Blog
En un mundo cada vez más impulsado por los datos, todas las organizaciones, tanto las empresas privadas, como los organismos públicos, buscan aprovechar su información para tomar decisiones más acertadas, mejorar la eficiencia de sus procesos y cumplir sus objetivos estratégicos. Sin embargo, crear una estrategia de datos efectiva es un desafío que no debe subestimarse.
Con frecuencia, organizaciones de todos los sectores caen en errores comunes que pueden comprometer el éxito de sus estrategias desde el principio. Desde ignorar la importancia del gobierno del dato hasta no alinear los objetivos estratégicos con las necesidades reales de la institución, estos fallos pueden traducirse en ineficiencias, incumplimientos normativos e, incluso, pérdida de confianza por parte de ciudadanos, empleados o usuarios.
En este artículo, exploraremos los errores más habituales en la creación de una estrategia de datos, con el propósito de ayudar tanto a entidades públicas como privadas a evitarlos. Nuestro objetivo es ofrecerles herramientas para construir una base sólida que les permita maximizar el valor de los datos en beneficio de su misión y sus objetivos.

Figura 1. Consejos para diseñar una estrategia de gobierno del dato. Fuente: elaboración propia
A continuación, se detallan algunos de los errores más comunes en la elaboración de una estrategia de datos, justificando su impacto y el grado de afectación que pueden tener en una organización:
Falta de vinculación con los objetivos de la organización y no identificación de las áreas clave
Para que la estrategia de datos sea efectiva en cualquier tipo de organización, es fundamental que esté alineada con sus objetivos estratégicos. Estos objetivos incluyen áreas clave como el incremento de los ingresos, la mejora del servicio, la optimización de costes o la experiencia del cliente/ciudadano. Además, priorizar las iniciativas es esencial para identificar las áreas de la organización que se beneficiarán más de la estrategia de datos. Este enfoque no solo permite maximizar el retorno de la inversión en datos, sino también asegurar que las iniciativas estén claramente conectadas con los resultados deseados, reduciendo posibles brechas entre los esfuerzos en datos y los objetivos estratégicos.
No definir objetivos claros a corto y medio plazo
Definir metas específicas y alcanzables en las etapas iniciales de una estrategia de datos es muy importante para establecer una dirección clara y demostrar su valor desde el principio. Esto impulsa la motivación de los equipos involucrados y genera confianza entre los líderes y las partes interesadas. Priorizar objetivos a corto plazo, como la implementación de un dashboard de indicadores clave o la mejora en la calidad de un conjunto específico de datos críticos, permite obtener resultados tangibles de manera rápida y justifica la inversión en la estrategia de datos. Estos logros iniciales no solo consolidan el respaldo de la dirección, sino que también fortalecen el compromiso de los equipos.
De igual forma, los objetivos a medio plazo son fundamentales para construir sobre los avances iniciales y preparar el terreno para proyectos más ambiciosos. Por ejemplo, la automatización de procesos de generación de informes o la implementación de modelos predictivos para áreas clave pueden ser metas intermedias que demuestren el impacto positivo de la estrategia en la organización. Estos logros permiten medir el progreso, evaluar el éxito de la estrategia y garantizar que esté alineada con las prioridades estratégicas de la organización.
Establecer una combinación de metas a corto y medio plazo asegura que la estrategia de datos mantenga su relevancia a lo largo del tiempo y continúe generando valor. Este enfoque ayuda a la organización a avanzar de manera estructurada, reforzando su posición tanto frente a sus competidores como en el cumplimiento de su misión en el caso de organismos públicos.
No realizar una evaluación de madurez previa para definir la estrategia lo más acotada posible
Antes de diseñar una estrategia de datos, es crucial realizar una evaluación previa que permita entender el estado actual de la organización en términos de datos y delimitar el alcance de manera realista y efectiva. Este paso no solo evita que los esfuerzos se dispersen, sino que también asegura que la estrategia esté alineada con las necesidades reales de la organización, maximizando así su impacto. Sin una evaluación previa, es fácil caer en el error de abordar iniciativas demasiado amplias o poco conectadas con las prioridades estratégicas.
Por lo tanto, realizar esta evaluación previa no es solo un ejercicio técnico, sino una herramienta estratégica que asegura que los recursos y esfuerzos estén bien dirigidos desde el principio. Con un diagnóstico claro, la estrategia de datos se convierte en una hoja de ruta sólida, capaz de generar resultados tangibles desde las primeras etapas. Cabe recordar que para realizar esta evaluación de madurez previa a la estrategia se podría utilizar la UNE 0080:2023, centrada en la evaluación de la madurez del gobierno y gestión del dato, proporciona un marco estructurado para esta evaluación inicial. Esta norma permite analizar de manera objetiva los procesos, tecnologías y capacidades de la organización en torno a los datos.
No llevar a cabo iniciativas de gobierno del dato
La definición de una estrategia sólida es fundamental para el éxito de las iniciativas de gobierno del dato. Es esencial contar con un área o unidad responsable del gobierno del dato, como una oficina del dato o un centro de excelencia, desde donde se establezcan las directrices claras y se coordinen las acciones necesarias para alcanzar los objetivos estratégicos comprometidos. Estas iniciativas deben estar alineadas con las prioridades de la organización, asegurando que los datos sean seguros, usables para los fines previstos y cumplan con la normativa y legislación vigente.
Un marco sólido de gobierno del dato es clave para garantizar la consistencia y la calidad de los datos, fortaleciendo la confianza en los informes y análisis que generan tanto valor interno como externo. Además, un enfoque adecuado reduce riesgos como el incumplimiento normativo, promoviendo un uso efectivo de los datos y protegiendo la reputación de la organización.
Por ello, es importante diseñar estas iniciativas con un enfoque integral, priorizando la colaboración entre las distintas áreas y alineándolas con la estrategia global de datos. Para profundizar en cómo estructurar un sistema de gobierno del dato efectivo, puedes consultar esta serie de artículos: De la estrategia del dato al sistema de gobierno de datos – Parte 1.
Enfocarse exclusivamente en la tecnología
Muchas organizaciones tienen la opinión errónea de que la adquisición de herramientas y plataformas sofisticadas será la solución definitiva a sus problemas de datos. Sin embargo, la tecnología constituye solo una parte del ecosistema. Sin los procesos adecuados, un marco de gobernanza y, por supuesto, personas, incluso la mejor tecnología fracasará. Esto es problemático porque puede dar lugar a enormes inversiones sin un retorno claro, así como a frustración entre los equipos cuando no obtienen los resultados esperados.
No involucrar a todas las partes interesadas ni definir los roles y responsabilidades
Una estrategia de datos sólida necesita sumar a todos los actores relevantes, ya sea en una administración pública o en una empresa privada. Cada área, departamento o unidad tiene una visión única de cómo los datos pueden ser útiles para alcanzar objetivos, mejorar servicios o tomar decisiones más informadas. Por eso, involucrar a todas las partes interesadas desde el principio no solo enriquece la estrategia, sino que también asegura que se alineen con las necesidades reales de la organización.
Asimismo, definir roles y responsabilidades claras es clave para evitar confusiones y duplicidades. Al saber quién es responsable de los datos, quién los gestiona y quién los usa, se garantiza un flujo de trabajo más eficiente y se fomenta la colaboración entre equipos. Tanto en el ámbito público como en el privado, este enfoque ayuda a maximizar el impacto de la estrategia de datos, asegurando que los esfuerzos estén coordinados y enfocados hacia un objetivo común.
No establecer métricas claras de éxito
Establecer indicadores clave de rendimiento (KPI) es fundamental para evaluar si las iniciativas están generando valor. Los KPI permiten demostrar los resultados de la estrategia de datos, reforzando el apoyo de los líderes y fomentando la disposición a seguir invirtiendo en el futuro. Al medir el impacto de las acciones, las organizaciones pueden garantizar la sostenibilidad y el desarrollo continuo de su estrategia, asegurando que esté alineada con los objetivos estratégicos y que aporte beneficios tangibles.
No posicionar la calidad de los datos en el centro
Una estrategia de datos sólida debe construirse sobre una base de datos confiables y de alta calidad. Ignorar este aspecto puede llevar a decisiones equivocadas, procesos ineficientes y pérdida de confianza en los datos por parte de los equipos. La calidad de datos no es solo un aspecto técnico, sino un habilitador estratégico: garantiza que la información utilizada sea completa, consistente, válida y oportuna.
Integrar la calidad de datos desde el principio implica definir métricas claras, establecer procesos de validación y limpieza, y asignar responsabilidades para su mantenimiento. Además, al colocar la calidad de datos en el centro de la estrategia, las organizaciones pueden desbloquear el verdadero potencial de los datos, asegurando que estos respalden con precisión los objetivos de negocio y refuercen la confianza de los usuarios. Sin calidad, la estrategia pierde fuerza y se convierte en una oportunidad desperdiciada.
No gestionar el cambio cultural ni la resistencia al cambio
La transición hacia una organización orientada a datos requiere no solo herramientas y procesos, sino también un enfoque claro en la gestión del cambio para involucrar a los empleados. Promover una mentalidad abierta hacia las nuevas prácticas es clave para garantizar la adopción y el éxito de la estrategia. Al priorizar la comunicación, la formación y el compromiso de los equipos, las organizaciones pueden facilitar este cambio cultural, asegurando que todos los niveles trabajen alineados con los objetivos estratégicos y maximizando el impacto de la estrategia de datos.
No planificar para la escalabilidad
Es fundamental que las organizaciones consideren cómo su estrategia de datos puede escalar a medida que crece el volumen de información. Diseñar una estrategia preparada para manejar este crecimiento asegura que los sistemas puedan soportar el aumento de datos sin necesidad de reestructuraciones futuras, lo que optimiza recursos y evita costos adicionales. Al planificar pensando en la escalabilidad, las organizaciones pueden garantizar una eficiencia operativa sostenible a largo plazo y aprovechar al máximo el valor de sus datos a medida que evolucionan sus necesidades.
