Documentación
When publishing open data, it is essential to ensure its quality. If data is well documented and of the required quality, it will be easier to reuse, as there will be less additional work for cleaning and processing. In addition, poor data quality can be costly for publishers, who may spend more money on fixing errors than on avoiding potential problems in advance.
To help in this task, the Aporta Initiative has developed the "Practical guide for improving the quality of open data", which provides a compendium of guidelines for acting on each of the characteristics that define quality, driving its improvement. The document takes as a reference the data.europe.eu data quality guide, published in 2021 by the Publications Office of the European Union.
Who is the guide aimed at?
The guide is aimed at open data publishers, providing them with clear guidelines on how to improve the quality of their data.
However, this collection can also provide guidance to data re-users on how to address the quality weaknesses that may be present in the datasets they work with.
What does the guide include?
The document begins by defining the characteristics, according to ISO/IEC 25012, that data must meet in order to be considered quality data, which are shown in the following image

Next, the bulk of the guide focuses on the description of recommendations and good practices to avoid the most common problems that usually arise when publishing open data, structured as follows:
- A first part where a series of general guidelines are detailed to guarantee the quality of open data, such as, for example, using a standardised character encoding, avoiding duplicity of records or incorporating variables with geographic information. For each guideline, a detailed description of the problem, the quality characteristics affected and recommendations for their resolution are provided, together with practical examples to facilitate understanding.
- A second part with specific guidelines for ensuring the quality of open data according to the data format used. Specific guidelines are included for CSV, XML, JSON, RDF and APIs.
- Finally, the guide also includes recommendations for data standardisation and enrichment, as well as for data documentation, and a list of useful tools for working on data quality.
You can download the guide here or at the bottom of the page (only available in Spanish).
Additional materials
The guide is accompanied by a series of infographics that compile the above guidelines:
- Infographic "General guidelines for quality assurance of open data".

- Infographic "Guidelines for quality assurance using specific data formats”.

Blog
Nowadays we can find a great deal of legislative information on the web. Countries, regions and municipalities make their regulatory and legal texts public through various spaces and official bulletins. The use of this information can be of great use in driving improvements in the sector: from facilitating the location of legal information to the development of chatbots capable of resolving citizens' legal queries.
However, locating, accessing and reusing these documents is often complex, due to differences in legal systems, languages and the different technical systems used to store and manage the data.
To address this challenge, the European Union has a standard for identifying and describing legislation called the European Legislation Identifier (ELI).
What is the European Legislation Identifier?
The ELI emerged in 2012 through Council Conclusions (2012/C 325/02) in which the European Union invited Member States to adopt a standard for the identification and description of legal documents. This initiative has been further developed and enriched by new conclusions published in 2017 (2017/C 441/05) and 2019 (2019/C 360/01).
The ELI, which is based on a voluntary agreement between EU countries, aims to facilitate access, sharing and interconnection of legal information published in national, European and global systems. This facilitates their availability as open datasets, fostering their re-use.
Specifically, the ELI allows:
- Identify legislative documents, such as regulations or legal resources, uniquely by means of a unique identifier (URI), understandable by both humans and machines.
- Define the characteristics of each document through automatically processable metadata. To this end, it uses vocabularies defined by means of ontologies agreed and recommended for each field.
Thanks to this, a series of advantages are achieved:
- It provides higher quality and reliability.
- It increases efficiency in information flows, reducing time and saving costs.
- It optimises and speeds up access to legislation from different legal systems by providing information in a uniform manner.
- It improves the interoperability of legal systems, facilitating cooperation between countries.
- Facilitates the re-use of legal data as a basis for new value-added services and products that improve the efficiency of the sector.
- It boosts transparency and accountability of Member States.
Implementation of the ELI in Spain
The ELI is a flexible system that must be adapted to the peculiarities of each territory. In the case of the Spanish legal system, there are various legal and technical aspects that condition its implementation.
One of the main conditioning factors is the plurality of issuers, with regulations at national, regional and local level, each of which has its own means of official publication. In addition, each body publishes documents in the formats it considers appropriate (pdf, html, xml, etc.) and with different metadata. To this must be added linguistic plurality, whereby each bulletin is published in the official languages concerned.
It was therefore agreed that the implementation of the ELI would be carried out in a coordinated manner by all administrations, within the framework of the Sectoral Commission for e-Government (CSAE), in two phases:
- Due to the complexity of local regulations, in the first phase, it was decided to address only the technical specification applicable to the State and the Autonomous Communities, by agreement of the CSAE of 13 March 2018.
- In February 2022, a new version was drafted to include local regulations in its application.
With this new specification, the common guidelines for the implementation of the ELI in the Spanish context are established, but respecting the particularities of each body. In other words, it only includes the minimum elements necessary to guarantee the interoperability of the legal information published at all levels of administration, but each body is still allowed to maintain its own official journals, databases, internal processes, etc.
