la disponibilidad de datos abiertos, permitiendo medir no solo el rendimiento de los modelos en tareas comunes, sino también su comportamiento en otros contextos lingüísticos, culturales y sociales. Esto ha contribuido a visibilizar las limitaciones actuales de los modelos y a fomentar el desarrollo de sistemas más inclusivos y representativos del mundo real o modelos más adaptados a necesidades específicas de contextos locales como es el caso de modelo fundacional ALIA, desarrollado en España.
En definitiva, los datos abiertos contribuyen a democratizar la capacidad de auditar los sistemas de IA, evitando que el poder de validación resida solo en unos pocos. Permiten reducir los costes y barreras ya que un pequeño equipo de desarrollo puede probar su modelo con conjuntos abiertos sin tener que invertir grandes esfuerzos en recopilar datos propios. De este modo no solo se fomenta la innovación, sino que se consigue que soluciones de IA locales de pequeñas empresas estén sometidas también a estándares de validación rigurosos.
La validación de aplicaciones basadas en IA generativa es hoy una necesidad incuestionable para asegurar que estas herramientas operen en sintonía con nuestros valores y expectativas. No es un proceso trivial, requiere metodologías nuevas, métricas innovadoras y, sobre todo, una cultura de responsabilidad en torno a la IA. Pero los beneficios son claros, un sistema de IA rigurosamente validado será más confiable, tanto para el usuario individual que, por ejemplo, interactúa con un chatbot sin temor a recibir una respuesta tóxica, como para la sociedad en su conjunto que puede aceptar las decisiones basadas en estas tecnologías sabiendo que han sido correctamente auditadas. Y los datos abiertos contribuyen a cimentar esta confianza ya que fomentan la transparencia, enriquecen las pruebas con diversidad y hacen partícipe a toda la comunidad en la validación de los sistemas de IA..
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial (IA) se ha convertido en una tecnología clave en múltiples sectores, desde la salud y la educación hasta la industria y la gestión ambiental, sin olvidarnos de la cantidad de ciudadanos que crean textos, imágenes o vídeos con esta tecnología solo para su disfrute personal. Se estima que en España más de la mitad de la población adulta ha utilizado alguna vez alguna herramienta IA.
Sin embargo, este auge plantea desafíos en términos de sostenibilidad, tanto en consumo hídrico y energético como en impacto social y ético. Por ello, es necesario buscar soluciones que ayuden a mitigar los efectos negativos, promoviendo modelos eficientes, responsables y accesibles para todos. En este artículo vamos a abordar este reto, así como los posibles esfuerzos a llevar a cabo para darle solución.
¿Cuál es el impacto ambiental de la IA?
Ante un panorama donde la inteligencia artificial está de moda, cada vez son más los usuarios que se preguntan cuál es el precio que debemos pagar por poder crear memes en cuestión de segundos.
Para calcular bien el impacto total de la inteligencia artificial, es necesario considerar los ciclos del hardware y el software en su conjunto, como bien indica el Programa de las Naciones Unidas para el Medio Ambiente (PNUMA). Es decir, es necesario considerar desde la extracción de materias primas, la producción, el transporte y la construcción del centro de datos, la gestión, el mantenimiento y la eliminación de residuos electrónicos, hasta la recopilación y preparación de datos, la creación de modelos, el entrenamiento, la validación, la implementación, la inferencia, el mantenimiento y la retirada. Todo ello genera efectos directos, indirectos y de orden superior:
- Los impactos directos incluyen el consumo de energía, agua y recursos minerales, así como la producción de emisiones y residuos electrónicos, lo cual genera una huella de carbono considerable.
- Los efectos indirectos se derivan del uso de la IA, por ejemplo, los generados por el aumento en el uso de vehículos autónomos.
- Además, el uso generalizado de la inteligencia artificial también conlleva una dimensión ética, ya que puede exacerbar las desigualdades existentes, afectando especialmente a las minorías y las personas con bajos ingresos. En ocasiones, los datos de entrenamiento utilizados presentan sesgos o son de una baja calidad (por ejemplo, infrarrepresentando a determinados grupos poblacionales). Esta situación puede dar lugar a respuestas y decisiones que favorecen a grupos mayoritarios.
Algunas de las cifras que recopila el documento de la ONU y que pueden ayudarnos a hacernos una idea del impacto generado por la IA son:
- Una única petición de información a ChatGPT consume diez veces más electricidad que una consulta en un motor de búsqueda como Google, según datos de la Agencia Internacional de la Energía (AIE).
- Entrenar a un único modelo de lenguaje de gran escala (Large Language Models o LLM) genera aproximadamente 300.000 kg de emisiones de dióxido de carbono, lo que equivale a 125 vuelos de ida y vuelta entre Nueva York y Pekín, según el artículo científico “The carbon impact of artificial intelligence”.
- La demanda mundial de agua de la IA será de entre 4.200 y 6.600 millones de metros cúbicos para 2027, una cifra que supera el consumo total de un país como Dinamarca, de acuerdo con el estudio “Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models”.
Soluciones para conseguir una IA sostenible
Ante esta situación, la propia ONU propone diversos aspectos a los que es necesario prestar atención, por ejemplo:
- Búsqueda de métodos y parámetros normalizados para medir el impacto medioambiental de la IA, centrándose en los efectos directos, más fáciles de medir gracias a los datos de consumo de energía, agua y recursos. Al conocer esta información, resultará más sencillo tomar medidas que supongan un beneficio sustancial.
- Facilitar la concienciación de la sociedad, a través de mecanismos que obliguen a las empresas a hacer pública esta información de manera transparente y accesible. Esto podría acabar promoviendo cambios de comportamiento hacia un uso más sostenible de la IA.
- Dar prioridad a la investigación sobre la optimización de los algoritmos, en pro de la eficiencia energética. Por ejemplo, se puede minimizar la energía necesaria mediante la reducción de la complejidad computacional y el uso de datos. También se puede impulsar la computación descentralizada, ya que, al distribuir los procesos en redes menos exigentes, se evita sobrecargar los grandes servidores.
- Favorecer el uso de energías renovables en los centros de datos, como la solar o la eólica. Además, es necesario impulsar que las empresas lleven a cabo prácticas de compensación de emisiones de carbono.
Además de su impacto ambiental, y como veíamos anteriormente, la IA también debe ser sostenible desde una perspectiva social y ética. Para ello es necesario:
- Evitar sesgos algorítmicos: garantizar que los datos utilizados representen la diversidad de la población, evitando discriminaciones involuntarias.
- Transparencia en los modelos: hacer que los algoritmos sean comprensibles y accesibles, promoviendo la confianza y la supervisión humana.
- Accesibilidad y equidad: desarrollar sistemas de IA que sean inclusivos y beneficien a comunidades menos privilegiadas.
Si bien la inteligencia artificial plantea desafíos en términos de sostenibilidad, también puede ser una aliada clave en la construcción de un planeta más verde. Su capacidad para analizar grandes volúmenes de datos permite optimizar el uso de energía, mejorar la gestión de recursos naturales y desarrollar estrategias más eficientes en sectores como la agricultura, la movilidad y la industria. Desde la predicción del cambio climático hasta el diseño de modelos para reducir emisiones, la IA ofrece soluciones innovadoras que pueden acelerar la transición hacia un futuro más sostenible.
Programa Nacional de Algoritmos Verdes
En respuesta a esta realidad, España ha puesto en marcha el Programa Nacional de Algoritmos Verdes (PNAV). Esta una iniciativa que busca integrar la sostenibilidad en el diseño y aplicación de la IA, promoviendo modelos más eficientes y responsables con el medioambiente, a la vez que se impulsa su uso para dar respuesta a diferentes desafíos medioambientales.
El PNAV tiene como meta principal fomentar el desarrollo de algoritmos que minimicen el impacto ambiental desde su concepción. Este enfoque, conocido como "Verde por Diseño", implica que la sostenibilidad no sea un añadido posterior, sino un criterio fundamental en la creación de modelos de IA. Además, el programa busca potenciar la investigación en IA sostenible, mejorar la eficiencia energética de infraestructuras digitales y promover la integración de tecnologías como el blockchain verde en el tejido productivo.