Falta de actualización y revisión continua de la estrategia
Los datos y las necesidades de las organizaciones están en constante evolución, por lo que es importante revisar y adaptar regularmente la estrategia para mantenerla relevante y efectiva. Una estrategia de datos flexible y actualizada permite responder de manera ágil a nuevas oportunidades y desafíos, asegurando que siga generando valor a medida que cambian las prioridades del mercado o de la organización. Este enfoque proactivo garantiza que la estrategia continúe alineada con los objetivos estratégicos y refuerza su impacto positivo a largo plazo.
Como conclusión, es importante destacar que el éxito de una estrategia de datos radica en su capacidad para alinearse con los objetivos estratégicos de la organización, estableciendo metas claras y fomentando la participación de todas las áreas involucradas. Un buen sistema de gobierno del dato, acompañado de métricas que permitan medir su impacto, es la base para garantizar que la estrategia genere valor y sea sostenible a lo largo del tiempo.
Además, abordar aspectos como la calidad de los datos, el cambio cultural y la escalabilidad desde el inicio es esencial para maximizar su efectividad. Enfocarse exclusivamente en tecnología o descuidar estos elementos puede limitar los resultados y poner en riesgo la capacidad de la organización para adaptarse a nuevas oportunidades y desafíos. Finalmente, revisar y actualizar la estrategia de manera continua asegura su relevancia y refuerza su impacto positivo.
Para profundizar en cómo estructurar una estrategia de datos eficaz y su conexión con un sistema de gobierno del dato sólido, te recomendamos explorar los artículos publicados en datos.gob.es: De la estrategia del dato al sistema de gobierno de datos – Parte 1 y Parte 2. Estos recursos complementan los conceptos presentados en este artículo y ofrecen una visión práctica para su implementación en cualquier tipo de organización.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
La capacidad de recopilar, analizar y compartir datos juega un papel crucial en el contexto de los desafíos globales a los que nos enfrentamos hoy en día como sociedad. Desde la contaminación y el cambio climático, pasando por la pobreza y las pandemias, hasta la movilidad sostenible y la falta de acceso a los servicios básicos. Los problemas globales exigen soluciones que puedan adaptarse a gran escala. Es ahí donde los datos abiertos pueden jugar un papel fundamental, ya que permiten que gobiernos, organizaciones y ciudadanos trabajen juntos de manera transparente, y facilitan el proceso hasta llegar a conseguir soluciones eficaces, innovadoras, adaptables y sostenibles.
El Banco Mundial como pionero en el uso integral de los datos abiertos
Uno de los ejemplos de buenas prácticas más relevantes que podemos encontrar a la hora de exprimir el potencial de los datos abiertos para afrontar los grandes desafíos globales es, sin duda, el caso del Banco Mundial, referente en el uso de los datos abiertos desde hace ya más de una década como herramienta fundamental para el desarrollo sostenible.
Desde el lanzamiento de su portal de datos abiertos en 2010, la institución ha llevado a cabo un completo proceso de transformación en cuanto al acceso y uso de los datos. Este portal, totalmente innovador en su día, se convirtió rápidamente en un modelo de referencia al ofrecer acceso libre y gratuito a una amplia gama de datos e indicadores que abarcan más de 250 economías. Además, su plataforma está en constante actualización y poco se parece en el presente a la versión inicial, ya que sigue mejorando continuamente y proporcionando nuevos conjuntos de datos y herramientas complementarias y especializadas con el objetivo de facilitar que los datos estén siempre accesibles y sean útiles para la toma de decisiones. Algunos ejemplos de esas herramientas serían:
- La Poverty and Inequality Platform (PIP): diseñada para monitorizar y analizar la pobreza y la desigualdad a nivel mundial. Con datos de más de 140 países, esta plataforma permite a los usuarios acceder a estadísticas actualizadas y comprender mejor las dinámicas del bienestar colectivo. También facilita la visualización de datos mediante gráficos interactivos y mapas, ayudando a los usuarios a obtener una comprensión clara y rápida de la situación en distintas regiones y a lo largo del tiempo.
- La Microdata Library: proporciona acceso a datos de encuestas y censos a nivel de hogar y empresa en diversos países. La biblioteca cuenta con más de 3.000 conjuntos de datos provenientes de estudios y encuestas realizadas tanto por el propio Banco, así como de otras organizaciones internacionales y agencias nacionales de estadística. Los datos están disponibles de forma gratuita y son totalmente accesibles para poder ser descargados y analizados.
- Los World Development Indicators (WDI): son una herramienta fundamental para poder seguir el progreso de la agenda de desarrollo global. Esta base de datos contiene una vasta colección de indicadores de desarrollo económico, social y ambiental, abarcando más de 200 países y territorios. Cuenta con datos que cubren áreas como pobreza, educación, salud, sostenibilidad ambiental, infraestructura y comercio. Los WDIs nos proporcionan un marco de referencia de confianza a la hora de analizar tendencias de desarrollo globales y regionales.


Figura 1. Capturas de los portales web Poverty and Inequality Platform (PIP), Microdata Library y World Development Indicators (WDI).
Un hito relevante que ha marcado la forma en la que el Banco Mundial hace uso de los datos ha sido la publicación del informe sobre el Desarrollo Mundial 2021, titulado "datos para mejorar nuestras vidas". Este informe se ha convertido en una publicación emblemática que explora el potencial transformador de los datos para abordar los grandes retos de la humanidad, mejorar los resultados de los esfuerzos invertidos en desarrollo y promover un crecimiento inclusivo y equitativo. A través del informe, la institución aboga por una nueva agenda social para los datos, incluyendo una gobernanza robusta, ética y responsable de los mismos, maximizando su valor para poder generar un beneficio económico y social significativo.
En el informe se examina cómo los datos pueden ser integrados en las políticas públicas y los programas de desarrollo para abordar los desafíos globales en áreas como educación, salud, infraestructuras o el cambio climático. Pero, además, supuso un antes y un después a la hora de reforzar el compromiso del Banco Mundial con los datos como motor de cambio a la hora de afrontar los grandes desafíos, adoptando desde entonces una nueva hoja de ruta con un enfoque del uso de los datos más innovador, transformador y orientado a la acción. Desde ese momento han venido pasando de la teoría a la práctica a través de sus propios proyectos, donde los datos se convierten en una herramienta fundamental durante todo el ciclo estratégico, como en los siguientes ejemplos:
- Datos abiertos y reducción del riesgo de desastres: en el informe "Bienes públicos digitales para la reducción del riesgo de desastres en un clima cambiante" se subraya cómo el acceso abierto a datos geoespaciales y meteorológicos facilita la toma de decisiones y una planificación estratégica más eficaz. También se hace referencia a herramientas como OpenStreetMap que permiten a las comunidades mapear en tiempo real áreas vulnerables. Esta democratización de los datos refuerza la respuesta ante emergencias y fomenta la resiliencia de las comunidades expuestas a los riesgos de inundaciones, sequías y huracanes.
- Datos abiertos ante los retos agroalimentarios: el informe "¿Qué se está cocinando?" muestra cómo los datos abiertos están revolucionando los sistemas agroalimentarios globales, haciéndolos más inclusivos, eficientes y sostenibles. En la agricultura, el acceso a datos abiertos sobre patrones climáticos, calidad del suelo y precios de mercado habilita a los pequeños agricultores para tomar decisiones informadas. Además, las plataformas que ofrecen datos geoespaciales abiertos sirven para fomentar la agricultura de precisión, permitiendo optimizar recursos clave como el agua y los fertilizantes, a la vez que se reducen costes y se minimiza el impacto ambiental.
- Optimización de los sistemas de transporte urbano: en Tanzania, el Banco Mundial ha respaldado un proyecto que utiliza los datos abiertos para mejorar el sistema de transporte público. La rápida urbanización de Dar es Salaam ha provocado una congestión de tráfico considerable en varias zonas, afectando tanto la movilidad urbana como la calidad del aire. Esta iniciativa aborda la congestión del tráfico mediante un sistema de información en tiempo real que mejora la movilidad y reduce el impacto ambiental. Este enfoque, basado en datos abiertos, no solo aumenta la eficiencia del transporte, sino que también contribuye a una mejor calidad de vida para los habitantes de la ciudad.
Predicando con el ejemplo
Por último, y dentro de esta misma visión integral, cabe destacar cómo este organismo internacional cierra el círculo de los datos abiertos a través de su utilización también como herramienta de transparencia y comunicación de sus propias actividades. Es por ello que entre las herramientas de datos destacadas de su catálogo podremos encontrar algunas como:
- Su portal de proyectos y operaciones: una herramienta que ofrece acceso detallado a los proyectos de desarrollo que la institución financia y ejecuta en todo el mundo. Este portal actúa como una ventana a todas sus iniciativas globales, proporcionando información sobre objetivos, financiación, resultados esperados y avances para los miles de proyectos del Banco.
- La plataforma Finances One: en la que centralizan todos sus datos financieros de interés público y los correspondientes a la cartera de proyectos de todas las entidades del grupo. Su objetivo es simplificar la presentación de información financiera, facilitando su análisis y compartición por parte de clientes y socios.
El impacto futuro de los datos abiertos en los grandes desafíos globales
Como hemos visto también anteriormente, la apertura de datos ofrece un potencial inmenso para avanzar en la agenda de desarrollo sostenible y poder así enfrentar los desafíos globales con mayor eficacia. El Banco Mundial ha venido demostrando cómo esta práctica puede evolucionar y adaptarse a los desafíos actuales. Su liderazgo en este ámbito ha servido como modelo para otras instituciones, mostrando el impacto positivo que los datos abiertos pueden tener en el desarrollo sostenible y a la hora de afrontar los grandes desafíos que afectan a la vida de millones de personas en todo el mundo.
No obstante, hay todavía un largo camino por recorrer, ya que es necesario seguir mejorando las políticas de transparencia y acceso a la información para que los datos puedan llegar a beneficiar al conjunto de la sociedad de forma más equitativa. Además, otro desafío clave es fortalecer las capacidades necesarias para maximizar el uso e impacto de estos datos, particularmente en los países en vías de desarrollo. Esto implica no solo ir más allá de facilitar el acceso, sino también trabajar en la alfabetización de datos y en el apoyo a la creación de las herramientas adecuadas que permitan que la información sea utilizada de manera efectiva.