With regard to the temporal scope, bodies have to apply these specifications in the following way:
- State regulations: apply to those published from 29/12/1978, as well as those published before if they have a consolidated version.
- Autonomous Community legislation: applies to legislation published on or after 29/12/1978.
- Local regulations: each entity may apply its own criteria.
How to implement the ELI?
The website https://www.elidata.es/ offers technical resources for the application of the identifier. It explains the contextual model and provides different templates to facilitate its implementation:
It also offers the list of common minimum metadata, among other resources.
In addition, to facilitate national coordination and the sharing of experiences, information on the implementation carried out by the different administrations can also be found on the website.
The ELI is already applied, for example, in the Official State Gazette (BOE). From its website it is possible to access all the regulations in the BOE identified with ELI, distinguishing between state and autonomous community regulations. If we take as a reference a regulation such as Royal Decree-Law 24/2021, which transposed several European directives (including the one on open data and reuse of public sector information), we can see that it includes an ELI permalink.
In short, we are faced with a very useful common mechanism to facilitate the interoperability of legal information, which can promote its reuse not only at a national level, but also at a European level, favouring the creation of the European Union's area of freedom, security and justice.
Content prepared by the datos.gob.es team.
Documentación
A data space is an ecosystem where, on a voluntary basis, the data of its participants (public sector, large and small technology or business companies, individuals, research organizations, etc.) are pooled. Thus, under a context of sovereignty, trust and security, products or services can be shared, consumed and designed from these data spaces.
This is especially important because if the user feels that he has control over his own data, thanks to clear and concise communication about the terms and conditions that will mark its use, the sharing of such data will become effective, thus promoting the economic and social development of the environment.
In line with this idea and with the aim of improving the design of data spaces, the Data Office establishes a series of characteristics whose objective is to record the regulations that must be followed to design, from an architectural point of view, efficient and functional data spaces.
We summarize in the following visual some of the most important characteristics for the creation of data spaces. To consult the original document and all the standards proposed by the Data Office, please download the attached document at the end of this article.
(You can download the accessible version in word here)

Documentación
This report published by the European Data Portal (EDP) aims to advance the debate on the medium and long-term sustainability of open data portal infrastructures.
It provides recommendations to open data publishers and data publishers on how to make open data available and how to promote its reuse. It is based on the previous work done by the data.europa.eu team, on research on open data management, and on the interaction between humans and data.
Considering the conclusions, 10 recommendations are proposed for increasing the reuse of data.
The report is available at this link: " Principles and recommendations to make data.europa.eu data more reusable: A strategy mapping report "
Blog
One of the key actions that we recently highlighted as necessary to build the future of open data in our country is the implementation of processes to improve data management and governance. It is no coincidence that proper data management in our organisations is becoming an increasingly complex and in-demand task. Data governance specialists, for example, are increasingly in demand - with more than 45,000 active job openings in the US for a role that was virtually non-existent not so long ago - and dozens of data management platforms now advertise themselves as data governance platforms.
But what's really behind these buzzwords - what is it that we really mean by data governance? In reality, what we are talking about is a series of quite complex transformation processes that affect the whole organisation.
This complexity is perfectly reflected in the framework proposed by the Open Data Policy Lab, where we can clearly see the different overlapping layers of the model and what their main characteristics are - leading to a journey through the elaboration of data, collaboration with data as the main tool, knowledge generation, the establishment of the necessary enabling conditions and the creation of added value.