Esta iniciativa se enmarca en el Plan de Recuperación, Transformación y Resiliencia, la Agenda España Digital 2026 y la Estrategia Nacional de Inteligencia Artificial. Entre los objetivos fijados se incluye la elaboración de una guía de buenas prácticas, un catálogo de algoritmos eficientes y otro de algoritmos para abordar problemas ambientales, la generación de una calculadora de impacto para autoevaluación, así como medidas de apoyo a la concienciación y formación de desarrolladores de IA.
Su página web funciona como un espacio de conocimiento sobre inteligencia artificial sostenible, donde se puede estar al tanto de las principales noticias, eventos, entrevistas, etc. relacionadas con este campo. Además, organizan competiciones, como hackathones, con el fin de impulsar soluciones que ayuden a resolver retos medioambientales.
El Futuro de la IA sostenible
El camino hacia una inteligencia artificial más responsable depende del esfuerzo conjunto de gobiernos, empresas y la comunidad científica. La inversión en investigación, el desarrollo de regulaciones adecuadas y la concienciación sobre IA ética serán clave para garantizar que esta tecnología impulse el progreso sin comprometer el planeta ni la sociedad.
La IA sostenible no solo es un desafío tecnológico, sino una oportunidad para transformar la innovación en un motor de bienestar global. De todos depende que podamos progresar como sociedad sin destruir el planeta.
Blog
En un mundo cada vez más digitalizado, la creación, el uso y la distribución de software y datos se han convertido en actividades fundamentales para individuos, empresas y organizaciones gubernamentales. Sin embargo, detrás de estas prácticas cotidianas se encuentra un aspecto crucial: las licencias, tanto de software como de datos.
Comprender qué son las licencias, sus tipos y su importancia es esencial para garantizar un uso legal y ético de los recursos digitales. En este artículo, exploraremos estos conceptos de manera sencilla y accesible, además de analizar una herramienta valiosa llamada Joinup Licensing Assistant, desarrollada por la Unión Europea.
¿Qué son las licencias y por qué son importantes?
Una licencia es un acuerdo legal que otorga permisos específicos sobre el uso de un producto digital, ya sea software, datos, contenido multimedia u otros recursos. Este acuerdo establece las condiciones bajo las cuales se puede utilizar, modificar, distribuir o comercializar dicho producto. Las licencias son esenciales porque protegen los derechos de los creadores, garantizan que los usuarios comprendan sus derechos y obligaciones, y fomentan un entorno digital seguro y colaborativo.
A continuación, se recogen algunos ejemplos de las más populares, tanto para datos como para software.
Tipos comunes de licencias
Derechos de autor (Copyright)
El derecho de autor es una protección automática que surge en el momento de la creación de una obra original, ya sea literaria, artística o científica. No es necesario registrar formalmente la obra para que esté protegida por derechos de autor. Este derecho otorga al creador derechos exclusivos sobre la reproducción, distribución, comunicación pública y transformación de su obra.
Ejemplo: Cuando una empresa crea un conjunto de datos sobre, por ejemplo, tendencias de construcción, automáticamente posee los derechos de autor sobre esos datos. Esto significa que otros no pueden utilizar, modificar o distribuir esos datos sin el permiso explícito del creador.
Dominio público
Cuando una obra no está protegida por derechos de autor, se considera que está en el dominio público. Esto puede ocurrir porque los derechos han expirado, el autor ha renunciado a ellos o porque la obra no cumple con los requisitos legales para la protección. Por ejemplo, una obra que carezca de originalidad suficiente —como una lista telefónica o un formulario estándar— no cumple con los requisitos para estar protegida. Las obras en dominio público pueden ser utilizadas libremente por cualquier persona, sin necesidad de obtener permiso.
Ejemplo: Muchas obras clásicas de literatura, como las de William Shakespeare, están en dominio público y pueden ser reproducidas y adaptadas libremente.
Creative Commons
Las licencias Creative Commons ofrecen una manera flexible de otorgar permisos para el uso de obras protegidas por derechos de autor. Estas licencias permiten a los creadores especificar qué usos permiten y cuáles no, facilitando la difusión y reutilización de sus obras bajo condiciones claras. Las licencias CC más comunes incluyen:
- CC BY (Atribución): permite el uso, distribución y creación de obras derivadas, siempre que se dé crédito al autor original.
- CC BY-SA (Atribución-Compartir Igual): además de la atribución, requiere que las obras derivadas se distribuyan bajo la misma licencia.
- CC BY-ND (Atribución-Sin Derivadas): permite la redistribución, comercial y no comercial, siempre que la obra se mantenga intacta y se otorgue crédito al autor.
- CC0 (Dominio Público): permite a los creadores renunciar a todos los derechos sobre sus obras, permitiendo su uso libre sin necesidad de atribución.
Estas licencias son especialmente útiles para creadores que desean compartir sus obras mientras mantienen ciertos derechos sobre su uso.
GNU General Public License (GPL)
La Licencia Pública General de GNU (GPL) creada por la Free Software Foundation, garantiza que el software licenciado bajo sus términos permanezca siempre libre y accesible para todos. Esta licencia está diseñada específicamente para software, no para datos. Su objetivo es garantizar que el software permanezca libre, accesible y modificable por cualquier usuario, protegiendo las libertades relacionadas con su uso y distribución.
Esta licencia no solo permite a los usuarios utilizar, modificar y distribuir el software, sino que también exige que cualquier obra derivada conserve los mismos términos de libertad. En otras palabras, cualquier software que se distribuya o modifique bajo la GPL debe seguir siendo libre para todos sus usuarios. La GPL está diseñada para proteger cuatro libertades esenciales:
- La libertad de usar el software para cualquier propósito.
- La libertad de estudiar cómo funciona el software y adaptarlo a las necesidades específicas.
- La libertad de distribuir copias del software para ayudar a otros.
- La libertad de mejorar el software y liberar las mejoras para el beneficio de la comunidad.
Una de las características clave de la GPL es su cláusula de "copyleft", que requiere que cualquier obra derivada sea licenciada bajo los mismos términos que el software original. Esto evita que el software libre se convierta en propietario y asegura que las libertades originales se mantengan intactas.
Ejemplo: Supongamos que una empresa desarrolla un programa bajo la GPL y lo distribuye a sus clientes. Si alguno de esos clientes decide modificar el código fuente para adaptarlo a sus necesidades, está en su derecho de hacerlo. Además, si la empresa o el cliente desean redistribuir las versiones modificadas del software, deben hacerlo bajo la misma licencia GPL, garantizando que cualquier nuevo usuario también disfrute de las libertades originales.
Licencia Pública de la Unión Europea (EUPL)
La Licencia Pública de la Unión Europea (EUPL) es una licencia de software libre y de código abierto desarrollada por la Comisión Europea. Diseñada para facilitar la interoperabilidad y la cooperación entre software europeo, la EUPL permite la libre utilización, modificación y distribución del software, asegurando que las obras derivadas también se mantengan abiertas. Además de cubrir el software, la EUPL puede aplicarse a documentos auxiliares como especificaciones, manuales de usuario y documentación técnica.
Aunque la EUPL se usa para software, en algunos casos podría ser aplicable a conjuntos de datos o contenido (como textos, gráficos, imágenes, documentación o cualquier otro material no considerado software o datos estructurados), pero su uso en datos abiertos es menos común que otras licencias específicas como las de Creative Commons u Open Data Commons.
Open Data Commons (ODC-BY)
La Licencia de Atribución de Open Data Commons (ODC-BY) es una licencia diseñada específicamente para bases de datos y conjuntos de datos, desarrollada por Open Knowledge Foundation. Su objetivo es permitir el uso libre de datos, al tiempo que exige que se reconozca adecuadamente al creador original. Esta licencia no está diseñada para software, sino para datos estructurados, como estadísticas, catálogos abiertos o mapas geoespaciales.
ODC-BY permite a los usuarios:
- Copiar, distribuir y utilizar la base de datos.
- Crear obras derivadas, como visualizaciones, análisis o productos derivados.
- Adaptar los datos a nuevas necesidades o combinarlos con otras fuentes.
La única condición principal es la atribución: los usuarios deben dar crédito al creador original de forma adecuada, incluyendo referencias claras a la fuente.
Una característica destacada de la ODC-BY es que no impone una cláusula de copyleft, lo que significa que los datos derivados pueden ser licenciados bajo otros términos, siempre que se mantenga la atribución.