El uso de datos abiertos está consiguiendo que cada vez más actores puedan participar en la creación de soluciones innovadoras y conseguir un cambio real. Todo ello da lugar a una nueva área de trabajo en expansión que, en las manos correctas y con el apoyo adecuado, puede desempeñar un papel crucial en la creación de un futuro más seguro, justo y sostenible para todos. Esperamos que sean muchas las organizaciones que sigan el ejemplo del Banco Mundial y adopten también un enfoque integral en el uso de los datos para afrontar los grandes retos de la humanidad.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
No hay duda de que los datos se han convertido en el activo estratégico para las organizaciones. Hoy en día, es esencial garantizar que las decisiones están fundamentadas en datos de calidad, independientemente del alineamiento que sigan: analítica de datos, inteligencia artificial o reporting. Sin embargo, asegurar repositorios de datos con altos niveles de calidad no es tarea fácil, dado que en muchos casos los datos provienen de fuentes heterogéneas donde los principios de calidad de datos no se han tenido en cuenta y no se dispone de contexto sobre el dominio.
Para paliar en la medida de lo posible esta casuística, en este artículo, exploraremos una de las bibliotecas más utilizadas en el análisis de datos: Pandas. Vamos a chequear cómo esta biblioteca de Python puede ser una herramienta eficaz para mejorar la calidad de los datos. También repasaremos la relación de alguna de sus funciones con las dimensiones y propiedades de calidad de datos incluidas en la especificación UNE 0081 de calidad de datos, y algunos ejemplos concretos de su aplicación en repositorios de datos con el objetivo de mejorar la calidad de los datos.
Utilizar de Pandas para Data Profiling
Si bien el data profiling y la evaluación de calidad de datos están estrechamente relacionados, sus enfoques son diferentes:
- Data Profiling: es el proceso de análisis exploratorio que se realiza para entender las características fundamentales de los datos, como su estructura, tipos de datos, distribución de valores, y la presencia de valores faltantes o duplicados. El objetivo es obtener una imagen clara de cómo son los datos, sin necesariamente hacer juicios sobre su calidad.
- Evaluación de calidad de datos: implica la aplicación de reglas y estándares predefinidos para determinar si los datos cumplen con ciertos requisitos de calidad, como exactitud, completitud, consistencia, credibilidad o actualidad. En este proceso, se identifican errores y se determinan acciones para corregirlos. Una guía útil para la evaluación de calidad de datos es la especificación UNE 0081.
Consiste en explorar y analizar un conjunto de datos para obtener una comprensión básica de su estructura, contenido y características, antes de realizar un análisis más profundo o una evaluación de la calidad de los datos. El objetivo principal es obtener una visión general de los datos mediante el análisis de la distribución, los tipos de datos, los valores faltantes, las relaciones entre columnas y la detección de posibles anomalías. Pandas dispone de varias funciones para realizar este perfilado de datos.
En resumen, el data profiling es un paso inicial exploratorio que ayuda a preparar el terreno para una evaluación más profunda de la calidad de los datos, proporcionando información esencial para identificar áreas problemáticas y definir las reglas de calidad adecuadas para la evaluación posterior.
¿Qué es Pandas y cómo ayuda a asegurar la calidad de los datos?
Pandas es una de las bibliotecas más populares de Python para la manipulación y análisis de datos. Su capacidad para gestionar grandes volúmenes de información estructurada hace que sea una herramienta poderosa en la detección y corrección de errores en repositorios de datos. Con Pandas, se pueden realizar operaciones complejas de forma eficiente, desde limpieza hasta validación de datos, todas ellas son esenciales para mantener los estándares de calidad. A continuación, se indican algunos ejemplos para mejorar la calidad de los datos en repositorios con Pandas:
-
Detección de valores nulos o inconsistentes: uno de los errores más comunes en los datos son los valores faltantes o inconsistentes. Pandas permite identificar estos valores fácilmente mediante funciones como isnull() o dropna(). Esto es clave para la propiedad de completitud de los registros y la dimensión de consistencia de datos, ya que los valores faltantes en campos críticos pueden distorsionar los resultados de los análisis.
# Identificar valores nulos en un dataframe
df.isnull().sum()
- Normalización y estandarización de datos: los errores en la consistencia de nombres o códigos son comunes en grandes repositorios. Por ejemplo, en un conjunto de datos que contiene códigos de productos, es posible que algunos estén mal escritos o no sigan una convención estándar. Pandas ofrece funciones como merge() para realizar una comparación con una base de datos de referencia y corregir estos valores. Esta opción es clave para mantener la dimensión y propiedad de consistencia semántica de los datos.
# Sustitución de valores incorrectos utilizando una tabla de referencia
df = df.merge(codigos_productos, left_on='codigo_producto', right_on='codigo_ref', how= ‘left’)
- Validación de requisitos de datos: Pandas permite crear reglas personalizadas para validar la conformidad de los datos con ciertas normas. Por ejemplo, si un campo de edad solo debería contener valores enteros positivos, podemos aplicar una función para identificar y corregir valores que no cumplan con esta regla. De esta forma, se puede validar cualquier regla de negocio de cualquiera de las dimensiones y propiedades de calidad de datos.
# Identificar registros con valores de edad no válidos (negativos o decimales)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
- Análisis exploratorio para identificar patrones anómalos: funciones como describe() o groupby() en Pandas permiten explorar el comportamiento general de los datos. Este tipo de análisis es fundamental para detectar patrones anómalos o fuera de rango en cualquier conjunto de datos, como, por ejemplo, valores inusualmente altos o bajos en columnas que deberían seguir ciertos rangos.
# Resumen estadístico de los datos
df.describe()
#Ordenar según categoría o propiedad
df.groupby()
- Eliminación de duplicados: los datos duplicados son un problema común en los repositorios de datos. Pandas ofrece métodos como drop_duplicates() para identificar y eliminar estos registros, asegurando que no haya redundancia en el conjunto de datos. Esta capacidad estaría relacionada con la dimensión de completitud y consistencia.
# Eliminar filas duplicadas
df = df.drop_duplicates()
Ejemplo práctico de aplicación de Pandas
Una vez presentadas las funciones anteriores que nos sirven para mejorar la calidad de los repositorios de datos, planteamos un caso para poner en práctica el proceso. Supongamos que estamos gestionando un repositorio de datos de ciudadanos y queremos asegurarnos de:
- Que los datos de edad no contengan valores no válidos (como negativos o decimales?
- Que los códigos de nacionalidad estén estandarizados.
- Que los identificadores únicos sigan un formato correcto.
- Que el lugar de residencia sea coherente.
Con Pandas, podríamos realizar las siguientes acciones:
1. Validación de edades sin valores incorrectos
# Identificar registros con edades fuera de los rangos permitidos (por ejemplo, menores de 0 o no enteros)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
2. Corrección de códigos de nacionalidad
# Uso de un dataset oficial de códigos de nacionalidad para corregir los registros incorrectos
df_corregida = df.merge(nacionalidades_ref, left_on='nacionalidad', right_on='codigo_ref', how='left')
3. Validación de indentificadores únicos
# Verificar si el formato del número de identificación sigue un patrón correcto
df['valid_id'] = df['identificacion'].str.match(r'^[A-Z0-9]{8}$')
errores_id = df[df['valid_id'] == False]
4. Verificación de coherencia en lugar de residencia
# Detectar posibles inconsistencias en la residencia (por ejemplo, un mismo ciudadano residiendo en dos lugares al mismo tiempo)
duplicados_residencia = df.groupby(['id_ciudadano', 'fecha_residencia'])['lugar_residencia'].nunique()
inconsistencias_residencia = duplicados_residencia[duplicados_residencia > 1]
Integración con diversidad de tecnologías
Pandas es una biblioteca extremadamente flexible y versátil que se integra fácilmente con muchas tecnologías y herramientas en el ecosistema de datos. Algunas de las principales tecnologías con las que Pandas tiene integración o se puede utilizar son:
-
Bases de datos SQL:
Pandas se integra muy bien con bases de datos relacionales como MySQL, PostgreSQL, SQLite, y otras que utilizan SQL. La biblioteca SQLAlchemy o directamente las bibliotecas específicas de cada base de datos (como psycopg2 para PostgreSQL o sqlite3) permiten conectar Pandas a estas bases de datos, realizar consultas y leer/escribir datos entre la base de datos y Pandas.
- Función común: pd.read_sql() para leer una consulta SQL en un DataFrame, y to_sql() para exportar los datos desde Pandas a una tabla SQL.
- APIs basadas en REST y HTTP:
Pandas se puede utilizar para procesar datos obtenidos de APIs utilizando solicitudes HTTP. Bibliotecas como requests permiten obtener datos de APIs y luego transformar esos datos en DataFrames de Pandas para su análisis.
- Big Data (Apache Spark):
Pandas se puede utilizar en combinación con PySpark, una API para Apache Spark en Python. Aunque Pandas está diseñado principalmente para trabajar con datos en memoria, Koalas, una biblioteca basada en Pandas y Spark, permite trabajar con estructuras distribuidas de Spark usando una interfaz similar a Pandas. Herramientas como Koalas ayudan a que los usuarios de Pandas puedan escalar sus scripts a entornos de datos distribuidos sin necesidad de aprender toda la sintaxis de PySpark.
- Hadoop y HDFS:
Pandas se puede utilizar junto con tecnologías de Hadoop, especialmente el sistema de archivos distribuido HDFS. Aunque Pandas no está diseñado para gestionar grandes volúmenes de datos distribuidos, puede utilizarse junto a bibliotecas como pyarrow o dask para leer o escribir datos desde y hacia HDFS en sistemas distribuidos. Por ejemplo, pyarrow se puede utilizar para leer o escribir archivos Parquet en HDFS.
- Formatos de archivos populares:
Pandas se utiliza comúnmente para leer y escribir datos en diferentes formatos de archivo, tales como:
- CSV: pd.read_csv()
- Excel: pd.read_excel() y to_excel()
- JSON: pd.read_json()
- Parquet: pd.read_parquet() para trabajar con archivos eficientes en espacio y tiempo.