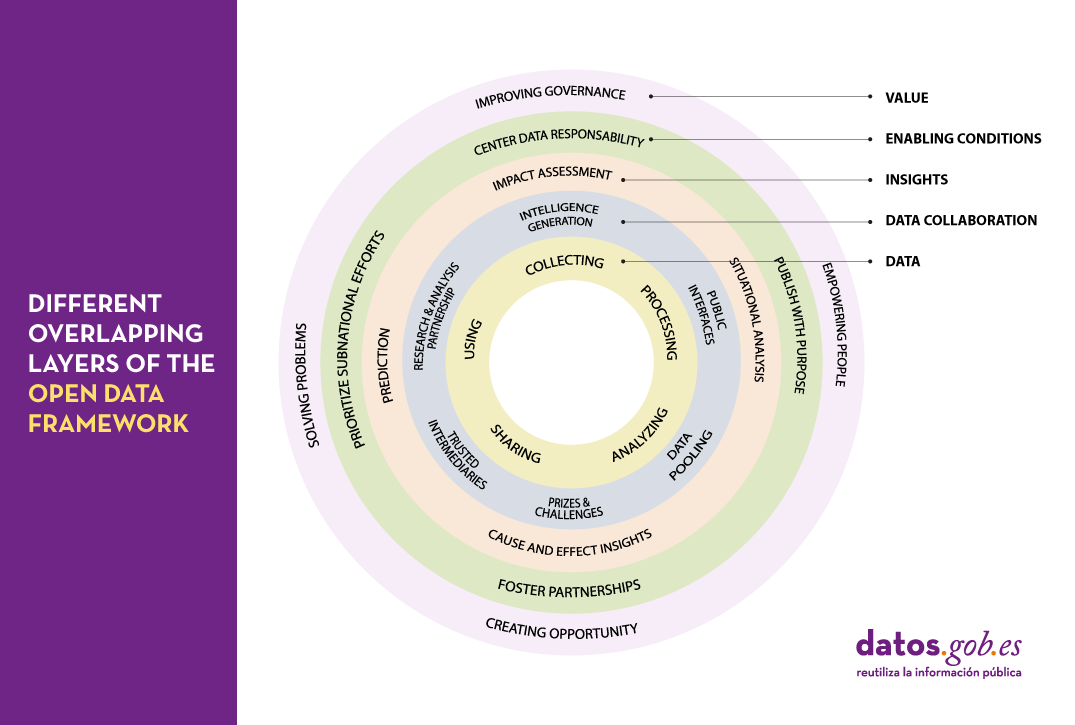
Let's now peel the onion and take a closer look at what we will find in each of these layers:
The data lifecycle
We should never consider data as isolated elements, but as part of a larger ecosystem, which is embedded in a continuous cycle with the following phases:
- Collection or collation of data from different sources.
- Processing and transformation of data to make it usable.
- Sharing and exchange of data between different members of the organisation.
- Analysis to extract the knowledge being sought.
- Using data according to the knowledge obtained.
Collaboration through data
It is not uncommon for the life cycle of data to take place solely within the organisation where it originates. However, we can increase the value of that data exponentially, simply by exposing it to collaboration with other organisations through a variety of mechanisms, thus adding a new layer of management:
- Public interfaces that provide selective access to data, enabling new uses and functions.
- Trusted intermediaries that function as independent data brokers. These brokers coordinate the use of data by third parties, ensuring its security and integrity at all times.
- Data pooling that provide a common, joint, complete and coherent view of data by aggregating portions from different sources.
- Research and analysis partnership, granting access to certain data for the purpose of generating specific knowledge.
- Prizes and challenges that give access to specific data for a limited period of time to promote new innovative uses of data.
- Intelligence generation, whereby the knowledge acquired by the organisation through the data is also shared and not just the raw material.
Insight generation
Thanks to the collaborations established in the previous layer, it will be possible to carry out new studies of the data that will allow us both to analyse the past and to try to extrapolate the future using various techniques such as:
- Situational analysis, knowing what is happening in the data environment.
- Cause and effect insigths, looking for an explanation of the origin of what is happening.
- Prediction, trying to infer what will happen next.
- Impact assessment, establishing what we expect should happen.
Enabling conditions
There are a number of procedures that when applied on top of an existing collaborative data ecosystem can lead to even more effective use of data through techniques such as:
- Publish with a purpose, with the aim of coordinating data supply and demand as efficiently as possible.
- Foster partnerships, including in our analysis those groups of people and organisations that can help us better understand real needs.
- Prioritize subnational efforts, strengthening of alternative data sources by providing the necessary resources to create new data sources in untapped areas.
- Center data responsability, establishing an accountability framework around data that takes into account the principles of fairness, engagement and transparency.
Value generation
Scaling up the ecosystem -and establishing the right conditions for that ecosystem to flourish- can lead to data economies of scale from which we can derive new benefits such as:
- Improving governance and operations of the organisation itself through the overall improvements in transparency and efficiency that accompany openness processes.
- Empowering people by providing them with the tools they need to perform their tasks in the most appropriate way and make the right decisions.
- Creating new opportunities for innovation, the creation of new business models and evidence-led policy making.
- Solving problems by optimising processes and services and interventions within the system in which we operate.
As we can see, the concept of data governance is actually much broader and more complex than one might initially expect and encompasses a number of key actions and tasks that in most organisations it will be practically impossible to try to centralise in a single role or through a single tool. Therefore, when establishing a data governance system in an organisation, we should face the challenge as an integral transformation process or a paradigm shift in which practically all members of the organisation should be involved to a greater or lesser extent. A good way to face this challenge with greater ease and better guarantees would be through the adoption and implementation of some of the frameworks and reference standards that have been created in this respect and that correspond to different parts of this model.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views expressed in this publication are the sole responsibility of the author.