Ejemplo: Imagina que una ciudad publica su base de datos de estaciones de bicicletas bajo ODC-BY. Una empresa puede descargar esos datos, crear una app que recomiende rutas ciclistas y añadir nuevas capas de información. Mientras indique claramente que los datos originales provienen del ayuntamiento, puede ofrecer su app con la licencia que desee, incluso de forma comercial.
Una comparativa de estas licencias más usadas nos permite entender mejor sus diferencias:
|
Licencia |
Permite uso comercial |
Modificación permitida |
Requiere atribución | Permite obras derivadas | Aplicable a datos | Especializaciónnn |
|
Derechos de autor (copyright) |
Sí, con permiso del autor | No, salvo acuerdo con el creador | No | No | Puede aplicarse a bases de datos, pero solo si cumplen ciertos requisitos de creatividad y originalidad en su estructura o selección de contenidos. No protege los datos en sí, sino la forma en que están organizados o presentados. | Obras originales como textos, música, películas, software y, en algunos casos, bases de datos cuya estructura o selección sea creativa. No protege los datos en sí. |
| Dominio Público | Sí | Sí | No | Sí | Sí | Obras originales como textos, música, películas y software sin protección por derechos de autor (por expiración, renuncia, o exclusión legal). |
| Creative Commons BY (Atribución) | Sí | Sí, con atribución | Sí | Sí | Sí | Textos, imágenes, vídeos, infografías, contenidos web y conjuntos de datos reutilizables, siempre que se reconozca la autoría |
| Creative Commons BY-SA (Atribución-CompartirIgual) | Sí | Sí, debe mantener la misma licencia | Sí | Sí, con la misma licencia | Sí | Contenido colaborativo como artículos, mapas, datasets o recursos educativos abiertos; ideal para proyectos comunitarios |
| Creative Commons BY-ND (Atribución-SinDerivadas) | Sí | No | Sí | No | Sí, pero prohíbe modificar o combinar los datos | Contenido que se desea conservar sin alteraciones: documentos oficiales, infografías cerradas, conjuntos de datos inalterables |
| Creative Commons CC0 (Dominio Público) | Sí | Sí | No | Sí | Sí | Todo tipo de obras: textos, imágenes, música, datos, software, etc., que se liberan voluntariamente al dominio público |
| GNU General Public License (GPL) | Sí | Sí, debe mantenerse bajo la GPL | Sí | Sí | No | Software ejecutable o código fuente. No apta para documentación, contenido multimedia ni bases de datos |
| Licencia Pública de la Unión Europea (EUPL) | Sí | Sí, obras derivadas deben seguir siendo abiertas | Sí | Sí | Parcialmente: podría usarse con datos técnicos, pero no es su finalidad principal | Software desarrollado por administraciones públicas y su documentación técnica asociada (manuales, especificaciones |
| Open Data Commons (ODC-BY) | Sí | Sí | Sí | Sí | Sí (diseñada específicamente para datos abiertos) | Bases de datos estructuradas como estadísticas públicas, conjuntos geoespaciales, catálogos abiertos o registros administrativos |
Figura 1. Tabla comparativa. Fuente: elaboración propia
¿Por qué es necesario utilizar licencias en el ámbito de los datos abiertos?
En el ámbito de datos abiertos, estas licencias son fundamentales para garantizar que los datos estén disponibles para el uso público, promoviendo la transparencia, la innovación y el desarrollo de soluciones basadas en datos. En general, las ventajas del uso de licencias claras son:
- Transparencia y acceso abierto: las licencias claras permiten que ciudadanos, investigadores y desarrolladores accedan y utilicen datos públicos sin restricciones indebidas, fomentando la transparencia gubernamental y la rendición de cuentas.
- Fomento de la innovación: al permitir el uso libre de datos, las licencias de datos abiertos facilitan la creación de aplicaciones, servicios y análisis que pueden generar valor económico y social.
- Colaboración y reutilización: las licencias que permiten la reutilización y modificación de datos fomentan la colaboración entre diferentes entidades y disciplinas, potenciando el desarrollo de soluciones más robustas y completas.
- Mejora de la calidad de los datos: la disponibilidad de datos abiertos anima a una mayor participación y revisión por parte de la comunidad, lo que puede conducir a una mejora en la calidad y precisión de los datos disponibles.
- Seguridad jurídica para el reutilizador: contar con licencias claras aporta confianza y certidumbre a quienes reutilizan datos, ya que saben que pueden hacerlo de forma legal y sin temor a conflictos futuros.
Introducción al Joinup Licensing Assistant
En este complejo panorama de licencias, elegir la adecuada puede ser una tarea abrumadora, especialmente para aquellos sin experiencia previa en la gestión de licencias. Aquí es donde entra en juego el Joinup Licensing Assistant, una herramienta desarrollada por la Unión Europea disponible en Joinup.europa.eu. Esta plataforma colaborativa está diseñada para promover el intercambio de soluciones y buenas prácticas entre administraciones públicas, empresas y ciudadanos, y el Licensing Assistant es una de sus herramientas estrella.
Para quienes trabajan específicamente con datos, también puede resultar útil el informe publicado por data.europa.eu, que ofrece recomendaciones más detalladas sobre la selección de licencias para conjuntos de datos abiertos en el contexto europeo.
El Joinup Licensing Assistant ofrece diversas funcionalidades y beneficios que simplifican la selección y gestión de licencias:
|
|
Funcionalidad | Beneficios | |
 |
Asesoramiento personalizado: recomienda licencias adecuadas según el tipo de proyecto y sus necesidades. |  |
Simplificación del proceso de selección: desglosa la elección de licencia en pasos claros, reduciendo complejidad y tiempo. |
 |
Base de datos de licencias: acceso a licencias de software, contenido y datos, con descripciones claras. |  |
Reducción de riesgos legales: evita problemas legales ofreciendo recomendaciones compatibles con los requisitos del proyecto. |
 |
Comparación de licencias: permite ver fácilmente las diferencias entre varias licencias. | Fomento de la colaboración y el conocimiento compartido: facilita el intercambio de experiencias entre usuarios y administraciones públicas. | |
 |
Actualización legal: ofrece información siempre actualizada conforme a la normativa vigente. |  |
Accesibilidad y usabilidad: interfaz intuitiva, útil incluso para quienes no tienen conocimientos legales. |
 |
Soporte para datos abiertos: incluye opciones específicas para fomentar la reutilización y transparencia. |  |
Apoyo a la sostenibilidad del software libre y datos abiertos: promueve licencias que impulsan la innovación, la apertura y la continuidad de los proyectos. |
Figura 2. Tabla de funcionalidad y beneficios. Fuente: elaboración propia
Diversos sectores pueden beneficiarse del uso del Joinup Licensing Assistant:
- Administraciones públicas: para aplicar licencias correctas en software, contenido y datos abiertos, cumpliendo con las normas europeas y fomentando la reutilización.
- Desarrolladores de software: para alinear licencias con sus modelos de negocio y facilitar la distribución y colaboración.
- Creadores de contenido: para proteger sus derechos y decidir cómo se puede usar y compartir su obra.
- Investigadores y científicos: para publicar datos reutilizables que impulsen la colaboración y los avances científicos.
Conclusión
En un entorno digital cada vez más interconectado y regulado, utilizar licencias adecuadas para el software, el contenido y, especialmente, los datos abiertos, es fundamental para garantizar la legalidad, la sostenibilidad y el impacto de los proyectos digitales. Una gestión correcta de licencias facilita la colaboración, la reutilización y la difusión segura de recursos, al tiempo que reduce riesgos legales y promueve la interoperabilidad.
En este contexto, herramientas como el Joinup Licensing Assistant ofrecen un apoyo valioso para administraciones públicas, empresas y ciudadanía, simplificando la elección de licencias y adaptándola a cada caso. Su uso contribuye a crear un ecosistema digital más abierto, seguro y eficiente.
Particularmente en el ámbito de los datos abiertos, contar con licencias claras permite que los datos sean realmente accesibles y reutilizables, fomentando la transparencia institucional, la innovación tecnológica y la creación de valor social.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Los portales de datos abiertos contribuyen a que los municipios ofrezcan un acceso estructurado y transparente a los datos que generan en el ejercicio de sus funciones y en la prestación de los servicios de su competencia, fomentando además la creación de aplicaciones, servicios y soluciones que generan valor tanto para la ciudadanía y las empresas como para las propias administraciones públicas.