- Feather: un formato de archivo rápido para intercambio entre lenguajes como Python y R (pd.read_feather()).
- Herramientas de visualización de datos:
Pandas se puede integrar fácilmente con herramientas de visualización como Matplotlib, Seaborn, y Plotly. Estas bibliotecas permiten generar gráficos directamente desde DataFrames de Pandas.
- Pandas incluye su propia integración ligera con Matplotlib para generar gráficos rápidos usando df.plot().
- Para visualizaciones más sofisticadas, es común usar Pandas junto a Seaborn o Plotly para gráficos interactivos.
- Bibliotecas de machine learning:
Pandas es ampliamente utilizado en el preprocesamiento de datos antes de aplicar modelos de machine learning. Algunas bibliotecas populares con las que Pandas se integra son:
- Scikit-learn: la mayoría de los pipelines de machine learning comienzan con la preparación de datos en Pandas antes de pasar los datos a modelos de Scikit-learn.
- TensorFlow y PyTorch: aunque estos frameworks están más orientados al manejo de matrices numéricas (Numpy), Pandas se utiliza frecuentemente para la carga y limpieza de datos antes de entrenar modelos de deep learning.
- XGBoost, LightGBM, CatBoost: Pandas es compatible con estas bibliotecas de machine learning de alto rendimiento, donde los DataFrames se utilizan como entrada para entrenar modelos.
- Jupyter Notebooks:
Pandas es fundamental en el análisis de datos interactivo dentro de los Jupyter Notebooks, que permiten ejecutar código Python y visualizar los resultados de manera inmediata, lo que facilita la exploración de datos y su visualización en conjunto con otras herramientas.
- Cloud Storage (AWS, GCP, Azure):
Pandas se puede utilizar para leer y escribir datos directamente desde servicios de almacenamiento en la nube como Amazon S3, Google Cloud Storage y Azure Blob Storage. Bibliotecas adicionales como boto3 (para AWS S3) o google-cloud-storage facilitan la integración con estos servicios. A continuación, se muestra un ejemplo para leer datos desde Amazon S3.
import pandas as pd
import boto3
#Crear un cliente de S3
s3 = boto3.client('s3')
#Obtener un objeto del bucket
obj = s3.get_object(Bucket='mi-bucket', Key='datos.csv')
#Leer el archivo CSV de un DataFrame
df = pd.read_csv(obj['Body'])
- Docker y contenedores:
Pandas se puede usar en entornos de contenedores utilizando Docker. Los contenedores son ampliamente utilizados para crear entornos aislados que aseguran la replicabilidad de los pipelines de análisis de datos.
En conclusión, el uso de Pandas es una solución eficaz para mejorar la calidad de los datos en repositorios complejos y heterogéneos. A través de funciones de limpieza, normalización, validación de reglas de negocio, y análisis exploratorio, Pandas facilita la detección y corrección de errores comunes, como valores nulos, duplicados o inconsistentes. Además, su integración con diversas tecnologías, bases de datos, entornos big data, y almacenamiento en la nube, convierte a Pandas en una herramienta extremadamente versátil para garantizar la exactitud, consistencia y completitud de los datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Evento
Los próximos días 11, 12 y 13 de noviembre se celebra en Granada una nueva edición de DATAfórum Justicia. La cita reunirá a más de 100 ponentes para debatir sobre temas relacionados con los sistemas digitales de justicia, la inteligencia artificial (IA) y el uso del dato en el ecosistema judicial.
El evento está organizado por el Ministerio de Presidencia, Justicia y Relaciones con las Cortes, con la colaboración de la Universidad de Granada, la Junta de Andalucía, el Ayuntamiento de Granada y la entidad Formación y Gestión de Granada.
A continuación, se resumen algunos de los aspectos más importantes de estas jornadas.
Una cita dirigida a un público amplio
Este foro anual está dirigido tanto a profesionales del sector público, como del privado, sin dejar de lado al público general, que quiera saber más sobre la transformación digital de la justicia en nuestro país.
El DATAfórum Justicia 2024 cuenta, además, con un itinerario específico dirigido a estudiantes, cuyo objetivo es proporcionar a los jóvenes herramientas y conocimientos de valor en el ámbito de la justicia y la tecnología. Para ello, contarán con ponencias específicas y se pondrá en marcha un DATAthon. Estas actividades están especialmente dirigidas a estudiantes de derecho, ciencias sociales en general, ingenierías informáticas o materias relacionadas con la transformación digital. Los asistentes podrán obtener hasta 2 créditos ECTS (European Credit Transfer and Accumulation System o, en español, Sistema Europeo de Transferencia y Acumulación de Créditos): uno por asistir a las jornadas y otro por participar en el DATAthon.
Los datos, protagonistas de la agenda
El Paraninfo de la Universidad de Granada acogerá a expertos provenientes de la administración, instituciones y empresas privadas, que contarán su experiencia haciendo hincapié en las nuevas tendencias del sector, los retos que hay por delante y las oportunidades de mejora.
Las jornadas comenzarán el lunes 11 de noviembre a las 9:00 horas, con la bienvenida a los alumnos y la presentación del DATAthon. La inauguración oficial, dirigida a todas las audiencias, será a las 11:35 horas y correrá a cargo de Manuel Olmedo Palacios, Secretario de Estado de Justicia, y Pedro Mercado Pacheco, Rector de la Universidad de Granada.
A partir de entonces se sucederán diversas charlas, debates, entrevistas, mesas redondas y conferencias, entre las que encontramos un gran número de temáticas relacionadas con los datos. Entre otras cuestiones, se profundizará en la gestión del dato, tanto en administraciones como en empresas. También se abordará el uso de los datos abiertos para prevenir desde bulos hasta suicidios o la violencia sexual.
Otro tema con gran protagonismo será las posibilidades de la inteligencia artificial para optimizar el sector, tocando aspectos como la automatización de la justicia, la realización de predicciones. Se incluirán ponencias de casos de uso concretos, como la utilización de IA para la identificación de personas fallecidas, sin dejar de lado cuestiones como la gobernanza de algoritmos.
El evento finalizará el miércoles 13 a las 17:00 horas con la clausura oficial. En esta ocasión, Félix Bolaños, Ministro de la Presidencia, Justicia y Relaciones con las Cortes, acompañará al Rector de la Universidad de Granada.
Puedes ver la agenda completa aquí.
Un Datathon para resolver los retos del sector a través de los datos
En paralelo a esta agenda, se celebrará un DATAthon en el que los participantes presentarán ideas y proyectos innovadores para mejorar la justicia en nuestra sociedad. Se trata de un concurso destinado a estudiantes, profesionales del ámbito legal e informático, grupos de investigación y startups.
Los participantes se dividirán en equipos multidisciplinares para proponer soluciones a una serie de retos, planteados por la organización, utilizando tecnologías orientadas a la ciencia de datos. Durante las dos primeras jornadas los participantes dispondrán de tiempo para investigar y desarrollar su solución original. En la tercera jornada, deberán presentar una propuesta a un jurado cualificado. Los premios se entregarán el último día, antes de la clausura y del vino español y concierto que darán final a la edición 2024 del DATAfórum Justicia.
En la edición de 2023 participaron 35 personas, divididas en 6 equipos que resolvieron dos casos prácticos con datos de carácter público y se otorgaron dos premios de 1.000 euros.
Cómo inscribirse
El plazo de inscripción al DATAfórum Justicia 2024 ya está abierto. Debe realizarse a través de la web del evento, indicando si se trata de público general, personal de la administración pública, profesionales del sector privado o medios de comunicación.
Para participar en el DATAthon es necesario registrarse también en el site dedicado al concurso.
La edición del año pasado, centrada en propuestas para aumentar la eficiencia y transparencia en los sistemas judiciales, fue un gran éxito, con más de 800 inscritos. Este año se espera también una gran afluencia de público, así que te animamos a reservar tu plaza lo antes posible. Se trata de una gran oportunidad para conocer de primera mano experiencias exitosas y poder intercambiar opiniones con expertos en el sector.
Blog
Marcos éticos generales
La ausencia de un marco ético, común y unificado para el uso de la inteligencia artificial en el mundo es solo aparente y, en cierto modo, un mito. Existen multitud de cartas, manuales y conjuntos de normas supranacionales que recogen principios de uso ético, si bien algunos de ellos han tenido que actualizarse con la aparición de nuevas herramientas y usos. La guía de la OCDE de estándares éticos para el uso de la inteligencia artificial, publicada en 2019 pero actualizada en 2024, incluye principios basados en valores y también recomendaciones para los responsables de políticas públicas. El Observatorio Global de Ética y Gobernanza de la IA de la UNESCO publicó en 2021 un material llamado Recomendación sobre la ética de la IA, adoptado en el mismo año por 193 países, y basado en cuatro principios básicos: los derechos humanos, la justicia social, la diversidad e inclusividad, y el respeto al ecosistema ambiental. También en 2021 la OMS recogía específicamente un documento de Ética y gobernanza de la IA para la salud, donde indicaba la necesidad de establecer responsabilidades para las organizaciones en el uso de la IA cuando esta afectase a pacientes y a trabajadores sanitarios. Sin embargo, diversas entidades y sectores a distintos niveles han tomado la iniciativa de establecer sus propias normativas y guías éticas, más ajustadas a su contexto. Por ejemplo, en febrero de 2024, el Ministerio de Cultura en España elaboraba una guía de buenas prácticas para establecer, entre otras directrices, que no podrían ser galardonadas las obras creadas exclusivamente con IA generativa.
Por tanto, el reto no está en la ausencia de guías éticas globales, sino en la excesiva globalidad de estos marcos. Con el legítimo objetivo de que resistan el paso del tiempo, sean válidos para la situación específica de cualquier país del mundo y se mantengan operativos ante nuevas disrupciones, estos estándares generales acaban recurriendo a conceptos que ya conocemos, como los que podemos leer en esta otra guía ética del Foro Económico Mundial: explicabilidad, transparencia, fiabilidad, robustez, privacidad, seguridad. Conceptos demasiado altos, predecibles, y que casi siempre miran la IA desde el punto de vista del desarrollador y no del usuario.