Entrevista
The open data portal of Aragon emerged in 2012 and has not stopped growing since then. It currently has more than 2,100 datasets and a large number of applications. During these years it has incorporated new features to adapt to the real needs of citizens, such as its information structure that improves interoperability and homogenises the available data, or the incorporation of applications such as Open Analytics Data, which offers statistics related to the use of the most important portals of the Government of Aragon.
In the last few months, they have been working on the Aragon Open Data Focus Initiative, aimed at getting to know open data publishers and users better. To find out more about this interesting project and the rest of the activities they are developing, we have spoken to Julián Moyano, Technical Advisor of the General Directorate of Electronic Administration and Information Society, Department of Science, University and Knowledge Society of the Government of Aragon.
Full interview
1. What is Aragon Open Data Focus and what are its strategic points?
Aragon Open Data Focus is a way of bringing the data of the Government of Aragon's open data portal closer to society, and to those people who are not so familiar with the data, in order to encourage their use and interpretation.
Bringing together the data available in Aragon Open Data has required a better understanding of the real needs of the users and groups involved. These are the four strategic points of this work:
- Firstly, we have started with an initial analysis of the data and services available in Aragon Open Data.
- Second, through this analysis we have defined potential groups of users and agents of interest.
- Thirdly, from this point onwards, different meetings have been organised with these groups to look for synergies and establish lines of work.
- Fourthly, all this has resulted in the service called Aragon Open Data Focus with digital stories and narratives based on available open data and the concerns of the users.
Aragón Open Data Focus es una manera de acercar los datos del portal de datos abiertos del Gobierno de Aragón, Aragón Open Data, a la sociedad, y a aquellas personas que no están tan familiarizadas con los datos para favorecer su uso e interpretación.
2. To learn more about the users’ needs, you have held various virtual meetings. What groups have you met with and what conclusions have you drawn from these conversations?
The meetings have been a very important part of Aragon Open Data Focus. At the beginning of 2020, 8 meetings had been planned in person, to encourage participation and direct contact with these agents involved. Due to the coronavirus pandemic, the first of those meetings had to be suspended, rescheduling the agenda of participants and calendar, to be held by videoconference. There has been a great deal of online activity and it has been very well received by the different groups of participants. The groups we have worked with have been:
- Public sector organisations: focused on companies and other public sector entities.
- Storytellers: journalists.
- Companies that reuse data.
- Students.
- Directors, managers and senior executives of private and public organisations.
- Developers and programmers from the technology sector.
- Auditors of public action, citizens' groups and social movements.
- Citizens, in general, new to open data.
The conclusions of all these meetings have been very valuable. The first of these is that it is necessary to talk and debate "one-on-one" with the agents involved, with the recipients of the services, with the possible and potential users of the data, in order to know their needs much better and share them in Aragon Open Data.
Some of the conclusions I would like to highlight that were obtained with the user groups were:
- Those responsible for public sector bodies are demanding more cooperation within the administrations in order to correctly articulate the effort in terms of transparency and open data.
- Users with a more technical profile and familiar with the data demand more data in open formats, of better quality, improved descriptions, level of disaggregation and updated in real time.
- Interested parties and users with more general profiles want possibilities to relate data from different sources, visualisations, geopositioning of available open data, map visualisations and downloadable geographical information in open formats and with the possibility of integrating them into other websites.
- In addition, open data portals need to improve their dynamization, dissemination and constant approach to data providers and users. Permanent and rapid attention is also requested to new demands for open data or the resolution of users' doubts, linking any action to the culture of openness and transparency on the part of Public Administrations.
It should also be noted that the content, dynamics and conclusions of each of the events are available on the Government of Aragon's website: https://www.aragon.es/-/los-datos-abiertos-mas-cerca-de-la-sociedad-aragon-open-data-focus.
3. What actions are you developing to respond to user requests?
The meetings have been intense, full of ideas, proposals and debates. Now it is time to record the conclusions of these meetings in order to work on the action lines and demands suggested.
It is necessary to emphasize that these meetings and their conclusions are aligned with the Strategy of Aragon Open Data in which the evolution of the web portal of Aragon Open Data and the map of agents (journalists, researchers, citizens) that work with open data to offer an integral vision of the service are analysed. That is why Aragon Open Data Focus has a place in this Strategy.
With this, we continue profiling, working and complying with its lines of action, which allow us to promote the implication of the users and develop a data governance model that covers their demands: working on the opening of new resources, improving the existing ones and favouring their use.
4. What obstacles have you encountered when setting up Aragon Open Data Focus?
The main obstacle, as I have already pointed out, has been the coronavirus pandemic. Aragón Open Data Focus had a markedly face-to-face character, to talk and debate with those involved in a direct way with participative dynamics. We even had events planned in small villages and the rural environment of Aragon, to disseminate and share ideas about open data and to know first-hand their demands and needs. The pandemic made us change its dynamics and do it online, which has not been a problem either to hold these "meetings" and obtain conclusions.