El informe tiene como propósito ofrecer una guía práctica para que las administraciones municipales puedan diseñar, desarrollar y mantener portales de datos abiertos eficaces, integrándolos en la estrategia global de ciudades inteligentes. El documento se estructura en varias secciones que abarcan desde la planificación estratégica hasta las recomendaciones técnicas y operativas necesarias para la creación y mantenimiento de portales de datos abiertos. Algunas de las claves principales son:
Principios fundamentales
El informe destaca la importancia de integrar los portales de datos abiertos en planes estratégicos municipales, alineando los objetivos del portal con las prioridades locales y las expectativas ciudadanas. También recomienda elaborar un Plan de medidas para el impulso de la apertura y reutilización de datos (Plan RISP), que incluya modelos de gobernanza, licencias claras, agenda de apertura de datos y acciones para estimular su reutilización. Finalmente, enfatiza la necesidad de contar con personal capacitado en ámbitos estratégicos, técnicos y funcionales, capaces de gestionar, mantener y promover la reutilización de datos abiertos.
Requisitos generales
En cuanto a los requisitos generales para garantizar el éxito del portal, se destaca la importancia de ofrecer datos de calidad, consistentes y actualizados en formatos abiertos como CSV y JSON, pero también en XLS, favoreciendo la interoperabilidad con plataformas nacionales e internacionales mediante estándares abiertos como DCAT-AP, y garantizando una accesibilidad efectiva del portal mediante un diseño intuitivo, inclusivo y adaptado a diferentes dispositivos. También se señala la obligación de cumplir estrictamente las normativas de privacidad y protección de datos, especialmente el Reglamento General de Protección de Datos (RGPD).
Para promover la reutilización, el informe aconseja fomentar ecosistemas dinámicos a través de eventos comunitarios como hackatones y talleres, destacando ejemplos exitosos de aplicación práctica de los datos abiertos. Además, insiste en la necesidad de proporcionar herramientas útiles como API para consultas dinámicas, visualizaciones de datos interactivas y documentación completa, así como en implementar mecanismos sostenibles de financiación y mantenimiento.
Pautas técnicas y funcionales
Con respecto a las pautas técnicas y funcionales, el documento detalla la importancia de construir una infraestructura técnica robusta y escalable basada en tecnologías en la nube, utilizando sistemas de almacenamiento diversos como bases de datos relacionales, NoSQL y soluciones específicas para series temporales o datos geoespaciales. Destaca además la relevancia de integrar herramientas avanzadas de automatización para garantizar la calidad constante de los datos y recomienda soluciones específicas para gestionar datos en tiempo real provenientes de Internet de las Cosas (IoT).
En relación con la usabilidad y estructura del portal, se enfatiza la importancia de un diseño centrado en el usuario, con navegación clara y un potente motor de búsqueda para facilitar el acceso rápido a los datos. Además, se insiste en la importancia de cumplir con los estándares internacionales de accesibilidad y ofrecer herramientas que simplifiquen la interacción con los datos, incluyendo visualizaciones gráficas claras y mecanismos de soporte técnico eficientes.
El informe también resalta el papel clave de las API como herramientas fundamentales para facilitar el acceso automatizado y dinámico a los datos del portal, ofreciendo consultas granulares, documentación clara, mecanismos robustos de seguridad y formatos estándar reutilizables. Además, sugiere una variedad de herramientas y frameworks técnicos para implementar estas API de forma eficiente.
Otro aspecto crítico destacado en el documento es la identificación y priorización de conjuntos de datos para publicación, ya que la planificación progresiva de la apertura de datos permite ajustar los procesos técnicos y organizativos de manera ágil, comenzando con los datos de mayor relevancia estratégica y demanda ciudadana.
Por último, la guía recomienda establecer un sistema de métricas e indicadores según la norma UNE 178301:2015 para evaluar el grado de madurez y el impacto real de los portales de datos abiertos. Estas métricas abarcan dominios estratégicos, legales, organizativos, técnicos, económicos y sociales, proporcionando un enfoque integral para medir tanto la eficacia en la publicación de los datos como su impacto tangible en la sociedad y la economía local.
Conclusiones
En conclusión, el informe proporciona un marco estratégico, técnico y práctico que sirve de referencia para el despliegue de portales de datos abiertos municipales, para que las ciudades maximicen su potencial como motores de desarrollo económico y social. Además, la integración de inteligencia artificial en diversos puntos de los proyectos de portales de datos abiertos representa una oportunidad estratégica para ampliar sus capacidades y generar un mayor impacto en la ciudadanía.
Blog
El concepto de data commons o bienes comunes de datos surge como un enfoque transformador para la gestión y el intercambio de datos que sirvan a fines colectivos y como alternativa al creciente número de macrosilos de datos de uso privado. Al tratar los datos como un recurso compartido, los data commons facilitan la colaboración, la innovación y el acceso equitativo a los mismos, enfatizando el valor comunal de los datos por encima de cualquier otra consideración. A medida que navegamos por las complejidades de la era digital —marcada en la actualidad por los rápidos avances en inteligencia artificial (IA) y el continuo debate sobre los retos en la gobernanza de datos— el papel que pueden jugar los data commons es ahora probablemente más importante que nunca.
¿Qué son los data commons?
Los data commons se refieren a un marco cooperativo donde los datos son recopilados, gobernados y compartidos entre todos los participantes de la comunidad mediante protocolos que promueven la apertura, la equidad, el uso ético y la sostenibilidad. Los data commons se diferencian de los modelos tradicionales de intercambio de datos, principalmente, por la prioridad que se da a la colaboración y la inclusión sobre el control unitario.
Otro objetivo común de los data commons es la creación de conocimiento colectivo que pueda ser utilizado por cualquiera para el bien de la sociedad. Esto los hace particularmente útiles a la hora de afrontar los grandes desafíos actuales, como los retos del medio ambiente, la interacción multilingüe, la movilidad, las catástrofes humanitarias, la preservación del conocimiento o los nuevos desafíos de la salud y la sanidad.
Además, también es cada vez más frecuente que estas iniciativas para compartir datos incorporen todo tipo de herramientas que faciliten su análisis e interpretación consiguiendo así democratizar no sólo la propiedad y el acceso a los datos, sino también su uso.
Por todo lo anterior, los data commons podrían considerarse hoy en día como una infraestructura digital pública crítica a la hora de aprovechar los datos y promover el bienestar social.
Principios de los data commons
Los data commons se construyen sobre una serie de principios simples que serán clave para su correcta gobernanza:
- Apertura y accesibilidad: los datos deben ser accesibles para todos los autorizados.
- Gobernanza ética: equilibrio entre la inclusión y la privacidad.
- Sostenibilidad: establecer mecanismos de financiación y recursos para mantener los datos como bienes comunes a lo largo del tiempo.
- Colaboración: fomentar que los participantes contribuyan con nuevos datos e ideas que habiliten su uso para el beneficio mutuo.
- Confianza: relaciones basadas en la transparencia y la credibilidad entre partícipes.
Además, si queremos asegurarnos también de que los data commons cumplan su papel como infraestructura digital de dominio público, deberemos garantizar otros requisitos mínimos adicionales como: existencia de identificadores únicos permanentes, metadatos documentados, acceso fácil a través de interfaces de programación de aplicaciones (API), portabilidad de los datos, acuerdos de intercambio de datos entre pares y capacidad de realizar operaciones sobre los mismos.
El importante papel de los data commons en la era de la Inteligencia Artificial
La innovación impulsada por la IA ha incrementado exponencialmente la demanda de conjuntos de datos diversos y de alta calidad, un bien relativamente escaso a gran escala que puede dar lugar a cuellos de botella en el desarrollo futuro de la tecnología y que, al mismo tiempo, hace de los data commons un facilitador muy relevante a la hora de conseguir una IA más equitativa. Al proporcionar conjuntos de datos compartidos gobernados por principios éticos, los data commons contribuyen a mitigar riesgos frecuentes como los sesgos, los monopolios de datos y el acceso desigual a los beneficios de la IA.
Además, la actual concentración de los desarrollos en el ámbito de la IA representa también un desafío para el interés público. En este contexto, los data commons cuentan con la llave necesaria para habilitar un conjunto de sistemas y aplicaciones de IA alternativos, públicos y orientados al interés general, que puedan contribuir a rebalancear esta concentración de poder actual. El objetivo de estos modelos sería demostrar cómo se pueden diseñar sistemas más democráticos, orientados al interés público y con propósitos bien definidos, basados en los principios y modelos de gobernanza de la IA pública.