Manifiestos de los medios
En esta línea, los grandes grupos de comunicación han invertido sus esfuerzos en desarrollar principios éticos específicos para el uso de la IA en la creación y difusión de contenidos, que constituye por ahora un vacío significativo en los grandes marcos e incluso en el propio Reglamento europeo. Estos esfuerzos se han materializado en ocasiones de manera individual, en forma de manifiesto, pero también en un nivel superior como colectivo. Entre los manifiestos más relevantes destacan el de Le Figaro, en el que su redacción establece que no publicará ningún artículo o contenido visual generado con IA, o el de The Guardian que, actualizado en 2023, afirma que la IA es una herramienta habitual en las redacciones, pero únicamente como asistencia para asegurar la calidad de su trabajo. Por su parte, los medios españoles no han emitido manifiestos propios, pero sí han apoyado diferentes iniciativas colectivas. El Grupo Prisa, por ejemplo, aparece en la lista de organizaciones que suscriben el Manifiesto por una IA responsable y sostenible, publicado por Forética en 2024. También son interesantes las declaraciones de los responsables de innovación y estrategia digital de El País, El Español, El Mundo y RTVE que encontramos en una entrevista publicada en Fleet Street en abril de 2023. Ante la pregunta de si existen en sus medios líneas rojas específicas en el uso de la IA, todos declaran tener una actitud abierta de exploración y no haber delimitado demasiado el uso. Tan solo RTVE, se desmarca con una afirmación: “Entendemos que es algo complementario y para ayudarnos. Cualquier cosa que haga un periodista no queremos que la haga una IA. Tiene que estar bajo nuestro control”.
Principios globales del periodismo
En el contexto editorial encontramos por tanto un panorama de normativas múltiples en tres niveles posibles: manifiestos propios de cada medio, iniciativas colectivas del sector y la adhesión a códigos éticos generales a nivel nacional. En este escenario, a finales de 2023 la News Media Alliance publicaba los Principios globales de la IA en el periodismo, un documento firmado por grupos editoriales a nivel internacional que recoge, a modo de decálogo, 12 principios éticos fundamentales divididos en 8 bloques:

Figura 1. Principios globales de la IA en el periodismo, News Media Alliance.
Cuando los revisamos en profundidad, encontramos en ellos algunos de los grandes conflictos que están marcando el desarrollo de la inteligencia artificial moderna, conexiones con el Reglamento Europeo de IA y reivindicaciones que son constantes por parte de los creadores de contenido:
- Bloque 1: Propiedad intelectual. Es el primer bloque y el más completo, desarrollado específicamente en cuatro principios éticos complementarios. Aunque parece el principio más evidente, está orientado a poner el foco en uno de los principales conflictos de la IA moderna: el uso indiscriminado de contenido publicado en internet (texto, imagen, vídeo, música) para entrenar modelos de aprendizaje sin consultar ni remunerar a los autores. El primer principio ético manifiesta el deber, por parte de los desarrolladores de sistemas de IA, de respetar las restricciones o limitaciones impuestas por los titulares de derechos de autor sobre el acceso y uso de los contenidos. El segundo expresa la capacidad de estos autores y grupos editoriales para negociar una remuneración justa por el uso de su propiedad intelectual. El tercero, legitima el copyright como base suficiente ante la ley para proteger los contenidos de un autor. El cuarto reclama reconocer y respetar los mercados existentes para la concesión de licencias, esto es: crear contratos, acuerdos y modelos de mercado eficientes para que los sistemas de IA puedan entrenarse con contenido de calidad, pero legítimo, autorizado y licenciado.
- Bloque 2: Transparencia. El segundo bloque es una continuación lógica del anterior, y aboga por la transparencia en el funcionamiento, una característica que aporta valor tanto a los autores de contenido como a los usuarios de los sistemas IA. Este principio coincide con la obligación central que el Reglamento Europeo establece para los sistemas de IA generativa: deben ser transparentes desde un principio y declarar con qué contenidos han entrenado, con qué procedimientos los han conseguido y en qué medida cumplen con los derechos de propiedad intelectual de los autores. Esta transparencia es esencial para que los creadores y grupos editoriales puedan hacer valer sus derechos, y se establece además que este principio deba cumplirse con carácter universal, independientemente de la jurisdicción en la que se realicen el entrenamiento o las pruebas.
- Bloque 3: Responsabilidad. En inglés accountability, una palabra que recoge la capacidad para rendir cuentas sobre una acción. El principio expresa que los desarrolladores y operadores de sistemas de IA deben ser responsables de los resultados (outputs) generados por sus sistemas, por ejemplo, en el caso de atribuir contenidos a los autores que no son reales, o si contribuyen a la desinformación o a socavar la confianza en la ciencia o los valores democráticos.
- Bloque 4: Calidad e integridad. La base del principio es que los contenidos generados por IA deben ser precisos, correctos y completos, y no deben distorsionar las obras originales. Sin embargo, sobre esta idea superficial se construye una más ambiciosa: la de que los grupos editoriales y de comunicación deben ser garantes de esta calidad e integridad, y por tanto proveedores oficiales de los desarrolladores y proveedores de sistemas de IA. El argumento fundamental es que la calidad del contenido para el entrenamiento definirá la calidad de los resultados del sistema.
- Bloque 5: Justicia. La palabra fairness en español puede traducirse también como equidad o imparcialidad. El principio recoge en su titular que el uso de IA no debe crear injusticias en los mercados, prácticas anticompetitivas o competencia desleal, lo que quiere decir que no debe permitirse su uso para fomentar abusos de dominio ni excluir a rivales del mercado. Este principio no va orientado a regular la competencia entre los desarrolladores de IA, sino entre estos y los proveedores de contenido: el texto, la música o las imágenes generadas con IA no deberían competir nunca en igualdad de condiciones con el contenido generado por los autores.
- Bloque 6: Seguridad. Se compone de dos principios éticos. Redundando en los anteriores, el primer principio de seguridad establece que los sistemas de IA generativa deben ser confiables en cuanto a las fuentes de información que utilizan y promueven, las cuales no deben alterar ni representar de manera incorrecta los contenidos, preservando su integridad original. Lo contrario podría traducirse en un debilitamiento de la confianza del público en las obras originales, en los autores e incluso en los grandes grupos de comunicación. Este principio aplica en gran medida a los nuevos motores de búsqueda asistidos por IA, como la nueva búsqueda en Google (SGE), el nuevo SearchGPT o el propio Copilot de Microsoft, que recopilan y refunden información de diferentes fuentes en un solo párrafo generado. El segundo punto unifica en un solo principio las problemáticas de privacidad de datos del usuario y, en apenas una frase, se refiere a los sesgos discriminatorios. Los desarrolladores deben poder explicar cómo, cuándo y para qué utilizan los datos de los usuarios, y deben asegurar que los sistemas no producen, multiplican o cronifican sesgos de discriminación a personas o colectivos.
- Bloque 7: Diseño ético. Se trata de un metaprincipio que engloba a todos los demás, y que establece que todos los principios deben incorporarse desde el diseño en todos los sistemas de IA, generativa o no. Históricamente se ha considerado la ética al final del proceso de desarrollo, como una cuestión secundaria o menor, por lo que el principio defiende que la ética debe ser una preocupación significativa y fundamental desde el mismo proceso de diseño del sistema. Tampoco puede relegarse la auditoría ética únicamente a aquellos casos en que los usuarios presentan una reclamación.
- Bloque 8: Desarrollo sostenible. Aparentemente es un principio global, de alto alcance, que establece que los sistemas de IA deben estar alineados con los valores humanos y operar de acuerdo con las leyes globales, con el fin de beneficiar a toda la humanidad y a las generaciones futuras. Sin embargo, en la última frase encontramos la orientación real del principio, una conexión con los grupos editoriales como proveedores de datos para los sistemas IA: “La financiación a largo plazo y otros incentivos para los proveedores de datos de entrada de alta calidad puede ayudar a alinear los sistemas con los objetivos sociales y extraer el conocimiento más importante, actualizado y procesable.”
El documento está firmado por 31 asociaciones de grupos editoriales de países como Dinamarca, Corea, Canadá, Colombia, Portugal, Brasil, Argentina, Japón o Suecia, por asociaciones a nivel europeo, como European Publishers Council o News Media Europe, y asociaciones a nivel mundial como WAN-IFRA (World Association of News Publishers). Entre los grupos españoles destacan la Asociación de Medios de Información (AMI) y la Asociación de Revistas (ARI).
La ética como instrumento
Los principios globales del periodismo promovidos por la News Media Alliance son particularmente precisos al proponer soluciones aterrizadas a dilemas éticos muy representativos de la situación actual, como es el uso del contenido de autor para la explotación comercial de los sistemas de IA. Son útiles a la hora de intentar establecer un marco ético sólido y, sobre todo, unificado y global que propone soluciones consensuadas. Al mismo tiempo, en el documento podemos percibir la ausencia de otros conflictos que afectan a la profesión y que también tendrían cabida en este decálogo. Es posible que la omnipresencia del conflicto de licenciamiento de datos, al que se hace referencia constante, haya dejado en un segundo plano otras inquietudes como la nueva velocidad de la desinformación, la capacidad de la investigación periodística para verificar contenido auténtico o el impacto de las fake news y los deepfakes en procesos democráticos. Los principios se han centrado en exponer las obligaciones que deberían tener las grandes tecnológicas en lo que respecta al uso de los contenidos, pero quizá sería esperable una extensión que abordase las responsabilidades éticas desde el punto de vista de los medios, como por ejemplo, en qué modelo ético debe basarse la integración de la IA en la actividad de las redacciones y cuál es la responsabilidad de los periodistas en este nuevo escenario. Por último, en el documento se pone de manifiesto una dualidad habitual: la canalización, a través de la propuesta ética, de la sugerencia de soluciones concretas que apuntan incluso a posibles acuerdos comerciales y de mercado. Es un reflejo claro de la capacidad potencial de la ética para ser mucho más que un marco moral, y convertirse en un instrumento multidimensional para orientar la toma de decisiones e influir en la creación de políticas públicas.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El portal europeo de datos abiertos (data.europa.eu) organiza regularmente sesiones formativas virtuales sobre cuestiones de actualidad en el sector de los datos abiertos, regulaciones que afectan y tecnologías relacionadas. En este post, repasamos las claves del último webinar sobe los conjuntos de datos de alto valor (HVD, por sus siglas en inglés, High Value Datasets)
Entre otras cuestiones, este seminario se centró en transmitir buenas prácticas, así como explicar las experiencias de dos países, Finlandia y Chequia, que formaron parte del informe “High-value Datasets Best Practices in Europe”, publicado por data.europa.eu, junto con Dinamarca, Estonia, Italia, Países Bajos y Rumania. El estudio se realizó inmediatamente después de la publicación del reglamento de implementación de HVDS, en febrero de 2023.