Beyond that, we have noticed that users have great expectations about open data, and sometimes it is not easy to respond to them in this type of conference for different reasons: the inexistence of data in the administration (it is the responsibility of another organisation), technical problems, or due to the characteristics of the open data available. Circumstances that, although they may justify, not excuse, in detail the situation, are difficult to understand by the user or data demander, when we are in the 21st century, in the era of data and the digital economy.
5. What are the benefits for public administrations of this type of initiative?
Above all, it allows us to go deeper into the real needs of users and groups with whom we have worked in order to better focus our actions and future lines of work.
6. A few years ago, you told us that the datasets most demanded by users of Aragon Open Data were those related to the budget. Has this situation changed? What type of information do re-users demand now?
The budget data is still one of the most used in Aragon Open Data, both as open datasets and in the service that reflects it: https://presupuesto.aragon.es/
Today, if we look at the number of accesses, currently, the most demanded (it doubles the second resource with the most accesses) is data related to the coronavirus in Aragon, followed by cartographic data, data on the CAP (Common Agricultural Policy) and statistical data.
7. How do you see the panorama of open data in Spain? What strengths do you think there are? And weaknesses? How could they be resolved?
The outlook in Spain is promising. Much has already been done to provide data in open formats by different public administrations at all territorial levels. Now, once their offer has grown in the number of datasets, the portals are been adapting to the demands of society which not only wants quantity, but also very specific data to make the most of it, for example: data on mobility, passenger transport, telecommunications infrastructures, digital services and health, in real time. This is in line with what the European Union has legislated on its new directive on open data and the re-use of public sector information as a strength. In other words, there is an important regulatory and institutional support for open data initiatives in Europe, in order to make the continent a truly data-based digital marketplace that improves the lives of citizens.
Weak points in the opening up of open data, which has good regulatory and legal backing, may be the response times for including a set of data requested from a given portal, and it would therefore be advisable to speed up the processes of opening up the data further. And in the event that there is no supplier acting as data manager, taking advantage of the possibilities of current technologies, for example, data recognition or automatic detection of schemes with quality and security validators, to allow open data to be opened and made available with the minimum of human intervention.
If data is an asset of the public administrations that serve citizens, companies and third parties in this new digital economy, they also have to lose that aura of closure and ownership, which they sometimes give off.
Blog
The Aporta Challenge, in line with many other initiatives promoted by public administrations, could not be unaware of the great challenges we are facing in this year 2020. For this reason, its third edition, while fulfilling its usual objective of promoting the use of data and related technologies, aims to contribute to solving problems related to digital education. Without doubt, this is one of the areas in which the need to propose new innovations to ensure that the pandemic does not cause serious damage to the potential of the younger generations has been most evident.
With the slogan "The value of data in digital education", datos.gob.es is proposing an Aporta Challenge that in 2020 reward ideas and prototypes that identify new opportunities for capturing, analysing and using the intelligence of data in the development of solutions for the educational sphere at any of its stages.
Identifying a problem
If we were to approach participation in the challenge as a data science project, the first thing we would do is determine the question we would like to solve, in short, choose a problem worth working on. In this article we propose some lines of work, but they are not restrictions, they are only intended to serve as inspiration to make it easier for us to choose an educational challenge with a great impact. We must always aspire to improve the world.
On the other hand, we can look at the large educational gaps defined by the Educa en Digital programme, which aims to complement the Digitalisation and Digital Skills Plan and to promote the digital transformation of education in Spain, making intensive use of ICT both in the classroom and in non-presential formats, and tackling specific problems thanks to developments linked to data and artificial intelligence. For each of the specific objectives we can think of a good number of issues on which we can work:
- The provision of digital educational devices and resources. For example, how can we help ensure that access to technology is not a barrier to access to education, especially for the most vulnerable groups? how can we reduce the requirements for accessing educational programmes remotely? how can we rely on the most economical devices that are most widely available to students? etc.
- The provision of digital educational resources, especially in relation to the previous point. On many occasions the problem we can work on does not have to be completely new, but we can find a more efficient approach to an apparently resolved issue. For example, how can we help a teacher to better monitor a large number of students? how can we improve the security of the applications used by students through public networks? how can we guarantee the privacy of students? etc.
- The adequacy of teachers' digital skills. In this line there are also a significant number of questions to be resolved: how can we improve the usability of tools for teachers and students? how can we promote skills related to collaboration or communication when people are not in the same physical space? how can we help STEM skills to be perceived as transversal? etc.
- The application of artificial intelligence to personalised education, which is almost a holy grail of Education. How can we create personalised learning paths for each group of students, or better still, optimising the learning pace of each student according to their individual characteristics? how can we predict the impact of changes in programmes on the evolution of group or student learning? how can we detect and avoid gender bias in models that work on any of the above problems?