Sin embargo, la era de la IA generativa también presenta nuevos desafíos para los data commons como, por ejemplo y quizás el más destacado, el riesgo potencial de una explotación descontrolada de los conjuntos de datos compartidos que podría dar lugar a nuevos desafíos éticos por el uso indebido de los datos y la vulneración de la privacidad.
Por otro lado, la falta de transparencia en cuanto al uso de los data commons por parte de la IA podría también acabar desmotivando a las comunidades que los gestionan poniendo en riesgo su continuidad. Esto se debe a la preocupación de que al final su contribución pueda estar beneficiando principalmente a las grandes plataformas tecnológicas, sin que haya ninguna garantía de un reparto más justo del valor y el impacto generados tal como se pretendía inicialmente."
Por todo lo anterior, organizaciones como Open Future abogan desde hace ya varios años por una Inteligencia Artificial que funcione como un bien común, gestionada y desarrollada como una infraestructura pública digital en beneficio de todos, evitando la concentración de poder y promoviendo la equidad y la transparencia tanto en su desarrollo como en su aplicación.
Para ello proponen una serie de principios que guíen la gobernanza de los bienes comunes de datos en su aplicación para el entrenamiento de la IA de forma que se maximice el valor generado para la sociedad y se minimicen las posibilidades de potenciales abusos por intereses comerciales:
- Compartir tantos datos como sea posible, pero manteniendo las restricciones que puedan resultar necesarias para preservar los derechos individuales y colectivos.
- Ser completamente transparente y proporcionar toda la documentación existente sobre los datos, así como sobre su uso, permitiendo además distinguir claramente entre datos reales y sintéticos.
- Respetar las decisiones tomadas sobre el uso de los datos por parte de las personas que han contribuido previamente a la creación de los datos, ya sea mediante la cesión de sus propios datos o a través de la elaboración de nuevos contenidos, incluyendo también el respeto hacia cualquier marco legal existente.
- Proteger el beneficio común en el uso de los datos y un uso sostenible de los mismos para poder asegurar una gobernanza adecuada a lo largo del tiempo, reconociendo siempre su naturaleza relacional y colectiva.
- Garantizar la calidad de los datos, lo que resulta crítico a la hora de conservar su valor como bien de interés común, especialmente teniendo en cuenta los potenciales riesgos de contaminación asociados a su uso por parte de la IA.
- Establecer instituciones fiables que se encarguen de la gobernanza de los datos y faciliten la participación por parte de toda la comunidad creada en torno a los datos, yendo así un paso más allá de los modelos existentes en la actualidad para los intermediarios de datos.
Casos de uso y aplicaciones
Existen en la actualidad múltiples ejemplos reales que nos ayudan a ilustrar el potencial transformador de los data commons:
-
Data commons sanitarios: proyectos como la iniciativa del National Institutes of Health en los Estados Unidos - NIH Common Fund para analizar y compartir grandes conjuntos de datos biomédicos, o el Cancer Research Data Commons del National Cancer Institute, demuestran cómo los data commons pueden contribuir a la aceleración de la investigación y la innovación en salud.
- Entrenamiento de la IA y machine learning: la evaluación de los sistemas de IA depende de conjuntos de datos de prueba rigurosos y estandarizados. Iniciativas como OpenML o MLCommons construyen conjuntos de datos abiertos, a gran escala y diversos, ayudando a la comunidad en general a ofrecer sistemas de IA más precisos y seguros.
- Data commons urbanos y de movilidad: las ciudades que aprovechan plataformas compartidas de datos urbanos mejoran la toma de decisiones y los servicios públicos mediante el análisis colectivo de datos, como es el caso de Barcelona Dades, que además de un amplio repositorio de datos abiertos integra y difunde datos y análisis sobre la evolución demográfica, económica, social y política de la ciudad. Otras iniciativas como el propio OpenStreetMaps pueden también contribuir a proporcionar datos geográficos de libre acceso.
- Preservación de la cultura y el conocimiento: con iniciativas tan relevantes en este campo como el proyecto de Common Voice de Mozilla para preservar y revitalizar los idiomas del mundo, o Wikidata, cuyo objetivo consiste en proporcionar un acceso estructurado a todos los datos provenientes de los proyectos de Wikimedia, incluyendo la popular Wikipedia.
Desafíos en los data commons
A pesar de su promesa y potencial como herramienta transformadora para los nuevos desafíos en la era digital, los data commons afrontan también sus propios desafíos:
- Complejidad en la gobernanza: llegar a conseguir un equilibrio correcto entre la inclusión, el control y la privacidad puede resultar una tarea delicada.
- Sostenibilidad: muchos de los data commons existentes libran una batalla continua para intentar asegurarse la financiación y los recursos que necesitan para mantenerse y garantizar su supervivencia a largo plazo.
- Problemas legales y éticos: abordar los retos relativos a los derechos de propiedad intelectual, la titularidad de datos y el uso ético siguen siendo aspectos críticos que todavía no se han resulto por completo.
- Interoperabilidad: asegurar la compatibilidad entre conjuntos de datos y plataformas es un obstáculo técnico persistente en casi cualquier iniciativa de compartición de datos, y los data commons no iban a ser la excepción.
El camino a seguir
Para desbloquear su pleno potencial, los data commons requieren de una acción colectiva y una apuesta decidida por la innovación. Las acciones clave incluyen:
- Desarrollar modelos de gobernanza estandarizados que consigan el equilibrio entre las consideraciones éticas y los requisitos técnicos.
- Aplicar el principio de reciprocidad en el uso de los datos, exigiendo a aquellos que se benefician de ellos compartir sus resultados de vuelta con la comunidad.
- Protección de datos sensibles mediante la anonimización, evitando que los datos puedan ser utilizados para vigilancia masiva o discriminación.
- Fomentar la inversión en infraestructura para apoyar el intercambio de datos escalable y sostenible.
- Promover la concienciación sobre los beneficios sociales de los data commons para impulsar la participación y la colaboración.
Los responsables políticos, investigadores y organizaciones civiles deberían trabajar juntos para crear un ecosistema en el que los data commons puedan prosperar, fomentando un crecimiento más equitativo en la economía digital y garantizando que los bienes comunes de datos puedan beneficiar a todos.
Conclusión
Los data commons pueden suponer una poderosa herramienta a la hora de democratizar el acceso a los datos y fomentar la innovación. En esta era definida por la IA y la transformación digital, nos ofrecen un camino alternativo hacia el progreso equitativo, sostenible e inclusivo. Al abordar sus desafíos y adoptar un enfoque de gobernanza colaborativa mediante la cooperación entre comunidades, investigadores y reguladores se podrá garantizar un uso equitativo y responsable de los datos.
De este modo se conseguirá que los data commons se conviertan en un pilar fundamental del futuro digital, incluyendo las nuevas aplicaciones de la Inteligencia Artificial, pudiendo servir además como herramienta habilitadora fundamental para algunas de las acciones clave que forman parte de la recién anunciada brújula Europea de competitividad, como la estrategia de la nueva Unión de Datos y la iniciativa de las Gigafábricas de IA.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Inteligencia Artificial (IA) ha dejado de ser un concepto futurista y se ha convertido en una herramienta clave en nuestra vida diaria. Desde las recomendaciones de películas o series en plataformas de streaming hasta los asistentes virtuales como Alexa o Google Assistant en nuestros dispositivos, la IA está en todas partes. Pero, ¿cómo se construye un modelo de IA? A pesar de lo que podría parecer, el proceso es menos intimidante si lo desglosamos en pasos claros y comprensibles.
Paso 1: definir el problema
Antes de empezar, necesitamos tener muy claro qué queremos resolver. La IA no es una varita mágica: diferentes modelos funcionarán mejor en diferentes aplicaciones y contextos por lo que es importante definir la tarea específica que deseamos ejecutar. Por ejemplo, ¿queremos predecir las ventas de un producto? ¿Clasificar correos como spam o no spam? Tener una definición clara del problema nos ayudará a estructurar el resto del proceso.
Además, debemos plantearnos qué tipo de datos tenemos y cuáles son las expectativas. Esto incluye determinar el nivel de precisión deseado y las limitaciones de tiempo o recursos disponibles.