Buenas prácticas ligadas a la puesta a disposición de datos de alto valor
Tras una introducción donde se explicó qué son y qué requisitos tienen que cumplir los datos de alto valor, durante el webinar, se detalló el alcance del informe. Concretamente, se identificaron retos, buenas prácticas y recomendaciones por parte de los estados miembros, como se detalla a continuación.
Marco político y legal
- Existe la necesidad de fomentar una cultura gubernamental prioritariamente práctica y enfocada a objetivos alcanzables, aprovechando valores culturales arraigados en los sistemas gubernamentales, como la transparencia.
- Se recomienda un enfoque estratégico basado en una perspectiva más amplia de la regulación, aprovechando esfuerzos realizados anteriormente para la implementación de directivas trascendentes como INSPIRE o DCAT como estándar para la publicación de datos. En este sentido, es oportuno priorizar acciones que se superponen con estas iniciativas existentes.
- Se recomienda utilizar licencias Creative Commons (CC).
- A nivel transversal, otro de los retos es combinar el cumplimiento de los requisitos de los conjuntos de datos de alto valor con las disposiciones del Reglamento General de Protección de Datos (RGPD), cuando hablamos de datos sensibles o personales.
Gobernanza y procesos
- Se anima a participar en asociaciones estratégicas y fomentar la colaboración a nivel nacional. Entre otras cuestiones se recomienda coordinar esfuerzos entre ministerios, agencias responsables de diferentes categorías de HVD y otros actores relacionados, especialmente en los Estados miembros con estructuras de gobernanza descentralizadas. Para ello, es relevante crear grupos de trabajo interdisciplinarios que faciliten la realización de un inventario de datos completo y aclaren qué agencia es responsable de cada conjunto de datos. Estos grupos permitirán compartir conocimiento y fomentar un sentido de comunidad y responsabilidad compartida, lo que contribuye al éxito general de los esfuerzos de gobernanza de datos.
- Se recomienda participar en intercambios periódicos con otros Estados miembros, para compartir ideas y soluciones a desafíos comunes.
- Es necesario promover la sostenibilidad a través de la responsabilidad individual de las agencias por sus respectivos conjuntos de datos. Garantizar la sostenibilidad de los portales nacionales de datos significa asegurarse de que los metadatos se mantengan con los recursos disponibles.
- Se aconseja desarrollar un marco integral de gobernanza de datos evaluando primero los recursos disponibles, incluida la experiencia técnica, las herramientas de gestión de datos y los aportes clave de las partes interesadas. Este proceso de evaluación permite una comprensión clara de las reglas, procesos y responsabilidades necesarias para una implementación efectiva de la gobernanza de datos.
Aspectos técnicos, calidad de los metadatos y nuevos requisitos
- Se propone desarrollar una comprensión integral de los requisitos específicos para los HVD. Esto implica identificar conjuntos de datos existentes para determinar su cumplimiento con los estándares descritos en el reglamento de implementación para los HVD. Es necesario constituir una base sistémica para identificar, mejorar la calidad y disponibilidad de los datos potenciando el valor general de los conjuntos de datos de alto valor.
- Se recomienda mejorar la calidad de los metadatos directamente en la fuente de datos antes de publicarlos en portales, siguiendo las pautas de publicación de conjuntos de datos de alto valor del DCAT-AP y los vocabularios controlados para las seis categorías de HVD. También es necesario mejorar la implementación de API y descargas masivas desde cada origen de datos. Su implementación presenta desafíos importantes debido a la escasez de recursos y experiencia, por lo que resulta imprescindible el fortalecimiento de capacidades y la dotación de recursos.
- Se sugiere fortalecer la disponibilidad de conjuntos de datos de alto valor a través de financiación externa o planificación estratégica. El reglamento exige que todos los HVD sean accesibles de forma gratuita por lo que algunos Estados miembros diversifican las fuentes de financiación buscando apoyo financiero por medio de vías externas, por ejemplo, aprovechando proyectos europeos. En este sentido, se recomienda adaptar los modelos de negocio progresivamente para ofrecer datos gratuitos.
Por último, el informe destaca una hoja de ruta de cumplimiento del reglamento de implementación de HVD, sugerida en base a ocho pasos:
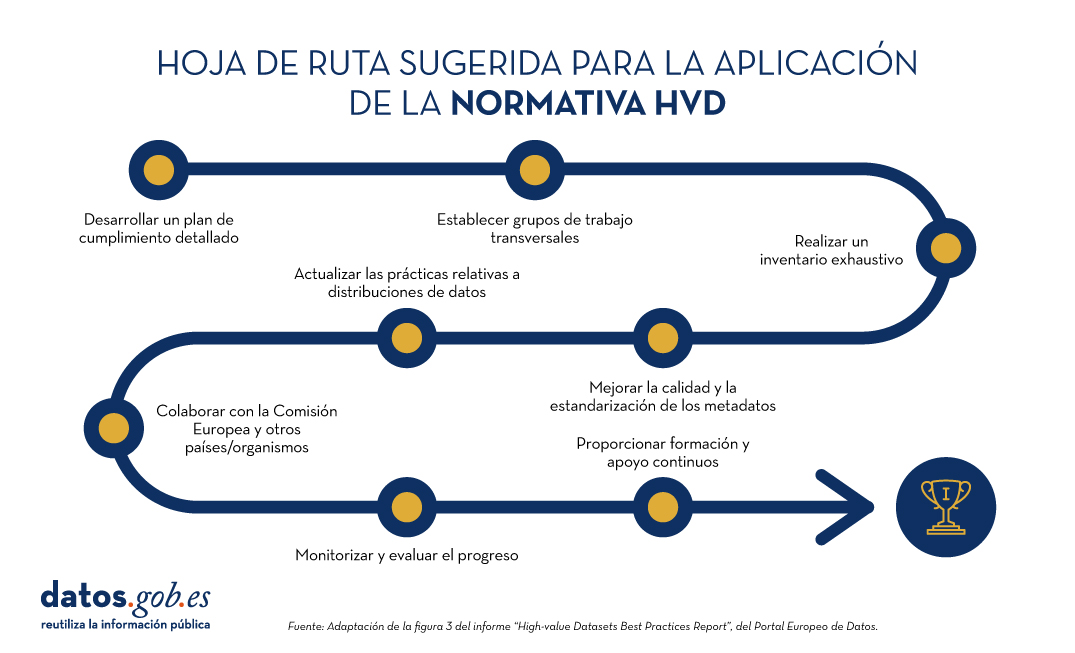
Figura 1: Hoja de ruta sugerida para la aplicación de la normativa HVD. Adaptación de la figura 3 del informe “High-value Datasets Best Practices Report”, del Portal Europeo de Datos.
El ejemplo de la República Checa
En una segunda parte del webinar, República Checa presentó su caso de implementación, que están abordando desde cuatro tareas principales: motivación, implementación regulatoria, responsabilidad de las agencias públicas proveedoras de datos y requerimientos técnicos.
- La motivación entre los diferentes agentes se está articulando a través de la constitución de grupos de trabajo.
- La implementación regulatoria se concentra en el análisis de datasets y la consistencia o inconsistencia con INSPIRE.
- Para impulsar la responsabilidad de las agencias públicas, se están llevando a cabo seminarios para compartir conocimiento en torno a la vinculación entre INSPIRE y HVD utilizando como vía de publicación el estándar DCAT-AP.
- Respecto a los requerimientos técnicos, se están integrando los requisitos de DCAT-AP e INSPIRE en las prácticas de metadatos adaptadas a su contexto nacional. Chequia ha desarrollado especificaciones para catálogos locales de datos abiertos, con el fin de garantizar la compatibilidad con el Catálogo Nacional de Datos Abiertos. No obstante, su mayor reto es una fuerte dependencia derivada de la falta de capacidades técnicas.
El ejemplo de Finlandia
A continuación, tomó la palabra Finlandia. Al contar con una legislación preexistente (INSPIRE y otras normas específicas sobre apertura de datos y gestión de información en administraciones públicas), Finlandia requirió solo ajustes menores para alinearse con la transposición nacional de la directiva de los HVD. El reto está en entender y hacer coexistir INSPIRE y los HVD.
Su estrategia principal se basa en el mapa sobre gestión de información en administraciones públicas, que asegura la armonización, interoperabilidad, gestión de alta calidad y seguridad para implementar los principios de apertura de datos. Además, han establecido dos grupos de trabajo para abordar la implementación de HVD:
- El primer grupo, que es un grupo coordinador de promotores de datos, se centró en cuestiones prácticas y técnicas. Como expertos legales, también brindaron orientación para comprender la regulación HVD desde una perspectiva legal.
- El segundo grupo, un grupo de coordinación interministerial, es un grupo de trabajo que garantiza que no haya conflictos ni superposiciones entre la regulación HVD y la legislación nacional. Este grupo administra el inventario, en formato hoja de cálculo, que contiene todos los elementos necesarios para un catálogo de HVD. Al identificar áreas donde los conjuntos de datos no cumplen con estos requisitos, las organizaciones pueden establecer una hoja de ruta para abordar las brechas y garantizar el cumplimiento total a lo largo del tiempo.
El secretariado de los grupos recae en un comité de datos geoespaciales. Ambos cuentan con una amplia red de partes interesadas para articular la discusión y el feedback de las medidas adoptadas.
De cara a futuro, destacan como reto la necesidad de ir alcanzando mayor experiencia técnica y a nivel ejecutivo.