In short, with the suggestions published in the bases and a little research, it is easy to locate a good number of issues on which we can do our bit to improve digital education. Without forgetting our own experience. We have all been at least students, and perhaps also teachers, at some point.
Examining the prior art
Before we begin our work, we must consider that it is very likely that, with or without success, others have identified and proposed solutions to the problem we have chosen. From their success or failure, we can also draw lessons so reviewing the state of the art is key to focusing our project well. In relation to educational technology it is interesting to review resources such as
- The activity of educational technology start-ups in repositories such as EU-startups or the WISE accelerator.
- Awards focused on educational technology such as the prestigious Global Learning XPRIZE or the WISE Prize for Education.
- The list of more than 2.500 educational innovation projects from around the world contained in the Leapfrogging Inequality: Remaking Education to Help Young People Thrive.
- The solutions that reuse open data in the area of education and that highlight portals such as the European data portal or datos.gob.es.
As you will see, many of the projects are focused on solving problems that are mostly present in countries less developed than ours. However, the pandemic has changed the rules of the game from what we could have foreseen and is challenging us again with problems that under normal circumstances we would consider to be overcome.
Locating datasets
Open data is present in almost every problem that is solved by data related technologies and it is usually one ingredient, not the only one. The foundations of the Aporta Challenge reflect this reality and impose very few restrictions on creators, using data sources listed in datos.gob.es is not even mandatory, despite being the driving force behind the challenge. At least one set of data generated by the public administrations must be used, but it can come from any source and can play any role within the project.
To locate data related to our project we can start with the more than 1,700 datasets of the datos.gob.es data catalogue, which federates a good part of the data available in Spanish portals. In the European Data Portal we can find more than 8,000 datasets related to education from all EU countries and another 3,000 datasets from the catalogue of the European Union open data portal.
International institutions that work for the development of education such as UNICEF or the World Bank also have open data catalogues in which we can locate resources that help us in some part of our project.
The Google dataset search engine, the AWS open data registry or the Microsoft Azure datasets are resources in which we can also find datasets to enrich any data-based project.
The data catalogue of institutions such as the US Government's Institute of Education Sciences, which although focused on the United States, undoubtedly contains data of great value for measuring and understanding the impact of initiatives developed to improve education and which can enrich many projects.
Another option that we should bear in mind is that it may not be enough to solve the problem we have chosen to clean up, reconcile and transform datasets from any of the sources that are publicly and openly available. Sometimes we need to work on generating or building our own dataset. And in that case a very good option is to make it publicly and openly available so that it can be reused and improved by others.
Defining the product
Finally, we have to think about the best way to deliver the result of our work so that it can be used by its recipients and have the impact we want. The options are multiple and again the bases do not impose restrictions. Some possibilities could be:
- Mobile Apps: The enormous penetration of the iOS and Android platforms means that any product we build for these platforms and publish in their respective stores is guaranteed to have a huge potential diffusion. In addition, there are options to carry out multiplatform developments and even to carry out developments with little (low-code) or no (non-code) software development knowledge.
- Websites: Web applications are probably still the most common mechanism for making a project of any kind available to society in general. The advances in managed services of the large cloud providers and the facilities they offer to make infrastructure available for free mean that it has never been easier to start a project. It is also possible to use non-code platforms such as appypie or low-code platforms such as Appian to reduce the initial barrier if we do not have a software developer on the team.
- Artificial Intelligence Algorithms: It is increasingly common for a data-based project to be delivered in the form of an automatic learning model or artificial intelligence. For example, Amazon AWS offers the possibility to list algorithms like Microsoft Azure in its Machine Learning Marketplace so that they can be consumed by other applications.
- Stories and Visualizations: Sometimes the best way to deliver results is through a visualization or a DataStory that allows you to communicate the result of your work. For this purpose, there are multiple options that range from the utilities that incorporate most of the generic Business Intelligence tools such as Tableau to others specialised in spatial location such as the Spanish Carto.
We wish all participants good luck and encourage you to work on a challenge that has a great impact on society.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Documentación
In the Action Plan of the International Open Data Conference, capacity development has become a priority within the international open data movement. After all, the need for training tools is essential for leaders responsible for PSI policies, data producers and reusers, public and private sector, and even citizens. For this reason, providing training tools that allow the different agents to advance in the openness and re-use of public data is a priority task.
To this end, eight training units have been developed within the dissemination, awareness raising and training line of Iniciativa Aporta, aimed at all types of public: from citizens who read for the first time about open data to public employees, responsible for open information initiatives who want to expand their knowledge in the field.