Paso 2: recopilar los datos
La calidad de un modelo de IA depende directamente de la calidad de los datos utilizados para entrenarlo. Este paso consiste en recopilar y organizar los datos relevantes para nuestro problema. Por ejemplo, si queremos predecir ventas, necesitaremos datos históricos como precios, promociones o patrones de compra.
La recopilación de datos comienza identificando las fuentes relevantes, que pueden ser bases de datos internas, sensores, encuestas… Además de los datos propios de cada empresa, existe un amplio ecosistema de datos, tanto abiertos como propietarios, a los que podemos recurrir en busca de la construcción de modelos más potentes. Por ejemplo, el Gobierno de España habilita a través del portal datos.gob.es múltiples conjuntos de datos abiertos publicados por instituciones públicas. Por otro lado, la empresa Amazon Web Services (AWS) a través de su portal AWS Data Exchange permite el acceso y suscripción a miles de conjuntos de datos propietarios publicados y mantenidos por diferentes empresas y organizaciones.
En este punto también se debe considerar la cantidad de datos necesaria. Los modelos de IA suelen necesitar grandes volúmenes de información para aprender de manera efectiva. También es crucial que los datos sean representativos y no contengan sesgos que puedan afectar los resultados. Por ejemplo, si entrenamos un modelo para predecir patrones de consumo y solo usamos datos de un grupo limitado de personas, es probable que las predicciones no sean válidas para otros grupos con comportamientos diferentes.
Paso 3: preparar y explorar los datos
Una vez recopilados los datos, es hora de limpiarlos y normalizarlos. En muchas ocasiones, los datos en bruto pueden contener problemas como errores, duplicidades, valores faltantes, inconsistencias o formatos no estandarizados. Por ejemplo, podríamos encontrarnos con celdas vacías en un conjunto de datos de ventas o con fechas que no siguen un formato coherente. Antes de alimentar el modelo con estos datos, es fundamental adecuarlos para garantizar que el análisis sea preciso y confiable. Este paso no solo mejora la calidad de los resultados, sino que también asegura que el modelo pueda interpretar correctamente la información.
Una vez tenemos los datos limpios es fundamental realizar la ingeniería de características (feature engineering), un proceso creativo que puede marcar la diferencia entre un modelo básico y uno excelente. Esta fase consiste en crear nuevas variables que capturen mejor la naturaleza del problema que queremos resolver. Por ejemplo, si estamos analizando ventas online, además de usar el precio directo del producto, podríamos crear nuevas características como el ratio precio/media_categoría, los días desde la última promoción, o variables que capturen la estacionalidad de las ventas. La experiencia demuestra que contar con características bien diseñadas suele ser más determinante para el éxito del modelo que la elección del algoritmo en sí mismo.
En esta fase, también realizaremos un primer análisis exploratorio de los datos, buscando familiarizarnos con ellos y detectar posibles patrones, tendencias o irregularidades que puedan influir en el modelo. En esta guía podemos encontrar mayor detalle sobre cómo realizar un análisis exploratorio de datos.
Otra actividad típica de esta etapa es dividir los datos en conjuntos de entrenamiento, validación y prueba. Por ejemplo, si tenemos 10.000 registros, podríamos usar el 70% para entrenamiento, el 20% para validación y el 10% para pruebas. Esto permite que el modelo aprenda sin sobreajustarse a un conjunto de datos específico.
Para garantizar que nuestra evaluación sea robusta, especialmente cuando trabajamos con conjuntos de datos limitados, es recomendable implementar técnicas de validación cruzada (cross-validation). Esta metodología divide los datos en múltiples subconjuntos y realiza varias iteraciones de entrenamiento y validación. Por ejemplo, en una validación cruzada de 5 pliegues, dividimos los datos en 5 partes y entrenamos 5 veces, usando cada vez una parte diferente como conjunto de validación. Esto nos proporciona una estimación más fiable del rendimiento real del modelo y nos ayuda a detectar problemas de sobreajuste o variabilidad en los resultados.
Paso 4: seleccionar un modelo
Existen múltiples tipos de modelos de IA, y la elección depende del problema que deseemos resolver. Algunos ejemplos comunes son regresión, modelos de árboles de decisión, modelos de agrupamiento, modelos de series temporales o redes neuronales. En general, existen modelos supervisados, modelos no supervisados y modelos de aprendizaje por refuerzo. Podemos encontrar un mayor detalle en este post sobre cómo las maquinas aprenden.
A la hora de seleccionar un modelo, es importante tener en cuenta factores como la naturaleza de los datos, la complejidad del problema y el objetivo final. Por ejemplo, un modelo simple como la regresión lineal puede ser suficiente para problemas sencillos y bien estructurados, mientras que redes neuronales o modelos avanzados podrían ser necesarios para tareas como reconocimiento de imágenes o procesamiento del lenguaje natural. Además, también se debe considerar el balance entre precisión, tiempo de entrenamiento y recursos computacionales. Un modelo más preciso generalmente requiere configuraciones más complejas, como más datos, redes neuronales más profundas o parámetros optimizados. Aumentar la complejidad del modelo o trabajar con conjuntos de datos grandes puede alargar significativamente el tiempo necesario para entrenarlo. Esto puede ser un problema en entornos donde las decisiones deben tomarse rápidamente o los recursos son limitados y requerir hardware especializado, como GPUs o TPUs, y mayores cantidades de memoria y almacenamiento.
Hoy en día, muchas bibliotecas de código abiertas facilitan la implementación de estos modelos, como TensorFlow, PyTorch o scikit-learn.
Paso 5: entrenar el modelo
El entrenamiento es el corazón del proceso. Durante esta etapa, alimentamos el modelo con los datos de entrenamiento para que aprenda a realizar su tarea. Esto se logra ajustando los parámetros del modelo para minimizar el error entre sus predicciones y los resultados reales.
Aquí es clave evaluar constantemente el rendimiento del modelo con el conjunto de validación y realizar ajustes si es necesario. Por ejemplo, en un modelo de tipo red neuronal podríamos probar diferentes configuraciones de hiperparámetros como tasa de aprendizaje, número de capas ocultas y neuronas, tamaño del lote, número de épocas, o función de activación, entre otros.
Paso 6: evaluar el modelo
Una vez entrenado, es momento de poner a prueba el modelo utilizando el conjunto de datos de prueba que apartamos durante la fase de entrenamiento. Este paso es crucial para medir cómo se desempeña con datos que para el modelo son nuevos y garantiza que no esté “sobreentrenado”, es decir, que no solo funcione bien con los datos de entrenamiento, sino que sea capaz de aplicar el aprendizaje sobre nuevos datos que puedan generarse en el día a día.
Al evaluar un modelo, además de la precisión, también es común considerar:
- Confianza en las predicciones: evaluar cuán seguras son las predicciones realizadas.
- Velocidad de respuesta: tiempo que toma el modelo en procesar y generar una predicción.
- Eficiencia en recursos: medir cuánto uso de memoria y cómputo requiere el modelo.
- Adaptabilidad: cuán bien puede ajustarse el modelo a nuevos datos o condiciones sin necesidad de un reentrenamiento completo.
Paso 7: desplegar y mantener el modelo
Cuando el modelo cumple con nuestras expectativas, está listo para ser desplegado en un entorno real. Esto podría implicar integrar el modelo en una aplicación, automatizar tareas o generar informes.
Sin embargo, el trabajo no termina aquí. La IA necesita mantenimiento continuo para adaptarse a los cambios en los datos o en las condiciones del mundo real. Por ejemplo, si los patrones de compra cambian por una nueva tendencia, el modelo deberá ser actualizado.
Construir modelos de IA no es una ciencia exacta, es el resultado de un proceso estructurado que combina lógica, creatividad y perseverancia. Esto se debe a que intervienen múltiples factores, como la calidad de los datos, las elecciones en el diseño del modelo y las decisiones humanas durante la optimización. Aunque existen metodologías claras y herramientas avanzadas, la construcción de modelos requiere experimentación, ajustes y, a menudo, un enfoque iterativo para obtener resultados satisfactorios. Aunque cada paso requiere atención al detalle, las herramientas y tecnologías disponibles hoy en día hacen que este desafío sea accesible para cualquier persona interesada en explorar el mundo de la IA.