Fin de la sesión
El webinar continuó con la participación de la empresa Compass Gruppe (Alemania) que comercializa, entre otros, datos procedentes del registro mercantil de Austria. Disponen de un portal que ofrece dichos datos vía API a través de un modelo de negocio freemium.
Además, se recordó la obligación que tienen los Estados miembros de reportar a Europa cada dos años los avances en HVD, una actividad con la que se espera impulsar la disponibilidad de metadatos armonizados federados sobre el portal europeo de datos. La idea es que los usuarios puedan encontrar todos los HVD de la Unión Europea, utilizando el filtrado disponible en el portal o a través de consultas SPARQL.
La combinación de las conclusiones del informe y las experiencias de los países ponentes, nos dan buenas pistas para orientar la implementación de los HVD, cumpliendo con la normativa europea. En resumen, la implementación de los HVD plantea los siguientes desafíos:
- Respaldar con la financiación necesaria el abordaje del proceso de apertura.
- Superar los retos técnicos para desarrollar accesos eficientes (API).
- Lograr una correcta convivencia entre INSPIRE y el reglamento de HVD.
- Consolidar grupos de trabajo que funcionen como un mecanismo robusto de avance y convergencia.
- Monitorizar los avances y realizar un seguimiento continuo del proceso.
- Invertir en la capacitación técnica del personal.
- Crear y mantener una fuerte coordinación ante la diversidad compleja de data holders.
- Potencial el aseguramiento de la calidad de los conjuntos de datos de alto valor.
- Acordar una estandarización necesaria desde el punto de vista empresarial.
Dando respuesta a estos retos, conseguiremos una apertura exitosa de los datos de alto valor, impulsando su reutilización en beneficio de toda la sociedad.
Puedes volver a ver la grabación de la sesión aquí
Blog
El activismo de datos es una práctica ciudadana cada vez más significativa en la era de las plataformas por su creciente contribución a la democracia, la justicia social y los derechos. Se trata de un activismo que utiliza los datos y su análisis para generar evidencias y visualizaciones con el objetivo de revelar injusticias, mejorar la vida de las personas y fomentar el cambio social.
Frente al uso masivo de datos de vigilancia por parte de determinadas corporaciones, el activismo de datos es ejercido por la ciudadanía y organizaciones no gubernamentales. Por ejemplo, la organización Forensic Architecture (FA), un centro de Goldsmiths dependiente de la Universidad de Londres, investiga violaciones de derechos humanos, incluidas las violencias de Estado, usando datos públicos, ciudadanos y satelitales, y metodologías como la inteligencia de fuentes abiertas (conocida como OSINT). El análisis de datos y metadatos, la sincronización de vídeos tomados por testigos o periodistas, así como de grabaciones y documentos oficiales, permiten reconstruir los hechos y generar un relato alternativo acerca de eventos y crisis.
El activismo de datos ha suscitado el interés de centros de investigación y organizaciones no gubernamentales, generando una línea de trabajo dentro de la disciplina de los estudios críticos. Esto ha permitido reflexionar sobre el efecto de los datos, las plataformas y sus algoritmos en nuestras vidas, así como acerca del empoderamiento que se genera cuando la ciudadanía ejerce su derecho a los datos y los usa para el bien común.

Imagen 1: Ecocidio en Indonesia (2015)
Fuente: Forensic Architecture (https://forensic-architecture.org/investigation/ecocide-in-indonesia)
Centros de investigación como Datactive o Data + Feminism Lab han creado teoría y debates sobre la práctica del activismo de datos. Asimismo, organizaciones como Algorights –una red colaborativa que fomenta la participación de la sociedad civil en el campo de las tecnologías de IA- y AlgorithmWatch -organización de derechos humanos- generan conocimiento, redes y argumentos para luchar por un mundo donde los algoritmos y la Inteligencia Artificial (IA)contribuyan a la justicia, la democracia y la sostenibilidad, en vez de debilitarlas.
Este artículo revisa cómo surgió el activismo de datos, qué interés ha suscitado en la ciencia social y su relevancia en la era de las plataformas.
Historia de una práctica
La producción de mapas usando datos ciudadanos podría ser de las primeras manifestaciones del activismo de datos tal y como se conoce ahora. Un mapa fundamental en la historia del activismo de datos fue el generado por víctimas y activistas con datos sobre el terremoto de Haití en 2010, sobre la plataforma keniata Ushahidi (“testimonio”, en Suajili). Una comunidad de humanitaristas digitales creó el mapa desde otros países y convocó a las víctimas y a sus familiares y conocidos para que compartieran datos de lo que estaba ocurriendo en tiempo real. En cuestión de pocas horas, los datos se verificaron y se visualizaron en un mapa interactivo que continuó actualizándose con más datos, y que fue decisivo a la hora de asistir a las víctimas en el terreno. Hoy en día se generan mapas de este tipo cada vez que surge una crisis, y se enriquecen con datos ciudadanos, satelitales y generados por drones dotados de cámaras para esclarecer hechos y generar evidencias.
Emergiendo de movimientos conocidos como cypherpunk y el tecnopositivismo o tecnoptimismo (basado en la confianza en que la tecnología es la respuesta a los retos de la humanidad), el activismo de datos ha ido evolucionando como práctica para adoptar posturas más críticas frente a la tecnología y a las asimetrías de poder que surgen entre quienes originan y ceden sus datos, y quienes los captan y analizan.
Hoy día, por ejemplo, la plataforma de producción de mapas comunitarios Ushahidi se ha empleado para crear datos sobre la violencia machista en Egipto y en Siria, y sobre ginecólogos confiables en India, por ejemplo. Actualmente, la invisibilización y el silenciamiento de las mujeres es la razón por la cual algunas organizaciones luchan por el reconocimiento y una política de visibilidad, algo que se hizo evidente con el movimiento #MeToo (#Cuéntalo en español). Las prácticas de datos feministas buscan visibilidad e interpretaciones críticas de la datificación (o la transformación de toda acción humana y no humana en datos mesurables y transformables en valor). Por ejemplo, Datos Contra el Feminicidio o Feminicidio.net ofrecen mapas y análisis de datos sobre el feminicidio en varios lugares del mundo.
El potencial para el empoderamiento algorítmico que ofrecen estos proyectos elimina las barreras a la igualdad, mejorando las condiciones que permiten a las mujeres resolver problemas, determinar cómo se recaban y se usan los datos y ejercer el poder.
Nacimiento y evolución de un concepto
En 2015 se publicó Los medios ciudadanos se encuentran con los grandes datos: el surgimiento del activismo de datos, en el que, por primera vez, se acuñaba y definía el activismo de datos como un concepto basado en prácticas observadas en activistas que se involucran políticamente con la infraestructura de datos. La infraestructura de datos incluye los datos, el software, el hardware y los procesos necesarios para convertir los datos en valor. Más adelante, Data activism and social change (London, Palgrave) y Activismo de datos y cambio social. Alianzas, mapas, plataformas y acción para un mundo mejor (Madrid: Dykinson) desarrollan marcos analíticos basados en casos reales que ofrecen formas de analizar otros casos.
Acompañando las variadas prácticas que existen dentro de activismo de datos, su estudio está creando espacios para la investigación feminista y postcolonialista sobre las consecuencias de la datificación. Mientras que los cronistas de la historia (principalmente fuentes masculinas) definieron la tecnología en relación con el valor sus productos, los estudios de datos feministas consideran a las mujeres como usuarias y diseñadoras de sistemas algorítmicos y buscan utilizar los datos para la igualdad, y alejarse de la explotación capitalista y sus estructuras de dominación.
El activismo de datos es hoy un concepto establecido en la ciencia social. Por ejemplo, Google Scholar ofrece más de 2.000 resultados sobre “data activism”. Varios investigadores e investigadoras lo emplean como perspectiva para analizar diversos asuntos. Por ejemplo, Rajão y Jarke exploran el activismo ambiental en Brasil; Gezgin estudia la ciudadanía crítica y el uso que hace esta de la infraestructura de datos; Lehtiniemi y Haapoja explora la agencia de datos y la participación ciudadana; y Scott examina la necesidad de los usuarios y usuarias de plataformas de desarrollar una vigilancia digital y cuidar de sus datos personales.
En el centro de estas preocupaciones se encuentra el concepto de agencia de datos, que se refiere a que las personas no sólo son conscientes del valor de sus datos, sino que también ejercen control sobre ellos, determinando cómo se usan y comparten. Se podría definir como acciones y prácticas relacionadas con la infraestructura de datos basadas en la reflexión y el interés individual y colectivo. Es decir, mientras darle un like a un post no se consideraría una acción con un alto grado de agencia de datos, participar en un hackaton –un evento colectivo en el que se mejora un programa informático o se crea— sí lo sería. La agencia de datos se basa en la alfabetización en datos, o el grado de conocimientos, acceso a los datos y a sus herramientas, y a las oportunidades para ejercerla que tienen las personas. El activismo de datos no es posible sin agencia de datos.
En el panorama en rápida evolución de la economía de plataformas, la convergencia del activismo de datos, los derechos digitales y la agencia de datos se ha vuelto crucial. El activismo de datos, impulsado por una creciente conciencia del posible uso indebido de los datos personales, alienta a individuos y colectivos a utilizar la tecnología digital para el cambio social, así como a abogar por una mayor transparencia y responsabilidad por parte de las gigantes tecnológicas. Dado que cada vez más la generación de datos y el uso de algoritmos determinan nuestras vidas en áreas como la educación, el empleo, los servicios sociales y la salud, el activismo de datos emerge como una necesidad y un derecho, más que como una opción.
____________________________________________________________________________
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Documentación
El Estudio de Madurez de Datos Abiertos 2022 nos ofrece una visión del nivel de desarrollo de las políticas que promueven los datos abiertos en los países, así como una evaluación del impacto esperado de las mismas. Entre sus hallazgos destaca que la medición del impacto de los datos abiertos es una prioridad, pero también un gran desafío en toda Europa.
En esta edición se ha registrado una disminución del 7% en el nivel de madurez promedio en la dimensión de impacto para los países de UE27 que coincide con la reestructuración de los indicadores de la dimensión impacto. Sin embargo, no se puede considerar tanto una disminución en el nivel de madurez, sino una imagen más precisa de la dificultad en evaluar el impacto resultante de la reutilización de los datos abiertos.