The training units are designed to understand the basic concepts of the open data movement, to know best practices in the implementation of open data policies and their re-use, methodological guidelines for open data, technical regulations such as DCAT-AP and NTI-RISP, in addition to the use of data processing tools, among other aspects.
In the development of resources, two types of learning have been taken into account. Learning by discovery, oriented to extend the knowledge to solve the doubts and reflections raised, and significant learning based on prior knowledge, through the use of practical examples to contextualize and apply the concepts treated.
In addition, the training modules contain complementary materials through links to external pages and documents to be downloaded without connection. In this way, the student is given the opportunity to enhance his knowledge and familiarize himself with relevant sources to obtain reliable and up-to-date information about the open data sector.
All units are distributed under the Creative Commons Share-Alike Attribution Licence (CC-BY-SA) which allows copying, distributing the material in any medium or format and adapting it to create new resources from it.

The training material developed by Iniciativa Aporta consists of eight didactic units that address the following contents of the open data sector:
- Basic concepts, benefits and barriers of open data
- Legal framework
- Trends and best practices on the implementation of open data practices
- The re-use of public data on its transformative role
- Methodological guidelines for open data
- DCAT-AP and NTI-RISP
- Use of basic tools for data treatment
- Best practices in the design of APIs and Linked Data

Each unit is designed in a way the student expands his knowledge on the open data sector. In order to facilitate their understanding, all of them have a similar structure that includes objectives, contents, evaluation activities, practical examples, complementary information and conclusions.
All the training units can be done online, directly from the datos.gob.es or, in its absence, it is also possible to download them on the user's device and even load it on an LMS platform.

Each unit is independent; enabling the student to acquire the necessary knowledge in a specific subject according to their training needs. However, those students who wish to have a more complete view of the PSI sector have the opportunity to perform the complete series of eight training units in order to know in depth the most relevant aspects of open data initiatives.

The training units are available in the "Documentation" section under the category "Training materials" to be carried out through the online portal or to be downloaded.
Training materials of the Aporta Initiative
Noticia
The open data ecosystem does not rest in summer. During the summer months we have seen both the opening of new content and the creation of interesting reuse projects. In Spain, we find pioneering initiatives related to areas such as sustainability and smart cities, humanities and culture or geographic data.
Below are some examples of the proposals that have been launched this summer related to open data.
Launch of new portals, repositories and tools to promote access to open data
Reusers have more and more content at their fingertips. An increasing number of initiatives are encouraged to make their data available to users, as well as organizations that go one step further and launch thematic repositories:
- Terrassa City Council launched a new open data portal in July. The portal includes a data catalogue with 133 datasets on demography, transport, urbanism and infrastructure, etc. It also includes an applications section, with examples of reuse.
- The Generalitat Valenciana has also launched a new open data portal, which allows users to consult and download various types of data: education, health, infrastructure... and it includes a space with information for reusers.
- The San Sebastian City Council has opened the GeoDonostia portal, in which it releases all the geographic data and 300 graphics -which will be extended- so that citizens and professionals can consult them.
- In the economic field, the Institute of Economic Studies of the Province of Alicante, INECA, has launched, thanks to the open data, the largest economic database in the province.
- As far as initiatives in the food sector are concerned, the groups AGR127 and RNM322 from the University of Cordoba, which form part of the 'Cereal Water' Task Force, are investigating new techniques and technologies to achieve a more sustainable cereal crop. All the data generated will soon be shared through their platform.
- Regarding art and humanities, the Guggenheim Museum of Bilbao opened its doors online through exhibitions and digital tours that allowed access to their works.
Where more advances are being experienced is in the field of sustainability and the search for smart and efficient cities. A good example is the city of Onda, whose project turned out to be the winner of the XII Aslan Awards. The project promotes the collection of real time data on public transport and incorporates a virtual assistant that solves the neighborhood's doubts.
The reuse of data in public administrations
But public bodies are not only opening up their information, they are also creating services to encourage its reuse:
- The City Council of Murcia has presented MUDATAlab, a laboratory that promotes the production and dissemination of humanistic related to the heritage of Murcia, based on the use of open data.
- Summer has been the time chosen by several data initiatives to launch competitions aimed at promoting the creation of solutions based on data reuse. The Junta de Castilla y León has opened the period to participate in the fourth edition of its data contest, which this year includes as a novelty a prize for data journalism. The Government of the Basque Country has approved a new call for its awards, which will be opened in September, as well as the new edition of the Barcelona Dades Obertes Challenge.
Public administrations not only publish data, but are also reusers of information services, as we have seen in this recent report. Some examples, developed during the last months, are
- Andalusia has released an application through which geolocalized information on free Internet access points can be consulted.
- In order to improve habitability in the city, the Santiago de Compostela City Council has announced that it will introduce a traffic system that will signal the availability of parking spaces in the parking lots using open data from its open data portal.