ANEXO I – Definiciones tipos de modelos
-
Regresión: técnicas supervisadas que modelan la relación entre una variable dependiente (resultado) y una o más variables independientes (predictores). La regresión se utiliza para predecir valores continuos, como ventas futuras o temperaturas, y puede incluir enfoques como la regresión lineal, logística o polinómica, dependiendo de la complejidad del problema y la relación entre las variables.
-
Modelos de árboles de decisión: métodos supervisados que representan decisiones y sus posibles consecuencias en forma de árbol. En cada nodo, se toma una decisión basada en una característica de los datos, dividiendo el conjunto en subconjuntos más pequeños. Estos modelos son intuitivos y útiles para clasificación y predicción, ya que generan reglas claras que explican el razonamiento detrás de cada decisión.
-
Modelos de agrupamiento: técnicas no supervisadas que agrupan datos en subconjuntos llamados clústeres, basándose en similitudes o proximidad entre los datos. Por ejemplo, se pueden agrupar clientes con hábitos de compra similares para personalizar estrategias de marketing. Modelos como k-means o DBSCAN permiten identificar patrones útiles sin necesidad de datos etiquetados.
-
Modelos de series temporales: diseñados para trabajar con datos ordenados cronológicamente, estos modelos analizan patrones temporales y realizan predicciones basadas en el historial. Se utilizan en casos como predicción de demanda, análisis financiero o meteorología. Incorporan tendencias, estacionalidad y relaciones entre los datos pasados y futuros.
-
Redes neuronales: modelos inspirados en el funcionamiento del cerebro humano, donde capas de neuronas artificiales procesan información y detectan patrones complejos. Son especialmente útiles en tareas como reconocimiento de imágenes, procesamiento de lenguaje natural y juegos. Las redes neuronales pueden ser simples o muy profundas (deep learning), dependiendo del problema y la cantidad de datos.
-
Modelos supervisados: estos modelos aprenden de datos etiquetados, es decir, conjuntos en los que cada entrada tiene un resultado conocido. El objetivo es que el modelo generalice para predecir resultados en datos nuevos. Ejemplos incluyen clasificación de correos en spam o no spam y predicciones de precios.
-
Modelos no supervisados: trabajan con datos sin etiquetas, buscando patrones ocultos, estructuras o relaciones dentro de los datos. Son ideales para tareas exploratorias donde no se conoce de antemano el resultado esperado, como segmentación de mercados o reducción de dimensionalidad.
- Modelo de aprendizaje por refuerzo: en este enfoque, un agente aprende interactuando con un entorno, tomando decisiones y recibiendo recompensas o penalizaciones según su desempeño. Este tipo de aprendizaje es útil en problemas donde las decisiones afectan un objetivo a largo plazo, como entrenar robots, jugar videojuegos o desarrollar estrategias de inversión.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El diseño de API web es una disciplina fundamental para el desarrollo de aplicaciones y servicios, al facilitar el intercambio fluido de datos entre diferentes sistemas. En el contexto de las plataformas de datos abiertos, las API cobran especial importancia, ya que permiten a los usuarios acceder de manera automática y eficiente a la información necesaria, ahorrando costes y recursos.
Este artículo explora los principios esenciales que deben guiar la creación de API web eficaces, seguras y sostenibles, en base a los principios recopilados por el Grupo de Arquitectura Técnica ligado a World Wide Web Consortium (W3C), siguiendo estándares éticos y técnicos. Aunque estos principios hacen referencia al diseño de API, muchos son aplicables al desarrollo web en general.
Se busca que los desarrolladores puedan garantizar que sus API no solo cumplan con los requisitos técnicos, sino que también respeten la privacidad y seguridad de los usuarios, promoviendo una web más segura y eficiente para todos.
En este post, analizaremos algunos consejos para los desarrolladores de las API y cómo se pueden poner en práctica.
Prioriza las necesidades del usuario
Al diseñar una API, es crucial seguir la jerarquía de necesidades establecida por el W3C:
- Primero, las necesidades del usuario final.
- Segundo, las necesidades de los desarrolladores web.
- Tercero, las necesidades de los implementadores de navegadores.
- Por último, la pureza teórica.
Así podremos impulsar una experiencia de usuario que sea intuitiva, funcional y atractiva. Esta jerarquía debe guiar las decisiones de diseño, aunque reconociendo que en ocasiones estos niveles se interrelacionan: por ejemplo, una API más fácil de usar para los desarrolladores suele resultar en mejor experiencia para el usuario final.
Garantiza la seguridad
Garantizar la seguridad al desarrollar una API es crucial para proteger, tanto los datos de los usuarios, como la integridad del sistema. Una API insegura puede ser un punto de entrada para atacantes que buscan acceder a información sensible o comprometer la funcionalidad del sistema. Por ello, al añadir nuevas funcionalidades, debemos cumplir las expectativas del usuario y garantizar su seguridad.
En este sentido, es esencial considerar factores relacionados con la autenticación de usuarios, encriptación de datos, validación de entradas, gestión de tasas de solicitud (o Rate Limiting, para limitar la cantidad de solicitudes que un usuario puede hacer en un periodo determinado y evitar ataques de denegación de servicio), etc. También es necesario monitorear continuamente las actividades de la API y mantener registros detallados para detectar y responder rápidamente a cualquier actividad sospechosa.
Desarrolla una interfaz de usuario que transmita confianza
Es necesario considerar cómo las nuevas funcionalidades impactan en las interfaces de usuario. Las interfaces deben ser diseñadas para que los usuarios puedan confiar y verificar que la información proporcionada es genuina y no ha sido falsificada. Aspectos como la barra de direcciones, los indicadores de seguridad y las solicitudes de permisos deben dejar claro con quién se están interactuando y cómo.
Por ejemplo, la función alert de JavaScript, que permite mostrar un cuadro de diálogo modal que parece parte del navegador, es un caso histórico que ilustra esta necesidad. Esta función, creada en los primeros días de la web, ha sido frecuentemente utilizada para engañar a usuarios haciéndoles creer que están interactuando con el navegador, cuando en realidad lo hacen con la página web. Si esta funcionalidad se propusiera hoy, probablemente no sería aceptada por estos riesgos de seguridad.
Pide consentimiento explicito a los usuarios
En el contexto de satisfacer una necesidad de usuario, una página web puede utilizar una función que suponga una amenaza. Por ejemplo, el acceso a la geolocalización del usuario puede ser de ayuda en algunos contextos (como una aplicación de mapas), pero también afecta a la privacidad.
En estos casos es necesario que el usuario consienta su uso. Para ello:
- El usuario debe entender a qué está accediendo. Si no puedes explicar a un usuario tipo a qué está consintiendo de forma inteligible, deberás reconsiderar el diseño de la función.
- El usuario debe poder elegir entre otorgar o rechazar ese permiso de manera efectiva. Si se rechaza una solicitud de permiso, la página web no podrá hacer nada que el usuario crea que ha descartado.
Al pedir consentimiento, podemos informar al usuario de qué capacidades tiene o no tiene la página web, reforzando su confianza en la seguridad del sitio. Sin embargo, el beneficio de una nueva función debe justificar la carga adicional que supone para el usuario decidir si otorga o no permiso para una función.
Usa mecanismos de identificación adecuados al contexto
Es necesario ser transparente y permitir a las personas controlar sus identificadores y la información adjunta a ellos que proporcionan en diferentes contextos en la web.
Las funcionalidades que utilizan o dependen de identificadores vinculados a datos sobre una persona conllevan riesgos de privacidad que pueden ir más allá de una sola API o sistema. Esto incluye datos generados pasivamente (como su comportamiento en la web) y aquellos recopilados activamente (por ejemplo, a través de un formulario). En este sentido, es necesario entender el contexto en el que se usarán y cómo se integrarán con otras funcionalidades de la web, asegurando de que el usuario pueda dar un consentimiento adecuado.
Es recomendable diseñar API que recopilen la mínima cantidad de datos necesarios y usar identificadores temporales de corta duración, a menos que sea absolutamente necesario un identificador persistente.
Crea funcionalidades compatibles con toda la gama de dispositivos y plataformas
En la medida de lo posible, asegura que las funcionalidades de la web estén operativas en diferentes dispositivos de entrada y salida, tamaños de pantalla, modos de interacción, plataformas y medios, favoreciendo la flexibilidad del usuario.