Es por ello, que con el fin de comprender mejor cómo progresar en el desafío de medir el impacto de los datos abiertos, hemos analizado las mejores prácticas existentes para la medición del impacto de los datos abiertos en Europa. Para conseguir este objetivo se ha trabajado con los datos proporcionados por los países en las respuestas al cuestionario del estudio y en particular con las de los once países que han tenido una puntuación superior a los 500 puntos en la dimensión de Impacto, independientemente de su puntuación global y de su posición en el ranking: Francia, Irlanda, Chipre, Estonia y República Checa que obtienen la máxima puntuación de 600 puntos; y Polonia, España, Italia, Dinamarca y Suecia que puntuaron por encima de los 510 puntos.
En el informe proporcionamos un perfil de cada uno de los diez países en el que se analizan de forma general los resultados del país en todas las dimensiones del estudio y de forma detallada los diferentes componentes de la dimensión impacto en la que resumen las prácticas que han llevado a su alta puntuación a partir del análisis de las respuestas al cuestionario.
A través de esta estructura de fichas el documento permite una comparación directa entre los indicadores de los países y ofrece una visión detallada de las mejores prácticas y los desafíos en el uso de datos abiertos en lo que se refiere a la medición del impacto a través de los siguientes indicadores:
-
“Conciencia estratégica”: Cuantifica la conciencia y preparación de los países para entender el nivel de reutilización y el impacto de los datos abiertos dentro de su territorio.
-
“Midiendo la reutilización”: Se centra en cómo los países miden la reutilización de datos abiertos y en qué métodos utilizan.
-
“Impacto creado”: Recopila datos sobre el impacto creado dentro de cuatro áreas de impacto: impacto gubernamental (anteriormente impacto político), impacto social, impacto ambiental e impacto económico.
Para finalizar el informe proporciona un análisis comparativo de estos países y extrae una serie de recomendaciones y buenas prácticas que tienen como objetivo de proporcionar ideas sobre cómo mejorar el impacto de la apertura de datos en cada uno de los tres indicadores medidos en el estudio.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Oficina del Dato elabora dos guías de ayuda para la concepción eficaz de espacios de datos
El concepto de espacio de datos, entendido como un ecosistema de compartición voluntaria de datos en un entorno de confianza, seguridad y soberanía, se va a desplegar con todo su potencial a lo largo de los próximos años, como apuesta clave de la Unión Europea para impulsar la economía del dato y preservar su soberanía digital. Dichos espacios se construyen alrededor de casos de uso concretos de compartición y explotación de datos donde satisfacer necesidades de negocio concretas, un proceso para el que no resulta sencillo descubrir dichas necesidades, ni su óptimo diseño, al estar presentes diversas consideraciones y áreas de conocimiento.
Para rebajar las barreras de entrada ligadas a su concepción, la Oficina del Dato, dependiente de la Secretaría de Estado de Digitalización e Inteligencia Artificial, ejerciendo su función de dinamizar el gobierno, gestión, compartición y el uso de datos, ha publicado sendas guías que facilitarán la puesta en marcha de casos de uso de compartición de datos: la Guía de evaluación de viabilidad de casos de uso y la Guía de diseño de casos de uso.
Ambos documentos tienen como objetivo ayudar a los potenciales creadores de espacios de datos a superar los desafíos propios de la puesta en marcha de un caso de uso de compartición de datos. En este sentido, las guías orientan paso a paso y en las sucesivas etapas del proceso, proporcionando plantillas con preguntas concretas a las diferentes situaciones que se irán presentando en su diseño. El uso de estas guías debe entenderse de forma iterativa, permitiendo un proceso de refinamiento; así, una vez establecida la viabilidad de un determinado escenario, se abordará su diseño detallado, en un proceso en el que la propia dinámica puede llevar a provocar un replanteamiento de la etapa original de viabilidad. De igual forma, las preguntas presentes en cada paso pueden provocar matizaciones en los pasos anteriores, permitiendo en todo momento una progresiva mejora.
Las guías tienen como origen el contenido de los trabajos realizados desde la iniciativa Data Sharing Coalition. Trabajos en los que, compartiendo experiencia y conocimiento, las organizaciones abordaron el desafío que supuso iniciar el camino de crear en la práctica casos de uso de compartición y explotación de datos. Tomando como base esta referencia, las guías que aquí presentamos han ido evolucionando y han sido particularizadas para el contexto español, siendo enriquecidas igualmente con las aportaciones de los participantes a los eventos de dinamización de espacios de datos organizados por la Oficina del Dato.
Guía de evaluación de viabilidad de casos de uso
La Guía de evaluación de viabilidad de casos de uso permite generar, describir y evaluar ideas de casos de uso escalables de compartición de datos. Con el objetivo final de tomar una decisión acerca de la viabilidad del escenario propuesto, la guía plantea una metodología estructurada a lo largo de cinco pasos: generación del caso de uso, definición de su alcance, evaluación del potencial, estudio de la complejidad de la interacción y toma de decisión final de viabilidad.

Guía de diseño de casos de uso
Una vez abordada la viabilidad del escenario planteado, y si ésta se estimase afirmativa, la Guía de diseño de casos de uso ofrece el soporte necesario para su puesta en marcha. En este punto, se incide tanto en su escalabilidad como en la reutilización de los datos más allá del ámbito inicial. A la hora de diseñar de forma óptima un caso de uso de intercambio y explotación de datos, creemos que las cuestiones de implementación técnica representan tan sólo uno de los factores a tomar en cuenta, resaltando también la criticidad de consideraciones tales como su gobernanza, el modelo de negocio, la experiencia de usuario y los diversos aspectos regulatorios sobre los que se articula y opera.
La Guía, a lo largo de diferentes etapas, aborda la definición detallada del caso de uso, fijando el objetivo y alcance, identificando las funcionalidades que permiten habilitar la compartición de datos, y detallando qué habilitadores permiten el desarrollo de dichas funcionalidades. Gracias al enfoque práctico de la guía, en ella se incluyen útiles plantillas de preguntas-clave que permiten descubrir fácilmente los diversos aspectos a considerar, abordando temas como los principios rectores del caso de uso, el modelo de iteración, los componentes funcionales, las reglas y regulaciones, los contratos, la privacidad, la gestión de la información y los riesgos, las herramientas de apoyo, o incluso los acuerdos de nivel de servicio o la planificación del proyecto.

Los documentos base de ambas guías, las plantillas de preguntas en formato de hoja de cálculo para facilitar su cumplimentación, así como un ejemplo relativo a la viabilidad del proyecto “Caminos de pasión” facilitado por la Fundación Santa María la Real, se encuentran disponibles a través de los siguientes enlaces.
Blog
La Asociación Multisectorial de la Información (ASEDIE), que reúne a las empresas infomediarias de nuestro país, vuelve a incluir entre sus objetivos anuales la promoción de la reutilización de información pública y privada.
Así y casi de forma paralela a la entrada del nuevo año, el pasado mes de diciembre, ASEDIE compartía los avances que ha experimentado el top 3 en la mayor parte de las comunidades autónomas, y las buenas expectativas que hay puestas en la segunda edición.
Desde que el pasado 2019 se lanzase esta iniciativa para promover la apertura de tres conjuntos de datos por parte de las comunidades autónomas, estas han ido poco a poco abriendo conjuntos de datos que han permitido mejorar el acceso a las fuentes informativas, a la par que están contribuyendo a impulsar el desarrollo de servicios y aplicaciones a partir de datos abiertos.
El objetivo de este proyecto, que en el año 2021 fue recogido como compromiso de Buenas Prácticas en el Observatorio del IV Plan de Gobierno Abierto y apoyado por las diecisiete Comunidades Autónomas, es armonizar la apertura de bases de datos del Sector Público con el ánimo de favorecer su reutilización, impulsando el desarrollo de la economía del dato.
Primera edición: accesible en quince comunidades autónomas
La primera edición del Top 3 de Asedie fue todo un éxito no solo por los conjuntos de datos seleccionados, sino también por el ratio de apertura logrado cuatro años después. Actualmente, quince de las diecisiete comunidades autónomas de nuestro país han logrado abrir a todos los públicos las tres bases de datos: cooperativas, fundaciones y asociaciones.
2023: el año para completar la apertura de la segunda edición
Con la finalidad de continuar fomentando la apertura de información pública en las distintas autonomías, en 2020, ASEDIE lanzó una nueva edición del top 3 para que aquellas comunidades que ya habían superado el reto anterior pudiesen seguir avanzando. Así, para esta segunda edición las bases de datos seleccionadas fueron las siguientes:
- Certificados de Eficiencia Energética
- Polígonos Industriales
- Sociedades Agrarias de Transformación
Como resultado, la segunda edición del top 3 ya es accesible en siete comunidades autónomas. Es más, las bases de datos relativas a los certificados de eficiencia energética, una información cada vez más requerida a nivel europeo, ya están disponibles en abierto en todas las comunidades autónomas de la geografía española.
Próximos pasos: ampliar el compromiso por la apertura de datos
Como no podía ser de otra forma, uno de los principales objetivos anuales de ASEDIE es continuar impulsando la colaboración autonómica para poder completar la apertura de la segunda edición del top 3 en el resto de comunidades autónomas.
De forma paralela, la próxima edición del Informe ASEDIE, se hará pública el próximo 22 de marzo, aprovechando la Semana de la Administración Abierta. Al igual que en otras ocasiones, este documento servirá para hacer balance de los hitos conseguidos en el ejercicio anterior, así como para enumerar los nuevos retos.
De hecho, en relación a los datos abiertos, el informe ASEDIE es una herramienta muy útil a la hora de ampliar conocimientos en este área de expertise ya que incluye una relación de casos de éxito de empresas infomediarias y ejemplos de los productos y servicios que elaboran.
En resumen, gracias a iniciativas como las desarrolladas por ASEDIE, cada vez es más constante y tangible la colaboración público-privada, al facilitar que las empresas puedan reutilizar la información pública de una manera más sencilla.