- The Cartographic and Geological Institute of Catalonia, ICGCat, has published a viewer of routes in the province with data extracted from the open data portal of the Catalan Government. In the same community, the Ministry of Agriculture has published a map of farms in Catalonia.
International proposals that promote the use of open data
Initiatives based on the use of open data are not only limited to Spain. There are also interesting proposals in the international arena that can serve as inspiration:
- Uruguay has created an open data system of trade and business intelligence that provides useful information to small and medium businesses.
- The Digital Agency for Public Innovation of Mexico City has presented a digital tool based on open data through which it will be possible to explore, consult and download information from the territorial cadastre.
- The Massachuetts Institute of Technology has collaborated with Toyota to launch open data to accelerate research in the field of autonomous driving.
- Argentina has launched an educational platform that includes virtual classrooms, a repository of educational content and a monitoring and research module, developed from open data.
These are some of the most striking examples to be found in the world of open data, but there are many more. If you know of any other interesting news, you can mention it in the comments or by sending an email to the Dynamization department: dinamizacion@datos.gob.es.
Blog
Measuring the impact of open data is not always easy. As we saw a few weeks ago, there are several theoretical models that are not easy to implement, so we have to look for different approaches. In the Aporta Initiative we use a mixed approach, as explained here: a quantitative analysis through indicators on data publication and its characteristics, and a qualitative one through the collection of cases of data use.
This approach is also used by various local, regional and state initiatives in our country. In today's article, we will focus on concrete examples of mechanisms implemented by Spanish open data initiatives to monitor and measure the impact of the use of their data.
Quantitative analysis
One of the first steps in monitoring impact is to know quantitatively if users are accessing the published data. To do this we can use different tools.
Dashboards
Thanks to the incorporation of web analytics tools in open data platforms, such as Google Analytics or Motomo (which until 2018 was called PIWIK), a series of indicators can be set around data consumption variables, such as how many users visit the web, what is their origin, which data sets are most in demand or in what format they are downloaded. All of this information is of great value when it comes to making decisions that imply improvements to continue promoting the reuse of public information.
With this data, dashboards can be created so that users can also know this information. This is the case of the Castellón Provincial Council, the Madrid City Council, the Catalan Government, Renfe, the Basque Government or the datos.gob.es itself.
Conducting surveys and periodic studies
In addition, it is advisable to carry out frequent public consultations and studies that allow us to know directly the impact of our data. The ONTSI periodically carries out a characterization study of the sector, and an analysis of the Public Administrations as reusers of their own data and that of third parties. Another example is the report on the Infomediary Sector of ASEDIE, now in its 8th edition. This report measures the products and services based on open data that have been generated. Both reports use a stable methodology that allows comparisons between different years.
Qualitative analysis
It consists of the identification of use cases through different mechanisms, such as
Application and enterprise tracking
Thanks to the mapping of open data use cases, we can know what the impact of a certain data set is. In many open data platforms, whether local, regional or state, we can find a section of applications or companies with examples and reuse success stories that in turn serve as reference and inspiration for the creation of new value services. In the case of datos.gob.es, we have a form for companies or applications that wish to register their information, but we also carry out a proactive search, through contact with the main actors in the ecosystem and media alerts.
Other examples of portals that have applications sections are Andalusia, Castilla y Leon, Navarra, Barcelona, Santander, Malaga, Zaragoza, Valencia, Vitoria or Bilbao, although there are many more.
Implementation of data communities
In order to be aware of new developments in the field of reuse and to exchange knowledge and experiences to align the data publication strategy with the needs of reusers, some initiatives have opted for the implementation of communities. This is the case of the Basque Country, which has created a space to centralize everything that happens around the reuse of its data. This community has been especially useful to collect and measure the work that has been developed on COVID-19 using open data. Under its umbrella there are also activities and competitions that encourage reuse.
For its part, the Castellón Provincial Council has created a Provincial Council of Reusers, a mixed public-private body made up of technicians from the provincial institution itself, and people with recognized professional backgrounds in different economic sectors. These professionals meet once a quarter to hold a conversation to monitor use cases and which favours constant feedback and the enrichment of the Provincial Council's open data strategy.
The National Library of Spain is working along the same lines and has launched a collaborative work platform so that those citizens who wish to do so can participate in specific projects to enrich the Library's data, making it more accessible and easier to reuse.
In short, all these activities allow monitoring the activity of an open data initiative and its impact on society. They help us to know what challenges we are solving in fields as important for humanity as the environment, health or education. In this way, we will be able to know its evolution over time and easily detect trends and possible areas of improvement, which will lead us to distribute the efforts and resources available in a more effective way.
Content elaborated by datos.gob.es team.