Por ejemplo, los modelos de diseño 'display: block', 'display: flex' y 'display: grid' en CSS, por defecto, colocan el contenido dentro del espacio disponible y sin solapamientos. De este modo funcionan en diferentes tamaños de pantalla y permiten a los usuarios elegir su propia fuente y tamaño sin causar desbordamiento de texto.
Agrega nuevas capacidades con cuidado
Añadir nuevas capacidades a la web requiere tener en consideración las funcionalidades y el contenido ya existentes, para valorar cómo va a ser su integración. No hay que asumir que un cambio es posible o imposible sin verificarlo primero.
Existen muchos puntos de extensión que permiten agregar funcionalidades, pero hay cambios que no se pueden realizar simplemente añadiendo o eliminando elementos, porque podrían generar errores o afectar a la experiencia de usuario. Por ello es necesario verificar antes la situación actual, como veremos en el siguiente apartado.
Antes de eliminar o cambiar funcionalidades, comprende su uso actual
Es posible eliminar o cambiar funciones y capacidades, pero primero hay que conocer bien la naturaleza y el alcance de su impacto en el contenido existente. Para ello puede ser necesario investigar cómo se utilizan las funciones actuales.
La obligación de comprender el uso existente se aplica a cualquier función de la que dependan los contenidos. Las funciones web no se definen únicamente en las especificaciones, sino también en la forma en que los usuarios las utilizan.
La práctica recomendada es priorizar la compatibilidad de las nuevas funciones con el contenido existente y el comportamiento del usuario. En ocasiones, una cantidad significativa de contenido puede depender de un comportamiento concreto. En estas situaciones, se desaconseja eliminar o cambiar dicho comportamiento.
Deja la web mejor de lo que la encontraste
La forma de añadir nuevas capacidades a una plataforma web es mejorando la plataforma en su conjunto, por ejemplo, sus características de seguridad, privacidad o accesibilidad.
La existencia de un defecto en una parte concreta de la plataforma no debe servir de excusa para añadir o ampliar funcionalidades adicionales con el fin de solucionarlo, ya que con ello se pueden duplicar problemas y disminuir la calidad general de la plataforma. Siempre que sea posible, hay que crear nuevas capacidades web que mejoren la calidad general de la plataforma, mitigando los defectos existentes de forma global.
Minimiza los datos del usuario
Hay que diseñar las funcionalidades para que sean operativas con la mínima cantidad necesaria de datos aportados por el usuario para llevar a cabo sus objetivos . Con ello, limitamos los riesgos de que se divulguen o utilicen indebidamente.
Se recomienda diseñar las API de forma que a los sitios web les resulte más fácil solicitar, recopilar y/o transmitir una pequeña cantidad de datos (datos más granulares o específicos), que trabajar con datos más genéricos o masivos. Las API deben proporcionar granularidad y controles de usuario, en particular si trabajan sobre datos personales.
Otras recomendaciones
El documento también ofrece consejos para el diseño de API utilizando diversos lenguajes de programación. En este sentido, proporciona recomendaciones ligadas a HTML, CSS, JavaScript, etc. Puedes leer las recomendaciones aquí.
Además, si estás pensando en integrar una API en tu plataforma de datos abiertos, te recomendamos la lectura de la Guía práctica para la publicación de Datos Abiertos usando APIs.
Siguiendo estas indicaciones podrás desarrollar sitios web consistentes y útiles para los usuarios, que les permitan alcanzar sus objetivos de manera ágil y optimizando recursos.
Evento
Los EU Open Data Days 2025 son un evento esencial para todos los interesados en el mundo de los datos abiertos y la innovación en Europa y el mundo. Este encuentro, que se celebrará los días 19 y 20 de marzo de 2025, reunirá a expertos, profesionales, desarrolladores, investigadores y responsables de políticas públicas para compartir conocimientos, explorar nuevas oportunidades y abordar los retos a los que se enfrenta la comunidad de datos abiertos.
El evento, organizado por la Comisión Europea a través de data.europa.eu, tiene como objetivo principal promover la reutilización de datos abiertos. Los participantes tendrán la oportunidad de aprender sobre las últimas tendencias en el uso de los datos abiertos, descubrir nuevas herramientas y debatir sobre las políticas y normativas que están modelando el panorama digital en Europa.
¿Dónde y cuándo se celebra?
El evento se celebrará en el Centro Europeo de Convenciones de Luxemburgo, aunque también se podrá seguir online, con el siguiente horario:
- Miércoles 19 de marzo de 2025, de 13:30 a 18:30.
- Jueves 20 de marzo de 2025, de 9:00 a 15:30.
¿Qué temáticas se abordarán?
Ya está disponible la agenda del evento, donde encontramos distintas temáticas, como, por ejemplo:
- Historias de éxito y buenas prácticas: el evento contará con la presencia de profesionales que desarrollan su trabajo en la primera línea de la política de datos europea, para que cuenten su experiencia. Entre otras cuestiones, estos expertos proporcionarán una guía práctica para inventariar y abrir los datos del sector público de un país, abordarán el trabajo que implica la compilación de conjuntos de datos de alto valor o analizarán las perspectivas sobre la reutilización de datos en los modelos de negocio. También se explicarán buenas prácticas para contar con metadatos de calidad o mejorar la gobernanza de datos y su interoperabilidad.
- Foco en el uso de inteligencia artificial (IA): los datos abiertos ofrecen una fuente invaluable para el desarrollo y avance de la IA. Además, la IA puede optimizar la localización, gestión y uso de estos datos, ofreciendo herramientas que ayuden a agilizar procesos y extraer un mayor conocimiento. En este sentido, en el evento se abordará el potencial de la IA para transformar los ecosistemas de datos gubernamentales abiertos, fomentando la innovación, mejorando la gobernanza y potenciando la participación ciudadana. Los responsables del portal nacional de datos de Noruega contará cómo emplean un motor de búsqueda basado en IA para mejorar la localización de datos. Además, se explicarán los avances en espacios de datos lingüísticos y su uso en modelos de lenguaje, y se analizará cómo combinar de forma creativa los datos abiertos para lograr un impacto social.
- Aprendizaje sobre visualización de datos: los asistentes al evento podrán explorar cómo la visualización de datos está transformando la comunicación, la elaboración de políticas y la participación ciudadana. A través de diversos casos (como el árbol genealógico de 3.000 personas de la realeza europea o las relaciones del Patrimonio Cultural Inmaterial de la UNESCO) se mostrará cómo los procesos iterativos de diseño pueden descubrir patrones ocultos en redes complejas, aportando ideas sobre la narración y la comunicación de datos. También se abordará cómo influyen los elementos de diseño, como el color, la escala y el enfoque, en la percepción de los datos.
- Ejemplos y casos de uso: se mostrarán múltiples ejemplos de proyectos concretos basados en la reutilización de datos, en campos como la energía, el desarrollo urbano o el medio ambiente. Entre las experiencias que se compartirán, encontramos una empresa española, Tangible Data, que contará cómo las esculturas físicas de datos convierten conjuntos de datos complejos en experiencias accesibles y atractivas.
Estos son solo algunos de los temas a tratar, pero también se hablará de ciencia abierta, el papel de los datos abiertos en la transparencia y la rendición de cuentas, etc.
¿Por qué son tan importantes los EU Open Data Days?
El acceso a datos abiertos ha demostrado ser una herramienta poderosa para mejorar la toma de decisiones, impulsar la innovación y la investigación, y mejorar la eficiencia de las organizaciones. En un momento en el que la digitalización está avanzando rápidamente, la importancia de compartir y reutilizar datos se hace cada vez más crucial para enfrentar desafíos globales como el cambio climático, la salud pública o la justicia social.
Los EU Open Data Days 2025 son una oportunidad para explorar cómo los datos abiertos pueden aprovecharse para construir una Europa más conectada, innovadora y participativa.
Además, para aquellos que decidan asistir de forma presencial, el evento será también una oportunidad para establecer contactos con otros profesionales y organizaciones del sector, creando nuevas colaboraciones que pueden dar lugar a proyectos innovadores.
¿Cómo puedo asistir?
Para asistir presencialmente, es necesario inscribirse a través de este enlace. Sin embargo, no es necesario el registro para atender el evento de manera online.
Para cualquier consulta, se ha habilitado una dirección de correo donde se atenderán todas las dudas relativas al evento: EU-Open-Data-Days@ec.europa.eu.
Más información en la página web del evento.